Deep Reinforcement Learning for Optimal Critical Care Pain Management with Morphine using Dueling Double-Deep Q Networks
Daniel Lopez-Martinez, Patrick Eschenfeldt, Sassan Ostvar and, Myles Ingram, Chin Hur, Rosalind Picard

TL;DR
This paper introduces a deep reinforcement learning framework that personalizes morphine dosing in ICU pain management, aiming to optimize pain relief while minimizing adverse effects.
Contribution
It presents a novel sequential decision-making model using dueling double-deep Q networks for personalized opioid dosing based on real-time patient data.
Findings
Reinforcement learning can provide effective personalized pain management recommendations.
The model was trained and validated using the MIMIC-3 database.
Results suggest potential for improving clinical decision support in ICU settings.
Abstract
Opioids are the preferred medications for the treatment of pain in the intensive care unit. While undertreatment leads to unrelieved pain and poor clinical outcomes, excessive use of opioids puts patients at risk of experiencing multiple adverse effects. In this work, we present a sequential decision making framework for opioid dosing based on deep reinforcement learning. It provides real-time clinically interpretable dosing recommendations, personalized according to each patient's evolving pain and physiological condition. We focus on morphine, one of the most commonly prescribed opioids. To train and evaluate the model, we used retrospective data from the publicly available MIMIC-3 database. Our results demonstrate that reinforcement learning may be used to aid decision making in the intensive care setting by providing personalized pain management interventions.
Click any figure to enlarge with its caption.
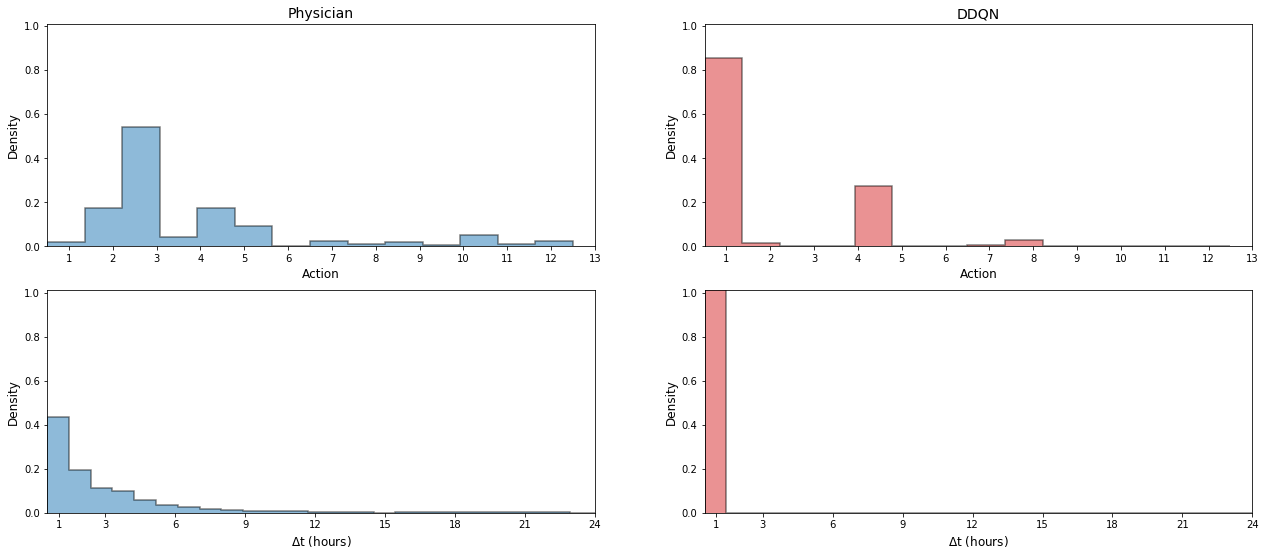 Figure 1
Figure 1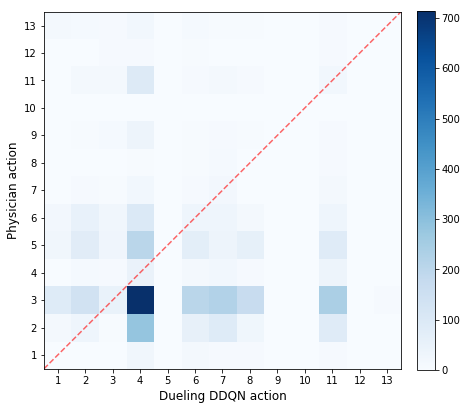 Figure 2
Figure 2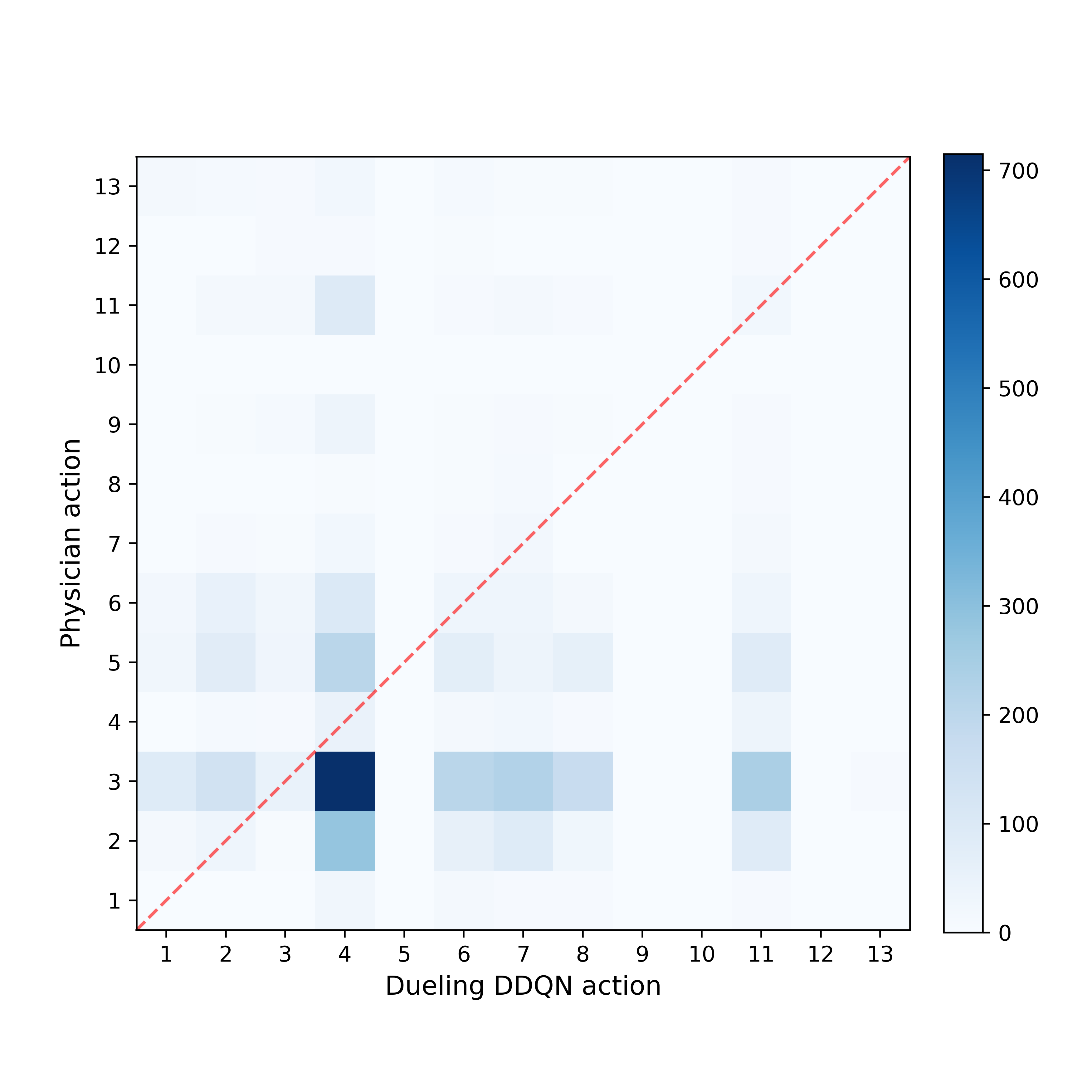 Figure 3
Figure 3 Figure 4
Figure 4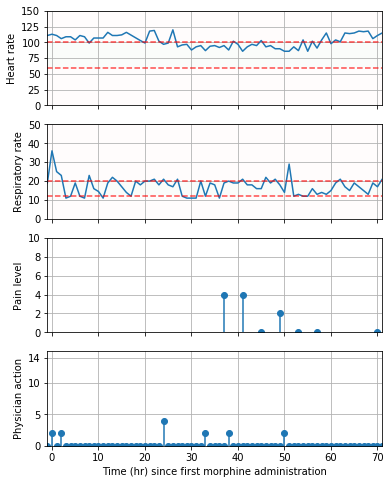 Figure 5
Figure 5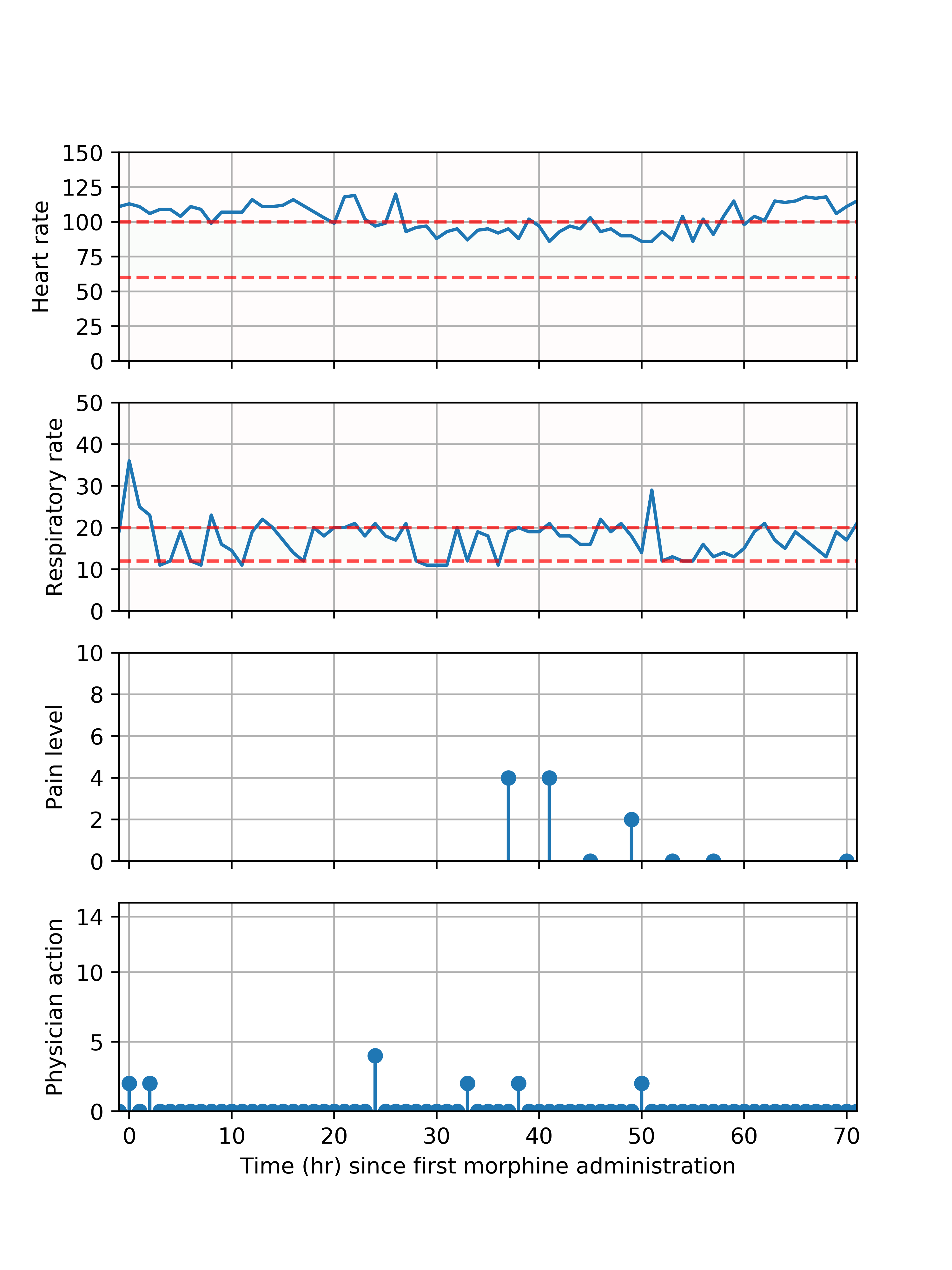 Figure 6
Figure 6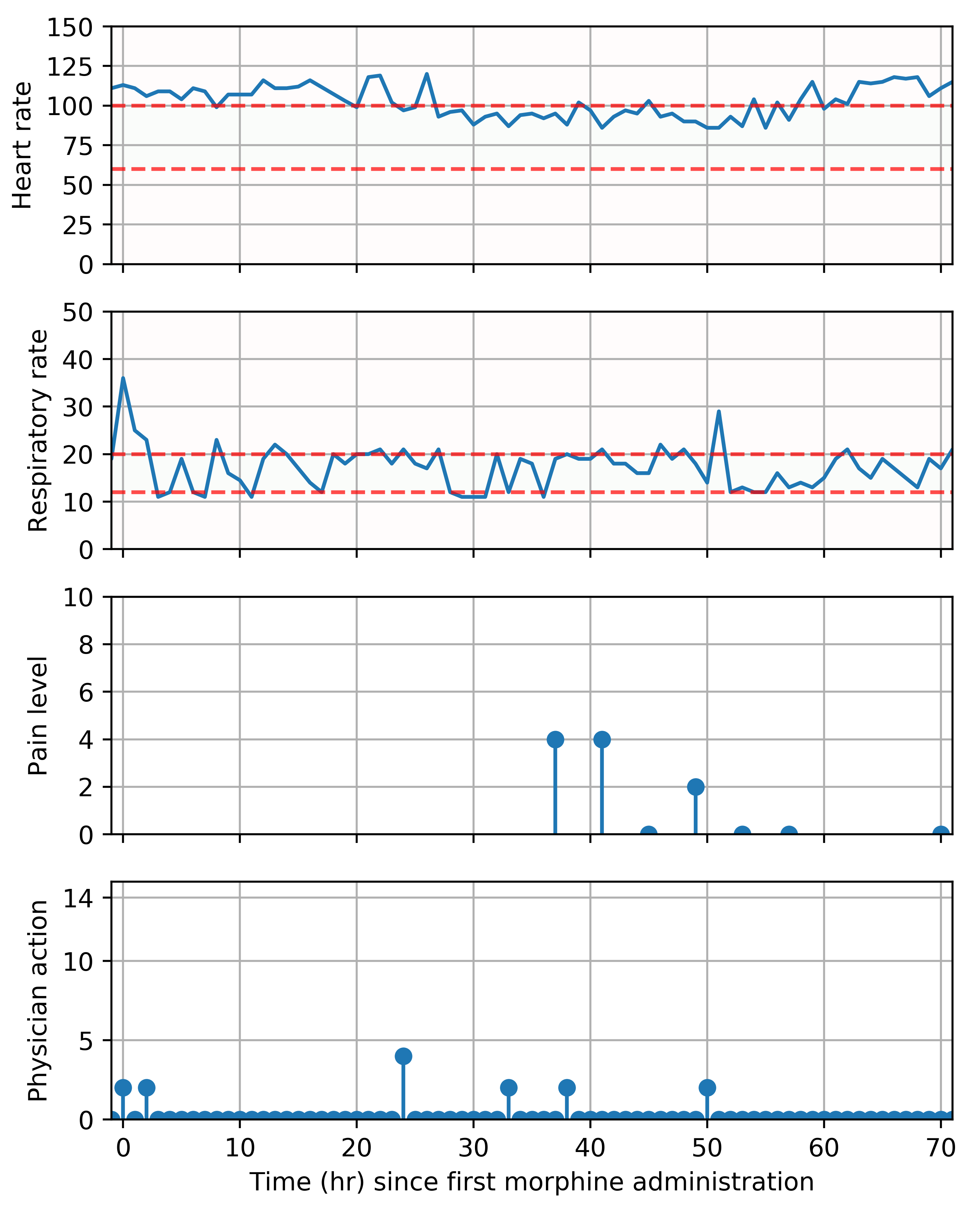 Figure 7
Figure 7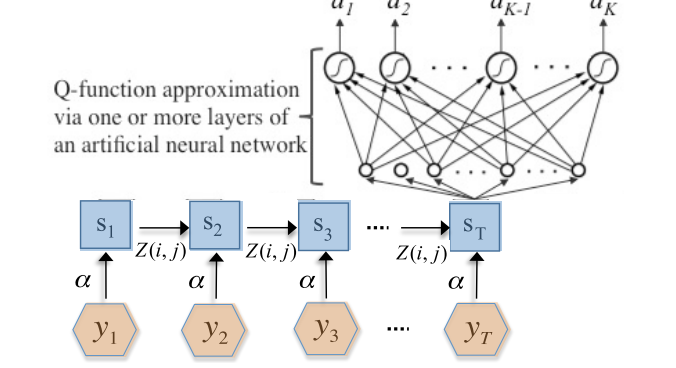 Figure 8
Figure 8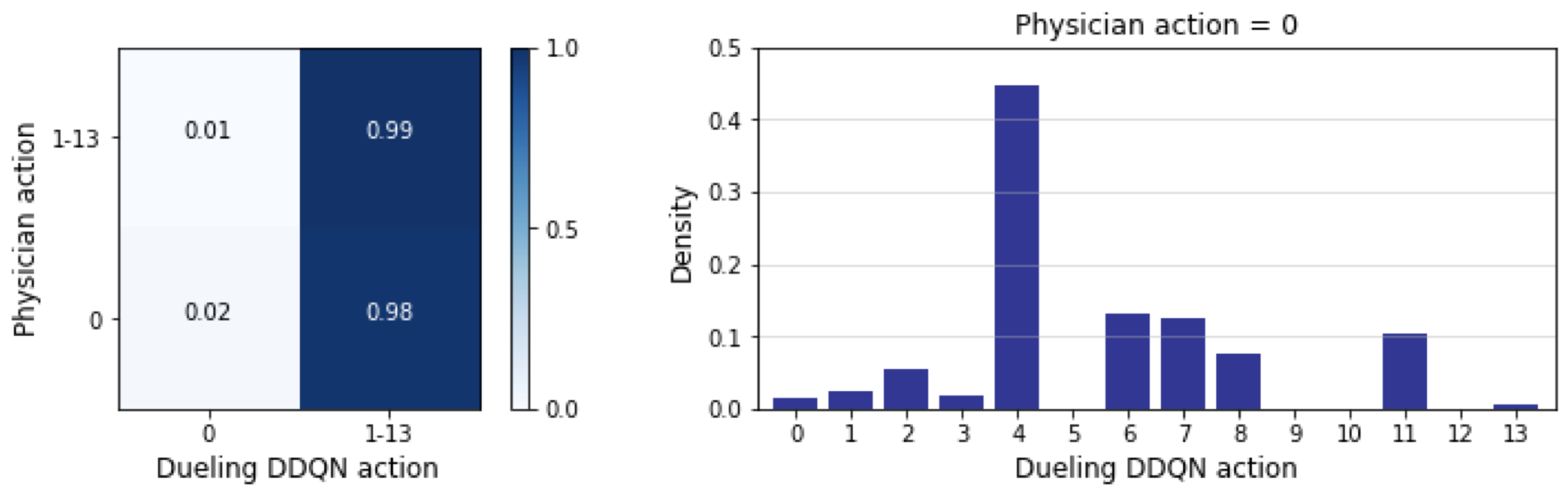 Figure 9
Figure 9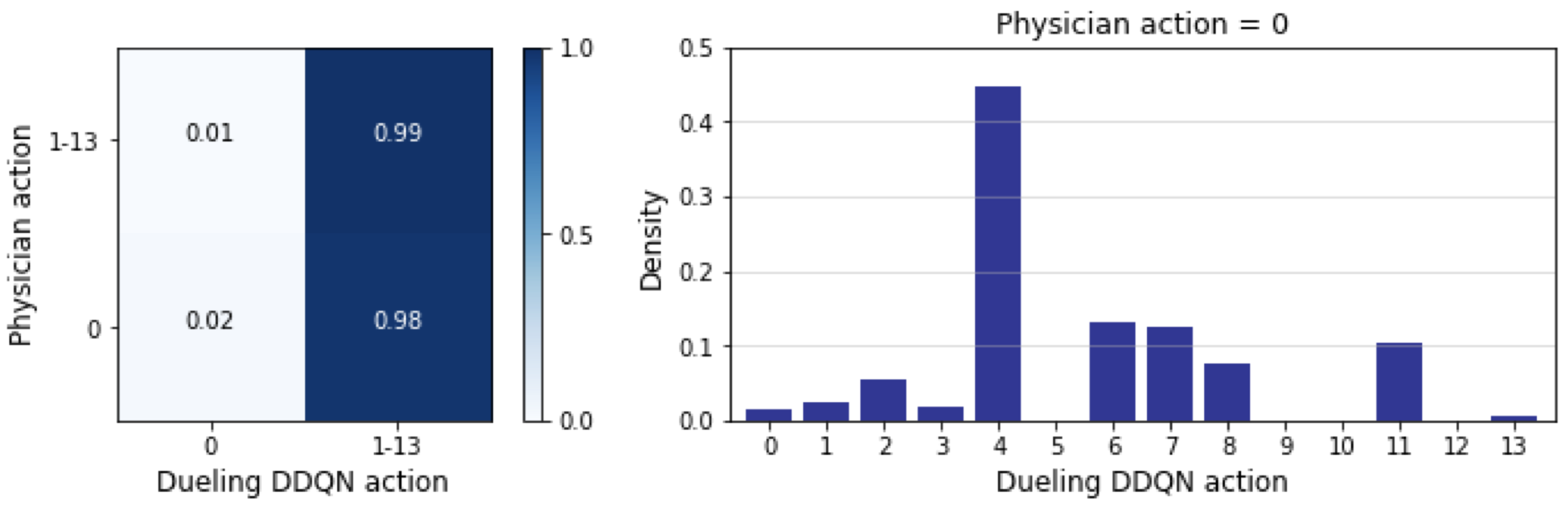 Figure 10
Figure 10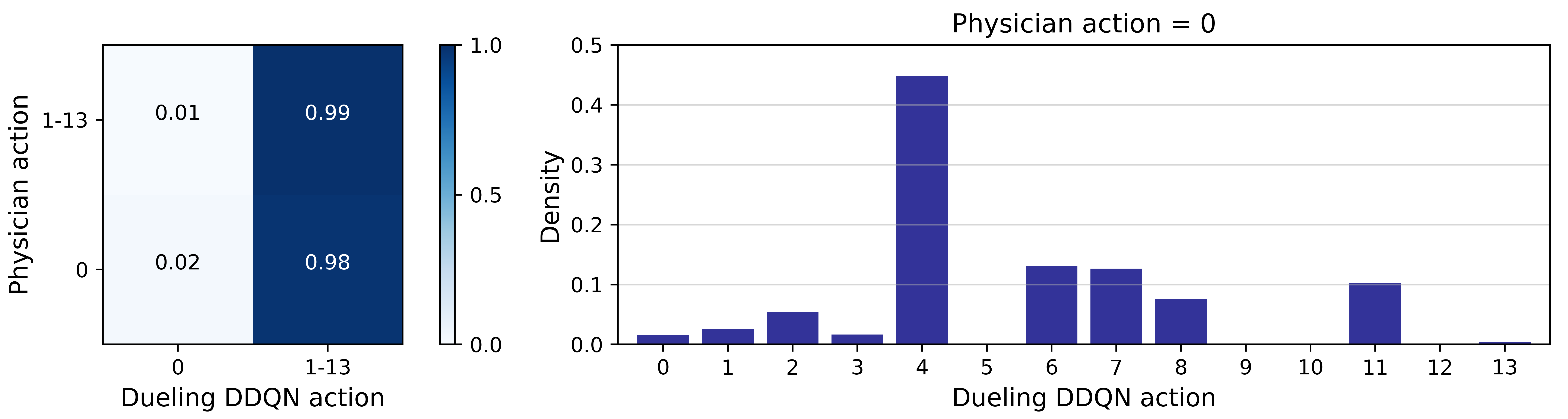 Figure 11
Figure 11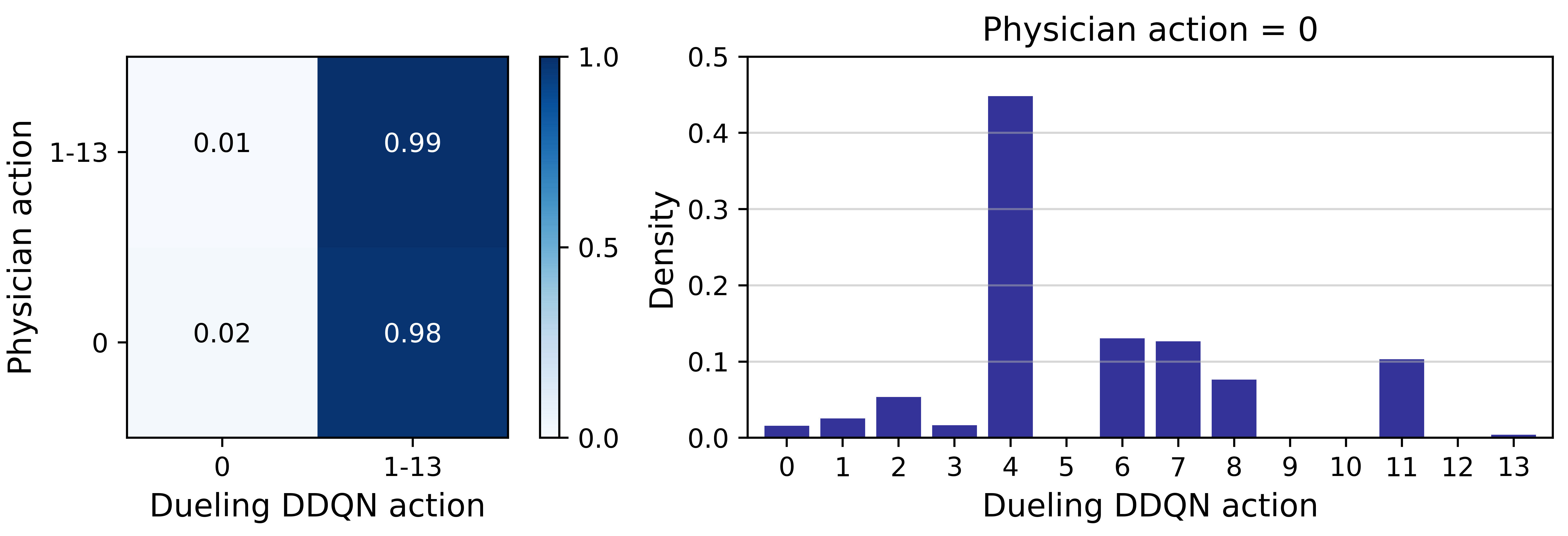 Figure 12
Figure 12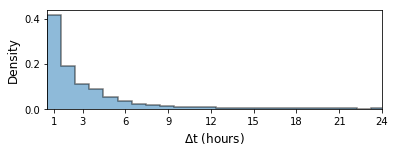 Figure 1
Figure 1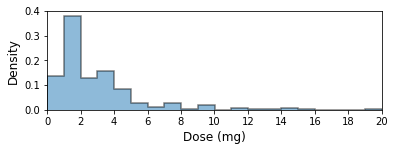 Figure 11
Figure 11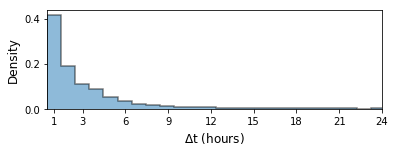 Figure 12
Figure 12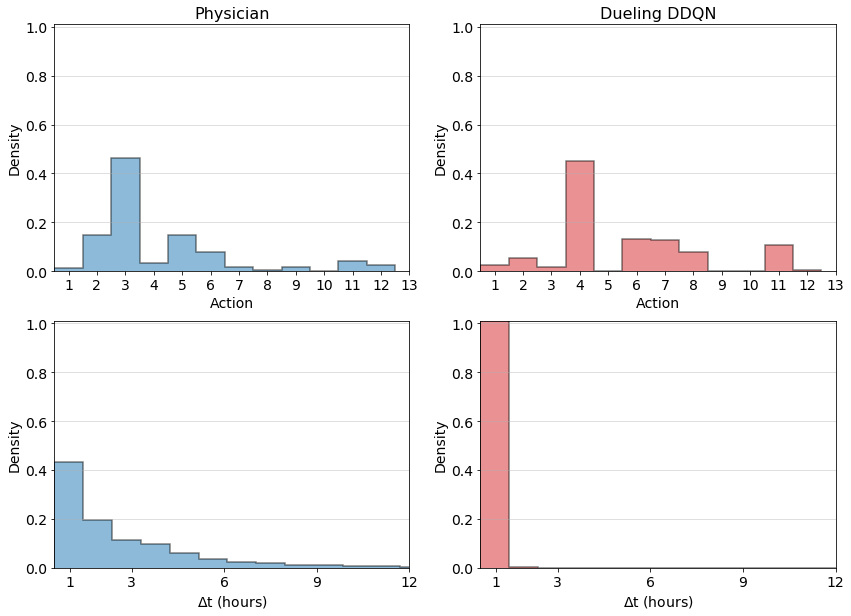 Figure 16
Figure 16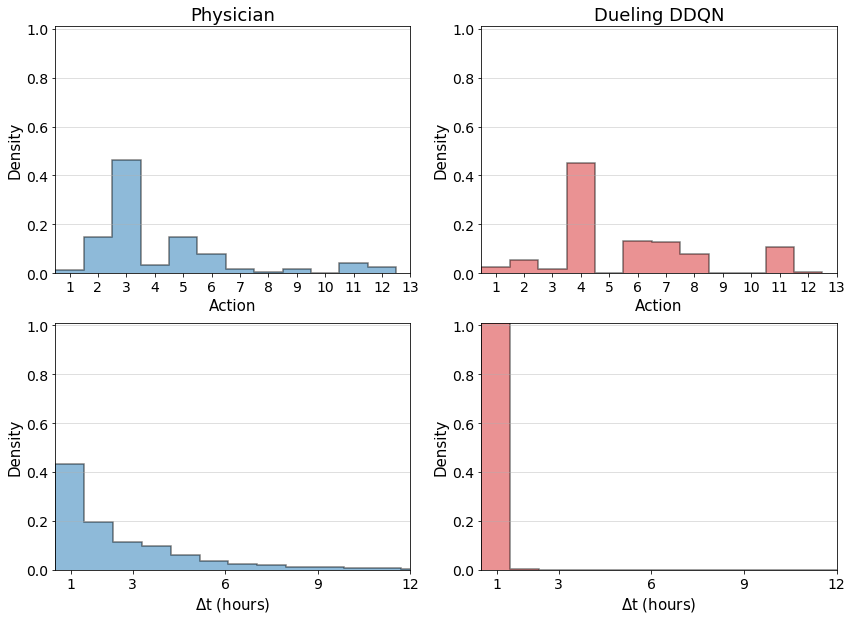 Figure 17
Figure 17 Figure 18
Figure 18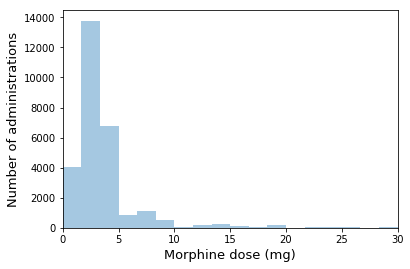 Figure 19
Figure 19Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Deep Reinforcement Learning for Optimal Critical Care Pain Management with Morphine using Dueling Double-Deep Q Networks
Daniel Lopez-Martinez1,2, Patrick Eschenfeldt3, Sassan Ostvar4, Myles Ingram4, Chin Hur4, and Rosalind Picard2 1Harvard-MIT Health Sciences and Technology [email protected]2Massachusetts Institute of Technology (MIT)3Massachusetts General Hospital4Columbia University
Abstract
Opioids are the preferred medications for the treatment of pain in the intensive care unit. While under-treatment leads to unrelieved pain and poor clinical outcomes, excessive use of opioids puts patients at risk of experiencing multiple adverse effects. In this work, we present a sequential decision making framework for opioid dosing based on deep reinforcement learning. It provides real-time clinically interpretable dosing recommendations, personalized according to each patient’s evolving pain and physiological condition. We focus on morphine, one of the most commonly prescribed opioids. To train and evaluate the model, we used retrospective data from the publicly available MIMIC-3 database. Our results demonstrate that reinforcement learning may be used to aid decision making in the intensive care setting by providing personalized pain management interventions.
I Introduction
Critically ill patients in the intensive care unit (ICU) commonly experience pain because of a multitude of factors including surgery, trauma, burns, and cancer, as well as enduring procedural pain [1]. Regardless of source, poorly managed pain adversely affects multiple organ systems and has a direct impact on outcomes, as the negative physiologic and psychologic consequences of pain are significant, long lasting, and can preclude patients from participating in their care.
In the ICU, opioids are the primary systemic medications for managing pain. The optimal choice of opioid and the dosing regimen used for an individual patient depend on many factors, including the intensity of pain. To assess the latter as well as to measure response to treatment, multiple pain intensity scales have been developed. These are unidimensional scales that measure intensity from 0 (no pain) to 10 (worst possible pain). Unfortunately, pain assessment scales fail in multiple patient populations (e.g. non-verbal children) and clinical situations (e.g. during paralysis). Hence, in recent years, an increasing body of work is addressing the problem of pain measurement using machine leaning with autonomic [2], brain activity [3] and facial expression [4] data, and by stratifying patients based on their pain responses to allow for personalized assessments [5]. However, machine learning for automatic pain management interventions remains an unexplored area.
In this work, we propose a novel approach for the automatic dosing of analgesics based on deep reinforcement learning. Specifically, we focus on morphine, one of the most commonly prescribed opioids in the ICU and a first line for the treatment of pain. Both under-treatment and over-treatment with morphine lead to severe adverse effects, such as those related to unrelieved pain and respiratory depression respectively. Our model aims to learn clinically interpretable optimal treatment policies and recommend individualized morphine interventions adapted to each patient’s evolving state, to minimize pain while avoiding adverse effects. To our knowledge, our work is the first to apply reinforcement learning for the recommendation of pain management regimes and the automatic dosing of analgesics.
II Background and related work
Reinforcement learning (RL) algorithms model time-varying state and action spaces, and learn actionable policies (mappings from states to actions) from training examples that do not represent optimal behaviour. At each time step , the RL agent observes the current environment state and takes an action from a discrete set of actions , subsequently receiving a reward and transitioning to a new state . The action is chosen following policy so that the return or expected sum of future rewards when taking that action and following policy thereafter is maximized. The future rewards are discounted by a factor that represents the trade off between immediate and later rewards.
Combining RL with deep neural networks has achieved tremendous success in complex problems such as the Atari, Go, and chess games [6, 7]. In medicine, deep reinforcement learning has been applied, for example, to unfractioned heparin dosing in the ICU [8], intravenous fluid and vasopressor dosing in sepsis patients [9, 10], and chemotherapy dosing in cancer patients enrolled in clinical trials [11].
III Methods
Morphine analgesia is characterized by tremendous interindividual variation and is influenced by multiple factors [12]. Hence, in the ICU, physicians continuously monitor patients to personalize morphine pain management. Our goal is to deduce optimal treatment policies, similar to those of physicians, that account for pain level as well as physiological state as captured by vital signs. We chose RL over supervised learning because no ground truth for treatment strategies exists and RL is able to infer optimal strategies from suboptimal training examples.
III-A Data and preprocessing
This work was conducted on the publicly available Multiparameter Intelligent Monitoring in Intensive Care III (MIMIC-3) database [13], which contains hospital admissions from approximately 38600 individuals aged years. From MIMIC-3, we extracted a cohort of ICU patients fulfilling 2 criteria: (1) at least one pain intensity score had been collected, and (2) at least one dose of intravenous morphine had been administered. A total of 6843 admissions fulfilled these criteria. We chose to focus on morphine since this was the most commonly prescribed opioid in the MIMIC-3 database, followed by hydromorphone and oxycodone.
III-B Feature extraction
For each patient, we extracted pain scores, analgesic administration events and vital signs. Data were aggregated into non-overlapping one-hour windows. When several data points were available within a window, we replaced them by either the mean (pain scores, vital signs) or the sum (analgesic administrations). To account for missing data, we utilized sample-and-hold interpolation as in [8]. In total, we extracted 20 hourly features.
III-B1 Pain scores
MIMIC-III contains scores in both numerical and text format. The latter were converted to a numeric score by using the scores referenced in the text (e.g. ”3-Mild to Mod” becomes 3). All scores were reported in a 0 (no pain) to 10 (maximum pain) scale.
III-B2 Morphine interventions
Morphine sulfate can be administered intravenously either as a bolus or as a continuous infusion with a steady rate for an extended period of time. In this work, we considered intravenous boluses only, which represented a majority of administrations for the studied admissions (59.4%). These typically have an onset of 5-10 min and a half life of 3-4 hr. [14]. The dose, in addition to time of administration, was recorded.
III-B3 Non-morphine analgesic interventions
In order to lower opioid consumption and to improve the quality of analgesia, morphine is commmonly administered with adjuvant analgesics [14]. This includes nonopiod coanalgesics such as nonsteroidal anti-inflammatory agents. Therefore, we also extracted administrations of 16 analgesics in addition to morphine.
III-B4 Physiological signals
Morphine induces respiratory depression [15] and impacts the cardiovascular system [16] with potentially fatal consequences. Hence, we extracted two relevant physiological signals: respiration rate (RR) and heart rate (HR).
III-C *Continuous State-space and Discretized Action-space *
The action space was discretized to 14 actions: [math], , , …, , , and mg of morphine intravenously. The state space, on the other hand, was continuous and directly captured the patient’s self-reported pain intensity and physiological state, as well as non-morphine analgesic interventions.
III-D Reward function
At each time stamp , the RL agent interacts with the environment and observes the state to choose whether to deliver a morphine IV bolus (actions 1-13) or to withhold morphine (action 0). The action is chosen to maximize the return, that is, the expected discounted future reward, defined as , where is the terminal timestep.
We defined a reward function that incentivizes pain reduction while seeking to maintain heart rate and respiration rate within adequate physiological ranges. For healthy adults at rest, heart rates between 60 and 100 beats per minute and respiration rates between 12 and 20 breaths per minute are considered acceptable.
[TABLE]
where and
[TABLE]
This function assigns the maximum reward when pain is absent and both heart rate and respiration rate are within the acceptable range, while diminishing as they move away from the ideal range.
III-E Reinforcement learning model architecture
To learn the optimal treatment policies, we use Q-learning [17], which works by learning an action-value function that provides the expected return of taking a given action at each state, that is, where the maximum is taken over all possible policies . In Q-learning, the optimal action-value function is estimated using the Bellman equation:
[TABLE]
where is the state transition distribution. Deep Q-learning uses neural networks to approximate [6] by sampling tuples and minimizing the squared error loss between the output and target values, where and are the weights used to parametrize the target network, using stochastic gradient descent.
In this work, following [9, 10], we combined two common extensions of the deep Q network (DQN) model: double-deep Q networks (DDQN) [18] and dueling Q networks (dueling DQN) [19]. These address several shortcomings of simple DQNs, such as their tendency to overestimate Q values.
Our final network architecture was therefore a Dueling Double-Deep Q Network (Dueling DDQN), It contained two hidden layers with 64 nodes each, with Leaky-ReLu activation functions and equally sized advantage and value streams. As in [9, 10], we used prioritized experience replay to sample transitions from the training set with probability proportional to the previous error. The network was implemented in TensorFlow.
IV Results
We separated 6843 hospital admissions into 70%/20%/10% training, validation and test sets respectively. The action space was discretized to 14 actions as described in Sec.III-C, based on visual inspection of the histogram of morphine doses in MIMIC-III. The dueling DDQN model was then trained using Adam optimization [20] with batch size 32. After training, we obtained the optimal policy for a given patient state , such that . Unfortunately, quantitative evaluation of off-policy models is challenging because it is difficult to assess the impact of deploying the learned policy in patient outcomes. Hence, we evaluated by qualitatively examining the choices of treatments proposed by the model, and comparing these with those made by physicians and our understanding of accepted clinical guidelines.
Fig.2 depicts the comparison of actions taken by the physicians with those recommended by the model, for every hour in the test set. Action 0 refers to no morphine administered, whereas actions 1-13 represent increasing morphine doses. Physicians do not often prescribe morphine to patients (only 5.80% hourly timestamps contained morphine administration), but when they do, in 99% of instances the model also recommended morphine administration. The agreement between physician actions and model recommendations in these instances is shown in Fig.3. The actions recommended for the model for the 94.2% instances in which physicians chose to withhold morphine are shown in Fig.2.
While physicians administer morphine sparsely, when they do, a second morphine dose is administered in the next hour in more than 40% of occasions, as shown in Fig.4. The model, on the other hand, recommended more continuous administration of morphine. This result is consistent with previous studies comparing intermittent bolus versus continuous infusion dosing of morphine, which have shown that continuous dosing provides similar or even better pain relief with no increase in acute adverse effects [21, 22].
V Conclusion
This work builds on recent research using reinforcement learning to automatically find optimal treatment policies to improve patient outcome from training examples that do not represent optimal behavior [8, 9, 10]. Here, we focus on the problem of dosing opioid analgesics in the ICU. While machine learning has been applied extensively to the problem of pain recognition, to our knowledge this is the first application of reinforcement learning for deducing optimal intervention regimens to manage pain. We aimed to demonstrate how deep reinforcement learning could be used to suggest clinically interpretable treatment strategies for pain using real-time patient data that are readily accessible. This work has many limitations and should be taken as an illustrative example. Morphine analgesia in the ICU is a complex decision problem influenced by multiple factors. However, our model simplified these clinical factors by constraining the amount of variables considered and defining a reward function that only aims to reduce pain while keeping heart and respiration rates within a pre-defined range. Therefore, possible directions for future work include improving the state space by adding more data modalities, extending the action space to include more dosing regimes (e.g. co-analgesics), and increasing the sophistication of the reward function to reflect the broader range of therapeutic goals. Another limitation is that we used data from a single center, which raises concerns about the generalizability of our findings. Hence, future studies should include multiple centers. Despite the limitations of this work, our learned policy is consistent with research that shows that continuous dosing is recommended over intermittent dosing.
Finally, deployment of this approach to opioid dosing in clinical settings would first require extensive prospective evaluation of the learned policies. The goal would not be to replace physicians’ clinical judgments about treatment, but to aid clinical decision making with insights about optimal decisions and automatically guide therapy.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Juliana Barr, Gilles L. Fraser, Kathleen Puntillo, E. Wesley Ely, Céline Gélinas, Joseph F. Dasta, Judy E. Davidson, John W. Devlin, John P. Kress, Aaron M. Joffe, Douglas B. Coursin, Daniel L. Herr, Avery Tung, Bryce R. H. Robinson, Dorrie K. Fontaine, Michael A. Ramsay, Richard R. Riker, Curtis N. Sessler, Brenda Pun, Yoanna Skrobik, and Roman Jaeschke. Clinical Practice Guidelines for the Management of Pain, Agitation, and Delirium in Adult Patients in the Intensive Care Unit.
- 2[2] Daniel Lopez-Martinez and Rosalind Picard. Continuous Pain Intensity Estimation from Autonomic Signals with Recurrent Neural Networks. In 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) , pages 5624–5627, Hawaii, 7 2018. IEEE.
- 3[3] Daniel Lopez-Martinez, Ke Peng, Sarah Steele, Arielle Lee, David Borsook, and Rosalind Picard. Multi-task multiple kernel machines for personalized pain recognition from functional near-infrared spectroscopy brain signals. In International Conference on Pattern Recognition (ICPR) , Beijing, 2018.
- 4[4] Daniel Lopez-Martinez, Ognjen Rudovic, and Rosalind Picard. Personalized Automatic Estimation of Self-Reported Pain Intensity from Facial Expressions. In 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) , pages 2318–2327, Hawaii, USA, 7 2017. IEEE.
- 5[5] Daniel Lopez-Martinez, Ognjen Rudovic, and Rosalind Picard. Physiological and Behavioral Profiling for Nociceptive Pain Estimation Using Personalized Multitask Learning. In Neural Information Processing Systems (NIPS) Workshop on Machine Learning for Health , Long Beach, USA, 2017.
- 6[6] Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement learning. Nature , 518(7540):529–533, 2 2015.
- 7[7] David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science , 362(6419):1140–1144, 12 2018.
- 8[8] Shamim Nemati, Mohammad M. Ghassemi, and Gari D. Clifford. Optimal medication dosing from suboptimal clinical examples: A deep reinforcement learning approach. In 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) , pages 2978–2981. IEEE, 8 2016.