On guiding video object segmentation
Diego Ortego, Kevin McGuinness, Juan C. SanMiguel, Eric Arazo, Jos\'e, M. Mart\'inez, Noel E. O'Connor

TL;DR
This paper introduces a guided convolutional neural network approach for video object segmentation that leverages foreground masks from existing algorithms to improve segmentation accuracy in challenging environments.
Contribution
It proposes a novel guided CNN framework that uses external foreground masks to enhance segmentation, combining color and motion features for better separation.
Findings
Outperforms non-guided segmentation methods on DAVIS 2016 dataset.
Effectively integrates color and optical flow features for segmentation.
Achieves state-of-the-art results in challenging environments.
Abstract
This paper presents a novel approach for segmenting moving objects in unconstrained environments using guided convolutional neural networks. This guiding process relies on foreground masks from independent algorithms (i.e. state-of-the-art algorithms) to implement an attention mechanism that incorporates the spatial location of foreground and background to compute their separated representations. Our approach initially extracts two kinds of features for each frame using colour and optical flow information. Such features are combined following a multiplicative scheme to benefit from their complementarity. These unified colour and motion features are later processed to obtain the separated foreground and background representations. Then, both independent representations are concatenated and decoded to perform foreground segmentation. Experiments conducted on the challenging DAVIS 2016…
Click any figure to enlarge with its caption.
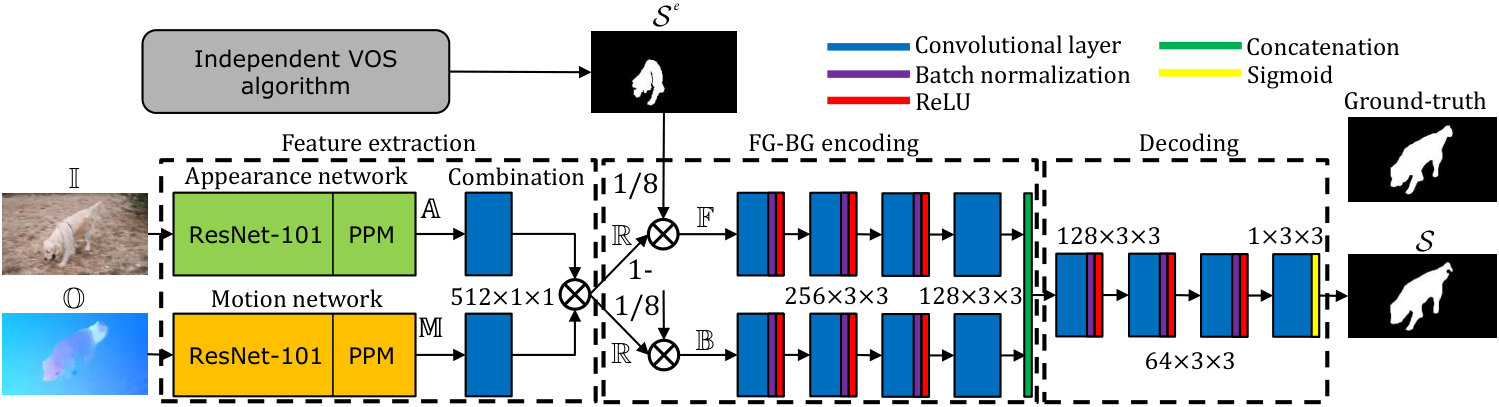 Figure 1
Figure 1 Figure 2
Figure 2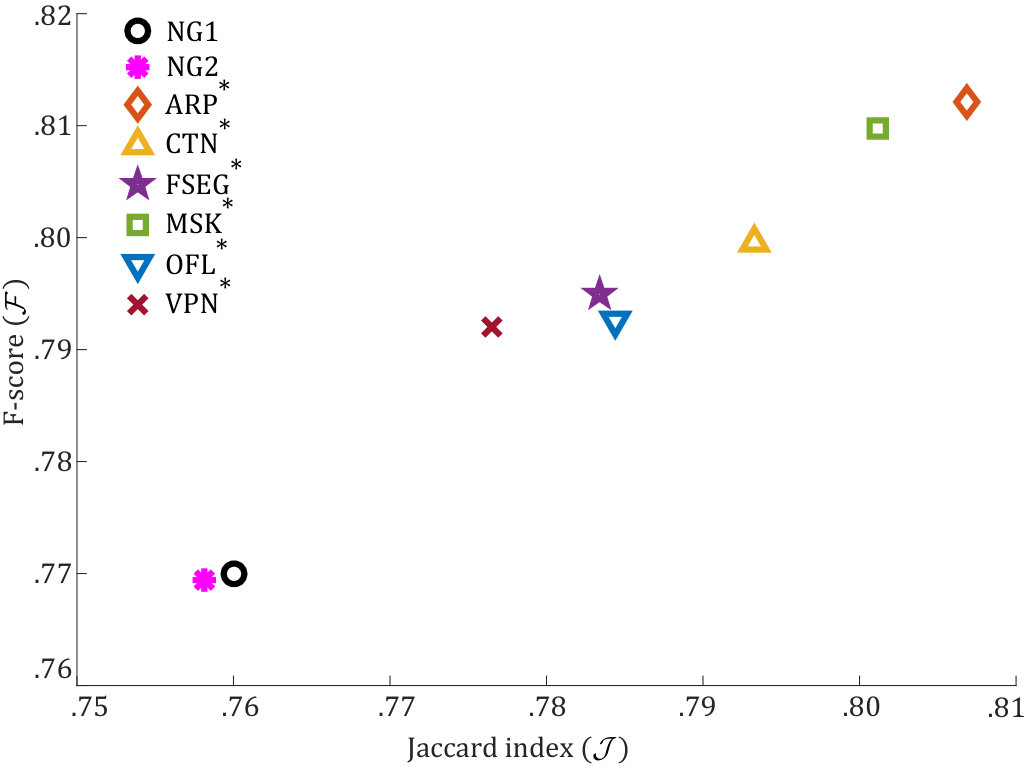 Figure 3
Figure 3| Algorithms | ||||||
|---|---|---|---|---|---|---|
| mean | std. | mean | std. | mean | std. | |
| ARP | .7609 | .1125 | .7051 | .1111 | .5363 | .3446 |
| ARP* | .8069 | .0631 | .8121 | .0799 | .3930 | .2675 |
| CTN | .7304 | .1048 | .6886 | .1147 | .3682 | .2176 |
| CTN* | .7933 | .0627 | .7996 | .0775 | .3969 | 2762 |
| FSEG | .7068 | .0804 | .6524 | .1036 | .4456 | .2809 |
| FSEG* | .7834 | .0673 | .7950 | .0773 | .3938 | .2566 |
| MSK | .7955 | .0817 | .7519 | .0929 | .3226 | .1978 |
| MSK* | .8012 | .0718 | .8097 | .0821 | .3805 | .2660 |
| OFL | .6738 | .1231 | .6279 | .1330 | .3608 | .2123 |
| OFL* | .7844 | .0764 | .7926 | .0933 | .3898 | .2805 |
| VPN | .6984 | .0902 | .6513 | .1002 | .4923 | .2630 |
| VPN* | .7765 | .0709 | .7920 | .0792 | .3918 | .2551 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
On guiding video object segmentation
Diego Ortego
Insight Centre for Data Analytics
Dublin City University (DCU)
Dublin (Ireland)
Kevin McGuinness
Insight Centre for Data Analytics
Dublin City University (DCU)
Dublin (Ireland)
Juan C. SanMiguel
VPULab
Universidad Autónoma de Madrid (UAM)
Madrid (Spain)
Eric Arazo
Insight Centre for Data Analytics
Dublin City University (DCU)
Dublin (Ireland)
José M. Martínez
VPULab
Universidad Autónoma de Madrid (UAM)
Madrid (Spain)
Noel E. O’Connor
Insight Centre for Data Analytics
Dublin City University (DCU)
Dublin (Ireland)
Abstract
This paper presents a novel approach for segmenting moving objects in unconstrained environments using guided convolutional neural networks. This guiding process relies on foreground masks from independent algorithms (i.e. state-of-the-art algorithms) to implement an attention mechanism that incorporates the spatial location of foreground and background to compute their separated representations. Our approach initially extracts two kinds of features for each frame using colour and optical flow information. Such features are combined following a multiplicative scheme to benefit from their complementarity. These unified colour and motion features are later processed to obtain the separated foreground and background representations. Then, both independent representations are concatenated and decoded to perform foreground segmentation. Experiments conducted on the challenging DAVIS 2016 dataset demonstrate that our guided representations not only outperform non-guided, but also recent and top-performing video object segmentation algorithms.
Index Terms:
Video object segmentation, foreground segmentation, attention, deep learning.
I Introduction
Segmenting an image into regions is key for identifying objects of interest. For example, image segmentation [1] clusters image pixels with common properties (e.g. colour, textures, etc), while semantic segmentation [2] categorises each pixel into a set of predefined classes. Foreground segmentation is a particular case of semantic segmentation with two categories: foreground and background. The former contains the objects of interest in an image, which may correspond to salient objects [3][4], generic objects [5][6], moving objects [7], spatio-temporal relevant patterns [8] or even weak labels [9]. The latter consists on the non-relevant data, being usually the static scene objects. Moreover, foreground segmentation in unconstrained environments is known as video object segmentation (VOS) and faces many challenges related to camera motion, shape deformations, occlusions or motion blur [10].
VOS has become an active research area, as demonstrated by the widespread use of the DAVIS benchmark [11]. Existing algorithms are supervised, semi-supervised and unsupervised. Supervised approaches employ frame-by-frame human intervention [12] whereas semi-supervised ones only require initialization (e.g. annotations of the objects to segment in the first frame) [13][14]. Conversely, unsupervised VOS does not involve human intervention, requiring the automatic detection of relevant moving objects [15].
Currently deep learning is significantly advancing computer vision performance [16] such as for VOS, where state-of-the-art approaches employ convolutional neural networks [7][17]. Performance improvement can be achieved by increasing the complexity of the network [18][19], but also by learning better models without requiring new architectures. For instance, loss function variations [20], transfer learning [21], data augmentation [22] or applying spatial attention [23] are techniques widely explored. In particular, spatial attention can be used to highlight activations in feature maps of the network, thus enabling training of more accurate models. In [23], attention is extracted from convolutional features from a semantic segmentation network to promote those activations that do not respond to several classes, but to only one. Also, [24] generates attention maps responding to visual patterns in different scales and levels from convolutional features, thus capturing different semantic patterns such as body parts, objects, or background that improve pedestrian attribute recognition. Furthermore, [25] uses three attentions maps (general, residual and channel attentions) extracted from convolutional features to weight the cross-correlation of a fully-convolutional siamese tracker that adapts the offline learned model to the online tracked targets. Additionally, content-based image retrieval [26] can be enhanced by using visual attention models to weight the contribution of the activations from different spatial regions.
This paper proposes a novel approach to improving the performance of an unsupervised VOS algorithm by using an independent foreground segmentation (i.e. the mask from an existing algorithm in the literature) to guide the segmentation process by focusing on relevant activations. First, given a video frame and its associated optical flow, two networks compute appearance and motion feature maps. Second, both feature maps are unified to exploit their complementarity. Third, the foreground mask of an independent algorithm is used to encode foreground and background information. Finally, both representations are concatenated and decoded to produce a foreground mask. We validate the proposed approach in the recent DAVIS 2016 dataset [11], demonstrating the improvements achieved by our approach, whose novelty lies in the use of an independent foreground mask to separate foreground and background representations and learn a better foreground segmentation model.
The remainder of this paper is organized as follows: Section II overviews the proposed approach whereas Section III and IV describe the proposed algorithm and the experiments performed. Finally, Section V concludes this paper.
II Algorithm overview
VOS can be formulated as a pixel-wise labelling of each video frame as either foreground (1) or background (0), thus generating a foreground segmentation mask . We propose an approach based on convolutional neural networks (CNNs) that uses a frame together with its corresponding optical flow and the foreground mask of an independent algorithm (from now on, the independent foreground mask), to compute a foreground segmentation (see Figure 1). Our CNN-VOS approach starts with an appearance network computing a convolutional feature map from a video frame and a motion network generating a convolutional feature map from the optical flow associated to . Both feature maps are then combined by element-wise multiplication to obtain a unique representation comprising both appearance and motion information. Subsequently, the independent foreground mask is used to weight and separately encode foreground and background information based on the previously computed feature maps, which are processed by two independent networks. Finally, the output of the two sub-networks is concatenated and decoded with a convolutional network to produce the foreground mask .
III Algorithm description
III-A Appearance network
The appearance network learns a model from spatial distribution of the colour information of a video frame . In particular, we use PSPNet [2], a fully-convolutional neural network for semantic segmentation which relies on ResNet [19] followed by a hierarchical context module (Pyramid Pooling Module) that harvest information from different scales. This module processes different downsamplings of ResNet features and later upsamples them for concatenating all features to form an improved representation that includes the original ResNet features. In particular, we use ResNet-101 to obtain by extracting the 512 feature maps obtained after the convolutional layer that follows the Pyramid Pooling Module, which contains both local and global representations.
III-B Motion network
In contrast to the appearance network, the motion network obtains a model again making use of PSPNet, but in this case from the optical flow . In particular, we convert the optical flow vectors [27] into a 3-channel colour-coded optical flow image [15] and train PSPNet to produce a foreground segmentation from the colour-coded optical flow . In order to get the model , we select the 512 feature maps at the same layer as done in the appearance network.
III-C Unified representation
The intuition behind using two networks with independent inputs (appearance and motion) is to benefit from the complementary of appearance and motion exhibited by moving objects [28]. Therefore, we exploit such complementarity by combining both feature maps following a multiplicative fusion (see the Combination stage in Figure 1) similarly to [29], where the authors multiply different sources of CNNs (appearance and motion) to enable the amplification or suppression of feature activations based on their agreement. In our approach, this fusion consists of a convolution applied to both the appearance features and the motion features followed by an element-wise multiplication of both sets of feature maps (which have the same dimensionality) to produce the unified encoding . Applying the convolutions helps to control the dimensionality while learning how to combine the feature maps before their multiplicative combination.
III-D Foreground and background encoding
Unlike many VOS literature which jointly process all features [15], we introduce an attention mechanism that splits the feature maps into foreground and background to better guide the learning process and obtain a better VOS model (see FG-BG encoding stage in Figure 1). In particular, we use an foreground mask (obtained from a state-of-the-art algorithm) which is downsampled to match the size of . Then, we split into foreground and background representations according to the guidance provided by the independent foreground . On the one hand, multiplying the feature maps by the independent foreground helps focusing on important spatial areas of the features by zeroing responses associated to background areas in , thus implementing an attention mechanism. On the other hand, maintaining information from the background regions through helps in the segmentation process, which may be useful as it assures a background representation is maintained, especially when errors in lead to the suppression of important foreground responses. Subsequently, and are individually processed by four convolutional layers to separately model foreground and background representations before concatenating them as presented in the FG-BG encoding stage in Figure 1. Finally, this set of concatenated foreground and background representations contain a high-level joint encoding of appearance and motion that is fed to four additional convolutional layers for decoding in order to compute the final prediction (see Decoding stage in Figure 1), i.e. the foreground segmentation mask .
III-E Architecture details
Our architecture is the fully-convolutional network shown in Figure 1. After the appearance and motion networks (both using the PSPNet architecture), there are two convolutional layers that use 512 kernels to process the feature maps and (both have 1/8 the original image resolution). Then, the multiplication of is preceded by a downsampling performed through average pooling with stride 8. Regarding the processing of and : before concatenating both we use four convolutional layers, three with depth 256 followed by batch normalization and ReLU and the final one with depth 128 to reduce the number of feature maps. As it is well known that reducing the feature map resolution may result in coarse predictions [30], we use dilated convolutions (1, 2, 4 and 8 depths) to aggregate context [31] while preserving the already reduced resolution (1/8). Finally, we apply four convolutional layers with dilated convolutions (128, 64, 64 and 1 depths). We use kernels throughout (unless otherwise stated).
IV Experimental work
IV-A Datasets and metrics
We evaluate the proposed approach on the DAVIS 2016 dataset [11] which covers many challenges of unconstrained VOS. We use all available test videos (20) whose length ranges from 40 to 100 frames with resolution. A unique foreground object is annotated in each frame. We use three standard performance measures [11] to account for region similarity (Jaccard index , i.e. intersection-over-union ratio between the segmented foreground mask and the ground-truth mask), for contour accuracy (F-score between contour pixels of the segmented and the ground-truth masks) and for temporal stability of foreground masks (by associating temporal smooth and precise transformations to good foreground segmentations). These measures are computed frame-by-frame and then averaged to compute a sequence-level score, which are also averaged to get dataset-level performance. Note that we do not consider DAVIS 2017 dataset as it is semi-supervised whereas our approach is unsupervised.
IV-B Implementation details
The training procedure consists of three stages. First, we train the appearance network to perform semantic segmentation on the PASCAL VOC 2012 dataset [32] using a total of 10582 training images. Second, we train the motion network to perform foreground segmentation based on optical flow data [27] using the annotations provided by [15] for 84929 frames of ImageNet-Video dataset [33]. Third, we freeze both the appearance and the motion networks and train the rest of the network on 22 of the 30 training video sequences of DAVIS 2016 dataset [11] (we use 8 sequences for validation). For this last step, masks of an independent algorithm are needed, so we use available foreground masks in DAVIS 2016111https://davischallenge.org/davis2016/soa_compare.html (the 13 algorithms evaluated in [11] and the algorithm proposed in [34]). We train the appearance and the motion networks for 30k and 90k iterations, respectively, using the “poly” learning rate policy described in [2]. However, for the third step we train the network for 20 epochs reducing the learning rate by ten each five epochs (starting with the value 0.1) and we select the best model using the performance in the validation set. We use batch size 8, data augmentation (random Gaussian blur, sized crops, rotations and horizontal flips), cross-entropy loss and Kaiming weight initialization [35] in all training steps.
IV-C Evaluation
We compare our approach against 6 recent and top-performing VOS alternatives (both unsupervised and semi-supervised): ARP [7], CTN [14], FSEG [15], MSK [17], OFL [36] and VPN [37]. To provide a fair comparison, we also use the segmentation masks of these alternatives for our proposal (indicated by ). Table I presents the average performance for the 20 test sequences of DAVIS 2016 in terms of Jaccard index , contour F-score and temporal stability . By comparing the independent foreground masks and the proposed approach (), we outperform all of them in terms of and . Regarding the temporal stability , we improve for 3 of the 6 algorithms. The reason is not improved for CTN, MSK, and OFL is that these are implicitly focused on transferring the same segmentation frame to frame, thus resulting in an inherent temporal stability that is difficult to improve upon from and unsupervised perspective. The improvements achieved are due to both the potential of our learned representations and the guiding mechanism introduced through the independent masks. As it is not possible to separate both facts from the results in Table I, we perform an additional experiment to highlight the potential of the learned representations. In particular, we have repeated the third step of the training process (see Subsection IV-B) without making use of independent foreground masks. We explore two non-guided alternatives, the first one implies removing the FG-BG encoding (see Figure 1), thus passing the representation directly to the decoder (NG1 alternative). The second alternative consists in using a dummy foreground mask where all pixels contain foreground (i.e. and contain the same information), thus avoiding the use of independent foreground masks to guide the segmentation while using a network (NG2 alternative) with the same number of parameters as the one proposed. Figure 2 presents the performance in terms of and for this two non-guided alternatives (NG1 and NG2), demonstrating that non-guided representations perform worse than the guided ones, i.e. those learnt with separate foreground-background representation.
Furthermore, directly comparing NG1 and NG2 performance (around ) with the selected alternatives in Table I shows that we obtain competitive results (only MSK with is better than NG1 and NG2).
Figure 3 gives some examples of foreground segmentations. The first column presents an example where the proposed mask (green) is capable of solving the mistakes of the non-guided representations (red) due to the guiding introduced by an independent algorithm (blue). The second and third columns show examples where the proposed approach (green) outperforms the independent algorithm (blue) due to the guiding scheme over representations that, without guiding (red), were lacking of object parts or introducing false positives.
V Conclusions
This paper proposes a VOS approach which takes advantage of independent (i.e. state-of-the-art) algorithm results to guide the segmentation process. This strategy enables learning an enhanced colour and motion representation for VOS due to specific attention on foreground and background classes. The experimental work validates the utility of our approach to improve foreground segmentation performance. Future work will explore the use of feedback strategies to induce the foreground-background separation from the produced result and not from independent algorithms.
Acknowledgement
This work was partially supported by the Spanish Government (MobiNetVideo TEC2017-88169-R), “Proyectos de cooperación interuniversitaria UAM-BANCO SANTANDER con Europa (Red Yerun)” (2017/YERUN/02 (SOFDL) and Science Foundation Ireland (SFI) under grant numbers SFI/12/RC/2289 and SFI/15/SIRG/3283. We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Titan Xp GPU used for this research.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] R. Achanta, A. Shaji, K. Smith, A. Lucchi, P. Fua, and S. Sï¿œsstrunk, “SLIC Superpixels Compared to State-of-the-Art Superpixel Methods,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 34, no. 11, pp. 2274–2282, 2012.
- 2[2] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia, “Pyramid Scene Parsing Network,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2017, pp. 6230–6239.
- 3[3] A. Borji, M.-M. Cheng, H. Jiang, and J. Li, “Salient Object Detection: A Benchmark,” IEEE Transactions on Image Processing , vol. 24, no. 12, pp. 5706–5722, 2015.
- 4[4] S. Wu, M. Nakao, and T. Matsuda, “Super Cut: Superpixel Based Foreground Extraction With Loose Bounding Boxes in One Cutting,” IEEE Signal Processing Letters , vol. 24, no. 12, pp. 1803–1807, 2017.
- 5[5] B. Alexe, T. Deselaers, and V. Ferrari, “Measuring the Objectness of Image Windows,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 34, no. 11, pp. 2189–2202, 2012.
- 6[6] S. Jain, B. Xiong, and K. Grauman, “Pixel Objectness,” Co RR , vol. abs/1701.05349, 2017.
- 7[7] Y. J. Koh and C. S. Kim, “Primary Object Segmentation in Videos Based on Region Augmentation and Reduction,” in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2017, pp. 7417–7425.
- 8[8] Y. J. Lee, J. Kim, and K. Grauman, “Key-segments for video object segmentation,” in Proceedings of IEEE International Conference on Computer Vision (ICCV) , 2011, pp. 1995–2002.