Optimal Clustering Framework for Hyperspectral Band Selection
Qi Wang, Fahong Zhang, Xuelong Li

TL;DR
This paper introduces an optimal clustering framework for hyperspectral band selection, improving the selection process by achieving optimal clustering results and automating the determination of the number of bands needed.
Contribution
It proposes a novel optimal clustering framework, a cluster ranking strategy, and an automatic band number determination method, advancing hyperspectral band selection techniques.
Findings
Outperforms state-of-the-art methods on various datasets.
Robustness demonstrated across multiple experiments.
Significantly improves band selection accuracy.
Abstract
Band selection, by choosing a set of representative bands in hyperspectral image (HSI), is an effective method to reduce the redundant information without compromising the original contents. Recently, various unsupervised band selection methods have been proposed, but most of them are based on approximation algorithms which can only obtain suboptimal solutions toward a specific objective function. This paper focuses on clustering-based band selection, and proposes a new framework to solve the above dilemma, claiming the following contributions: 1) An optimal clustering framework (OCF), which can obtain the optimal clustering result for a particular form of objective function under a reasonable constraint. 2) A rank on clusters strategy (RCS), which provides an effective criterion to select bands on existing clustering structure. 3) An automatic method to determine the number of the…
Click any figure to enlarge with its caption.
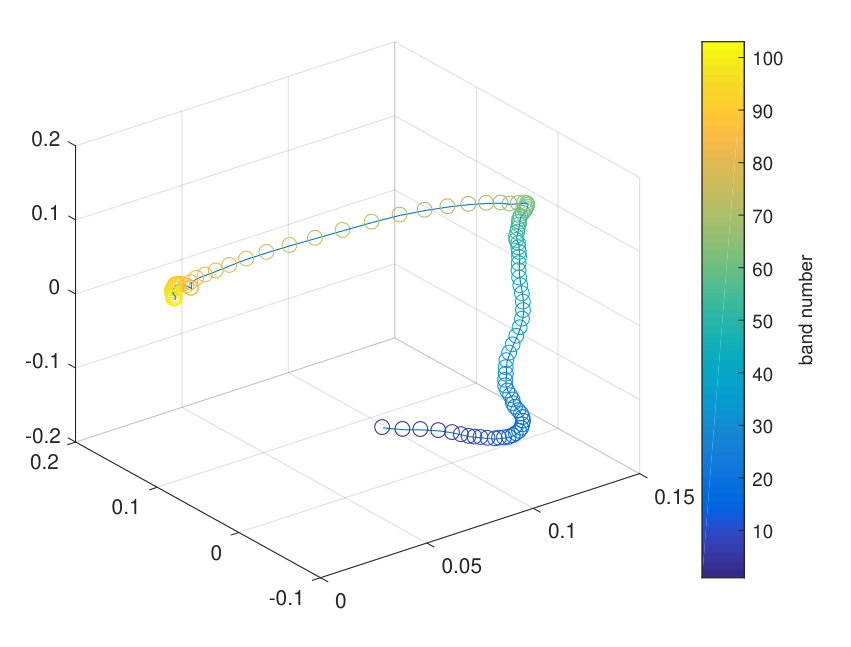 Figure 1
Figure 1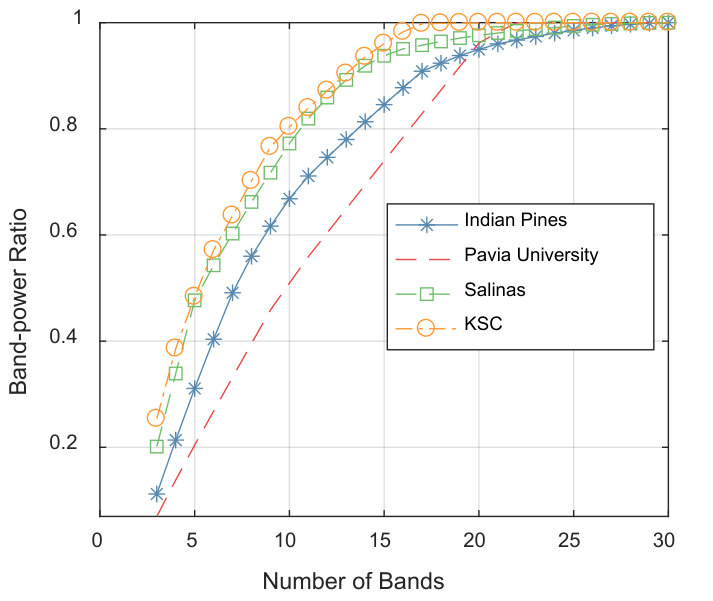 Figure 2
Figure 2 Figure 3
Figure 3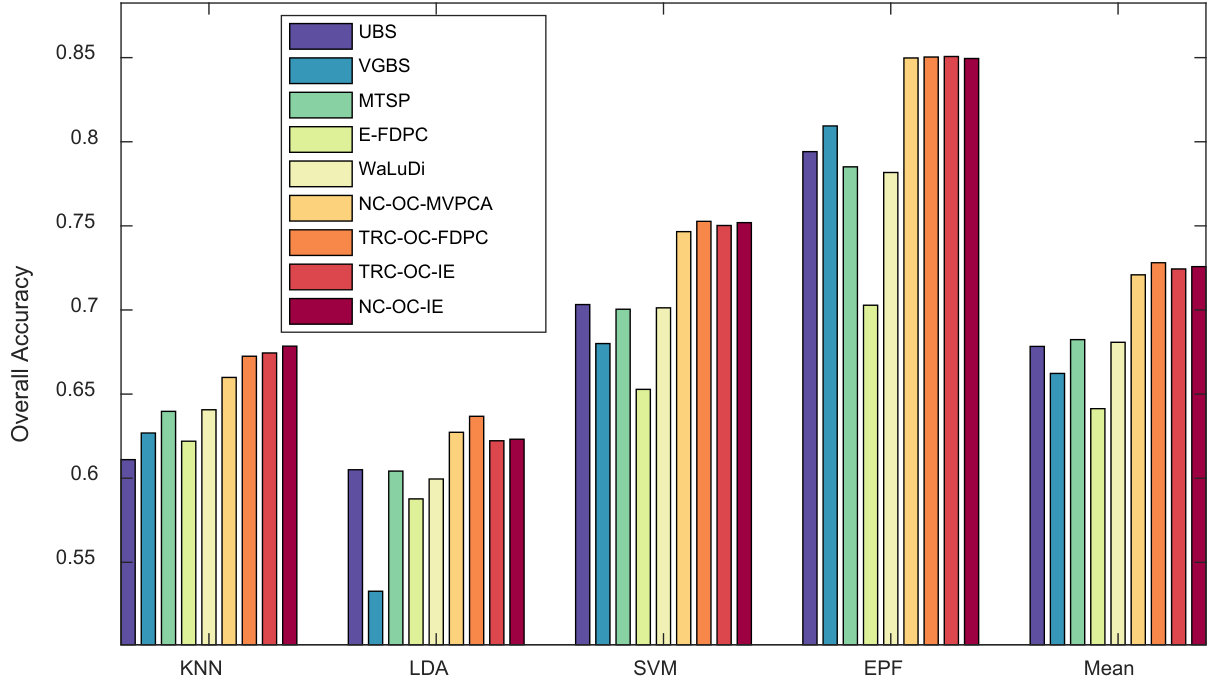 Figure 4
Figure 4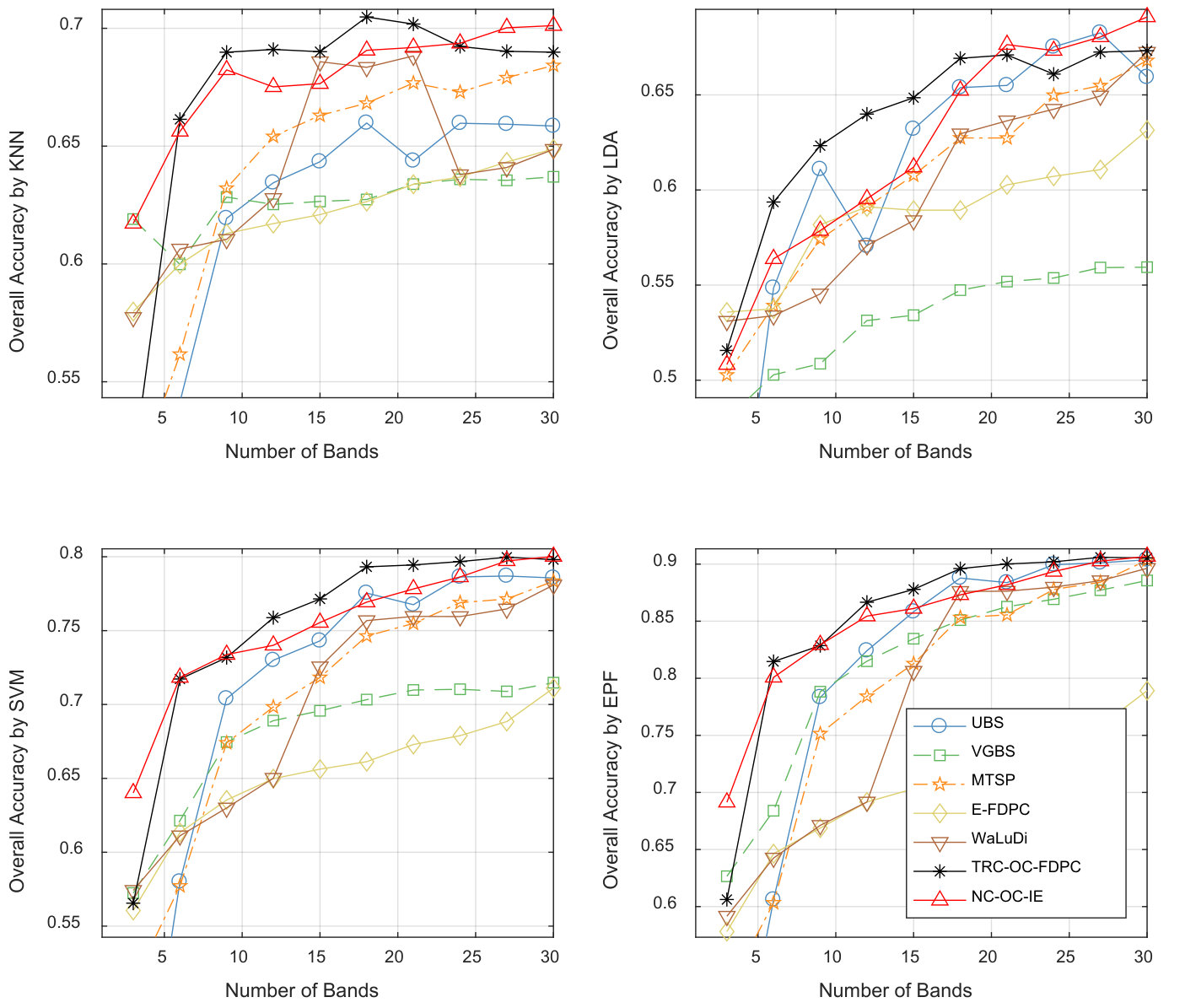 Figure 5
Figure 5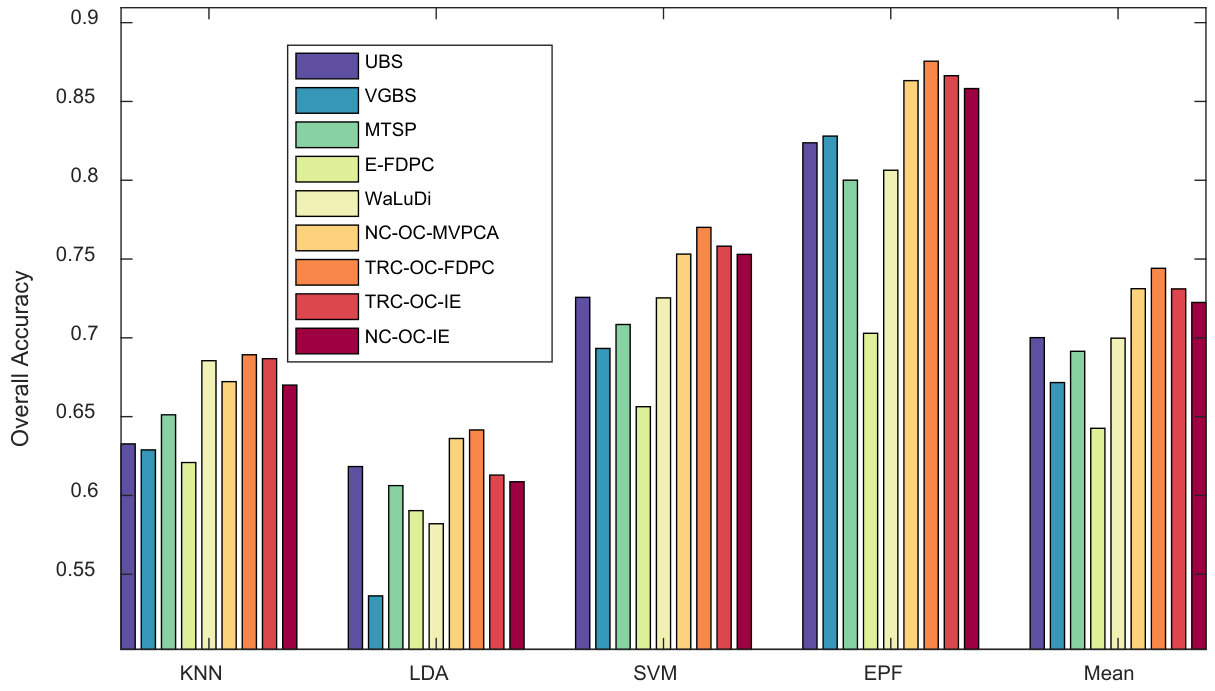 Figure 6
Figure 6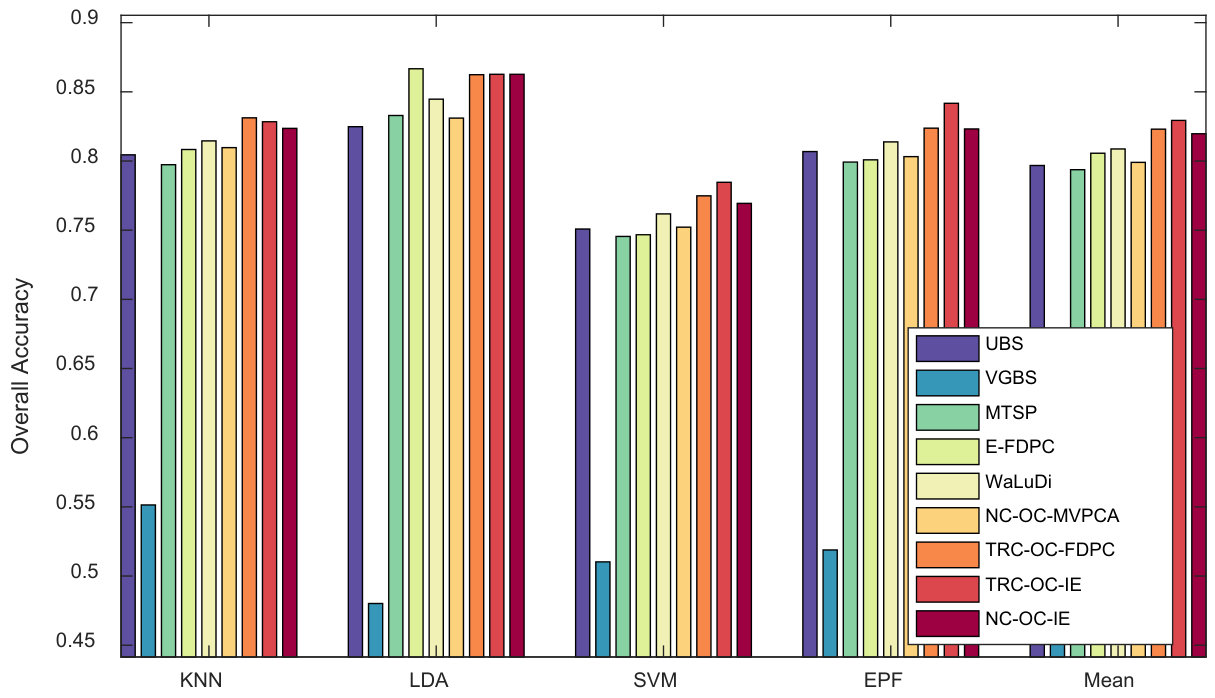 Figure 7
Figure 7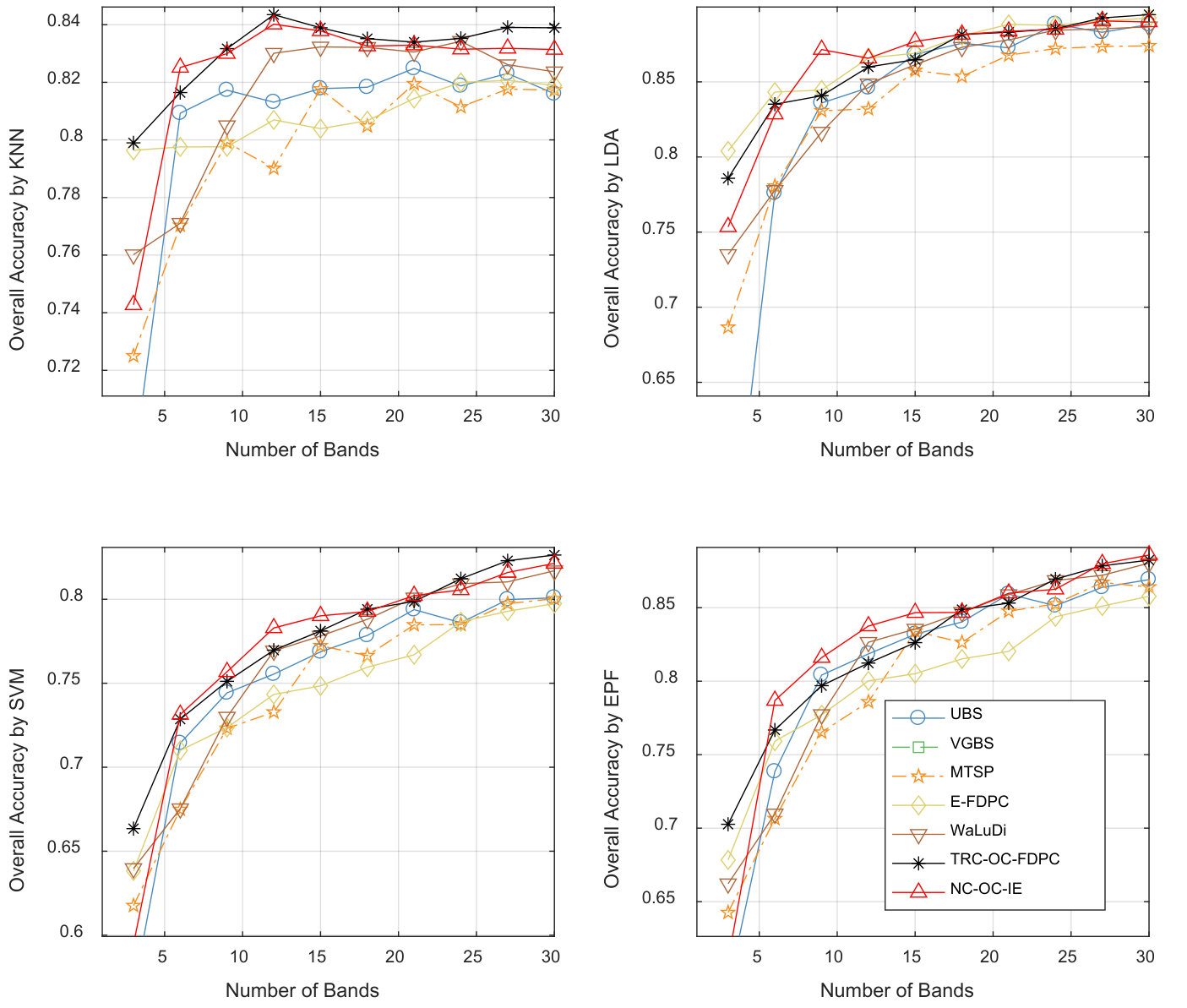 Figure 8
Figure 8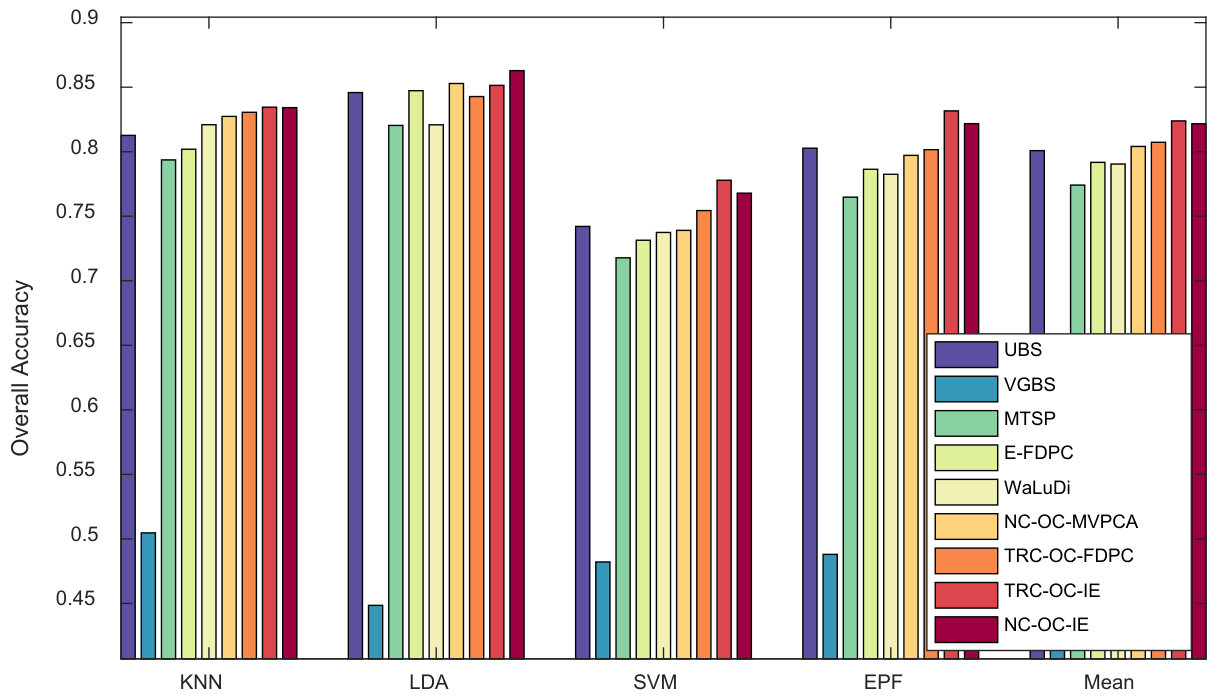 Figure 9
Figure 9 Figure 10
Figure 10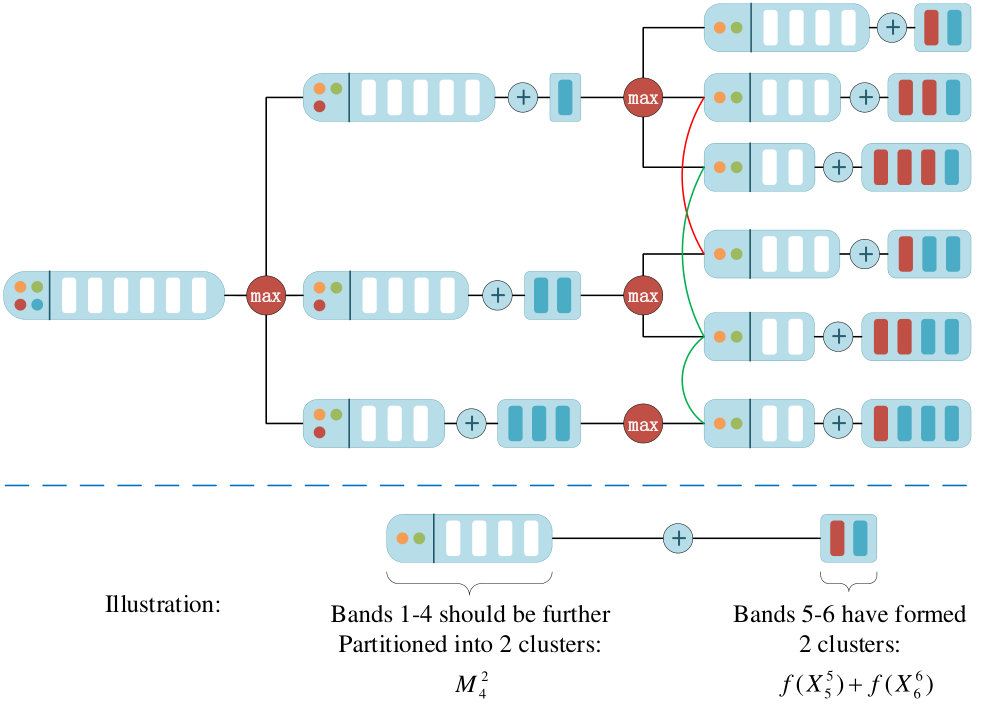 Figure 11
Figure 11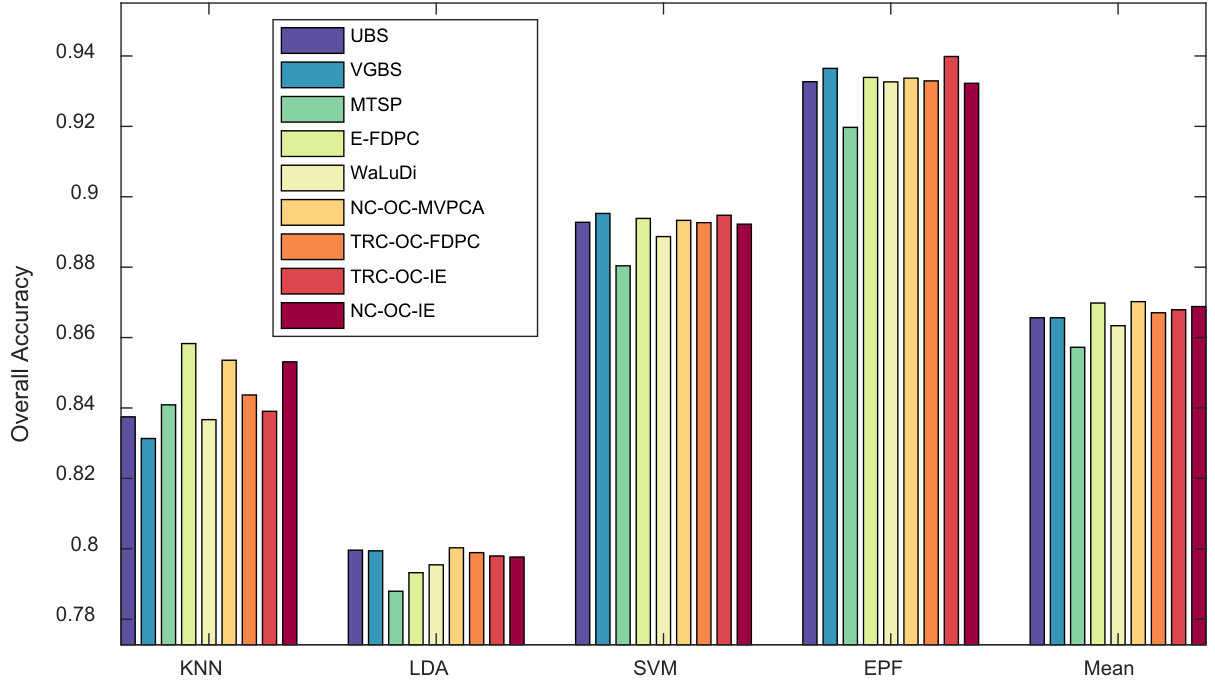 Figure 12
Figure 12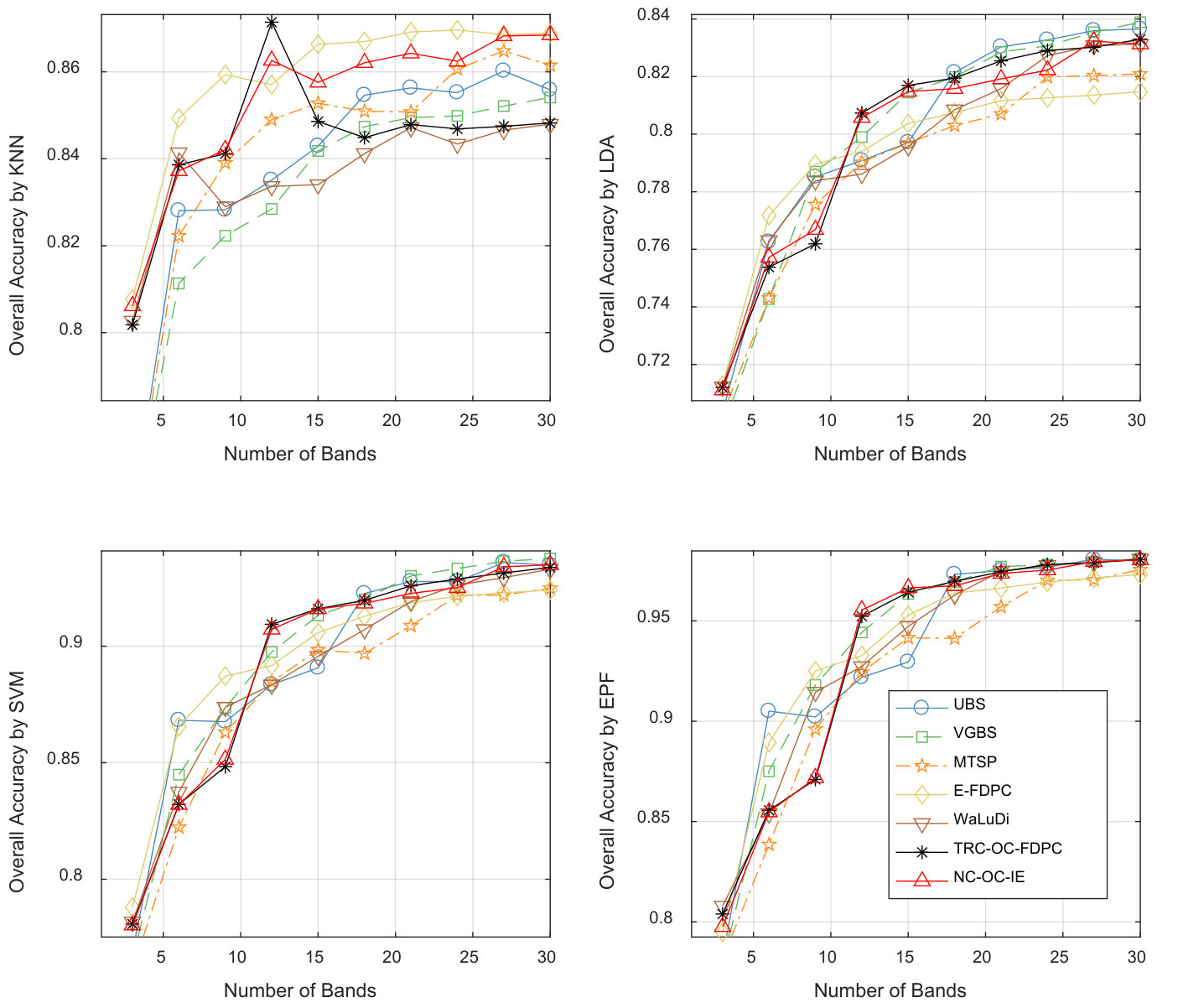 Figure 13
Figure 13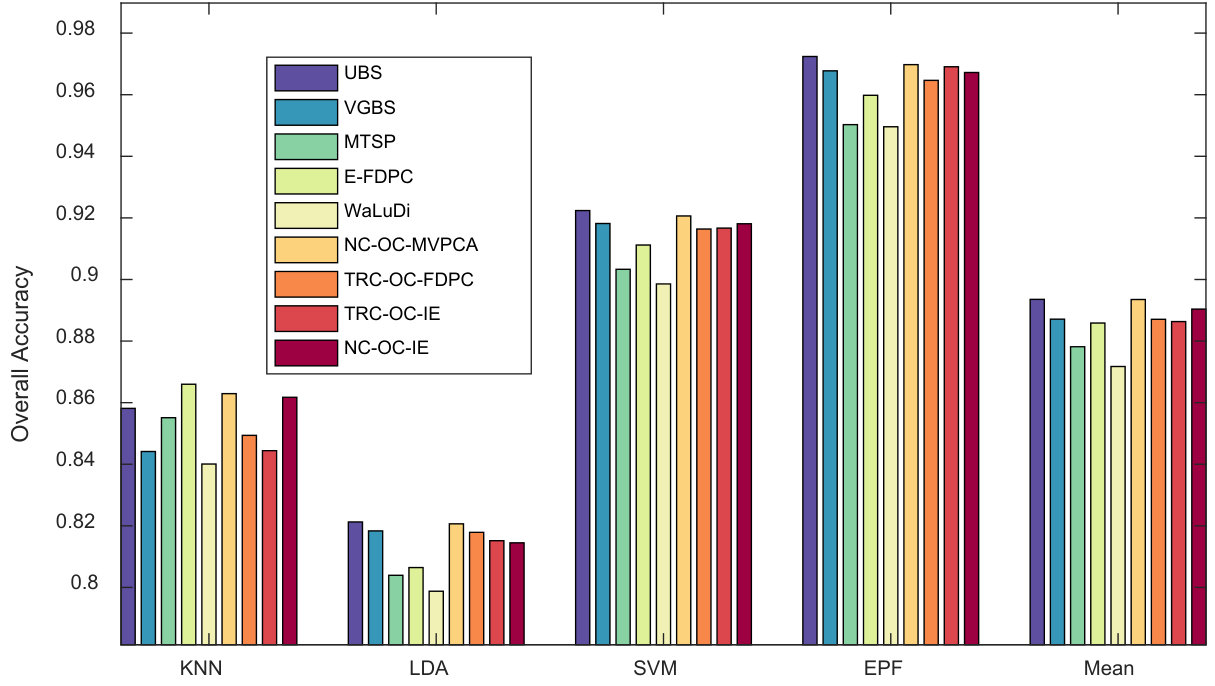 Figure 14
Figure 14 Figure 15
Figure 15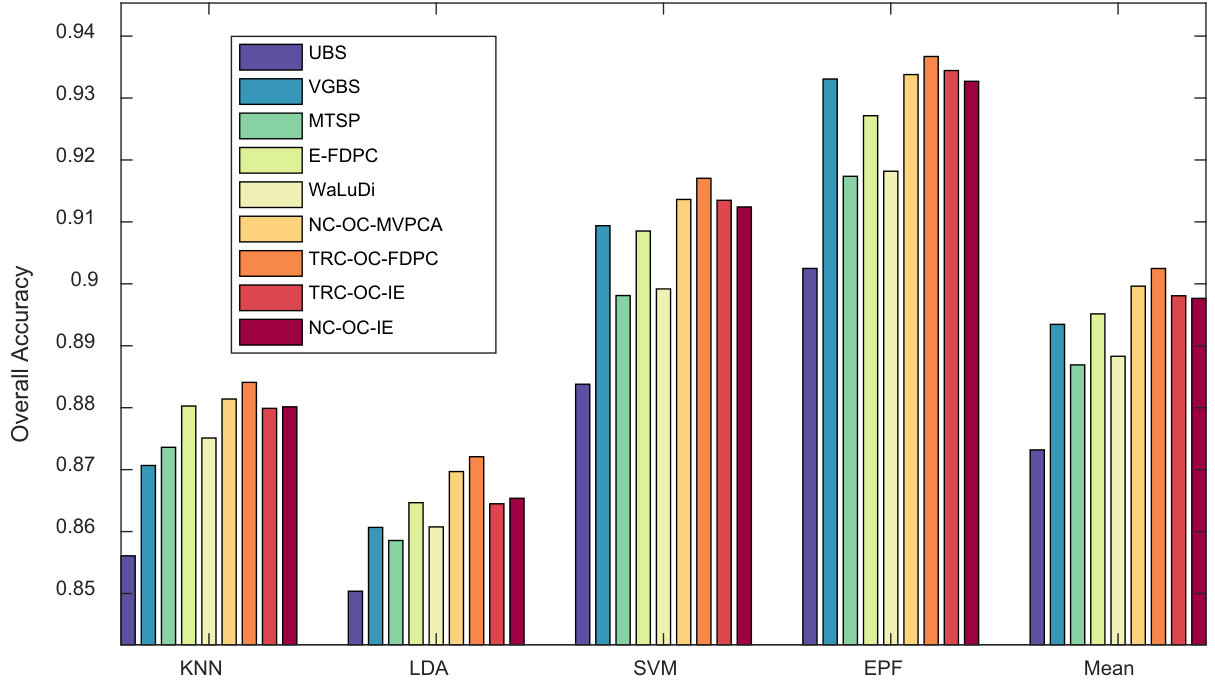 Figure 16
Figure 16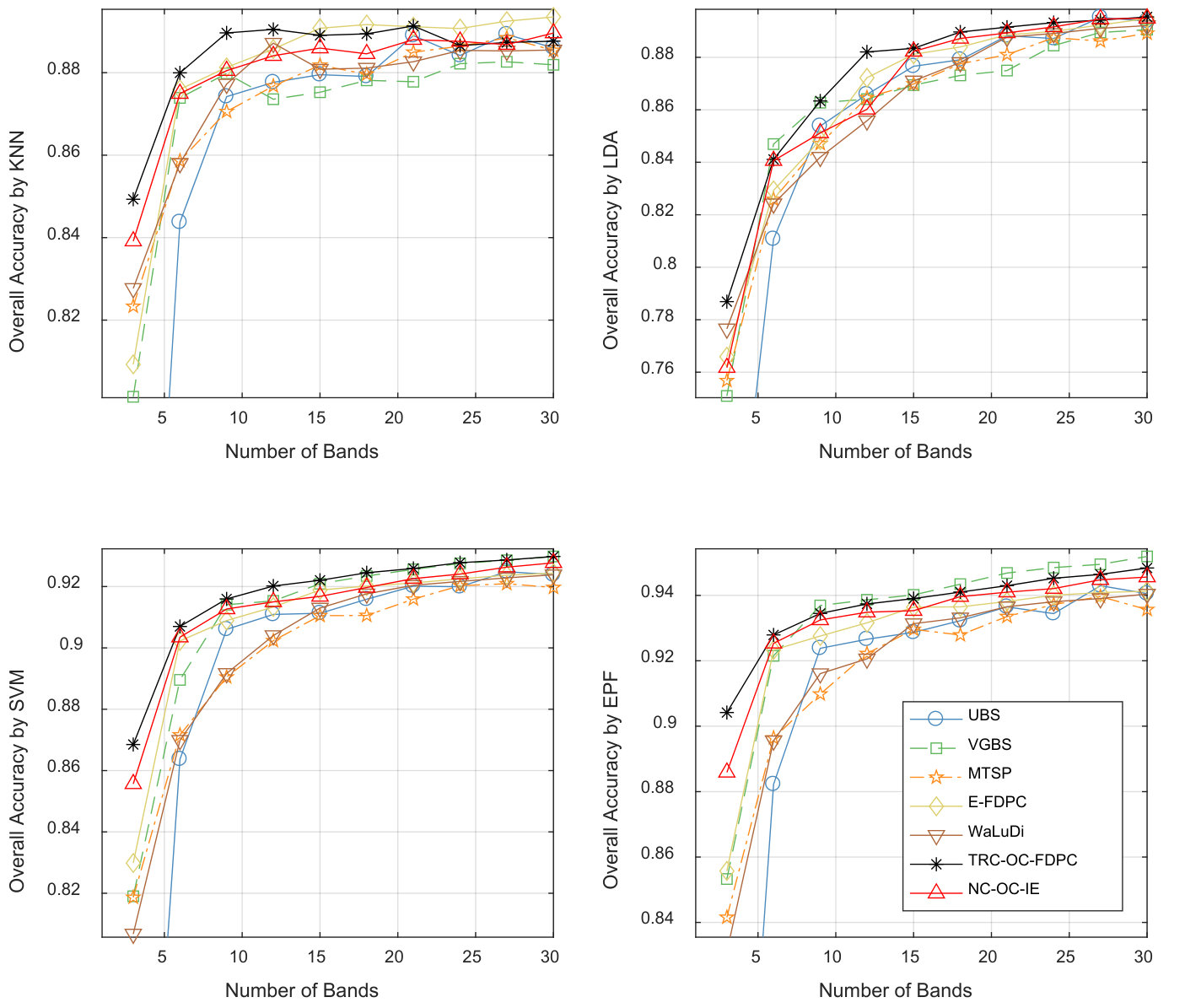 Figure 17
Figure 17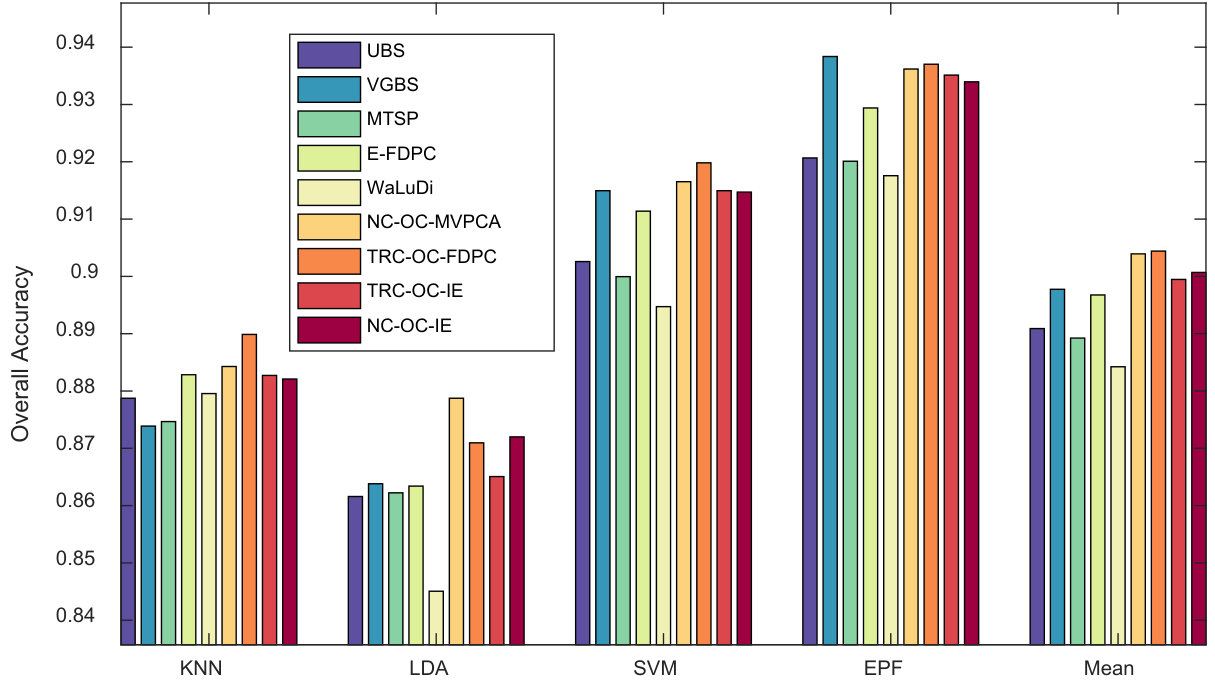 Figure 18
Figure 18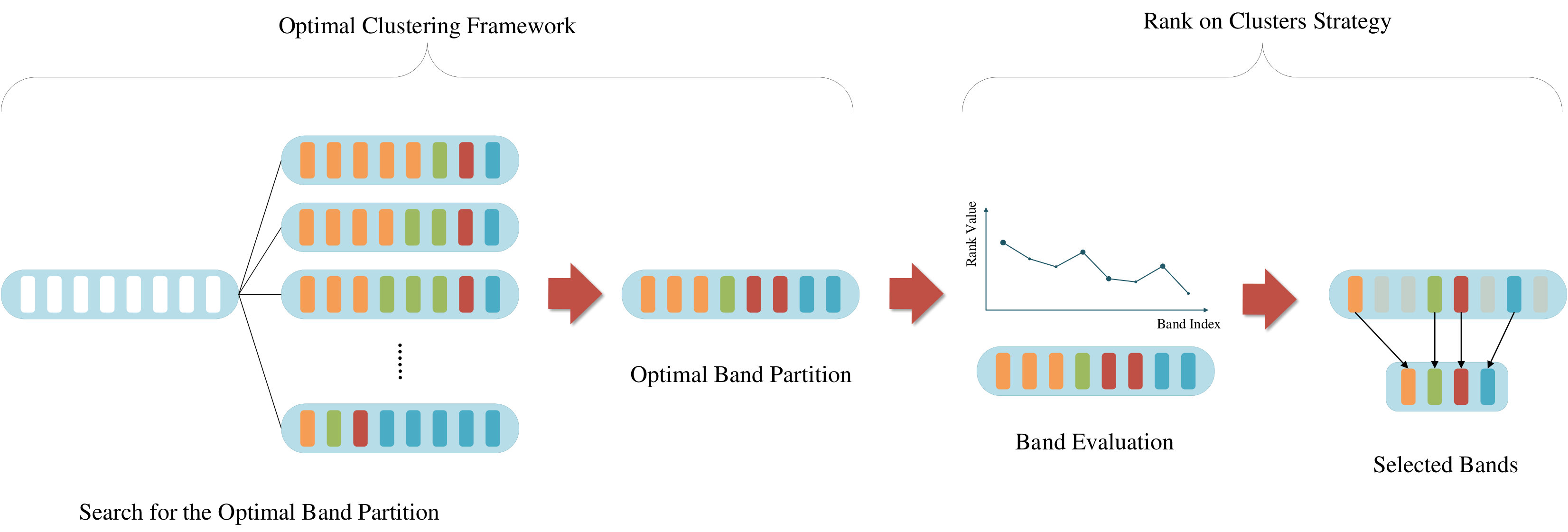 Figure 19
Figure 19| Method Names | Selected Bands |
|---|---|
| TRC-OC-FDPC | 8/16/28/30/43/50/67/92/123/133/ |
| 146/176/182/188/ | |
| NC-OC-IE | 17/29/42/48/54/119/122/137/146/179/ |
| 185/195/204/213/ | |
| TRC-OC-IE | 15/21/29/42/54/79/89/116/122/127/ |
| 146/147/179/201/ | |
| NC-OC-MVPCA | 17/29/42/48/57/119/122/137/173/180/ |
| 185/195/204/213/ | |
| UBS | 1/16/31/46/62/77/92/113/128/143/ |
| 173/188/203/219/ | |
| VGBS | 1/13/18/20/23/29/34/35/39/57/ |
| 61/75/88/89/ | |
| MTSP | 12/13/29/37/44/45/81/90/112/141/ |
| 179/186/202/215/ | |
| E-FDPC | 50/67/80/92/105/109/118/124/134/137/ |
| 142/152/167/179/ | |
| WaLuDi | 31/49/56/61/67/77/83/99/104/128/ |
| 138/163/183/189/ |
| Indian Pines | Pavia University | Salinas | KSC | |
|---|---|---|---|---|
| NC-OC-MVPCA | 0.40s | 0.85s | 1.08s | 2.48s |
| NC-OC-IE | 0.50s | 0.77s | 0.91s | 1.84s |
| TRC-OC-IE | 0.48s | 0.81s | 1.03s | 1.91s |
| TRC-OC-FDPC | 0.51s | 0.72s | 1.15s | 1.98s |
| VGBS | 0.21s | 0.21s | 0.37s | 0.76s |
| MTSP | 16.59s | 9.52s | 17.26s | 17.39s |
| E-FDPC | 0.07s | 0.24s | 0.29s | 0.79s |
| WaLuDi | 1.69s | 7.66s | 10.20s | 36.14s |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Optimal Clustering Framework for Hyperspectral Band Selection
Qi Wang, Fahong Zhang, and Xuelong Li This work was supported by the National Key R&D Program of China under Grant 2017YFB1002202, National Natural Science Foundation of China under Grant 61773316, Fundamental Research Funds for the Central Universities under Grant 3102017AX010, and the Open Research Fund of Key Laboratory of Spectral Imaging Technology, Chinese Academy of Sciences.Q. Wang is with the School of Computer Science, with the Center for Optical Imagery Analysis and Learning (OPTIMAL) and with the Unmanned System Research Institute (USRI), Northwestern Polytechnical University, Xi’an 710072, Shaanxi, China. E-mail: [email protected]. Zhang is with the School of Computer Science and the Center for Optical Imagery Analysis and Learning (OPTIMAL), Northwestern Polytechnical University, Xi’an 710072, Shaanxi, China. E-mail: [email protected]. X. Li is with the Xi’an Institute of Optics and Precision Mechanics, Chinese Academy of Sciences, Xi’an 710119, Shaanxi, P. R. China and with the University of Chinese Academy of Sciences, Beijing 100049, P. R. China. Email: [email protected]. ©2018 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. Q. Wang, F. Zhang, and X. Li, “Optimal clustering framework for hyperspectral band selection,” IEEE Trans. Geoscience and Remote Sensing, vol. 56, no. 10, pp. 5910-5922, 2018, 10.1109/TGRS.2018.2828161.
Abstract
Band selection, by choosing a set of representative bands in hyperspectral image (HSI), is an effective method to reduce the redundant information without compromising the original contents. Recently, various unsupervised band selection methods have been proposed, but most of them are based on approximation algorithms which can only obtain suboptimal solutions toward a specific objective function. This paper focuses on clustering-based band selection, and proposes a new framework to solve the above dilemma, claiming the following contributions:
- An optimal clustering framework (OCF), which can obtain the optimal clustering result for a particular form of objective function under a reasonable constraint.
- A rank on clusters strategy (RCS), which provides an effective criterion to select bands on existing clustering structure.
- An automatic method to determine the number of the required bands, which can better evaluate the distinctive information produced by certain number of bands. In experiments, the proposed algorithm is compared to some state-of-the-art competitors. According to the experimental results, the proposed algorithm is robust and significantly outperform the other methods on various data sets.
Index Terms:
Hyperspectral band selection, normalized cut, dynamic programming, spectral clustering.
I Introduction
Hyperspectral image (HSI) processing has attracted considerable attention in recent years. HSIs can provide rich band information from different wavelengths and thus get widely used in various research field, such as biological analysis [1] and medical imaging processing [2]. HSIs record the reflectances of electromagnetic waves of different wavelengths, and the reflectance of each electromagnetic wave is stored in a 2-D image. Hence, a HSI is a data cube which contains hundreds of 2-D images. Though significant success in the field of HSI application has been obtained, how to deal with the large dimensional data is still a challenging problem, since high correlations and dependencies among them cause huge computational complexity as well as “Hughes phenomenon” [3]. In view of this, the reduction in HSI is deemed to be a very important work.
Generally, HSI reduction can be achieved by feature extraction or feature selection (also known as band selection) techniques. For feature extraction [4, 5, 6, 7, 8], the original HSI is projected into a lower dimensional space and a reduced data set is generated. While for band selection, some discriminative bands are chosen to represent the original data set without modification. In experiments, feature extraction could usually achieve better performance. However, band selection is usually more preferred since it can can preserve the information of the original data in physical sense, making the reduced data sets more interpretable.
According to the involvement of the labeled and the unlabeled samples, band selection can be divided into supervised [9, 10, 11, 12, 13], semi-supervised [14, 15, 16, 17] and unsupervised [18, 19, 20, 21, 22, 23] methods. Supervised and semi-supervised methods utilize the labeled samples to guide the selection process. However, since the acquisition of the labeled samples is a difficult task, sometimes they are not very practical in real application. Therefore, we mainly focus on unsupervised band selection in this paper.
According to the employed searching strategy [24], unsupervised band selection can be categorized into ranking-based, clustering-based, greedy-based and evolutionary-based methods. Ranking-based methods assign each band a rank value and simply select the top-rank bands with the desired number. Clustering-based methods first separate all the bands into clusters, and then select the most representative bands in each cluster to constitute the band subset. Greedy-based methods are iterative processes. In each iteration, the currently optimal band will be selected founded on the previous results.
As for evolutionary-based methods, they first generate a candidate band set, and then repeatedly update it via a specific evolutionary strategy until the convergence condition is satisfied.
Taking an overall review of the above mentioned kinds of band selection methods, one issue can be found that the existing methods can only obtain an approximately optimal solution. For example, greedy-based methods are only optimal in current iteration, rather than in global. Also, evolutionary-based methods are based on some random processes and usually trapped into local optimums. The main reason of this phenomenon is that the solution space of band selection problem is too large to attain the optimal solution in limited time. For point-wise selection [11], the number of ways to select bands from a bands HSI is . For group-wise selection [11], the number of ways to cluster the bands increases to the Stirling Number of the Second Kind [25], denoted as . Suppose and , the value of is about , and the value of is about . Consequently, achieving an optimal solution is considered to be a very difficult task, especially for clustering-based methods.
In this paper, we focus on clustering-based methods, and propose a general framework which can uncover the optimal clustering structure under a reasonable constraint.
The main contributions of this paper are listed as follows.
-
An optimal clustering framework (OCF) is proposed to search for the optimal clustering structure in HSI. Though achieving the optimal clustering result has been demonstrated NP-hard for many kinds of objective function, the proposed OCF can still find the optimal solution under a reasonable constraint for HSI data sets. Moreover, the proposed OCF is a general framework, which means different kinds of objective function can be optimized via the same procedure once they comply with the specific form.
-
A ranking on clusters strategy (RCS) is proposed as an effective criterion to select the representative bands under the achieved clustering structure. By applying an arbitrary ranking algorithm on the clustering result, RCS can better exploit the advantages of clustering-based and ranking-based methods, and generate a band subset with lower correlation and more discriminative information.
-
An automatic method to determine the required number of bands is proposed. Through reducing the correlation among bands, we aim to uncover how much distinctive information can be produced by certain number of bands. Experiments show that this method can offer a promising estimation of band number for various data sets.
The remainder of this paper is organized as follows. In Section II, related unsupervised band selection methods are introduced. In Section III, OCF and RCS are formulated. Then in Section IV, we show some instances to implement a band selection algorithm based on OCF and RCS. After that, the experimental results on four real HSI data sets are shown in Section V. Finally, conclusions are made in Section VI.
II Related Work
As introduced in Section I, unsupervised band selection can be categorized into ranking-based, clustering-based, greedy-based and evolutionary-based methods. In this section, some representative band selection methods will be introduced sequentially.
II-A Ranking-based methods
Ranking-based methods [26, 27] aim at designing a criterion to evaluate the importance of each band, and use the top-rank bands to constitute the band subset. The advantage of ranking-based methods is that the most discriminative bands can be discovered. However, there is usually high correlation among the selected bands. To give examples, some representative ranking-based methods will be introduced.
Maximum-variance principal component analysis (MVPCA) [26] is a joint band prioritization and band-decorrelation approach. In MVPCA, a data-sample covariance matrix is firstly constructed. Second, eigenvalue decomposition is performed over the covariance matrix, and a loading factor matrix is constructed. Finally, all the bands are prioritized according to the loading factor matrix. From another point of view, bands are prioritized by their variances essentially. MVPCA is rational since bands with higher variances contain more distinct information of ground objects and are more discriminative in general. Nevertheless, it is sensitive to noisy bands since they usually have large variances. Moreover, the top-rank bands are usually highly correlated, leading to a large amount of redundant information among the selected bands.
Constrained band selection (CBS) [27] is a band correlation minimization process. It first design a finite impulse response (FIR) filter for each band, and minimize the averaged least squares filter output. Then bands are ranked according to the solution of the above minimization problem since it can measure the correlation between one particular band and the entire HSI. CBS is less sensitive to noisy bands because they usually have lower correlation with the other bands, and hence will be assigned with smaller ranking values. But similar to MVPCA, the top-rank bands may still be highly correlated since the interaction among the selected bands are neglected.
II-B Clustering-based methods
Clustering-based methods [28, 29, 30, 31, 32, 33] first separate the whole bands into clusters, and then select one in each to constitute the band subset. Unlike ranking-based methods, clustering-based methods focus on the reduction of the correlation among bands. In the following, several representative methods are listed and discussed.
In WaLuMI and WaLuDi [28], hierarchical clustering is utilized to partition the bands into clusters. In order to measure the distances among these bands, two criteria are involved, known as mutual information and Kullback-Leibler divergence. First, the total band set is separated into clusters using the Ward’s linkage method. After that, the band which has the highest similarity with the other bands is selected in each cluster. Through hierarchical clustering, WaLuMI and WaLuDi can effectively reduce the correlation among bands. However, these methods are sensitive to noisy bands since they usually have low correlations with the others and easy to form single-band clusters.
Enhanced fast density-peak-based clustering (E-FDPC) [29] can be viewed as a clustering-based as well as a ranking-based method. Based on the idea that a cluster center should have large local density and inter-cluster distance, E-FDPC prioritizes each band via combining these two indicators. Then similar to ranking-based methods, the top-rank bands are selected to constitute the band subset. Through investigating the intra-cluster distance of bands, E-FDPC can reduce the possibility that two correlated bands are selected simultaneously. Nevertheless, it is difficult to measure the local density and intra-cluster distance exactly.
Squaring weighted low-rank subspace clustering (SWLRSC) [30] firstly constructs a low-rank coefficient matrix by solving the low-rank optimization problem. Then a squaring weighted strategy is used to obtain the similarity matrix. After that, the spectral clustering is conducted using the matrix and the clustering result is generated. Finally, the bands which are closest to the centroid of each cluster are chosen to constitute the band subset. By constructing such a low-rank coefficient matrix, the relationship among bands can be better exploited. However, it’s time consuming to find such a low-rank presentation for large-scale HSI data sets.
II-C Greedy-based methods
Greedy-based methods [34, 35, 21] greedily select or remove one band from the candidate band subset, and make sure that the objective function is optimized in each iteration. Though the optimal solution cannot be obtained, greedy-based methods still offer a good substitution to it. In the following, two representative methods are introduced.
Volume gradient band selection (VGBS) [34] is a geometry-based method, in which bands are treated as points lying in a high dimensional space. In the beginning of the algorithm, all of the bands are considered as candidate bands and constitute a parallelotope. Then, bands lead to the minimal losses of the parallelotope volume will be removed repeatedly. The algorithm stops when the desired number of bands is remained in the subset. VGBS can effectively reduce the correlation among bands since low-correlated bands often construct a large-volume parallelotope. Nevertheless, noisy bands often contribute a lot to this volume and are easy to be selected. Hence VGBS often do not perform well in data sets with large noises.
Different from VGBS, sequential forward selection (SFS) [35] starts with an empty band subset, and iteratively adds bands to it until the desired number of them have been obtained. Minimum estimated abundance covariance (MEAC) is the objective function in SFS. In each iteration, the band which can maximally decrease the MEAC value of current band subset will be selected. SFS method is efficient in computation, but sensitive to the initial condition.
II-D Evolutionary-based methods
Evolutionary-based methods [36, 17, 20, 37] first generate a band subset with the desired number of bands randomly, and then apply some evolutionary algorithms to update it, seeking a nearly optimal solution. Here two representative methods are introduced.
In multi-task sparsity pursuit (MTSP) [36], a compressive band descriptor is first constructed as a reduction of the original HSI. Then a multi-task learning based criterion is proposed to evaluate the effectiveness of the band descriptor. Finally the immune clonal strategy is utilized to search for the optimal band combination. Compared to greedy-based methods, the utilized immune clonal strategy is proved with powerful global searching ability. However, in order to accelerate the calculation of the objective function, some intrinsic information is lost when constructing the compressive descriptor.
Multi-objective optimization band selection (MOBS) [20] presents a multi-objective model for band selection, in which information entropy and the number bands are considered as two objective functions. They are optimized simultaneously by a multi-objective evolutionary algorithm. MOBS is less sensitive to parameters and can obtain a more stable performance, but using the sum of information entropy to evaluate a band subset is sometimes too simple to capture the interrelationship among bands.
III Optimal Clustering Framework
This section details the proposed OCF and introduces the overall procedure as shown in Fig. 1 to design a band selection algorithm. First, the idea of dynamic programming is briefly reviewed as the background knowledge. Second, the rationality of CBIC is analysed and discussed. Third, the proposed framework which can generate the optimal clustering result is introduced and demonstrated. After that, a more general framework is shown as an extension to the original one. Finally, we propose a novel strategy to determine the selected bands based on the achieved clustering result.
III-A Introduction to Dynamic Programming
Dynamic programming (DP) is an effective optimization technique that was proposed by Berman (R.Bellman), etc. in 1951 [38, 39]. In DP, a complex problem is repeatedly broken down into a series of subproblems until they are simple enough to be resolved directly. Then these subproblems are constantly combined to solve the more complex ones and finally solve the original problem. One problem must have two attributes to be suitable for DP.
-
Optimal substructure. This attribute says a problem can be broken down into simpler subproblems with the same form, and the solution of the original problem can be obtained through these subproblems.
-
Overlapping subproblems. This means that while some subproblems are broken down into simpler ones, there should be overlaps among them. In other words, a subproblem should be reused several times for the solving of different and more complex subproblems. If this attribute is not satisfied, the number of subproblems will increase exponentially, bringing unaffordable computational complexity.
III-B Contiguous Band Indexes Constraint
In HSI, bands represent the reflectance of the scene to electromagnetic waves in various wavelengths. Seen from physical view, electromagnetic waves with closer wavelengths produce similar reflectances. Hence bands with similar wavelengths usually have stronger correlation [40, 41]. Fig. 2 plots all the bands in Pavia University data set, in which each band is vectorized and projected to a three-dimensional feature space through PCA transformation. As we can see, when we connect the bands in the order of their indexes, we get a very smooth curve. This phenomenon further proves that strong correlation exists between bands with close wavelengths. Inspired by this, we propose a contiguous band indexes constraint (CBIC) for band clustering problem, which claims that bands in the same cluster should have contiguous wavelengths.
According to the analysis in Section I, the number of all the possible solutions for band clustering problem is . Under the proposed constraint, this number is reduced to . When and , the value of is about , which is much smaller than that of (). Consequently, the proposed constraint can effectively reduce the size of the solution space for band clustering problem.
Owing to CBIC, the original clustering problem is converted to finding a series of critical bands to separate the whole bands into intervals. This enables us to search for the optimal solution in a more efficient way.
III-C OCF Formulization
This subsection details the proposed optimal clustering framework (OCF). First, we define some notations that will be used throughout the paper. Denote as the -th band vector and for each as band intervals. Here is the number of pixels, and is the number of bands in HSI. specifies the critical band indexes vector (CBIV), in which . Here is the index of the -th critical band, i.e., the last band of cluster , and is the number of selected bands. For convenience of expression, we set . Noting that once is determined, the whole band set can be separated into subsets: , ,…, .
In a clustering algorithm, how to design an effective objective function is an important issue. A straightforward idea is to individually evaluate the contribution of each cluster, and then sum up these contributions as a measurement of the whole clustering result. Though very simple, this strategy has been adopted by many well-known clustering methods (e.g., k-means and spectral clustering [42]) and demonstrated to be effective.
Following this idea, we define a mapping to evaluate the contribution of each band interval . Since the clustering result is determined by a series of critical bands under CBIC, the contribution of cluster can be represented by . Based on the above consideration, a general form of the objective function is given as:
[TABLE]
Without loss of generality, we assume that function is supposed to be maximized. So our optimization problem turns to be:
[TABLE]
After the optimization problem is clarified, the solution will be given in two steps, named as problem decomposition and subproblem combination, respectively. It should be pointed out that, the mapping here is still a general form, which means the solution will be available for arbitrary definition of .
- Problem decomposition. Let be the solution of a simpler subproblem of Eq. (2):
[TABLE]
where and . Intuitively, is the optimal solution when our target is to partition the first bands into intervals (the original one is to partition the whole bands into intervals). Specially, is the solution of Eq. (2).
Then by enumerating all the possible value of , Eq. (3) can be derived into:
[TABLE]
By substituting into Eq. (3), we have:
[TABLE]
For better comprehension of Eq. (4), an example to decompose this problem is given in Fig. 3.
- Subproblem combination. The above analysis uncovers the optimal substructure attribute implied in the original problem. According to Eq. (4) and Eq. (5), all the , for each , can be obtained since is already known. Similarly, all the can also be achieved based on the previous results. Through this order of calculation, all the values of including can be obtained efficiently.
We are now at a point to recover the CBIV corresponding to , since it is needed to acquire the final clustering result. Denote as the maximizer corresponding to :
[TABLE]
It is easy to see that there is:
[TABLE]
Since is known, can be recovered by substituting into Eq. (7) sequentially.
For more details about the framework, refer to the pseudo code shown in Algorithm 1.
III-D Extended-OCF
In this part, the proposed OCF will be extended to a more general form, so it can be suitable for more kinds of objective function that may be more effective. In Eq. (1), the objective function is defined as the sum of the contribution of each band interval. In fact, we can attain a more general form of the objective function via replacing the original sum operator by an arbitrary binary operator : as follows.
[TABLE]
In fact, the optimization of Eq. (8) is nearly the same as Eq. (1). The only difference is to replace “” operator with “” in Eq. (4).
Consequently, given a tuple , an objective function can be designed by Eq. (8). Also, it can be readily solved via OCF.
III-E Rank on Clusters Strategy
After the bands have been separated into clusters, conventional clustering-based band selection methods usually select one band in each cluster individually by applying some kinds of criteria, e.g., to select which is closest to the centroid [30]. However, this kind of strategy is found ineffective in experiments since the most discriminative bands in each cluster may not be discriminative with respect to the total bands.
To tackle this problem, a simple but effective strategy is proposed to select bands under the achieved clustering structure. The basic idea is to rank the bands according to their discriminations, and select those with higher rank values, while ensuring that there is only one band selected in each cluster.
Here we give a more formal description. First, bands are assigned with rank values, denoted as , where is the rank value of the -th band. Then we use to record the index of the cluster that each band belongs to. To be specific, if , there is . Suppose the indexes of selected bands form a vector . Our purpose is to solve the following optimization problem:
[TABLE]
Obviously, the solution is to select the band with the highest rank value in each cluster:
[TABLE]
Intuitively, RCS first assigns rank values to the bands, and bands with the highest rank values in each cluster are selected to constitute the desired band subset. In this way, both the discrimination of bands and the correlation among bands are taken into account to acquire a more superior band subset.
IV Implementation of OCF
In the previous section, we have learnt that how to implement a band selection algorithm based on OCF when given an objective function and a ranking method. In this section, the selection of these two factors and some other issues in implementing the framework will be discussed. First, the objective functions and ranking methods utilized in this paper will be introduced. Then, the computational complexity to implement the proposed algorithm will be analysed. Finally, a novel method to identify the number of the selected bands will be presented.
IV-A Objective Function
In this paper, two objective functions are adopted to carry out OCF, namely normalized cut (NC) and top-rank cut (TRC).
Normalized cut criterion. NC is an effective graph-theoretic criterion that first adopted in spectral clustering (SC) [43, 42]. Assume there is a weighted undirected graph: , where is the node set and with entries is the similarity matrix. A -way partition of can be denoted by , in which and . The NC and normalized association (NA) [42] are defined as:
[TABLE]
NC is supposed to be minimized since partitions with small NC values have high correlation within groups and low correlation between groups. According to Eq. (11) and (12), . Hence, the minimization of NC is equivalent to the maximization of NA. Without losing generality, we focus on the maximization of NA in the following discussion.
Though the optimization of NC (or NA) has been demonstrated NP-hard [43], it is much easier to be solved when CBIC is imposed.
According to CBIC, a graph partition is dependent on a CBIV and there is . In this sense, NA can be rewritten as follows:
[TABLE]
As we can see, Eq. (13) is a special case of Eq. (1) where the mapping is defined as:
[TABLE]
Consequently, NA can be finally maximized by inputting into Algorithm 1.
One remaining problem is about how to measure the similarities among bands. Here we adopt a non-parameter method called local scaling [44] to construct such a similarity matrix:
[TABLE]
where is the local scaling parameter, and is the -th neighbor of ( is set to according to [44]).
Top-rank cut criterion. Except for NC, a novel top-rank cut (TRC) criterion is proposed in this paper. There are two motivations to design TRC.
- Sometimes, a band interval with minimal contribution to the value of objective function has even negative effect on an algorithm’s performance. This stems from the fact that there may exist noisy bands in that interval. Hence, to maximize this minimal contribution among all the band intervals may be a more effective way to attain the clustering result.
- Since in the proposed RCS, only the bands with the highest rank values will be selected in each subset. Those bands are more important and should have larger priorities when designing the objective function.
According to Section III-D, we will give the definition of TRC by giving the tuple , where the binary operator is the maximization operation: , and the mapping is defined as:
[TABLE]
in which is the rank value of calculated when conducting RCS.
To explain with it, TRC characterizes a band partition in the following steps:
- Choose the bands with the highest rank values in each cluster.
- For each chosen band , calculate the sum of similarities between and the other bands out of the cluster it belongs to. This sum value is the score of the corresponding cluster.
- The maximum score among all the clusters is just the TRC value of this band partition. It should be pointed out that, different from NC, the value of TRC should be minimized to achieve a promising result. TRC is easy to be optimized through some minor modifications of Algorithm 1.
IV-B Ranking Methods for RCS
To conduct the proposed RCS, a ranking method is needed to evaluate the importance of bands. In this subsection, some ranking criteria will be presented and discussed to accomplish this task.
-
MVPCA [26]. As stated in Section II, MVPCA evaluate the bands according to their variances. Generally, low variance means that different ground objects have similar characteristic, and are difficult to be recognized. In contrary, large variance represents for more distinctive information, so that ground objects are easier to be distinguished. Unfortunately, one disadvantage of MVPCA is that it is sensitive to noises since noisy bands usually have large variances.
-
E-FDPC [29]. E-FDPC ranks each band by assessing whether it is a suitable cluster center. First, a cluster center should have large local density, i.e., there should be lots of bands close to it. Second, it should be distant from the bands that have larger local densities than it. For E-FDPC, the first property eliminates the noisy bands since they usually have low local density, while the second property helps to reduce the correlation among bands.
-
Information entropy (IE) [45]. IE is a noise insensitive criterion to measure the information hidden in a stochastic variable. For a band , its entropy can be defined as:
[TABLE]
where is the gray-scale color space, and can be calculated according to the gray-level histogram of [19, 20].
Until now, we have listed all the objective functions and ranking methods utilized in this paper. For convenient expression, the devised algorithm will be named following the pattern “objective function”-OC-“ranking method”, e.g., TRC-OC-FDPC denotes that TRC and E-FDPC are utilized to implement the algorithm.
IV-C Analysis of Computational Complexity
The conduction of the proposed algorithm can be decomposed into steps, they are pre-processing step, clustering step and selection step. In the following, we will discuss the theoretical computational complexity for each step.
Pre-processing step. In this step, we seek to calculate the mapping for each kind of objective function. For both NC and TRC, a similarity matrix should be first calculated according to Eq. (15), and this takes computational complexity. For TRC, each band should be further aligned with rank values, whose complexity is depending on the utilized ranking methods (which will be discussed in the third step). Based on these preparatory works, the mapping can be calculated according to Eq. (14) and (16) by taking complexity for both NC and TRC.
Clustering step. In this step, the optimal CBIV is obtained by optimizing the objective functions. According to Algorithm 1, time is needed for both NC and TRC.
Selection step. In the last step, bands should be assigned with rank values to conduct RCS. For MVPCA, E-FDPC and IE, their computational complexities are , and , respectively.
Since , we know that all versions of the proposed algorithm cost time. This is acceptable for most of the applications. One should be noted that, the efficiency of the proposed framework is limited by the pre-processing step and selection step. The clustering step, which is considered as the main step, is rather more efficient. Hence we believe the proposed framework is potential to be suitable for more time-critical applications only if simpler objective functions and ranking methods are utilized.
IV-D Determine the Number of the Selected Band
In [26], a variance-based band-power ratio is defined to determine the required number of bands. It first calculates the variances for each , and sort them in descending order. Then define a band-power ratio:
[TABLE]
where is the sum of variances of all the bands. According to this ratio, we can know how many bands is needed to produce a certain percentage of band-power. However in HSI, bands with large variances may still be strongly correlated, so there is common part among band power they produce. With consideration of this characteristic, a improved method is proposed to measure how much power can be produced by low-correlated bands.
We first estimate a upper bound of the required number of band , which is given by , where is a ratio between [math] and . Suppose is the indexes of selected bands by NC-OC-MVPCA (the proposed band selection algorithm using NC and MVPCA). Without loss of generality, we assume there is . Then, the correlation-reduced band-power ratio is formulized as:
[TABLE]
where . Since the correlation among bands has been reduced in clustering process, this method can better characterize the distinct information hidden in different bands. Finally, given a desired correlation-reduced band-power ratio , we can determine the required number of bands by .
V EXPERIMENT
In this section, comparative experiments are conducted on different HSI data sets. First, we introduce the experimental setups, including the employed data sets, comparison methods, classification settings and the number of the required bands. Then the classification results of all the four data sets are shown and analysed. Finally the computational times of different methods are compared.
V-A Experimental Setup
Data set. Four real-world HSI data sets captured by two different image systems are used in the experiments. They are introduced as follows.
-
Indian Pines Scene. Indian Pines Scene was captured by AVIRIS sensor in North-Western Indiana in 1992. It consists of pixels and spectral reflectance bands in the wavelength range of m. There are 16 classes of objects contained in the image. Water absorbtion bands including , and are removed and a total of bands are utilized.
-
Pavia University Scene. Pavia University Scene was acquired by the Reflective Optics System Imaging Spectrometer (ROSIS) system during a flight campaign over Pavia, Northern Italy in 2002. After some pixels with no information discarded, an image of size is used. Pavia University Scene has bands and classes of land cover objects.
-
Salinas Scene. Salinas Scene was captured by AVIRIS sensor in Salinas Valley, California in 1998. The image size of Salinas Scene is with a spectral coverage within m. There also spectral bands and classes of interests in the image. Similarly, water absorption bands are discarded including , and , and finally a total of bands are used in the experiments.
-
Kennedy Space Center (KSC). KSC was captured by AVIRIS sensor in Florida, on March 23, 1996. It was acquired from an altitude of approximately km, with a spatial resolution of m. there are total bands after removing bands with low SNR or water absorption, and each band is with size and has classes of land cover objects.
Comparison method. To verify the effectiveness of the proposed algorithms, several state-of-the-art methods are included as competitors. They are WaLuDi [28], uniform band selection (UBS) [27], volume gradient band selection (VGBS) [34], enhanced fast density-peak-based clustering (E-FDPC) [29], and multi-task sparsity pursuit (MTSP) [36]. About the parameters among them, WaLuDi, UBS, VGBS and E-FDPC are parameter-free so only is needed to be set. For MTSP, its parameters are tuned on Indian Pines and fixed for the other three data sets. Note that the proposed framework itself are parameter-free. The only parameters that needed to be set are and the number of the selected bands involved by E-FDPC, denoted as . Considering that E-FDPC is used to prioritize all the bands, is fixed to for all the data sets.
Classification setting. Four classifiers are utilized to examine the classification accuracies of different band selection methods. They are k-nearest neighborhood (KNN) [46], linear discriminant analysis (LDA) [47], support vector machine (SVM) [48], and edge-preserving filtering (EPF) [49]. In the experiments, of the samples for each class are chosen randomly to train the classifiers, while the rest are used in testing. To simplify the problem, background is not considered. In order to reduce the instability caused by the random selection of the training samples, the final results are achieved by averaging individual runs.
Number of the required bands. To determine the number of the required bands, the upper bound in Section IV-D is set to , and is set to empirically for all the four data sets. Function are plotted in Fig. 4. According to Eq. (19), the numbers of the required bands are , , and for Indian Pines, Pavia University, Salinas and Kennedy Space Center, respectively.
V-B Result Analysis
In this part, we compare the proposed algorithms with some state-of-the-art methods. Overall accuracy (OA) is involved as the evaluation criterion. In each data set, three indicators will be compared. They are:
- OA curves, i.e., OA values versus the number of the selected band ( is set every intervals from - ).
- Average OA against different number of bands.
- OA value when the number of bands is determined by Eq. (19). In the experiments, four versions of the proposed algorithm will be examined. They are TRC-OC-FDPC, NC-OC-IE, TRC-OC-IE and NC-OC-MVPCA. For simplicity, only the first two of them will be shown in OA curves. For comparison purpose, selected bands for all the methods in Indian Pines are listed in Table I (their indexes are that before the removal of noisy bands).
Indian Pines Scene. Fig. 5, 6 and 7 show the above three kinds of indicators on Indian Pines using different classifiers. In Fig. 5, we can see TRC-OC-FDPC and NC-OC-IE achieve the best performance, with stable and high OA values against different number of bands and classifiers. When refer to Fig. 6, the proposed algorithms achieve higher average OAs compared to the others. Fig. 7 shows the OA values when bands are selected. The proposed algorithms also show significant superiority in this case.
Pavia University Scene. Similar to Indian Pines Scene, the above three indicators are shown in Fig. 8, 9 and 10. In Fig. 8, the results are different with respect to classifiers. While KNN is employed, NC-OC-IE attains a stable OA curve but TRC-OC-FDPC acquires a large decrease when bands are selected. For other classifiers, they both perform poor when the number of bands is or , but are superior to all the competitors when it is or . In Fig. 9, the difference among methods is very small. When averaging the results produced by all the classifiers, NC-OC-MVPCA slightly outperforms E-FDPC and ranks the first. In Fig. 10 when bands are selected, UBS and NC-OC-MVPCA outperform the others on LDA, SVM and EPF, while E-FDPC performs better on KNN. When averaging the results, NC-OC-MVPCA and UBS achieve the best performance.
Salinas Scene. For Salinas Scene, the above three indicators are shown in Fig. 11, 12 and 13. In Fig. 11, TRC-OC-FDPC achieves a satisfactory performance, and is superior to the other methods in general. NC-OC-IE also achieves good performance. It is more robust against various classifiers compared to the other competitors. When referring to the average OA value as shown in Fig. 12, the proposed algorithms are more effective than the others in most of the cases. In Fig. 13, the proposed algorithms are inferior to VGBS when EPF is employed, but are still more superior to the others for other classifiers.
Kennedy Space Center. Similar to the above data sets, Fig. 14, 15 and 16 show the results of KSC. In Fig. 14, one can observe that NC-OC-IE and TRC-OC-FDPC show significant superiority to the others on KNN, SVM and EPF. While for LDA, E-FDPC also attains good performance. In Fig. 15, three versions of the proposed algorithm dominate the others. However, NC-OC-MVPCA achieves a relatively worse result. In Fig. 16, the proposed algorithms achieve excellent and robust performance, especially for TRC-OC-IE and NC-OC-IE.
In the following, we will discuss about some interesting issues and give some deep analyses towards the experimental results.
-
Stability against classifiers. From the results, some competitors have instable performance on different classifiers. For example, VGBS performs the best on Salinas Scene when EPF is employed, but rather poor when KNN or LDA are utilized. Similarly, E-FDPC is superior to the others on Pavia University when KNN is used, but not for the other classifiers, especially when more than bands are selected. This may be blamed on the selection of noisy bands, which results in poor performance on classifiers that are sensitive to noises. Compared to the other competitors, the overall performance of the proposed algorithms is more robust against classifiers. This proves that they are noise-insensitive to some extent.
-
Robustness against data sets. Some competitors are also not robust enough against different data sets. For instance, E-FDPC achieves high OA values on Salinas Scene, but ranks the last on Indian Pines Scene. This is because it is an extremely complex problem to select the optimal bands in HSI, and local optimal solution, which will cause instability is always unavoidable. Moreover, if there are parameters to be tuned for a method, fluctuation in accuracy may also occur. Fortunately, these problems can be well solved by OCF, since it provides a non-parameter way to achieve the optimal clustering structure under CBIC.
-
Performance of UBS. It is surprising that UBS achieves a good performance through a simple strategy that to select the bands uniformly. Here we try to give an explanation from physical point of view. As stated in Section III-B, bands with close wavelengths usually have stronger correlation. In UBS, the minimum difference of wavelength between two adjacent bands is maximized, so the correlation among the selected bands is reduced. From another point of view, the good performance of UBS proves that difference of wavelength is a good measurement for band correlation. Hence imposing the proposed CBIC on band clustering is suitable for HSI data sets.
-
Performance on KSC data sets. In fact, KSC data set is seriously polluted by salt noises (pixels with abnormally high intensities) as shown in Fig. 17. Hence, the performance on KSC data sets can examine whether a method is robust to noises. According to Fig. 15, NC-OC-MVPCA and VGBS both achieve relatively poor performance. This is in accordance with the analyses in Section II that the variance-based MVPCA and geometry-based VGBS are very sensitive to noises. On the other hand, the other versions of the proposed algorithm achieve satisfactory results on KSC. This further proves that they are noise-insensitive.
-
Band number determination. According to the plotted OA curves, Eq. (19) offers a promising estimation of . One can observe this from two aspects. First, as illustrated in Fig. 5, 8, 11 and 14, the increasing rate of OA values tends to be slower at band numbers around the estimations. Second, the relative relation of the required band numbers among different data sets is captured. For instance, Pavia University has a slower increasing rate than Salinas as shown in Fig. 8 and 11. Accordingly, the required band number of Pavia University is , more than that of Salinas (). However, this method still has room for improvement. On KSC data set, the estimation of band number is less than the real value. This is because too large band power is assigned to the noisy bands by MVPCA.
V-C Comparison of Computational Time
In order to evaluate the efficiency of the proposed algorithms, we compare the computational times of various methods on the above four HSI data sets. The experiments are conducted using an Intel Core i5-4590 3.30-GHz CPU with 16-GB RAM, and all the methods are implemented in MATLAB R2016b. Table II shows the processing time of different band selection methods when selecting 15 bands on each data set. According to it, we can find that all versions of the proposed algorithm cost moderate computational time among the other methods. Though they are not as efficient as VGBS and E-FDPC, they take less time compared to MTSP and WaLuDi. Therefore, the proposed algorithms are computationally acceptable while guaranteeing the superior performance.
VI Conclusion
In this paper, an optimal clustering framework (OCF) is proposed to search for the optimal clustering structure on HSI, and a rank on clusters strategy (RCS) is developed to select the discriminative bands under the achieved clustering structure. A correlation-reduced band-power ratio is also presented to automatically determine the number of the required bands. Based on the proposed OCF and RCS, several versions of algorithm are devised by applying various objective functions and ranking methods. Experiments on four data sets demonstrate that they are robust and effective.
In the future, we will focus on two issues to improve the proposed framework. One is to learn the low-dimensional manifold embedded in HSI, so as to construct a more effective similarity matrix to describe the correlation among bands. Another is to design a more powerful objective function to capture the discrimination of band subsets.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] B. Luo, C. Yang, J. Chanussot, and L. Zhang, “Crop yield estimation based on unsupervised linear unmixing of multidate hyperspectral imagery,” IEEE Trans. Geoscience and Remote Sensing , vol. 51, no. 1, pp. 162–173, 2013.
- 2[2] H. Akbari, Y. Kosugi, K. Kojima, and N. Tanaka, “Detection and analysis of the intestinal ischemia using visible and invisible hyperspectral imaging,” IEEE Trans. Biomed. Engineering , vol. 57, no. 8, pp. 2011–2017, 2010.
- 3[3] G. F. Hughes, “On the mean accuracy of statistical pattern recognizers,” IEEE Trans. Information Theory , vol. 14, no. 1, pp. 55–63, 1968.
- 4[4] B. Rasti, M. O. Ulfarsson, and J. R. Sveinsson, “Hyperspectral feature extraction using total variation component analysis,” IEEE Transactions on Geoscience and Remote Sensing , vol. 54, no. 12, pp. 6976–6985, 2016.
- 5[5] B. Liu, X. Yu, P. Zhang, A. Yu, Q. Fu, and X. Wei, “Supervised deep feature extraction for hyperspectral image classification,” IEEE Transactions on Geoscience and Remote Sensing , vol. PP, no. 99, pp. 1–13, 2017.
- 6[6] W. Sun, G. Yang, B. Du, L. Zhang, and L. Zhang, “A sparse and low-rank near-isometric linear embedding method for feature extraction in hyperspectral imagery classification,” IEEE Transactions on Geoscience and Remote Sensing , vol. 55, no. 7, pp. 4032–4046, 2017.
- 7[7] X. Kang, S. Li, and J. A. Benediktsson, “Feature extraction of hyperspectral images with image fusion and recursive filtering,” IEEE Transactions on Geoscience and Remote Sensing , vol. 52, no. 6, pp. 3742–3752, 2014.
- 8[8] X. Kang, S. Li, L. Fang, and J. A. Benediktsson, “Intrinsic image decomposition for feature extraction of hyperspectral images,” IEEE Transactions on Geoscience and Remote Sensing , vol. 53, no. 4, pp. 2241–2253, 2014.