Probabilistic Predictive Principal Component Analysis for Spatially-Misaligned and High-Dimensional Air Pollution Data with Missing Observations
Phuong T. Vu, Timothy V. Larson, Adam A. Szpiro

TL;DR
This paper introduces probabilistic predictive PCA methods tailored for high-dimensional, spatially-misaligned air pollution data with missing observations, enhancing prediction accuracy through model-based imputation.
Contribution
It develops a novel probabilistic predictive PCA framework that effectively handles missing data and spatial misalignment in multi-pollutant air quality datasets.
Findings
Improved spatial prediction accuracy for PM2.5 concentrations.
Effective handling of complex missing data patterns.
Enhanced predictive performance over existing PCA methods.
Abstract
Accurate predictions of pollutant concentrations at new locations are often of interest in air pollution studies on fine particulate matters (PM), in which data is usually not measured at all study locations. PM is also a mixture of many different chemical components. Principal component analysis (PCA) can be incorporated to obtain lower-dimensional representative scores of such multi-pollutant data. Spatial prediction can then be used to estimate these scores at new locations. Recently developed predictive PCA modifies the traditional PCA algorithm to obtain scores with spatial structures that can be well predicted at unmeasured locations. However, these approaches require complete data, whereas multi-pollutant data tends to have complex missing patterns in practice. We propose probabilistic versions of predictive PCA which allow for flexible model-based imputation that…
Click any figure to enlarge with its caption.
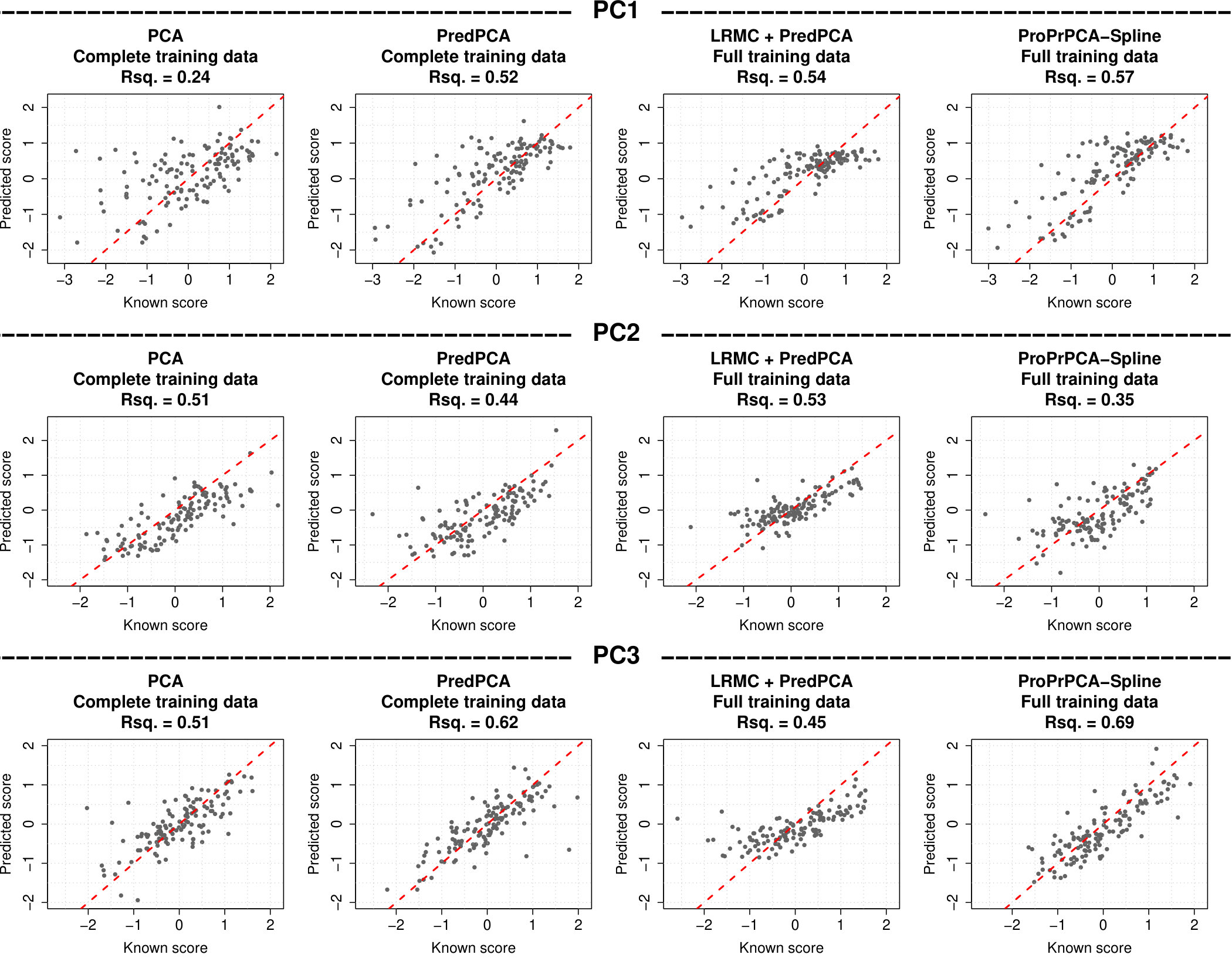 Figure 1
Figure 1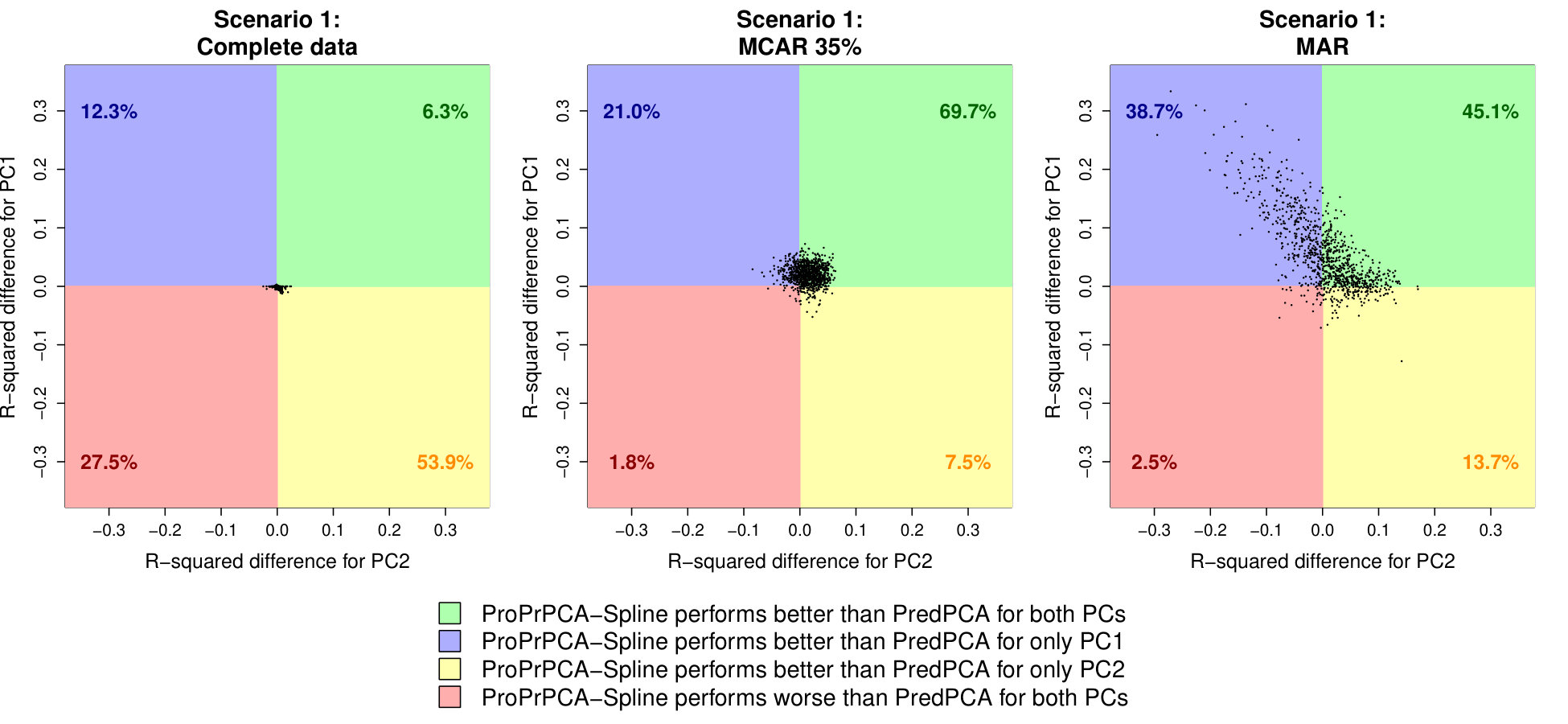 Figure 2
Figure 2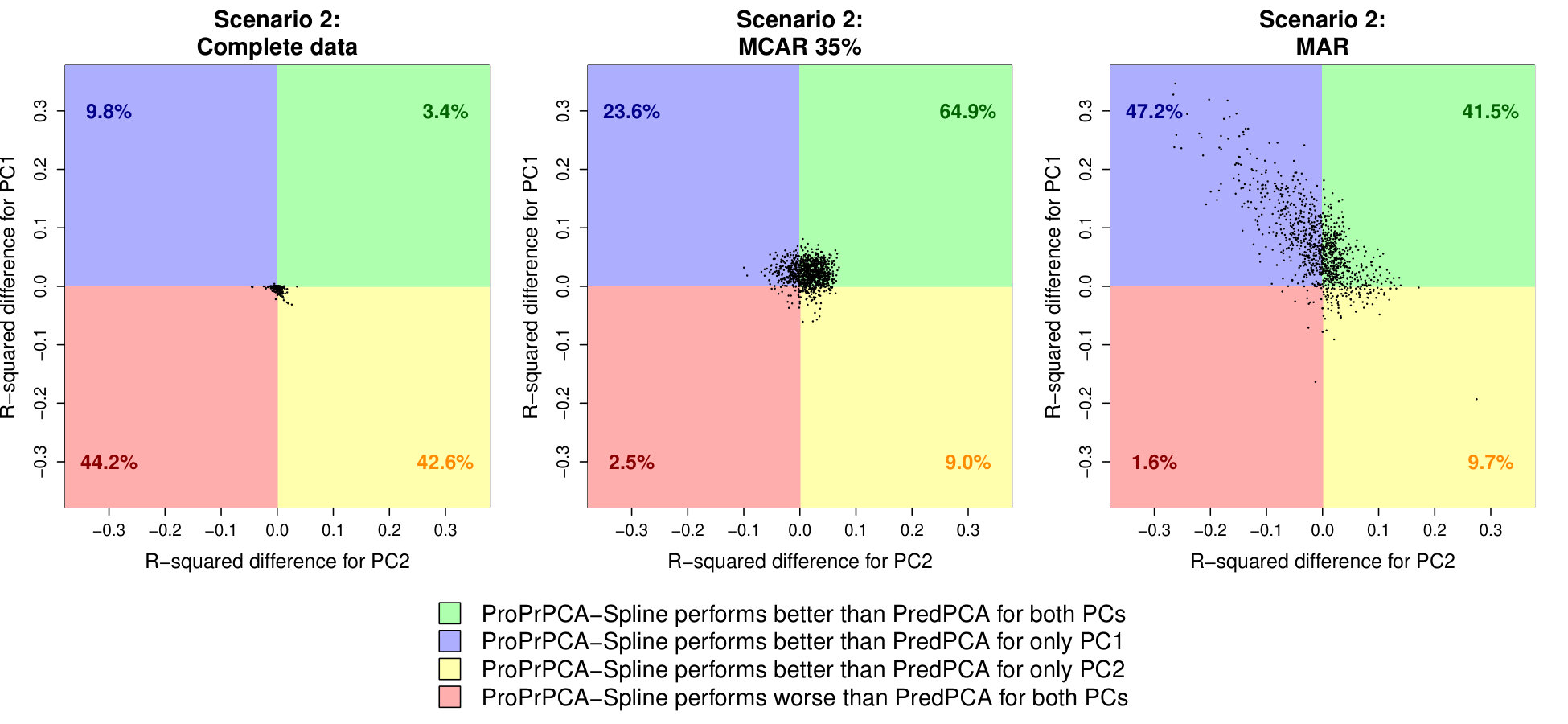 Figure 3
Figure 3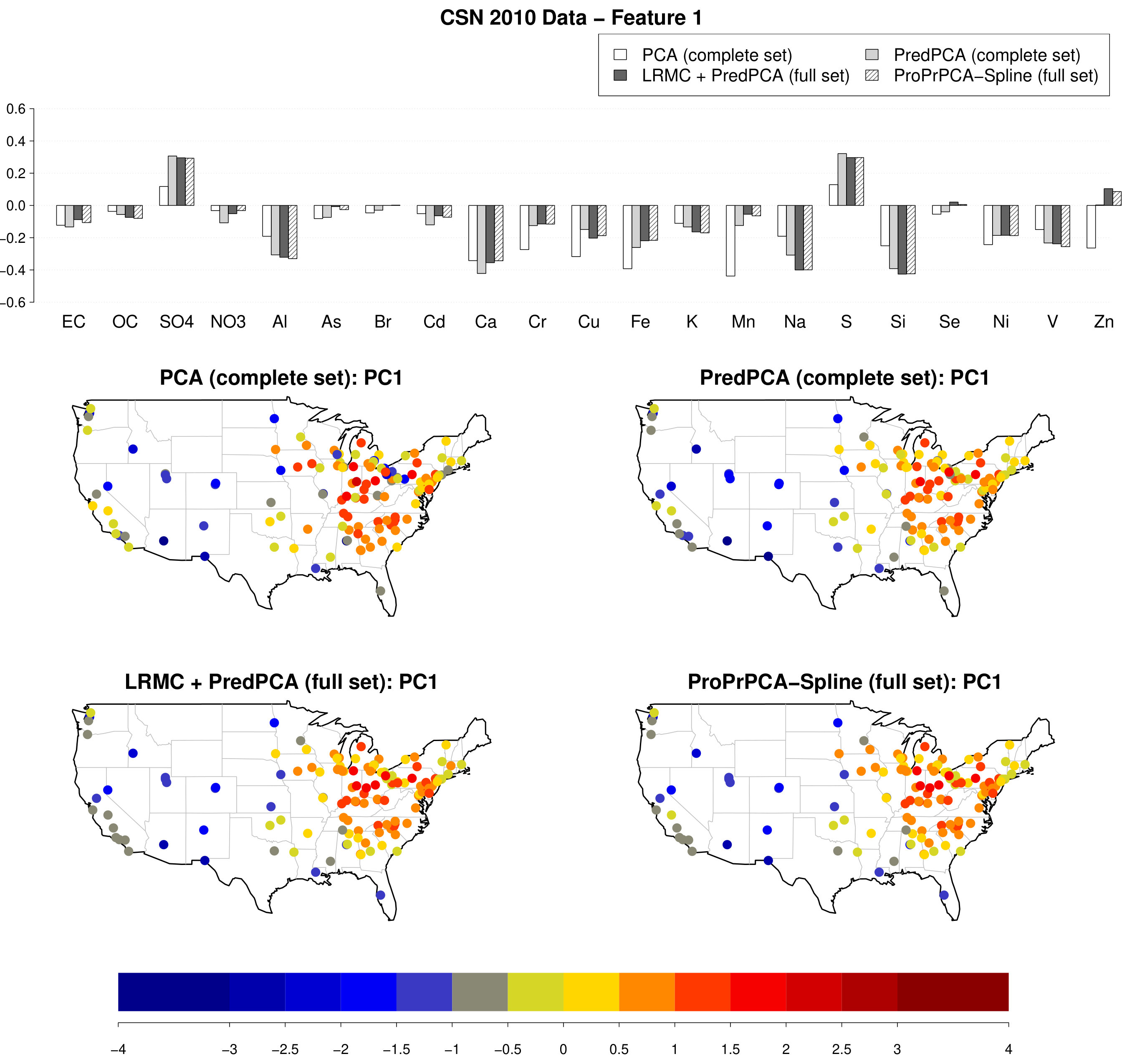 Figure 4
Figure 4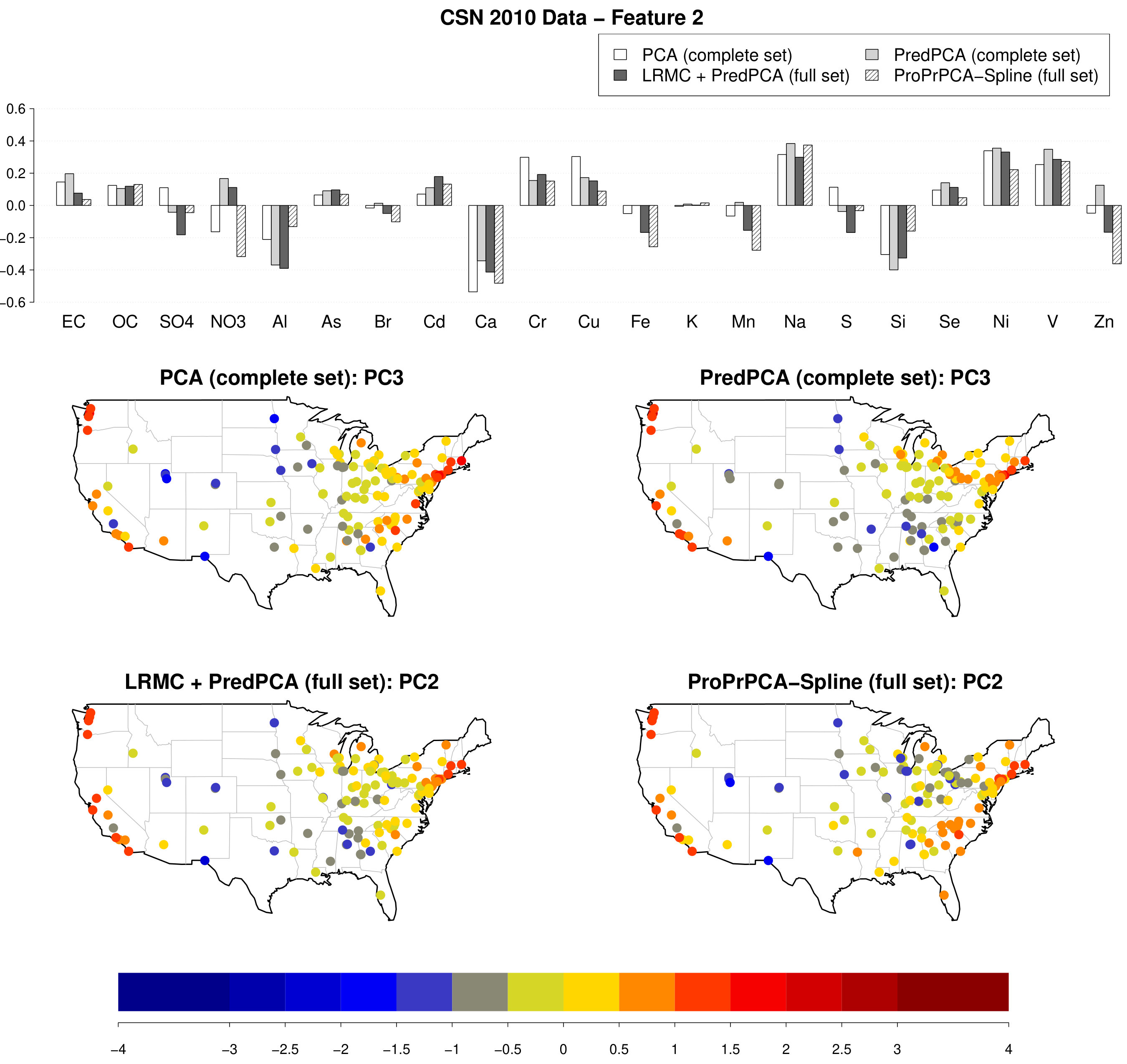 Figure 5
Figure 5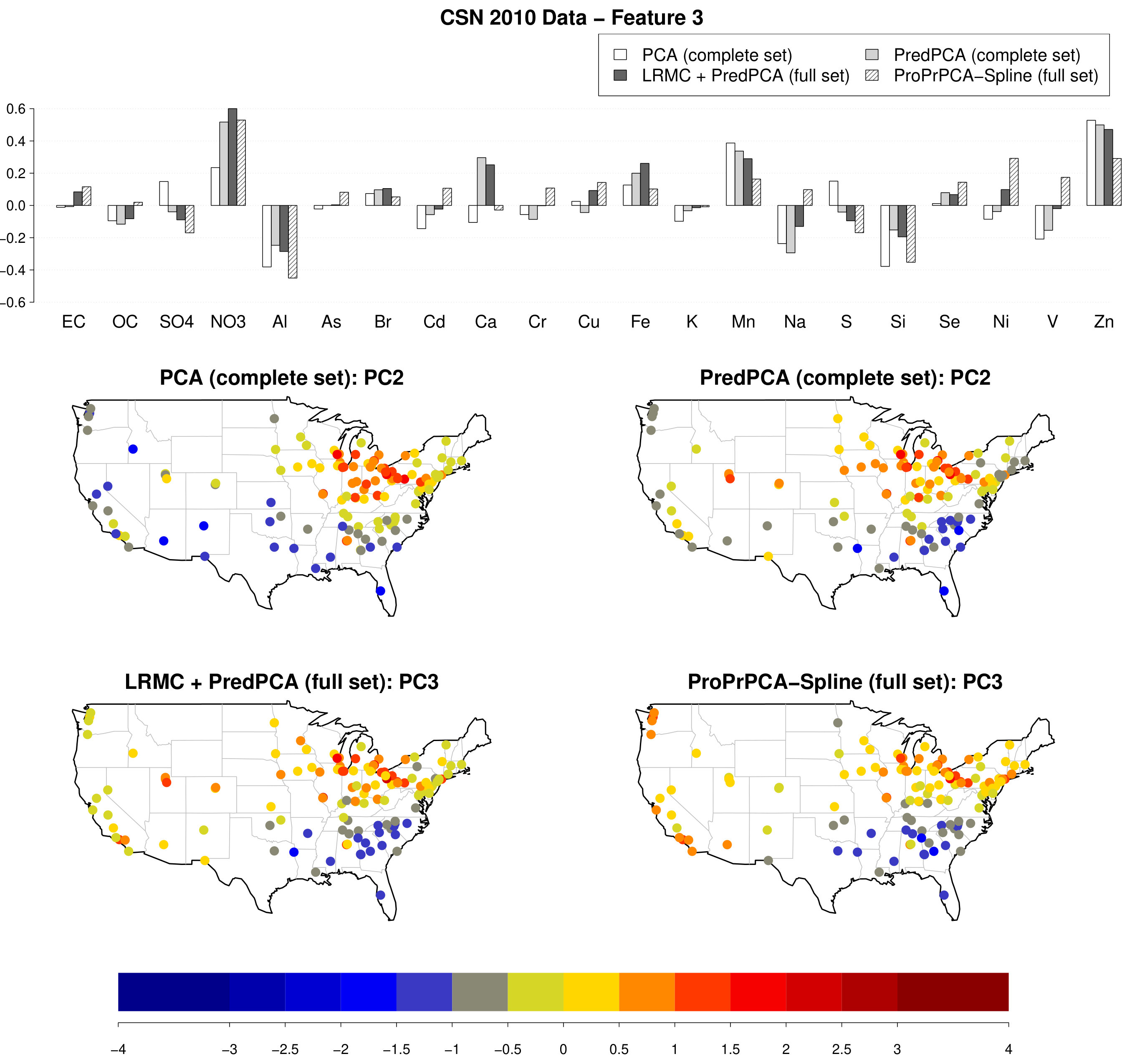 Figure 6
Figure 6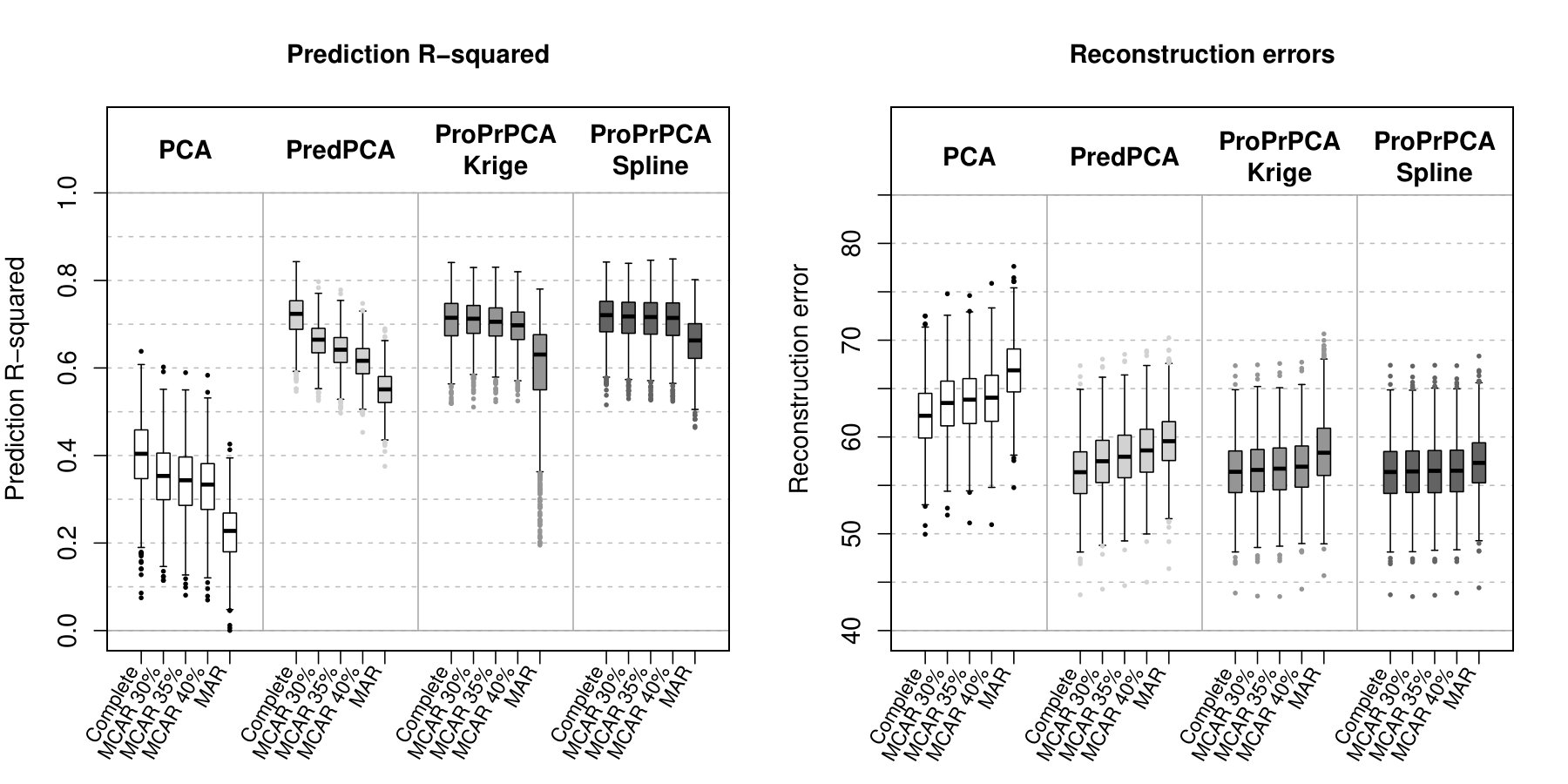 Figure 7
Figure 7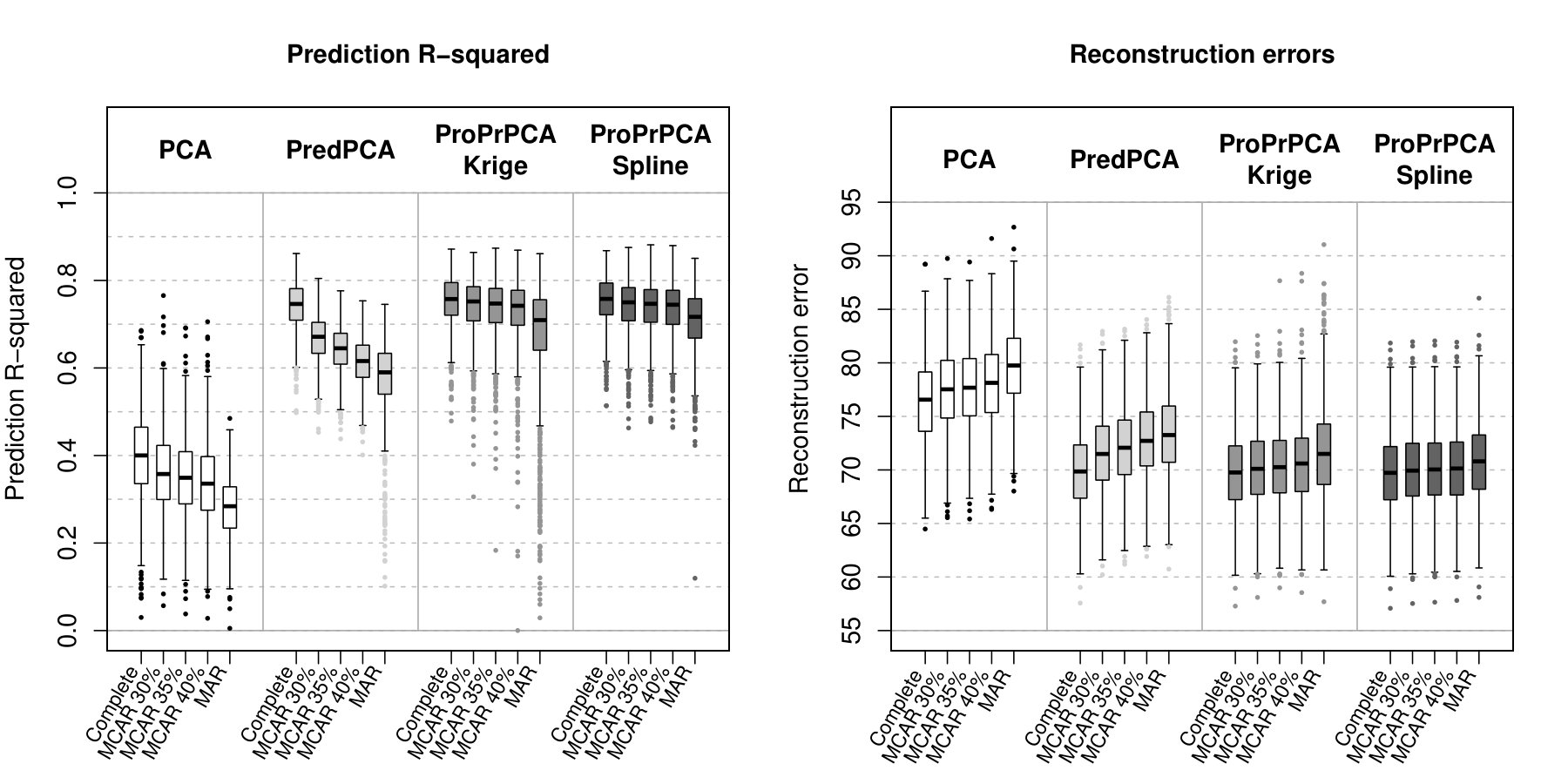 Figure 8
Figure 8| Input , , , and |
| for in do |
| where , , and |
| Initialize , , , and |
| while not converged or do |
| where |
| end while |
| , , |
| end for |
| Output , , , |
| PCA | 0.40 (0.11) | 0.41 (0.09) | 0.80 (0.07) |
|---|---|---|---|
| PredPCA | 0.88 (0.04) | -0.07 (0.04) | 0.46 (0.09) |
| ProPrPCA-Krige | 0.85 (0.04) | -0.11 (0.08) | 0.50 (0.08) |
| ProPrPCA-Spline | 0.86 (0.03) | -0.12 (0.07) | 0.49 (0.07) |
| PCA | 0.53 (0.06) | 0.39 (0.04) | 0.75 (0.03) |
|---|---|---|---|
| PredPCA | 0.89 (0.02) | 0.01 (0.02) | 0.45 (0.04) |
| ProPrPCA-Krige | 0.88 (0.02) | 0.03 (0.04) | 0.47 (0.04) |
| ProPrPCA-Spline | 0.89 (0.02) | 0.01 (0.03) | 0.46 (0.04) |
| PC1 | Complete | MCAR 35% | MAR |
|---|---|---|---|
| PCA | 0.83 | 0.80 | 0.61 |
| PredPCA | 0.84 | 0.81 | 0.63 |
| ProPrPCA-Krige | 0.83 | 0.83 | 0.64 |
| ProPrPCA-Spline | 0.84 | 0.83 | 0.69 |
| PC1 | Complete | MCAR 35% | MAR |
|---|---|---|---|
| PCA | 0.01 | 0.01 | 0.00 |
| PredPCA | 0.81 | 0.78 | 0.63 |
| ProPrPCA-Krige | 0.70 | 0.66 | 0.41 |
| ProPrPCA-Spline | 0.81 | 0.80 | 0.72 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
††footnotetext: Corresponding author: Phuong T. Vu, Department of Biostatistics, University of Washington, F-600, Health Sciences Building, Box 357232, Seattle, WA 98195-7232. Email: [email protected].
Probabilistic Predictive Principal Component Analysis for Spatially-Misaligned and High-Dimensional Air Pollution Data with Missing Observations
Phuong T. Vu
Department of Biostatistics, University of Washington
Timothy V. Larson
Department of Civil & Environmental Engineering, University of Washington
Adam A. Szpiro
Department of Biostatistics, University of Washington
(August 22, 2019)
Abstract
Accurate predictions of pollutant concentrations at new locations are often of interest in air pollution studies on fine particulate matters (PM2.5), in which data is usually not measured at all study locations. PM2.5 is also a mixture of many different chemical components. Principal component analysis (PCA) can be incorporated to obtain lower-dimensional representative scores of such multi-pollutant data. Spatial prediction can then be used to estimate these scores at new locations. Recently developed predictive PCA modifies the traditional PCA algorithm to obtain scores with spatial structures that can be well predicted at unmeasured locations. However, these approaches require complete data, whereas multi-pollutant data tends to have complex missing patterns in practice. We propose probabilistic versions of predictive PCA which allow for flexible model-based imputation that can account for spatial information and subsequently improve the overall predictive performance.
Keywords: air pollution, multi-pollutant analysis, missing data, dimension reduction
1 Introduction
In recent years, there has been a growing interest in studying the role and health impact of PM2.5, which is fine particulate matter with aerodynamic diameter less than 2.5 m (Brook et al.,, 2004). PM2.5 is a complex mixture of many components, and its chemical profile may vary drastically across time and space (Brook et al.,, 2004; Bell et al.,, 2007; Dominici et al.,, 2010). Obtaining a lower-dimensional representation of PM2.5 multi-pollutant data is often necessary, as including many correlated pollutants in a statistical model is problematic. Principal component analysis (PCA) (Jolliffe,, 1986) is an unsupervised dimension reduction technique that has gained popularity in multi-pollutant analysis (Dominici et al.,, 2003).
Examples of environmental studies utilizing PM2.5 data include studies on the associations between various health outcomes and long-term (Pope III et al.,, 2002; Künzli et al.,, 2005; Miller et al.,, 2007; Chan et al.,, 2015; Kaufman et al.,, 2016) or short-term (Gold et al.,, 2000; Tolbert et al.,, 2007; Pascal et al.,, 2014; Achilleos et al.,, 2017; Hsu et al.,, 2017; Tian et al.,, 2017) exposures to PM2.5. Many studies have suggested that the associations between PM2.5 total mass and various health outcomes can be modified by some specific constituents or the overall chemical composition (Franklin et al.,, 2008; Bell et al.,, 2009; Krall et al.,, 2013; Zanobetti et al.,, 2014; Dai et al.,, 2014; Kioumourtzoglou et al.,, 2015; Wang et al.,, 2017; Keller et al.,, 2018).
In the United States, PM2.5 studies often rely on data collected from regulatory monitoring networks managed by the Environmental Protection Agency (EPA). Unfortunately, for many pollution-health association studies, these fixed monitoring sites are usually not at the same locations where health outcomes are available. Such spatial misalignment motivates an exposure modeling stage in which a spatial prediction model, such as land-use regression or universal kriging, is often used to estimate the exposure at unmeasured locations where pollutant data is not observed (Brauer et al.,, 2003; Künzli et al.,, 2005; Crouse et al.,, 2010; Bergen et al.,, 2013; Chan et al.,, 2015).
Derivation of a lower-dimensional representation of PM2.5 multivariate data prior to making these spatial predictions is necessary, as predicting chemically and spatially correlated pollutant surfaces is challenging and intractable in most cases. As PCA is capable of performing dimension reduction without meddling with the health outcomes, it can be easily integrated in the analysis of spatially-misaligned data. Using PCA, a lower-dimensional scores of the multi-pollutant data at monitoring locations can be obtained. These monitoring scores, along with geographic covariates, can then be used in a spatial prediction model to estimate the corresponding scores at unmeasured locations. However, PCA does not account for exogenous geographic information and spatial correlations across neighboring locations. Hence, PCA may produce scores that summarize the monitoring data well but are difficult to be predicted at unmeasured locations. A spatially predictive PCA algorithm (Jandarov et al.,, 2017) was developed to mitigate this issue by producing scores with spatial patterns that can be subsequently predicted well at new locations.
An additional challenge arises in practice where there is often a large amount of missing data, especially for multi-pollutant monitoring data. For example, not all PM2.5 components are measured at all monitoring sites, either due to environmental considerations, logistic constraints or lack of resources. The missing patterns can sometimes be complex or spatially informative. Neither traditional PCA nor predictive PCA is well-equipped to deal with missing data, and thus a separate imputation step is required prior to dimension reduction. Existing non-parametric imputation schemes, ranging from simple mean imputation to sophisticated matrix completion, do not account for external spatial information. They may therefore distort the underlying spatial structure in the original data even before the dimension reduction stage, and thus negatively impact the predictive performance in the final stage.
In this paper, our goal is to enhance the dimension reduction procedure under the presence of missing data by proposing a probabilistic framework in place of the deterministic algorithm of predictive PCA. Similar to Jandarov et al., (2017), our methods seek to produce principal components that can be well predicted at new locations. The added probabilistic assumptions allow for flexible model-based imputation that takes into account the embedded geographic and spatial information, and thus eliminates the need for a preprocessing stage with non-parametric imputation.
2 Motivating example
To illustrate the merit of our proposed methods, we use data collected nationally by the Air Quality System (AQS) network of monitors managed by the EPA. Measurements of annually averaged PM2.5 total mass and its components are only collected at a few subnetworks of AQS. For consistency with previous related work (Keller et al.,, 2017; Jandarov et al.,, 2017), we choose to use the 2010 data from the Chemical Speciation Network (CSN), of which monitoring sites are located strategically in various urban areas. Data is available for 21 components of PM2.5: elemental carbon (EC), organic carbon (OC), sulfate ion (SO), nitrate ion (NO), aluminum (Al), arsenic (As), bromine (Br), cadmium (Cd), calcium (Ca), chromium (Cr), copper (Cu), iron (Fe), potassium (K), magnesium (MN), sodium (Na), sulfur (S), silicon (Si), selenium (Se), nickel (Ni), vanadium (V), and zinc (Zn).
Geographic covariates are obtained for all available sites through the Exposure Assessment Core Database by the MESA Air team at the University of Washington. Data on roughly 600 Geographic Information System (GIS) covariates are available, including distances from roads, distances from major pollution sources, land-use information, vegetation indices, etc. The specific sources and attributions of these geographic covariates are carefully described in Bergen et al., (2013).
Data for 2010 is available for 221 CSN sites, with only 130 of those sites having complete data on all 21 components. Overall the amount of missing data in 2010 is roughly 32.1%. Not only do we compare the predictive performances following the application of different PCA methods, but we also examine how different the chemical profiles are when considering only complete sites versus all available data. The data processing, analysis procedures, and results are discussed in Section 6.
3 Review of PCA and predictive PCA
We denote \mbox{\boldmathX}\in\mathds{R}^{n\times p} as the exposure data with pollutants observed at monitoring sites with spatial coordinates \mbox{\boldmaths}_{1},...,\mbox{\boldmaths}_{n}. The exposure data may contain missing elements as some pollutants are not measured at all monitoring site. Let \mbox{\boldmathr}_{i} be a vector of geographic covariates pertaining to the -th monitoring sites. Variables corresponding to locations where exposure data is of interest but not measured are distinguished by an asterisk, i.e. n^{*},\mbox{\boldmathX}^{*},\mbox{\boldmaths}^{*}_{1},...,\mbox{\boldmaths}^{*}_{n^{*}},\mbox{\boldmathr}^{*}_{1},...,\mbox{\boldmathr}^{*}_{n^{*}}.
The data of interest, \mbox{\boldmathX}^{*}, is high-dimensional but inaccessible. If \mbox{\boldmathX}^{*} were observed, dimension reduction could be applied directly to obtain a lower-dimensional representation \mbox{\boldmathU}^{*}\in\mathds{R}^{n^{*}\times q} where . Because of spatial misalignment, a spatial prediction model is required to estimate the unobserved exposures. Modeling highly correlated surfaces is challenging and inefficient given the final aim of recovering only the lower-dimensional \mbox{\boldmathU}^{*}. Thus, a sensible modeling procedure under the presence of spatially misaligned multi-pollutant data with missing observations may consist of several steps: (1) imputation for missing data, (2) dimension reduction to derive scores at monitoring sites, and (3) spatial prediction to estimate corresponding scores at new locations. In this paper, we focus on dimension reduction using PCA, an unsupervised technique that is suitable for handling spatially-misaligned data.
Traditional PCA provides a mapping from the original -dimensional exposure surface to a corresponding -dimensional representation where \mbox{\boldmathX}\approx\mbox{\boldmathU}\mbox{\boldmathV}^{\mathsf{T}} for . We refer to the orthogonal columns of \mbox{\boldmathV}\in\mathds{R}^{p\times q} as the loadings or principal directions. The columns of \mbox{\boldmathU}\in\mathds{R}^{n\times q}, \{\mbox{\boldmathu}_{1},...,\mbox{\boldmathu}_{q}\}, are the principal component (PC) scores. These PC scores can be thought of as linear combinations of the original features of . These newly transformed variables are considered uncorrelated due to orthogonality of the loadings, which is an attractive feature of PCA. The PCA algorithm is also optimal in the sense that the derived PC scores are conveniently ordered by the amount of variability explained in .
While PCA provides a unique solution in the reduced dimensions, the algorithm can be reformulated into a series of biconvex optimization problems, in which the loading and corresponding score of each PC can be solved in an iterative fashion (Shen and Huang,, 2008),
[TABLE]
Utilizing such optimization framework, Jandarov et al., (2017) develop a spatially predictive PCA algorithm (PredPCA hereafter) by directly incorporating spatial information in the objective function:
[TABLE]
where \mbox{\boldmathZ}=\begin{bmatrix}\mbox{\boldmathR}&\tilde{\mbox{\boldmathR}}\end{bmatrix}, in which \mbox{\boldmathR}\in\mathds{R}^{n\times k} contains GIS covariates, and \tilde{\mbox{\boldmathR}}\in\mathds{R}^{n\times\tilde{k}} contains thin-plate spline basis functions. The induced PC score, \mbox{\boldmathZ}\mbox{\boldmath\alpha}/\|\mbox{\boldmathZ}\mbox{\boldmath\alpha}\|_{2}, is constrained to have an underlying smooth spatial structure guided by geographic and spatial information encoded in . An advantage of PredPCA over PCA is the capability to identify principal directions that lead to spatially predictable PC scores at unmeasured locations. Recent work by Bose et al., (2018) further improves PredPCA by adaptively selecting information to be included in for each PC.
When monitoring data is incomplete, simply omitting locations with missing data may reduce the usable sample size substantially; thus, imputation is often required prior to dimension reduction. Non-parametric techniques, ranging from mean imputation to matrix completions, are based on observed pollutant values but not additional spatial information. When the missingness is spatially informative, such imputation schemes may heavily bias the results of these algorithms.
In the next section, we propose a probabilistic framework that aims to derive spatially predictive PC scores, with the ability to handle incomplete monitoring data and induce flexible model-based imputation that accounts for spatial and geographic information.
4 Probabilistic predictive PCA
4.1 Probabilistic formulation with a latent variable model: the Krige algorithm
Tipping and Bishop, (1999) proposed a probabilistic formulation of PCA based on a Gaussian latent variable model. Their model assumes \mbox{\boldmathX}=\mbox{\boldmathu}\mbox{\boldmathv}^{\mathsf{T}}+\mbox{\boldmathE}, where \mbox{\boldmathu}\sim\mathcal{N}(\mbox{\boldmath0},\mbox{\boldmathI}_{n}), \mbox{\boldmathv}\in\mathds{R}^{p}, \|\mbox{\boldmathv}\|_{2}=1, and the elements of are independently and identically distributed (i.i.d.) with mean zero and variance . We extend this framework by directly imposing a spatial mean and covariance structure on the latent variable space. That is, given a desired number of PCs, , our model assumes
[TABLE]
where \mbox{\boldmath\beta}_{l}\in\mathds{R}^{k} includes the coefficients corresponding to the geographic covariates in , while has zero mean and spatial covariance , with denoting the spatial covariance parameters of the latent space. We use similar constraint \|\mbox{\boldmathv}_{l}\|_{2}=1, and assume that has no nugget effect. The latent score \mbox{\boldmathu}_{l} is stochastic with a full spatial distribution.
Let be the collection of the model parameters, \{\mbox{\boldmathv}_{l},\mbox{\boldmath\beta}_{l},\gamma_{l}^{2},\bm{\xi}_{l}\}, corresponding to the -th PC. When the monitoring data is complete, estimate of the first loading, \mbox{\hat{\mbox{\boldmath}}}_{1}, can be obtained using the original data matrix . The corresponding score \mbox{\hat{\mbox{\boldmath}}}_{1} at monitoring locations can then be calculated by projecting onto the direction of \mbox{\hat{\mbox{\boldmath}}}_{1}. In later steps, can be estimated using \mbox{\boldmathX}_{l}=\mbox{\boldmathX}_{l-1}-\mbox{\hat{\mbox{\boldmath}}}_{l-1}\mbox{\hat{\mbox{\boldmath}}}_{l-1}^{\mathsf{T}}, where \mbox{\boldmathX}_{1}=\mbox{\boldmathX}. The PC score \mbox{\hat{\mbox{\boldmath}}}_{l} can then be derived by projecting \mbox{\boldmathX}_{l} onto \mbox{\hat{\mbox{\boldmath}}}_{l}. Note that we use projection of the data matrix to obtain the PC score in each step instead of using model estimate of the latent mean \mbox{\boldmathR}\mbox{\boldmath\beta}_{l}. When some elements of are missing, estimation of is based only on the observed elements of \mbox{\boldmathX}_{l}. Estimated PC score \mbox{\hat{\mbox{\boldmath}}}_{l} can then be made by projecting the model-based imputed exposure data onto the direction of \mbox{\hat{\mbox{\boldmath}}}_{l}.
Our approach to estimate in each step is similar to the EM algorithm employed by Tipping and Bishop, (1999). We consider the latent variable \mbox{\boldmathu}_{l} to be the “missing” portion, and thus the “complete” data consists of the observed \mbox{\boldmathX}_{l} and the latent variable \mbox{\boldmathu}_{l}. The goal is then to maximize the joint likelihood of \mbox{\boldmathX}_{l} and \mbox{\boldmathu}_{l}. The mathematical details and algorithms for both complete and missing monitoring data are described in the Supplemental Materials. We refer to this framework as the probabilistic predictive PCA, or ProPrPCA, hereafter. Specifically, we call this algorithm ProPrPCA-Krige due to the kriging formulation in the model assumptions.
Our ProPrPCA-Krige model is closely related to the SupSVD model recently proposed by Li et al., (2016). The SupSVD model is expressed as \mbox{\boldmathX}=\mbox{\boldmathU}\mbox{\boldmathV}^{\mathsf{T}}+\mbox{\boldmathE} where \mbox{\boldmathU}=\mbox{\boldmathY}\mbox{\boldmathB}+\mathbf{F}. Here is a the latent score matrix, is a full-rank loading matrix, and are error matrices. Li et al., (2016) also propose an EM approach to estimate the model parameters. The ProPrPCA-Krige model is also related to the envelope model proposed in Cook et al., (2010), which is a more general version compared to SupSVD. As discussed in Li et al., (2016), the SupSVD model attempts to extract a low-rank representation of the original data based on some auxiliary data, while the envelope model aims to reduce variation in regression coefficient estimation. We note that our model is motivated by spatial misalignment where data are not observed at cohort locations, but some geographic information is available. The end goal is also different from the SupSVD and envelope models, as we seek to accurately predict a low-rank representation of the data at unmeasured locations. Thus, our model is designed such that patterns of available covariates and spatial structure are properly induced in the latent scores at locations where we have data, so that we can easily predict them at new locations. An additional contribution is that we develop EM algorithms for parameter estimation for both complete and missing data scenarios.
4.2 Probabilistic formulation with thin-plate spline basis: the Spline algorithm
While the ProPrPCA-Krige algorithm is cohesive with a prediction stage using universal kriging, the parameter estimation appears to be computational burdensome. In general, the EM algorithm is often computationally expensive and convergence is not always guaranteed. We propose a more simplified version of ProPrPCA,
[TABLE]
where contains thin-plate spline functions similar to PredPCA. Compared to the ProPrPCA-Krige model, the latent score \mbox{\boldmathu}_{l} no longer has a stochastic component. Instead, \mbox{\boldmathu}_{l} is now a smooth structure enriched with spatial patterns included in .
The overall procedure to obtain PC scores is similar to the Krige algorithm. The algorithm with complete monitoring data is shown in Table 1. When some elements of \mbox{\boldmathX}_{l} are missing, estimation of \hat{\Theta}_{l}=\{\mbox{\boldmathv}_{l},\mbox{\boldmath\beta}_{l},\gamma_{l}^{2}\} is based on the observed elements of \mbox{\boldmathX}_{l}, and estimated PC score \hat{\mbox{\boldmathu}}_{l} can be derived by projecting the model-based imputed exposure matrix onto the direction of \mbox{\hat{\mbox{\boldmath}}}_{l}. When the monitoring data is complete, the algorithm for parameter estimation at each step is straightforward. The mathematical derivations and the algorithm for missing data are described in the Supplemental Materials. We refer to this model as ProPrPCA-Spline due to the use of thin-plate spline basis functions.
5 Simulations
We conduct two sets of simulations to compare the different PCA approaches. The first set involves a low-dimensional setting with three-pollutant exposure surfaces. The second set illustrates a higher-dimensional setting with 15 generated pollutant surfaces. In both cases, the multi-pollutant data is generated on a grid (.
In each simulation, we randomly choose 400 training locations and 100 testing locations. We then apply the four competing methods (PCA, PredPCA, ProPrPCA-Krige, and ProPrPCA-Spline) to the training data, \mbox{\boldmathX}^{train}, to obtain the corresponding loading \mbox{\hat{\mbox{\boldmath}}}_{l}^{train} and score \mbox{\hat{\mbox{\boldmath}}}_{l}^{train}, for where is a desired number of PCs. We then use \mbox{\hat{\mbox{\boldmath}}}_{l}^{train} and relevant covariate information to obtain \hat{\mbox{\boldmathu}}_{l}^{test}, predicted scores at testing locations, in a universal kriging model with an exponential covariance assumption. Finally, we compare the predicted scores to the known scores, \mbox{\boldmathu}_{l}^{test}, which is defined by projecting \mbox{\boldmathX}^{test} onto the direction of \mbox{\hat{\mbox{\boldmath}}}_{l}^{train}.
We also consider various scenarios in which some training data is missing. These scenarios include missing completely at random (MCAR) , with 30%, 35%, and 40% of missing data, and missing at random (MAR), in which the missing patterns are associated with the generated spatial covariates. When there is missing data, we apply low-rank matrix completion (LRMC) via the SoftImpute algorithm (Mazumder et al.,, 2010) to fill in the missing entries prior to PCA and PredPCA.
There are several metrics to evaluate the predictive performance. The metric of interest is the prediction R2 adapted from Szpiro et al., (2011), which reflects the correlation between \mbox{\hat{\mbox{\boldmath}}}_{l}^{test} and \mbox{\boldmathu}_{l}^{test}. We also look at the reconstruction error (RE), defined as \|\mbox{\boldmathX}^{test}-\hat{\mbox{\boldmathX}}^{test}\|_{F} where \hat{\mbox{\boldmathX}}^{test}=\hat{\mbox{\boldmathU}}^{test}(\hat{\mbox{\boldmathV}}^{train})^{\mathsf{T}}, \hat{\mbox{\boldmathU}}^{test}=\begin{bmatrix}\mbox{\hat{\mbox{\boldmath}}}_{1}^{test}&...&\mbox{\hat{\mbox{\boldmath}}}_{q}^{test}\end{bmatrix}, and \hat{\mbox{\boldmathV}}^{train}=\begin{bmatrix}\mbox{\hat{\mbox{\boldmath}}}_{1}^{train}&...&\mbox{\hat{\mbox{\boldmath}}}_{q}^{train}\end{bmatrix}.
5.1 Three-dimensional exposure surfaces
We simulate three-dimensional surfaces with \{\mbox{\boldmathx}_{1},\mbox{\boldmathx}_{2},\mbox{\boldmathx}_{3}\}, and three independent covariates \{\mbox{\boldmathr}_{1},\mbox{\boldmathr}_{2},\mbox{\boldmathr}_{3}\}. Only \mbox{\boldmathr}_{1}\sim\mbox{{\cal N}}(\mbox{\boldmath0},\mbox{\boldmathI}_{N}) is “observed” and thus used in the universal kriging model. Both \mbox{\boldmathr}_{2}\sim\mbox{{\cal N}}(\mbox{\boldmath0},\mbox{\boldmathI}_{N}) and \mbox{\boldmathr}_{3}\sim\mbox{{\cal N}}(\mbox{\boldmath0},\mbox{\boldmathI}_{N}) are unobserved and primarily used to induce correlations across \{\mbox{\boldmathx}_{1},\mbox{\boldmathx}_{2},\mbox{\boldmathx}_{3}\}. We generate data such that \mbox{\boldmathx}_{1}=4\mbox{\boldmathr}_{1}+2\mbox{\boldmathr}_{3}+\mbox{\boldmath\epsilon}_{1}, \mbox{\boldmathx}_{2}=3\mbox{\boldmathr}_{2}+\mbox{\boldmath\epsilon}_{2}, and \mbox{\boldmathx}_{3}=2\mbox{\boldmathr}_{1}+4\mbox{\boldmathr}_{2}+\mbox{\boldmath\epsilon}_{3}, where \mbox{\boldmath\epsilon}_{1},\mbox{\boldmath\epsilon}_{2},\mbox{\boldmath\epsilon}_{3}\sim\mbox{{\cal N}}(\mbox{\boldmath0},\Sigma), where has an exponential structure with partial sill , nugget , and range . Under this setting, only \mbox{\boldmathx}_{1} and \mbox{\boldmathx}_{3} are predictable by \mbox{\boldmathr}_{1}. While not dependent on \mbox{\boldmathr}_{1}, \mbox{\boldmathx}_{2} is moderately correlated with \mbox{\boldmathx}_{3} via \mbox{\boldmathr}_{2}. We also generate a second set of data in which the errors \mbox{\boldmath\epsilon}_{1},\mbox{\boldmath\epsilon}_{2},\mbox{\boldmath\epsilon}_{3}\sim\mbox{{\cal N}}(\mbox{\boldmath0},\mbox{\boldmath1}) . For MAR scenarios, \mbox{\boldmathx}_{1} is missing at training locations where \mbox{\boldmathr}_{1} values are larger than its 80th sample percentile, while \mbox{\boldmathx}_{2} and \mbox{\boldmathx}_{3} have 20% MCAR. We look at the first PC for these simulations, i.e. .
Figure 1 shows the prediction R2’s and REs across 1,000 simulations for data generated with spatially correlated noise. Table 2 displays the means and standard deviations of the estimated loadings from each method when the training data is complete. The principal direction produced by PCA is loaded heavily on \mbox{\boldmathx}_{3} and only moderately on both \mbox{\boldmathx}_{1} and \mbox{\boldmathx}_{2}. This leads to poor predictive performance for PCA (median R). Meanwhile, loadings from the other three methods put the most weight on \mbox{\boldmathx}_{1} and some on \mbox{\boldmathx}_{3}, thus they have higher prediction R2’s (median R2’s are about 0.75) and lower REs.
Under MCAR scenarios, prediction R2’s substantially decrease and REs increase for both PCA and PredPCA as the amount of missing data increases. Median R2 of PredPCA drops to as low as 0.64 when training data is 35% MCAR. On the other hand, there are only some subtle reductions in the predictive performances of both ProPrPCA approaches. Under MAR, the performances of both PCA and PredPCA are significantly worse. While ProPrPCA-Krige performs better than PredPCA on average, the variability in performance is high across simulations. Despite not achieving the same level as when the data is complete, ProPrPCA-Spline has the highest predictive performance among the four competing methods.
Table 3 shows the estimated loadings with complete data, while Figure 2 shows the prediction R2’s and REs across 1,000 simulations for data generated with independent noise. Similar trends, where ProPrPCA outperforms the rest when missing data is more severe, are also observed in this set of generated data.
5.2 High-dimensional exposure surfaces
We also demonstrate the performance of ProPrPCA algorithms via simulations with 15 generated pollutants. The full setup is described in the Supplemental Materials. Overall, the high-dimensional exposure surfaces are generated from three underlying scores, \mbox{\boldmathu}_{1}, \mbox{\boldmathu}_{2}, and \mbox{\boldmathu}_{3}. The data generating mechanism is such that \mbox{\boldmathu}_{1} is the most spatially predictable, \mbox{\boldmathu}_{2} is moderately predictable, and \mbox{\boldmathu}_{3} is not predictable by any covariates used in the universal kriging model. The loadings used to generate the data are sparse, in order to clearly identify the behaviors of the PCA methods. That is, the first five pollutants, (\mbox{\boldmathx}_{1},\mbox{\boldmathx}_{2},\mbox{\boldmathx}_{3},\mbox{\boldmathx}_{4},\mbox{\boldmathx}_{5}), are generated from \mbox{\boldmathu}_{1}. Meanwhile, (\mbox{\boldmathx}_{6},\mbox{\boldmathx}_{7},\mbox{\boldmathx}_{8},\mbox{\boldmathx}_{9},\mbox{\boldmathx}_{10}) are generated from \mbox{\boldmathu}_{2}, and (\mbox{\boldmathx}_{11},\mbox{\boldmathx}_{12},\mbox{\boldmathx}_{13},\mbox{\boldmathx}_{14},\mbox{\boldmathx}_{15}) are generated from \mbox{\boldmathu}_{3}. For MAR scenario, we induce a mild spatial pattern in the missing data for the first five pollutants. In these simulations, we evaluate the predictive performance based on two PCs, i.e. .
We create two scenarios: scenario 1 with Var(\mbox{\boldmathu}_{1})=10, Var(\mbox{\boldmathu}_{2})=7.5, and Var(\mbox{\boldmathu}_{3})=5, and scenario 2 with Var(\mbox{\boldmathu}_{3})=10, Var(\mbox{\boldmathu}_{1})=7.5, and Var(\mbox{\boldmathu}_{2})=5. In scenario 1, where the order of variance contribution is the same as the order of spatial predictability, we expect all methods to identify linear combinations of \mbox{\boldmathu}_{1} and \mbox{\boldmathu}_{2} as the first two PCs when training data is complete. In scenario 2, the non-predictable score \mbox{\boldmathu}_{3} has the highest variance contribution. Thus we expect PCA to identify linear combinations of \mbox{\boldmathu}_{3} and \mbox{\boldmathu}_{1} for the first two PCs, with a large contribution of \mbox{\boldmathu}_{3} for the first PC. Meanwhile, we anticipate the other predictive methods to still pick linear combinations of \mbox{\boldmathu}_{1} and \mbox{\boldmathu}_{2}.
Table 4 shows the results for the prediction R2’s across 1,000 simulations under scenario 1. As expected under scenario 1, all methods perform comparably when the training data is complete. While the results for MCAR 30% and 40% are not shown in this chapter, we observed similar patterns to the three-dimensional simulations where the performance of PCA and PredPCA decreases steadily as the amount of MCAR missing data increases. Under MCAR 35% setting, ProPrPCA-Spline has the best median R2’s for both PCs.
Under MAR, data among the first five pollutants are more likely to be missing at locations with extreme geographic covariate values. This setup effectively has an impact on the actual variance contributions of the underlying scores in a given sample, and particularly lowers the variability contributed by \mbox{\boldmathu}_{1}. As a result, for PC1, PCA is likely to produce loadings with higher contribution from \mbox{\boldmathu}_{2} than before. As the predictive methods (PredPCA and ProPrPCA) attempt to balance out the trade-off between data representativeness and spatial predictability, these methods will also likely to obtain linear combinations with more weights from \mbox{\boldmathu}_{2} for PC1 than before. Subsequently, linear combinations obtained for PC2 will have more weights from \mbox{\boldmathu}_{1} than before. This explains the decreases in median R2’s of PC1 for all methods but slight increases for PC2. ProPrPCA-Spline notably has the best median R2 for PC1.
We further compare the differences in R2 values between ProPrPCA-Spline and PredPCA in Figure 3. With complete training data, ProPrPCA-Spline outperforms PredPCA for only less than 60% of the simulations, and the magnitude of the difference between the two methods is rather negligible. Under MCAR 35%, ProPrPCA-Spline outperforms PredPCA for both PCs in 69.7% of the 1,000 simulations, and, for 28.5% of the time, ProPrPCA-Spline is better in one of the PCs. Finally, under MAR, there are only 2.5% of the simulations in which ProPrPCA-Spline is worse than PredPCA for both PCs. There are 38.7% of the simulations where ProPrPCA-Spline is better for only PC1 (blue top-left quadrant). Particularly for points lying in this quadrant, the greater spread along the y-axis implies that a higher increase in R2 for PC1 is often accompanied by a smaller decrease in R2 for PC2. Thus ProPrPCA-Spline shows more prominent benefits for PC1 without trading off too much in predictability of PC2.
Table 5 and Figure 4 show the corresponding results under scenario 2. In this scenario, as expected, PCA often identifies linear combinations of \mbox{\boldmathu}_{3} and \mbox{\boldmathu}_{1} as the first two PCs, and thus the predictive performance is generally poor, especially for PC1. ProPrPCA-Krige severely underperforms compared to PredPCA and ProPrPCA-Spline, even with complete data. Both PredPCA and ProPrPCA-Spline produce similar median R2’s with complete data. Similar to scenario 1, ProPrPCA-Spline performs consistently well with an increasing amount of MCAR, while the performance of PredPCA deteriorates. ProPrPCA-Spline shows clear benefits under MAR, particularly for PC1 (0.72) compared to PredPCA (0.63). The visualization of the differences in prediction R2’s between ProPrPCA-Spline and PredPCA in Figure 4 further supports similar conclusions to those of scenario 1.
6 Data application
6.1 Methods
In this section, we first compare the pollutant profiles obtained by different dimension reduction methods to the annual average 2010 CSN data. Prior to our analysis, we take a similar approach to Keller et al., (2017) and convert the mass concentrations of PM2.5 components to proportions by dividing by the total mass of PM2.5, and then log-transform these proportions. We also follow a similar preprocessing procedure as described in Keller et al., (2017) and Jandarov et al., (2017) to the GIS covariates to be used in the predictive algorithms and spatial prediction model. That is, we remove covariates that are missing at all chosen sites, have the same values in at least 80% of the sites, or have at least 2% of their values being more than five standard deviations away from the sample mean. We also remove land-use covariates whose maximal value is only 10% among all chosen sites. Finally, we apply PCA on the processed GIS data and use the first five PCs in later stages.
After the preprocessing procedure, we end up with a total of 221 CSN sites, only 130 of which have complete data on all 21 PM2.5 components. We first apply three methods, PCA, PredPCA, and ProPrPCA-Spline, on the 130 sites with complete data (the “complete” set). We then proceed to apply these methods on all 221 CSN sites (the “full” set), where LRMC is applied prior to PCA and PredPCA. The goal is to assess how the estimated loadings and PC scores change when using only sites with complete data compared with using all available sites. The design matrix, , used in PredPCA and ProPrPCA-Spline includes the five PCs of GIS covariates and thin-plate spline basis functions generated from the spatial coordinates, similar to Jandarov et al., (2017). We do not use ProPrPCA-Krige in our comparison because of its computational cost and inferior performance compared to ProPrPCA-Spline in our previously described simulations.
We also conduct leave-one-site-out cross-validation to compare the predictive performances among these methods. In each round of cross-validation, we leave out one site among the complete sites as test data. We then perform dimension reduction and fit a universal kriging model on training data comprised of either only the remaining complete sites (the “complete” training data), or all remaining sites (the “full” training data), while the testing data in each round stays the same. The goal is to assess the predictive performance of different methods with both complete and missing data.
6.2 Results
6.2.1 The multi-pollutant profile
Figure 5 shows the estimated loadings and the spatial distributions of corresponding scores of the first PC for four combinations of method and dataset: PCA applied to the complete set, PredPCA applied to the complete set, imputation followed by PredPCA applied to the full set, and ProPrPCA-Spline applied to the full set. The results for ProPrPCA-Spline when using the complete set (not shown here) are essentially identical to PredPCA results.
The estimated PC1 loadings are similar across PredPCA applied to either sets and to ProPrPCA-Spline, with highly positive weights on SO and S and highly negative weights on Al, Ca, Na, and Si. Highly positive scores are observed in the east and part of the Midwest, probably due to sulfur emissions from coal combustion (Thurston et al.,, 2011; Hand et al.,, 2012). Negative scores are observed in the west and southwest, and have a classic resuspended soil profile (Thurston et al.,, 2011; Tong et al.,, 2012; Clements et al.,, 2017). While the spatial distribution of PCA scores looks similar to other methods, loadings obtained by PCA applied to the complete set are fundamentally different than the rest, with much weaker positive weights on SO and S, and strongly negative weights on many additional elements, including Cr, Cu, Fe, Mn, Ni, Zn.
Figure 6 shows the estimated loadings and the score distributions for the PC that has a highly positive composition of Na, Ni, and V. This feature corresponds to PC3 obtained by PCA or PredPCA applied to the complete set, and PC2 obtained by PredPCA or ProPrPCA-Spline applied to the full set. ProPrPCA-Spline results in highly positive scores along the west coast, the east coast, and southeast region, possibly due to residual oil combustion (Thurston et al.,, 2011), and marine aerosol (Thurston et al.,, 2011; Kotchenruther,, 2017). ProPrPCA-Spline also identifies pronounced negative loadings on Zn and NO. The remaining three combinations of methods and datasets are able to produce fairly similar maps with strongly positive scores along the west coast and across the northern east coast, although they fail to highlight some relevant coastal locations in the southeast region.
Figure 7 shows the results for features highly positive in NO and Zn, which corresponds to PC2 obtained by PCA or PredPCA applied to the complete set, and PC3 obtained by PredPCA or ProPrPCA-Spline applied to the full set. For all methods, highly positive scores are observed in the northern Midwest, possibly due to nitrate hazes (Coutant et al.,, 2003; Pitchford et al.,, 2009; Hand et al.,, 2012). Additionally, loadings produced by ProPrPCA-Spline are also strongly positive in Ni, V, and negative in Al, Si, with greater magnitude compared to other methods. Thus, moderately positive scores are also observed along the west coast. ProPrPCA-Spline also results in highly positive scores in the southeast region due to the calcium poor soils in that region compared to Al and Si content (Shacklette and Boerngen,, 1984).
6.2.2 Cross-validation results
Finally, we look at the predictive performances in leave-one-site-out cross-validations, and the results are shown in Figure 8. While having decent performance for PC2 and PC3 (R), using PCA applied to the complete training data yields a poor result for PC1 (R). PredPCA has similar performances for PC1 with either complete or full training data. However, there is a substantial trade-off in performances between PC2 and PC3, which can potentially be explained by the switching between PC2 and PC3 observed in the pollutant profile. ProPrPCA-Spline applied on the full training data shows the highest predictive performance for PC1 (R) and PC3 (R), but suffers from a decrease in the ability to predict PC2 well (R).
A possible explanation to the overall relatively low R2’s for all methods is that we use the same pre-specified spatial information encoded in to characterize the spatial variability across all PCs, which may not be effective. A potential solution, which is beyond the scope of this paper, is adaptive selection of features to be included in , which is proposed and discussed in Bose et al., (2018).
7 Discussion
In this chapter, we propose a probabilistic extension to the PredPCA algorithm developed by Jandarov et al., (2017). The proposed ProPrPCA algorithms can be applied to misaligned multi-pollutant data with missing observations. The ultimate goal is to improve the predictive performance of the exposure modeling stage that is often required in air pollution studies that rely on fixed site monitoring data. In spite of its simplicity, these probabilistic extensions are nontrivial and effective in mitigating the impact of missing data on the predictive performance of the exposure model. The proposed methods also eliminate the necessity of a separate imputation procedure prior to dimension reduction. The scientific motivation, especially in health-pollution studies on PM2.5 and its components, includes the ability to use estimated PC scores at study locations as effect modifiers for the main health associations of interest.
We have demonstrated via simulations that ProPrPCA-Spline consistently outperforms its competitors under various missing observation scenarios. Its computational speed is on par with both PCA and PredPCA, which are non likelihood-based methods. The complex version, ProPrPCA-Krige, assumes a universal kriging formulation for the latent variable, with the mean model enriched by spatial covariates, and spatial correlations among the residuals. ProPrPCA-Spline incorporates thin-plate spline basis functions, which can be regarded as an alternative to a fixed low-rank kriging model (Kammann and Wand,, 2003). Intuitively, the latent specification of ProPrPCA-Krige would have been cohesive with the later prediction stage using universal kriging. Possible explanations for the inferior performance of the Krige algorithm in simulations include the difficult nature of the numerical optimization for spatial variance parameters, the number of parameters to estimate, and no guaranteed convergence to the global optima using the EM algorithm.
PCA is closely related to factor analysis (Harman,, 1976), k-mean clustering (MacQueen,, 1967), or positive matrix factorization (Paatero and Tapper,, 1994), which have recently been used as source apportionment or dimension reduction for exposure data prior to health analyses (Sarnat et al.,, 2008; Ostro et al.,, 2011; Zanobetti et al.,, 2014; Ljungman et al.,, 2016). These applications, however, have been limited to time-series analysis in specific regions, without the challenge of spatial misalignment and severe missing data. Recent work by Keller et al., (2017) and Jandarov et al., (2017) has modified the traditional clustering and PCA methods, respectively, to the setting of spatially-misaligned multi-pollutant data, where the products of the dimension reduction procedure are desired to be spatially predictable. We further extend these frameworks by considering the realistic challenge of missing monitoring data. Our proposed framework essentially performs model-based imputation, which is cohesive and complementary to the spatial prediction stage. While one can impute the original data with sophisticated low-rank matrix completion techniques, which also operate based on the assumption of a latent variable structure, such methods only rely on observed measures. Therefore, if the missing patterns depend on external geographic covariates, such imputation schemes cannot recover the correct data structure.
In the literature, spatial latent variable models have been explored under the Bayesian framework. For example, Wang and Wall, (2003) proposed a generalized common spatial factor model using MCMC techniques. Hogan and Tchernis, (2004) formulated a Bayesian factor analysis model, which was later extended by Liu et al., (2005) to motivate a generalized spatial structural equations model, and by Zhu et al., (2005) to deal with spatiotemporal data. These rich modeling approaches have not been utilized in the setting of multi-pollutant analysis with spatial misalignment. The main goal of these models is often to explain the associations between the original variables and the underlying factors. Here the goal of an improved PCA algorithm is to obtain a lower-dimensional representation of the data in a spatially predictive way for subsequent use in spatial prediction and health regression.
The multi-stage procedure in analyzing health-pollution association under spatial misalignment is a common and pragmatic approach (Crouse et al.,, 2010; Bergen et al.,, 2013; Chan et al.,, 2015). However, it is important to be mindful of the potential implications of measurement errors and model uncertainty of the spatial prediction stage on the health inference model, a topic which has been discussed extensively in Szpiro and Paciorek, (2013). Additionally, these authors emphasized that the spatially structured components of the covariates used in the health model should be included in the exposure modeling stage to guarantee a consistent estimation of the health effects. In the multi-pollutant setting with missing observations, additional stages of imputation and dimension reduction lead to more complicated layers of uncertainty. Our proposed methods eliminate the need of a separate imputation step prior to dimension reduction, as these two steps are handled simultaneously using a model-based approach. A possible alternative to the multi-stage paradigm is a unified approach where both exposure and health data are considered simultaneously in a joint model, while leveraging the factor analysis framework to perform dimension reduction. Szpiro and Paciorek, (2013) point out several disadvantages of such joint model, including sensitivity to influential or outlying health data, vulnerability to model mis-specifications, and computational burden, especially with multi-pollutant data.
While we focus our discussion in this chapter exclusively on studies involving data on PM2.5 and its components, our proposed method is both appropriate for other multi-pollutant studies and applicable to other fields in general where spatial misalignment necessitates an exposure modeling procedure. Future work includes further understanding and improvement of the ProPrPCA-Krige algorithm, and a possible extension to spatiotemporal data.
8 Supporting Information
Data used in this paper are available upon request through the MESA Air team at the University of Washington. Supplemental materials can be provided upon email request.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Achilleos et al., (2017) Achilleos, S., Kioumourtzoglou, M.-A., Wu, C.-D., Schwartz, J. D., Koutrakis, P., and Papatheodorou, S. I. (2017). Acute effects of fine particulate matter constituents on mortality: A systematic review and meta-regression analysis. Environment International , 109:89–100.
- 2Bell et al., (2007) Bell, M. L., Dominici, F., Ebisu, K., Zeger, S. L., and Samet, J. M. (2007). Spatial and temporal variation in PM 2.5 chemical composition in the United States for health effects studies. Environmental Health Perspectives , 115(7):989.
- 3Bell et al., (2009) Bell, M. L., Ebisu, K., Peng, R. D., Samet, J. M., and Dominici, F. (2009). Hospital admissions and chemical composition of fine particle air pollution. American Journal of Respiratory and Critical Care Medicine , 179(12):1115–1120.
- 4Bergen et al., (2013) Bergen, S., Sheppard, L., Sampson, P. D., Kim, S.-Y., Richards, M., Vedal, S., Kaufman, J. D., and Szpiro, A. A. (2013). A national prediction model for PM 2.5 component exposures and measurement error–corrected health effect inference. Environmental Health Perspectives , 121(9):1017.
- 5Bose et al., (2018) Bose, M., Larson, T., and Szpiro, A. A. (2018). Adaptive predictive principal components for modeling multivariate air pollution. Environmetrics , 29(8).
- 6Brauer et al., (2003) Brauer, M., Hoek, G., van Vliet, P., Meliefste, K., Fischer, P., Gehring, U., Heinrich, J., Cyrys, J., Bellander, T., Lewne, M., and Brunekreef, B. (2003). Estimating long-term average particulate air pollution concentrations: application of traffic indicators and geographic information systems. Epidemiology , 14(2):228–239.
- 7Brook et al., (2004) Brook, R. D., Franklin, B., Cascio, W., Hong, Y., Howard, G., Lipsett, M., Luepker, R., Mittleman, M., Samet, J., Smith, S. C., and Tager, I. (2004). Air pollution and cardiovascular disease. Circulation , 109(21):2655–2671.
- 8Chan et al., (2015) Chan, S. H., Van Hee, V. C., Bergen, S., Szpiro, A. A., De Roo, L. A., London, S. J., Marshall, J. D., Kaufman, J. D., and Sandler, D. P. (2015). Long-term air pollution exposure and blood pressure in the Sister Study. Environmental Health Perspectives , 123(10):951.