A New Uncertainty Framework for Stochastic Signal Processing
Rishabh Singh, Jose C. Principe

TL;DR
This paper introduces a novel stochastic signal processing framework that decomposes local signal structures in Gaussian RKHS using a quantum-inspired metric, enhancing sensitivity to rapid signal changes.
Contribution
It proposes a new uncertainty-based framework utilizing local Gaussian RKHS decomposition with a quantum-inspired metric for improved signal characterization.
Findings
Framework enables sample-by-sample local analysis.
Uses a quantum-inspired metric for local data structure quantification.
Potentially improves detection of quick signal dynamics.
Abstract
The fields of signal processing and information theory have evolved with the goal of developing formulations to extract intrinsic information from limited amount of data. When one considers the modeling of unpredictably varying processes and complex dynamical signals with a large number of unknowns (such as those encountered in the fields of finance, NLP, communications, etc.), there is a need for algorithms to have increased sensitivity with short spans of data, while maintaining stochastic generalization ability. This naturally calls for an increased focus on localized stochastic representation. So far, most metrics developed for characterizing signals envision data from entropic and probabilistic points of view that lack sensitivity towards quick changes in signal dynamics. We hypothesize that models that work with the intrinsic uncertainties associated with local data induced metric…
Click any figure to enlarge with its caption.
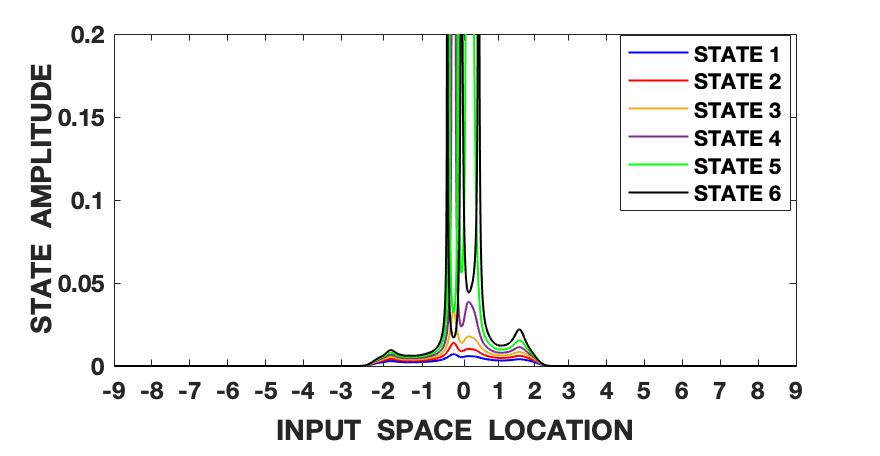 Figure 1
Figure 1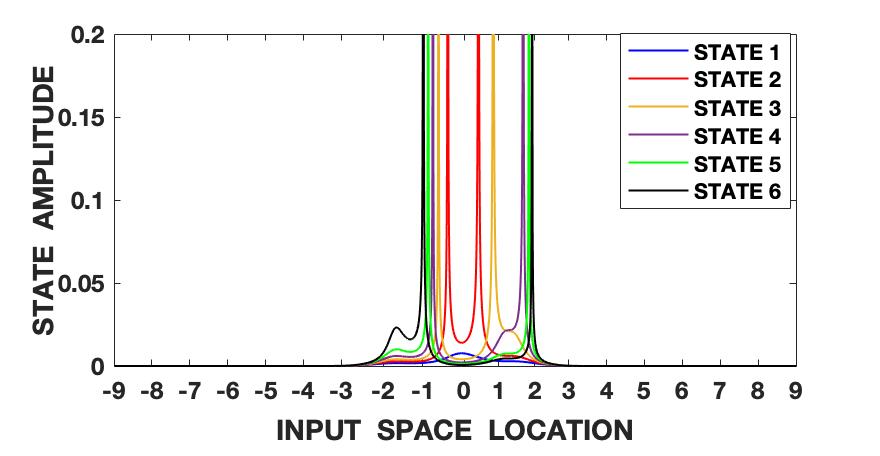 Figure 2
Figure 2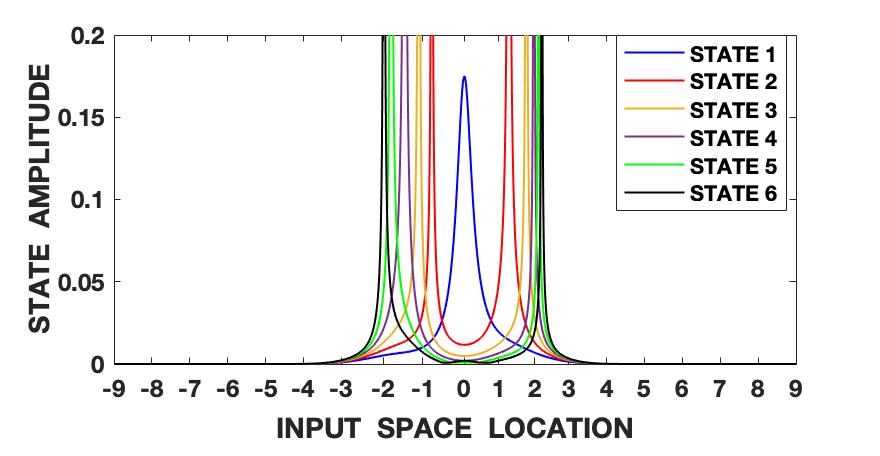 Figure 3
Figure 3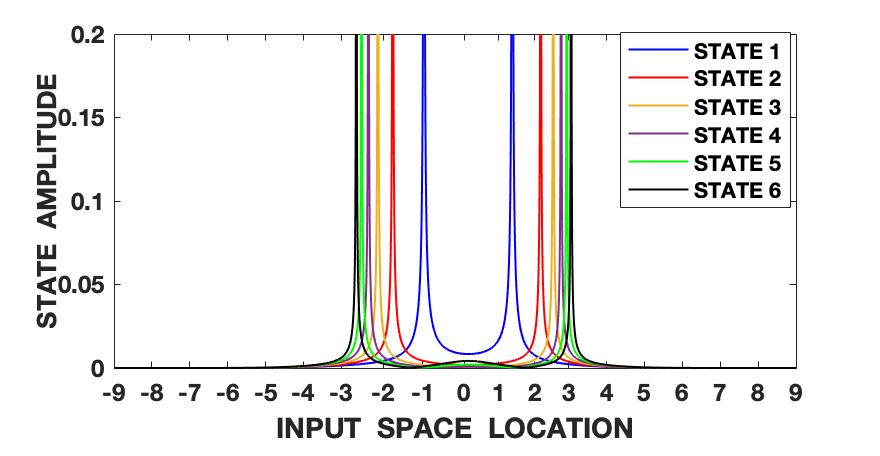 Figure 4
Figure 4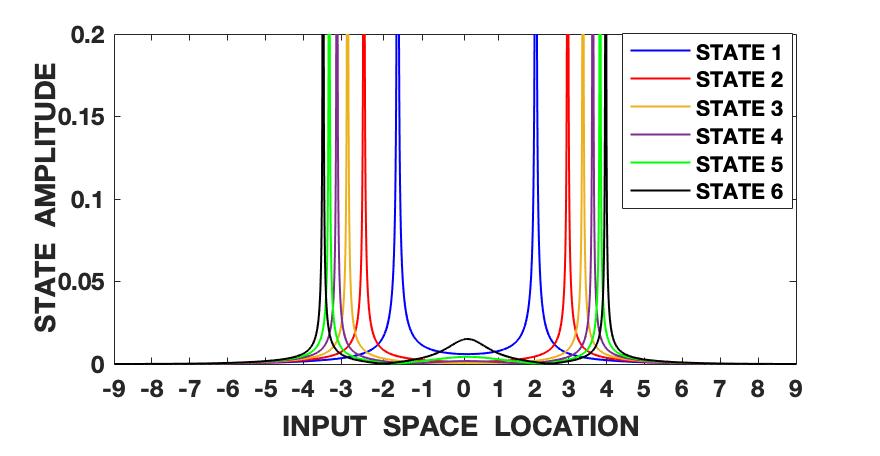 Figure 5
Figure 5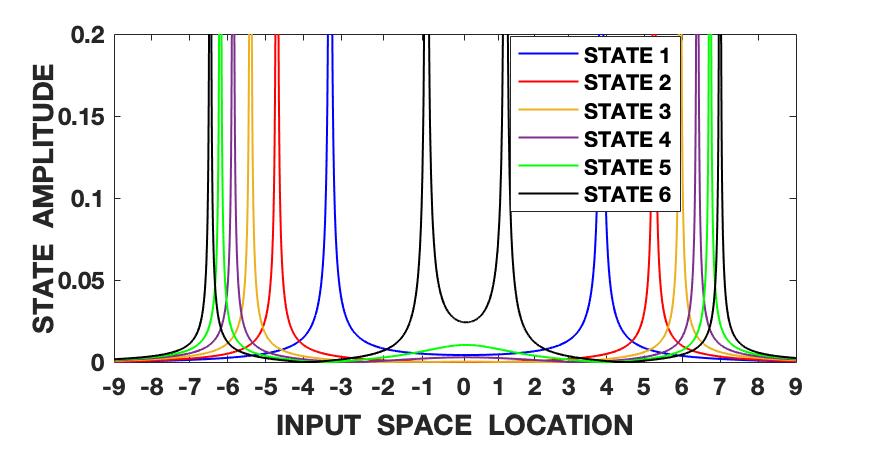 Figure 6
Figure 6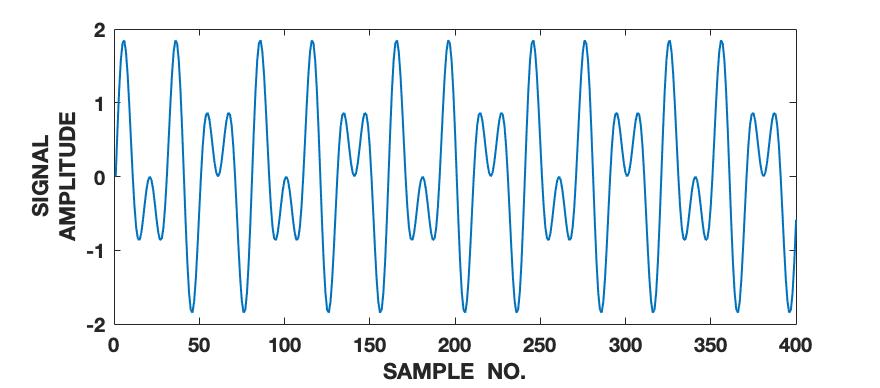 Figure 7
Figure 7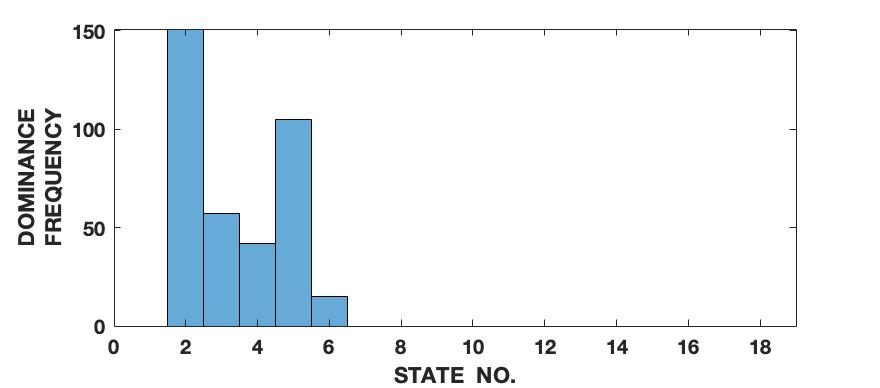 Figure 8
Figure 8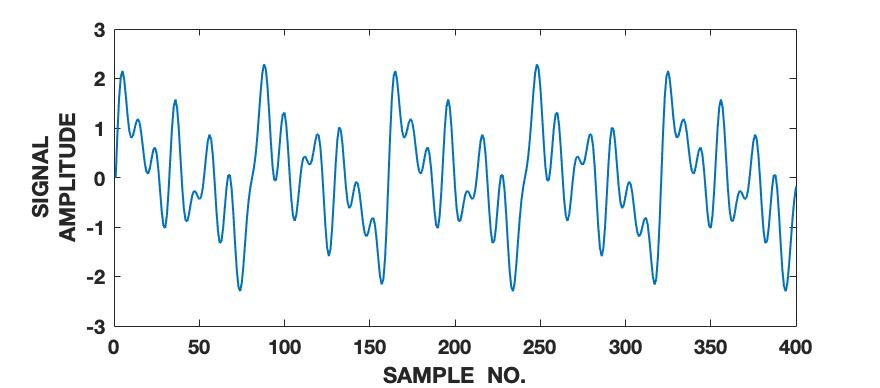 Figure 9
Figure 9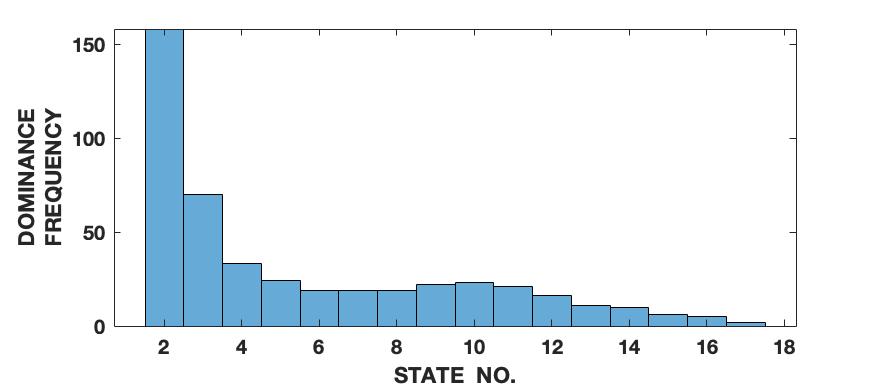 Figure 10
Figure 10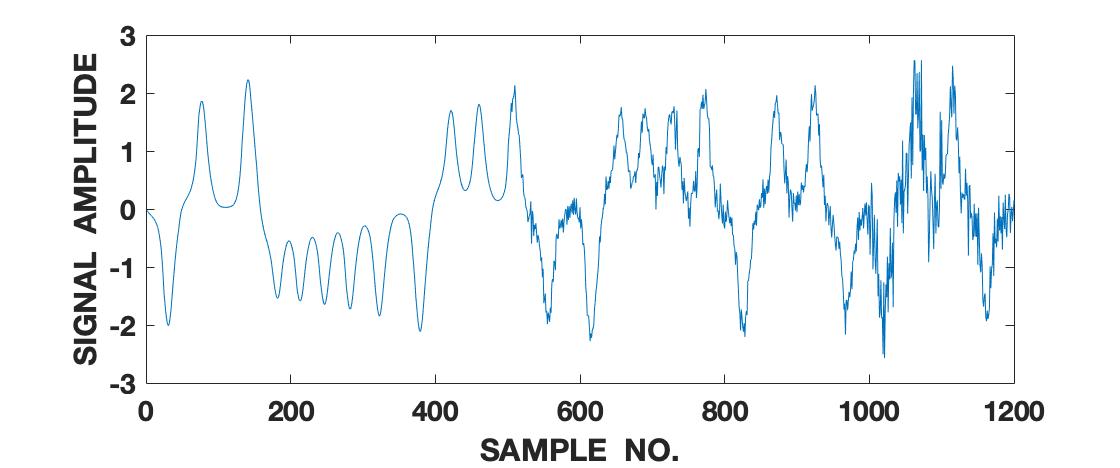 Figure 11
Figure 11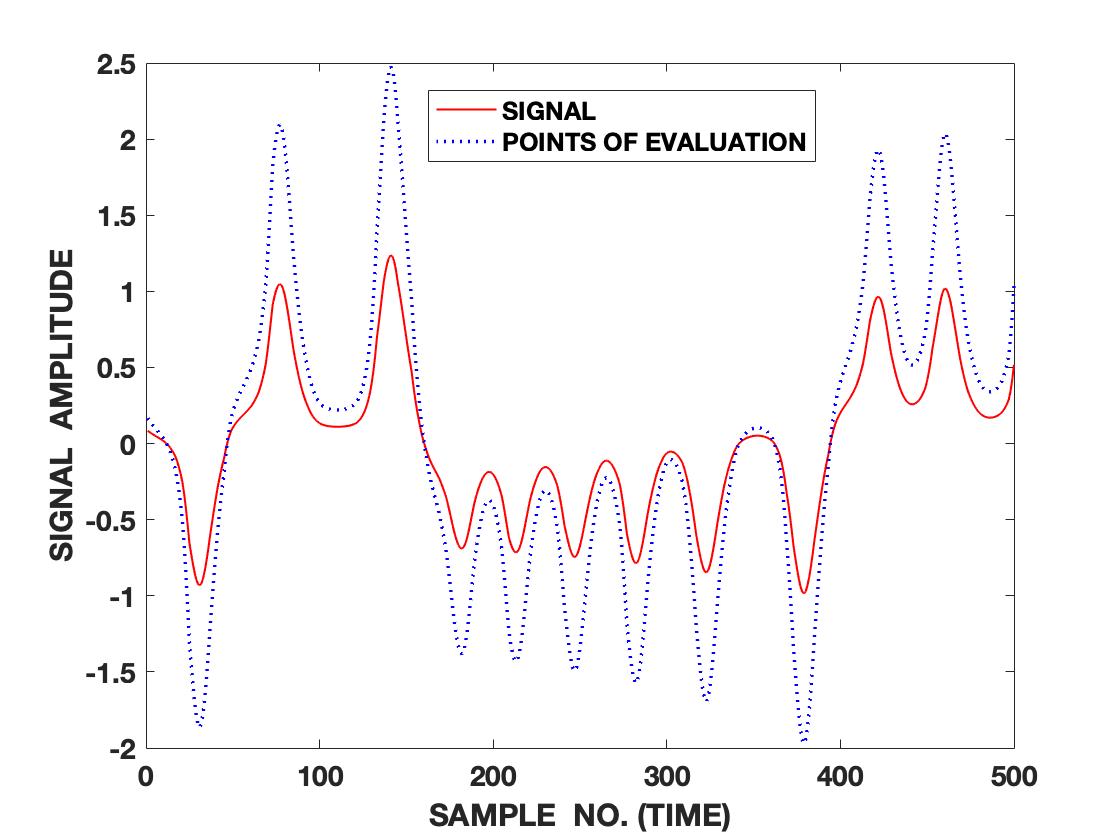 Figure 12
Figure 12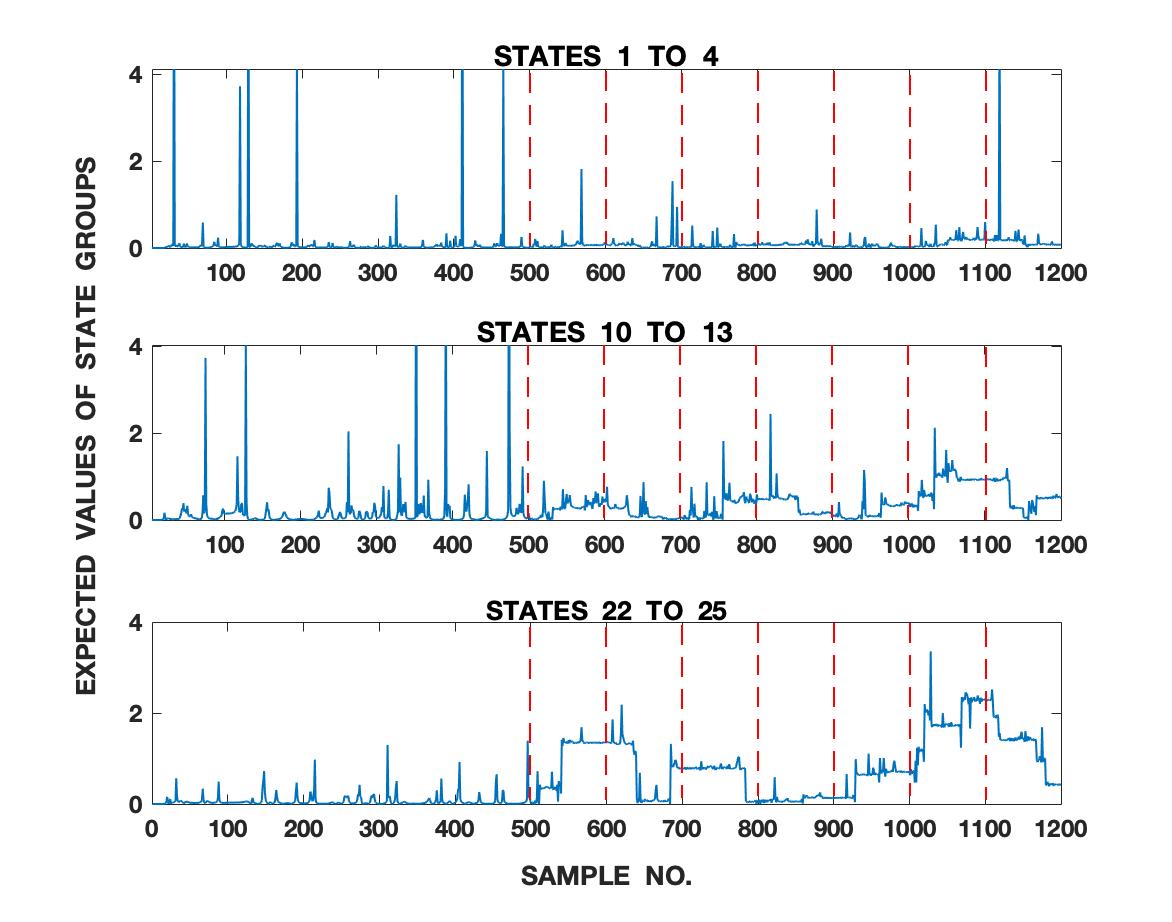 Figure 13
Figure 13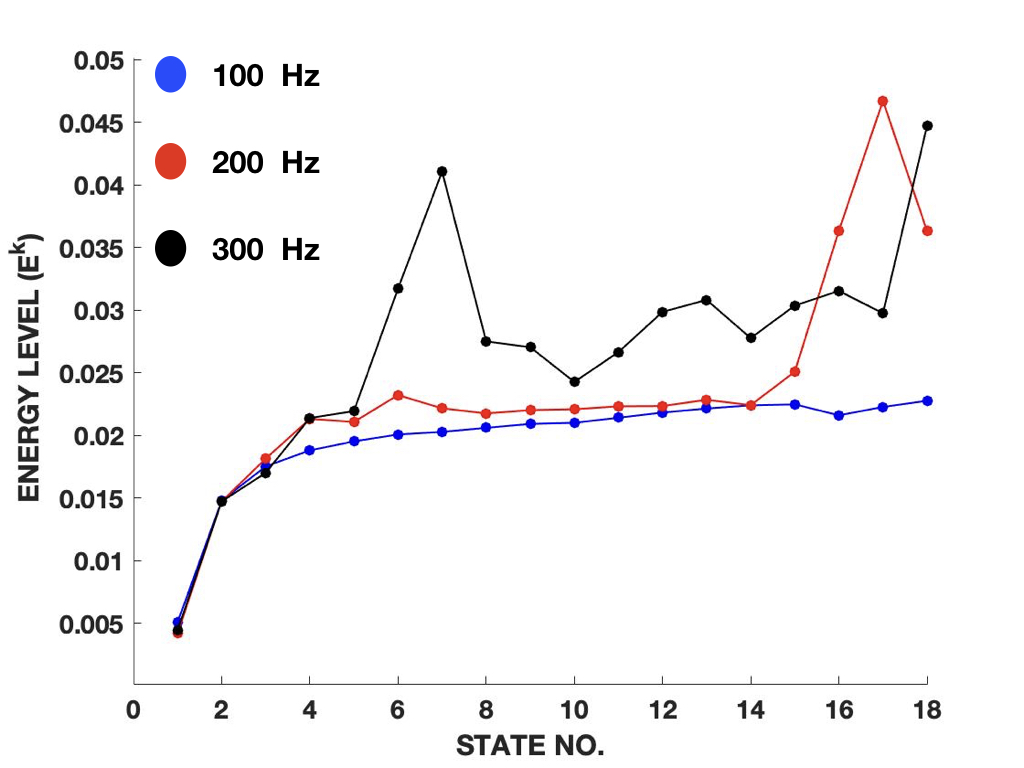 Figure 14
Figure 14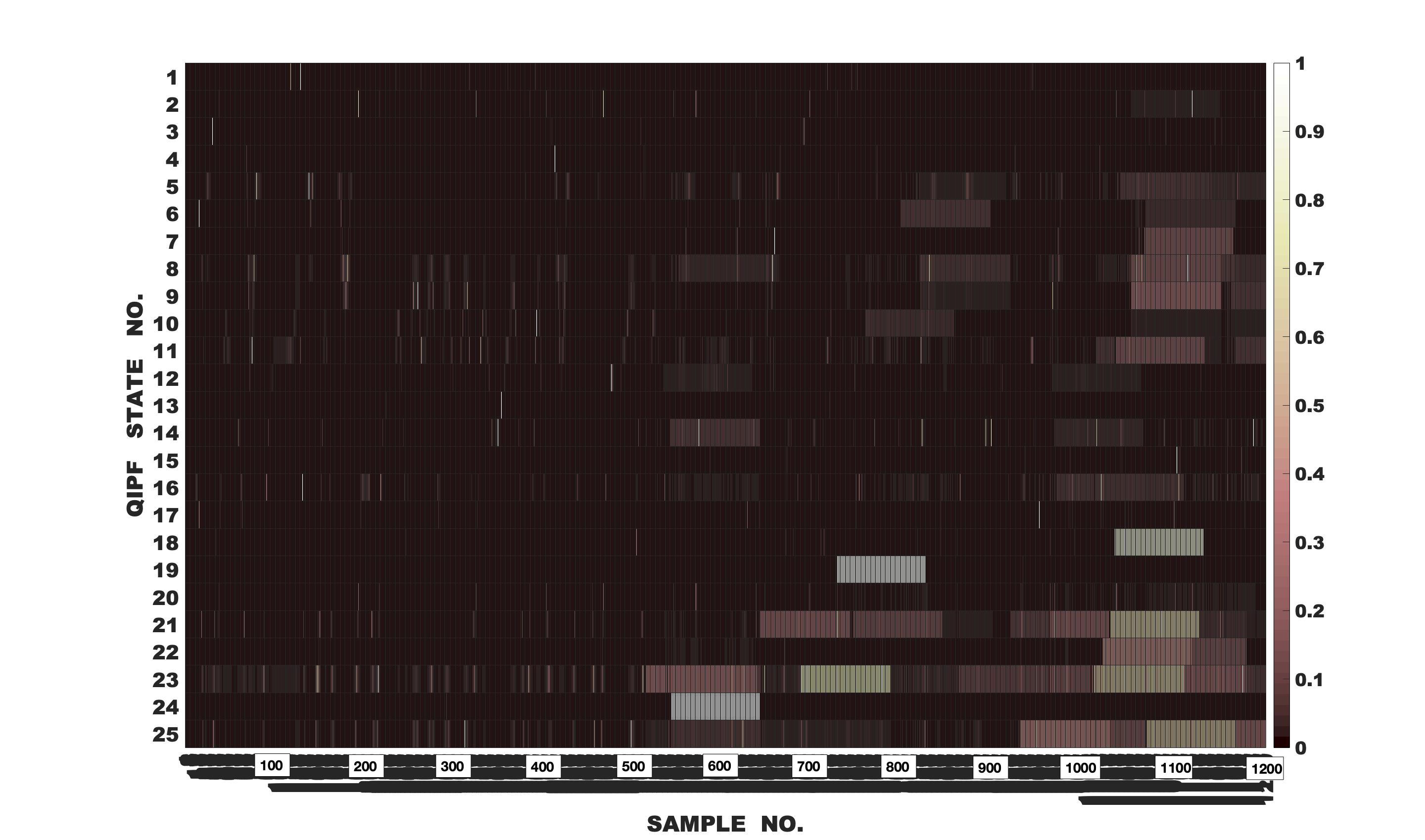 Figure 15
Figure 15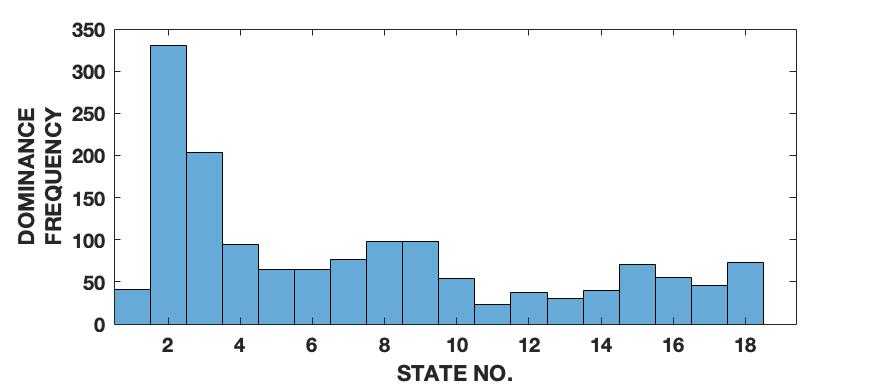 Figure 16
Figure 16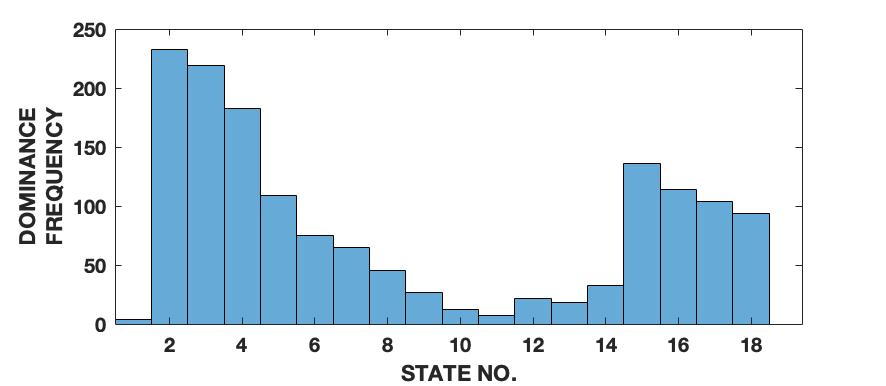 Figure 17
Figure 17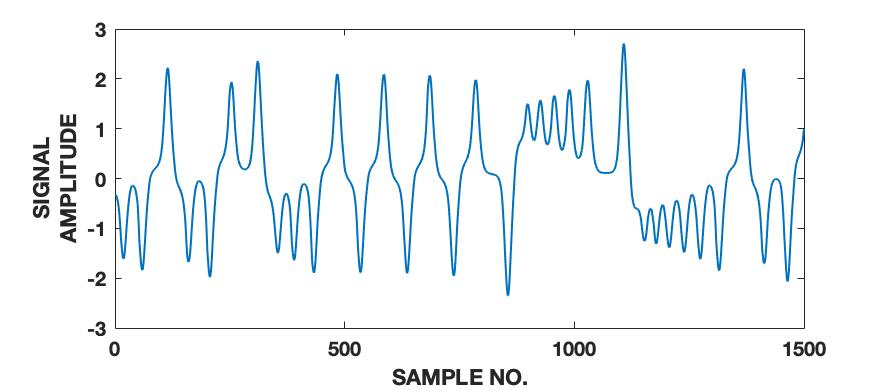 Figure 18
Figure 18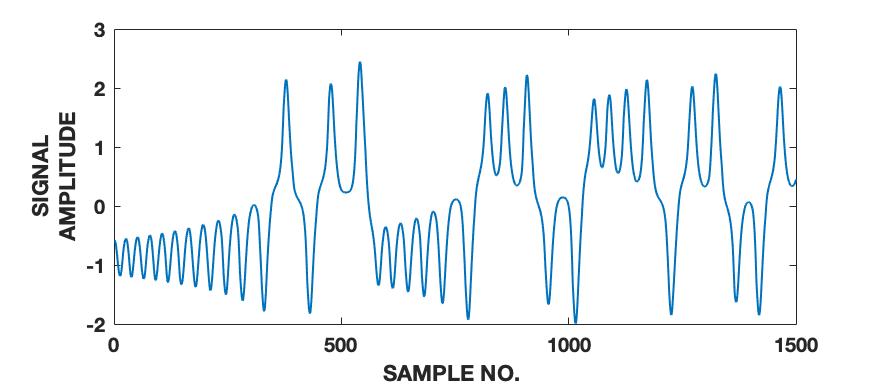 Figure 19
Figure 19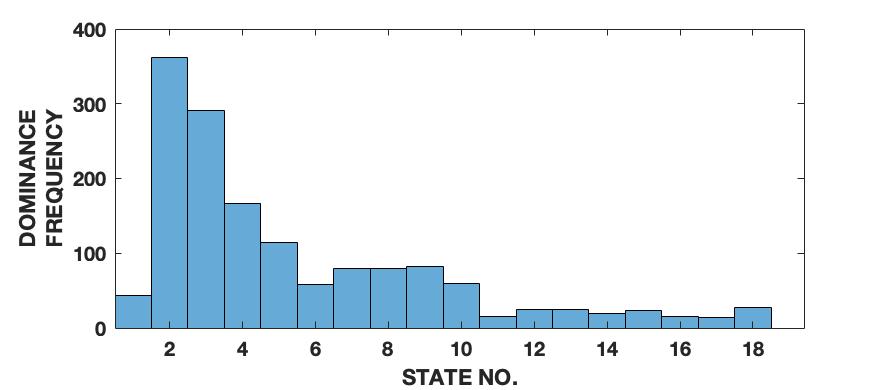 Figure 20
Figure 20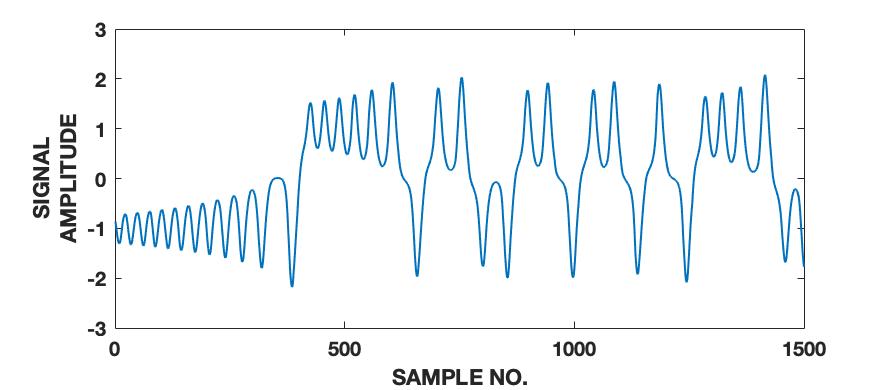 Figure 21
Figure 21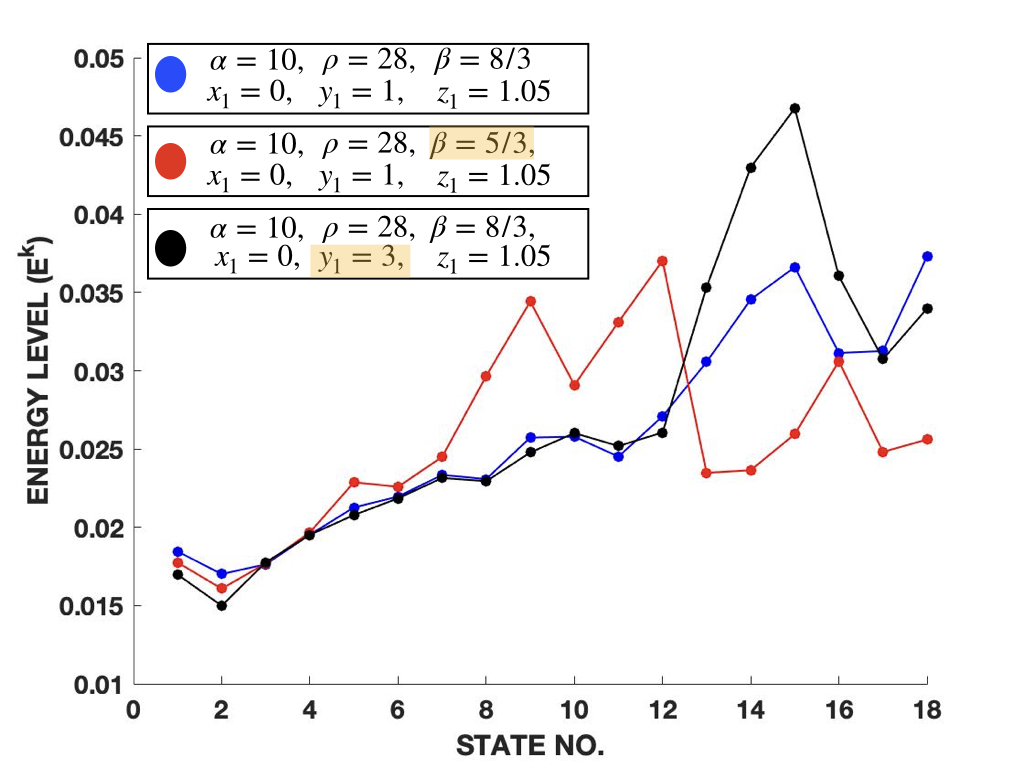 Figure 22
Figure 22 Figure 23
Figure 23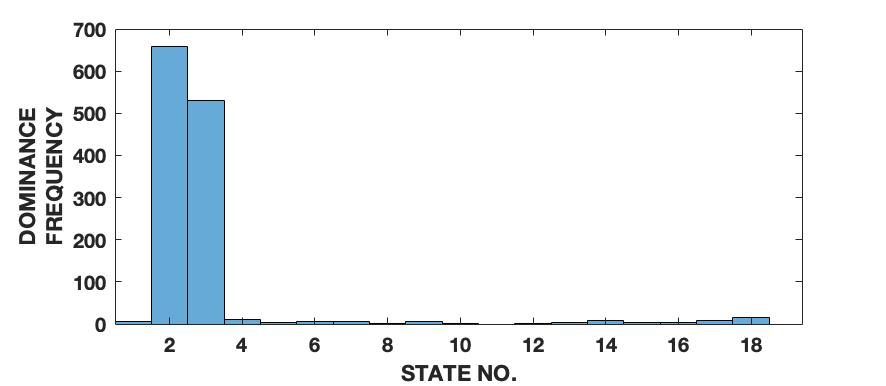 Figure 24
Figure 24 Figure 25
Figure 25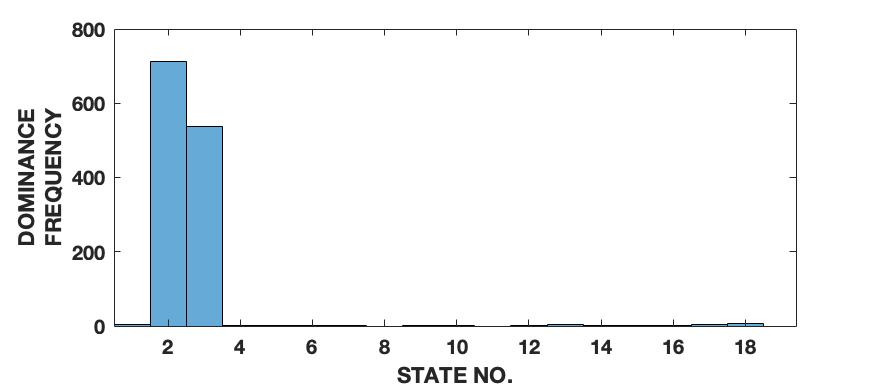 Figure 26
Figure 26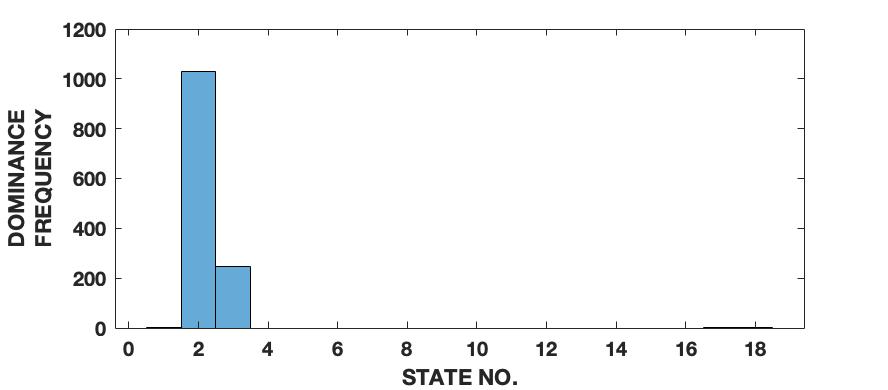 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29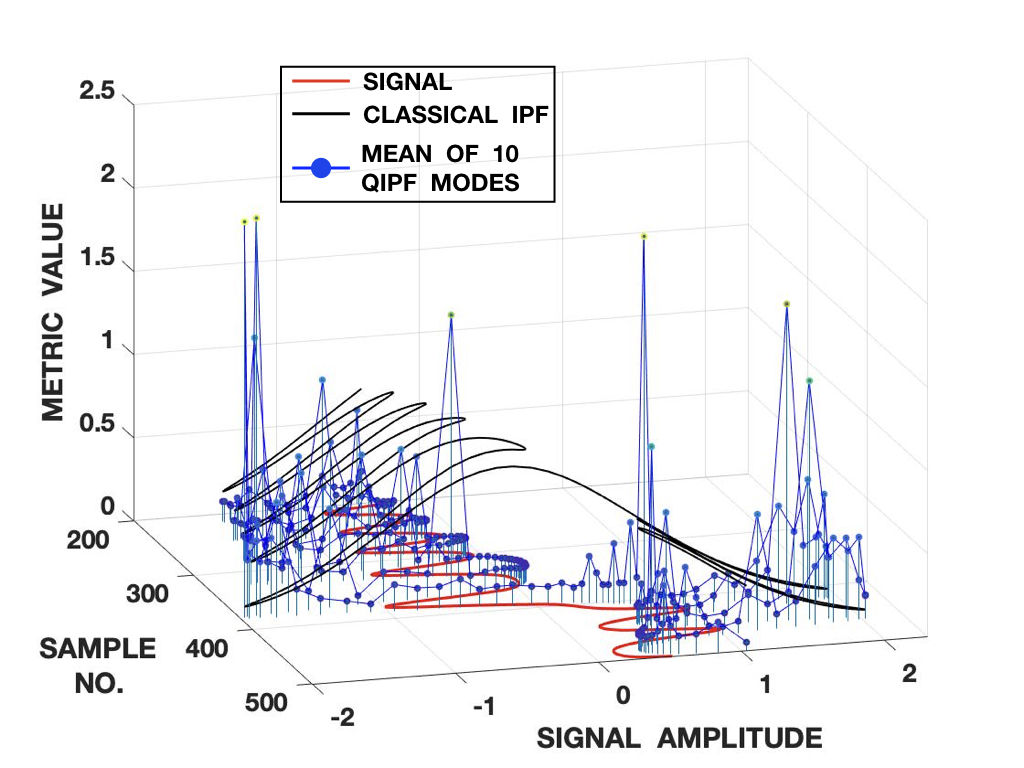 Figure 30
Figure 30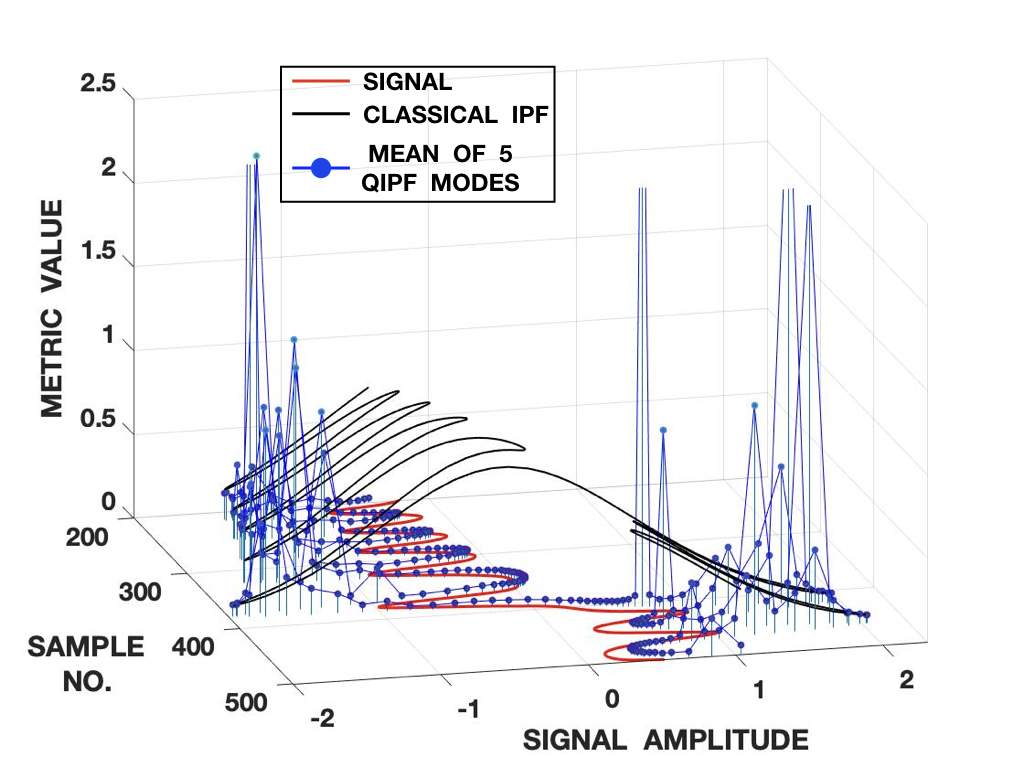 Figure 31
Figure 31| Sample Interval | SNR (DB) | Variance |
|---|---|---|
| 500-600 | 16.7 | 0.021 |
| 600-700 | 20.4 | 0.009 |
| 700-800 | 14.2 | 0.038 |
| 800-900 | 16.3 | 0.034 |
| 900-1000 | 14.5 | 0.035 |
| 1000-1100 | 5.5 | 0.281 |
| 1100-1200 | 10.3 | 0.093 |
| Kernel Width | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Framework | 0.2 | 0.4 | 0.5 | 0.6 | 0.8 | 1 | |||||||||
| States 1-3 | 1.1860 | 1.0996 | 0.9047 | 0.5578 | 2.5123 | 1.7937 | |||||||||
| QIPF | States 4-6 | 1.4799 | 0.8292 | 2.8727 | 4.4312 | 1.7927 | 1.6161 | ||||||||
| States 7-10 | 1.4956 | 3.7847 | 3.7879 | 1.4028 | 1.2349 | 1.2133 | |||||||||
| Bayesian Surprise | 1.8301 | 1.6548 | 1.6681 | 1.6255 | 1.2913 | 0.5803 | |||||||||
| Entropy Difference | 1.9174 | 1.7482 | 1.5896 | 1.4160 | 1.0191 | 0.7853 | |||||||||
| Classical IP | 0.3174 | 0.2942 | 0.2644 | 0.2451 | 0.2343 | 0.2400 | |||||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Mechanics and Entropy · Gaussian Processes and Bayesian Inference · Neural Networks and Applications
A New Uncertainty Framework for Stochastic Signal Processing
Rishabh Singh, and Jose C. Principe R. Singh and J. Principe are with the Department of Electrical and Computer Engineering, University of Florida, Gainesville, FL, 32601 USA e-mail: [email protected]
Abstract
The fields of signal processing and information theory have evolved with the goal of developing formulations to extract intrinsic information from limited amount of data. When one considers the modeling of unpredictably varying processes and complex dynamical signals with a large number of unknowns (such as those encountered in the fields of finance, NLP, communications, etc.), there is a need for algorithms to have increased sensitivity with short spans of data, while maintaining stochastic generalization ability. This naturally calls for an increased focus on localized stochastic representation. So far, most metrics developed for characterizing signals envision data from entropic and probabilistic points of view that lack sensitivity towards quick changes in signal dynamics. We hypothesize that models that work with the intrinsic uncertainties associated with local data induced metric spaces would be significantly more sensitive towards signal characterization. To this end, we develop a new framework for stochastic signal processing that is based on decomposing the local metric space of the signal in a Gaussian Reproducing Kernel Hilbert Space (RKHS). A major advantage of our framework is that we are able to implement this decomposition on a sample-by-sample basis. The key aspects of our framework are the following: (1) We use a data defined metric related to Parzen density estimation for quantifying the local structure of data in the Gaussian RKHS. (2) We use a quantum description of this metric which consequently introduces uncertainty in the structure of the local kernel space. Since the RKHS has been well established and known for providing universal data fitting capabilities, we submit that local quantifiers of the kernel space data projection could significantly improve acquisition of signal information.
Index Terms:
Uncertainty, stochastic, decomposition, metric space, dynamical signals, local quantifiers, kernel space, quantum, RKHS.
I Introduction
I-A Information Theory: Historical Perspective
An important achievement of Information Theory (IT) was the quantification of statistical uncertainty with the definition of entropy [1], which remains the leading methodology in use today. This paper focusses on other possible definitions of uncertainty with physical underpinnings, emanating from the duality between particles and waves in quantum theory, which can be applied to functional spaces but do not require the definition of a statistical measure. However, we first review some critical concepts in the field of IT that have led to the applications of entropy for real world problems. The concept of entropy has been at the forefront of IT ever since its inception in the domain of statistics by Shannon [1]. At its origins, Gibbs entropy has been a well-known metric for describing micro-states in a thermodynamical system. Hence, Shannon’s formulation of this concept as a metric associated with behavior of data opened the doors to a completely new realization of information theory based on the uncertainty formulations in physics. Subsequent to its development, Jaynes formulated a method in the context of statistical mechanics to estimate the probability distribution of data as the distribution which maximizes the entropy of the system of data (assumed as micro-states) based on certain macro-state constraints which are typically chosen as some ensemble properties of data [2]. This work has been widely celebrated in the field of density estimation [3], [4]. It also created the foundations of physics based interpretation of information theory. Further developments in information theory and stochastic signal processing have been closely intertwined with entropy and several other derived metrics and generalized forms of entropy [5], [6]. A significant related work is that of Renyi in 1956 where he proposes a generalized formulation of the Shannon’s entropic measure [7]. Renyi’s entropy has the following form:
[TABLE]
Here, is a discrete random variable with denoting the probability of taking the value .
One of the difficulties of applying IT to machine learning is that the data statistics are not usually known a-priori and hence the IT descriptors of entropy, mutual information and divergence must be estimated directly from data [8]. Perhaps the simplest of the approaches is to employ statistical methodologies of density estimation [9] and plug-in the estimators in the IT formulas. We will review first some alternatives.
I-B Maximum Entropy Method of Moments
An important extension to Jaynes’ work is the maximum entropy method of moments which is useful for the estimation of density functions in systems with undersized samples [10]. The main idea here is to construct an approximate density function of a particular system of samples by imposing constraints unique to the system (typically chosen as the moment means) on the various moments associated with data. It consists of a system of two equations from which one can obtain the Lagrangian multipliers (or the weights associated with various data moments) and the probability densities using numerical techniques such as the Newton-Raphson method. Determination of Lagrangian weights quantify the uncertainty associated with the different moments of data. Several application extensions and analysis of this method have been introduced over the past few decades [11, 12, 13]. This method of maximizing entropy with respect to the various moments of data is simple and elegant with very few assumptions in its formulation. However, the solution of the different Lagrangian multipliers and density values are not guaranteed since the optimization is based on numerical techniques. The possibility of spurious results increase when large number of moments are used. Furthermore, moment correlations are being ignored which leads to more difficulties in solving the optimization problem.
I-C Point Estimate Methods
A highly relevant class of methods involved in the formulation and modeling of data statistics are the point estimation methods (PEM) which make it possible to evaluate statistical moments of data using approximate realizations of their density only at specific points in the input space. Introduced by Hahn, Shapiro and Cox [14, 15], PEM methods, at their onset, usually involved Taylor series expansions of random variables about their means. This involves computation of higher order derivatives of functions and can hence become computationally very expensive. One of the popular earlier works in point estimate methods was that of Rosenblueth where he develops a method for estimating densities of correlated variables by assuming the joint distribution of the variables to be concentrated within a set of hyper-quadrants of the space associated with the variables [16, 17]. This method becomes impractical for large numbers of quadrants. Li introduced an improved formulation based on Rosenblueth’s method that only needs the first two statistical moments to compute PEM with almost the same accuracy as that of Rosenblueth’s method [18]. A thorough mathematical analysis and evaluation of various spatial point processes is provided in [19]. A more recent work by Decreusefond and Flint introduces a generalized formulation for point processes with the only constraint being that the processes consist of Papangelou intensities [20].
Although the statistical underpinning of IT is widely accepted, Crutchfield presents a rather unique non-probabilistic perspective of information theory where he regards the information space as a metric space (instead of a probabilistic one) created by information sources [21]. He stresses more on the topological structure (geometry) created by information and develops an information theoretic distance measure in such a space that more closely follows the metric properties of distance as compared to other measures (such as mutual information, Kullback information gain, etc.). This serves as an inspiration for us to treat the kernel space projections of data samples as a metric space instead of a probabilistic one in our framework (as we previously have done in [8]).
I-D Advances in Uncertainty Quantification Methods
The field of uncertainty quantification aims to evaluate the effect of intrinsic uncertainties present in the input signal on the model’s performance. Earlier methods of uncertainty quantification were based on large number of Monte Carlo simulations of a model to evaluate its variability [22]. This is obviously a very expensive computational procedure though reliable in terms of accuracy. To mitigate the high computational cost, surrogate models (or meta-models) were introduced as new response surfaces to give fast evaluations of changes in input statistics [23, 24]. Two such surrogate models that have gained wide popularity are Gaussian process regression [25] and polynomial chaos expansion [26, 27]. Both of these algorithms can be implemented in a non-intrusive manner which means that the model being evaluated can be treated as a black box. Wiener first introduced the idea behind polynomial chaos (PC) algorithms in 1938 when he suggested that Hermite polynomials and homogenous chaos had an important influence in integration theory related to Brownian motion [28]. However, only recently have PC based surrogate models become widely popular [29].
A polynomial chaos model involves expression of a stochastic process with finite second order moments in terms of orthogonal basis functions (given by Wiener-Askey scheme [30]):
[TABLE]
Here, represents the basis functions (or stochastic modes) and represents second order random variables of the stochastic process parameterized by . represents the PC coefficients or weights of the stochastic modes. The choice of the family of basis functions depends on the distribution of the random variables () and is given by the Wiener-Askey scheme. Any chosen basis function family, nevertheless, satisfies the following orthogonality conditions:
[TABLE]
where and represent the basis function orders.
The main objective in PC expansion is to determine the coefficients ( values in (2)) corresponding to the different modes. This can be done using intrusive or non-intrusive methods. A popular example of an intrusive method is Galerkin projection, which involves solving a system of deterministic equations where the coefficients are considered as the unknowns [31]. Galerkin projection first involves generalizing (2) in the following manner:
[TABLE]
Projecting (4) into the different polynomial basis functions , we obtain:
[TABLE]
This is a system of deterministic equations. These can be solved using integration of the unknowns (the coefficients) with respect to the particular random variable over a suitably sized stochastic space.
An example of a non-intrusive method to solve the PC coefficients is linear regression [32]. Here the coefficients are computed using an overdetermined least squares problem of the following form:
[TABLE]
A popular class of ’surprise’ quantification algorithms over the past few decades have been those related to Bayesian approaches [33, 34, 35]. Bretthorst, in his work, shows how the entropy method of moments can be formulated in terms of Bayesian probability theory [36]. Through this approach, Lagrangian multipliers are expressed in terms of their marginalized posterior distributions with respect to the number of multipliers and data. Markov Chain Monte Carlo based techniques are then used in obtaining the solutions. While this approach finds solutions that are more optimal than the method of moments, there are significant computational costs involved with Bayesian approaches and Monte Carlo methods that cannot be ignored. A very popular algorithm in this class that gained significant attention over the past decade is that based on a Bayesian definition of surprise by Itti and Baldi [37, 38]. The authors formulate the definition of surprise by using the concept of relative entropy. They evaluate the expected Kullback-Leibler (KL) divergence between the prior and posterior distributions of the model after obtaining new data. The formulation is given below:
[TABLE]
Here, is the set of models in a model space given by . represents the observed data. We can infer from the formulation that if an observed data leads to a significant change in the posterior distribution of the model, it will subsequently lead to high KL divergence between the prior and posterior thereby causing a high surprise quantity.
I-E Quantum Modeling of Stock Markets
The idea of applying quantum theory to data analysis has been pervasive in the field of econophysics [39-45]. The main motivation for doing so comes from treating dynamical signals with a large number of unknown generating functions (such as stock data) as a mixture of different quantum eigenstates associated with its underlying distribution. The earliest such attempts of using physics to describe data can be traced back to 1933 when Frisch attempted to use concepts of classical physics to model finance related dynamics [39]. One of the first crucial attempts in linking quantum physics with finance was made with the quantum field theory interpretation of financial markets where critical concepts from quantum mechanics such as path integrals and differential manifolds were intensively used in the study of the dynamics of financial markets [40, 41]. Recent work in this field involves non-classical oscillator models of the Chinese stock markets [42], [43], [44] [45].
I-F Proposed Framework and Contributions
We propose a framework for characterizing a real valued signal or time series in terms of its intrinsic dynamical moments by decomposing its point-wise stochasticity. Here, stochasticity refers to the uncertainty associated with the local structure of data functionals, instead of a probability measure. In principle, our methodology can also be linked to Gaussian process theory [25], except that we do not operate in the data space with its intrinsic probability law. Instead, we prefer to concentrate on the Reproducing Kernel Hilbert Space (RKHS) equivalent functional representation to quantify the local kernel structure of the data. Hence our framework is more closely associated with point estimate methods. The hallmark of our framework of signal decomposition lies in its ability to perform sample-by-sample decomposition of stochasticity, which is not possible to implement using current techniques. This is done by using a functional called the information potential field, which is motivated from Parzen density estimation of data using Gaussian kernel windows [8]. Hence, due the universal approximation property of the Gaussian RKHS, we are able to provide an inclusive local representation of the data, without making assumptions on the type of distribution or stochastic process associated with the data. This enables our framework to exhibit sensitivity towards local signal characteristics while simultaneously providing a generalized representation over all past samples. Since the information potential field is based on the average of the pairwise distances of a point from all available samples, it becomes feasible to treat the associated functional in RKHS as a force field (where the samples are assumed to be identical “information particles”) and hence formulate a physical description of the information potential field based on the time-independent Schrödinger equation [46]. This quantum description of the information potential field has significant consequence in our framework since it provides a quantification of uncertainty associated with the local RKHS structure. A crucial feature of this quantum description is that the wave-function is defined in the RKHS where the basis functions keep getting updated with every sample. The time-independent Schrödinger equation hence represents the local structure of the RKHS (which formally corresponds to a point-wise estimate of the PDF in a probabilistic interpretation [47]) as a combined representation of updated standing waves at any time instance. Since the temporal dependencies of the signal are embedded in the wave-function along all even order moments (see section III), the Schrödinger equation, despite being time-independent, provides an efficient spatiotemporal characterization of a time series. As is evident from the literature of entropy and stochastic decomposition, uncertainties associated with data consist of a mixture of contributions from different moments of data or its stochastic representation [13], [16], [26]. Hence, we utilize this quantum description of the signal’s local RKHS structure to extract higher order intrinsic modes (eigenstates) associated with its uncertainty and their corresponding eigenvalues. We do this by projecting the wave-function into successively higher orders of Hermite polynomial space at every sample. This is similar to formulations associated with polynomial chaos expansion in the field of uncertainty quantification and it also follows the principles of the well-known solution of the quantum harmonic oscillator. The projections, in our case however, are carried out on a sample-by-sample basis. Thereafter, we compute the corresponding information potentials associated with the various extracted modes. The computed information potentials at the different modes summarize the signal uncertainties (in the RKHS) at these modes. The overall framework is depicted in fig. 1 with the associated formulations and reasoning described in detail in sections II and III. A summary of the main steps involved in our sample based framework is as follows:
- •
Quantum description of the local RKHS space using an information potential field created by the selected kernel (and hence a description of uncertainty). We restrict the analysis to the Gaussian kernel in this paper.
- •
Extraction of different modes of the wave-function associated with the quantum description of the kernel space using Hermite polynomial embeddings.
- •
Evaluation of the Laplacians over the wave-function modes.
- •
Computation of the information potential along each mode using the computed Laplacians.
Apart from the ability to operate on a sample-by-sample basis, our framework for uncertainty decomposition of signals presents several advantages over related methods summarized before. Due to the way the Lagrangians are computed, a fundamental limitation of the maximum entropy method of moments is that the moment correlations embedded in the data are ignored. This limits the analysis of the PDF to a very restricted space close to the space of available samples. Our framework, on the other hand, expands the space of analysis much further away from the space of samples by evaluating dynamical moments of the wave-function, which in itself, already contains information related to all even order temporal dependencies of the data (i.e. pairwise differences between the point under consideration and all the other samples that have occurred over time). This also makes our framework advantageous over some of the work associated with probabilistic interpretations of PCA [48],[49], where stochasticity is limited to second order statistics due to assumption of Gaussianity. Moreover, we show in section III that the quantum description of the information potential field in our framework involves computation of the Laplacian which takes into account both temporal and inter-modal local dynamics. Furthermore, Hermitian expansions of the wave-function provide a systematic relationship between the successive moments of the wave-function (and hence between the different quantum states of the information potential field). Hence, our framework maximizes information gain and also provides a more stable basis for evaluating as many moments as needed unlike the method of moments where moment expansions depend on the feasibility of the optimization problem for finding the Lagrangians. We show in the formulation of our framework in section III that the eigenvalues associated with the different modes are empirically defined as a result of simply imposing a constraint on the information potential field corresponding to any mode to be always positive. This highly simplifies the eigenvalue determination process and hence provides an advantage to our framework when compared to polynomial chaos based methods where eigenvalue determination process is an optimization problem and hence faces convergence and computational cost issues depending on the type of numerical technique used. Our proposed framework also has several advantages over the stock modeling methods in the field of econometrics summarized before. All of the aforementioned work on quantum modeling are restricted to only specific properties pertaining to the class of stock market data being considered thereby not providing a general framework. In many of these models ([44], for instance), authors make specific assumptions on the stochasticity of data (type of motion, drifts, etc) based on the fluctuations of particular stocks. We make no assumptions on the stochastic nature of data. Additionally, unlike some of the stock models (for instance, in [43]) where authors use time-dependent quantum formulations of the stock data PDF, we use a time-independent Schrödinger equation since our local functional, defining the wave equation, implicitly contains all temporal dependencies of the data. This use of a time-independent formulation greatly simplifies our framework.
II Background Information
II-A Derivation of Information Potential Field (IPF)
Renyi’s entropy of order alpha () for a continuous random variable x is given by:
[TABLE]
The case of , Renyi’s quadratic entropy, is particular important because it leads to an efficient nonparametric family of estimators using the Parzen window method [50]. In this case, Renyi’s quadratic entropy becomes just the log of the expected value of the probability density function, i.e.
[TABLE]
Let us call the argument of the logarithm , the information potential (IP) of the data set, which is a number that is nothing but the mean value of the PDF. Let us assume that we use a Gaussian window for the Parzen density estimation, with bandwidth (or kernel size) . One can readily estimate directly from experimental data the information potential,
[TABLE]
i.e., the IP is a number obtained by the double sum of the Gaussian functions centered at differences of samples with a larger kernel size. There is a physical interpretation of if we think of the samples as particles in a potential field, hence the name information potential. Let us define a function over the data space as
[TABLE]
which we will call the information potential field (IPF). is a continuous function obtained by the sum of Gaussian bumps centered on the samples, which is the estimated PDF obtained by the Parzen window, but it can also be interpreted as a potential field similar to gravity, over the space of the samples. In fact, if we attribute unitary mass to all our samples, we can say that the IPF is always positive and regions of space with more samples will have a larger IP, while regions of the space with few samples will have a lower IP. Here, the shape of the Parzen window will determine the “gravity”, instead of the inverse law of physics. The information potential in Renyi’s entropy is nothing but the total potential field created by the samples in the data set, i.e. .
II-B Quantum Information Potential field (QIPF)
The idea of a potential field (aka probability density) over the space of the samples can be readily extended with quantum theoretical concepts [46]. The Schrödinger stationary (time-independent) equation for a particle in the presence of a potential field can be written as
[TABLE]
where is the Plank’s constant, the mass of the particle and the wave function determines the spatial probability of the particle with . is the potential energy as a function of position, corresponds to the allowable energy state of the particle and becomes the corresponding eigenvector. For a set of information particles with a Gaussian kernel, the wave-function for one dimensional information particle becomes,
[TABLE]
We can also rescale such that there is a single free parameter in (12) to yield
[TABLE]
Solving for , we obtain:
[TABLE]
which we call the quantum information potential field (QIPF) denoted by . This can also be simplified as:
[TABLE]
To determine the value of uniquely, we require that , which makes where . Note that is the eigenfunction of and is the lowest eigenvalue of the operator, which corresponds to the ground state. Given the data set, we expect to increase quadratically outside the data region and to exhibit local minima associated with the locations of highest sample density (clusters). This can be interpreted as clustering since the potential function attracts the data distribution function to its minima, while the Laplacian drives it away, producing a complicated potential function in the space. We should remark that, in this framework, sets the scale at which the minima are observed. This derivation can be easily extended to multidimensional data.
We can see that is also a potential function that differs from in (11) because it is associated with a quantum description of the IPF. The two fields are similar to each other for Gaussian kernels since the derivative of the Gaussian is a Gaussian, but it presents a big advantage because now can be operated independently as a counterpart of the samples, describing the duality between particles (samples) and waves (functionals).
III Proposed Approach: Extracting Modes of Uncertainty in the RKHS
As one can notice, when we derive information potential as a special case of Parzen’s density estimator, it becomes a localized PDF estimator. However, from a deterministic sense, information potential field (IPF) is nothing but a local functional based on the averaged pairwise distance of a point from all the other points in the Gaussian kernel space. From this perspective, its quantum description introduces uncertainty in the functional space associated with the sample location being considered at any point of time: One can consider that at an information particle location, we have no uncertainty (the field collapses to a delta function), but at any point in the RKHS that has no sample, there is an uncertainty that is quantified by the wave-function. Our framework attempts to utilize these concepts to extract the different eigenstates of the QIPF associated with the signal. The main motivation for doing so comes from assuming the signal was created by a quantum physical system that is governed by a large number of unknown forces. Consequently, the extracted eigenstates associated with the quantum framework of the signal would provide a characterization of the intrinsic governing forces acting on the system that produced the signal.
As is well known in the field of quantum physics, the time-independent Schrödinger equation describing the dynamics of the quantum harmonic oscillator can be formulated as:
[TABLE]
where the different terms have their usual meaning. It is widely known that (17) can be solved using the power series method by introducing a dimensionless variable as an expression of given by . This yields wave-functions of the different modes, , that are in fact, consecutive projections of in the space of Hermite polynomials. These solutions are given as:
[TABLE]
Hence, the solution to the Schrödinger equation for the harmonic oscillator yields infinite eigenfunctions (denoted by ) that are embedded in the orthogonal space of Hermite polynomials. Their corresponding eigenvalues are denoted by .
One can obtain similar Hermitian embeddings by projecting the wave-function of the QIPF (13) into the orthogonal spaces of consecutive Hermite polynomials. Our conjecture is that by doing so, we are obtaining the approximate intrinsic modes associated with the local RKHS structure (or the local PDF, from a probabilistic perspective) of the signal as defined by the corresponding information potential field. Hence, by exploiting the Hermitian relationship between the different higher order modes of the QIPF, it becomes possible to construct its eigenfunctions. This is conceptually very similar to working with the moment expansions of the characteristic function in statistics, but without imposing a preset family of basis functions (the complex exponentials). Here, one uses a data centric decomposition instead. The generating function of the Hermite polynomial family is given by:
[TABLE]
Upon inserting the QIPF wave-function in (19), we obtain the following generating function for the wave-functions at different eigenstates:
[TABLE]
The recurrence property of Hermite polynomials allows us to analytically compute successive orders of eigenfunctions without having to use the generating function given by (19). This saves significant computational time when evaluating higher order eigenfunctions of the signal’s QIPF in real time by computing the next order of polynomial expansion from current and previous orders using the following relation:
[TABLE]
Since the Hermite polynomial expansion is being done in the Gaussian kernel space (which is an even function), we only consider even order Hermite expansions [51]. Thus, on expanding (20) for different even values of n (eigenstates), we get the following series of eigenfunctions in the QIPF:
[TABLE]
The family of functions thus obtained in (22) form a new space of orthogonal basis functions within the RKHS totally defined by the time series. While the Gaussian kernel framework provides us with a with a universal tool for signal representation, the subsequent Hermitian projections (quantified as wave-functions) decomposes the local RKHS structure of the signal in terms of its various underlying moments thereby quantifying uncertainties along those moments.
We can normalize the Hermitian expansions such that they satisfy the following relation:
[TABLE]
We now evaluate the QIPF of samples at the different eigenfunction projections of the wave-function using (15) which is generalized here for all orders of expansion:
[TABLE]
Here, represents the mode of the Schrödinger information potential at sample , is the corresponding eigenvalue of the mode at sample and is the mode wave-function value at sample . The Laplacian operator used in the second term in (24) provides a critical advantage to our framework since it efficiently characterizes the local dynamics of the signal along time as well as across the extracted modes. The energy values at the different eigenfunction evaluations of information potential are determined empirically by asserting the requirement that , leading to:
[TABLE]
term gives the energy magnitudes (eigenvalues) of different modes at every sample. This term represents a global quantity in the QIPF since it is a result of constraining the QIPF at the particular mode to be always positive throughout the past samples. An appealing aspect of this term is that it is empirically defined without the use of optimization or regression methods as is done in the eigenvalue determination in polynomial chaos method. Therefore, (24) provides a unified representation of the QIPF at different energy levels or modes. Due to the simplicity of the constraint, it may be argued that the eigenvalues in our case do not provide exact measures of the contribution of each mode. However, we show in our experimental evaluations in section IV that they are capable of uniquely characterizing the dynamics of different signals. The proposed framework is summarized in fig. 1 and Algorithm 1.
IV Simulation Results and Analysis
In order to study the trends of the extracted QIPF modes in the sample space and analyze their response to various kernel widths, we first perform a spatial analysis of the different QIPF modes. We implement our framework on 500 samples of Lorenz series (which is a chaotic dynamical signal) to extract the first 6 even order modes of the QIPF. All simulations are conducted using MATLAB R2018b on a 2.3 Ghz intel i5 processor machine. The generating functions of the Lorenz series consist of the following mutually coupled differential equations (with , and as system parameters):
[TABLE]
The Lorenz series is generated with the parameters set as , and . The initial conditions are set as , and . The signal is also normalized to zero mean and unit variance and hence roughly varies between the amplitude levels of -2 and 2. We follow the steps shown in fig. 1 and algorithm 1 and first compute the fundamental wave-function (13) of the quantum information potential field (QIPF) at different locations in the input space using all of the 500 samples of the signal. This is followed by computation of the Hermite polynomial embeddings of the fundamental mode wave-function. We use 6 successive even order Hermite polynomial expansions for our analysis. We compute the QIPF corresponding to each of the extracted modes of the wave-function using (24) and (25), where represents the mode number and represents the sample number. Fig. 2 shows the plots of these modes extracted at a range of locations in the input space using different kernel widths. Several observations can be made from the plots. Firstly, one can observe that the different QIPF modes peak in a mutually exclusive manner and spread out upon increasing the kernel width. The mutual exclusivity can be attributed to the orthogonal nature of Hermite polynomial expansions. Secondly, we observe that the QIPF modes, in general, peak at their edges away from the mean and hence emphasize the more uncertain regions of the sample space. The higher order states successively emphasize the more distant regions in the input space. The trends of the different QIPF states in the region within the dynamic range of the signal are more sensitive to the kernel width. For extremely low kernel widths, as can be seen from fig. 2(a), the first few QIPF modes are completely diminished and the higher order modes dominate the signal’s representation in all regions of sample space. Since the local kernel space of the signal modeled using extremely low kernel widths will be very uncertain, it is expected for higher order modes to dominate the signal’s representation in such cases. On increasing the kernel width (fig. 2(b)), some lower order modes (modes 2 and 3) begin to dominate the signal’s representation in the region around the mean. For moderate kernel widths (figs. 2(c) and 2(d)), the first mode of the QIPF dominates the immediate region around the mean. For larger kernel widths (figs. 2(e) and 2(f)) which exceed the dynamic range of the signal, we can see that high order modes begin to emerge in the region around the mean. Since very large kernel widths imply equally likely outcomes (increased uncertainty), it is logical for the higher order modes to dominate the signal’s representation around the mean region. This behavior is remarkably similar to physical systems. Suppose that we have a drum, with a skin membrane. If we increase the tension of the membrane and hit it, the drum will vibrate for a long time. In our potential field, the stiffness is controlled by the kernel size. If the kernel size is large, the QIPF becomes stiffer leading to the energy in the higher QIPF modes to increase. If one decreases the kernel size, the membrane becomes more elastic leading to many local modes that decay much faster. One remarkable variable that we have not yet fully identified is the wavelength of the QIPF propagation, but its dependency on the kernel size is clear.
We analyze how the different regions and local dynamics of a signal are represented by our framework in real time by doing a sample-by-sample implementation (a causal analysis without access to the entire signal beforehand). As an illustrative example to this end, we implement our framework on 500 samples of Lorenz series generated and normalized in the same way as before. However, this time, the signal is scaled to half its original amplitude level. The samples of the scaled signal are used for computing the QIPF. The points at which QIPF is computed, however, are sample locations of the unscaled signal as is shown in fig. 3(a). This is done to evaluate the QIPF at regions outside of the dynamical range of the signal (in addition to the inside ones). It should be noted that the points of evaluation inside the dynamical range of the signal do not generally overlap with the scaled signal. They do, however, have roughly the same dynamical structure at the corresponding points. We evaluate the QIPF at each point of evaluation by extracting the QIPF modes and taking their average. We use a moderate kernel width of 0.7. At each point of evaluation, only the past samples of the scaled signal are utilized for the computations at that point. Fig. 3(b) shows the average of first 5 extracted modes of the QIPF at each point of evaluation along with the classical (conventional) information potential field values and fig. 3(c) shows the same for the first 10 modes of the QIPF. For visual clarity, only values from 200th to 500th points of
evaluation are shown for both cases. We can observe that in both cases, there is a significant difference between the sensitivity of the QIPF and that of the classical IPF. They also follow opposite trends with respect to the points of evaluation since the conventional (classical) IPF follows the PDF of the signal whereas the QIPF follows the uncertainty. The QIPF can also be seen to drastically increase at points of evaluation that are outside of the dynamical range of the scaled signal. It tends to be the lowest at high sample density regions. Upon comparing fig. 3(b) and fig. 3(c), one can notice that increasing the number of modes of the QIPF leads to a more detailed evaluation of how uniquely uncertainty gets quantified at every point (even within the dynamical signal range). One can observe more jumps/peaks in the uncertainty within the dynamical signal range when the number of modes is increased, especially at points where the signal dynamics visibly change.
To demonstrate the effectiveness of the proposed framework in characterizing a signal in terms of its various intrinsic dynamical modes, we use a pedagogical example of how a sine wave function differs from Lorenz series with respect to their composition of dominant QIPF modes. Since our framework in based on the decomposition of local kernel space structure in terms of even order oscillator harmonics, we expect the sine wave, which consists of a single oscillator generating function, to get encoded in much fewer QIPF modes when compared to Lorenz series which is a chaotic dynamical system. We generate a sine wave having a frequency of 100 Hz and sampled at a rate of 8000 samples per second to mimic a continuous signal for a total time of 0.16 seconds. The Lorenz series is generated in the same way as before (without amplitude scaling). Both signals are normalized to zero mean and unit variance. We compute the QIPF modes using (24) and (25) and extract 18 successive even order modes of the QIPF to encode the uncertainties at the different sample locations of each signal. The kernel width used for doing so for both signals is fixed to 0.3, which is sufficiently small for more emphasis of the local regions of the sample space. Fig. 4 shows the signals (left column) and the corresponding histogram plots (right column) of the number of times the value of each QIPF mode dominated over the others throughout the durations of the signals. As can be seen in fig. 4, there are only two dominant modes in case of the sine wave (modes 2 and 3). The dominant modes of Lorenz series, on the other hand, are significantly more spread out towards higher orders thus indicating a more complex dynamical structure of the signal.
We extend this analysis to different frequencies and sampling rates of the sine wave signal (figs. 5 and 6) as well as different parameters and initial conditions of the Lorenz series (fig. 7). It is interesting to note in fig. 5 that the effect of increasing the signal’s frequency () has no significant effect on the distribution of QIPF modes that dominate the signal (which is still limited to modes 2 and 3). There is, however, a slight reduction in the third mode’s proportion when the signal is aliased as can be seen in fig. 5(c). Fig. 6 shows the same analysis done on sine waves generated using a mixture of different frequency components. As can be seen from the corresponding histogram plots, the distribution of dominant QIPF modes begins to spread out more towards the higher modes when the number of frequency components in the signal increases. The modal distribution of the Lorenz series, in fig. 7, can be seen to be significantly more responsive towards changing generating system parameters and initial conditions. Since chaotic dynamical systems have a high sensitivity and long-term dependency towards system parameters and initial conditions, this result is expected. Overall, these results show that our framework is more dependent on the genrating system parameters than local changes when charaterizing signals in terms of composition of modes.
We also compute the QIPF energy levels (or eigenvalues) of the first 18 even order modes of the information potential extracted from various signals. The formulation for computing the energy levels associated with various states is given by (25), which is the minimum value of the Laplacian at each mode required to constraint the QIPF at that mode to be positive throughout time. Fig. 8(a) shows the normalized energy levels associated with the first 18 even order states of sine wave signals of different frequencies. All of these signals are generated using the same sampling rate (8000 Hz) and the samples in the first 0.05 seconds of each signal are considered for the computations. The eigenvalues shown here for each mode are computed using all of the samples simultaneously. Fig 8(b) similarly shows the normalized QIPF energy levels associated with the first 18 even order QIPF modes of the Lorenz series signals generated using different parameters or initial conditions. 500 samples for each Lorenz series signal are used for the evaluations. It can be seen from both subfigures in fig. 8 that the energy levels increase consistently with the state number. It is interesting to note here that the slope of the energy level vs state number curve generally flattens out rather quickly (within first 4-5 modes) for the sine wave signals as compared to that associated with the Lorenz series signals. This suggests (and is also expected) that higher order states do not contribute significantly in the representation of the sine wave dynamics as they do in the representation of Lorenz series signals. This is also consistent with the trends observed in fig. 5. For increased frequency sine wave, however, larger variance is observed in the energy levels of higher order states, likely due to increasingly varying characteristics and sensitivities of the higher order modes. For both the classes of signals in fig. 8, one can observe that the first few modes of the QIPF are quite similar. Discriminative properties particular to specific signals (caused due to change in parameters, initial conditions or fundamental frequency components) start to get reflected in higher order QIPF states.
In order to illustrate the sensitivity of the proposed framework on the changing dynamical behavior and uncertainties associated with the signal, we implement our framework on a sample-by-sample basis on 1200 samples of Lorenz series where the last 700 samples are corrupted using heteroscedastic white Gaussian noise. The noise variance (and consequently the SNR) randomly changes after every 100 samples (as shown in table 1). The first 500 samples are uncorrupted. We use a window of past 100 samples to perform computations at each sample location. The signal under consideration is shown in fig. 9. The noise is added from the 500th sample onwards. We compute the first 25 states of the QIPF at every sample location using the same formulations given by (24) and (25) and as depicted in fig. 1. We use a kernel width of 0.4. The heat-map shown in fig. 10 represents the values of the different states of the QIPF at all sample locations. For clarity of analysis, all values in the heat-map matrix are normalized with respect to values only in its corresponding row (i.e. all values of the particular state throughout time). From the heat-map, we can observe how the different states of the QIPF react to the inclusion of noise. The first few states (1 to 5) show very little response to noise changes in general. As we move on to the middle order states (6 to 15), we observe increased response to some high changes in the noise statistics. Higher order states (state 16 onwards) can be seen to be even more sensitive towards changes in noise statistics. The highest order states can be seen to respond drastically towards all types of noise inclusion from the very first interval itself. Fig. 11 shows the expected value of the different sets of QIPF states (1-4, 10-13 and 22-25) at each sample location. The sensitivity trends of the different sets of states are apparent here with the expected value of the first 4 states changing negligibly with noise inclusion. The expected value of the middle order states (10 to 13) can be seen to be significantly more responsive towards some of the high noise transitions (especially from the 1000th sample onwards). Expected value of the higher order states (22 to 25) shows increased sensitivity towards all changes in noise variances as is evident from its relatively quick response towards all intervals of noise. Furthermore, the changes in the expected value of higher order states can also be seen to be roughly correlated with the changes in SNR values asscociated with the noise. It is interesting to observe here that addition of noise does not lead to more oscillations or spikes in the expected state values even though the framework is implemented on a sample-by-sample basis. At the same time, however, the expected value of higher order states changes significantly at different noise intervals. This is indicative of the framework’s ability to identify the global signal statistics despite operating locally.
We use this approach to quantify the sensitivity of our framework towards statistical changes in the signal and thereby compare our framework with entropy based surprise quantification methods [37], [38]. We perform the quantification and analysis using our framework on 5000 samples of Mackey Glass chaotic dynamical series. This dynamical system is governed by the following non-linear delay differential equation:
[TABLE]
where is the delay and , and are other parameters.
The 5000 samples are generated by setting the delay parameter () as 30 and other parameters as , . Heteroscedastic noise (in the range of 0-20 decibels), with the variance changing after every 500 samples, is added to the last 2500 samples of the generated Mackey Glass signal. We implement our framework on the signal by extracting the first 10 even order QIPF modes followed by finding the expected values of states 1 to 3, 4 to 6 and 7 to 9 at each sample location denoted by , and respectively, where is the sample number. We then quantify the change detection performance of the three groups of states by measuring their sensitivity with respect to the change in noise variance. The sensitivity () is measured by evaluating the change in Euclidean norm of the state values from one interval of the noise corrupted samples to the next where the variance of the noise changes. It is given as:
[TABLE]
Here is the sample interval and is 1-3, 4-6 or 7-9 depending on which state group we consider. is the decibel measure of noise in the sample interval . Hence, using this measure, we evaluate the change in a particular state group with respect to the change in noise from one sample interval, , to the next, . The sample intervals are non-overlapping and have a length of 500 samples which is the same as the interval length in the heteroscedastic noise where the variance is constant. We compare the sensitivity of our framework with that of the Bayesian surprise model (7) which measures the amount of surprise associated with each data sample by evaluating the KL divergence between the prior and posterior model distributions. It is reformulated here as below:
[TABLE]
For comparisons, we use the Parzen density (using Gaussian kernel windows) as the model distribution in the Bayesian surprise framework since the information potential, which is used by our framework as the local kernel space quantifier, is ultimately a metric derived from Parzen density estimation (as has been shown in section II). The model distribution in the Bayesian surprise framework is updated with every sample. However, the space over which integral computations are done at every sample (model space in (29)) is fixed to be a regularly spaced set of values lying in the dynamic range of the generated Mackey Glass series. The sensitivity here is measured by replacing and in (28) with the two integral computations seen in (29). Here is the set of updated distributions with respect to the data in the next interval of samples. Hence, sensitivity related to KL divergence evaluated here measures the differences in statistics of the neighboring interval of samples where the noise variances are different from each other. The other metric we compare our framework with is the sensitivity associated with simply the entropy differences between the different sample intervals where the noise variance changes. The sensitivity values for the different frameworks evaluated at various kernel widths are shown in table II. The values shown are the average results of 10 simulation runs for each framework. Before evaluating the sensitivities, normalization of values (to zero mean and unit variance) was done for each framework with respect to the evaluated values at all samples and independent of other frameworks. It can be seen here that for all kernel widths above 0.2, our framework has higher sensitivity to changes in signal statistics than other models. Upon analyzing how the sensitivity of our framework changes with respect to kernel width, one can notice that the higher order set of QIPF states are more sensitive at lower kernel widths. On increasing the kernel width, the lower order QIPF states start becoming more sensitive when compared to higher order states. This is expected because increasing the kernel width starts to spread out the higher order states to beyond the dynamical range of the signal within which changes take place. However, there is also a compromise here because the best sensitivity values (among the different state groups) can be seen to decrease when the kernel width is increased thus indicating that the higher order states capture the changes in signal statistics better than the lower order states. Our framework is the most sensitive at moderate kernel widths of 0.5 and 0.6 (at which the higher order state group is most sensitive) for this example. In general, the variation of state sensitivity with respect to the kernel width also depends on the dynamcal structure of the signal.
V Conclusion
In this paper, we have introduced a new framework for stochastic signal processing that utilizes the information potential as the local kernel space quantifier and exploits its quantum physical description to extract its various dynamical modes that quantify uncertainty. We have stressed on the importance of local metric space structures in the charaterization of signals, instead of probabilistic measures. We have shown how this framework can be implemented on a sample-by-sample basis and have highlighted its several key advantages compared to other methods both theoretically and experimentally. We have also shown that our framework is highly sensitive towards the local intrinsic dynamics of the signal while also being able to provide a generalized global stochastic representation. As future work, we intend to apply this framework in the context of adaptive filtering and predictive algorithms. We also intend to utilize this framework as an RKHS based uncertainty quantifier to analyze the performance and robustness of deep learning models.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C.E. Shannon and W. Weaver, “The Mathematical Theory of Communication,” University of Illinois Press , Urbana, 1949.
- 2[2] E.T. Jaynes, “Information Theory and Statistical Mechanics,” Physical Review , Vol. 106, No. 4, 1957.
- 3[3] George R. Terrell, “The Maximal Smoothing Principle in Density Estimation,” Journal of the American Statistical Association , 85:410, 470-477, DOI: 10.1080/01621459.1990.10476223
- 4[4] Hang K. Ryu, “Maximum entropy estimation of density and regression functions,” Journal of Econometrics , Volume 56, Issue 3, 1993, Pages 397-440, ISSN 0304-4076
- 5[5] C. Tsallis, “Possible generalization of Boltzmann-Gibbs statistics,” Journal of Statistical Physics , 52 (1988), p. 479.
- 6[6] S. Kullback and R.A. Leibler, “On information and sufficiency,” Annals of Mathematical Statistics 55 (1951) 79–86.
- 7[7] A Renyi, “On measures of entropy and information,” In Proc. Fourth Berkeley Symp. Math. Stat. Prob. , 1960, volume 1, page 547, Berkeley, 1961. University of California Press.
- 8[8] J. C. Principe, “Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives,” Springer, New York (2010).