Factored Contextual Policy Search with Bayesian Optimization
Robert Pinsler, Peter Karkus, Andras Kupcsik, David Hsu, Wee Sun Lee

TL;DR
This paper introduces a structured approach to contextual policy search by factoring contexts into target and environment components, enhancing data efficiency and generalization in robotic learning through Bayesian optimization.
Contribution
It proposes a novel factorization of context variables in Bayesian optimization-based policy search, improving learning speed and generalization in complex robotic tasks.
Findings
Faster learning in robotic simulations.
Improved generalization across different task contexts.
Effective application of factorization in Bayesian optimization.
Abstract
Scarce data is a major challenge to scaling robot learning to truly complex tasks, as we need to generalize locally learned policies over different task contexts. Contextual policy search offers data-efficient learning and generalization by explicitly conditioning the policy on a parametric context space. In this paper, we further structure the contextual policy representation. We propose to factor contexts into two components: target contexts that describe the task objectives, e.g. target position for throwing a ball; and environment contexts that characterize the environment, e.g. initial position or mass of the ball. Our key observation is that experience can be directly generalized over target contexts. We show that this can be easily exploited in contextual policy search algorithms. In particular, we apply factorization to a Bayesian optimization approach to contextual policy…
Click any figure to enlarge with its caption.
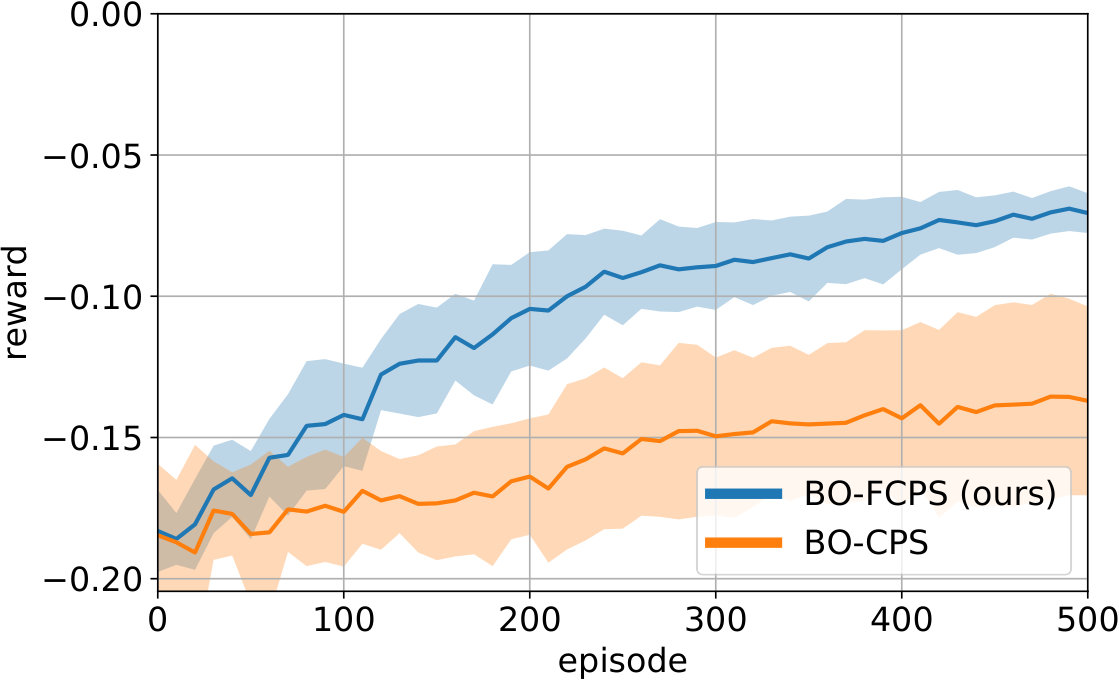 Figure 1
Figure 1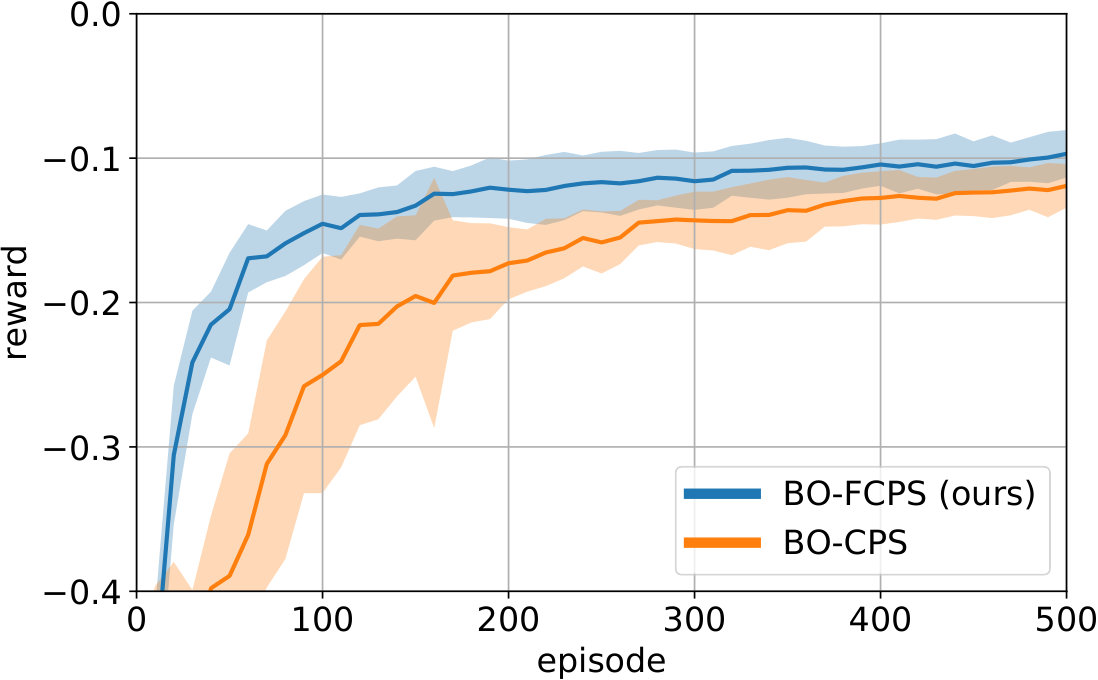 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4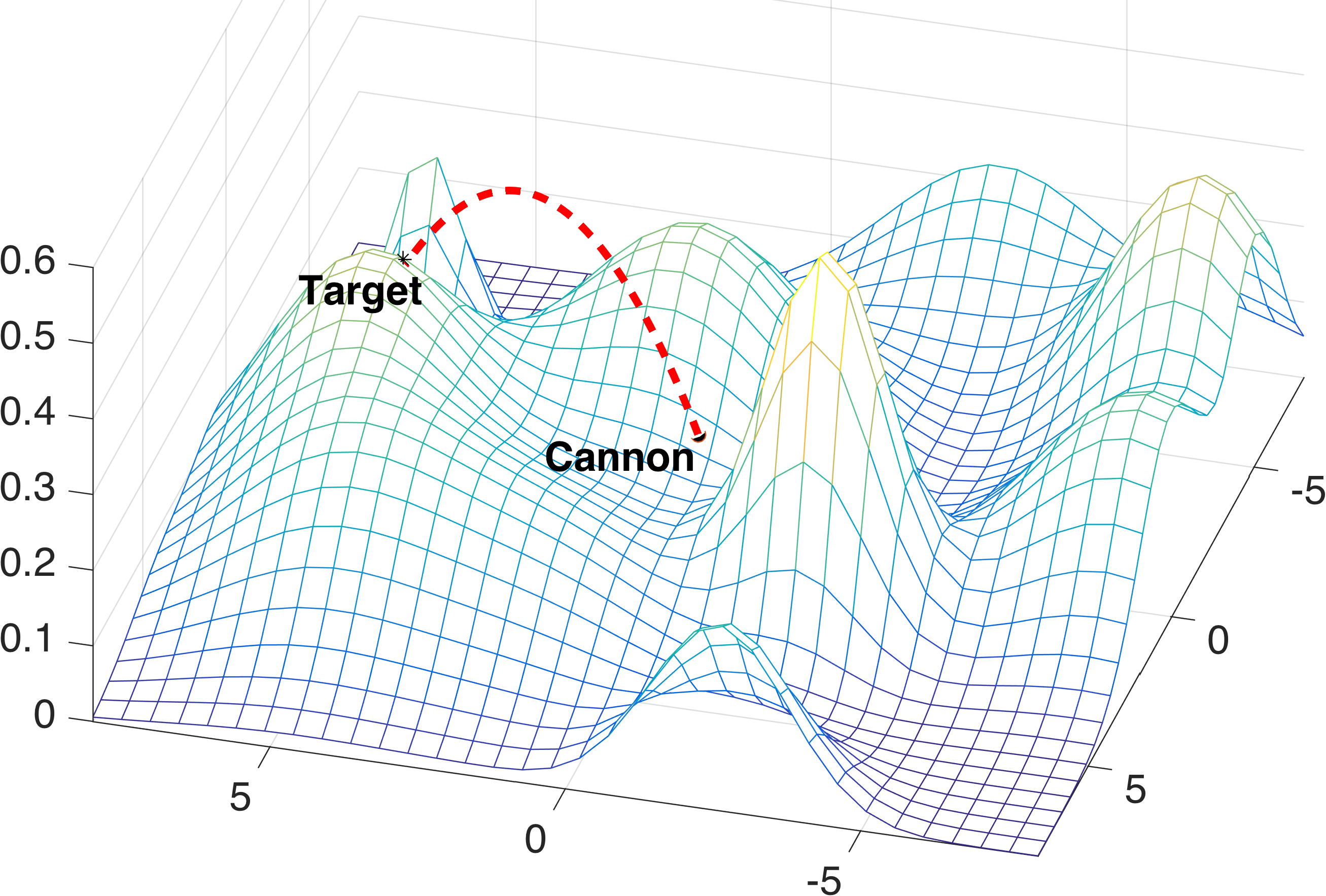 Figure 5
Figure 5 Figure 6
Figure 6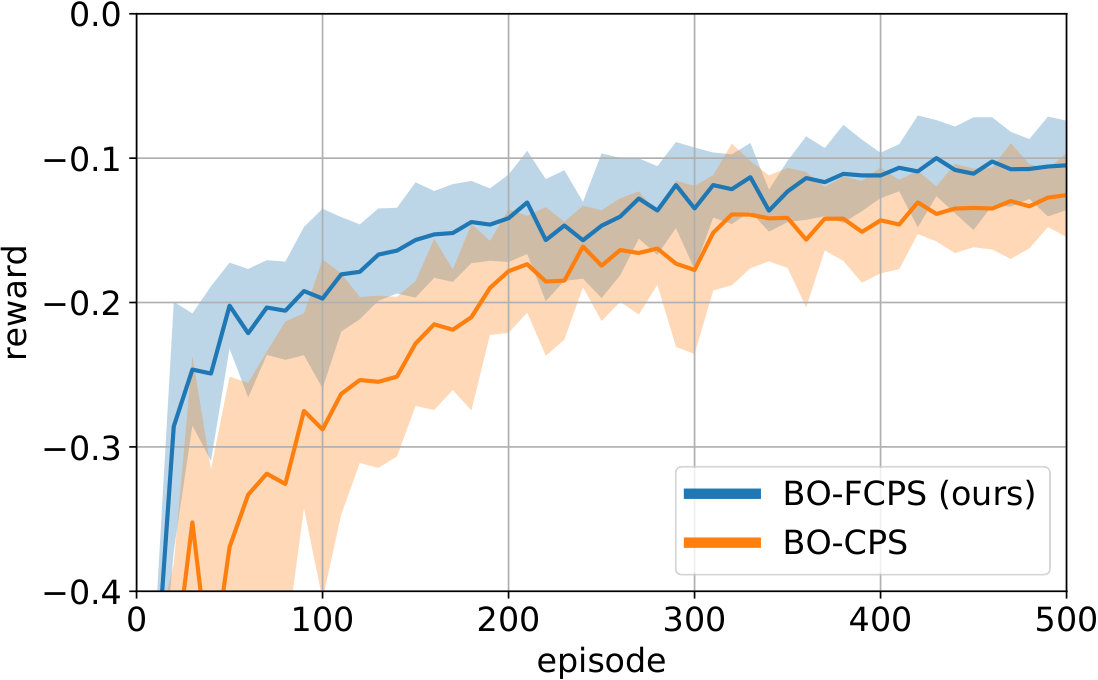 Figure 7
Figure 7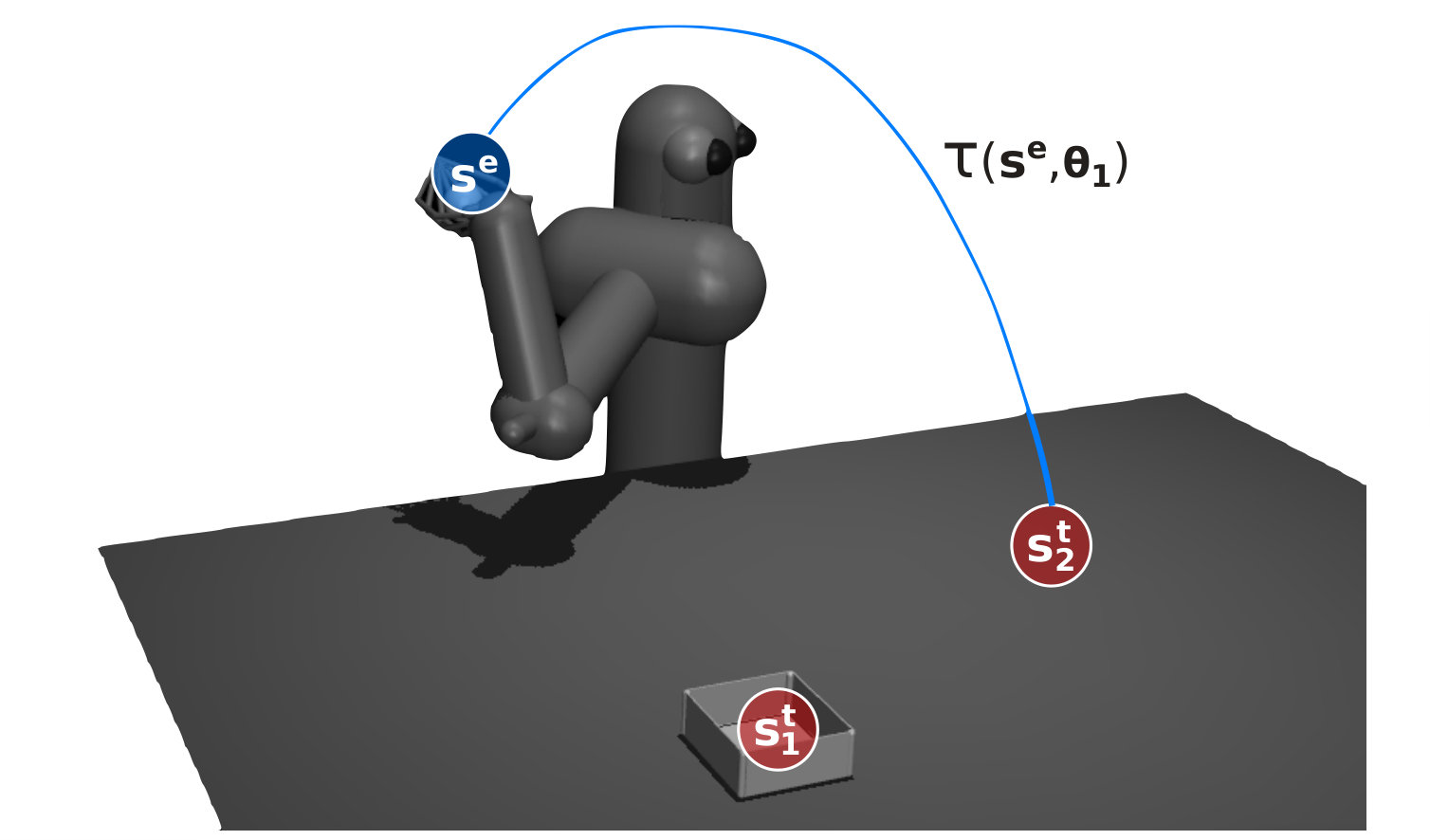 Figure 8
Figure 8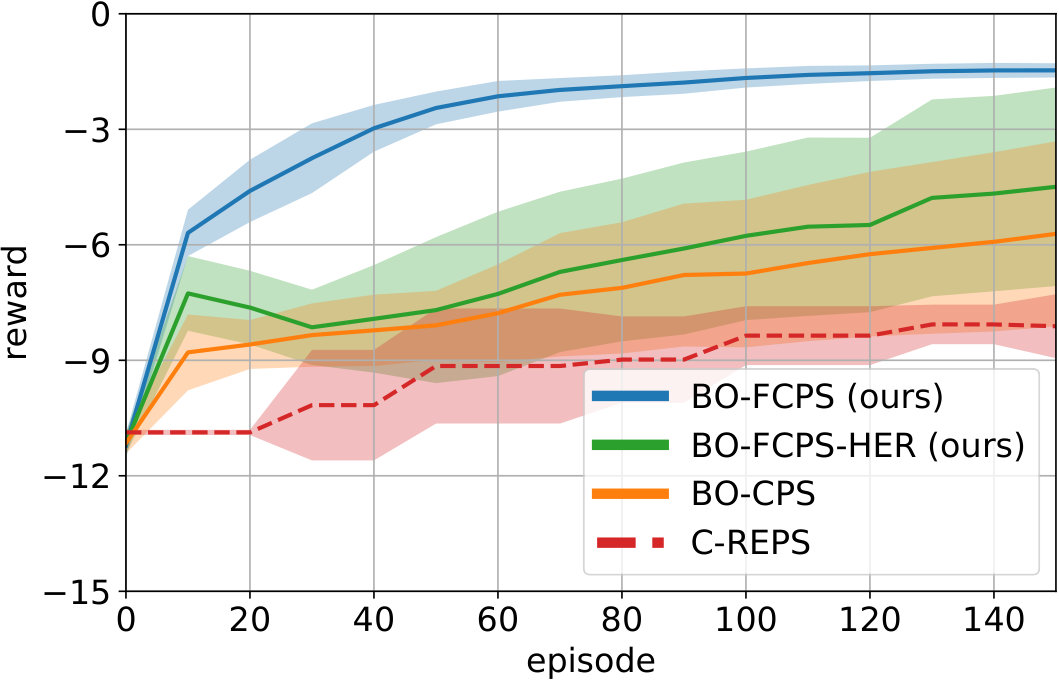 Figure 9
Figure 9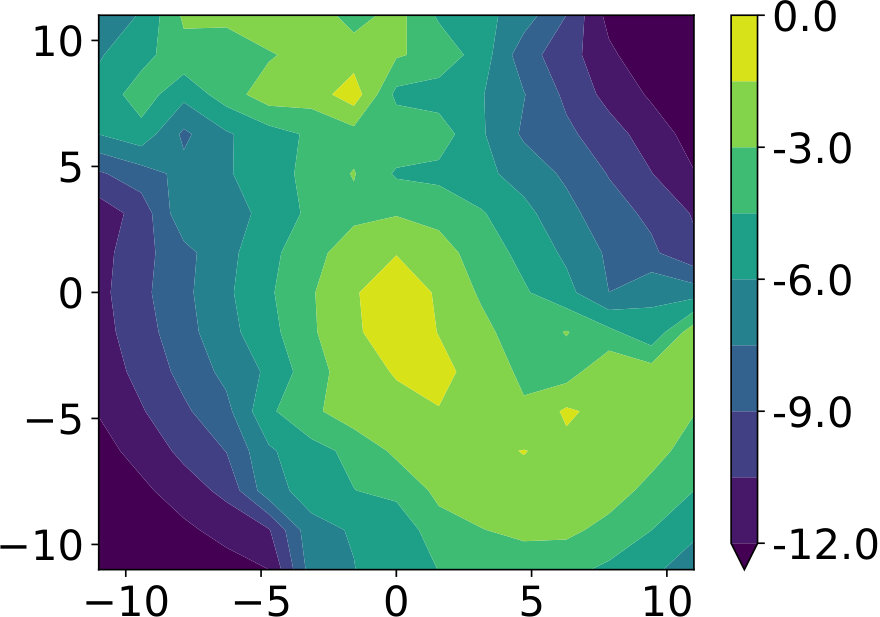 Figure 10
Figure 10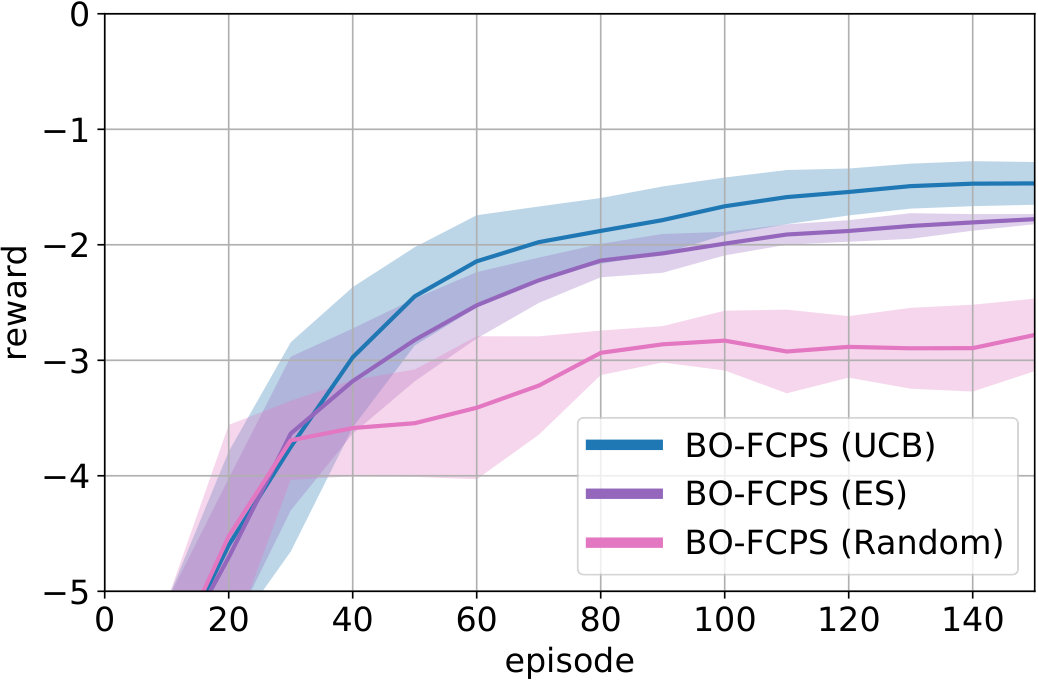 Figure 11
Figure 11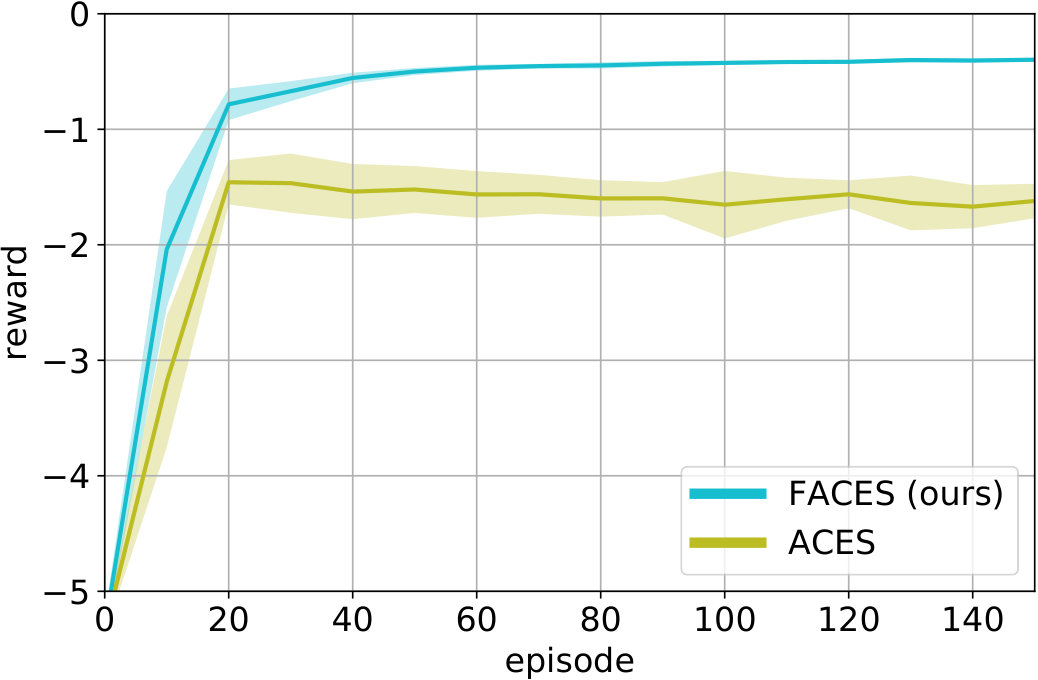 Figure 12
Figure 12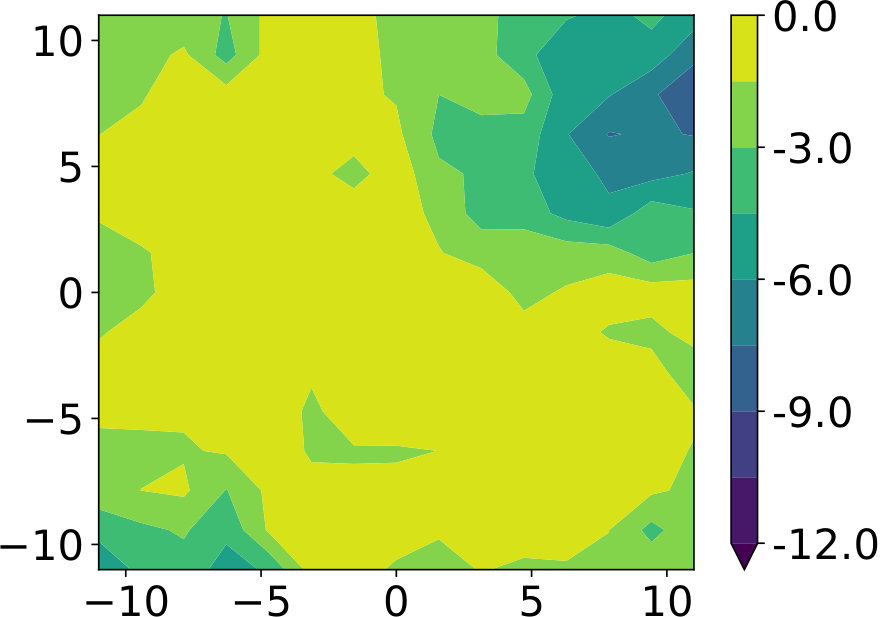 Figure 13
Figure 13| C-REPS | -496 ( 17) | -955 ( 56) | -1357 ( 62) |
|---|---|---|---|
| BO-CPS | -461 ( 28) | -843 ( 70) | -1148 ( 151) |
| BO-FCPS-HER (ours) | -447 ( 24) | -809 ( 71) | -1111 ( 140) |
| BO-FCPS (ours) | -303 ( 34) | -414 ( 44) | -499 ( 56) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Factored Contextual Policy Search with Bayesian Optimization
Robert Pinsler*∗1*, Peter Karkus*∗2*, Andras Kupcsik3,4, David Hsu2 and Wee Sun Lee2 1University of Cambridge, UK 2National University of Singapore, Singapore 3Bosch Center for AI, Germany 4Idiap Research Institute, Switzerland.* denotes equal contribution. PK conceived the idea and performed initial experiments. RP extended the approach and evaluation, and wrote most of the manuscript. Correspondence to [email protected] receives funding from iCASE RG89603 supported by Nokia. PK, DH and WSL acknowledge funding from Singapore Ministry of Education AcRF grant MOE2016-T2-2-068. PK is supported by the NUS Graduate School for Integrative Sciences and Engineering Scholarship.
Abstract
Scarce data is a major challenge to scaling robot learning to truly complex tasks, as we need to generalize locally learned policies over different task contexts. Contextual policy search offers data-efficient learning and generalization by explicitly conditioning the policy on a parametric context space. In this paper, we further structure the contextual policy representation. We propose to factor contexts into two components: target contexts that describe the task objectives, e.g. target position for throwing a ball; and environment contexts that characterize the environment, e.g. initial position or mass of the ball. Our key observation is that experience can be directly generalized over target contexts. We show that this can be easily exploited in contextual policy search algorithms. In particular, we apply factorization to a Bayesian optimization approach to contextual policy search both in sampling-based and active learning settings. Our simulation results show faster learning and better generalization in various robotic domains. See our supplementary video: https://youtu.be/MNTbBAOufDY.
I INTRODUCTION
Enabling robots to operate in truly complex domains requires learning policies from a small amount of data and generalizing learned policies over different tasks. Policy search methods with low-dimensional, parametric policy representations enable data-efficient learning of local policies [1]. Contextual policy search (CPS) [2, 3] further enables generalization over different task settings by structuring the policy. CPS uses an upper-level policy to select parameters of a lower-level policy given context , where the context specifies the task. The goal is to learn a policy that maximizes the expected reward .
We propose to further structure the contextual policy representation by introducing a factorization of the context space. In particular, we factorize a context vector into two components: (1) target contexts that specify task objectives, e.g. for a ball throwing task the target coordinates of the ball, and (2) environment contexts that characterize the environment and the system dynamics, e.g. initial position of the ball. Formally, we assume that the expected reward is given by , where is a trajectory with unknown dynamics , and is the reward function. The key difference between and is that the dynamics only depend on . We can exploit this property and re-evaluate prior experience in light of a new target context, leading to improved data-efficiency and better generalization.
For example, assume a robot is learning to throw balls at different targets (Fig. 1). The robot is asked to aim at . It chooses parameters , executes the throw, and observes a ball trajectory that hits target , . This yields a reward . Assume the robot is now asked to aim at target . Standard CPS methods try to generalize prior experience solely based on the upper-level policy , e.g. by assuming that rewards obtained under similar contexts are correlated. Context factorization instead allows to treat the two context types differently. The target context can be used to evaluate directly, yielding the exact reward we would get for when targeting . That is because a trajectory is independent from the target context. The same is not true for environment contexts, and thus we must rely on the upper-level policy to generalize over them.
We demonstrate the benefits of factorization by applying it to CPS approaches based on Bayesian optimization (BO) [4]; however, other CPS methods would be also possible. First, we consider a passive learning setting, where the context is given to the robot, and introduce a factored variant of BO for CPS (BO-CPS) [5, 6]. We then consider an active learning setting [7], where the robot can choose the context during learning. We introduce factored contexts to ACES [8], a CPS method based on entropy search [9]. For moderately low-dimensional search spaces, e.g. when learning pre-structured policies, such global optimization techniques achieve high data-efficiency by directly searching for the optimal parameters using a surrogate reward model.
So far we assumed that we can re-evaluate the reward function for arbitrary target contexts. This assumption is reasonable in real robot applications, where rewards typically encode objectives defined by the system designer. However, if the agent only has access to samples from the reward function, we can still exploit factored contexts by re-evaluating the current trajectory w.r.t. the achieved outcome. This approach can be seen as an extension of hindsight experience replay (HER) [10], a recently proposed data augmentation technique for goal-oriented RL algorithms.
We analyze the proposed methods first on a toy task. We then validate the benefits of context factorization on three simulated robotics environments from the OpenAI Gym [11], where we employ dynamic movement primitives [12] to efficiently generate trajectories. We show that context factorization is easy to implement, can be broadly applied to CPS problems, and consistently improves data-efficiency and generalization for various robotic tasks.
II RELATED WORK
There are several CPS approaches that generalize over a context space. One group of work first learns different local policies and then uses supervised learning to interpolate policy parameters over contexts [13, 14]. These methods are suitable for problems where local policies are available or easy to learn, but they are inefficient otherwise. The second group of work jointly learns local policies and generalizes over the context space [15, 16, 2]. These approaches were applied to a variety of real-world tasks, including playing table tennis [16], darts [16] and hockey [2]. Although all tasks involve target contexts, generalization over contexts solely relies on correlation. Similarly, CPS approaches based on BO [6, 8, 17, 18] learn a probabilistic reward model that generalizes over the context space through correlation. In this paper, we extend two BO approaches with factorization, namely BO-CPS [5, 6] and ACES [8].
To the best of our knowledge, there is no prior work that explicitly factors the context space. Similar ideas are implicitly used by Kober et al. [16] who learn a contextual policy for discrete targets while performing a higher-level task. While they map experience gained in one context to another, they do so for estimating discrete outcome probabilities and not for improving the policy. GP-REPS [19] iteratively learns a transition model of the system using a Gaussian process (GP) [20], which is then used to generate trajectories offline for updating the policy. The authors consider generating additional samples for artificial contexts, but they do not define an explicit factorization.
The idea of replacing the goal of a trajectory has recently been explored in HER [10], which increases data-efficiency in goal-based RL tasks with sparse rewards. The key idea is to augment the dataset with additional experience by replacing the original target context of a rollout to be the achieved outcome. Instead of replacing the target context after each rollout, we replace the target context of all previous episodes before each rollout and re-evaluate the entire dataset. Our approach additionally generalizes over environment contexts that are typical in CPS problems. If we have only access to sample rewards, we show how context factorization can be used to extend HER to CPS.
III BACKGROUND
III-A Bayesian Optimization for Contextual Policy Search
In a CPS problem, the agent observes a context before each episode, where the context specifies the task setting and is a distribution over contexts. To solve the task, the agent maintains an upper-level policy over parameters of a lower-level policy, e.g. a dynamic movement primitive [12]. Executing the lower-level policy with parameters generates a trajectory that yields reward . The goal of the agent is to learn an upper-level policy that maximizes the expected reward,
[TABLE]
BO-CPS [5, 6] frames CPS as a BO problem. BO is a global search method for optimizing real-valued functions, assuming only access to noisy sample evaluations. Starting from a prior belief about the objective, BO employs an acquisition function to guide the sampling procedure. In BO-CPS, a probabilistic reward model is learned from data samples , which allows to evaluate potential parameters for a query context . BO-CPS commits to a GP prior [20] with predictive posterior , and uses the GP-UCB acquisition function [21],
[TABLE]
where trades off exploration and exploitation. The policy parameters are selected by the upper-level policy , which optimizes the acquisition function given the query context,
[TABLE]
where , and is the Dirac delta function. The algorithm is summarized in Alg. 1.
III-B Active Contextual Entropy Search
Active contextual entropy search (ACES) [8] is an extension of entropy search (ES) [9] to the active CPS setting, where both the parameters and the context are chosen by the agent before an episode. ACES maintains a conditional probability distribution , expressing the belief about being optimal in context . The most informative query point is chosen by maximizing the expected information gain integrated over the context space,
[TABLE]
where is a set of randomly chosen representer points. The expected information gain in context after performing a hypothetical rollout with is given by
[TABLE]
where the expectation is taken over , and is an updated dataset that contains the hypothetical query point. In practice, Eq. 3 requires further approximations, which are explained in the original work [9, 8]. The algorithm is summarized in Alg. 3.
III-C Dynamic Movement Primitives
Dynamic movement primitives (DMPs) are often used as lower-level policies in robot learning tasks. A DMP [12] is a spring-damper system whose hyper-parameters can be flexibly adapted while retaining the general shape of the movement. These include the final position , final velocity and temporal scaling . The motion is further modulated by a non-linear forcing function with basis functions parameterized by phase variable . The parameters determine the shape of the movement and can be obtained by imitation learning. Each generated DMP trajectory is followed by the control policy of the robot, which implements a low-level feedback controller.
IV FACTORED CONTEXTUAL POLICY SEARCH
In this section, we introduce context factorization and show how it can be integrated into CPS algorithms.
We propose to factorize a context vector into two types of contexts, :
- •
target contexts which specify the task objective, and
- •
environment contexts which characterize the environment and the system dynamics.
Formally, we assume that the reward function is given by 111In general, the reward function may also depend on and . We omit this dependence for improved readability; the principle remains the same., where the trajectory is generated by unknown system dynamics, . Importantly, while the dynamics function depends on environment contexts, it does not depend on target contexts. This means that we can exchange the target context of a rollout without altering its trajectory, allowing to re-evaluate a rollout under different target contexts. For example, in our ball throwing task (Fig. 1) we can re-evaluate a previously observed trajectory pretending we were aiming at a different target. We cannot do the same with environment contexts, e.g. the initial ball pose, because a different initial pose would result in a different trajectory. In the following, we exploit factored contexts to reduce the data requirements of CPS algorithms. To what extend factorization can be exploited depends on the knowledge of the reward function . First, we assume that the reward function is fully known or that it can be evaluated for arbitrary targets . This allows to construct highly data-efficient algorithms, as we demonstrate on a passive (Section IV-A) and active (Section IV-B) CPS algorithm. In Section IV-C, we drop the assumption of a known reward function and propose an extension of hindsight experience replay [10] to the CPS setting using context factorization.
IV-A Bayesian Optimization for Factored CPS
Context factorization can be easily incorporated into BO-CPS. The resulting algorithm, Bayesian optimization for factored contextual policy search (BO-FCPS), is shown in Alg. 2. It maintains a dataset 222Instead of storing the entire trajectory, in practice we may only record its sufficient statistics for computing the reward, i.e. an outcome . that can be used to re-evaluate past experiences for a new query context . Given reward function , we construct a query-specific dataset,
[TABLE]
for learning a specialized reward model,
[TABLE]
before each rollout. This model is specific to the current target context . Jointly, the set of all possible reward models w.r.t. arbitrary targets generalizes directly over the target context space. Thus, each reward model only needs to generalize over environment contexts and policy parameters , leading to a reduced input space compared to the original reward model. This has the added benefit of a smaller search space during optimization. The parameters for context are found by optimizing the acquisition function given the target-specific reward model (Eq. 1, 2). We employ the DIRECT [22] algorithm for optimization, followed by L-BFGS [23] to refine the result.
We can formally compare BO-FCPS and BO-CPS if we assume that both approaches share the same dataset and the same GP hyper-parameters. In this case, the reward model of BO-FCPS evaluated at a particular target context is always at least as accurate as the one learned by BO-CPS. To see this, recall that BO-FCPS differs from BO-CPS in two ways: (1) BO-FCPS re-computes the rewards for , and (2) BO-FCPS does not consider the rewards at other target contexts . Re-computing the rewards is trivially beneficial because BO-FCPS knows the true reward for target context given a trajectory , whereas BO-CPS needs to infer the reward from correlations between target contexts. Disregarding rewards at other target contexts does not degrade the predictive performance of our model either. That is because for a given context-parameter pair the only source of uncertainty w.r.t. their expected reward is in the execution of the trajectory and its effect on the environment. Since the trajectory does not depend on the target context, evaluating the same trajectory under different target contexts does not reveal more information about the trajectory itself.
Note that while a better reward model at a given target context leads to better greedy performance, e.g. during offline evaluation, it does not necessarily imply higher cumulative rewards during learning. Furthermore, in practice both the dataset and the GP hyper-parameters would be different. Empirically, BO-FCPS does achieve both higher online and offline performance, as we show in Section V. We defer a more extensive theoretical analysis to future work.
IV-B Factored Active Contextual Entropy Search
In the active learning setting, the agent chooses both the policy parameters and the context . Applying GP-UCB is problematic as it would not take the varying difficulty of tasks into account [7]. Instead, we follow ACES [8] and use an ES-based acquisition function, which aims to choose the most informative query points for global optimization [9].
We integrate factored contexts into ACES as follows. In each iteration, we map previous experience to all representer points in the context space, i.e. we construct different datasets as in Eq. 5. From these datasets, we construct a set of GP models that we use to evaluate the ACES acquisition function. In particular, we employ the corresponding when the expected information gain after a hypothetical query is evaluated for . Similar to BO-FCPS, we therefore directly use the target-specific GPs instead of relying on the correlation between target contexts.
Note that the choice on the target-type query context is actually indifferent if we ignore rewards during training, and thus we only need to select by maximizing
[TABLE]
We call the resulting algorithm factored active contextual entropy search (FACES). The algorithm is shown in Alg. 4.
IV-C Hindsight Experience Replay for Factored CPS
So far we have assumed that the agent has access to the reward function . If we cannot query the reward function at arbitrary points, it is still possible to leverage factored contexts. In particular, we replace the current target context after a rollout by the achieved target and evaluate it again, yielding reward . Thus, the only requirement is to be able to obtain the sample reward in addition to the actual reward . The additional data point can then be added to the training dataset , and standard CPS methods such as BO-CPS, cost-regularized kernel regression [16] or contextual relative entropy policy search (C-REPS) [3, 2] can be used without further modifications. Such an approach can be seen as an extension of HER to the CPS setting. We believe we are the first ones that explicitly make this connection.
V EXPERIMENTS AND RESULTS
We perform experiments to answer the following questions: (a) does context factorization lead to more data-efficient learning for passive and active BO-based CPS algorithms; (b) how does the choice of acquisition function influence the performance; (c) does context factorization improve generalization; (d) is our method effective in more complex robotic domains? We address questions (a)-(c) through experiments on a toy cannon task, and (d) on three simulated tasks from the OpenAI Gym [11]. For the Gym tasks, we employ an extension [24] of the DMP framework [12] to efficiently generate goal-directed trajectories.
V-A Toy Cannon Task
The toy cannon task is a popular domain for evaluating CPS algorithms [25, 6, 8]. As shown in Fig. 2(a), a cannon is placed in the center of a 3D coordinate system and has to shoot at targets on the ground in the range of m. The contextual policy maps from 2D targets to 3D launch parameters : horizontal orientation , vertical angle and speed ms. The reward function is given by , where is the achieved hitting location of a trajectory . To increase the difficulty of the problem, we add Gaussian noise () to the desired launch angle during training and randomly place hills in the environment. The learning agent is unaware of the hills and the target contexts carry no information on the elevation.
First, we compare both our factored BO approach (BO-FCPS) and our factored HER-style BO approach (BO-FCPS-HER) to standard BO-CPS. Each algorithm uses the GP-UCB acquisition function. We employ a zero-mean GP prior, , with squared-exponential kernel , where , and contains positive length-scale parameters . The GP hyper-parameters are optimized by maximizing the marginal likelihood. We also compare to C-REPS, which performs local policy updates instead of global optimization. We use a linear Gaussian policy with squared context features that is updated every 30 episodes subject to the relative entropy bound .
The offline performance of each algorithm is shown in Fig. 2(b). BO-FCPS requires only 60 episodes to find a good policy, a considerable improvement over standard BO-CPS. BO-FCPS-HER improves on BO-CPS as well, although the variance is much larger. This is because the GP hyper-parameter optimization sometimes got stuck in a local minimum, overfitting to the context variables while ignoring the influence of the parameters . We hypothesize that a full Bayesian treatment would mitigate this issue. C-REPS is not competitive on this low-dimensional task since the policy adapts too slowly. The above findings are confirmed by the online performances, which are summarized in Table I.
In Fig. 2(c), we evaluate the dependence of BO-FCPS on the acquisition function. We compare three variants: BO-FCPS with GP-UCB (UCB), entropy search (ES) and a random acquisition function. Using GP-UCB over ES leads to slightly faster learning as ES tends to explore too much. Likewise, random exploration is not sufficient for data-efficient learning. We therefore focus on GP-UCB.
Next, we demonstrate why evaluating previous rollouts for the given target context leads to improved generalization. We only present contexts during training, while the agent has to generalize to the entire context space during evaluation. As depicted in Fig. 3, BO-FCPS generalizes much better to unseen contexts due to a much more accurate reward model at locations where it has already shot to. When evaluated in previously unseen contexts, the mean rewards achieved by BO-FCPS were higher by ; while the improvement was in contexts that were sampled during training.
Finally, we consider an active learning setting, where the agent observes an additional context variable that indicates whether the learning agent should shoot or not. If , the agent receives reward as before, and an action penalty otherwise. The agent should therefore actively select , for which the reward function is much harder to learn. We compare FACES to ACES, and use 200 representer points to approximate the acquisition functions. The results are shown in Fig. 4. Similar to the passive case, factorization is greatly beneficial: FACES achieves much faster learning than ACES.
V-B Simulated Robotic Tasks
Finally, we apply BO-FCPS to three distinct robotics tasks from the OpenAI Gym [11, 26], namely:
- •
FetchPush-v1: Push a box to a goal position.
- •
FetchSlide-v1: Slide a puck to a goal position that is out of reach of the robot.
- •
Thrower-v2: Throw a ball to a goal position.
The BO-FCPS algorithm is used to select the DMP parameters for performing each task according to the current context. We deviate from the original task specification of Thrower-v2 by replacing the joint-space controller in favor of task-space control to reduce the dimensionality of the problem. The same controller is employed in the Fetch environments. Moreover, we use the final distance between the object and the target context as the reward function in each environment. For more details, please refer to [11, 26].
For FetchPush and FetchSlide, both the initial object position and the desired goal position are varied. The lower-level policy consists of two 3-dimensional task-space DMPs that are sequenced together. The first DMP is used to bring the robot arm into position to manipulate the object, where the trajectory is modulated by 25 basis functions per dimension, and the shape parameters are learned by imitation. The second DMP is used to execute the actual movement (i.e. pushing, sliding), starting from the final position of the first DMP. The upper-level policy adapts the approach angle of the first DMP w.r.t. the object, yielding a goal position that is a fixed distance away from the object, and the goal position of the second DMP. We use for FetchSlide and for FetchPush.
For the Thrower environment, only the desired goal position is varied. The lower-level policy is a single 3-dimensional task-space DMP with 25 basis functions, where the shape parameters are learned by imitation. The upper-level policy selects the goal position and goal velocity of the DMP, resulting in a 6-dimensional parameter vector .
Results are shown in Fig. 5. Our proposed approach consistently outperforms standard BO-CPS, suggesting that our earlier findings on the toy cannon task apply to more complex simulated robotic domains as well.
VI DISCUSSION AND FUTURE WORK
We introduced context factorization and integrated it into passive and active learning approaches for CPS with BO. The improvement we can expect from factorization depends on the characteristics of the task. It is most effective if a large part of the learning challenge is about generalizing across contexts, as opposed to learning a good policy for a single context. In general, the larger the space of target contexts over environment contexts and policy parameters, the more factorization is expected to be beneficial.
In this paper, we focused on BO for CPS. One shortcoming of BO is that it does not scale well to high-dimensional problems. Future work may address scalability and explore alternative acquisition functions such as predictive entropy search [27]. Since context factorization is not specific to BO, it could also be applied to other CPS algorithms, e.g. C-REPS [2] or contextual CMA-ES [28]. A simple approach would be to populate the dataset with additional re-evaluated samples, similar to HER. Finally, we demonstrated the benefits of factorization in extensive simulated experiments. In the future, we plan to demonstrate the approach on a real robot system as well.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. P. Deisenroth, G. Neumann, J. Peters, et al. , “A survey on policy search for robotics,” Foundations and Trends in Robotics , vol. 2, no. 1–2, pp. 1–142, 2013.
- 2[2] A. G. Kupcsik, M. P. Deisenroth, J. Peters, G. Neumann, et al. , “Data-efficient generalization of robot skills with contextual policy search,” in Proceedings of the AAAI Conference on Artificial Intelligence , pp. 1401–1407, 2013.
- 3[3] C. Daniel, G. Neumann, and J. Peters, “Hierarchical relative entropy policy search,” in Artificial Intelligence and Statistics , pp. 273–281, 2012.
- 4[4] E. Brochu, V. M. Cora, and N. De Freitas, “A tutorial on bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning,” ar Xiv preprint ar Xiv:1012.2599 , 2010.
- 5[5] A. Krause and C. S. Ong, “Contextual gaussian process bandit optimization,” in Advances in Neural Information Processing Systems , pp. 2447–2455, 2011.
- 6[6] J. H. Metzen, A. Fabisch, and J. Hansen, “Bayesian optimization for contextual policy search,” in Proceedings of the Second Machine Learning in Planning and Control of Robot Motion Workshop , 2015.
- 7[7] A. Fabisch and J. H. Metzen, “Active contextual policy search,” Journal of Machine Learning Research , vol. 15, no. 1, pp. 3371–3399, 2014.
- 8[8] J. H. Metzen, “Active contextual entropy search,” ar Xiv preprint ar Xiv:1511.04211 , 2015.