TL;DR
This paper introduces an uncertainty-aware PCA method that extends traditional PCA to handle data with uncertainty, enabling more accurate dimensionality reduction and sensitivity analysis on probabilistic data.
Contribution
It generalizes PCA to multivariate probability distributions, providing a mathematically grounded approach that accounts for data uncertainty and offers new visualization tools.
Findings
Improved accuracy over sampling-based methods
Allows sensitivity analysis of data uncertainty
Provides closed-form propagation of normal distributions
Abstract
We present a technique to perform dimensionality reduction on data that is subject to uncertainty. Our method is a generalization of traditional principal component analysis (PCA) to multivariate probability distributions. In comparison to non-linear methods, linear dimensionality reduction techniques have the advantage that the characteristics of such probability distributions remain intact after projection. We derive a representation of the PCA sample covariance matrix that respects potential uncertainty in each of the inputs, building the mathematical foundation of our new method: uncertainty-aware PCA. In addition to the accuracy and performance gained by our approach over sampling-based strategies, our formulation allows us to perform sensitivity analysis with regard to the uncertainty in the data. For this, we propose factor traces as a novel visualization that enables to better…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2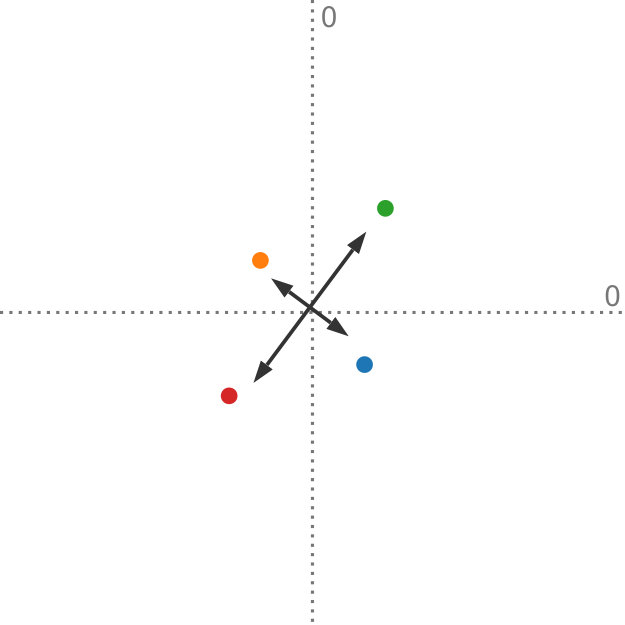 Figure 3
Figure 3 Figure 4
Figure 4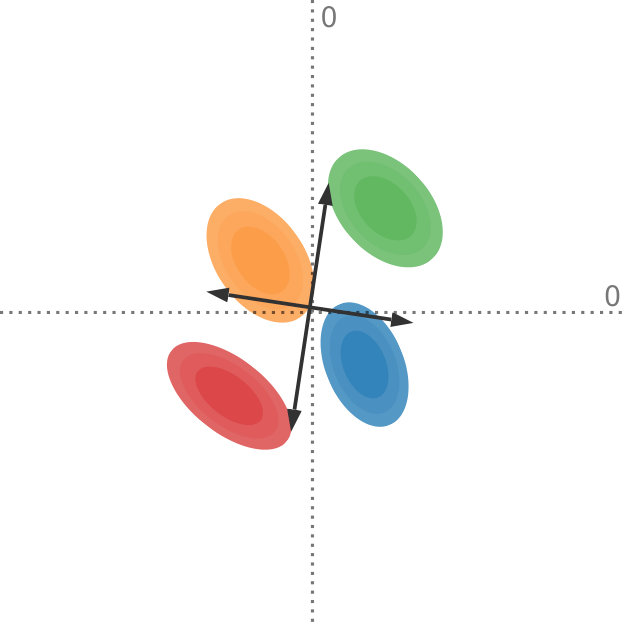 Figure 5
Figure 5 Figure 6
Figure 6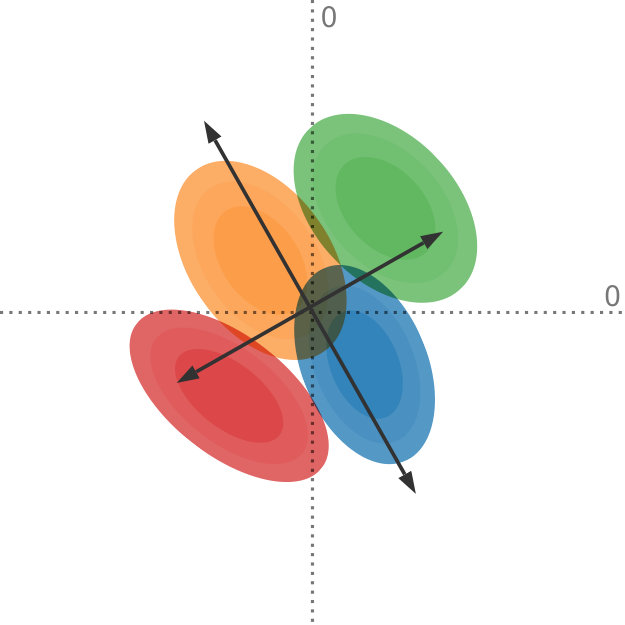 Figure 7
Figure 7 Figure 8
Figure 8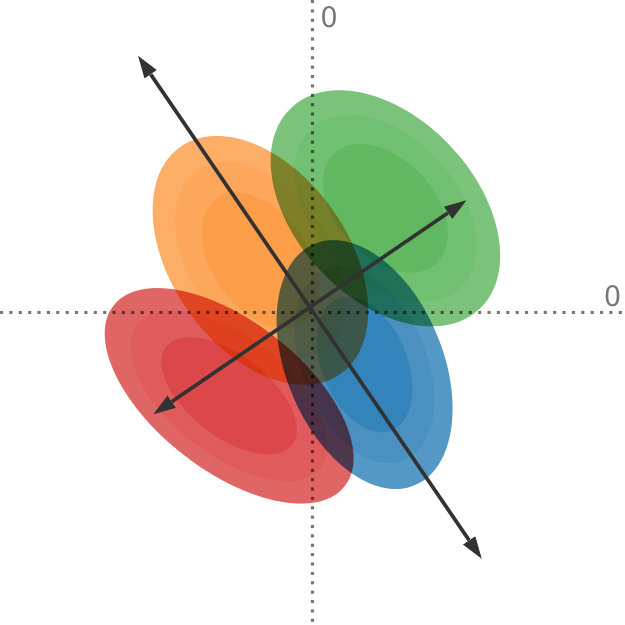 Figure 9
Figure 9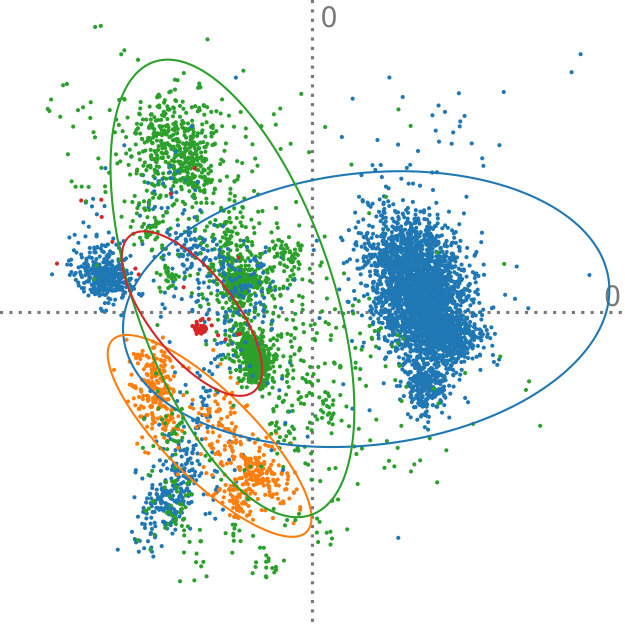 Figure 10
Figure 10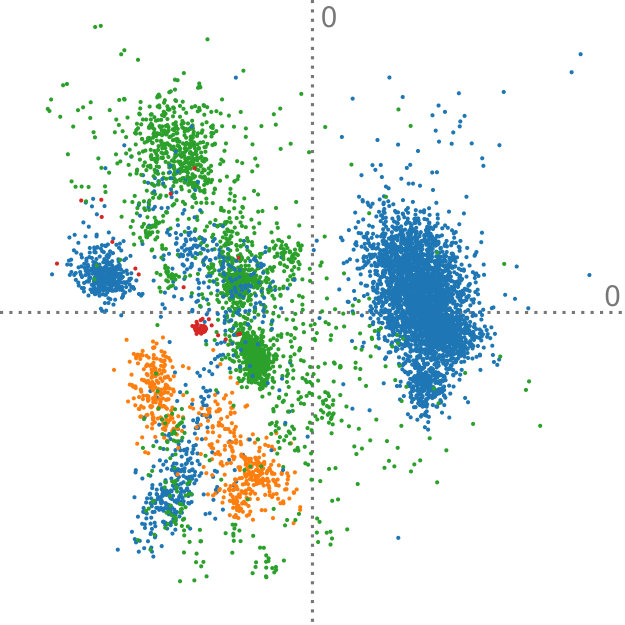 Figure 11
Figure 11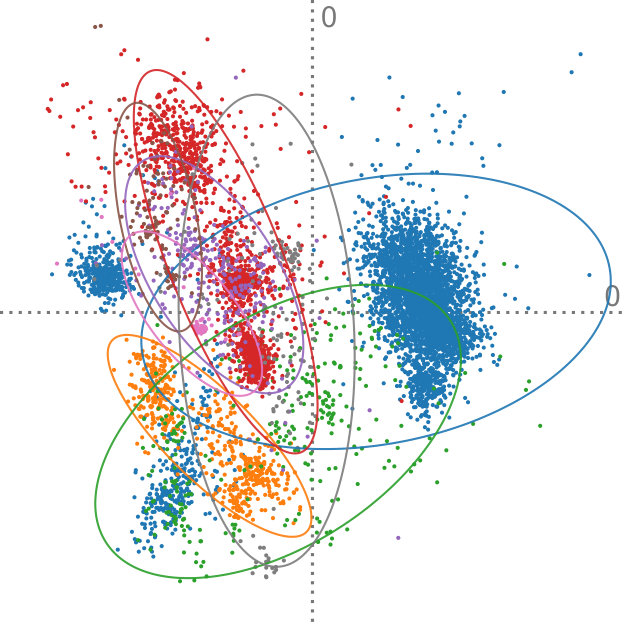 Figure 12
Figure 12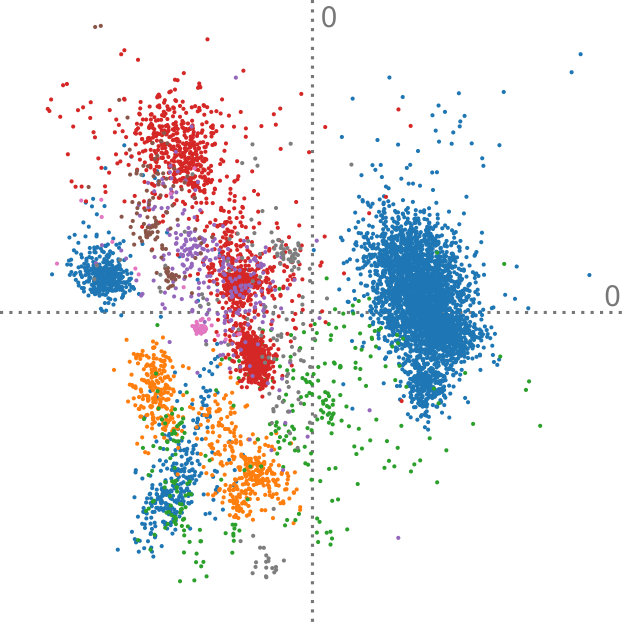 Figure 13
Figure 13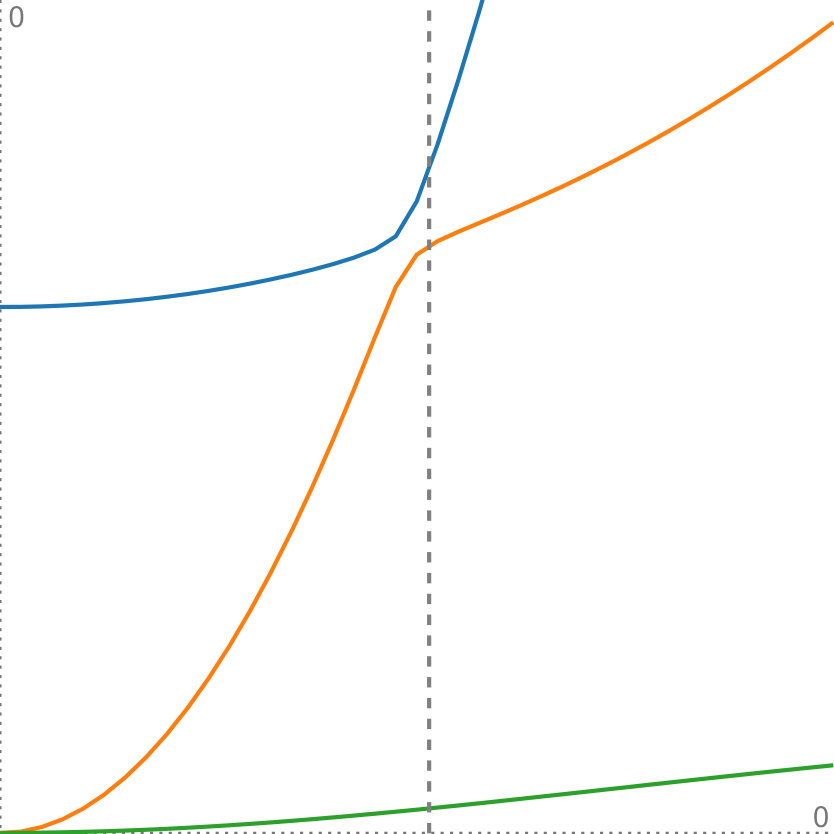 Figure 14
Figure 14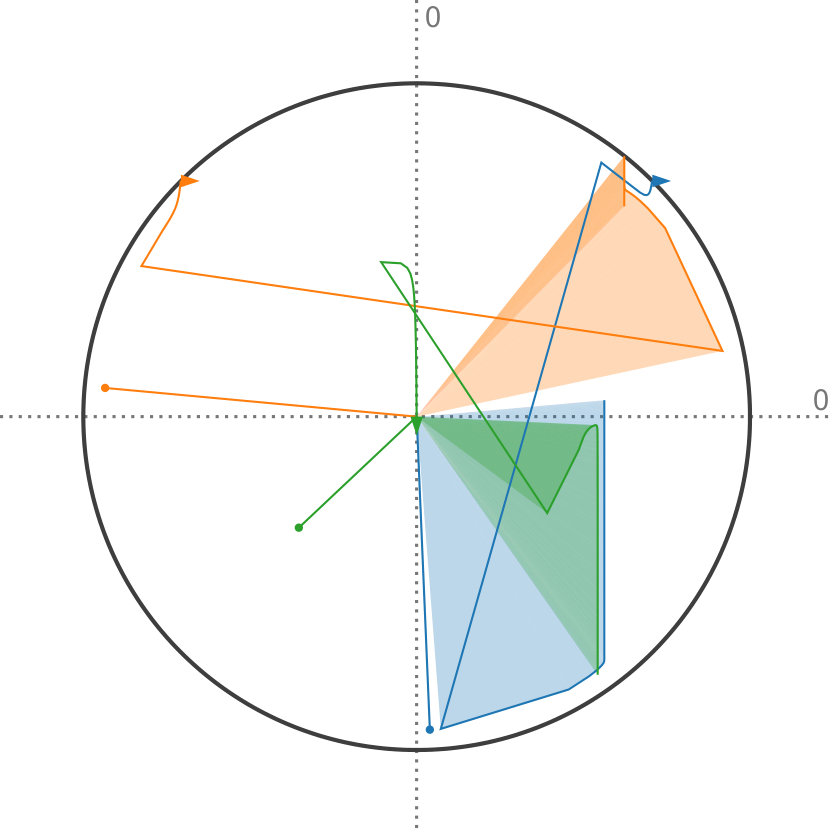 Figure 15
Figure 15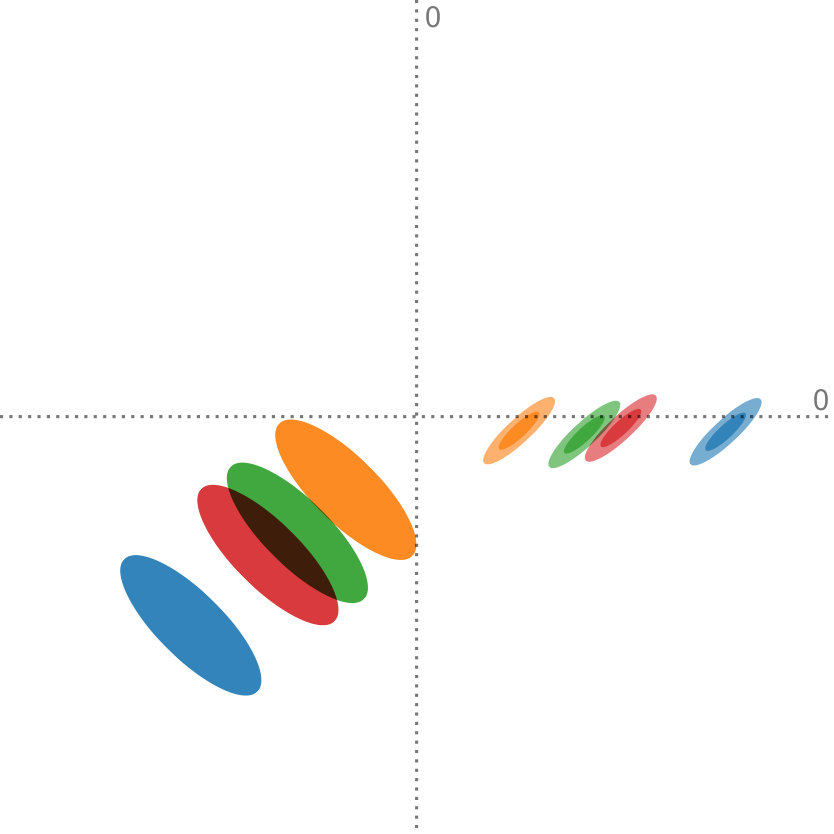 Figure 16
Figure 16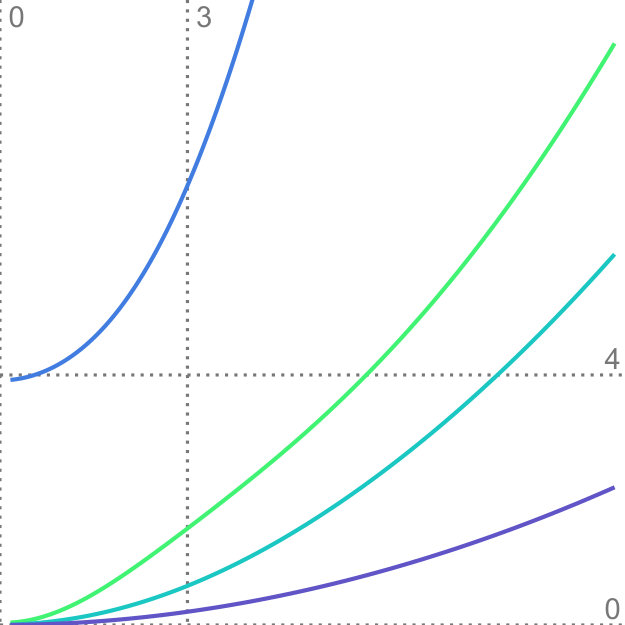 Figure 17
Figure 17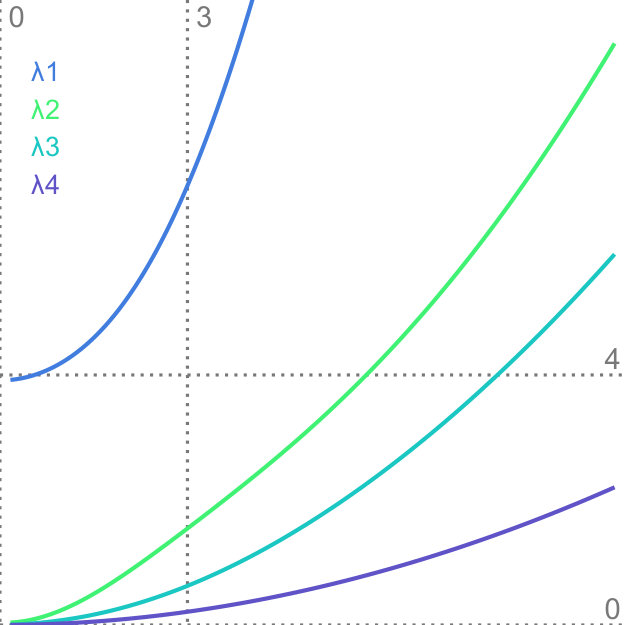 Figure 18
Figure 18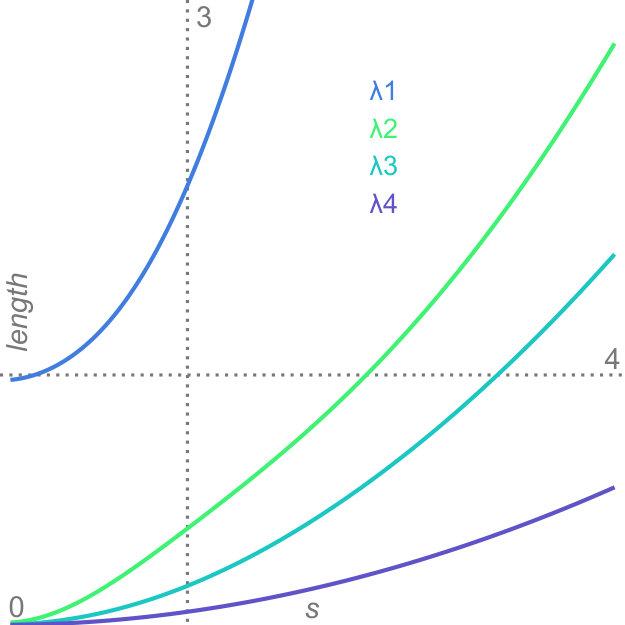 Figure 19
Figure 19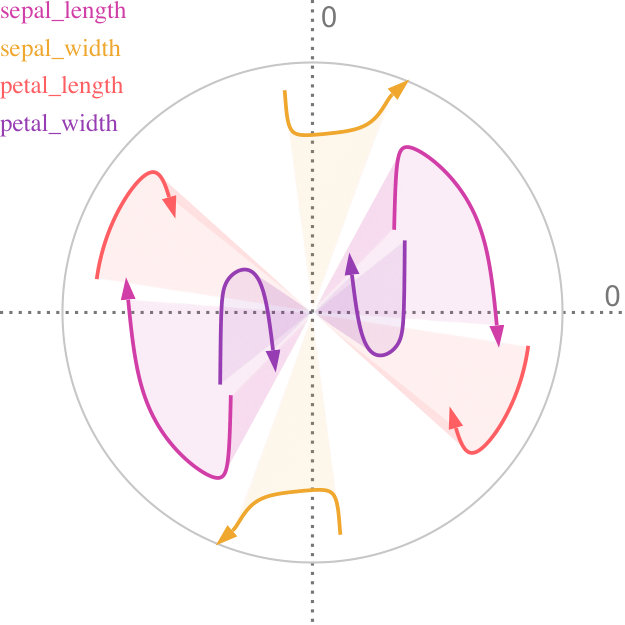 Figure 20
Figure 20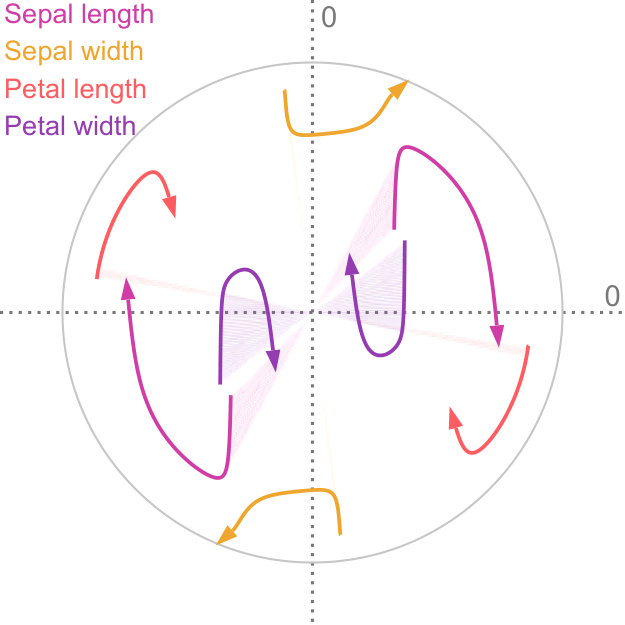 Figure 21
Figure 21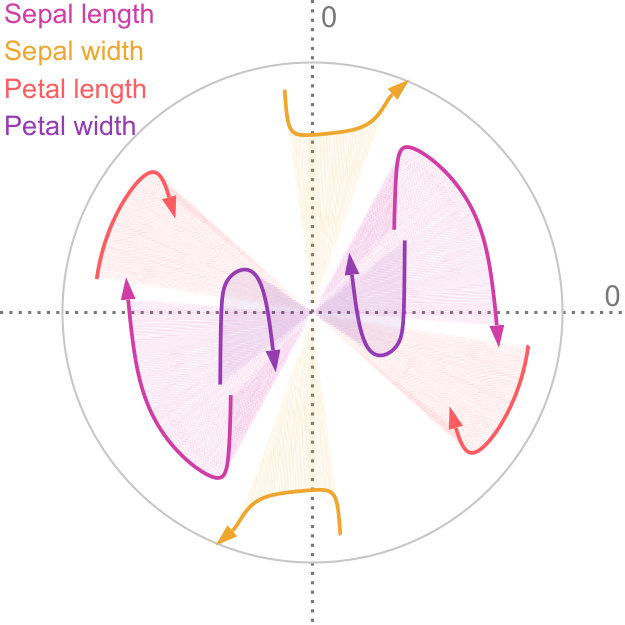 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24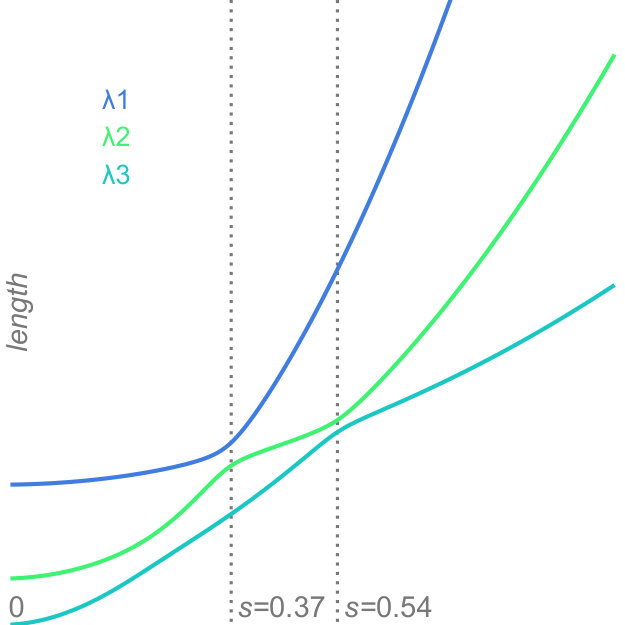 Figure 25
Figure 25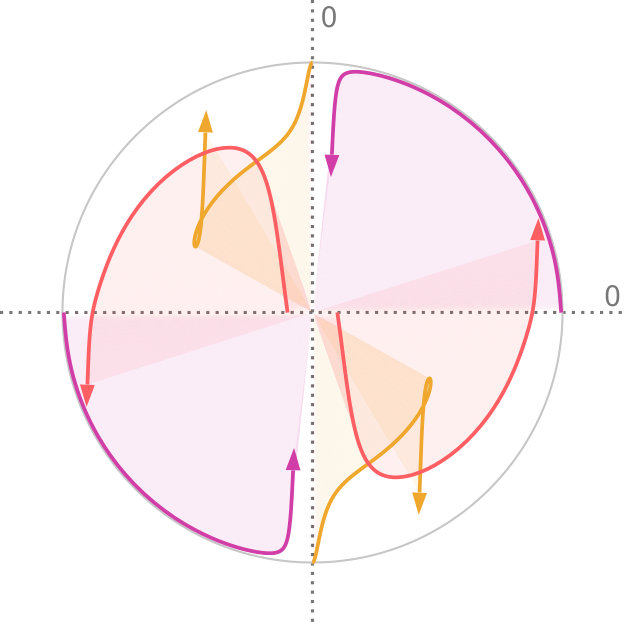 Figure 26
Figure 26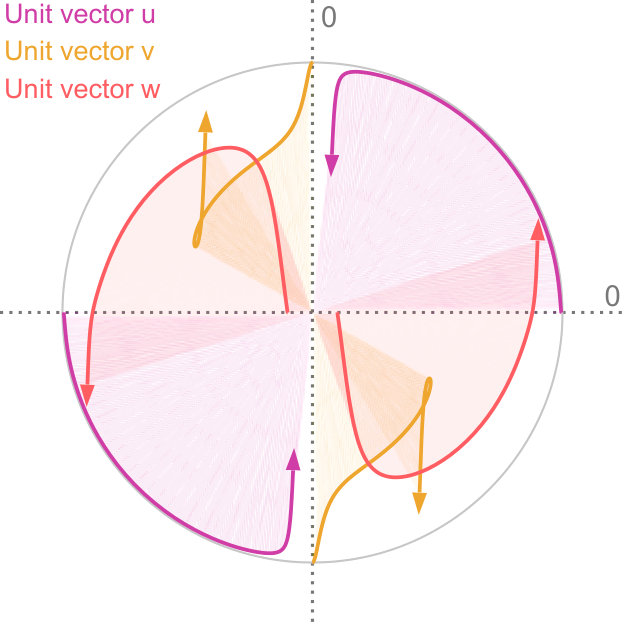 Figure 27
Figure 27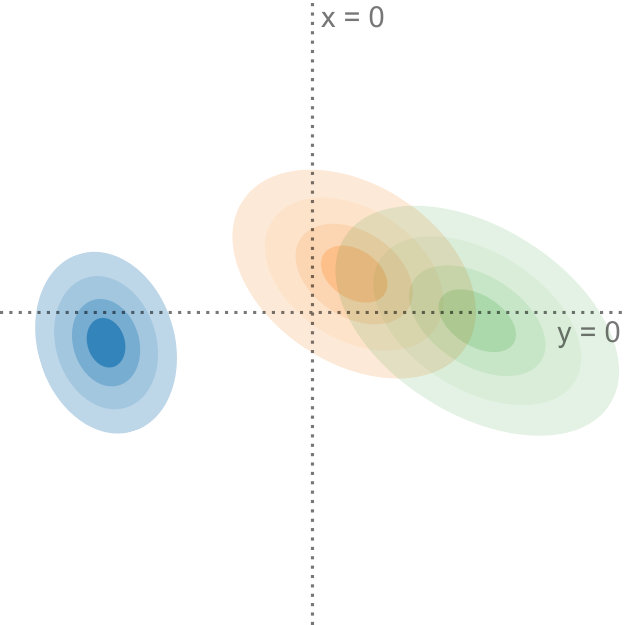 Figure 28
Figure 28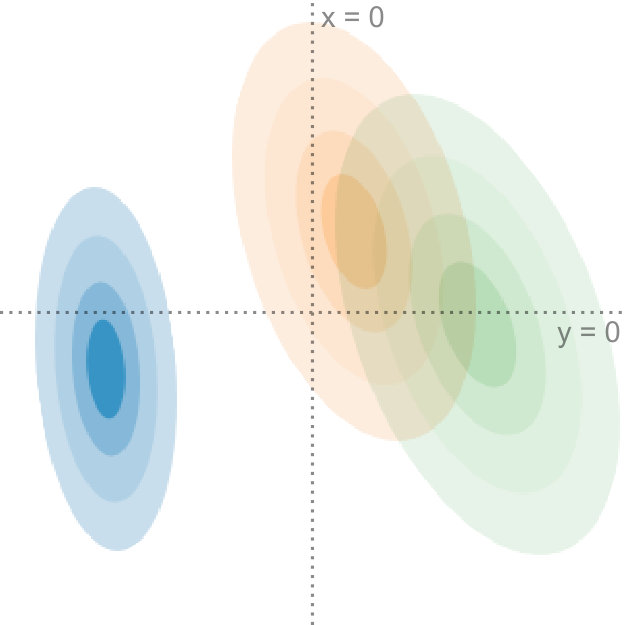 Figure 29
Figure 29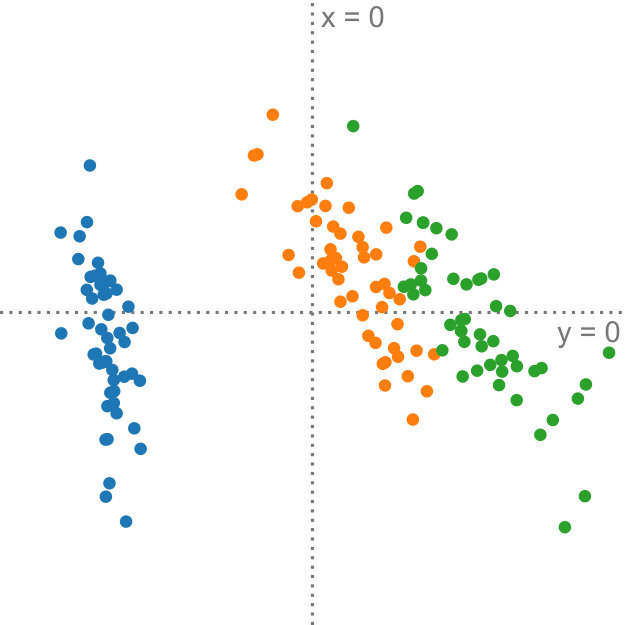 Figure 30
Figure 30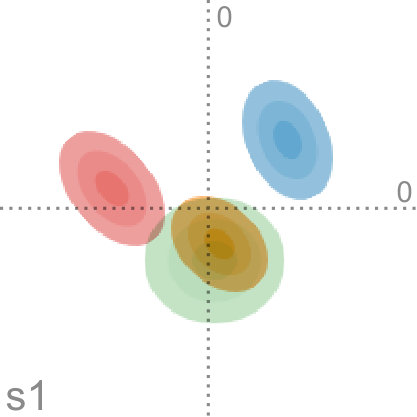 Figure 31
Figure 31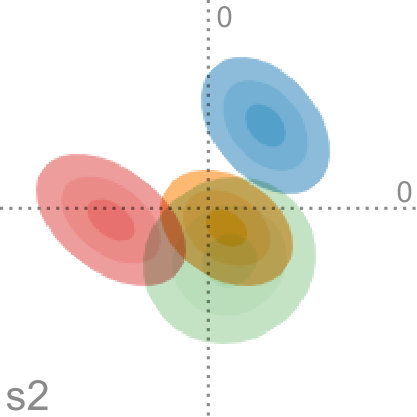 Figure 32
Figure 32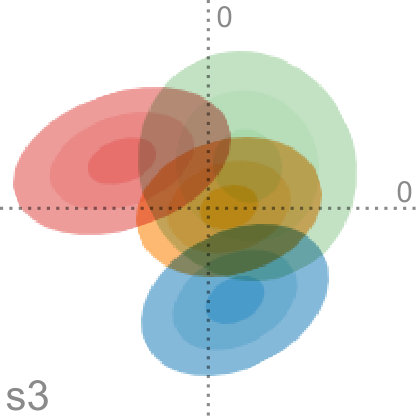 Figure 33
Figure 33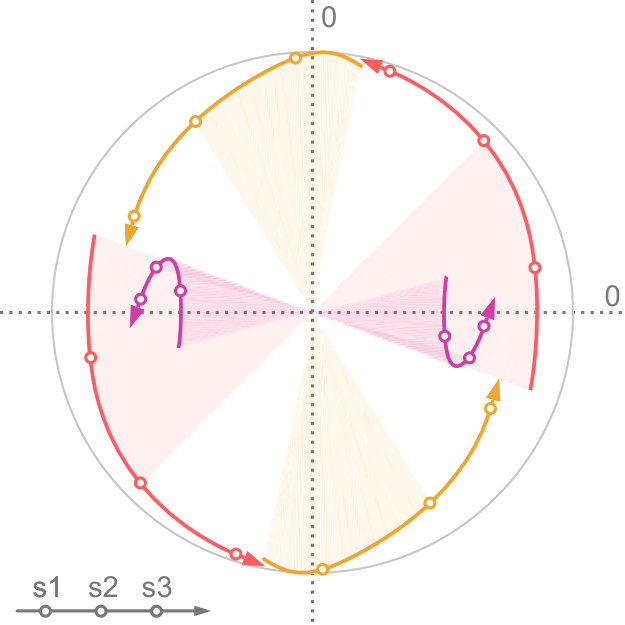 Figure 34
Figure 34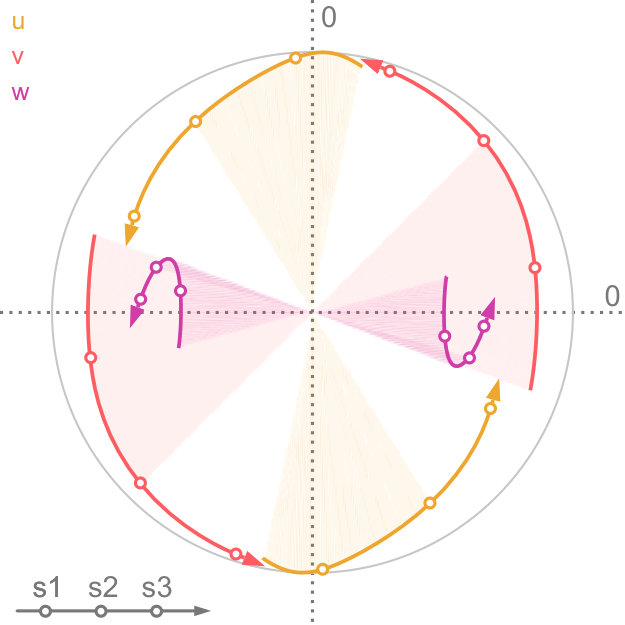 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37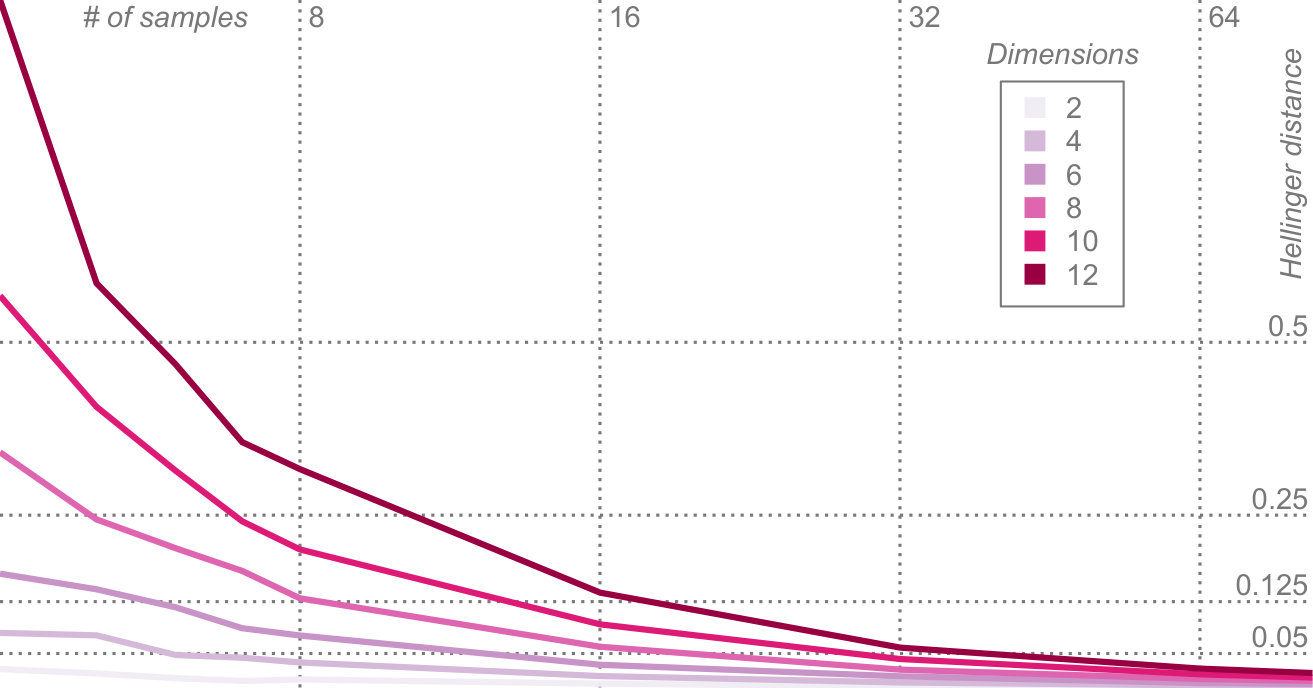 Figure 38
Figure 38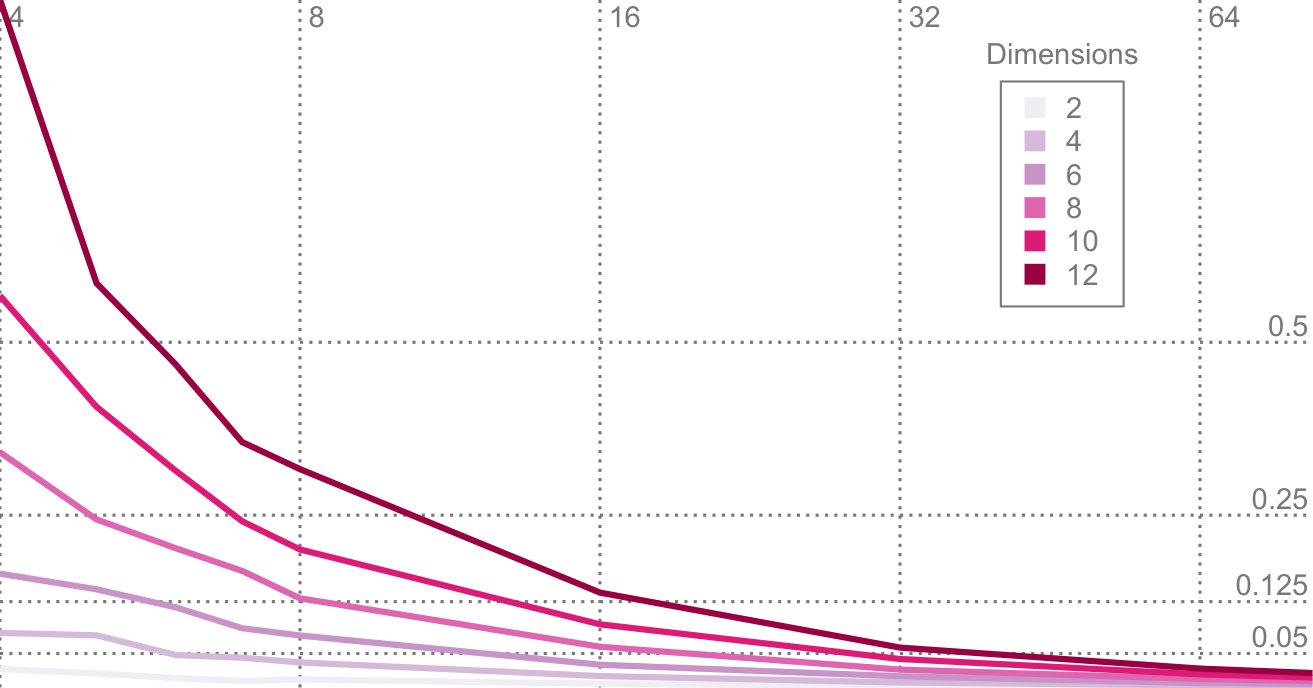 Figure 39
Figure 39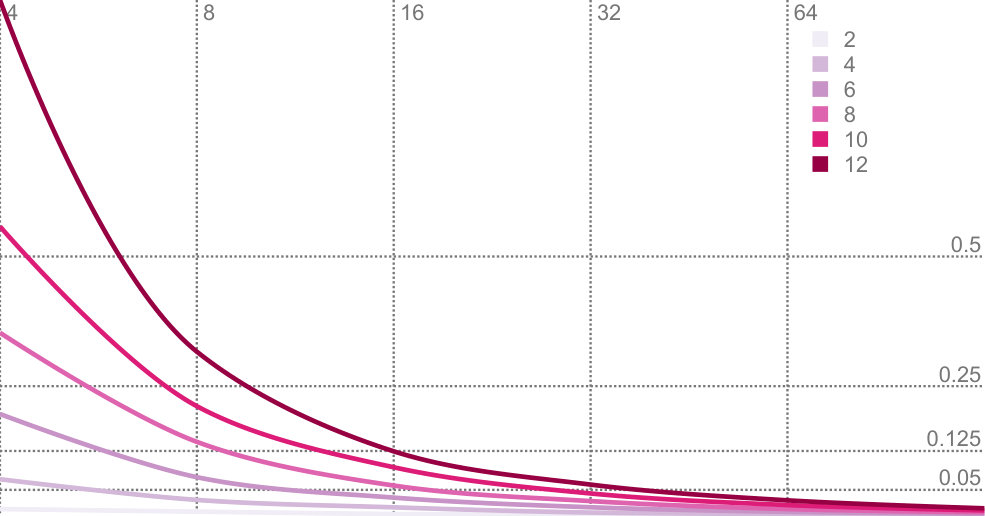 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsPrincipal Components Analysis
\preprinttext
To appear in IEEE Transactions on Visualization and Computer Graphics. \onlineid1124 \vgtccategoryResearch \vgtcpapertypealgorithm/technique
\authorfooter J. Görtler, T. Spinner, D. Streeb, and O. Deussen
are with the University of Konstanz, Germany.
E-mail: {firstname.lastname}@uni-konstanz.de D. Weiskopf is with the University of Stuttgart, Germany.
E-mail: [email protected]
Uncertainty-Aware Principal Component Analysis
Jochen Görtler
Thilo Spinner
Dirk Streeb
Daniel Weiskopf
and Oliver Deussen
Abstract
We present a technique to perform dimensionality reduction on data that is subject to uncertainty. Our method is a generalization of traditional principal component analysis (PCA) to multivariate probability distributions. In comparison to non-linear methods, linear dimensionality reduction techniques have the advantage that the characteristics of such probability distributions remain intact after projection. We derive a representation of the PCA sample covariance matrix that respects potential uncertainty in each of the inputs, building the mathematical foundation of our new method: uncertainty-aware PCA. In addition to the accuracy and performance gained by our approach over sampling-based strategies, our formulation allows us to perform sensitivity analysis with regard to the uncertainty in the data. For this, we propose factor traces as a novel visualization that enables to better understand the influence of uncertainty on the chosen principal components. We provide multiple examples of our technique using real-world datasets. As a special case, we show how to propagate multivariate normal distributions through PCA in closed form. Furthermore, we discuss extensions and limitations of our approach.
keywords:
Uncertainty, dimensionality reduction, principal component analysis, linear projection, machine learning
\teaser
[Regular PCA]
[s = 0.5]
[s = 0.8]
[s = 1.0]
Data uncertainty can have a significant influence on the outcome of dimensionality reduction techniques. We propose a generalization of principal component analysis (PCA) that takes into account the uncertainty in the input. The top row shows the dataset with varying degrees of uncertainty and the corresponding principal components, whereas the bottom row shows the projection of the dataset, using our method, onto the first principal component. In Figures (a) and (b), with relatively low uncertainty, the blue and the orange distributions are comprised by the red and the green distributions. In Figures (c) and (d), with a larger amount of uncertainty, the projection changes drastically: now the orange and blue distributions encompass the red and the green distributions.
Introduction
Dimensionality reduction techniques can be applied to visualize data with more than two or three dimensions, projecting the data to a lower-dimensional subspace. These projections should be meaningful so that the important properties of the data in the high-dimensional space can still be reconstructed in the low-dimensional representation. In general, dimensionality reduction techniques can either be linear or non-linear [21]. Linear dimensionality reduction has the advantage that properties and invariants of the input data are still reflected in the resulting projections. Another advantage of linear over non-linear methods is that they are easier to reason about because the subspace for the projection is always a linear combination of the original axes. Also, linear methods are usually efficient to implement [4].
Arguably the most frequently used linear method is principal component analysis (PCA). It is most effective if the dimensions of the input data are correlated, which is common. PCA uses this property and finds the directions of the data that contain the largest variance. This is achieved by performing eigenvalue decomposition of the sample covariance matrix that is estimated from the input. The input to conventional PCA is a set of points. However, we often encounter data afflicted with uncertainty or variances. According to Skeels et. [31], there are several sources for this uncertainty. Measurement errors might arise from imperfect observations. In many cases, we rely on data that is the output of predictive models or simulations that provide probabilistic estimations. And lastly, uncertainty is inevitable when aggregating data, as some of the original information has to be discarded. The natural way to model these instances of uncertain data is by using probability distributions over possible realizations of the data.
In this paper, we derive a generalization of PCA that directly works on probability distributions. Like regular PCA, our new method of uncertainty-aware PCA solely requires that the expected value and the covariance between dimensions of these distributions can be determined—no higher-order statistics are taken into account. This uncertainty of the input data can have a strong impact on the resulting projection, because it directly influences the magnitude of the eigenvalues of the sample covariance matrix.
In addition to extending PCA, we introduce factor traces as a visualization that shows how the projections of the original axes onto the subspace change with a varying degree of uncertainty. This enables to perform a sensitivity analysis of the dimensionality reduction with respect to uncertainty and gives an interpretable representation of the linear projection that is performed. Our paper has four main contributions:
- •
a closed-form generalization of PCA for uncertain data,
- •
sensitivity analysis of PCA with regards to uncertainty in the data,
- •
factor traces as a new visualization technique for the sensitivity of linear projections, and
- •
establishing a distance metric between principal components.
In Figure Uncertainty-Aware Principal Component Analysis, we compare our method to regular PCA and illustrate why it is important to consider the uncertainty in the data when determining the projection: it shows a projection of four bivariate probability distributions, each with varying levels of uncertainty, that are projected onto a single dimension. For input with low uncertainty, the red and green data points define the extent of the projected data. With increasing uncertainty and due to the shape of the underlying distributions, the projection looks quite different: now the orange and blue data points mark the extent of the projected data. This change in the projection shows that it is important to incorporate the uncertainty information adequately into our dimensionality reduction algorithms. Although all distributions in this example are Gaussian, our method works on any probability distribution for which the expected value and the covariance can be determined.
1 Related Work
The survey by Nonato and Aupetit [21] offers a broad overview of dimensionality reduction from a visualization perspective. Principal component analysis [23] is one of the oldest and most popular techniques. It is often applied to reduce data complexity, which is a common task in visualization. By construction, PCA yields the linear projection that retains the most variance of the input data in the lower-dimensional subspace. Probabilistic PCA [36] extends traditional PCA by adding a probabilistic distribution model. In contrast to our method, an unknown isometric measurement error is assumed. Likewise, many extensions have been introduced to PCA [16, 3]. For example, Kernel PCA [28] enables non-linear projections by first transforming objects into a higher-dimensional space in which a good linear projection can be found. Techniques such as Bayesian PCA [2, 22, 20], and the method introduced by Sanguinetti et al. [26] focus on estimating the dimensionality of the lower-dimensional space. Robust PCA methods [1, 39, 40] target datasets with outliers. Different extensions to PCA have also been developed in the context of fuzzy systems. The technique described by Denoeux and Masson [5] applies PCA to fuzzy numbers by training an artificial neural network that incorporates the different possible realizations for each fuzzy number. Giordani and Kiers [10] provide an overview of methods that can be used to apply PCA to interval data. In contrast, we extend traditional PCA to an uncertainty-aware linear technique for exploratory visualization that works on general probability distributions.
Next to PCA, Factor Analysis (FA) [32] is a well known linear method. Its goal is to identify (not necessarily orthogonal) latent variables underlying a higher-dimensional space of measurements. Factor Analysis models measurement errors, yet constraining the errors to be uncorrelated is common. One reason for this is that modeling correlated errors can be problematic if the actual errors are unknown [11]. In our description, we assume that all errors are known, or can at least be estimated. Many other linear techniques such as Classical Multi-Dimensional Scaling [38] and Independent Component Analysis [13] are covered by Cunningham and Ghahramani [4]. To the best of our knowledge, none of them can deal with data that has explicitly encoded (measurement) errors.
Liu et al. [19] provide an overview of the visualization and exploration of high-dimensional data. The Star Coordinates [15] visualization technique, for example, provides interactive linear projections of high-dimensional data. Recently measure-driven approaches for exploration have gained interest, e.g., by Liu et al. [18] as well as by Lehmann and Theisel [17]. Visualizing the projection matrix of linear dimensionality reduction techniques (instead of projections of the data) can be done with factor maps or Hinton diagrams [12, 2].
Advances in visualizing uncertainty and errors often originate from the need to represent prediction results [33]. More generally, visualizing Gaussian distributions by a set of isolines is a common practice. In this paper, we aim at bringing uncertainty-aware dimensionality reduction and visualization together. For example, our technique can be used to extend Wang et al.’s [42] approach to visualizing large datasets by allowing a fast approximate visualization of clusters. Furthermore, correlated probability distributions are often the result of Bayesian inference, which is widely used in prediction tasks, where the result is always a probability distribution. In this domain, Gaussian processes [24] are a prime example of correlated uncertainty.
Lately, there has been a push in the visualization community to gain a better understanding of the intrinsic properties of projection methods. However, the focus mainly has been on exploring non-linear approaches. For instance, Schulz et al. [27] propose a projection for uncertainty networks based on sampling different realizations of the data and investigate potential effects of uncertainty. With DimReader, Faust et al. [8] address the problem of explaining non-linear projections. Their technique uses automatic differentiation to derive a scalar field that encodes the sensitivity of the projected points against perturbations. Wattenberg et al. [43] examine how the choice of parameters affects the projection results of t-SNE. Similarly, Streeb et al. [35] compare a sample of (non-)linear techniques and influences of their parameters on projections.
2 Statistical Background
The typical way to model uncertainty is by using probability distributions over the data domain. This approach is well established in other fields, such as measurement theory and Bayesian statistics. Before getting to the gist of our method, we want to give a quick overview of the statistical background we need for our technique. More details can be found in the textbook by Wickens [44].
2.1 Random Variables and Random Vectors
A random variable is used to describe the values of possible outcomes of a random phenomenon. It is usually defined as a real-valued scalar . Probability distributions are used to assign a probability (density) to each outcome of the random variable—both concepts are closely tied together. To extend this one-dimensional case to multi-dimensional phenomena, we can group several random variables into a multivariate random variable, which is also called a random vector. Throughout this article, we denote random vectors by , with . Analogously, the corresponding multivariate probability distributions span the same -dimensional domain. An interesting property arises from the fact that can be viewed as a position vector: it can be manipulated using affine transformations. These transformations can, for example, be used to scale, translate, or rotate . Generally, an affine transformation has the form . It consists of a linear transformation and a translation vector that together transform an input to obtain a new random vector , which can be described using a modified distribution.
2.2 Summary Statistics
For many applications, it is helpful to summarize the probability distributions into simpler, yet characteristic quantities. Ideally, these simple terms still allow us to make statements about the shape and properties of the original distribution. Such descriptions are called summary statistics. The most well-known statistics are the first and second moments, which, in the real-valued case, are also called mean and variance. They are used to describe the center of gravity and the spread of a distribution. For multi-dimensional data, the mean is a -dimensional vector, and the variance is replaced by the covariance that also reflects correlations between each of the components. Because the covariance describes these relationships, it has the form of a symmetric matrix. Every covariance matrix is always positive semi-definite—we provide a detailed discussion in the appendix.
For some distributions, these two summary statistics are explicitly defined. The multivariate normal (MVN) distribution, which is widely used in many domains, has an interesting property—it is completely determined by its first and second moments. Therefore, if follows an MVN distribution, with mean and covariance matrix , we write:
[TABLE]
Sometimes our random vector is given by a set of samples from an arbitrary distribution. Given this set, we can estimate the first and second moments of using the sample mean , which is defined in terms of the expected value :
[TABLE]
and the sample covariance matrix :
[TABLE]
The term is the expected outer product and can be approximated as follows:
[TABLE]
In the previous section, we explained how to transform a random vector using affine transformations. Transforming in this way also influences the summary statistics. For the mean, it holds that:
[TABLE]
In a similar fashion, we can transform the covariance matrix:
[TABLE]
Both equations follow from the linearity of the expected value operator . Intuitively, only the mean of is influenced by the translation . The covariance matrix, in contrast, is invariant to translation. The reason for this is that the covariance only captures the relative variance of each component because it is always centered around the sampling mean by the term . In the following section, we will use these above definitions to formulate our method.
3 Method
We have motivated the different causes of uncertainty in the input data in the introduction. In this part, we describe the necessary adaptions to the framework of PCA that are required to handle uncertainty, as modeled in the previous section. We will first show how to adapt the computation of the covariance matrix to work on probability distributions, which is a fundamental part of our technique. Then, we will describe how this fits into the context of regular PCA. Afterward, we will demonstrate how our method allows us to perform PCA analytically on uncertain data, using multivariate normal distributions as an example. Finally, we will show that our approach is a generalization of regular PCA. This allows us to combine certain and uncertain data within the same mathematical framework and provides us with the foundation for sensitivity analysis, as described in Section 4.
3.1 Model
PCA is used to find the directions of the data with the largest variance by looking at the covariance of the input. We adopt this concept to arbitrary distributions to handle uncertain data. For our method, we only require that the expected value and the covariance can be determined for each of the distributions. It is important to note that this does not imply that the input distributions necessarily have to follow a Gaussian distribution. We want to illustrate this for a small example: let us consider an input distribution made up of two clusters spread about its mean. Then, the covariance of the distribution still captures the spread of the data, namely along the direction of the location of the two clusters. So even though the distribution might not be sufficiently described only by mean and covariance, its overall extent is still represented adequately using these first- and second-order statistics. In Section 5.3, we will show an example of a dataset that exhibits this property. And in Section 7.3, we will discuss its implications on the resulting projection.
It is important that there is an established relationship between the units of the original axes for PCA to yield a meaningful result. The usual approach to achieve this is to normalize the input data accordingly. The same preprocessing step needs to be performed for our method. For probability distributions, this can be performed using affine transformations, as outlined above.
3.2 Uncertain Covariance Matrices
As we have mentioned before, the goal of our method is to perform PCA on a set of probability distributions that are used to model the uncertainty, as described in Section 2. Formally, we represent this collection of distributions as random vectors . For each of these random vectors, we require that we can determine its expected value and its pairwise covariance . It is important to note that can conceptually be interpreted as a random vector of second order, as its components are random vectors themselves.
Our approach adapts the computation of the covariance matrix to account for uncertainty in the data. Regular PCA works on a set of points. Therefore, the covariance matrix can be understood as the computation of the expected products of deviations of these points from the sample mean. In contrast, our approach works on a set of random vectors, which changes the problem in the following way: Because of the uncertainty in the data, we do not know the actual deviation of each random vector from the overall sample mean. But we can determine the deviation that is to be expected for each of the distributions. We do this conceptually by integrating over the deviation of all possible realizations of each probability distribution. In the framework of PCA, where only the first- and second-order moments are taken into account, it turns out we do not even have to evaluate this integral: we can derive the covariance matrix directly from the summary statistics.
From Equation 1, we can derive a property of the covariance matrix that we will need later on: it gives us a way to compute the expected outer product of a particular random vector with itself. We achieve this by solving Equation 1 for :
[TABLE]
For distributions, we use the following equation, which is akin to computing the expected products of expected deviations. To avoid confusion with the expected value of each random vector , we denote the expectation operator that stems from the covariance method with :
[TABLE]
We can expand this further by making use of Equation 3:
[TABLE]
[TABLE]
The different terms in Equation 4 have particular interpretations. First, we recognize that the term is the same as performing regular PCA on the means of each of the distributions. The second term computes the average covariance matrix over all random vectors:
[TABLE]
It reflects the uncertainty that each random vector has and how these uncertainties influence the overall covariance in the dataset—it is also the major difference between our method and regular PCA, which cannot handle probability distributions. The last term is called centering matrix and also part of regular PCA. It consists of the outer product of the empirical mean of our dataset. The empirical mean of our dataset can be computed as follows:
[TABLE]
Algorithm 1 provides the corresponding pseudocode for Equation 4. The proof that Equation 4 yields a symmetric, positive semi-definite matrix and therefore is an actual covariance matrix can be found in the Appendix of this document.
3.3 PCA Framework and Diagonalization
Now that we have constructed the covariance matrix while respecting the uncertainty, we can continue with the remaining steps of the PCA algorithm. After setting up the covariance matrix, we retrieve its eigenvalues and corresponding eigenvectors . This can be done using eigenvalue decomposition:
[TABLE]
Let be the desired target number of dimension for our dimensionality reduction. We then choose the largest by their corresponding eigenvalue , yielding principal components . We can then project each distribution onto the subspace that is spanned by these principal components , where is a linear projection that can be described using a linear transformation.
It is important to note that eigenvalues and eigenvectors have certain characteristics that complicate their analysis. The orientation of is not completely defined, therefore . In practice, the computation of is performed numerically, which can lead to instabilities and rounding errors. We will discuss the impact of this on the analysis of linear projections in Section 4.
3.4 Linear Transformation of MVN Distributions
Now that we have defined the projection , we need to transform each distribution into the subspace . In the following, we will describe how this can be carried out for multivariate normal distributions, as they are often used to model errors or uncertainty in the data. As mentioned in Section 1, several existing techniques already model uncertainty using MVN distributions. In these works, the distributions are usually described using an error model, which means that a measurement is disturbed by an error term . This is commonly written as:
[TABLE]
To retrace the closed-form derivation of the covariance matrix that we described in Section 3.2, it is easier to think of this error in terms of a single random vector that can be equivalently defined as follows:
[TABLE]
Figure 1 shows examples of different error models that can be created depending on the shape of . We also visualize the corresponding principal components of the dataset, determined by using our method.
The dimensionality of is . To perform the actual projection, we assume that are unit vectors, and write them in a column matrix :
[TABLE]
It is important to note that a projection is an affine transformation, as defined in Section 2. Accordingly, we can project a normal distribution as follows:
[TABLE]
The resulting distribution remains multivariate normally distributed.
3.5 Reduction to Regular PCA
In this section, we will show that our method is a mathematical generalization of conventional PCA. The main difference between the two algorithms lies in the setup of the covariance matrix, as described by Equation 4. Our method includes an additional term that reflects the uncertainty of each input (Equation 5). To reduce our formulation to regular PCA, we will scale the covariance of each of the distributions by a constant factor . This decreases the spread of the covariance matrix, and because of this, implicitly reduces the amount of uncertainty within each distribution.
To scale the covariance matrices, we will again make use of the properties of affine transformations for covariance matrices, as discussed in Section 2. Let be a scale matrix that has the form . We can now use Equation 2 to scale :
[TABLE]
In practice, we can make use of the fact that a scale matrix is always a diagonal matrix. In our case, each diagonal entry is equal to , therefore . This allows us to simplify the equation above even further:
[TABLE]
Figure 3 shows a set of multivariate normal distributions, all scaled with different weights. Another property of this description is that we can use to interpolate between the certain and uncertain representation of our data. Algorithm 1 shows how to incorporate the scaling factor into the computation of the covariance matrix. In the next section, we will use this fact to investigate how much the uncertainty influences the resulting projection.
4 Sensitivity Analysis
We have shown in previous sections that uncertainty in the input can have a strong influence on the resulting set of principal components. Therefore, to better understand this relationship, we investigate to what amount the dimensionality reduction depends on the shape of each of the probability distributions. In Section 3.5, we have shown that our method is a generalized formulation of conventional PCA. We achieved this by scaling the covariances of each distribution with a factor that describes the importance of the uncertainty. Now, we will leverage this model to show how the fitted projection varies for different scaling factors in the interval . This interval can be split up in two parts to investigate two different scenarios. For , we can interpolate between uncertainty-aware PCA and regular PCA. Conversely, by choosing we can extrapolate what the projection would look like if the uncertainty were higher. In the following, we propose a novel visualization technique that is tailored to analyze the effects of different scaling factors and hence influences of different levels of uncertainty.
4.1 Factor Traces
Factor Analysis shares many similarities with PCA and is often used for the explanatory analysis of multi-dimensional datasets. The individual latent factors, akin to principal components, are usually represented using factor maps. To create a factor map, the unit vectors of each dimension in feature space are projected according to the latent factors of the data [34]. We extend this technique to enable the exploration of the effects of uncertainty on PCA.
Factor maps visualize static latent information that is hidden in the input data. However, we are interested in visualizing the progression of uncertainty. We do this by looking at the factor traces that are described by the change of principal components under the varying degree of uncertainty. In particular, we perform sensitivity analysis by continuously scaling the covariances of the distributions from the original dataset using as a scaling factor, as described above. Figure 4 shows an example of factor traces of a three-dimensional dataset. For each a different subspace is chosen. As a result, the projected unit vectors describe a trace in the image space. Thereby, we obtain a compact representation of the analogous transformation of the feature space coordinate system. As we mentioned before, there are two intervals for that are of interest for the analysis of the sensitivity with respect to the uncertainty. The interval is highlighted by shading the area under the trace. In contrast, for the interval we only show the trace to avoid visual clutter, and we use an arrowhead to represent .
In practice, we progressively sample in the interval using a hyperbolic function. At the heart of principal component analysis is the decomposition of the covariance matrix into its eigenvalues and eigenvectors. This entails various challenges for the interpretation of the projection. While the eigenvectors of a positive semi-definite matrix are always orthogonal to each other, their orientation is ambiguous as their sign can change. In the resulting sequence, it can happen that the sign of and flips. This, in return, leads to a mirrored projection. We account for this in factor traces by providing both projections of the unit vectors of the original axes. For example, this becomes apparent when looking at the purple trace in Figure 4. We discuss the limitations of this approach in Section 7.
4.2 Interpretation
Factor traces simultaneously visualize different properties of the original dataset with respect to the corresponding projection: the length of each trace describes how strongly each original axis is affected by the uncertainty in the data, whereas the distance of each part of the trace to the center depicts the linear combination of the original unit vectors that define the projection. Factor traces also offer a way to analyze the robustness of the resulting projections with respect to uncertainty. The covariance matrices and the overall shape of the data determine the corresponding eigenvalues. Because the principal components are sorted by their eigenvalues and only the largest eigenvalues are chosen, their respective values also have a large effect on the resulting projection. Figure 5 shows factor traces of two different datasets, together with plots of their eigenvalues. With an increasing , sometimes the distance between two eigenvalues decreases more and more. In some cases, it appears that the eigenvalues will cross, but instead, they will eventually start to move away from each other again. This effect closely resembles avoided crossings, a quantum phenomenom [41]. The reason for this effect is that two eigenvalues coalesce as they end up with the same length [29]. Eigenvalues that avoid crossing manifest in distinctive bumps in their corresponding eigenvalue plots, which can be seen in Figure 5d. The first dataset in Figure 5 does not contain any avoided crossings. By contrast, Figure 5c and Figure 5d show a three-dimensional dataset with two bumps (highlighted by the dotted lines). Avoided crossings make it difficult to reason about the behavior of the eigenvectors and consequently the resulting projection in these points. In some cases—Figure 5c, for example—we can observe sharp turns in the corresponding factor traces. Here, the avoided crossing is between and .
In conjunction with PCA, factor traces can aid the exploratory analysis of datasets by giving insights into the behavior of the principal components under uncertainty. Apart from showing how the projection changes under uncertainty, factor traces can help gauge how robust and hence how trustful the projected view of the dataset is. While our approach can aid in assessing projections, the visualization of high-dimensional data involving a large variety of distributions remains a difficult challenge. Generally, factor traces work well for datasets with up to six original dimensions. Above this limit, the representation becomes more difficult to understand due to overplotting. As shown in Figure 5, the interpretation of factor traces can be further enhanced by taking the corresponding eigenvalue plot into account. Depending on the dataset, we see the possibility to encode this information directly onto the factor trace, either by thickness or color.
5 Examples
Our method can handle various types of data uncertainty. Following the classification of Skeels et al. [31], we will take a look at examples from the measurement precision level and the completeness level. Measurement precision can play a substantial role in the analysis of datasets, especially for qualitative studies and experiments, where it is hard to assign certain values to responses. One way to deal with this uncertainty is to assign fuzzy numbers or even explicitly encoded probability distributions to each of the data points, as we will show in Section 5.1. Furthermore, we will look at different types of aggregations as sources for uncertainty on the completeness level. Apart from these examples, we see potential use cases for our method in visualizing preprocessed data for real-time analysis, or data that has been aggregated to protect the privacy of individuals, such as medical data. Regarding aggregation, Section 7 gives more details about the computational complexity of our approach. Please note that in the following examples, we use different representations for the distributions to highlight the projections found by our method.
5.1 Student Grades
Our uncertainty-aware PCA method can be used to perform dimensionality reduction on data with explicitly encoded uncertainty. Amongst others, such data can be found in the domain of fuzzy systems. As an example, we adopt the synthetic student grade dataset established by Denoeux and Masson [5]. It consists of four test results (M1, M2, P1, P2) for each of six students. The possible marks for the tests range from 0 to 20, and the dataset is highly heterogenous: grades can be represented either as real numbers, such as , without any uncertainty, or as intervals, such as . Furthermore, many grades are given by qualitative statements like fairly good or bad. Both intervals and linguistic labels contain uncertainty, modeled using uniform distributions and trapezoidal distributions, respectively. The original paper also contains one unknown value. We model the missing value using a normal distribution , which we extract from prior information: the mean is similar to previous test results, and the variance represents realistic deviations in both directions from this mean. Figure 6 shows the PCA on this dataset. It is important to note that PCA performed solely on the means of the input, as shown in Figure 6a, fails to capture important uncertainty information in the data. Our method (Figure 6b) appropriately depicts the uncertainty that is present in P1 of Tom and Bob. This draws a very different picture from the result of regular PCA because the topology changes: it is quite possible that Tom performed similar to Jane—a fact that is not readily visible from Figure 6a. The importance of P1 on the resulting projection can also be seen in the factor trace (Figure 6c) for this dataset: with an increasing amount of uncertainty factored into our method, the trace of P1 moves toward the outside of the unit circle. The interpretation for this is that most of the information of this axis is preserved after projection.
5.2 Iris Dataset
The Iris dataset111https://archive.ics.uci.edu/ml/datasets/iris has widely been used to study projection and machine learning algorithms. It is four-dimensional and consists of 150 specimen of the Iris plants. Additionally, each instance can be attributed to one of three classes, and the instances are distributed equally among the classes. The clusters of the Iris dataset can be well described using multivariate normal distributions. We aggregate the data into three distributions, by their class label, on which we then perform uncertainty-aware PCA. The result of this can be seen in Figure 7a. For comparison, we also perform conventional PCA and color each point according to its class label—the results are shown in Figure 7b. Both projections are almost identical. This shows that our method can find projections with only a fraction of the original 4D data: three multivariate normal distributions instead of 150 points.
This example also illustrates two different ways to visualize data that has additional labels. To convey the class information, we need to support the visual aggregation of each cluster. When using conventional projection methods, this aggregation is usually performed in the image space. Figure 7b, for example, uses color. Another technique that is commonly used for aggregation in the image space is kernel density estimation. For clusters that roughly follow a normal distribution, our method provides a different approach: it allows aggregation in the feature space, where all the information is still present, and subsequent projection of the aggregated information. Subsequently, no further aggregation has to be performed in the image space. In Section 6, we provide a more detailed comparison to sampling-based strategies.
Figure 5a shows the factor traces for the Iris dataset. Here, we can see that petal width moves closest to the center of our visualization. This means that the dimensionality reduction, projects along this axis, especially for . Furthermore, sepal width and petal length have almost no shaded area. Because we use the shaded area to encode and highlight the interval , this illustrates that the projection of these two axes remains almost the same while interpolating between regular PCA and our method.
5.3 Anuran Calls Dataset
The Anuran Calls dataset222https://archive.ics.uci.edu/ml/datasets/Anuran+Calls+(MFCCs) contains acoustic sound features extracted from frog recordings. In total, there are 7195 instances of such calls, and they are grouped by family, genus, and species labels. Again, we perform aggregation of the instances, in this case, by looking at the family class label. However, the interesting aspect of this dataset is that, in contrast to the Iris dataset (Section 5.2), there is a different amount of instances per class. There are calls from four different frog families in this dataset—the numbers of instances per class are 4420, 2165, 542, and 68. These families can further be subgrouped by genus, yielding eight distinct clusters. Furthermore, it is important to note that many groups do not follow a normal distribution and exhibit varying modality, as can been seen in Figure 8.
So far, we have assumed that all aggregated distributions represent the same amount of instances. This can lead to overemphasized clusters if their original sample count is small. Concerning this dataset, this would mean that the family with 4420 instances would receive the same amount of weight as the family with 68 instances. To achieve a better fit to the actual data that these distributions stand for, we can adapt our method to take class weights into account by slightly modifying Equation 4. In particular, it suffices to use the weighted average to evaluate . The computation of the sample mean needs to be adjusted accordingly.
Figure 8 shows the comparison of our method, adapted to handle cluster weights, to regular PCA on the original set of points. For Figure 8ab, the data is clustered by family, yielding four distributions. Figure 8bc was aggregated by genus, which results in eight distinct discrete probability distributions. For the projections that were created using our method, we show the covariances that were extracted from each of the different clusters. This demonstrates that even if the clusters do not follow a simple distribution, such as the blue cluster in Figure 8b, our technique is still able to reconstruct the original PCA. The projections that are found for the point data and the aggregated data are visually the same. Assigning weights to each cluster according to the amount of data that it represents is an obvious application of this extension to our method. However, we can also imagine that this technique can be used in a more exploratory setting, for example, by investigating the effect of one cluster on the resulting principal components.
6 Comparison To Sampling
In this section, we provide a comparison of our method with another strategy that could be used to construct the covariance matrix for uncertain data: sampling. Instead of directly computing on the distributions, we can draw samples from each of them. If we concatenate the resulting set of points, we can use the conventional way for computing the covariance matrix as specified by Equation 1.
To compare the resulting covariance matrices, we need a suitable distance metric. We choose the Hellinger distance. It is commonly used to compare the results of linear models [37]. This distance metric is typically used to compare two multivariate normal distributions and . It is based on the Bhattacharyya coefficient, which can be used to describe the overlap between and :
[TABLE]
The Mahalanobis distance is a special case of the Bhattacharyya distance () for distributions that share the same covariance. Using the definition of the Bhattacharyya coefficient, the Hellinger distance is defined as
[TABLE]
To apply this distance metric to the problem of comparing the results from principal component analysis, it is important to note that PCA is completly defined by its sample mean and overall covariance matrix. Together, we interpret these two artifacts as a multivariate normal distribution. The resulting distribution can then be compared using the Hellinger distance. In contrast to a description based on eigenvalues and eigenvectors, our method is invariant against flipping and no further preprocessing has to be performed.
For our experiment, we applied PCA to a synthetic dataset with 10 distributions , each following a normal distribution . All the means are drawn from another overarching multivariate normal distribution:
[TABLE]
The covariance of each of the distributions is constant across the dataset. It is created by reversing the elements of . Because of this, all covariances also share the same determinant.
Figure 9 shows the results of our experiment. For each data point we performed 40 runs and chose the median outcome. We can draw several conclusions form our experiment. First, it shows that the sampling approach converges to our method with an increasing number of samples. This indicates that our method is a valid way to compute PCA on probability distributions. Second, it shows that our method scales far better than the sampling-based approach with a growing number of dimensions. We expect the curse-of-dimensionality to be the reason for this.
7 Discussion
In the following, we discuss the uncertainty-aware extension of PCA that we introduced, demonstrated, and assessed above from different perspectives. To begin with, we compare its computational complexity to traditional PCA. We follow up with more details on its application to interactive visualization, especially concerning scalability. Finally, we discuss the general limitations of PCA and how these carry over to our method.
7.1 Computational Complexity
In general, our method has the same computational complexity as regular PCA. For a dataset with samples and features, regular PCA has a computational complexity of for the computation of the covariance matrix. Retrieving the eigenvalues and eigenvectors has a complexity of .
With our method, samples are -dimensional probability distributions instead of points. In many cases, the probability density function of a random vector is known analytically, and as well as can be looked up in constant time . Our adapted computation of the global covariance matrix can be performed in since we additionally need to compute the average covariance matrix over all distributions. Asymptotically, however, the constant factor can be neglected. This results in a complexity of for determining the covariance matrix.
We share the extraction of the eigenvalues and eigenvectors with regular PCA. As mentioned above, this can be performed in . Thus, our technique is of similar complexity as standard PCA. Please note that in this analysis, we consider the aggregation of clusters as a preprocessing step (more details in the next section). Its complexity would add to the total complexity, but is not considered here. In the following section, we provide details on why preparing clusters is of special importance for the application of our technique to data visualization.
7.2 Interactive Visualization and Scalability
Big data is gaining relevance, and the amount of data that can be acquired and stored grows rapidly. For example, the Large Hadron Collider (LHC) at CERN exceeded 200 Petabytes of collected sensor data already in 2017 [9]. At the same time, it often is critical to visualize such data for exploration, analysis, and knowledge generation [25]. Processing latencies are of significant concern for interactive visualization regarding big data. We tackle this problem by separating the computationally complex task of data aggregation from the projection and visualization tasks. Since our method is aware of the shape of the distributions, we can approximate the projection of clustered datasets by the projection of their respective distributions. For a large number of samples in a -dimensional feature space, this aggregation step is computationally costly since the covariance matrices have to be computed in . The advantage of our method is that the aggregation can be done instantly during data acquisition and, in case memory demands are of concern, there is even no need to store raw data persistently [42]. In some fields, it is already common practice to aggregate data as a preprocessing step, for example, the in-situ analysis in large-data visualization [7]. Using our method, the characteristics of the data are preserved during the complete pipeline, and its influence on the projection can still be taken into account during the analysis process. Please note that when a cluster of multiple data points is aggregated by abstracting it as a normal distribution, the estimation of the covariance matrix is an inevitable step. To do so, the number of data points needs to be sufficient concerning the number of dimensions, and there must not be problems with (local) outliers [30]. Similarly, a small number of clusters can be a problem in high-dimensional space [14]. By scaling the uncertainty of each cluster depending on the number of data points, it contains, our method compensates for differences in cluster sizes, as outlined in Section 5.3. However, more research needs to be done in the direction of assessing whether the additional information provided by each clusters’ weight and error covariance matrix can fully counter this problem.
7.3 Limitations of PCA
In practice, PCA is applied to all kinds of datasets, where it is commonly used as a tool for exploratory analysis. Conceptually, our approach yields a projection operator that is more aware of the uncertainty in the data. Just as with other linear methods, important information that is present in the non-principal components gets discarded due to the orthographic projection, which can guide the analysis into the wrong direction. Our method inherits this limitation. For regular PCA, methods have been developed to mitigate these effects—we provide an overview in Section 1. For one, this is because one of the terms of our method essentially performs PCA on the expected values of each of the distributions, as described in Section 3.2. With regard to the uncertainty in the data, a second limiting factor can arise: if the fraction of the covariance introduced by the uncertainty in the data is small in comparison to the covariance introduced by the expected values, and if the uncertainty happens to be orthogonal to the projection, it can also remain covert in the final representation. Future research may investigate how non-linear methods, which could alleviate this problem, can be generalized to probability distributions too.
Several other factors pose challenges to finding the correct principal components. The presence of outliers in the data can strongly influence the resulting projection. This stems from the quadratic term in the computation of the covariance matrix. When outliers are of concern, forms of Robust PCA (see Section 1), which rely on solving optimization problems, can be applied. It remains to be seen how similar approaches can be adapted to uncertainty-aware PCA. Although PCA was originally developed for real-valued data, it is often also used on datasets where some of the axes represent ordinal, and sometimes even categorical values. Naturally, these axes can contain uncertainty information as well. Furthermore, as of now, we do not explicitly model missing values. In the context of regular PCA, several techniques have been developed to deal with this—Dray and Josse [6] provide a summary of approaches that can be applied in this case. One straightforward way to handle these inputs in our framework nonetheless is imputation, as we have done in the student grade example provided in Section 5.1. With our method, these imputed values can even take the form of more complex distributions, which is why we see this as a practical workaround.
8 Conclusion
In this paper, we have presented a technique for performing principal component analysis on probability distributions. Unlike previous work, which mainly was concerned with non-correlated error models, our method works on arbitrary distributions. We achieve this by incorporating first and second moments of the uncertain input data into the calculation of the global covariance matrix. Our formulation of the global covariance matrix offers the potential for various extensions to traditional PCA. Particularly, in this paper, we have shown the application to aggregated datasets (Section 5.2 and Section 5.3) and datasets with explicitly encoded errors (Section 5.1).
Principal component analysis, and linear dimensionality reduction techniques in general, have the advantage over non-linear methods that the projections remain interpretable. The principal components found by PCA are linear combinations of the axes from the original data space. With our technique, scaling the influence of the covariances of each of the distributions allows us to perform sensitivity analysis concerning uncertainty. The factor traces we propose are a visual method to assess how uncertainty in the data is reflected by the contributions of each original dimension to the principal components. Further, our technique preserves the low computational complexity and clear algorithmic structure of traditional PCA. This enables the assessment of uncertainty induced differences to the projection by sampling different parameters for scaling the uncertainty. As a result, our technique constitutes a next step towards the earnest consideration of uncertainty in the analysis of high-dimensional data and forms the foundation for straightforward extensions in numerous directions.
Appendix
We show that our method, provided by Equation 4, indeed yields a covariance matrix by looking at the different terms of this equation. A matrix is positive semi-definite if , for every non-zero vector .
Theorem 1**.**
The outer product of a vector with itself always results in a symmetric, positive semi-definite matrix.
Proof.
Let be a nonzero vector. Using the definition of positive semi-definitness from above,
[TABLE]
The symmetry follows from the definition of matrix multiplication. ∎
Our method differs from regular PCA in one term, which is defined in Equation 5: In essence, this term computes the arithmetic mean of the covariance matrices of each distribution . A matrix is a covariance matrix if and only if it is symmetric and positive semi-definite. By definition, always satisfies this property.
Theorem 2**.**
Let be a set of covariance matrices, then the arithmetic mean of this set is a covariance matrix.
Proof.
Let be a nonzero vector and positive semi-definite matrices. Both addition , and multiplication with a scalar result in positive semi-definite matrices:
[TABLE]
Because of this and the properties of symmetric matrices, it follows that the arithmetic mean of is a symmetric and positive semi-definite matrix and therefore also a covariance matrix. ∎
Acknowledgements.
We are very grateful to Sven Kosub, who helped us flesh out the mathematical model presented in Section 3. This work was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) – Project-ID 251654672 – TRR 161. Additionally, this work has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 825041.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J.-H. Ahn and J.-H. Oh . A constrained EM algorithm for principal component analysis . Neural Computation , 15(1):57–65 , 2003 . doi: 10 . 1162/089976603321043694 · doi ↗
- 2[2] C. Bishop . Bayesian PCA . In Advances in Neural Information Processing Systems , vol. 11 , pp. 382–388 . MIT Press , 1999 .
- 3[3] C. J. C. Burges . Dimension reduction: A guided tour . Foundation and Trends in Machine Learning , 2(4):275–365 , 2009 . doi: 10 . 1561/2200000002 · doi ↗
- 4[4] J. P. Cunningham and Z. Ghahramani. Linear dimensionality reduction: Survey, insights, and generalizations. Journal of Machine Learning Research , 16(1):2859–2900, 2015.
- 5[5] T. Denoeux and M.-H. Masson . Principal component analysis of fuzzy data using autoassociative neural networks . IEEE Transactions on Fuzzy Systems , 12(3):336–349 , 2004 . doi: 10 . 1109/tfuzz . 2004 . 825990 · doi ↗
- 6[6] S. Dray and J. Josse . Principal component analysis with missing values: a comparative survey of methods . Plant Ecology , 216(5):657–667 , 2014 . doi: 10 . 1007/s 11258-014-0406-z · doi ↗
- 7[7] S. Dutta, C.-M. Chen, G. Heinlein, H.-W. Shen, and J.-P. Chen . In situ distribution guided analysis and visualization of transonic jet engine simulations . IEEE Transactions on Visualization and Computer Graphics , 23(1):811–820 , 2017 . doi: 10 . 1109/tvcg . 2016 . 2598604 · doi ↗
- 8[8] R. Faust, D. Glickenstein, and C. Scheidegger . Dim Reader: Axis lines that explain non-linear projections . IEEE Transactions on Visualization and Computer Graphics , 25(1):481–490 , 2019 . doi: 10 . 1109/TVCG . 2018 . 2865194 · doi ↗
