TL;DR
This paper introduces harmonic networks using DCT filters in CNNs, demonstrating their effectiveness in limited training data scenarios and comparing favorably to wavelet-based scattering networks.
Contribution
It proposes a computationally efficient harmonic block with DCT filters for CNNs, enhancing performance with limited training samples.
Findings
Harmonic networks perform well with limited data.
DCT-based harmonic blocks compare favorably to wavelet scattering networks.
Efficient filter design reduces overfitting in CNNs.
Abstract
Convolutional neural networks (CNNs) are very popular nowadays for image processing. CNNs allow one to learn optimal filters in a (mostly) supervised machine learning context. However this typically requires abundant labelled training data to estimate the filter parameters. Alternative strategies have been deployed for reducing the number of parameters and / or filters to be learned and thus decrease overfitting. In the context of reverting to preset filters, we propose here a computationally efficient harmonic block that uses Discrete Cosine Transform (DCT) filters in CNNs. In this work we examine the performance of harmonic networks in limited training data scenario. We validate experimentally that its performance compares well against scattering networks that use wavelets as preset filters.
Click any figure to enlarge with its caption.
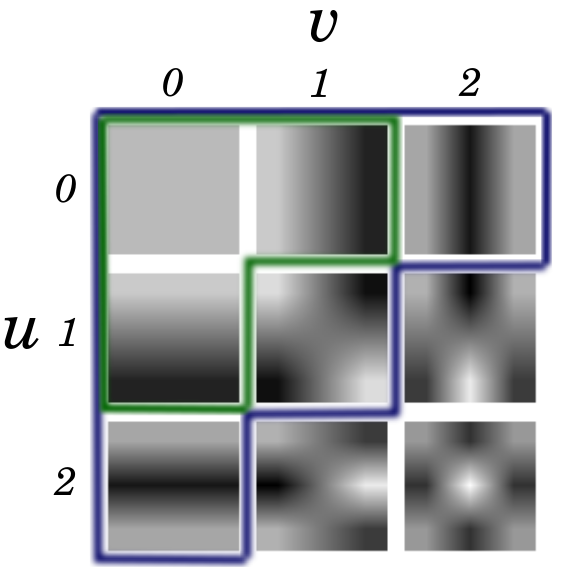 Figure 1
Figure 1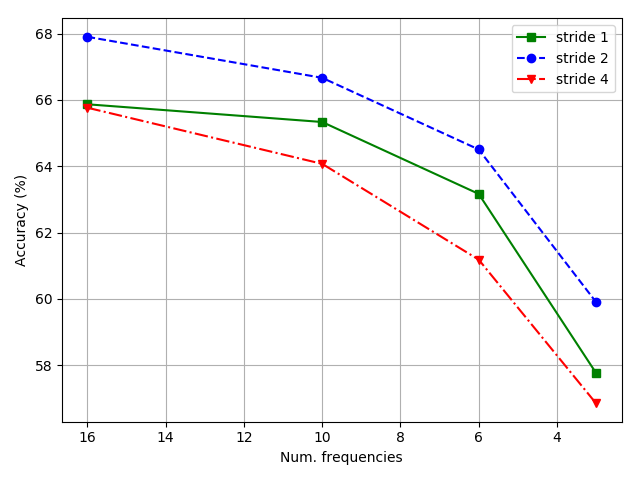 Figure 2
Figure 2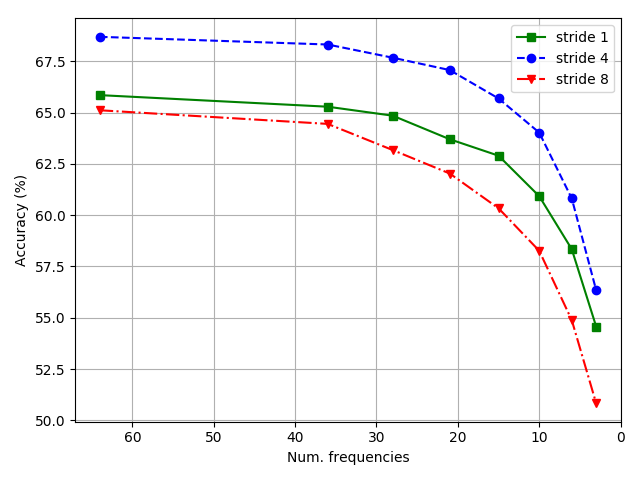 Figure 3
Figure 3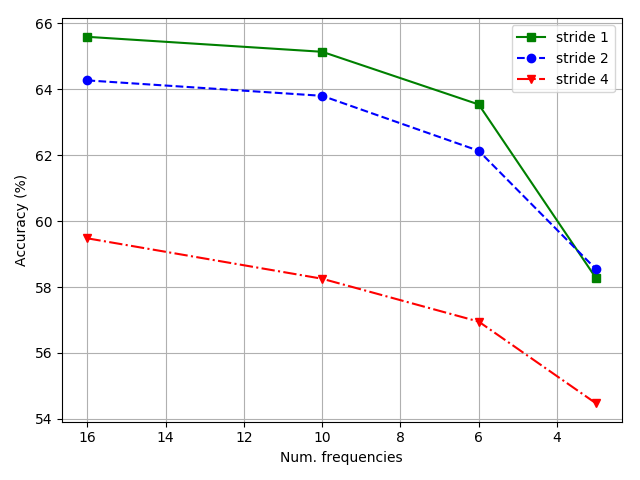 Figure 4
Figure 4| Training size | Scat. net. [2] | Conv. net. | Sep. conv. net. | Harm. net. |
|---|---|---|---|---|
| 300 | 4.7 | 3.9 | 4.67 | 3.71 |
| 1000 | 2.3 | 1.88 | 1.91 | 1.84 |
| 2000 | 1.3 | 1.39 | 1.35 | 1.21 |
| 5000 | 1.03 | 0.97 | 1.06 | 0.86 |
| 10000 | 0.88 | 0.7 | 0.76 | 0.65 |
| 20000 | 0.58 | 0.59 | 0.57 | 0.57 |
| 40000 | 0.53 | 0.48 | 0.47 | 0.45 |
| 60000 | 0.43 | 0.44 | 0.46 | 0.38 |
| Method | 100 | 500 | 1000 | Full |
|---|---|---|---|---|
| WRN 16-8 | 34.41.8 | 52.21.8 | 62.80.7 | 95.6 |
| Scat + WRN [3] | 38.91.2 | 54.70.6 | 62.01.1 | 93.1 |
| Harm WRN 16-8 | 37.71.9 | 58.21.4 | 67.00.4 | 95.6 |
| Harm WRN 16-8 | 37.92.4 | 58.40.9 | 67.20.5 | 95.6 |
| Harm WRN 16-8 | 37.21.7 | 57.01.0 | 65.90.8 | 95.3 |
| Method | 10-folds | all |
|---|---|---|
| WRN 16-8 | 73.50 0.87 | 87.29 0.21 |
| Scat + WRN [3] | 76.00 0.60 | 87.60 |
| Harm WRN 16-8 | 76.95 0.93 | 90.45 0.12 |
| Harm WRN 16-8 | 76.65 0.90 | 90.39 0.08 |
| Harm WRN 16-8 progressive | 77.19 1.02 | 90.28 0.20 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Harmonic Networks with Limited Training Samples
††thanks: This work is supported by the ADAPT Centre for Digital Content Technology funded under the Science Foundation Ireland Research Centres Programme grant 13/RC/2106 and co-funded under the European Regional Development Fund. The second author is also supported by the European Union’s Horizon 2020 research and innovation programme under the Marie Sklodowska-Curie grant agreement No.713567.
Matej Ulicny, Vladimir A. Krylov, Rozenn Dahyot
ADAPT Centre, School of Computer Science & Statistics, Trinity College Dublin, Dublin, Ireland
{ulinm, Vladimir.Krylov, Rozenn.Dahyot}@tcd.ie
Abstract
Convolutional neural networks (CNNs) are very popular nowadays for image processing. CNNs allow one to learn optimal filters in a (mostly) supervised machine learning context. However this typically requires abundant labelled training data to estimate the filter parameters. Alternative strategies have been deployed for reducing the number of parameters and / or filters to be learned and thus decrease overfitting. In the context of reverting to preset filters, we propose here a computationally efficient harmonic block that uses Discrete Cosine Transform (DCT) filters in CNNs. In this work we examine the performance of harmonic networks in limited training data scenario. We validate experimentally that its performance compares well against scattering networks that use wavelets as preset filters.
Index Terms:
Lapped Discrete Cosine Transform, harmonic network, convolutional filter, limited data
I Introduction
We have recently proposed a new form of neural network layer called harmonic block [1] that relies on using windowed cosine transform at several frequencies in lieu of learned filters. This harmonic block only involves learning weights for combining several frequency responses together in the frequency domain. Furthermore, uninformative frequencies can be dropped out to improve the computational complexity of the network without compromising performance, i.e. compression [1]. This paper extends further the proposed harmonic block by: 1) showing how it relates to the modified discrete cosine transform when considering overlap in computing convolution, 2) proposing an improved, computationally more efficient implementation, and 3) showing that the CNNs using the harmonic block outperform scattering network, based on the use of wavelet-based filters [2, 3] when training data is scarce. The PyTorch implementation of the harmonic block is provided at \urlhttps://github.com/matej-ulicny/harmonic-networks.
The rest of the paper is organised as follows. We first review the related literature (Sec. II) and present the harmonic block (Sec. III). We then report the experimental validation (Sec. IV) and conclusions of the study (Sec. V).
II Related work
II-A DCT & CNNs
Wang and Zhang [4] propose a double JPEG compression detection algorithm based on a convolutional neural network (CNN) to detect tampered area for image forensics. The 1-dimensional CNN is designed to classify histograms of discrete cosine transform (DCT) coefficients, which differ between single-compressed areas (tampered areas) and double-compressed areas (untampered areas) [4, 5, 6]. Alternatively, raw DCT (discrete cosine transform) coefficients from JPEG images has also been proposed as input of a 2-dimensional CNN [7]. Spectral image representations combined with neural networks have also been used for object recognition. For instance, truncation of DCT coefficients has been shown to speed up training of fully connected sparse autoencoders [8] and improve face recognition with linear discriminant analysis and radial basis function network [9]. DCT transform has been used in conjunction with CNNs for image classification as an input pre-processing step [10, 11]. Ghosh and Chellappa [12] transformed feature maps inside the CNN pipeline and noted convergence improvements.
II-B Wavelets & CNNs
Common approach in literature is to use wavelet transform to extract invariant features prior to classification. One such example is the Scattering convolution network composed of complex Morlet wavelet filters [2] and a PCA or SVM classifier. Wavelet responses were also used with NN-based classifier [13], or with a set of CNNs each operating on exclusive frequency sub-band [14]. Silva et al. used wavelet filters to enhance edges prior to CNN processing [15]. Rotation and scale invariant wavelet based scattering networks with subsequent CNN were formulated in [3, 16]. These hybrid networks were shown to reach comparable classification accuracy to deeper CNNs.
Several studies incorporated wavelets in CNN computational graphs. New feature pooling strategies were designed based on fast Fourier transform [17] or fast wavelet transform [18]. Haar wavelet responses of the input image have been concatenated to features at different stages of CNN to address texture classification [19]. Lu et al. [20] designed a similar approach for medical image segmentation, however based on dual-tree complex wavelets. Robustness to scale and orientation of CNN is increased by modulating learned filters by a set of Gabor filters [21]. Rotation equivariance of learned features was accomplished by incorporated complex circular harmonics into CNNs [22]. Jacobsen et al. proposed to learn convolution filters as a composition of Gaussian derivative filter basis [23].
II-C Compressing CNNs
Compression of neural networks has received a lot of attention from researchers. Jaderberg et al. [24] approximated full-rank CNN filters by separable rank-1 filters. DCT transform has been used for model compression, to cluster weights into buckets based on their DCT representation [25], or to represent weights as residuals from their cluster centers in DCT domain [26].
III Harmonic block
III-A Overlapping cosine transform
DCT computed on overlapping windows is also known as Lapped Transform or Modified DCT (MDCT), equivalent to our harmonic block using strides. The overlapped DCT has a long history in signal compression and reduces artefacts at window edges [27]. Dedicated strategies for efficient computations have been proposed [27], including algorithms and hardware optimisations. Our current implementation uses standard deep learning libraries (PyTorch) and is not currently taking full advantage of these more advanced DCT implementations.
DCT transform is equivalent to the discrete Fourier transform of real valued functions with even symmetry within twice larger window. DCT lacks imaginary component given by the sine transform of real valued odd functions. However, harmonic block allows convolution with DCT basis with arbitrary stride creating redundancy in the representation. Ignoring the boundary limitations, sine filter basis can be devised by shifting the cosine filters. Given the equivariant properties of convolution, instead of shifting the filters the same result is achieved by applying original filters to the shifted input. Considering DCT-II formulation:
[TABLE]
a corresponding sine transform is
[TABLE]
which is equivalent to
[TABLE]
The shift given by for any can be directly converted to shift in pixels applied to data . After simplification, sine transform can be expressed as
[TABLE]
which is equivalent to the cosine transform of the image shifted by defined in (5).
[TABLE]
This value represents the stride to shift the cosine filters to capture correlation with sine function.
III-B Definition of harmonic block
The harmonic block [1] is designed to replace fully learned convolution of multidimensional input features . Input channels are convolved using the DCT basis functions given size of the desired receptive field :
[TABLE]
Specifically, we employ -normalised filters :
[TABLE]
Due to properties of natural images, high frequency responses are generally of lower magnitude. Employing batch normalization (BN) on DCT coefficients of the RGB channels has been found useful [1] for propagating energy of the whole spatial-frequency spectrum. Output features are learned as superpositions of the DCT coefficients, described in detail in Algorithm 1, where the learned parameters inside each harmonic block are denoted as .
The downside of Algorithm 1 is that in order to be executed in parallel, extra memory has to be allocated to store the responses of DCT filters at every layer. Since most of the blocks do not need to use BN they become linear. Hence DCT transform and linear combination can be merged into a single linear operation. In other words, equivalent features can be obtained by factorizing filters as linear combination of DCT basis functions. Therefore we propose here Algorithm 2 that is a more efficient alternative to Algorithm 1. This reformulation is similar to structured receptive field [23] utilizing different basis functions. The theoretical number of multiply-add operations compared to the standard convolutional layer increases by a factor of for Algorithm 1, and by for Algorithm 2, where the input image size for the block is . The experimental performance of the two algorithms is compared in Section IV-A.
Control over the filters allows one to achieve reduced computational complexity by selecting subsets of filters to approximate the signal. A -subset is a collection of all filters such that their indices satisfy the condition . Fig. 1 shows example of some subsets of 3-by-3 DCT filters.
IV Experimental evaluation
IV-A Computational requirements
Firstly we compare the two implementations of a harmonic block, see Sec. III-B. Experiment is conducted on well performing wide residual network (WRN) [28] trained on CIFAR10 dataset. The baseline WRN 16-8 (for architecture details and training procedure see [28]) with dropout rate 0.2 is compared with harmonic WRN with all convolution layers replaced by blocks defined in Algorithm 1 with additional BN in the first block. The network runtime and memory requirements for Algorithm 1 far exceed those of the baseline WRN (implemented via deep learning framework and run on GPUs) despite being more flexible and having similar amount of arithmetic operations, see discussion in [1]. Fully harmonic WRN based on Algorithm 2 (except the first layer due to the presence of BN) largely outperforms Algorithm 1 and shows only a modest increase in runtime and memory usage over the baseline WRN [28] while having competitive performance.
IV-B Overlapping DCT experiments
In Section III-A we demonstrated that the discrete sine transform can be inferred from the DCT on overlapping blocks. Here we show experimentally the benefits of DCT transform with overlapping windows by using overcomplete representation with strides of 1 pixel or fixing stride to the half of the window size. Effect of striding is evaluated on a shallow harmonic network composed of only one normalized harmonic block with 4x4 receptive field, followed by a Rectified Linear Unit (ReLU) activation and connected to a fully connected layer with softmax classifier. This simple architecture allows one to clearly see the contribution of striding. The network is trained with SGD using learning rate 0.01, Nesterov momentum 0.9, weight decay 0.0005 and batch size 128 for 30 epochs decaying learning rate by factor 10 halfway. Since striding reduces the spatial resolution of the features, to match the model complexity, lower dimensional features are resized to have size of features produced by stride 1. As expected, network without overlapping windows performs notably worse even with full spectrum (see Fig. 2(a)).
In order to compare models with similar numbers of parameters, instead of replicating features, networks with larger stride employ a higher number of output features: 200 for non-overlapping, 50 for half-window overlap in contrast to 16 when using stride 1. The same experiment is performed using 8x8 filters learning 625, 200 and 16 feature maps respectively. In this setting network with stride 1 and with full window stride perform comparably on full spectrum as can be seen on Fig. 2(b) and Fig. 2(c), but performance degrades more rapidly for non-overlapping filters as the visual spectrum shrinks. The best result was obtained when using half window stride.
IV-C Limited Data
Deep neural networks require abundant data to achieve high accuracy. It has been shown in [2, 3] that scattering network using geometric priors can learn better discrimination boundaries when presented with a small subset of training samples. We demonstrate capabilities of harmonic networks when learning from limited subsets of data on three datasets.
IV-C1 MNIST
Bruna and Mallat [2] have chosen a dataset of handwritten digits to test their fully handcrafted scattering network with respect to stability to deformations and classification performance on data subsets. We compare our harmonic network to the “classical” CNN, learned depth-separable convolution network and to the fully handcrafted scattering network (as reported by [2]). Table II shows the harmonic network achieves the lower classification error for all sizes of the training set. The baseline network is composed of 3 convolution layers with 32, 64 and 128 filters, respectively, and with overlapping average pooling between them. Convolutional layers are followed by a fully connected layer with 512 neurons. Batch normalization and ReLU are applied after each layer. The harmonic network uses the same configuration replacing convolution with harmonic block while using additional BN in the first block. Harmonic networks are also compared to the depth-separable convolution network that has the same structure but has randomly initialized learnable filters instead of DCT filters. Training is done with SGD for 30 epochs with learning rate 0.1 reduced after every 10 epochs by a factor 10. Weight decay ranges from 0.0005 (for training size 300) to 0.05 (training size 60000). Harmonic networks outperform other networks in all configurations, see Tab. II.
IV-C2 CIFAR10
We replicate the experiment in [3] and train harmonic network on random subsets of CIFAR10 dataset with size 100, 500 and 1000 samples preserving equal number of labels per class. Harmonic WRN 16-8 with dropout rate 0.2 is trained as in [3]. Harmonic layers relying on combinations of fixed filters give advantage on limited data compared to fully learned CNNs and to scattering CNN hybrids111The exact subsets used to train scattering CNN hybrids are not known, we report the numerical results from [3]. except for the smallest training dataset, see Tab. III.
IV-C3 STL10
STL10 [29] is a natural image dataset similar to CIFAR10. Images are 9696 and only 5000 training images are labeled. The large set of provided unlabeled images is not utilized in this experiment. We design harmonic WRN 16-8 model (based on Algorithm 2) for this task with several necessary modifications. The first layer uses stride 2, and the feature resolution at the final stage is 1212. We apply dropout 0.3 inside residual blocks and train the network on the whole training set with learning rate of 0.1 decayed by factor 0.2 after 300, 400, 600, 800 epochs, and stopping the training after 1000. The baseline network design and training procedure is similar to [30] that uses additional cutout regularization and reports 87.26% 0.23 on test set containing 8000 images when trained on batches of 128 images. The harmonic WRN 16-8 achieves 88.1% 0.23 trained with the same settings. Decreasing the batch size to 32 improves our result to 90.45% surpassing the deeper scattering WRN [3] by nearly 3%. Furthermore, when only predefined folds of 1000 samples serve as the training data, we obtain the best accuracy by progressively reducing the number of used frequencies along with spatial resolution: full filter bank is applied on features of size 4848, filters with on 2424 and finally if features are 1212. The results of STL10 experiments are summarised in Tab. IV.
V Conclusion
We have proposed a computationally efficient alternative to the original harmonic block based on DCT [1]. The implementation is characterized by a very small increase in the number of multiply-add operations compared to a standard convolutional layer, thus enabling the wider use of harmonic networks as a tool for reducing model overfitting. The experimental reported in this manuscript confirm that the harmonic block outperforms the well established scattering networks using wavelets [2, 3] when limited data is available for training. We provide the PyTorch implementation of the improved harmonic block. Future work will investigate the effect of window functions that are also often used in Modified DCT as part of the harmonic block, and test its performance in large scale experiments.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Ulicny, V. A. Krylov, and R. Dahyot, “Harmonic networks: Integrating spectral information into CN Ns,” ar Xiv preprint ar Xiv:1812.03205 , 2018.
- 2[2] J. Bruna and S. Mallat, “Invariant scattering convolution networks,” IEEE transactions on pattern analysis and machine intelligence , vol. 35, no. 8, pp. 1872–1886, 2013.
- 3[3] E. Oyallon, S. Zagoruyko, G. Huang, N. Komodakis, S. Lacoste-Julien, M. B. Blaschko, and E. Belilovsky, “Scattering networks for hybrid representation learning,” IEEE Transactions on Pattern Analysis and Machine Intelligence , pp. 1–1, 2018.
- 4[4] Q. Wang and R. Zhang, “Double JPEG compression forensics based on a convolutional neural network,” EURASIP Journal on Information Security , vol. 2016, p. 23, Oct 2016.
- 5[5] I. Amerini, T. Uricchio, L. Ballan, and R. Caldelli, “Localization of JPEG double compression through multi-domain convolutional neural networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , pp. 1865–1871, July 2017.
- 6[6] M. Barni, L. Bondi, N. Bonettini, P. Bestagini, A. Costanzo, M. Maggini, B. Tondi, and S. Tubaro, “Aligned and non-aligned double JPEG detection using convolutional neural networks,” J. Vis. Comun. Image Represent. , vol. 49, pp. 153–163, Nov. 2017.
- 7[7] B. Li, H. Luo, H. Zhang, S. Tan, and Z. Ji, “A multi-branch convolutional neural network for detecting double JPEG compression,” Co RR , vol. abs/1710.05477, 2017.
- 8[8] X. Zou, X. Xu, C. Qing, and X. Xing, “High speed deep networks based on discrete cosine transformation,” in Image Processing (ICIP), 2014 IEEE International Conference on , pp. 5921–5925, IEEE, 2014.
