Learned Image Compression with Soft Bit-based Rate-Distortion Optimization
David Alexandre, Chih-Peng Chang, Wen-Hsiao Peng, Hsueh-Ming Hang

TL;DR
This paper proposes a novel soft bit-based method for learned image compression that improves rate-distortion optimization by enabling differentiable quantization and accurate rate estimation, leading to state-of-the-art results.
Contribution
Introduction of soft bits for differentiable quantization, enhancing rate-distortion optimization in learning-based image compression.
Findings
Achieves state-of-the-art MS-SSIM and PSNR performance.
Effectively couples rate estimation with context-adaptive coding.
Provides a differentiable distortion objective function.
Abstract
This paper introduces the notion of soft bits to address the rate-distortion optimization for learning-based image compression. Recent methods for such compression train an autoencoder end-to-end with an objective to strike a balance between distortion and rate. They are faced with the zero gradient issue due to quantization and the difficulty of estimating the rate accurately. Inspired by soft quantization, we represent quantization indices of feature maps with differentiable soft bits. This allows us to couple tightly the rate estimation with context-adaptive binary arithmetic coding. It also provides a differentiable distortion objective function. Experimental results show that our approach achieves the state-of-the-art compression performance among the learning-based schemes in terms of MS-SSIM and PSNR.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12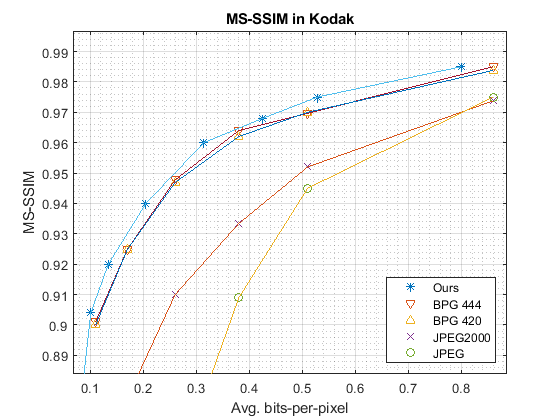 Figure 13
Figure 13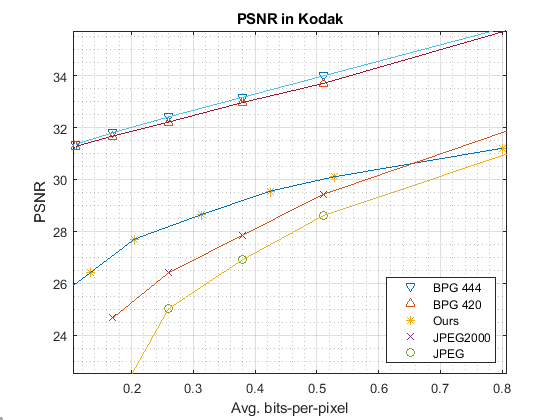 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23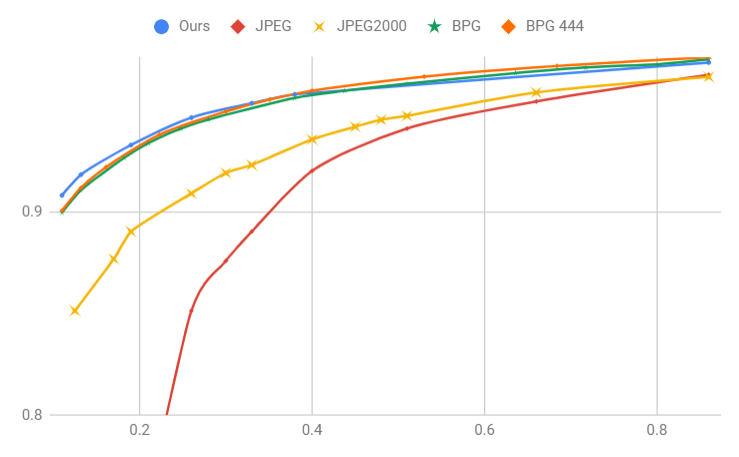 Figure 24
Figure 24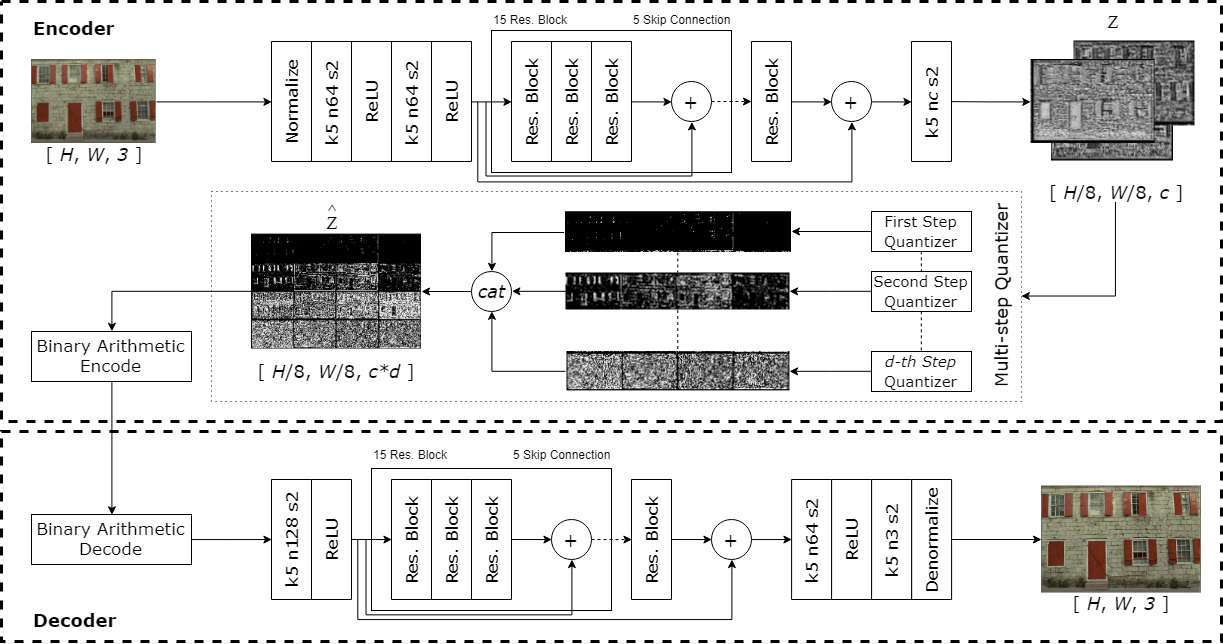 Figure 25
Figure 25 Figure 26
Figure 26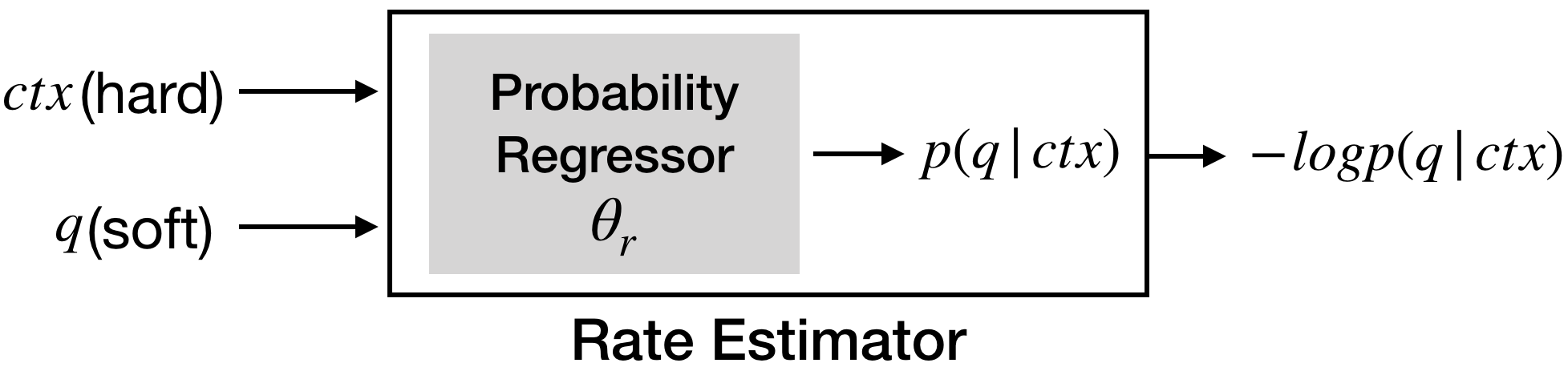 Figure 27
Figure 27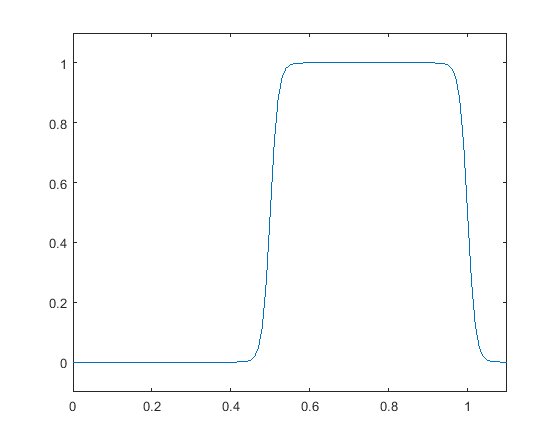 Figure 28
Figure 28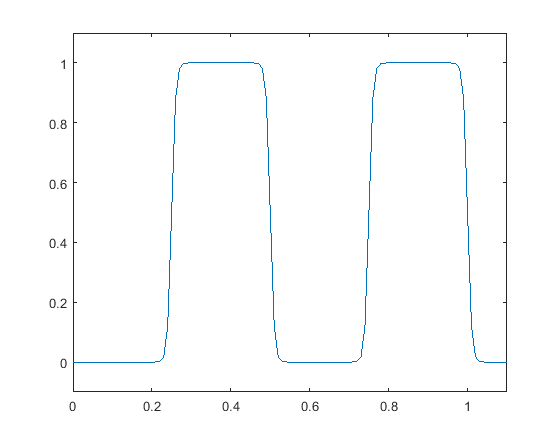 Figure 29
Figure 29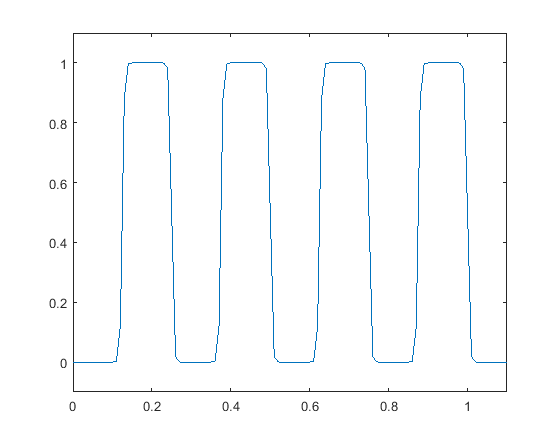 Figure 30
Figure 30 Figure 31
Figure 31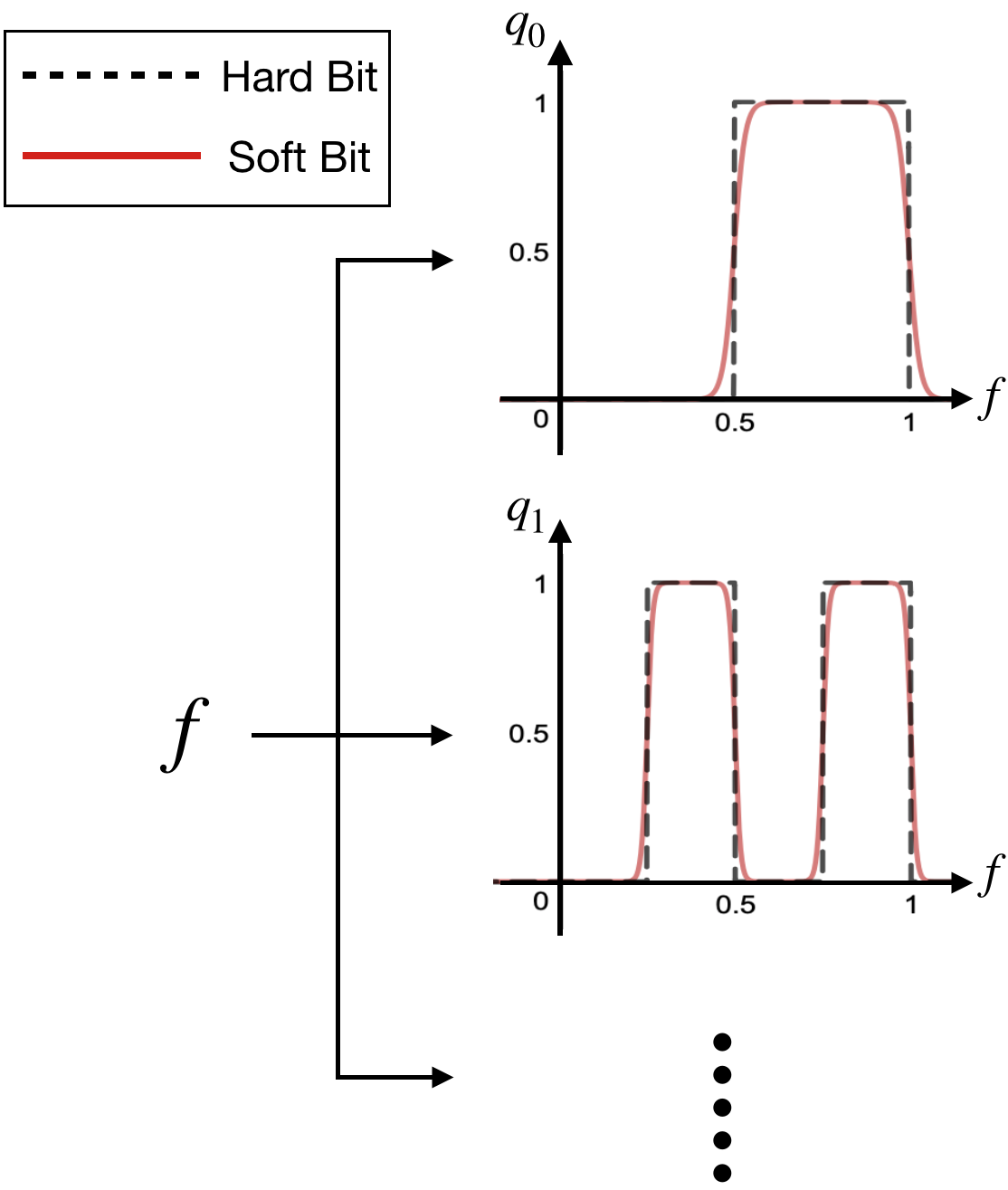 Figure 32
Figure 32Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAdvanced Data Compression Techniques · Advanced Image Processing Techniques · Advanced Vision and Imaging
Learned Image Compression with Soft Bit-based Rate-Distortion Optimization
Abstract
This paper introduces the notion of soft bits to address the rate-distortion optimization for learning-based image compression. Recent methods for such compression train an autoencoder end-to-end with an objective to strike a balance between distortion and rate. They are faced with the zero gradient issue due to quantization and the difficulty of estimating the rate accurately. Inspired by soft quantization, we represent quantization indices of feature maps with differentiable soft bits. This allows us to couple tightly the rate estimation with context-adaptive binary arithmetic coding. It also provides a differentiable distortion objective function. Experimental results show that our approach achieves the state-of-the-art compression performance among the learning-based schemes in terms of MS-SSIM and PSNR.
**Index Terms— ** Autoencoder, Deep Learning, Image Compression, Soft Bits
1 Introduction
Learning-based image compression has recently attracted lots of attention due to the renaissance of deep learning. Unlike the traditional methods, the learning-based schemes can be adapted to any differentiable objective, opening up many optimization possibilities. For example, Li et al. [1] propose a content-weighted image compression model that performs region-adaptive compression via a learnable importance map.
Most learning-based methods[1, 2, 3, 4, 5, 6, 7, 8] rely on training an autoencoder end-to-end with the aim of striking a good balance between distortion and rate losses. Two challenges arise. First, the quantization process for lossy feature map compression causes zero gradients during the back-propagation process. Second, the rate loss is often painful to estimate accurately, as it is highly coupled with entropy coding, the operation of which is generally not differentiable.
Several prior arts are proposed to address these issues. Li et al. [1] overcome the zero gradients by a straight-through mechanism, which simply considers the quantizer to be an identity function during the back-propagation process. Agustsson et al. [5] and Mentzer et al. [3] introduce a non-uniform soft quantizer with a smooth mapping function as a surrogate of the hard quantizer. Ballé et al. [6, 7] and Theis et al. [8] adopt an additive noise model for the quantizer.
In comparison with the quantization issue, the rate estimation is even more challenging. Li et al. [1] use the sum of importance map features as a rough estimate of the rate. Theis et al. [8] estimate the rate from the upper-bound of non-differentiable number of bits. For better estimation, Ballé et al. [6, 7] and Minnen et al. [4] compute the differential entropy of the quantizer output based on the additive noise model. To bind the rate estimation tightly to the actual entropy coding, Mentzer et al. [3] use the context probability model implemented by PixelRNN [9] to compute the self-information of each coding symbol. Their scheme is, however, complicated due to the use of PixelRNN [9] and the non-binary arithmetic coding.
In this paper, we propose a learned image compression system with soft-bit-based rate-distortion optimization. It has the striking feature of combining effective coding tools from modern image codecs (e.g., uniform quantization, binary bitplane coding with on-the-fly probability updating, and simple context models) with the strong suit of deep learning (e.g., non-linear autoencoder). Moreover, we introduce the notion of soft bits to represent quantization indices of feature samples so that both rate and distortion losses can be estimated accurately in a differentiable manner. Experimental results show that our method achieves the state-of-the-art rate-distortion performance among the learning-based schemes.
The remainder of this paper is organized as follows: Section 2 describes the proposed method. Section 3 details the training procedure. Section 4 presents the experimental results. Section 5 concludes this work.
2 Proposed Method
This section details the framework of our image compression system, including the overall architecture, the operation of each component, and the modeling of compression rate and distortion for end-to-end training. Notation-wise, we use a bold letter (e.g., ) to refer collectively to a high-dimensional tensor and a Roman letter (e.g., ) to denote its element in some order.
2.1 Overall Architecture
Fig. 1 illustrates our proposed framework. There are two data paths, one for operating the model in the test mode (that is, for putting it into use in practice) and the other for its training (i.e., training mode).
The data path in the test mode, as indicated by the solid arrow lines, begins with encoding an image of size in 4:4:4 YUV format through a convolutional encoder into a compact set of feature maps , of which each feature sample is a real number. For lossy compression, is uniformly quantized by a -bit, power-of-two quantizer , leading to a fixed-point binary representation , where is the quantization step size. That is, the quantization (output) index is the first significant bits of in its binary representation (e.g., for ). Like most image compression systems, either learning-based or conventional, the quantization indices are compacted further by lossless arithmetic coding. Motivated by JPEG2000 [10], we arrange as bitplanes and perform context-adaptive bit-plane encoding/decoding (CABIC/CABID), of which we will discuss more in the following sections. To reconstruct the input approximately, the feature sample is first recovered via inverse quantization (IQ) , followed by convolutional decoding . Currently, our encoder and decoder come from an autoencoder proposed in [3]; their parameters are however learned by our training framework, which aims to strike a good trade-off between rate and distortion by minimizing the following objective function with respect to :
[TABLE]
where is defined to be a weighted sum of mean-square errors between YUV components of and , with the error of Y component weighted 4 times that of the U/ V component.
The data path in training mode, as outlined by the dashed arrow lines, is designed for end-to-end model training. Training a learning-based compression system is often faced with two issues: (1) the quantization effect, which describes the stair-like mapping from to , gives rise to zero gradients almost everywhere, and (2) the rate cost needed to achieve a rate-distortion optimized design is difficult to estimate accurately. To address these issues, we introduce the notion of soft bits as an alternative to the hard bit representation of the quantization indices . As an example, instead of rendering into ”1”,”1”,”0”,”0” for as done previously, we express these binary hard bits as real-valued soft bits, e.g. ”0.91”, ”0.95”, ”0.1”, ”0.07”, by the soft bit conversion (SB Conv.) module. In doing so, each of these soft bits is formulated as a differentiable function of . Not only can they be used together with a differentiable rate estimator, implemented by a learnable neural network with parameter in Fig. 1, to give an accurate estimate of the coding cost, but they can also be used to approximate in a differentiable manner (by the Inv. SB Conv. module).
To sum up, our framework has three networks to be learned end-to-end: the encoder, the decoder, and the rate estimator. Among these, only the encoder and the decoder will actually operate in the test mode, while the rate estimator is activated for training only.
2.2 Soft Bit Conversion
The soft bit conversion plays a central role in enabling our compression system end-to-end trainable. It is to convert the binary, hard-bit representation of the quantization index of a feature sample into a differentiable function of , namely the soft-bit representation. In the previous example, the binary fixed-point representation of for a feature sample is ”1100” when is quantized uniformly with a step size of . We observe that each of these hard bits , , , is in fact a function of . For instance, the first bit equals to 1 when is in the interval and 0 when in the interval of . The mappings for the first two bits are visualized in Fig. 2 (see the hard-bit curves). Apparently, due to their rectangular waveforms, the derivative with respect to is zero almost everywhere, making the training with back-propagation impossible.
To circumvent this difficulty, we approximate these hard-bit mappings by a superposition of sigmoid functions (see the soft-bit curves in Fig. 2). This is motivated by the fact that any rectangular waveform can be expressed as a superposition of step functions, which in turn can be approximated by sigmoid functions with a adequately chosen hyper-parameter :
[TABLE]
As an example, it is seen that:
[TABLE]
With this approximation, is modeled by the soft bits using in the back-propagation process. Note that one may as well use the soft quantization technique in [3] to model the mapping from to directly.
Although our current model implements a power-of-two uniform quantizer, the soft-bit representation for quantization indices can readily be applied to non-uniform quantizers.
2.3 Context-adaptive Bit-plane Coding (CABIC)
Before describing our soft-bit-based rate estimation, we present briefly how the quantization indices of feature maps are coded in the test mode. We first organize into bitplanes. A bitplane is formed collectively by the same binary digits of quantization indices. For example, the most significant bitplane consists of all the of feature samples. Bits are then coded starting from the most significant bitplane to the least significant one, with different feature maps processed in the same manner yet separately.
To encode a bitplane, we adopt the context-adaptive binary arithmetic coding technique. Inspired by JPEG2000, we classify every bit into a significant bit or a refinement bit. Using Fig. 3 for illustration, for coding a significant bit of the quantization index at , we refer to the binary significant status of the surrounding indices at , , and . This yields a total of 16 context patterns (or ctx values for short), each corresponding to a binary probability model that is updated on-the-fly. For coding a refinement bit, the ctx value is computed based on the bit values of quantization indices at in the previous bitplane along with those of in the current bitplane. Since refinement bits are less predictable, we reduce the number of their ctx values to 9 only.
Note that we adopt the traditional hand-crafted design for arithmetic coding because (1) it allows simple adaptation of the context probability model to learn local image statistics and (2) it avoids the need to perform neural network inference at bit level, which introduces extra processing latency in the highly sequential arithmetic decoding process.
2.4 Rate Estimator
To estimate the code length needed to represent an input bit at training time, we refer to its self-information. The self-information of a probabilistic event is defined to be the negative logarithm of its probability . In our case, the probability of a coding bit is maintained in a context probability model, which keeps track of , where denotes its context pattern/value. It is however noted that is approximated by the relative frequency of given the , e.g. how many times the event occurs given the present , which is a statistics quantity not differentiable with respective to .
To overcome this problem, we train a rate estimator that includes a neural network as a probability regressor to fit collected from the training data, as illustrated in Fig. 4. In particular, the probability regressor takes as input the soft bits version of so that it generates non-zero gradient of the estimated rate (computed to be ) with respect to the encoder parameter :
[TABLE]
It can be seen that if the hard bit mapping is used, the term would be replaced with , which vanishes.
Eq. (4) additionally gives us some important insights into how the estimated rate cost of an input bit would influence the update of the encoder parameter . Its contribution to the change of in a gradient update step will be more significant if is in its less probable state, i.e., , or if its conditional probability distribution is more biased, i.e., is larger. The latter occurs when or vice versa.
3 Training
The encoder, decoder, and rate estimator are trained in two alternating phases. In the first phase, we collect the statistics of the context probabilities from the feature maps, and update the rate estimator by minimizing the regression error between and . In the second phase, we incorporate the rate estimator to give an estimate of the rate cost and update both the encoder and decoder by minimizing with respect to their network parameters . During training, we set the batch size to 8 and the learning rate to .
The training dataset contains 1,672 images provided by the Challenge on Learned Image Compression (CLIC) 2018 [11]. They are randomly cropped into 128x128 patches, and the horizontal and vertical flipping is performed for data augmentation.
4 Experimental results
This section compares the rate-distortion performances of the proposed method with the other codecs. The comparison is conducted on Kodak dataset [12] by compressing test images at several rates with a varying number of feature maps. Specifically, our encoder is configured to produce 4 feature maps for bits-per-pixel (bpp) lower than 0.25, 8 for bpp’s between 0.25 and 0.5, and 16 for bpp’s higher than 0.5. For every test image, we first calculate the average PSNR and MS-SSIM over its three color components. We then present the average values over the entire dataset as a single quality indicator.
From Fig. 5, we see that our method performs comparably to BPG and Mentzer et al.’s [3] while outperforming JPEG and JPEG2000 by a large margin across a wide range of bpp’s. On the other hand, in terms of PSNR, it is much inferior to BPG but is superior to the other baselines. These observations are in line with the findings of the other researchers that the learning-based methods often show much better MS-SSIM performance, especially at low rates. It is worth pointing out that our model is trained by minimizing the mean-squared error while Mentzer et al. [3] optimize theirs for MS-SSIM. This explains why their method has low PSNR. Fig. 6 further displays reconstructed images produced by these codecs for subjective quality evaluation.
Fig. 7 shows the bit allocation among feature maps due to our soft-bit-based rate-distortion optimization. Three observations can be made: (1) the dynamic range of feature samples is adjusted by the encoder depending on the compression rate, as evidenced by the zero bitplanes at lower bpp’s; (2) some feature maps are more important than the others in the rate-distortion sense, as evidenced by the uneven bit distribution across feature maps; and (3) the bit allocation is spatially varying, as indicated by the uneven bit distribution across different regions. These together produce a net effect similar in spirit to the importance map mechanism [1].
5 Conclusion
This paper introduces a learned image compression system with soft-bit-based rate-distortion optimization. The soft bit representation allows the rate estimation to be tightly coupled with entropy coding, giving an accurate rate estimate. We also show that learning-based compression methods can leverage well-designed coding tools from modern image codecs for a more cost-effective solution.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Li, W. Zuo, S. Gu, D. Zhao, and D. Zhang, “Learning convolutional networks for content-weighted image compression,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , 2018, pp. 3214–3223.
- 2[2] O. Rippel and L. Bourdev, “Real-time adaptive image compression,” in International Conference on Machine Learning , 2017, pp. 2922–2930.
- 3[3] F. Mentzer, E. Agustsson, M. Tschannen, R. Timofte, and L. Van Gool, “Conditional probability models for deep image compression,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2018, vol. 1, p. 3.
- 4[4] D. Minnen, J. Ballé, and G. D. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,” in Advances in Neural Information Processing Systems , 2018, pp. 10794–10803.
- 5[5] E. Agustsson, F. Mentzer, M. Tschannen, L. Cavigelli, R. Timofte, L. Benini, and L.V. Gool, “Soft-to-hard vector quantization for end-to-end learning compressible representations,” in Advances in Neural Information Processing Systems , 2017, pp. 1141–1151.
- 6[6] J. Ballé, V. Laparra, and E. P Simoncelli, “End-to-end optimized image compression,” ar Xiv preprint ar Xiv:1611.01704 , 2016.
- 7[7] J. Ballé, D. Minnen, S. Singh, S. J. Hwang, and N. Johnston, “Variational image compression with a scale hyperprior,” ar Xiv preprint ar Xiv:1802.01436 , 2018.
- 8[8] L. Theis, W. Shi, A. Cunningham, and F. Huszár, “Lossy image compression with compressive autoencoders,” in International Conference on Learning Representations , 2017.