Context awareness and embedding for biomedical event extraction
Shankai Yan, Ka-Chun Wong

TL;DR
This paper introduces a scalable, context-aware framework for biomedical event extraction that leverages bi-directional LSTM embeddings to significantly improve detection accuracy over existing methods.
Contribution
It proposes a novel bottom-up detection framework with context embedding via bi-directional LSTM, achieving state-of-the-art performance on biomedical event datasets.
Findings
Achieved average F-score of 0.92 on BioNLPST-BB dataset.
Nearly doubled the F-score compared to previous methods on the same dataset.
Demonstrated the effectiveness of context-aware embeddings in biomedical event detection.
Abstract
Motivation: Biomedical event detection is fundamental for information extraction in molecular biology and biomedical research. The detected events form the central basis for comprehensive biomedical knowledge fusion, facilitating the digestion of massive information influx from literature. Limited by the feature context, the existing event detection models are mostly applicable for a single task. A general and scalable computational model is desiderated for biomedical knowledge management. Results: We consider and propose a bottom-up detection framework to identify the events from recognized arguments. To capture the relations between the arguments, we trained a bi-directional Long Short-Term Memory (LSTM) network to model their context embedding. Leveraging the compositional attributes, we further derived the candidate samples for training event classifiers. We built our models on the…
Click any figure to enlarge with its caption.
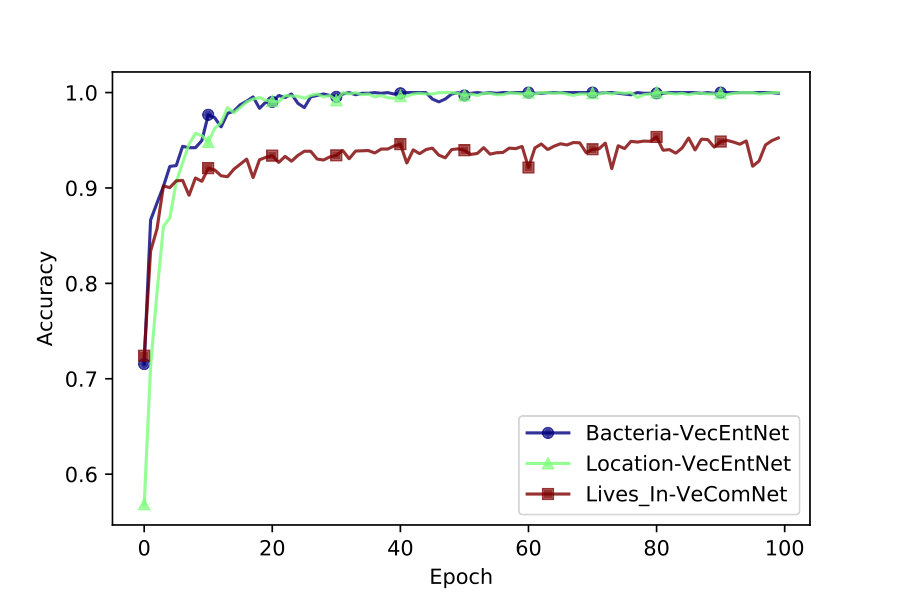 Figure 1
Figure 1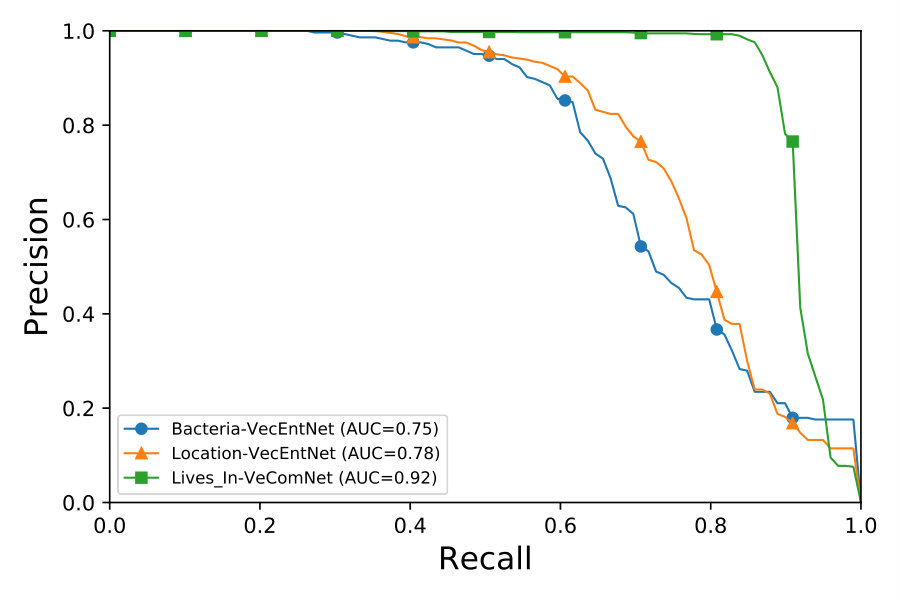 Figure 2
Figure 2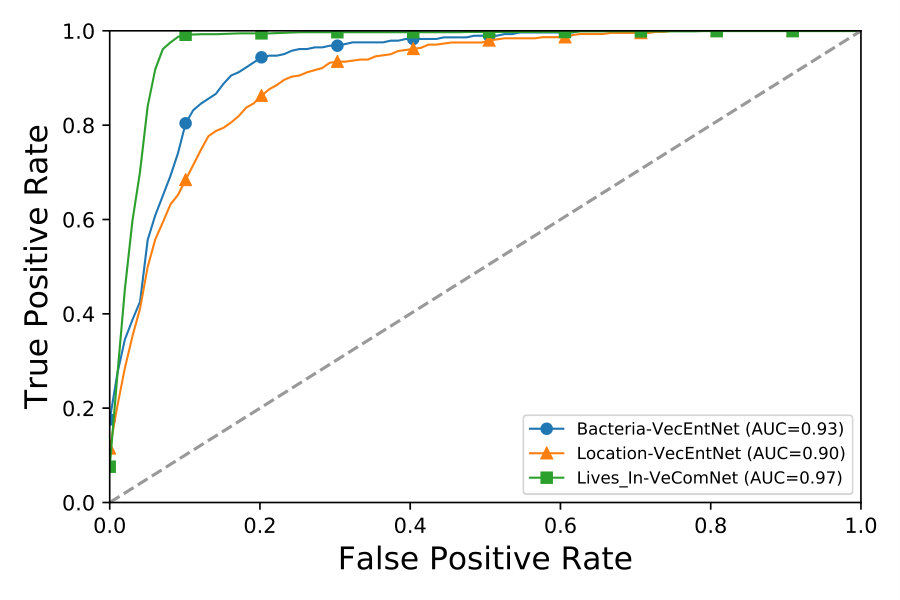 Figure 3
Figure 3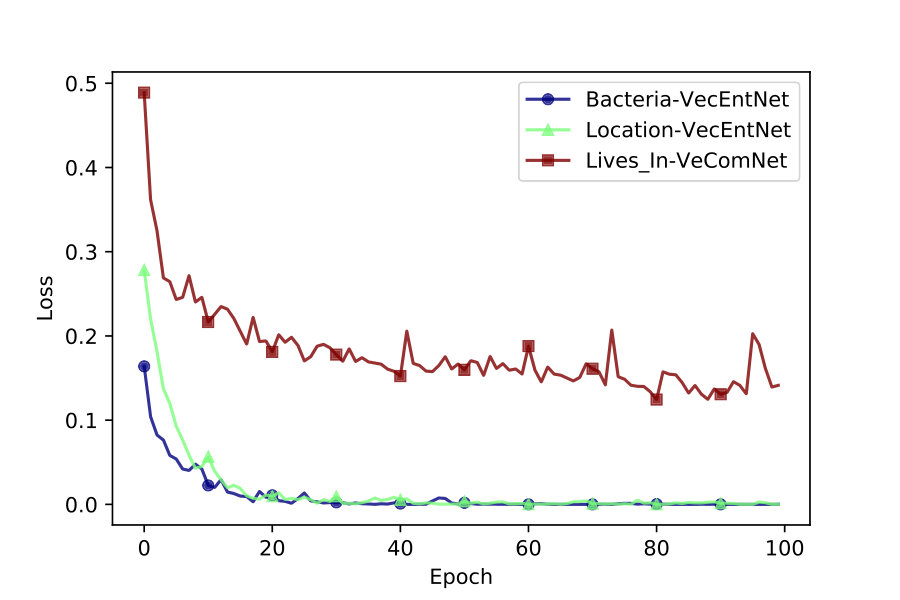 Figure 4
Figure 4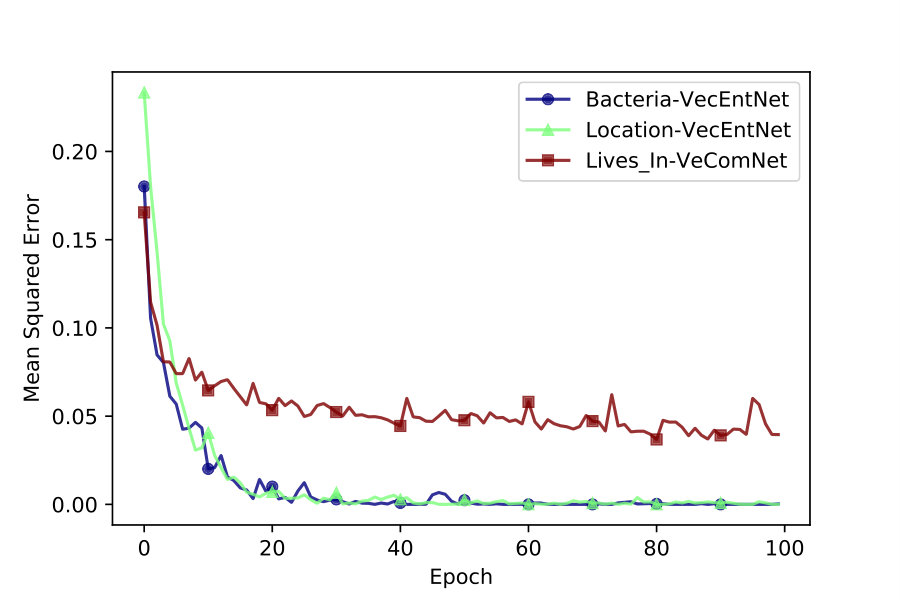 Figure 5
Figure 5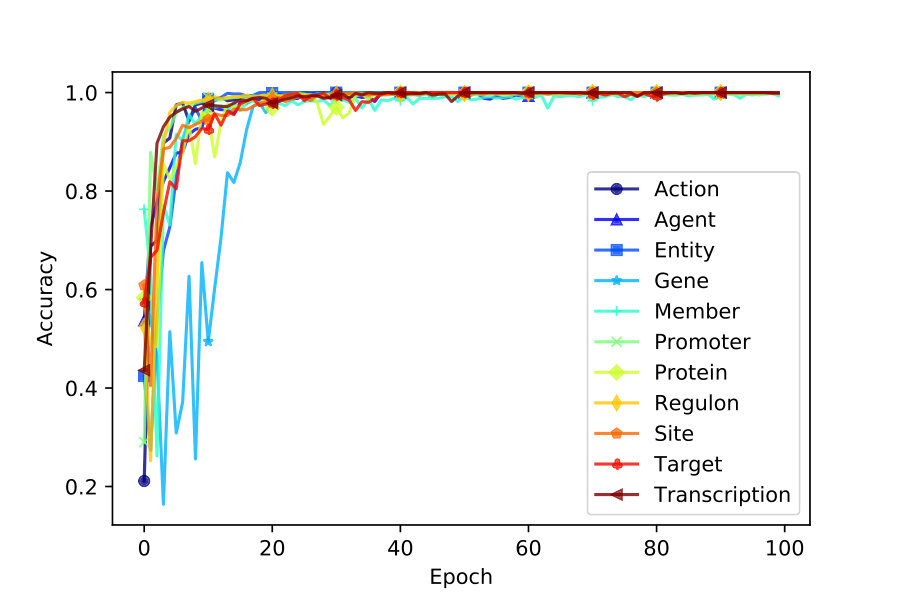 Figure 6
Figure 6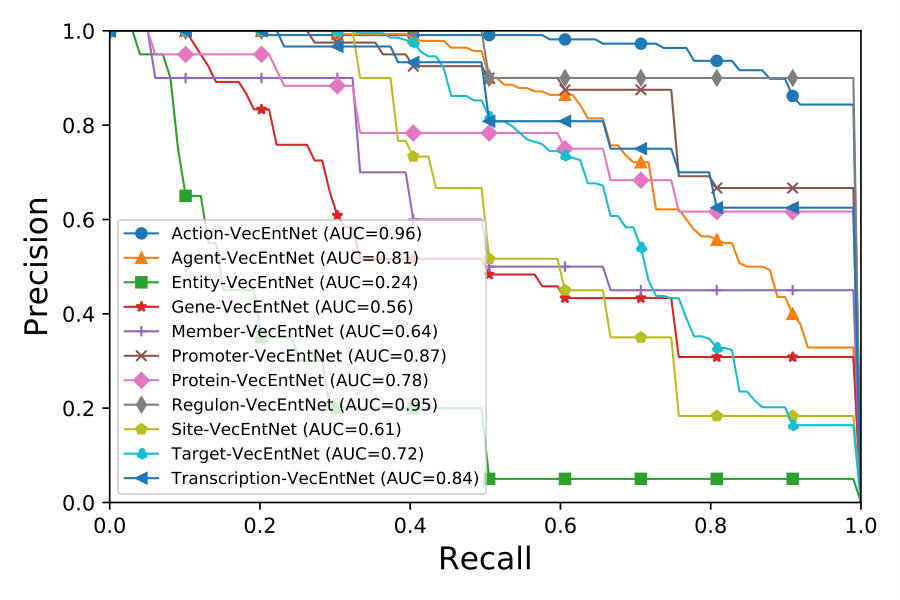 Figure 7
Figure 7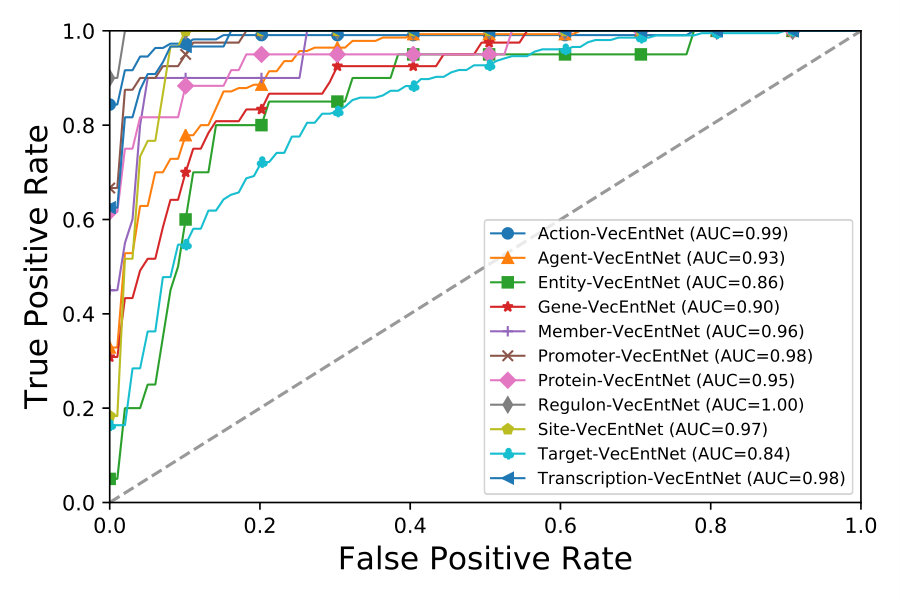 Figure 8
Figure 8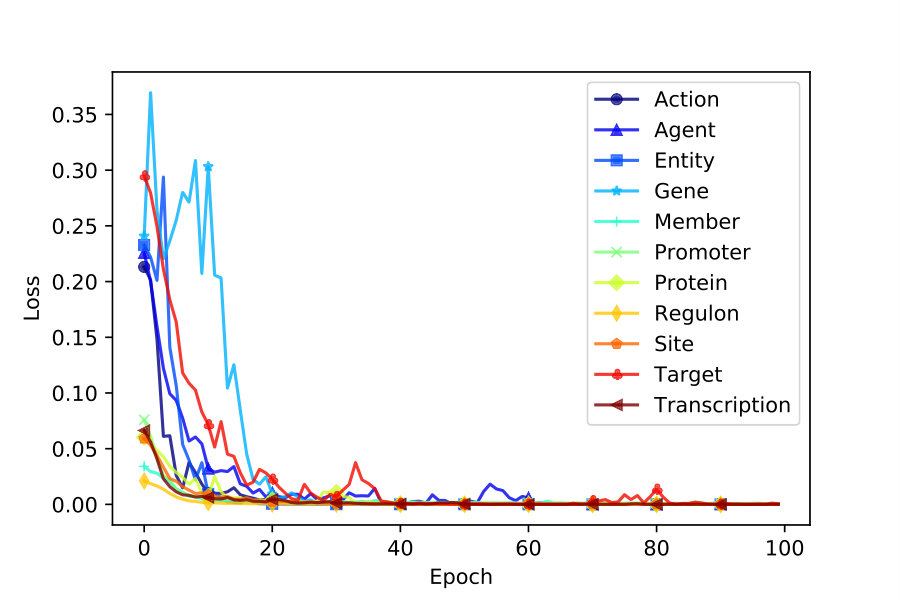 Figure 9
Figure 9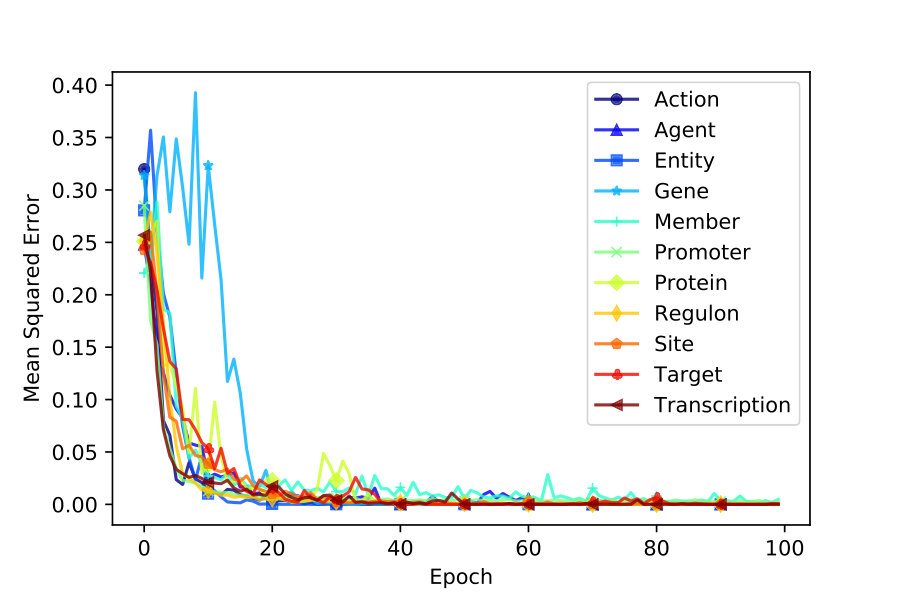 Figure 10
Figure 10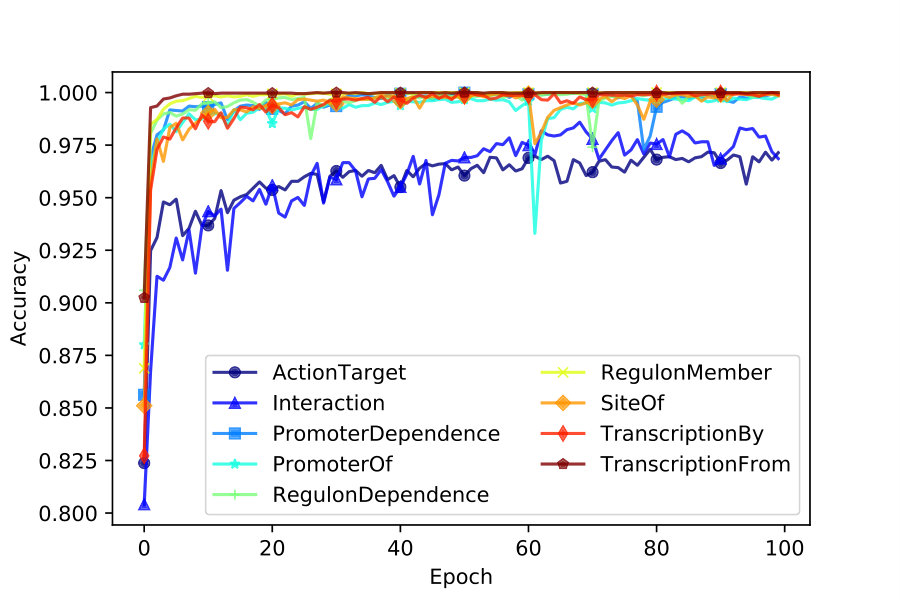 Figure 11
Figure 11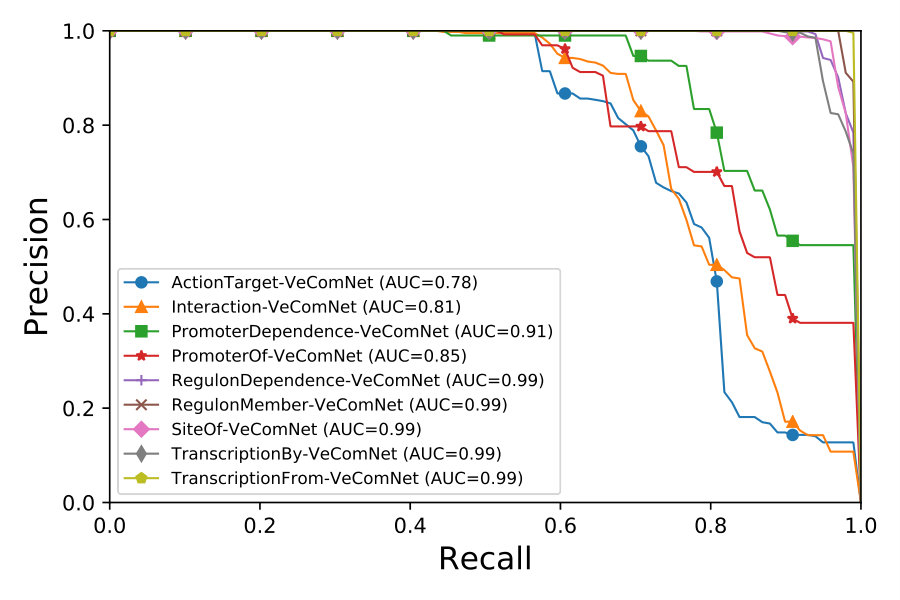 Figure 12
Figure 12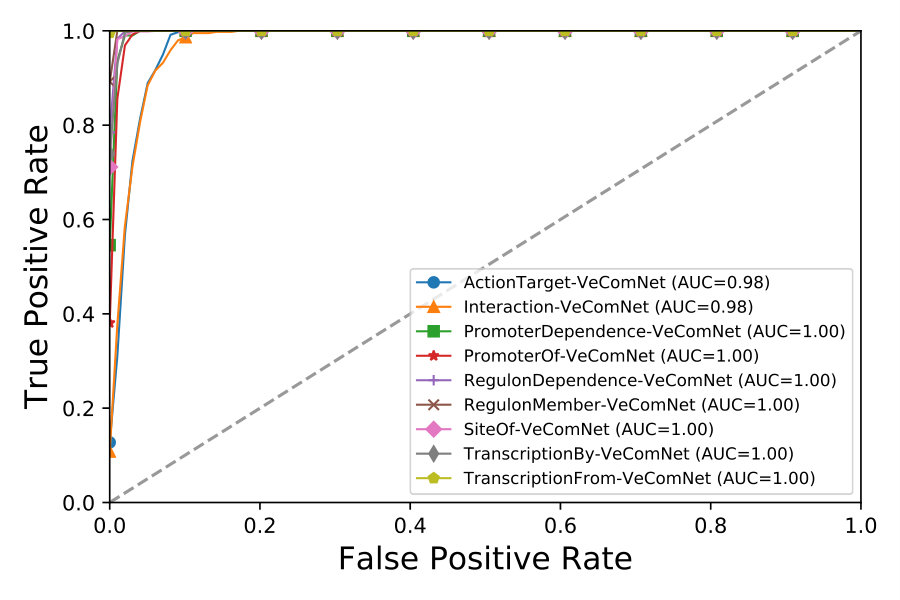 Figure 13
Figure 13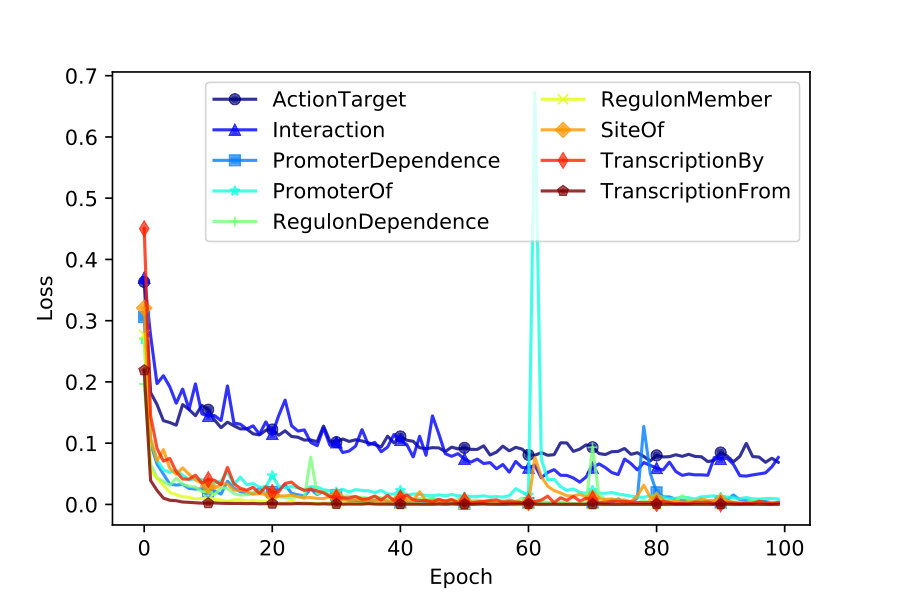 Figure 14
Figure 14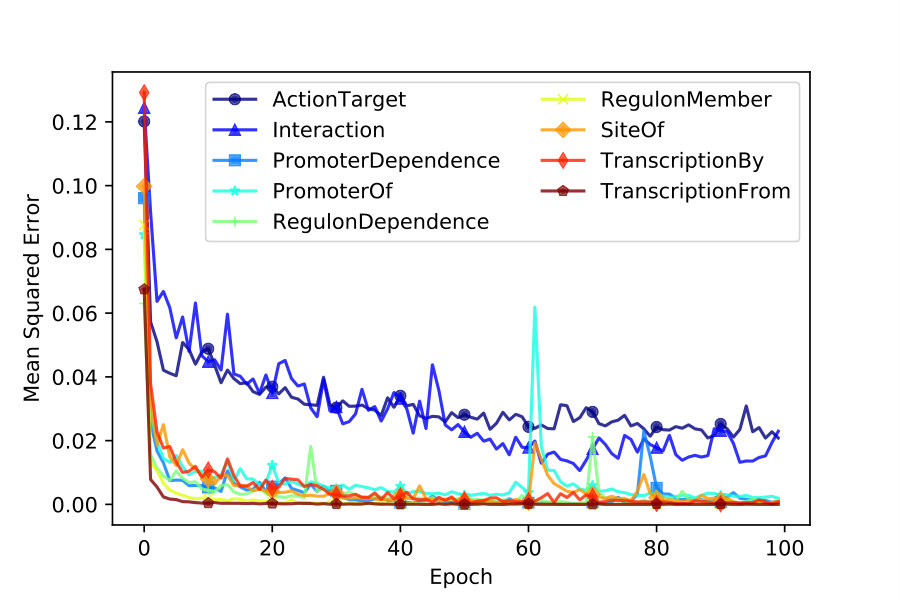 Figure 15
Figure 15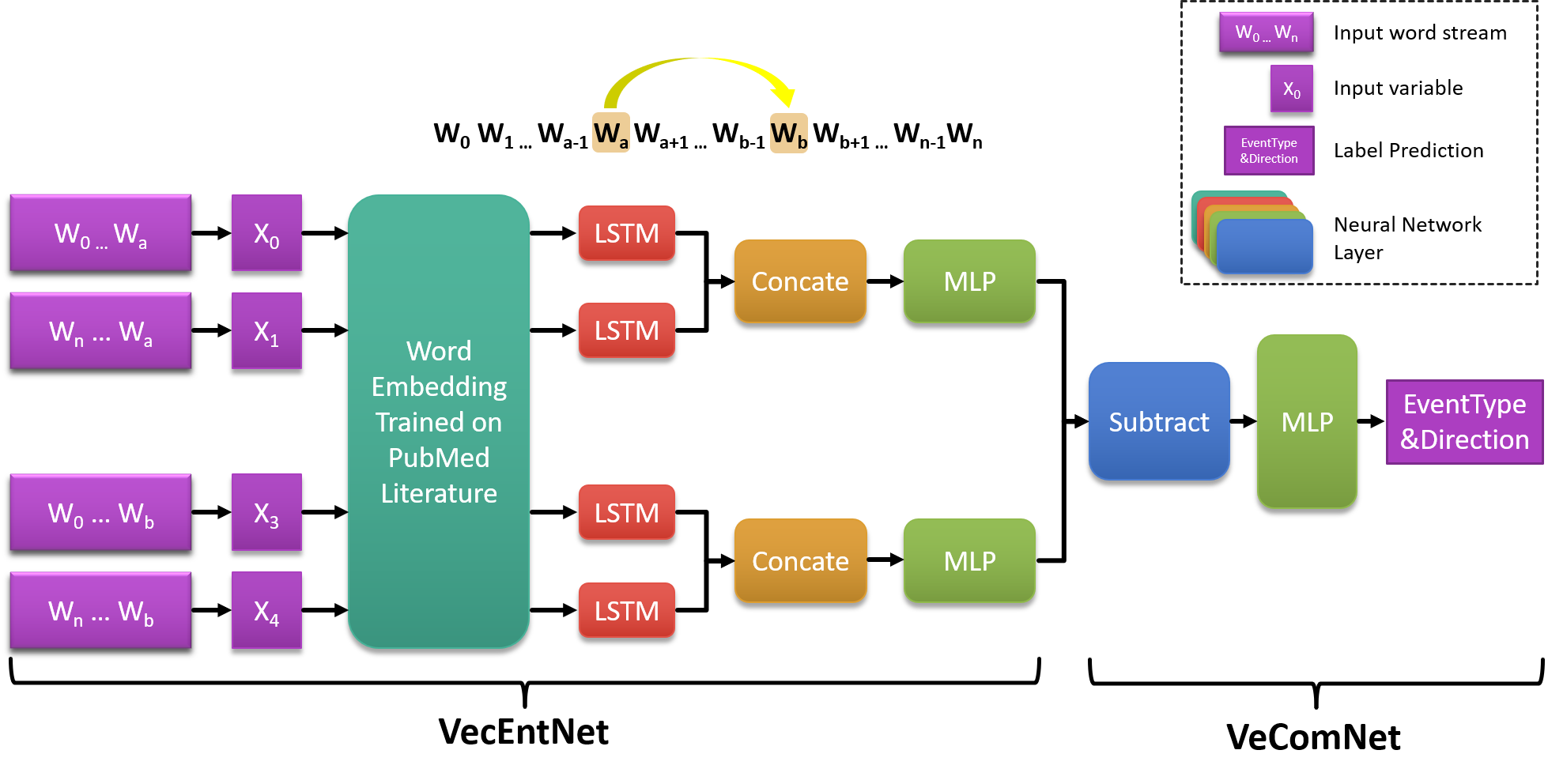 Figure 16
Figure 16| Task | Event Type | Arguments | Train -ing Set | Develo -pment Set |
|---|---|---|---|---|
| BioNLP Shared Task 2011 - Bacteria Gene Interactions | ActionTarget | Action->Target | 108 | 18 |
| Interaction | Agent->Target | 126 | 18 | |
| PromoterDependence | Promoter->Protein | 32 | / | |
| PromoterOf | Promoter->Gene | 36 | / | |
| RegulonDependence | Regulon->Target | 11 | / | |
| RegulonMember | Regulon->Member | 15 | / | |
| SiteOf | Site->Entity | 17 | / | |
| TranscriptionBy | Transcription->Agent | 25 | 3 | |
| TranscriptionFrom | Transcription->Site | 14 | / | |
| BioNLP Shared Task 2016 - Bacteria Biotopes | Lives_In | Bacteria->Location | 327 | 223 |
| Task | Argument Type | Training Set | Development Set |
| BioNLP Shared Task 2011 - Bacteria Gene Interactions | Action | 92 | 16 |
| Agent | 125 | 15 | |
| Entity | 15 | / | |
| Gene | 36 | 3 | |
| Member | 15 | / | |
| Promoter | 38 | / | |
| Protein | 29 | / | |
| Regulon | 10 | / | |
| Site | 29 | / | |
| Target | 185 | 21 | |
| Transcription | 31 | 3 | |
| BioNLP Shared Task 2016 - Bacteria Biotopes | Bacteria | 168 | 118 |
| Location | 260 | 184 |
| VecEntNet | |
|---|---|
| context window size | 10 |
| LSTM hidden/output units | 128 |
| MLP input units | 256 |
| MLP hidden units | 128 |
| Batch size | 32 |
| Epoch | 10 |
| Action | Agent | Entity | Gene | Member | Promoter | Protein | Regulon | Site | Target | Transcription | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| # of Training Samples | 108 | 140 | 15 | 36 | 15 | 38 | 29 | 10 | 29 | 185 | 31 |
| Accuracy | 0.97 | 0.83 | 0.86 | 0.91 | 0.97 | 0.97 | 0.92 | 0.99 | 0.94 | 0.77 | 0.97 |
| Precision | 0.92 | 0.56 | 0.09 | 0.32 | 0.48 | 0.70 | 0.52 | 0.68 | 0.45 | 0.61 | 0.60 |
| Recall | 0.93 | 0.93 | 0.65 | 0.55 | 0.80 | 0.90 | 0.72 | 1.00 | 0.80 | 0.73 | 0.98 |
| F score | 0.92 | 0.70 | 0.15 | 0.37 | 0.54 | 0.77 | 0.50 | 0.77 | 0.52 | 0.66 | 0.75 |
| Train time (s) | 603.73 | 696.15 | 512.58 | 710.31 | 677.00 | 469.79 | 595.32 | 391.12 | 591.96 | 660.29 | 610.50 |
| Test time (s) | 1.65 | 1.59 | 1.56 | 1.79 | 2.15 | 0.89 | 1.02 | 0.82 | 0.94 | 1.87 | 1.09 |
| ActionTarget | Interaction | PromoterDependence | PromoterOf | RegulonDependence | RegulonMember | SiteOf | TranscriptionBy | TranscriptionFrom | |
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | 0.93 | 0.91 | 0.98 | 0.98 | 0.99 | 0.99 | 0.98 | 0.97 | 0.99 |
| Precision | 0.70 | 0.73 | 0.82 | 0.79 | 0.97 | 0.99 | 0.95 | 0.60 | 0.99 |
| Recall | 0.91 | 0.82 | 0.84 | 0.78 | 0.99 | 0.99 | 0.98 | 0.98 | 0.99 |
| F score | 0.79 | 0.77 | 0.82 | 0.76 | 0.98 | 0.99 | 0.97 | 0.75 | 0.99 |
| Train time (s) | 4.99 | 5.04 | 5.00 | 5.03 | 5.55 | 5.67 | 6.18 | 5.69 | 5.78 |
| Test time (s) | 0.15 | 0.15 | 0.16 | 0.16 | 0.16 | 0.17 | 0.16 | 0.16 | 0.14 |
| VecEntNet | VeComNet | ||
|---|---|---|---|
| Bacteria | Location | Lives_In | |
| Accuracy | 0.88 | 0.82 | 0.92 |
| Precision | 0.66 | 0.69 | 0.89 |
| Recall | 0.74 | 0.77 | 0.96 |
| F score | 0.69 | 0.72 | 0.92 |
| Train time (s) | 771.44 | 757.76 | 4.83 |
| Test time (s) | 0.72 | 0.74 | 0.15 |
| Method | VeComNet | Uturku [29] | ||||
|---|---|---|---|---|---|---|
| Event Type | Precision | Recall | F-score | Precision | Recall | F-score |
| ActionTarget | 0.7 | 0.91 | 0.79 | 0.94 | 0.92 | 0.93 |
| Interaction | 0.73 | 0.82 | 0.77 | 0.75 | 0.56 | 0.64 |
| PromoterDependence | 0.82 | 0.84 | 0.82 | 1.00 | 1.00 | 1.00 |
| PromoterOf | 0.79 | 0.78 | 0.76 | 1.00 | 1.00 | 1.00 |
| RegulonDependence | 0.97 | 0.99 | 0.98 | 1.00 | 1.00 | 1.00 |
| RegulonMember | 0.99 | 0.99 | 0.99 | 1.00 | 0.50 | 0.67 |
| SiteOf | 0.95 | 0.98 | 0.97 | 1.00 | 0.17 | 0.29 |
| TranscriptionBy | 0.60 | 0.98 | 0.75 | 0.67 | 0.50 | 0.57 |
| TranscriptionFrom | 0.99 | 0.99 | 0.99 | 1.00 | 1.00 | 1.00 |
| Average | 0.788 | 0.834 | 0.791 | 0.91 | 0.83 | 0.79 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBiomedical Text Mining and Ontologies · Machine Learning in Bioinformatics · Topic Modeling
Context awareness and embedding for biomedical event extraction
Shankai Yan
Department of Computer Science
City University of Hong Kong
Hong Kong SAR
&Ka-Chun Wong
Department of Computer Science
City University of Hong Kong
Hong Kong SAR
Abstract
Motivation: Biomedical event detection is fundamental for information extraction in molecular biology and biomedical research. The detected events form the central basis for comprehensive biomedical knowledge fusion, facilitating the digestion of massive information influx from literature. Limited by the feature context, the existing event detection models are mostly applicable for a single task. A general and scalable computational model is desiderated for biomedical knowledge management.
Results: We consider and propose a bottom-up detection framework to identify the events from recognized arguments. To capture the relations between the arguments, we trained a bi-directional Long Short-Term Memory (LSTM) network to model their context embedding. Leveraging the compositional attributes, we further derived the candidate samples for training event classifiers. We built our models on the datasets from BioNLP Shared Task for evaluations. Our method achieved the average F-scores of 0.81 and 0.92 on BioNLPST-BGI and BioNLPST-BB datasets respectively. Comparing with 7 state-of-the-art methods, our method nearly doubled the existing F-score performance (0.92 vs 0.56) on the BioNLPST-BB dataset. Case studies were conducted to reveal the underlying reasons.
Availability: https://github.com/cskyan/evntextrc
1 Introduction
The unbridled growth of publications in biomedical literature databases offers a great opportunity for researchers to stand on the shoulders of giants for cutting-edge advancements. Nonetheless, it is also a challenge to digest the extensive information from the huge volume of textual data. Information Extraction (IE) is an effective approach to summarize the knowledge into expressive forms for management and comprehension; it can be integrated with other knowledge resources for innovative discovery [1]. Examples include protein-protein interactions [2], drug-drug interaction [3], causal relationships between biological entities [4], and other topic-oriented association mining systems [5, 6].
Over the past decades, considerable efforts have been devoted towards rule-based [7] and trigger-based [8, 9] detection methods for biomedical event extraction from PubMed abstracts [10]. In general, trigger detection dominates the whole prediction process which performance will greatly affect the final event detection [11]. Trigger identification method has been well-studied and improved. The latest trigger-based approach using deep neural network has shown its strength in general event extraction tasks [12]. Combining with lexical and semantic features, word embedding [13] is proposed to build an advanced trigger classifier [14]. Nevertheless, trigger detection is a multi-class classification problem with limited annotation labels. The well-known datasets from BioNLP Shared Task (BioNLPST) include BioNLP’09 [15], BioNLP’11 [16], BioNLP’13 [17], and BioNLP’16 [18]. The trigger-based methods are based on the dependency parse tree and character n-grams. The dependency parser in natural language processing (NLP) is well-studied [19] and has been developed from empirical techniques to neural network models [20]. However, there is a performance deviation from the traditional applications when applying to biomedical literature due to the contextual variations. The parser that was developed specifically for biomedical text mining (BioNLP) such as McCCJ [21] is necessary for biomedical information extraction [22]. Bi-directional LSTM has been applied to medical event detection in clinical records [23]. Nonetheless, its events are binary relations which are very different from the complex events in BioNLPST.
One of the major concerns behind this is that the prediction errors would propagate along the whole pipeline. The training data for trigger detection is quite limited because the ground truth labels are not even given in the BioNLP Shared Task datasets. In addition, the training samples are not easily selected manually. Consequently, it becomes an unbalanced multi-class classification problem which is the main barrier to performance improvement in the subsequent biomedical text mining tasks.
In this study, we proposed a novel method to detect biomedical events using a different strategy. We do not need the annotation of triggers and the cumbersome dependency parsing for each sentence. We aspire to model the context embedding for each argument. The argument embeddings are adopted to detect directed relations. The proposed neural network model is applicable to general event extraction, thanks to the universality of the underlying neural language models [24]. Our method is specially designed for biomedical event extraction while keeping replaceable components (e.g. pre-trained word embedding) for general event extraction tasks. The remainder of this paper is organized in the following order. Firstly, we briefly introduce the datasets and indicate the defectiveness of the existing approaches. Next, we sketch out the framework of our approach and then elaborate the procedures in detail. After that, we evaluate our method and make a comprehensive comparison with other approaches on the BioNLP Shared Task dataset. Then, we demonstrate the effectiveness of our method by investigating the underlying reasons through experiments.
2 Datasets
In order to ensure fair comparisons among different approaches, we adopted two datasets from the BioNLP Shared Task with 1 (BioNLPST-BB) and 9 (BioNLPST-BGI) event type(s). They consist of the events of bacteria localization and the genetic processes concerning the bacterium Bacillus subtilis respectively. We aim to measure how the performance change with different event types for model generalization estimation. The development set is initially used to validate the prediction model or tune the hyper-parameters. However, it only contains 3 out of 10 event types in BioNLPST-BGI. Therefore, we combine the training set and the development set as a single annotated dataset for each task. As shown in Table 1, the event types are extremely imbalanced in BioNLPST-BGI; it means that the event detection is an imbalanced multi-class classification problem.
The events come from the sentences of PubMed abstracts and the biological entities are annotated by curators or name entity recognition (NER) tools. The objective of event detection is to predict the relationships among the pre-annotated or recognized entities. For example, the sentence “We now report that the purified product of gerE (GerE) is a DNA-binding protein that adheres to the promoters for cotB and cotC.” has totally 6 pre-annotated entities, “T1:purified product of gerE”, “T2:GerE”, “T3:DNA-binding protein”, “T4:promoters”, “T5:cotB”, “T6:cotC”. It contains two “PromoterOf” events (E1:promoters->cotB; E2:promoters->cotC) and two “Interaction” events (E3:GerE->cotB; E4:GerE->cotC). The events are different from the traditional binary relations (e.g. gene-gene interaction) due to the difficulty of recognizing their directions and the diversity of the entity types as well as the event types. Under the context of knowledge graph topology, our prediction is a directed edge with a specific type instead of a plain binary relation. The before-mentioned example can be used to construct a directed graph consists of 6 nodes (entities) and 4 edges (events). We directly adopted the tokenization and NER results (e.g. “T1:Protein”, “T2:Protein”, “T3:ProteinFamily”, “T4:Promoter”, “T5:Gene”, and “T6:Gene”) from the annotated datasets.
Besides the event annotations (e.g. E1:T4->T6, E2:T4->T5, E3:T2->T5, E4:T2->T6), the argument labels (e.g. “T1:Protein”, “T2:Protein”, “T3:ProteinFamily”, “T4:Promoter”, “T5:Gene”, “T6:Gene”) within each event type are also used in our method. Table 2 shows the summary of the argument numbers in each task. It is obvious that the labels for the argument types are also imbalanced. The arguments are all annotated on the recognized entities. Therefore, we assume that the error rate of the entity recognition is very low, and we can consider it as known information.
The triggers used in most of the existing approaches are not officially released in the datasets and they are manually annotated by the researchers. However, those trigger words vary across different tasks; it heavily requires manual preprocessing. Furthermore, the classification errors in the trigger detectors can propagate to the argument detection and event detection. The nonexistence of trigger words does not affirm none events since different authors may have different styles of writing and the triggers are not guaranteed to appear in the sentence. Therefore, we do not use any trigger-based method in our study. Instead, the context of the arguments within each event is considered while constructing features.
3 Methodology
3.1 An overview of the event detection framework
The overall workflow of our proposed event detection method is shown in Figure 1. We take the tokenized words in the dataset as input and transform them into word vectors that trained on the PubMed literature. For each event argument and , we input the stream of words on both sides of them to a bi-directional LSTM for constructing the context embeddings [25] of arguments. We train the context embedding model (VecEntNet) using the annotations of arguments in each task. The context embeddings are further adopted to train the event detection model (VeComNet) for detecting event type and direction.
3.2 Word embedding
To construct robust features for argument recognition, we use the distributed representations of words in a sentence instead of the traditional N-gram features [13]. The adopted word vectors are pre-trained on a corpus of 10,876,004 biomedical abstracts from PubMed, which contains 1,701,632 distinct words and 200 dimensions [26]. The training is actually a transformation from the one hot encoding of the words to a continuous space with dimension reduction. Such unsupervised training on a large corpus captures the general features of each word and help prevent over-fitting for downstream tasks.
3.3 Bi-directional LSTM
LSTM [27] is a recurrent neural network (RNN) cell that can be trained to decide which information should be forgotten or kept. Bi-directional LSTM (BLSTM) is broadly utilized for NLP tasks to learn contextual representations from phrases or sentences [25]. Therefore, we use the words surrounding the recognized entities to train the contextual representations. As shown in Figure 1, and are recognized as two biological entities which can be a word or a phrase. The word embedding sequences and are extracted from two directions as the inputs of a bi-directional LSTM. In practice, we set up a window size to normalize the sizes of two word-sequences and use a dummy word to pad the sequence with length less than . The inputs are then modified as followed.
[TABLE]
where stands for the surrounding words of entity , is the sequence of word embeddings from the to word. We adopt a closed boundary strategy to construct the contextual word sequences because the named entities itself may contain useful information to distinguish the argument context. As for the example mentioned in section 2, the word “promoters” itself indicates that it is probably an “Agent” argument in the event of “PromoterOf”, since it is a general word that is also applicable to other entities. In contrast, the words “cotB” and “cotC” have no contributions to the context modeling, which will be forgotten in BLSTM. Given the window size , the inputs for event promoters->cotB are . The word streams are then input into cells. In contrast, the output of is the concatenation output vector of the left-to-right and the right-to-left . In the above-mentioned example, the outputs of the layers are represented as concatenations with and concatenations with , where is the last output of the layer.
[TABLE]
3.4 Argument embedding
We use Multi-Layer Perceptron (MLP) to train the argument classification model. As observed in Table 2, the skewed label distribution is a challenge for argument identification. We separate this multi-label classification problem into several binary classification problems under the one-vs-all strategy. Then we train each argument classifier separately using the estimator formulated in Equation 3. We use Dropout layer [28] with drop out rate 0.2 in MLP as regularization to prevent over-fitting.
[TABLE]
where is a fully connected layer in MLP, is the hyperbolic tangent activation function, and is the activation function of the last layer of MLP. To tackle the imbalanced problem, we first estimate the distribution of the binary labels from the training dataset, and then use weighted binary cross-entropy in Equation 4 as the loss function to optimize the neural network model.
[TABLE]
where is the true label of sample and represents the weight of positive class. The class weight is estimated as with the number of positive class and the total number of the samples .
After VecEntNet is trained, we are able to extract the argument embedding from the first layer of the MLP (Equation 5) for event detection. In particular, the triggers are actually embedded in the context of each argument. The trigger information, as well as their relations to the arguments, is encoded into the argument embedding which is used for event detection.
[TABLE]
For the classifier of an event type , we take the input as the concatenation of both argument embeddings for each recognized entity of candidate pairs within one sentence (Equation 6). Since we are not aware of the true argument type for each entity, we use both embedding types with different orders for the entity pairs.
[TABLE]
VeComNet is designed for detecting the event types as well as the event direction of a candidate pair of recognized entities. To be consistent, we also build the multi-class classifiers under the one-vs-all strategy for event detection. For an event type , we encode the direction as 1 and others as 0. As a result, the label for a directed event type has two bits, in which one bit encodes the existence of this event type and another one encodes the direction. Therefore, the binary classification problem for each event type is transformed into a multi-label classification problem.
Similar to word vector, argument vector also possess the compositional attribute. To reflect the direction from the model, we use a subtract layer to combine the two input vectors as (Equation 7) and use it to predict the direction. The subtraction of the two argument vectors can be regarded as the multiplication of the concatenation of them and a factor matrix , where denotes the identity matrix. We explicitly multiply this factor matrix to conduct the vector composition before proceeding to the fully connected layer. In addition, the subtraction layer can decrease the number of neurons in the MLP, and thus its model generalization. As for the existence, we take the of as input to another MLP for existence prediction.
[TABLE]
The resultant directed event estimator is demonstrated in Equations 8 and 9 representing the existence and direction respectively.
[TABLE]
[TABLE]
where and are fully connected layers, is a layer for absolute value calculation, is the Rectified Linear Unit activation function. Binary cross-entropy is adopted as loss function and Stochastic Gradient Descent (SGD) is adopted as the optimizer to train the classifiers for each event type.
4 Results
The training set and development set are combined to form an annotated dataset. We evaluate our method under 10-fold cross-validation. For the arguments or events in BioNLPST-BGI with less than 20 data instances, we change to 5-fold cross-validation to ensure that the testing set would not have less than 2 classes. To ensure the training quality of those few labels, we randomly duplicate the samples in the training set so that the binary class ratio is bounded by 5. Only the training samples are duplicated when training the argument embedding. The testing samples are neither duplicated nor used in argument embedding. We trained our models on a Linux machine equipped with a 32-core CPU and 32GB RAM. The hyper-parameters used in the experiments are summarized in Tables 4 and 4. Parameter analysis is also conducted to show the robustness of our method. The results shown in the Supplementary indicate that our method are not sensitive to the hyper-parameters.
4.1 Performance of VecEntNet and VeComNet during training
We use accuracy and mean squared error to keep track of iterative training. As depicted in Figures 2 and 4, VecEntNet converges roughly at the \nth10 epoch and keeps stable in the following training. Therefore, we use 10 epochs as the default hyper-parameter in the subsequent experiments. Figure 2 shows that only the argument “Gene” converges slower than others. Nevertheless, the overall performance of training VecEntNet and VeComNet is desirable.
4.2 Performance of VecEntNet and VeComNet under 10-fold cross-validation
We evaluate the overall performance with precision, recall, and F-score under 10-fold cross-validation experiments. We can observe from Figure 5 that VecEntNet performs very well in most of the argument classifications on BioNLPST-BGI. However, it is expected that VecEntNet can be underestimated on the tasks with limited training samples such as “Entity”, “Gene”, and “Site”. Nevertheless, VeComNet achieves robust performance by leveraging the argument embedding learned by VecEntNet. As for the performance on BioNLPST-BB dataset shown in Figure 7, we can learn that VecEntNet as well as VeComNet performs better and keeps stable once sufficient data is given. Our proposed model definitely performs well on balanced data but it is also applicable to imbalanced labels due to the weighted loss function adopted in VecEntNet. The detailed performance is tabulated in Tables 5, 6, and 7
As for the two worst cases of argument classification, “Entity” and “Gene” (F scores = 0.15 and 0.37), their corresponding event detection is still satisfactory (F scores = 0.97 and 0.76). We can also observe that the argument with better performance (“Site” and “Promoter”) within the same event type compensate the defectiveness of the worse one.
4.3 Performance comparison with other top-ranked approaches
We compared our performance with that of the best method in the competition on BioNLPST-BGI dataset with respect to each event type. As tabulated in Table 8, VeComNet and the Uturku’s approach [30, 31] have their own merits. VeComNet performs the best on “Interaction”, “RegulonMember”, “SiteOf”, “TranscriptionBy” events with significant improvement on the F-scores (0.12, 0.32, 0.68, 0.4) compared to the best existing approach; and has competitive performance on “RegulonDependence” and “TranscriptionFrom” events. The performance of VeComNet on other events are stable and impressive due to which its average performance is better than the Uturku’s approach. The compared method from Uturku seems over-fitting to the dataset since in most of the event types it achieved the ideal F-scores of 1.0 where our proposed method does not. Our method outstands from other approaches according to its generalization ability instead of the ideal F-scores. But the deep learning model adopted in VeComNet is limited by the number of training samples.
From Table 9 we can observe that VeComNet has the strongest power in single event prediction. The less arguments and event types contained in the detection task, the more powerful VeComNet will be. Besides, VeComNet is a generic model that can be used in different event detection tasks without any tuning and modification. The robustness and strong predictive power of VeComNet enables it to be a promising model in the area of biomedical event extraction.
5 Case studies
To reveal how our method works, we randomly picked some cases from the testing dataset for case demonstration. The sample sentence ‘The expression of rsfA is under the control of both sigma(F) and sigma(G).’ with ID ‘PMID-10629188-S5’ in the testing dataset of BioNLPST-BGI has four recognized entities (:‘expression’, :‘rsfA’, :‘sigma(F)’, :‘sigma(G)’) and three events (ActionTarget: , Interaction: , Interaction: ) as ground true annotations. We obtained 11 argument models by fitting VecEntNet on the training dataset with the entity annotations. We further gained the argument embeddings for each possible pair of entities in both training and testing datasets. For the above-mentioned sample, some of the candidate pairs generated are . And the argument models for event type ActionTarget are and . We take them as functions and the candidate pairs of entities as input. The argument embeddings we obtained for are . Since we are not aware of the argument type the entities belong to, we concatenated both argument embeddings for each entity and let VeComNet to determine. The argument embeddings are obtained for other candidate entity pairs with respect to different event types in a similar way. We used argument embeddings as the input of VeComNet models. The predicted labels for the aforementioned candidate entity pairs are with respect to ActionTarget event and with respect to Interaction event, in which the first label indicates the existence of the corresponding event and the second label indicates whether the event is pointed from the first entity to the second one. The binary labels were further post-processed to generate the predicted biomedical events. For instance, the candidate pairs and are predicted as and for ActionTarget and Interaction evnets respectively. It means that it exists an ActionTarget event (expression->rsfA) and an Interaction event (rsfA->sigma(F)) in this sentence.
6 Discussion
For many years, scientific literature has served as the major outlet for novel discovery and result dissemination. To extract useful knowledge from the literature for management and query, information extraction is proposed to automate this process. Biomedical event extraction is particularly important because it is able to systematically organize the knowledge as controlled representations such as directed knowledge graphs. However, the existing event detection methods are not satisfactory in performance because most of them are constrained in the trigger-based approach which relies on the lexical and syntactic features from dependency parsing. The quality of manual trigger annotation and the error propagation from trigger detection to the event detection have limited our progress for years.
In this study, we proposed a bottom-up event detection framework using deep learning techniques. We built an LSTM-based model VecEntNet to construct argument embeddings for each recognized entity. We further utilized compositional attributes of the argument vectors to train a directed event classifier VeComNet.
LSTM and context embedding have been shown its applicability in several other NLP tasks. Our main contribution is the proposed framework for argument embedding using Bi-directional LSTM and the downstream directed event detection using multi-output neural network. This strategy for event detection is proposed for the first time in this study. It overcomes the error propagation as well as extra annotations of trigger-based approaches. Besides, the continuous space of argument embedding significantly lessen the sensitivity of event detection. In addition, we developed our own loss functions for training the argument embedding with unbalanced data and training the multi-output neural network for directed event detection. These are the key reasons why our method can achieve outstanding performance. Broadly speaking, the proposed method is suitable for general event extraction by using the pre-trained word embedding in the specific area.
Our method is not sensitive to the hyper-parameters and it works well for a wide range of tasks. The experimental results indicate that the proposed method is competent in the biomedical event extraction. In the future, we envision that it can fundamentally benefit the related downstream tasks in biomedical text mining with broad impacts.
Acknowledgements
The authors are grateful to the organizers of BioNLP Shared Task who provide the public annotated dataset. The authors would also like to thank Prashant Sridhar for his English proofreading.
Funding
The work described in this paper was substantially supported by three grants from the Research Grants Council of the Hong Kong Special Administrative Region [CityU 21200816], [CityU 11203217], and [CityU 11200218]. We acknowledge the donation support of the Titan Xp GPU from the NVIDIA Corporation.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Dietrich Rebholz-Schuhmann, Anika Oellrich, and Robert Hoehndorf. Text-mining solutions for biomedical research: enabling integrative biology. Nature Reviews Genetics , 13(12):829–839, dec 2012.
- 2[2] Emily K Mallory, Ce Zhang, Christopher Ré, and Russ B Altman. Large-scale extraction of gene interactions from full text literature using Deep Dive. Bioinformatics , 2015.
- 3[3] Zhehuan Zhao, Zhihao Yang, Ling Luo, Hongfei Lin, and Jian Wang. Drug drug interaction extraction from biomedical literature using syntax convolutional neural network. Bioinformatics , 32(22):btw 486, jul 2016.
- 4[4] Livia Perfetto, Leonardo Briganti, Alberto Calderone, Andrea Cerquone Perpetuini, Marta Iannuccelli, Francesca Langone, Luana Licata, Milica Marinkovic, Anna Mattioni, Theodora Pavlidou, Daniele Peluso, Lucia Lisa Petrilli, Stefano Pirrò, Daniela Posca, Elena Santonico, Alessandra Silvestri, Filomena Spada, Luisa Castagnoli, Gianni Cesareni, Andrea Cerquone Perpetuini, Marta Iannuccelli, Francesca Langone, Luana Licata, Milica Marinkovic, Anna Mattioni, Theodora Pavlidou, Daniele Peluso,
- 5[5] Kun Ming Kenneth Lim, Chenhao Li, Kern Rei Chng, and Niranjan Nagarajan. @M Inter: automated text-mining of microbial interactions. Bioinformatics , 32(19):2981–2987, oct 2016.
- 6[6] Andres Cañada, Salvador Capella-Gutierrez, Obdulia Rabal, Julen Oyarzabal, Alfonso Valencia, and Martin Krallinger. Lim Tox: a web tool for applied text mining of adverse event and toxicity associations of compounds, drugs and genes. Nucleic Acids Research , 45(W 1):W 484–W 489, jul 2017.
- 7[7] Q.-C. Bui and P. M. A. Sloot. A robust approach to extract biomedical events from literature. Bioinformatics , 28(20):2654–2661, oct 2012.
- 8[8] J. Bjorne, F. Ginter, S. Pyysalo, J. Tsujii, and T. Salakoski. Complex event extraction at Pub Med scale. Bioinformatics , 26(12):i 382–i 390, jun 2010.