TL;DR
This paper introduces a deep learning model combining autoencoders and sparse coding for improved classification, demonstrating superior results over traditional SRC methods across multiple datasets.
Contribution
It proposes a novel deep transductive framework that integrates deep feature learning with sparse representation for classification.
Findings
Outperforms state-of-the-art SRC methods on three datasets
Learns robust deep features for sparse coding
Provides open-source implementation for reproducibility
Abstract
We present a transductive deep learning-based formulation for the sparse representation-based classification (SRC) method. The proposed network consists of a convolutional autoencoder along with a fully-connected layer. The role of the autoencoder network is to learn robust deep features for classification. On the other hand, the fully-connected layer, which is placed in between the encoder and the decoder networks, is responsible for finding the sparse representation. The estimated sparse codes are then used for classification. Various experiments on three different datasets show that the proposed network leads to sparse representations that give better classification results than state-of-the-art SRC methods. The source code is available at: github.com/mahdiabavisani/DSRC.
Click any figure to enlarge with its caption.
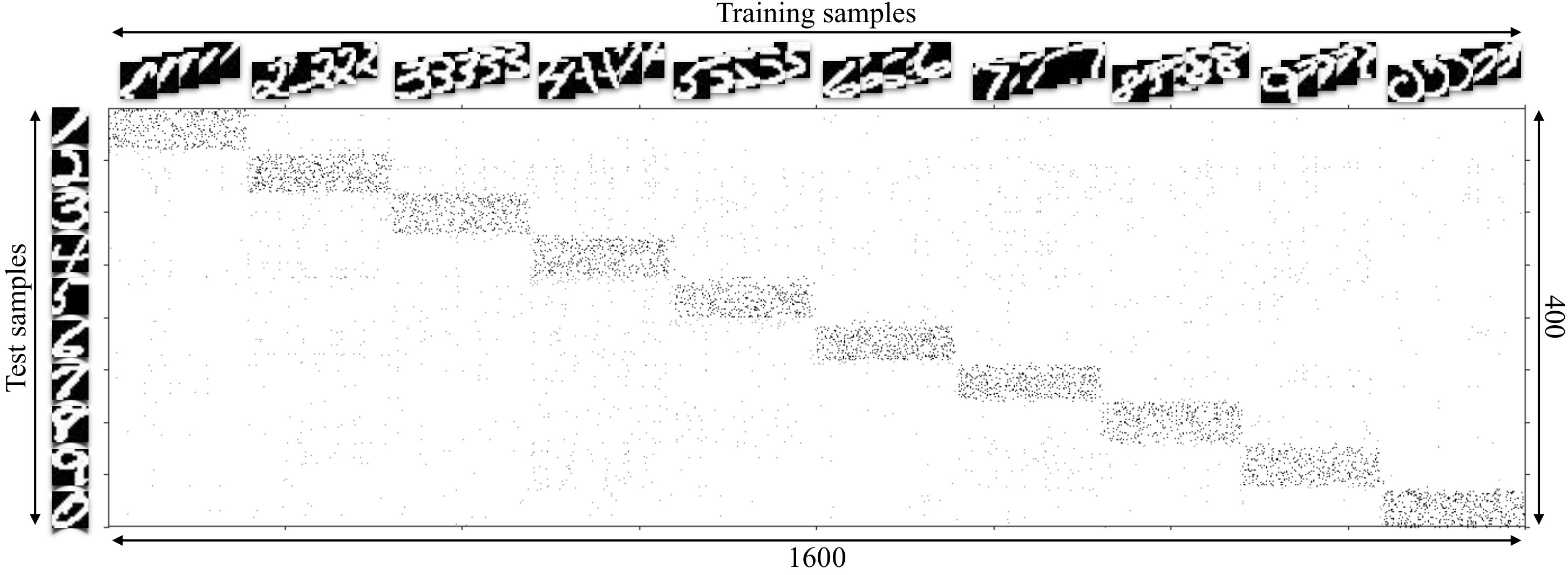 Figure 1
Figure 1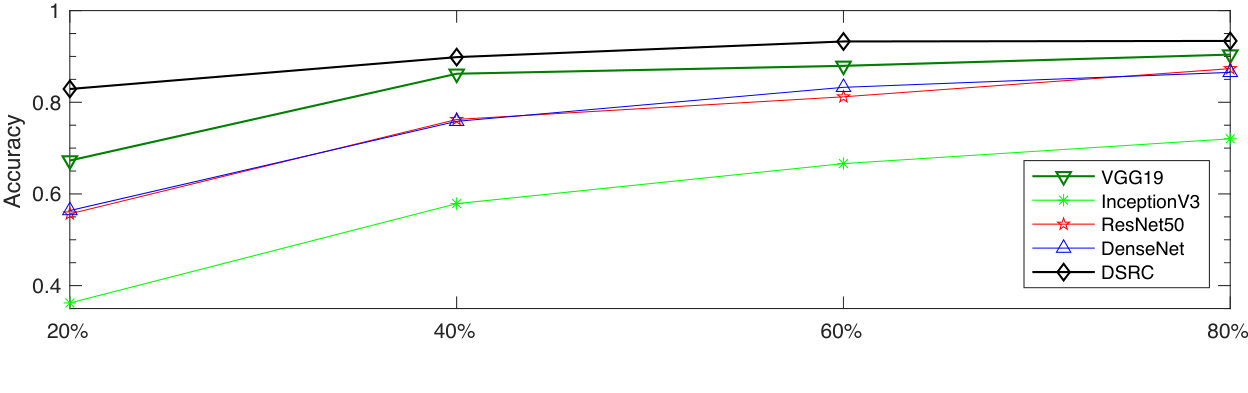 Figure 2
Figure 2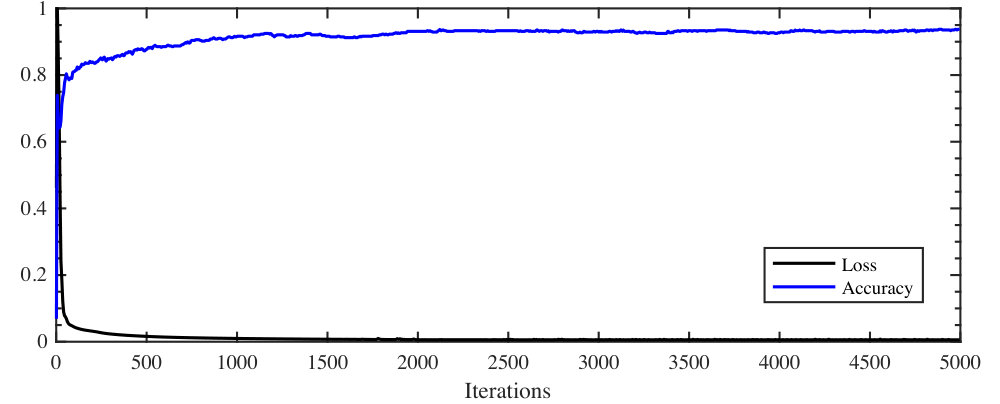 Figure 3
Figure 3 Figure 4
Figure 4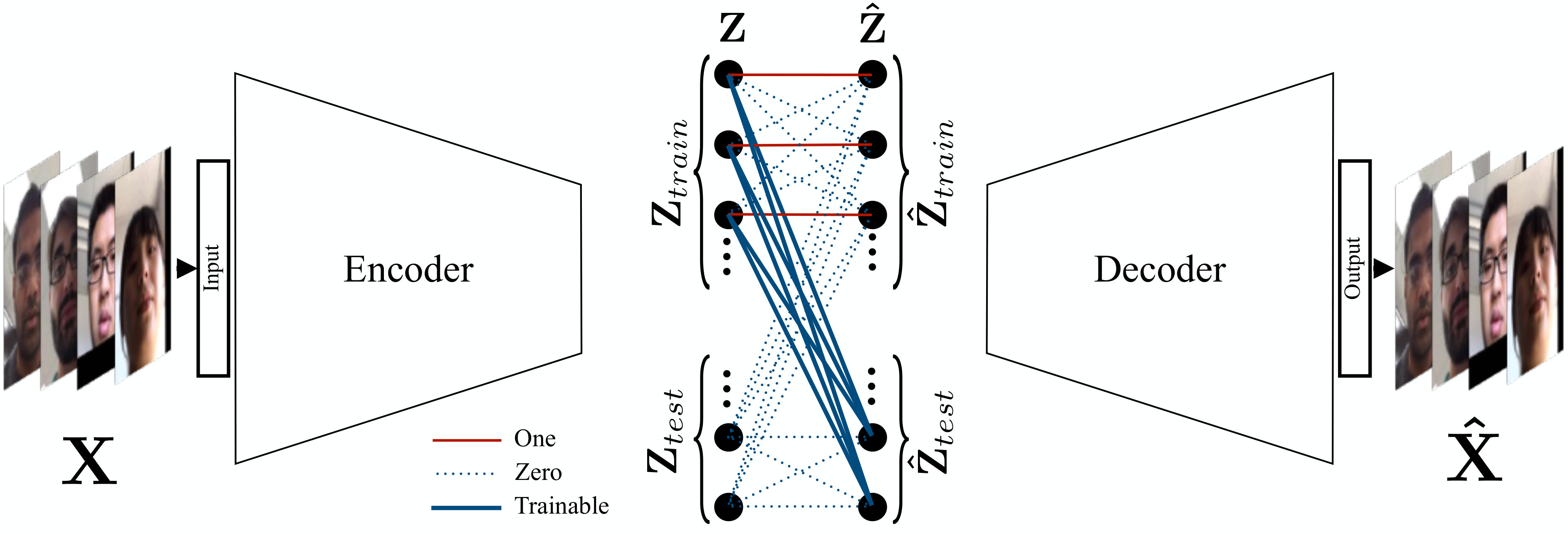 Figure 5
Figure 5| Layer | Input | Output | Kernel | (stride, pad) | |
| Encoder | Conv 1 | Conv 1 | (2,1) | ||
| Conv 2 | Conv 1 | Conv 2 | (2,1) | ||
| Conv 3 | Conv 2 | Conv 3 | (1,0) | ||
| Conv 4 | Conv 3 | (1,0) | |||
| Sparse coding layer | Parameters | - | |||
| Decoder | deconv 1 | deconv 1 | (1,0) | ||
| deconv 2 | deconv 1 | deconv 2 | (2,1) | ||
| deconv 3 | deconv 2 | (2,1) |
| Dataset | SRC | KSRC | AE-SRC | VGG19-SRC | InceptionV3-SRC | Resnet50-SRC | Denesnet169-SRC | DSRC (ours) |
|---|---|---|---|---|---|---|---|---|
| USPS | 87.78 | 91.34 | 88.65 | 91.27 | 93.51 | 95.75 | 95.26 | 96.25 |
| SVHN | 15.71 | 27.42 | 18.69 | 52.86 | 41.14 | 47.88 | 37.65 | 67.75 |
| UMDAA-01 | 79.00 | 81.37 | 86.70 | 82.68 | 86.15 | 91.84 | 86.35 | 93.39 |
| DSRC | DSC-SRC | DSRC0.5 | DSRC1.5 | DSRC2 | |
|---|---|---|---|---|---|
| USPS | 96.25 | 78.25 | N/C | 95.75 | 96.25 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsSolana Customer Service Number +1-833-534-1729
Deep Sparse Representation-based Classification
Mahdi Abavisani, and Vishal M. Patel M. Abavisani is with the department of Electrical and Computer Engineering at Rutgers University, Piscataway, NJ USA. email: [email protected]. Vishal M. Patel is with the department of Electrical and Computer Engineering at Johns Hopkins University, Baltimore, MD USA. email: [email protected]. This work was partially supported by the NSF grant 1618677 and by US Office of Naval Research (ONR) Grant YIP N00014-16-1-3134.
Abstract
We present a transductive deep learning-based formulation for the sparse representation-based classification (SRC) method. The proposed network consists of a convolutional autoencoder along with a fully-connected layer. The role of the autoencoder network is to learn robust deep features for classification. On the other hand, the fully-connected layer, which is placed in between the encoder and the decoder networks, is responsible for finding the sparse representation. The estimated sparse codes are then used for classification. Various experiments on three different datasets show that the proposed network leads to sparse representations that give better classification results than state-of-the-art SRC methods. The source code is available at: github.com/mahdiabavisani/DSRC.
Index Terms:
Deep learning, sparse representation-based classification, deep sparse representation-based classification.
I Introduction
Sparse coding has become widely recognized as a powerful tool in signal processing and machine learning with various applications in computer vision and pattern recognition [1, 2, 3]. Sparse representation-based classification (SRC) as an application of sparse coding was first proposed in [1], and was shown to provide robust performance on various face recognition datasets. Since then, SRC has been used in numerous applications [4, 5, 6, 7, 8, 9]. In SRC, an unlabeled sample is represented as a sparse linear combination of the labeled training samples. This representation is obtained by solving a sparsity-promoting optimization problem. Once the representation is found, the label is assigned to the test sample based on the minimum reconstruction error rule [1].
The SRC method is based on finding a linear representation of the data. However, linear representations are almost always inadequate for representing non-linear structures of the data which arise in many practical applications. To deal with this issue, some works have exploited the kernel trick to develop non-linear extensions of the SRC-based methods [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]. Kernel SRC methods require the use of a pre-determined kernel function such as polynomial or Gaussian. Selection of the kernel function and its parameters is an important issue in training when kernel SRC methods are used for classification.
In this paper, we propose a deep neural network-based framework that finds an explicit nonlinear mapping of data, while simultaneously obtaining sparse codes that can be used for classification. Learning nonlinear mappings with neural networks has been shown to produce remarkable improvements in subspace clustering tasks [21, 22]. We introduce a transductive model, which accepts a set of training and test samples, learns a mapping that is suitable for sparse representation, and recovers the corresponding sparse codes. Our model consists of an encoder that is responsible for learning the mapping, a sparse coding layer which mimics the task of constructing the mapped test samples by a combination of the mapped training samples, and a decoder that is used for training the networks.
I-A Sparse representation-based classification
In SRC, given a set of labeled training samples, the goal is to classify an unseen set of test samples. Suppose that we collect all the vectorized training samples with the label in the matrix , where is the dimension of each sample and is the number of samples in class , then the training matrix can be constructed as
[TABLE]
where and we have a total of classes.
In SRC, it is assumed that an observed sample can be well approximated by a linear combination of the samples in if is from class . Thus, it is possible to predict the class of a given unlabeled data by finding a set of samples in the training set that can better approximate . Mathematically, these samples can be found by solving the following optimization problem
[TABLE]
where counts the number of non-zero elements in . The minimization problem (2) finds a sparse solution for the linear system. However, since the optimization problem (2) is an NP-hard problem, in practice, a sparsity constraint is enforced by the -norm of which is a convex relaxation of the above problem [23, 24]. Thus, in practice the following minimization problem is solved to obtain the sparse codes
[TABLE]
where is a positive regularization parameter. Once is found, one can estimate the class label of as follows
[TABLE]
where is the characteristic function that selects the coefficients associated with the class .
II Deep sparse representation-based classification network
We develop a transductive classification model based on sparse representations. In a transductive model, as opposed to inductive models, both training and test sets are observed, and the learning process pursues reasoning from the specific training samples to a specific set of test cases [25]. We build our method based on convolutional autoencoders. In particular, our network contains an encoder, a sparse coding layer, and a decoder. The encoder receives both the training and test sets as raw data inputs and extracts abstract features from them. The sparse coding layer recovers the test cases by a sparse linear combination of the training samples, and concatenates them along with the training features which are then fed to the decoder. The decoder maps both the training embeddings and the recovered test embeddings back to the original representation of the data. Figure 1 gives an overview of the proposed deep SRC (DSRC) framework.
**Sparse representation: ** Let and, be the given vectorized training and testing data, respectively. We feed to the encoder, where it develops the corresponding embedding features . The minimization problem (3) for a single test observation can be re-written for a matrix of testing embedding features as
[TABLE]
where is the coefficient matrix that contains the sparse codes in its columns, and is a positive regularization parameter. Note that the first penalty term in equation (5) is equivalent to the penalty term used for a fully-connected neural network layer with the input of , the output of and trainable parameters of . As a result, considering the sparsity constraint, one can model the optimization problem (5) in a neural network framework with a fully-connected layer with sparse parameters which have no non-linearity activation or bias nodes. We use such a model inside our sparse coding layer to find the sparse codes for the observed test set.
The sparse coding layer is located between the encoder and decoder networks. Its task for is to pass them to the decoder, and for the test features it will pass their reconstructions that are found from (5), as , to the decoder. Thus, assuming that and are the outputs of the sparse coding layer for training and testing features, we have
[TABLE]
where is the identity matrix. Therefore, if the decoder’s input is , from (6) we can calculate as , where
[TABLE]
In equation (7), and are zero matrices. One can write an end-to-end training objective that includes sparse coding and training of the encoder-decoder as follows
[TABLE]
where is the union of all the trainable parameters including encoder and decoder’s parameters and . Here, is the output of the decoder (i.e. reconstructions), and and are positive regularization parameters. Note that the optimization problem (8) simultaneously finds sparse codes and a set of desirable embedding features that are especially suitable for providing efficient sparse codes.
Classification: Once the sparse coefficient matrix is found, it can be used for associating the class labels to the test samples. For each test sample in , its embedding features , and the corresponding sparse code column in are used to estimate the class labels as follows
[TABLE]
The proposed DSRC method is summarized in Algorithm 1.
III Experimental results
In this section, we evaluate our method against state-of-the-art SRC methods. The USPS handwritten digits dataset [26], the street view house numbers (SVHN) dataset [27], and the UMDAA-01 face recognition dataset [28] are used in our experiments. Figure 2 (a), (b), and (c) show sample images from these datasets. Since the number of parameters in the sparse coding layer scales with the multiplication of training and testing sizes, we randomly select a smaller subset of the used datasets and perform all the experiments on the selected subset. In all the experiments, the input images are resized to .
We compare our method with the standard SRC method [1], Kernel SRC (KSRC) [14], SRC on features extracted from an autoencoder with similar architecture to our network (AE-SRC), and SRC on features extracted from the state-of-the-art pre-trained networks. In our experiment with the pre-trained networks, the networks are pre-trained on the Imagenet dataset [29]. For this purpose, we use the following four popular network architectures: VGG-19[30], Inception-V3 [31], Resnet-50 [32] and Densenet-169 [33]. We feed these networks with our datasets, extract the features corresponding to the last layer before classification, and pass them to the classical SRC algorithm. Note these networks accept inputs. Thus, as a preprocessing step, we resample the input images to images before feeding them to the pre-trained networks.
We compare different methods in terms of their five-fold averaged classification accuracy. In all the experiments, unless otherwise stated, we randomly split the datasets into sets of training and testing samples, where of the samples are used for testing, and of the samples are used as the training set.
Network structure: The encoder network of our model consists of stacked four convolutional layers, and the decoder has three fractionally-strided convolution layers (also known as deconvolution layers). Each plugged in convolution or fractionally-strided convolution is coupled with a ReLu nonlinearity as well, but does not have a batch-norm layer. Table I gives the details of the network, including the kernel sizes and the number of filters.
Training details: We implemented our method with Tensorflow-1.4 [34]. We use the adaptive momentum-based gradient descent method (ADAM) [35] to minimize the loss function, and apply a learning rate of . Before we start training on our objective function, in each experiment, we pre-train our encoder and decoder on the dataset without the sparse coding layer. In particular, we pre-train the encoder-decoder for epochs with the objective of where indicates the union of parameters in the encoder and decoder networks. We use a batch size of for this stage. However, in the actual stage of training, we feed all the samples including the training and testing samples as a single large batch. We set the regularization parameters as and in all the experiments.
III-A USPS digits
The first set of experiments is conducted on the USPS handwritten digits dataset [26]. This dataset contains 7291 training and 2007 test grayscale images of ten digits (0-9). Figure 2 (a), shows example images from this dataset. We perform the experiments on a subset with a total size of samples. In particular, we randomly select and samples per digit from the training and testing sets, respectively. The first row of Table II shows the performance of various SRC methods. As can be observed from this table, the proposed method performs significantly better than the other methods including the classical and deep learning-based methods.
Figure 3 shows the coefficient matrix , extracted from , the matrix of the network trained for this experiment. For better visualization, we show the absolute value of the transposed (i.e. ). Thus, each row of the matrix in Figure 3 corresponds to the sparse codes for one of the test samples. Similarly, columns in this figure are coefficients related to the training samples. This matrix is sparse and shows a block diagram pattern, where most of the non-zero coefficients for each test sample are those that correspond to the training samples with the same class as the observed test sample.
Analysis of the network: To understand the effects of some of our model choices, we compare the performance of our DSRC method with variations of it by changing the regularization norm on in the loss function (8). We replace the term in (8) by , where and , and report their performances by DSRC0.5, DSRC1.5 and DSRC2, respectively.
In addition, if we do not follow the specific structure described in equation (7), and instead have a fully connected layer with parameters which receives and reconstructs , the architecture of the network will be similar to the deep subspace clustering networks (DSC) proposed in [21] for the task of subspace clustering. As an ablation study, we use this method to extract sparse codes and then apply the same classification rule as in (9) to estimate class labels for the test set. We call this method DSC-SRC.
Table III reveals that while the regularization norm on the coefficient matrix is selected between and , it does not have much effect on the performance of the classification task. However, in our experiments, we observed that for norms smaller than 1, the problem is not stable and often does not converges. In addition, DSC-SRC cannot provide a desirable performance. Note that the fully-connected layer in this method (counterpart to our sparse coding layer) does not limit the testing features to be reconstructed with only the training features. As a result, it is possible that testing features shape an isolated group that does not have a strong connection to the training features. This makes it more difficult to estimate a label for the test samples.
III-B Street view house numbers
The SVHN dataset [27] contains 630,420 color images of real-world house numbers collected from Google Street View images. This dataset has three splits as the training set with 73,257 images, the testing set with 26,032 images and an extra set containing 531,131 additional samples. In this experiment, similar to our experiments on MNIST, we randomly select 160 images per digit from the training split and 40 per digit from the test split. This dataset is much more challenging than MNIST. This is in part due to the large variations of data. Furthermore, many samples in this dataset contain multiple digits in an image. The task is to classify the center digit.
The second row in Table II compares the performance of different SRC methods. This table demonstrates the advantage of our method. While the classification task is much more challenging on SVHN than MNIST, the gap between the performance of our method and the second best performance is even more. The next best performing method is VGG19-SRC which performs behind the accuracy of our method.
III-C UMD mobile faces
The UMD mobile face dataset (UMDAA-01) [28] contains 750 front-facing camera videos of 50 users captured while using a smartphone. This dataset has been collected over three different sessions. This dataset was originally collected for the active authentication task, but since its frames include challenging facial image instances with various illumination and pose conditions it has also been used for other tasks [36, 37]. In this experiment, we randomly select 50 facial images per subjects from the data in Session 1. Figure 2 shows some sample images from this dataset.
The performance of various SRC methods on the UMDAA-01 dataset are tabulated in the third row of Table II. As can be seen, our proposed DSRC method similar to the experiments with SVHN provides remarkable improvements as compared to the other SRC methods. This clearly shows that more challenging datasets are better represented by our method. This is because our method not only efficiently finds the sparse codes, but also it seeks for a representation of data (the output of the encoder) that is especially suitable for sparse representation.
Comparison to state-of-the-art classification networks: While deep neural networks perform very well when they are trained on large datasets, in the case of limited number of labeled training samples, they often tend to overfit to the training samples. The objective of this experiment is to analyze the performance of our approach in such circumstances. We compare our method to the following classification networks: VGG-19[30], Inception-V3 [31], Resnet-50 [32] and Densenet-169 [33]. We first pre-train the networks on the Imagenet dataset [29], and then fine-tune them on the available training samples in UMDAA-01.
Figure 4 shows the performance of the classification networks on four different versions of UMDAA-01 dataset with varying number of training samples. The four versions are created by randomly splitting the dataset into sets of training and testing samples that respectively contain , , and of the total number of samples as training samples and use the rest of samples as the testing set. As the figure suggests, accuracy improves by increasing the number of training samples in all the cases. However, the results show better performances for DSRC even when less training data is available.
IV Conclusion
We presented an autoencoder-based sparse coding network for SRC. In particular, we introduced a sparse coding layer that is located between the conventional encoder and decoder networks. This layer recovers sparse codes of embedding features that are received from the encoder. The spare codes are later used to estimate the class labels of testing samples. We discussed a framework that allows an end-to-end training. Various experiments on three different image classification datasets showed that the proposed network leads to sparse representations that give better classification results than state-of-the-art SRC methods.
Appendix: Convergence
To empirically show the convergence of our proposed method, in Figure 5, we plot the values of the objective function of DSRC in the experiment with the UMDAA-01 dataset and its classification accuracy in different iterations. The reported loss values in Figure 5 are scaled to have a maximum value of one. As can be seen from the figure, our algorithm converges in a few iterations.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Wright, A.Y. Yang, A. Ganesh, S.S. Sastry, and Yi Ma, “Robust face recognition via sparse representation,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 31, no. 2, pp. 210 –227, feb. 2009.
- 2[2] Michal Aharon, Michael Elad, Alfred Bruckstein, et al., “K-svd: An algorithm for designing overcomplete dictionaries for sparse representation,” IEEE Transactions on signal processing , vol. 54, no. 11, pp. 4311, 2006.
- 3[3] E. Elhamifar and R. Vidal, “Sparse subspace clustering: Algorithm, theory, and applications,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 35, no. 11, pp. 2765–2781, 2013.
- 4[4] Xue Mei and Haibin Ling, “Robust visual tracking and vehicle classification via sparse representation,” IEEE transactions on pattern analysis and machine intelligence , vol. 33, no. 11, pp. 2259–2272, 2011.
- 5[5] Sumit Shekhar, Vishal M Patel, Nasser M Nasrabadi, and Rama Chellappa, “Joint sparse representation for robust multimodal biometrics recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 36, no. 1, pp. 113–126, 2014.
- 6[6] Mahdi Abavisani, Mohsen Joneidi, Shideh Rezaeifar, and Shahriar Baradaran Shokouhi, “A robust sparse representation based face recognition system for smartphones,” in 2015 IEEE Signal Processing in Medicine and Biology Symposium (SPMB) . IEEE, 2015, pp. 1–6.
- 7[7] Mohsen Joneidi, Alireza Zaeemzadeh, Shideh Rezaeifar, Mahdi Abavisani, and Nazanin Rahnavard, “Lfm signal detection and estimation based on sparse representation,” in 2015 49th Annual Conference on Information Sciences and Systems (CISS) . IEEE, 2015, pp. 1–5.
- 8[8] Pramuditha Perera and Vishal M Patel, “Face-based multiple user active authentication on mobile devices,” IEEE Transactions on Information Forensics and Security , vol. 14, no. 5, pp. 1240–1250, 2019.
