Random Fixed Boundary Flows
Zhigang Yao, Yuqing Xia, Zengyan Fan

TL;DR
This paper introduces the concept of fixed boundary flows on non-linear Riemannian manifolds, providing a method to analyze noisy multivariate data with fixed start and end points, and demonstrates its convergence and practical applications.
Contribution
It defines and analyzes random fixed boundary flows on manifolds, develops an algorithm for computation, and proves its convergence to the population flow.
Findings
The fixed boundary flow decomposes into three segments, including a principal flow in Euclidean space.
The random fixed boundary flow converges to the population flow with high probability.
The method is applicable to real data sets, demonstrating interpretability and utility.
Abstract
We consider fixed boundary flow with canonical interpretability as principal components extended on non-linear Riemannian manifolds. We aim to find a flow with fixed starting and ending points for noisy multivariate data sets lying on an embedded non-linear Riemannian manifold. In geometric term, the fixed boundary flow is defined as an optimal curve that moves in the data cloud with two fixed end points. At any point on the flow, we maximize the inner product of the vector field, which is calculated locally, and the tangent vector of the flow. The rigorous definition derives from an optimization problem using the intrinsic metric on the manifolds. For random data sets, we name the fixed boundary flow the random fixed boundary flow and analyze its limiting behavior under noisy observed samples. We construct a high level algorithm to compute the random fixed boundary flow and the…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1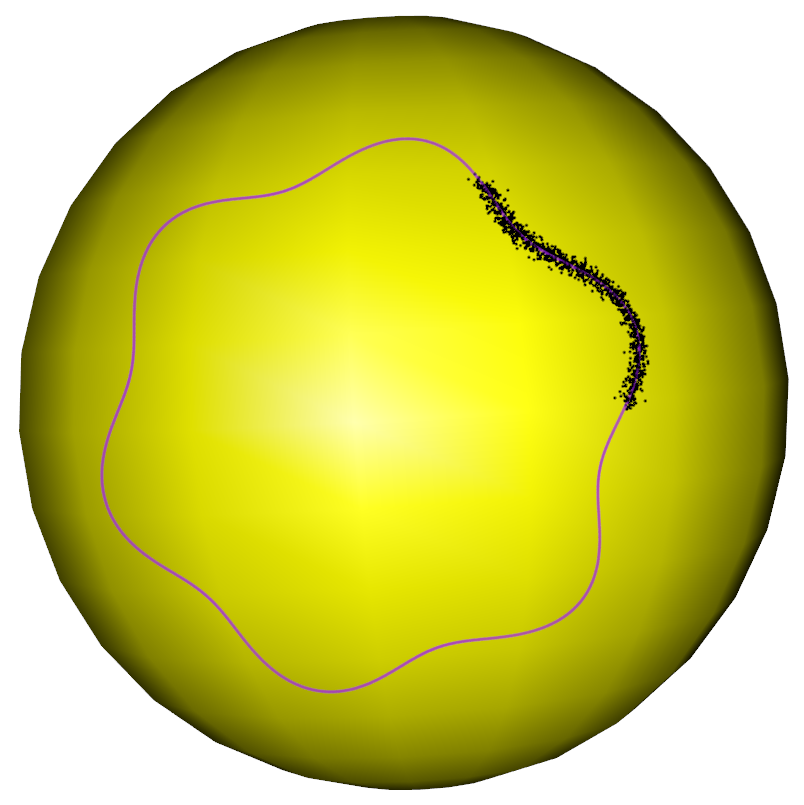 Figure 2
Figure 2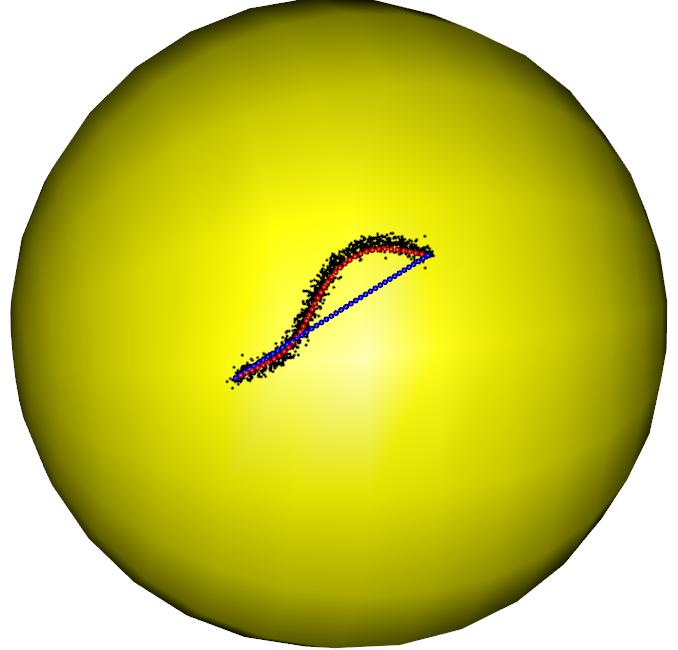 Figure 3
Figure 3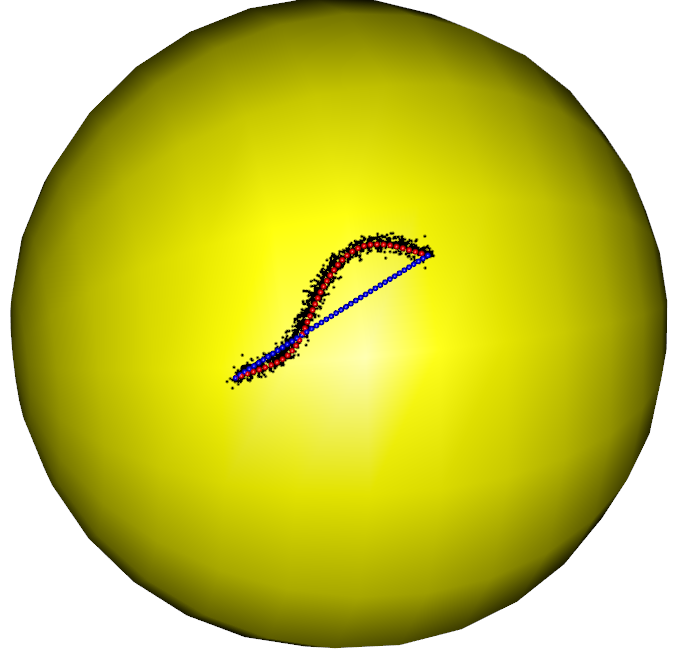 Figure 4
Figure 4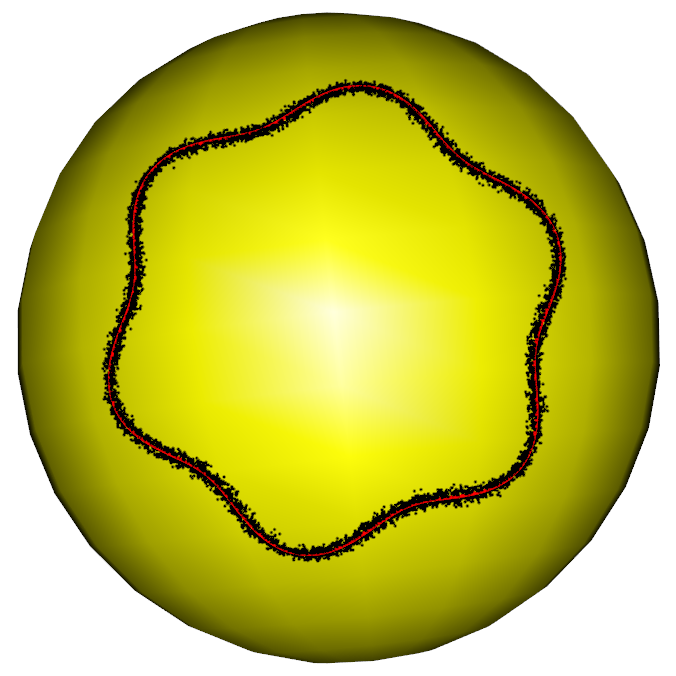 Figure 5
Figure 5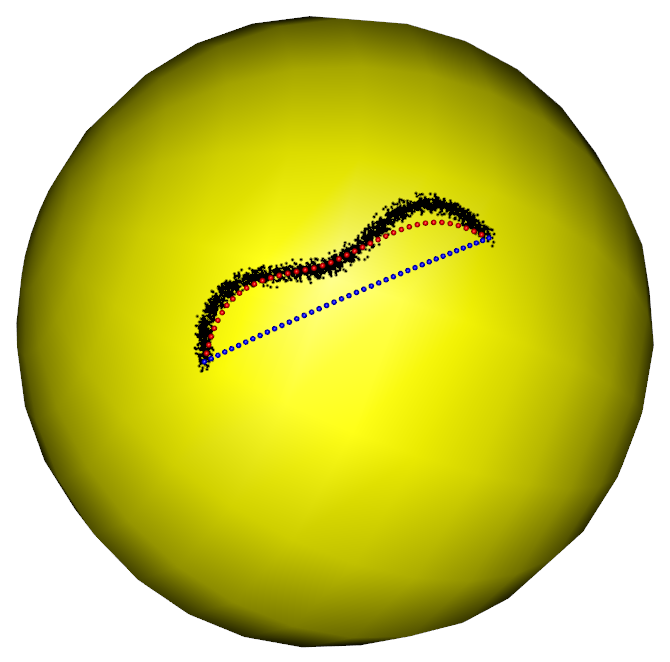 Figure 6
Figure 6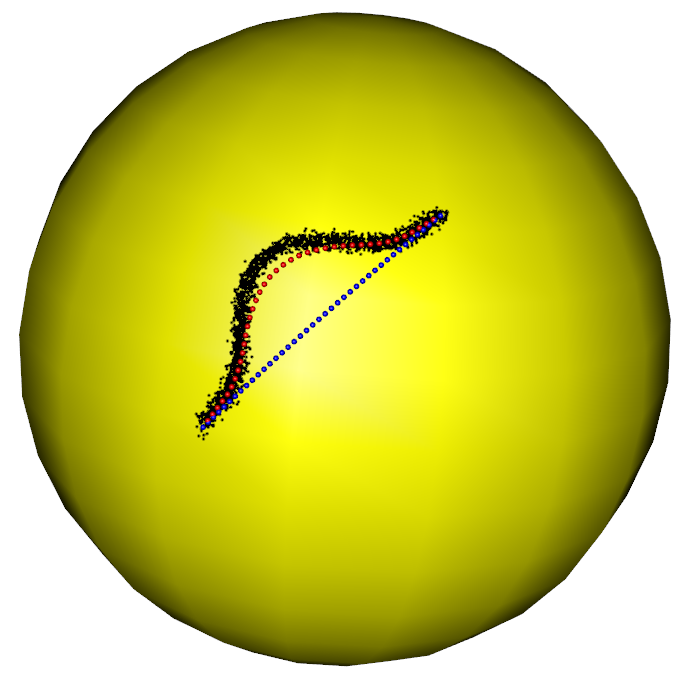 Figure 7
Figure 7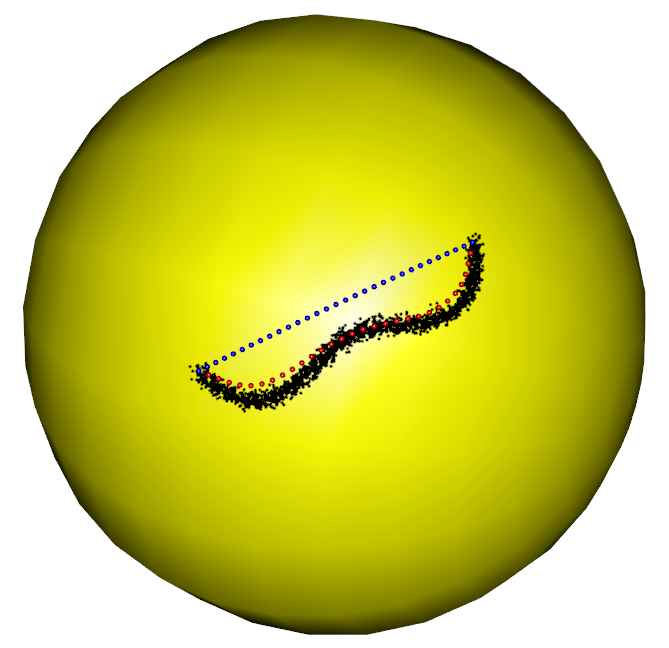 Figure 8
Figure 8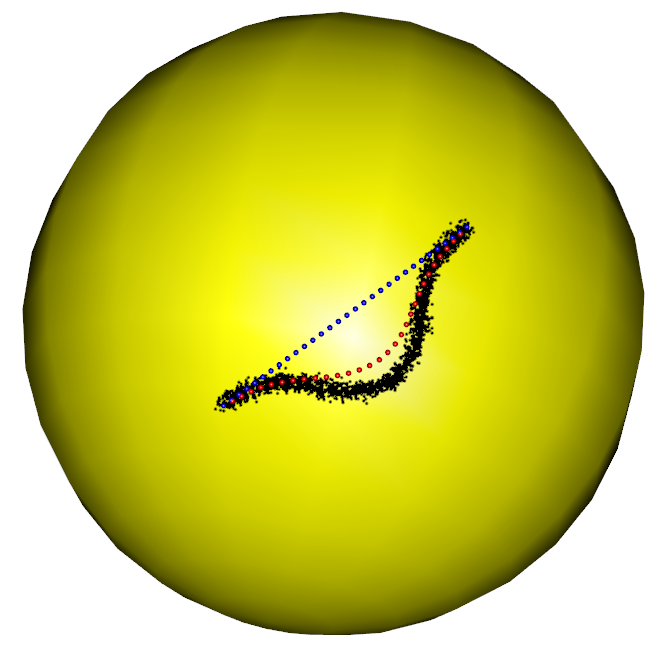 Figure 9
Figure 9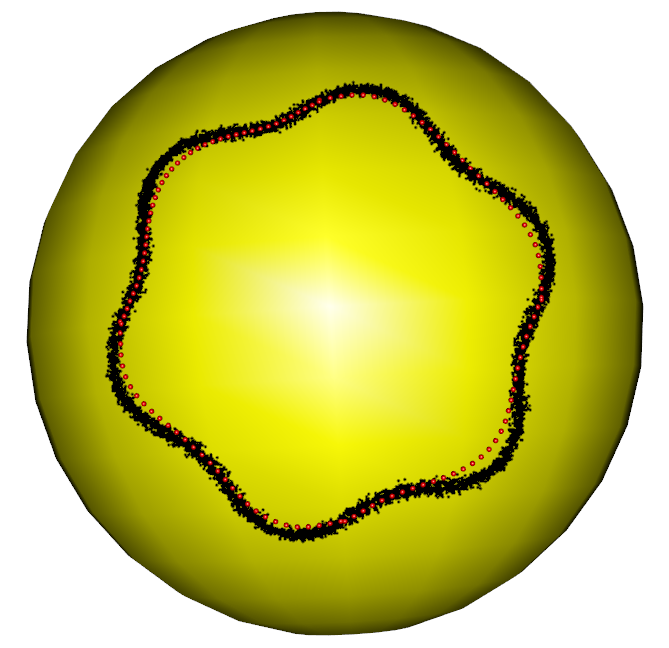 Figure 10
Figure 10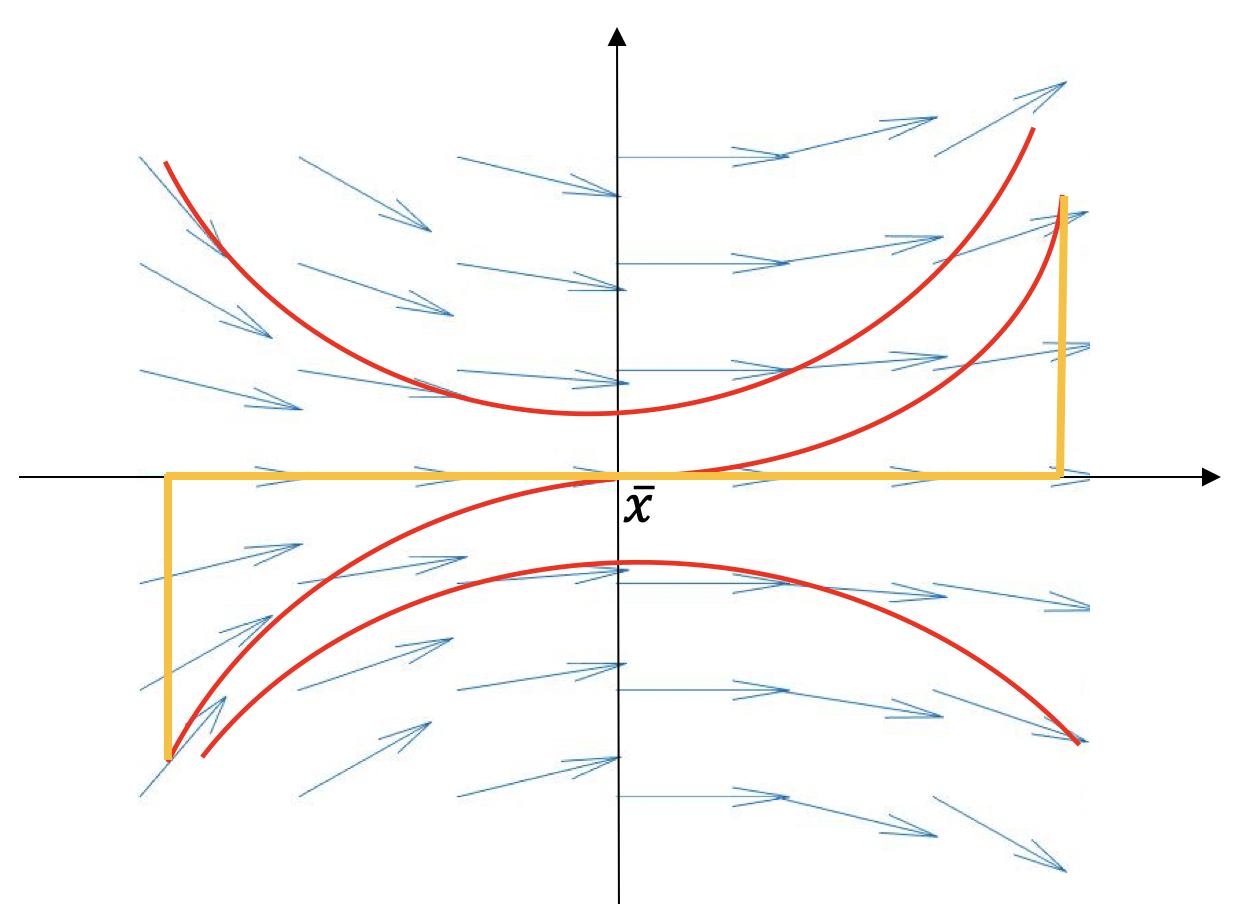 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14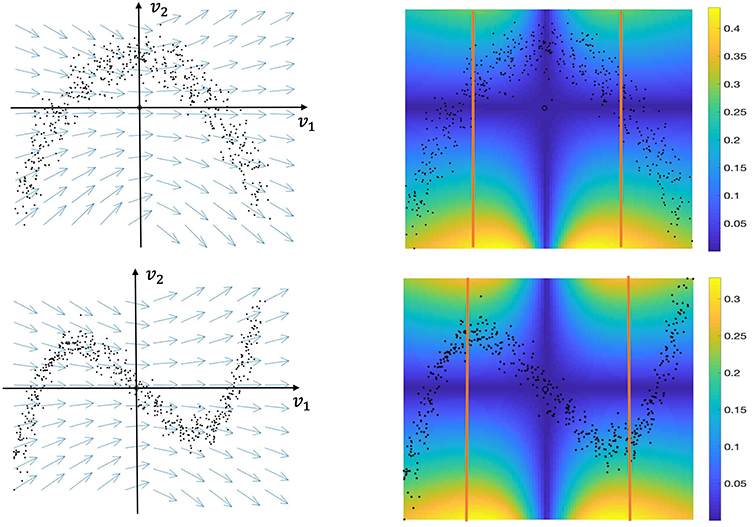 Figure 15
Figure 15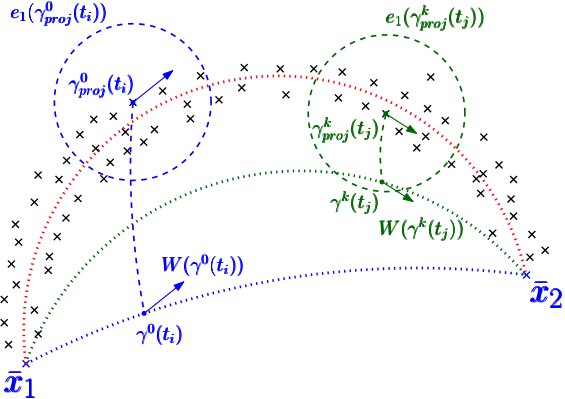 Figure 16
Figure 16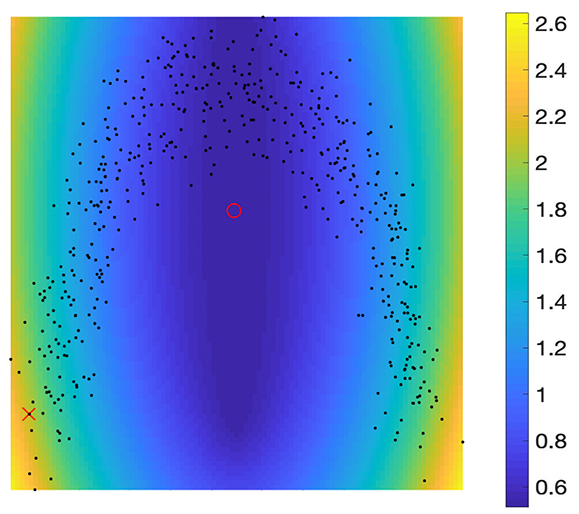 Figure 17
Figure 17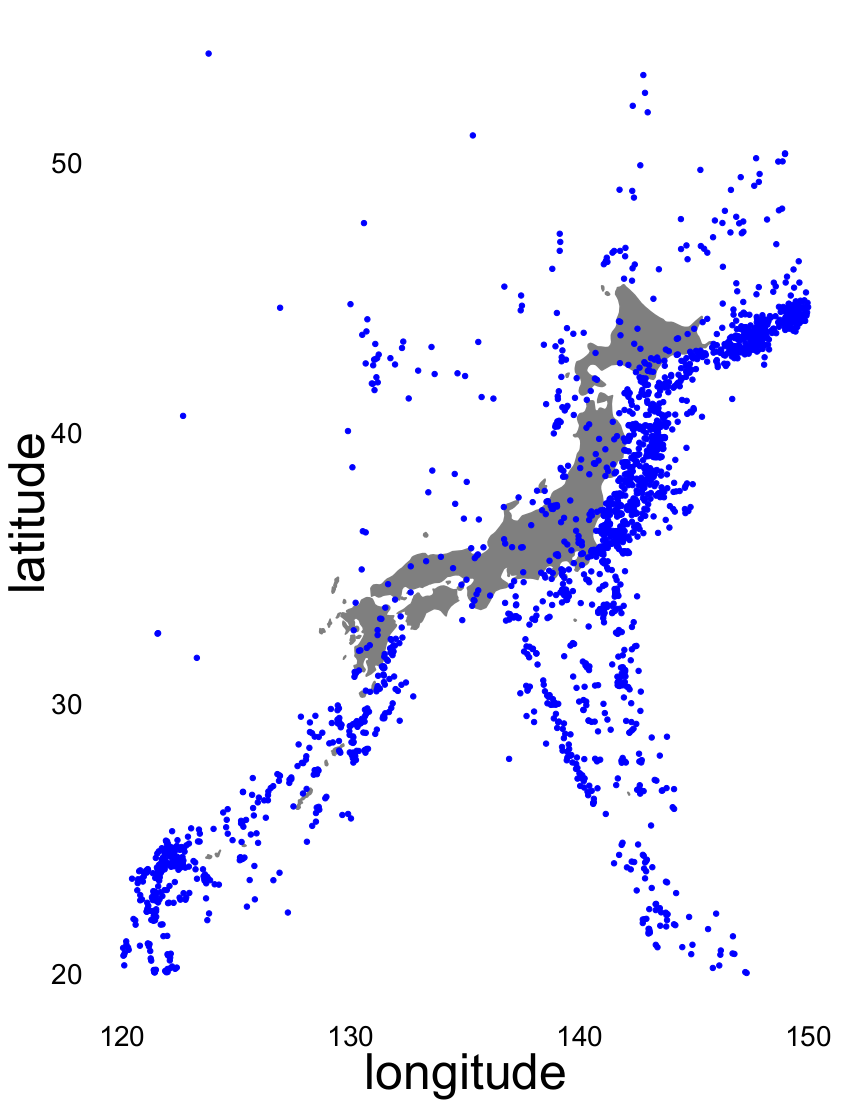 Figure 18
Figure 18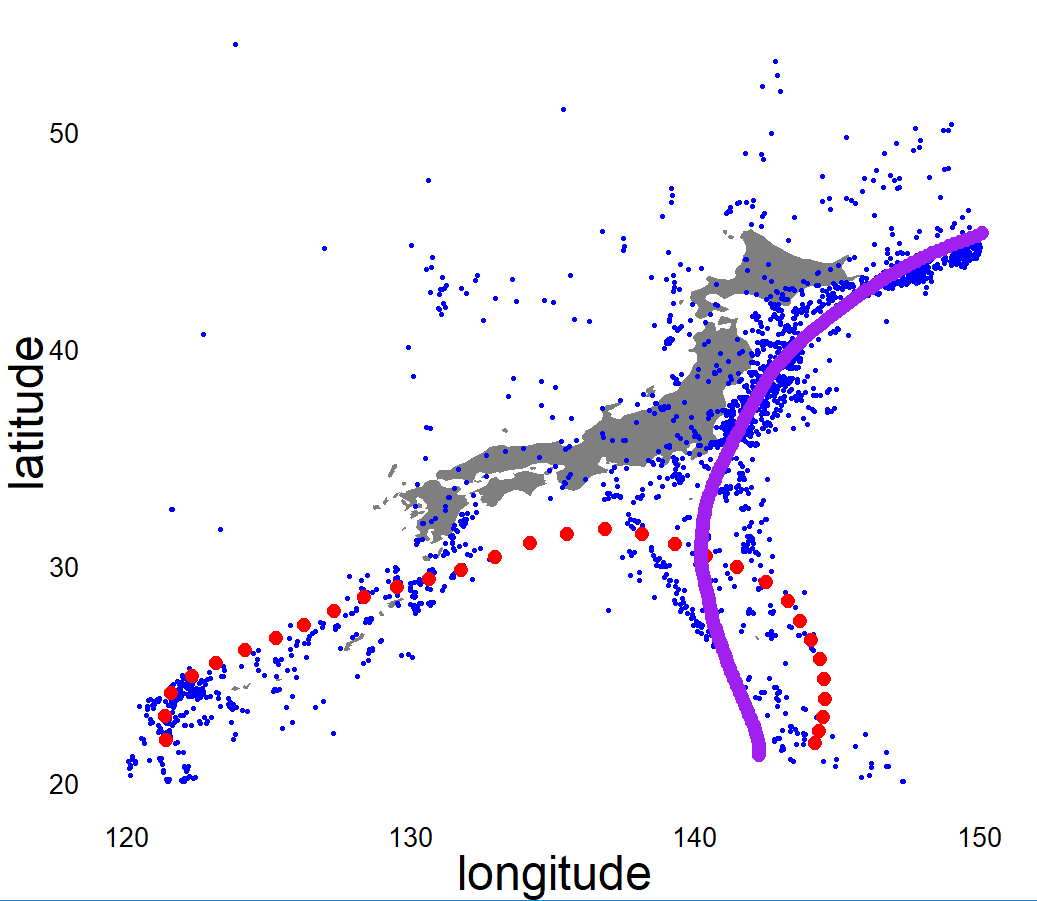 Figure 19
Figure 19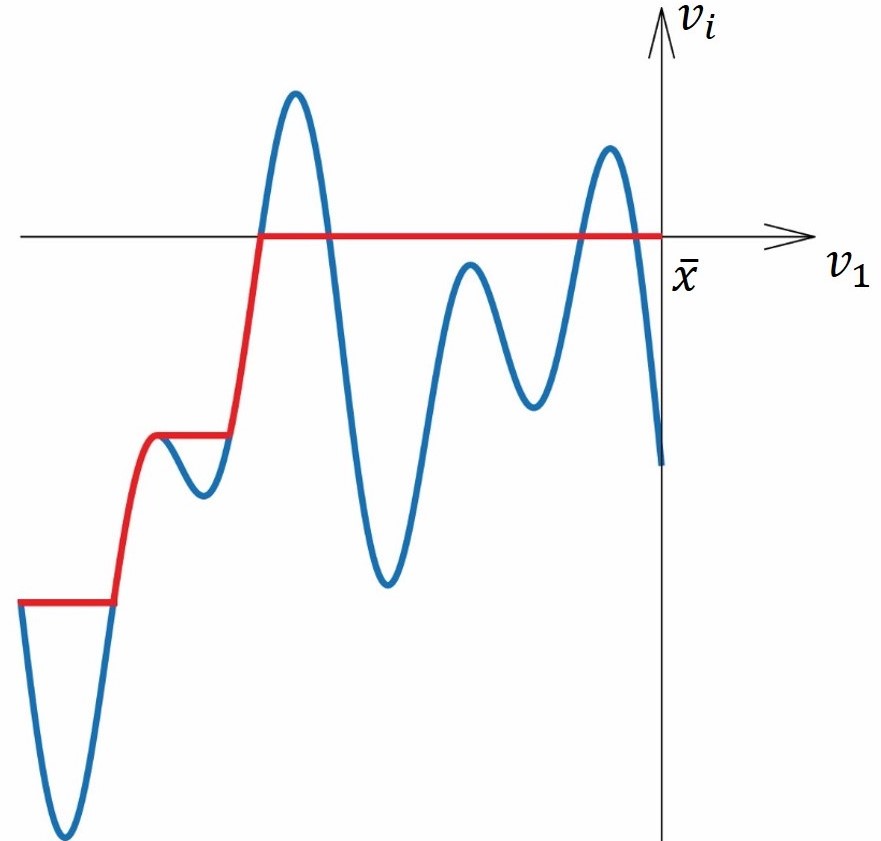 Figure 20
Figure 20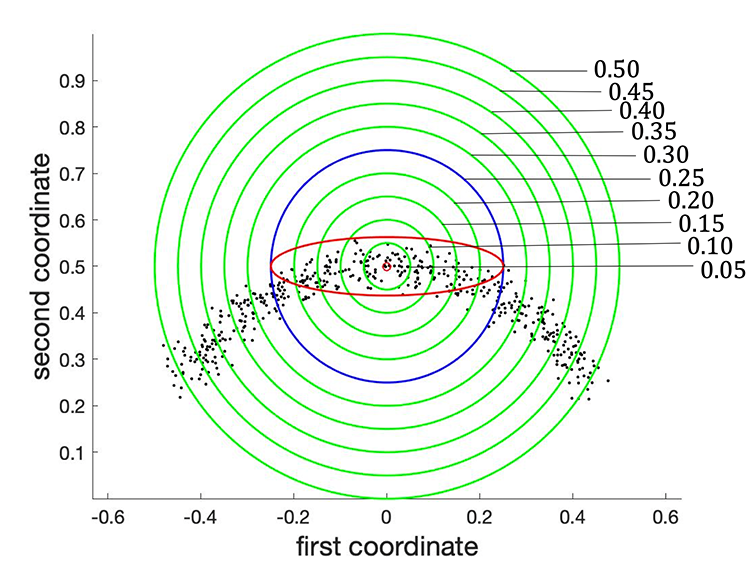 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24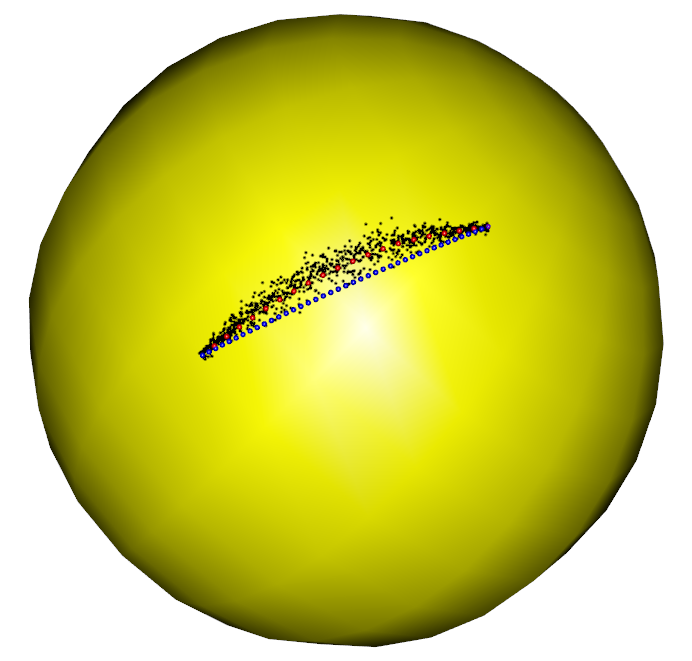 Figure 25
Figure 25 Figure 26
Figure 26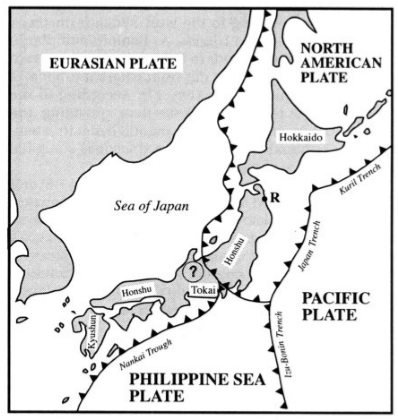 Figure 27
Figure 27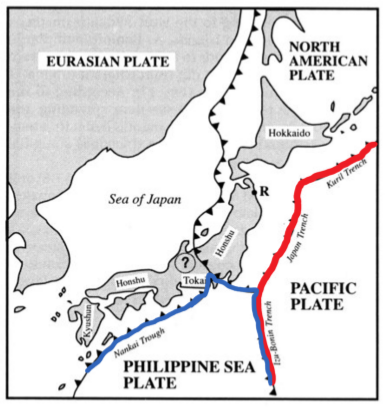 Figure 28
Figure 28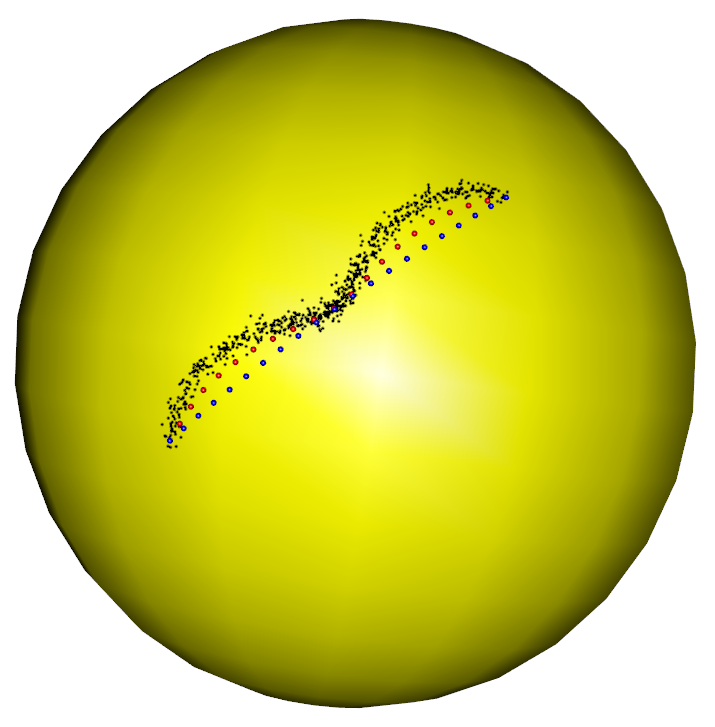 Figure 29
Figure 29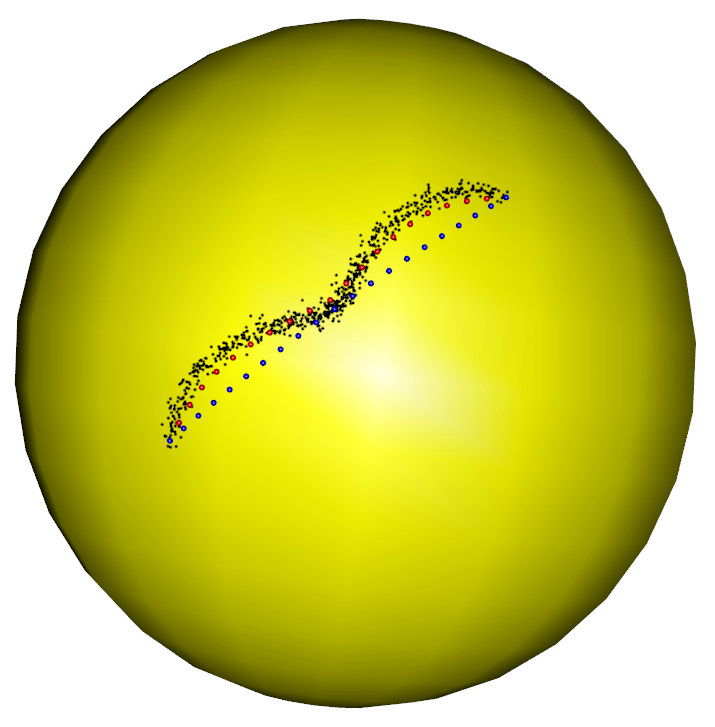 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34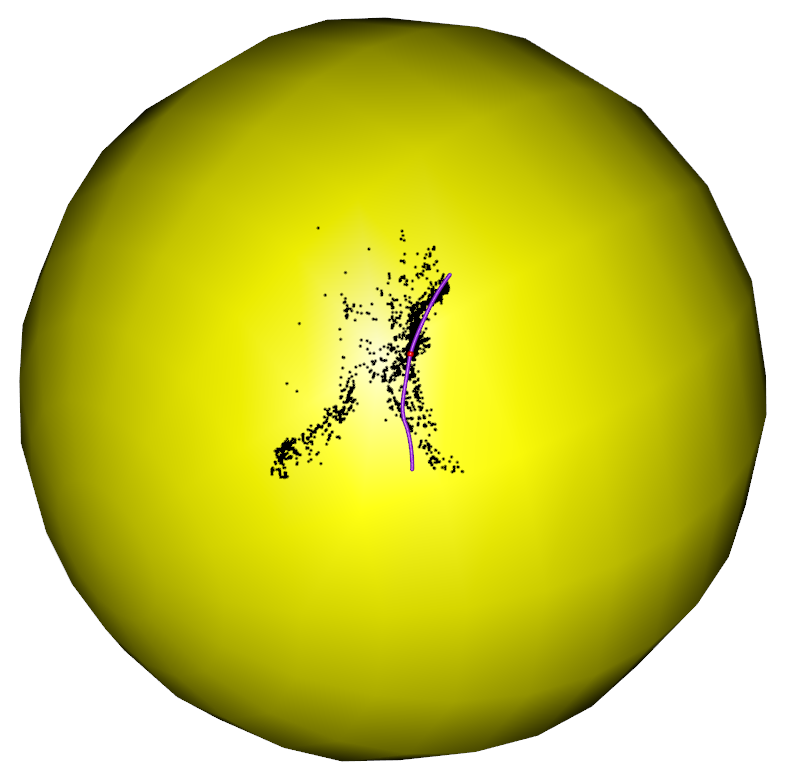 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37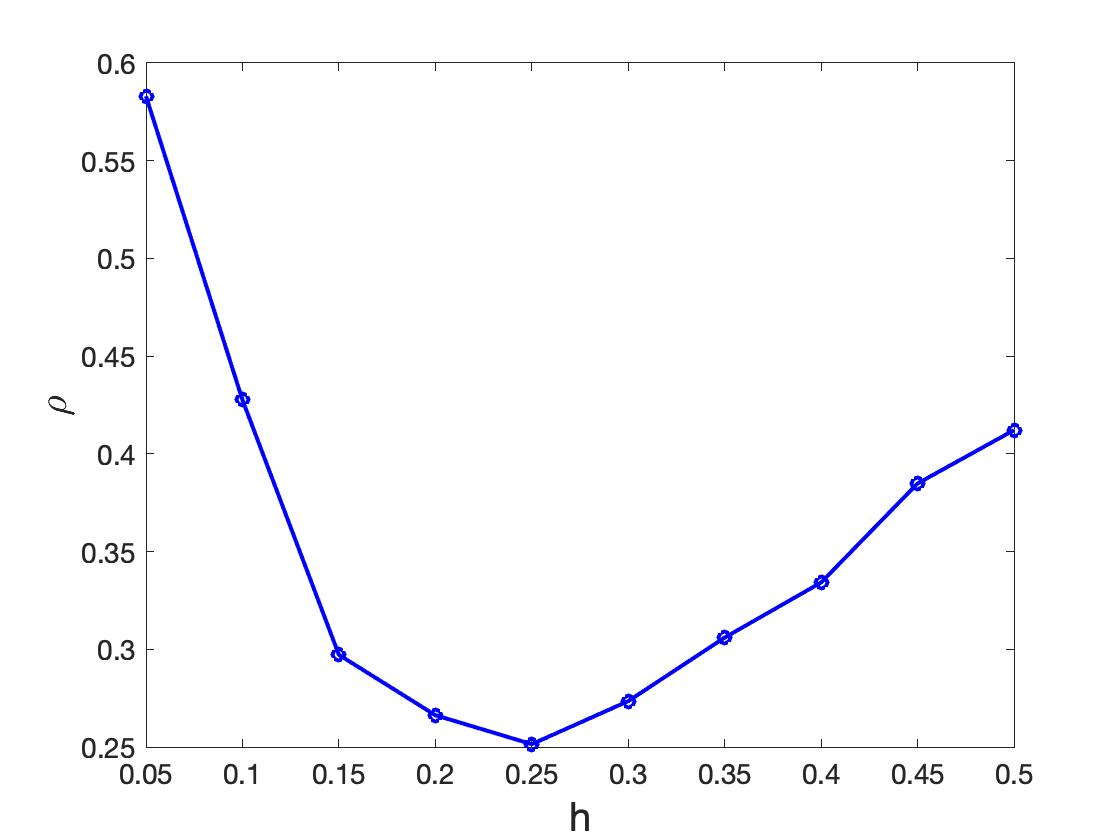 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Unit Sphere | Right-circular unit cone | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| noisy “C”-shaped | noisy six-fold | noisy two-fold | noisy band | noisy “C” shape | noisy “S” shape | ||||||
| 0.0074(0.0017) | 0.0093(0.0022) | 0.0122(0.0025) | 0.12 | 0.0095(0.0021) | 0.06 | 0.0080(0.0018) | 0.06 | 0.0101(0.0025) | |||
| 0.0063(0.0010) | 0.0090(0.0009) | 0.0110(0.0026) | 0.14 | 0.0088(0.0012) | 0.08 | 0.0066(0.0013) | 0.08 | 0.0095(0.0013) | |||
| 0.0063(0.0014) | 0.0121(0.0012) | 0.0133(0.0011) | 0.16 | 0.0094(0.0009) | 0.10 | 0.0067(0.0012) | 0.10 | 0.0126(0.0014) | |||
| 0.0073(0.0011) | 0.0180(0.0059) | 0.0164(0.0009) | 0.18 | 0.0103(0.0009) | 0.12 | 0.0077(0.0009) | 0.12 | 0.0167(0.0013) | |||
| 0.0078(0.0009) | 0.0257(0.0071) | 0.0204(0.0011) | 0.20 | 0.0122(0.0007) | 0.14 | 0.0099(0.0009) | 0.14 | 0.0215(0.0019) | |||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsLandslides and related hazards · Hydrology and Drought Analysis · Morphological variations and asymmetry
Random Fixed Boundary Flows
Abstract
We consider fixed boundary flow with canonical interpretability as principal components extended on non-linear Riemannian manifolds. We aim to find a flow with fixed starting and ending points for noisy multivariate data sets lying on an embedded non-linear Riemannian manifold. In geometric term, the fixed boundary flow is defined as an optimal curve that moves in the data cloud with two fixed end points. At any point on the flow, we maximize the inner product of the vector field, which is calculated locally, and the tangent vector of the flow. The rigorous definition derives from an optimization problem using the intrinsic metric on the manifolds. For random data sets, we name the fixed boundary flow the random fixed boundary flow and analyze its limiting behavior under noisy observed samples. We construct a high level algorithm to compute the random fixed boundary flow and the convergence of the algorithm is provided. We show that the fixed boundary flow yields a concatenate of three segments, of which one coincides with the usual principal flow when the manifold is reduced to the Euclidean space. We further prove that the random fixed boundary flow converges largely to the population fixed boundary flow with high probability. We illustrate how the random fixed boundary flow can be used and interpreted, and showcase its application in real data sets.
Zhigang Yao
Department of Statistics and Data Science
21 Lower Kent Ridge Road
National University of Singapore, Singapore 117546
Center of Mathematical Sciences and Applications
20 Garden Street
Harvard University
Cambridge, USA 02138
email: [email protected] or [email protected]
Yuqing Xia
School of Data Science
Zhejiang University of Finance and Economics
Hangzhou, China 310018
email: [email protected]
Zengyan Fan
School of Science and Technology
463 Clementi Road
Singapore University of Social Sciences, Singapore 599494
email: [email protected]
Keywords: vector field, manifolds, curve, boundary condition, tangent space
1 Introduction
Most existing statistical methods assume a linear dependency between features. As the dimensionality of features increases, the representation of the features in a high-dimensional space becomes more complex and it thus becomes more challenging to understand the relationships between features. In many applications, modern data structures are often complex and not necessarily linear. Indeed it is often the case that there is a lower-dimensional structure, namely a manifold embedded in the high-dimensional ambient space (Fefferman et al., 2016; Fefferman et al., 2018), as in the examples of geometric shapes in the shape space (Turk and Levoy, 1994; Dryden and Mardia, 2016; Kilian et al., 2007; Bradley et al., 2013) and graphs in computer graphics (Phillips et al., 1997; Gross, 2005; Arjovsky et al., 2017).
A series of methods that aim to recover the underlying structure of the lower-dimensional manifold have been developed over the past two decades. These methods, usually called manifold learning, are focused mostly on mapping data in a -dimensional space into a set of points close to an -dimensional () manifold. Among them, is a method known as known as the Principal Component Analysis (PCA), which is commonly used to reduce the feature dimension in the Euclidean space. To address features lying in a non-linear space (i.e., a manifold), methods such as LLE (Roweis and Saul, 2000), Isomap (Tenenbaum et al., 2000), MDS (Cox and Cox, 2000), and LTSA (Zhang and Zha, 2004), which determine the low-dimensional embedding, preserving local properties of the data, may be preferable. A comprehensive review of such work appears in Ma and Fu (2011).
Another line of research relating to statistics on manifolds is centered on the extension of existing methods defined in the Euclidean space to the manifold space. The manifold space can be the actual physical space that the data lies on or the learnt manifold created through the manifold learning methods. In recent decades, numerous non-linear approaches have been developed to analyze the data on the manifold directly (Jupp and Kent, 1987; Fletcher et al., 2004; Huckemann and Ziezold, 2006; Kume et al., 2007; Fletcher and Joshi, 2007; Kenobi et al., 2010; Jung et al., 2012; Eltzner et al., 2018). Throughout the paper, we focus on the known manifold, based on the assumption that the manifold embedding is known.
Next, we will mainly review the “curve fitting” methods on manifolds. A geodesic is a generalization of the straight lines in the standard Euclidean space to the manifold. The principal geodesic analysis (Fletcher et al., 2004), which extends the PCA to the manifold, was proposed to describe the non-linear variability of data on a manifold. The principal curves, proposed in Hastie and Stuetzle (1989), are flexible one-dimensional curves that pass through the middle of data points. Having said that, principal curves are able to better capture the non-linear variation of data in comparison to all other regression lines in the Euclidean space. Ozertem and Erdogmus (2011) redefined principal curves and surfaces in terms of the gradient and the Hessian of the probability density estimate, based on the consideration that every point on the principal surface should be at the local maximum of the probability density in the local orthogonal subspace, and not the expected value as in Hastie and Stuetzle (1989). For applications in classification tasks, Ladicky and Torr (2011) proposed a new curve fitting method to find the smooth decision boundary with bounded curvature.
A recent piece of work on principal flows (Panaretos et al., 2014) works as an extension of the principal curves on Riemannian manifolds. Therefore, the principal flows are also flexible one-dimensional curves, which pass through the Fréchet mean of the data points. The principal flows are able to capture the non-geodesic pattern of variation both locally and globally. Instead of handling curves with an explicit parameterization, Liu et al. (2017) combine the level set method with the principal flow algorithm to obtain a fully implicit formulation, so that the obtained co-dimension one surface on the manifold fits the data set well.
When the data comes with multiple paths, it would be quite natural to want to isolate one of the paths in particular - that with a fixed direction. All the methods outlined above/earlier fail to determine flows with fixed directions. Hence, we propose flows with a fixed direction, each determined by fixed data boundaries, namely their start and end points. For example, we consider seismological events that took place in the Sea of Japan between 1904 and 2015, with the epicentres plotted as green dots in Figure 1(b). From the information of tectonic plates shown in Figure 1(a), we observe that the seismological events in this analysis tended to occur around the tectonic plate boundaries (shown as black curves with triangles in Figure 1(a)). Specifically, we deduce that the seismological events occurred frequently along the boundaries of four tectonic plates: the North American plate, the Eurasian plate, the Philippine Sea plate and the Pacific plate. Given these seismological events, the principal flow passes through the Fréchet mean and captures local variations that depend on the value for the scale parameter, . Since there are a greater number of seismological events along the boundary of the Pacific plate, the resulting Fréchet mean appears around the Pacific plate and the principal flow starts moving from the Fréchet mean. In Figure 1(b), the red curve represents the principal flow of the earthquake data for a scale parameter of miles. We observe that the principal flow moves along the boundary of the Pacific plate (red curve in Figure 1(c)). When we focus on the seismological events caused by the Philippine Sea plate, the principal flow will not be of interest in terms of finding a boundary. In this sense, the trend along the boundary highlighted in blue in Figure 1(c) would be more appropriate. Although we could derive a flow similar to that shown in blue by selecting the data with latitudes and longitudes around the Philippine Sea plate, it is hard to accurately determine which data points to include in practice. Hence, we propose fixed boundary flows, where the flow will be automatically determined by using boundary points that are chosen by users manually. If we select start and end points around the Philippine Sea plate, the obtained fixed boundary flow for a scale parameter of miles is shown in blue in Figure 1(b). Furthermore, we observe that the fixed boundary flow starts from the fixed starting point, moves along the boundary of the Philippine Sea plate (blue curve in Figure 1(c)) and terminates at the fixed ending point.
In order to clarify the aforementioned concepts and parameters, we hereby review the technique proposed for principal flows in brief and demonstrate that this technique comes up short when considering boundary constraints. Throughout this paper we work within the context of a complete Riemannian manifold of dimension , and is isometrically embedded into the Euclidean space with . The related preliminaries in Riemannian geometry can be found in the Supplementary Materials. Given data points on the Riemannian manifold, the methodology for the principal flow seeks to solve for a curve on the manifold that passes through the Fréchet mean of the data, such that the tangent vector along the curve locally follows the direction of maximal variation of the data in a local tangent space. As we will define later, the vector field characterizes the direction of maximal variation and the scale parameter characterizes how locally or globally we wish to describe a path of maximal variation. A flow with a large scale parameter captures the global trend while a flow with a reduced scale parameter describes the finer structure.
Mathematically, the principal flow finds a curve starting at a Fréchet mean and maximizing
[TABLE]
where and are the first eigenvalue and the first unit eigenvector of the local tangent covariance matrix , respectively. The definition of is reviewed in the Supplementary Materials, and we remark that is computed with the projections of data points onto , which implies that the first eigenvector also locates in the tangent space at . The subscript of indicates that is calculated from the data points of cardinality , while the subscript of indicates the locality. Specifically, is computed using the data points in , the Euclidean ball centered at of radius . With a different , the eigenvectors form the vector field . To avoid confusion, we will omit the subscript and of hereafter. The first eigenvalue is assumed to be simple throughout, which guarantees the uniqueness of . We note that the projection onto the local tangent space might be impossible in practice, in the case that either or the formula of the local tangent space is unavailable. Under these circumstances, we might omit the projection step in computing and use the local covariance matrix in ambient space instead.
Let us think of a simple example: noisy “C”-shaped data in as shown in Figure 2. Furthermore, by setting , we will use this example to demonstrate that determining fixed boundary flows is not a simple extension of the work of principal flows. The first eigenvalue in (1.1) varies with with Figure 2 visualizing its changes. One may see that the first eigenvalue reaches its trough at the Fréchet mean, which in turn implies that the first eigenvalue would have been increasing along any direction after its departure from . By differentiating (see derivation given in the Supplementary Materials) we have
[TABLE]
and that increases most rapidly along its gradient, that is, and . Therefore, maximizing either or at locally leads to two half-lines along and starting from . Hence, maximizing the optimization problem (1.1), which is the product of and locally, leads to the principal flow along through , as represented by the dashed line on the left panel.
Things are very different when one considers the fixed boundary flows, which begin from the fixed starting point , move along the data points and end at the fixed ending point . From the right panel of Figure 2, we observe that the is large at the boundary and will decrease when a curve moves towards the data cloud’s center from . Furthermore, from the differentiation form, decreases most rapidly along its gradient , as shown by the red arrow in the right panel of Figure 2 and increases most rapidly along , the dashed arrow shown on the right panel of Figure 2. Therefore, if one maximizes the inner product at in (1.1), in favor of the curve moving along the vector field , one should take . This means the curve would move along the red arrow in the right panel of Figure 2, which makes decrease most rapidly. While if one maximizes , one should take , in favor of the curve moving along since it is the gradient of . However, taking makes decrease fastest. From this point of view, we conclude that maximizing and the inner product in (1.1) is mutually conflicting. Such conflict makes the fixed boundary flows unique, unlike the principal flows, meaning one cannot, therefore, simply extend the optimization problem of principal flows to fixed boundary flows.
We are now motivated to consider the fixed boundary flows that capture the manifold data variation in a way that differs from the principal flows. To achieve this, we initialize an optimization problem to capture a smooth flow for non-random data lying on the manifold that starts and ends at pre-defined points in Section 2. For each point of the flow, its tangent vector is close to the vector field at that point. When noise presents, the data follows from the underlying distribution of the population flow on the manifold and it is thus non-deterministic. And so too are the fixed boundary flows. The random fixed boundary flows, generalizing the fixed boundary flows, are proposed in Section 3.1. An efficient algorithm to determine the random fixed boundary flow, with its convergence of the random fixed boundary flow, is outlined in Section 3.2. In Sections 4 and 5, we illustrate that the random fixed boundary flow is able to capture patterns of variation in synthetic, seismic and real-world image data. Several statistical properties and theories of the fixed boundary flow are examined in Section 6.
2 Fixed boundary flows
Fixing two boundary points produces an infinite number of flows. To begin with, we describe the class of curves that provide the candidates of the fixed boundary flows. Given and , we define the class as:
[TABLE]
where is the value of the vector field , calculated form local data at , and denotes the length of the parametric flow from to , for all . Here, denotes the geodesic distance between and and is a given constant. The choice of controls the size of . Since t\in[0,{{\color[rgb]{0,0,0}C\Delta}}], the length of the flows in the class is less than . A smaller C filters out the flows that (1) are far away from the data cloud by restricting the length of flows in the class , and (2) overfits the data (this is because overfitted flows tend to go through all data points which will increase its length). We assume without loss of generalization, otherwise the manifold should be rescaled. For any flow , we could determine its moving direction and vector field at every point. The moving directions and vector fields vary with different points and different flows. To follow the direction of highest variation, we aim to find a flow with a moving direction that matches the vector field as much as possible at any given point on the flow. From the classical mechanics perspective, we seek a flow with fixed starting and ending points, that best approximate the vector field globally. Conventional local Euclidean approaches fail to achieve this without being able to accommodate the boundary conditions globally, while forcing the flow to stay on the manifold. We term such an optimal flow the fixed boundary flow; that is, it is defined as a smooth flow on the manifold , starting and ending at the fixed points, with a derivative vector that is maximally compatible with the vector field , calculated from local data.
Definition 2.1**.**
(Fixed boundary flow at scale ) Let , where is the neighborhood that contains the data on the manifold. Assume that have distinct first and second eigenvalues for any . A fixed boundary flow of with given and is the curve satisfying
[TABLE]
where is the vector field over the neighborhood of for .
The fixed boundary flow is the solution of the optimization problem defined in (2.2).
3 Random fixed boundary flows
Besides being high-dimensional, the data on the manifold is usually noisy, representing some underlying distribution. One accessible way to illustrate the noisy data is shown in the following assumption.
Definition 3.1**.**
(Population flow) Given boundary points and , there exists a population flow under unit speed parameterization, depending on the continuous vector field distribution. Assume that passes through and , which means and with .
Assumption 3.1**.**
The data points satisfy
[TABLE]
where are ordered indices sampled from uniform distribution between on and are i.i.d. Gaussian noises.
Remark 3.1**.**
*Also, and . As shown in Figure 3, and are chosen to be at the inner end of the data cloud so that there are enough samples in the neighborhood of and . Section 3.2 will further formulate the relationship between () and the end points of the population flow. *
Under Assumption 3.1, the relation between the fixed boundary flow and is summarized in the following theorem.
Theorem 3.1**.**
Suppose Assumption 3.1 holds, the vector field is calculated at scale and . For any and given , there exist constants and such that if , then with probability .
The proof of Theorem 3.1 is given in Appendix B in the Supplementary Materials. From Theorem 3.1, we observe that the inner product is close to its maximum, that is, with sufficiently small . This means that the integrand in the optimization problem (2.2) achieves a very large value along the main segment of the flow . Note that we choose to work with simply because there might not be enough samples at the two ends of . Here, boundary and are at the inner end of the data cloud so that the main segment is away from and . Hence, well approximates the optimal solution to (2.2), as illustrated by Figure 3. The theoretical analysis will focus on the main segment of . For convenience, we use simplifying for the rest of the paper.
Now, let us turn to the random fixed boundary flows. Under Assumption 3.1 and given fixed boundaries, a random fixed boundary flow is the empirical flow, , computed from the data points with the fixed boundary. Our focus here is twofold. First is to determine the random fixed boundary flows through an efficient algorithm without intensive computation. Second is to investigate the distance property between the random fixed boundary flow and the population flow , where a theoretical analysis of the bound of the Hausdorff distance is derived from the geometry property of the underlying manifold.
3.1 Determination of random fixed boundary flows
The aim of the proposed approach is to determine the random fixed boundary flow via a discrete flow with the fixed boundary. Furthermore, each point of the discrete flow moves along the direction of the vector field, which captures the localized variation maximally. From this perspective, the proposed approach attains an approximate solution for the original optimization problem in (2.2).
Given the fixed boundary points and , the implementation begins with a discrete flow starting at and ending at , with a user-defined resolution . The choice of the initial flow can be a geodesic on the manifold or a straight line from to in the ambient space, neither derailing the convergence of the algorithm, as we will show. The initial flow is denoted by , with and satisfied and . Then, the proposed approach will iteratively update the flow from until the convergence criterion is met. Gradually, at each point, the flow is determined to maximize the localized variation of the data. Hence, user-defined values for the scale parameter , shrinkage constant and stopping criterion constant , are each needed during iterations.
During the iterations, we update the discrete flow , , for by maximizing the optimization problem (2.2). There are four core steps with this aim in mind: choosing scale parameter, calculating local covariance matrix, determining vector field, and updating. Here, we elaborate on each of these core steps, as shown in Figure 4.
- (1)
Choosing scale parameter: we choose an appropriate scale parameter , where and is a shrinkage constant. In our study, we let . One may note that the shrinkage constant makes the scale parameter decrease during the iterations. Hence, the scale parameter guarantees the capture of the local variation.
- (2)
Calculating local covariance matrix: the local covariance matrix is determined by using the discrete flow that we have obtained from the previous iteration. Specifically, we use the points , , with odd indices to calculate the local covariance matrix. Determining the local covariance matrix is a vital step for the following updating step of the discrete flow. We note that the points , , may not lie inside the data cloud. To capture the local variation accurately, we propose to project these points back inside the data cloud. To this aim, we first project these points to the nearest data points. As the nearest data points might be outliers, we further select the local data points within the distance of from the nearest data points and obtain the mean points. Eventually, the projected points , are the nearest data points to the mean points. Then, the projected points are used to select the local data points to further compute the local covariance matrix. Denote by the data points in the neighborhood of the Euclidean ball with center and radius . Eventually, the local covariance matrix is computed at the mean of the local data points and can be calculated by
[TABLE]
where .
- (3)
Determining vector field: following on from the local covariance matrix that we obtained in the previous step, the vector field is to determine at the mean points . Denote by the vector field at point , . By now, the local variation is captured by the local covariance matrix . Hence, the direction along the first eigenvector shows the maximum variation. We let the vector field .
- (4)
Updating: as the boundary points are fixed, we first let and . For the points with odd indices, we let , . The vector field is used to update the points with even indices. Specifically, we map the points to the directions of the two adjacent vector fields and for . We denote the two projected points by and . Hence, we update the points by using the mean point of and .
It is crucial to ensure that the random fixed boundary flow always moves along the direction that maximizes the vector field. Therefore, a stop criterion is necessary to the implementation. According, we terminate the iteration process when the optimization function does not change too much. Lastly, interpolation and projection will be implemented to ensure that the points on the resulting random fixed boundary flow are equidistant and lie on the manifold. The detailed algorithm is summarized in Algorithm 1. The convergence of the random fixed boundary flow will be investigated in Section 3.2.
3.2 Convergence of the random fixed boundary flow
In the following statement, and denotes the cardinality of . We use upper , or lower to denote constants greater or less than 1. Here, a constant means a value independent of , and . Values of and with various subscripts may differ from line to line.
Recalling our Assumption 3.1, samples are blurred by Gaussian noise. Hence, by Gaussian concentration, the maximal distance between a point and is bounded above by with probability at least . If is sufficiently small such that
[TABLE]
we can further bound the maximal distance between a point and above by , with probability , since the following holds
[TABLE]
This inequality above shows that the samples mainly lie in the tube surrounding . Considering a point satisfying with , the intersection cannot be ignored, hence the following assumption holds true.
Assumption 3.2**.**
For any , if satisfies , then .
Note that Step 3(a) of Algorithm 1 projects points to the data cloud by finding its nearest samples in . Assumption 3.2 bounds the distance between the given point and the projected point above, which essentially leads to the convergence. Algorithm 1 selects decreasing scales with a given in each iteration, until the scale is less than or the objective function hardly changes. Each iteration takes the output discrete flow of the previous iteration as input, updates the vector field with a smaller scale and outputs a discrete flow using the updated vector field. Theorems 3.2 - 3.4 with full proofs in Appendix C in the Supplementary Materials, together prove that the random fixed boundary flow converges to the population flow , given certain conditions of the initial discrete flow.
Specifically, Theorem 3.2 exploits the -th iteration and bounds above when (a) its input discrete flow is sufficiently close to , (b) the points in the discrete flow are sufficiently dense, and (c) the points with odd indices are not too close to the two ends of the population flow. Note that (c) is needed since the vector field near the two ends does not follow the population flow. This means that the fixed boundaries and should be chosen not too close to the two ends, and , in practice. Theorem 3.3 proves that imposing constraints on the initial discrete flow, that is the input discrete flow for , also leads to the upper bound of . Theorem 3.4 proves the convergence of the random fixed boundary flow, as the projection of onto .
Theorem 3.2**.**
Suppose the discrete curve at the -th iteration satisfies the following conditions:
- (a)
,
- (b)
* for any ,*
- (c)
\|\tilde{\gamma}^{{\scriptscriptstyle(k)}}(t_{2j+1})-\gamma^{\ast}(0)\|\geq(2C_{1}+{{\color[rgb]{0,0,0}3.5}})h^{{\scriptscriptstyle(k)}}* and \|\tilde{\gamma}^{{\scriptscriptstyle(k)}}(t_{2j+1})-\gamma^{\ast}(r^{*})\|\geq(2C_{1}+{{\color[rgb]{0,0,0}3.5}})h^{{\scriptscriptstyle(k)}} for any ,*
For any given , there exists such that any point in the polyline
[TABLE]
is also within Hausdorff distance to with probability .
We only sketch the proof of Theorem 3.2. Recalling Algorithm 1, the polyline is composed of segments passing and along . Lemma 3.1 in the Supplementary Materials proves are within Hausdorff distance to . Lemma 3.2 proves the vector field at approximate the tangent vector of in the order of . Based on these, Lemma 3.3 in the Supplementary Materials proves that the segments which pass along approximates in the order of . Hence, the polyline which is composed of these segments is also within Hausdorff distance to .
Theorem 3.3**.**
If the conditions (a)-(c) in Theorem 3.2 hold for and the constants in Theorem 3.2 further satisfies
[TABLE]
then for any given , with probability .
According to the stopping criteria, when Algorithm 1 stops. Hence, the final polyline satisfies
[TABLE]
Note that the interpolation step generates a discrete curve containing , and the projection step will not change the order of the Hausdorff distance as Theorem 3.4 has proved. To be precise, the final discrete curve of Algorithm 1 is located in a tube along the population curve with a radius in order of .
Theorem 3.4**.**
If , then , where is the projection of onto .
4 Simulations
To illustrate the performance of random fixed boundary flows, we studied several random data sets generated on two manifolds, a unit sphere and a right-circular unit cone. The two manifolds are in with intrinsic dimension . In the simulation, the boundary points were selected manually from the given data set so that there are enough data points around the boundary points to calculate the local variation. To generate the random fixed boundary flows, we applied the proposed algorithm with different values of the scale parameter . Here, we note that the random fixed boundary flow is a discrete curve with derivatives that approximately capture the direction of the maximum local variation depending on . Throughout the numerical studies in sections 4 and 5, we use RFBFs to denote random fixed boundary flows.
In the first part of the simulation, we evaluate the performance of the RFBFs on the unit sphere. The noisy data sets are randomly generated from three population flows, which are plotted in purple in Figure 5 (a)-(c). Specifically, Gaussian noise is added to the points on the population flows with a constraint such that the perturbed points remain on the test manifold. In this manner, we generated three noisy data sets, each representing different types of variation on the unit sphere. The first data set is concentrated around a “C”-shaped curve on the unit sphere, thus presenting a variation pattern along the geodesic. After that, we considered two data sets from two non-convex closed flows. In this setting, the simulated data sets present local variation patterns along the non-convex flows. In particular, the second data set is generated from a quarter of the six-fold star-shaped flow, and the third data set is concentrated around a half of the two-fold star-shaped flow.
To obtain RFBFs, the initial flows used in our analysis are straight lines connecting and . One may use other initial flows, for example, the geodesic from to . Given a set of randomly generated data, we obtained a RFBF with a specific . For the data sets plotted in Figure 5 (a)-(c), the RFBFs obtained with a specific value of are illustrated in red in Figure 5 (d)-(f). To further investigate the performance, we obtained ten sets of random data for each population flow. The RFBFs are then obtained with a sequence of for the random data. An analysis of the mean errors for the Hausdorff distances between the population flow and RFBFs are summarized in Table 1. From the numerical results, we note that the RFBFs are able to capture the variation globally and locally. As we lower , the performance accuracy of the RFBFs improves generally. On the other hand, overfitting may occur as we lower gradually.
For the two non-convex population flows in Figure 5 (b)-(c), we also generated noisy data sets from the whole closed flows. As boundary points are required to obtain RFBFs, we handled these noisy data sets parts by parts. For example, we fitted the noisy six-fold data set quarter by quarter and the noisy two-fold data set half by half. We specified the boundary points for each part of the whole data set and obtained the RFBFs with predetermined values of . The obtained RFBFs are shown in red in Figure 6. To compare the performance accuracy, we further applied the level set methods in Liu et al. (2017) to the random data sets and plotted the obtained curves in blue in Figure 6. In contrast to the level set methods, the RFBFs are able to capture the local variation better, especially at the parts of the curves with high curvature. We also note that the level curve methods reach the locations outside the data cloud at some parts of the two-fold data.
In the second part of the simulation study, the testing manifold is extended to a right-circular unit cone, with apex at , height and radius . Three types of random data sets are generated to examine the performance of RFBFs on the right-circular unit cone. The first data set is concentrated around a band on the cone. For the second and third data sets, they are generated from a “C”-shaped and “S”-shaped population flows on the tested manifold. The RFBFs with a predetermined value of are illustrated in red in Figure 7. As the data plotted shown, we observe that the RFBFs work well to capture different types of variations on the cone. Similarly, we fitted RFBFs with a sequence of for ten randomly generated data sets. To examine the performance accuracy, the mean errors of the Hausdorff distances between the population flows and RFBFs are summarized in Table 1. As expected, the obtained RFBFs do indeed divine the variation accurately on the cone as we lower . It becomes more challenging to capture the variation accurately for all three types of variation investigated when the variation pattern becomes more complicated.
5 Real Data Application
5.1 Seismological Data
Here we explain the full analysis of the previously mentioned seismological events. The data set was sourced from the International Seismological Center (ISC) and features significant earthquakes (magnitude in Richter scale and above, including continental events of magnitude ) between 1904 and 2015. The earthquake epicentre data is plotted in black in Figure 8. Before we fit the RFBF for the earthquake data, we first investigate the distribution of the first eigenvalue for the data. This is shown in Figure 8, from which we observe that the variation of the first eigenvalue among the earthquake epicentres along the distribution of the earthquakes is quite non-uniform. Furthermore, we also observe that the first eigenvalue changes with different values of , which changes the determination of local variation. Hence, the analysis of seismological events is an example with a varying first eigenvalue and we will investigate the performance of RFBF for this case.
We note that earthquakes tend to occur around the tectonic plate boundaries. As has been mentioned earlier, the shape of the plate boundaries shown in Figure 1(a) carries the global variation (from east to west, or north to south) and the localized variation along different plates. If we select and around the Philippine Sea plate manually, we expect the RFBFs would move along the plate boundary and mirror the blue curve shown in Figure 1(c). At the same time, the movement of the RFBFs will also reflect the local variation pattern of the data, which is captured by . In our analysis, we scaled the data onto the unit sphere and selected three different sets of and along the Philippine Sea plate manually. Figure 9 illustrates the earthquake data on a flat world atlas with the three sets of and , namely (a)-(c), (d)-(f) and (g)-(i). To visualise and compare the performance, we fit RFBFs using three values of . As we expected, the RFBFs move along the boundary of the Philippine Sea plate and capture the variation between the given boundary points. Furthermore, we let vary and visualize the RFBFs that reflect the various localized variation patterns. Given the boundary points, we note that the RFBFs work well in capturing the variation patterns of the data. As we lower , the RFBFs uncover the global and local variation pattern more accurately. For example, when we set , the RFBFs in Figure 9 (a), (d) and (g) move inside the data cloud and trace the global variation from south to north better than the RFBFs in the other plots of Figure 9. When we gradually increase the value of , more data points will be involved in the determination of the local variation and this also influences the trend of the RFBFs. In the last three plots of Figure 9, we select two sets of boundary points with opposite directions. Comparing the results in Figure 9 (a)-(c) and (g)-(i), we note that the direction of the boundary points does not inordinately affect the RFBFs with the same .
5.2 Labeled Faces in the Wild
In this section, we consider another concrete case – Labeled Faces in the Wild (LFW) in Huang et al. (2007). The data set comprising face photographs is designed to provide a system of face recognition with over images of faces collected from the web. Each face image is labeled with the name of the person in that image. Note also that among those face images are people who have two or more distinct photographs in the data set.
In our study, we downloaded images of people with four images of each person. To facilitate the analysis, the face region was cropped from the original image and resized to pixels. The images of the face region for the individuals can be found in the Supplementary Materials. As the analysis uses four different images for each individual, the data set can be written as , where are vectors in the ambient space . We assume that the data points lie on the unit sphere , which is embedded in . To begin with, we chose two images with the largest distance from one another in the ambient space, setting them as and . As shown in Figure 10, the image of Andy Roddick in Figure 10(a) is the starting image, and the image of Jack Straw in Figure 10(p) is the ending image in our analysis. Then, we fit RFBFs with various values of .
The obtained RFBFs are discrete flows of face images which capture the variation of facial structure from the starting image to the ending image. With the exception of the boundary images on the RFBFs, we generated a sequence of fake faces, which are plotted in Figure 10 (b)-(o). The person plotted in each fake face image is not a real person that can be identified in the given image set. On the contrary, the person is constructed using the characteristics extracted from the local and global variation pattern of the given images. The intermediate face images on the RFBF reflect the progressive face changing from the starting image to the ending image. There are some noteworthy conclusions that we draw from the RFBFs. First, the skin tone of Andy Roddick shown in the starting image of Figure 10 (a) appears somewhat wheatish, while Jack Straw’s face, plotted in the ending image of Figure 10 (p), possesses a light skin tone. Through the fake faces constructed on the RFBF, we are able to observe the gradual changes of skin tone from dark to light. Second, we note that the Andy Roddick dons a cap in the starting image and Jack Straw’s hairstyle features a fringe in the ending image. For the first few images in Figure 10 (b)-(f), the fake faces on the RFBF are also wearing caps. In the last few images plotted in Figure 10 (m)-(o), the fake faces of the RFBF have fringes. Hence, we are also able to monitor the change of hairstyle through the intermediate fake faces on the RFBF. Although RFBFs are able to reveal some progressive face changes, the characteristics captured by the RFBFs are one-dimensional. Hence, the variation pattern analyzed by the RFBFs is limited when we are dealing with high-dimensional data with large values. We will consider the extension of RFBFs in the future.
6 Fixed Boundary Flow for Non-random Data in Euclidean Space
The aim of this section is to prove that fixed boundary flows for non-random data are canonical, in the sense that they will pass through the usual principal component, in the context of Euclidean spaces. Hereafter, we suppose is a linear subspace of , and , which implies
[TABLE]
Under this configuration, we will figure out the supremum of defined in (2.2) subjected to the constraint defined in (2.1).
Proposition 6.1**.**
Suppose \gamma_{*}:[0,{{\color[rgb]{0,0,0}C\Delta}}]\to\mathcal{M} such that
[TABLE]
If \gamma_{*}({{\color[rgb]{0,0,0}C\Delta}})=\bar{x}_{2}, then is the unique optima of (2.2)
Proof.
Since and are units for any , we have
[TABLE]
and the equation holds only if for any . Hence, is the only curve that enables the equation to hold, and is accordingly the unique optima of (2.2). ∎
Proposition 6.1 analyzes the optima of (2.2) under a strict condition that with . If the condition is relaxed to be , things are more difficult. For further analysis, we suppose the original point of to be , and to be the basis with . For convenience, we denote to be the -th coordinate of any and hereafter.
Before giving our final proposition, we define some important sets and curves first. With representing Hadamard multiplication, we denote a subset of , where the curves have the same direction with ,
[TABLE]
The red curves in Figure 11 (a) demonstrate flows satisfying , that is, the curves have the same direction as . Denote and as the projections of and , respectively, onto the first axis. And () as the set of the curves from () to (), orthogonal to and satisfying . We set
[TABLE]
And we also set as the straight line between and , that is .
Let be the concatenation of and , that is satisfying
[TABLE]
then is continuous and in the closure of by Proposition 4.1 in the Supplementary Materials. The yellow curve in Figure 11 (a) demonstrates .
In Figure 11 (a), we use the blue arrows to demonstrate an example of the vector field satisfying Assumption 6.1. Generally speaking, this refers to the arrows at the left half plane pointing towards and arrows at the right half plane pointing in the opposite direction. Moreover, the arrows straighten horizontally as they approach the second axis. We summarize the assumptions on the vector field in Assumption 6.1 (b) and (c).
Assumption 6.1**.**
**
- (a)
* and .*
- (b)
For any , and for any .
- (c)
Suppose and are in . If and , then for any .
Assumption 6.1 is not strict. Figure 12 illustrates (b) and (c) of Assumption 6.1 with two data sets, as represented by black points that are concentrated around a “C”-shaped curve and an “S”-shaped curve in . The two diagrams in the left-hand panel show the vector fields for the two data sets, both of which satisfy Assumption 6.1(b), while the diagrams in the right-hand panel show how varies at different points of . Specifically, gets larger when the color transitions to yellow, and smaller when the color transitions to blue. One can conclude from the two diagrams in the right panel that the vector field between the two orange lines satisfies Assumption 6.1(c).
We can now set out sthe second proposition, which is under the general condition with . This proposition shows that if we restrict in , the fixed boundary flow will pass through the usual principal component.
Proposition 6.2**.**
If , then
[TABLE]
The proof of Proposition 6.2 can be found in Appendix D in the Supplementary Materials. Also in Appendix D in the Supplementary Materials, we further explain the inequality
[TABLE]
Combining the inequality in Proposition 6.2 and the inequality (7.6), we conclude that the optimal solution of (2.2) always passes through the usual principal component. The scheme to show the inequality (7.6) is organized as follows. As shown in Figure 11(b) and (c), we construct (the red curve) by any (the blue curve), and illustrate . In particular, if the dimension of the space is 2, the comparison between and can be achieved by calculating the integration over the gray area using Green’s Theorem.
7 Discussion
The determination of a fixed boundary flow for data points on non-linear manifolds is a very different problem from the case of principal flow. We propose the notion of a fixed boundary flow to define a curve with fixed starting and ending points and a tangent velocity that matches the maximal variation of data in its neighborhood at each point. The local geometry of data variation is represented by the tangent space at the given point, which compels us to use the local vector fields. Based on this choice, we formulate an optimization framework to construct a smooth curve on the manifold, with a tangent vector that always matches the local vector fields. There is no doubt that the solution to the optimization problem, and equivalently, the fixed boundary flow, depends on how a neighborhood is defined at a certain point, just as with principal flow.
The choice of the neighborhood depending on the scale parameter determines how local or global covariation features are captured by the fixed boundary flow. Algorithm 1 provides a way to select a series of decreasing till , which obliges us to focus on the global trend of the curve first and the local second. Using this algorithm, we generate a curve represented by . We discuss below the construction of a “confidence band” for the resulting fixed boundary flow . As we define the confidence band for the flow on the manifold, it should be a confidence ellipsoid. Note that the samples in roughly lie within an ellipsoid with principal axes of length , , respectively. Thus, we use the formulation of to construct the “confidence band”. Specifically, for any point on the computed fixed boundary flow , we can define an ellipsoid of dimension in the intersection of and the normal space at , which could cover most samples in this intersection. By allowing the orthonormal be a basis of , the confidence ellipsoid is of dimension obeying
[TABLE]
where is the projection of onto and V=\big{(}U(\tilde{\gamma}(t))U(\tilde{\gamma}(t))^{T}-\dot{\tilde{\gamma}}(t)\dot{\tilde{\gamma}}(t)^{T}\big{)}(e_{2},\cdots,e_{m}). Note that can be estimated with certain theoretical guarantees (see Tyagi et al. (2013)). We remark that usually approximates , that is, . This makes full column rank, and consequently, the dimension of the ellipsoid is . If is happened to be orthogonal to , the dimension of the ellipsoid would reduce to . With certain covering ellipsoid conditions for the samples in the neighborhood, one might consider bounding and under the current setting. Some of the results in Yao and Zhang (2020) will be helpful in this respect. As this is part of our ongoing work, we intend to further investigate it in the future.
Acknowledgements
ZY is grateful for the financial support from his Singapore Ministry of Education (MOE) Tier 1 funding (A-0004809-00-00) and Tier 2 funding (A-0008520-00-00) at the National University of Singapore. ZY thanks Professor Shing-Tung Yau for his comments and discussion and the support from the Center of Mathematical Sciences and Applications at Harvard University.
Appendix A: Preliminaries
In this section, we will introduce some preliminaries in Riemannian geometry and review the principal flows. We focus on studying a complete Riemannian manifold of dimension , equipped with a metric . The smooth Riemannian manifold can be isometrically embedded into the Euclidean space , . Assuming that the embedding is known, there exists a known differentiable function , and we have
[TABLE]
The Riemannian metric on the Riemannian manifold is induced by an inner product defined in the tangent space at each point , and the tangent space is denoted by
[TABLE]
where is the derivative matrix of evaluated at . Since the tangent space is able to locally approximate the manifold, we define two mappings between the tangent space and the manifold. The exponential map at takes a tangent vector denoted by
[TABLE]
and there exists a unique geodesic satisfying with initial velocity . Therefore, the exponential map is locally defined by in the neighborhood of . The inverse of the exponential map, the logarithm map, is denoted by
[TABLE]
Before we review principal flows, we recall the Fréchet mean and tangent space PCA, which are basic elements to construct principal flows. Let be the data points lying on the manifold , where there exists a connected open set , such that covers . The Fréchet mean is the point that minimizes the sum of square distances under the Riemannian metric
[TABLE]
The tangent components at form a basis for the tangent space , and they are given by the first eigenvectors of the scale local tangent covariance matrix
[TABLE]
where , and .
When , and , the local tangent covariance matrix reduced to be
[TABLE]
Noting is unit length, , we could calculate the derivation of as follows:
[TABLE]
Appendix B: Proof of Theorem 3.1
In subsequent proof, we need a special case of Theorem 8 by Yao and Xia (2019), where the manifold degenerates into a curve, that is, the dimension of the manifold is . We state this special case of Theorem 8 below, where we use instead of as the scale, to ensure the same as the symbol in this paper.
Theorem 7.1** (Slight deformation of Theorem 8 by Yao and Xia (2019)).**
Let be a point off a curve , be the projection of onto , . We have
[TABLE]
where denotes the orthogonal projection onto the normal space of and . Here is the orthogonal component of and is the first eigenvector of .
To bound the summation of some power of above, we need Proposition 2.3 by Yao and Xia (2019) as follows.
Proposition 7.1** (Proposition 2.3 by Yao and Xia (2019)).**
Suppose ; then we have, for any positive integer :
- (1)
**
- (2)
**
- (3)
\mathbb{E}\big{(}\|\xi\|_{2}^{k}-\mathbb{E}(\|\xi\|_{2}^{k})\big{)}^{3}=C_{3}\sigma^{3k}**
- (4)
* and are independent if and are independent,*
where , , and are three constants depending on and .
Based on the above proposition, we obtain the upper bound of the summation of each for points lying in a tube surrounding .
Proposition 7.2**.**
For a given , there exists such that if , then
[TABLE]
holds with probability for any satisfying , , and .
Proof.
Noticing are i.i.d. samples drawn from Gaussian distribution, we can obtain the expectation , variance and the third moment of according to Proposition 7.1. By Berry-Esseen Theorem, the cumulative distribution of \big{(}\sum_{i\in{\cal I}(x,h)}\|\xi_{i}\|^{k}-\mu_{k}|{\cal I}(x,h)|\big{)}/\big{(}\sigma_{k}\sqrt{|{\cal I}(x,h)|}\big{)} denoted by satisfies
[TABLE]
where is the cumulative distribution function of standard normal distribution. So, there exists depending on , and such that
[TABLE]
with probability at least .
To estimate , we calculate the probability of based on ,
[TABLE]
Letting be the projection of onto , then since . Since and , there exists such that and satisfy . Hence, \ell(\gamma^{\ast}\cap B_{d}(x,h/2))\geq\|x_{1}-x^{*}\|+\|x^{*}-x_{2}\|\geq\big{(}\|x_{1}-x\|-\|x-x^{*}\|\big{)}+\big{(}\|x-x_{2}\|-\|x-x^{*}\|\big{)}\geq h/2. Since each entry of obeys Gaussian distribution, obeys Chi-squared distribution. According to the cdf of Chi-squared distribution, we could obtain , and thereby . Thus, whether or not can be treated as a Bernoulli distribution with expectation no less than . Applying Berry-Esseen theorem to the Bernoulli trials, there exists such that with probability , which implies,
[TABLE]
Setting
[TABLE]
one could verify and , which implies . Hence, we could take
[TABLE]
to complete this proof. ∎
Proof of Theorem 3.1.
For any , plugging into Theorem 7.1, we have
[TABLE]
where the second inequality holds by Proposition 7.2 with probability , and the last inequality holds since .
Let , the tangent vector of at , and , the first eigenvector of . By the definition of and , we have and . Hence . Noting
[TABLE]
we have , that is, , which completes the proof. ∎
Appendix C: Proof of Theorem 3.2 - Theorem 3.4
Lemma 7.1**.**
Suppose , , and . For any given , there exists independent on and such that with probability .
Proof.
In this proof, we simplify to be for convenience. For , we use to represent the projection of onto , and similarly, use to represent the projection of onto . Denoting the tangent space of at to be , we have
[TABLE]
where by (3.3) in the main manuscript and
[TABLE]
To get a tight bound on , we denote to be the orthogonal projection onto the normal space of at and obtain
[TABLE]
where the second term of the last inequality follows Theorem 4.18 by Federer (1959). Noting
[TABLE]
and with high probability by Proposition 7.2, we could bound
[TABLE]
which completes the proof. ∎
Lemma 7.2**.**
Let be a point off , be the projection of onto , and be the tangent vector of at . If and for , then for any given , there exists such that with probability .
Proof.
Since , . Plugging into Theorem 7.1, we have
[TABLE]
where the second inequality holds by Proposition 7.2 with probability , and the last inequality holds since .
By the definition of and , we have and . Hence . ∎
Proposition 7.3**.**
Suppose and are normal vectors, then .
Proof.
To prove this proposition, we calculate and respectively as per and which complete the proof. ∎
Proposition 7.4**.**
If and , then .
Proof.
Let and . By Taylor’s expansion,
[TABLE]
where and since and . Hence, we could obtain . ∎
Proposition 7.5**.**
Suppose , , and . If , then .
Proof.
This proof is conducted in two steps: First, we show that there is such that and then we bound . These two claims conclude .
To begin with,
[TABLE]
where by Lemma 7.2. Denote the projection of onto to be , then
[TABLE]
Taking and in Proposition 7.4, we have , which completes the proof. ∎
We impose constrains to rather than and , and obtain the following Lemma. We use to denote the segment between and hereafter, that is, .
Lemma 7.3**.**
Suppose the discrete curve at the -th iteration satisfies the following conditions:
- (a)
,
- (b)
* for any ,*
- (c)
* and for any .*
For any given , there exists such that the segments s\big{(}\gamma_{{\rm proj},2j+1}^{{\scriptscriptstyle(k)}}(t_{2j}),\gamma_{{\rm proj},2j+1}^{{\scriptscriptstyle(k)}}(t_{2j+2})\big{)} for any are within Hausdorff distance to with probability .
Proof.
Since for each , is non-empty according to Assumption 3.2 in the main manuscript. As the closest point to , exists and . Moveover, since is the mean of . Noting , the nearest sample in the data cloud to , which is the final projection of to the data cloud denoted by , satisfies
[TABLE]
Hence, the distance between and the ends of can be bounded below as
[TABLE]
Plugging into Lemma 7.1, we conclude with probability . Moreover,
[TABLE]
for . Hence, the conditions on in Proposition 7.5 are satisfied for with probability . We utilize Proposition 7.5 to prove the conclusion for the segment between and . Since is the projection of onto the line passing along direction , can be written as with . Thus,
[TABLE]
Analogically, can be written as with
[TABLE]
Any point on the segment between and is a convex combination of and , that is, such a point equals
[TABLE]
with a certain . Also, we could verify that . Hence, any point on the segment between and satisfies the condition of Proposition 7.5 and thereby it has a distance less than to , where is independent on . ∎
Proposition 7.6**.**
If , and , then for any .
Proof.
Letting and be the projections of and onto respectively, then . Letting be the tangent space of at ,
[TABLE]
by Theorem 4.18 in Federer (1959).
Based on the above inequalities, we start to bound for . Denoting be the normalized tangent vector of at , then
[TABLE]
Let the projection of onto be . We could bound as
[TABLE]
and thereby we could bound by Proposition 7.4. Hence, we have
[TABLE]
∎
Proof of Theorem 3.2.
For any , we will show that as the two projections of to and respectively, and are not far away from each other:
[TABLE]
where the last inequality holds by (7.2) and (7.3). According to Lemma 7.3, the two segments s\big{(}\gamma_{{\rm proj},2j-1}^{{\scriptscriptstyle(k)}}(t_{2j-2}),\gamma_{{\rm proj},2j-1}^{{\scriptscriptstyle(k)}}(t_{2j})\big{)} and s\big{(}\gamma_{{\rm proj},2j+1}^{{\scriptscriptstyle(k)}}(t_{2j}),\gamma_{{\rm proj},2j+1}^{{\scriptscriptstyle(k)}}(t_{2j+2})\big{)} are within Hausdorff distance to with probability . And thereby the two points and are within Hausdorff distance to . Plugging and into Proposition 7.6, we could prove the Hausdorff distance between and is less than for any . Similarly, we could also prove and are within the same Hausdorff distance. As the union of all the segments, . ∎
Proposition 7.7**.**
Given the initial discrete curve , if there exists constants , and satisfies
- (a)
* and ,*
- (b)
, for any
- (c)
* for any ,*
- (d)
* and for any .*
- (e)
**
then the three conditions of Lemma 7.3 hold with probability for any .
Proof.
Since , , the conditions and hold for any . In order to prove the three conditions hold for if they hold for , we only need to prove the three conditions hold for if they hold for . If the conditions hold for , then Lemma 7.3 holds. We obtain the segments \{s\big{(}\gamma_{{\rm proj},2j+1}^{{\scriptscriptstyle(k)}}(t_{2j}),\gamma_{{\rm proj},2j+1}^{{\scriptscriptstyle(k)}}(t_{2j+2})\big{)}\} for any are within Hausdorff distance to with probability . Hence, by Proposition 7.6, we obtain
[TABLE]
which is the first condition of Lemma 7.3 with probability .
is a continuous polyline starting at and ending at . Removing the points in and from , we obtain
[TABLE]
Since , is non-empty. Hence, we could select a discrete curve , , from , such that nearby points are within distance , that is, for any , the second condition of Lemma 7.3 at the -th iteration. Moreover, since , we have for , which is the third condition of Lemma 7.3. ∎
Proof of Theorem 3.3.
By Proposition 7.7, the three conditions of Lemma 7.3 hold with probability for any . When the conditions hold, we have
[TABLE]
by Theorem 3.2. Hence,
[TABLE]
∎
Proof of Theorem 3.4.
Since , we have . Using this inequality, we could obtain the following inequalities:
[TABLE]
∎
Appendix D: Data set of Labelled Faces in the Wild in Section 5.2
In our study, we downloaded images of people with four images of each person. The images of the face region for the individuals are shown in Figure 13.
Appendix E: Proof of Proposition 6.2
Proposition 7.8**.**
If , then belongs to the closure .
Proof.
For simplicity, we denote to be the closure of a set . Let be the set of polynomials and be the set of continuous functions. Based on the Stone-Weierstrass Theorem, we have , which implies that the closure of is . Based on this conclusion, we have
[TABLE]
and
[TABLE]
Since is continuous and satisfies , we conclude that . ∎
Proof of Proposition 6.2.
For any , there exists such that , since and . Define by and by . It is easy to verify that , and thereby
[TABLE]
by Assumption 6.1 (b) and (c).
Considering that and are constant, we have and thereby
[TABLE]
where . Since we can always reparameterize to be a unit speed one, say , the concatenate of and belongs to . Hence,
[TABLE]
We can similarly verify that
[TABLE]
Moreover, by , we have and thereby
[TABLE]
Hence,
[TABLE]
Since , the supremum can be achieved, which completes the proof. ∎
Next, we will discuss the inequality
[TABLE]
Actually, if satisfies , then we define by . We specially set , and for we set
[TABLE]
where is defined in the proof of Proposition 6.2. Using Assumption 6.1 (b), we can verify that .
In Figure 14, we display the cross sectional area of along the first and -th axis for . In the left panel, the blue curve is and the red curve is . Without loss of generality, we focus on and . The other three cases in (7.7) can be similarly verified.
First, we compare the integrals over the orange curve and the yellow curve in Figure 14. Then the integral on denoted by is
[TABLE]
and . Then, is the integral of over the closed anticlockwise curve consisting of and the inverse of . When , such integral is equal to an integral over the gray region denoted by shown in the right panel of Figure 14 by Green Theorem, that is,
[TABLE]
since for based on Assumption 6.1(c). For , if holds for any and holds for any , the conclusion can be extended to a higher dimension by the Stokes’ theorem.
Second, we compare the integrals over the purple and pink curve in Figure 14. By Assumption 6.1 (b), the integral of over the purple curve is negative, while the integral over the pink curve is zero. So, the integral of over the purple curve is less than the pink curve. The above discussion summarizes for any . Moreover,
[TABLE]
where the last inequality can be verified by similar proof of Proposition 6.2. Implementing the above discussion for analogically, we also have
[TABLE]
Along with (7.5) we conclude
[TABLE]
which supports the inequality (7.6).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Arjovsky et al. (2017) Arjovsky, M., S. Chintala, and L. Bottou (2017). Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning (ICML) , pp. 214–223.
- 2Bradley et al. (2013) Bradley, D., D. Nowrouzezahrai, and P. Beardsley (2013, july). Image-based reconstruction and synthesis of dense foliage. ACM Transactions on Graphics (TOG) 32 (4), 74:1–74:10.
- 3Cox and Cox (2000) Cox, T. F. and M. A. Cox (2000). Multidimensional scaling . Chapman and hall/CRC.
- 4Dryden and Mardia (2016) Dryden, I. L. and K. V. Mardia (2016). Statistical shape analysis: with applications in R , Volume 995. John Wiley & Sons.
- 5Eltzner et al. (2018) Eltzner, B., S. Huckemann, T. Hotz, and K. Mardia (2018). Torus principal component analysis with applications to rna structure. Annals of Applied Statistics 12 , 1332–1359.
- 6Federer (1959) Federer, H. (1959). Curvature measures. Transactions of the American Mathematical Society 93 (3), 418–491.
- 7Fefferman et al. (2018) Fefferman, C., S. Ivanov, Y. Kurylev, M. Lassas, and H. Narayanan (2018). Fitting a putative manifold to noisy data. In Proceedings of the 31st Conference On Learning Theory , Volume 75, pp. 688–720. PMLR.
- 8Fefferman et al. (2016) Fefferman, C., S. Mitter, and H. Narayanan (2016). Testing the manifold hypothesis. Journal of the American Mathematical Society 29 (4), 983–1049.