TL;DR
SinGAN is a novel generative model trained on a single natural image that can produce diverse, high-quality samples maintaining the original image's global structure and textures, enabling various image manipulation applications.
Contribution
We introduce SinGAN, the first single-image GAN that captures internal patch distributions at multiple scales without relying on textures only.
Findings
Generates diverse, high-quality samples from a single image
Maintains global structure and fine textures in generated images
User studies show generated images are often mistaken for real
Abstract
We introduce SinGAN, an unconditional generative model that can be learned from a single natural image. Our model is trained to capture the internal distribution of patches within the image, and is then able to generate high quality, diverse samples that carry the same visual content as the image. SinGAN contains a pyramid of fully convolutional GANs, each responsible for learning the patch distribution at a different scale of the image. This allows generating new samples of arbitrary size and aspect ratio, that have significant variability, yet maintain both the global structure and the fine textures of the training image. In contrast to previous single image GAN schemes, our approach is not limited to texture images, and is not conditional (i.e. it generates samples from noise). User studies confirm that the generated samples are commonly confused to be real images. We illustrate the…
Click any figure to enlarge with its caption.
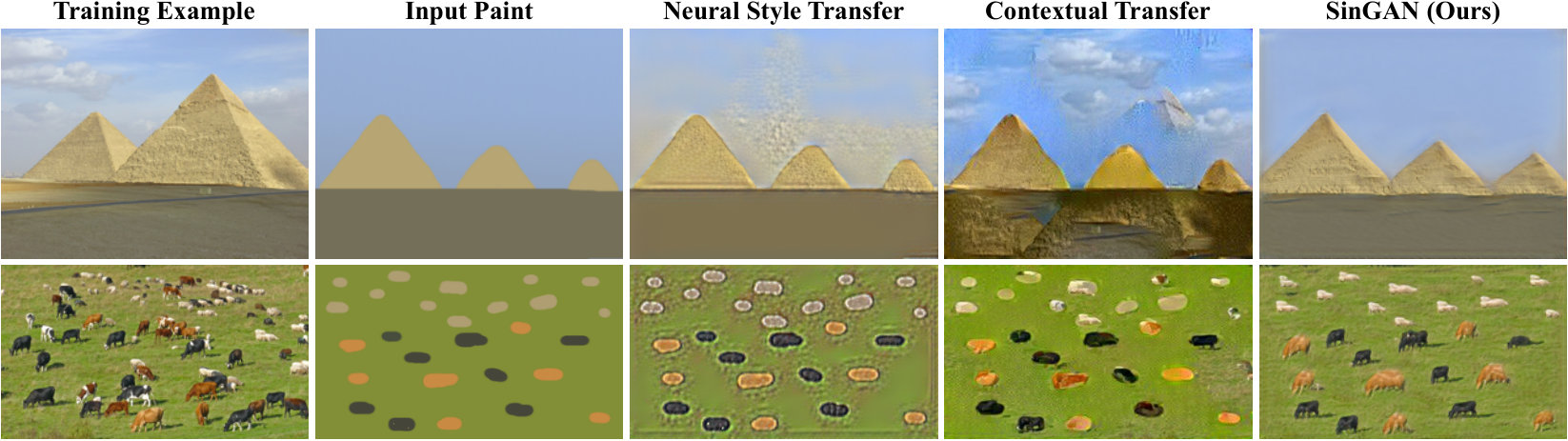 Figure 1
Figure 1 Figure 2
Figure 2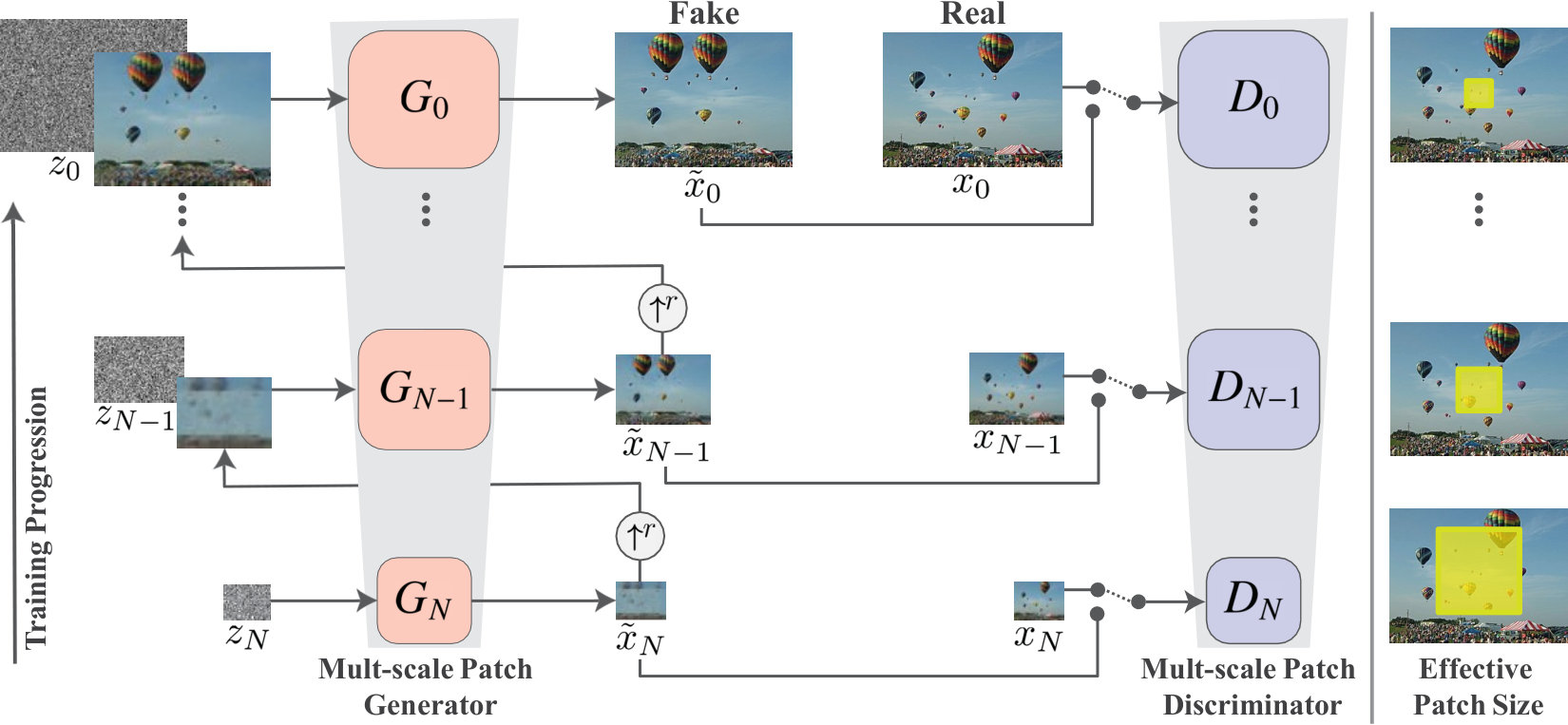 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7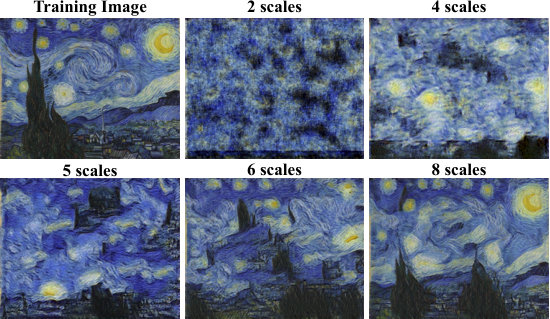 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10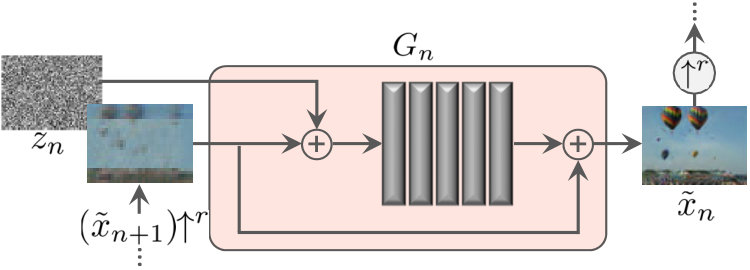 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13| 1st Scale | Diversity | Survey | Confusion |
|---|---|---|---|
| 0.5 | paired unpaired | ||
| 0.35 | paired unpaired | ||
| 1st Scale | SIFID | Survey | SIFID/AMT Correlation |
|---|---|---|---|
| 0.09 | paired unpaired | ||
| 0.05 | paired unpaired | ||
| External methods | Internal methods | ||||
|---|---|---|---|---|---|
| SRGAN | EDSR | DIP | ZSSR | SinGAN | |
| RMSE | 16.34 | 12.29 | 13.82 | 13.08 | 16.22 |
| NIQE | 3.41 | 6.50 | 6.35 | 7.13 | 3.71 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
SinGAN: Learning a Generative Model from a Single Natural Image· youtube
Taxonomy
MethodsConvolution · Dogecoin Customer Service Number +1-833-534-1729
SinGAN: Learning a Generative Model from a Single Natural Image
Tamar Rott Shaham
Technion
Tali Dekel
Google Research
Tomer Michaeli
Technion
Abstract
We introduce SinGAN, an unconditional generative model that can be learned from a single natural image. Our model is trained to capture the internal distribution of patches within the image, and is then able to generate high quality, diverse samples that carry the same visual content as the image. SinGAN contains a pyramid of fully convolutional GANs, each responsible for learning the patch distribution at a different scale of the image. This allows generating new samples of arbitrary size and aspect ratio, that have significant variability, yet maintain both the global structure and the fine textures of the training image. In contrast to previous single image GAN schemes, our approach is not limited to texture images, and is not conditional (i.e. it generates samples from noise). User studies confirm that the generated samples are commonly confused to be real images. We illustrate the utility of SinGAN in a wide range of image manipulation tasks.
1 Introduction
Generative Adversarial Nets (GANs) [19] have made a dramatic leap in modeling high dimensional distributions of visual data. In particular, unconditional GANs have shown remarkable success in generating realistic, high quality samples when trained on class specific datasets (e.g., faces [33], bedrooms[47]). However, capturing the distribution of highly diverse datasets with multiple object classes (e.g. ImageNet [12]), is still considered a major challenge and often requires conditioning the generation on another input signal [6] or training the model for a specific task (e.g. super-resolution [30], inpainting [41], retargeting [45]).
Here, we take the use of GANs into a new realm – unconditional generation learned from a single natural image. Specifically, we show that the internal statistics of patches within a single natural image typically carry enough information for learning a powerful generative model. SinGAN, our new single image generative model, allows us to deal with general natural images that contain complex structures and textures, without the need to rely on the existence of a database of images from the same class. This is achieved by a pyramid of fully convolutional light-weight GANs, each is responsible for capturing the distribution of patches at a different scale. Once trained, SinGAN can produce diverse high quality image samples (of arbitrary dimensions), which semantically resemble the training image, yet contain new object configurations and structures111Code available at: https://github.com/tamarott/SinGAN (Fig. 1).
Modeling the internal distribution of patches within a single natural image has been long recognized as a powerful prior in many computer vision tasks [64]. Classical examples include denoising [65], deblurring [39], super resolution [18], dehazing [2, 15], and image editing [37, 21, 9, 11, 50]. The most closley related work in this context is [48], where a bidirectional patch similarity measure is defined and optimized to guarantee that the patches of an image after manipulation are the same as the original ones. Motivated by these works, here we show how SinGAN can be used within a simple unified learning framework to solve a variety of image manipulation tasks, including paint-to-image, editing, harmonization, super-resolution, and animation from a single image. In all these cases, our model produces high quality results that preserve the internal patch statistics of the training image (see Fig. 2 and our project webpage). All tasks are achieved with the same generative network, without any additional information or further training beyond the original training image.
1.1 Related Work
Single image deep models
Several recent works proposed to “overfit” a deep model to a single training example [51, 60, 46, 7, 1]. However, these methods are designed for specific tasks (e.g., super resolution [46], texture expansion [60]). Shocher et al. [44, 45] were the first to introduce an internal GAN based model for a single natural image, and illustrated it in the context of retargeting. However, their generation is conditioned on an input image (i.e., mapping images to images) and is not used to draw random samples. In contrast, our framework is purely generative (i.e. maps noise to image samples), and thus suits many different image manipulation tasks. Unconditional single image GANs have been explored only in the context of texture generation [3, 27, 31]. These models do not generate meaningful samples when trained on non-texture images (Fig. 3). Our method, on the other hand, is not restricted to texture and can handle general natural images (e.g., Fig. 1).
Generative models for image manipulation
The power of adversarial learning has been demonstrated by recent GAN-based methods, in many different image manipulation tasks [61, 10, 62, 8, 53, 56, 42, 53]. Examples include interactive image editing [61, 10], sketch2image [8, 43], and other image-to-image translation tasks [62, 52, 54]. However, all these methods are trained on class specific datasets, and here too, often condition the generation on another input signal. We are not interested in capturing common features among images of the same class, but rather consider a different source of training data – all the overlapping patches at multiple scales of a single natural image. We show that a powerful generative model can be learned from this data, and can be used in a number of image manipulation tasks.
2 Method
Our goal is to learn an unconditional generative model that captures the internal statistics of a single training image . This task is conceptually similar to the conventional GAN setting, except that here the training samples are patches of a single image, rather than whole image samples from a database.
We opt to go beyond texture generation, and to deal with more general natural images. This requires capturing the statistics of complex image structures at many different scales. For example, we want to capture global properties such as the arrangement and shape of large objects in the image (e.g. sky at the top, ground at the bottom), as well as fine details and texture information. To achieve that, our generative framework, illustrated in Fig. 4, consists of a hierarchy of patch-GANs (Markovian discriminator) [31, 26], where each is responsible for capturing the patch distribution at a different scale of . The GANs have small receptive fields and limited capacity, preventing them from memorizing the single image. While similar multi-scale architectures have been explored in conventional GAN settings (e.g. [28, 52, 29, 52, 13, 24]), we are the first explore it for internal learning from a single image.
2.1 Multi-scale architecture
Our model consists of a pyramid of generators, , trained against an image pyramid of : , where is a downsampled version of by a factor , for some . Each generator is responsible of producing realistic image samples w.r.t. the patch distribution in the corresponding image . This is achieved through adversarial training, where learns to fool an associated discriminator , which attempts to distinguish patches in the generated samples from patches in .
The generation of an image sample starts at the coarsest scale and sequentially passes through all generators up to the finest scale, with noise injected at every scale. All the generators and discriminators have the same receptive field and thus capture structures of decreasing size as we go up the generation process. At the coarsest scale, the generation is purely generative, i.e. maps spatial white Gaussian noise to an image sample ,
[TABLE]
The effective receptive field at this level is typically of the image’s height, hence generates the general layout of the image and the objects’ global structure. Each of the generators at finer scales () adds details that were not generated by the previous scales. Thus, in addition to spatial noise , each generator accepts an upsampled version of the image from the coarser scale, i.e.,
[TABLE]
All the generators have a similar architecture, as depicted in Fig. 5. Specifically, the noise is added to the image , prior to being fed into a sequence of convolutional layers. This ensures that the GAN does not disregard the noise, as often happens in conditional schemes involving randomness [62, 36, 63]. The role of the convonlutional layers is to generate the missing details in (residual learning [22, 57]). Namely, performs the operation
[TABLE]
where is a fully convolutional net with 5 conv-blocks of the form Conv()-BatchNorm-LeakyReLU [25]. We start with kernels per block at the coarsest scale and increase this number by a factor of every scales. Because the generators are fully convolutional, we can generate images of arbitrary size and aspect ratio at test time (by changing the dimensions of the noise maps).
2.2 Training
We train our multi-scale architecture sequentially, from the coarsest scale to the finest one. Once each GAN is trained, it is kept fixed. Our training loss for the th GAN is comprised of an adversarial term and a reconstruction term,
[TABLE]
The adversarial loss penalizes for the distance between the distribution of patches in and the distribution of patches in generated samples . The reconstruction loss insures the existence of a specific set of noise maps that can produce , an important feature for image manipulation (Sec. 4). We next describe in detail. See Supplementary Materials (SM) for optimization details.
Adversarial loss
Each of the generators is coupled with a Markovian discriminator that classifies each of the overlapping patches of its input as real or fake [31, 26]. We use the WGAN-GP loss [20], which we found to increase training stability, where the final discrimination score is the average over the patch discrimination map. As opposed to single-image GANs for textures (e.g., [31, 27, 3]), here we define the loss over the whole image rather than over random crops (a batch of size ). This allows the net to learn boundary conditions (see SM), which is an important feature in our setting. The architecture of is the same as the net within , so that its patch size (the net’s receptive field) is .
Reconstruction loss
We want to ensure that there exists a specific set of input noise maps, which generates the original image . We specifically choose , where is some fixed noise map (drawn once and kept fixed during training). Denote by the generated image at the th scale when using these noise maps. Then for ,
[TABLE]
and for , we use .
The reconstructed image has another role during training, which is to determine the standard deviation of the noise in each scale. Specifically, we take to be proportional to the root mean squared error (RMSE) between and , which gives an indication of the amount of details that need to be added at that scale.
3 Results
We tested our method both qualitatively and quantitatively on a variety of images spanning a large range of scenes including urban and nature scenery as well as artistic and texture images. The images that we used are taken from the Berkeley Segmentation Database (BSD) [35], Places [59] and the Web. We always set the minimal dimension at the coarsest scale to px, and choose the number of scales s.t. the scaling factor is as close as possible to . For all the results, (unless mentioned otherwise), we resized the training image to maximal dimension px.
Qualitative examples of our generated random image samples are shown in Fig. 1, Fig. 6, and many more examples are included in the SM. For each example, we show a number of random samples with the same aspect ratio as the original image, and with decreased and expanded dimensions in each axis. As can be seen, in all these cases, the generated samples depict new realistic structures and configuration of objects, while preserving the visual content of the training image. Our model successfully preservers global structure of objects, e.g. mountains (Fig. 1), air balloons or pyramids (Fig. 6), as well as fine texture information. Because the network has a limited receptive field (smaller than the entire image), it can generate new combinations of patches that do not exist in the training image Furthermore, we observe that in many cases reflections and shadows are realistically synthesized, as can be seen in Fig. 6 and Fig. 1 (and the first example of Fig. 8). Note that SinGAN’s architecture is resolution agnostic and can thus be used on high resolution images, as illustrated in Fig. 7 (see 4Mpix results in the SM). Here as well, structures at all scales are nicely generated, from the global arrangement of sky, clouds and mountains, to the fine textures of the snow.
Effect of scales at test time
Our multi-scale architecture allows control over the amount of variability between samples, by choosing the scale from which to start the generation at test time. To start at scale , we fix the noise maps up to this scale to be , and use random draws only for . The effect is illustrated in Fig. 8. As can be seen, starting the generation at the coarsest scale (), results in large variability in the global structure. In certain cases with a large salient object, like the Zebra image, this may lead to unrealistic samples. However, starting the generation from finer scales, enables to keep the global structure intact, while altering only finer image features (e.g. the Zebra’s stripes). See SM for more examples.
Effect of scales during training
Figure 9 shows the effect of training with fewer scales. With a small number of scales, the effective receptive field at the coarsest level is smaller, allowing to capture only fine textures. As the number of scales increases, structures of larger support emerge, and the global object arrangement is better preserved.
3.1 Quantitative Evaluation
To quantify the realism of our generated images and how well they capture the internal statistics of the training image, we use two metrics: (i) Amazon Mechanical Turk (AMT) “Real/Fake” user study, and (ii) a new single-image version of the Fréchet Inception Distance [23].
AMT perceptual study
We followed the protocol of [26, 58] and performed perceptual experiments in 2 settings. (i) Paired (real vs. fake): Workers were presented with a sequence of 50 trials, in each of which a fake image (generated by SinGAN) was presented against its real training image for 1 second. Workers were asked to pick the fake image. (ii) Unpaired (either real or fake): Workers were presented with a single image for 1 second, and were asked if it was fake. In total, 50 real images and a disjoint set of 50 fake images were presented in random order to each worker.
We repeated these two protocols for two types of generation processes: Starting the generation from the coarsest (th) scale, and from scale (as in Fig. 8). This way, we assess the realism of our results in two different variability levels. To quantify the diversity of the generated images, for each training example we calculated the standard deviation (std) of the intensity values of each pixel over 100 generated images, averaged it over all pixels, and normalized by the std of the intensity values of the training image.
The real images were randomly picked from the “places” database [59] from the subcategories Mountains, Hills, Desert, Sky. In each of the 4 tests, we had 50 different participants. In all tests, the first 10 trials were a tutorial including a feedback. The results are reported in Table 3.1.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Yuki M Asano, Christian Rupprecht, and Andrea Vedaldi. Surprising effectiveness of few-image unsupervised feature learning. ar Xiv preprint ar Xiv:1904.13132 , 2019.
- 2[2] Yuval Bahat and Michal Irani. Blind dehazing using internal patch recurrence. In 2016 IEEE International Conference on Computational Photography (ICCP) , pages 1–9. IEEE, 2016.
- 3[3] Urs Bergmann, Nikolay Jetchev, and Roland Vollgraf. Learning texture manifolds with the periodic spatial GAN. ar Xiv preprint ar Xiv:1705.06566 , 2017.
- 4[4] Yochai Blau, Roey Mechrez, Radu Timofte, Tomer Michaeli, and Lihi Zelnik-Manor. The 2018 pirm challenge on perceptual image super-resolution. In European Conference on Computer Vision Workshops , pages 334–355. Springer, 2018.
- 5[5] Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 6228–6237, 2018.
- 6[6] Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale GAN training for high fidelity natural image synthesis. ar Xiv preprint ar Xiv:1809.11096 , 2018.
- 7[7] Caroline Chan, Shiry Ginosar, Tinghui Zhou, and Alexei A Efros. Everybody dance now. ar Xiv preprint ar Xiv:1808.07371 , 2018.
- 8[8] Wengling Chen and James Hays. Sketchygan: towards diverse and realistic sketch to image synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 9416–9425, 2018.
