Asynchronous "Events" are Better For Motion Estimation
Yuhu Guo, Han Xiao, Yidong Chen, Xiaodong Shi

TL;DR
This paper introduces the first neural asynchronous method for processing event streams from event-based cameras, significantly improving motion estimation by leveraging asynchronous event data rather than traditional accumulated frames.
Contribution
The paper presents a novel deep neural network that asynchronously analyzes event streams, capturing dynamic information more effectively than previous synchronous accumulation methods.
Findings
Achieves significant performance improvements over state-of-the-art baselines.
Effectively leverages asynchronous event data for motion estimation.
Demonstrates robustness and accuracy in extensive experiments.
Abstract
Event-based camera is a bio-inspired vision sensor that records intensity changes (called event) asynchronously in each pixel. As an instance of event-based camera, Dynamic and Active-pixel Vision Sensor (DAVIS) combines a standard camera and an event-based camera. However, traditional models could not deal with the event stream asynchronously. To analyze the event stream asynchronously, most existing approaches accumulate events within a certain time interval and treat the accumulated events as a synchronous frame, which wastes the intensity change information and weakens the advantages of DAVIS. Therefore, in this paper, we present the first neural asynchronous approach to process event stream for event-based camera. Our method asynchronously extracts dynamic information from events by leveraging previous motion and critical features of gray-scale frames. To our best knowledge, this…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3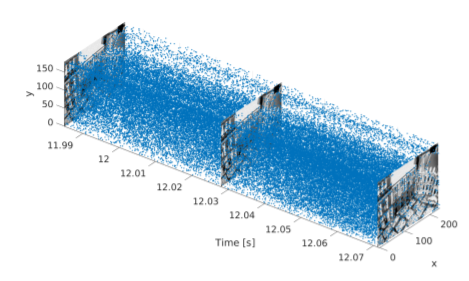 Figure 4
Figure 4 Figure 5
Figure 5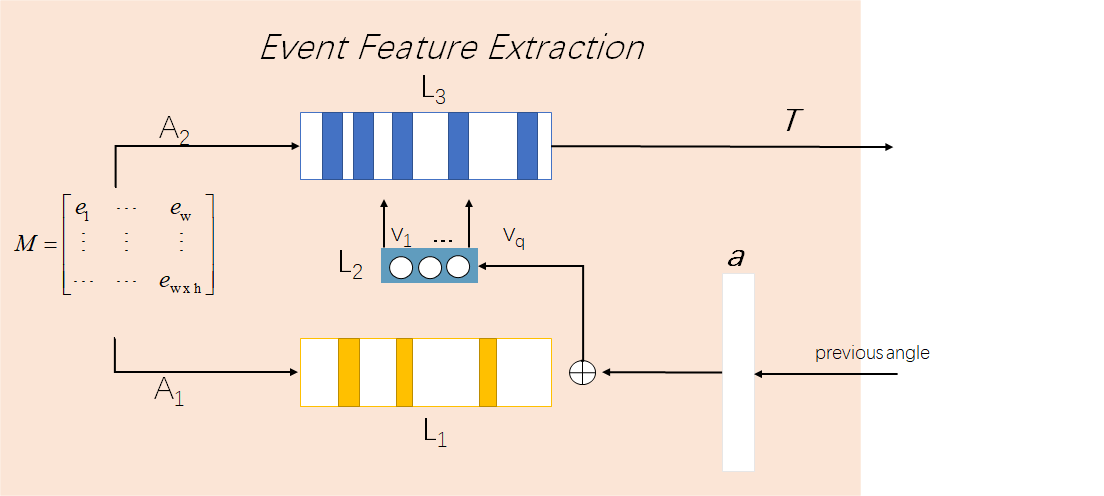 Figure 6
Figure 6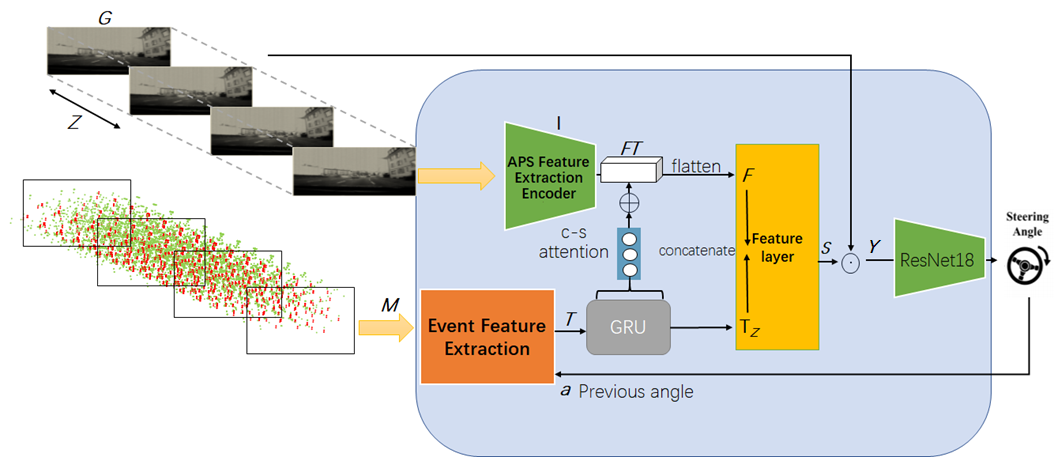 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10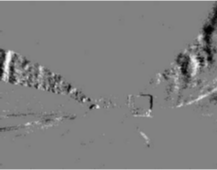 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15| Maqueda(APS) | Maqueda(ResNet18) | Maqueda(ResNet50) | Asynchronous(Ours) | |
|---|---|---|---|---|
| day | 4.57 (0.047) | 2.99 (0.551) | 2.33 (0.728) | 2.17 (0.812) |
| day sun | 20.07 (0.125) | 10.87 (0.742) | 9.47 (0.805) | 8.05 (0.875) |
| evening | 7.23 (0.172) | 5.45 (0.518) | 5.01 (0.602) | 4.67 (0.734) |
| night | 6.96 (0.181) | 4.51 (0.654) | 3.82 (0.753) | 3.94 (0.711) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAnomaly Detection Techniques and Applications · Human Pose and Action Recognition · Advanced Vision and Imaging
Asynchronous ”Events” are Better For Motion Estimation
Yuhu Guo1,2
Han Xiao1,2111Corresponding Author
Yidong Chen1
Xiaodong Shi1 1 Department of Intelligence Science and Technology,
Xiamen University, Fujian Province, 361005, PR China,
2 School of Information Science and Technology, Xiamen University Malaysia, Malaysia
[email protected], [email protected]
Abstract
Event-based camera is a bio-inspired vision sensor that records intensity changes (called “events”) asynchronously in each pixel. As an instance of event-based camera, Dynamic and Active-pixel Vision Sensor (DAVIS) combines a standard camera and an event-based camera. However, traditional models could not deal with the event stream asynchronously. To analyze the event stream asynchronously, most existing approaches accumulate events within a certain time interval and treat the accumulated events as a synchronous frame, which wastes the intensity change information and weakens the advantages of DAVIS. Therefore, in this paper, we present the first neural asynchronous approach to process event stream for event-based camera. Our method asynchronously extracts dynamic information from events by leveraging previous motion and critical features of gray-scale frames. To our best knowledge, this is the first neural asynchronous method to analyze event stream through a novel deep neural network. Extensive experiments demonstrate that our proposed model achieves remarkable improvements against the state-of-the-art baselines.
1 Introduction
Event-based cameras are novel bio-inspired vision sensors such as Dynamic and Active-pixel Vision Sensor (DAVIS) Brandli et al. (2014). Compared to traditional cameras that capture gray-scale frames at a fixed time interval, event-based cameras record the asynchronous event when a single pixel intensity changes. Thus, the output of event-based cameras is the event stream rather than the gray-scale images. For the most conventional event-based camera, event is represented as where indicate the position of the pixel, is the time stamp and indicates the polarity that brightness increase or decrease. Thus, event-based cameras gain the low-latency that compared to traditional cameras (e.g. with ). Besides, event-based cameras also show superiority in terms of dynamic range, low bandwidth (e.g. ), high temporal resolution, low storage capacity, low processing time and power consumption Binas et al. (2017). To jointly exploit the advantages of both event-based camera and traditional camera, the Dynamic and Active-pixel Vision Sensor (DAVIS)Brandli et al. (2014) has been presented in recent years.
DAVIS contains an event-based camera and a standard cameras. Thus, the data stream of DAVIS consists asynchronous event stream and synchronous gray-scale low-rate frames (i.e. images) in fixed time interval. Given the advantages introduced in the first paragraph, event-based cameras outperform standard cameras in multiple tasks, such as motion estimation, feature extraction and object tracking. Regarding the asynchronous events of event-based cameras, existing models could not fully develop the potentials of event-based camera, because most of them adopt a simple solution, which accumulates events as a new frame in a certain time interval Mueggler et al. (2015). Recently, inspired by Lagorce et al. (2017), there are several researchers who attempt to split the synchronous accumulated frames into two parts Maqueda et al. (2018); Zhu et al. (2018), which corresponds to brightness and darkness events respectively. Demonstrated in Fig.2, (b) and (c) are the different methods to accumulate the events into fix-rate frames Maqueda et al. (2018). From the two sub-figures, we observe many redundant information such as trees and clouds, according to the corresponding gray-scale image (a). The redundant information disturbs the performance promotion, which is the critical issue of current models.
Therefore, in this paper, we present a novel neural architecture to asynchronously analyze the event stream. Specifically, first, gray-scale images are encoded into image-specific feature tensor, while we construct the event matrix under the same time stamp and leverage event feature extraction module to compress the event matrix into timestamp-specific vector. Second, GRU Cho et al. (2014) processes the timestamp-specific vectors in the sequence of time stamp to achieve the hidden representation for each time stamp. Third, with the input of the hidden representations in the fix-rate time interval, we leverage the channel-wise and spatial-wise attention mechanism Chen et al. (2017) to address the image-specific tensor into image-specific feature tensor. Fourth, we concatenate the flatten image-specific feature tensor and time interval aligned timestamp-specific vector as the input of feature layer, while the feature layer applies MLP to produce a mask to cover the original gray-scale image as masked image. Last, we employ ResNet He et al. (2016) to map the masked image into the steering angle as the target in self-driving task. It is worth to note that our model deals with events for every timestamp rather than accumulating the events in a fixed time interval, which makes our model an asynchronous framework.
Extensive experiments demonstrate our method outperforms the state-of-the-art baselines in motion estimation task on the public benchmark dataset of Event Camera self-driving dataset Binas et al. (2017), which justifies the effectiveness of our asynchronous neural architecture.
To summarize, our contributions are two-fold:
- •
We propose a novel asynchronous approach for the event stream to capture the most critical dynamic information from the event-based camera DAVIS. To our best knowledge, this is the first time in published literature to address this issue of asynchronous event analysis in a neural architecture.
- •
We leverage the attention mechanism that jointly analyzes asynchronous events and gray-scale images (i.e. APS stream) collected by the DAVIS sensor, which achieves substantial improvements against the state-of-the-art baselines in the task of motion estimation.
2 Related Work
Recently, event-based cameras have gained extraordinary improvements against standard cameras in many fields. However, the main challenge for event-based cameras is how to leverage the event sequence. Traditional models do not provide the toolbox to handle the event sequence precisely, because they apply the simple solution that to accumulate events in a certain time interval , to make the analysis process similar to synchronous image frames, Mueggler et al. (2015); Maqueda et al. (2018). To collect sufficient events during the interval time, most approaches would apply a large time interval (e.g. ). Inspired by Lagorce et al. (2017), several researchers attempt to split the synchronous frames into two parts that positive events (brightness increase) and negative events (brightness decrease) respectively.
Zhu et al. (2018) presents a 4-channel neural architecture to address optical flow estimation issues, the first two channels of which encode the number of positive and negative events and the last two channels of which encode the timestamp of the most recent positive and negative events at that pixel.
Current state-of-the-art model Maqueda et al. (2018) splits the synchronous frames into separate histograms for positive and negative events as two channels, which are processed into feature vectors and then feed the feature vector into ResNet to achieve the target of self-driving that steering angle.
Moreover, synchronous methods increase the latency of events cameras, which is against the low-latency property of event-based cameras. Therefore, according to the DAVIS characteristics, Gehrig et al. (2018) presents an asynchronous approach that combines the events and gray-scale images provided by the DAVIS sensor to track features from the geometric model, which leverages each occurring event. Moreover, this asynchronous model beats the state-of-the-art synchronous models in feature tracking task. And there is previous work that also focuses on tracking features by event-based camera Kueng et al. (2016); Zhu et al. (2017). And recently extensions of popular image-based key point detectors have been developed for event-based camerasMueggler et al. (2017); Vasco et al. (2016)
Moeys et al. (2016) jointly analyzes the gray-scale images and synchronous events by a simple convolutional network. This model is also proved successful on the robot control scenario. Notably, all of the above mentioned neural networks are trained on synchronous event frames in a certain time interval.
Furthermore, Amir et al. (2017) develops a real-time gesture recognition system with a novel chip of the name TrueNorth. And the ability of event-based cameras to provide rich data for solving pattern recognition problems has been initially shown in Pérez-Carrasco et al. (2013); Orchard et al. (2015); Lungu et al. (2017)
Regarding our novelty, this paper presents the first deep learning driven framework to analyze the events stream asynchronously. Moreover, compared to synchronous redundant event training frames, we leverage each event to extract dynamic information, which is ignored by the synchronous approaches. Furthermore, we apply the channel-wise and spatial-wise attention mechanism Chen et al. (2017) for our model and verify the effectiveness of attention methods.
3 Method
3.1 Representation of Event Cameras and Events Stream
Compared to standard cameras, event-based cameras track intensity changes in each pixel and record the changes when the log intensity changes are larger than the predefined threshold :
[TABLE]
where is the intensity in the timestamp on the image plane and is the predefined threshold.
Each event consists four elements namely pixel location, time stamp and polarity information:
[TABLE]
where mean the -th x- and y-position of the event, is -th time stamp for -th event , and indicates the -th polarity for each event that the brightness change (increase or decrease). Due to the asynchronous properties of the events, it is not easy to extract the important dynamic events that are inputs to the APS feature extraction encoder.
3.2 Architecture
Overall, our neural architectures are composed of five steps.
First, gray-scale images with the size of are encoded into image-specific feature tensor by APS feature extraction encoder where is the number of channels. Then we construct the event matrix under the same time stamp and leverage event feature extraction module to compress the event matrix into timestamp-specific vector where is a hyper-parameter. Notably, we will discuss the construction of event matrix and event feature extraction module in next subsections.
Second, GRU processes the -th timestamp-specific vector in the sequence of time stamp to achieve the hidden representation for -th time stamp.
Third, with the input of the hidden representation in the fix-rate time interval , we leverage the channel-wise and spatial-wise attention mechanism Chen et al. (2017) to address the image-specific tensor into image-specific feature tensor . We flatten the image-specific feature tensor into image-specific feature vector .
Then, we concatenate the image-specific vector and -th timestamp-specific vector as the input of feature layer, while the feature layer applies to produce a mask image to cover the original gray-scale image as masked image . Last, we employ ResNet He et al. (2016) to map the masked image into the steering angle as the target in self-driving task.
3.2.1 APS Feature Extraction Encoder
The input of this module is original gray-scale image , and the output is the image-specific feature tensor . The functionality is to extract the hidden features from images. Regarding the detailed structure of this module, please refer to Bojarski et al. (2016).
3.2.2 Event Matrix Construction
The input of event matrix construction module is the event set under the same time stamp, while the output is the polarity matrix with the same size of original gray-scale image . Specifically, if there exist the event , the entry of event matrix is . The other entries that are not recorded in the events are filled with [math].
3.2.3 Event Feature Extraction Module
The inputs of this module are the event matrix and the latest angle composed vector where indicates the number of the latest steering angles (the final output of the model). The output of this module is timestamp-specific vector . The functionality is to encode the event in an asynchronous manner. The process is illustrated in Fig.4.
First, we project the event matrix with linear layer as
[TABLE]
where is the parameter matrix of this linear layer with the size of . Second, we multiply the output of linear layer with latest angle vector :
[TABLE]
Third, we project matrix with another linear layer:
[TABLE]
where is the parameter matrix of this linear layer with the size of . Forth, we generate the attention vector from :
[TABLE]
where is the attention vector with the size of . Last, we achieve the output of this module (i.e. timestamp-specific vector ) by applying column-specific multiplication between and :
[TABLE]
where means the column-specific multiplication operation.
4 Experiments
4.1 Performance Metrics
To follow the previous literature, we employ the root-mean-squared error (RMSE) to metric the performance Maqueda et al. (2018):
[TABLE]
where RMSE measures the average magnitude of the prediction error, showing how close the observed values are to those predicted value by the model. We also apply the explained variance (EVA) to evaluate our model stability as Maqueda et al. (2018)
[TABLE]
where is given by the variance of the residuals between observed values and predicted value . EVA measures the proportion of variation in the predicted values with respect to those of the observed values. If predicted value fits the observed value approximately, the total variance will be greater than the residual variance, which leading to EVA greater than . On the other hand, if the performance is unsatisfactory, the total variance will be equal or less than the residual variance, resulting in EVA equal or less than [math],respectively.
[TABLE]
where is the original RMSE and is the RMSE, which we want to compared with original one. We will employ the average Improvement in our Results & Analysis subsection in 4 scenarios to compared with different methods directly.
4.2 Datasets
We apply the public benchmark dataset Binas et al. (2017) for our experiments. The dataset contains over 12 hours driving recordings, which are collected by vehicles under real and challenging scenarios. Given the fact that the data are collected by DAVIS, the dataset consists of asynchronous events and gray-scale images (APS), along with vehicle speed, GPS position, driver steering and throttle. Maqueda et al. (2018) segmented the recordings into four subsets, namely day, day sun, evening and night, according to the weather and scenarios. The duration of recordings ranges from minutes to hours. And most of steering angles are slight deviations of degrees. Also the speed is uniformly distributed over the range . Notably, subsets differ in not only the weather conditions and illumination, but also in the travelled route. For example, there is number of turns on city and town, but hardly exists on the high way scenarios.
4.3 Implementation
Similarly as previous study, we also split the data to four parts according to the scenarios: day, day sun, evening and night Binas et al. (2017). Compared with the state-of-the-art baseline, we apply the same dataset segment, the same pre-processing and the same tricks, which makes our experiments a fair comparison.
We have tested many experimental settings and achieve the optimal setting as: , , , in dataset or in . Besides, our model is trained by ADAM Kingma and Ba (2014), with the hyper-parameter settings:, and , and our initial learning is .
We will release our codes and the documents for the codes upon acceptance.
4.4 Results & Analysis
Regarding the experimental results in Table 2, we could study two critical questions:
How to prove that our asynchronous approach is better than traditional synchronous approaches for the event stream information? 2. 2.
Why our asynchronous approach is better at extracting dynamic information?
For a fair comparison, we deploy the same ResNet18 or ResNet50 networks as the feature encoders in our model as two experimental settings. We can observe that if we only apply gray-scale image as the input, both RMSE and EVA would be bad. Obviously, the average RMSE is different among different sets, because the RMSE is dependent on the absolute value of the steering ground truth.
On the other hand, our model outperforms the only gray-scale image input, approximately improved over % in average. The effectiveness of our model stems from to filter the redundant information such as the clouds or the backgrounds. Specifically, in our method, we employ the same gray-scale images, but we design an attention-mask to cover the gray-scale images by element-wise multiplication operation to filter out the redundant information. Thus, Our asynchronous approach also beats all the baselines in the settings of ResNet18 over about % in average. The results demonstrate that the performance improvements stem from the attention masks which are generated in an asynchronous framework. In this way, we answer the first critical question that our asynchronous approach is better than traditional methods that are synchronous.
Notably, in our asynchronous approach, the setting of ResNet50 outperforms the settings of ResNet18 in the sub-dataset of day, day sun, and evening scenarios over approximately % (average in RMSE), which accords to our common sense. Therefore, it is reasonable to conjecture that to leverage the more effective CNN network, such as ResNet101 or inception, we could get a much better performance.
Note in the dataset of night, the baseline model of ResNet50 leads the performance a bit. The main reasons behind why our ResNet18-based model can not beat ResNet50-based baseline in night scenarios are listed:
- •
Our final network is simple, which ResNet18 is more simple than ResNet50. But noting that we beat the ResNet18-based baseline which is the comparative model, our method indeed outperforms the baselines. To consider that our model beats the ResNet50-based baseline in other three datasets, our model outperforms the baseline extensively.
- •
Binas et al. (2017) remarks that most of gray-scale images at night are too dark. The figure 5 (d) shows that it is hardly to capture clear images at night dataset relative to other three sub figures, because of low brightness intensity. Thus, the darkness of night would also affect the event-based camera for recording the events. Although our method is good at capturing the important events at night, after our attention-mask covers the gray-scale images, it still can not gain sufficient information, compared to the other scenarios.
- •
Besides, most of night situation driving at free way or city, is under a high speed. Due to the flaw of standard camera at high velocities, the gray-scale images would get blurred. Regarding our model, we leverage the generated attention mask to process the blurred gray-scale images, which leads to unsatisfactory performance
Regarding the second question, we generate the visualization of different frames in each method based on the codes of Kim and Canny (2017). As we mentioned, DAVIS camera combines a standard camera and an event-based camera. Thus, the differences of two cameras could be observed from Figure 2 (a) and (b). The traditional gray-scale images can capture all scenes. But, it cannot attend to dynamic points at high velocities. In the comparison, event-based cameras can directly capture the dynamic points from the scenes. In this way, it ignores a lot of non-critical still information, which is the reason why the event-based camera can handle motion estimation task under a high speed object.
However, one individual time stamp is not sufficient to collect information, so previous studies present the method that accumulates the events in a certain time interval Maqueda et al. (2018) to avoid information loss. Although their methods are efficient, as you can observe from Figure 2 (b) and (c) that it still has the useless events (noise). To address this issue, we present our asynchronous attention-based approach to select the most representative points. To compare with all the baselines, the visualization of our attention masks over the APS frame is demonstrated in Figure 2 (d) and (h), where red color indicates dense part while blue color indicates sparse part. From the visual results, it is concluded that our mask rearranges the dynamic points captured by our network. Besides, most of selected points focus on the specific object and edge which are the most critical information of self-driving, such as cars, houses and route lines. Specifically, compared to the synchronous approaches, our method ignores tree, sky and clouds, which are noise for self-driving task. In conclusion, our asynchronous approach is better at extracting dynamic information because it can avoid the redundant information and noise to address the critical points.
5 Conclusion
In this paper, we show an attention-based asynchronous approach for self-driving task. Our method leverages the event stream asynchronously and extracts dynamic points for the sense without redundant information.Moreover, we leverage the attention mechanism that jointly analyzes asynchronous events and gray-scale images to achieve substantial improvements over the state-of-the-art baselines in the task of motion estimation. Experiments prove that our asynchronous approach can beat synchronous approaches extensively.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Amir et al. [2017] A. Amir, B. Taba, D. Berg, T. Melano, J. Mc Kinstry, C. D. Nolfo, T. Nayak, A. Andreopoulos, G. Garreau, M. Mendoza, J. Kusnitz, M. Debole, S. Esser, T. Delbruck, M. Flickner, and D. Modha. A low power, fully event-based gesture recognition system. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 7388–7397, July 2017.
- 2Binas et al. [2017] Jonathan Binas, Daniel Neil, Shih-Chii Liu, and Tobi Delbrück. DDD 17: end-to-end DAVIS driving dataset. Co RR , abs/1711.01458, 2017.
- 3Bojarski et al. [2016] Mariusz Bojarski, Davide Del Testa, Daniel Dworakowski, Bernhard Firner, Beat Flepp, Prasoon Goyal, Lawrence D. Jackel, Mathew Monfort, Urs Muller, Jiakai Zhang, Xin Zhang, Jake Zhao, and Karol Zieba. End to end learning for self-driving cars. Co RR , abs/1604.07316, 2016.
- 4Brandli et al. [2014] C. Brandli, R. Berner, M. Yang, S.-C. Liu, and T. Delbruck. A 240x 180 130db 3ups latency global shutter spatiotemporal vision sensor. IEEE Journal of Solid-State Circuits , 49(10):2333–2341, 2014.
- 5Chen et al. [2017] Long Chen, Hanwang Zhang, Jun Xiao, Liqiang Nie, Jian Shao, Wei Liu, and Tat-Seng Chua. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In CVPR , 2017.
- 6Cho et al. [2014] Kyunghyun Cho, Bart van Merriënboer, Çağlar Gülçehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder–decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages 1724–1734, Doha, Qatar, October 2014. Association for Computational Linguistics.
- 7Gehrig et al. [2018] Daniel Gehrig, Henri Rebecq, Guillermo Gallego, and Davide Scaramuzza. Asynchronous, photometric feature tracking using events and frames. In The European Conference on Computer Vision (ECCV) , September 2018.
- 8He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 770–778, 2016.