Clustering Images by Unmasking - A New Baseline
Mariana-Iuliana Georgescu, Radu Tudor Ionescu

TL;DR
This paper introduces a novel image clustering method based on unmasking, which iteratively trains classifiers and removes discriminant features to determine cluster similarity, demonstrating improved performance across multiple tasks.
Contribution
It is the first to apply unmasking for image clustering, offering a new baseline that outperforms traditional methods like k-means and recent state-of-the-art approaches.
Findings
Improves clustering performance across various tasks
Effective with both deep and shallow features
Outperforms k-means and recent methods
Abstract
We propose a novel agglomerative clustering method based on unmasking, a technique that was previously used for authorship verification of text documents and for abnormal event detection in videos. In order to join two clusters, we alternate between (i) training a binary classifier to distinguish between the samples from one cluster and the samples from the other cluster, and (ii) removing at each step the most discriminant features. The faster-decreasing accuracy rates of the intermediately-obtained classifiers indicate that the two clusters should be joined. To the best of our knowledge, this is the first work to apply unmasking in order to cluster images. We compare our method with k-means as well as a recent state-of-the-art clustering method. The empirical results indicate that our approach is able to improve performance for various (deep and shallow) feature representations and…
Click any figure to enlarge with its caption.
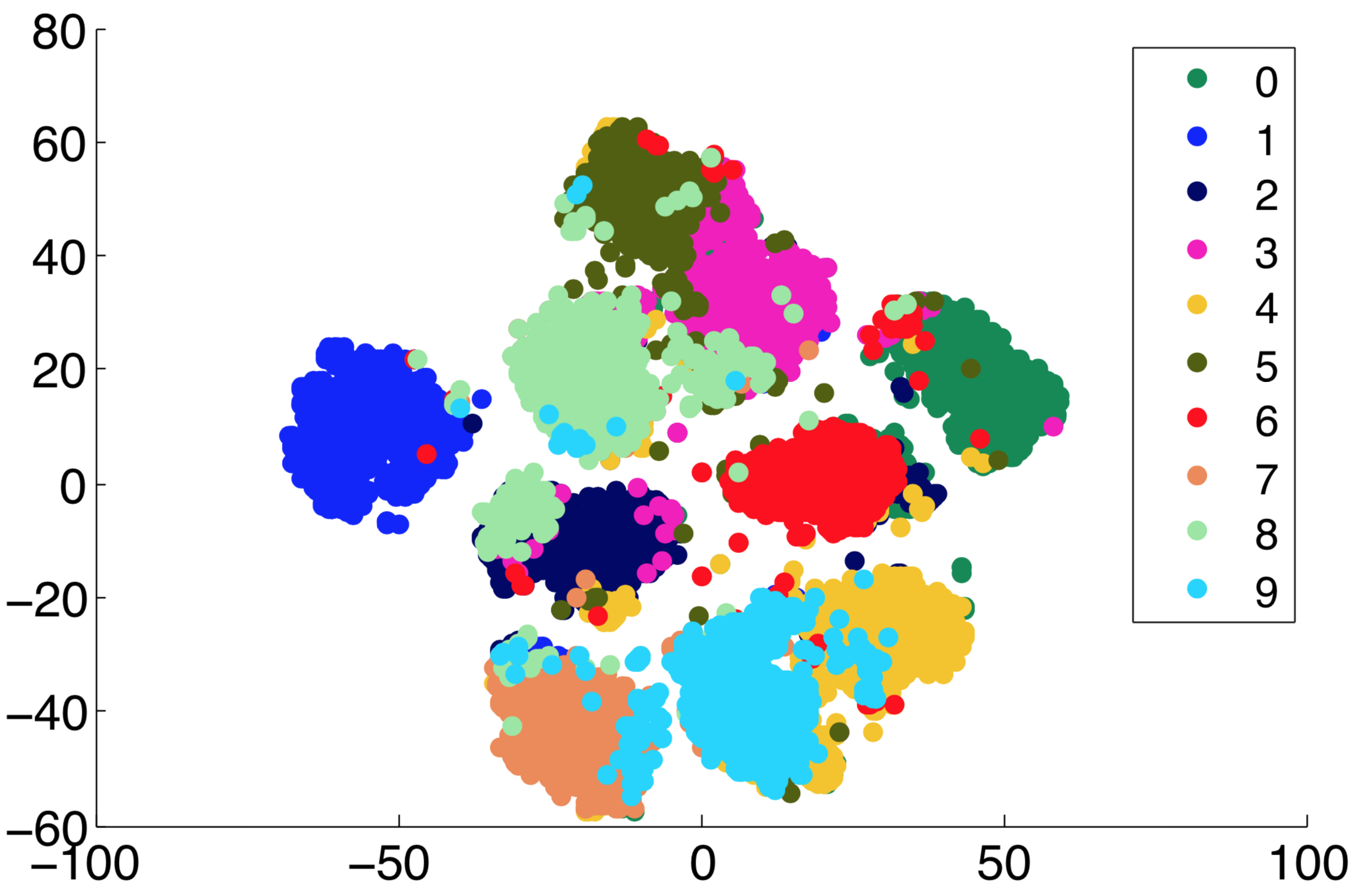 Figure 1
Figure 1| Method | ACC | NMI |
|---|---|---|
| Random chance | - | |
| SVM | - | |
| K-means | ||
| IDEC [6] | ||
| Unmasking (n=1) | ||
| Unmasking |
| Features | Method | UIUCTex | Oxford Flowers | ||
|---|---|---|---|---|---|
| ACC | NMI | ACC | NMI | ||
| - | Random chance | - | - | ||
| SVM | - | - | |||
| VGG-f | K-means | ||||
| Unmasking (n=1) | |||||
| Unmasking | |||||
| SVM | - | - | |||
| BOVW | K-means | ||||
| Unmasking (n=1) | |||||
| Unmasking | |||||
| SVM | - | - | |||
| AlexNet | K-means | ||||
| Unmasking (n=1) | |||||
| Unmasking | |||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
CLUSTERING IMAGES BY UNMASKING – A NEW BASELINE
Abstract
We propose a novel agglomerative clustering method based on unmasking, a technique that was previously used for authorship verification of text documents and for abnormal event detection in videos. In order to join two clusters, we alternate between training a binary classifier to distinguish between the samples from one cluster and the samples from the other cluster, and removing at each step the most discriminant features. The faster-decreasing accuracy rates of the intermediately-obtained classifiers indicate that the two clusters should be joined. To the best of our knowledge, this is the first work to apply unmasking in order to cluster images. We compare our method with k-means as well as a recent state-of-the-art clustering method. The empirical results indicate that our approach is able to improve performance for various (deep and shallow) feature representations and different tasks, such as handwritten digit recognition, texture classification and fine-grained object recognition.
**Index Terms— ** Clustering, unmasking, unsupervised learning, agglomerative clustering
1 Introduction
Unmasking [1] is an unsupervised method which is based on testing the degradation rate of the cross-validation accuracy of learned models, as the best features are iteratively dropped from the learning process. Koppel et al. [1] offered evidence that this unsupervised technique can solve the authorship verification problem with very high accuracy. More recently, Ionescu et al. [2] have used unmasking to detect abnormal events in video, without requiring any training data. To the best of our knowledge, we are the first to propose a clustering approach based on unmasking. Our approach falls in the category of agglomerative clustering methods, and it joins two clusters by alternating between two steps: training a binary classifier to distinguish between the samples from one cluster and the samples from the other cluster, and removing at each step the most discriminant features. If the samples from the two clusters belong to the same class, than the samples become indistinguishable when discriminant features are gradually removed. Hence, the faster-decreasing accuracy rates of the intermediately-obtained classifiers indicate that the two clusters should be joined.
We conduct experiments on the MNIST [3], the UIUCTex [4] and the Oxford Flowers [5] data sets in order to compare the proposed clustering method with the k-means clustering algorithm. On the MNIST data set, we also consider as baseline a recent method presented in [6]. The empirical results indicate that our approach can significantly outperform all these baselines.
The paper is organized as follows. Related works are presented in Section 2. Our approach is presented in Section 3. The experiments are discussed in Section 4. We draw our conclusions in Section 5.
2 Related work
Researchers have made considerable effort [6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23] to improve the performance over the commonly-used clustering algorithms, such as k-means. Hence, various clustering algorithms have emerged that differ significantly in how they form the data clusters. Clustering methods can be roughly divided into several categories, including hierarchical clustering methods [7, 12], partitioning methods [8, 16, 17, 21, 23, 24], density-based methods [10, 11], and deep learning methods [6, 19, 20, 22]. Some researchers have focused on addressing specific clustering problems, including clustering large data sets [7, 9], clustering data with categorical values [8, 21], subspace clustering [11] and correlation clustering [10, 13]. With the recent need to process larger and larger data sets, the willingness to trade the semantic meaning of the generated clusters for computational performance has been increasing. This led to the development of pre-clustering methods such as Canopy clustering [9], which can process huge data sets efficiently, but the resulting clusters are only a rough pre-partitioning of the data set. These partitions can be subsequently analyzed with existing slower methods such as k-means clustering. For high-dimensional data, many of traditional clustering methods fail due to the curse of dimensionality, which renders particular distance functions problematic in high-dimensional spaces. This led to new clustering algorithms for high-dimensional data that focus on subspace clustering [11] and correlation clustering [13]. The reader is referred to [15] for a complete review of the major clustering methods.
More closely-related to our work, are recent methods focused particularly on clustering images [6, 14, 18, 20, 22]. While some researchers have focused strictly on the clustering task [14, 18], others considered learning unsupervised image embeddings using neural networks [22, 25] or auto-encoders [6, 20, 26]. Different from the recent approaches focused on learning deep image embeddings, our work is particularly focused on the clustering task. As shown in the experiments, various features can be plugged into our clustering framework, including features that are trained in an unsupervised manner [25].
3 Clustering by unmasking
Clustering is the task of assigning a set of objects into groups (termed clusters) such that the objects in the same cluster are more similar to each other than to those in other clusters. We approach the clustering task by proposing an agglomerative clustering algorithm that joins clusters based on unmasking. Our algorithm takes as input a set of training samples and the number of desired clusters , and provides as output the cluster assignments of the given samples, as well as the resulted cluster centroids, that can be used to cluster new (test) samples based on the distance to the closest centroid. Our algorithm also takes as input some additional parameters required by the unmasking technique, which will be explained next. Unmasking is based on estimating how well a linear classifier can distinguish between the samples of two clusters, which means that the clusters must contain at least a few data samples to begin with. Therefore, our algorithm starts with an initial number of clusters , with and . In the experiments, we tried two alternative approaches to form the initial clusters. One approach is to randomly select data points as cluster centroids, and assign the rest of the data points to clusters based on the Euclidean distance to the nearest centroid. This approach is equivalent to the standard k-means initialization of the clusters, the only difference being that . The other approach is based on setting and on generating artificial data samples from the original data samples by adding various transformations such as Gaussian noise, horizontal or vertical flips, rotations, random crops and illumination changes. Each artificially-generated sample is assigned to the same cluster as the original image it came from. We note that the second approach is particularly suitable for clustering image samples, but it constrains our algorithm to be applied only on image data.
After building the initial clusters, we start joining the clusters until we end up with the desired number of clusters . For each pair of clusters and , we compute a score that indicates the likelihood of the statement “clusters and should be joined” to be true. In order to compute this score, we apply unmasking, as described next. We initially assume that the samples in cluster belong to a different class than the samples in cluster , and we assign binary labels accordingly. The goal of applying unmasking is to test whether this assumption (hypothesis) is actually true, by iteratively training and testing a binary classifier to distinguish between the labeled training samples, while removing the most discriminant features at each iteration. Before applying the classifier, the samples in each cluster are randomly split into a training set and a testing set of equal size. Hence, the training set contains half of the positively-labeled samples from cluster and half of the negatively-labeled samples from cluster , while the testing set contains the rest of the data samples from clusters and . Next, we train a linear Support Vector Machines (SVM) classifier on the training set (until convergence) and evaluate it on the testing set, retaining the accuracy rate. We note that although SVM is a supervised approach, it is never trained on ground-truth labels. We then sort the weights of the SVM by their absolute values, in descending order, we take the first indexes of the sorted list, and we remove the corresponding features from all the samples in the training and testing sets. Since the classifier assigned higher weights (in absolute value) to these features, it means that the removed features are the most discriminant. We repeat steps and for iterations, retaining the accuracy rate at each iteration. Since we remove features at each iteration, the accuracy rate of the binary classifier naturally tends to drop over time. However, if the samples in the two clusters belong to different classes, i.e. the assumed hypothesis is true, then the accuracy rate will drop at a slower pace. On the other hand, if the samples in the two clusters belong to the same class, i.e. the assumed hypothesis is false, then the classifier will have a hard time in distinguishing between samples as features get removed, and the accuracy rate will drop faster. Hence, the score of joining clusters and is computed as one minus the accuracy rate averaged over the iterations. Along with , the number of unmasking iterations and the number of discriminant features that are removed at each iteration represent input parameters of our algorithm.
After computing the score for each pair of clusters, we merge each cluster with a cluster (using a Greedy approach), such that the score of joining clusters and is maximum, for all , with . If we reach the number of clusters at any point during the merging process, we halt the execution and return the current cluster assignments. Otherwise, we continue by computing the merging scores for the newly-formed clusters. Our algorithm ends when the current number of clusters is equal to . Along with the cluster assignments, our algorithm also returns the centroid for each cluster. In the testing stage, a new sample (not seen during clustering) is assigned to a cluster, if the Euclidean distance to the respective cluster centroid is minimum.
4 Experiments
Data sets. The first data set used in the evaluation is MNIST [3]. The MNIST database contains train samples and test samples, size-normalized to pixels, and centered by center of mass in fields.
The second set of experiments are conducted on the UIUCTex data set [4]. UIUCTex contains texture images of pixels representing different types of textures such as bark, wood, floor, water, and more. There are classes, with texture images per class. Textures are viewed under significant scale, viewpoint and illumination changes. Images also include non-rigid deformations. The data set is split into for training and for testing.
The third data set included in the evaluation is the Oxford Flowers data set [5] with categories. There are a total of images in the data set, with a number of images per category. The data set is split into for training and for testing.
Baselines. In all experiments, we consider k-means as a baseline clustering method. We also consider as baseline a stub version of our clustering by unmasking approach, which performs only iterations, in order to demonstrate the utility of training the binary SVM and removing the discriminant features into several iterations, according to the full version of our algorithm. On the MNIST data set, there are some unsupervised methods [6, 20, 22] that report results, but only on the entire set, which includes both training and testing. However, to demonstrate the generalization capacity of our clustering algorithm, we use the official training and testing split. In this context, we choose as baseline one recent work [6] that provides the code online at https://github.com/XifengGuo/IDEC. We used the provided code in order to compute the accuracy rate of the Improved Deep Embedded Clustering (IDEC) [6] on the MNIST test set. We did not find any results reported by recent clustering methods on UIUCTex or Oxford Flowers, perhaps because small data sets are generally more challenging for unsupervised methods, as also noted by Faktor et al. [18]. In each and every experiment, we include the results of the random chance baseline as well as the results of the supervised SVM.
Features. Since our algorithm is designed strictly for clustering (not for unsupervised learning of feature embeddings), we can plug in various deep or handcrafted features. For the MNIST data set, we consider the raw pixels as features. However, for the UIUCTex and the Oxford Flowers data sets containing natural images, raw pixels are not discriminative enough. We thus consider three different kinds of features, as described next. First of all, we consider deep supervised features provided by the first fully-connected layer of VGG-f [27], known as fc6, resulting in a -dimensional feature vector for each image. Although VGG-f is pre-trained on a different task [28], the clustering method can no longer be considered a fully-unsupervised approach when VGG-f features are plugged in. Nevertheless, the method can be viewed as an unsupervised transfer learning approach. We remove the daisy and the iris classes from the Oxford Flowers data set, since these classes are already learned by the VGG-f model. Second of all, we consider handcrafted features computed with a standard bag-of-visual-words (BOVW) model [29] based on dense SIFT descriptors [30, 31]. The descriptors are quantized into visual words by k-means clustering. The visual words are then stored in a randomized forest of k-d trees to reduce search cost. Finally, a histogram of visual words is computed for each image, by counting the occurrences of each visual word in the image. In our experiments, we use visual words. In addition, for the Oxford Flowers data set, we include color descriptors along with the SIFT descriptors. Third of all, we consider deep unsupervised features that are extracted from the pre-trained AlexNet architecture provided by Caron et al. [25]. In their experiments, Caron et al. [25] showed that the activation maps produced by the mid-level convolutional layers yield optimal accuracy rates. Therefore, we extract features from the conv3 layer of their unsupervised neural network. The final features are obtained by adding a max-pooling layer after the conv3 layer, which produces a -dimensional feature vector for each image. Finally, we would like to stress out that the handcrafted BOVW features and the deep features provided by the pre-trained model of Caron et al. [25] are obtained in a completely unsupervised fashion.
Parameter tuning. We tune all parameters on the training sets. On the MNIST data set, we choose , while for the other data sets, we set equal to the number of training samples. For the number of unmasking iterations, we experiment with . In each case, the number of features to be removed is set depending on and on the dimension of the feature vectors, such that in the last iteration, there are still some features left for training the SVM.
Evaluation metrics. We use the same evaluation protocol as in previous works [6, 14, 20, 22] and employ the unsupervised clustering accuracy (ACC) and the Normalized Mutual Information (NMI) score as performance metrics. For the ACC metric, the optimal mapping between the ground-truth assignments and the cluster assignments provided by an unsupervised algorithm needs to determined using the Hungarian algorithm. We report results only on the test sets.
Results. Table 1 shows the results obtained on the MNIST test set. In terms of accuracy, our approach surpasses k-means by more than and the state-of-the-art IDEC approach [6] by nearly . We note that the performance improvements over k-means and IDEC are statistically significant, according to a paired McNemar’s test performed at a significance level of . Using a single iteration for unmasking () yields results that are comparable to those obtained by IDEC. This shows the importance of applying unmasking over multiple iterations, in this particular case . We note that the performance gap between the supervised SVM and our approach is greater than . In terms of NMI, our clustering method outperforms all unsupervised baselines. We provide a t-SNE [32] visualization of our MNIST clustering results in Figure 1. The figure shows that our algorithm provides well-formed clusters for digits [math], , , , and , while making some confusions between the pair of clusters and , and the pair of clusters and .
Table 2 presents the results obtained on the UIUCTex and the Oxford Flower test sets. The results are generally higher in the unsupervised transfer learning setting, i.e. when we use deep features from the supervised VGG-f model. In the fully-unsupervised setting, i.e. when we use BOVW or AlexNet features, all methods obtain slightly better results with the unsupervised AlexNet features. Nonetheless, our clustering by unmasking approach obtains better performance than k-means, irrespective of the feature set. We note that our approach attains the highest improvements over k-means on the UIUCTex data set. For instance, using the BOVW features, the improvement in terms of accuracy over k-means is slightly higher than . Nevertheless, our accuracy is significantly higher than the accuracy of k-means on both data sets, according to a paired McNemar’s test performed at a significance level of . The baseline that uses a single iteration for unmasking () yields lower performance, even compared to k-means, in all except one case. One again, these results show the importance of applying unmasking over multiple iterations, as designed by Koppel et al. [1].
5 Conclusion
In this paper, we presented an agglomerative clustering approach based on unmasking. We compared our approach with k-means as well as a recent unsupervised method [6], showing significantly better results in image clustering, using various deep and handcrafted features. In future work, we aim to evaluate our clustering method on other kinds of data, and to use other binary classifiers (instead of SVM) for unmasking.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Moshe Koppel, Jonathan Schler, and Elisheva Bonchek-Dokow, “Measuring Differentiability: Unmasking Pseudonymous Authors,” Journal of Machine Learning Research , vol. 8, pp. 1261–1276, Dec. 2007.
- 2[2] Radu Tudor Ionescu, Sorina Smeureanu, Bogdan Alexe, and Marius Popescu, “Unmasking the abnormal events in video,” in Proceedings of ICCV , 2017, pp. 2895–2903.
- 3[3] Yann Le Cun, Leon Bottou, Yoshua Bengio, and Pattrick Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE , vol. 86, no. 11, pp. 2278–2324, November 1998.
- 4[4] Svetlana Lazebnik, Cordelia Schmid, and Jean Ponce, “A Sparse Texture Representation Using Local Affine Regions,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 27, no. 8, pp. 1265–1278, Aug. 2005.
- 5[5] Maria-Elena Nilsback and Andrew Zisserman, “A Visual Vocabulary for Flower Classification,” in Proceedings of CVPR , 2006, vol. 2, pp. 1447–1454.
- 6[6] Xifeng Guo, Long Gao, Xinwang Liu, and Jianping Yin, “Improved Deep Embedded Clustering with Local Structure Preservation,” in Proceedings of IJCAI , 2017, pp. 1753–1759.
- 7[7] Tian Zhang, Raghu Ramakrishnan, and Miron Livny, “BIRCH: an efficient data clustering method for very large databases,” SIGMOD Record , vol. 25, no. 2, pp. 103–114, 1996.
- 8[8] Zhexue Huang, “Extensions to the k-means algorithm for clustering large data sets with categorical values,” Data Mining and Knowledge Discovery , vol. 2, no. 3, pp. 283–304, 1998.