On the Convergence Rates of Learning-based Signature Generation Schemes to Contain Self-propagating Malware
Saeed Valizadeh, Marten van Dijk

TL;DR
This paper models the interaction between malware propagation and defense mechanisms that learn and generate signatures over time, demonstrating how learning rates impact containment effectiveness.
Contribution
It introduces a new propagation model incorporating learning-based signature generation and evaluates its effectiveness through simulation and analysis.
Findings
Higher learning rates improve malware containment.
Signature-based defenses can significantly slow down malware spread.
Simulation results confirm the importance of timely learning in defense strategies.
Abstract
In this paper, we investigate the importance of a defense system's learning rates to fight against the self-propagating class of malware such as worms and bots. To this end, we introduce a new propagation model based on the interactions between an adversary (and its agents) who wishes to construct a zombie army of a specific size, and a defender taking advantage of standard security tools and technologies such as honeypots (HPs) and intrusion detection and prevention systems (IDPSes) in the network environment. As time goes on, the defender can incrementally learn from the collected/observed attack samples (e.g., malware payloads), and therefore being able to generate attack signatures. The generated signatures then are used for filtering next attack traffic and thus containing the attacker's progress in its malware propagation mission. Using simulation and numerical analysis, we…
Click any figure to enlarge with its caption.
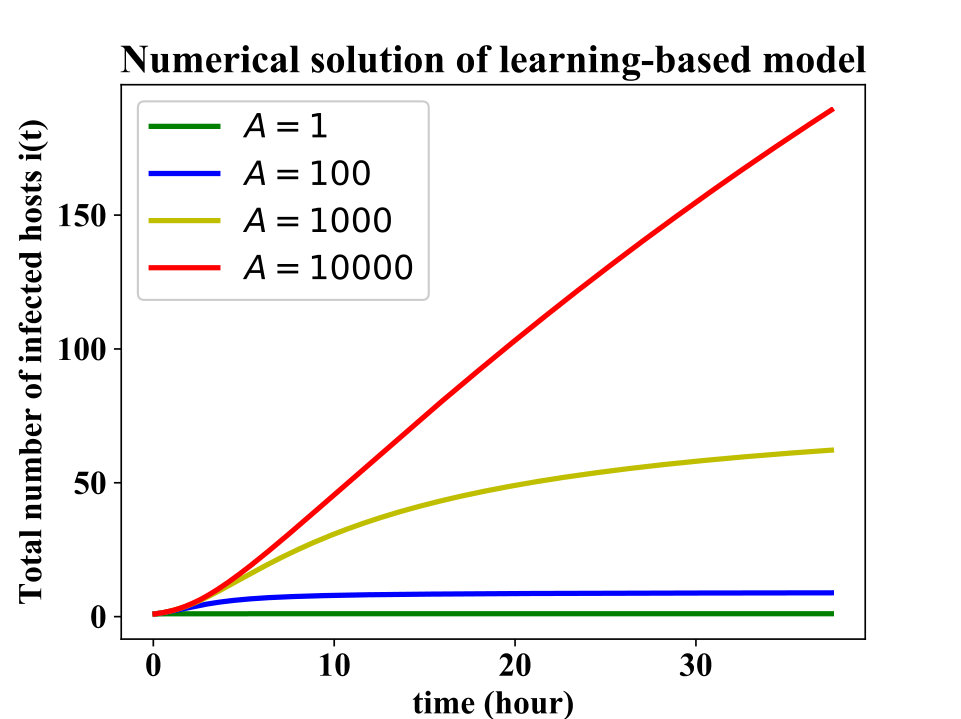 Figure 1
Figure 1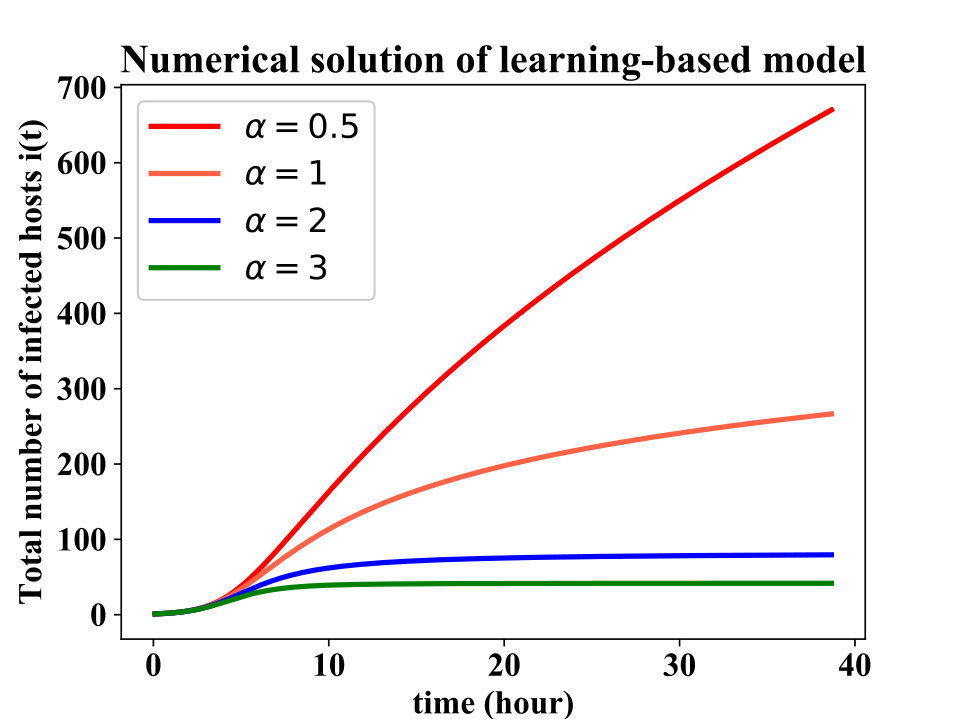 Figure 2
Figure 2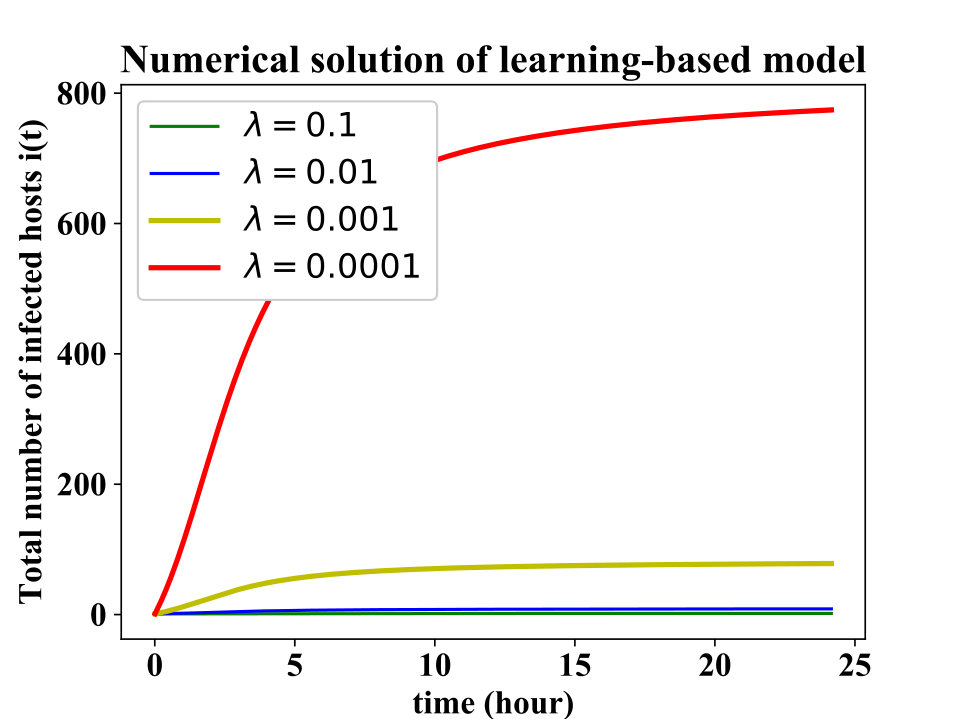 Figure 3
Figure 3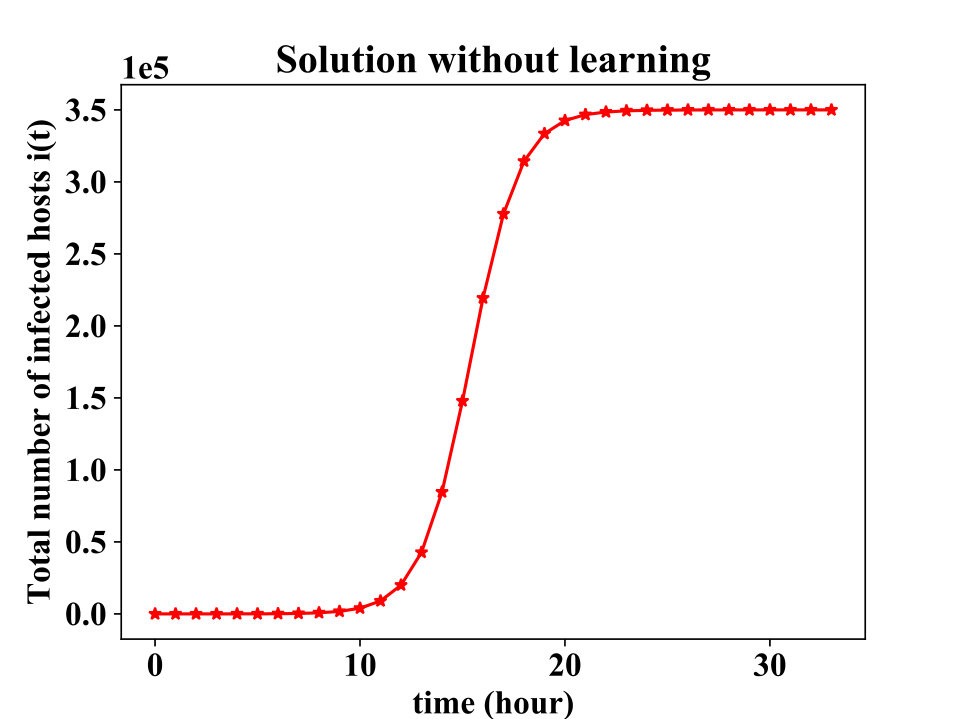 Figure 4
Figure 4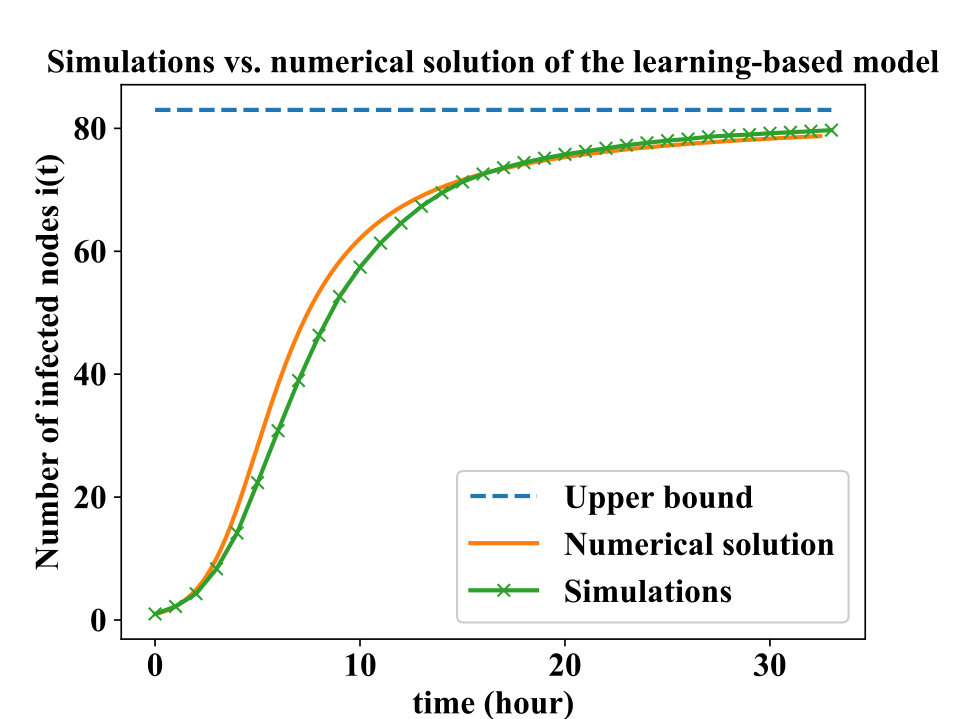 Figure 5
Figure 5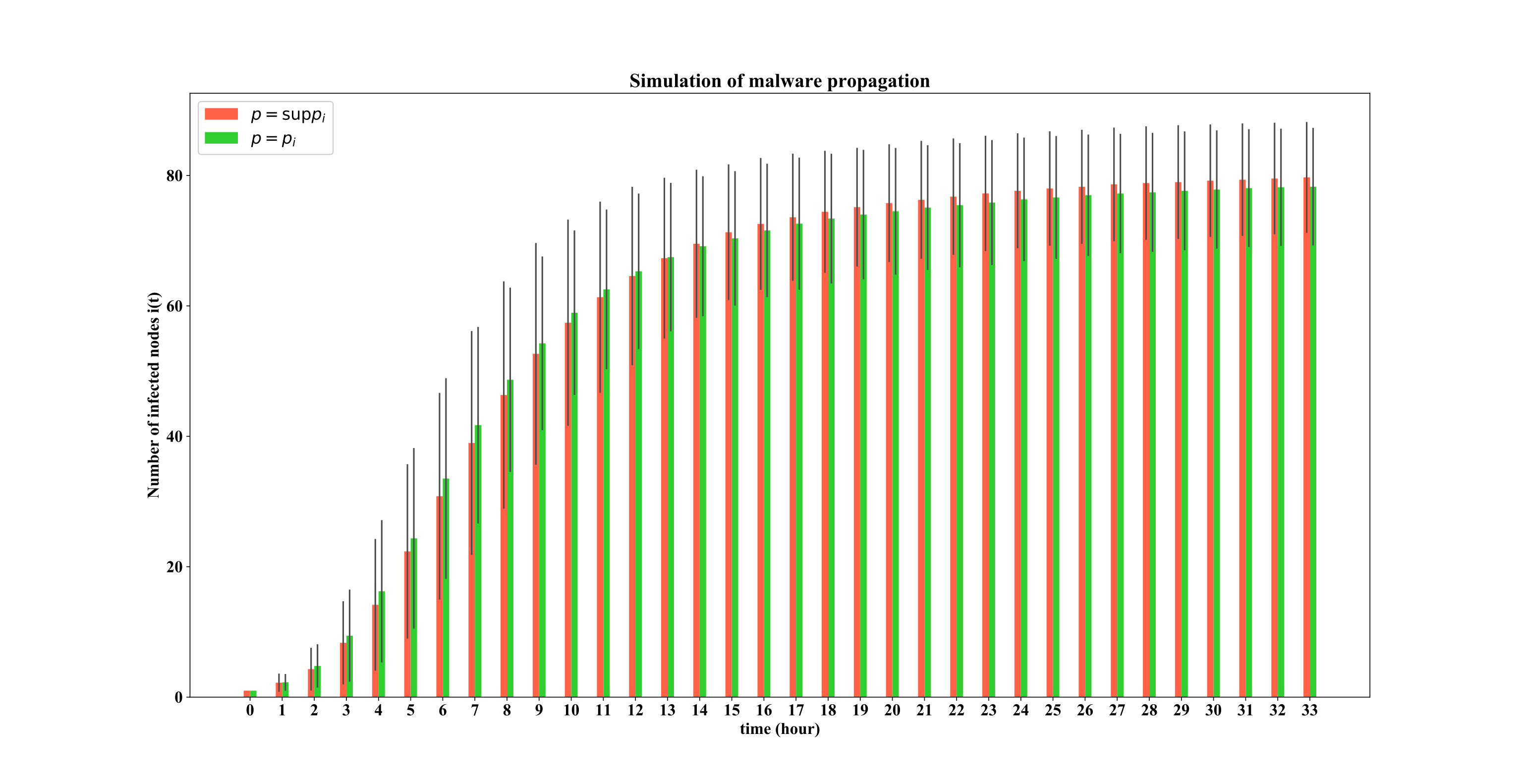 Figure 6
Figure 6| Notation | Explanation |
|---|---|
| Total number of nodes in the address space | |
| Total number of vulnerable nodes (i.e., susceptible population) | |
| Average scanning rate of an infected machine | |
| Total number of infected nodes at time | |
| Defender’s filtering probability based on its current knowledge of malware | |
| Probability of marking an incoming malicious traffic as suspicious on classifier level | |
| Total number of attack samples collected at time | |
| Average rate of attack sample collection by the defense system | |
| Amplification factor in learning | |
| Deceleration factor in learning |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsNetwork Security and Intrusion Detection · Advanced Malware Detection Techniques · Spam and Phishing Detection
On the Convergence Rates of Learning-based Signature
Generation Schemes to Contain Self-propagating Malware
††thanks: This work was funded by NSF grant CNS-1413996 “MACS: A Modular Approach to Cloud Security.”
Saeed Valizadeh
Dept. Computer Science and Engineering
*University of Connecticut
*Storrs, CT, USA
Marten van Dijk
Dept. Electrical and Computer Engineering
*University of Connecticut
*Storrs, CT, USA
Abstract
In this paper, we investigate the importance of a defense system’s learning rates to fight against the self-propagating class of malware such as worms and bots. To this end, we introduce a new propagation model based on the interactions between an adversary (and its agents) who wishes to construct a zombie army of a specific size, and a defender taking advantage of standard security tools and technologies such as honeypots (HPs) and intrusion detection and prevention systems (IDPSes) in the network environment. As time goes on, the defender can incrementally learn from the collected/observed attack samples (e.g., malware payloads), and therefore being able to generate attack signatures. The generated signatures then are used for filtering next attack traffic and thus containing the attacker’s progress in its malware propagation mission. Using simulation and numerical analysis, we evaluate the efficacy of signature generation algorithms and in general any learning-based scheme in bringing an adversary’s maneuvering in the environment to a halt as an adversarial containment strategy.
Index Terms:
Botnet, Malware propagation modeling, Self-replicating code, Worms, Intrusion detection and prevention system, Honeypots, Security games
I Introduction
With the rise of advanced and novel malware (e.g., Stuxnet worm [1], and WannaCry ransomware cryptoworm [2]) and the expanding population of Internet residents, especially the explosion of connected Internet of Things (IoT) devices, new methods, and research for understanding malware behaviors and jousting with sophisticated botnets seem to be crucial. Of specific interest to us are two types of malware, worms [3], and autonomous bots [4], mainly due to their wide-ranging audience, and self-propagating characteristics. These types of malware execute a “seek-and-infect” mission strategy. For instance, a scanning worm conventionally infects a target by utilizing vulnerability exploitation, and it automatically probes the environment to independently propagate itself (or modified copies of itself) from the infected machine to other vulnerable hosts in a network. Consequently, a straightforward way of assembling an army of infected hosts is spreading the malicious code in the form of a scanning worm. This zombie army which is also known as a botnet is indeed a collection of compromised machines distributed over a network (usually the Internet) and controlled by its originator (known as a botmaster) through a command and control (C&C) structure [5]. Afterward, these infiltrated workstations (bots) can be managed for different malicious purposes including but not limited to ransom campaigns, massive spam-marketing, large-scale information harvesting and processing, click fraud, pay-per installation, and, distributed denial-of-service (DDoS) attacks.
The never-ending battle between adversaries and system defenders drives both parties to improve their methods and technologies to enhance their chances of prosperity. On the one hand, attackers and network penetrators come up with new attack methods and evasion techniques to bypass (or even deny) defensive systems in any possible manner. Code obfuscation, session splicing, fragmentation attacks, string matching and DDoS attacks [6] are among the most common techniques used by the adversaries to decrease the attack detection probability or to increase the chances of attack prosperity. An armored malware (e.g., a metamorphic or polymorphic worm) buys itself more propagation time by being hard to identify and disassemble. On the other hand, a large number of studies on malware detection/prevention techniques, IDPSes, and HP technologies have been carried out to present more effective methods and designs to reach better accuracy and performance [7, 8, 9]. For instance, fast and automatic signature generation schemes are introduced to fight against even the mightiest type of malware [10, 11, 12, 13, 14, 15, 16]. Some claim that they can generate high-quality signatures (with negligible false alarm rates) based on only a few malware samples111E.g., see Hamsa [14] which only requires 100-500 malware samples in the suspicious flow pool to reach a %5 false negative rate, even for a previously unknown worm usually captured via honeypots or a heuristic flow classifier.
Although there exist various number of research for worm-like malware propagation modeling, in addition to proposals for containment strategies such as content-based filtering based on automatic and distributed signature generation of the malware, the question unanswered here is how and why does the malware spread, especially the kinds targeting a broad audience, if it is the case that we can generate high quality and reliable signatures, even for an armored malware?
Our Approach. To answer such questions, the effectiveness of content-based filtering strategies222As one of the most effective and feasible solutions to tackle the spreading of worm-like malware based on automatic signature generation schemes must be studied. Hence, in this paper, instead of presenting yet another malware detection/prevention methodology, we revisit the spread of malware phenomenon, especially the self-propagating ones such as worms and bots, from a new perspective. We introduce a new model for capturing the interactions of an adversary and its agents with the defensive system during the early phases of a zombie army construction. Unlike a malware propagator who usually follows a passive attack strategy for malware distribution to a broad audience, meaning that the attack technology usually remains the same after unleashing the first few samples of the malware, the defender can incrementally learn regarding the attack technology (specifically, from observed malware payloads). As time elapses, and the defender captures more attack data, it can reach better detection rates and accuracy. This learning rate indeed reflects into higher quality malware signatures which can be used for online malicious traffic filtering and hence malware containment purposes.
Contributions & Results. The main contributions of our work can be summarized as follows:
- •
Motivated by the advances in networking infrastructure and technologies such as the introduction of software-defined networking (SDN), and also the widespread embrace of automated machine learning (AutoML) techniques in different realms of networking and security fields, we introduce a novel malware propagation model called “learning-based model” suitable for today’s technologies and more advanced malware.
- •
The previous outdated models are mainly focused on the attacker’s strategies (specifically target discovery and scanning rates [17, 18, 19]), or in best cases, an ill-defined cleaning of the infection or patching processes [20, 21, 22]. However, we show how the increased knowledge of the defender can be taken into consideration by modeling the learning rate of the defense system as a function (which is the probability of detecting and filtering a next malicious payload) where represents the number of malicious payloads for a specific exploit so far collected.
- •
The model leads to the development of an automatic self-replicating malware containment strategy that prevents the spread of the malware beyond its early stages of propagation.
- •
We provide precise conditions on the convergence rates of a learning-based signature generation algorithm that determines whether the malware spread will ultimately settle or not.
- •
We derive tight upper and lower bounds on the total number of hosts the malware propagator can infect.
- •
The model is general enough and enables us to evaluate the effectiveness of learning-based signature generation schemes and containment strategies.
- •
We study learning functions of the form in which is considered to slow down the learning process, and is the amplification factor in the learning. This enables us to capture characteristics of both yesteryears malware (e.g., a monomorphic worm) and also today’s more advanced ones such as polymorphic malware.
- •
Numerical analysis and simulation results show that regardless of attacker’s scanning rates, with a proper learning function that converges fast enough to , the propagation will be contained and only a negligible number of susceptible population will be infected.
Paper Organization. The rest of this paper is organized as follows. Section II briefly reviews existing worm-like malware’s propagation models in addition to automatic signature generation schemes and content-based filtering of such malware. We present a new learning-based propagation model in section III followed by the corresponding numerical analysis and simulation results of this model for various learning functions in section IV, and V. We finally conclude the paper and discuss future works in section VI.
II Background and Related Work
The three potential solutions to mitigate a self-replicating code’s rampancy are prevention, treatment, and containment strategies. The prevention and treatment schemes can be summarized as following secure software/application development procedures in hopes of having vulnerability-free software, or patching/updating vulnerable systems as soon as vulnerabilities are discovered. Unlike the containment techniques, such conducts are usually vital for pre/post incident time and not during the period of an incident. In this section, we first review content-based filtering and automatic signature generation schemes as the most effective containment strategy [23] to hinder the spread of a malware. Moreover, we study some of the most relevant propagation models existing in the literature before presenting our model.
II-A Content-based filtering and Automatic Signature Generation Schemes
Human interventions and attack response time must be minimized in order to be able to prevent widespread infections. To this end, automatic, distributed and real-time detection and containment strategies, even for the mightiest type of worm, i.e., a polymorphic one, are introduced in the literature. Such signature-based detection and prevention techniques are of particular interest of this work as “an ounce of prevention is worth a pound of cure” meaning that such containment strategies can be very efficient for thwarting the spread of malware, especially during the early phases of a botnet construction and worm propagation, only if a high-quality signature can be generated (automatically). Such signatures can be created based on various attributes (e.g., length of the fields or invariant substrings of the byte sequences) of a class of malware, and later these signatures will be used for content-based malicious traffic filtering (even for extreme cases such as previously unknown malware or an armored one, e.g., a polymorphic worm). While designing a new automatic signature generation scheme is not the objective of this manuscript, here we review the most notable works in this area in order to better understand such schemes especially their architecture so that we can build a realistic propagation model based on a general learning algorithm (on which the signature generator is built upon) which we explain in later sections.
Autograph [10] is one of the first proposals for automatic (and optionally distributed) signature generation for a polymorphic worm, utilizing a naive portscan-based flow classifier (for TCP worms) to lessen the volume of traffic on which it performs a content-prevalence analysis. The flow classification enables Autograph to construct a suspicious flow pool on which it executes TCP flow reassembly for the payloads and outputs the most frequently occurring byte sequences across the flows as signatures. EarlyBird [13] uses a similar approach as Autograph in generating signatures by taking advantage of Rabin fingerprints.
On the other hand, Polygraph [11] forms signatures that consist of multiple disjoint content substrings to address the inefficiency of single, contiguous string-based signature generation techniques (such as Honeycomb [12], EarlyBird, and Autograph). Its underlying assumption for signature generation is that for a real-world exploit to function correctly, various invariant substrings must often be present in all alternatives of a malware payload; and these substrings typically correspond to return addresses, protocol framing, and in some cases, defectively obfuscated code. Hamsa [14] is another fast content-based signature generation method which generates multiset tokens as signatures. In comparison with Polygraph, it can provide better attack resilience and noise tolerance (accuracy). PolyTree [15] can show how the worm variants evolve and make the signature refinement task upon a new worm sample arrival quick using an incremental signature tree construction. This is based on the observation that worm signatures are related and a tree structure can properly reflect their familial resemblance which enables organizing the extracted signatures from worm samples into a tree structure. Unlike the aforementioned proposals which generate exploit-specific signatures, the paper in [16] presented an automatic vulnerability-driven network-based length-based signature generator called LESG for zero-day polymorphic worms exploiting buffer overflow vulnerabilities based on the fact that specific protocol fields in such attacks are usually longer than those in a conventional protocol usage.
II-B * Propagation Modeling and Estimating a Botnet Size*
In malware propagation models, possible states concerning vulnerable population during a malware attack are susceptible (S), infectious (I), and recovered (R). According to a host’s state at different times, and based on the transition between such states, malware propagation models can be categorized into three classes: if a host can only have one of the susceptible or infectious states and not being able to be recovered after an infection, the model is called susceptible-infectious (SI). If the model considers a permanent revival for an infected machine, meaning that the host remains in an immune state after the recovery process, the model is called susceptible-infectious-recovered (SIR) and finally if there is the chance of being infected again after a recovery the model is called susceptible-infectious-susceptible (SIS).
The classical simple epidemic model which is an SI modeling is the most commonly used model in the literature and can be simply described by the following differential equation in which denotes the total number of vulnerable nodes to the epidemic (i.e., the susceptible population), and at each time step, the so far infectious hosts propagate the epidemic with a constant rate .
[TABLE]
An extension to the classical simple epidemic model is the Kermack-McKendrick model (also known as the classical general epidemic model [24]) which is one of the mostly used SIR models in the literature. In this modeling, the effects of a removal process in the infectious hosts population is taken into consideration. Consider as the number of removed hosts from previously infected hosts, and as the constant rate of removal, hence, the Kermack-McKendrick model can be expressed by:
[TABLE]
where .
Another proposal based on Kermack-McKendrick model is [22] in which it provides a diurnal model for different time zones for botnet propagation modeling by introducing a correction factor (“the diurnal shaping function”) in the total number of online (available) hosts based on the time region. Therefore the diurnal worm propagation model can be represented by:
[TABLE]
The two-factor model [20] is as an extension to Kermack-McKendrick’s model which enhances it in two manners. First, it separates the removal process into two parts, one for the elimination of infectious hosts (due to cleaning) and the other for purging the susceptible population (due to patching and system updates). Second, it considers a time-varying infection rate to take worm traffic’s impact on the network infrastructure into consideration (e.g., congestion in the network).
[TABLE]
where , and denotes the number of removed hosts from the susceptible population.
Analytical active worm propagation model (AAWP) which is a similar approach in the discrete time setting is presented in [21].
Stochastic modeling of active worms is another line of research in this area. Sellke et al. [18] model the propagation of the malware through a branching process, i.e., each infected machine in one generation will independently produce some random number of infected machines in next-generation according to a fixed probability distribution. The model can determine the extinction condition of the malware and provide an upper bound on the total number of infected hosts. Rohloff et al. [19] used a simple stochastic density-dependent Markov jump process to model worm propagation. Each state in the chain represents the number of so far infected machines , in addition to the total number of remaining susceptible population . The model does not consider any removal/cleaning actions meaning that the total number of vulnerable hosts is always constant at each transition of the Markov chain. The time it takes for this chain to reach its absorbing state is calculated. For more information regarding malware propagation models we refer to the survey presented in [25].
The models mentioned above mainly focus on the treatment processes –such as patching a susceptible node or cleaning an infected machine– for vulnerable population and infection rate reduction purposes. In practice, these treatment strategies, however, are not suitable for the expeditious spread of the malware and therefore short-term reliefs for an outbreak. Moore et al. [23] showed that a content-based filtering strategy is the most vital containment strategy to limit the spread of the malware via isolating it from the susceptible population. Therefore, in this paper, we mainly focus on the containment solutions made possible based on a defense system’s learning engine which makes the propagation of the epidemic more difficult. Valizadeh and van Dijk [26] originated the notion of learning in Markov-based cyber-attack modeling and described a general “game of consequences” in which the attacker’s chances of making a progressive move in the game depends on its previous actions. This notion of learning has been previously used in learning-based signature generation schemes for the polymorphic worm but never been applied to propagation models. The advances in network technologies (especially SDN) and automated machine learning (AutoML) motivate us to take advantage of such learning mechanisms and introduce a new learning-based propagation modeling suitable for today’s and future’s infrastructure and technology.
Moreover, the most critical shortcoming of the traditional models is that they suffer from not taking both parties’ capabilities, actions and strategies into consideration for the model development. Therefore, these static models are incapable of representing the dynamic nature of today’s network attack-defense scenarios. Our modeling differs from the previously mentioned models in the sense that as the time elapses, we can take enhanced attack/defense strategies into consideration by recognizing the players’ interactions as a learning process, especially from the defense systems’ perspective. This presented framework enables us to explicitly study how the learning rates of a defense system can affect future interplays of the players and their probability of success in the malware propagation game. Moreover, instead of considering an ill-defined removal/cleaning rate, we can describe where the containment process could come from by considering an incremental learning mechanism for the defender.
III A Learning-based Propagation Model
In this section, we study how a content-based filtering strategy–which utilizes a general learning-based signature generation scheme– can play a role in containing the propagation of a self-replicating code. More specifically, regardless of the limits on the accuracy of any learning-based automatic signature generation algorithm, we study the efficacy of such schemes in ceasing the propagation of the malware under the assumption of their constructability.
To understand the effect of a defense system’s learning engine on the containment of the malware, we model the defender’s learning engine (i.e., a signature generator algorithm) as a function , which takes so far collected/observed suspicious traffic (i.e., attack payloads) and outputs a signature for that class of malware. This generated signature is then used for online content-based traffic filtering in which each incoming malware traffic can be filtered with probability (true positive) or with the system fails in detecting a malicious packet (or it falsely labels it as benign, i.e., false negative). Later, we briefly discuss the occurrence of false positives in the model. Moreover, we are interested in the infection modeling during the Window of Vulnerability (WoV) time as the number of vulnerable systems is not yet shrunken to insignificance and the attacker’s exploit is useful in this period. This means that we do not take patching and cleaning of the susceptible and infected population into consideration.
III-A Idealized Deployment, Network and Learning Model
We consider a logically centralized defense system (e.g., an IDPS) employed in the network, that is the containment system is universally deployed within the address space, and the learning engine works with all the observed/collected information regarding the worm infections (i.e., samples) and then distribute the generated signatures to defense system agents (e.g., edge routers, inline network-based intrusion detection systems (NIDS)). Similar to [27], we also consider that the learning algorithm will update its internal state after observing each new incoming batch of data, and these updates will be made over all of the so far accumulated samples. In this regard, with these updates, the learning engine might be able to find a high-quality signature over a more extended period, while without such updates, no learning would be possible. Moreover, we assume that the signature generation task on the accumulated samples is performed with no delay. Also, the signature distribution to the defense agents will be done immediately.
Automatic signature generation schemes (e.g., see [10, 11, 14, 15]) commonly take advantage of a heuristic flow classifier for constructing a suspicious flow pool in order to reduce the volume of traffic on which further analysis must be performed. Therefore, we also consider that a copy of traffic is given to a flow classifier for suspicious flow pool construction. For simplicity and generality, however, we model the defense system’s classifier and traffic analysis task as a probabilistic sampling process [28] in which each malicious packet can be sampled with probability . Note that reflects the classifier’s accuracy in which it is the probability that an incoming packet will be marked as suspicious traffic conditioned on the fact that it is indeed malicious. The captured payloads from the classifier are given to the signature generator engine for signature generation. The generated signatures then are used for the inline packet filtering by the defense system. This allows us not to be concerned about the transmission protocol (TCP/UDP), and in general more stealthier propagation schemes (e.g., second channel delivery) which are usually more robust against anomaly-based detection systems, as they will not trigger any events during the propagation333Note that this is a practical assumption as the most common form of a self-replicating code found in the wild is a self-carried (malware payload is transferred in a packet by itself) malware which, regardless of the transmission scheme (TCP or UDP) utilizes a blind scan strategy as its target discovery (see Table 1 in [29])..
One very common problem among any IDPS is the inability to provide absolutely complete and accurate detection rates. This incompleteness and inaccuracy usually lead to the occurrence of a false detection of a malicious activity as benign or vice versa. Due to the existence of false alarms (especially false positives), it is a common practice not to utilize black/whitelisting prevention policies for the IDPS. This means that we do not care about stealthy attacks in which the attacker can conceal its real identity and disguise the source of attack traffic to decrease the chance of being located through common known practices such as IP address spoofing, use of proxies, etc. However, false positives (labeling a benign packet/activity as suspicious on the classifier level or malicious for inline filtering) play an essential role in the accuracy of the generated signatures and therefore the normal operations of the network in which the defense system is implemented. Note that in our model, false positives can occur on two levels. First, the classifier may mark a benign packet as suspicious which eventually could lead to inaccurate signatures or taking a long time to generate true signatures. To address this problem, we consider a deceleration factor in our modeling to take the impact of such false positives in delaying the signature generation into consideration. Second, since the generated signatures are used for online filtering of incoming packets, a false positive at this level may drop a benign packet at the network level. However, notice that such incidents do not impact the accuracy of our model, i.e., the total number of infected nodes at any instance of time will not be affected.
III-B A Learning-based Malware Propagation and Containment Model
Our goal is to show that a sufficiently increasing learning rate will stop malware from propagating and only a few number of susceptible nodes will be infected. Consider the SI modeling represented in (1), as follows
[TABLE]
where represents the number of infected nodes at time , is the size of address space, and is equal to the average scanning rate of an infected machine. Rather than modeling the above equation, let us assume that we already will be able to bound to a number so that
[TABLE]
would be a good approximation for some constant
[TABLE]
In fact this approximation gives the adversary an advantage since which makes the new differential equation (5) a best case scenario for the adversary.
We adapt (5) to include prevention of infection: If the defender gathers samples of malicious payloads at a certain rate , then the defender collects samples at time . Notice that unlike the previous models in which the higher the scanning rate of the malware, the sooner the whole population become infected, in our modeling, however, a high scanning rate will also potentially provide more samples to the defense system which can lead to constructing a valid signature sooner and therefore holding the attack’s progress. If we denote the number of samples collected up to time by , and defining , then satisfies
[TABLE]
The defender’s knowledge of how to recognize and prevent malicious payloads increases as a result of observing and collecting malicious traffic. We assume captures this learning – with probability , where is the number of samples collected so far, the adversarial payload is prevented from doing any harm. With probability , the payload may proceed and this leads to the following adjustment of (5):
[TABLE]
Equation (7) is the learning-based model and this is what we study; It shows that in addition to hitting a vulnerable target, an infected machine’s endeavors to infecting a new device by submitting an ominous packet to the target must not get filtered by the defense system.
We will analyze monotonically increasing learning rates of the form
[TABLE]
for some exponent and constant . The exponent reflects how collected samples amplify the learning rate while constant is included to slow down the learning process, i.e., delayed learning. In this fashion, the learning function can be adjusted to take both yesteryears’ worms and today’s more advanced malware’s characteristics into consideration in the model. For instance, for a naive, monomorphic malware, which the signature generation is more straightforward and can be done based on only a few malware samples, a small slow-down factor and a large enough amplification factor can be used in the model to capture the swiftness of signature generation task. On the other hand, for a more potent malware, e.g., polymorphic/metamorphic worms, a large slow-down factor and small amplification factor can depict the hardness of signature generation task when dealing with such malware.
Substituting into (7) yields
[TABLE]
Now notice that (6) expresses as where is the first derivative of . By denoting the second derivative of and substituting these into (8) gives the final differential equation which we wish to solve:
[TABLE]
We are interested in bounding . Initially,
[TABLE]
meaning that there is a single infected node within the network at time zero (patient zero) and the defender’s knowledge of the attack is zero at the beginning (zero-day vulnerability/exploit).
We now present the following theorem (for the analysis and the proof see the appendix) which provides lower and upper bounds on the total number of nodes the attacker can infect.
Theorem 1
For , . For , . For ,
[TABLE]
Corollary 1
In order to contain the malware from propagation, the convergence rate of a learning-based signature generation scheme must have an amplification factor .
Corollary 2
For , we have:
- •
the number of nodes that will be infected is proportional to the deceleration factor .
- •
substituting , and , gives meaning that is independent from the malware’s scanning rate .
III-C Model Extensions and Limitations
In this section, we briefly discuss some possible scenarios which require further investigations or can be modeled through the same methodology presented in this work. Where possible, we provide general guidance for the curious reader on how such cases can be analyzed with a few adjustments to the model.
An adaptive adversary with multiple exploits: After observing no progress in the malware propagation mission (i.e., being contained with some limited number of agents), an adaptive adversary may decide to improve and update its attack technology. For instance, a bot herder can update the malware binary on its bots for different purposes. This includes enhancing and extending attack vectors and technologies by adding new functionalities or evasion techniques, migrating to different C&C servers, and considering recent and revised exploits. Our framework, can also capture such strong and possibly well-funded adversary. From the attacker’s perspective, each new exploit (or in other words an enhanced attack technology) should be associated with some probability (as each exploit might correspond to a different set of vulnerable nodes within the network). From the defender’s perspective, the signature generator, if it cannot generate a single universal signature which matches all the malware’s instances, must be able to generate multiple signatures each of which matches some subset of flows in the suspicious flow pool. Therefore, multiple detection rate functions and learning rates should be considered for each class of malware.
A deceptive attacker capable of misleading the learning engine: There exist various attacks against signature generation schemes especially those with learning based on pattern extraction (see [30, 31, 32, 33]). Noise injection attacks in which the attacker can systematically inject noise (or deliberately crafted attack samples) in the training pool to mislead the defender’s learning engine are amongst the most notable challenges for signature generation schemes in adversarial settings. In developing the learning-based model, we decided not to consider a deceptive adversary since in practice, a malware propagator usually follows a passive attack strategy for the propagation of the malware with a broad audience (e.g., worms/bots), meaning that the attack technology usually remains the same after unleashing the first few samples of the malware. That is the malware propagation game is not a dynamic interaction between the attacker and the defender (especially from the attacker’s perspective) and although such attacks are theoretically possible, they have not yet been observed in the wild. In general, when dealing with a delusive adversary, the learning rate of the defense system may not always be positive, and the learning engine’s false positive rates should be taken into consideration in the model. We leave this problem for future studies and refer the reader to [27] which studies the signature generation in adversarial settings and proves lower bounds on the number of mistakes any pattern extraction learning algorithm can take under common assumptions.
Host-level detection and prevention: When the malware resides on a machine, it surely exhibits abnormal and erratic behavior (both externals such as unusual port usage [34] and internals such as irregular system call sequences [35]) on that machine. Therefore, one possibility is taking the knowledge gained at the host-level into consideration for the purpose of attack/malware signature generation by means of monitoring events on endpoint devices through a HIDS. Such signatures can be generated based on the malware residual activity on the target machine or the specific exploit/vulnerability used by the adversary during the infection. Hence, a cumulative function can be considered for the host-level signatures which depends on the total number of so far infected machines. Therefore, one can easily fine-tune the model to capture such defensive scenarios by multiplying the adversary’s probability of success at each time step with meaning that not only it must hit the right target (i.e., a vulnerable host), the malware should not be neutralized too at the host level. The function gets updated once a new node becomes infected. There exist proposals for combined detection methods, i.e., taking both host-level and network-level information into consideration to fight against a worm/bot malware. For example, [36] introduced a C&C protocol-independent detection framework based on the combination of information gained from both host and network level bot activities. We decided not to count such strategies, since considering a universal host-level defense system installed on all the network devices is an unrealistic assumption in almost any practical situation.
IV Numerical Analysis of the Learning-based Model
The learning-based model is a general malware propagation model with several parameters. Notice that when the learning function is set to zero, i.e., , and , we have exactly the classical epidemic model. Although the effects of cleaning the infection and patching the susceptible population can be easily included in the model, we decided to ignore such conducts since they have been well studied in the literature. Also, we are interested in evaluating the impacts of learning even in the worst case scenarios for the defender (i.e., giving a leg up to the attacker by considering ).
For the purpose of illustration, we consider a hypothetical polymorphic worm, propagating in an address space of size (the entire IPv4 address space), while the size of susceptible hosts’ population is . We assume a blind scan strategy for which each infected host performs a uniform scanning in the address space with an average rate of scans per hour444These are the actual infamous codeRed1v2’s epidemic parameters [19]. We use these values only for the purpose of illustrations since the malware is well studied and the parameters are already known.. Moreover, we consider , and , meaning that initially there exists one infected machine at time zero, and the defender has no knowledge regarding the attack (signature).
Although we proved upper and lower bounds on the total number of infected nodes (see Theorem 1), for the general learning-based model, we cannot get closed-form solutions. Instead, we present numerical solutions of the differential equation by using Python scipy.integrate package.
Fig. 1 depicts the solution of the learning-based model when the learning parameter is set to zero. As mentioned earlier, without a learning process the model is equivalent to the classical epidemic model, and the saturation in the curve depicts how the whole susceptible population will be infected as time elapses.
We now study the impact of different parameters on the total number of infected nodes in the learning-based model.
Fig. 2 depicts how the amplification factor plays a role in the modeling. The and growth in the population of infected hosts, for , and respectively, can be seen from this plot which is consistent with Theorem 1. In addition, notice that based on the theorem, for , the upper bound on the total number of infected nodes is , which gives , and for and respectively. The value of for large enough s based on the numerical solution of the differential equation for these two cases is and which is very close to the upper bound.
In order to study the impact of other parameters (i.e., , and ) in the learning-based model, we numerically solved the differential equation for a constant to see how the other parameters play a role while the amplification factor is set to an acceptable value. Fig. 3 depicts how the deceleration factor impacts . In addition, the classifier’s accuracy’s impact on the malware containment is shown in Fig. 4. As it can be seen from this plot, the larger the , the sooner the attacker’s progress is contained in the environment.
V Simulation Results
In this section, we want to see how reasonable is the assumption of giving the adversary the advantage of in our analysis by simulating the malware propagation process. Algorithm 1 provides a high-level overview of malware’s self-propagation activity. The simulator’s inputs are (set of all nodes and susceptible nodes within the address space respectively), and an adversarial exploit , in addition to the filtering probability based on the so far collected samples and the corresponding generated signatures, and the defense system’s sampling rate . The termination rule is whether the attacker compromises all the susceptible population or the defender finds a true signature, that is . Note that the transmit method returns a tuple, i.e., if the transmitted packet by an infected machine is filtered by the defense system or is sampled at the flow classifier level. We simulate two different scenarios. In the first scenario, we give the attacker a leg-up by considering a constant (i.e., ; this requires removing line 18 in Algorithm 1, and updating the termination rule in line 19 to ). For the second scenario, we consider to be a function of so far infected nodes (i.e., ). For both cases, we consider and a learning function of the form as it satisfies the containment requirement (i.e., ). We again use the same propagation parameters we used in the numerical analysis section only for the purpose of illustration.
Fig. 5 shows the expected number of infected nodes among 100 simulation runs of the learning-based model. As it can be seen from this figure, the infected population are almost the same for both cases of , and meaning that is indeed a good approximation, and considering a constant in the model is a reasonable assumption. Notice that this behavior was expected since in the learning-based model as time elapses and , the chances of making progress for the malware propagator get smaller and smaller (causes the saturation observed in the plots). This means that the value of remains relatively small in comparison to and therefore can be bounded to a number . Fig. 6 on the other hand, compares the result of simulations with the numerical solution of the learning-based model. For both scenarios, the upper bound on the size of the infected population can be used as a tight estimate.
VI Concluding remarks and future directions
This presented work offers a fresh look at a 15-year old research area (worm epidemic modeling). Although the self-propagating class of malware may seem to be an old555The Morris worm was the first computer worm released on the Internet on Nov. 1988, almost three decades ago. type of a threat due to the decline in the “worm-like” common vulnerabilities exposures (CVEs) [2], the rise of self-propagating ransomware (e.g., the WannaCry cryptoworm) and the highly sophisticated malware such as Stuxnet worm attest that the network vector is one of the few attack vectors which is capable of passing the test of time. Taking advantage of the network vector and releasing the malware in a worm-like fashion, meaning that the malware is equipped with a self-propagating functionality, can provide the attackers a more potent malware which is capable of causing widespread damage. This means that the security community and professionals need to take the self-propagating class of malware more serious to first better understand such malware’s life cycle and then to be able to come up with feasible solutions to tackle this problem. To this end, we revisited the spread of malware phenomenon, especially worm and bot type malware, from an entirely new perspective. We have modeled the interactions of an adversary and its agents with a defensive system during the construction of a botnet as an incremental online learning process. By focusing on the learning rate of a defense system’s learning engine and signature generation algorithm, we presented a novel and general propagation model called the learning-based model suitable for today’s technology and infrastructure.
Unlike the existing outdated static modelings in this area, the learning-based model is a dynamic one which can capture the increased knowledge of the defender regarding the attack technology into consideration for bringing next adversarial actions into a halt. We studied monotonically increasing learning functions for which we showed how different system parameters play a role in the malware containment process. In particular, we show that a learning function with amplification factor allows the attacker to succeed in its zombie army construction mission. The deceleration factor in learning must remain small enough for the containment purposes meaning that the defender cannot wait for too long learning about a used exploit, and once the learning starts it must continue with an associated detection probability converging fast enough to . Using the learning-based model, we provided a precise bound on the convergence of a learning-based scheme that ensures that the worm propagation reaches minimal saturation in the number of infected hosts during the worm’s life cycle. We have shown that learning-based signature generation schemes can be very effective for malware propagation containment purposes only if their convergence rates satisfies our presented criteria. The presented security analysis recommends with a proof for in our framework, which were consistent with the numerical analysis and simulation results. The attacker needs to find just one exploit for which the defender is too slow to react or too slow in learning. Instead of focusing on higher scan rates, the attacker must invest in more stealthier and robust target discovery schemes and malware delivery techniques which would not raise suspicions, leading to smaller value s and therefore fewer attack samples will be provided to the defense system.
A possible direction for future work is to estimate the learning-based model’s parameters, especially the learning rate , based on the size of suspicious traffic pool (i.e., number of observed malicious payloads) given a “worst-case adversary”. Our framework lays the foundation for such work and allows to provide a worst-case probabilistic bound on the number of compromised nodes based on the estimated which in turn, offers guidance to the system defender in how to earmark its resources and use the model for damage assessment and prediction purposes.
We believe our study can provide network security researchers and architects valuable lessons and more robust understandings of both attack and defense technologies concerning malware with a broad audience. Besides, with the advent of software-defined networking (SDN) in which the entire network infrastructure can be controlled from a centralized software controller, and the embrace of AutoML in defense technologies, new generations of traditional cyber defense technologies (e.g., HPs, IDPSes, firewalls, etc.), which are more capable, scalable and secure, are already being introduced. This could be a new opportunity and a fresh start to fight against the botnet phenomenon or the spreading of the malware in general. For future work, we would like to evaluate the performance of common automatic signature generation schemes using real data from enterprise networks by porting the learning-based containment mechanism to edge and local routers, especially in a software-defined network environment.
Appendix A Proof of Theorem 1
In order to make the next derivations readable we introduce
[TABLE]
Differential equation (9) in terms of and after reordering terms reads
[TABLE]
We derive
[TABLE]
Substituting this expression into (10), dividing by , and multiplying with yields
[TABLE]
Assuming , then taking integrals on the left and right side gives the equation
[TABLE]
for some constant . For , we have and . Substituting this into the above equation solves
[TABLE]
Now we substitute into (11) and multiply both sides with :
[TABLE]
Equivalently, we have
[TABLE]
Taking integrals on the left and right side gives the expression
[TABLE]
for some constant . Substituting gives and . Plugging in (12) proves
[TABLE]
As an immediate consequence we can take the derivative (using the chain rule) with respect to on both sides. This shows that (this can also directly be concluded from (11))
[TABLE]
Notice that is increasing (since ) with . Therefore, if , then and
[TABLE]
Case I (): Substituting this into (14) yields for ,
[TABLE]
proving
[TABLE]
Case II (): As a second consequence of (14), we derive for ,
[TABLE]
Hence,
[TABLE]
Substituting this back into (15), and noticing that gives
[TABLE]
This proves that only a learning rate with amplification will prevent the malware from propagating to all vulnerable nodes.
Case III (): For completeness, if , then taking integrals that led to (11) for , now lead to
[TABLE]
with
[TABLE]
Notice that and we use the same argument as we did above for . We again have and substituting this back gives
[TABLE]
These lower bounds can be improved by recursively substituting lower bounds back into (15) and (16), respectively.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. Jin, S. Valizadeh, and M. van Dijk, “Snapshotter: Lightweight intrusion detection and prevention system for industrial control systems,” in 2018 IEEE Industrial Cyber-Physical Systems (ICPS) . IEEE, 2018, pp. 824–829.
- 2[2] Cisco, “Annual Cybersecurity Report,” 2018, [Accessed October-2018]. [Online]. Available: https://bit.ly/2ul 3d OM
- 3[3] N. Weaver, V. Paxson, S. Staniford, and R. Cunningham, “A taxonomy of computer worms,” in Proceedings of the 2003 ACM workshop on Rapid malcode . ACM, 2003, pp. 11–18.
- 4[4] Panda Security, “What is a botnet?” 2017, [Accessed May-2018]. [Online]. Available: https://bit.ly/2Sb 2WJA
- 5[5] M. Feily, A. Shahrestani, and S. Ramadass, “A survey of botnet and botnet detection,” in Emerging Security Information, Systems and Technologies, 2009. SECURWARE’09. Third International Conference on . IEEE, 2009, pp. 268–273.
- 6[6] J. A. Marpaung, M. Sain, and H.-J. Lee, “Survey on malware evasion techniques: State of the art and challenges,” in Advanced Communication Technology (ICACT), 2012 14th International Conference on . IEEE, 2012, pp. 744–749.
- 7[7] N. Idika and A. P. Mathur, “A survey of malware detection techniques,” Purdue University , vol. 48, 2007.
- 8[8] M. H. Bhuyan, D. K. Bhattacharyya, and J. K. Kalita, “Network anomaly detection: methods, systems and tools,” Ieee communications surveys & tutorials , vol. 16, no. 1, pp. 303–336, 2014.