Analysis of Chinese Tourists in Japan by Text Mining of a Hotel Portal Site
Elisa Claire Alem\'an Carre\'on, Hirofumi Nonaka, Toru Hiraoka

TL;DR
This study develops a text mining approach using a mathematical model and machine learning to analyze Chinese tourists' reviews of Japanese hotels, providing an affordable market research tool.
Contribution
Introduces a novel mathematical model for keyword extraction and sentiment analysis tailored for Chinese hotel reviews, enhancing classification accuracy and business insights.
Findings
High classification performance achieved
Effective identification of relevant keywords
Potential for cost-effective market research
Abstract
With an increasingly large number of Chinese tourists in Japan, the hotel industry is in need of an affordable market research tool that does not rely on expensive and time-consuming surveys or interviews. Because this problem is real and relevant to the hotel industry in Japan, and otherwise completely unexplored in other studies, we have extracted a list of potential keywords from Chinese reviews of Japanese hotels in the hotel portal site Ctrip1 using a mathematical model to then use them in a sentiment analysis with a machine learning classifier. While most studies that use information collected from the internet use pre-existing data analysis tools, in our study, we designed the mathematical model to have the highest possible performing results in classification, while also exploring on the potential business implications these may have.
Click any figure to enlarge with its caption.
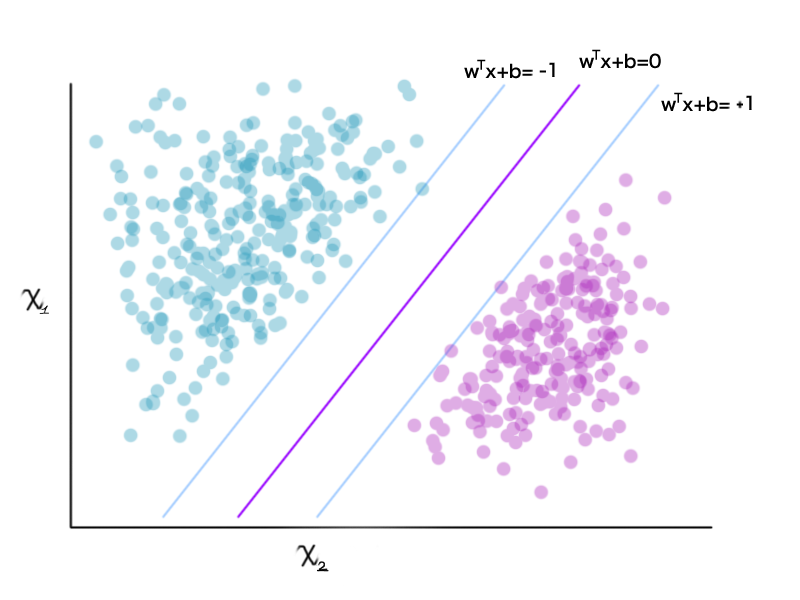 Figure 1
Figure 1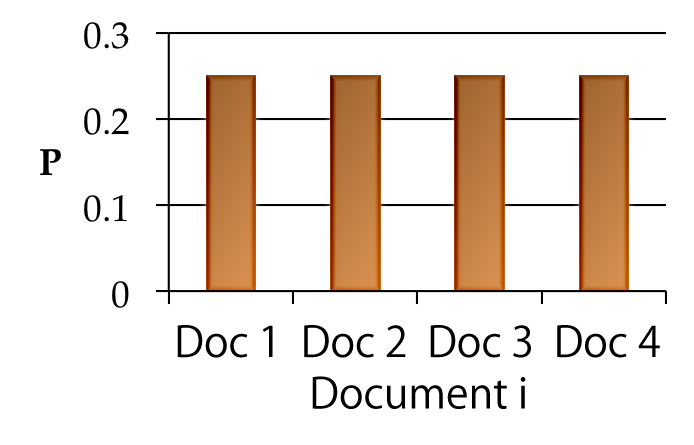 Figure 2
Figure 2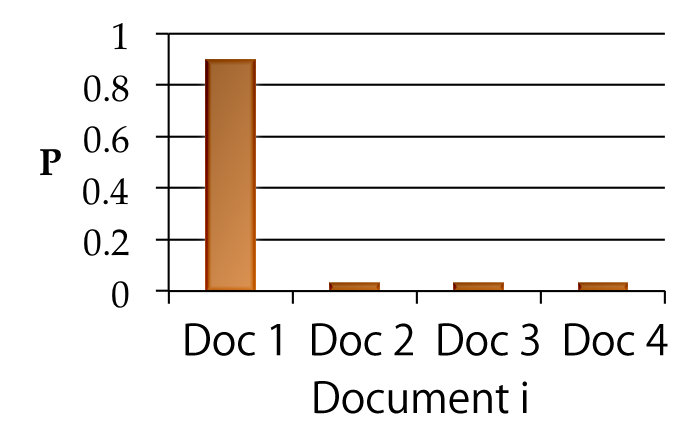 Figure 3
Figure 3| Keyword List |
|
|
|
|
||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Positive () | 0.58 | 0.16 | 0.69 | 0.16 | ||||||||
| Negative () | 0.88 | 0.07 | 0.92 | 0.05 | ||||||||
| Combined | 0.90 | 0.09 | 0.93 | 0.05 |
| Word | Translation | Word | Translation | Word | Translation |
|---|---|---|---|---|---|
| 园林 | garden | 烤肉 | Barbecue | 人员 | personnel |
| 花园 | flower garden | 中文 | Chinese text | 华人 | Chinese person |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Analysis of Chinese Tourists in Japan by Text Mining of a Hotel Portal Site
Elisa Claire Alemán Carreón
Hirofumi Nonaka
Toru Hiraoka
Nagaoka University of Technology, Nagaoka, Japan
University of Nagasaki, Nagasaki, Japan
Abstract
With an increasingly large number of Chinese tourists in Japan, the hotel industry is in need of an affordable market research tool that does not rely on expensive and time consuming surveys or interviews. Because this problem is real and relevant to the hotel industry in Japan, and otherwise completely unexplored in other studies, we have extracted a list of potential keywords from Chinese reviews of Japanese hotels in the hotel portal site Ctrip111Ctrip: www.ctrip.com/ using a mathematical model to then use them in a sentiment analysis with a machine learning classifier. While most studies that use information collected from the Internet use pre-existing data analysis tools, in our study we designed the mathematical model to have the highest possible performing results in classification, while also exploring on the potential business implications these may have.
keywords:
Text Mining, Sentiment Analysis, Support Vector Machine, Machine Learning, Entropy
††journal: Proceedings of the 18th International Symposium on Advanced Intelligent Systems (ISIS2017)
1 Introduction
In Japan, the population of Chinese tourists has increased over the recent years, with a 107.3% increase from 2014 to 2015 [1] and so on. This change in a customer base for many industries, mainly the hotel industry, brings forward a need for an affordable and reliable method to study this new market; which has not been explored in other studies before. Surveys and interviews, previously used both in business and other studies, present difficulties and an increase in costs and time, besides the fact that these studies [2, 3] do not target Japan or Chinese customers [4].
Using the available text reviews of Japanese hotels by Chinese customers available in the website Ctrip, our new method proposal is to use a mathematical model using Shannon’s Entropy, a concept which can determine a word’s probabilistic distribution, to determine a list of relevant keywords to be used in the context of classifying positive and negative emotions in a hotel review using a Support Vector Machine.
There are other studies using similar techniques, mostly with English texts [5, 6] but not many that apply these knowledges practically, and those that do [7] don’t analyze the implications fully. The ones that do focus on Chinese sentiment classification [8] or its business applications [9] are scarce, and use formal words that describe emotions that are unlikely to appear in our reviews. This is why we developed our own sentiment analysis model to provide a practical tool for future marketing choices in our study. In contrast to these studies, in our entropy based keyword extraction we are using words used by a specific group of users that are characteristic of documents written in different emotional states, which has a better capacity for more precise results in the sentiment analysis classification by the Support Vector Machine.
2 Methodology
2.1 Word Segmentation
For a statistical analysis to be made possible for each word, we segmented the collected Chinese texts without spaces into words using the Stanford Word Segmenter [10].
2.2 Entropy Based Keyword Extraction
In this study, we based the extraction of the keywords that are influenced by the users’ emotional judgement on the calculation of an entropy value for each word. Speaking in Information Theory terms, Shannon’s Entropy is the expected value of the information content in a signal [11]. Applying this knowledge to the study of words allows us to observe the probability distribution of any given word inside the corpus. For example, a word that keeps reappearing in many different documents will have a high entropy, given that predicting on which document it would appear becomes uncertain. On the contrary, a word that only was used in a single text and not in any other documents in the corpus will be perfectly predictable to only appear in that single document, bearing an entropy of zero. This concept is shown in the figure below.
With this logic in mind, we used a set of documents that were previously tagged as positive or negative by a group of Chinese students. If a word has a higher entropy in positive documents than in negative documents by a factor of alpha (), then it means its probability distribution is more spread in positive texts, meaning that it is commonly used in positive tagged documents compared to negative ones.
To calculate the entropy in a set of documents, for each word that appears in each document , we counted the number of times a word appears in positive comments as , and the number of times a word appears in negative comments as . Then, as shown in the formulas below, we calculated the probability of each word appearing in each document shown below as (1) and (2).
[TABLE]
[TABLE]
We then substitute these values in the formula that defines Shannon’s Entropy. We calculated the entropy for each word in relation to positive documents as (3), and the entropy for each word in relation to negative texts as (5). That is, as is shown in (4) and (6), all instances of the summation when the probabilities or are zero and the logarithm of these becomes undefined are substituted as zero into (3) and (5).
[TABLE]
[TABLE]
[TABLE]
[TABLE]
After calculating the positive and negative entropies for each word, we measured their proportion using the mutually independent coefficients for positive keywords and for negative keywords, for which we applied several values experimentally. A positive keyword is determined when (7) is true, and likewise, a negative keyword is determined when (8) is true.
[TABLE]
[TABLE]
2.3 Sentiment Analysis Using Support Vector Machine
In machine learning, Support Vector Machines are supervised learning models commonly used for statistical classification or regression [12]. Using already classified and labeled data with certain features and characteristics, an SVM learns to classify new unlabeled data by drawing the separating (p-1)-dimensional hyperplane in a p-dimensional space. Each dimensional plane is represented by one of the features that a data point holds. Then each data point holds a position in this multi-dimensional space depending on its features. The separating hyperplane and the supporting vectors divide the multi-dimensional space by minimizing the error of classification. A two-dimensional example is shown below.
The linear kernel for the SVM classification is defined by the formula (9) below. The influence that each point of the training data inputs into the vector is defined by their weight , included in the Weight Vector . The bias coefficient determines the position of the hyperplane.
[TABLE]
Then, the conditions shown in (10) are applied when classifying new data.
[TABLE]
Now, the initial condition is set as . Then each possible separating vector is tested, and when a classification for fails, the value for is changed as follows in (11) by a value of .
[TABLE]
This process is repeated until all points of the training data are classified correctly. The resulting formula for classification (12) is as follows.
[TABLE]
In Natural Language Processing, when it comes to statistically analyzing documents, each possible word in that corpus is a feature, or a dimensional plane. Then, the value of that feature will be marked as the number of times a word is contained in a document .
We implemented this theory in Python using the Support Vector Classifier (SVC) included in the library scikit-learn222Scikit-Learn http://scikit-learn.org/. To vectorize the documents into word vector spaces we used the method CountVectorizer included in the same library. We then managed these vectors using the mathematics library numpy333Numpy. http://numpy.org/.
To evaluate each of our trained machines, we used the K-fold Cross Validation method, which has been proven to provide good results [13]. In each test, we calculated then the Precision, Recall, [14] and Accuracy values for our predictions.
3 Experiments
3.1 Dataset
We crawled a total of html files, from which were unique Japanese hotels. From these pages, we extracted a total of reviews, which turned into separate sentences. In our corpus, there were different words used, from which were noise characters.
3.2 Sentiment Analysis Experiments
Before performing the sentiment analysis, we had a group of Chinese student collaborators tag a sample of our collected data, and then calculated the Shannon’s entropy values for each word in positive and negative tags.
We then altered the comparison coefficient and to different values, from which we extracted different lists of positive and negative keywords to be tested in an SVM. We changed the values of and in 0.25 intervals from 1.0 to 3.75.
In our study, we investigated different parameters to decide the kernel and model of the learning machine. The best performing kernel for the SVM was the Linear one, with a .
Based on our K-Fold Cross Validation () results, we chose the best performing positive and negative lists. We decided to make a combined list of these two previous lists and train the SVM with this. With this Combined list, the Accuracy was of and the measure was , both excellent results for classification.
Following this observation, we predicted whether a sentence was positive or not from the remaining unlabeled data using this model. We then made another prediction of whether a sentence was negative or not using the Negative ( in formula (8)) keyword list trained linear SVM. Having both of these predictions, we decided to classify the documents based on a consensus of the two, having the categories “positive”, “neutral” and “negative”.
4 Results and Discussion
4.1 About the Methodology
We have shown that the entropy based keyword extraction method has many advantages for this field of study. Not only this, but we have obtained a result that exceeds a 0.9 performance (accuracy and , which can be considered as high.
4.2 About the Results
Now, these are the relevant keywords extracted from the entropy calculations that were used to train the SVM for positive and negative classifying. Because the keyword list for positive words is larger than 100 words, we will only show the top words that are better suited for analysis, such as nouns and adjectives.
5 Conclusion and Future Work
In our study, with the objective to understand what Chinese customers of Japanese hotels demand and feel we extracted keywords from a Chinese portal site with reviews of Japanese hotels. In the evaluation process of our ma- chine learning experiments, we obtained our highest performance ( and ) using both positive and negative keywords extracted using Shannon’s entropy as a base to train a linear kernel SVM.
In regards to the needs of Chinese customers of Japanese hotels we found that the Chinese customers in our database were less concerned with price and more particularly with food, gardens or parks near the hotel, good service and transport, as well as the use of Chinese language to cater to them specifically.
It could be thought that some of the keywords being used were not about the hotels themselves, but for the surrounding area, which is a subject we will leave for future works. Another subject to investigate is how these keywords could be rated to determine the most important of the demands of Chinese customers of Japanese hotels.
References
- [1]
Japan National Tourism Organization, April 2017 foreigner visits statistical data [data file in excel format divided by nationality, month and year], Tech. rep., Japan National Tourism Organization, (in Japanese) (2017).
URL http://www.jnto.go.jp/jpn/statistics/visitor_trends/
- [2]
R. Chang, J. Kivela, A. Mak, Food preferences of Chinese tourists, Annals Of Tourism Research 37 (4) (2010) 989–1011.
doi:10.1016/j.annals.2010.03.007.
- [3]
T. Truong, B. King, An evaluation of satisfaction levels among Chinese tourists in Vietnam, International Journal Of Tourism Research 11 (6) (2009) 521–535.
- [4]
Y.-f. Ma, P. Zheng, K. Bai, Study on the discrepancies of decision-making behavior of tourists to China——take tourists from Japan and America as a case study [j], Journal of Arid Land Resources and Environment 1.
- [5]
J. Bollen, H. Mao, X. Zeng, Twitter mood predicts the stock market, Journal Of Computational Science 2 (1) (2011) 1–8.
doi:10.1016/j.jocs.2010.12.007.
- [6]
B. O’Connor, R. Balasubramanyan, B. Routledge, N. Smith, From tweets to polls: Linking text sentiment to public opinion time series, in: Proceedings Of The Fourth International AAAI Conference On Weblogs And Social Media, 11(1-2), 2010, p. 122–129.
- [7]
W. He, S. Zha, L. Li, Social media competitive analysis and text mining: A case study in the pizza industry, International Journal Of Information Management 22 (3) (2013) 464–472.
doi:10.1016/j.ijinfomgt.2013.01.001.
- [8]
S. Lee, A linguistic approach to emotion detection and classification (ph. d.), Ph.D. thesis, The Hong Kong Polytechnic University (2010).
- [9]
H. Zhang, Z. Yu, M. Xu, Y. Shi, Feature-level sentiment analysis for Chinese product reviews., In Proceedings of the 2011 3Rd International Conference On Computer Research And Development 2 (2011) 135–140.
doi:10.1109/iccrd.2011.5764099.
- [10]
P. Chang, M. Galley, C. Manning, Optimizing Chinese word segmentation for machine translation performance, in: Statmt ’08 Proceedings Of The Third Workshop On Statistical Machine, Columbus,Ohio,USA, 2008, pp. 224–232.
URL http://nlp.stanford.edu/pubs/acl-wmt08-cws.pdf
- [11]
C. Shannon, A mathematical theory of communication, Bell System Technical Journal 27 (3) (1948) 279–423.
doi:10.1002/j.1538-7305.1948.tb01338.x.
- [12]
C. Cortes, V. Vapnik, Support-vector networks, Machine Learning 20 (3) (1995) 273–297.
- [13]
R. Kohavi, A study of cross-validation and bootstrap for accuracy estimation and model selection, International Joint Conference On Artificial Intelligence 14 (1995) 2.
- [14]
D. Powers, Evaluation: From precision, recall and f-measure to roc, informedness, markedness & correlation, Journal Of Machine Learning Technologies 2 (1) (2011) 37–63.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Japan National Tourism Organization, April 2017 foreigner visits statistical data [data file in excel format divided by nationality, month and year] , Tech. rep., Japan National Tourism Organization, (in Japanese) (2017). URL http://www.jnto.go.jp/jpn/statistics/visitor_trends/
- 2[2] R. Chang, J. Kivela, A. Mak, Food preferences of Chinese tourists, Annals Of Tourism Research 37 (4) (2010) 989–1011. doi:10.1016/j.annals.2010.03.007 . · doi ↗
- 3[3] T. Truong, B. King, An evaluation of satisfaction levels among Chinese tourists in Vietnam, International Journal Of Tourism Research 11 (6) (2009) 521–535. doi:10.1002/jtr.726 . · doi ↗
- 4[4] Y.-f. Ma, P. Zheng, K. Bai, Study on the discrepancies of decision-making behavior of tourists to China——take tourists from Japan and America as a case study [j], Journal of Arid Land Resources and Environment 1.
- 5[5] J. Bollen, H. Mao, X. Zeng, Twitter mood predicts the stock market, Journal Of Computational Science 2 (1) (2011) 1–8. doi:10.1016/j.jocs.2010.12.007 . · doi ↗
- 6[6] B. O’Connor, R. Balasubramanyan, B. Routledge, N. Smith, From tweets to polls: Linking text sentiment to public opinion time series, in: Proceedings Of The Fourth International AAAI Conference On Weblogs And Social Media, 11(1-2), 2010, p. 122–129.
- 7[7] W. He, S. Zha, L. Li, Social media competitive analysis and text mining: A case study in the pizza industry, International Journal Of Information Management 22 (3) (2013) 464–472. doi:10.1016/j.ijinfomgt.2013.01.001 . · doi ↗
- 8[8] S. Lee, A linguistic approach to emotion detection and classification (ph. d.), Ph.D. thesis, The Hong Kong Polytechnic University (2010).