Formal Verification of Decision-Tree Ensemble Model and Detection of its Violating-input-value Ranges
Naoto Sato, Hironobu Kuruma, Yuichiroh Nakagawa, Hideto Ogawa

TL;DR
This paper presents a formal verification method for decision-tree ensemble models to identify input ranges causing failures, enabling the creation of input filters to enhance system reliability.
Contribution
It introduces a novel formal verification approach for DTEMs that extracts failure-inducing input ranges, improving reliability in safety-critical systems.
Findings
Successfully verified DTEMs using a house price dataset
Extracted input ranges leading to failures
Demonstrated method scalability and feasibility
Abstract
As one type of machine-learning model, a "decision-tree ensemble model" (DTEM) is represented by a set of decision trees. A DTEM is mainly known to be valid for structured data; however, like other machine-learning models, it is difficult to train so that it returns the correct output value for any input value. Accordingly, when a DTEM is used in regard to a system that requires reliability, it is important to comprehensively detect input values that lead to malfunctions of a system (failures) during development and take appropriate measures. One conceivable solution is to install an input filter that controls the input to the DTEM, and to use separate software to process input values that may lead to failures. To develop the input filter, it is necessary to specify the filtering condition of the input value that leads to the malfunction of the system. Given that necessity, in this…
Click any figure to enlarge with its caption.
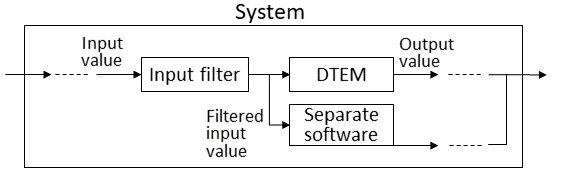 Figure 1
Figure 1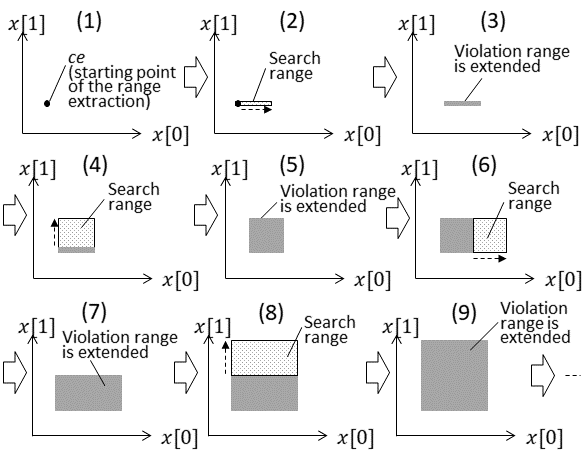 Figure 2
Figure 2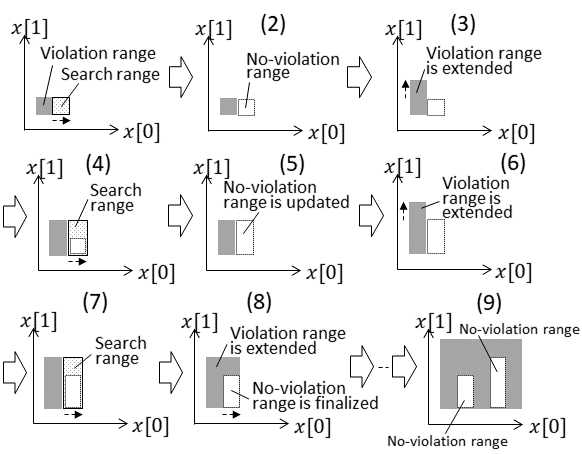 Figure 3
Figure 3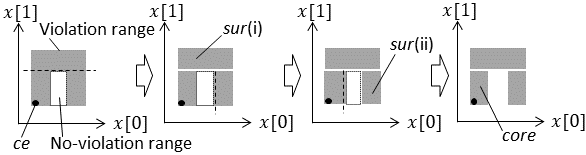 Figure 4
Figure 4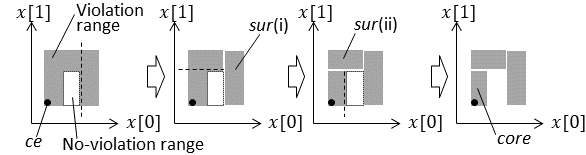 Figure 5
Figure 5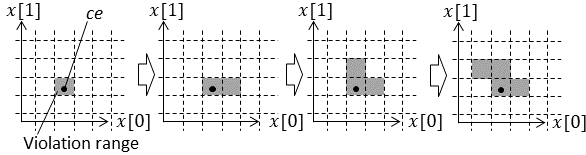 Figure 6
Figure 6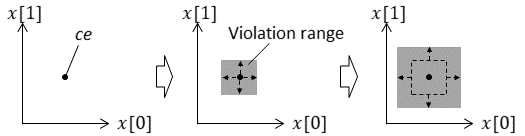 Figure 7
Figure 7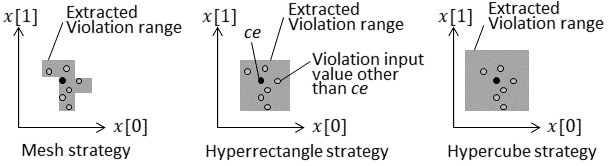 Figure 8
Figure 8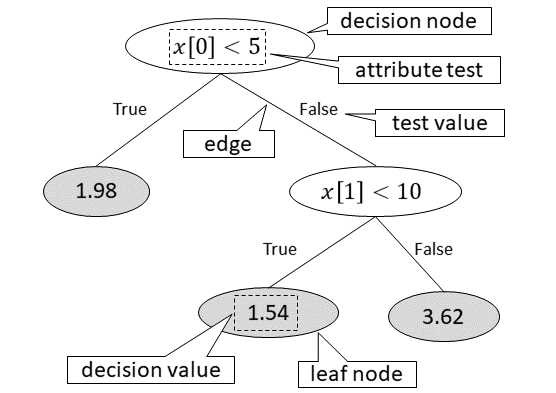 Figure 9
Figure 9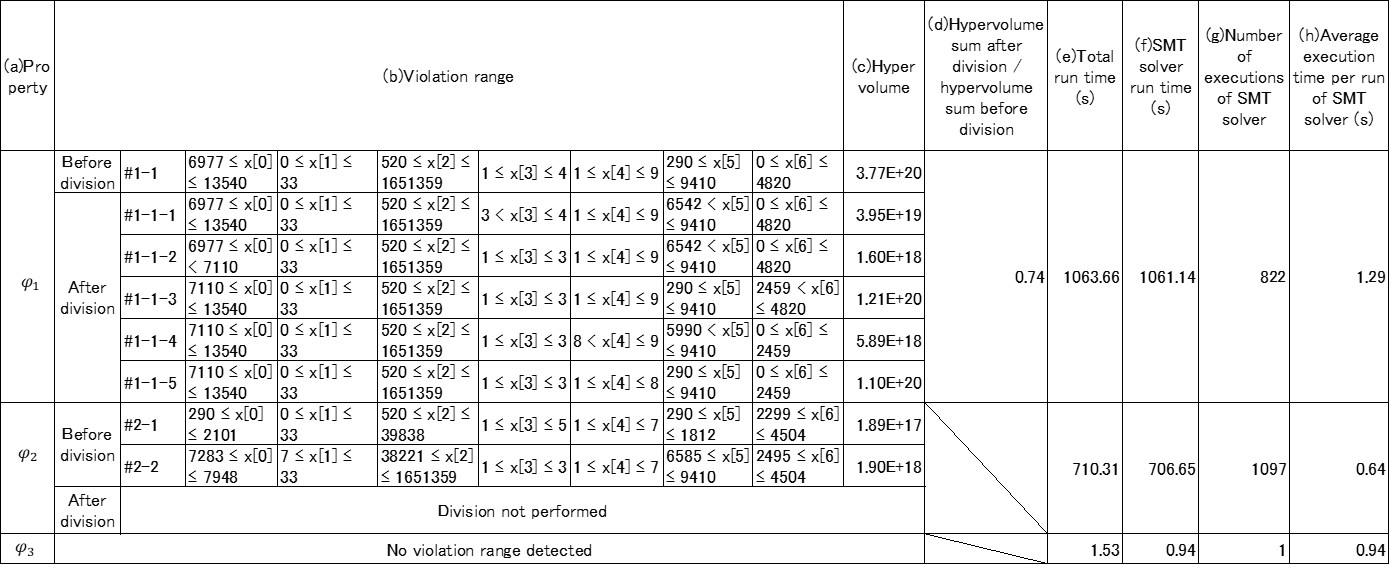 Figure 10
Figure 10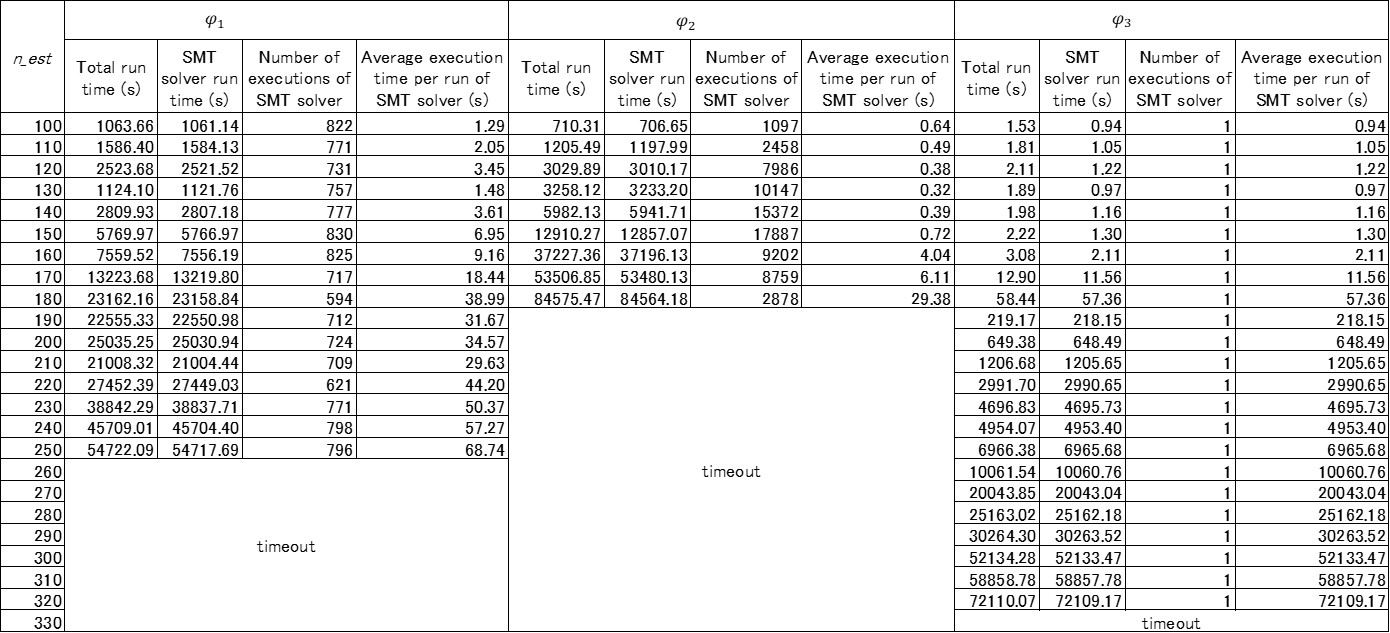 Figure 11
Figure 11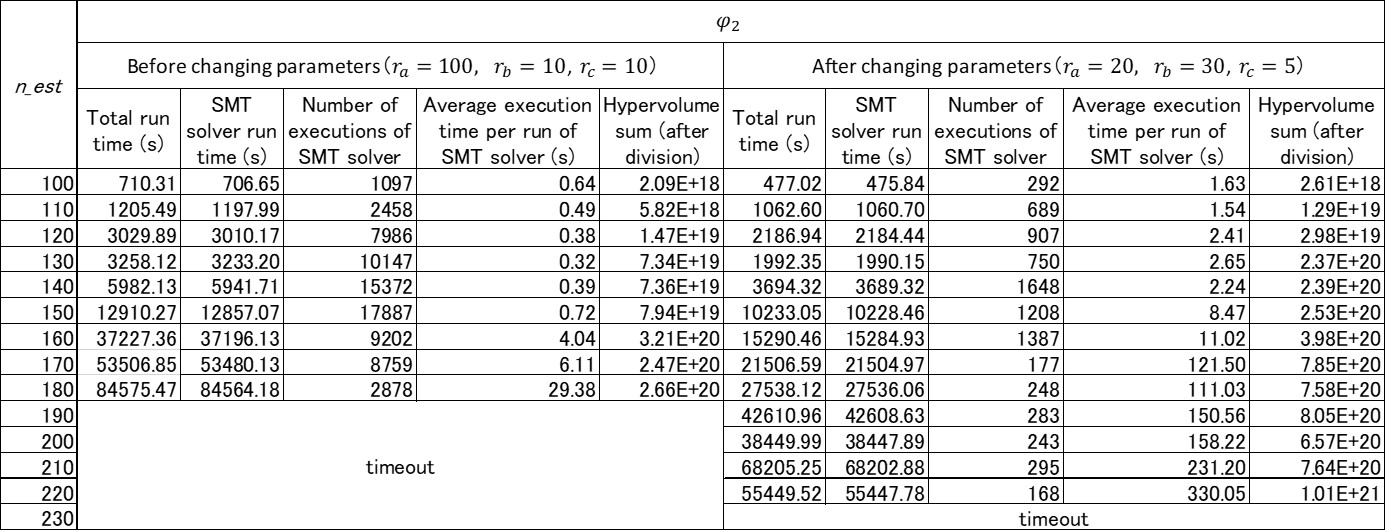 Figure 12
Figure 12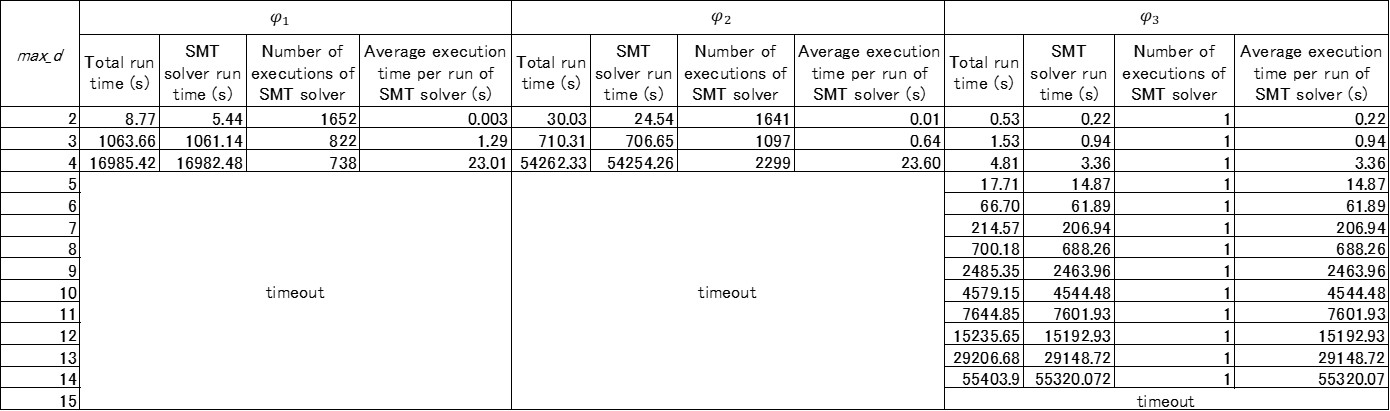 Figure 13
Figure 13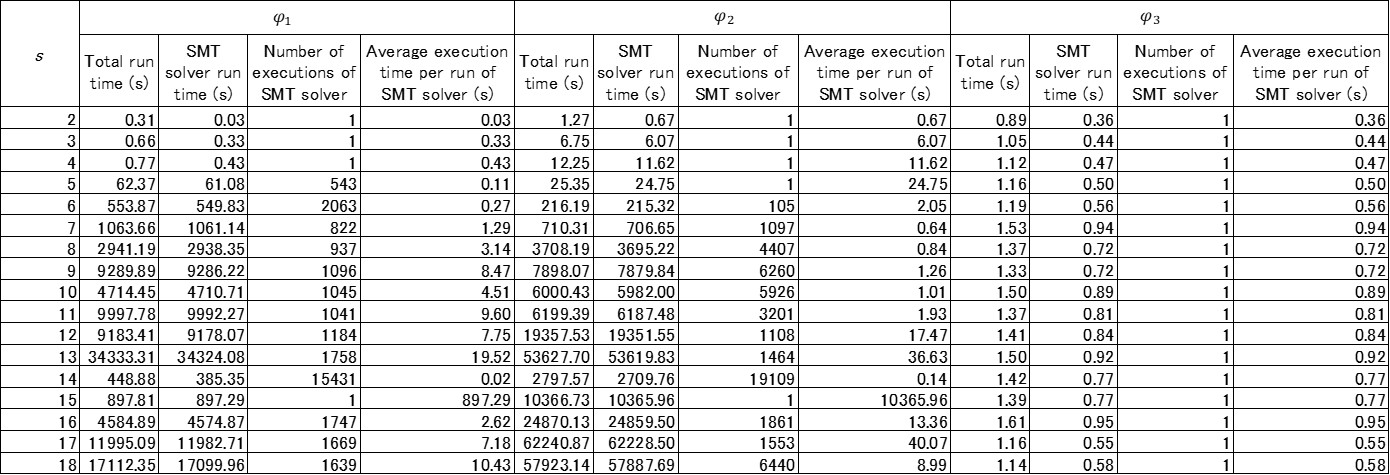 Figure 14
Figure 14Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Formal Verification of Decision-Tree Ensemble Model and Detection of its Violating-input-value Ranges
Naoto Sato1, Hironobu Kuruma1, Yuichiroh Nakagawa1, Hideto Ogawa1
1Research & Development Group, Hitachi, Ltd.
Abstract
As one type of machine-learning model, a “decision-tree ensemble model” (DTEM) is represented by a set of decision trees. A DTEM is mainly known to be valid for structured data; however, like other machine-learning models, it is difficult to train so that it returns the correct output value for any input value. Accordingly, when a DTEM is used in regard to a system that requires reliability, it is important to comprehensively detect input values that lead to malfunctions of a system (failures) during development and take appropriate measures. One conceivable solution is to install an input filter that controls the input to the DTEM, and to use separate software to process input values that may lead to failures. To develop the input filter, it is necessary to specify the filtering condition of the input value that leads to the malfunction of the system. Given that necessity, in this paper, we propose a method for formally verifying a DTEM and, according to the result of the verification, if an input value leading to a failure is found, extracting the range in which such an input value exists. The proposed method can comprehensively extract the range in which the input value leading to the failure exists; therefore, by creating an input filter based on that range, it is possible to prevent the failure occurring in the system. In this paper, the algorithm of the proposed method is described, and the results of a case study using a dataset of house prices are presented. On the basis of those results, the feasibility of the proposed method is demonstrated, and its scalability is evaluated.
I Introduction
Recently, software developed by machine learning has been used in various systems. Deep learning using deep neural networks (DNNs) is widely used for predicting and classifying image data, audio data [1][2], and so on. For structured data, ensemble learning methods using decision trees, such as random forests [3] and gradient-boosting decision trees [4], are also effective [5][6][7][13][8][9][10][11].
A decision-tree ensemble model (DTEM) is represented as a set of decision trees. The prediction result output from a DTEM is calculated as the sum or average value of the scores associated with the leaves of the decision trees. The DTEM is expected to be generalized, namely, to return the appropriate output value even if it is given an input value not included in the training data.
However, in general, it is difficult to train a DTEM to return the appropriate output value for every input value, that is, a DTEM returns an inappropriate output value with a certain probability. Therefore, in particular, when a DTEM is used in a mission-critical system, whose behavior significantly affects business and society, it is important to comprehensively detect input values that lead to system failures during development, and take appropriate measures. As countermeasures, retraining or additional training of the DTEM are possible means; however, for the reason mentioned above, it is difficult to completely eliminate the possibility of failures occurring. Accordingly, as a practical measure, it is possible to create an input filter to control the input value to the DTEM and to use separate software to process the filtered input values that leads to failures (Fig. 1). The implementation of the separate software is arbitrary. For example, the input value might be rejected to be processed.
A policing function [12] is also useful to prevent failures. It is separated from the DTEM, and checks the output value of the DTEM againtst a certain property at runtime. If the output value does not meet the property, that is, the output value leads to failures, the policing function controls the output value. However, when comparing the input filter and the policing function, the input filter is more efficient because the input filter detects and controls failures before the DTEM runs.
To create the input filter, it is necessary to specify which input values should be filtered as the filtering condition. In this paper, we therefore propose a method to formally verify whether a DTEM meets certain property and, if that properties is not satisfied, extracts the range (part of the input-value space) in which all input values violating the property are included. By setting the range extracted by the proposed method as the filtering condition of the input filter, it is possible to prevent the failure of the system due to the DTEM. The feasibility of the proposed method is evaluated by showing a case study in which the proposed method was applied experimentally. Moreover, the scalability of the proposed method is evaluated by changing the dimension of the input values of the DTEM, the number of decision trees constituting the DTEM, and the maximum value of the depth of those decision trees. Hereafter, input values that violate the property are referred to as “violating input values.” And the range in which the violating input value exists is called the “violation range.” It should be noted that not all input values included in the violation range will be violating input values.
As for the proposed method, the decision trees that compose the DTEM are encoded to a formula, and the formula is verified by using a satisfiability modulo theories (SMT) solver. Although this approach has mainly been applied to DNNs [15][16][17][18][14][19], to the authors’ knowledge, no case in which this approach is applied to a DTEM has been reported. Given that situation, the first contribution of this paper is to demonstrate that our approach, namely, logically encoding a machine-learning model and verifying the model by solving the resulting a formula with an SMT solver, is also applicable to a DTEM.
When the DTEM violates a property, as a result of the verification, an example of a violating input value (and its corresponding output value)—called a “counterexample”—is obtained. As a naive way to get the filtering condition, all violating input values are detected by repeating the verification. If an input value matches any violating input values, it is filtered. However, a large number of similar violating input values may exist around a certain violating input value. In particular, if the input value is represented by a multidimensional vector whose elements are numeric variables (not categorical variables), input values obtained by slightly changing the values of some elements of the violating input value are also likely to violate the property. In this case, since the verification is repeated as many times as the number of the violating input values, detecting all the violating input values is not practical in terms of calculation time.
Targeting a DTEM whose input values are multi-dimensional vectors whose elements are numeric variables, the proposed method extracts the violation range by searching around the origin at which a violating input value was first detected and gradually expanding the search range until the violating input value is not detected. With this method, the violating input values around the origin can be kept within the range. However, input values that do not violate the property are also included in the range. Even though they do not violate the property, they are also filtered as well as the violating input values. Thus, it is desireble to prevent as many input values that do not violate the property as possible from being included in the violation range. Therefore, as for the proposed method, the extracted violation range is divided into a number of smaller ranges. Then, for each divided range, whether a violating input value exists within the range is checked. As a result, it is possible to narrow down the original violation range. As for the second contribution of this paper, targeting a DTEM taking multi-dimensional vectors of numerical variables as input values, we propose a method to extract the violation range and narrow it down. Moreover, the feasibility and scalability of the proposed method are evaluated through a case study.
The rest of this paper is organized as follows. In Section II, a decision tree and a DTEM are formally defined. In Section III, the proposed method is overviewed. In Section IV, among the procedures that compose the proposed method, the procedure for verifying the DTEM is explained. In Section V, the procedure for extracting the violation range on the basis of the verification result is explained. In Section VI, the procedure for narrowing down by dividing the extracted violation range is explained. In Section VII, the feasibility and scalability of the proposed method are evaluated through a case study using a data set of house prices. In Section VIII, the usefulness and applicability of the proposed method are discussed. In Section IX, related work is described, and in Section X, the conclusions drawn from this study are presented.
II Preliminaries
For any DTEM , variables representing input and output values of are given as and , respectively. It is assumed that is represented by a vector of length such that . As for targeted in this paper, since multi-dimensional vectors with numeric variables as elements are assumed as input values, represents each numeric variable. And the domain of is represented as . First, in Section II-A, the decision trees that compose are formally defined. Next, in Section II-B, is formally defined.
II-A Decision Tree
A decision tree represents a procedure for determining the class to which a given input value belongs [20][21]. A decision tree consists of decision nodes, edges, and leaf nodes. The expression of input value is associated with the decision node (Fig. 2). In this paper, the expression of the decision node is called an “attribute test.” Each decision node has multiple child nodes, and each child node is connected by an edge. Each edge is labeled with the evaluation result of the attribute test. When an input value is given, the edge with the same label as the result of evaluating the attribute test is selected. Hereafter, the evaluation result of the attribute test is called the “test value.”
If the child node connected to the selected edge is a decision node, the same procedure is performed for that decision node. If the child node is a leaf node, the value associated with that leaf node becomes the name of the class to which the input value belongs. As for the decision trees making up the DTEM, numeric values are used as class names, and those numeric values are used to calculate the output value of the DTEM. Hereafter, this value is called “the decision value.”
Arbitrary decision tree constituting can be expressed in the form , where represents a set of decision nodes, represents a set of leaf nodes, and represents a root node included in . is a set of edges, each of which edge is represented by a pair consisting of a connection-source node and a connection-destination node. That is, it can be defined as . Here, is a function that associates an attribute test with a decision node. represents a set of arbitrary expressions for input value . Similarly, is a function that associates a test value with an edge, where represents a set of test values. In the example in Fig. 2, . Here, is a function that associates a decision value with a leaf node. The decision tree is acyclic. This is defined, by using transitive closure of , as .
It is assumed that the decision tree that constitutes the DTEM, which is the subject of this paper, has more than one decision nodes, and branches from a decision node to at least two child nodes. Therefore, if the number of nodes included in is expressed as , holds. In a similar manner, is established. As for the number of edges, , holds.
II-B Decision Tree Ensemble Model(DTEM)
Arbitrary can be expressed as . represents a set of decision trees constituting . If the number of decision trees included in is taken as , the decision trees included in can be expressed as . The decision values of trees are represented as , respectively.
Moreover, represents a function that takes as arguments and returns . The specification of depends on the implementation of DTEM. For example, in the case of random forests, the average of the decision values is . Alternatively, in the case of a gradient-boosting decision tree, the sum of the decision values is . In this paper, the calculations depending on the implementation of the DTEM are generalized with .
III Outline of Proposed Method
The proposed method is outlined in Algorithm 1. As for the proposed method, is taken as the DTEM to be verified. A property of is denoted by , and represents a domain of . Parameters , , and are described later. Algorithm 1 outputs the value of variable , which is a set of violation ranges for .
Function on line 4 returns formula , meaning that “Input value of is included in domain .” Procedure on line 6 verifies whether an input value that violates and satisfies constraint . If such an input value is detected, that value is assigned to variable . If no such input value is detected, “None” is assigned to . Procedure is described in detail in Section IV. Procedure on line 8 extracts the violation range for from around . The extracted range is assigned to variable . Moreover, a range in which no input value violates is extracted by the process of extracting ; therefore, a set of such ranges is output as variable . Hereafter, a range in which no violating input value exists is referred to as a “no-violation range.” Procedure is shown in detail in Section V.
The extracted violation range, , is divided as follows. First, on line 9, is copied to variable . On line 10, is a function that returns a decision of whether to execute procedure on line 13. Parameter is used as a reference value for the decision. Although the details of are not specified here, for example, it can be implementated so as to return “True” if the volume of core is equal to or more than percent of the volume of . On line 13, procedure divides into multiple pieces. This division is performed on the basis of a no-violation range, which is an element of . Of the ranges obtained by division, the inner range including (which is the starting point of range extension) is taken as a new , and the set of other outer ranges is taken as . The is explained in detail in Section VI.
If contains a number of no-violation ranges, it is used for the division from the range pushed to last, which is the outermost no-violation range in terms of violating input value . Therefore, the ranges stored in do not include no-violation ranges because they are outside the outermost no-violation range. Accordingly, the elements of are added to without dividing them further (line 14). On the contrary, the new might include a no-violation range. Therefore, on line 10, it is evaluated by whether will be divided further. If is not divided any more, it is added to .
Then, on line 17, function is used to create a constraint representing “Input value x of is out of the range indicated by .”, and that constraint is conjunctively appended to . After that, by re-executing formal_verification on line 6, it is verified whether an input value violates outside . If an input value that violates is detected as a result of the verification, the violation range is extracted and divided by the same procedure. extracted by Algorithm 1 represents the range in which an input value violates . Therefore, by creating an input filter (shown in Fig. 1) based on , it is possible to filter the violating input value.
IV Formal Verification of Decision Tree Ensemble Model
The procedure of in Algorithm 1 is shown in detail hereafter. For any decision tree that constitutes DTEM , a set of all paths extractable from is denoted by . As stated in Section II-A, since a decision tree is assumed to be acyclic, the elements of are paths of finite length. Arbitrary path can be represented by a sequence of nodes, . Among these nodes, represent decision nodes, and represents a leaf node. Since has one or more decision nodes, holds. Here, the specification of an arbitrary path of is defined as by using functions , , and (defined in Section II-A) as follows:
[TABLE]
The argument of function represents an edge between nodes and . By using , the specification of is expressed as follows:
[TABLE]
As explained in Section II-B, the output value of is calculated by from decision values . Therefore, the specification of is expressed by by using and as follows:
[TABLE]
Furthermore, is defined by using (i.e., a property to be satisfied by ) and constraint (which indicates that is included in domain ) as follows:
[TABLE]
is input into the SMT solver to determine its satisfiability. If is unsatisfiable, it is guaranteed that no input value satisfies in the range constrained by . If and satisfying are detected, the detected is returned as the violating input value, . It is thus possible to verify whether satisfies by encoding to formula and solving the satisfiability problem by using the SMT solver.
V Violation Range Extraction
V-A Overview
As for , a violating input value is searched in the range around violating input value as a starting point by using . If a violating input value is detected, the range is extracted as the violation range. Here, to promote intuitive understanding, it is assumed that variable representing the input value of is represented by a two-dimensional vector, namely, . The method for extracting the violation range by is outlined in Fig. 3.
The violation range is extended by alternately increasing the values of and . In step (1), the violating input value obtained on line 6 of Algorithm 1 is set as the initial value of the violation range. Next, in step (2), a search range is set from the initial value to upper direction of , and whether a violating input value exists within that search range is verified by the method described in Section IV. If a violating input value is detected in the search range, as shown in step (3), the search range is imported into the violation range. In step (4), the search range is set to upper direction of . From then on, the same procedure is repeated to extend the violation range. Although omitted in Fig. 3, in a similar manner as described above, the violation range is also extended to lower directions of and .
As for , at the same time the violation range is extracted, no-violation ranges existing in that range are extracted. The method of extracting no-violation ranges is outlined in Fig. 4.
In step (1) of Fig. 4, the search range is set in the upper direction. Here, it is assumed that no violating input value exists in the search range. In that case, the no-violation range is created as shown in step (2). After the violation range is extended in the upper direction in step (3), the search range is reset in the direction in step (4). If a violating input value still does not exist in the search range, the no-violation range set in step (2) is extended by step (5). It is assumed that the violation range can be extended in steps (6), (7), and (8). In that case, the extension of the no-violation range is ended. Accordingly, when no violating input value exists in the search range, the search range is extracted as the no-violation range. As shown in step (9), a plurality of no-violation ranges may be created. One of the features of the proposed method is to extract this no-violation range. The extracted no-violation range is the utilized in described in Section VI.
Regarding the proposed method, as a strategy for extending the violation range, alternately increasing the values of and is adopted. Other strategies, however, may be considered to extend the violation range. For example, a strategy by which the values of and are increased simultaneously can be considered. Strategies for extending the violation range are discussed in Section VIII.
V-B Algorithm
The procedure of is shown in detail in Algorithm 2.
Algorithm 2 returns , which represents a violation range for , and , which represents a range in which no violating input value exists. The violation range can be defined by the lower-limit values and the upper-limit values of variables . Therefore, it is supposed that violation range is composed of and , where and represent [math] and respectively. Here, the lower-limit value of variables () is represented by . Similarly, the upper-limit value is represented by .
First, on lines 3 and 4, is initialized with . On line 9, whether has been extended in the previous loop is checked, and if has been extended, a further extension is tried. On line 11, the variable for which the range is to be expanded, , is selected. For the selected here, line 12 attempts to expand the upper limit of the variable, and line 13 tries to expand the lower limit of the variable. If neither the upper limit nor the lower limit can be expanded for all variables , = False is returned, and the procedure ends.
The upper and lower limits are extended on lines 12 and 13 by EXPAND. The procedure of EXPAND is described below with the case that the upper limit is expanded taken as an example. The parameter of EXPAND represents the direction of expansion. That is, in this example, is passed as an argument. On line 21, variable is initialized with . where represents the search range. On lines 23 and 27, for variable is updated. is a function that returns the direction opposite to the extension direction indicated by . is a function that accepts parameter as an argument and returns a vector of the same length as . Vector is used to set the search range of to the range . Because the search range of variable is not updated, it is given as . As a result, is created on the upper bound of in the direction.
When is defined, the upper-limit or lower-limit value of is sometimes not included in the search range, that is, the search range is defined by using “¡” or “¿.” Accordingly, it is necessary to hold that information about with-equal or without-equal. In this paper, to simplify explanation, it is omitted how to keep that information in . The function on line 28 redefines the common range of and as a new . As the violation range is extended, is eventually created outside , and then their common ranges become empty. In this way, the termination of the procedure is assured.
On line 29, is created by conjunctively appending the constraint “the input value for is included in ” to . Line 30 verifies whether satisfies under constraint . As a result of verification, if the violating input value is detected within , the upper limit of the violation range, , is extended to (line 32).
Lines 33, 35, and 39 create an element of . If no violating input value is detected in the search range as a result of the verification on line 30, the search range is saved in (line 39). stores a tentative no-violation range in the direction. The range stored in will be extended as long as a violating input value is not detected in the direction (line 39). If a violating input value is detected in that direction, the latest range stored in is finalized as a no-violation range and added to (line 34).
VI Violation Range Division
VI-A Overview
As for , violation range extracted by is divided. The division is based on a no-violation range, which is an element of . Among the divided ranges, the range including violating input value (which is the starting point of the range extension) is set as a new , and the other ranges are called s. If includes a violating input value, it is added to . Since it is possible to repeatedly divide , the number of ranges in may be increased with each division. For example, as for the violation range shown in step (9) in Fig. 4, the method of is outlined in Fig. 5
In Fig. 5, first, the violation range is divided at the upper-limit value of the no-violation range on the axis. Next, the range is divided at the upper-limit value of the no-violation range on the axis. Finally, the range is further divided by using the lower-limit value of the no-violation range on the axis. As a result this division, the violation range is divided into three ranges: (i), (ii), and .
It is clear that there exits a violating input value in because includes violating input value at least. (i) also includes another violating input values in this case since the violation range was extended as shown in step (8) in Fig. 4. However, (ii) may not include a violating input value. Whether (ii) include a violating input value can be checked by using . If (ii) does not include a violating input value, it is removed from the violation range.
This method aims to narrow the violation range by dividing it and verifying whether outer ranges s created by the division include violating input values. This is based on the assumption that outer ranges of the no-violation range are also likely not to include a violating input value. Outer ranges are “adjacent to” the no-violation range and also “beyond” the no-violation range from the starting point of the range extension. Accordingly, input values in outer ranges are assumed to be “similar to” the input values in the no-violation range and also “more different” from violating input values around the starting point than the input values in the no-violation range. Therefore, we consider that outer ranges created by the division on the basis of the no-violation range are likely to include no violating input value.
When dividing the violation range on the basis of the no-violation range, the order of the division can be changed. For example, the dividing order shown in Fig. 6 can be considered. In this case, the division is performed in the following order: at the upper-limit value of the no-violating range on the axis, at the upper-limit value on the axis, and at the lower-limit value on the axis.
It is said that the dividing order that makes the violation range narrower is more effective. However, the extent to which the violation range can be narrowed by a certain dividing order depends on the DTEM and property to be verified. It is therefore not known which dividing order is effective unless the division is actually performed. Accordingly, as for the proposed method, multiple divisions are tried at random, and the order that makes the violation range the narrowest is adopted.
The violation range is divided by the surface of the no-violation range (corresponding to the dotted lines in Fig. 5 and Fig. 6). Since the no-violation range is an -dimensional hyperrectangle, the number of dividing planes is . Therefore, the number of ways to divide the violation range is As for the proposed method, dividing orders, whose number equals parameter , are randomly selected and the results of the divisions are compared according to the sum of the hypervolumes of the ranges in . The dividing order that minimizes the sum of the hypervolumes is adopted
VI-B Algorithm
The procedure of is shown in details in Algorithm 3.
In Algorithm 3, violation range is divided on the basis of no-violation range . Then, as a result of division, a new and are returned. On line 3, extracts the (-1)-dimensional hyperplanes constituting hyperrectangle , and creates the set . The number of elements in is . On line 4, creates as many arbitrary dividing orders using elements of as , and the set of the created dividing orders is assined to . Line 6 picks out arbitrary element of . is an array (with length of ) having the hyperplanes constituting as elements. On line 9, the top element of is assined to . By on line 10, is divided with as the dividing plane. Of the two ranges created by the division, the range that includes is taken as the new , and the other is taken as . on line 12 verifies whether the violating input value is included in the range of that . If a violating input value exists within the range of , is added to (line 14). The division with is repeated for each element of . On line 17, is used to calculate the sum of the hypervolumes of the violation range represented by the elements of and . The procedures from lines 7 to 18 are repeated according to the number of elements of , that is, times. In this manner, for each dividing order randomly created on line 4, and , which are division results, and , which is the sum of the hypervolumes, are obtained. On line 20, the result of division that gives the smallest is extracted by function , and is used as the final return value.
In this way, the violation range is divided by on the basis of the no-violation range created by . It should be noted that is not executed if no-violation range is created by .
VII Case Study
VII-A Setup
As a subject of the case study, DTEM is created by using a dataset of house prices 111https://www.kaggle.com/harlfoxem/housesalesprediction as a training data set. XGBoost [13] was adopted to implement . receives a -dimensional vector, , as an input value, and returns a house price as output value , where are, respectively, grade of house, condition of house, number of bedrooms, size of living room, size of parking space, size of ground floor, and size of basement. The number of decision trees constituting is , and the maximum depth of each decision tree is . As properties to be verified, , , and are defined as follows:
[TABLE]
Here, in represents size of living room. The larger the living room, the higher the price. Therefore, it is defined as that if the size of the living room is 7000 or more, the price is 500,000 or more. Moreover, the price output by is expected to be realistic in regard to a house price. Accordingly, is defined as expressing that the price is higher than 50,000. Similarly, is taken as the property that the price is less than 10,000,000.
Next, domain of is defined. In this case study, is defined on the basis of the maximum and minimum values of the training dataset. For each variable (), the maximum value included in the training dataset is represented as , and the minimum value is similarly represented as . These values are used to define as follows:
[TABLE]
Function (which determines the search range in ) is implemented with parameter as an argument as follows:
[TABLE]
Here, is created on the basis of the width of the domain (i.e., the difference between and ), where function rounds up a real number to an integer. In this case study, is supposed. shown in Algorithm 1 is implemented so as to return “True” if the hypervolume of is percent or more of the hypervolume of . In this case study, is also supposed. Furthermore, parameter for determining the number of elements of in is taken as .
The proposed method was implemented in Python 222Available on https://github.com/hitachi-rd-yokohama
/deep_saucer/tree/master/xgb_encoding. The Z3 Theorem Prover [36] was used as a SMT solver in . Moreover, this case study was performed on a Windows 10*®* PC equipped with two Intel*®* Core™ i7-8700 3.2-GHz processor with 6 cores, 16-GB memory.
VII-B Results and Evaluation
The results of applying the proposed method are listed in Table I. The violation range detected by the proposed method is shown in column (b) for each property shown in column (a). In column (b), the violation range before division by and the violation range after division are shown. In column (c), the hypervolume of each violation range is shown. Column (d) shows a value obtained by dividing the sum of hypervolumes of the violation range after division by the sum of hypervolumes of the violation range before division. This value is used to evaluate the effect of narrowing the violation range by . Column (e) shows the time elapsed to execute the proposed method. Column (f) shows the time taken to execute the SMT solver as part of the method. Column (g) shows the number of times of the SMT solver is executed (i.e., number of calls), and column (h) shows the result of dividing (f) by (g), that is, the average execution time per run of the SMT solver.
As a result of executing for , a violating input value was detected. Then, starting from the detected violating input value, is executed, and the violation range shown in #1-1 is extracted. Moreover, by dividing this violation range by , the violation ranges shown in #1-1-1 to #1-1-5 were obtained. This division reduced the hypervolume of the violation range to about 74 percent of the hypervolume before the division.
Similarly, with respect to , the violation ranges shown in #2-1 and #2-2 were extracted by . In this case, the division by was not performed because the hypervolume of each violation range was less than % of the hypervolume of . However, it is confirmed that when is , reduces the hypervolume of the violation range to about 33% of the violation range before the division. As for , no violating input value was detected. That is, it was confirmed that satisfies .
The above results demonstrate that the DTEM can be formally verified by the method described as , that is, encoding the DTEM in a formula and solving it with an SMT solver. Moreover, it was confirmed that the violation range can be extracted by . It was also confirmed that using makes it possible to narrow the violation range. It can be therefore be concluded that the feasibility of the proposed method was demonstrated.
Next, we evaluate the scalability of the proposed method. If total execution time and execution time of the SMT solver are focused on, it becomes clear that the time taken to execute the SMT solver occupies most of the total execution time. In other words, the execution time of the proposed method is considered to be largely dependent on the execution time of the SMT solver. As a factor that affects the execution time of the SMT solver, for example, the number and depth of the decision trees constituting can be considered. However, various heuristics are implemented and black-boxed in the SMT solver, so it is difficult to predict how much these factors affect the execution time of the SMT solver. Accordingly, in this study, we change the value of the factor considered to affect the execution time of the SMT solver and measure the execution time. The following experiment uses the same settings as described in Section VII-A unless otherwise stated. Moreover, a practically acceptable execution time is assumed as 24 hours, and the execution is aborted if it exceeds 24 hours.
VII-B1 (1) Number of decision trees
The number of decision trees constituting is represented by . In proportion to the increase of , the number of paths of increases. The length of formula increases in proportion to the number of paths of . That is, with the increase of , the length of the formula increases by . Therefore, it is considered that the execution time of the SMT solver tends to increase with the increase of . The execution times of the proposed method when the value of was changed are listed in Table II.
The results in Table II show that the execution time of the SMT solver tends to increase as increases. As for the verification of , timeout occurs when . If the number of executions of the SMT solver is focused on, it turns out that the SMT solver was executed frequently in the case of . In such a case, changing parameters , , and may reduce the number of executions of the SMT solver and, thereby, shorten the execution time.
Parameter determines the size of the search range in . In the implementation shown in Equation 9, the smaller the value of is , the larger the search range is. Therefore, the number of times to call can be reduced if the value of is changed smaller. Note that, in that case, it is highly likely that the extracted violation range is wider than before decreasing . That is, the extracted violation range includes more input values that do not violate the property. is referred to as a reference value for determining whether or not to execute . In the implementation shown in Section VII-A, the larger the value of is, the lower the possibility of dividing the violation range is. Thus, the number of times to call is reduced if the value of is changed larger. In that case, however, the possibility of narrowing the violation range is reduced. determines how many dividing orders are tried in . Therefore, if the value of is changed smaller, the number of times to call decreases. We changed the values of these parameters to , , and and then retried the verification of . Execution times before and after changing the parameters are listed in Table III.
As shown in Table III, by changing the values of , , and , even in the case of , execution of the SMT solver could be completed without incurring the timeout. This demonstrates that when execution cannot be completed within a practical time due to the number of executions of the SMT solver, the execution time can be shortened by adjusting the values of these parameters. It should, however, be noted that when these parameters are adjusted to reduce the execution time, the extracted violation range may become wider. In fact, from Table III, it turns out that the total volume of the violation range is increased by changing the value of parameters. On the contrary, it may be possible to narrow the violation range more strictly by changing these parameters if it is acceptable that the execution time become longer. That is, by changing these parameters, it is possible to adjust the balance between the fineness of the result and the execution time.
VII-B2 (2) Depth of decision trees
The maximum depth of a decision tree is taken as . When the depth of a decision tree increases by 1, the number of paths extracted from one decision tree is doubled. (Moreover, the length of each path also increases in proportion to .) Therefore, the length of formula is of . Accordingly, if increases, it is considered that the execution time of the SMT solver tends to increase. The execution times of the proposed method when the value of was changed are listed in Table IV.
It is clear from the results in Table IV that the average execution time of the SMT solver increases as increases. In particular, as for the verification of and , the execution time increases by 10 to 100 times each time increases by one. When time-out is invalidated and is verified with = 5, it takes about 70 hours to complete execution, and the average execution time of SMT solver is about 46 seconds. From these results, it can be said that has a big influence on the execution time of the proposed method.
VII-B3 (3) Dimension of input value
The loop in line 11 of in which is called is executed by the number of dimension . In addition, as increases, the number of variables appearing in also increases, that is, becomes more complicated. For the reasons above, it is considered that the execution time of the SMT solver tends to increase with increasing . In the house-price dataset used in this study, we can use up to 18 attributes as elements of . Therefore, these attributes was used to change dimension of in the range of . The execution times of the proposed method when the value of was changed are listed in Table V.
It is clear from the results in Table V that execution time tends to increases as increases. However, the execution time sometimes decreases though increases, for example, in the verificaiton of , . In other cases, execution time increases rapidly as when in the verification of . Therefore, the correlation of with the execution time is considered to be weaker than that of and with execution time.
From the results in Table III, Table IV, and Table V, it can be concluded that , , and are factors that increase the execution time of the proposed method. In particular, and are important factors that determines the applicability of the proposed method. Specifically, the proposed method is practical if is less than around 200 and is less than 5 at least.
VIII Discussion
As for the proposed method, the search range is set around the violating input value detected first, and if a violating input value exists within the search range, the search range is defined as the violation range. Furthermore, by setting the search range around the violation range, the violation range is expanded in the same manner. After the violation range is extracted, it is confirmed whether another violating input value exists outside the violation range. If another violating input value exists, the violation range is extracted in the same way starting from that violating input value. In this manner, it is assured that all violating input values fall within any violation range. Therefore, by creating the input filter shown in Fig. 1 based on the violation ranges extracted by the propsed method, all violating input values leading to system failures can be filtered.
Moreover, as for the proposed method, the violation range can be narrowed by dividing the extracted violation range. Through a case study, the feasibility of the division of the violation range was confirmed. The extent to which the violation range can be narrowed depends on the DTEM or the property to be verified; thus, it is difficult to estimate the effectiveness of the division in advance. However, dividing the violation range is still useful to narrow the violation range on a trial basis.
In the case study described in Section VII-B, it was shown that the number of decision trees constituting the DTEM, , maximum depth of the decision trees, , and dimension of the input value are factors that increase the execution time of the proposed method. Among those factors, has the greatest influence on the execution time. On the other hand, the correlation of with execution time is considered to be relatively weak. Here, the length of the formula is focused on. As mentioned above, becomes longer by exponential order with increasing . On the contrary, the length of does not change even if increases. From these facts, it is inferred that the execution time of the proposed method strongly depends on the length of .
The purpose of the proposed method is creating the filtering condition for the input filter. In that case, the proposed method is required to complete execution within a practical time. However, even if execution of the proposed method is not completed within a practical time, the proposed method can be utilized by outputting the violation range extended up to that point when the execution was interrupted. The violation range extracted at the time execution is suspended does not include all violating input values. However, it is useful for realizing where violating input values exist around. For example, it is possible to use the input values included in the violation range as training data for additionally training the DTEM. Thus, the proposed method can be useful, even in the case of a large-scale DTEM whose execution is not completed within the practical time.
As described in Section I, as a method for obtaining the condition to filter input value that violates a property, a method that outputs all the violating input values can be considered. However, for a certain violating input value, be a large number of similar violating input values might exist, and the values of some elements in them might be slightly changed. Accordingly, from the viewpoint of calculation time, it is not practical to detect all violating input values. Furthermore, as another approach, extracting the path condition [29] of the decision trees constituting DTEM is considered hereafter.
First, in the same manner as the proposed method, the violating input value is detected by verification. If the detected violating input value is input into the DTEM, the execution path of each decision tree is uniquely determined. Here, the condition of the input value to execute these paths is called “path condition”. The path condition can be extracted by executing the DTEM with the violating input value or by analyzing the decision trees. If an input value satisfies the path condition and it is input into the DTEM, the same paths are executed as they are when the violating input value is input. Moreover, if the same paths are executed, the same output value is returned. Therefore, for all input values satisfying the path condition, the DTEM returns the same output value. Here, by assigning the output value to variable appearing in the property to be verified and negating the assigned property, a conditional expression for the input value is created. For example, let the output value be , the conditional expression of property is . If an input value satisfies the conjunction of the path condition and the conditional expression of the property, it means that the corresponding output value is , and at that time, the property is not satisfied. Hereafter, the conjunction is called the “violation condition.” By repeating the the above procedure, other violation conditions can be extracted. Finally, the set of the extracted violation conditions can be used as the filtering condition of the input filter.
Since the violation condition extracted by this method filters only input values that violate the property, this method creates the filtering condition more precisely than the proposed method. However, from the viewpoint of calculation time, this method is considered to be less practical than the proposed method because it is likely to extract a large number of violation conditions. For example, in the case of a DTEM composed of 100 decision trees with two paths each, there are combinations of paths, that is, about combinations. The violation condition extracted in a single verification is only one of the combinations, and it is highly likely that there will be a large number of similar violation conditions in which part of the path condition differs. In that case, since the number of verifications by the SMT solver is also enormous, this method is not practical.
In general, the fineness of the result and the execution time have a trade-off relationship. As for the strategy to extend the violation range, this trade-off relationship should be discussed. As for the proposed method, the violation range is extended in each direction of () in order. Hence, violation ranges are extracted in the form of hyperrectangles. The extension strategy of the proposed method is therefore called a “hyperrectangle strategy.” Here, the mesh strategy described below can be considered as a strategy for extracting the violation range more precisely than the hyperrectangle strategy. An example of extending the violation range according to mesh strategy is shown in Fig. 7.
As for this mesh strategy, first, the space of input values is divided into meshes. Then, the mesh including the violating input value is taken as the initial violation range. Next, whether the violating input value exists in the mesh adjacent to the violation range is verified. If a violating input value exists in the adjacent mesh, the adjacent mesh is taken into the violation range. Then, if no violating input value exists in any mesh adjacent to the violation range, the extension of the violation range is ended. When this strategy is adopted, the number of adjacent meshes increases as the violation range is extended. For example, suppose that the violation range is an -dimensional hypercube and the number of meshes on one side of the violation range is . In this case, the number of adjacent meshes to the violation range is . The verification is performed for the number of adjacent meshes to extend the violation range by one round. Therefore, the amount of calculation to extend the violation range by one round increases as the violation range is extended. On the other hand, in the case of the hyperrectangle strategy, to extend the violation range by one round in the same situation, the verification is performed only times. That is, it advantageous that the violation range can be extended with a fixed amount of calculation regardless of the size of the violation range.
Moreover, a strategy to increase the values of simultaneously can be considered. This strategy can extend the violation range in a shorter time than the hyperrectangle strategy. In this case, the violation range is extracted in the form of a hypercube, so this strategy is called a “hypercube strategy.” An example of extending the violation range on the basis of the hypercube strategy is shown in Fig. 8.
When the hypercube strategy is adopted, the number of verifications for extending the violation range by one round is one. However, the violation range extracted by the hypercube strategy is coarser than that of other strategies. An example of the extracted violation range for each strategy is shown in Fig. 9. The hypercube strategy is highly likely to include a range in which no violating input value exists in the violation range. Therefore, if an input filter is created based on the violation range created by the hypercube strategy, many input values satisfying the property will be filtered.
Finally, in terms of execution time, mesh strategies are considered less practical than hyperrectangle strategies. The hypercube strategy is considered to be less practical in terms of the fineness of the results. Therefore, we adopted a hyperrectangle strategy with a good balance between the fineness of the result and execution time.
As mentioned in Section VII-B, changing the values of , , and makes it possible to adjust the balance between fineness of the result and execution time. These parameters should be changed by the user according to the DTEM and property to be verified, and also allowable execution time. As for finding an appropriate parameter value, the following procedure can be considered. First, the parameter values are set so that execution time is short, and it is confirmed by actually executing the procedure that the execution time can be shoter than the allowable time. After that, the parameters are gradually changed to improve the fineness of the result. This procedure improves the fineness of the results within the constraints of execution time.
Among the proposed methods, and are applicable to machine-learning models other than a DTEM. On the contrary, is a procedure specialized for a DTEM, so it must be to replaced with a verification method suitable for the target machine-learning model. For example, in the case of a DNN, methods for encoding and verifying the DNN in a formula have been proposed [15][16][17][18][14][19]. By replacing in the proposed method with such a method, it is possible to extract the violation range of the DNN.
IX Related Work
As described in Section I, Bogdiukiewicz et al. proposed a method to develop a policing function for autonomous systems [12]. The policing function checks output values of intelligent function such as a machine learning model at runtime. The policing function is useful to prevent failures as well as the input filter. However, the policing function works after the intelligent function executes. It means that the policing function detects and controls the possible failure later than the input filter. Therefore, the proposed method for creating the input filter is more useful in develepment of systems which require quick handling of failures.
In shown in Section IV, a rule-form formula composed of conditions and conclusions is extracted from the DTEM. Extracting a specification from a program in the form of rules has been studied [22][23][24][25][26][27][28]. In these studies, the control path of the program is extracted by static analysis or symbolic execution, and the rule is created on the basis of the branch condition that constitutes the control path. The method proposed in this paper extracts the decision tree path and creates a rule-form formula based on the attribute test associated with the decision node that composes the path. It can thus be said that it adopts the same approach.
As for the verification of the rule-form formula, methods have been established to verify properties such as consistency, redundancy, and completeness [30]. Furthermore, a method for extracting “minimal unsatisfiable subsets,” which are useful for causal analysis when the rule set does not satisfy consistency, has also been proposed [31][32][33]. Validation of rule programs used in a business rule management system has also been studied [35]. As in the case of the method proposed in this paper, the verification of the the rule-form formula is translated to checking the satisfiability problem.
Moreover, as described in Section I, an approach of encoding a DNN model in a formula and verifying it by determining the satisfiability of the formula has been proposed in recent years [15][16][17][18][14][19]. It can be said that the method for verifying the DTEM proposed in this paper also takes this approach. However, a study describing a specific method for verifying a DTEM has not been reported. One of the contributions of this paper is formally specifying a verification method for a DTEM and demonstrating its feasibility through a case study.
No similar studies on extracting violation ranges as described in Section V and dividing violation ranges as described in Section VI have been reported. One of the reasons for that situation is that the problems solved by these methods are unique to software developed by machine learning. In regard to conventional software, namely, algorithmic programs, when a counterexample is detected by verification, the fault that caused the counterexample is analyzed, and the fault is removed by correcting the algorithm. Verification and correction are then repeated until no counterexample is detected. On the other hand, in the case of a machine learning model, a possible method for handling such faults is retraining or additional training using the detected counterexample (and data similar to it). Although this approach may eliminate the fault, retraining and additional training may affect the entire model, and another new fault may be inserted. That is, “regression” occurs. Although this regression also occurs in the case of algorithmic programs, in that case, regression occurs due to a developer’s mistake; therefore, such mistakes must be careful corrected to avoid regression. On the contrary, in the case of a machine-learning model, it is difficult for the developer to control retraining and additional training so that regression does not occur. In other words, it can be said that it is inherently difficult to create a complete machine-learning model that always returns the expected output value. Accordingly, when a machine-learning model is implemented in a system, the proposed method is used to implement the input filter. That is, the proposed method solves a specific problem that occurs with the use of machine-learning models.
X Conclusion
When a DTEM is implemented in a system, the input filter can be effectively used to prevent system failures. As a means of creating the filtering condition for the input filter, a method for extracting the violation range of the DTEM, whose input values are multi-dimensional vectors whose elements are numeric variables, was proposed. The proposed method consists of procedures for formally verifying the DTEM, extracting the violation range, and narrowing the extracted violation range. The violation range extracted by the proposed method includes all violating input values. The proposed method is therefore useful to create the filtering condition. After showing the algorithms for these procedures, the results of a case study using a dataset on the house prices were presented. On the basis of the results of this case study, the feasibility of the proposed method is demonstrated. Through the case study, the scalability of the proposed method is also evaluated. The number of decision trees constituting the DTEM, the maximum depth of the decision trees, and the dimension of the input value are factors that increase the execution time of the proposed method. Specifically, it was concluded that the proposed method is practical if the number of decision trees is less than around 200 and the maximum depth of the decision trees is less than 5 at least.
Future issues include improving the scalability of the proposed method. Since the form of the formula created by the proposed method is constant, the method’s scalability may be improved by implementing heuristics specialized for that form in the SMT solver. Moreover, the procedure for finding appropriate values of parameters , , and shown in Section VIII can be incorporated into the proposed method. Furthermore, by adding case studies using other datasets, the limitation of the proposed method can be evaluated in more detail.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet Classication with Deep Convolutional Neural Networks. Advances in Neural Information Processing Systems, pages 1097-1105, 2012.
- 2[2] G. Hinton, L. Deng, D. Yu, G. Dahl, A. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. Sainath, and B. Kingsbury. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Processing Magazine, 29(6):82-97, 2012.
- 3[3] L. Breiman: Random forests. Maching Learning, 45(1), 5-32, (2001).
- 4[4] J.H. Friedman: Greedy function approximation: a gradient boosting machine. Annals of statistics, pp.1189-1232 (2001).
- 5[5] P. Li: Robust logitboost and adaptive base class (abc) logitboost. ar Xiv preprint ar Xiv:1203.3491 (2012).
- 6[6] M. Richardson, E. Dominowska, and R. Ragno: Predicting clicks: estimating the click-through rate for new ads. In Proceedings of the 16th international conference on World Wide Web, pp.521-530. ACM (2007).
- 7[7] C.J.C. Burges: From ranknet to lambdarank to lambdamart: An overview, Microsoft Research Technical Report MSR-TR-2010-82 (2010).
- 8[8] R.A.V. Rossel, and T. Behrens: Using data mining to model and interpret soil diffuse reflectance spectra, Geoderma 2010, 158, pp.46-54 (2010).