Spectrum-enhanced Pairwise Learning to Rank
Wenhui Yu, Zheng Qin

TL;DR
This paper introduces spectral features derived from hypergraph structures of purchase records to improve recommendation systems, addressing limitations of side information by enhancing user and item modeling and optimizing ranking with spectral similarity.
Contribution
The paper proposes a novel spectral feature extraction method from hypergraph structures and integrates them into matrix factorization and BPR optimization for better recommendations.
Findings
Spectral features improve recommendation accuracy significantly.
Models outperform several state-of-the-art approaches.
Spectral features effectively capture user-item similarities.
Abstract
To enhance the performance of the recommender system, side information is extensively explored with various features (e.g., visual features and textual features). However, there are some demerits of side information: (1) the extra data is not always available in all recommendation tasks; (2) it is only for items, there is seldom high-level feature describing users. To address these gaps, we introduce the spectral features extracted from two hypergraph structures of the purchase records. Spectral features describe the \textit{similarity} of users/items in the graph space, which is critical for recommendation. We leverage spectral features to model the users' preference and items' properties by incorporating them into a Matrix Factorization (MF) model. In addition to modeling, we also use spectral features to optimize. Bayesian Personalized Ranking (BPR) is extensively leveraged to…
Click any figure to enlarge with its caption.
_c1.jpg) Figure 1
Figure 1_c2.jpg) Figure 2
Figure 2_c3.jpg) Figure 3
Figure 3_c4.jpg) Figure 4
Figure 4_c5.jpg) Figure 5
Figure 5_c6.jpg) Figure 6
Figure 6_clothes_F1.jpg) Figure 7
Figure 7_clothes_K.jpg) Figure 8
Figure 8_eta1_eta2.jpg) Figure 9
Figure 9_eta_clothes.jpg) Figure 10
Figure 10_eta_jewelry.jpg) Figure 11
Figure 11_hyper_i.jpg) Figure 12
Figure 12_hyper_u.jpg) Figure 13
Figure 13_interaction.jpg) Figure 14
Figure 14_jewelry_F1.jpg) Figure 15
Figure 15_jewelry_K.jpg) Figure 16
Figure 16_len_spe_fea.jpg) Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23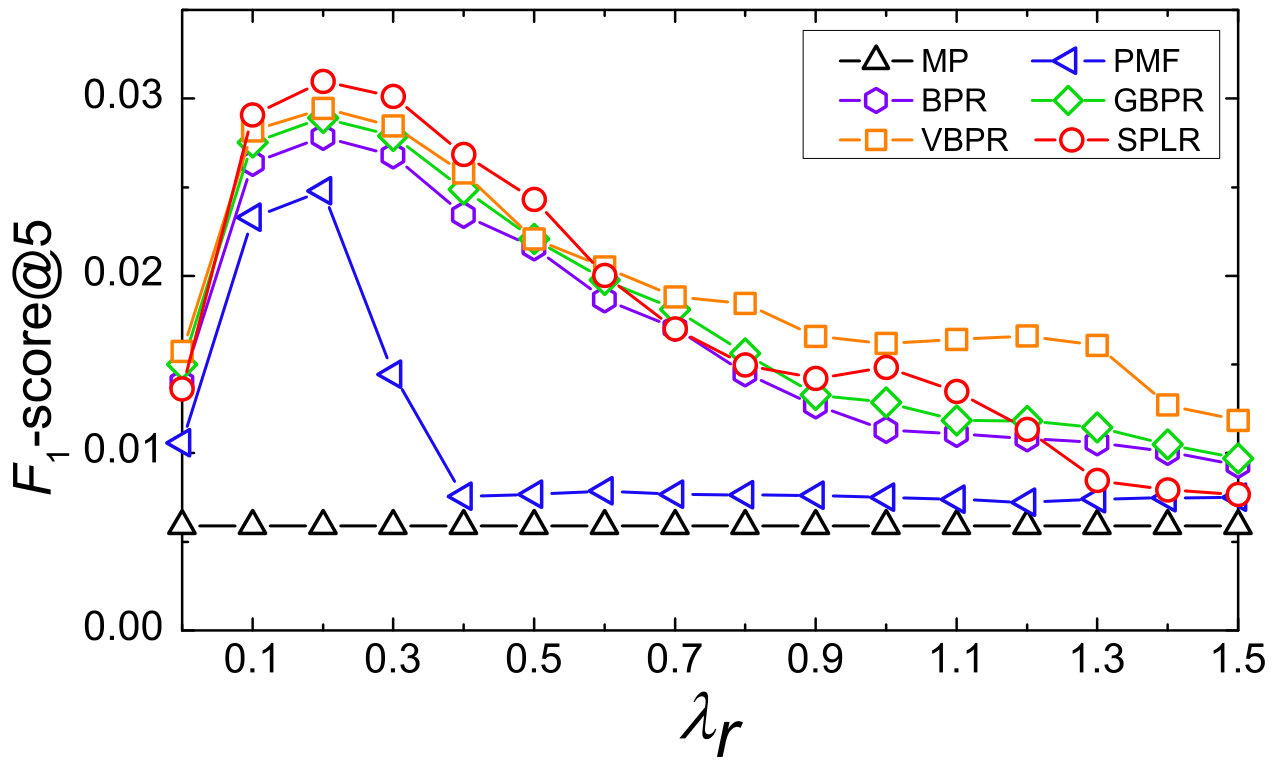 Figure 24
Figure 24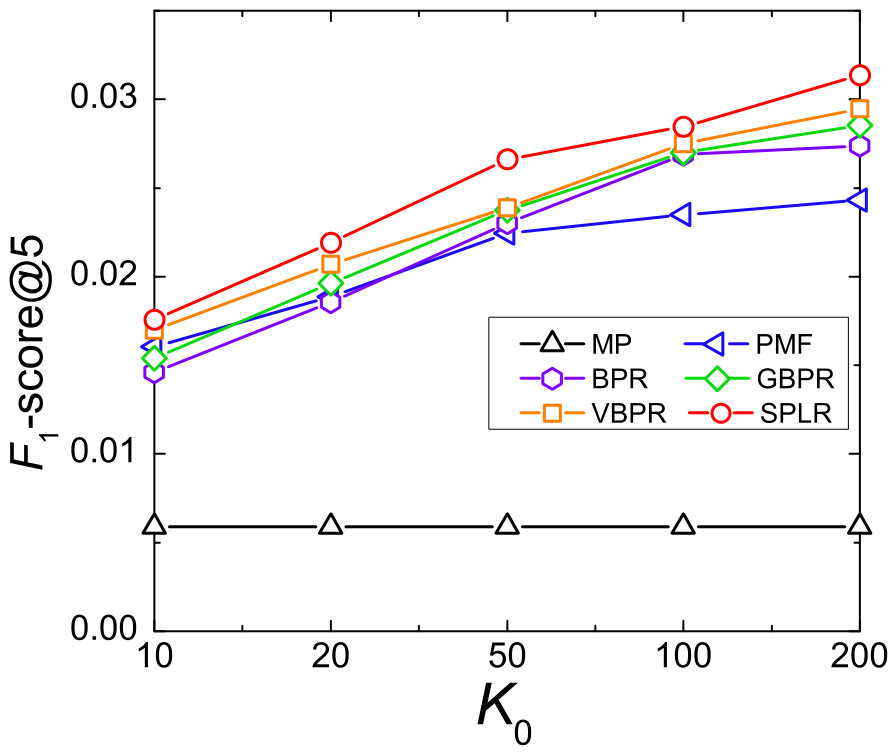 Figure 25
Figure 25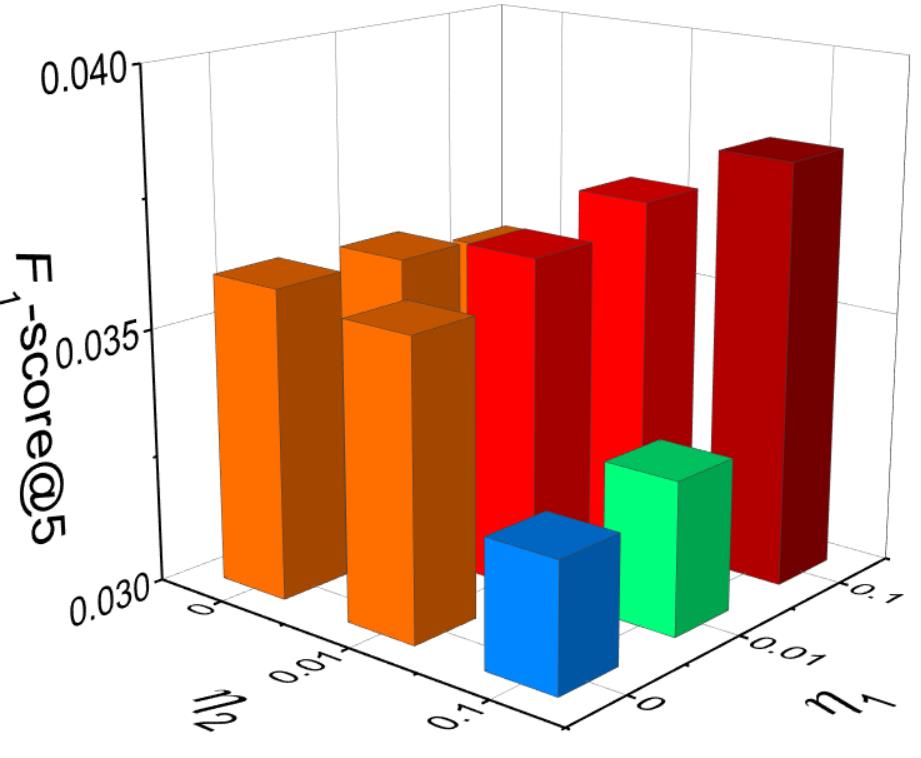 Figure 26
Figure 26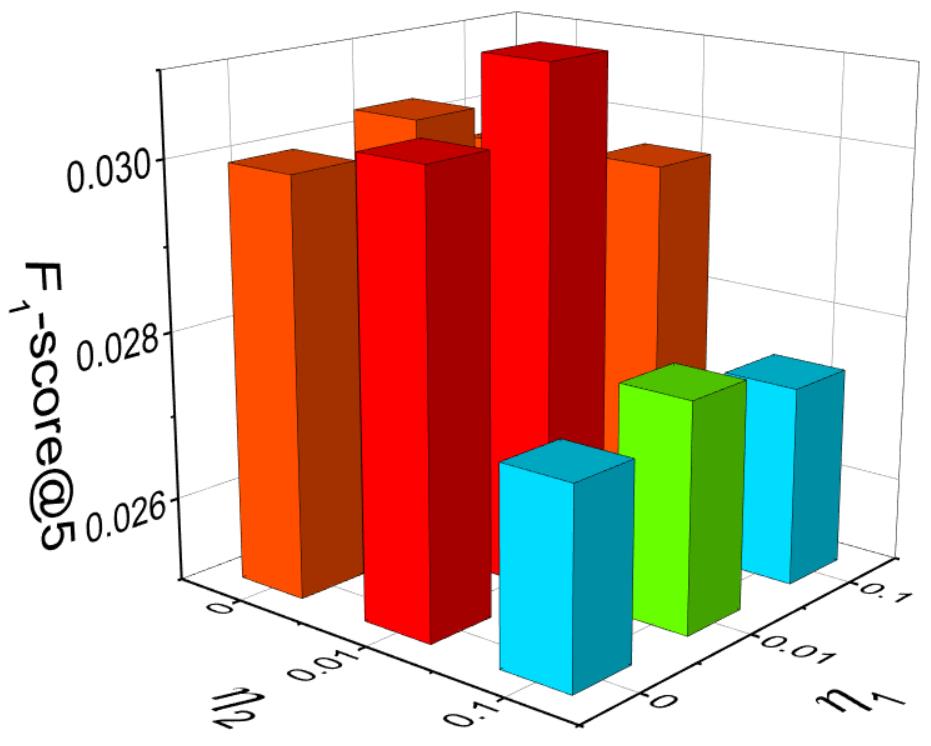 Figure 27
Figure 27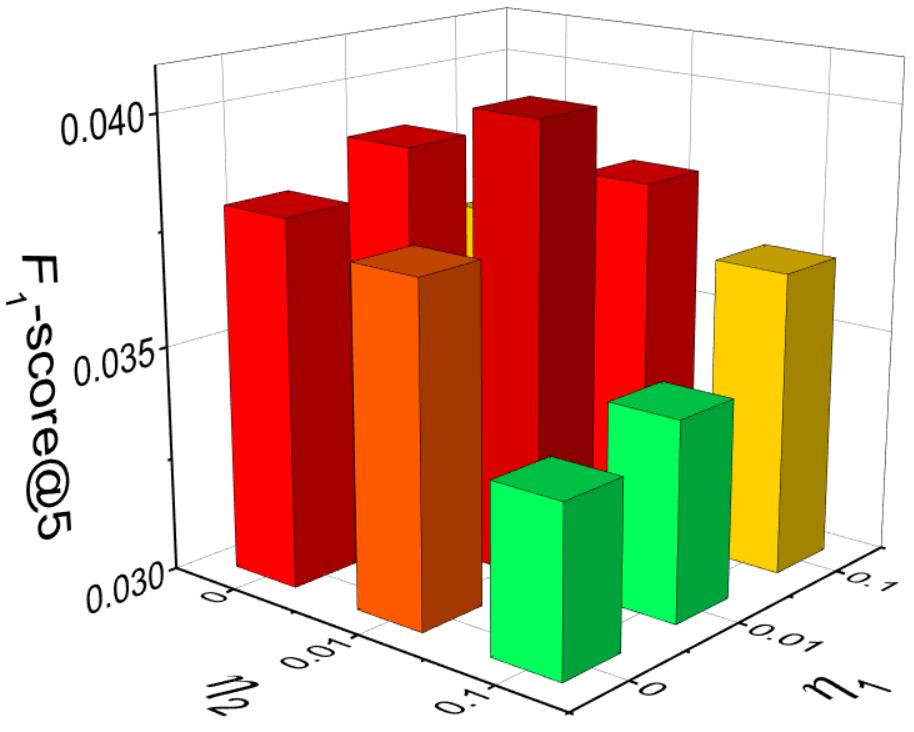 Figure 28
Figure 28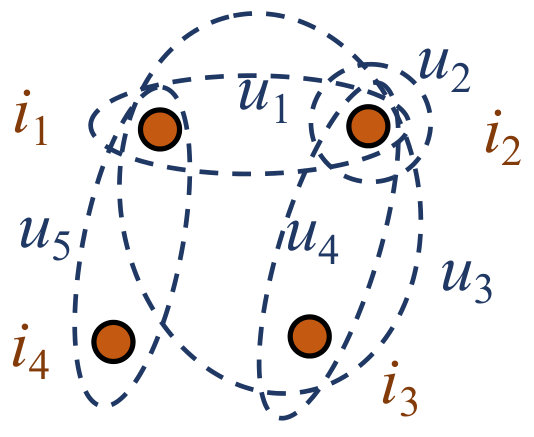 Figure 29
Figure 29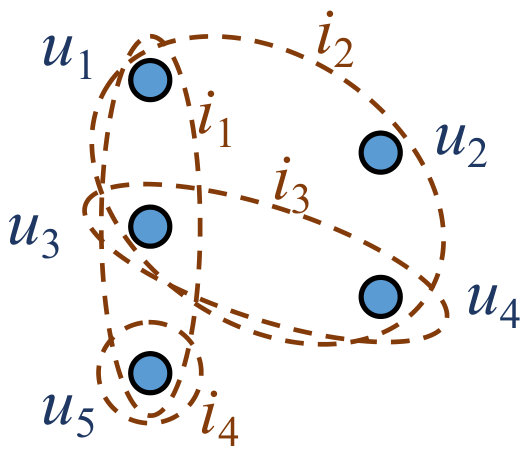 Figure 30
Figure 30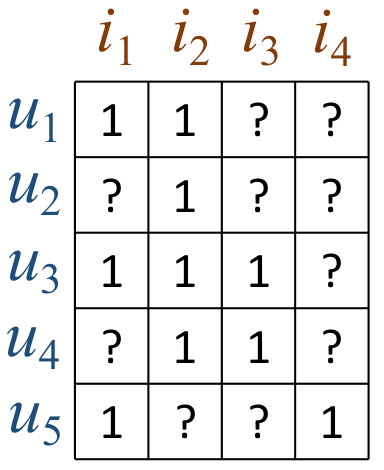 Figure 31
Figure 31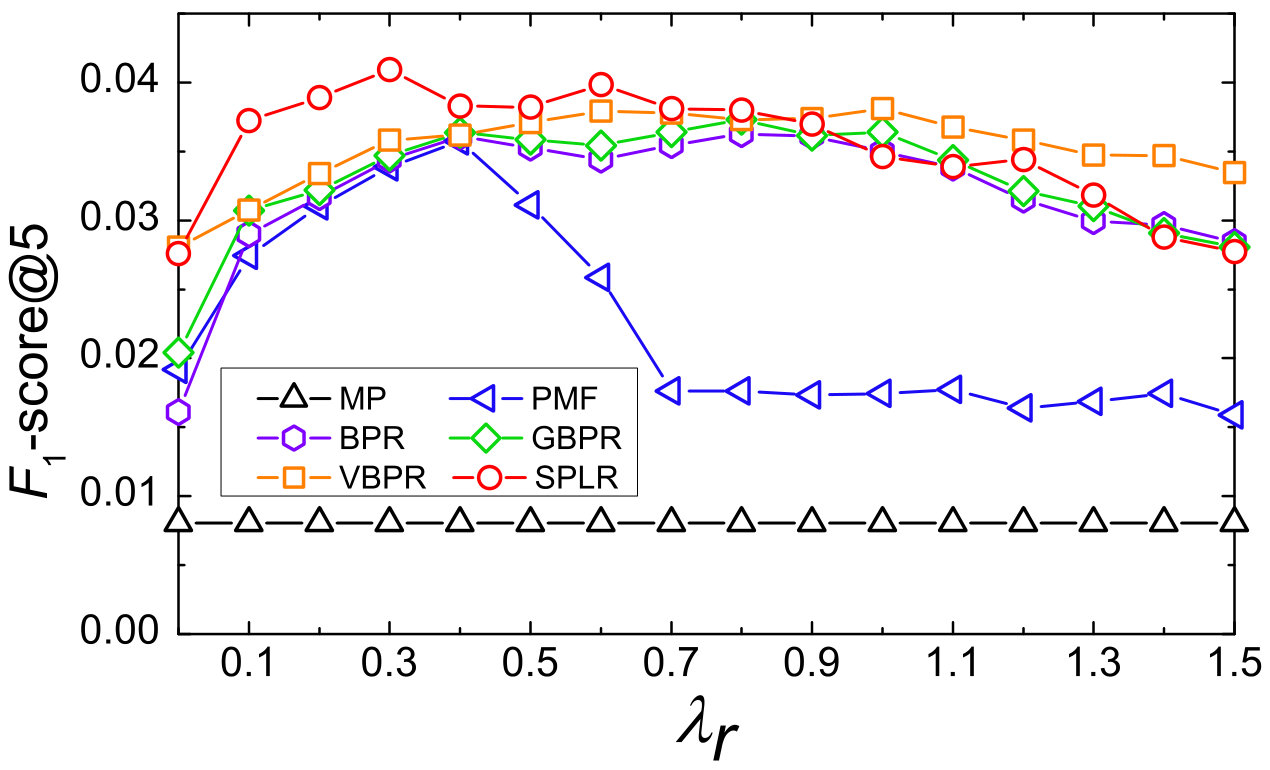 Figure 32
Figure 32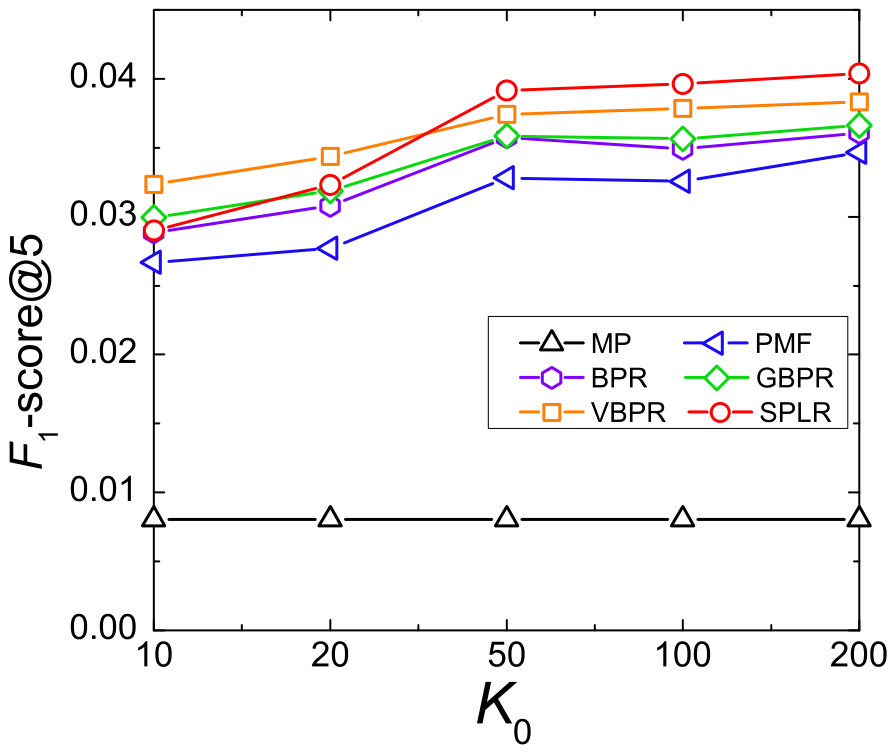 Figure 33
Figure 33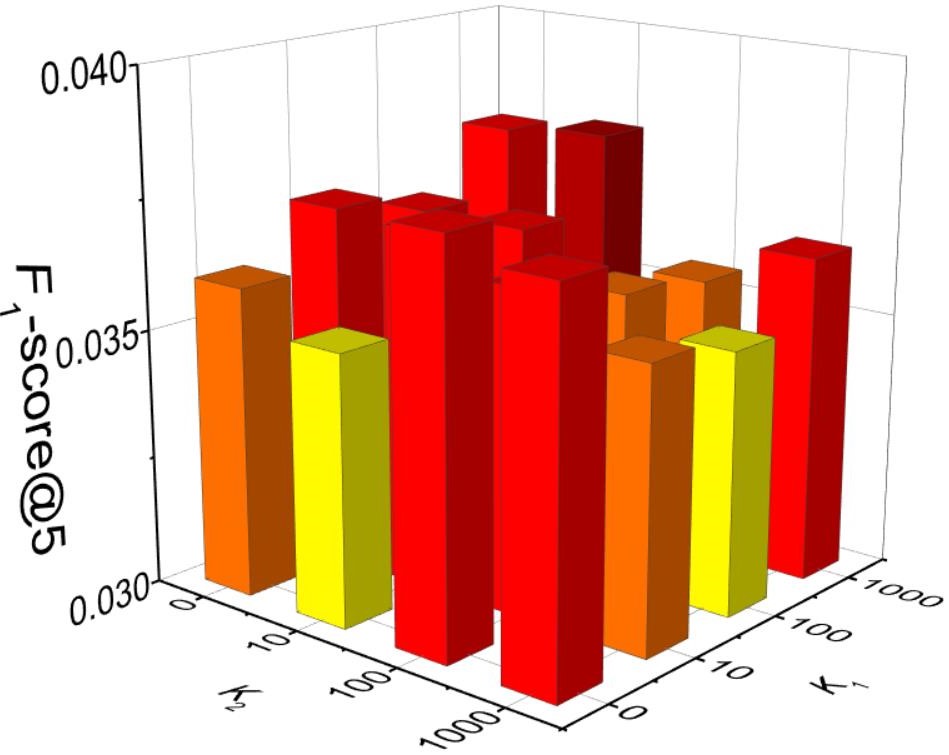 Figure 34
Figure 34| Dataset | Purchase | User | Item | Sparsity |
|---|---|---|---|---|
| Clothes | 115841 | 32728 | 8777 | 99.9597% |
| Jewelry | 37314 | 15924 | 3607 | 99.9350% |
| Datasets | Metrics (%) | MP | PMF | BPR | GBPR | VBPR | SPLR | Improvement | ||
|---|---|---|---|---|---|---|---|---|---|---|
| BPR | GBPR | |||||||||
| Jewelry | -1@ | 2 | ||||||||
| 5 | ||||||||||
| 10 | ||||||||||
| 20 | ||||||||||
| @ | 2 | |||||||||
| 5 | ||||||||||
| 10 | ||||||||||
| 20 | ||||||||||
| Clothes | -1@ | 2 | ||||||||
| 5 | ||||||||||
| 10 | ||||||||||
| 20 | ||||||||||
| @ | 2 | |||||||||
| 5 | ||||||||||
| 10 | ||||||||||
| 20 | ||||||||||
| Metrics (%) | MF_BPR | SCF_BPR | Improvement | |
|---|---|---|---|---|
| -1@ | 2 | |||
| 5 | ||||
| 10 | ||||
| 20 | ||||
| @ | 2 | |||
| 5 | ||||
| 10 | ||||
| 20 | ||||
| Metrics (%) | MF_BPR | MF_SPLR | Improvement | |
|---|---|---|---|---|
| -1@ | 2 | |||
| 5 | ||||
| 10 | ||||
| 20 | ||||
| @ | 2 | |||
| 5 | ||||
| 10 | ||||
| 20 | ||||
| None | Spectral features | CNN feature | Spectral features | ||
|---|---|---|---|---|---|
| & CNN feature | |||||
| -1@ | 2 | ||||
| 5 | |||||
| 10 | |||||
| 20 | |||||
| @ | 2 | ||||
| 5 | |||||
| 10 | |||||
| 20 | |||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRecommender Systems and Techniques · Image Retrieval and Classification Techniques · Advanced Graph Neural Networks
Spectrum-enhanced Pairwise Learning to Rank
Wenhui Yu
Tsinghua UniversityBeijingChina
and
Zheng Qin
Tsinghua UniversityBeijingChina
(2019)
Abstract.
To enhance the performance of the recommender system, side information is extensively explored with various features (e.g., visual features and textual features). However, there are some demerits of side information: (1) the extra data is not always available in all recommendation tasks; (2) it is only for items, there is seldom high-level feature describing users. To address these gaps, we introduce the spectral features extracted from two hypergraph structures of the purchase records. Spectral features describe the similarity of users/items in the graph space, which is critical for recommendation. We leverage spectral features to model the users’ preference and items’ properties by incorporating them into a Matrix Factorization (MF) model.
In addition to modeling, we also use spectral features to optimize. Bayesian Personalized Ranking (BPR) is extensively leveraged to optimize models in implicit feedback data. However, in BPR, all missing values are regarded as negative samples equally while many of them are indeed unseen positive ones. We enrich the positive samples by calculating the similarity among users/items by the spectral features. The key ideas are: (1) similar users shall have similar preference on the same item; (2) a user shall have similar perception on similar items. Extensive experiments on two real-world datasets demonstrate the usefulness of the spectral features and the effectiveness of our spectrum-enhanced pairwise optimization. Our models outperform several state-of-the-art models significantly.
Collaborative filtering, spectral feature, pairwise learning to rank, latent community, latent category.
††copyright: rightsretained††journalyear: 2019††copyright: iw3c2w3††conference: Proceedings of the 2019 World Wide Web Conference; May 13–17, 2019; San Francisco, CA, USA††booktitle: Proceedings of the 2019 World Wide Web Conference (WWW ’19), May 13–17, 2019, San Francisco, CA, USA††doi: 10.1145/3308558.3313478††isbn: 978-1-4503-6674-8/19/05††ccs: Information systems Collaborative filtering††ccs: Information systems Social recommendation††ccs: Information systems Recommender systems††ccs: Human-centered computing Social recommendation
1. Introduction
Recommender systems have been widely used in online services such as E-commerce and social media sites to predict users’ preference based on their interaction histories. Modern recommender systems uncover the underlying latent factors that encode the preference of users and properties of items. In recent years, to strengthen the presentation ability of the models, various features are incorporated for additional information, such as visual features from product images (He and McAuley, 2016; Zhao et al., 2016; Yu et al., 2018), textual features from review data (Chen et al., 2017a; Chen et al., 2016), and auditory features from music (Cao et al., 2015). However, these features are not generally applicable, for example, visual features can only be used in product recommendation, while not in music recommendation. Also, these features are unavailable in some recommendation tasks, such as point-of-interest recommendation (Ye et al., 2011; Yuan et al., 2013). Even they are available, we need extra efforts to collect and process them. Moreover, we can only get features for items while there is seldom high-level feature for users. To address these gaps, we introduce spectral features extracted from the purchase records for both items and users in this paper. We then use the spectral features to (1) model users’ preference and items’ properties and to (2) optimize the proposed model.
Recommender systems predict the missing value by uncovering the similarity of users/items, thus the information of similarity is vital in recommendation tasks. For example, in user-/item-based collaborative filtering, we recommend by calculating the similarity among users/items (Goldberg, 1992; Sarwar et al., 2001); in model-based collaborative filtering, the low-rank form ensures the linear dependence of latent factors, i.e., the similarity among users/items (Koren, 2009; Bennett and Lanning, 2007; Rendle, 2011). Inspired by this, we propose a new feature that contains the similarity information. We define the front eigenvectors of a Laplacian matrix as the spectral feature. Devised for spectral clustering (Ng et al., 2002), the spectral feature describes the distance among vertices in a graph space thus contains abundant information of similarity. The spectral feature extracts information from the purchase history rather than additional data, thus it is generally applicable and works in almost all situations. Also, we can extract spectral features for both users and items.
We define the set of users near in the graph space as a latent community, which means they have similar purchase behaviors. For an item preferred by a specific user, it may get a high score for her latent community members. Also, the set of items near in the graph space is defined as a latent category, items in the same latent category have similar properties. Users who like certain item may have interests in the latent category the item belongs to. Of special notice is that a latent category is not like a real category, items in it may be relevant items, similar items, etc., in a word, items strongly connected in the graph. In this paper, we incorporate the spectral features into a Matrix Factorization (MF) model (Rendle et al., 2009; Koren, 2009) to propose our Spectrum-enhanced Collaborative Filtering (SCF) model. By learning spectral dimensions, SCF uncovers users’ preference for latent categories and items’ fitness for latent communities.
Compared with other side information features, our spectral feature is more suitable for the implicit feedback data. Implicit feedback data is like “purchase” or “browse” in E-commerce sites, “like” in social media sites, “click” in advertisements, etc. In real-world applications, the data of user behaviours in “one-class” (implicit feedback) is easier to collect and more generally applicable than “multi-class” scores (explicit feedback). The spectral features, which are independent of extra data, are more suitable for the implicit feedback data, since they maintain the advantages of easy to collect and generality.
Besides providing information of similarity, we also use the spectral features to enhance the pairwise learning. When optimizing model on implicit feedback data, Bayesian Personalized Ranking (BPR) is widely used due to the outstanding performance (Rendle et al., 2009; He and McAuley, 2016; Yu et al., 2018). It aims to maximize the likelihood of pairwise preference over positive samples and negative samples. However, there is a critical issue: All missing values are simply treated as negative samples in BPR. In fact, some of the missing values are indeed unlabelled positive samples, users may like them but just have not seen them yet. To deal with this issue, we cluster all items and users by spectral features to construct the latent categories and latent communities, respectively. We assume that a user shows stronger preference for items that are in the same latent category with what she purchased, or items that purchased by her neighbors in the same latent community, than other missing entries. Considering the enriched preference relationship, we propose an optimization method called Spectrum-enhanced Pairwise Learning to Rank (SPLR), and optimize SCF with it. Finally, we validate the effectiveness of our proposed model by comparing it with several baselines on the Amazon.Clothes and Amazon.Jewelry datasets. Extensive experiments show that we improve the performance significantly by exploring spectral features.
Specifically, our main contributions are listed as follows:
- •
We leverage novel spectral features in recommendation tasks to capture the similarity information of users/items, and propose an SCF model by injecting these features to the MF model.
- •
We propose a spectral clustering-enhanced pairwise ranking method, SPLR, to optimize our model. We construct latent categories and latent communities to enrich the positive samples.
- •
We extend our model and propose a framework to use side information features for modeling and for optimization. We can explore any kinds of features in our framework, including spectral features and other conventional features. Multiple features can be utilized at a time.
- •
We devise comprehensive experiments on two real-world datasets to demonstrate the effectiveness of our proposed methods.
2. Related Work
After Matrix Factorization (MF) is utilized to deal with recommendation tasks (Bennett and Lanning, 2007; Koren, 2009; Rendle et al., 2009), modern recommender systems develop rapidly. MF models learn the latent factors of users and items by reconstructing the purchase records in a low-rank form. Latent factors represent the preference of users and properties of items. Many variants are proposed to promote the ability to model the complex preference that users exhibit toward items based on their past interactions. (He et al., 2017; He and Chua, 2017) used deep structure to learn embedding. (Chen et al., 2017b; He et al., 2018b) took time into account when making predictions. (He et al., 2016; Zhang et al., 2016) focused on fast algorithms for online recommendation.
2.1. Side Information Features
One important way to enhance the presentation ability is to leverage the side information. Theoretically, latent dimensions can capture all relevant factors, but they usually cannot in applications due to the sparsity of the datasets, thus extra information is desired. The visual features are widely used since users’ decisions depend largely on products’ appearance (He and McAuley, 2016; McAuley et al., 2015; Yu et al., 2018; Zhao et al., 2016). (He and McAuley, 2016; McAuley et al., 2015) predicted consumers’ behavior with the CNN feature. Yu et al. (2018) utilized the aesthetic feature to model users’ aesthetic preference on clothes. Zhao et al. (2016) leveraged several visual features to recommend movies. There are also many efforts exploring the textural feature to recommend (McAuley and Leskovec, 2013; Chen et al., 2017a), McAuley and Leskovec (2013) proposed models with the textural feature from the review data and Chen et al. (2017a) extracted the textural feature from time-synchronized comments for key-frame recommendation. In music recommendation, the auditory feature is generally used, Cao et al. (2015) extracted the auditory feature by a pre-trained deep structure to recommend music.
Various features are used for different kinds of information. However, one feature, the spectral feature, has never been explored. In this paper, we extract the spectral features from the hypergraphs of users and items, which represent the similarity of vertices in the hypergraphs. Compared with features mentioned above, the spectral features are independent of additional information so they are suitable for more situations. Moreover, conventional features are all for items, while we extract spectral features for both users and items.
2.2. Graph-enhanced Recommendation
In recent years, hypergraph gains increasing attention in the recommendation domain (Lierde and Chow, 2017; Rao et al., 2015; Cai et al., 2008). Lierde and Chow (2017) proposed a user-based collaborative filtering enhanced with the hypergraph: The similarity of the users is calculated with the hypergraph embedding. (Rao et al., 2015; Cai et al., 2008) filtered the latent factors with hypergraph regularized term to smooth them. There are also some efforts promoting the recommendation performance with social networks (Walter et al., 2008; Jamali and Ester, 2010). Walter et al. (2008) calculated similarities with the social networks embedding for memory-based collaborative filtering. Jamali and Ester (2010) calculated the latent factors of a user with its neighbors to give the prediction. Graph convolution networks are also widely used in recommendation tasks (Berg et al., 2017; Zheng et al., 2018). Berg et al. (2017) proposed a graph convolutional auto-encoder that learns the structural information of a graph for latent factors of users and items. Zheng et al. (2018) constructed random walk laplacian matrix of the user-item bipartite graph and then introduced a deep spectral convolutional network to capture the user-item connectivity information.
In this paper, we introduce a new way to explore graph structures in recommendation tasks. We extract features from the Laplacian matrix of the hypergraphs of users and items, and make prediction with the MF term jointly. We also utilize these features to optimize our proposed method.
2.3. Learning to Rank
As implicit feedback data is easier to collect, it is extensively used in real-world application. However, prediction on implicit feedback dataset is a challenging task because there are only positive samples and unobserved samples. We cannot discriminate negative samples and unlabeled positive samples from the unobserved ones. Rendle et al. (2009) treated all unobserved samples as negative ones when sampling while some of them are indeed unlabelled positive samples. Users may like them but just have not seen them yet. To address this gap, many works improved the pairwise learning to rank method. It is assumed that all users are independent in BPR, Pan and Chen (2013) tried to relax this constraint and proposed a method called group preference-based Bayesian personalized ranking (GBPR), which modeled the preference of user groups. Qiu et al. (2014) constructed the preference chain of item groups for each user. Liu et al. (2018) utilized collaborative information mined from the interactions between users and items. (Zhang et al., 2013; Rendle and Freudenthaler, 2014) proposed dynamic negative sampling strategies to maximize the utility of a gradient step by choosing “difficult” negative samples. (Ding et al., 2018; Pan et al., 2015) used view information to enrich positive samples. (Cao et al., 2007; Liu et al., 2014) proposed listwise ranking methods instead of pairwise ones. Hwang et al. (2016) utilized both implicit and explicit feedback data to improve the quality of negative sampling.
In existing efforts, only low-order connections are considered when measuring the similarity among vertices (Pan and Chen, 2013; Qiu et al., 2014; Liu et al., 2018). In this paper, we use the spectral features, which contains the information of high-order connections, to enhance the pairwise learning. We cluster all items/users by spectral features to construct latent categories/communities. For vertices (users/items) in the same cluster, they are strongly connected111We use “strongly connected” to indicate that vertices are connected by many paths in the graph (including direct connections or high-order connections), which is different from the conception in directed graphs (Sharir, 1981). in the hypergraph thus are very similar to each other. For each user, we regard items in the same latent category with her positive samples and items purchased by her latent community members as the potential samples, and assume that the user prefers them than other negative samples.
3. Spectrum-enhanced Collaborative Filtering
In this section, we propose a novel recommendation model called Spectrum-enhanced Collaborative Filtering (SCF). We first introduce the spectral features and then inject them into an MF model. In this paper, bold uppercase letters refer to matrices. For example, is a matrix, is the -th row of , is the -th column of , and is the value at the -th row and the -th column of . is the matrix for user and is the matrix for item, is the -th matrix.
3.1. Spectral Feature
In a recommendation task, we use matrix to denote the interactions between users and items (there are users and items in total). if user purchased items and otherwise. Our task is to predict the missing values (0 in ) to recommend top- items for each user.
The hypergraph is a generalization of the simple graph, where an hyperedge (edge in hypergraph) connects any number of vertices rather than just two. A hypergraph is usually represented with the incidence matrix (there are vertices and hyperedges). Each row in is for a vertex and each column is for a hyperedge. if vertex is connected by hyperedge and otherwise. We can see that a hypergraph can represent the purchase records by nature. We define two hypergraph structures, a user hypergraph and an item hypergraph. In the user hypergraph, users are vertices and items are hyperedges while in the item hypergraph, items are vertices and users are hyperedges.
For a hypergraph represented with the incidence matrix , the Laplacian matrix is defined as (Zhou et al., 2006):
[TABLE]
where the diagonal matrix denotes the degrees of vertices, the diagonal matrix denotes the weights of hyperedges, and the diagonal matrix denotes the degrees of hyperedges. Laplacian matrix is a difference operator of a hypergraph (Narang et al., 2013), for any signal , it satisfies:
[TABLE]
where is the set of vertices connected to vertex i. We can see the effect of the Laplacian matrix is to take the first-order difference in the neighborhood of vertex . In many machine learning tasks, the parameter is smoothed by minimizing the Laplacian regularization term (Rao et al., 2015; Feng et al., 2018).
To extract the spectral feature, we factorize the Laplacian matrix with eigen-decomposition: , where is the eigenvalue matrix, all eigenvalues are in ascending order, i.e., . We define the matrix formed by the first eigenvectors as the spectral feature matrix: , and is the spectral feature of vertex . The spectral feature can be used for spectral clustering (Ng et al., 2002; Lierde and Chow, 2017) and graph Fourier transform (Narang et al., 2013). It contains the information of the similarity among vertices thus we can measure the similarity of two vertices and with . Though eigen-decomposition is computationally expensive (taking the user hypergraph as an example, with time complexity, where is the user number), however, is highly sparse in recommendation tasks. Considering there are non-zero elements in , the time complexity could be with Lanczos method (Paratte and Martin, 2016; Grimes et al., 1994), which is much smaller than .
3.2. Hybrid Model
For the hybrid model (SCF), we incorporate the spectral features into a basic MF model, which is the state-of-the-art for rating prediction as well as modeling implicit feedback, to reconstruct the interaction matrix with the low-rank form:
[TABLE]
where is the reconstruction, and are the latent factors of users and items respectively. is the preference of user and is the properties of item . and are the spectral features of users and items respectively. is the preference matrix of users, is the fitness matrix of items.
Considering that strongly connected users/items shall have similar preference/properties, / contains the information of similarity among users/items. We use the similarity information to enhance the MF predictor. We call the three terms in Equation (2) as model-based, item-based, and user-based collaborative terms respectively. In a conventional item-based collaborative filtering model, we calculate the similarity between each pair of items. For a positive sample and a missing sample , if is similar with , we recommend to current user. Similarly, in the second term of our predictor, for current user and her purchased item , is high. For a similar item , is high, thus is high as well, and can be recommended to . We can see that this procedure is just the same as item-based collaborative filtering, so we call the second term of Equation (2) item-based collaborative term. And the third term, for the same reason, is called user-based collaborative term.
Now we briefly discuss the advantage of our item-based collaborative term over conventional item-based collaborative filtering. In item-based collaborative filtering, when calculating the similarity between a pair of items, only first-order connections are taken into account, while in our item-based collaborative term, high-order connections are also considered. Take Figure 1(c) as an example, and are not connected by certain hyperedge directly, hence the similarity is 0 in conventional item-based collaborative filtering. While in our model, connections -- and --- are also considered, therefore (we will discuss the reason detailedly in the next section). In fact, in Equation (2), three models give the final prediction jointly: An MF model, and two hypergraph spectrum-enhanced memory-based collaborative filtering models.
4. Spectrum-enhanced Pairwise Learning
Besides providing information to model users’ preference and items’ property, spectral features are also used to optimize the model. Optimization on implicit feedback data usually takes the form of pairwise learning, which maximizes the likelihood of relative preference over a pair of positive and negative feedbacks:
[TABLE]
where and are the sets of users and items. is the set of positive items of . is the sigmoid function. is defined in the Equation (2) and . The last term is the regularization term to prevent overfitting, where is the regularization coefficient, {\left\Arrowvert\;\;\right\Arrowvert}_{\rm F} is the Frobenius norm of the matrix, and represents the parameters of the model.
There is a critical issue: A user did not purchase an item may not because she has no interest in it, but just because she has never seen it yet. Our task is to uncover users’ preference and recommend them unseen items they are interested in. However, in BPR, all missing entries are treated as negative samples nevertheless some of them are indeed unlabeled positive samples. To address this gap, we enrich the positive samples by the spectral clustering.
4.1. Objective Function
We cluster all vertices (items/users) by the normalized spectral features. Vertices in the same cluster are strongly connected in the hypergraph, though may not be connected directly.
Latent category: We define a cluster of items as a latent category, items in it are of the similar kind, or highly relevant, since they are purchased by the same user or users with similar preference. For certain item , the latent category it belongs to is denoted as . We argue that if a user likes , she may like the items in with a high probability.
Latent community: Similarly, we define a cluster of users as a latent community, users in it purchase the same items, similar items, or relevant items, thus they have similar preference. For certain user , the latent community she belongs to is denoted as . If a user likes , her latent community members may like as well.
To give the relative preference, we construct three sets for each user :
[TABLE]
where is the user-based collaborative potential set, is the item-based collaborative potential set. We have the preference relationship:
[TABLE]
We can see that, is the set of items that may have interests in returned by the memory-based collaborative filtering.
BPR tries to optimize the standard AUC that is designed for binary classification (Bradley, 1997), while we try to optimize a generalized AUC (GAUC) (Song and Meyer, 2015; Liu et al., 2018),
[TABLE]
where is the standard AUC, and are confidence coefficients. We use differentiable loss which is identical to . We can see that GAUC is the weighted combination of three standard AUC terms. To maximize it, we propose our Spectrum-enhanced Pairwise Learning to Rank (SPLR) optimization:
[TABLE]
4.2. Model Learning
To maximize the SPLR objective function, we take the first-order derivatives of Equation (4.1) with respect to each model parameter:
[TABLE]
We use to denote certain row of , the derivatives in Equation (4.2) are:
[TABLE]
in Equation (9) is certain row of in Equation (4.2), for example, the -th row when .
The detailed procedure is shown in Algorithm 1. We calculate the Laplacian matrices with the Equation (2) (line 1) and decompose them, the first / eigenvectors of / form / (line 2). We then construct the three sets in Equation (6) for each user (line 3). Lines 5-14 show the process of model learning. For each record , we choose potential samples from (line 9) and negative samples from (line 10), is the sampling rate. The model is optimized with the pairs , , , , , , , , . We finally calculate the derivatives given by Equation (4.2) with a batch of pairs (line 12) and update the parameters (line 13).
Like many existing works (Zhao et al., 2014; Pan and Chen, 2013; Qiu et al., 2014), we also use the connections of users and items to enhance the pairwise learning. However, in previous works, only one-order connections are utilized while in our SPLR model, we leverage connections with all orders. In a hypergraph, we have , where is the normalized adjacency matrix. indicates the -order connections, therefore contains the information of all connections less than -order in the hypergraph. For the -th eigenvector of , is the corresponding eigenvalue, we have . Since , is also the eigenvector of , therefore contains information of all-order connections in the hypergraph. Constructed with the spectral features, latent communities/categories also take the high-order information into consideration, that is the superiority of our model over existing learning to rank methods.
5. Experiments
In this section, we design experiments on real-world datasets to validate the effectiveness of our models. We evaluate our proposed methods focusing on the following three key research questions:
RQ1: How is the performance of our entire spectrum-enhanced recommendation model (effectiveness of SCF_SPLR)?
RQ2: How is the performance of the spectral features to model users’ preference and items’ properties (effectiveness of SCF_BPR)?
RQ3: How is the performance of the SPLR optimization criterion (effectiveness of MF_SPLR)?
5.1. Datasets
In this paper, we perform experiments on the Amazon dataset (He and McAuley, 2016), which is the consumption records from Amazon.com. We consider two large categories Amazon.clothes and Amazon.jewelry, which are filtered from the Amazon dataset. We take users’ review histories as implicit feedback. Some details of the datasets are shown in Table 1.
5.2. Baselines
We adopt the following methods as baselines for performance comparison:
- •
MP: This Most Popular method ranks items according to their popularity. It is a non-personalized method to benchmark the recommendation performances.
- •
PMF: This Probabilistic Matrix Factorization method, which was proposed by (Salakhutdinov and Mnih, 2007), is a frequently used state-of-the-art approach for rating-based optimization and prediction. We set the score of positive samples as 1 and missing values as 0.
- •
BPR (MF_BPR): This Bayesian Personalized Ranking me-thod is the most widely used ranking-based method for implicit feedback (Rendle et al., 2009). It regards all unobserved samples as negative samples and maximizes the likelihood of users’ preference over a pair of positive sample and negative sample.
- •
GBPR (MF_GBPR): This Group Preference-based Bayesian Personalized Ranking method (Pan and Chen, 2013) is an extension of BPR, which tries to relax BPR’s assumptions to a group pairwise preference assumption. We fix the number of grouped users to 3.
- •
VBPR: This Visual Bayesian Personalized Ranking method is a stat-of-the-art visual-based recommendation method (He and McAuley, 2016). The visual features are extracted from the product images with a pre-trained deep convolutional neural network (CNN).
5.3. Experiment Settings
The eigen-decomposition of Laplacian matrices is implemented with sparse.linalg() function of scipy library in python. The Amazon dataset is filtered with 5-core (remove users and items with less than 5 purchase records) and records before 2010 is removed. We then filter Jewelry and Clothes datasets from Amazon. Each dataset is split into training set (80%), validation set(10%), and test set (10%) randomly. Cold items and users (items and users with no record in training set) in validation and test sets are removed. We adapt -score and normalized discounted cumulative gain () to evaluate the performance of the baselines and our proposed model. Mini-batch stochastic gradient descent (MSGD) is leveraged to optimize our model. The learning rate is determined by grid searching in the range of and the batch size is determined in the range of . We evaluate different number of latent factors in the range of , the regularization coefficient in the range of , and the weighted parameters and in the range of . We conduct our experiments by predicting top- items to each user. The sampling rate is set as 5 (select 5 negative/potential samples for each positive sample to construct pairs) in all pairwise learning to balance the accuracy and efficiency.
5.4. Performance of Our Entire Model (RQ1)
In this subsection, we report the performance of our entire model (SCF model optimized with SPLR, SCF_SPLR, abbreviated as SPLR) and baselines to give some analysis. We tune all models in the validation set and test the performance in the test set. The impact of some important hyperparameters, such as the number of latent factors, regularization coefficient, and weighted parameters, are shown. When training, we iterate the whole dataset 200 times to learn models and select 1000 samples randomly from the test/validation set to test all models in each iteration (except MP, we just test 200 times without training). We record the best performance of each model during this procedure as the evaluation of it. We execute all models 5 times and then report the mean and standard deviation. The learning rate is set as 0.05 and the batch size is set as 5000 for all models.
The performance of all models is represented in Table 2, we can see that all personalized models outperform MP significantly in all situations — about 3-6 times improvement. Comparison between BPR and PMF shows the superiority of pairwise learning over point-wise one. Considering the group behaviour, GBPR gets a further enhancement and outperforms BPR in all situations. As an enhanced learning to rank method, we compare our model with BPR and GBPR, and the improvement is shown in the last two columns in Table 2. We can see that our model dramatically outperforms these two models. In GBPR, only one-order user connections are utilized while in SPLR, the spectral features capture high-order connections for both users and items, thus provides high-level and comprehensive description of the similarity among vertices.
We also report the performance of VBPR, the state-of-the-art side information-based model. With the extra visual feature, it performs the best among all baselines. As we can see, our model can even outperform VBPR in most situations. Though both utilizing “side” information to enhance the accuracy, VBPR uses “outside” information, i.e., extra visual data, while SPLR uses “inside” information extracted from the purchase records. From the last two columns of Table 2, we can see that in Jewelry dataset, the relative improvement of our model decreases with the increasing of (the number to recommend), while in Clothes dataset, the relative improvement is stable. That is not because the our model performs badly with a large , it is the property of the dataset. We can see that in Jewelry set, the gap (relative improvement) between any two pairwise learning models decreases with the increasing of .
To analyze the sensitivity of our model, we report the performance (-score@5) with different hyperparameters. The impact of regularization coefficient is represented in Figure 2. Though both filtered from Amazon dataset, these two datasets have pretty different properties. From Figure 2(a), we can see that all models perform quiet differently to each other in Jewelry dataset, PMF, BPR, GBPR, VBPR, and SPLR get the best performance when is set to 0.4, 0.8, 0.8, 1.0, and 0.3 respectively. While in Figure 2(b), all models get the best performance when is set to 0.2. With the increasing of , accuracy of the point-wise learning method decreases rapidly compared with pairwise learning methods.
We also report -score@5 with different length of latent factors to get the best . In both two datasets, performance of all models (except MP) increase with the increasing of dimensions. We can see that due to the smaller size, the purchase record matrix of Jewelry has a smaller rank than that of Clothes: The performance in Jewelry tends to be stable after is larger than 50 while the performance in Clothes keeps increasing obviously with changing from 10 to 200. To get the best performance, we set as 200 for all models.
The impact of weighting parameters is illustrated in Figure 4. Our model performs the best when and in these two datasets. When and , SPLR (SCF_SPLR) degenerates into SCF_BPR. From the figures we can see that SPLR outperforms SCF_BPR 4.70% in Jewelry validation dataset and 4.03% in Jewelry validation dataset on -score@5. We can see that the enhancement of SLPR is not so significant, this is because we have explored the similarity information by incorporating the spectral features into SCF_BPR model, which outperforms MF_BPR significantly (Table 3). We leverage SPLR optimization to explore the similarity information thoroughly for further accuracy improvement.
We demonstrated the effectiveness of our entire model in this subsection, and in next subsections, we illustrate the effectiveness of each part of our model — spectral feature-enhanced model (SCF_BPR) and spectral clustering-enhanced pairwise learning optimization strategy (MF_SPLR).
5.5. Effectiveness of SCF_BPR (RQ2)
In this subsection, we denote all models with the model names and optimization methods. We rename BPR as MF_BPR, which means MF model optimized with BPR algorithm. Similarly, SCF_BPR is SCF model optimized with BPR. We demonstrate the effectiveness of spectral features by comparing SCF_BPR with other baselines. We first report the sensitivity with the number of eigenvectors by grid searching in the range of {0,10,100,1000}. All experiments in this and next subsection are conducted in Jewelry dataset.
The sensitivity of SCF_BPR with the length of spectral features is shown in Figure 5. When and , SCF_BPR performs the best. When and , SCF_BPR degenerates into MF_BPR. SCF_BPR outperforms MF_BPR 7.2% on -score@5 in Jewelry validation set. From Figure 5 we can see that user feature and item feature do not jointly work well since SCF_BPR does not perform well when and are both large. In real-world application, we can set and to balance the accuracy and the efficiency.
The performance of SCF_BPR and baselines in test set is shown in Table 3. To save space, only the performance of MF_BPR is reported, since it is the most important baseline. We can check Table 2 for the performance of other baselines. With the spectral features providing similarity information, SCF_BPR outperforms MF_BPR 7.27% and 6.38% on -score and respectively in the best situation.
5.6. Effectiveness of MF_SPLR (RQ3)
The sensitivity of MF_SPLR with the weighting parameters and are shown in Figure 6. We can see that MF_SPLR performs the best when and . When and , MF_SPLR degenerates to MF_BPR. MF_SPLR outperforms MF_BPR 6.13% -score@5 in Jewelry validation set. Comparing Figure 4(a) and Figure 6 we can see that though both enhanced with SPLR optimization, MF_SPLR gains more improvement than SCF_SPLR, and the SPLR terms are weighted more in MF_SPLR (, in MF_SPLR while , in SCF_SPLR). It is because that the similarity information has been leveraged in SCF_SPLR by modeling with the spectral features. While in SCF_SPLR, SPLR is the only way to utilize the similarity information.
The performance of MF_SPLR and baselines in Jewelry test set is shown in Table 4. From the table we can see that SCF_BPR outperforms MF_BPR 8.20% and 5.42% on -score and respectively in the best situation. Comparing Tables 2, 3, and 4, we can see that the improvement of the entire model is less than the sum of the improvement of each part. That may be because our model utilizes the similarity information by modeling (SCF) and optimizing (SPLR), thus these two parts provide the same information in different ways.
In Figure 7, we show some latent categories of the Jewelry set, which contains all watches and jewelries. There are six latent categories in Figure 7. Not like a real category, items in a latent category are relevant items or similar items (items strongly connected in the hypergraph). For example, in Figure 7, items are watches and some relevant commodities, such as watch bands and watch boxes222https://www.amazon.com/dp/B005IHDLYC/?tag=tc0f3f-20. Users who want to by watches may have interests in this category. Though items in the same latent categories may be different kinds of commodities, they are in the same style. For example, items in Figure 7 are designed for business men, they are luxurious, with metallic luster, look mature and steady. On the contrary, different categories may contain items of the same kind, but they are in different styles. For example, the category in Figure 7 is also for watches, however is in a totally different style from that in Figure 7. Most items in this category are plastic and cheap digital watches for sports and boys may have interests in them. Items in Figure 7 are watches and jewelries for young girls, they look simple and elegant. Jewelries in Figure 7 and Figure 7 are luxurious and exaggerative, which are full of diamonds and gemstones. Items in Figure 7 are in punk style and rebellious teenagers may prefer them.
Figure 7 shows how the item spectral feature helps to recommend. The item spectral feature indicates the style of the item, circle of interest the item belongs to, the price level, target users, etc. Modeling with the item spectral feature (SCF) makes the items in the same latent category tend to have similar score. And optimizing with the item spectral feature (SPLR) makes the items in the positive category (latent category containing positive samples) tend to have a high score. For the user spectral feature, we can draw the same conclusion.
Both spectral features and latent factors are extracted from graph structures which are constructed from the purchase records (one bipartite graph and two hypergraphs). In fact, they both mine the similarity information while with different emphasis — user/item spectral features describe the similarity of users/items, while latent factors describe the similarity between a user and an item. Spectral features and latent factors complete each other in describing the similarity information and enhance the effectiveness of the recommendation model.
6. Extension
In this paper, we proposed new spectral features and incorporated them into an MF model to predict users’ preference. We then introduced new spectral clustering-based pairwise learning method to optimize our model. In this section, we extend our model and propose a framework of learning to rank models enhanced with side information features. Not only the spectral features, all features can be leveraged in our framework. Assuming there are features for users , , and features for items , , , the prediction is given by:
[TABLE]
where is the preference of user based on the -th item feature. These item features can be high-level features like the spectral feature, CNN feature, auditory feature, or low-level features like the color histogram or tags. is the fitness of item based on the -th user feature. These user features can be high-level features like the spectral feature, or the low-level information vector containing such as age, genders, addresses, etc.
For pairwise learning, we use the latent community and latent category to construct the potential set in Equation (6), where is the latent community of user clustered by the -th feature and is the latent category of item clustered by the -th feature.
Experimental results of our extended model are shown in Table 5. These four columns are performances of our extended models with no feature (i.e., MF_BPR), with the spectral features (i.e., SCF_SPLR), with the CNN feature (i.e., VBPR optimized with visual clustering-enhanced pairwise learning to rank), and with the spectral features plus the CNN feature. Enhanced with the spectral features, SCF_SPLR outperforms MF_BPR 9.20% on -score@5. Leveraging appearance information, our extended model with the CNN feature outperforms MF_BPR 11.13% on -score@5. Comparing Table 2 and Tale 5 we can see that it also outperforms VBPR 4.03% on -score@5 due to the enhanced pairwise learning optimization. Our extended model with the CNN feature and spectral features outperforms MF_BPR 14.88% on -score@5.
7. Conclusion and Future Work
In this paper, we investigated the usefulness of the spectral features in recommendation tasks. We first introduced novel spectral features, which contain similarity information, and injected them into an MF structure to model users’ preference and items’ properties. We then clustered the spectral features to construct the latent communities and categories for users and items respectively, and used them to enhance the pairwise learning. We finally extended our model and proposed a framework for side information-enhanced pairwise learning. Experiments on challenging real-world datasets show that our proposed methods significantly outperform state-of-the-art models.
For future work, we will investigate the effectiveness of our proposed spectral features in the setting of explicit feedback. Also, we are interested in explaining the recommendation result to users with the information of latent communities and categories. Lastly, we will use neural networks (He et al., 2017, 2018a) to learn how to combine features, such as the item spectral feature and user spectral feature, or spectral features and other kinds of features.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Bennett and Lanning (2007) James Bennett and Stan Lanning. 2007. The netflix prize. In KDD Cup . New York, NY, USA, 35.
- 3Berg et al . (2017) Rianne Van Den Berg, Thomas N. Kipf, and Max Welling. 2017. Graph Convolutional Matrix Completion. Computing Research Repository - Co RR (2017).
- 4Bradley (1997) Andrew P. Bradley. 1997. The Use of the Area Under the ROC Curve in the Evaluation of Machine Learning Algorithms. Pattern Recogn. (1997), 1145–1159.
- 5Cai et al . (2008) D. Cai, X. He, X. Wu, and J. Han. 2008. Non-negative Matrix Factorization on Manifold. In 2008 Eighth IEEE International Conference on Data Mining (ICDM ’08) . 63–72.
- 6Cao et al . (2015) Zhe Cao, Tao Qin, Tie Yan Liu, Ming Feng Tsai, Dawen Li, Hang Liang, Minshu Zhan, and Daniel P. W. Ellis. 2015. Content-Aware Collaborative Music Recommendation Using Pre-trained Neural Networks. In International Society for Music Information Retrieval (ISMIR ’15) . 129–136.
- 7Cao et al . (2007) Zhe Cao, Tao Qin, Tie Yan Liu, Ming Feng Tsai, and Hang Li. 2007. Learning to rank:from pairwise approach to listwise approach. In International Conference on Machine Learning (ICML ’07) . 129–136.
- 8Chen et al . (2017 b) Jingyuan Chen, Hanwang Zhang, Xiangnan He, Liqiang Nie, Wei Liu, and Tat-Seng Chua. 2017 b. Attentive Collaborative Filtering: Multimedia Recommendation with Item- and Component-Level Attention. In International Conference on Research and Development in Information Retrieval (SIGIR ’17) . 335–344.