Bayesian Factor Analysis for Inference on Interactions
Federico Ferrari, David B Dunson

TL;DR
This paper introduces a Bayesian latent factor model, FIN, for inferring complex interactions among correlated chemical exposures affecting health, with theoretical guarantees and practical evaluation.
Contribution
It develops a novel Bayesian factor analysis framework that captures interactions and main effects in correlated predictors and responses, extending to higher order interactions.
Findings
The model achieves accurate inference in simulations.
Application to NHANES data reveals meaningful chemical interactions.
Posterior consistency is established under certain conditions.
Abstract
This article is motivated by the problem of inference on interactions among chemical exposures impacting human health outcomes. Chemicals often co-occur in the environment or in synthetic mixtures and as a result exposure levels can be highly correlated. We propose a latent factor joint model, which includes shared factors in both the predictor and response components while assuming conditional independence. By including a quadratic regression in the latent variables in the response component, we induce flexible dimension reduction in characterizing main effects and interactions. We propose a Bayesian approach to inference under this Factor analysis for INteractions (FIN) framework. Through appropriate modifications of the factor modeling structure, FIN can accommodate higher order interactions and multivariate outcomes. We provide theory on posterior consistency and the impact of…
Click any figure to enlarge with its caption.
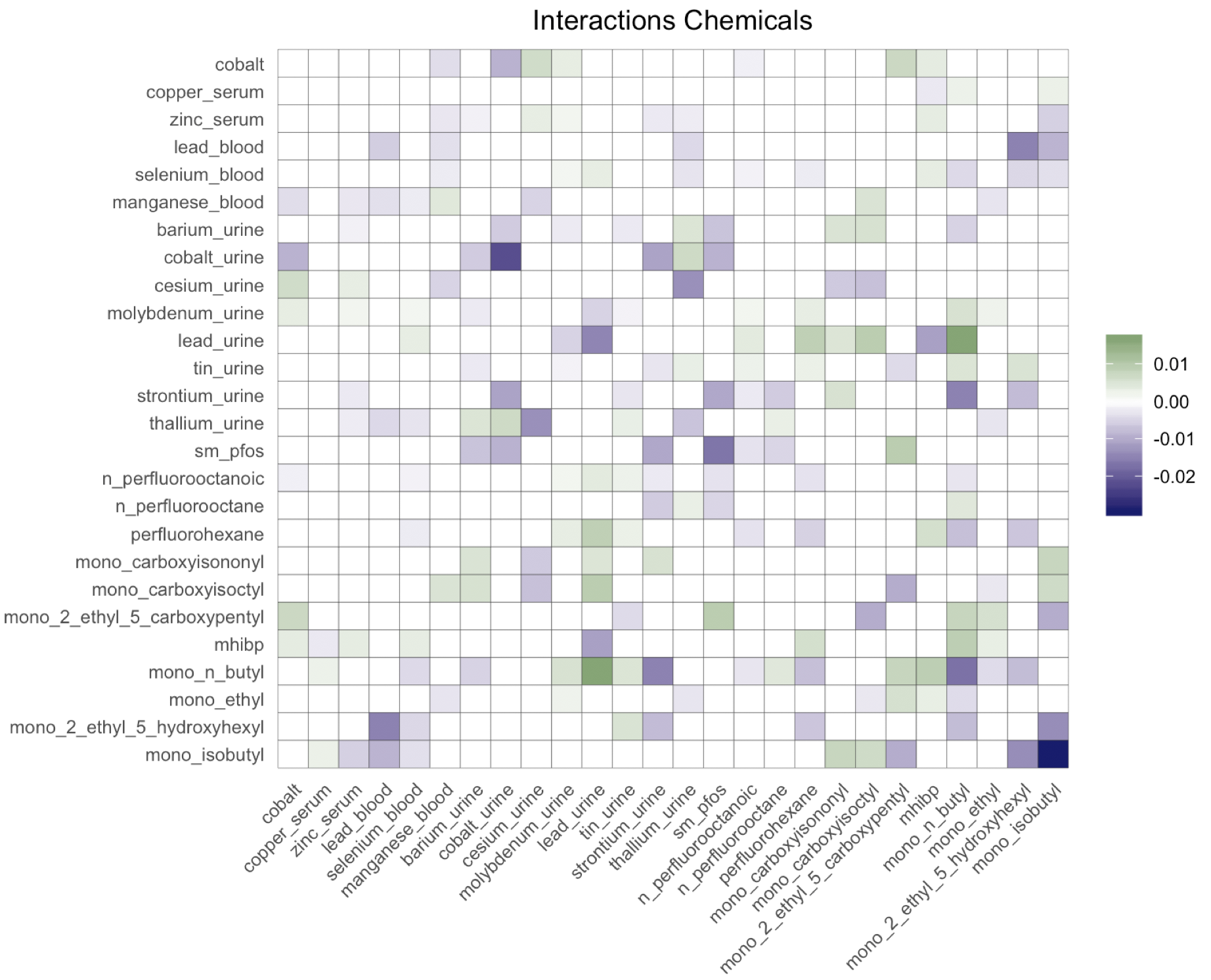 Figure 1
Figure 1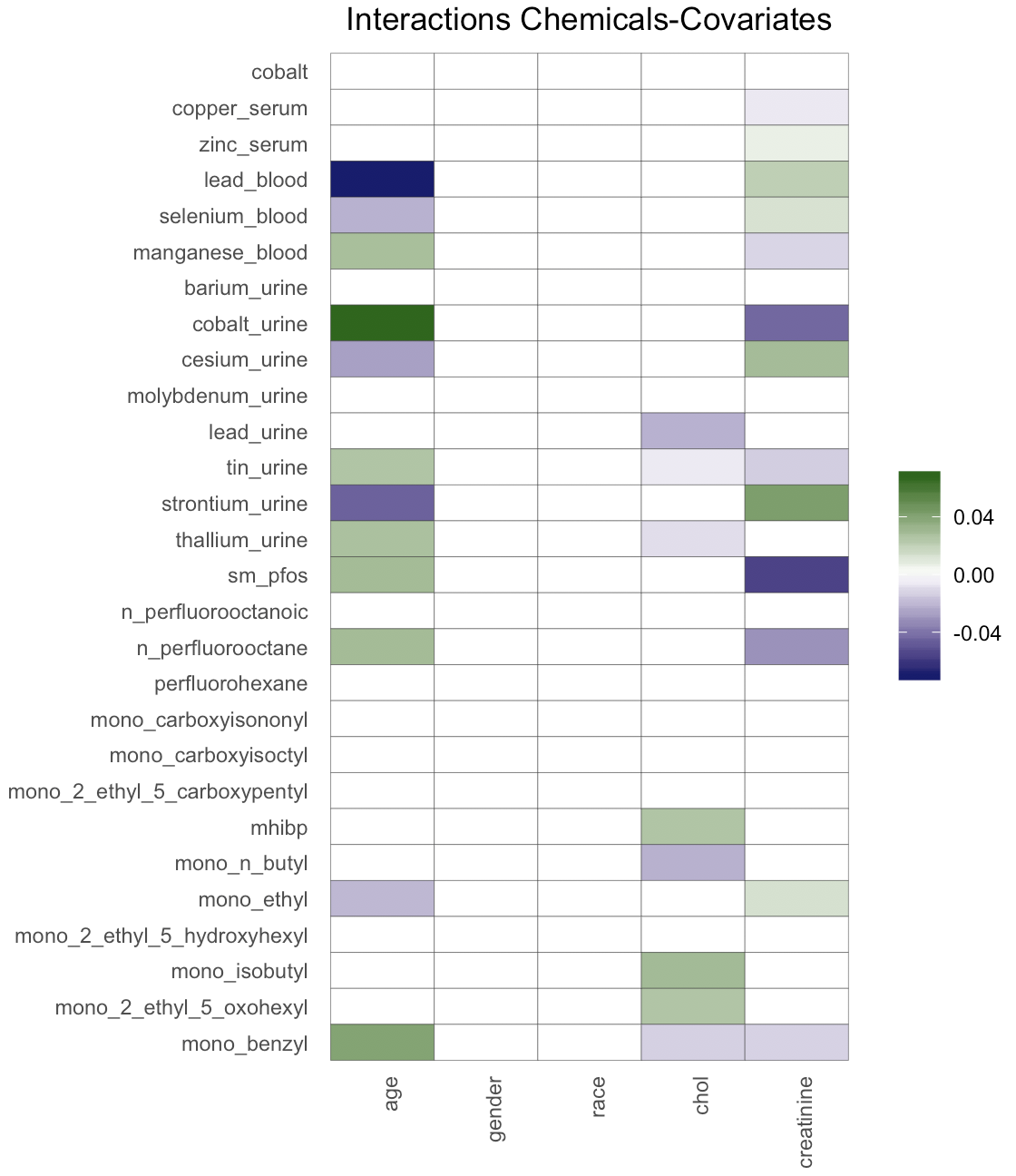 Figure 2
Figure 2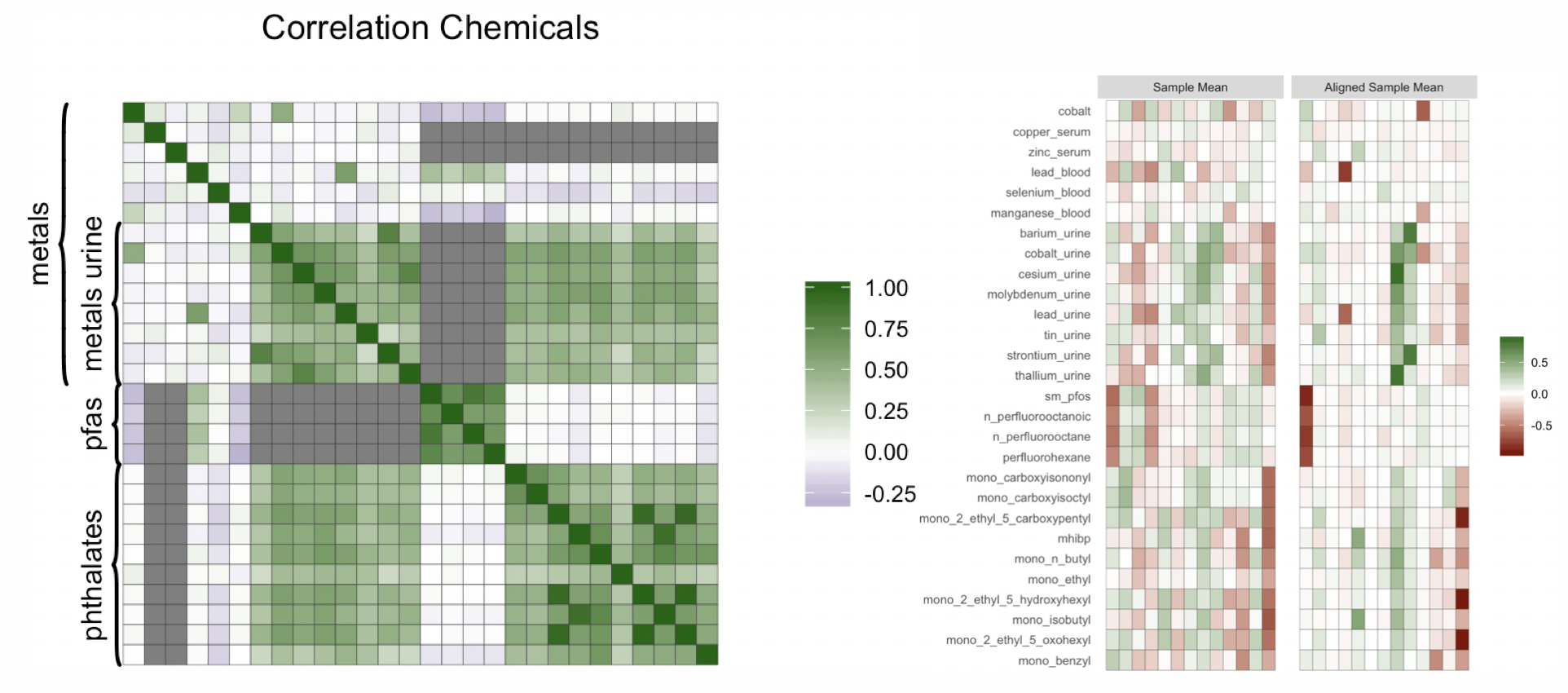 Figure 3
Figure 3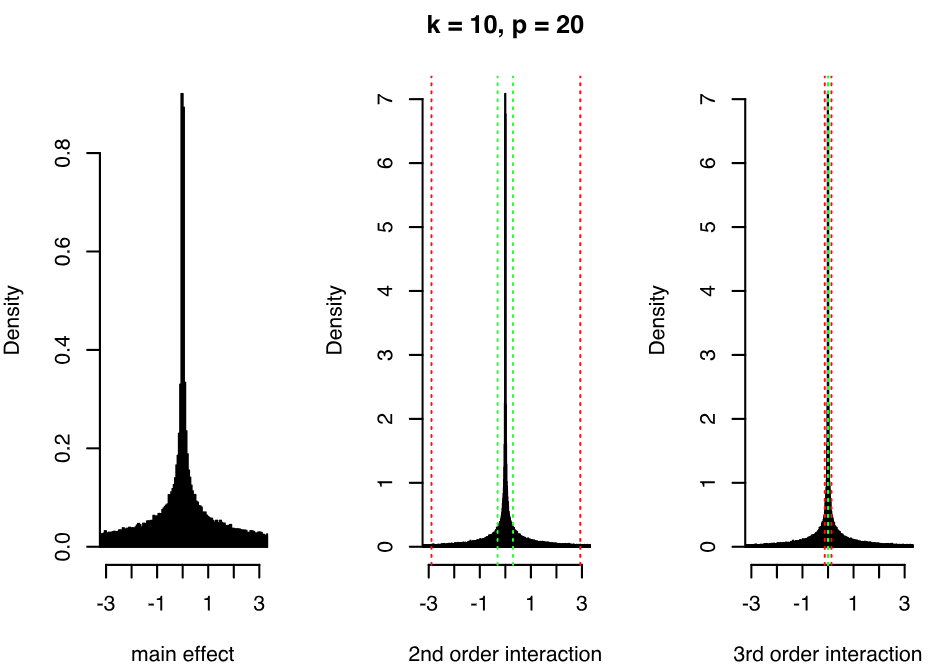 Figure 4
Figure 4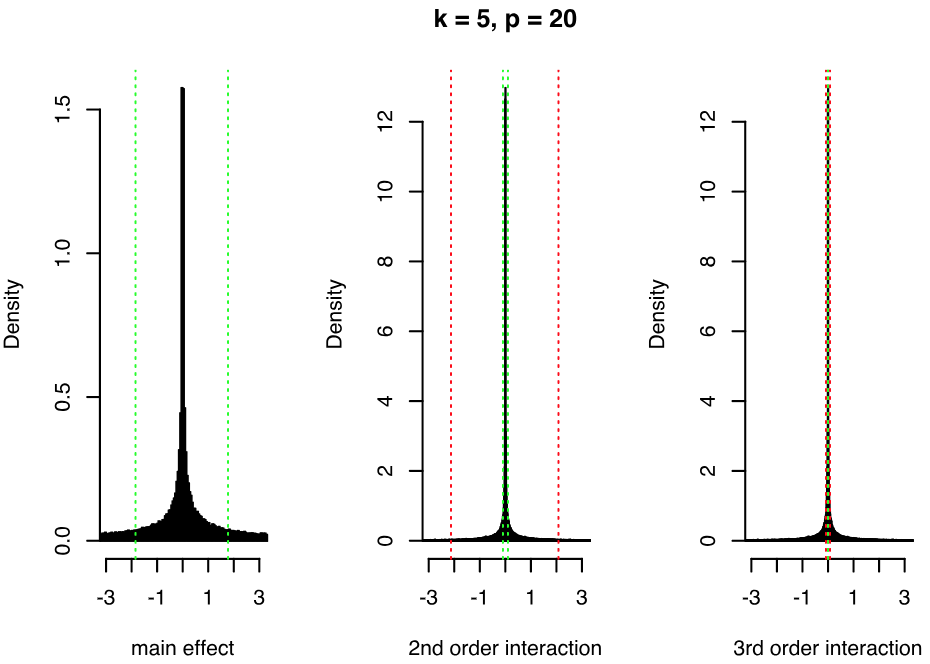 Figure 5
Figure 5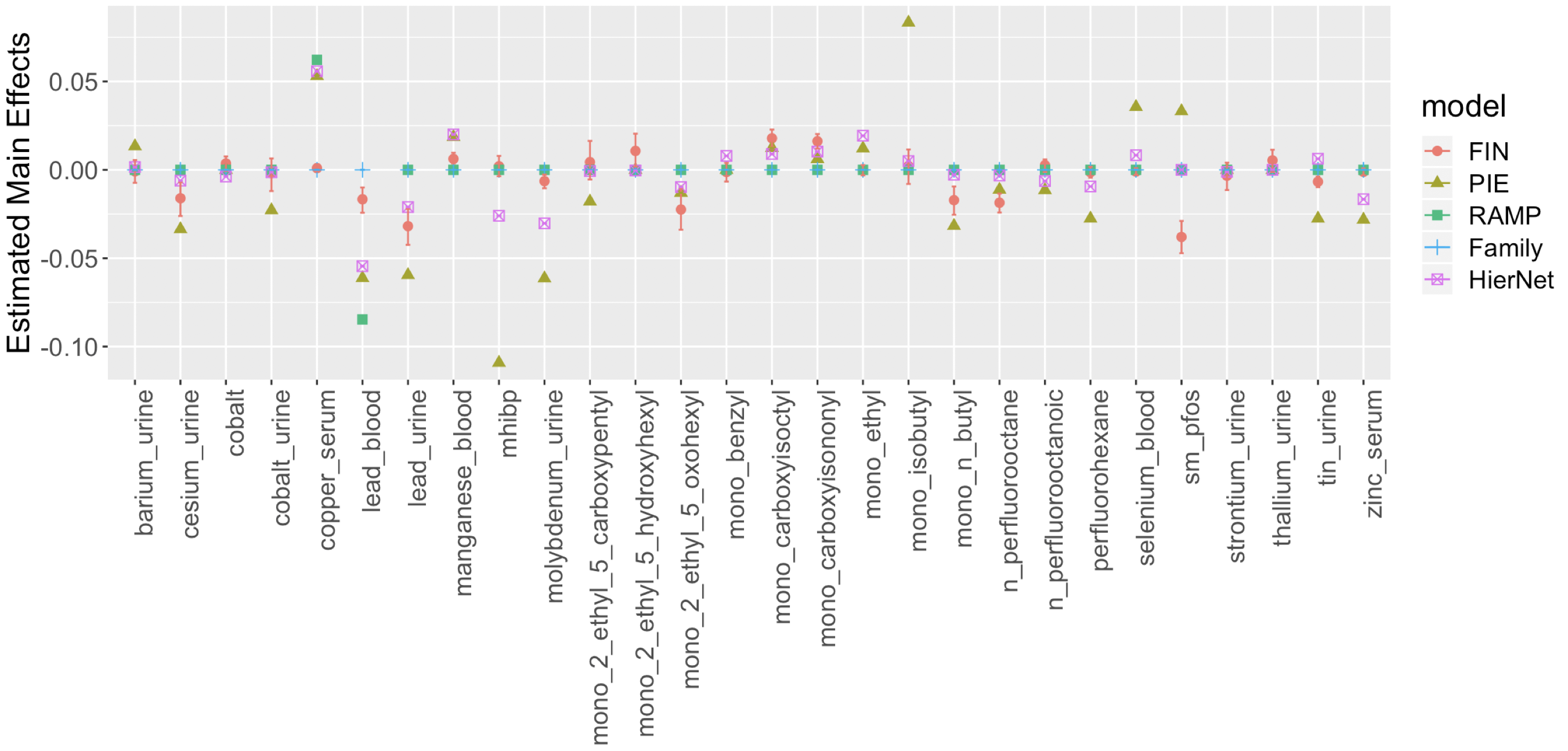 Figure 6
Figure 6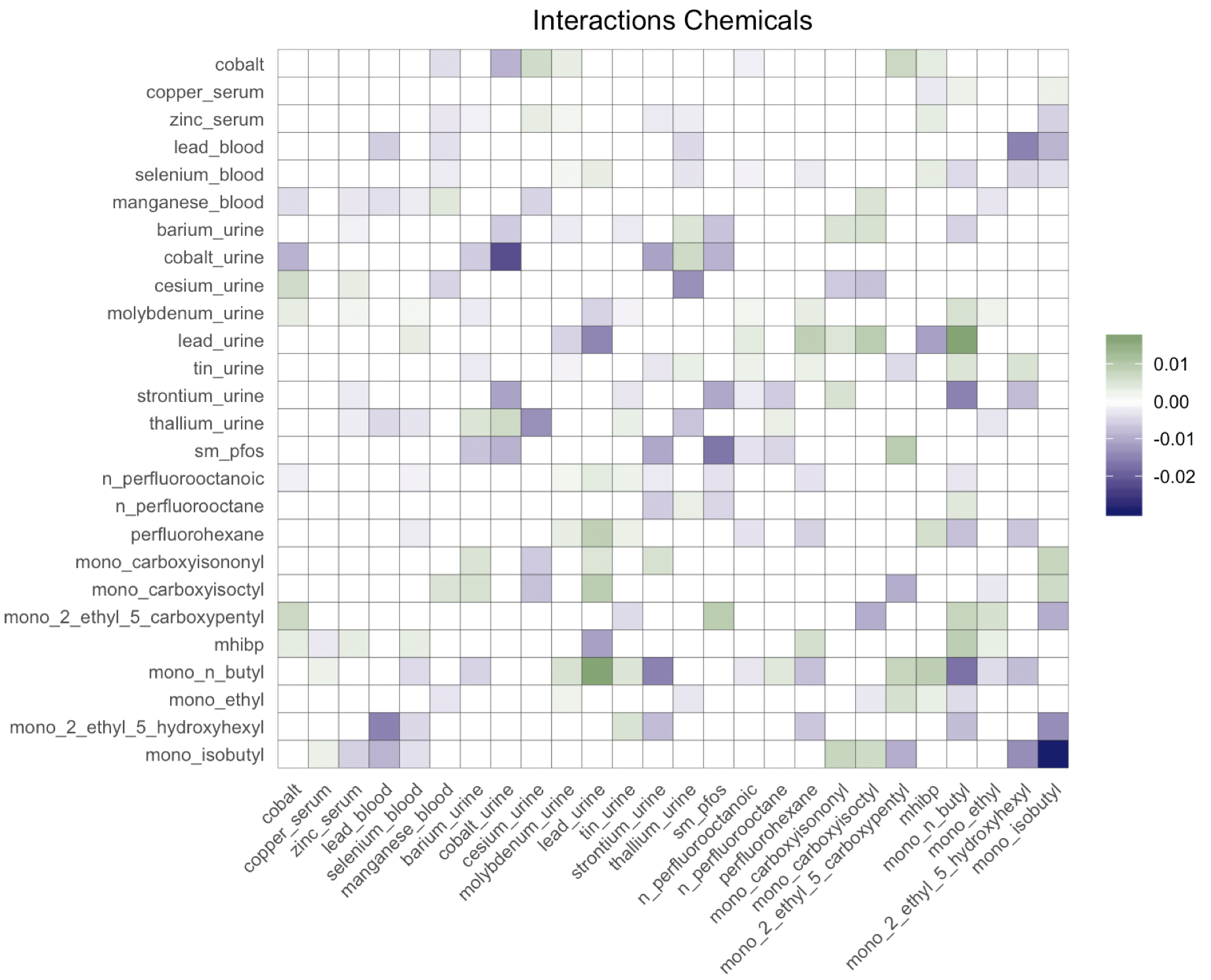 Figure 7
Figure 7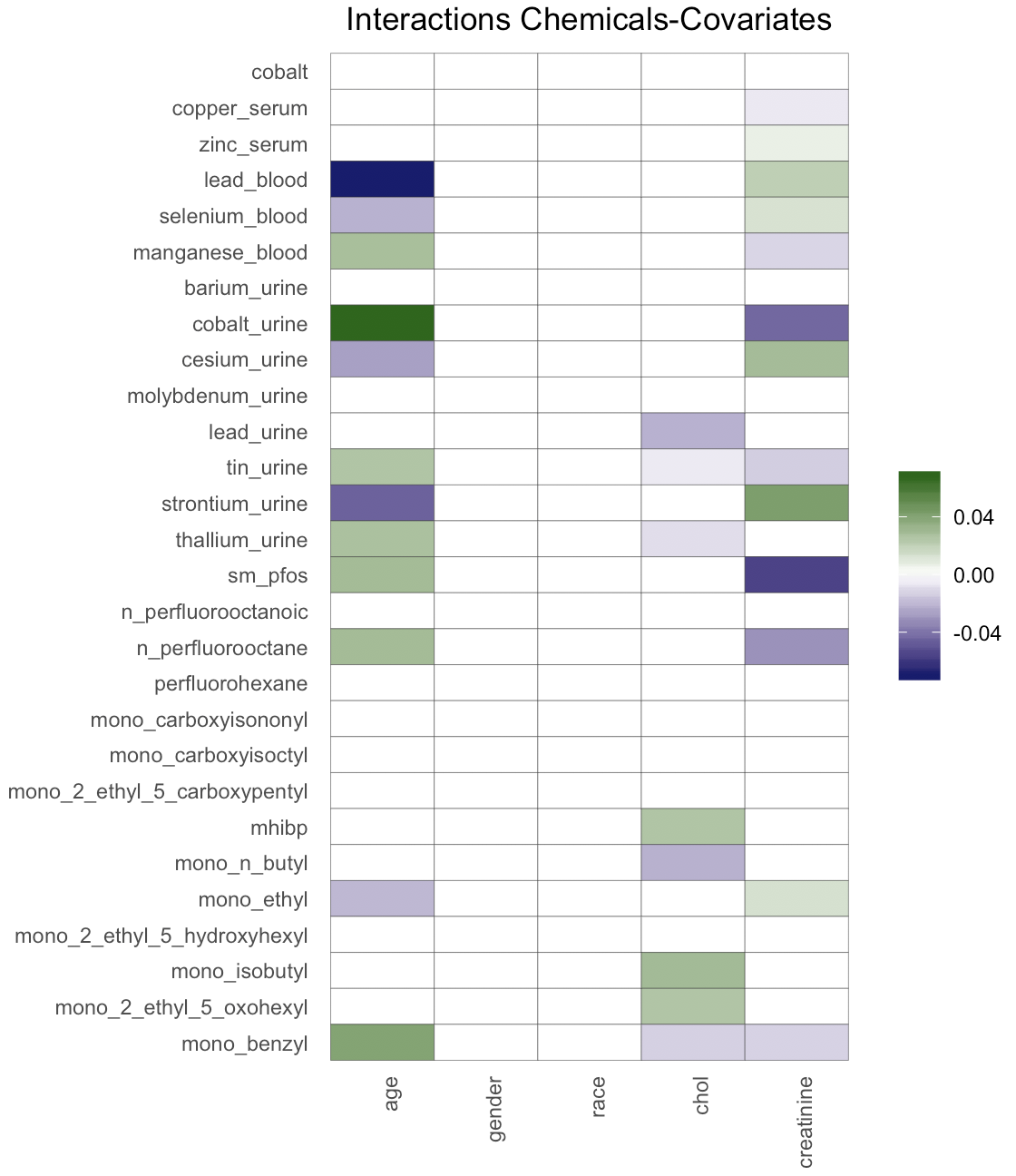 Figure 8
Figure 8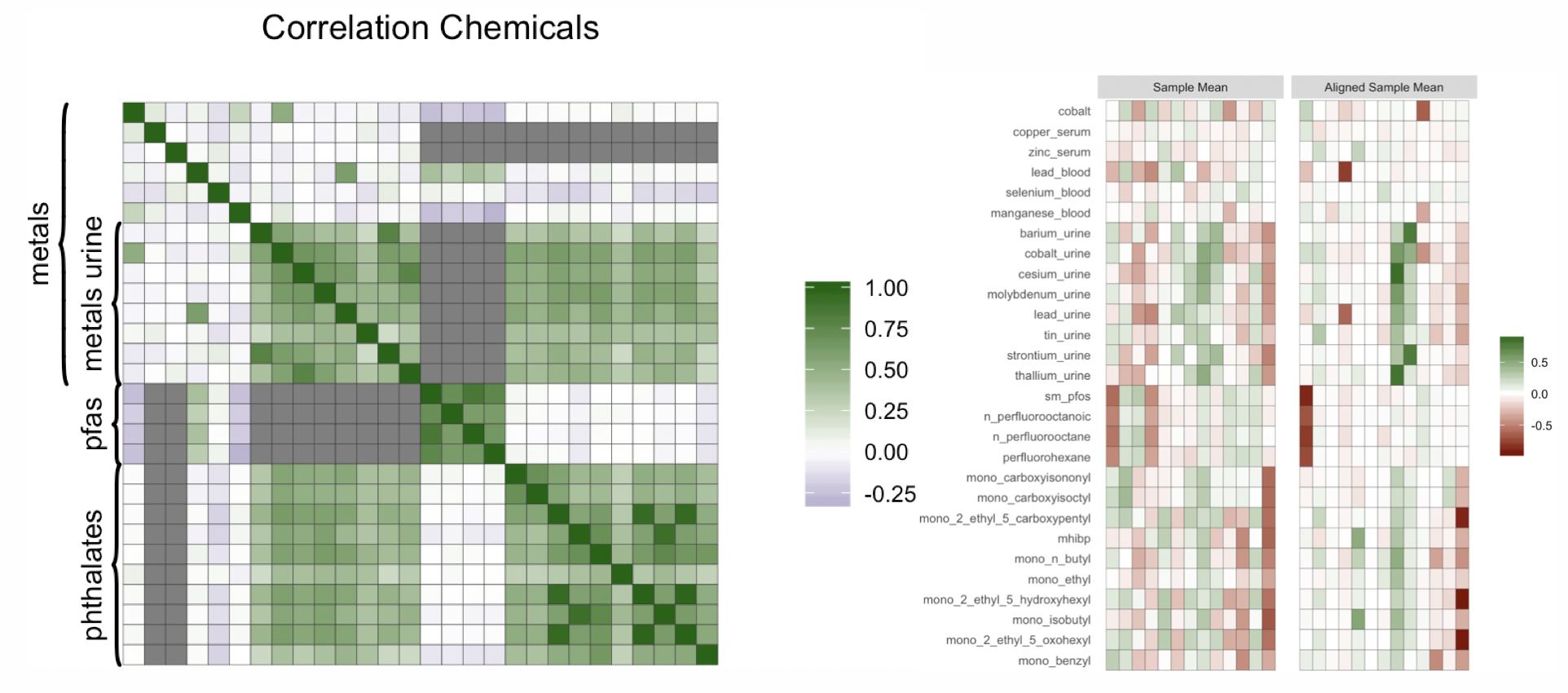 Figure 9
Figure 9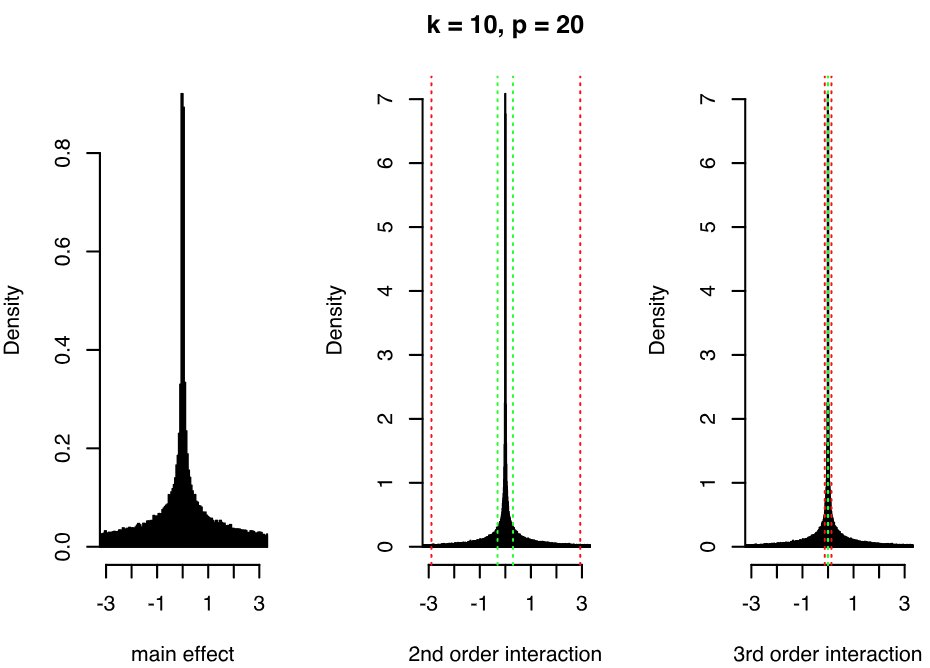 Figure 10
Figure 10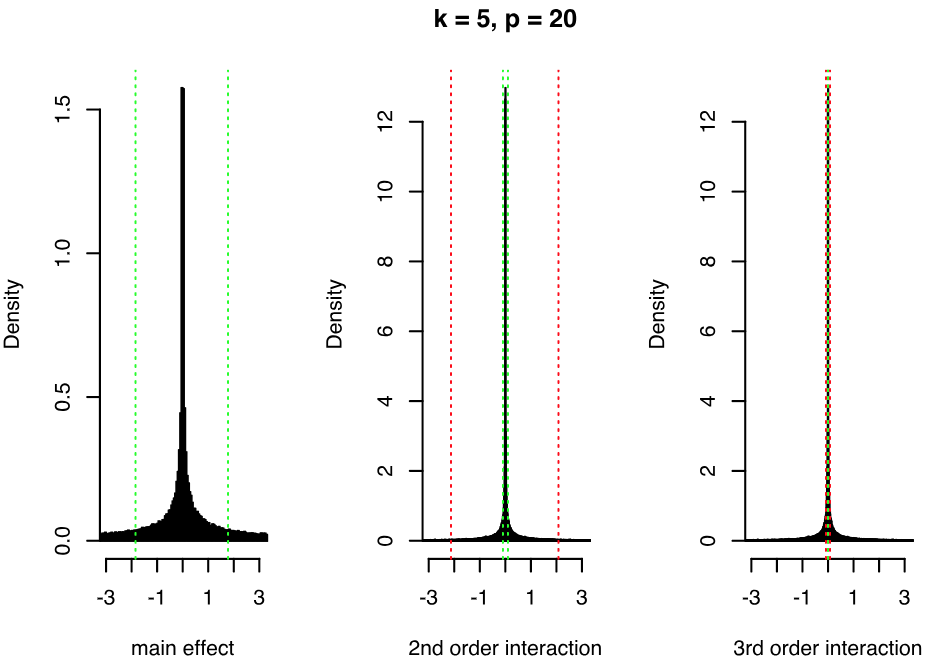 Figure 11
Figure 11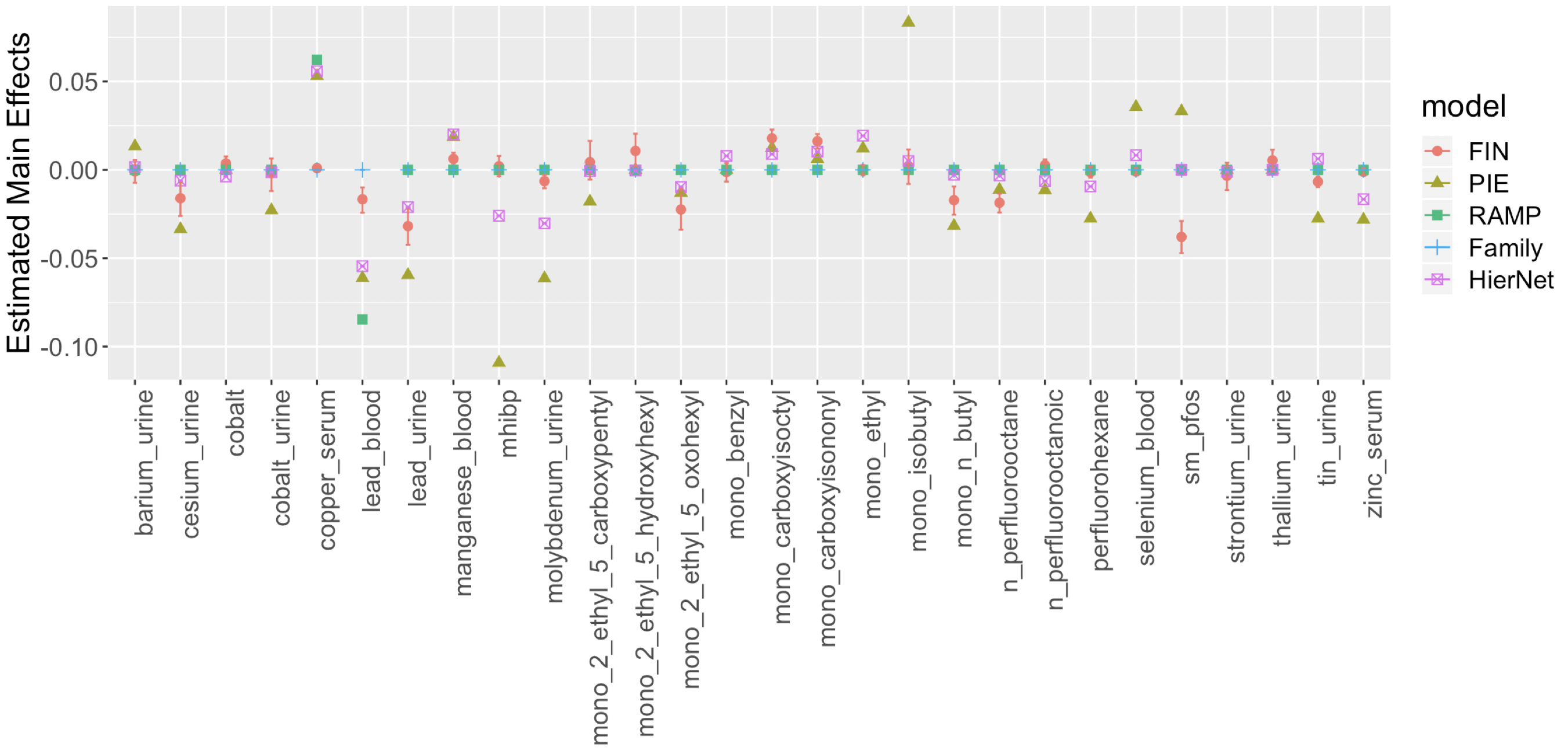 Figure 12
Figure 12| HierNet | FAMILY | PIE | RAMP | FIN | ||
| test error | ||||||
| FR | ||||||
| factor | main MSE | |||||
| TP main | ||||||
| TN main | ||||||
| TP int | ||||||
| TN int | ||||||
| test error | ||||||
| FR | ||||||
| linear | main MSE | |||||
| TP main | ||||||
| TN main | ||||||
| TP int | ||||||
| TN int | ||||||
| test error | ||||||
| FR | ||||||
| independent | main MSE | |||||
| TP main | ||||||
| TN main | ||||||
| TP int | ||||||
| TN int |
| HierNet | FAMILY | PIE | RAMP | FIN | ||
| test error | ||||||
| FR | ||||||
| factor | main MSE | |||||
| TP main | ||||||
| TN main | ||||||
| TP int | ||||||
| TN int | ||||||
| test error | ||||||
| FR | ||||||
| linear | main MSE | |||||
| TP main | ||||||
| TN main | ||||||
| TP int | ||||||
| TN int | ||||||
| test error | ||||||
| FR | ||||||
| independent | main MSE | |||||
| TP main | ||||||
| TN main | ||||||
| TP int | ||||||
| TN int |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Bayesian Factor Analysis for Inference on Interactions
Federico Ferrari
Department of Statistical Science, Duke University
and
David B. Dunson
Department of Statistical Science, Duke University
Abstract
This article is motivated by the problem of inference on interactions among chemical exposures impacting human health outcomes. Chemicals often co-occur in the environment or in synthetic mixtures and as a result exposure levels can be highly correlated. We propose a latent factor joint model, which includes shared factors in both the predictor and response components while assuming conditional independence. By including a quadratic regression in the latent variables in the response component, we induce flexible dimension reduction in characterizing main effects and interactions. We propose a Bayesian approach to inference under this Factor analysis for INteractions (FIN) framework. Through appropriate modifications of the factor modeling structure, FIN can accommodate higher order interactions. We evaluate the performance using a simulation study and data from the National Health and Nutrition Examination Survey (NHANES). Code is available on GitHub.
Keywords: Bayesian Modeling; Chemical Mixtures; Correlated Exposures; Quadratic regression; Statistical Interactions
1 Introduction
There is broad interest in incorporating interactions in linear regression. Extensions of linear regression to accommodate pairwise interactions are commonly referred to as quadratic regression. In moderate to high-dimensional settings, it becomes very challenging to implement quadratic regression since the number of parameters to be estimated is . Hence, classical methods such as least squares cannot be used and even common penalization and Bayesian methods can encounter computational hurdles. Reliable inferences on main effects and interactions is even more challenging when certain predictors are moderately to highly correlated.
A lot of effort has been focused on estimating pairwise interactions in moderate high-dimensional and ultra high-dimensional problems. We refer to the former when the number of covariates is between and and to the latter when . When , the number of parameters to be estimated is greater than . When , one-stage regularization methods like Bien et al. (2013) and Haris et al. (2016) can be successful. Some of these methods require a so-called heredity assumption (Chipman, 1996) to reduce dimensionality. Strong heredity means that the interaction between two variables is included in the model only if both main effects are. For weak heredity it suffices to have one main effect in the model. Heredity reduces the number of models from to or for strong or weak heredity, respectively (Chipman, 1996). For ultra high-dimensional problems, two stage-approaches have been developed, see Hao et al. (2018) and Wang et al. (2019). However, these methods do not report uncertainties in model selection and parameter estimation, and rely on strong sparsity assumptions.
We are particularly motivated by studies of environmental health collecting data on mixtures of chemical exposures. These exposures can be moderately high-dimensional with high correlations within blocks of variables; for example, this can arise when an individual is exposed to a product having a mixture of chemicals and when chemical measurements consist of metabolites or breakdown products of a parent compound. There is a large public heath interest in studying EE, EG and GG interactions, with E = environmental exposures and G = genetic factors. However, current methods for quadratic regression are not ideal in these applications due to the level of correlation in the predictors, the fact that strong sparsity assumptions are not appropriate, and the need for uncertainty quantification. Regarding the issue of sparsity, some exposures are breakdown products of the same compound, so it is unlikely that only one exposure has an effect on the outcome. Also, it is statistically challenging to tell apart highly correlated covariates with limited data. For this reason, it is appealing given the data structure to select blocks of correlated exposures together instead of arbitrarily selecting one chemical in a group.
To address these problems, one possibility is to use a Bayesian approach to inference in order to include prior information to reduce dimensionality while characterizing uncertainty through the posterior distribution. There is an immense literature on Bayesian methods for high-dimensional linear regression, including recent algorithms that can scale up to thousands of predictors (Bondell and Reich, 2012), (Rossell and Telesca, 2017), (Johndrow et al., 2017), (Nishimura and Suchard, 2018). In addition some articles have explicitly focused on quadratic regression and interaction detection (Zhang and Liu, 2007), (Cordell, 2009), (Mackay, 2014). Bayes variable selection and shrinkage approaches will tend to have problems when predictors are highly correlated; this has motivated a literature on Bayesian latent factor regression (Lucas et al., 2006), (Carvalho et al., 2008).
Latent factor regression incorporates shared latent variables in the predictor and response components. This provides dimensionality reduction in modeling of the covariance structure in the predictors and characterizing the impact of correlated groups of predictors on the response. Such approaches are closely related to principal components regression, but it tends to be easier to simultaneously incorporate shrinkage and uncertainty quantification within the Bayesian framework. In addition, within the Bayes latent factor regression paradigm, typical identifiability constraints such as orthogonality are not needed (see, for example Bhattacharya and Dunson (2011)). The main contribution of this article is to generalize Bayesian latent factor regression to accommodate interactions using an approach inspired by Wang et al. (2019). This is accomplished by including pairwise interactions in the latent variables in the response component. We refer to the resulting framework as Factor analysis for INteractions (FIN). There is a rich literature on quadratic and nonlinear latent variable modeling, largely in psychometrics (refer, for example, to Arminger and Muthén (1998)). However, to our knowledge, such approaches have not been used for inferences on interactions in regression problems.
In Section 2 we describe the proposed FIN framework, including extensions for higher order interactions. In Section 3 we provide theory on model misspecification and consistency. Section 4 contains a simulation study. Section 5 illustrates the methods on NHANES data. Code is available at https://github.com/fedfer/factor_interactions. Proofs of Proposition 2 and Proposition 3 are included in the Supplementary Material.
2 Model
2.1 Model and Properties
Let denote a continuous health response for individual , and denote a vector of exposure measurements. We propose a latent factor joint model, which includes shared factors in both the predictor and response components while assuming conditional independence. We include interactions among latent variables in the response component. We also assume that, given the latent variables, the explanatory variables and the response are continuous and normally distributed. We assume that the data have been normalized prior to the analysis so that we omit the intercept. The model is as follows:
[TABLE]
where . In a Bayesian fashion, we assume a prior for the parameters that will be specified in Section 2.2. Model is equivalent to classical latent factor regression models; refer, for example, to West (2003), except for the term. Here, is a symmetric matrix inducing a quadratic latent variable regression that characterizes interactions among the latent variables.
The above formulation can be shown to induce a quadratic regression of on . To build intuition consider the case in which as done in West (2003) for the special case in which . The many-to-one map has multiple generalized inverses such that . If we substitute in the regression equation, we obtain
[TABLE]
The following proposition gives a similar result in the non deterministic case:
Proposition 1**.**
Under model (1), the following are true:
- (i)
,
- (ii)
,
where and .
This shows that the induced regression of on from model (1) is indeed a quadratic regression. Let us define the induced main effects as and the matrix containing the first order interactions as . Notice that we could define as a diagonal matrix and we would still estimate pairwise interactions between the regressors, further details are given in Sections 2.3 and 2.5.
In epidemiology studies, it is of interest to include interactions between chemical exposures and demographic covariates. The covariates are often binary variables, like race or sex, or continuous variables that are non-normally distributed, like age. Hence, we do not want to assume a latent normal structure for the covariates. Letting be a vector of covariates, we modify model to include a main effect for and an interaction term between and the latent factor :
[TABLE]
where is a matrix of interaction coefficients between the latent variables and the covariates, and are main effects for the covariates. Following Proposition 1 we have that
[TABLE]
where is a matrix of pairwise interactions between exposures and covariates. In the sequel, we focus our development on model for ease in exposition, but all of the details can be easily modified to pertain to model .
2.2 Priors and MCMC Algorithm
In this section we define the priors for , briefly describe the computational challenges given by model and summarize our Markov Chain Monte Carlo sampler in Algorithm 1. We choose an Inverse-Gamma distribution with parameters for and for . The elements of and are given independent Gaussian priors. For , a typical choice to attain identifiability requires for and for (Geweke and Zhou, 1996). However, some Bayesian applications, like covariance estimation (Bhattacharya and Dunson, 2011), do not require identifiability of . The same holds for inference on induced main effects and interactions for model . Notice that model is invariant to rotations:
[TABLE]
where is a orthogonal matrix (). However, the induced main effects satisfy
[TABLE]
The same holds for induced interactions, showing that we do not need to impose identifiability constraints on . We choose the Dirichlet-Laplace (DL) prior of Bhattacharya et al. (2015) row-wise, corresponding to
[TABLE]
where , , DE refers to the zero mean double-exponential or Laplace distribution, and is an upper bound on the number of factors, as the prior allows effective deletion of redundant factor loadings through row-wise shrinkage. The DL prior provides flexible shrinkage on the factor loadings matrix, generalizing the Bayesian Lasso (Park and Casella, 2008) to have a carefully chosen hierarchical structure on exposure-specific () and local () scales. This induces a prior with concentration at zero, to strongly shrink small signals, and heavy-tails, to avoid over-shrinking large signals. The DL prior induces near sparsity row-wise in the matrix , as it is reasonable to assume that each variable loads on few factors.
In Section 2.4, we describe how the above prior specification induces an appealing shrinkage prior on the main effects and interactions, and discuss hyperparameter choice. In practice, we recommend the rule of thumb that chooses such that , where is the largest singular value of the correlation matrix of . Proposition 2 in Section 3 provides theoretical justification for this criterion. As an alternative to row-wise shrinkage, we could have instead used column-wise shrinkage as advocated in Bhattacharya et al. (2015) and Legramanti et al. (2019). Although such approaches can be effective in choosing the number of factors, we found in our simulations that they can lead to over-shrinkage of the estimated main effects and interactions.
The inclusion of pairwise interactions among the factors in the regression of the outcome rules out using a simple data augmentation Gibbs sampler, as in West (2003), Bhattacharya and Dunson (2011). The log full conditional distribution for is:
[TABLE]
where is a normalizing constant. We update the factors using the Metropolis-Adjusted Langevin Algorithm (MALA) (Grenander and Miller, 1994), (Roberts et al., 1996). Sampling the factors is the main computational bottleneck of our approach since we have to update vectors, each of dimension . The overall MCMC algorithm and the MALA step are summarized in Algorithm 1.
2.3 Higher Order Interactions
FIN can be generalized to allow for higher order interactions. In particular, we can obtain estimates for the interaction coefficients up to the order with the following model:
[TABLE]
which is a polynomial regression in the latent variables. We do not include interactions between the factors, so that the number of parameters to be estimated is . When , this model is equivalent to being a diagonal matrix. Recall that , where and are defined in Proposition 1. Since we do not include interactions among the factors, let us just focus on the marginal distribution of the factor, i.e where and . Below we provide an expression for , which can be calculated using non-central moments of a Normal distribution, see Winkelbauer (2012) for a reference.
[TABLE]
where , and . We just need to sum up over the index in and we can read out the expressions for the intercept, main effects and interactions up to the order. In particular, we have that the intercept is equal to . When this reduces to , where . The expression for the main effects coefficients on is . When this becomes , hence . Similarly the expression for the interaction between and is equal to and when we have which is equal to .
In general, if we are interested in the order interactions, we can find the expression on the top summation for when is odd and on the bottom summation for when is even. Finally notice that with parameters we manage to estimate parameters thanks to the low dimensional factor structure in the covariates.
2.4 Induced Priors
In this section, we show the behavior of the induced priors on the main effects and pairwise interaction coefficients under model using simulated examples, and we show the induced grouping of coefficients when we have prior information on the covariance structure of . We endow with a normal prior having zero mean and covariance equal to , where is a diagonal matrix. Then, conditional on and , the induced prior on is also Normal with mean [math] and covariance equal to . Recall from Proposition 1 that the induced main effect coefficients are equal to . This expression is equivalent to West (2003) and we can similarly characterize the limiting case of , i.e. when the factors explain all of the variability in the matrix of regressors . Let and , together with enforcing to be orthogonal, we have that . It follows that has the generalised singular g-prior (or gsg-prior) distribution defined by West (2003), whose density is proportional to .
Now, consider the extension presented in the previous section, where we include powers of the factors in the regression of . In Figure 1, we show the induced marginal priors for main effects, pairwise interactions and order interactions when and when and are given priors element-wise. Increasing (or decreasing) the variance of the priors on and will directly increase (or decrease) the variance of the induced main effects and pairwise interactions, as and are linear functions of and respectively. For a fixed , there is increasing shrinkage towards zero with higher orders of interaction. However, we avoid assuming exact sparsity corresponding to zero values of the coefficients, a standard assumption of other methods. Although most of the mass is concentrated around zero, the distributions have heavy tails. We can indeed notice that the form of the priors resembles a mixture of two normal distributions with different variances, and that we place a higher mixture weight on the normal distribution concentrated around zero as we increase the order of interactions. This is because higher order interactions contain products of the elements of , previously defined in Proposition 1, and the elements of are affected by the DL prior shrinkage, since is a function of . Also, notice that the priors have higher variance as we increase the number of latent factors .
In environmental epidemiology, it is common to have prior knowledge of groups of exposures that are highly correlated and it is natural to include such information in the specification of . One possibility is to impose a block sparsity structure in which each group of chemicals is restricted to load on the same factor. Then, cross group dependence is allowed including additional factors and endowing the factor loadings with a DL prior. Suppose that the variables in can be divided in groups: of dimensions , where and . Letting , where is , we can assign a block sparsity structure to :
[TABLE]
In the Supplementary Material we show the effect of the block sparsity structure on the a priori induced groupings of main effects and interactions when , so that .
3 Properties of the Model
In this section we prove that the posterior distribution of is weakly consistent for a broad set of models. Let denote the Kullback-Leibler divergence between and , where
[TABLE]
We will assume that represents the true data-generating model. This assumption is not as restrictive as it may initially seem. The model is flexible enough to always characterize and model quadratic regression in the response component, while accurately approximating any covariance structure in the predictor component. In fact it always holds that:
[TABLE]
where and are functions of as in Proposition 1, and the true number of factors is . When , we can write any covariance matrix as . We take an “over-fitted” factor modeling approach, related to Bhattacharya and Dunson (2011), Rousseau and Mengersen (2011), and choose to correspond to an upper bound on the number of factors. In practice, we recommend the rule of thumb that chooses such that , where is the largest singular value of the correlation matrix of . We have found this choice to have good performance in a wide variety of simulation cases. However, there is nonetheless a potential concern that may be less than in some cases. Proposition 2 quantifies the distance in terms of Kullback-Leibler divergence between the true data generating model and the likelihood under model miss-specification as approaches infinity.
Proposition 2**.**
Fix , , and assume that . As increases the posterior distribution of and concentrates around and , satisfying:
[TABLE]
where is the largest singular value of .
Unsurprisingly, the bound of Proposition 2 resembles the Eckart-Young theorem for low-rank approximation based on the Singular Value Decomposition of a matrix. The Eckart-Young theorem states that the rank approximation of a matrix minimizing the Frobenoius norm is such that . In a similar fashion as Principal Component Analysis and Factor Analysis, we can inspect the singular values of the correlation matrix of the regressors in order to choose the number of factors to include in the model, and thanks to Proposition 2 we know how far the posterior distribution will concentrate from the truth.
The next proposition provides a sufficient condition in order to achieve posterior consistency when . Notice that we achieve posterior consistency on the induced main effects and pairwise interactions.
Proposition 3**.**
Fix . Whenever , for any there exists an such that:
[TABLE]
where is the sup-norm.
One can easily define a prior on such that it places positive probability in any small neighborhood of , according to . The prior defined in Section 2.2 satisfies this condition. Consequently, the posterior distribution of is weakly consistent due to Schwartz (1965). The proofs of Proposition 2 and Proposition 3 can be found in the Supplementary Material.
4 Simulation Experiments
In this section we compare the performance of our FIN method with four other approaches: PIE (Wang et al., 2019), RAMP (Hao et al., 2018), Family (Haris et al., 2016) and HierNet (Bien et al., 2013). These methods are designed for inference on interactions in moderate to high dimensional settings. We generate and covariates in three ways:
[TABLE]
In the factor scenario we set the true number of factors equal to for and equal to when . FIN achieved similar performance when we chose a smaller number of latent factors. The average absolute correlation in the covariates is between and for the factor and linear scenarios when . These two simulation scenarios are the most similar to the environmental epidemiology data analysis in Section 5. The complexity gains of FIN with respect to a Bayesian linear models with interactions is analyzed in the Supplementary Material.
For each scenario, we generate the continuous outcome according to a linear regression with pairwise interactions:
[TABLE]
where half of the main effects are different from zero and for . We distinguish between a sparse matrix of pairwise interactions , with only non-zero interactions, or dense, where of the elements are different from zero.
For each value of we have six simulation scenarios: factor, linear or independent combined with sparse or dense pairwise interactions. We generate the non-zero main effects and interaction coefficients from a Uniform distribution in the interval such that the regression equation follows the strong heredity constraint. Strong heredity allows an interaction between two variables to be included in the model only if the main effects are. This is done to favor RAMP, Family and HierNet, which assume the heredity condition. We repeat the simulations times and evaluate the performance on a test dataset of units computing predictive mean square error, mean square error for main effects, Frobenious norm (FR) for interaction effects, and percentage of true positives (TP) and true negatives (TN) for main effects and interactions. The percentage of TP and TN main effects is defined as follows:
[TABLE]
where is the estimated main effect for feature and is the true coefficient. FIN is the only method reporting uncertainty quantification and we set whenever zero is included in the credible interval. We equivalently define the percentage of true positive and true negative interactions.
The MCMC algorithm was run for iterations with a burn-in of . We observed good mixing. In particular, the Effective Sample Size (ESS) was always greater than across our simulations, both for main effects and interactions. We set the hyperparameter of the Dirichlet-Laplace prior equal to . We obtained similar results for in the interval . The results are summarized in Table 1-2 for and in Table 1-2 of the Supplementary Material for . Across all the simulations, we chose such that .
In the factor scenario, FIN outperforms the other methods in predictive performance and estimation of main effects and interactions, whereas the rate recovery of true main effects and interactions is comparable to HierNet and PIE with sparse and outperforms the other methods when is dense. The latter scenario is the most challenging with respect to selection of main effects and interactions. Most of the other methods either select or shrink to zero all the effects. In the linear scenario, FIN also shows the best performance together with PIE and Hiernet. Despite the model misspecification with independent covariates, FIN has a comparable predictive performance with respect to the other methods, which do not take into account correlation structure in the covariates. The predictive intervals provided by FIN contained the true value of on average approximately of the time in the factor scenario, for the linear scenario, and for the independent scenario. The average bias in the posterior predictive mean is negligible in each simulation scenario.
The optimization method performed by HierNet (Bien et al., 2013) tends to favor interactions only in presence of large component main effects, and in doing so overshrinks interactions estimates, especially in the dense scenario. Penalized regression techniques PIE (Wang et al., 2019) and RAMP (Hao et al., 2018) tend to over-shrink coefficient estimates and select too few predictors, particularly in the dense scenario. On the other hand, FAMILY (Haris et al., 2016) performs a relaxed version of the penalized algorithm by refitting an unpenalized least squares model, which results in a high false positive rate of main effects. We also considered different signal-to-noise ratios with and . The results are very similar to the results we have presented; hence, we omit them.
5 Environmental Epidemiology Application
The goal of our analysis is to assess the effect of ten phthalate metabolites, four perfluoroalkyl (pfas) metabolites and fourteen metals on body mass index (BMI). Phthalates are mainly used as plasticizers and can be found in toys, detergents, food packaging, and soaps. They have previously been associated with increased BMI (Hatch et al., 2008) and waist circumference (WC) (Stahlhut et al., 2007). There is a growing health concern for the association of phthalates (Kim and Park, 2014), (Zhang et al., 2014) and pfas metabolites (Braun, 2017) with childhood obesity. Metals have already been associated with an increase in waist circumference and BMI, see Padilla et al. (2010) and Shao et al. (2017), using data from the National Health and Nutrition Examination Survey (NHANES).
We also consider data from NHANES, using data from the years 2015 and 2016. We select a subsample of individuals for which the measurement of BMI is not missing, though FIN can easily accommodate missing outcomes through adding an imputation step to the MCMC algorithm. Figure 3 contains a plot of the correlation between exposures. Several pairwise correlations are missing, as for example between pfas and most metals, because some chemicals are only measured within subsamples of the data. The average absolute correlation between the exposures is around , similarly to the factor and linear simulation scenarios presented in Section 4. We also include in the analysis cholesterol, creatinine, race, sex, education and age. We apply the transformation to the chemicals, cholesterol and creatinine. Histograms of the chemical measurements can be found in Figure 1 of the Supplementary Material. We also apply the transformation to BMI in order to make its distribution closer to normality, which is the assumed marginal distribution in our model. The log-transformation is commonly applied in environmental epidemiology in order to reduce the influence of outliers and has been employed in several studies using NHANES data (Nagelkerke et al., 2006), (Lynch et al., 2010), (Buman et al., 2013). We leave these transformations implicit for the remainder of the section.
We assume a latent normal structure for the chemicals, which are included in the matrix , and use the other variables as covariates, which are included in the matrix . We estimate a quadratic regression according to model . We specify independent Gaussian priors for elements of and . Algorithm 1 can be easily adapted for model . The matrix has missing data and Figure 2 of the Supplementary material contains a plot of the missingness pattern. Since we are modeling the chemical measurements, we can simply add a sampling step to the MCMC algorithm to sample the missing data according to . Similarly, of chemicals have been recorded under the limit of detection (LOD). In order to be coherent with our model we can sample these observations as:
[TABLE]
where is the limit of detection for exposure and is a truncated normal distribution with mean , variance and support in . We imputed the missing data using MICE (White et al., 2011) to compute the correlation matrix of chemicals. We noticed from the Eigendecomposition of the correlation matrix that the first eigenvectors explain more than of the total variability; hence we set the number of factors equal to .
Figure 2 on the right shows the posterior mean of the matrix of factor loadings , before and after applying the MatchAlign algorithm of Poworoznek and Dunson (2019), which resolves rotational ambiguity and column label switching for the posterior samples of . The matrix of factor loadings reflects the correlation structure of the chemicals. We can distinguish three families of chemicals: metals collected from urine, pfas and phathalates. The pfas chemicals load mostly on the factor, the metals from urine on the factor together with the phthalates, which is expected since there is high correlation between the two groups of chemicals. Finally, a group of highly correlated phthalates loads on the factor.
We also estimated a regression with pairwise interactions using the methods PIE, RAMP, Family and HierNet introduced in Section 4. These methods do not directly deal with missing data, so we imputed the missing data using MICE (White et al., 2011). Figure 3 shows the estimated main effects of the chemicals. The signs of the coefficients are generally consistent across different methods.
Figure 4 shows the posterior mean of the matrix of chemical interactions and of the matrix of pairwise interactions between exposures and covariates. As expected, we estimate a “dense” matrix of interactions. This is due to exposures being breakdown products of the same compound and high correlation between chemicals belonging to the same family. For example the correlation between the pfas metabolites is equal to , with only observations containing complete measurements. Interactions between highly correlated pfas metabolites have been observed in animal studies (Wolf et al., 2014), (Ding et al., 2013). Linear (Henn et al., 2011), (Lin et al., 2013) and nonlinear interactions (Valeri et al., 2017) between metals have been associated with neurodevelopment. Interactions between phathalates and other chemicals have been related to human semen quality (Hauser et al., 2005). Finally, we estimate several interactions between chemicals and age, cholesterol and creatinine, which are usually expected in environmental epidemiology applications (Barr et al., 2004). The code for reproducing the analysis is available at https://github.com/fedfer/factor_interactions.
6 Discussion
We proposed a novel method that exploits the correlation structure of the predictors and allows us to estimate interaction effects in high dimensional settings, assuming a latent factor model. Using simulated examples, we showed that our method has a similar performance to state-of-the-art methods for interaction estimation when dealing with independent covariates and outperforms the competitors when there is moderate to high correlation among the predictors. We provided a characterization of uncertainty with a Bayesian approach to inference. Our FIN approach is particularly motivated by epidemiology studies with correlated exposures, as illustrated using data from NHANES.
NHANES data are obtained using a complex sampling design, that includes oversampling of certain population subgroups, and contains sampling weights for each observation that are inversely proportional to the probability of begin sampled. We did not employ sampling weights in our analysis because our goal was to study the association between exposures and BMI rather than providing population estimates. One possibility to include the sampling weights in our method is to jointly model the outcome and the survey weights (Si et al., 2015), without assuming that the population distribution of strata is known.
Our MCMC algorithm can be efficiently employed for and in the order of thousands and hundreds respectively, which allows us to estimate around interactions when . However, it is necessary to speed up the computations in order to apply our method to bigger , which is common with genomics data. The computational bottleneck is the Metropolis Hastings step described in Section 2.2. One possibility is to include the heredity constraint (Chipman, 1996) while estimating the factors.
In order to allow departures from linearity and Gaussianity, it is of interest to model the regression on the health outcome as a non-linear function of latent factors. Non parametric latent models have desirable properties in term of convergence rates (Zhou et al., 2017) and large support for density estimation (Kundu and Dunson, 2014). Verma and Engelhardt (2018) developed a dimension reduction approach with latent variables for single cell RNA-seq data building on Gaussian process latent variable models (GP-LVM). Although attractive from a modeling perspective, a major challenge is efficient posterior computation. Another promising direction to decrease modeling assumptions is to rely on a copula factor model related to Murray et al. (2013).
Acknowledgments
This research was supported by grant 1R01ES028804-01 of the National Institute of Environmental Health Sciences of the United States Institutes of Health. The authors would like to thank Evan Poworoznek, Antonio Canale, Michele Caprio, Amy Herring, Elena Colicino and Emanuele Aliverti for helpful comments.
Appendix
Proof of Proposition 1.
(i) Let us drop the index for notation simplicity and always assume that we are conditioning on all the parameters. The posterior distribution of is Normal with covariance and mean where . This follows from a simple application of Bayes Theorem. Now:
[TABLE]
Recall that the expectation of a quadratic form of a random vector with mean and covariance matrix is equal to .
[TABLE]
(ii) Recall that , and , from simple algebra it follows that
[TABLE]
From the prior specification , hence let us focus on the term and show that it is equal to :
[TABLE]
Now . In fact when , we have that and when , since . ∎
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Arminger and Muthén (1998) Arminger, G. and B. O. Muthén (1998). A Bayesian approach to nonlinear latent variable models using the Gibbs sampler and the Metropolis-Hastings algorithm. Psychometrika 63 (3), 271–300.
- 2Barr et al. (2004) Barr, D. B., L. C. Wilder, S. P. Caudill, A. J. Gonzalez, L. L. Needham, and J. L. Pirkle (2004). Urinary creatinine concentrations in the us population: implications for urinary biologic monitoring measurements. Environmental Health Perspectives 113 (2), 192–200.
- 3Bhattacharya and Dunson (2011) Bhattacharya, A. and D. B. Dunson (2011). Sparse Bayesian infinite factor models. Biometrika , 291–306.
- 4Bhattacharya et al. (2015) Bhattacharya, A. K., D. Pati, N. S. Pillai, and D. B. Dunson (2015). Dirichlet-Laplace priors for optimal shrinkage. Journal of the American Statistical Association 110 512 , 1479–1490.
- 5Bien et al. (2013) Bien, J., J. Taylor, and R. Tibshirani (2013). A lasso for hierarchical interactions. Annals of Statistics 41 (3), 1111.
- 6Bondell and Reich (2012) Bondell, H. D. and B. J. Reich (2012). Consistent high-dimensional Bayesian variable selection via penalized credible regions. Journal of the American Statistical Association 107 (500), 1610–1624.
- 7Braun (2017) Braun, J. M. (2017). Early-life exposure to edcs: role in childhood obesity and neurodevelopment. Nature Reviews Endocrinology 13 (3), 161.
- 8Buman et al. (2013) Buman, M. P., E. A. Winkler, J. M. Kurka, E. B. Hekler, C. M. Baldwin, N. Owen, B. E. Ainsworth, G. N. Healy, and P. A. Gardiner (2013). Reallocating time to sleep, sedentary behaviors, or active behaviors: associations with cardiovascular disease risk biomarkers, nhanes 2005–2006. American Journal of Epidemiology 179 (3), 323–334.