Wearable Travel Aid for Environment Perception and Navigation of Visually Impaired People
Jinqiang Bai, Zhaoxiang Liu, Yimin Lin, Ye Li, Shiguo Lian, Dijun Liu

TL;DR
This paper introduces a wearable device resembling eyeglasses that aids visually impaired individuals in environment perception and navigation by detecting obstacles, categorizing objects, and guiding users through audio cues, enhancing safety and independence.
Contribution
The study presents a novel wearable assistive device integrating RGB-D sensing and deep learning for obstacle detection, semantic understanding, and navigation guidance for the visually impaired.
Findings
Participants successfully avoided obstacles using the device.
The device accurately categorized obstacles in real-time.
Users navigated complex environments more safely.
Abstract
This paper presents a wearable assistive device with the shape of a pair of eyeglasses that allows visually impaired people to navigate safely and quickly in unfamiliar environment, as well as perceive the complicated environment to automatically make decisions on the direction to move. The device uses a consumer Red, Green, Blue and Depth (RGB-D) camera and an Inertial Measurement Unit (IMU) to detect obstacles. As the device leverages the ground height continuity among adjacent image frames, it is able to segment the ground from obstacles accurately and rapidly. Based on the detected ground, the optimal walkable direction is computed and the user is then informed via converted beep sound. Moreover, by utilizing deep learning techniques, the device can semantically categorize the detected obstacles to improve the users' perception of surroundings. It combines a Convolutional Neural…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1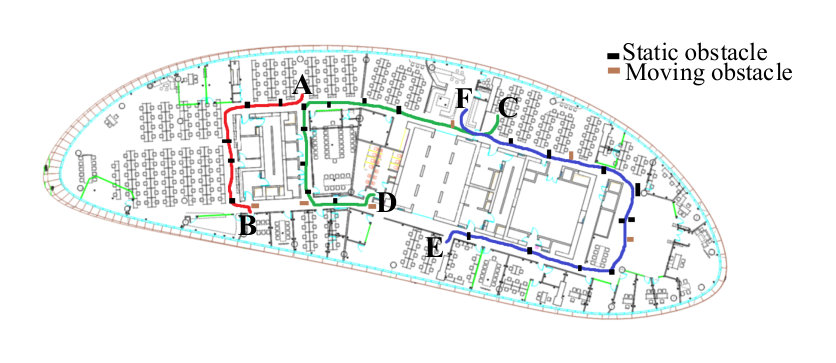 Figure 2
Figure 2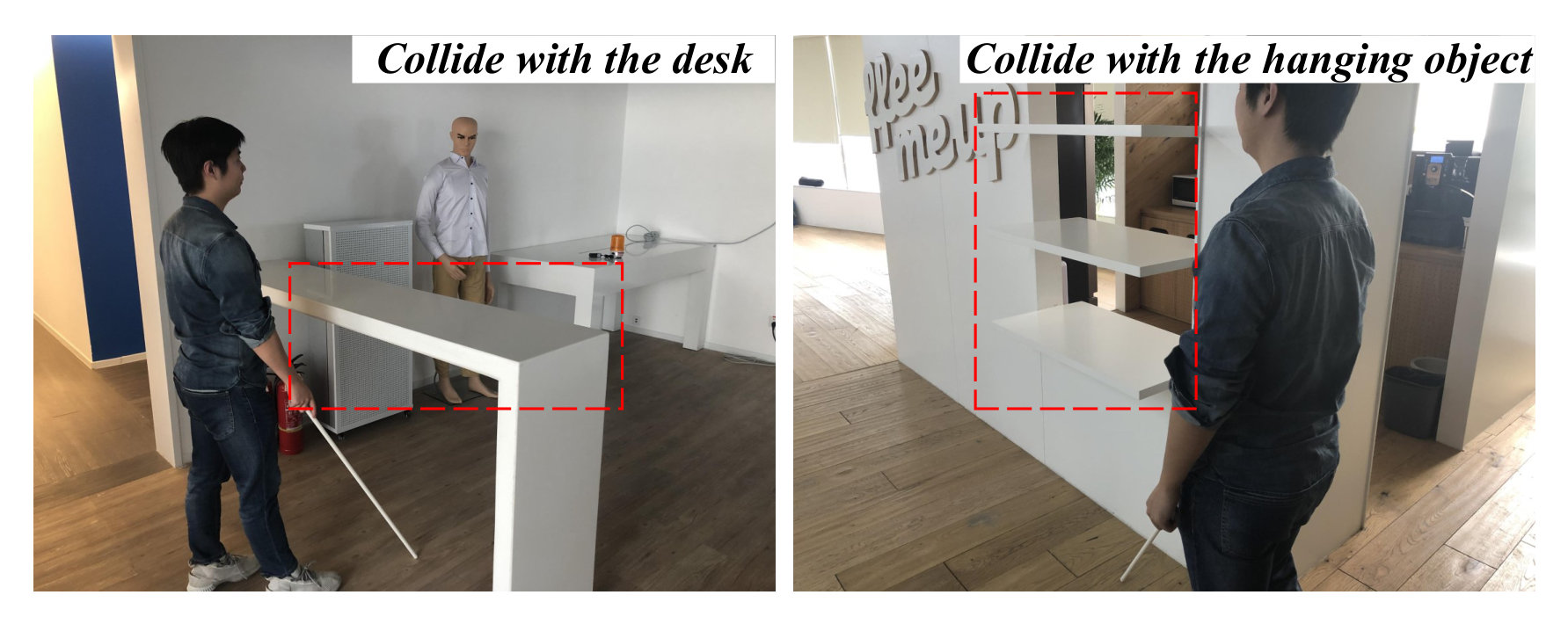 Figure 3
Figure 3 Figure 4
Figure 4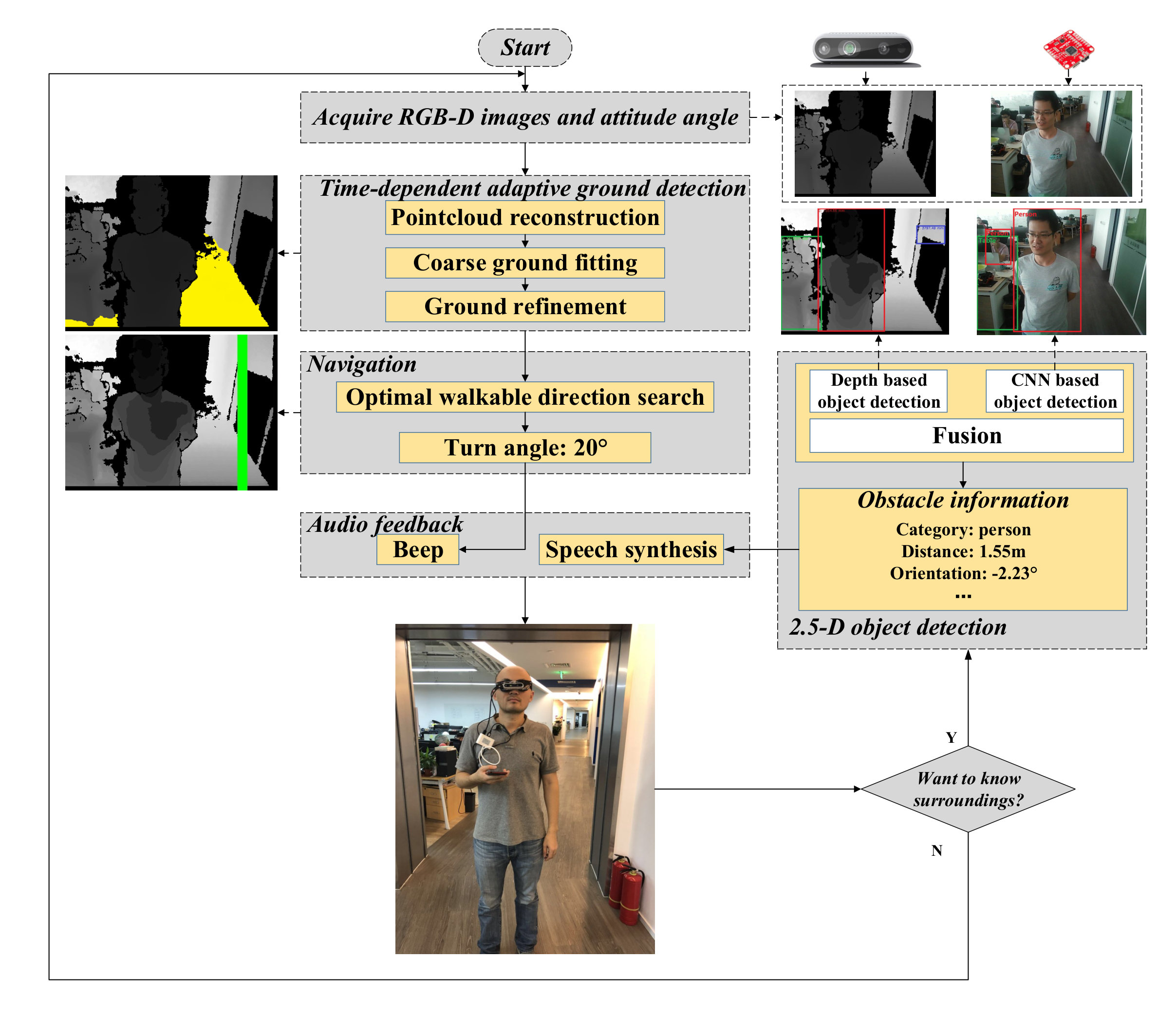 Figure 5
Figure 5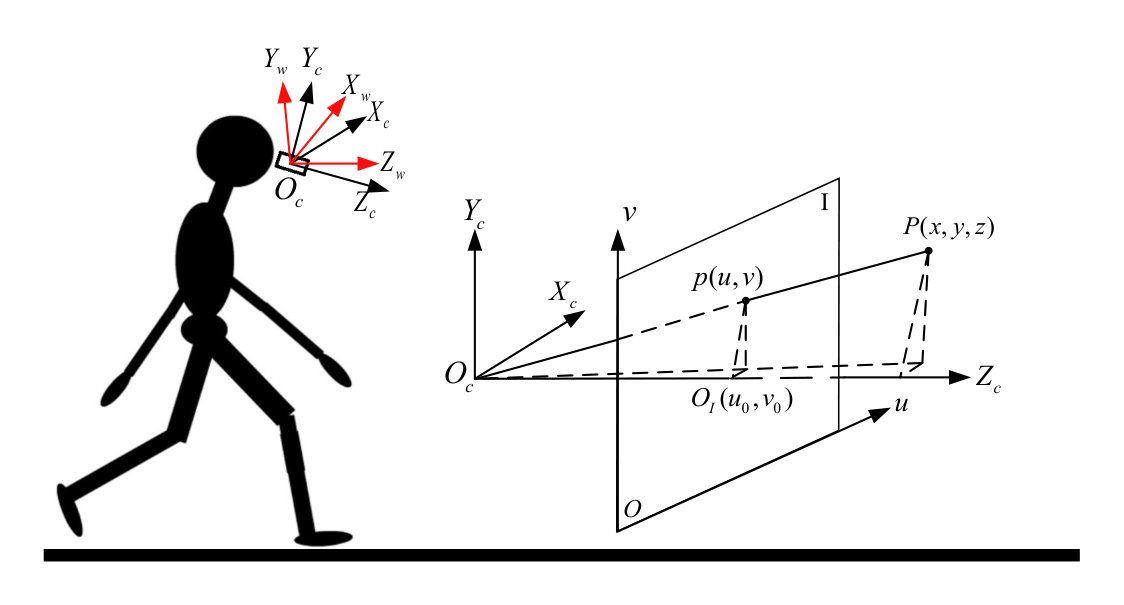 Figure 6
Figure 6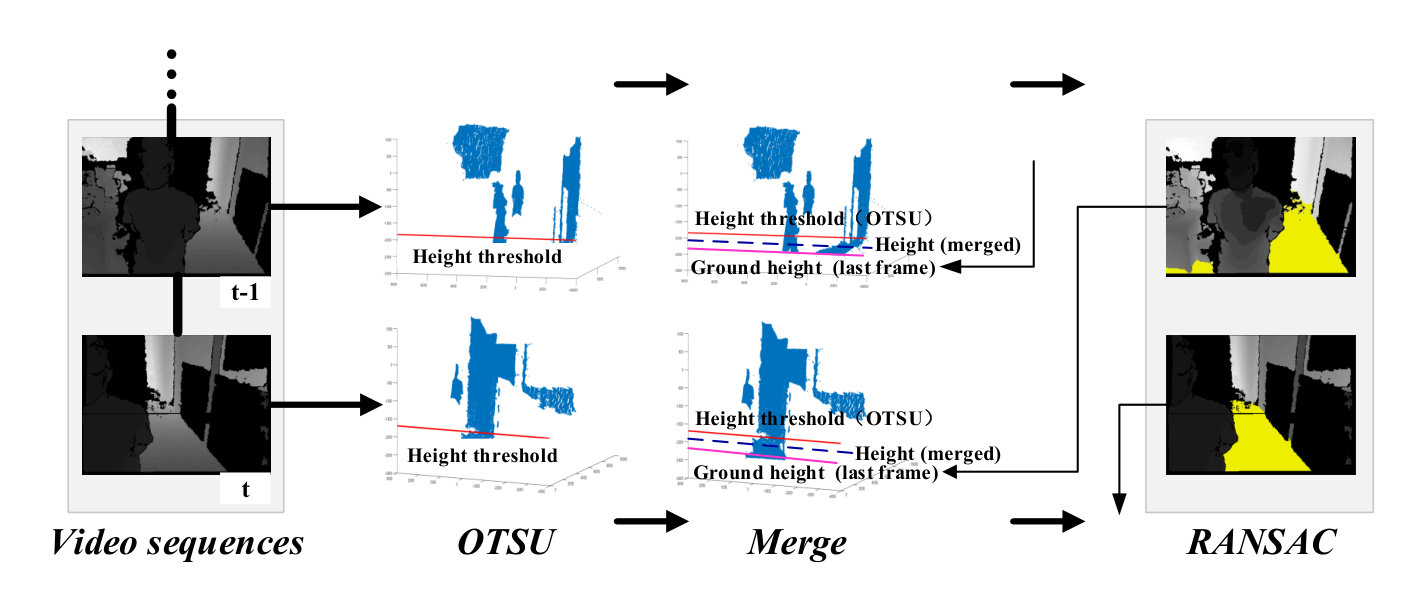 Figure 7
Figure 7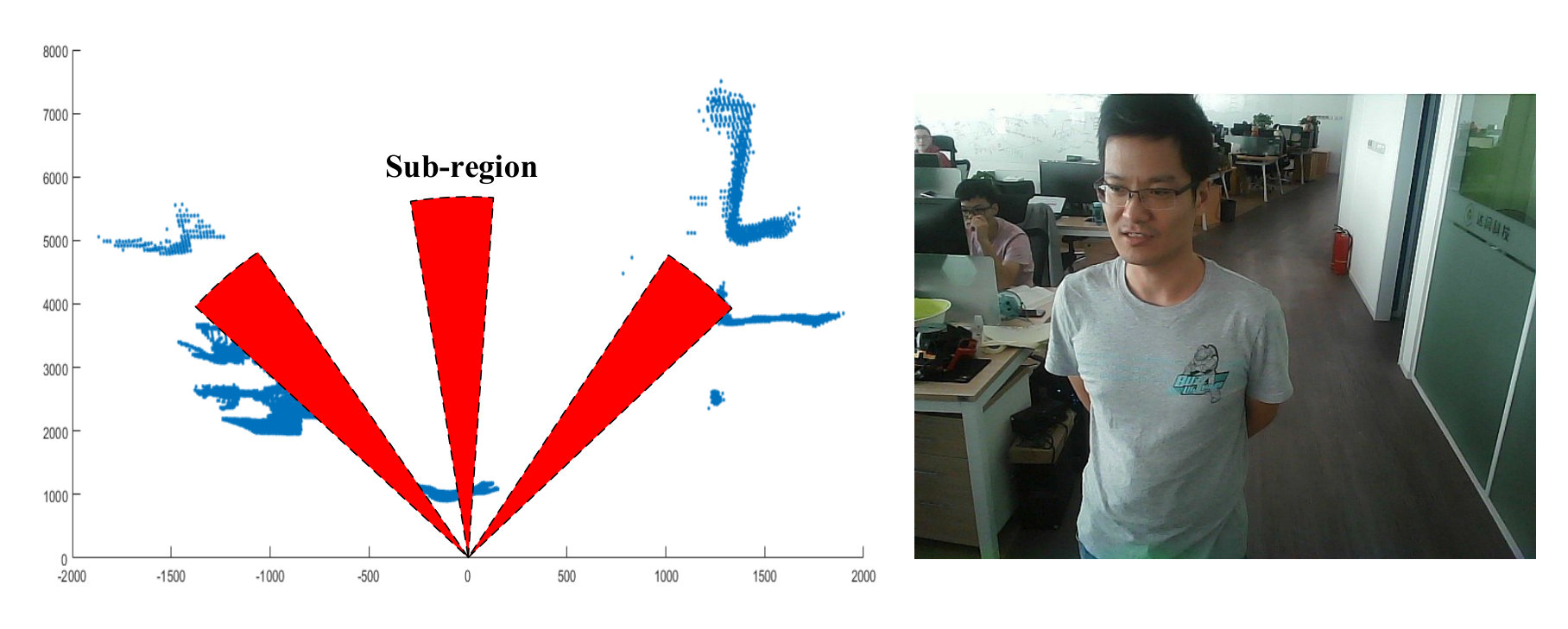 Figure 8
Figure 8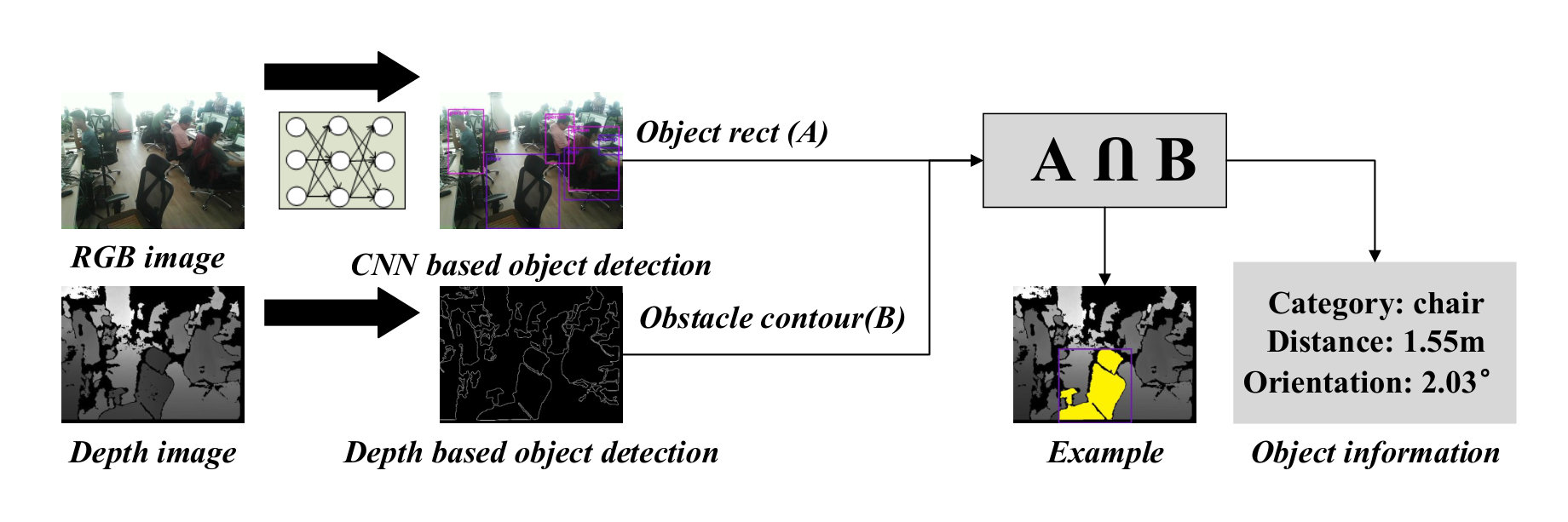 Figure 9
Figure 9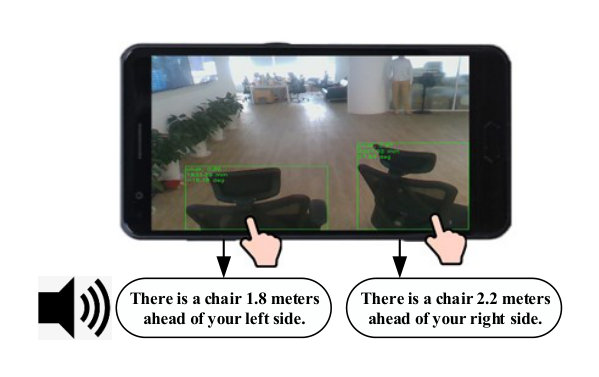 Figure 10
Figure 10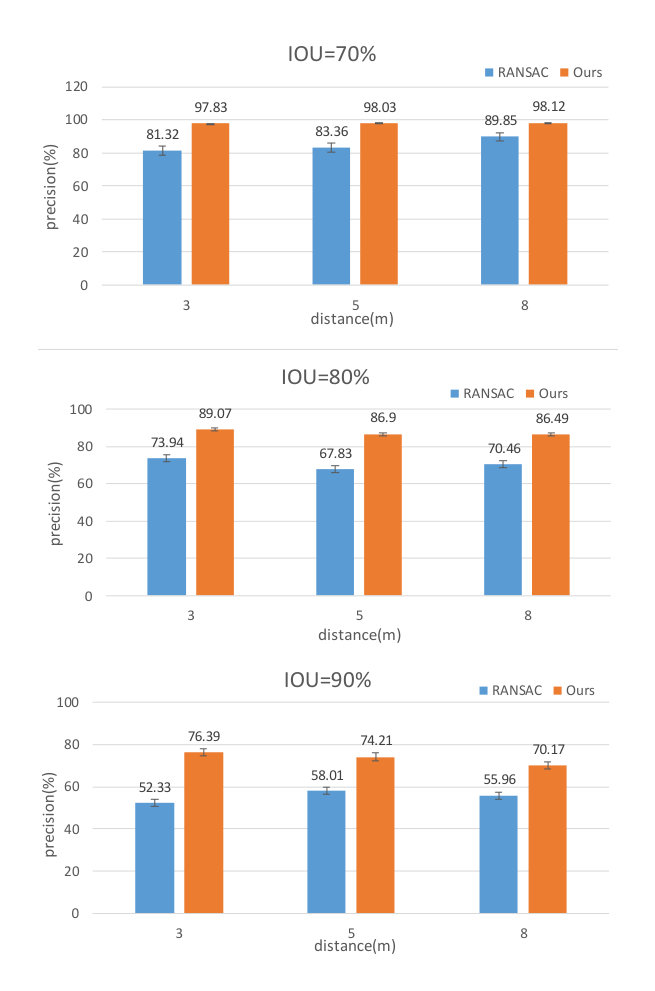 Figure 11
Figure 11 Figure 12
Figure 12| Paths | Length(m) | Obstacles | Average time(s) | Total collisions | ||
| Ours | Cane | Ours | Cane | |||
| AB | 22 | 6 | 70.8 | 71.5 | 0 | 0 |
| CD | 43 | 11 | 232.3 | 268.2 | 0 | 19 |
| EF | 80 | 12 | 478.1 | 512.3 | 0 | 23 |
| Processing step | Average time (ms) |
|---|---|
| RGB and Depth images acquisition | 0.66 |
| Ground detection | 13.53 |
| Optimal walkable direction search | 7.19 |
| 2.5-D Object detection | 114.13 |
| Total (except 2.5-D object detection) | 22.17 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTactile and Sensory Interactions · Video Surveillance and Tracking Methods · Gaze Tracking and Assistive Technology
Wearable Travel Aid for Environment Perception and Navigation of Visually Impaired People
Jinqiang Bai, Zhaoxiang Liu, Yimin Lin, Ye Li, Shiguo Lian, Dijun Liu J. Bai is with is with the School of Electronic Information Engineering, Beihang University, Beijing, 10083, China, e-mail: [email protected]. Liu, Y. Lin, Y. Li, and S. Lian are with the AI Department, CloudMinds Technologies Inc., Beijing, 100102, China, e-mail: robin.liu, anson.lin, yale.li, [email protected]. Liu is with China Academy of Telecommunication Technology, Beijing, 10083, China, e-mail: [email protected] received xx, xx; revised xx, xx.
Abstract
This paper presents a wearable assistive device with the shape of a pair of eyeglasses that allows visually impaired people to navigate safely and quickly in unfamiliar environment, as well as perceive the complicated environment to automatically make decisions on the direction to move. The device uses a consumer Red, Green, Blue and Depth (RGB-D) camera and an Inertial Measurement Unit (IMU) to detect obstacles. As the device leverages the ground height continuity among adjacent image frames, it is able to segment the ground from obstacles accurately and rapidly. Based on the detected ground, the optimal walkable direction is computed and the user is then informed via converted beep sound. Moreover, by utilizing deep learning techniques, the device can semantically categorize the detected obstacles to improve the users’ perception of surroundings. It combines a Convolutional Neural Network (CNN) deployed on a smartphone with a depth-image-based object detection to decide what the object type is and where the object is located, and then notifies the user of such information via speech. We evaluated the device’s performance with different experiments in which 20 visually impaired people were asked to wear the device and move in an office, and found that they were able to avoid obstacle collisions and find the way in complicated scenarios.
Index Terms:
Wearable assistive device, navigation, Convolutional Neural Network, object recognition.
I Introduction
According to the World Health Organization (WHO), there are about 285 million visually impaired people all over the world [1]. Visual impairment makes it challenging for them to perform autonomous navigation and environment perception in unfamiliar environments [2, 3]. Visually impaired people usually asked white canes or guide dogs for help when detecting obstacles over the past years. However, they may still suffer injuries from hanging obstacles, such as scaffoldings and portable ladders, as white canes and guide dogs can only detect obstacles at heights up to their chests [4, 5]. Recently, Electronic Travel Aids (ETAs) [6] utilizing advanced sensing techniques have greatly improved the travelling experience of visually impaired people. However, the ultrasonic sensor based ETAs are poor at obstacle identification due to the wide beam angle of ultrasonic sensors, and the laser sensors based ETAs are expensive, heavy and have high power consumption, which make them unsuitable for wearable applications [4, 7]. Although vision based ETAs (e.g. monocular camera based [8], stereo camera based [9, 10] and Red, Green, Blue and Depth (RGB-D) camera based [11, 12]) have been widely used for assisting visually impaired people to avoid obstacles and find obstacle-free paths, some problems still exist. For example, a chair may be considered as an obstacle when a blind person is looking for a seat, or no path will be found to enter a room with closed doors. Whereas suppose the object recognition technique be adopted, the visually impaired people can find the chair to sit or open the door to enter the room. Therefore, there is a need for developing new assistive devices to help visually impaired people in navigation and environment perception.
This paper proposes a wearable assistive device (see Fig. 1) for visually impaired people’s navigation and environment perception. The presented device detects the ground accurately and rapidly by leveraging an adaptive ground height segmentation algorithm and utilizing the ground height continuity among adjacent frames. With the detected ground, the optimal walkable direction can be computed and corresponding beep sound will be played out for blind navigation. Meanwhile, we adopt a lightweight Convolutional Neural Network (CNN) to semantically categorize the detected objects in the RGB image and then extract the object contour in the depth image to identify where the object is located. All the semantic information is finally converted to speech to inform the user about the perceived surroundings.
II Related Work
This research builds on important related work of ground detection and object recognition. Because the vision based assistive devices have advantages over the ultrasonic or laser sensor based devices as mentioned above, this section focuses the relevant works on vision based ground detection and object recognition.
II-A Ground Detection
General ground detection algorithms can be divided into scene segmentation based algorithms and surface normal vector estimation based algorithms.
Segmentation: Saitoh et al. [10] proposed a mean-shift algorithm to fit the ground plane. If the angle between the fitting ground and the horizontal plane is less than a threshold, the ground will be taken as a traversable area. However, the algorithm is too sensitive to the threshold. Rodriguez et al. [14] proposed a Random Sample Consensus (RANSAC) [15] based ground plane detection method and the potential obstacle was represented by polar grid. The ground detection error of this method reaches more than ten percent, leading to high obstacle detection errors. The wearability of the system and the integration of its main components into smaller devices should also be improved.
Surface normal vector estimation: Koester et al. [16] presented a gradient and surface normal vector based detection algorithm to compute the accessible sections effectively even in crowded scenes. However, the success rate of detection heavily relies on the quality of 3-Dimensional(D) reconstruction process. Bellone et al. [17] estimated the normal vectors to a local surface via Principal Component Analysis (PCA) and generated an unevenness point descriptor to detect traversable and non-traversable regions. The performance of the method was greatly affected by the search radius, which limits its applications in practice. Aladren et al. [7] used depth and color images to detect the ground in longer distance. Although their system achieved high ground detection accuracy, it is too computational expensive (2 frames per second) for visually impaired people to navigate in real time. Similar to our work, Imai et al. [18] proposed a ground detection approach which considered both ground height and normal vectors. However, since the ground height was computed only by one column data in depth image, it is prone to error if an obstacle happened to exist in this column. In contrast, the ground height in our approach is computed more robustly and rapidly through weighting the ground heights in previous and current frames.
II-B Object Recognition
Tapu et al. [21] presented a real-time obstacle detection and classification system for safe navigation of visually impaired people. The system used Scale Invariant Feature Transform (SIFT) and Features from Accelerated Segment Test (FAST) features to extract points of interest, and used Support Vector Machine (SVM) and Bag of Visual Words (BoVW) to classify these points. Although the system achieved 90% precision of classification, the information about object distance is not available, and this will result in misguidance to blind individuals. Lee et al. [11] proposed a robust depth-based obstacle detection system to obtain obstacle information which contains the distance, while it did not employ object recognition techniques, leading to poor environment perception functions.
Since AlexNet [22] won the ImageNet Challenge: ILSVRC 2012 [23], CNN based object detection methods have become unprecedentedly popular. Although these methods have higher detection accuracy, they usually have large network sizes and high hardware performance requirements. Kaur et al. [24] proposed a faster Recursive Convolutional Neural Network (RCNN) based scene perception system for visually impaired individuals. The system is able to provide the obstacle category and distance information. However, the distance information is obtained only through a single-line laser, making it unavailable or prone to error for some obstacles. Tapu et al. [25] proposed a DEEP-SEE framework that used both computer vision algorithms and CNN to detect objects encountered during navigation. Although its recognition accuracy is satisfactory, the heavy computation load makes it difficult to be implemented on a smartphone.
Lightweight CNN based 2-D object detection algorithms [26][27][28][29][30] have made great progress in recent years. They usually provide object category and location information in 2-D images, while there is still a lack of distance information. As a result, an object painted on the ground may be considered as an obstacle, and the visually impaired people will be misled.
To overcome the above limitations, we propose a 2.5-D object detection method that can provide the object category, distance and orientation information to make visually impaired people travel more easily.
III System Design
As shown in Fig. 2, the system first acquires RGB image and depth image from an RGB-D camera, and also obtains the camera attitude angle from an Inertial Measurement Unit (IMU) attached on the camera. Then based on the above sensor data, a time-dependent adaptive ground detection algorithm is performed to detect ground. Next, an optimal walkable direction search algorithm is employed to find the direction that visually impaired people can follow. This direction will then be converted to beep sound to give the users instructions. When the user wants to know the surroundings, he can double tap the smartphone screen to trigger the 2.5-D object detection function. The surrounding information including category, distance and orientation of all obstacles will be provided to the user through speech. The algorithms will be described in the following sections in detail.
III-A Time-Dependent Adaptive Ground Detection
Pointcloud reconstruction: As shown in Fig. 3, the camera coordinate system is centered at the camera, and the positive axis, axis, and axis are defined as the camera’s facing direction, up direction and left direction respectively. The world coordinate system is centered at the camera coordinate system center, the positive axis, axis, and axis are the user’s facing direction, vertically upward direction, and left direction respectively. Both coordinate systems are the left-handed Cartesian coordinate systems. The pixel value of point in the depth image represents the distance between point and the camera, which is equal to . With the camera attitude angle measured by the IMU, the corresponding 3-D pointcloud in the world coordinate system can be calculated through:
[TABLE]
where is the camera intrinsic parameter matrix, point is the reconstructed point in the world coordinate system, is the camera pitch angle, is the camera roll angle.
Coarse ground fitting: As shown in Fig. 4, the initial ground height threshold is calculated adaptively using the OTSU algorithm [31] in the current frame. Since the change of ground height in two adjacent frames is usually limited, the ground height of the previous frame is used to reduce the perturbation of other planes (e.g. desk, sofa) (see Fig. 9). The final ground height threshold is computed as:
[TABLE]
where are the weights.
Due to the inherent limitation of the depth camera, the depth accuracy always drops down with the increase of distance. Besides, the obstacles that are too far away from the person do not need to be considered. Therefore, only the points within a threshold are used in order to reduce computation cost. By making use of the ground height and the distance threshold , the 3-D points for fitting the coarse ground can be computed as:
[TABLE]
Then the coarse ground is fitted with RANSAC algorithm [15], and represented as:
[TABLE]
Ground refinement: The normal vector of coarse ground plane can be obtained directly by Eq. 4, and the ground pitch angle will then be computed through:
[TABLE]
where is the normal vector of plane .
According to the ground pitch angle and the empirical slope angle, the coarse ground will be classified as one of the four types: horizontal, upslope, downslope and non-ground. If it is non-ground, then the visually impaired people will be directly informed that they cannot move on; otherwise, the coarse ground will be refined with the unevenness tolerance through:
[TABLE]
where is the distance from point to the coarse ground, is the final 3-D point cloud of refined ground.
Finally, the refined ground height is obtained through:
[TABLE]
and it will be used in next frame.
III-B Optimal Walkable Direction Search
If no ground is detected, the system will directly inform the visually impaired people and stop proceeding the optimal walkable direction search algorithm. Otherwise, the optimal walkable direction is calculated as follows.
Since the walkable direction relies on the detected ground, only the 3-D points within the ground plane need to be considered for walkable direction search. These points are selected by:
[TABLE]
where is the 3-D points on ground plane, is the ground height, are the plane parameters defined in Eq. 4, and is a constant for preventing the person from being collided with overhanging obstacles.
Then the 3-D points are projected onto the plane (see Fig. 5). The nearest points in all sectors (each sector is represented as the sub-region in Fig. 5 and the angle of each sub-region is 0.5∘) can be easily obtained. The award of each sector is computed as:
[TABLE]
where is the angle of a sector, is the passable width (greater than the person’s body width), is the axis coordinate values of the nearest point in sector , and are the weights, and is the total number of sectors. This award function ensures that the person moves toward the direction with smaller turn angle and longer traversable distance.
Next, the optimal walkable direction is obtained by:
[TABLE]
where is a distance threshold, is the nearest distance of the sector with the maximum award, is the index of the sector with the maximum award, and is the total number of sectors. If is less than a small value , it is considered to have a very large risk of collision with obstacles. In that case, the optimal walkable direction does not exist, and the system will inform the users to turn left or right with a large angle to search a walkable direction. If is larger than , the optimal walkable direction is that corresponding to the sector with the maximum award. If the turning angle is very small (e.g. ), the system will directly inform the users to go straight to prevent them from vacillating to the left and right.
III-C 2.5-D Object Detection
CNN based object detection: As the MobileNet V2 [32] achieves relatively better results than other networks [26][28][29][30] by using depth-wise separable convolutions, and has lower computational complexity and smaller model size, it is utilized here for object detection. The training is implemented on the COCO dataset, which includes 91 classes, such as person, car, bus, chair, etc. These classes are enough for helping visually impaired people have a general perception of surroundings. However, 2-D object detection cannot be directly used for blind navigation due to the lack of object distance information. For example, if an object painted on ground is recognized as an obstacle, it will lead visually impaired people to make an incorrect decision. Therefore, we also use the depth image based object detection to solve the above problem.
Depth image based object detection: The detected ground (see Section III-A) is firstly removed from the depth image. Then the close morphological processing111https://opencv.org/ is performed to merge the small objects. Next, the external contours of the obstacles are extracted and their areas are computed. If the area is less than the threshold , the corresponding obstacle will be merged into its nearest obstacle or taken as noise; otherwise, the obstacle location can be obtained as:
Compute the moment of each contour, and the centroid of the contour can be obtained according to the zero-order and the first-order moment; 2. 2.
According to the contour centroid and the camera intrinsic parameter matrix in Eq. 1, the obstacle location is represented as :
[TABLE]
where is the contour centroid, and is the depth value of contour centroid.
Combination: The objects obtained by MobileNet V2 in the RGB image can be easily mapped to the depth image according to camera calibration matrix . Then the intersection area between the mapped area and the detected contour can be calculated (see Fig. 6):
[TABLE]
If ( represents the area of region ) is greater than a threshold (e.g. 0.7), it means the mapped area and the detected contour is the same object. Then the object distance is the minimum non-zero depth value within the intersection area , and the object orientation relative to the user can be obtained with Eq. 11. This way, the key surrounding information including obstacle category, distance and orientation can be provided.
III-D Audio Feedback
Navigation feedback: The beep sound is used to provide the navigation information to the user. When the visually impaired person encounters an obstacle that blocks his way, the system will keep beeping to alarm him that he cannot go straight. In that case, he should turn left or right to search the optimal walkable direction. When the beep sound stops, the user can continue moving.
2.5-D object detection feedback: When the visually impaired person walks in a relatively complicated environment, the 2.5-D object detection function can be activated by double tapping the smartphone screen, and the results will be converted to speech via a text-to-speech module and broadcast to the user. An example of 2.5-D object detection feedback is shown in Fig. 7, the object category (e.g. chair), distance (e.g. 1.8 m) and orientation (e.g. ahead of left side) are displayed. Because the visually impaired people are usually insensitive to the exact azimuth angle of the object, only 3 direction types: left-front (), front (), and right-front () are provided.
IV Experimental Results and Discussions
The performance of the proposed system is evaluated in real scenarios. Firstly, the ground detection is tested since it plays an important role in the whole system. Then, we recruit 20 visually impaired persons to test the navigation and object detection function. We follow the protocol approved by the Bejing Fangshan District Disabled Persons’ Federation for recruitment and experiments. All the people who participated in this experiment approved that the results (including data, images and videos) can be published with anonymity. Finally, the computational cost is evaluated to test the real-time performance.
IV-A Experiments on Ground Detection
To evaluate the proposed ground detection method quantitatively, we manually labelled a random sample of 1000 images captured in indoor scenario to get the ground truth. Fig. 8 shows the precision of the detected ground with different distance and different Intersection over Union (IOU) percentages. The IOU percentage is computed as:
[TABLE]
where is the number of overlapping pixels between the detected ground and the ground truth, is the number of detected ground pixels, and is the number of ground truth pixels.
As shown in Fig. 8, comparing with the RANSAC algorithm, the proposed method has a higher precision in all scenarios. Some comparative examples are shown in Fig. 9. By taking the advantage of the ground height continuity among adjacent frames, the proposed method is more robust to the interferences of other planes (such as sofa, table) than the RANSAC algorithm. It provides a solid base for the following object detection.
IV-B Experiments on Real Scenarios
Navigation task: Three paths in an office (see Fig. 10) are selected to evaluate the navigation performance. There are many obstacles including static and moving obstacles in these paths. Then 20 visually impaired people who were not familiar with these environments are asked to navigate following these paths with the help of either a white cane or the proposed device. They are trained for about 10 minutes to get familiar with our system. The average walking time and number of collisions with obstacles are recorded (see TABLE I). The visually impaired people using our proposed system spend less walking time than using the white cane. This proves that the proposed system has a higher navigation efficiency in unfamiliar environments.
As shown in TABLE I, the users have more collisions with obstacles when using a white cane. This is because they usually use the white cane to detect the obstacles on the ground instead of those hanging in the mid-air, and it is observed that almost all studied users collide with the desk or the hanging objects on the path CD and EF (see Fig. 11). Whereas with the proposed device, they are able to avoid collisions with those obstalces. This proved that the proposed system is more secure for visually impaired people.
2.5-D object detection task: Some complicated scenarios are designed to test if the 2.5-D object detection can help visually impaired people to travel more efficiently. Such examples include the scenario where the way is blocked by two chairs (see Fig. 12) and crowded with other obstacles. With only the navigation function in our proposed system, the user cannot find the moving direction after multiple searches and will turn back. However, if he activates the 2.5-D object detection and perceives more information about surroundings, he is able to move the chair and search the moving direction. This prevents the visually impaired people from taking more detours and improves their environmental perception abilities. This shows that the 2.5-D object detection indeed helps visually impaired people to travel more efficiently and brings a better travel experience to them.
IV-C Computational Cost
All algorithms are implemented on a smartphone with Qualcomm Snapdragon 820 CPU 2.0 GHz and RAM of 4 GB. The average computational time of the proposed system is calculated and shown in TABLE II. The images acquisition, ground detection, optimal walkable direction search and 2.5-D object detection cost about 0.66 ms, 13.53 ms, 7.19 ms and 114.13 ms respectively. The total time that all algorithms cost excluding the 2.5-D object detection is about 27.17 ms on average. Since the 2.5-D object detection is only activated when the visually impaired people want to know the surrounding information or enter a complicated scenario, the proposed system is able to provide real-time assistance for users’ daily traveling.
V Conclusion
This paper presents a wearable device which provides navigation and object detection assistance for visually impaired people. To provide reliable navigation, a ground detection algorithm that uses the ground height continuity between two adjacent frames is presented. Then an optimal walkable direction search method is developed to determine the moving direction. To improve the environmental perception ability of visually impaired people, a 2.5-D object detection function is presented. Audio feedback is used to inform the visually impaired people for both the navigation instructions and object detection results. Experimental results show that the proposed system can help visually impaired people travel efficiently and brings a better traveling experience for them. In future, the small-size obstacle detection will be considered.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Bai, S. Lian, Z. Liu, K. Wang and D. Liu, “Smart guiding glasses for visually impaired people in indoor environment,” IEEE Trans. Consum. Electron., vol. 63, no. 3, pp. 258-266, 2017.
- 2[2] K. Yang, K. Wang, R. Cheng, W. Hu, X. Huang and J. Bai, “Detecting traversable area and water hazards for the visually impaired with a p RGB-D sensor,” Sensors, vol. 17, no. 8, pp. 1890, 2017.
- 3[3] C. Ye, X. Qian. “3D object recognition of a robotic navigation aid for the visually impaired,” IEEE Trans. Neural Syst. & Rehabil. Eng., vol. 26, no. 2, pp. 441-450, 2018.
- 4[4] J. Bai, S. Lian, Z. Liu, K. Wang, D. Liu, “Virtual-blind-road following-based wearable navigation device for blind people,” IEEE Trans. Consum. Electron., vol. 64, no. 1, pp. 136-143, 2018.
- 5[5] H. Zhang, C. Ye. “An indoor wayfinding system based on geometric features aided graph SLAM for the visually impaired,” IEEE Trans. Neural Syst. & Rehabil. Eng., vol. 25, no. 9, pp. 1592-1604, 2017.
- 6[6] D. Dakopoulos and N. G. Bourbakis, “Wearable obstacle avoidance electronic travel aids for blind: A survey,” IEEE Trans. Systems, Man, Cybern., vol. 40, no. 1, pp. 25-35, 2010.
- 7[7] A. Aladren, G. Lopez-Nicolas, L. Puig and J. J. Guerrero, “Navigation assistance for the visually impaired using RGB-D sensor with range expansion,” IEEE Systems J., vol. 10, no. 3, pp. 922-932, 2016.
- 8[8] R. Tapu, B. Mocanu, T. Zaharia. “A computer vision system that ensure the autonomous navigation of blind people,” IEEE E-health & Bioeng. Conf., Iasi, Romania, 2013, pp. 1-4.