TL;DR
This paper introduces a deep learning recommender system that captures complex non-linear user-item relationships using signed distance measures, significantly outperforming existing models on multiple real-world datasets.
Contribution
The paper proposes a novel deep memory recommender leveraging signed distance to model non-linear user-item interactions explicitly and implicitly.
Findings
Achieved significant improvements over ten state-of-the-art models.
Performed well in both general and shopping basket-based recommendation tasks.
Validated on six real-world datasets.
Abstract
Personalized recommendation algorithms learn a user's preference for an item by measuring a distance/similarity between them. However, some of the existing recommendation models (e.g., matrix factorization) assume a linear relationship between the user and item. This approach limits the capacity of recommender systems, since the interactions between users and items in real-world applications are much more complex than the linear relationship. To overcome this limitation, in this paper, we design and propose a deep learning framework called Signed Distance-based Deep Memory Recommender, which captures non-linear relationships between users and items explicitly and implicitly, and work well in both general recommendation task and shopping basket-based recommendation task. Through an extensive empirical study on six real-world datasets in the two recommendation tasks, our proposed approach…
Click any figure to enlarge with its caption.
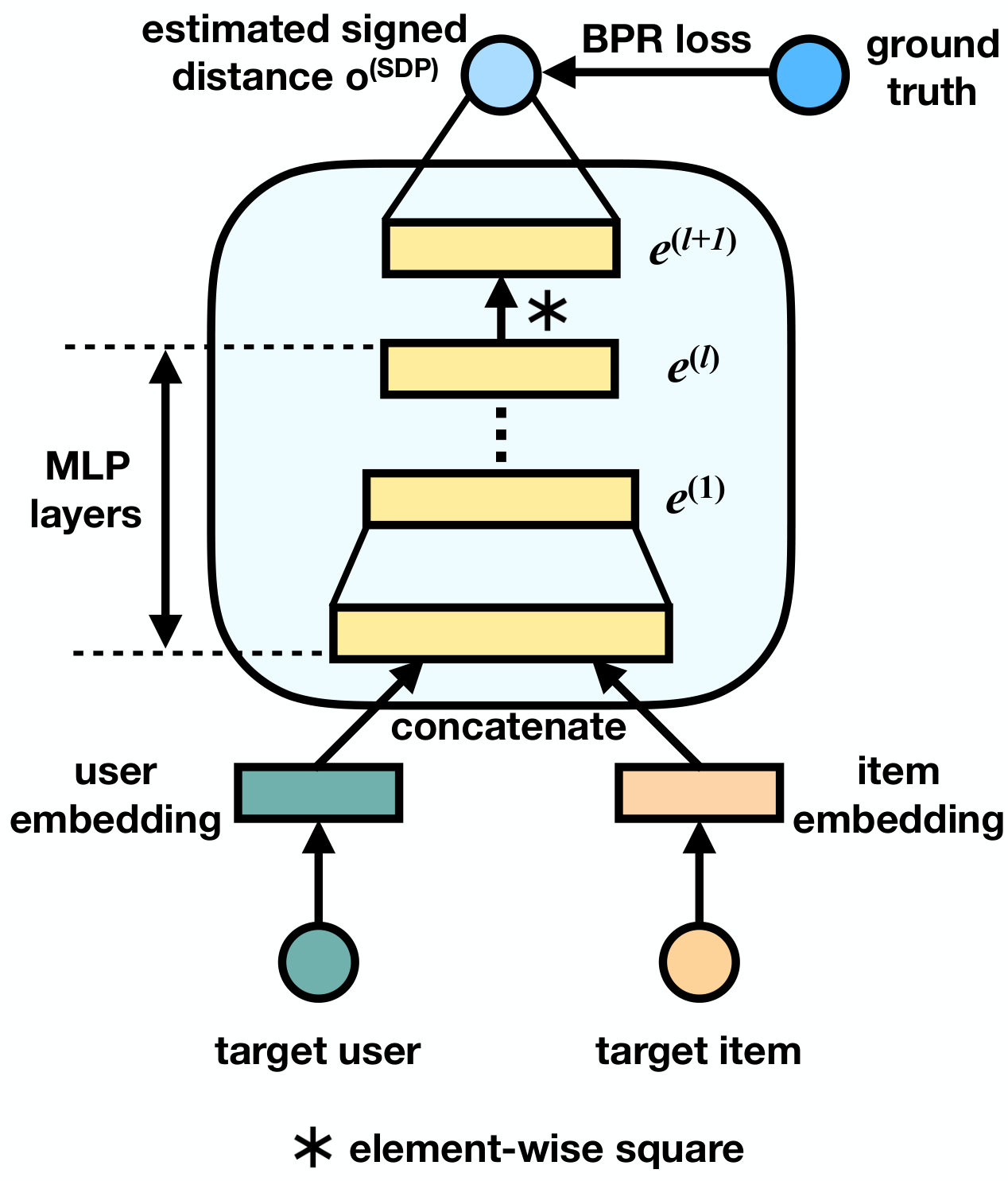 Figure 1
Figure 1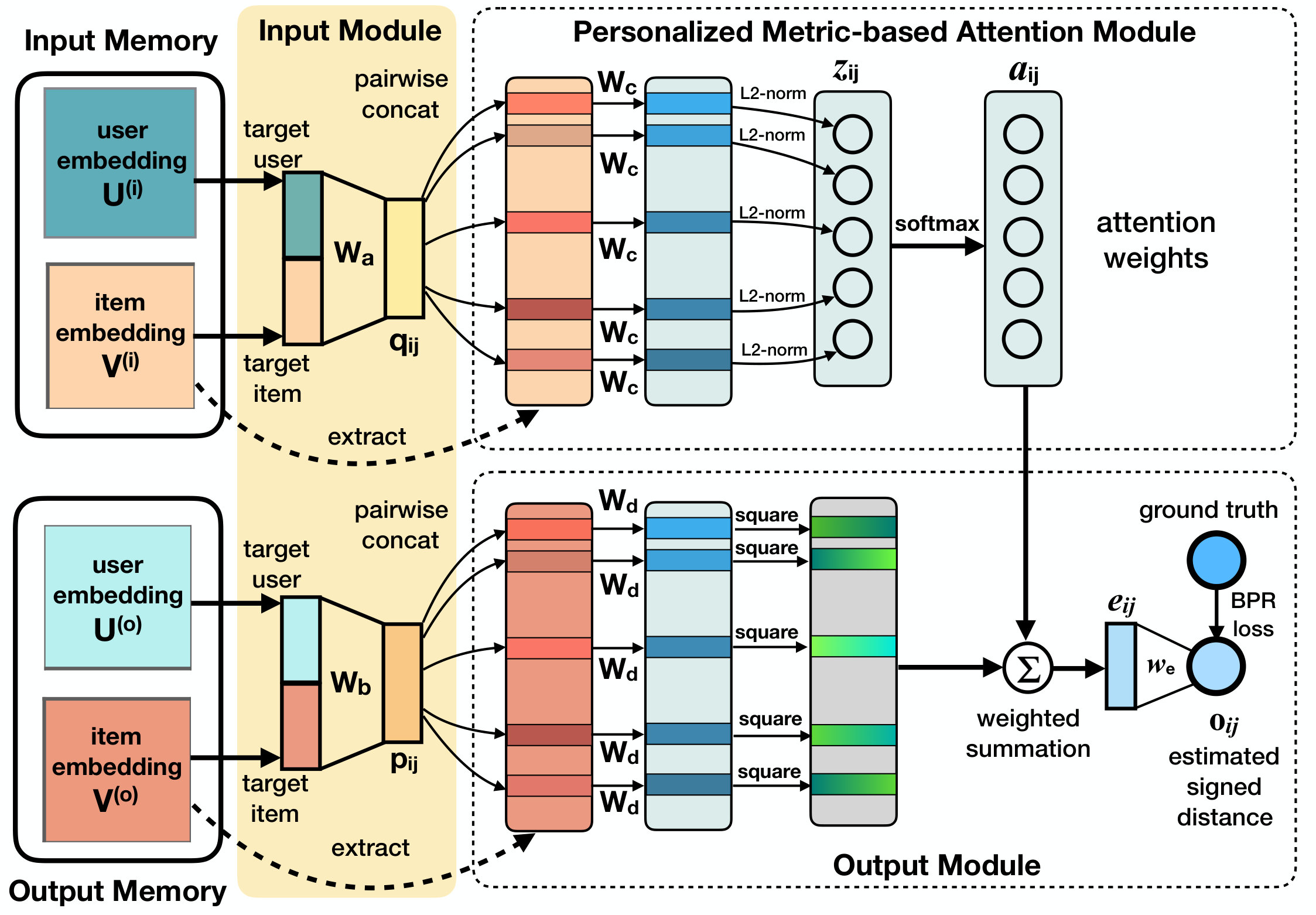 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4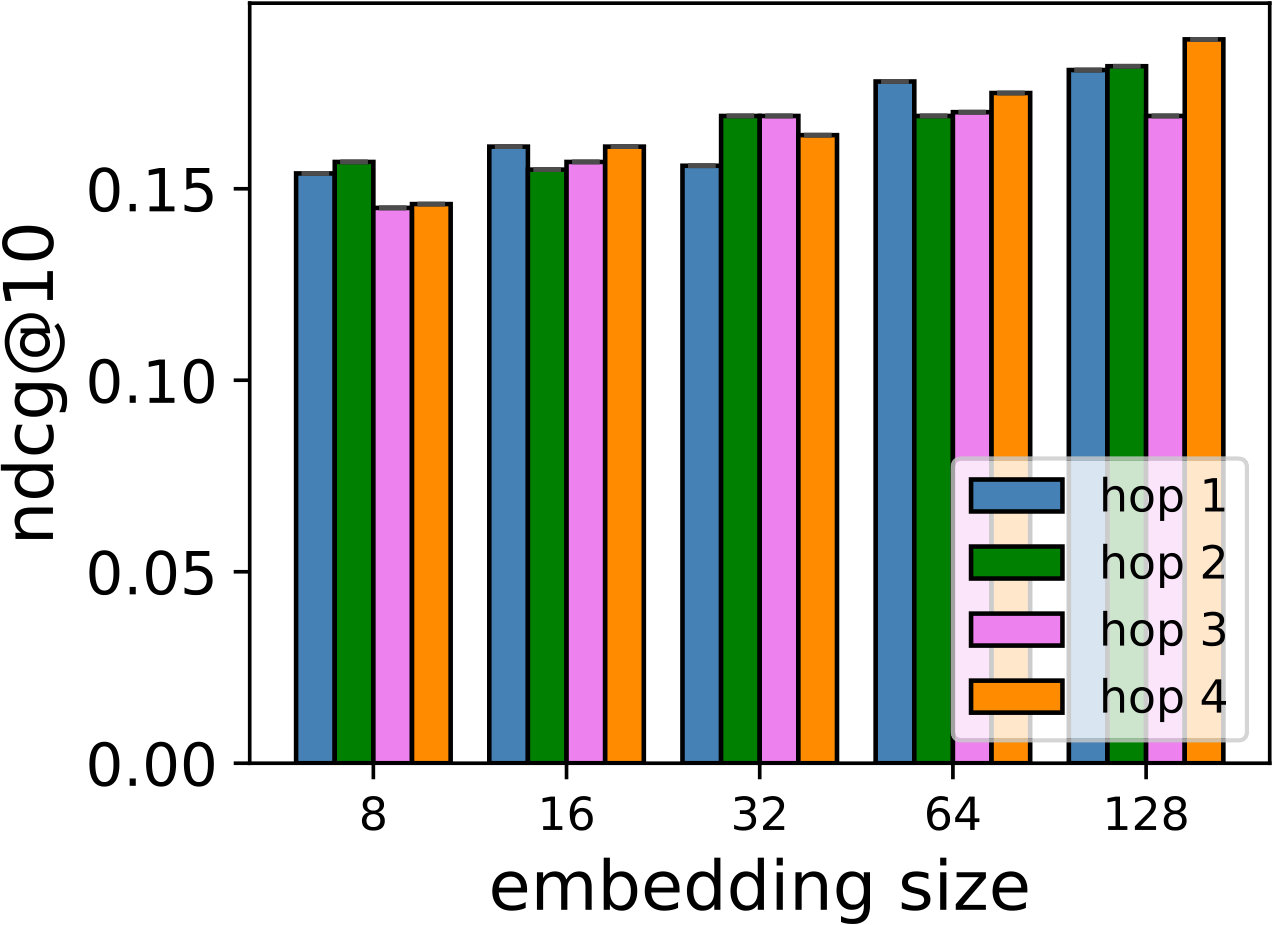 Figure 5
Figure 5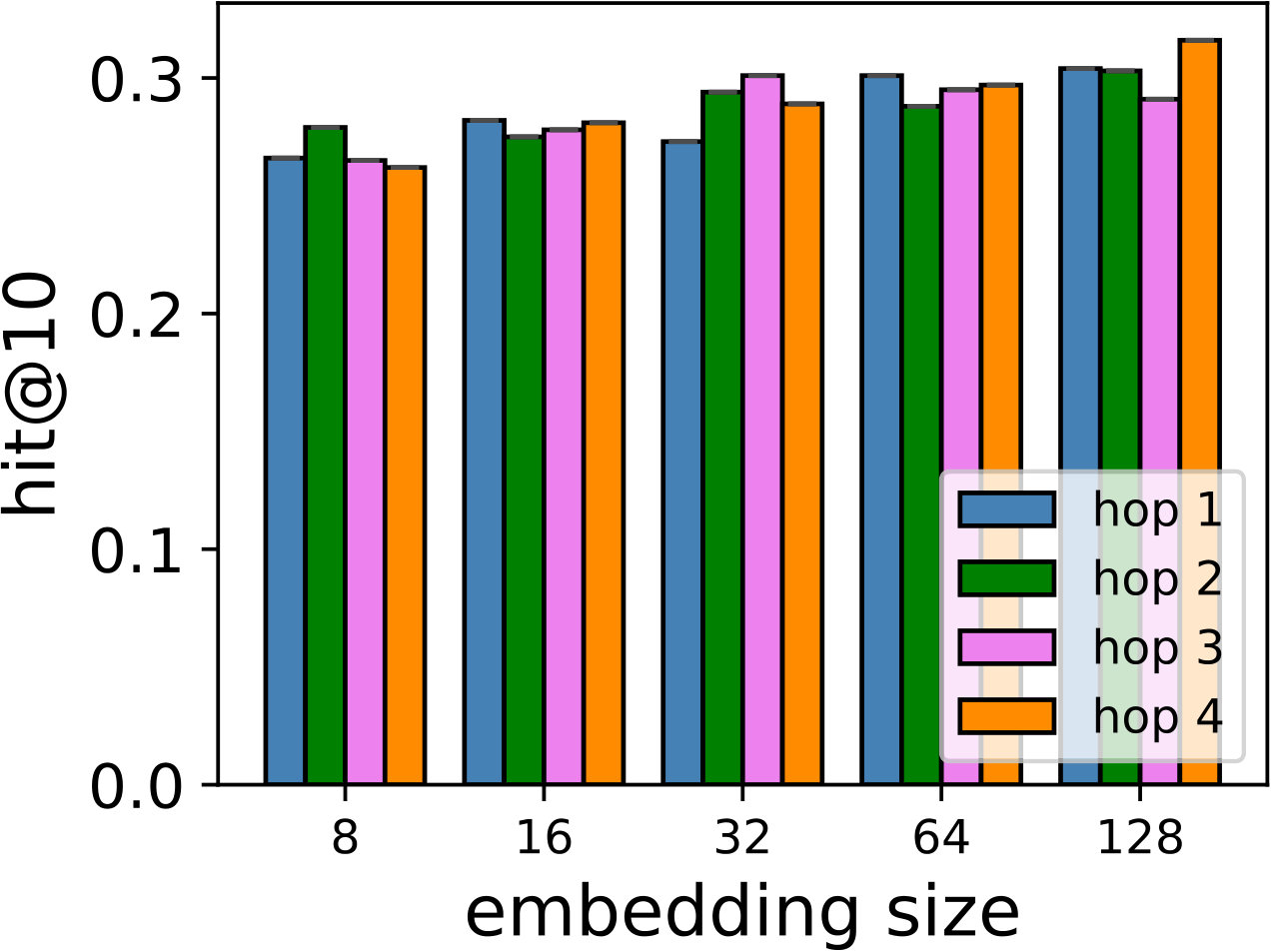 Figure 6
Figure 6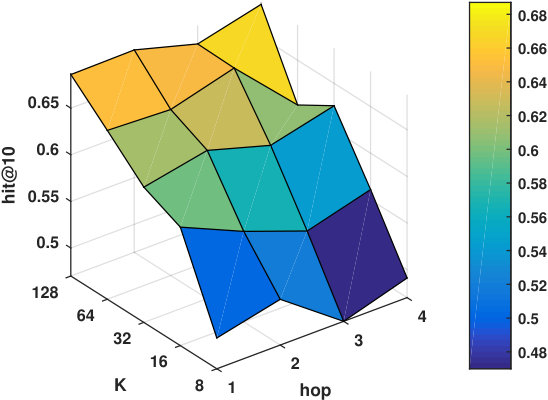 Figure 7
Figure 7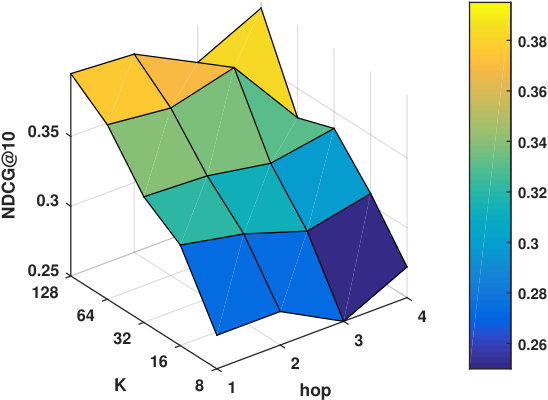 Figure 8
Figure 8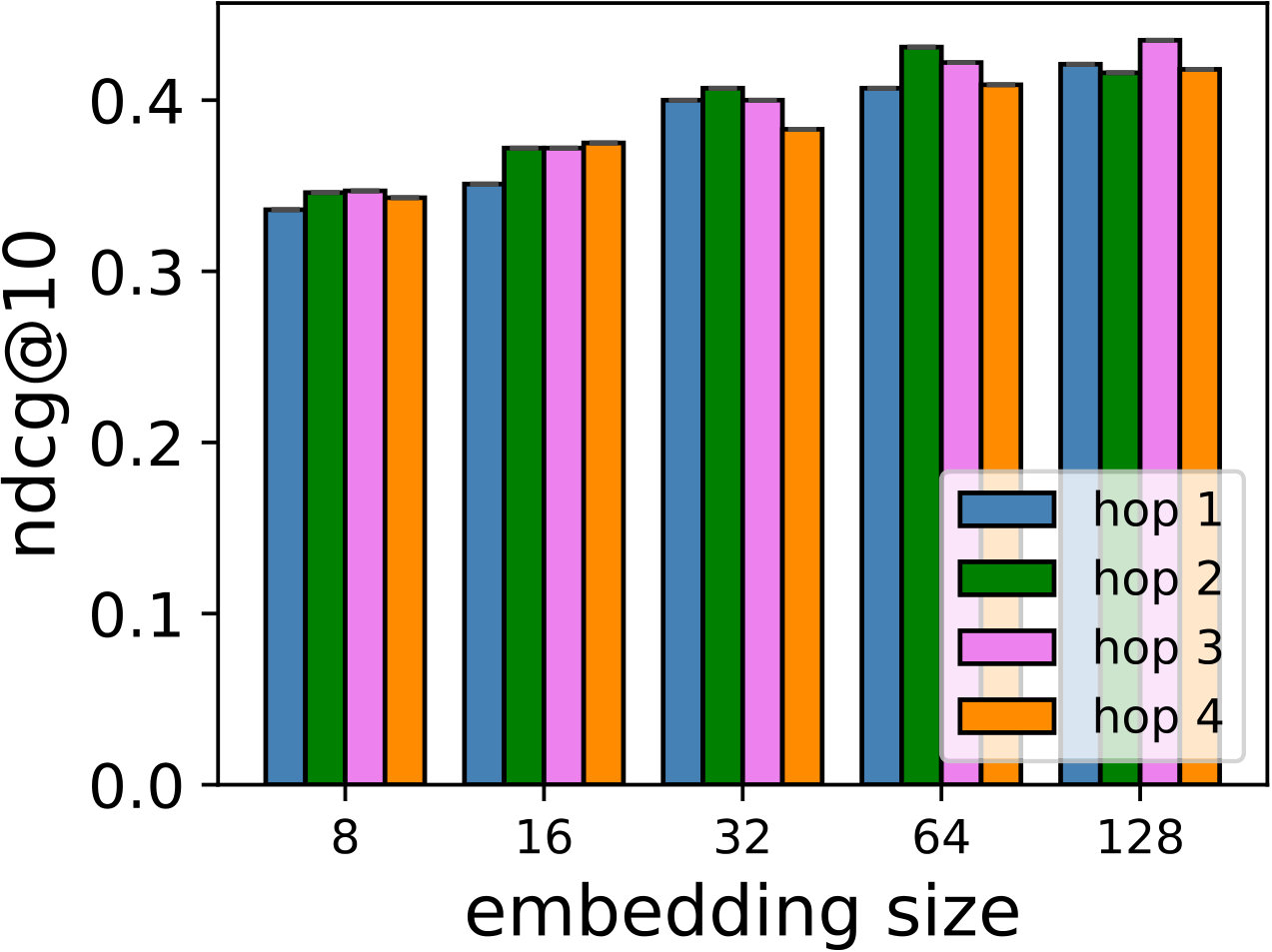 Figure 9
Figure 9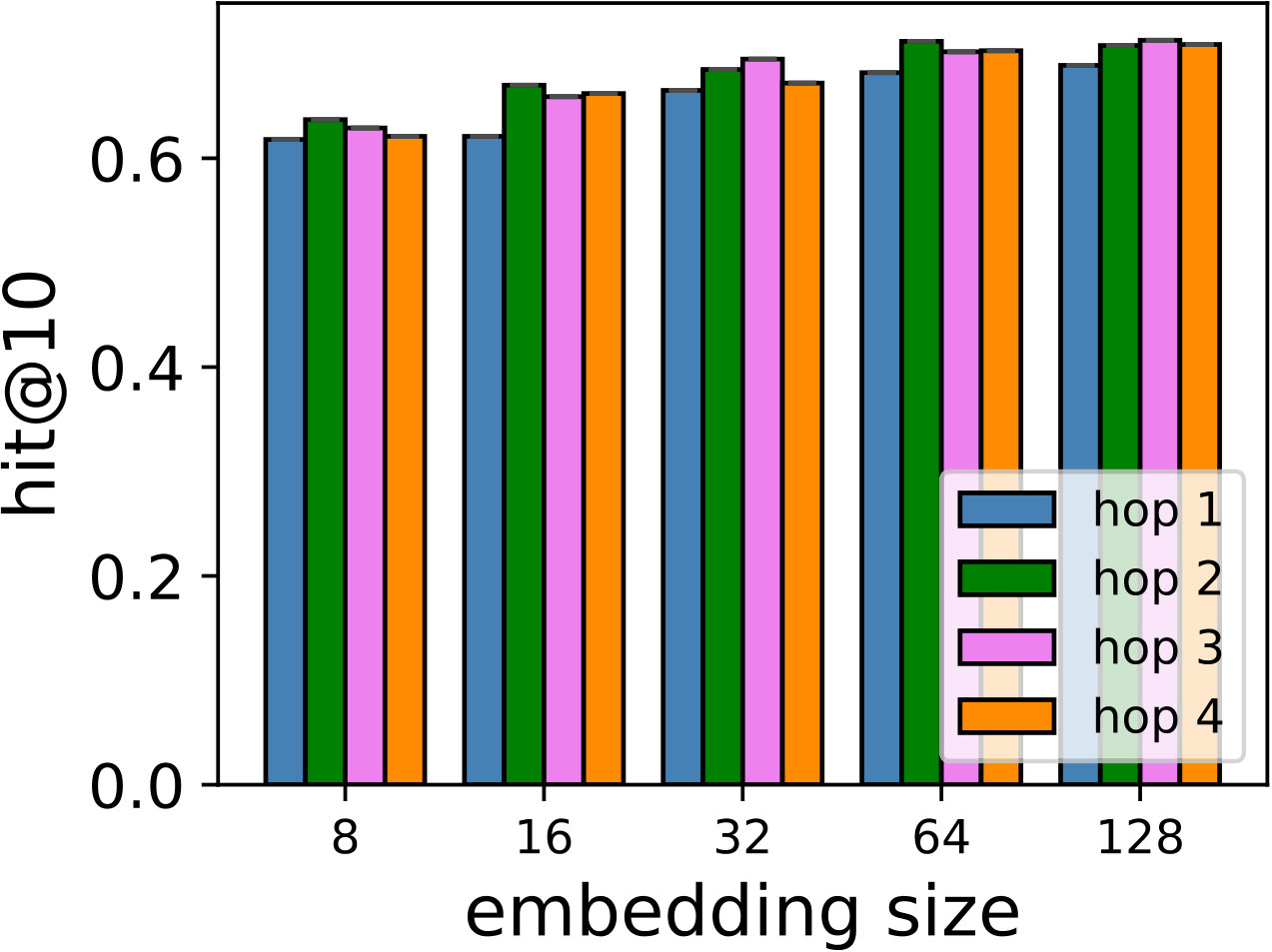 Figure 10
Figure 10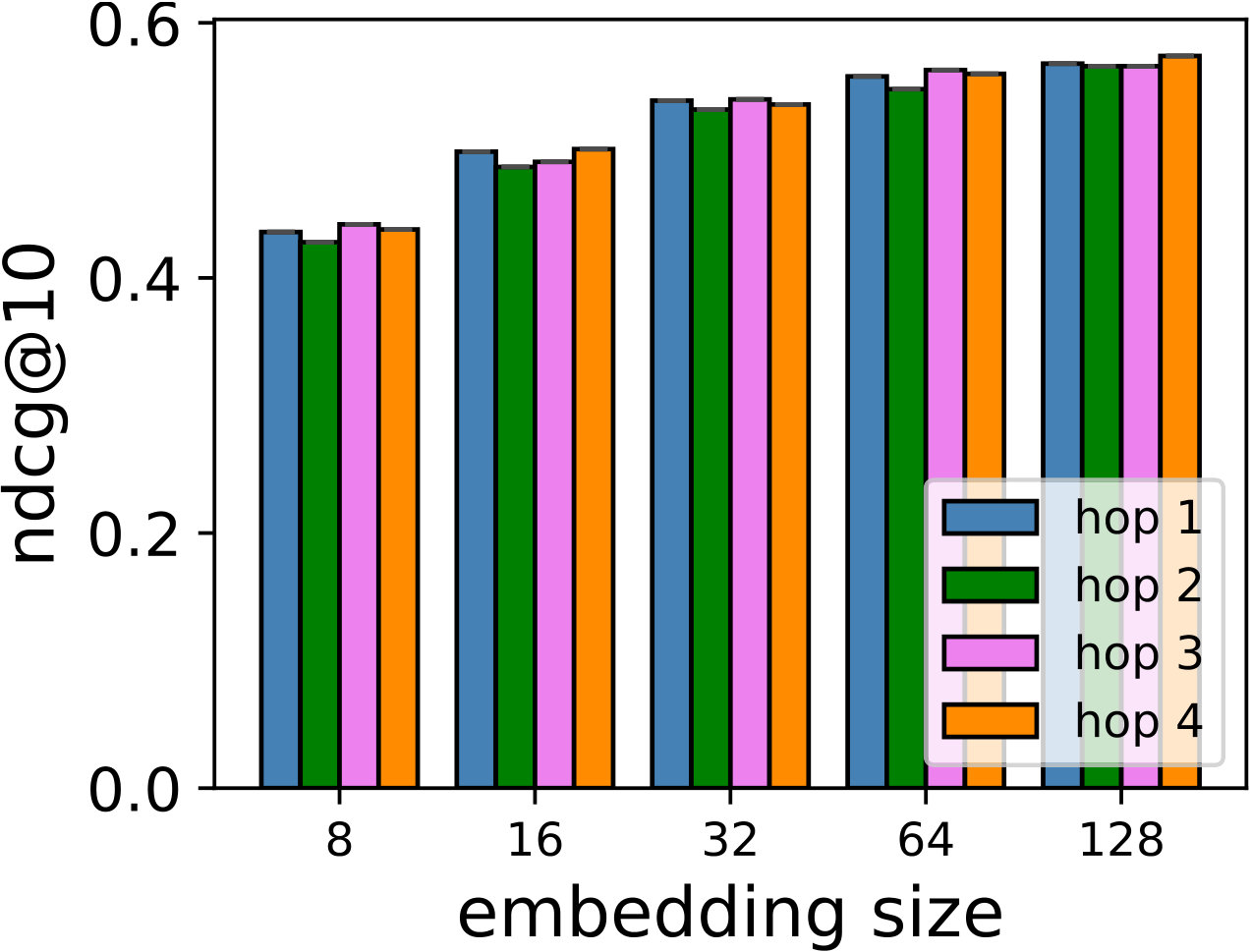 Figure 11
Figure 11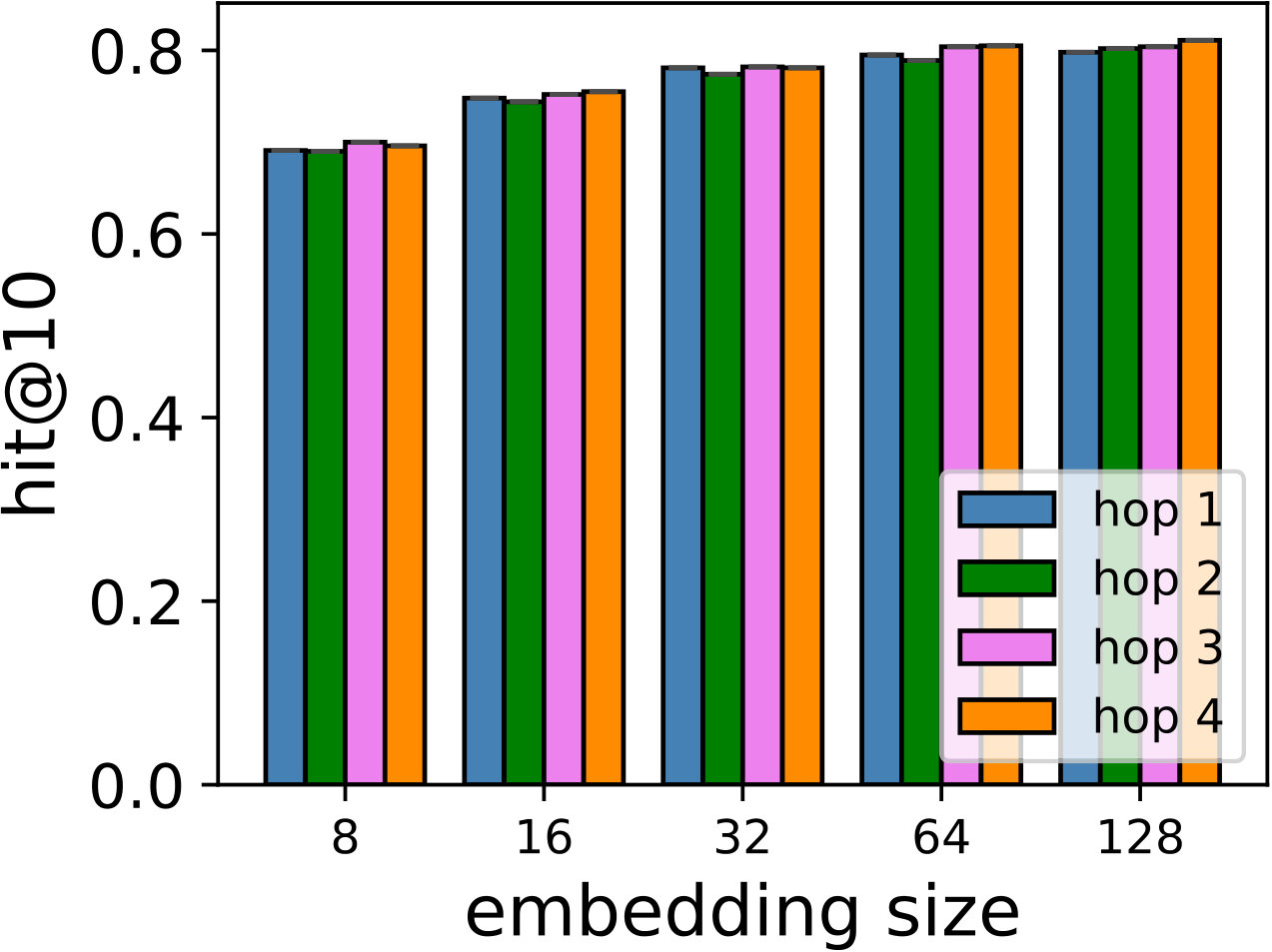 Figure 12
Figure 12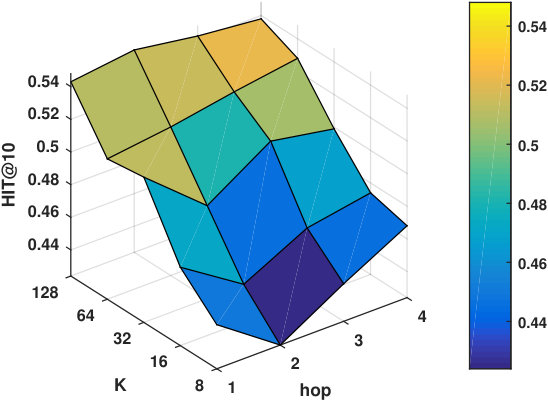 Figure 13
Figure 13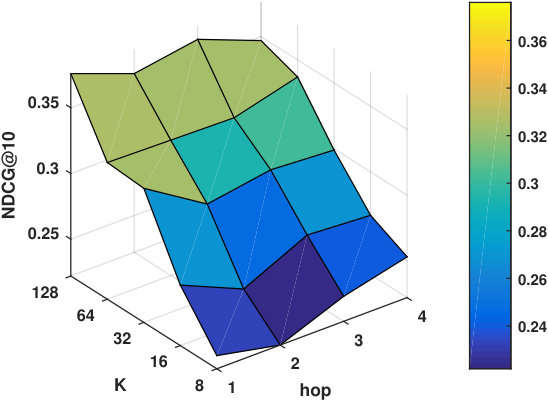 Figure 14
Figure 14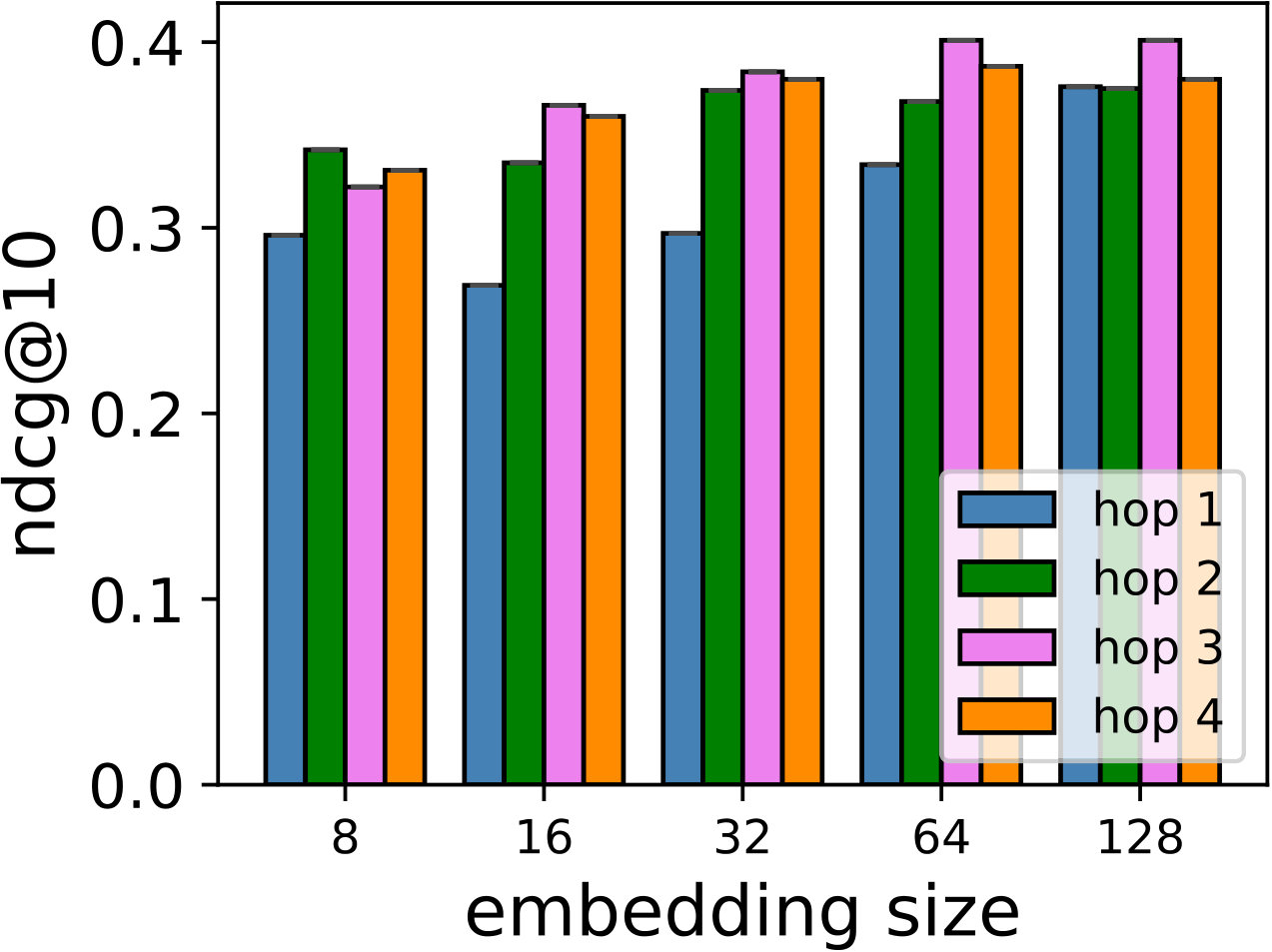 Figure 15
Figure 15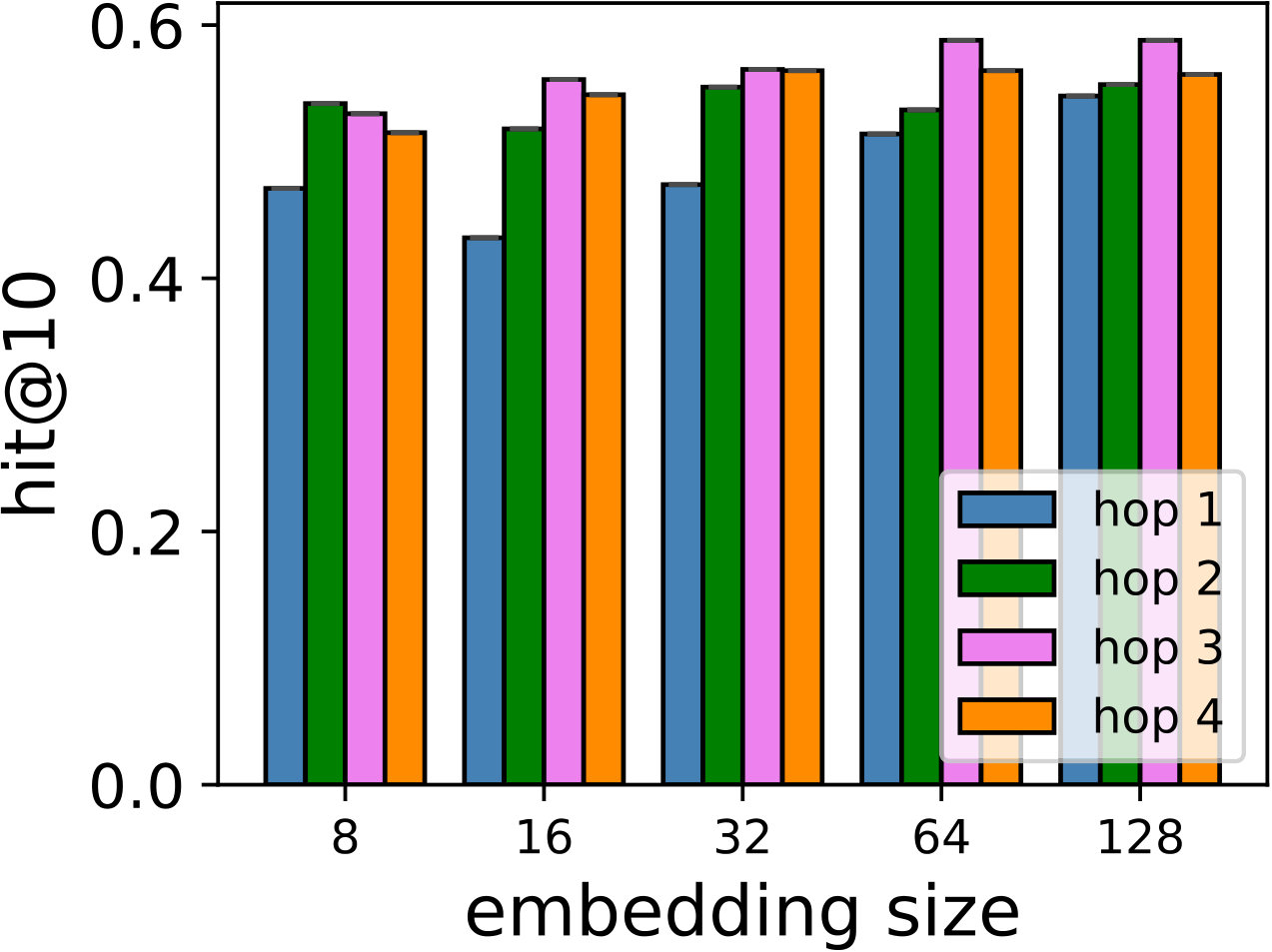 Figure 16
Figure 16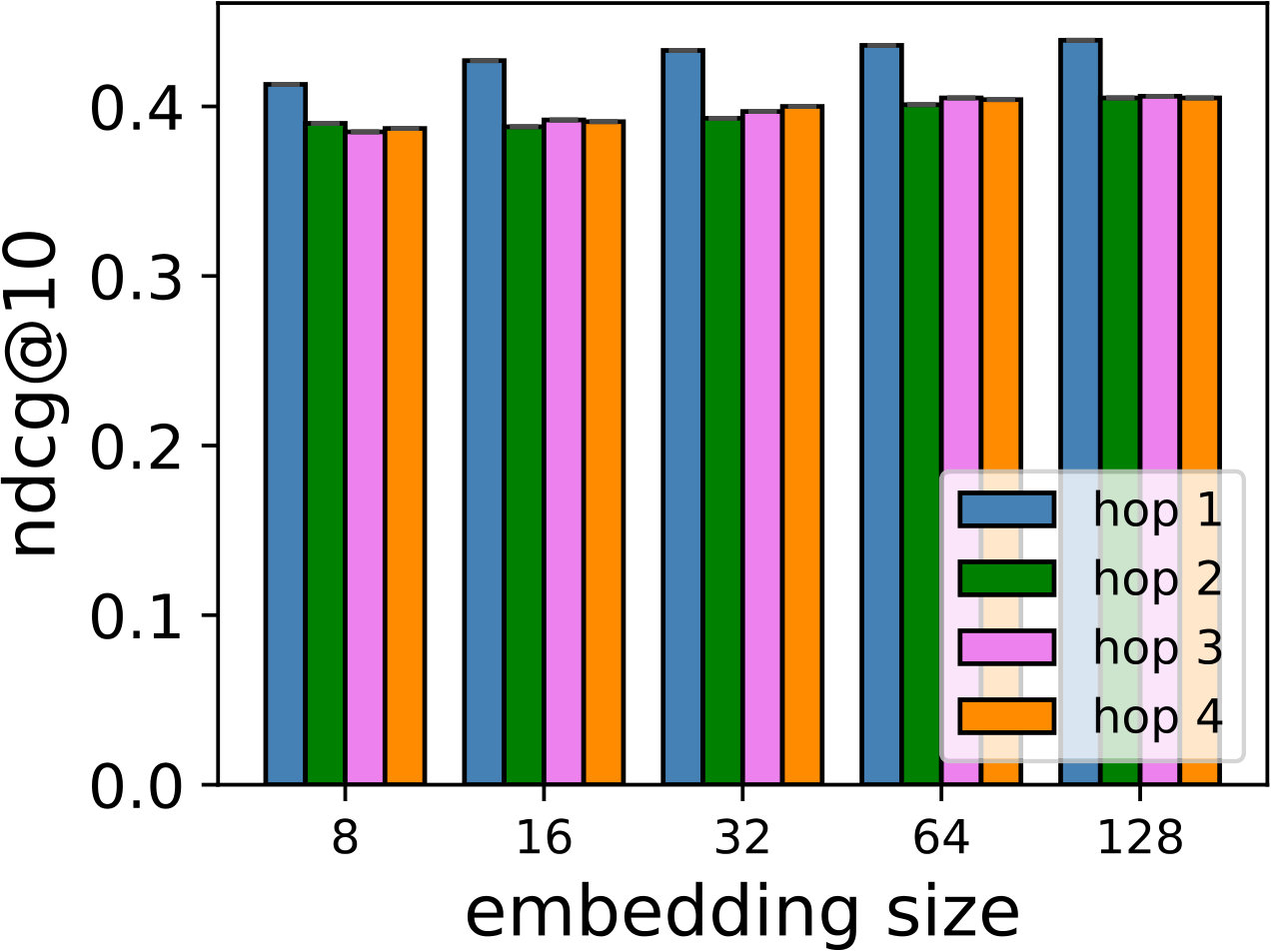 Figure 17
Figure 17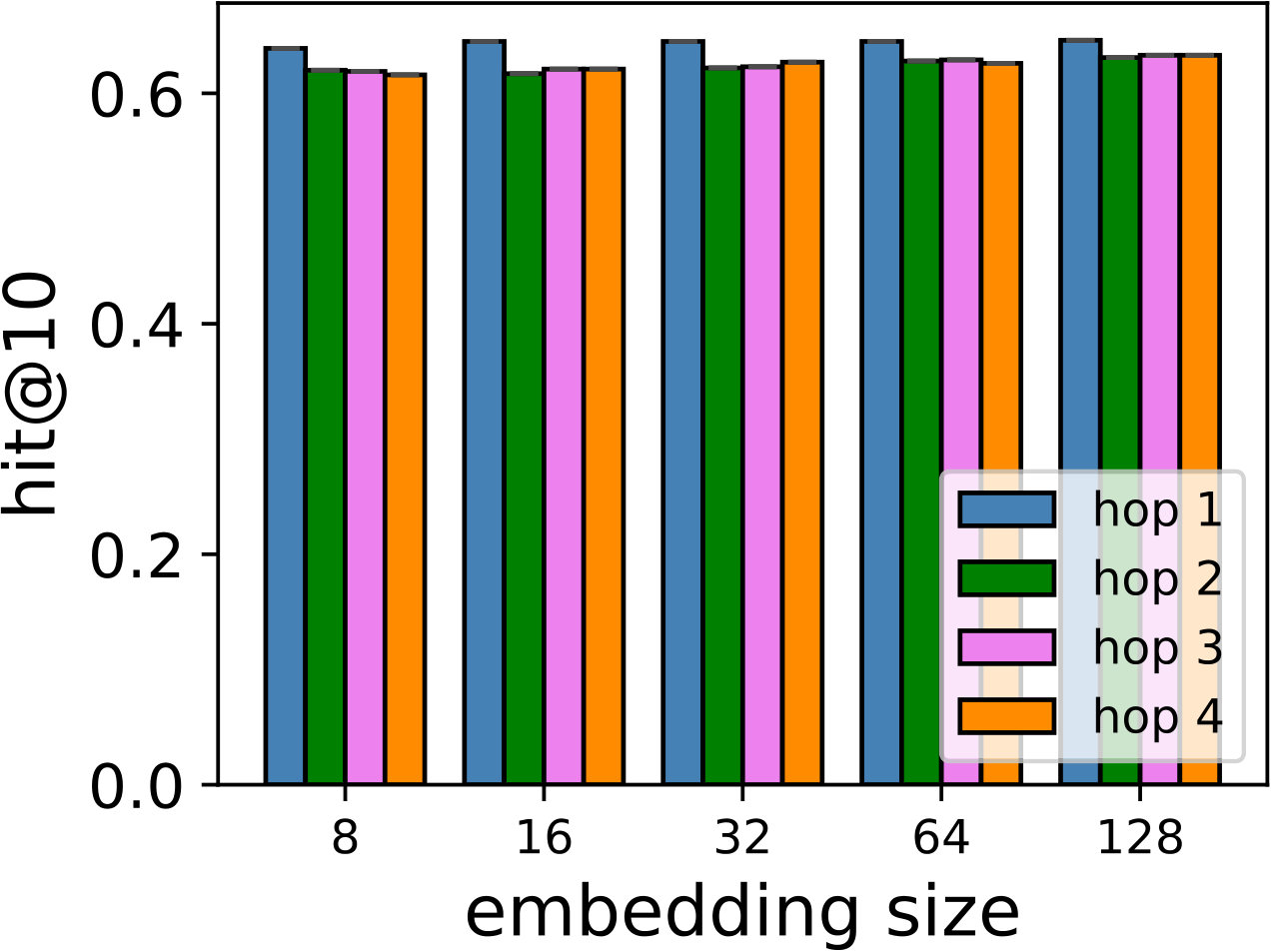 Figure 18
Figure 18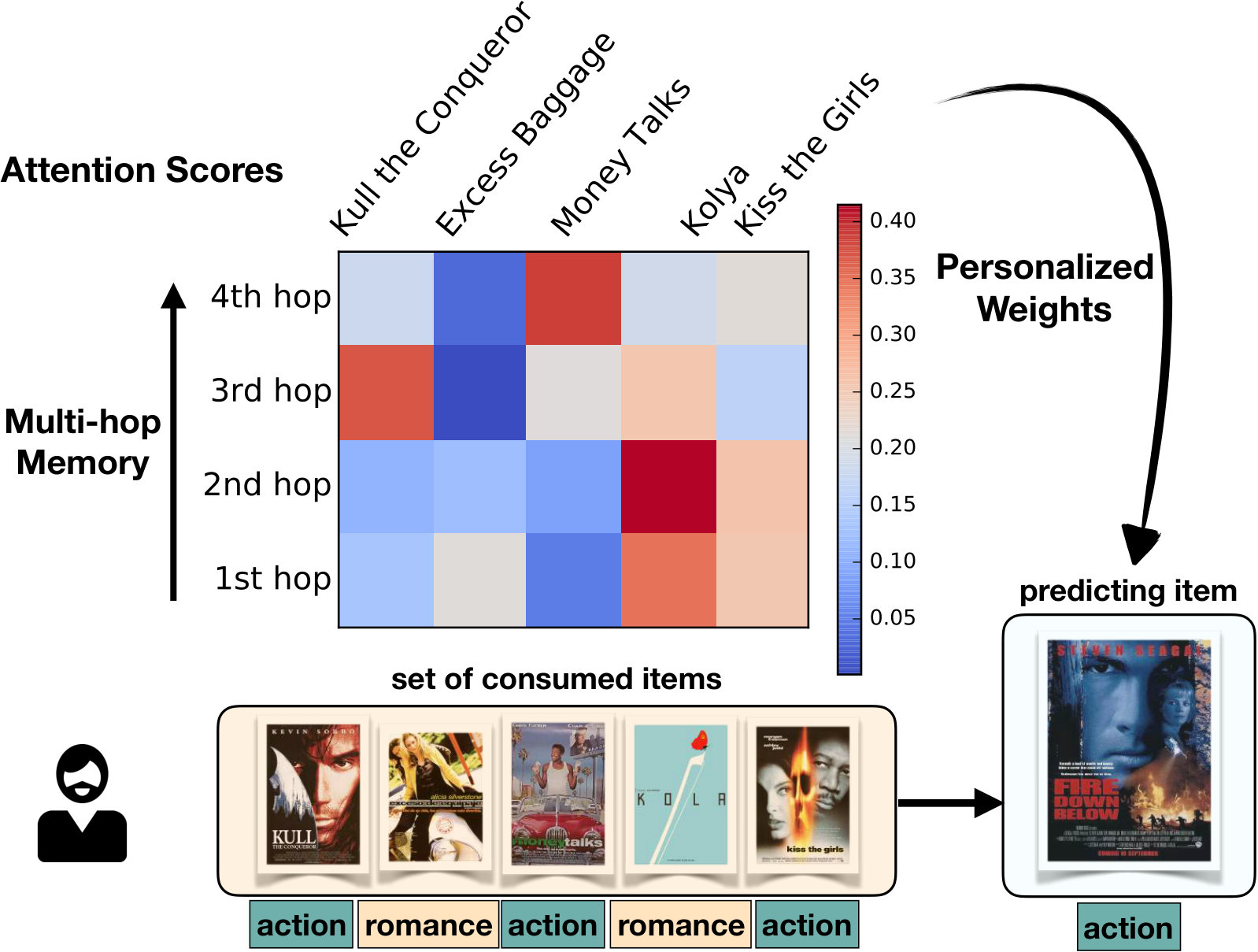 Figure 19
Figure 19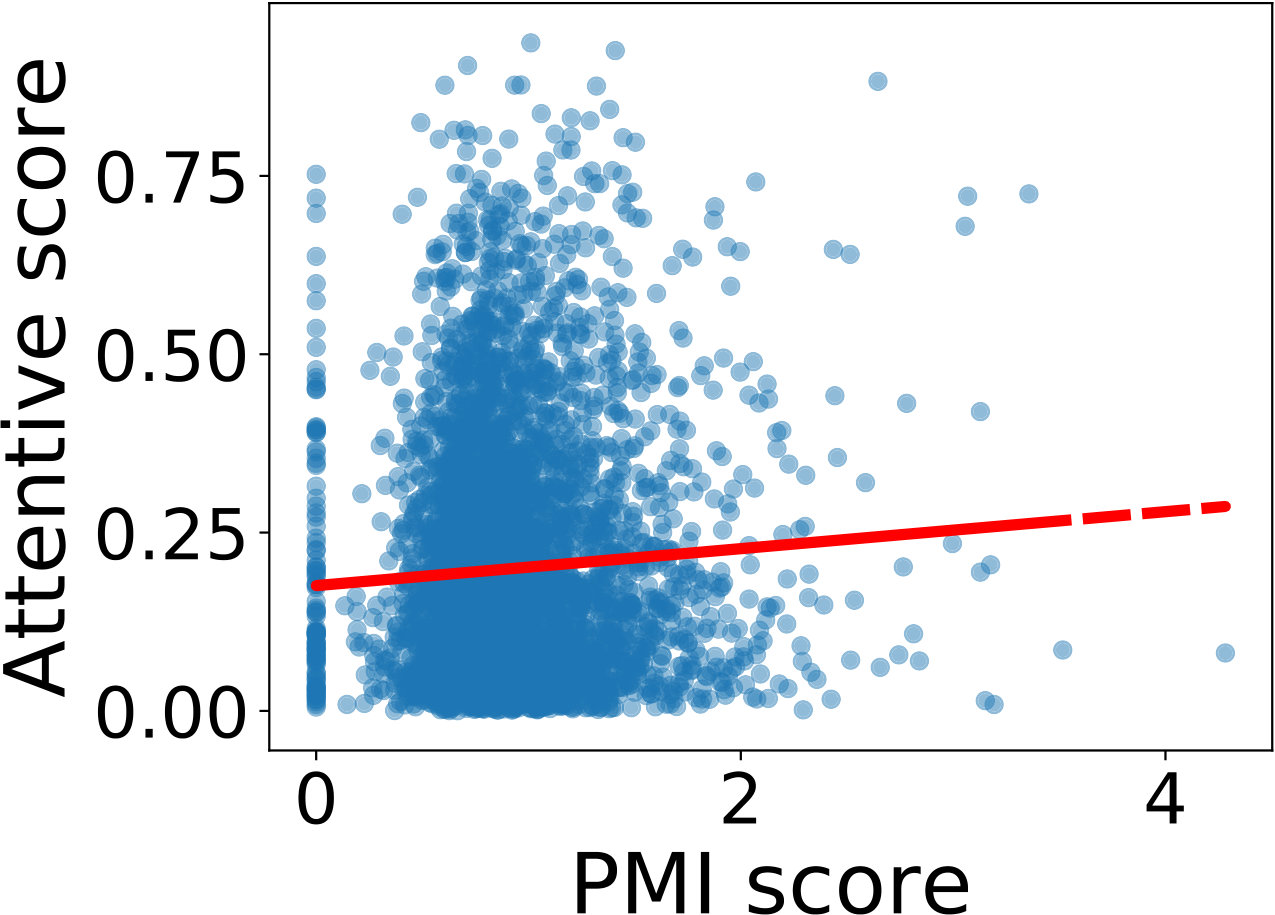 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23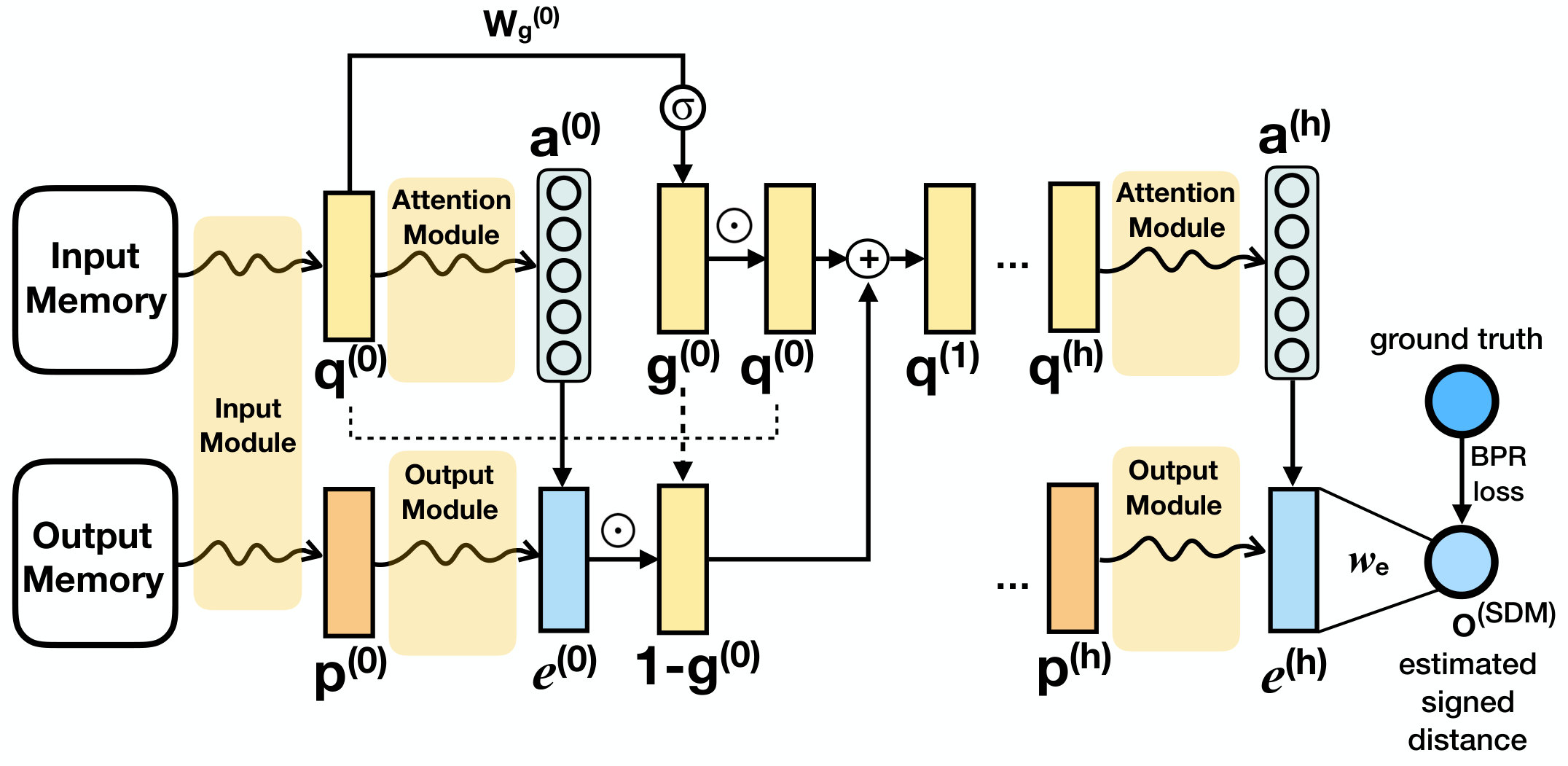 Figure 24
Figure 24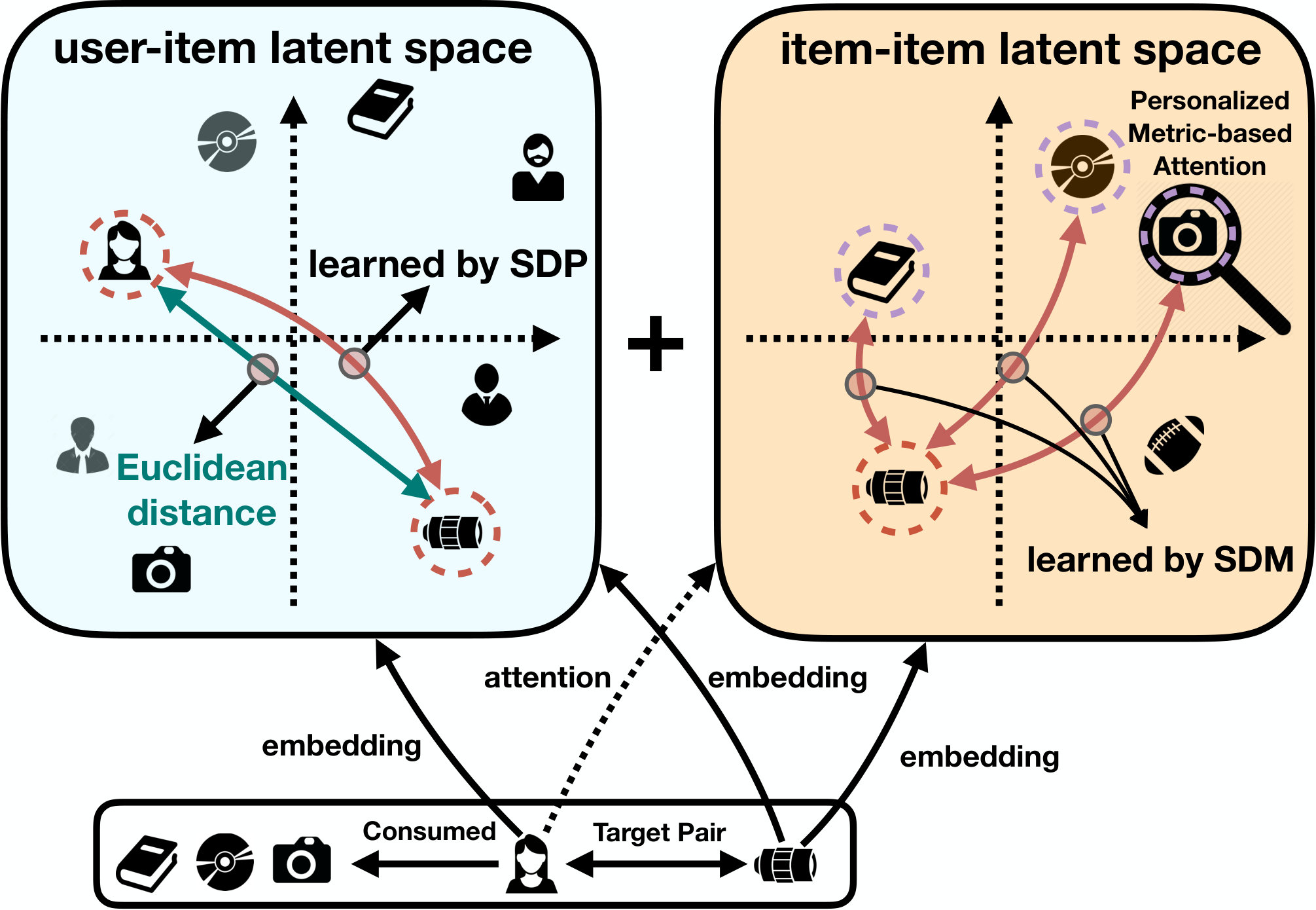 Figure 25
Figure 25| Statistics | ML-100k | ML-1M | Netflix | Epinions |
|---|---|---|---|---|
| # of users | 943 | 6,040 | 1,888 | 23,137 |
| # of items | 1,682 | 3,706 | 3,724 | 23,585 |
| # of interactions | 100,000 | 1,000,209 | 103,254 | 461,982 |
| Density (%) | 6.3% | 4.5% | 1.5% | 0.08% |
| Statistics | IJCAI-15 | Tafeng |
|---|---|---|
| # of users | 2,433 | 22,851 |
| # of items | 4,534 | 22,291 |
| avg # of items in a transaction | 6.28 | 9.28 |
| # of generated instances | 15,422 | 523,653 |
| Density (%) | 0.14% | 0.10% |
| Method type | Method | ML-100k | ML-1M | Netflix | Epinions | ||||
| hit@10 | NDCG@10 | hit@10 | NDCG@10 | hit@10 | NDCG@10 | hit@10 | NDCG@10 | ||
| \pbox1cmGeneral Recommenders (Group 1) | Item-KNN | 0.166 | 0.073 | 0.235 | 0.110 | 0.039 | 0.019 | 0.121 | 0.096 |
| SLIM | 0.520 | 0.298 | 0.677 | 0.420 | 0.358 | 0.212 | 0.249 | 0.189 | |
| MF-BPR | 0.554 | 0.316 | 0.595 | 0.352 | 0.352 | 0.193 | 0.384 | 0.232 | |
| CML | 0.596 | 0.326 | 0.662 | 0.390 | 0.447 | 0.254 | 0.376 | 0.237 | |
| NeuMF++ | 0.623 | 0.341 | 0.716 | 0.438 | 0.509 | 0.279 | 0.428 | 0.274 | |
| CMN++ | 0.620 | 0.344 | 0.729 | 0.442 | 0.523 | 0.293 | 0.423 | 0.272 | |
| \pbox1cmSequential Recommenders (Group 2) | PRME | 0.638 | 0.381 | 0.724 | 0.486 | 0.509 | 0.329 | 0.538 | 0.346 |
| PRME_s | 0.674 | 0.398 | 0.734 | 0.491 | 0.539 | 0.348 | 0.380 | 0.244 | |
| TransRec | 0.684 | 0.402 | 0.770 | 0.524 | 0.511 | 0.345 | 0.551 | 0.357 | |
| Caser | 0.674 | 0.386 | 0.826 | 0.606 | 0.480 | 0.253 | 0.326 | 0.268 | |
| Ours | SDP | 0.616 | 0.349 | 0.694 | 0.424 | 0.497 | 0.279 | 0.416 | 0.266 |
| SDM | 0.713 | 0.435 | 0.816 | 0.584 | 0.584 | 0.379 | 0.575 | 0.390 | |
| SDMR | 0.695 | 0.562 | 0.810 | 0.662 | 0.592 | 0.449 | 0.568 | 0.423 | |
| \pbox1cmCompared to Group 1 | Imprv. of SDM | 14.54% | 26.51% | 11.93% | 32.13% | 11.71% | 29.32% | 34.35% | 42.34% |
| Imprv. of SDMR | 11.65% | 63.44% | 11.11% | 49.77% | 13.24% | 53.20% | 32.71% | 54.38% | |
| \pbox1cmCompared to Group 2 | Imprv. of SDM | 4.24% | 8.21% | -1.21% | -3.63% | 8.35% | 8.91% | 4.36% | 9.24% |
| Imprv. of SDMR | 1.61% | 39.80% | -1.94% | 9.24% | 9.83% | 29.02% | 3.09% | 18.49% | |
| Method | IJCAI-15 | Ta-Feng | ||
|---|---|---|---|---|
| hit@10 | NDCG@10 | hit@10 | NDCG@10 | |
| PRME | 0.276 | 0.177 | 0.594 | 0.365 |
| PRME_s | 0.229 | 0.133 | 0.590 | 0.355 |
| TransRec | 0.262 | 0.168 | 0.622 | 0.401 |
| Caser | 0.173 | 0.096 | 0.605 | 0.373 |
| SDP | 0.323 | 0.201 | 0.633 | 0.401 |
| SDM | 0.316 | 0.189 | 0.646 | 0.439 |
| SDMR | 0.336 | 0.222 | 0.627 | 0.559 |
| Imprv. of SDM | 14.49% | 6.78% | 3.86% | 9.48% |
| Imprv. of SDMR | 21.74% | 25.42% | 0.80% | 39.40% |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Signed Distance-based Deep Memory Recommender
Thanh Tran, Xinyue Liu, Kyumin Lee, Xiangnan Kong
Department of Computer Science
Worcester Polytechnic InstituteMassachusettsUSA
tdtran, xliu4, kmlee, [email protected]
(2019)
Abstract.
Personalized recommendation algorithms learn a user’s preference for an item by measuring a distance/similarity between them. However, some of the existing recommendation models (e.g., matrix factorization) assume a linear relationship between the user and item. This approach limits the capacity of recommender systems, since the interactions between users and items in real-world applications are much more complex than the linear relationship. To overcome this limitation, in this paper, we design and propose a deep learning framework called Signed Distance-based Deep Memory Recommender, which captures non-linear relationships between users and items explicitly and implicitly, and work well in both general recommendation task and shopping basket-based recommendation task. Through an extensive empirical study on six real-world datasets in the two recommendation tasks, our proposed approach achieved significant improvement over ten state-of-the-art recommendation models.
Memory recommender; signed distance; metric-based attention.
††copyright: rightsretained††journalyear: 2019††copyright: iw3c2w3††conference: Proceedings of the 2019 World Wide Web Conference; May 13–17, 2019; San Francisco, CA, USA††booktitle: Proceedings of the 2019 World Wide Web Conference (WWW ’19), May 13–17, 2019, San Francisco, CA, USA††doi: 10.1145/3308558.3313460††isbn: 978-1-4503-6674-8/19/05
1. Introduction
Recommender systems (Aggarwal, 2016) have been deployed in many online applications such as e-commerce, music/video streaming services, social media, etc. They have played a vital role for users to explore new items and for companies to increase their revenues. Most of recommendation algorithms model user preferences and item properties based on observed interactions (e.g., clicks, reviews, ratings) between users and items (Koren, 2009, 2010; Liu et al., 2016). In a perspective, we can view most of the recommendation models as a measurement of similarity or distance between a user and an item. For instance, the well known latent factor (i.e., matrix factorization) models (Koren, 2008) usually employ an inner product function to approximate the similarity between the user and the item. Although the latent factor models achieved competitive performance in some datasets, they did not correctly capture complex (i.e., non-linear) relationships between users and items because the inner product function follows limited linear nature.
Existing recommendation algorithms faced difficulties in finding good kernels for different data patterns (Liu et al., 2016), only focused on user-item latent space without considering the item-item latent space together (He et al., 2017b; Liang et al., 2018; Wu et al., 2016; Li et al., 2015; Sedhain et al., 2015), or required additional auxiliary information (e.g., item description, music content, reviews) (Kim et al., 2016; Van den Oord et al., 2013; Liu et al., 2017; Chen et al., 2017; Lu et al., 2018a). To overcome the drawbacks, in this paper we aim to propose and build a deep learning framework to learn a non-linear relationship between a user and a target item by measuring a distance from the observed data. In particular, we propose Signed Distance-based Deep Memory Recommender (SDMR), which captures non-linear relationship of the user and item explicitly and implicitly, combines explicitly and implicitly measured relationship to produce a final distance score for the recommendation, and performs well in both general recommendation task and shopping basket-based recommendation task.
SDMR internally combines two signed distances, each of which is measured by our proposed Signed Distance-based Perceptron (SDP) and Signed Distance-based Memory Network (SDM). On one hand, SDP explicitly measures a non-linear signed distance between the user and the item. Many existing models (He et al., 2016; Hu et al., 2008) rely on a pre-defined metric such as Euclidean distance (the green line in Figure 1) which is much more limited than the customized non-linear signed distance learned from the data (the red curves in Figure 1). On the other hand, SDM implicitly measures a non-linear signed distance between the user and the item via the user’s recently consumed items. SDM is similar to the item neighborhood-based recommender (Sarwar et al., 2001; Ning and Karypis, 2011) in nature. However, it is more advanced in several aspects, as shown in the right side of Figure 1. First, SDM only focuses on a set of recently consumed items of the target user (e.g., the book, CD and camera in Figure 1) as context items. Second, it employs additional memories to learn a novel personalized metric-based attention on the consumed items. The goal of our proposed attention is to compute weights of each consumed item w.r.t. the target item (i.e., the camera lens). In the example, the attention module assigns higher weights on the camera and lower weights on the book and CD. Unlike our approach, most of the existing neighborhood-based models consider contribution of consumed items to the target item equally, leading to suboptimal results. Last but not the least, we update the attention weights via a gated multi-hop to build a long-term memory within SDM. This multi-hop design helps refine our attention module and produces more accurate attentive scores.
The contributions of this work are summarized as follows:
We design a deep learning framework which can tackle both general recommendation task and shopping basket-based recommendation task.
We propose SDMR that combines two signed distance scores internally measured by SDP and SDM, which capture non-linear relationship between a user and an item explicitly and implicitly.
To better balance the weights among consumed items of the user, we propose a novel multi-hop memory network with a personalized metric-based attention mechanism in SDM.
Extensive experiments on six datasets in two different recommendation tasks demonstrate the effectiveness of our proposed methods against ten baselines.
2. Related Work
Latent Factor Models (LFM) have been extensively studied in the literature, which include Matrix Factorization (Hu et al., 2008), Bayesian Personalized Ranking (Rendle et al., 2009), fast matrix factorization for implicit feedbacks (eALS) (He et al., 2016), etc. Despite their success, LFM suffer from several limitations. First, LFM overlook associations between the user’s previously consumed items and the target item (e.g. mobile phones and phone cases). Second, LFM usually rely on inner product function, whose linearity limits the capability of modeling complex user-item interactions. To address the second issue, several non-linear latent factor models have been proposed, with the help of Gaussian process (Lawrence and Urtasun, 2009) or kernels (Liu et al., 2016; Zhou et al., 2012). However, they either require expensive hyper-parameter tuning or face difficulties in finding good kernels for different data patterns.
Neighborhood-based models (Sarwar et al., 2001; Ning and Karypis, 2011) are usually based on the principle that similar users prefer similar items. The problem turns into finding the neighbors of a user or an item based on a pre-defined distance/similarity metric, such as cosine vector similarity (Lang, 1995; Billsus and Pazzani, 2000), Person Correlation similarity (Deshpande and Karypis, 2004), etc. The recommendation quality highly depends on a chosen metric, but finding a good pre-defined metric is usually very challenging. Furthermore, these models are also sensitive to the selection of neighbors. Our proposed SDM is similar to neighborhood-based models in nature, but it exploits a novel personalized metric-based attention for assigning attentive weights to context items. Therefore, our approach is more robust and less sensitive than conventional neighborhood-based models.
NeuMF (He et al., 2017b) is a neural network that generalizes matrix factorization via Multi Layer Perceptron (MLP) for learning non-linear interaction functions. Similarly, some other works (Liang et al., 2018; Wu et al., 2016; Li et al., 2015; Sedhain et al., 2015) substitute MLP with auto-encoder architecture. It is worth noting that all these approaches are limited by only considering the user-item latent space, and overlook the correlations in the item-item latent space. Besides, some deep learning based works (Lu et al., 2018b; Tay et al., 2018b; Seo et al., 2017; Ma et al., 2019, 2018) employ auxiliary information such as item description (Kim et al., 2016), music content (Van den Oord et al., 2013), item visual features (Liu et al., 2017; Chen et al., 2017), reviews (Lu et al., 2018a) to address the cold-start problem. However, this auxiliary information is not always available, and it limits their applicability in many real-world systems. Another line of works use deep neural networks to model temporal effects of consumed items (Hidasi et al., 2015; Wu et al., 2017; Quadrana et al., 2017; Tang and Wang, 2018). Although our proposed methods do not explicitly consider the temporal effects, SDM utilizes the time information to select a set of recently consumed items as the context items of the target item.
The most closely related work to our work is recently proposed (Collaborative Memory Network (CMN) (Ebesu et al., 2018)). In this work, Memory Network (Sukhbaatar et al., 2015) is adapted to measure similarities between users and user neighbors. Key differences between our work and CMN are as follows: (i) First, we follow an item neighborhood based design, whereas CMN follows a user neighborhood based design. The prior work showed that item neighborhood based models slightly outperformed user neighbor based models (Linden et al., 2003; Sarwar et al., 2001); (ii) Second, our proposed SDM model uses our proposed personalized metric-based attention mechanism and produces signed distance scores as output, whereas CMN exploited a traditional inner product based attention; (iii) Third, we use a gated multi-hop architecture (Liu and Perez, 2017), which was shown to perform better than the original multi-hop design (Sukhbaatar et al., 2015).
3. Problem Statement
In this section, we describe two recommendation problems: (i) general recommendation task; and (ii) shopping basket-based recommendation task. In following sections, we focus on solving them.
General recommendation task: Given a whole item set , and a whole user set . Each user may consume several items in , denoted as a set of context items . In this task, given previously consumed items of a user , a recommendation model predicts a next target item that may prefer, denoting this task as estimating . Note that some existing works assume independent relationships between and context items in the set , leading to (He et al., 2017b, 2016). In our work, we model the ’s preference on in two steps: (i) an explicit preference of on in a signed distance based perceptron, and (ii) an implicit preference of on via summing attentive effects of context items toward target item in a signed distance based memory network.
Shopping Basket-based recommendation task: This problem is based on the fact that users go shopping offline/online and add some items into a basket/cart together. Each shopping basket/cart is seen as a transaction, and each user may shop once or multiple times, leading to one or multiple transactions. Let as a set of the user ’s transactions, where denotes the number of user ’s transactions. Each transaction consists of several items in the whole item set . In this problem, it is assumed that all the items in are inserted into the same basket at the same time, ignoring the actual order of the items being inserted and considering ’s transaction time as each item’s insertion time. Given a target item , the rest of the items in will be seen as the context items of , denoted as (i.e. ). Then, given the set of context items , a recommendation model predicts a conditional probability , which is interpreted as the conditional probability that will add the item into the same basket with the other items .
Both of the recommendation tasks above are popular in the literature (Quadrana et al., 2017; Rendle et al., 2010; Feng et al., 2015; He et al., 2017b). The general recommendation task differs from the shopping basket-based recommendation task because there is no specific context items of the target item in the general recommendation task. Note that the two tasks are personalized recommendation problems. In fact, there are non-personalized recommendation problems such as session-based recommendation (Hidasi et al., 2015), where users (i.e. user IDs) are not available in transactions. However, in this paper, we focus on personalized recommendation tasks because they are more preferred in the literature (Quadrana et al., 2017; Rendle et al., 2010; Feng et al., 2015).
4. Proposed Methods
Our proposed Signed Distance-based Deep Memory Recommender (SDMR) consists of two major components: Signed Distance-based Perceptron (SDP) and Signed Distance-based Memory network (SDM). We first describe an overview of our models as follows:
Given a target user and a target item as two one-hot vectors, we pass the two vectors through the user and item embedding spaces to get user embedding and item embedding .
On one hand, our proposed Signed Distance-based Perceptron (SDP) will measure a signed distance score between and by a multi-layer perceptron network.
On the other hand, given target user , target item , and the user ’s recently consumed context items as the input, our Signed Distance-based Memory network (SDM) will measure a signed distance score between user and item via attentive distances between context items and target item .
Then, the Signed Distance-based Deep Memory Recommender (SDMR) model will measure a total distance between user and item by learning a combination of SDP and SDM. The smaller the total distance is, the more likely user will consume item .
Next, we describe SDP, SDM, and SDMR in detail.
4.1. Signed Distance-based Perceptron (SDP)
We first propose Signed Distance-based Perceptron (SDP) that explicitly learns a signed distance between a target user and a target item . An illustration of SDP is shown in Figure 2. Let the embedding of a target user be , and the embedding of a target item be , where is the number of dimensions in each embedding. First, SDP takes a concatenation of these two embeddings as the input and proceeds as follows:
[TABLE]
where refers to a non-linear activation function at the layer (e.g. sigmoid, ReLu or tanh), and denotes an element-wise square function (e.g ). Through experimental results, we choose tanh as the activation function because it yields slightly better results than ReLu. From now on, we will use to denote the tanh function. It can be easily observed that Eq. (1) – (4) form a trivial Multi-Layer Perceptron (MLP) network, which is a popular design (He et al., 2017b; Xue et al., 2017) to learn a complex and non-linear interaction between user embedding and item embedding . Our new design starts at Eq. (5) – Eq. (6). In Eq. (5), we apply the element-wise squared function to the output vector of the MLP and obtain a new output vector . Next, in Eq. (6), we use a fully connected layer to combine different dimensions in and yields a final distance value . Our idea of using in here is that after applying the element-wise square function in Eq. (5), all the dimensions in will be non-negative. Thus, we consider each dimension of as a distance value. The edge weights will then be used to combine those distant dimensions to provide a more fine-grained distance.
We note that SDP can be reduced to a squared Euclidean distance with the following setting: at Eq. (1), with denotes an identity matrix and so ; the activation is an identity function; the number of MLP layers ; the edge-weights layer at Eq. (6): (e.g. the all-ones matrix), bias . Note that if in Eq. (6) is an all-negative layer, it will yield a negative value, which we name as a signed distance111https://en.wikipedia.org/wiki/Signed_distance_function score. If we see each user as a point in multi dimensional space, and the user’s preference space is defined by a boundary , we can interpret this signed distance score as follows: When the item is out of the user ’s preference boundary , the distance between them is positive (i.e. ¿ 0) and it reflects that user does not prefer item . When the distance between user and item is shortened and is right on the boundary , the distance between them is zero and it indicates user likes item . As is coming inside , the distance between them becomes negative and reflects a higher preference of user on item . In short, we can see SDP as a signed distance function, which could learn a complex signed distance between a user and an item via a MLP architecture with non-linear activations and an element-wise square function . In the recommendation domain, the signed distances will provide more fine-grained distance values, thus, reflecting users’ preferences on items more accurately.
4.2. Signed Distance-based Memory Network (SDM)
We propose a multi-hop memory network, Signed Distance-based Memory network (SDM), to model implicit preference of a user on the target item via the user’s previously consumed items (i.e., context items). The implicit preference is represented as a signed distance. First, we describe a single-hop SDM, and then describe how to extend it into a multi-hop design. Following the traditional architecture of a memory network (Sukhbaatar et al., 2015; Liu and Perez, 2017; Xiong et al., 2016), our proposed single-hop SDM has four main components: a memory module, an input module, an attention module, and an output module. The overview of SDM’s architecture is presented in Figure 3. We will go into details of each SDM’s module as follows:
4.2.1. Memory Module:
We maintain two memories called input memory and output memory. The input memory contains two embedding matrices and , where and are the number of users and the number of items in the system, respectively. denotes the embedding size of each user and each item. Similarly, the output memory also contains two embedding matrices and . As shown in Figure 3, the input memory will be used to calculate attention weights of a user’s consumed items (i.e., context items), whereas the output memory will be used to measure a final signed distance between the target user and the target item via the user’s context items.
Given a target user , a target item and a set of user ’s consumed items as context items , the output of this module is the embeddings of user , item , and all context items : ( ¡¿). Since this module has a separated input memory and output memory, we obtain ( ¡¿) as the output of the input memory, and ( ¡¿) as the output of the output memory. It is obvious that is the -th row of , and are the corresponding -th and -th row of . A similar explanation is applied to , and .
4.2.2. Input Module:
The goal of the input module is to form a non-linear combination between the target user embedding and the target item embedding. Given the target user embedding and the target item embedding from the input memory in the memory module, following the widely adopted design in multimodal deep learning work (Zhang et al., 2014; Srivastava and Salakhutdinov, 2012), the input module simply concatenates the two embeddings, and then applies a fully connected layer with a non-linear activation (i.e. tanh function) to obtain a coherent hidden feature vector as follows:
[TABLE]
where is the weights of input module. Note that can be seen as a query embedding in Memory Network (Sukhbaatar et al., 2015).
Similarly, if the inputs of the input module are the target user embeddings and the target item embeddings from the output memory, we can form a non-linear combination between and (i.e. an output query), denoted as , as follows:
[TABLE]
4.2.3. Attention Module:
The goal of the attention module is to assign attentive scores to different context items (or candidates) given the combined vector (or a query) of the target user and target item obtained in Eq. (7). First, we calculate the squared distance between and each candidate item as follows:
[TABLE]
where refers to the distance (or Euclidean distance), which is widely used in previous works to measure similarity among items (Feng et al., 2015) or between users and items (Hsieh et al., 2017). To better understand our intuition in Eq. (9), we will break it into smaller parts and explain them. First, similar to the intuition of Eq. (7), we have f\Big{(}\mathbf{W}_{c}\begin{bmatrix}\bm{q}_{ij}\\ \bm{v}_{k}^{(i)}\end{bmatrix}+\bm{b}_{c}\Big{)} component to define a non-linear combination between the input query and each context item embeddings . Then, will measure the squared distance of the combined vector. It is worth to note that with a following setting: = where refers to an identity matrix and is an all-zeros matrix; is an identity function; = ; bias terms . Then, in Eq. (7), \bm{q}_{ij}=f\Big{(}\mathbf{W}_{a}\begin{bmatrix}\bm{u}_{i}^{(i)}\\ \bm{v}_{j}^{(i)}\end{bmatrix}+\bm{b}_{a}\Big{)}=\bm{v}_{j}^{(i)}; in Eq. (9), f\Big{(}\mathbf{W}_{c}\begin{bmatrix}\bm{q}_{ij}\\ \bm{v}_{k}^{(i)}\end{bmatrix}+\bm{b}_{c}\Big{)}=\bm{v}_{j}^{(i)}-\bm{v}_{k}^{(i)}, and , which simply generalizes a squared distance between the target item and the context item . Additionally, with another setting: = ; is an identity function; = ; bias terms . Then, in Eq. (7), \bm{q}_{ij}=f\Big{(}\mathbf{W}_{a}\begin{bmatrix}\bm{u}_{i}^{(i)}\\ \bm{v}_{j}^{(i)}\end{bmatrix}+\bm{b}_{a}\Big{)}=\bm{u}_{i}^{(i)}-\bm{v}_{j}^{(i)}, in Eq. (9), f\Big{(}\mathbf{W}_{c}\begin{bmatrix}\bm{q}_{ij}\\ \bm{v}_{k}^{(i)}\end{bmatrix}+\bm{b}_{c}\Big{)}=\bm{u}_{i}^{(i)}-\bm{v}_{j}^{(i)}+\bm{v}_{k}^{(i)}, and , which simply generalizes a squared distance between the target item and the context item where the user plays as a translator (He et al., 2017a). The two examples above show that our proposed design can learn a more generalized distance between target and context items.
The output squared distance in Eq. (9) will show how similar the target item and the context item are. The lower the distance score is, the more similar two items and are. Next, we use the Softmax function to normalize and obtain attentive score between and as follows:
[TABLE]
where is the set of user ’s neighborhood items. The minus sign in Eq. (10) is used to assign a higher attention score for a lower distance between two items (, ).
We note that the distance (or Euclidean distance) satisfies four conditions of a metric 222https://en.wikipedia.org/wiki/Metric_(mathematics). While the crucial triangle inequality property of a metric was shown to provide a better performance compared to the inner product (Shrivastava and Li, 2014; Ram and Gray, 2012; Hsieh et al., 2017) in recommendation domains, to our best of knowledge, most of existing attention designs (Vaswani et al., 2017; Luong et al., 2015; Lin et al., 2017; Choi et al., 2018; Seo et al., 2016; Bahdanau et al., 2014; Xu et al., 2015) adopted the inner product for measuring attentive scores. Hence, this proposed attention design is the first attempt to bring metric properties into the attention mechanism.
Similar to (Tay et al., 2018a), we limit the number of considering context items by choosing the user ’s most recently consumed items before target item as the context items of target item . Here, can be selected via tuning with a development dataset. The soft attention vector containing attentive contribution scores of context items toward the target item of a user is given as follows:
[TABLE]
4.2.4. Output Module:
Given the attentive scores in Eq.(11) and the combined vector of the user embedding and item embedding from the output memory and , the goal of this output module is to measure a total output distance between the output target item embeddings and all the user ’s output context item embeddings using attention weights and the output query as follows:
[TABLE]
where is calculated as follows:
[TABLE]
In here, let \bm{r}_{ijk}=f\Big{(}\mathbf{W}_{d}\begin{bmatrix}\bm{p}_{ij}\\ \bm{v}_{k}^{(o)}\end{bmatrix}+\bm{b}_{d}\Big{)}. Similar to the previously discussed intuition in Eq (9), is a flexible combination between and each output context item embeddings ; is an element-wise squared function. Our idea in Eq. (12), (13) is similar to the idea in Eq. (5), (6) of the SDP model. First, in Eq. (13), each context item will attentively contribute to the target item via a squared Euclidean measure. Second, in Eq. (12), each non-negative dimension in will be considered as a distance dimension and we use an edge-weights layer to combine them flexibly. When there is only one context item in , then in Eq. (13), the attention score =1.0, leading to , which is similar to Eq. (5). In this case, SDM will measure the distance between target item and context item in the same way as SDP model does. Note that Eq. (13) is similar to Eq. (6) so SDM can also learn a signed distance value, which also provides a more fine-grained distance compared to a general distance value.
4.2.5. Multi-hop SDM:
Inspired by previous work (Sukhbaatar et al., 2015) where the multi-hop design helped to refine the attention module in Memory Network, we also integrate multiple hops to further extend our SDM model to build a deeper network (Figure 4). As the gated multi-hop design (Liu and Perez, 2017) was shown to perform better than the original multi-hop design with a simple residual connection in (Sukhbaatar et al., 2015), we employ this gated memory update from hop to hop as follows:
[TABLE]
where is the input query embedding as shown in Eq. (7) at hop , and bias are hop-specific parameters, is the sigmoid function, is the output of Eq. (13) at hop , is the input query embedding at the next hop . So the attention could be updated at hop accordingly using as follows:
[TABLE]
The multi-hop architecture with gated design further refines the attention for different users based on the previous output from hop to hop. Hence, if the final hop is then the SDM model with hops, denoted as SDM-h, will use to yield a final signed distance score as follows:
[TABLE]
where is calculated as:
[TABLE]
Weight constraints in multi-hop SDM model: To save memory, we use the global weight constraint in multi-hop SDM. Particularly, input memory and output memory are shared among different hops. All the weights are shared from hop to hop = = … = ; = = … = ; = = … = ; = = … = ; and so do all bias terms. The gate weights are also global weights: = = … = .
4.3. Signed Distance-based Deep Memory Recommender (SDMR)
Now we propose Signed Distance-based Deep Memory Recommender (SDMR), a hybrid network that combines SDP and SDM. The first approach to combine them is to employ a weighted summation of the output scores from SDP and SDM as follows:
[TABLE]
where is the signed distance score obtained at Eq. (6), is the signed distance score obtained at Eq. (17), and is a hyper-parameter to control the contribution of SDP and SDM. When =0, SDMR becomes SDM. When =1, SDMR becomes SDP.
However, to avoid tuning an additional hyper-parameter , we do not use Eq. (19) for SDMR. Instead, we let SDMR self-learns the combination of SDM and SDM as follows:
[TABLE]
where is the final layer embedding from SDP and is obtained at Eq. (5), is the final hop output from the multi-hop SDM obtained at Eq. (18). We note that SDP and SDM are first pre-trained separately using the BPR loss function (see the next section). Then, we obtain from SDP, and from SDM, and keep them fixed in Eq. (20) to learn and . We use ReLU in Eq. (20) because ReLU encourages sparse activations and helps to reduce over-fitting when combining the two components SDP and SDM.
4.4. Loss Functions
We adopt the Bayesian Personalized Ranking (BPR) as our loss function, which is similar to the idea of AUC (area under the curve):
[TABLE]
where we uniformly sample tuples in a form of for user with positive item (consumed) and negative item (unconsumed) . is a hyper-parameter to control the regularization term, and is the sigmoid function. Note that other pairwise probability functions could be plugged in Eq. (21) to replace . Both SDP and SDM are end-to-end differentiable since we uses soft attention over the output memory. Hence, we can utilize back-propagation to learn our models with stochastic gradient descent or Adam (Kingma and Ba, 2014).
5. Empirical Study
We evaluate our SDP, SDM, SDMR models against ten state-of-the-art baselines in two recommendation tasks: (i) general recommendation task, and (ii) shopping basket-based recommendation task. We mainly aim to answer the following research questions (RQs):
RQ1: How do SDP, SDM, and SDMR perform compared to other state-of-the-art models in both general recommendation task and shopping basket-based recommendation task?
RQ2: Why/How does the multi-hop design help to improve the proposed models’ performance?
5.1. Datasets
General recommendation task: In this task, we evaluate our proposed models and state-of-the-art methods using different datasets with various density levels as follows:
Movielens (Resnick et al., 1994): It is a widely adopted benchmark dataset for collaborative filtering evaluation. We use two versions of this benchmark dataset, namely MovieLens100k (or ML-100k) and MovieLens1M (or ML-1M).
Netflix Prize 333https://www.netflixprize.com/: It is a real-world dataset collected by Netflix. This dataset was collected from 1999 to 2005, and consists of 463,435 users and 17,769 items with 56.9M of interactions. Since the dataset is extremely large, we subsample the Netflix dataset by randomly picking one-month data for evaluation.
Epinions (Massa and Avesani, 2007) 444http://www.trustlet.org/downloaded_epinions.html: It is an online rating dataset where users can share product feedback by giving explicit ratings and reviews.
In preprocessing preparation, we adopted a popular k-core preprocessing step (He and McAuley, 2016b; Liang et al., 2018; Tran et al., 2018) (with k-core = 5) to filter out inactive users with less than five ratings and items which are consumed by less than five users. Since ML-100k and ML-1M are already preprocessed, we only apply 5-core preprocessing step on the Netflix and Epinions datasets. We also binarize the rating scores as implicit feedback by converting all observed rating scores as positive interactions and the remaining as negative interactions. The statistics of the four datasets are summarized in Table 1.
Shopping basket-based recommendation task: We use two real-world transaction datasets as follows:
IJCAI-15 555https://tianchi.aliyun.com/datalab/dataSet.htm?id=1: It consists of shopping logs of users from Tmall 666https://www.tmall.com. Since the original dataset is extremely large scale. We subsample IJCAI-15 by randomly picking 20k transactions for evaluation.
Tafeng 777http://stackoverflow.com/questions/25014904/download-link-for-ta-feng-grocery-dataset: It is a grocery store transaction data. It contains four month transaction data from November 2000 to February 2001 by T-Feng supermarket.
Users in both IJCAI-15 and Tafeng datasets are logged under four types of actions: click, add-to-cart, purchase, and add-to-favourite. We consider all the four types as the click action. We only keep transactions with at least five items. This is because we will take one item out for testing, another item for development. In the remaining three items, one will be taken out as a target item and the two items will be used as the context items. Attentive scores will be assigned to the context items. In each of original transactions, we generate data instances of the format where is the target/predicting item and is a set of all other items in the same transaction with . In particular, in each transaction , each time we pick one item out as a target item and leave the rest of items in as corresponding context items. Subsequently, for each transaction containing items, we can generate data instances. The statistics of the two transactional datasets are summarized in Table 2.
For an easy reference, we call (ML-100k, ML-1M, Netflix, Epinions) as Group-1 dataset and (IJCAI-15, Ta-Feng) as Group-2 datasets.
5.2. Baselines and State-of-the-art Methods
We compared our proposed models against several strong baselines in the general recommendation task as follows:
Itemknn (Sarwar et al., 2001): It is an item neighborhood-based collaborative filtering method. It exploited cosine item-item similarities to produce recommendation results.
Bayesian Personalized Ranking (MF-BPR) (Rendle et al., 2009): It is a state-of-the-art pairwise matrix factorization method for implicit feedback datasets. It minimizes - + where (, ) is a positive interaction and (, ) is a negative sample.
Sparse LInear Method (slim) (Ning and Karypis, 2011): It learns a sparse item-item similarity matrix by minimizing the squared loss , where A is a user-item interaction matrix and W is a sparse matrix of aggregation coefficients of context items.
Collaborative Metric Learning (CML) (Hsieh et al., 2017): It is a state-of-the-art collaborative metric-based model that utilizes Euclidean distance to measure similarities between users and items. For fair comparison, we learn CML with BPR loss by minimizing , where is a squared Euclidean distance, (, ) is a positive interaction and is a negative sample.
Neural Collaborative Filtering (NeuMF++) (He et al., 2017b): It is a state-of-the-art matrix factorization method using deep learning architecture. We use a pre-trained NeuMF to achieve its best performance, and denote it as NeuMF++.
Collaborative Memory Network (CMN++) (Ebesu et al., 2018): It is a state-of-the-art memory network based recommender. Its architecture follows traditional user neighborhood based collaborative filtering approaches. It adopts a memory network to assign attentive weights for other similar users.
Even though our approaches do not model the order of consumed items in the user’s purchase history (e.g. rigid orders of items), since we consider latest items as the context items to predict the next item, we still compare our models with some key sequential models to further show our models’ effectiveness as follows:
Personalized Ranking Metric Embedding (PRME) (Feng et al., 2015):
Given a user , a target item , and a previous consumed item , it models a personalized first-order Markov behavior with two components: , where is a squared distance. Then PRME is learned by minimizing BPR loss.
PRME_s: It is our extension of PRME, where the distance between the target item and the previous consumed item is replaced by the average distance between and each of previous items: . We use BPR loss to learn PRME_s.
Translation-based Recommendation (TransRec) (He et al., 2017a): It uses first-order Markov and considers a user as a translator of his/her previous consumed item to a next item . In another word, where is an item bias term, is a distance function (e.g. or distance). We use distance because it was shown to perform better than (He et al., 2017a). TransRec is then learned with BPR loss.
**Convolutional Sequence Embedding Recommendation
(Caser)** (Tang and Wang, 2018): It is a state-of-the-art sequential model. It uses convolution neural network with many horizontal and vertical kernels to capture the complex relationships among items.
The strong sequential baselines above surpassed many other sequential models such as: TransRec outperformed FMC(Rendle et al., 2010), FPMC (Rendle et al., 2010), HRM (Wang et al., 2015); Caser surpassed GRU4Rec (Hidasi et al., 2015) and Fossil (He and McAuley, 2016a), so we exclude them in our evaluation.
Comparison: In the general recommendation task, we compare our proposed models with all ten strong baselines listed above. In the shopping basket-based recommendation task, since the sequential models often work better than general recommendation-based models (see Table 5.3), we only compared our proposed models with sequential baselines. We name general recommendation baselines (i.e. ItemKNN, BPR, SLIM, CML, NeuMF++, CMN++) as Group-1 baselines, and call sequential baselines (i.e. PRME, PRME_s, TransRec, Caser) as Group-2 baselines for an easy reference.
5.3. Experimental Settings
Protocol: We adopt the widely used leave-one-out setting (He et al., 2017b; Xue et al., 2017), in which for each user, we reserve her last interaction as the test sample. If there are no timestamps available in the dataset, then the test sample is randomly drawn. Among the remaining data, we randomly hold one interaction for each user to form the development set, while all others are utilized as the training set. Since it is very time-consuming and unnecessary to rank all the unobserved items for each user, we follow the standard strategy to randomly sample 100 unobserved items for each user. Then, we rank them together with the test item (He et al., 2017b; Koren, 2008).
Assigning item orders: Sequential models need rigid orders of consumed items but consumed items in the same transaction (in IJCAI-15 and TaFeng datasets) are assigned the same timestamp of the transaction containing these items. Hence, we assigned the item timestamps where the orders of items are kept as in the original dataset. This may give credits to sequential models but not our methods (because our methods will use all consumed items in the same transaction as context items and do not model the item orders).
Hyper-parameters selection: We perform a grid search for the embedding size from and regularization terms from in all the models. We select the best number of hops for CMN++ and our SDM from . In NeuMF++, we select the best number of MLP layers from . In our models, we fix the batch size to . We adopt Adam optimizer (Kingma and Ba, 2014) with a fixed learning rate of 0.001. Similar to CMN++ and NeuMF++, the number of negative samples is set to 4. We use one layer perceptron for SDP (more complex datasets may need more than one layer to get better results). In the four datasets used in general recommendation task (e.g ML-100k, ML-1M, Netflix, Epinions), to avoid too many zero paddings for users with a smaller number of consumed items or too many context items are kept in the memory, which unnecessarily slow down the model’s execution, we follow (Tay et al., 2018a) to limit the number of context items using latest s consumed items. We search s in {5, 10, 20}. In the two shopping basket-based recommendation datasets (i.e. IJCAI-15 and TaFeng), since the maximum number of items in a transaction is small (e.g. 13 in IJCAI-15, and 18 in TaFeng), we consider all the other items in the same transaction with the target item as its context items. All the hyper-parameters are tuned using the development dataset. Our source code is available at: https://github.com/thanhdtran/SDMR.
Evaluation Metrics: We evaluate all models’ performance by two widely used metrics: Hit Ratio (hit@), and Normalized Discounted Cumulative Gain (NDCG@), where is a truncated number or top-k item recommendation. Intuitively, hit@ shows whether the test item is in the top-k list or not, while NDCG@ accounts for the position of the hits by assigning higher scores to the hits at top ranks and downgrading the scores to hits by at lower ranks.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Aggarwal (2016) Charu C Aggarwal. 2016. Recommender systems . Springer.
- 3Bahdanau et al . (2014) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural machine translation by jointly learning to align and translate. ar Xiv preprint ar Xiv:1409.0473 (2014).
- 4Billsus and Pazzani (2000) Daniel Billsus and Michael J Pazzani. 2000. User modeling for adaptive news access. User modeling and user-adapted interaction 10, 2-3 (2000), 147–180.
- 5Chen et al . (2017) Jingyuan Chen, Hanwang Zhang, Xiangnan He, Liqiang Nie, Wei Liu, and Tat-Seng Chua. 2017. Attentive collaborative filtering: Multimedia recommendation with item-and component-level attention. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval . 335–344.
- 6Choi et al . (2018) Heeyoul Choi, Kyunghyun Cho, and Yoshua Bengio. 2018. Fine-grained attention mechanism for neural machine translation. Neurocomputing 284 (2018), 171–176.
- 7Deshpande and Karypis (2004) Mukund Deshpande and George Karypis. 2004. Item-based top-n recommendation algorithms. ACM Transactions on Information Systems 22, 1 (2004), 143–177.
- 8Ebesu et al . (2018) Travis Ebesu, Bin Shen, and Yi Fang. 2018. Collaborative Memory Network for Recommendation Systems. In Proceedings of the 41st ACM International Conference on Research and Development in Information Retrieval .
