Array BP-XOR Codes for Hierarchically Distributed Matrix Multiplication
Suayb S. Arslan

TL;DR
This paper introduces array BP-XOR codes for fault-tolerant distributed matrix multiplication, optimizing performance on hierarchical architectures like GPUs, and analyzes their latency and scalability benefits over existing methods.
Contribution
It proposes a novel array BP-XOR coding scheme tailored for hierarchical compute architectures, improving fault tolerance and performance in distributed matrix multiplication.
Findings
Outperforms existing strategies in end-to-end execution time with stragglers.
Provides a trade-off analysis between latency and communication cost.
Achieves order-optimal computation in various regimes based on latency analysis.
Abstract
A novel fault-tolerant computation technique based on array Belief Propagation (BP)-decodable XOR (BP-XOR) codes is proposed for distributed matrix-matrix multiplication. The proposed scheme is shown to be configurable and suited for modern hierarchical compute architectures such as Graphical Processing Units (GPUs) equipped with multiple nodes, whereby each has many small independent processing units with increased core-to-core communications. The proposed scheme is shown to outperform a few of the well--known earlier strategies in terms of total end-to-end execution time while in presence of slow nodes, called . This performance advantage is due to the careful design of array codes which distributes the encoding operation over the cluster (slave) nodes at the expense of increased master-slave communication. An interesting trade-off between end-to-end latency and total…
Click any figure to enlarge with its caption.
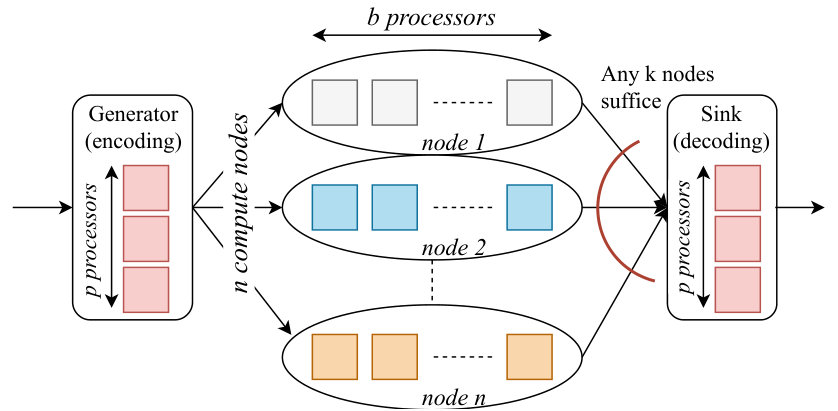 Figure 1
Figure 1 Figure 2
Figure 2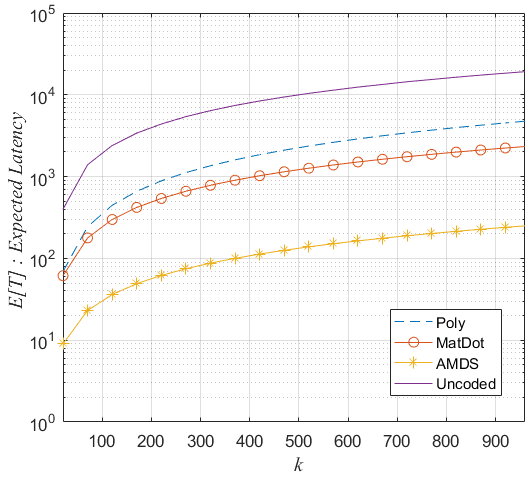 Figure 3
Figure 3 Figure 4
Figure 4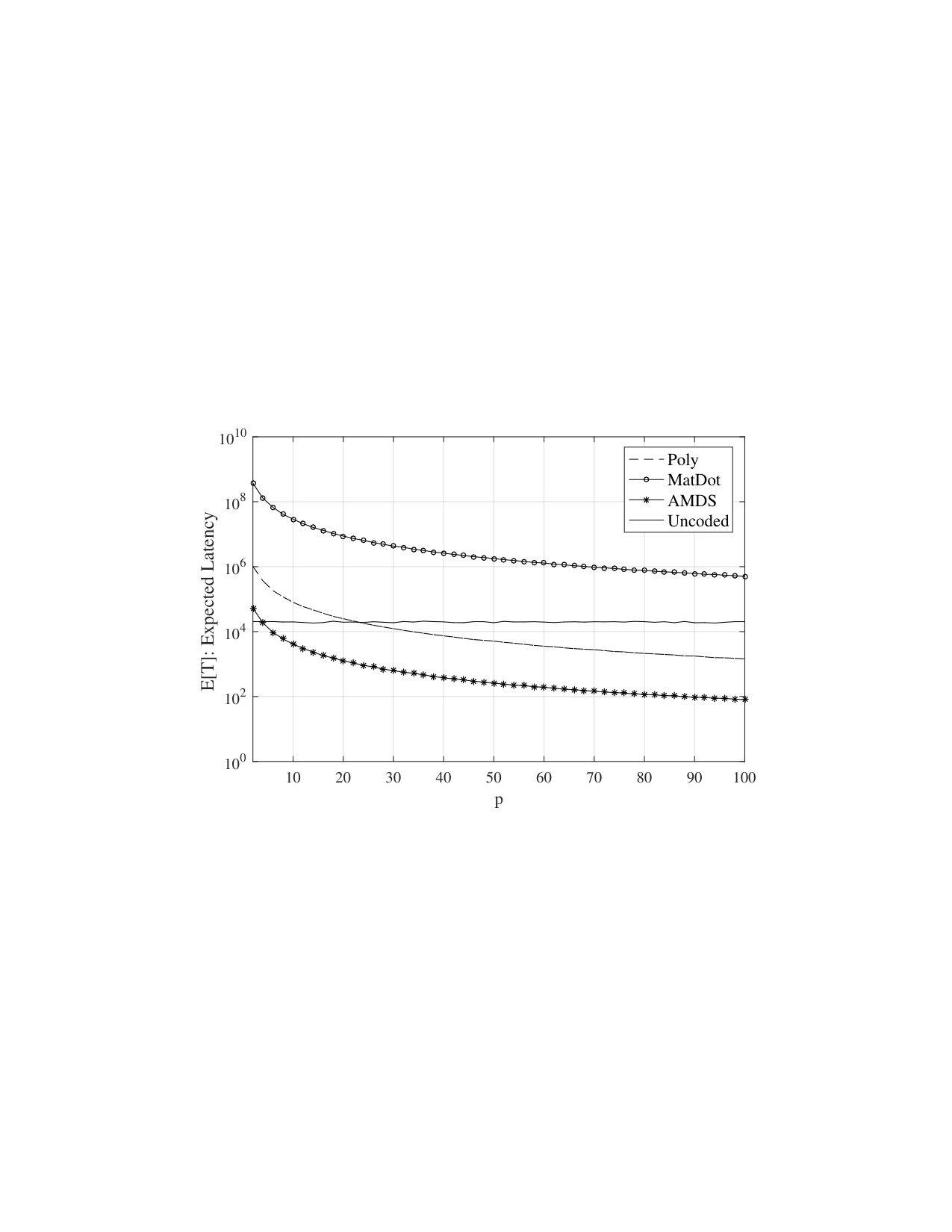 Figure 5
Figure 5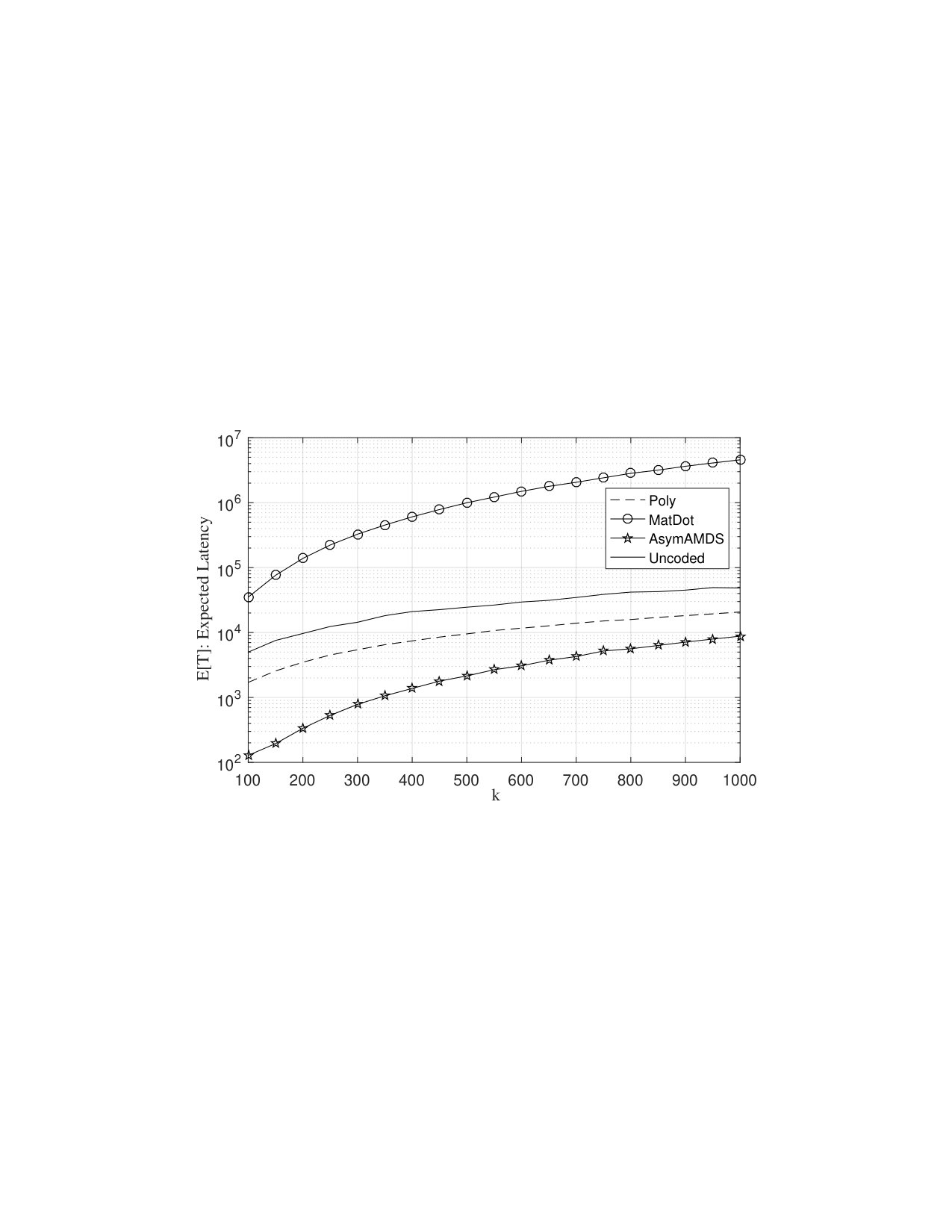 Figure 6
Figure 6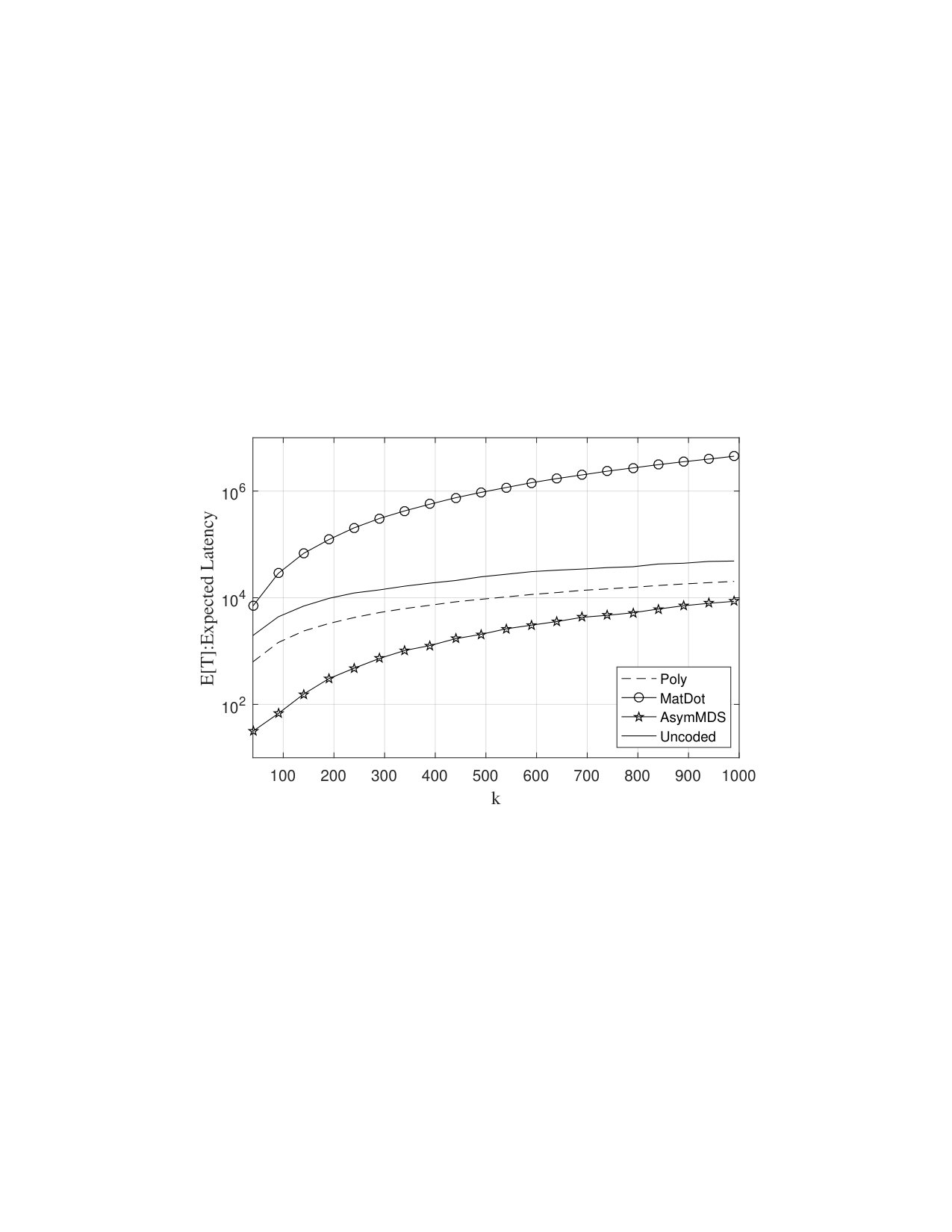 Figure 7
Figure 7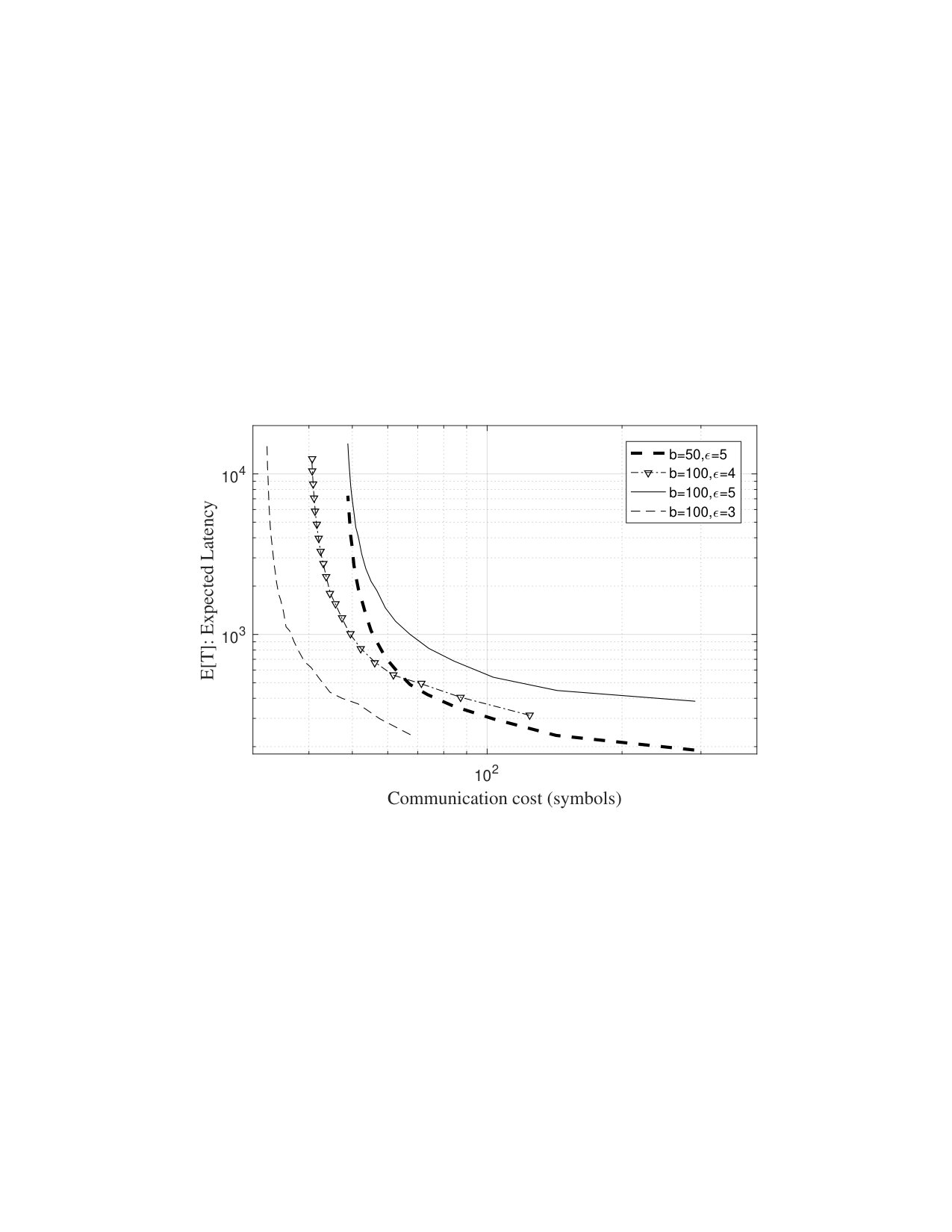 Figure 8
Figure 8| node 1 | node 2 | node 3 | node 4 | node 5 | |
|---|---|---|---|---|---|
| processor 1 | |||||
| processor 2 |
| node 1 | node 2 | node 3 | node 4 | node 5 | |
|---|---|---|---|---|---|
| processor 1 | |||||
| processor 2 |
| node 1 | node 2 | node 3 | node 4 | node 5 | |
|---|---|---|---|---|---|
| processor 1 | |||||
| processor 2 | |||||
| processor 3 |
| Scheme | master-slave (map) | slave-master (reduce) |
|---|---|---|
| Uncoded | ||
| Polynomial codes | ||
| MatDot codes | ||
| Exact MDS BP-XOR | ||
| Asym. MDS BP-XOR |
| Parameter | Value |
|---|---|
| 20 | |
| 50 | |
| 7 | |
| 50 | |
| 1 |
| Method | Encode@Master | Decode@Master | Cluster Time | Comm. Cost overhead | |||
| Polynomial | 100 | 37 | 4924.9 | 1524.6 | 1.3 | 6450.8 | 0.37 |
| 1000 | 27 | 37003.9 | 23844.5 | 3.64 | 60852.04 | 0.027 | |
| 10000 | 27 | 361689.5 | 343903.7 | 5.9 | 705599.1 | 0.0027 | |
| MatDot | 100 | 37 | 4925.5 | 100809.7 | 1.46 | 105736.66 | 198.4 |
| 1000 | 27 | 36917.2 | 9746604 | 1.1 | 9783522.3 | 1098 | |
| 10000 | 27 | 361558.4 | 1543655907 | 1 | 1544017466.4 | 10098 | |
| AMDS | 100 | 6 | 0 | 126 | 51.5 | 177.5 | 10.6 |
| 1000 | 6 | 0 | 1262.2 | 67.5 | 1329.7 | 8.19 | |
| 10000 | 6 | 0 | 12520 | 83.6 | 12603.6 | 8.02 | |
| AsymAMDS | 100 | 37 | 0 | 496.3 | 49.6 | 545.9 | 42.4 |
| 1000 | 27 | 0 | 4949 | 67.1 | 5016.1 | 32.7 | |
| 10000 | 27 | 0 | 50338.6 | 83.2 | 50421.8 | 32.07 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Array BP-XOR Codes for Hierarchically Distributed Matrix Multiplication
Suayb S. Arslan S. S. Arslan is with the Department of Computer Engineering, MEF University, Maslak, Istanbul, Turkey, e-mail: [email protected] contents of the paper are partially presented in two IEEE International Symposium on Information Theory (ISIT) conferences which were held in 2018 and 2019 in Colorado, USA and Paris, France, respectively.Copyright (c) 2021 IEEE. Personal use of this material is permitted. However, permission to use this material for any other purposes must be obtained from the IEEE by sending a request to [email protected].
Abstract
A novel fault-tolerant computation technique based on array Belief Propagation (BP)-decodable XOR (BP-XOR) codes is proposed for distributed matrix-matrix multiplication. The proposed scheme is shown to be configurable and suited for modern hierarchical compute architectures such as Graphical Processing Units (GPUs) equipped with multiple nodes, whereby each has many small independent processing units with increased core-to-core communications. The proposed scheme is shown to outperform a few of the well–known earlier strategies in terms of total end-to-end execution time while in presence of slow nodes, called stragglers. This performance advantage is due to the careful design of array codes which distributes the encoding operation over the cluster (slave) nodes at the expense of increased master-slave communication. An interesting trade-off between end-to-end latency and total communication cost is precisely described. In addition, to be able to address an identified problem of scaling stragglers, an asymptotic version of array BP-XOR codes based on projection geometry is proposed at the expense of some computation overhead. A thorough latency analysis is conducted for all schemes to demonstrate that the proposed scheme achieves order-optimal computation in both the sublinear as well as the linear regimes in the size of the computed product from an end-to-end delay perspective.
Index Terms:
Distributed systems, coded computation, array codes, projection geometry, belief propagation, matrix multiplication.
I Introduction
Today data science led to enormous computation and storage requirements that have transcended all expectations. The imminent consequence of this has been the distribution of data and associated computation work over large clusters of commodity processing and storage devices that are typically less capable than enterprise systems. Moreover, when these devices work together in large groups, their mean-time-to-failure can drop from a few years to a few days making their availability significantly less than the execution time of many current high-performance computing applications [1, 2, 3]. On the other hand, due to fail-stop or slow compute nodes, coined as stragglers in literature, the main objective of distributed computing may be compromised i.e., total end-to-end latency is severely impacted by the slowest workers in the cluster which renders the any-topology distributed computation ineffective. In a master-slave configuration, for instance, the serial portion of the overall computation may lead to a bottleneck at the master node if heavy and dependent calculations are performed. In [4], it is shown that stragglers may run eight times slower than the average worker performance using Amazon EC2 instances. Recently, fault–tolerant and efficient parallel matrix computations have gained momentum due to their immediate application to various machine learning and inference algorithms [5]. However, the majority of these studies primarily deals with a faulty device problem which may lead to erroneous computation or else inevitable round-off errors accounted for by algorithmic approaches [6]. I wish you the best of success.
The primary study that tackles the stragglers (i.e., slow–performing nodes) is based on a parameter server concept in which machine learning algorithms are shown to scale on a distributed network [7] in presence of fail-stop system behaviors. Later, the alternative idea of coded computation is proposed to provide computation redundancy in robust system design against the stragglers. More specifically, in order to economically use the compute infrastructure, a coded computation framework based on a family of Maximum Distance Separable (MDS) codes is proposed in [8]. We realize that coded computation can be seen as the reincarnation of algorithm-based fault tolerance for various computation tasks such as matrix–matrix multiplication [9]. Later that study, the idea is exhaustively exercised in various computing tasks including large matrix multiplications, gradient computing [10] and its more recent extensions [11], convolutions [12], optimizations [13] and Fourier transforms [14]. Despite the proposed coding scheme considering a large-scale matrix multiplication as an example, we can extend it to other types of computation that have matrix multiplication (dot products) at the core such as linear signal transformations and multi-class classifications. Particularly, the training phase of distributed machine learning algorithms are most affected by the presence of stragglers and coded computation has been investigated to solve the main trade-off between overall communication cost and service latency [15]. To ensure the scalability of distributed computing, the overall job execution time must be minimized. However, most of the previous literature have focused on the parallel task time in which the encode/decode time is excluded from the overall end-to-end latency performance. On the other hand, the main performance objective of this study would be the minimum end-to-end latency rather than measuring the pure parallel task time by allowing distributed encoding and low-complexity decoding. Rateless codes are investigated in the context of coded computing [16] which naturally enables near–linear time complexity for the decoding. However, this study is based on matrix-vector multiplication and uses Robust Soliton distribution where the maximum degree per node does not have a bound making the distributed encoding infeasible due to unacceptable communication load. Note that a distinctive feature of distributed computing is to be able to distribute encoding over the cluster nodes which is largely ignored by the past literature. In [17], sparse codes are proposed which possess similar features so that encoding could be distributed. However, the authors mostly focused on recovery threshold, computation complexity and decoding time rather than mathematically analyzing the encoding workload. Distribution of encoding (in information-theoretic sense) is considered very recently [18] where authors introduce errors in the encoding process and investigate the fundamental limits for accurate decoding and set necessary conditions. In such a setting an adversary is assumed whereas, in our scenario, no such adversary exists. Moreover, straggler mitigation was not taken into account. In this paper, we propose array codes to ensure low-complexity encoding/decoding and efficient distribution of parallel as well as encoding workload over the cluster nodes. We further propose asymptotic extensions to allow for increased failures in scaling clusters.
I-A Linear Array Codes
Array codes are linear codes defined for two-dimensional data structures organized typically in a matrix format including both data and parities as columns. These codes are quite attractive candidates for burst error recovery in communication [19] and distributed storage systems [20] and provide data reliability with optimal time/space consumption thanks to block Maximum Distance Separability (MDS) property in the code construction process. Moreover, a great deal of work has been done and many improvements have been proposed for these codes over the years [21] to secure simpler math, low-complexity computations and the block MDS property all at the same time.
Typically, any linear code can be represented using a bipartite graph either using the parity check matrix or the generator matrix of the code [22]. Using the generator matrix representation, the corresponding bipartite graph has two types of nodes: Nodes that are used to decode (check or coded nodes) and nodes that are decoded (information nodes). Nodes in bipartite graph representation are connected with edges to represent node adjacency. The neighbors of node (neighbor set), denoted by , is the set of all nodes connected to node . The cardinality of the neighbor set is called the degree of node . The Belief Propagation (BP) algorithm a.k.a. message passing algorithm is a low complexity iterative decoding process (updating nodes and edges) to reconstruct data from unerased coded nodes using the sparse bipartite graph representation of the code. We begin by setting all the contents of information nodes to NULL. Then, we look for a degree-one coded node and copy the contents to its neighbor information nodes by replacing NULL. Next, we update all the coded nodes that are connected to this neighbor and eliminate the edges that established neighborhood relationships. This completes the first step, and in the next iteration, we continue applying the same methodology until there remains no information node with NULL content. If the algorithm stops prematurely during iteration, we claim a decoding failure, otherwise, we report a decoding success. Array codes have recently been studied under BP decoding [23] and useful upper bounds are derived in [24] that theoretically establishes the relationship between the block length (and hence the rate of the code), decodability, and sparsity of the generator matrix i.e., the encoding/decoding complexity of the code.
I-B Motivation and Contributions
First of all, for a given file block size, we primarily demonstrate in this study that by relaxing the block MDS constraint on the code construction process, the previously found bounds on the code block length [24] can be relaxed while ensuring successful decoding of the file block through low complexity BP algorithm. In other words, previous works on array MDS BP-XOR codes, due to their construction, do not allow the number of failures to grow with the block length while maintaining a code rate smaller than one. Such an observation shall yield more flexible and powerful code constructions for distributed computing. For instance, a carefully chosen fixed code rate would allow dealing with linearly scaling stragglers in a large network of computing devices [2]. Furthermore, we introduce asymptotically MDS array codes as an alternative and shall consider a discrete geometry construction based on Mojette Transform that is recently studied within the context of low density parity check codes and is shown to reduce the node repair complexity [25]. By providing and establishing an appropriate set of code parameters, we explicitly construct codes that fulfill the desired theoretical requirements.
On the other hand, most of the existing works have focused on small to moderate size matrix multiplication operation and thereby improving the worker node task runtime while the encoding/decoding times at the master node are assumed to be negligibly small. However, although the master node workload may be acceptable for small-scale (few tens of nodes) networks and moderately sized matrices, it shall be extremely prohibitive for large-scale (over thousands of nodes) compute tasks. Hence, the total execution time is considered to be the real optimization criterion whereby the encoding and decoding processes need to be low complexity, parallelizable and distributable. While achieving better total execution time, the system should not lose the recovery threshold performance due to stragglers [26]. In our study, we address this issue by distributing the encoding operation over the compute cluster and allowing BP to resolve the actual matrix multiplication operation at the master. Secondly, modern compute nodes are equipped with multiple typically equal-quality cores such as Central Processing Unit (CPU) instances possessing over hundreds of physical cores or Graphical Processing Unit (GPU) instances with thousands of CUDA cores. By considering each core as a standalone network processor, and the distinctive cost nature of communications between these cores and with other network nodes, it is intuitive that coding can be exploited for optimal utilization of the underlying infrastructure.
Overall, one of the main differentiations of this study is that it focuses on end-to-end user delay rather than the pure parallel task time and clearly demonstrates advantages/disadvantages of the proposed coded computation with scaling clusters both for sublinear as well as the linear regime in the size of the product at hand. We recognize the fixed number of straggler proofing using the original array BP-XOR code constructions and further proposed to use asymptotical versions to address scaling number of stragglers. In addition, we assumed a hierarchically clustered compute architecture with varying degrees of parallelism which aligns with the realistic infrastructures built today with Google and Amazon virtualized environments. Furthermore, the proposed coding scheme allows distributing encoding workload over the cluster nodes at the expense of more bandwidth utilization opening up new options in the computation-bandwidth trade-off space. For the sake of generality, we consider generic matrix sizes instead of square matrices.
The rest of the paper is organized as follows. In Section II, system model is introduced. In Section III, array BP-XOR codes are primarily introduced for distributed computation, and then, its asymptotical version is formally defined. A discrete geometry construction is proposed to enhance the achievable code rate of the classic case. Section IV analyzes the end-to-end average latency performance as well as communication costs of the proposed class of codes in a distributed coded computation setting and Section V provides numerical results to support our arguments. Finally, Section VI concludes the paper. Some of the proofs are intentionally omitted for the smooth flow of the paper and later provided in appendices.
II Coded Computation System Model
Let us consider the multiplication of two large matrices i.e., where and and denotes any algebraic field. For a generic matrix , we use to denote the -th row and the -th column for the rest of the paper. Thus, computing amounts to dot products (each containing multiplications and additions). In our system, the Generator unit (a.k.a. the master node) either communicates individual rows/columns of and or their sums to compute nodes and corresponding dot products will be performed by nodes each equipped with processors in which only processors are assigned to task execution by the local scheduler. Note that if , each processor will have to execute more than one dot product. In that case, we group (partition) rows of and columns of in such a way to equally distribute computation on the available processors in the network. The following remark presents a particular partitioning strategy that might be needed to achieve the constraint .
Remark 2.1**.**
For any given integer satisfying the relation , we divide the columns of in to equal size () matrices and the columns of in to equal size () matrices. In that case, processors multiply two matrices of sizes and . Note that we do not guarantee i.e., total number of submatrix computations being less than total number of processors without an additional constraint. Suppose for instance and . With that constraint, we can multiply fractions of matrices in each node whereby each processor unit performs small matrix multiplications of sizes and where is typically assumed to be large. In that case, we have matrix multiplications of sizes implying .
Since core-to-RAM communication is orders of magnitude faster than node-to-node communication, we consider an appropriate multi-processor setting that takes into account this observation. The summary of the coded master-slave compute cluster architecture is illustrated in Fig. 1. Note that a similar multi-processor setting is considered in [27] where non-linear local functions are computed with a fixed and equal number of local cores per node.
In this setting, the matrices being operated on are provided as inputs to the Generator unit where the encoding operation typically takes place on processors. However, the encoding operation can alternatively be distributed over the cluster nodes if the associated coding structure allows so111For instance as it will be demonstrated with this study, array codes based on pure XOR logic that can be decoded using belief propagation can provide such flexibility at the expense of increased communication cost. as shall be shown with the help of an example in the next section. Encoded rows/columns of the matrices are communicated with the nodes of the cluster in which a total of processors compute the matrix–matrix multiplication together. We assume the cluster processors are slower than that of the master node by a factor of . Finally, the Sink unit collects a subset of processor outputs to initiate decoding i.e., putting together the final product in place. Generator and Sink are not necessarily two physical nodes as drawn in this figure. Rather, they are abstracted units that may reside in the same physical (master) node. By construction, having all processor outputs of any out of nodes will suffice to reconstruct .
As shown in Fig. 1, the total execution time in our clustered distributed setting is given by the sum of encoding time , master-slave transmission time , the overall slave task time where each slave completes its execution with time , slave-master transmission time and finally the decoding time at the master denoted by . Hence, we can express the overall latency similar to [29] and [28] as
[TABLE]
where is the set of all minimal decodable subsets of processor outputs. Most of the past work focuses on minimizing the parallel task time while paying little if no attention to encode/decode times. Plus, some of the previous works favor parallel task execution times at the expense of consuming more bandwidth and master system CPU resources [32]. However, as the system size (as well as the matrix sizes) scales, the encode/decode times of the master node will become the main bottleneck of the overall system performance. In our work, will represent the sum of computation times, i.e., which will constitute the main focus of this paper.
III Asymptotically MDS Array BP-XOR Codes for Matrix Multiplication
Before defining the class of asymptotically MDS array BP-XOR codes, let us provide the conventional definition of MDS BP-XOR codes using the notation of [24]. Accordingly, let be the symbol size in bits and be the symbol set from which we select our information as well as coded symbols. The fundamental operation we use is the Exclusive OR (XOR). In our study, nodes represent blocks of data that contain one or more symbols in it. Symbols are the smallest data unit over which XOR operations are defined.
III-A Array BP-XOR codes for Coded Computation
An array BP-XOR code is a two dimensional rate binary linear code in which the coding symbol is the XOR of a subset of source symbols , typically structured as a data matrix, and can be reconstructed from any columns of the linear code using BP algorithm for an appropriate integer . The degree of a coded symbol , denoted as ( , the maximum node degree number of the code), is the number of information symbols that participate in logical XOR operation i.e., such that for all . A -erasure correcting array BP-XOR code is block MDS if the source symbols can be reconstructed from columns of .
Just like product codes [29], [30], we encode computation in two dimensions however with the exception that the encoding is not only in vertical and horizontal directions, both could be in any carefully chosen direction, which shall provide more flexibility between the distribution of encoding and the use of bandwidth. In addition, every computation task of the product-coded scheme involves only a single dot product whereas our scheme performs a maximum of dot products per processor yielding dot products per node in the worst case. However, in the product-coded scheme, the master node performs heavy and unbalanced encoding operations which will be shown to be a bottleneck from an overall latency point of view. With the array BP-XOR codes, encoding operation may be distributed over the clustered computation network at the expense of increased bandwidth consumption between the master node and the processors of the cluster nodes. On the other hand, distributing the decoding task among the network nodes is still an open research topic.
Example 1: To illustrate specifically the assigned jobs for each node, let us suppose we would like to compute (with ) the following simple matrix multiplication,
[TABLE]
by using MDS array BP-XOR code with , given in Table I with the designated computation distribution among nodes each equipped with two processors. For instance, node 1 receives the entire matrices (, ) and () to be able to compute on its processor 1, and and hance on its processor 2. On the other hand, node 5 gets (, ) and to compute on its processor 1 and on its processor 2 which reduces the bandwidth compared to what node 1 gets.
From these examples, we observe based on the code construction that encoding can optionally be carried out in the master or the cluster nodes. However, in some of the subcomputations such as or (colored gray in Table I), the encoding has to be distributed. On the other hand, for the rest of the subcomputations, the encoding can be distributed among other compute nodes at the expense of more communication. However, if we choose to minimize the bandwidth, the master could help with the encoding by executing row or column additions. In Section IV.B, to be able to simplify the system description we assume the worst case scenario in terms of communication cost i.e., times larger than that of competent schemes, and let all encoding processes take place on cluster nodes.
Note that with this setting as soon as any two out of five nodes complete their processing, the master node will initiate a belief propagation decoding to put together . Although in this case four-processor outputs of any selection of two nodes are sufficient to reconstruct the result, we have to wait for all ingredient processors (due mainly to block MDS property) to finish their execution. On the other hand, the recovery threshold of this code can be shown to be 7, i.e., any 7 processor executions will be sufficient to reconstruct the result in the worst case.
For comparison purposes, let us also give an example for a polynomial code [26] with similar parameters i.e., and . Let us define and . With this definition, the node 1 shall receive , , and and compute the dot product on processor 1 and on processor 2 as shown in Table II. The rest of the nodes receive the same amount of data and executes exactly two products. Note that the distribution of the tasks can be done in any order as the computation of each task has the same complexity. Unlike MDS array BP-XOR codes, node processors in this case computes a single dot product provided that the master first encodes and generates s and s. On the other hand, due to the sparse nature of MDS array BP-XOR codes, some nodes (such as node 5) consumes less bandwidth at the expense of more dot product computations. Also the encoding operation at the master is simpler compared to polynomial codes. The recovery threshold of polynomial codes is given by achieving the minimum possible.
Example 2: Let us suppose we would like to compute (with ) the following matrix multiplication,
[TABLE]
by using MDS array BP-XOR code with , as given in Table III with the designated computation distribution among nodes each equipped with three processors/cores. As can be seen, computations in gray cells do not share any common terms from matrices and . Thus, encoding for these computations has to be distributed. Note that the ratio of required distributed encoding is 6/15 = 0.4 for this code whereas it was 2/10 = 0.2 for the code given in Table I, showing the natural dependency on the code construction.
III-B Asymptotical Extensions
Let to be the maximum node degree of a given array BP-XOR code, we note from [24] that if it is not hard to show that
[TABLE]
from which we easily deduce that the upper bound on can be arbitrarily large (i.e., for ) and allow any arbitrarily small code rate to be possible. However, for it is observed that the array code blocklength is upper bounded based on a specific choice of [24]. In addition, we observe from the same study that for and large enough i.e., we have . This also implies that for a large enough information block length , the achievable rate will be close to 1, putting a constraint on the code design rate. This ultimately means that the portion of straggler tolerance would not be scaling well with the size of the cluster. By fixing , we shall control the complexity of encoding/decoding processes and as we shall see in later sections the overall end-to-end computation latency. We considered an asymptotic extension of such codes next to allow better flexibility in terms of choosing the right code rate for the given coded computation system (i.e., scaling number of stragglers) at the expense of using slightly more processors work per node (Remember that we assume to have cores per node to respond to such requirement if need be).
For a given positive integer satisfying , a asymptotically MDS array BP-XOR code is a linear code with -th column for a generator matrix such that . Thus, the generator matrix for is given by the matrix,
[TABLE]
A -erasure correcting asymptotically MDS array BP-XOR can perfectly reconstruct the data matrix from any column combinations of using BP decoding and as we have . Note that the raw source data need not be in standard form. For any positive integer satisfying and , the generator matrix should work fine for different arrangements of the data block matrix such as . We finally note that the code is not in two-dimensional standard rectangle form as in . However, we introduced another parameter to be able to make asymptotically MDS array BP-XOR codes analogous to standard MDS array codes defined over rectangle shape binary matrices.
For a given fixed code rate and , let us define to be the maximum coding overhead222Since columns of may have different sizes, the overhead depends on which columns are used for reconstruction. Thus, is the maximum over all combinations of columns. Eventually, the coding overhead depends on the number of columns in the code, so called array code blocklength. of satisfying . The asymptotically optimal overhead property implies that as we have . Let us provide the following theorem that sets the necessary condition/s on the parameters for the existence of asymptotically MDS array BP-XOR codes.
Theorem 3.1**.**
Let be a asymptotically MDS array BP-XOR code such that the maximum coded node degree satisfies . Then, we have
[TABLE]
where and is the maximum coding overhead.
Proof.
Since the code is assumed to be block MDS, i.e., it is able to tolerate column erasures of , each information symbol must appear in at least columns, otherwise information symbols cannot be reconstructed. Since there are symbols, we shall have
[TABLE]
minimum symbol appearances in . On the other hand, we observe that belief propagation decoding needs to have degree-one encoding symbols to start decoding. So we need at least degree-one symbols in distinct columns of (in the worst case of column erasures when each may comprise one degree-one symbol). Similarly, we need at least one degree-two, one degree-three, , one degree- coding symbols to make sure that BP decoding continues. Although it is possible to have multiple degree-two symbols and continue BP decoding, by making this choice we attempt to maximize the appearance of information symbols in . Note that if these symbols happen to be in distinct unerased columns, the bound could be tightened, otherwise the bound might still be loose for say if which is not usually typical. Therefore, in such a formulation a total of symbols are assigned degrees. The rest of the symbols can have at most degree. Thus, can have at most
[TABLE]
or equivalently,
[TABLE]
appearances of information symbols. We can rewrite (6) in a more compact form as
[TABLE]
Using the natural relation , and assuming we have , we can collect all terms that includes on the left hand size and find an upper bound on as follows,
[TABLE]
which leads to
[TABLE]
where which completes the proof. Note that if we will have and hence equation (III-B) becomes identical to equation (1) of [24] i.e.,
[TABLE]
except the term . This term is essentially what makes the upper bound improved (tighter). ∎
There are two cases that are interesting to consider for understanding the asymptotical performance. First, if tends large we will have . Hence,
[TABLE]
where is logical one if is true, otherwise it is zero. This indicator function is used due to the flooring operation and only equals to in the limit. Thus, if the code becomes array MDS in the limit, there remains no dependence of on . On the other hand, if we let large but fixed , and if gets large, we shall have
[TABLE]
which can be made arbitrarily large if we choose an appropriate for a fixed and large . This essentially demonstrates that as the array BP-XOR code becomes near-optimal in terms of recovery performance, the upper bound on the number of code columns can dramatically be improved.
Although the desirable properties of the coding overhead are found, we still need specific constructions to quantify or bound the coding overhead and hence present tighter bounds on (and ) for a specific construction. Based on this observation, we shall present a code construction method that uses the result of Theorem 3.1 and has an appropriate with the properties as summarized with the following remark.
Definition 3.2**.**
For a given fixed code rate and , let to be the maximum coding overhead of satisfying . The asymptotically optimal (MDS) overhead property implies that as we have .
III-C Discrete Geometry Constructions of Asymptotically-MDS array BP-XOR codes
In this section, we will introduce a particular construction of asymptotically MDS array BP-XOR codes based on discrete geometry [41] and show that they can be regarded as a special type of the class of asymptotically MDS BP-XOR codes.
The discrete geometry construction is also known as Mojette Transform (MT) codes which are based on discrete version of Radon Transform [40], and can be used to generate redundancy not just for rectangle two dimensional data grid but also for any convex data grid. In our study, we consider matrix (rectangle) data for simplicity and let encoder compute a linear set of projections at angles specified by a couple of coprime integers (with ) from a discrete data structure . Suppose that we generate projections with parameters . The length of the projection , denoted by , is a function of angle parameters and the data grid size . It can be expressed in a closed form as follows [41],
[TABLE]
Note that in this construction, generated projections can be treated as the columns of the asymptotically-MDS BP-XOR code. Each bin or symbol of the -th projection, based on , can be computed as given by the following compact formulation
[TABLE]
for all satisfying the inequality,
[TABLE]
where is the transformation operator acting on , stands for Boolean XOR operation, is the discrete unit function and is Kronecker delta function which are respectively given by
[TABLE]
An example code with parameters , with projections with parameters is shown in Fig. 2. Also shown in the same figure transformed symbols etc. which are the symbols of the projection with . MT codes can be decoded using BP algorithm and the exact reconstruction of user data matrix is possible if the projection parameters are selected judiciously according to the following Katz criterion.
Theorem 3.3** (Katz Criterion[44]).**
For a given asymptotically-MDS BP-XOR code defined by projections on a data matrix where only projections with parameters are available. Exact data reconstruction is possible using iterative BP if
[TABLE]
Proof.
This can be interpreted as the reconstruction of a rectangle grid using inverse Mojette transformation of projections [42]. It is not hard to see that this reconstruction technique is identical to the belief propagation algorithm for erasure recovery which was applied to discrete tomography and image reconstruction in the past [43]. The condition that ensures reconstruction is known as the Katz criterion where the full proof can be found in [44]. ∎
Theorem 3.4**.**
If denotes the maximum degree of the th projection defined by the parameters . We have and hence .
Proof.
Considering the equation (14) and the worst case scenario, we would like to find the number of and values such that . It is not hard to see that the maximum number of values that can satisfy this equation is given by due to . Similarly, the maximum number of values that can satisfy this equation is given by due to . Since the number of possibilities for and are also constrained by the two dimensional rectangle shape, we have the maximum encoding symbol degree equal to the minimum of the two i.e., . Thus, the maximum degree of all the code symbols is given by the maximum degree of all the projections i.e., . ∎
Next, we quantify the coding overhead for MT-based asymptotically MDS BP-XOR codes by considering and cases separately.
III-C1 Case
First of all, note that depending on the choices of , the coding overhead as well as the maximum degree of the code can change. Although there are multiple choices for , we provide the typical choice below that also ensures good coding overhead.
Construction 3.5**.**
Let us consider the following choice of coprime integers,
[TABLE]
where is known as canonical enumeration of integers [45] that goes with the name A007306 and satisfies for .
Note that this construction satisfies the Katz criterion simply because collecting any projections will lead us to have . If we use the coprime integers as given by the Construction 3.5, we have never equal to zero and . We note that we have for . We next quantify the coding overhead for this particular construction and show the asymptotically optimal property.
Theorem 3.6**.**
For the Mojette code with parameters as given in Construction 3.5, for , we have
[TABLE]
where is the fixed rate of the array BP-XOR code.
Proof.
See appendix A for the proof of this theorem. ∎
For fixed and (i.e., fixed ), if then it is clear that proving the asymptotical property. On the other hand, for fixed and , if then we have . In fact, it is not hard to see that . Therefore, due to these desirable properties of the overhead and considering the inequality (12), we can make arbitrarily large. Particularly we can find the following lower bound on for and ,
[TABLE]
which yields the inequality
[TABLE]
This final lower bound shows that the value for the block length can be arbitrarily large for judiciously selected large . Note that the case has the least constraint on the code block length for any MDS array BP-XOR code. However, in the case of fixed the complexity could be prohibitive due to large . In that sense, the case is more interesting for the class of asymptotically MDS array BP-XOR codes.
III-C2 Case
With classical array BP-XOR codes, the block length is constrained by the following upper bound for ,
[TABLE]
which is the same for asymptotically MDS array BP-XOR codes as mentioned in Section II. However, as the block length gets large as well, we shall no longer have constraints on the size of the block length for asymptotically MDS BP-XOR codes.
Next, we provide another set of parameters for Mojette code that shall satisfy . The possibilities of the pair selection for making is not unique. We will consider the typical class as given in Construction 3.7.
Construction 3.7**.**
Let us consider the following choice of coprime integers for projections,
[TABLE]
where is a positive even number, and rounds to the next biggest odd number of the argument, respectively.
Note that using construction 3.7, it is easy to verify for non-negative . Also, we have . It is of interest to quantify the coding overhead to be able to find the upper bounds on the code block length.
Theorem 3.8**.**
For the Mojette code with parameters as given in construction 3.5, for , we have
[TABLE]
where is a positive integer, and rounds to the next biggest odd integer of the argument, respectively.
Proof.
See Appendix B for the proof of this theorem. ∎
Note that as long as , we have for large demonstrating the asymptotically optimal overhead property. Similarly, for fixed and , if then we have . Finally, using equation (12) we can express the upper bound on as follows,
[TABLE]
We provide some numerical results that compute the upper bounds for comparison. Let us set and assume a large value, such as (this choice is completely arbitrary) and compare the upper bounds on with using classical MDS array BP-XOR codes and their asymptotically optimal version proposed in our study, abbreviated as AMDS. We present results in Fig. 3 in which a) demonstrates that classical MDS array BP-XOR codes are only possible for very small values of . On the other hand, although the same is true for asymptotically MDS BP-XOR codes for small , it is also observed that for large enough our bounds are larger than the required (fixed by the code rate), allowing possible constructions to achieve the corresponding code rate asymptotically. In Fig. 3 b), we present the possible minimum code rate (due to the upper bound on the block length) as a function of assumed nominal code rate for different coding schemes. The region above all curves represent achievable code rates. As can be seen, with increasing , AMDS provides more freedom in choosing the right code rate. Fig. 3 a) also presents the upper bound behavior for small on the top-left corner. The plot includes a curve “required ” to denote the required value for for the corresponding code rate .
In order to see clearly the range of rates that are possible with both constructions, the same figure b) depicts the minimum rate that is possible as a function of the assumed rate. Note that with asymptotically MDS array BP-XOR codes, the upper bound on depends on the coding overhead which is a function of the code rate. Thus, the minimum code rate changes as the assumed code rate changes. For each assumed rate, we calculate the upper bound and then compute the minimum code rate possible. With respect to classical MDS BP-XOR codes, since the upper bound does not change with varying assumed code rates (since the coding overhead is always zero), the curves are flat. As can be observed, the region that lies above the curves is the possible code rates. However, there is no guarantee each and every assumed rate would be achievable. However, as can be seen for large , it becomes impossible to construct classical array MDS BP-XOR codes with a rate smaller than unity. In contrast, by relaxing the exact MDS condition, we can improve the region of achievability.
IV End-to-End Latency Performance Analysis
In this section, we shall primarily focus on the total computational latency of the proposed coded system. Then, we will shortly touch upon the communication cost and compare it with other well–known coded computation schemes in the literature.
IV-A Computation Latency
Similar to the past studies, our time analysis also focuses on exponential task time for each processor. More specifically, we choose the most basic operation to be the “long dot product” operation ( multiplications and additions for a typically large ) in our system, distributed exponentially with parameter i.e., having the probability density function and the cumulative distribution function (cdf) . If processor of a cluster node performs such dot products, then its cdf will be , a scaled version of the original distribution [8]. Also, the processing power of each master node processor is times greater than that of the compute cluster which makes the master processor computation rate to be . The parameter is referred to as compute factor for the rest of our discussion. To minimize the workload of processors and maximize the parallelization, we assume and for the rest of our discussion.
For a given group of processors, the order statistics of is represented by . The expected value of the maximum of s each distributed exponentially with rate can be shown to be where is the harmonic number. Similarly, the expected value of the order statistics of exponential random variables of rate is . Note that for sufficiently large , we have the approximation .
In the uncoded case, the average latency characterization is straightforward. Since there is no encode/decode operation at the master, all it takes to compute the product is to distribute dot products over processors and collect the result for a successful merge. In that case, the slowest processor output will determine the expected latency for the overall product computation i.e., for large . The following theorem characterizes the asymptotical computation time of both encoding/decoding and parallel task completion for single dimensional MDS polynomial codes scattered across the compute cluster introduced in Fig. 1. Throughout this section, we assumed without loss of generality.
Theorem 4.1**.**
Let us use Polynomial code [26] to distribute computation over processors, the asymptotic latency (, ) is given by
[TABLE]
where is the compute factor of the system.
Proof.
Note that in general s and s (in our previous example) contain dot products each. The encoder performs these dot products for each processor except one (total of ), giving us a total of dot products executed in a sequential manner. Decoding is based on the interpolation of a polynomial of degree and the best known algorithm to solve this is on the order of operations [37]. Although operations are likely to be more than a dot product and not fully parallelizable, we estimate the complexity in this particular way to target the most favorable scenario, giving the competitors the best chance of winning. Note also that the master processing is exponentially distributed with parameter due to independence and there are processors in operation bringing up the factor in the expression. On the other hand, the parallel executions perform only single dot product and any column collections i.e., executions will suffice to recover the multiplication result, amounting to an expect delay of . Adding the expected encoding/decoding time and the parallel task time, the result follows. ∎
Although polynomial codes provide order optimal parallel task time, the encode/decode time shall be the bottleneck for the overall performance if (and it practically) does not scale with the increasing matrix sizes. Later studies have shown that MatDot codes can further improve the recovery threshold at the expense of worse performance [32]. The following theorem characterizes its overall computation performance.
Theorem 4.2**.**
Let us use MatDot code to distribute computation over processors, the asymptotic latency (, ) is given by
[TABLE]
where is the compute factor of the system.
Proof.
We realize that the encoding of MatDot codes is very similar to polynomial codes resulting in the same order number of dot products executed in a sequential manner at the master. Similarly, decoding is based on polynomial interpolation but unlike polynomial codes, it suffices to collect successful processor outputs to reconstruct the multiplication result which reduces the decoder complexity. Hence for elements, we have on the order of operations, again which may not be simple dot product. All encode/decode operations are performed by processors in parallel and hence the factor. On the other hand, the parallel executions perform only a single outer product which is at least as complex as a single dot product. In fact, it may be assumed that the outer product is at most equal to dot products. Although the exact complexity figures for the outer product can be incorporated into this expression, a simple lower bound would suffice to demonstrate the degraded total latency performance of MatDot codes compared to its competitors. Finally, since any executions will suffice to recover the the original result (a polynomial of degree ), it amounts to an expected parallel processing delay of . Adding the expected encoding/decoding and the parallel task time in the same order, the result will follow. ∎
Using the same line of thought and assuming a single outer product is at most as complex as dot products, then we can asymptotically upper bound the expected latency as follows
[TABLE]
We realize that even though the parallel task execution time performance of MatDot codes could be better compared to polynomial codes in the most favorable case, its total computation time is worse (in all circumstances) with scaling . In addition, as we shall see later, it has worse communication cost as well to help reduce . In both computation schemes however, the encode/decode times seem to be the main latency bottleneck, especially for small and .
Next, we provide the latency performance of MDS array BP-XOR codes (AMDS) in the sublinear regime in the size of the product which distributes the encoding operation over the cluster nodes in order to achieve better end-to-end latency performance at the expense of increased bandwidth.
Theorem 4.3**.**
Let us use MDS array BP-XOR code over nodes each with processors, for a fixed maximum node degree , the asymptotic latency () is given by
[TABLE]
Proof.
See Appendix C for the proof of this theorem. ∎
In this expression, we primarily note that implication of being constant is that the number of backup nodes is sublinear in , i.e., . However, the number of workers, i.e., processors can still grow by increasing the parameter . We finally note that the bound on given in (11) satisfies the constraint of intermediate order statistics [38] and the average latency is linear in achieving the order optimal computation. Needless to point out that in all of these theorems, we assumed moderate and which aligns with the assumption that master nodes are typically more capable.
Next, we provide the latency performance of a class of MDS array BP-XOR codes (AMDS) in linear regime in the size of the product i.e., . In other words, the number of stragglers increases linearly with where we assume total number of nodes to compute the matrix multiplication for a fixed . Note that classical MDS array BP-XOR codes cannot achieve as since . Hence, the following theorem applied to the asymptotical version of MDS array BP-XOR codes only.
Theorem 4.4**.**
Let us use a asymptotically MDS array BP-XOR code used over nodes for some . Let also each node to be equipped with processors for , executing dot products at most for a fixed node degree . If we define and and to be minimum and maximum of all s, respectively, then the asymptotic latency () can be upper bounded by
[TABLE]
where
[TABLE]
* and is the maximum coding overhead.*
Proof.
See Appendix D for the proof of this theorem. ∎
We note that with and , this general result will be identical to the result of Theorem 4.3. We also notice that for a fixed , asymptotical version has parallel task time of whereas original version has . This means that although the asymptotical version allows us better flexibility in choosing the number of stragglers in the network, due to unbalanced computation allocation among network nodes, its parallel execution becomes worse. However, the overall execution time is still linear in , achieving the order optimal computation time from an end-to-end perspective.
IV-B Communication Costs
In polynomial codes, after encoding operation takes place in the master node, the generator communicates symbols for both matrices ( and ) to the processor to compute for . Since a total of processors are used, it communicates a total of symbols (compare this to the uncoded case where a total of symbols are communicated instead). The sink node collects only symbols–the number dictated by the recovery threshold (the outcome of dot products) to initiate successful polynomial interpolation.
In the case of MatDot codes, the generator communicates the same amount of information (in vector form) with the processors i.e., a total of symbols. However, the processors compute and communicate matrices instead of dot products. The decoder only needs to receive processor outputs for successful reconstruction, each being a matrix of size i.e., a total of symbols are communicated to the decoder. Hence the number of symbols communicated with the sink for successful decoding is which effectively boosts the term in Eqn. (1).
Using MDS array BP-XOR codes, the generator will have to communicate symbols for each processor in the worst case. Using a total of processors, the generator communicates symbols, which boosts the term in Eqn. (1). Since for an order optimal latency performance we typically choose a fixed and , MDS array BP-XOR code provides better latency characteristics due to utilizing less bandwidth compared to MatDot codes on master-slave (map) link instead of slave-master (reduce) link. Finally, the sink collects at least symbols (just like polynomial codes) to initiate the linear-time iterative decoding.
In the case of asymptotically MDS array BP-XOR codes [33], the generator will communicate symbols for each processor in the worst case. Using a total of processors, the generator communicates a total of symbols, which similarly boosts the term in Eqn. (1). Finally, the sink collects at least symbols (more than that of MDS array BP-XOR and polynomial codes) to initiate the linear-time iterative decoding. Note that the asymptotically MDS array codes provide more flexibility in terms of coding rate (the number of stragglers), it also leads to and more symbols (compared to the non-asymptotic version) to communicate for master-slave and slave-master links, respectively.
V Numerical Results
Let us provide the expected end-to-end computational latency of the aforementioned coded computation schemes for matrix–matrix multiplication. We would like to remark that we only consider codes that have the MDS property in this study. This way we ensure that the computation takes place on the same number of compute nodes/processors for a given workload despite low-complexity approaches such as LDPC codes [35] could be employed to reduce encoding complexity at the expense of distributing computation over many more processors without taking into account the underlying hierarchical computation architecture.
We employ a Monte Carlo simulation to assess the average end-to-end computation time. Since we assume scaling clusters in our study, we assume to tend to large values. Unless stated otherwise, the simulation parameters summarized in Table V are used and we mostly are interested in the range . We have also set the number of stragglers to maximum possible i.e.,
[TABLE]
to make sure that an appropriate selection (high rate) of an MDS array BP-XOR code can be made. As have been the measure of comparison of the past studies (since [8]), we plot the expected total computation latency as a function of growing as illustrated in Fig. 4 a). In the uncoded case, the master node does not perform any computations and the matrix multiplication is distributed over processors. Due to stragglers, its performance is worse than polynomial codes and MDS Array BP-XOR codes (AMDS). Another natural observation is that since encoding/decoding requirements are escalating as , the total computation latency performances of all schemes get worse. However, AMDS demonstrate an order of magnitude better latency performance compared to polynomial codes thanks to its suitable structure that allows low complexity decoding and distributed encoding. This family of codes achieves this performance at the expense of using more bandwidth between the master and slave nodes. Although MatDot codes ensure a better recovery threshold, the decoding complexity makes its end-to-end latency performance worse than its competitors.
In Fig. 4 b), we have fixed and used all values given in Table V except and . We have set and varied both between 2 and 100. Hence, as we go from left to right along the abscissa, the master’s parallel computation capability would increase. Note that the uncoded scheme is not affected by the master’s computation capabilities as it does not call for any encoding and decoding processes. Also, fixing implies that the number of stragglers is i.e., fixing meaning that the code rate . For a typical choice of , this implies that using only a few extra computations, AMDS coding scheme provides almost five times (20000 versus 4108) better total computation latency compared to the uncoded scheme.
One of the limitations of the original AMDS code is that the number of straggler tolerance is sublinear in as the cluster scales. In other words, the previous numerical setting such as implied that the system is only tolerant to six stragglers since . This might be a quite limitation of the code’s usability for real clusters in which the number of stragglers may typically scale with the number of nodes [2], [39].
Let us suppose we have a scaling cluster with a fixed straggler ratio which is shown to be quite typical in high-performance computing systems [2]. Note that in order to generate redundant computation for scaling stragglers using AMDS codes, we need to tolerate extra computation overhead. We plot In Fig. 5 a) the expected latency as a function of for various coding schemes. We have also included uncoded performance as the baseline for comparison. As can be seen, the asymptotical version (AsymAMDS) provides an order of magnitude better expected latency compared to Polynomial codes for small size clusters (). However, as the size of the cluster increases, mainly due to increased coding overhead , the computation overhead becomes a sublinear function of , making the overall encode/decode process a non-linear function of . This is why for large (for instance ), the latency performance gets closer to that of Polynomial codes.
Generally speaking, the amount of time it takes for a computation to complete isn’t the only important factor. We must take communication latency into account, as well as the bandwidth traffic generated during computing. To do so, we present the resulting tradeoff between the end-to-end computation latency and communication cost overhead. To be able to numerically present the communication cost overhead, we divide the total communication cost by the cost of an uncoded case and subtract one. For instance, using AsymAMDS codes, we divide the master-slave communication cost of by and subtract one, which results in . Following a similar logic, the total communication cost overhead (including both master–slave and slave–master communications) can be given as . Since the communication cost of Polynomial codes is minimal and that of MatDot codes scales with , we only illustrate the tradeoff curve using AsymAMDS codes for brevity. We use and by varying values (and indirectly due to the bound in (III-B)) over the range between 40 and 5000. As can be seen from Fig. 5 b), the relationship is inverse and as we allow more communication between the master and slave nodes, we obtain better average access latency performance. One of the observations is that for a fixed , as the coding overhead increases, the trade-off curve shifts right which increases the communication cost overhead. On the other hand, for a fixed coding overhead, as increases we also observe that expected total computation time increases as well. Hence, we desire minimal values. However, choosing these values as small as possible would significantly limit the achievable code rate and eventually reduce the percentage of stragglers that can be tolerated in the cluster.
In Table VI, we have finally provided the breakdown of the latency figures between the encode time spent in the master, decoding time and finally the time spent in the cluster nodes. We have assumed and an outer product to be approximately equal to dot products for MatDot codes. We have conducted over 10000 simulations and reported the averages. As can be seen, a similar trade-off between and the communication cost overhead can be observed. Also, we can realize that cluster time with the proposed coding schemes increase compared to Polynomial and MatDot codes due to distributed encoding and multiple () dot product computations per node. Although AsymAMDS performs worse than AMDS in terms of latency and communication cost, it allows more flexibility for the selection of the right code rate making it suitable for scaling stragglers scenarios.
VI Conclusion
A fault-tolerant massive matrix product scheme is presented under a realistic hierarchical compute cluster model using MDS array BP-XOR codes. The implications of the limitations on the maximum block length of such codes constrain to a fixed size of stragglers. On the other hand for scaling stragglers, an asymptotic version based on projection geometry is proposed to provide an efficient solution to the massive matrix multiplication process in which stragglers also scale. The proposed scheme has a few novelties: (1) it allows the computation of encoding to be distributed over the cluster nodes at the expense of increased communication cost, (2) it has an extremely efficient decoding process based on pure XOR logic. Furthermore, (3) it can be used as component codes of -dimensional product coding schemes to allow for more powerful coded computations. Finally, (4) due to the iterative nature of decoding, this coding scheme is one of the best candidates for future master-less computation frameworks. Parallelization of the iterative decoding process over the slave nodes is quite possible and will be investigated in later work. One of the other ongoing works is the minimization of the communication cost through intelligent compression, due to offloading encoding operation to cluster nodes.
Appendix A Proof of Theorem 3.6
Let us start by defining the following utility function,
[TABLE]
Also let . Using these definitions, we state the following lemma next.
Lemma A.1: For the projection set given as in (16), we have the sum that can be expressed in a closed form using the utility function
[TABLE]
This lemma can easily be proved by considering odd and even cases using induction, separately. Note that the integer sequence is given by A002620 [45]. Using this result, for a given pair of projections and satisfying , with the associated projection parameters and selected based on construction 3.5 (Eqn. (16)), we can deduce that
[TABLE]
Note that since , it is sufficient to collect projections for perfect reconstruction. Thus, the upper/lower bounds given in equation (31) are particularly useful if we set and to be able find the contributions from the largest projections in the sum that appears in the worst case coding overhead expression. Let be the index such that and define the set
[TABLE]
The worst case coding overhead in this case is given by the following
[TABLE]
where Eqn. (34) follows from the Lemma A.1. Again, using Lemma A.1 and Equation (31), and through some algebra, we can bound the worst case coding overhead as follows,
[TABLE]
which can be accurately approximated for as
[TABLE]
from which the result follows.
Appendix B Proof of Theorem 3.8
Let us start with the following lemma which shall be useful to prove the theorem.
Lemma B.1: For the projection set given as in (21) with projections, we have the sum that can be expressed in a closed form using the utility function
[TABLE]
Proof.
Let us consider the sum for even and odd separately. First we assume to be odd. Let us define the set
[TABLE]
and notice that . Since these sets are disjoint, we have
[TABLE]
Using this relationship and the result of Lemma A.1, we can express
[TABLE]
Now let us assume to be even. For this particular assumption we can rewrite . Using this observation and the result of Lemma A.1, we can express
[TABLE]
which completes the proof of the lemma. ∎
According to Theorem 3.3, we need to have . This implies projections are sufficient for perfect reconstruction. For a given pair of projections and satisfying , with the associated projection parameters and selected based on construction 3.6, we can deduce that
[TABLE]
To be able find the contributions from the largest projections, we set and . Using similar arguments to Appendix A, we can express the worst case coding overhead in this case as follows
[TABLE]
Using equation (42) and , we can accurately approximate the worst case coding overhead as follows,
[TABLE]
which completes the proof.
Appendix C Proof of Theorem 4.3
In the proposed scheme, encoding does not involve any dot products at the master but it uses more bandwidth for (in terms of symbols) communication. Let us first consider the parallel task time in which we need to consider the distribution of order statistics rather than expectation. We initially consider a single network node, then we extend our analysis to expected order statistics for multiple nodes. Unlike expectation, the distribution of order statistics is more challenging.
For simplicity, we consider asymptotics and recognize that the order statistics of s i.e., (for cores or processors) converges in distribution to a Gaussian if 333This is also known as intermediate order statistics [38]. (where we define below the random variable for convenience). The distribution of can be expressed as
[TABLE]
which shall model the delay for the th cluster node with processors. From the cluster point of view and perfect reconstruction, we need any nodes completing their assigned task to be able to reconstruct .
We recall th expected order statistics from [34] and through some algebraic manipulations, we can reach at
[TABLE]
where . For processors, we need to wait until all processors complete their job. Also, we need nodes to finish their task before reconstruction. Thus, we consider as the limiting case which leads to
[TABLE]
We note that the cumulative distribution function of the standard normal can be written as an infinite sum and can be approximated (for )
[TABLE]
from which it follows that
[TABLE]
Let us define where which shall make . By replacing in equation (49), this would imply that we have
[TABLE]
Next, we note that as and can use equation (50) to approximate
[TABLE]
Similarly, the denominator in (47) can be expressed as . Finally, the decoding performs dot products sequentially in the worst case, leading to an average delay of . However, if we perform these operations in parallel processors, and we need to wait for all operations to finish, we would obtain a delay of . Adding the expected decoding time and the parallel task time with due to block MDS property, the result follows.
Appendix D Proof of Theorem 4.4
Similar to non–asymptotical version, let us first consider the parallel task time where we shall assume Gaussian approximation for the distribution of order statistics for analytical tractability. We initially consider a single network node, then we extend our analysis to expected order statistics for multiple nodes.
Based on intermediate order statistics i.e., and using the same notation for the random variable that characterizes the total latency for the th node , we shall have
[TABLE]
which shall model the delay for the th cluster node with processors, each executing at most dot products and denotes the Gaussian distribution, where means “converges in distribution”. For perfect reconstruction, we need any nodes completing their assigned task to be able to reconstruct .
Through some algebra, the th expected order statistics can be found to be of the form
[TABLE]
where , and
[TABLE]
where these results easily follow using the normal analysis for order statistics in [34] and for general distributions, the upper bound on the expected value of the th order statistics as given in [36]. Note that setting (and hence ) for all satisfying will lead to (47).
Let and be the ordered set with . Based on this definition, We realize that we can bound the square term in equation (54) as follows
[TABLE]
where the latter inequality follows because is at most . This leads to
[TABLE]
On the other hand, using Jensen’s inequality we can upper bound given by the sequence of inequalities
[TABLE]
which leads to
[TABLE]
where and . We also use to be compatible with the main text of the paper.
Similar to the approximation given in (51) for large , we can express
[TABLE]
Finally, using the bound derived earlier for and , we can rewrite
[TABLE]
where
[TABLE]
On the other hand, the decoding performs dot products sequentially in the worst case, leading to an average delay of . However, if we perform these operations in parallel processors, and since we would need to wait for all operations to finish, the latency would be . Adding the expected decoding time and the parallel task time, the result follows.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] B. Schroeder and G. A. Gibson. “Understanding disk failure rates: What does an MTTF of 1,000,000 hours mean to you?.” ACM Transactions on Storage (TOS) 3.3 (2007): 8-es.
- 2[2] B. Schroeder and G. A. Gibson, “A Large-Scale Study of Failures in High-Performance Computing Systems,” in IEEE Transactions on Dependable and Secure Computing, vol. 7, no. 4, pp. 337-350, Oct.-Dec. 2010.
- 3[3] Y. Yuan, Y. Wu, Q. Wang, G. Yang, and W. Zheng, “Job failures in high performance computing systems: A large-scale empirical study” Computers & Mathematics with Applications, 63(2), 2012, 365-377.
- 4[4] N. J. Yadwadkar, B. Hariharan, J. E. Gonzalez, and R. Katz, “Multi-task learning for straggler avoiding predictive job scheduling,” The Journal of Machine Learning Research, vol. 17, no. 1, 2016, pp. 3692–3728.
- 5[5] P. Wu, C. Ding, L. Chen, F. Gao, T. Davies, C. Karlsson and Z. Chen, “Fault tolerant matrix-matrix multiplication: correcting soft errors on-line,” In Proceedings of the second workshop on Scalable algorithms for large-scale systems ACM., 2011, pp. 25–28.
- 6[6] Z. Chen and J. Dongarra, ”Algorithm-Based Fault Tolerance for Fail-Stop Failures,” in IEEE Transactions on Parallel and Distributed Systems, vol. 19, no. 12, pp. 1628-1641, Dec. 2008.
- 7[7] M. Li, D. G. Andersen, J. W. Park, A. J. Smola, A. Ahmed, V. Josifovski, J. Long, E. J. Shekita, and B.-Y. Su, “Scaling distributed machine learning with the parameter server,” in Proc. 11th USENIX Conf. Operating Syst. Des. Implementation, 2014, pp. 583–598.
- 8[8] K. Lee, M. Lam, R. Pedarsani, D. Papailiopoulos, and K. Ramchandran, “Speeding up distributed machine learning using codes,” in 2016 IEEE International Symposium on Information Theory (ISIT) , Jul. 2016, pp. 1143–1147.