Observational Constraints on the Dark Energy Equation of State
Williams J. M. Ribeiro

TL;DR
This paper uses observational data and statistical methods to constrain the evolution of dark energy's equation of state, finding no significant deviations from the standard cosmological model, Lambda-CDM.
Contribution
It introduces a nearly model-independent approach combining multiple datasets to constrain dark energy evolution using Markov Chain Monte Carlo sampling.
Findings
No strong evidence for deviations from Lambda-CDM
Constraints consistent with a cosmological constant
Multi-dataset analysis enhances robustness
Abstract
Late-time cosmic acceleration is one of the most interesting unsolved puzzles in modern cosmology. The explanation most accepted nowadays, dark energy, raises questions about its own nature, e.g. what exactly is dark energy, and implications to the observations, e.g. how to handle fine tuning problem and coincidence problem. Hence, dark energy evolution through cosmic history, together with its equation of state, are subjects of research in many current experiments. In this dissertation, using Markov Chain Monte Carlo sampling, we try to constrain the evolution of the dark energy equation of state in a nearly model-independent approach by combining different datasets coming from observations of baryon acoustic oscillations, cosmic chronometers, cosmic microwave background anisotropies and type Ia supernovae. We found no strong evidence that could indicate deviations from CDM…
Click any figure to enlarge with its caption.
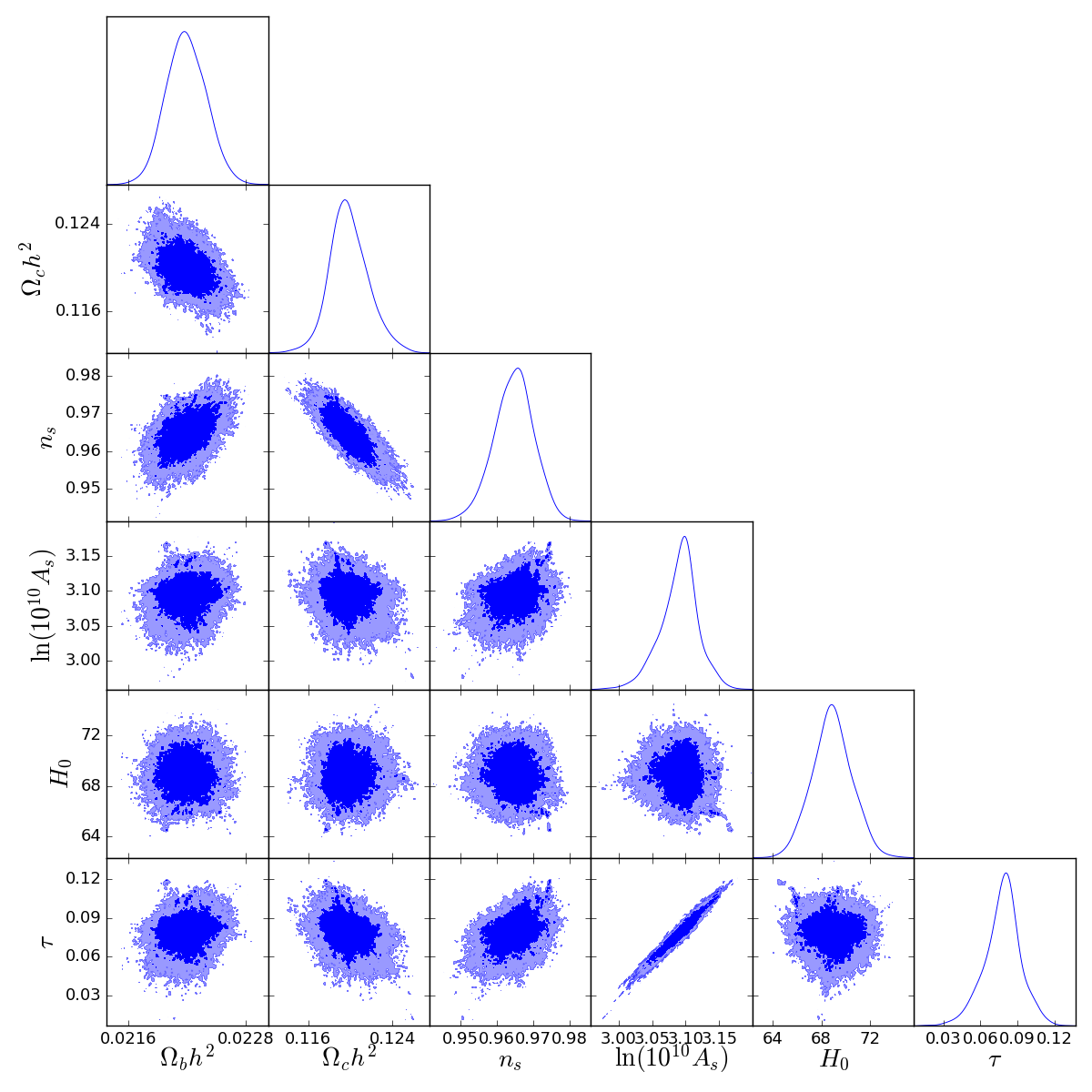 Figure 1
Figure 1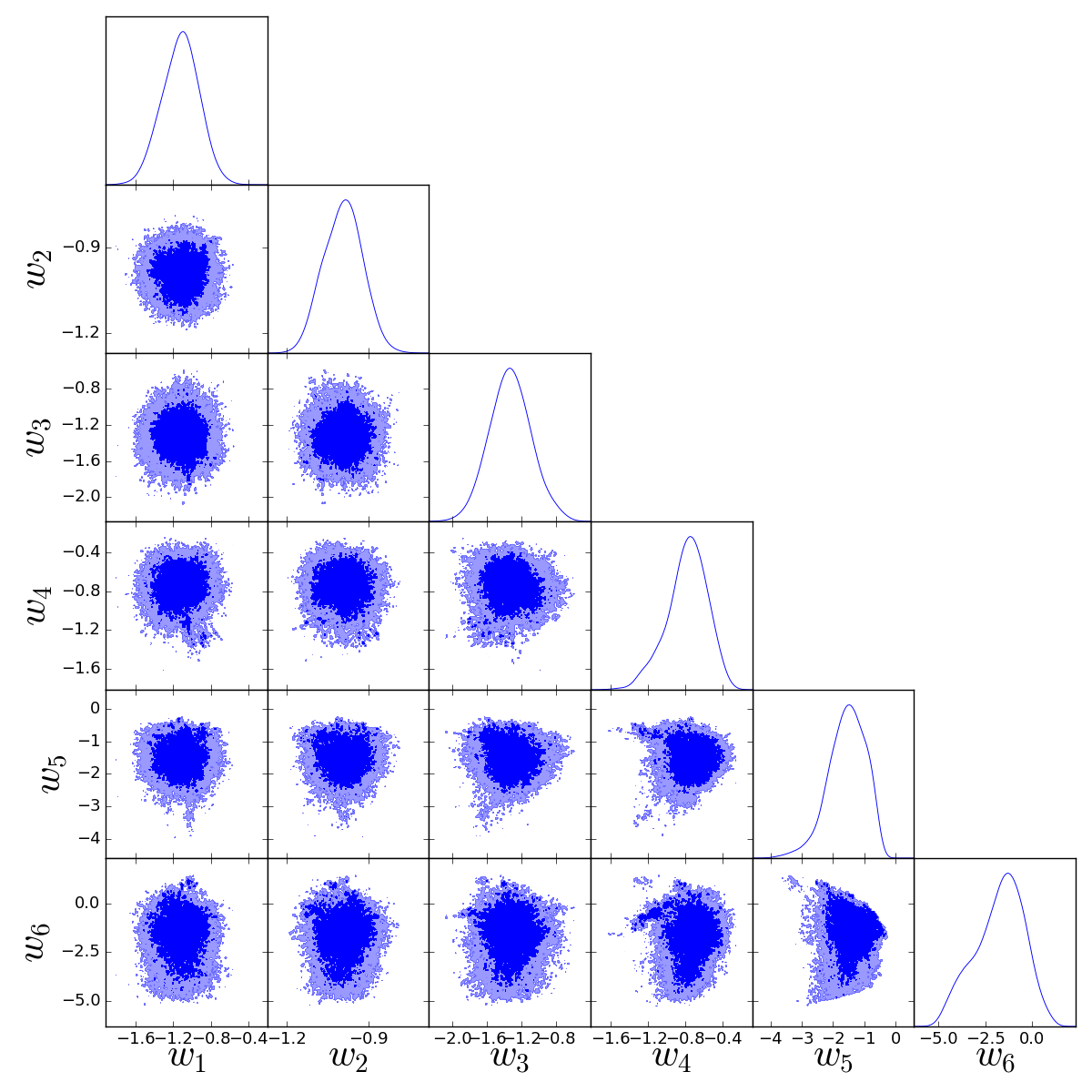 Figure 2
Figure 2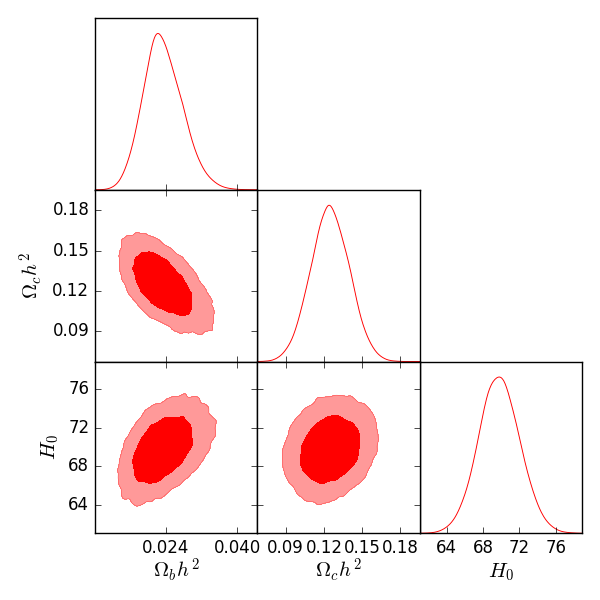 Figure 3
Figure 3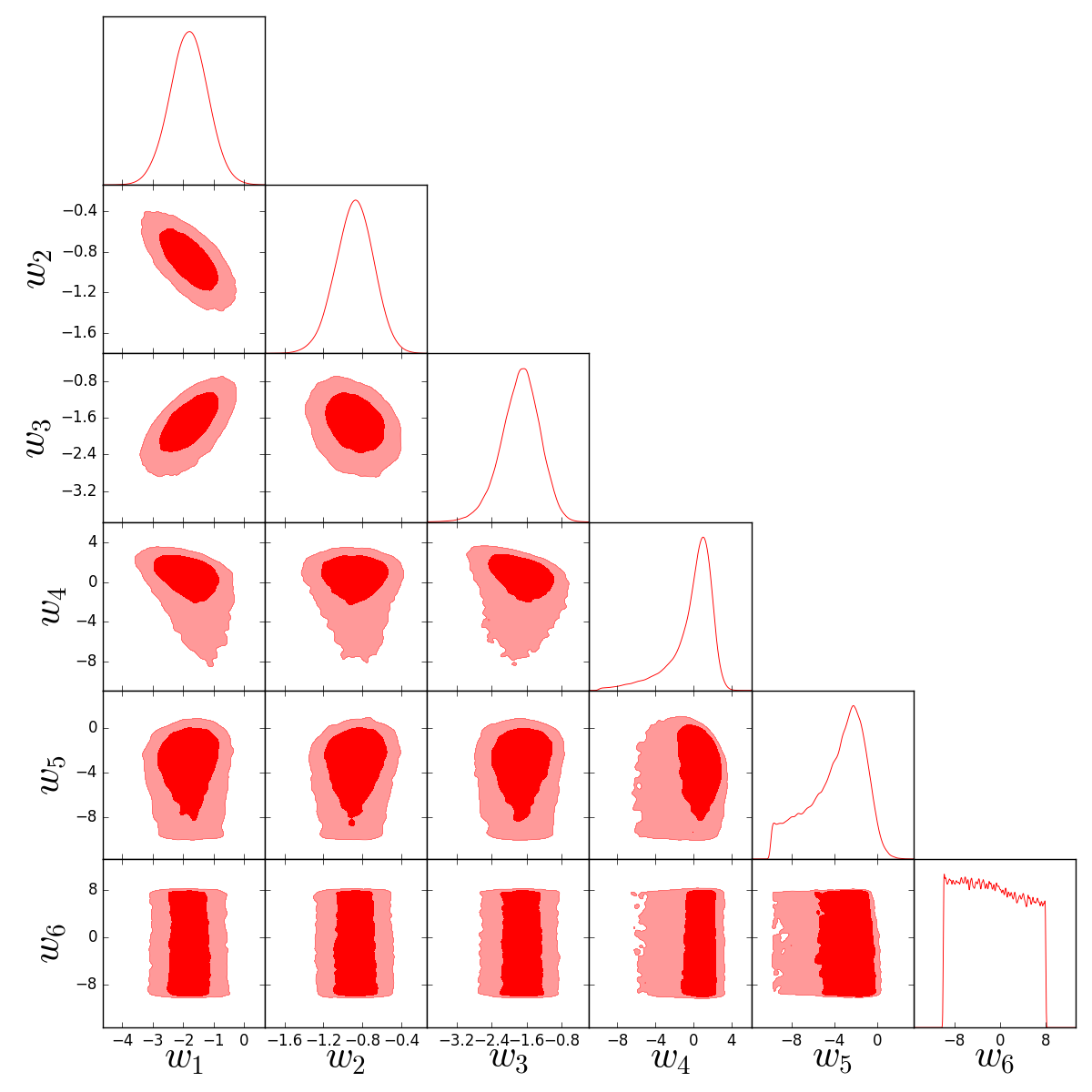 Figure 4
Figure 4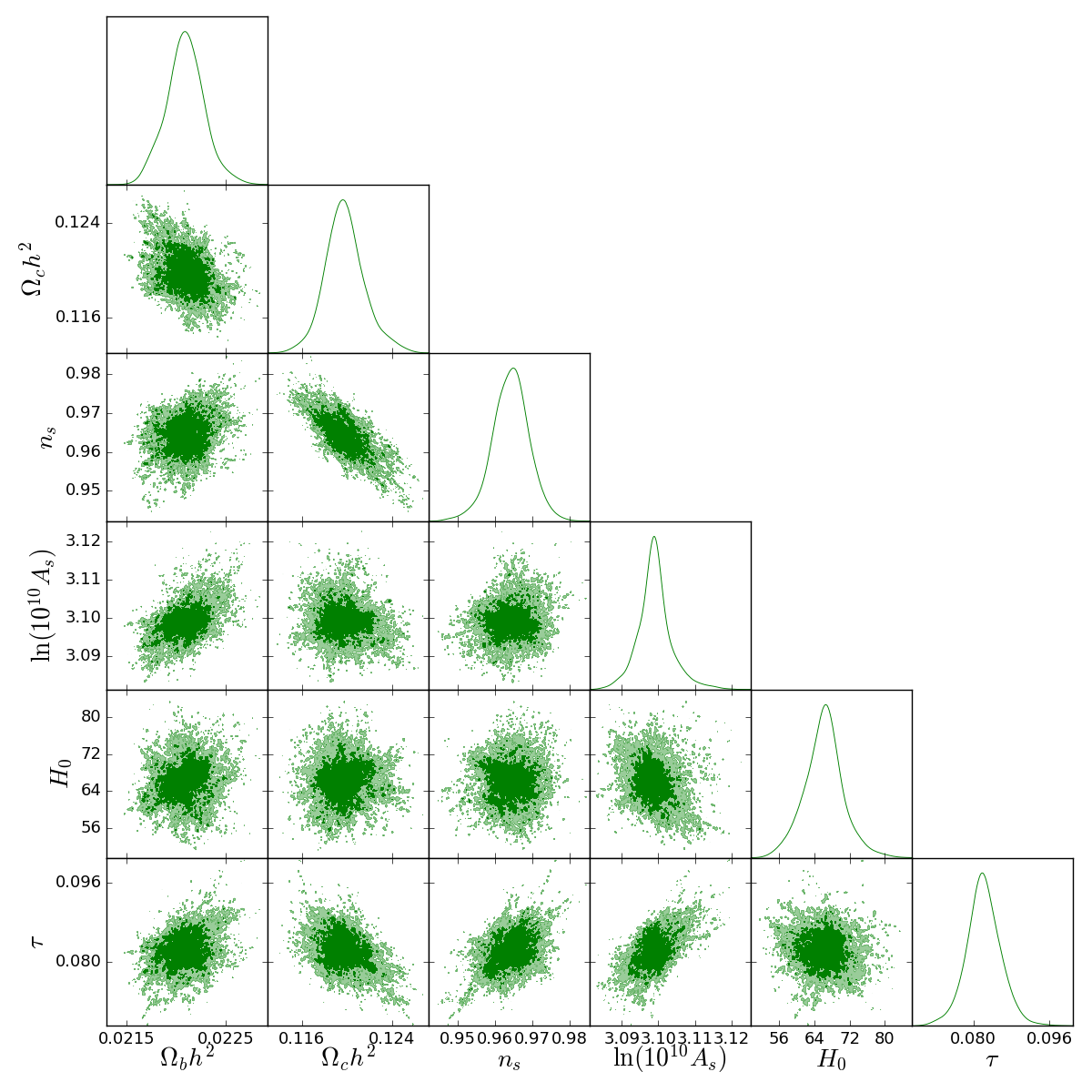 Figure 5
Figure 5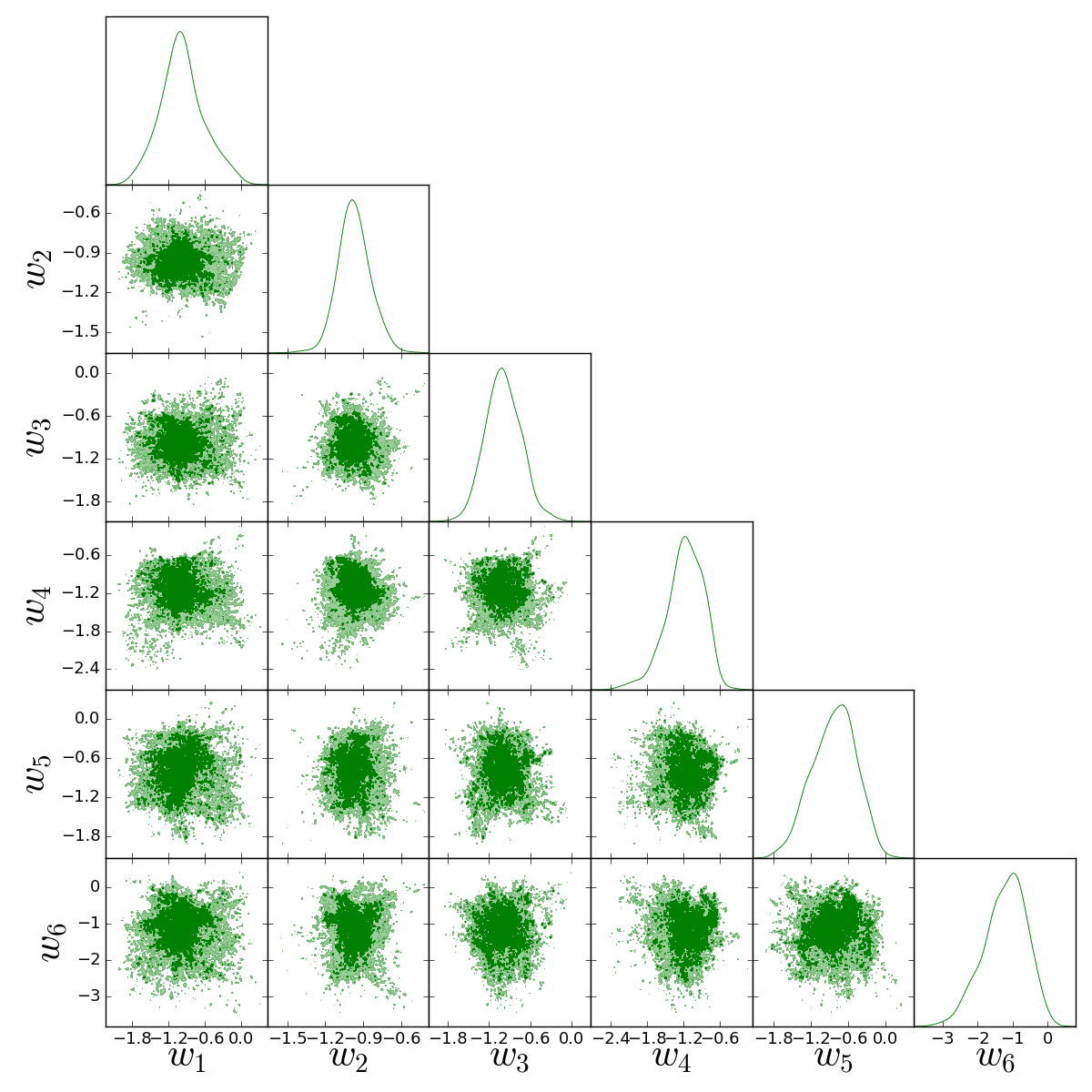 Figure 6
Figure 6 Figure 7
Figure 7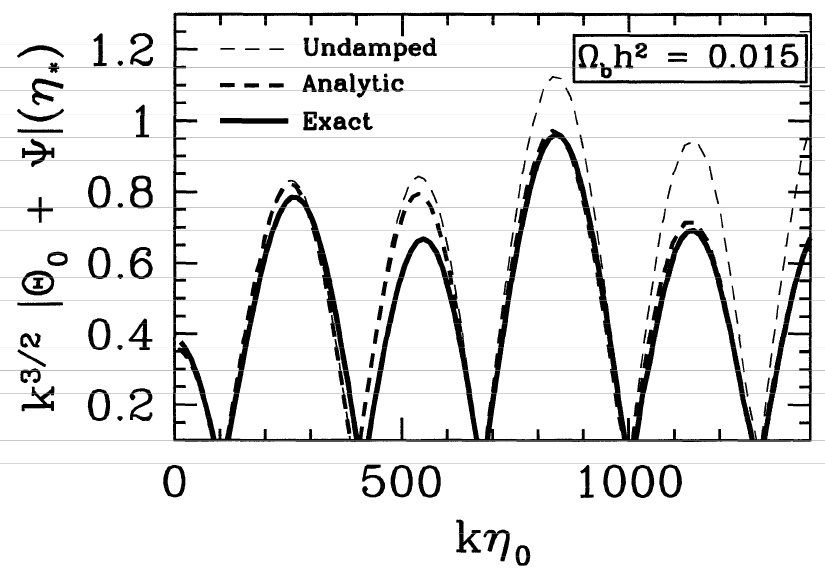 Figure 8
Figure 8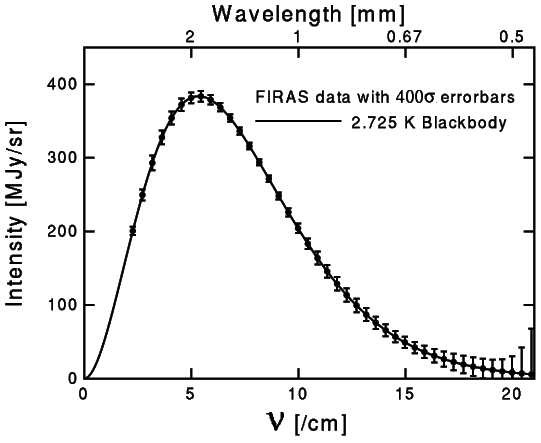 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11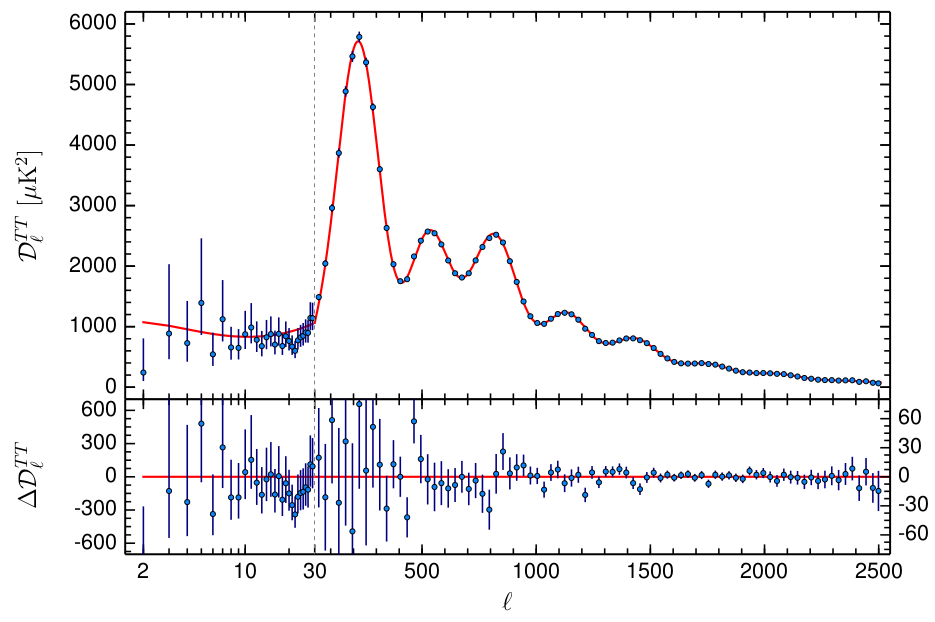 Figure 12
Figure 12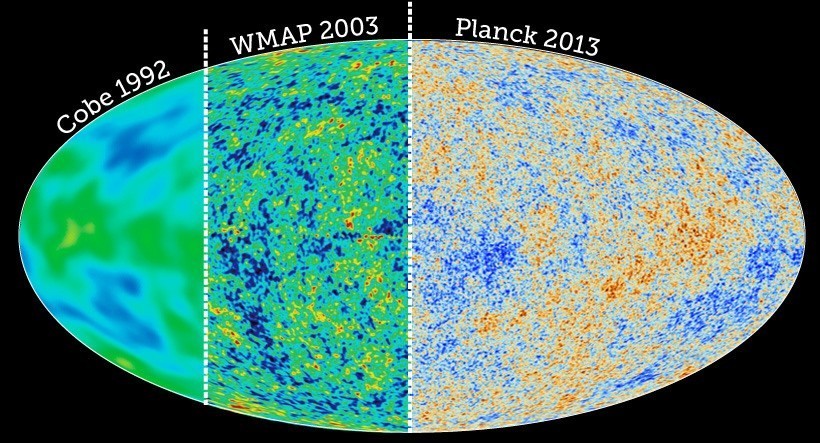 Figure 13
Figure 13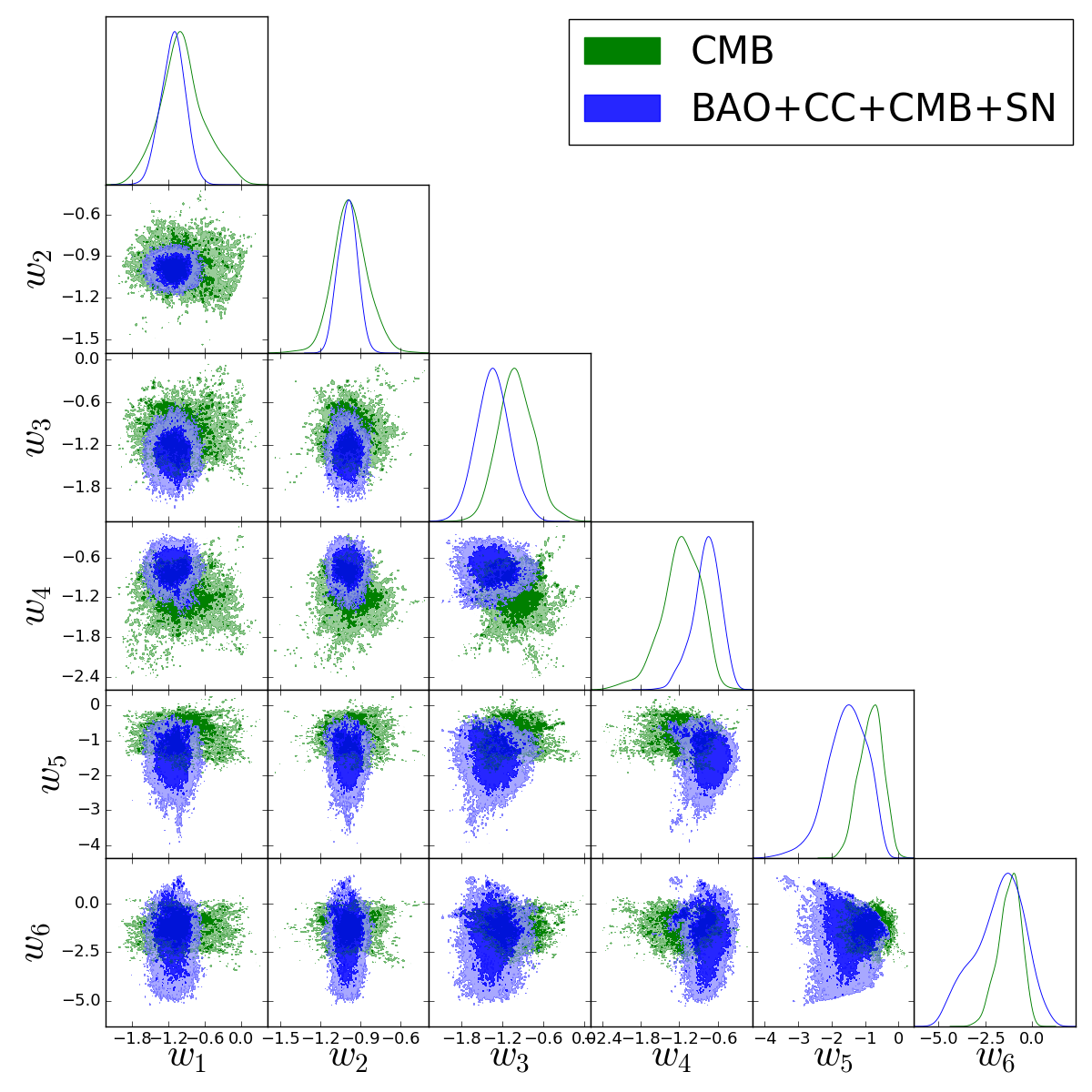 Figure 14
Figure 14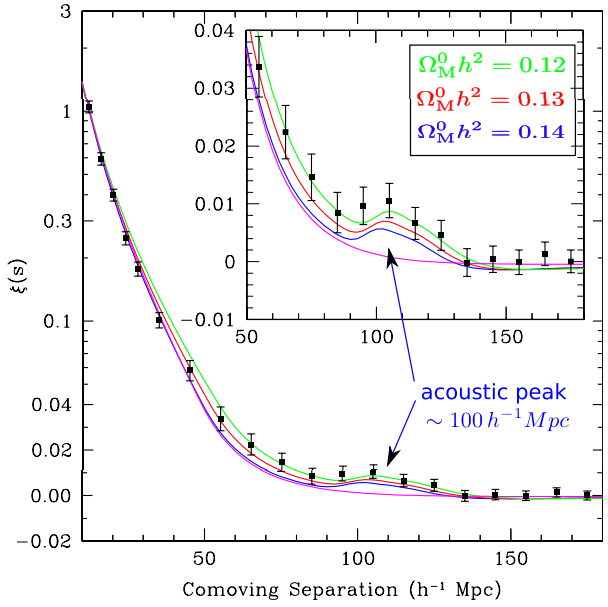 Figure 15
Figure 15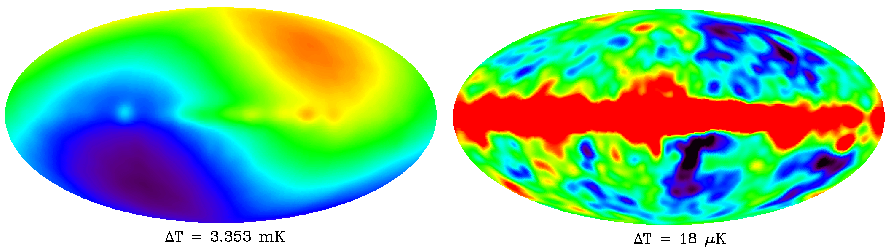 Figure 16
Figure 16 Figure 17
Figure 17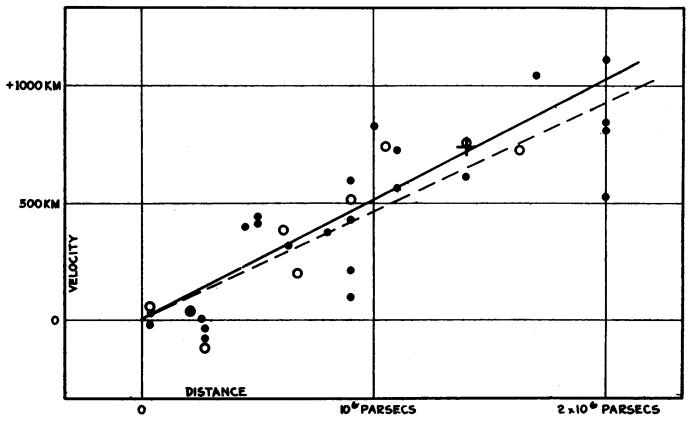 Figure 18
Figure 18 Figure 19
Figure 19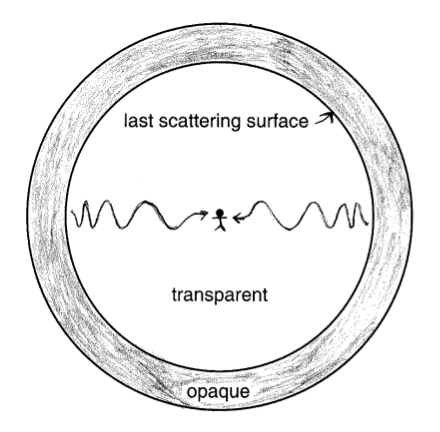 Figure 20
Figure 20 Figure 21
Figure 21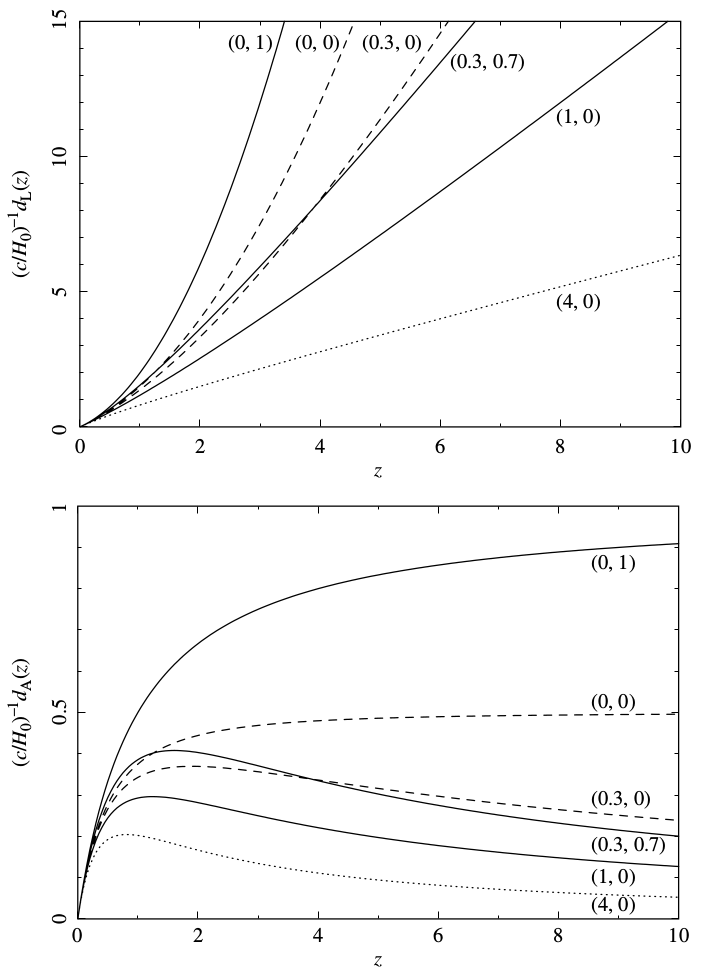 Figure 22
Figure 22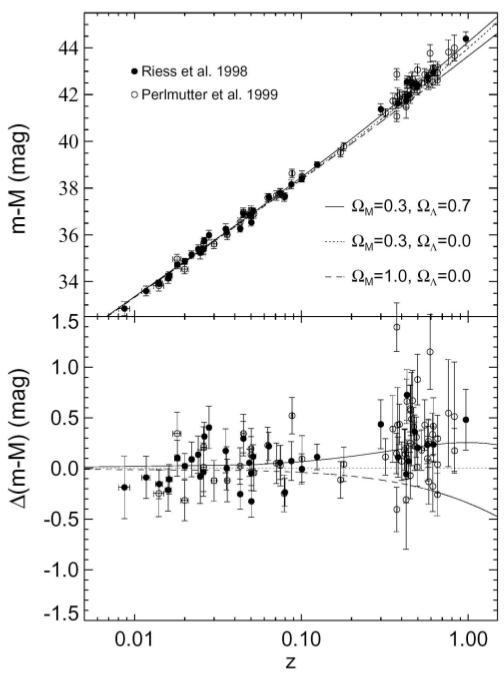 Figure 23
Figure 23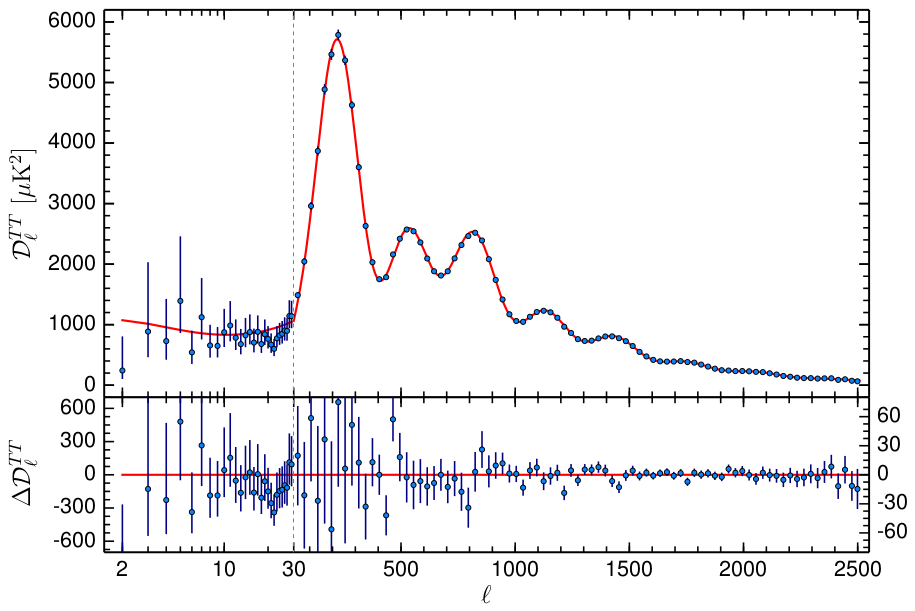 Figure 24
Figure 24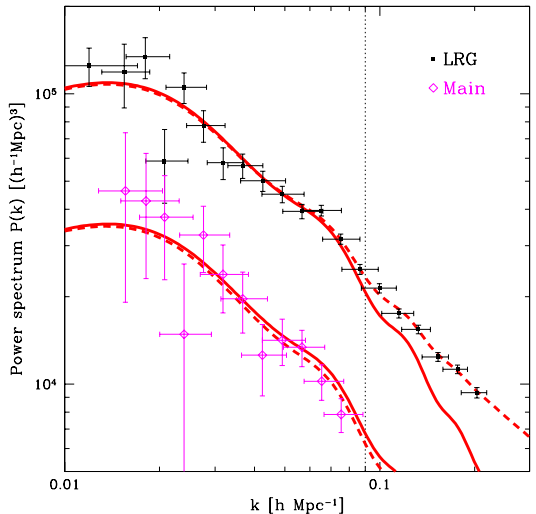 Figure 25
Figure 25 Figure 26
Figure 26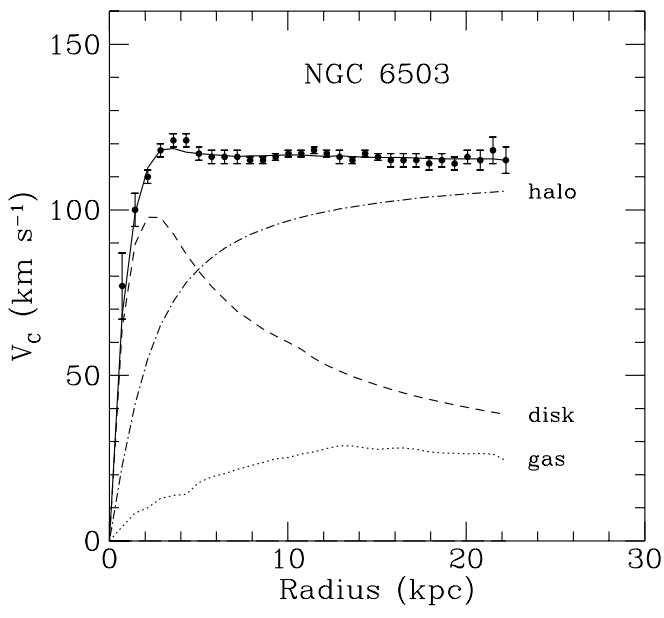 Figure 27
Figure 27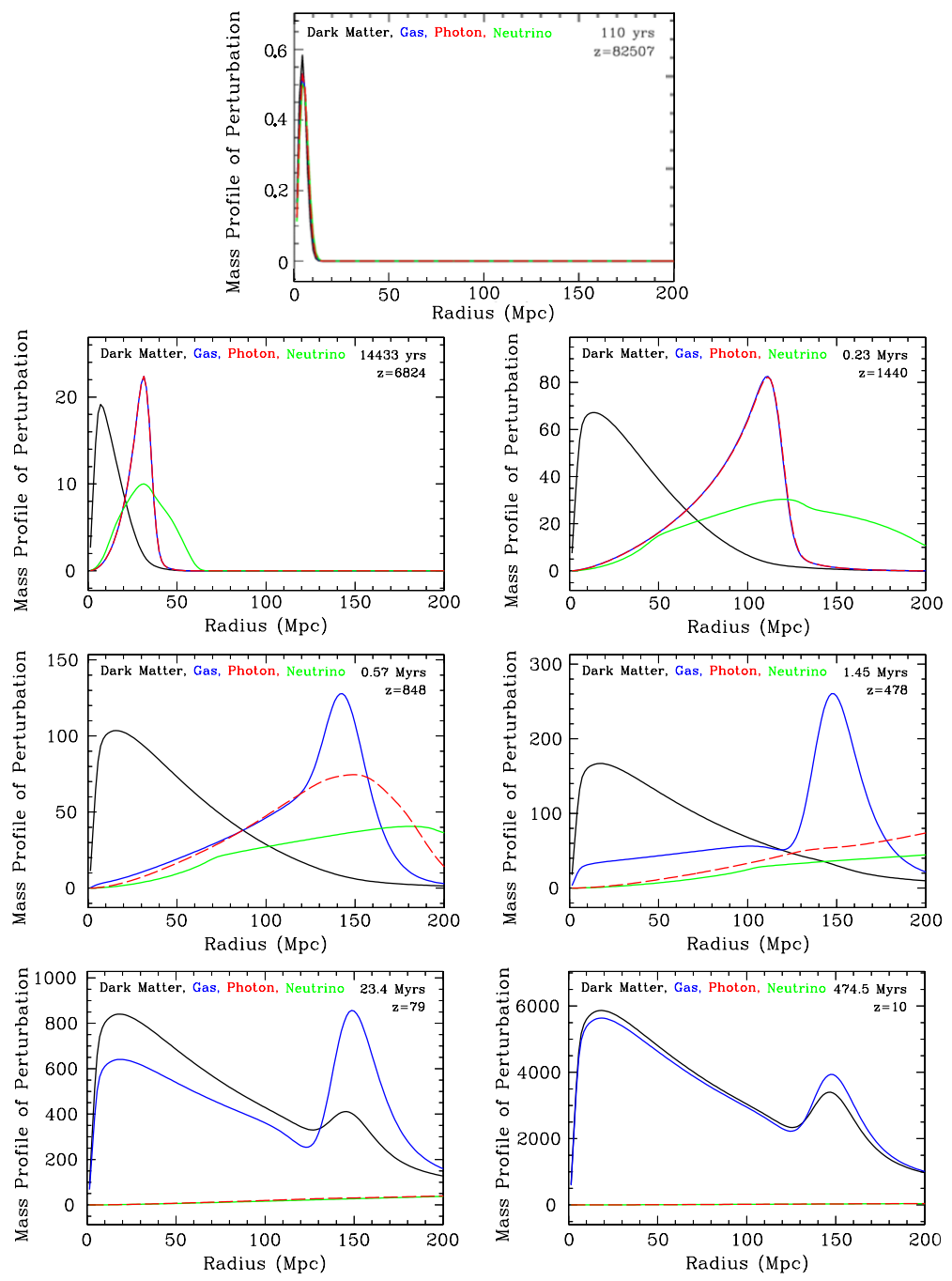 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30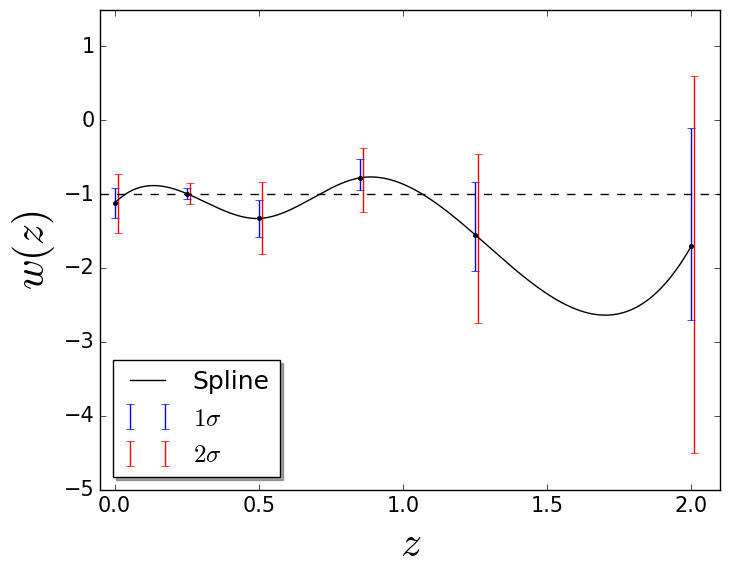 Figure 31
Figure 31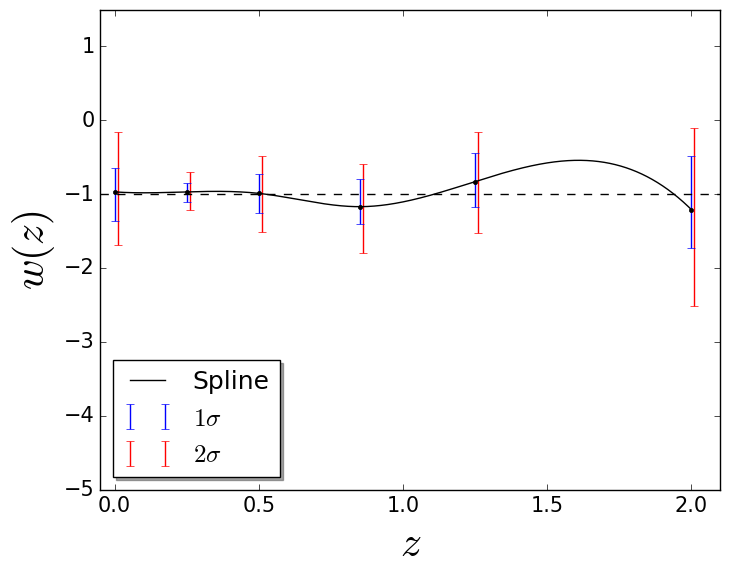 Figure 32
Figure 32| Survey | Parameter | Effective redshift | Measurement |
|---|---|---|---|
| 6DF | 0.106 | ||
| SDSS-MGS | 0.15 | ||
| BOSS-LOWZ | 0.32 | ||
| WiggleZ | 0.44 | ||
| BOSS-CMASS | 0.57 | ||
| WiggleZ | 0.60 | ||
| WiggleZ | 0.73 |
| Redshift slice | |||
|---|---|---|---|
| 1040.3 | -807.5 | 336.8 | |
| 3720.3 | -1551.9 | ||
| 2914.9 |
| Parameter | Prior range | Central | Width | Definition |
|---|---|---|---|---|
| [0.005, 0.1] | 0.0221 | 0.0001 | Baryon density today | |
| [0.001, 0.99] | 0.120 | 0.001 | Cold dark matter density today | |
| [0.8, 1.2] | 0.965 | 0.004 | Scalar spectrum index | |
| ln | [2, 4] | 3.100 | 0.001 | Log power of scalar amplitude |
| [20, 100] | 67.3 | 1.0 | Current expansion rate in | |
| [0.01, 0.8] | 0.08 | 0.01 | Thomson optical depth due to reionization | |
| [-10, 8] | -1.0 | 1.0 | 1st dark energy equation of state parameter | |
| [-10, 8] | -1.0 | 1.0 | 2nd dark energy equation of state parameter | |
| [-10, 8] | -1.0 | 1.0 | 3rd dark energy equation of state parameter | |
| [-10, 8] | -1.0 | 1.0 | 4th dark energy equation of state parameter | |
| [-10, 8] | -1.0 | 1.0 | 5th dark energy equation of state parameter | |
| [-10, 8] | -1.0 | 1.0 | 6th dark energy equation of state parameter | |
| [0, 200] | 65 | 10 | CIB contamination at (217-GHz) | |
| [0, 1] | 0 | 0.1 | SZCIB cross-correlation | |
| [0, 10] | 5 | 2 | tSZ contamination at 143 GHz | |
| [0, 400] | 255 | 24 | Point source contribution in 100100 | |
| [0, 400] | 40 | 10 | Point source contribution in 143143 | |
| [0, 400] | 40 | 12 | Point source contribution in 143217 | |
| [0, 400] | 100 | 13 | Point source contribution in 217217 | |
| [0, 10] | 0 | 3 | kSZ contamination | |
| [0, 50] | 7 | 2 | Dust contamination at in 100100 | |
| [0, 50] | 9 | 2 | Dust contamination at in 143143 | |
| [0, 100] | 17 | 4 | Dust contamination at in 143217 | |
| [0, 400] | 80 | 15 | Dust contamination at in 217217 | |
| [0, 3] | 0.999 | 0.001 | Power spectrum calibration for the 100 GHz | |
| [0, 3] | 0.995 | 0.002 | Power spectrum calibration for the 217 GHz | |
| [0.9, 1.1] | 1.000 | 0.002 | Absolute map calibration for Planck | |
| [0.0, 0.3] | 0.135 | 0.020 | Time stretching coefficient for supernovae | |
| [1.5, 4.0] | 3.0 | 0.3 | Supernovae color coefficient | |
| [-25, -15] | -19.05 | 0.15 | Supernovae absolute magnitude | |
| [-0.3, 0.3] | -0.05 | 0.10 | Correction for supernovae absolute magnitude | |
| - | - | - | Matter density today | |
| - | - | - | Dark energy density today | |
| - | - | - | Mean chi square |
| Parameter | Best fit | limits | limits | Planck (TT+lowP) |
|---|---|---|---|---|
| 0.0257 | ||||
| 0.106 | ||||
| 68.2 | ||||
| -1.80 | - | |||
| -0.80 | - | |||
| -1.63 | - | |||
| 1.11 | - | - | ||
| -1.6 | - | - | ||
| 2.8 | - | - | - | |
| 0.282 | ||||
| 0.718 | ||||
| 486.2 | - |
| Parameter | Best fit | limits | limits | Planck (TT+lowP) |
| 0.02204 | ||||
| 0.1211 | ||||
| 0.9648 | ||||
| ln | 3.0998 | |||
| 65.5 | ||||
| 0.0822 | ||||
| -0.89 | - | |||
| -1.05 | - | |||
| -1.05 | - | |||
| -1.21 | - | |||
| -0.94 | - | |||
| -1.10 | - | |||
| 0.333 | ||||
| 0.665 | ||||
| 11268.7 | - |
| Parameter | Best fit | limits | limits | Planck (TT+lowP) |
| 0.02215 | ||||
| 0.1199 | ||||
| 0.9639 | ||||
| ln | 3.091 | |||
| 70.2 | ||||
| 0.079 | ||||
| -0.94 | - | |||
| -0.958 | - | |||
| -1.42 | - | |||
| -0.75 | - | |||
| -1.55 | - | |||
| -1.13 | - | |||
| 0.288 | ||||
| 0.710 | ||||
| 11756.3 | - |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsCosmology and Gravitation Theories · Geophysics and Gravity Measurements · Computational Physics and Python Applications
Universidade de São Paulo
Instituto de Física
Vínculos Observacionais sobre a Equação de Estado da Energia Escura
Williams Jonata Miranda Ribeiro
Orientador: Prof. Dr. Elcio Abdalla
Dissertação de mestrado apresentada ao Instituto de Física para a obtenção do título de Mestre em Ciências
Banca Examinadora:
Prof. Dr. Elcio Abdalla (IF-USP)
Prof. Dr. Gastão Cesar Bierrenbach Lima Neto (IAG-USP)
Prof. Dr. Carlos Alexandre Wuensche de Souza (INPE)
São Paulo
2018
See pages 1 of fichacatalografica.pdf
University of São Paulo
Institute of Physics
Observational Constraints on the Dark Energy Equation of State
Williams Jonata Miranda Ribeiro
Advisor: Prof. Dr. Elcio Abdalla
Dissertation presented to the Institute of Physics of the University of São Paulo in partial fulfillment of the requirements for the degree of Master of Science
Examining Committee:
Prof. Dr. Elcio Abdalla (IF-USP)
Prof. Dr. Gastão Cesar Bierrenbach Lima Neto (IAG-USP)
Prof. Dr. Carlos Alexandre Wuensche de Souza (INPE)
São Paulo
2018
Acknowledgments
First, I would like to thank God for renewing my strength in the most difficult moments I had been through in my master’s. Without His power, I would not have gone so far.
Also, I would like to thank my advisor Dr. Elcio Abdalla for accepting me to be part of his research group, even though in the beginning I had no prior knowledge about general relativity and cosmology at all.
I am very thankful to my whole family for all the support during these years of study and specially to my father Francisco Junior for his encouragement, which was essential for my personal growth.
I could not forget to mention the friends I made during these years in São Paulo (and the ones I already knew) who have assisted me in many ways in my journey, helping me either with physics or with conversations and laughs that kept me going: Bonifácio Lima, Christianne Moraes, Kariny Bonjorno, Naim Comar, Renan Boschetti, Riis Rhavia, Rodrigo Pinheiro and Thiago Silveira.
I would like to specially thank the postdoc André Costa for all the assistance, tips, discussions and even time invested on my work that made me to progress so much. A gratefully thanks to my friend Caroline Guandalin for the interesting discussions about cosmology and for lending me her computer to perform the simulations for my work (thank you very much!!!). Also, thanks to the colleagues Alessandro Marins and Leonardo Werneck for the programming tips that helped me to improve my code and my computer skills.
My sincere acknowledgement to the science agency CNPq, Conselho Nacional de Desenvolvimento Científico e Tecnológico - Brasil. This dissertation would not be possible without its financial support.
Abstract
Late-time cosmic acceleration is one of the most interesting unsolved puzzles in modern cosmology. The explanation most accepted nowadays, dark energy, raises questions about its own nature, e.g. what exactly is dark energy, and implications to the observations, e.g. how to handle fine tuning problem and coincidence problem. Hence, dark energy evolution through cosmic history, together with its equation of state, are subjects of research in many current experiments. In this dissertation, using Markov Chain Monte Carlo sampling, we try to constrain the evolution of the dark energy equation of state in a nearly model-independent approach by combining different datasets coming from observations of baryon acoustic oscillations, cosmic chronometers, cosmic microwave background anisotropies and type Ia supernovae. We found no strong evidence that could indicate deviations from CDM model, which is the standard model in cosmology accepted today.
Keywords: Cosmology. Dark Energy. Equation of State. Cosmological Parameters. Monte Carlo.
Resumo
A aceleração cósmica atual é um dos mais interessantes enigmas não resolvidos da cosmologia moderna. A explicação mais aceita hoje em dia, a energia escura, levanta questões acerca de sua própria natureza, como o que é exatamente a energia escura, e as implicações para as observações, por exemplo como lidar com o problema do ajuste fino e o problema da coincidência. Por isso, a evolução da energia escura durante a história cósmica, juntamente com sua equação de estado, são objetos de pesquisa em inúmeros experimentos atuais. Nesta dissertação, usando amostragem por cadeias de Markov de Monte Carlo, tentamos restringir a evolução da equação de estado da energia escura em uma abordagem quase independente de modelo ao combinar diferentes conjuntos de dados provenientes de observações de oscilações acústicas de bárions, cronômetros cósmicos, anisotropias da radiação cósmica de fundo e supernovas tipo Ia. Não encontramos evidências fortes que pudessem indicar desvios do modelo CDM, o qual é o modelo padrão aceito hoje na cosmologia.
Palavras-Chave: Cosmologia. Energia Escura. Equação de Estado. Parâmetros Cosmológicos. Monte Carlo.
Contents
-
1.2 Cosmological redshift, Hubble law, critical density and equation of state
-
1.5 Radiation-matter equality, Universe dominated by dark energy and Hubble parameter evolution
-
2.2.2 Anisotropy power spectrum and Einstein-Boltzmann equations
-
2.2.4 Primordial fluctuations: scalar spectral index and amplitude perturbation
-
2.4.3 Luminosity distance, distance modulus and B-band generalized model
Introduction
In 1998, a remarkable discovery set up a new era in modern cosmology: through observations of type Ia supernovae, it was realized that the Universe is going through a phase of accelerated expansion [1, 2]. As our common sense leads us to the idea that the expansion is decelerated due to the effects of gravitation (which was the general belief until 1997), many theories were (and are still being) developed in order to explain this acceleration. Among them, the currently accepted theory is that there exists some kind of “exotic fluid” with negative pressure, named dark energy, that contributes to approximately of our Universe and that is the responsible for this accelerated phase. Other explanations include models of dark energy with repulsive gravity [3], modifications to general relativity [4], models of vacuum decaying [5, 6], interacting dark matter-dark energy models [7, 8, 9, 10], and many others as explored in [11]. Nowadays, besides type Ia supernovae, many kinds of independent observations confirm the accelerated phase: cosmic microwave background anisotropies [12], large-scale structure [13], baryon acoustic oscillations [14], cosmic chronometers [15], etc. Thus, in this work we are going to assume dark energy as the correct explanation for the current Universe dynamics.
One of the ways of describing dark energy is considering it as a barotropic fluid (a fluid whose density depends only on its pressure) with equation of state , which is defined as the ratio between the pressure and the density of the fluid. The model that better matches the observations is named CDM model, in which during all cosmic history. Despite its success in explaining many independent measurements, it is still not the final history for the fact that it does not solve problems like the cosmological constant problem [16] (also called fine tuning problem) and the coincidence problem [17]. Other well known models in literature are the CDM model, which assigns a value different of but still constant for and the CPL model (Chevallier-Polarski-Linder), which considers as a dynamical dark energy equation of state that varies with time [18, 19]. There are also parametrizations that try to capture the evolution of either by performing Taylor expansions or by using something called kink parametrization, which takes into account rapid transitions of dark energy equation of state (something not allowed by a conventional Taylor expansion) [20, 21]. Several constraints in these models can be found in [22, 23, 24, 25].
There is no fundamental theory that can predict whether dark energy equation of state has a static value or evolves with time. In addition to the fact that this quantity cannot be measured directly, strong degeneracy with cosmological parameters makes its evolution hard to predict, specially for high redshifts [26]. Also, although one can write the dark energy equation of state as a function of the background expansion (and consequently as a function of luminosity distance), accurate measurements of the latter coming from cosmic chronometers and type Ia supernovae cannot give good constrains on because in this approach there is an additional dependence on the derivative of the background expansion and because we need estimates of the present density of pressureless matter that only comes from large-scale structure methods, which actually measures the present density of clustered matter (both kinds of matter are not necessarily the same) [11, 27].
The importance of dark energy equation of state lies in the fact that its evolution determines the current state of the Universe, e.g. an accelerated expansion requires [27], its eventual fate, e.g. a phantom dark energy defined by leads to a finite-time singularity called big-rip singularity [28], and the evolution of dark energy itself via continuity equation. Nowadays, the main collaboration for studying the nature of dark energy is the Dark Energy Survey (DES) research project [29], but there are other projects being designed for studying the dark sector such as Euclid [30], BINGO [31, 32], J-PAS [33] and DESI [34].
Instead of testing specific models, a more robust way of extracting information from the evolution of is using different observational datasets in order to reconstruct the evolution of the dark energy equation of state in a model-independent approach (as much as possible) and check if the datasets lead to an agreement with CDM model or not. To this end, we are going to use a method known as principal components analysis (PCA) [35, 36, 37] along with MCMC sampling applied to several datasets in order to obtain estimates for dark energy equation of state in a few redshifts.
Chapter 1 Overview
The initial chapter defines the general terms and concepts used in modern cosmology by using the framework of the Friedmann-Lemaître-Robertson-Walker (FLRW) metric, which agrees with observations that display the Universe as homogeneous and isotropic at large scales. We also construct the tools in such a way that the need for dark matter and dark energy becomes clear for explaining many independent measurements.
1.1 Homogeneous and isotropic Universe
We consider the most general line element that describes a homogeneous and isotropic 4-dimensional spacetime, the FLRW metric, given by (using units of ) [27]
[TABLE]
where is the metric tensor, is the scale factor which depends on the cosmic time and represents the spatial part of the FLRW metric with constant curvature K, given by
[TABLE]
For curvature, , and represent open, flat and closed geometries, respectively. We are also using spherical coordinates and Einstein’s summation convention which states that terms with equal upper and lower indices are summed over.
Besides cosmic time , we also define another useful “time” named conformal time and defined by
[TABLE]
which is the amount of time a photon would take to travel from where we are to the furthest observable distance provided the universe ceased expanding. It is interesting sometimes to work with the conformal time instead of cosmic time because it may simplify the evolution equations. From now on, a prime (′) indicates derivative with respect to the conformal time.
The Universe evolution dynamics is described by the Einstein equations. The first step to obtain them is to evaluate the connections from the metric tensor ,
[TABLE]
We also define the Ricci tensor and the Ricci scalar (or scalar curvature), respectively, as
[TABLE]
and
[TABLE]
From (1.5) and (1.6) we can evaluate the Einstein tensor
[TABLE]
from where we obtain the cosmological dynamics by solving the Einstein equations
[TABLE]
where represents the energy-momentum tensor of matter components.
From the FLRW metric, the only non-vanishing connection coefficients are
[TABLE]
where , a dot representing a derivative with respect to cosmic time . The quantity , called Hubble parameter, describes the rate of expansion of the Universe.
Using (1.5), (1.6) and (1.7), we can evaluate the components from the Ricci tensor, Ricci scalar and the components from the Einstein tensor, which are given by, respectively,
[TABLE]
[TABLE]
Considering a FLRW space-time imposes a constraint on the energy-momentum tensor, which should be represented by a perfect fluid in the form
[TABLE]
where is the four-velocity of the fluid in comoving coordinates, with and representing the energy density and pressure, respectively. The and components of the Einstein equations (1.8) can be obtained using (1.11) and (1.12), from which one obtains the Friedmann equations
[TABLE]
and
[TABLE]
The importance of these equations lies in the fact that they relate the evolution dynamics of the Universe to its own constitution and space geometry. Combining these equations by eliminating the curvature term yields
[TABLE]
Multiplying (1.13) by , differentiating and using (1.15), one yields
[TABLE]
which is the continuity equation for the cosmological components. This equation may also be derived from relations satisfied by the Einstein tensor, the Bianchi identities
[TABLE]
denoting the covariant derivative, which leads to the conservation of the energy-momentum tensor that implies in (1.16).
We may rewrite equation (1.13) in a way that makes it easier to study the evolution of cosmological parameters,
[TABLE]
Equation (1.18) defines a constraint among cosmological parameters, such that the amount of each component in the Universe must respect it at any moment of the cosmic evolution [38].
Referring to values today with the superscript , let us define the density parameters . They are given by relativistic particles, non-relativistic matter, dark energy and curvature, respectively, as
[TABLE]
in which we can identify relativistic particles as electromagnetic radiation () and neutrinos (), non-relativistic matter as baryons () and cold dark matter (), and dark energy (which we shall introduce later) as a cosmological constant () or a more general fluid (). These cosmological parameters are of great interest, because if we can accurately measure or infer them from observations then it might be possible to understand the current state of the Universe, its initial moments and predict its future.
1.2 Cosmological redshift, Hubble law, critical density and equation of state
At first glance, Friedmann equations give us no information about the evolution of the scale factor in the FLRW metric: is it increasing, decreasing or is it a constant? This information comes from observations of distant galaxies that are seen to recede from us based on the displacement of their spectral lines to the red part of the spectrum [39]. Thereby, here we relate these shifts on the spectral lines to the scale factor.
In the FLRW metric, let us define our position at the center of coordinates, without loss of generality, and consider a light ray coming toward us in the radial direction. This light ray obeys the equation , such that (1.1) implies
[TABLE]
Considering a light ray coming towards us from a distant source at position at cosmic time , as the distance decreases the cosmic time increases and therefore we must choose the minus sign in (1.20). Defining our position as at time , one finds
[TABLE]
Taking (1.21) in a differential form and using the fact that the radial coordinate is time-independent, we see that the interval between departure of subsequent light signals is related to the interval between arrivals of these light signals by
[TABLE]
Considering these “signals” as subsequent wave fronts, the emitted frequency is and the observed frequency is , therefore
[TABLE]
If the scale factor is increasing, then , showing that the wavelength of photons stretches during its travel to us due to the Universe expansion. This is called redshift and is exactly what we observe today. Conventionally, the redshift is related to the scale factor by
[TABLE]
In an expanding Universe, the relation between the physical distance and the comoving distance to an object is given by . Taking the derivative of the equation with respect to cosmic time , yields
[TABLE]
The fist term in (1.25) represents the Hubble flow, while the second term represents movements with respect to the local Hubble flow and is called peculiar velocity . In the special case in which an object moves exclusively due to the Hubble flow (that is, the object moves only because of the expansion), the comoving distance does not change and the second term vanishes. In the general case, the projection of the object velocity in the radial direction is given by
[TABLE]
In most cases the peculiar velocity of galaxies does not exceed [27]. Therefore, if the second term in (1.26) is negligible in comparison with the first one, then
[TABLE]
in which the replacement of by the present value is justified in the limit of low redshifts (). Equation (1.27) represents the Hubble law, discovered in 1929 by Edwin Hubble when he plotted the recessional velocity of galaxies versus distance to them [39]. Although his data were scarce and noisy, Hubble correctly concluded that the Universe was expanding. The Hubble parameter today is usually written in the form
[TABLE]
in which the parameter describes the uncertainty on the value of and we shall name it reduced Hubble parameter. The original Hubble measurements are displayed in Fig. 1.1.
An important quantity of interest in cosmology is the critical density, which is defined as the total energy density necessary for the Universe to be spatially flat [38]. From (1.18), one may rewrite it as
[TABLE]
which is related to the total equivalent mass density by . Thus, for any spatially flat cosmological model, one requires and is common to write the corresponding mass density as a critical density, which is given by
[TABLE]
The critical density today can be written as
[TABLE]
where we have used . Therefore, if the total density of the Universe is greater than then the Universe is spatially closed and if the total density is smaller than then we live in a spatially open Universe.
Another useful definition is the equation of state of a fluid (in cosmology, modeled as a dilute gas), which is the ratio of its pressure to its density and is given by (in natural units)
[TABLE]
such that, as we shall see from thermodynamics, relativistic particles and non-relativistic matter have equation of state and , respectively. This is an important quantity that governs the evolution of different species in the Universe and, when related to dark energy, it tells us if the Universe is going through an accelerated expansion or not and if it will expand forever or collapse in the near future [27].
Several parametrizations for dark energy equation of state have been proposed so far. The main ones are based on the expansion
[TABLE]
where are parameters to be adjusted using observational datasets and are phenomenological dependencies on redshift (or scale factor). The cases most considered in the literature are
[TABLE]
In case (i), if we have a CDM model and if we have a CDM model. In case (ii), the model in which was studied in [40, 41]. Also at linear order, case (iii) is called CPL model [18, 19] and case (iv) was firstly introduced in [42]. The evolution of dark energy equation of state is the main objective of study in this work.
1.3 Cosmic distances
In order to relate observations to quantities of interest (e.g. matter density, curvature,…), it is important to define distances in cosmology. However, defining distance measures in the Universe can be confusing because light received by us from a distant galaxy was emitted when the Universe was younger and, therefore, the physical distance has increased since the time of emission because of the finite velocity of light. For that matter, defining cosmic distances in terms of the comoving distance may be a better approach.
As usual, we will work in a FLRW spacetime (1.1) by setting (), () and () in (1.2). Therefore, the 3-dimensional space line-element can be expressed as
[TABLE]
where
[TABLE]
The function (1.39) can be written in an unified way
[TABLE]
in which one might recover the flat case by taking the limit .
Now, let us show that the comoving distance is a function of the Hubble parameter and, thereby, the cosmological parameters. The trajectory of a photon traveling along the direction follows the geodesic equation (we have now restored in in the line element). Similarly to the derivation of the cosmological redshift, let us consider the case where light is emitted at time in position (redshift ), reaching an observer at time at position (redshift ). Integrating the geodesic equation, one recovers the comoving distance
[TABLE]
Combining the definition of the Hubble parameter with (1.24), one obtains the relation and therefore the comoving distance is given by
[TABLE]
1.3.1 Luminosity distance
We define now the cosmic distance most important in the study of type Ia supernovae, which was the first observation that determined the accelerated expansion rate of the Universe. This distance indicator is called luminosity distance () and is defined by
[TABLE]
where is the absolute luminosity of a source (in SI units, measured in ) and is the observed flux (in SI units, measured in ).
As one can see, the observed luminosity (detected at and ) is different from the absolute luminosity from the source (emitted at with the redshift ). By definition, the flux is , where is the area of a sphere at considering the space curvature. Then the luminosity distance (1.43) is given by
[TABLE]
In order to rewrite the ratio in terms of redshift, let us define the energy of a pulse emitted at the time-interval as , which implies that the absolute luminosity is . On the same way, the observed luminosity is , where is the energy of light detected at the time-interval . As the energy of a photon is directly proportional to its frequency (inversely proportional to ) we have that . Moreover, as the light signal propagates with the same velocity through its path, then , where and represent the wavelength of light at the emission and detection points, respectively. This implies that . Hence we find that
[TABLE]
and luminosity distance reduces to
[TABLE]
Combining (1.40) and (1.42) with (1.46), then luminosity distance can finally be expressed as
[TABLE]
where , as given by (1.19). As one can see, our expression for luminosity distance is strongly dependent on the cosmology adopted because there is a dependence with the cosmological parameters ( depends on the ’s, as we shall see) that affects the evolution of .
1.3.2 Angular diameter distance
Another useful definition of cosmic distance is the angular diameter distance, which is very popular in CMB and BAO data analysis and is defined by
[TABLE]
where is the angle subtended by an object of actual size orthogonal to the line of sight.
In order to express (1.48) in terms of the FLRW metric, suppose we have two radial null geodesics (light paths) meeting at the observer at time with angular separation , which have been emitted from a source of size at time at a comoving coordinate (we also assume that constant along the photon paths). From the angular part of the FLRW metric we have
[TABLE]
Therefore, we may identify the angular diameter distance as
[TABLE]
which also displays strong dependence on the cosmology adopted just like luminosity distance. The evolution of and for some cosmologies is shown in Fig. 1.2.
It is interesting to notice that combining (1.47) and (1.50) yields the relation
[TABLE]
which is called reciprocity or duality or Etherington relation [43], valid for all cosmological models based on Riemannian geometry as long as flux is conserved. This relation has been tested by many authors [44] and it seems to be in good agreement with data.
1.4 Cosmic components
In this section we shall study the species that are supposed to form the Universe today. These are generally classified into relativistic particles, non-relativistic matter and dark energy. There is an additional component, presumably a scalar field, that is supposed to have dominated the Universe during the inflationary era, but this component is not of our immediate interest here. Therefore, we will focus on the main components and analyze its thermodynamic properties of interest for the thermal history of the Universe.
During cosmic ages, many processes have happened so rapidly that the equilibrium was achieved for most of the time, with different kinds of particles sharing the same temperature. We wish to measure quantities like density and pressure in terms of this equilibrium temperature. For that matter, it is necessary to introduce the occupation number or distribution function or phase space occupancy of a species, which counts the number of particles in a given region in phase space around position and momentum [45]. Considering a particle with momentum and mass , from special relativity the energy of this particle is , where . Thus, the distribution function of some species in equilibrium at temperature is given by
[TABLE]
where is the chemical potential for each of the species. The plus and minus signs are defined depending on which kind of particles we are dealing with: plus representing Fermi-Dirac statistics and minus the Bose-Einstein statistics.
Equation (1.52) defines the general case where the distribution may depend on the position of the species, but in an homogeneous Universe we can relax this assumption and write . By Heisenberg’s principle, no particle can be localized in a region of phase space smaller than , therefore it is a fundamental size which defines the number of phase space elements in the volume as . By defining as the number of internal degrees of freedom (e.g. spin states), the energy density and pressure are given by
[TABLE]
In (1.53) and (1.4), the integrals are not evaluated over because the energy density and pressure are defined as quantities per unit volume. In the first equality of (1.4) we have used the fact that the pressure per unit number density of particles is given by ( is the particle velocity), and in the second equality we used the relation (using units of ) from special relativity (which can be derived combining the equations and ). For the final expressions, we have adopted . In what follows, we particularize (1.53) and (1.4) for different particle species.
1.4.1 Relativistic species
The limit of relativistic species is equivalent to consider in (1.53) and (1.4), i.e. . For non-degenerate particles () one obtains
[TABLE]
where we have used and . Equation (1.56) shows that for relativistic particles without degeneracies the equation of state is .
The main relativistic particle that one might want to study is the photon, which is a boson. For this kind of particle, to account for the two spin states. Also, we could have solved (1.53) and (1.4) for photons simply by considering the chemical potential as zero, which is expected theoretically because in the early Universe photon number is not conserved (e.g. electrons and positrons can annihilate to produce photons) [45]. Moreover, one might safely ignore the chemical potential because precision measurements on the CMB spectrum (which shall be described in the next chapter) constrain the chemical potential to [46]. This leads the CMB photon density to be
[TABLE]
The COBE satellite showed that the CMB spectrum is very close to the spectrum of a black-body radiation with a temperature of [47], as one can see in Fig. 1.3, which has been improved with WMAP satellite to the value [48]. Sticking to the value measured by COBE satellite and using the conversion factor , the energy density of CMB photons today is . Therefore, the photon density parameter is
[TABLE]
in which we have used (1.31). The reduced Hubble parameter has a current value close to [49], which implies . The amount of radiation in the present Universe is very low because, as we shall see later, radiation density scales as so that it dilutes faster than other components. The scaling of radiation density leads to a scaling in the temperature of CMB photons of , which evolves this way even after the photons went out of equilibrium with matter [50].
Another relativistic particle to be added to the cosmic inventory is the neutrino, which has a very small mass. Neutrinos are fermionic particles with zero chemical potential and there are three types of species in the standard model (electron neutrino , muon neutrino and tau neutrino ). As each species has one spin degree of freedom and we have to account for anti-neutrinos, from (1.55) the neutrino energy density is given by
[TABLE]
where is the effective number of neutrino species and is the background neutrino temperature, predicted to have the value (this relation comes from the conservation of entropy before and after the annihilation of electrons and positrons [27]). Unlike cosmic microwave background, which is measured with great accuracy, cosmic neutrino background has only indirect evidences due to the fact that neutrinos interact very weakly [51].
Although the effective number of neutrinos in the standard model is , the presence of relativistic degrees of freedom changes this value slightly to the value [52]. As the temperature of neutrinos and photons are linked via the relation , by using (1.57) and (1.59) one shows that neutrino density and photon density are linked via . Hence the radiation density parameter today, which accounts for photons and relativistic neutrinos, is given by
[TABLE]
with given by (1.58). Considering again and , one obtains , which shows that today radiation is very diluted.
1.4.2 Non-relativistic matter
Now we consider the case of non-relativistic particles (). From (1.53) and (1.4), one gets
[TABLE]
which are valid for both bosons and fermions. Equation (1.62) is in the form of an equation of state, similar to (1.32), and thus one infers that , as expected, because . The case is also called dust. The above expressions show that non-relativistic matter is not simply described only in terms of temperature (as relativistic particles do), and therefore we need to measure the density of non-relativistic particles (baryons and dark matter) directly from observations [27].
Baryons compose the visible matter we can observe in the Universe: mostly protons and neutrons (although we also include electrons in this classification even knowing they are leptons, because protons and neutrons are so much more massive than electrons that virtually all the mass in atoms is in the baryons). In literature there are four main techniques used to measure baryon density: observation of baryons from gas in group of galaxies [53]; baryon counting by spectra analysis of distant quasars [54]; sensitivity to baryon density on the amount of light elements produced during the Big Bang nucleosynthesis epoch [55]; effects of change in baryon density on the CMB anisotropy spectrum [56]. The tightest constraint on baryon density comes from recent measurements of Planck satellite [49], which constrains baryon density to the value
[TABLE]
at confidence level. Using , for the central value in (1.63).
All of these different techniques are in quite good agreement [57], ranging baryon density from with respect to the critical density. However, total matter density in the Universe is higher than this and, therefore, there must be some kind of matter which is not baryonic to account for this discrepancy.
In 1933, Zwicky [58] studied the Coma cluster by measuring radial velocities of galaxies (which by the time were called nebulae). He found a surprising result: galaxy velocities were highly dispersed to be explained by the “visible” stellar material, which indicated that the cluster density was much higher than density inferred from luminous matter only. His conclusion was that there was some kind of “missing matter” to account for the matter unobserved, which he dubbed dark matter. Another evidence comes from 1970’s when rotation curves of spiral galaxies showed that there was indeed some “missing matter” in these objects by the observation that rotation curves were flat to very large radii from the galactic center, when in fact the behavior expected was a declining one [59]. This fact is evidenced in Fig. 1.4.
These evidences and recent studies on the field (e.g. gravitational lensing [61], large-scale structure [62], Bullet Cluster [63]) also support the existence of dark matter, suggesting it as another kind of non-relativistic matter that differs from baryons because it does not interact electromagnetically but only gravitationally. In addition, the most probable kind of dark matter is cold dark matter (CDM), which considers dark matter as non-relativistic due to the fact that if dark matter was hot (relativistic), then structure formation would not have achieved the level of development observed today because relativistic particles hardly cluster, streaming out of overdense regions easily, and baryons would not have enough potential wells to fall into and form structures.
There are a few candidates to the origin of dark matter, which are divided into astrophysical candidates (e.g. white dwarfs, black holes and neutron stars) and particle candidates (e.g. axions and Weakly Interacting Massive Particles). We also cannot rule out new physics as non-standard gravitational effects unpredicted by general relativity, although this is unlikely due to the huge amount of independent observations that point to the existence of dark matter. The best constraint we have to date comes again from Planck satellite [49], which constrains dark matter density to the value
[TABLE]
at confidence level. By using , for the central value in (1.64), which displays dark matter as a dominating component over baryonic matter.
1.4.3 Dark energy
Observing the previous values calculated for the density of cosmic components, it is interesting to note that baryons and dark matter account for approximately of the total energy budget of the Universe, while photons and neutrinos are negligible. Moreover, CMB measurements [64] along with inflationary scenarios [65] put tight constraints on the contemporary Universe curvature, , displaying our Universe as flat and showing that the total density is close to the critical density. As one can see, there is a lack of some cosmic component to account for the remaining and this is where dark energy comes in: it gives an explanation for the lacking matter in the Universe and for the late-time cosmic acceleration measured years ago by observing type Ia supernovae [1, 2]. Dark energy evidence due to type Ia supernovae can be clearly seen by analyzing Fig. 1.5 and Fig. 1.6.
Planck constraint on the dark energy density, for a cosmological constant (which shall be explained latter), is given by [49]
[TABLE]
at confidence level, which agrees with the missing .
1.5 Radiation-matter equality, Universe dominated by dark energy and Hubble parameter evolution
Let us consider a Universe dominated, at some point of its evolution, by a single fluid (component) with equation of state . If is a constant, one can analytically solve for the evolution of the density and scale factor for a flat Universe. Using (1.13) and (1.16), one obtains the solutions (with )
[TABLE]
where is a constant. For instance, if one considers radiation as the dominant component then the total density scales as and the scale factor as . On the other hand, in a matter-dominated era the pressure is negligible and thus the total density scales as and the scale factor as .
Consider the primitive Universe, with dominance of radiation (density and pressure ) and non-relativistic matter (density and pressure ). As these components scale as and , we have
[TABLE]
The redshift of the transition from radiation-dominance to matter-dominance, which corresponds to the radiation-matter equality (), is
[TABLE]
where is given by (1.58) and (1.60). If one considers the effective number of neutrino species , we get
[TABLE]
and, using Planck result [49], one obtains for the central value, which displays the radiation-matter equality as a previous event to the decoupling of photons, as we shall see.
As mentioned in the introduction, many observations show that the Universe is going through an accelerated phase nowadays. In order to explain this framework from the point of view of a component dominance, which is supposed to drive this acceleration, we require in equation (1.15), which leads to
[TABLE]
with assumed to be positive. Therefore, a component that follows this requirement and dominates the Universe today could be a simple explanation for the accelerated expansion. Such an unusual component with negative pressure is what we call dark energy. This is our motivation here to consider dark energy as a good candidate to explain the late-time acceleration and thereby to study its equation of state evolution.
An interesting case is the so-called cosmological constant, defined when , which implies from (1.16) that is a constant during all epochs. From the first Friedmann equation, one can infer that is a constant in a flat Universe and therefore the scale factor evolves exponentially as . Actually, this model might give an explanation for dark energy because no one knows if the acceleration will last forever or end in a near future [27].
From the discussion above, let us consider dark energy as a fluid with equation of state , which satisfies the equation
[TABLE]
By integrating it using the relation , one obtains the way dark energy density evolves, given by
[TABLE]
such that the integral form is kept because we are considering the general case in which may be time-dependent.
Expanding the first Friedmann equation in the components,
[TABLE]
as already mentioned, one can rewrite (1.74) as a constraint equation for the cosmological parameters today, given by
[TABLE]
If we combine (1.18) and (1.74), we get one of the main equations used in cosmology,
[TABLE]
which displays the Hubble parameter evolution as a function of redshift, the cosmological parameters today and dark energy equation of state.
Chapter 2 Datasets description
In order to constrain the evolution of the dark energy equation of state, in this section we shall describe the observational datasets we are going to use in Chapter 4 and the theoretical background required to model these observations. From now on, even whether not mentioned, we will stick to a flat geometry as testified by many observations [12, 56, 67].
2.1 Baryon acoustic oscillations
2.1.1 Overview
The observable Universe is not composed simply by randomly-positioned galaxies all over space, but there are many structures (e.g. clusters, super-clusters, voids) arranged in a very specific way (also called cosmic web). One of the main objectives of cosmology is to understand how these structures were developed and came to be what we observe today.
In the early Universe, temperature was so high and the Universe so dense that one can consider matter and radiation coupled as a single fluid, named photon-baryon fluid. Such a high temperature prevented formation of atoms because electrons were constantly being “casted out” of hydrogen atoms, and also prevented photons of propagating freely through space because the mean free path was too low due to scattering with electrons. Moreover, the photon-baryon fluid is also a plasma.
The standard vision of gravity is that regions in space more dense than its surroundings tend to attract more matter than underdense regions, becoming even more dense, but this is not exactly what happens in the early Universe. Instead, small overdensities of baryonic matter over the whole space, coming from the inflationary era, try to grow due to gravitational instability, but they are soon counterbalanced by the pressure imbalance of the plasma caused by the photons and heat trapped in it. This pressure is so high that overdensities just oscillate on its amplitude instead of growing by gravity, with spherical sound waves being emitted from each overdensity and propagating through the Universe, similar to sound waves propagating in a fluid.
This situation goes on until approximately 380.000 years after the Big Bang, at the point the Universe has expanded enough such that matter-radiation decoupling occurs, allowing electrons and nuclei to form neutral atoms. The plasma pressure is then released and the sound waves are frozen in, forming an overdense spherical shell of characteristic comoving radius of approximately Mpc, with center on the initial overdensity. Nevertheless, these oscillations in the primordial plasma, named baryon acoustic oscillations (BAO), end up but leave an imprint due to the spherical shell mainly in the galaxy distribution, causing two galaxies to be more likely separated by this characteristic scale[14].
A scheme on the evolution of perturbations in the primordial era for some redshifts is displayed in Fig. 2.1, where we plot the density of each component times the square of the characteristic comoving radius versus the comoving radius, such that the mass in the overdensity is the area under the curve. Initial point-like overdensities for each component (dark matter, gas containing nuclei and electrons, photons and neutrinos) evolve, having in mind that these perturbations occur in many places over the Universe and their effects sum linearly because fluctuations are very small. Due to the fact that initial perturbations are adiabatic, in the beginning all species are perturbed almost by the same amount (species at ) because the energy perturbation of neutrinos and photons is bigger than dark matter and gas. The first component to decouple from the others and free-stream is the neutrino because it interacts very weakly and, as a relativistic particle, it does not cluster. As dark matter interacts only gravitationally, it stands still because has no intrinsic motion for the fact that it is cold dark matter. The gas and photons are coupled to each other as already described and the spherical sound wave starts to propagate with origin in the initial overdensity (species at ). These component perturbations grow almost nothing during radiation era: gas and photon perturbations do not grow because of the coupling and dark matter perturbations due to Meszaros effect [68].
As the Universe evolves, the photon-gas perturbation continues to propagate, the neutrinos have completely streamed away and dark matter perturbation remains still but gets larger due to gravitational forces that tend to attract more material (species at ). In the meantime, the Universe is cooling to the point that photons decouple from gas and start to stream away just as neutrinos did, while baryon perturbation stops propagating and starts to grow freely (species at ). What remains is a dark matter perturbation at the original center and a baryon perturbation in a shell of radius 150 Mpc from the center (species at ), which start to attract each other and grow quickly due to combined gravitational forces (species at ). Finally, we are left with similar profiles for dark matter and gas that enhance the acoustic peak (species at ). As galaxies form in regions that are overdense, now becomes intuitive the reason why galaxies are more probable to be found separated by this characteristic scale.
In order to have a good idea about the way one obtains the acoustic scale from galaxy distribution, we need to look at Fig. 2.2. Representing galaxies by dots, in the left hand panel the characteristic scale is clearly visible because there are many voids and the galaxy rings are dense. On the other way, the right hand panel displays a more realistic situation where galaxy rings are less dense and the voids are filled with other galaxy rings, which visually masks the characteristic scale. Therefore, the only way of recovering the characteristic BAO radius is using statistics, which requires mapping enormous volumes of the sky to detect the BAO signal that is very weak at large scales but yet measurable from galaxy redshift surveys[69].
2.1.2 Correlation function and power spectrum
The tool that allows one to measure the BAO peak is the correlation function, while cosmological information is better extracted from the power spectrum. In order to understand both, one needs to define the density contrast [71]
[TABLE]
which shows us deviations from the background density . Now we define the correlation function as the spatial average
[TABLE]
made over the whole volume by taking many points ( and ) in pairs to perform the evaluation. In this average, we are using the same separation distance considered at various locations, which is called sample average. The correlation function tells us if there are any correlations between overdensities separated by the distance that could indicate some mechanism creating dependence on the distance, quantifying the excess clustering on a given scale. Also, when the correlation function depends only on the separation and not on the locations and , we have statistical homogeneity (the system has the same statistical properties everywhere). In this case, the correlation function as a sample average can be written as
[TABLE]
where the integration is made over all possible positions.
In practice, for obtaining the correlation function one has to compare the real catalog of galaxies with a mock galaxy distribution generated randomly. We can therefore obtain an estimate of the correlation function as
[TABLE]
where DD represents the number of galaxies at distance counted by an observer at a galaxy in the real catalog, while DR also represents the number of galaxies at distance but now counted in the random catalog. In the literature, there are other estimators for the correlation function which have been compared rigorously in [72]. The first BAO detection was made by Eisenstein et al. [14] while analyzing a spectroscopic sample of 46748 luminous red galaxies (LRG) measured from the Sloan Digital Sky Survey (SDSS), where a peak corresponding to the BAO scale was found at Mpc, as we can see in Fig. 2.3.
Sometimes it is useful to derive some quantities in the Fourier space. For that matter, we will apply the Fourier transform and its inverse, respectively, with the convention
[TABLE]
When studying perturbation theory in cosmology, one finds that it is interesting to work with the density contrast in Fourier space because this decouples the evolution equations, making the equations to evolve independently [27]. Since the average of a perturbed variable is zero, the first important quantity related to perturbations is a quadratic function. Therefore, we define the power spectrum as
[TABLE]
definition that applies to any perturbed variable in Fourier space (as we will see, temperature perturbations in the CMB follow the same pattern).
The Fourier transform of the density contrast of a density field is given by
[TABLE]
and, by using the definition of the power spectrum in the form
[TABLE]
where the normalization is identified with the volume V considered, we have
[TABLE]
With the change , it follows that
[TABLE]
with defined by (2.3), which tells us that the power spectrum is the Fourier transform of the correlation function (Fourier pair). Therefore, it follows conversely that
[TABLE]
If the correlation function does not depend on the direction but only on the modulus and, accordingly, the power spectrum depends only on , then the system has spatial isotropy and the power spectrum simplifies to
[TABLE]
Because the correlation function and the power spectrum are related by a Fourier transform via (2.11), features displayed in one have consequences on the other. As a simple example, if has the form of a delta function centered at a scale , the result is an oscillation pattern in the power spectrum. Although the correlation function of a real survey is not a delta but a small bump, this feature is still preserved and the acoustic peak in induces oscillations in the power spectrum, which characterizes the baryon acoustic oscillations, as shown in Fig. 2.4.
2.1.3 Perturbation evolution in the primordial plasma
In order to get a quantitative picture of the baryon acoustic oscillations, one needs to consider the fact that baryons are tightly coupled to photons in the primordial plasma (). This implies that perturbations in both components are similar until recombination and analyzing photon features is the same as analyzing baryon features. Thus, let us define the Fourier transform of , the temperature perturbation of photons, as
[TABLE]
in which and is the photon direction. From now on we will work in the conformal time.
Instead of working with directly, one might use the th multipole moment of the temperature field, defined by
[TABLE]
where is the th Legendre polynomial. The multipole moments are an average over all photon directions and the first ones have specific names: is the monopole, is the dipole, is the quadrupole, and so on. Besides, photon perturbations can be characterized either by or by all the moments .
The set of equations that describe the evolution of photon and baryon perturbations in the early Universe comes from the general Boltzmann equation
[TABLE]
which relates changes in the distribution function of species to possible collision terms that may also depend on the distribution function (e.g. Compton scattering). After long calculations and linearization of the perturbations, the final evolution equations relevant to BAO analysis are [45]
[TABLE]
[TABLE]
[TABLE]
where is the baryon velocity, is the ratio of baryon to photon density, is the optical depth defined by ( is the electron density and is the Thomson cross section), and and are perturbations about the flat FLRW metric, corresponding to the Newtonian gauge
[TABLE]
in which is the Newtonian potential and is the perturbation in the spatial curvature.
In order to derive the BAO evolution equation, it is necessary to show that multipole terms higher than the dipole are negligible in the tightly coupled regime. This limit corresponds to the scattering rate of photons being much larger than the expansion rate (). The idea now is to turn the differential equation (2.17) into an infinite set of coupled equations for with the advantage that higher moments are very small. Thus, we multiply (2.17) by and integrate over . Combining with (2.15), equation (2.17) for yields
[TABLE]
To solve the integral, we use the recurrence relation for Legendre polynomials
[TABLE]
to obtain
[TABLE]
Now we analyze the order of magnitude of each term. As , the first term on the left (of order ) is much smaller than the term on the right (of order ). If we neglect the term for a moment, it follows that in the tightly coupled limit
[TABLE]
and, for horizon size modes , it implies that , which justifies neglecting the term. The whole assumption is valid for , such that the monopole and dipole terms dominate over all other multipoles in the primordial plasma.
The next step is to multiply (2.17) by and and integrate over . One obtains
[TABLE]
and
[TABLE]
where we are using the fact that higher multipoles can be neglected. The above equations are supplemented by the equations governing baryon density perturbations, (2.18) and (2.19). One might rewrite the baryon velocity equation, (2.19), as
[TABLE]
The second term in (2.27) is much smaller than the first one because it is proportional to a factor of order . Thus, at lowest order, . One might use this information to expand everywhere in the second term using this low order expression, obtaining
[TABLE]
In order to get rid of , the above expression is inserted into (2.26). By rearranging the equation, one obtains
[TABLE]
With the pair (2.25) and (2.29), we have two first-order coupled equations characterizing the monopole and the dipole in the tightly-coupled limit. It is interesting to turn then into a second-order equation by differentiating (2.25) and eliminating using (2.29), which leads to
[TABLE]
At last, to disappear with we use (2.25) and we finally obtain
[TABLE]
where is the Hubble parameter in the conformal time, is defined as a forcing function and is the propagation velocity (or sound speed) of the fluid given by
[TABLE]
The sound speed depends on the baryon density and the photon density, which implies that in the primordial Universe, when photon density was much larger that baryon density, sound waves propagated at the relativistic velocity . As the Universe continued the expansion, baryons became more important and this velocity was reduced (baryons make the fluid heavier, lowering the sound speed). Although (2.31) is written for the monopole, it is also valid for baryon density perturbations because due to the photon-baryon coupling. Besides, equation (2.31) is a wave equation with friction and source terms, which is the “heart” of the baryon acoustic oscillations. As the terms for and have very similar forms, and noticing that , one may rewrite (2.31) as
[TABLE]
Because (2.33) is an inhomogeneous second-order differential equation, it is necessary to use Green’s function method to solve it. First we find the solutions to the homogeneous part and then we use these to find the particular solution. In principle, there is a damping term in (2.33) and we should solve it considering this, with the right-hand side equal to zero. However, in the primordial Universe the pressure of the photon-baryon fluid induces oscillations with time scale much shorter than the expansion of the Universe (also is small around this epoch) [45], and therefore it is a good first approximation to discard the damping term and consider only the oscillating solutions. Thus, the homogeneous solution is
[TABLE]
with
[TABLE]
where we define the sound horizon as
[TABLE]
which, since is the sound wave propagation velocity, is the comoving distance traveled by the sound waves until the epoch .
The general solution to a second-order equation is a linear combination of the homogeneous solutions and a particular solution. One might construct the particular solution by integrating the source term weighted by the Green’s function that is a combination of the homogeneous solutions. The general result is
[TABLE]
In this equation, we are considering very small except in the rapidly varying sines and cosines. In the term, for example, is evaluated with in its complete form (2.32). As the constants and are fixed by the initial conditions ( and constants, at ), must vanish and . In the integrand, the denominator is in the limit we are considering and the numerator reduces to , leading to
[TABLE]
Equation (2.1.3) is an approximated solution that describes the oscillations in the baryon-photon fluid in the tightly coupled limit. This solution matches the exact solution with very good agreement, getting the peak locations correctly and the heights fairly well, as one can see in Fig. 2.5. Therefore, all we need are the external gravitational potentials from dark matter and then we can calculate the effect of these potentials on the anisotropies. Also, now we have an accurate way of finding the frequency of the oscillations and the location of the acoustic peaks. In the limit that the second term in (2.1.3) is negligible, the cosine term dominates and therefore the peaks should appear at the positions
[TABLE]
The dipole term is also non-negligible at this point of the cosmic history, and it will be useful in the next section because it contributes to the CMB spectrum. This one is obtained by differentiating (2.1.3) and inserting it in (2.25), which leads to
[TABLE]
2.1.4 BAO acoustic scale and relative BAO distance
The BAO acoustic scale, which corresponds to the sound horizon in a specific , can be formally defined as the comoving distance traveled by sound waves in the photon-baryon fluid until baryons are released from Compton drag of photons [27]. This is called drag epoch (not to be confused with recombination epoch), defined as the epoch at which baryons “stop noticing” photons, occurring at redshift . The sound horizon at is
[TABLE]
where
[TABLE]
is the square of the effective sound speed of sound waves in the primordial plasma, as mentioned before. There is a fitting formula for the redshift due to Eisenstein and Hu [75], given by
[TABLE]
where
[TABLE]
and .
Equation (2.41) can be solved analytically if one takes into account the fact that dark energy is negligible for . Thus, one obtains
[TABLE]
where and is the scale factor at the radiation-matter equality (1.70). Integrating the above equation, yields
[TABLE]
where and . Recent measurements from Planck Satellite [49] constrain the BAO sound horizon value with great accuracy (approximately ) to be Mpc, with , which is the basic information for using BAO as a “cosmological ruler” in order to constrain cosmological parameters, especially the dark energy equation of state [76].
The power spectrum contains information about structures in the Universe and may be obtained analyzing the angular and redshift distribution of galaxies, which divides modes into perpendicular () and parallel () to the line of sight. It can be showed [27] that the quantities
[TABLE]
and
[TABLE]
can, in principle, be measured independently and give good estimates for the evolution of the angular diameter distance and the Hubble parameter [77]. Just as the modes, the angle corresponds to observations perpendicular to the line of sight and the redshift difference to observations in the radial direction.
The BAO data so far is not sufficient for making good measurements on and independently [78]. A way around this is to define a combined distance scale ratio that takes into account the combination of two spatial dimensions perpendicular to the line of sight and one dimension along the line of sight, defined by
[TABLE]
In literature, observational data is displayed in a slightly different manner from (2.49), as it follows. The main information that specifies a determined galaxy survey is the relative BAO distance, defined by
[TABLE]
where
[TABLE]
is the related effective distance. Combining (2.50), (2.46) and (1.50), the explicit form of the relative BAO distance in a flat spatial geometry is
[TABLE]
Another useful descriptor for BAO data is the acoustic parameter , which is independent of and is defined by [14]
[TABLE]
We shall be using BAO observational data displayed in Table 2.1. These are the main BAO data found in literature, which are used extensively for testing models and they also make part of parameter estimation codes for cosmology like CosmoMC [79] and Monte Python [80].
As WiggleZ data are correlated, we also show in Table 2.2 the inverse covariance matrix for the three WiggleZ measurements.
2.2 Cosmic microwave background radiation
2.2.1 Overview
In 1963, Penzias and Wilson [82] accidentally discovered a form of radiation that could be detected in all sky directions, which was invariant whether they changed the position of the detectors. This signal, dubbed Cosmic Microwave Background (CMB) radiation, was first predicted by George Gamow and Robert Dicke in the 1940’s, independently, and is one of the cosmic relics from which one can extract information about the primordial Universe. This discovery reinforced the Hot Big Bang model because if the Universe started in a hot, dense and opaque state, then one of the consequences would be a microwave background radiation [66].
As previously mentioned, the basic idea about CMB radiation is that in the primordial Universe there was a strong coupling between matter and radiation until the epoch where, after the Universe had expanded enough (), photons decoupled from baryonic matter, propagating freely ever since and having almost null interaction with matter on its path. These photons are the ones we observe today in the form of microwave radiation.
There are three closely related epochs that need to be distinguished and that occur around this redshift: the recombination epoch, defined as the time in which baryons stop being ionized and become neutral by combining with electrons; the photon decoupling epoch, in which photon scattering rate with electrons becomes smaller than Hubble parameter (which is the expansion rate of the Universe), turning the Universe from opaque to transparent; and the epoch of last scattering surface (Fig. 2.6), defined as the time in which a CMB photon last scattered off an electron. Once the expansion rate becomes larger than the scattering rate, it is very unlikely that a photon will scatter again, which makes the last scattering epoch very close to the photon decoupling epoch. That is why in the last section these moments in the history of the Universe were taken to be the same, but here they are properly defined.
The CMB measurements were performed for the first time by COBE satellite in 1992 [47] and refined by other satellite measurements such as WMAP in 2003 [83] and Planck in 2013 [84]. The difference among these experiments can be seen in Fig. 2.7. Even though experiment improvements were huge, some of the important discoveries provided by COBE data are still valid and can be elucidated in the following terms:
To any direction in the sky (angular coordinates ()), CMB spectrum is very close to the one of an ideal black-body (Fig. 1.3) with mean temperature
[TABLE] 2. 2.
There is a dipole distortion in the temperature maps due to Doppler effect caused by the motion of COBE satellite relative to the frame of reference where CMB is isotropic (Fig. 2.8), which means that different hemispheres from the sky are slightly blueshifted (or redshifted) to higher (or smaller) temperatures; 3. 3.
After dipole distortion removal, the remaining temperature fluctuations are very small in amplitude. This can be better understood if one defines the dimensionless temperature fluctuation across the sky as
[TABLE]
Without dipole distortion, the root mean square temperature fluctuation (which is an average over all points in the sky except the ones in the region contaminated by our own galaxy foreground emission) for COBE data is
[TABLE]
indicating an extraordinary closeness to isotropy.
Due to the huge complexity of the equations involved in generating the full CMB temperature spectrum (there are nine coupled equations that account for all components and for the metric, called Einstein-Boltzmann equations), numerical simulations are necessary to solve the problem. For this purpose, open-source codes such as CAMB [87] and CLASS [88] were created, which are written in Fortran and C, respectively. Even with these difficulties, we can elucidate in general lines the equations that lead to CMB anisotropies and also study important parameters that describe some characteristics of the spectrum.
2.2.2 Anisotropy power spectrum and Einstein-Boltzmann equations
Let’s consider temperature fluctuations across the sky as measured from a particular experiment. Since each point in the sky has a unique temperature defined on the surface of the celestial sphere, it is intuitive to expand the fluctuations in spherical harmonics as
[TABLE]
in which represent spherical harmonic functions. Useful information can only be extracted by using statistics since we have a temperature distribution over the whole sky. Thereby, the most important statistical descriptor of is the 2D correlation function (and its corresponding Fourier pair, the 2D power spectrum ) likewise BAO information uses the 3D correlation function (and 3D power spectrum ).
For this purpose, consider two different directions in the sky at the last scattering surface. These points have directions and separated by the angle such that . The correlation between temperature fluctuations for pair of directions is defined as the product of the fluctuations averaged over all points separated by the same angle , in the form
[TABLE]
If it was possible to obtain from measurements the precise form of for angles from to , we would have a complete statistical description for the fluctuations over all scales. Unfortunately, there are experimental limitations that make it impossible because only a limited range of angular scales are accessible with precision [66]. Using (2.57) and (2.58), the correlation function can be written as
[TABLE]
where are Legendre polynomials.
The important thing in the expansion (2.59) are the coefficients, because now we can characterize the correlation function by its multipole moments, which are the way CMB data are usually displayed. Generally speaking, a multipole moment is a measure of temperature fluctuations at angular scale [45]. Thus, it does not matter whether one prefers to use or to plot the anisotropy spectrum.
In order to obtain the coefficients, one needs to recall the definition of temperature perturbation as mentioned in the last section, which comes from the equation
[TABLE]
As one can see, the temperature field is defined at every point in space () and time (), but our observations can only be performed here () and now (). The information we receive is based exclusively on the direction of the incoming photons (), which means we observe temperature fluctuations in all directions but we cannot, at least at first sight, infer that the temperature in a specific direction is due to a photon that came right from the last scattering surface because a photon might have its path altered due to sources in the way (there are other effects to account for potential wells in the path between last scattering surface and us, such as Sunyaev-Zel’dovich and Sachs-Wolfe [50]). Instead of working with angular coordinates (), we will stick to the photon direction coordinate and rewrite the expansion (2.57) as
[TABLE]
All the relevant information from the temperature field is encapsulated by the amplitudes (which are related to , as we shall see). In order to invert (2.61) and write as a function of , we can use the orthogonality condition for the spherical harmonics, normalized via
[TABLE]
in which is the solid angle covered by . Multiplying (2.61) by , integrating it and using (2.62), the result for is
[TABLE]
where we have written in terms of its Fourier transform , which is the one we have equations to work with.
The ’s cannot be exactly predicted, and as usual it is their statistical properties we are interested in order to extract information. For this purpose, the distribution from which they are drawn is the main goal of CMB measurements [45]. As the coefficients are assumed to be statistically independent [27], we define the mean and variance of the ’s, respectively, as
[TABLE]
where the variance is called CMB temperature power spectrum.
We can now find an expression for by using (2.63) and (2.64). For that matter, we need first to evaluate , where dependence is implicit. To solve the problem, we need to rewrite the temperature perturbation as , in which dark matter perturbation does not depend on . As the ratio does not depend on the initial amplitude of a mode, it can be taken out of the average. Thus,
[TABLE]
where in the second equality it was considered the fact that different modes are uncorrelated [27] and that the ratio depends only on the magnitude of and the product [45]. Therefore, combining (2.63), (2.64) and (2.2.2) yields
[TABLE]
One can expand and using the inverse of (2.15), , which leads to
[TABLE]
The two angular integrals are equal to (or the complex conjugate) in the case and , otherwise they are zero. The remaining combines with the angular part of the integral (which is equal to one), leading to
[TABLE]
If one uses (2.68) to evaluate CMB power spectrum, it is necessary to know the form of the matter power spectrum, dark matter overdensity and the multipole moments as a function of scale, while performing an integral over all Fourier modes. Approximate solutions for these terms can be found in [45] and [50], but there is no general solution for the problem and, in practice, one needs a code for solving numerically the set of Einstein-Boltzmann equations. As an example, for CDM model we have nine coupled differential equations describing interactions among components and the metric of the Universe (scalar perturbations are the main source of CMB anisotropies). These equations are summarized as [45]
[TABLE]
and, if dark energy is not CDM, a new equation must be added to account for dark energy perturbations and possible interactions with other components.
From these ones, three of them were already used in BAO section in a compact form (eqs. (2.17), (2.18) and (2.19)). The term and are terms due to polarization of the CMB, and represent CDM overdensity and velocity, respectively, and is the neutrino perturbation (it is the analogue of the photon perturbation variable ). It is now clear that either one uses approximations together with equation (2.68) or solves numerically the full set of Einstein-Boltzmann equations to find (in order to get more accurate results) and combines with (2.63) and (2.64) to obtain finally the CMB power spectrum. In the literature, temperature power spectrum is usually plotted as
[TABLE]
in units of , as displayed in Fig 2.9.
Our approach for evaluating CMB power spectrum is numerical: we use CAMB code [79, 89], a code publicly available for over a decade, very well tested and improved by the community. In order to predict CMB power spectrum with high accuracy, we also take into account lensing in the code, which improves the smoothing effect on the acoustic peaks by . This is the correct procedure as pointed out in [49].
2.2.3 Optical depth
An important cosmological parameter related to CMB spectrum is the Thomson scattering optical depth due to reionization . Before giving a definition of it, it is useful to introduce some concepts. The Universe has gone through important phases in its history, some of them having hydrogen as the main factor related to these phase transitions. We can cite, for example, recombination (as already described earlier) and reionization epoch, the latter being the period in which the Universe goes from being neutral to becoming ionized due to the formation of the first generation of galaxies, which emitted ultraviolet radiation and started ionizing large intergalactic gas clouds [90].
Even though in this epoch there was a considerable amount of helium, the significant physics can be understood simply by considering just hydrogen in its neutral form (for which we shall use the letter ) and its ionized form (a single proton, letter ). Charge neutrality requires the number density of free protons and free electrons to be the same, . In order to quantify the ionization level of the Universe, one defines free electron fraction (or fractional ionization) as
[TABLE]
in which the subscript stands for baryons. The quantity ranges from when baryons are fully ionized to when the Universe is entirely neutral.
In the reionization period, the interactions happened primarily between photons and electrons through Thomson scattering, which made these particle to exchange energy and momentum. Thus, the mean free path of a photon in this epoch (the mean distance it travels before scattering from a electron) is
[TABLE]
where is Thomson scattering cross-section (). Due to the fact that photons travel at the speed of light , their scattering rate is
[TABLE]
Photons we observe today came from the last scattering surface and, in its path toward us, may have suffered scattering in the reionization epoch. Therefore, at the time interval the probability that a photon is scattered off an electron is . The definition of optical depth to reionization is the integral of the scattering rate over all cosmic history, which is equivalent to the expected number of scatterings it has suffered since earlier times. Mathematically,
[TABLE]
where is the number density of free electrons produced by reionization. Even though the integral is over all cosmic history, we do not need to worry about the fact that there is a small residual ionization fraction coming from recombination because this one is of order , being safely neglected [91].
Using the relation and (2.79), one can rewrite as
[TABLE]
Considering the fact that reionization happens at a matter-dominated epoch, and therefore
[TABLE]
Equation (2.84) can be used to evaluate either by using some differential equation describing the evolution of [45] or by parametrizations of as a function of , as it is standard procedure in CAMB code [91]. Recent measurements for come from Planck satellite, yielding the value [49].
2.2.4 Primordial fluctuations: scalar spectral index and amplitude perturbation
Inflation is the best scenario to explain why uncorrelated scales observed today have such similar temperatures, as we have seen, at the same time it solves other independent problems in cosmology and particle physics at once [92]. Besides, inflation is a mechanism for generating the primordial fluctuations that led to CMB anisotropies, which is why improvements on CMB measurements could confirm inflationary theories. One of the ways of checking whether CMB points to inflation is to work with the primordial power spectrum (scalar spectrum) that comes from the metric perturbations (2.20), which can be demonstrated to be [45]
[TABLE]
where is the Planck mass, is the scalar spectral index, is the scalar amplitude at horizon crossing , is the growth function which describes the growth of matter perturbations at late times [45], is the matter density parameter today and is the slow-roll inflation parameter defined by
[TABLE]
which measures changes in the Hubble rate during inflationary era that are supposed to be small due to dominance of the potential energy.
If a spectrum has the property that is a constant (i.e., has no dependence on the scale), then it is called a scale-invariant (also called scale-free or Harrison-Zel’dovich) spectrum, which is characterized by . Therefore, the scalar index quantifies deviations from scale invariance and from perfect de Sitter limit [93]. For example, most models of inflation are based on the idea that a scalar field (called inflaton) runs the inflationary era, “slowly rowling” to the minimum of the potential energy during the short period that inflation takes place. In these models, it can be demonstrated [93] the relation
[TABLE]
where is another slow-roll inflation parameter, given by
[TABLE]
with representing now the zero-order term from the space-time dependent scalar field.
From (2.87), it becomes obvious that an inflationary scenario predicts a deviation from scale invariance, since and are predicted to be small but non-zero. This is exactly what is observed: Planck measurements constrain the scalar spectral index to the value [49], giving much credit to the inflationary scenario.
It is customary to model the almost scale-invariant spectrum as a power-law close to a reference scale (also called pivot scale or tilt) as [93]
[TABLE]
where is the amplitude of the scalar spectrum measured at the pivot scale , approximately in the middle of the logarithmic range of scales probed by Planck. The choice of value is made to reduce degeneracy between and [49].
Using (2.85), it is possible to identify the spectrum amplitude as , which is constrained by Planck measurements to be [49], where is the natural logarithm (the logarithm of is also called log power of the primordial curvature perturbations). From (2.89), the scalar index can also be defined as
[TABLE]
We shall not work with tensor power spectrum that comes from tensor perturbations () neither with higher-order effects such as running of scalar (), since Planck measurements are weakly sensitive to these parameters [49].
While CMB theoretical power spectrum comes from CAMB code, CMB data comes from the most recent measurements of the Planck satellite. This information is encoded in the Planck likelihood code package (also called Plik), available at [94], which takes as input the theoretical power spectrum and a set of “nuisance” parameters describing unresolved foreground and instrument calibration, and outputs the log-likelihood (which shall be described in the next chapter). In this dissertation, we use two likelihood codes: Plik TT likelihood, which uses a high- () temperature-only dataset together with 16 “nuisance” parameters, and low TEB likelihood (lowP), which uses low- () temperature plus polarization datasets with a single “nuisance” parameter. The latter likelihood code is important to break the large degeneracy between and [95], while using polarization for high- multipoles is not necessary because it does not effectively improve parameter constraints [49].
2.3 Cosmic chronometers
2.3.1 Overview
Cosmic chronometers (or cosmic clocks) is a nearly model-independent tool developed for directly measuring the evolution of the Hubble parameter. This method is based on objects (in this case, galaxies) from which one may roughly infer the variation in the age of the Universe with the redshift [96]. Using these “cosmological clocks”, one may infer the age difference between samples of nearby early-type galaxies (ETG) from its spectral lines and also measure the redshift difference between them. The connection between these measurements and the Hubble parameter is made by identifying the derivative with the ratio and by using the straightforward equation
[TABLE]
to describe the Hubble parameter observationally. As this formula is very simple and has no integral nature (differently from methods based on integrated quantities, such as luminosity distance from supernovae), it has a good sensitivity for constraining a dynamical dark energy equation of state. Also, the way cosmic chronometers are applied, with a “differential age method”, is much more reliable than working with an “absolute age method”, which is much more susceptible to systematics and potential effects of galaxy evolution [97]. Therefore, the relevant physics is ranged between the redshifts where the differential is applied.
Although the idea of this method seems very simple, complications in estimating are huge. For better exploration of the method, one needs to select samples of red elliptical galaxies in the form of passively evolving galaxies, which are defined as the ones with old stellar population, low-rate stellar formation and with stellar mass above [98]. Besides, errors in the final estimates can be large (even more than ), requiring combination with other independent datasets to better constrain parameters.
One of the best ways to perform the analysis is to use the 4000 Å break (which we shall name D4000) present in ETG spectra, since it is linearly related to the age of the galaxy in the case where the galaxy has an old stellar population. This break models a discontinuity in the spectrum from these galaxies close to the wavelength Å, which occurs due to metal absortion lines with amplitude that scales linearly with metallicity Z and age of the stellar population [98]. Because star formation history (SFH) has a small influence only if one considers old passively evolving galaxies, the criteria adopted above must be respected. The 4000 Å break feature is displayed in Fig. 2.10.
2.3.2 Differential age method from galaxy surveys
The D4000 is defined as ratio between the continuum flux densities in a red band (4050-4250Å) and a blue band (3750-3950Å) around the 4000Å wavelength [99]. It is written as
[TABLE]
although reference [98] adopts a slightly different range for the bands in order to reduce errors due to dust reddening: 3850-3950Å and 4000-4100Å. From now on, this narrower band definition will be represented as .
As mentioned, if the galaxy is old and passively evolving, there is a linear relation between and galaxy age (with constant metallicity) of the form
[TABLE]
where is a factor to be calculated by means of stellar population models and is a “nuisance” parameter that must vanish by applying the differential age method as
[TABLE]
Now becomes clear one of the advantages of the method: it directly traces the age evolution of ensembles of galaxies.
Thereby, Hubble evolution can be rewritten as a function of and , which leads to
[TABLE]
As an example, measurements of for a sample of 11324 ETGs are displayed in Fig. 2.11 as gray dots (these data are the base for the calculation of 8 from the 31 cosmic chronometers measurements for that will be presented later on). Orange and green dots represent the median value of in a determined redshift bin for different mass ranges: green for lower galaxy masses and orange for higher galaxy masses. The choice of the size of the bins depends on the amount of galaxies available to perform the statistic, and it has a crucial importance in the sampling. Also, for a redshift smaller than , metallicity is a feature that can be estimated from the spectrum, while for a redshift larger than this information is no longer available and one needs to take a conservative choice for metallicity [98].
Another procedure that has to be made is to calibrate the relation between and galaxy age by using models of stellar population synthesis in order to evaluate . It is important to confirm that there is no bias coming from the model, and for that matter reference [98] employs two independent samples of synthetic spectra (BC03 and MaStro), finding no significant difference between them. Other details about all the procedures to obtain estimates for are fully described in reference [96] and [98].
The dataset for cosmic chronometers we are going to use is a compilation of 31 measurements for in the redshift range , as shown in Table 2.3.
2.4 Supernovae
2.4.1 Overview
A supernova is an event that occurs due to the death of certain types of stars, such that its brightness can be so intense as the brightness of a whole galaxy, as can be seen in Fig. 2.12. Historically, supernovae were divided in two classes, according to their spectra: Type I and Type II supernovae. Type I supernovae have no hydrogen absorption lines in their spectra, while Type II supernovae do [66]. For Type I supernovae there are three subdivisions: Type Ia (SN), characterized by an absorption line of singly ionized silicon; Type Ib, defined as supernovae with a line of helium in their spectra; and Type Ic, the ones that lack both lines. As Type Ib and Type Ic have similar properties to Type II supernovae (they are formed due to core collapse of the original star), we will focus on Type Ia supernovae because they have mechanisms of origin and evolution totally different of the previous ones and they are objects with “standardizable” properties.
It is believed that Type Ia supernovae occur when a white dwarf (a star whose gravity is counterbalanced with its electron degeneracy pressure) in a binary system accretes enough matter from its binary companion until it reaches Chandrasekhar limit [102], which renders the white dwarf unstable by increasing its temperature and density, ultimately leading to a thermonuclear explosion (this can be demonstrated by applying Fermi-Dirac statistics) [50]. Because the exploding star has always a mass close to this limit (approximately , see Fig. 2.13), supernovae absolute luminosity varies for only a small amount at peak brightness, making them one of the best distance indicators we have today in cosmology (we call objects with this property standardizable candles for fact that their luminosity can be standardized). Thus, the main information one needs to extract from a supernova is the light curve (absolute luminosity versus time since peak brightness).
The occurrence rate of supernovae in our galaxy is one per century, approximately. Even though it is a small rate, the fact that supernovae explosion is extremely luminous makes much easier to detect them even at very large distances (up to ). For some days (and sometimes months), Type Ia supernovae light can even outshine light from its host galaxy.
Although variation in the absolute magnitude of different supernovae is small, this effect needs to be taken into account and supernovae need calibration in order to use their information as a cosmological probe. For example, the average luminosity of Type Ia supernovae is, at peak brightness, , while Cepheid methods for determining distances show that Type Ia supernovae peak luminosity lie in range [66]. In order to treat this variation in magnitude, M. Phillips [104] studied a sample of nine supernovae in the B, V and I bands of the spectrum, showing there is a linear relation between peak magnitude and the amount in magnitude that the light curve decays from its peak brightness at the time interval of 15 days (). For this reason, it becomes evident there is a correlation between light curve width and peak luminosity: the higher the peak brightness, the broader the light curve (Fig. 2.14). One of the first calibrations using this method was performed at the end of the 1990s from a local sample () with the Calán/Tololo survey [105].
2.4.2 Magnitude system
In order to relate luminosity distance (1.47) to observational data, one needs first to define the concept of magnitude used to express luminosity and flux. The magnitude system, created by the Greek astronomer Hipparchus in the second century BC, was divided into six classes depending on the apparent brightness of visible stars: the brightest ones were of first magnitude, the faintest ones were of sixth magnitude and the intermediate ones were of second magnitude, third magnitude and so on. Some time later, it was discovered that human eye responds to a large range of light intensity, actually better described in logarithmic scale, and this suggested to define the magnitude system in terms of a logarithmic function, as follows.
We define the bolometric apparent magnitude of a light source in terms of the source’s bolometric flux as
[TABLE]
where is the reference flux with value . The negative sign ensures that an object with a large flux has small bolometric apparent magnitude (e.g. ). The reference flux was defined considering the star Vega, such that visible stars to the naked eye are typically in range .
The second quantity to be defined is the bolometric absolute magnitude from a light source in terms of its luminosity , given by
[TABLE]
where the reference luminosity is . The quantity is defined as the bolometric apparent magnitude that a light source would have if it were at a luminosity distance of pc from the observer (e.g. for Type Ia supernovae at the peak brightness and, for the Sun, ) [27, 66]. The reference is based on this definition, since it is the luminosity of a source at 10 parsecs of distance producing the reference flux . The magnitude system seems awkward at first glance, but it is nothing more than the logarithmic measure of both flux and luminosity.
2.4.3 Luminosity distance, distance modulus and B-band generalized model
With these definitions, the relation between bolometric apparent magnitude, bolometric absolute magnitude and luminosity distance is given by, using (1.43),
[TABLE]
which may be rewritten as
[TABLE]
where must be given in Megaparsecs.
Since measured quantities such as flux and luminosity are usually quoted in terms of magnitudes, it is convenient to write luminosity distance in terms of distance modulus to a light source, defined by
[TABLE]
Due to calibration of type Ia supernovae, as mentioned before, equation (2.100) must be generalized to the form ( in Megaparsecs) [67]
[TABLE]
where , and are nuisance parameters ( represents supernovae absolute magnitude), is the apparent magnitude in the B-band (or observed peak magnitude in the rest-frame B band), describes the time stretching of the light curve and represents the supernova color parameter at maximum brightness ( and are parameters that model the light curve). Besides, luminosity distance is defined in two different redshift measurements: is the redshift in the Sun’s reference frame and represents the redshift in CMB reference frame. These redshift definitions must be accounted because luminosity distance is a combination of the real comoving distance (measured when peculiar velocities and gravitational redshifts are subtracted) with a factor of coming from relativistic beaming and time dilation (each one contributing with ) [108]. Therefore, luminosity distance must be written as .
It was found that supernovae absolute magnitude is dependent on host galaxy properties in a way still not fully understood [109], but that has important implications in cosmology such that a simple model must be assumed for in the form
[TABLE]
where represents the host stellar mass.
In our analysis, supernovae samples were taken from Joint Light-curve Analysis (JLA) dataset, which contains 740 supernovae distributed in the redshift range and that can be obtained in [110]. For JLA dataset, the covariance matrix is given by [111]
[TABLE]
where
[TABLE]
[TABLE]
The first three terms in (2.4.3) account for errors in redshift due to peculiar velocities, errors in the magnitude due to gravitational lensing and intrinsic errors that are not already accounted in the former terms, respectively. The fourth term accounts for errors in the observed magnitude, the fifth term takes into account errors in the stretching factor , and the sixth accounts for colour error, while the remaining terms represent their covariances. Terms in are all diagonal, while terms in have also non-diagonal elements accounting for the same thing as (except for the first three terms in (2.4.3)) and including systematics. All the terms in (2.105) are provided in [110].
Chapter 3 Statistical analysis
In this chapter, we review some statistical tools necessary to analyze our datasets: likelihood function, Bayes’ theorem, Markov chain Monte Carlo technique and principal component analysis. These tools are standard in modern cosmology, and their use is essential for a correct parameter estimation.
3.1 Likelihood function and Bayes’ theorem
Suppose we know that a random variable has a probability distribution function (PDF) which is a function of an unknown parameter . The “” distinguishes the random variable from the parameter . This PDF is defined as a conditional probability of having the data given the theoretical parameter , where it is obvious that different will lead to different PDF’s. Besides, if one samples as then it is more likely that has a value that maximizes , while if has a particular value, then it is better to choose such that it maximizes the occurrence of that . Therefore, the best are the parameters that maximize , where generally parameter space is large and one usually writes in the compact form . This leads us to the maximum likelihood method, which consists in finding parameters that maximize the likelihood function by solving the equations
[TABLE]
In cosmology, sometimes data are pretty scarce and one has to use information from previous experiments in order to better constrain information. Besides, one is often worried about estimating the theoretical parameters from the data. The way to handle this problem is to use Bayesian statistics: instead of working with , the probability of having the data given the model, it is more important to work with , the probability of having the model given the data. These probabilities are related through the so-called Bayes’ theorem [112]:
[TABLE]
where data are denoted by and theoretical parameters are denoted by . In this equation, is the conditional probability of having the data given the theory, and are the probability of having the theory and the data, respectively, and is the conditional probability of having the theory given the data. Thus,
[TABLE]
in which is called prior probability for the parameters , is the PDF of the data , is the likelihood function and (or simply ) is called posterior probability. The latter contains valuable information: it is the probability distribution for the theoretical parameters based on the observed data and knowledge from previous experiments.
Since is a probability distribution, one can normalize it to unity as
[TABLE]
which leads to
[TABLE]
where is the parameter dimension.
The term is called evidence and is just a normalization factor, having no influence on the estimation of . On the other hand, the prior is an essential term and has large influence in the final estimation. For example, if a previous experiment convincingly excluded, say, , therefore one might safely use this information in the form . As another example, if for some reason we believe that a parameter has the value (this is actually the parameter describing absolute map calibration for Planck), then we could use for a Gaussian prior with mean 1 and standard deviation 0.0025. In general, one usually excludes nonphysical values, e.g. along with using flat priors, which is given by in a specified range where is defined and outside (such that ). If one uses only flat priors, then
[TABLE]
meaning that the posterior corresponds to the likelihood function in this case.
3.2 Parameter estimation
After collecting data, it is important to translate them into a model, which is a theoretical background we assume to be true. The model has some parameters in it, which one wants to determine. Therefore, parameter estimation is the analysis performed to obtain estimates of the parameters, errors, or ideally the complete posterior probability distribution , which takes into account some priors assumed. Thus, in order to find the maximum posterior estimators , equation (3.1) needs to be replaced by
[TABLE]
By discarding the evidence factor , we need to normalize the posterior with an overall normalization through the integral
[TABLE]
where this one is extended to the whole parameter range. Using the normalized posterior (i.e. , to which we shall continue to use ), we can evaluate the regions of confidence for the parameters, defined by
[TABLE]
where is the region for which the integral above yields . One usually chooses the values (denoted as 1, 2 and 3, respectively).
It is common to have interest in some specific subset of parameters and consider the others as “nuisance” which we would be happy to get rid of. For example, supernovae theory predicts for distance modulus the equation , from which the main parameter of interest is . The general posterior depends on the full set of parameters (, , and ) but we can turn it into a function only of by integrating out all the other parameters,
[TABLE]
where the integration is over the domain of the “nuisance” parameters. This procedure is called marginalization and allows one to translate a multidimensional posterior into a one or two-dimensional probability distribution, which makes visualization of the problem much easier. For instance, if the maximum posterior estimator of is 0.3 and
[TABLE]
in the region , the final result is quoted as at confidence level (or ).
Let us assume that the posterior ( and denoting arrays of parameters and data ) is single-peaked. A common estimator for the parameters is the expected value (or mean) defined by
[TABLE]
and variance defined by
[TABLE]
where we use Markov Chain Monte Carlo method (which shall be explained in the next section) to sample the posterior , in which are taken directly from the posterior by construction [112]. Also, it is common to work with standard deviation instead of variance: .
It is usual to approximate the likelihood function close to the peak with a multivariate Gaussian in parameter space, in the cases where the likelihood is single-peaked and well behaved (its peak is well located, not dispersed). This can be seen whether one performs a Taylor expansion close to the peak of the log likelihood,
[TABLE]
which leads to
[TABLE]
where is called Hessian matrix and controls whether the estimates of and are correlated or not [113]. Besides, in cosmology, for many problems of interest the observational data generally have a Gaussian distribution and therefore
[TABLE]
where is the observed data, is the theoretical prediction for given a set of parameters and is the inverse covariance matrix associated with : . The function inside square brackets (up to the constant ) is usually denoted as the chi-square function
[TABLE]
and if there is no correlation between data, then (3.17) simplifies to
[TABLE]
where stands for data variance. In this case, maximizing the likelihood function is equivalent to minimizing the function and, thus, one needs to find a set of parameters intrinsic to theory such that the latter agrees as best as it can with observations.
It is fundamental to combine different datasets for better constraining parameters because each observation has its own degenerate directions, i.e. directions in parameter space poorly constrained by the data. Thus, pairs of datasets have much stronger power constraints than each one separately because it is only their combination that mutually breaks parameter degeneracies [112]. For any datasets, one might consider them as coming from independent experiments such that their combination happens when one performs the product of the likelihoods. Equivalently, this is the same thing as adding up the chi-square functions from all the experiments. For the datasets described in the previous chapter,
[TABLE]
3.3 Markov Chain Monte Carlo method: emcee
Generally, problems in cosmology have large dimensionality in parameter space (up to 20, 30 parameters). This fact makes it unfeasible to evaluate the full likelihood function (and consequently the posterior) in a finite grid mainly because each point in the grid is in general expensive computationally, which would require a large amount of time to solve the problem completely. Besides, a considerable hypervolume inside the grid has a very small likelihood and it is thus of no interest, which turns this approach very inefficient.
In order to concentrate in the region of interest where the likelihood is high, we will work with Markov Chain Monte Carlo (MCMC) method. This one aims to generate a set of points that sample the target density, in this case the likelihood (which leads to the posterior) in an efficient manner. MCMC draws random points in parameter space using Markov process: the next point depends on the previous one but not in the entire sampling history. By sampling the posterior with MCMC, one might estimate the quantities of interest for the parameters such as mean, variance, etc.
The main idea behind MCMC method is to sample a new point from the present point , accepting the new point in the chain with probability that depends on the ratio between the new and old target density values ( and , respectively). The distribution which generates a new point based on the present one is called proposal distribution , generally taken to be a Gaussian that matches the target distribution. On the same manner, one can also define a reversible proposal distribution , which gives a distribution to reverse the chain (reversible distributions play an important role in MCMC algorithms, such as homogeneity of the chain [114]). A basic MCMC algorithm is the so-called Metropolis-Hastings (M-H) algorithm, where the probability of acceptance of a new point is
[TABLE]
and if the chain is reversible (symmetric proposal distribution) M-H simplifies to Metropolis algorithm
[TABLE]
The basic idea of Metropolis algorithm (which can be generalized for M-H) is that if the new point has a target density higher than the target density of the present point , the new point is always accepted. However, if has a target density smaller than the target density of , then the new point is accepted with probability given by (3.21), which means that in the latter case the point might be accepted or not and this makes MCMC exploration in parameter space much more efficient than grid approach. Detailed description of MCMC methods can be found in [115, 116, 114].
In cosmology, Monte Carlo methods are generally applied to data using known softwares such as CosmoMC [79] and Monte Python [80], which are based on Metropolis-Hastings. In this work, as an alternative approach, we will focus on a MCMC method that is mostly used in astrophysics and which has been extensively improved by the community: emcee, a pure-Python implementation which is an affine invariant MCMC ensemble sampler [117]. This code is designed for better exploration of parameter space, with improvements in efficiency and speed when compared to other standard MCMC methods. A faster sampler is preferable because reduces the number of likelihood evaluations, which generally have high computational cost, and thus accuracy is achieved in a minor number of steps.
Affine invariance means that by applying an affine transformation in the proposal distribution one is able to sample the target distribution efficiently even if this one is highly anisotropic, which would render sampling much more expensive computationally. For example, if one considers the skewed probability distribution in
[TABLE]
for small , it follows that traditional MCMC methods have difficulty to sample this distribution. However, if one performs the affine transformation
[TABLE]
the initial challenging problem turns into the easier problem of sampling the distribution
[TABLE]
which is an isotropic density that even a simple Metropolis-Hastings would not have problems to solve. This example motivates an affine invariant sampler: an algorithm which samples target distributions equally well under all linear transformations, being insensitive to covariances among parameters [117]. Although target distributions in cosmology are not highly anisotropic, some parameters might be correlated and emcee is able to take this into account.
The base algorithm for emcee is called stretch move and converges faster than M-H methods, therefore with superior performance [117]. It is based on evolving an ensemble of walkers where the proposal distribution for one walker depends on the position of the walkers in the complementary ensemble , in which position means the N-dimensional vector in parameter space characterizing each walker. Thus, in order to draw a new position from the current position , the proposal distribution is given by an affine transformation as
[TABLE]
where is a walker chosen randomly from and is a random variable sampled from a distribution . This distribution is important because if it satisfies the relation
[TABLE]
then the proposal (3.25) is symmetric, that is, the chain looks the same when run forward or backward in time [114], which can be stated as
[TABLE]
The appropriate acceptance probability for stretch move is
[TABLE]
in which is the parameter space dimension. Also, the choice made for is [117]
[TABLE]
where is a scale parameter adjusted for better performance, set to 2. It is interesting to notice that the idea of using the position of other walkers to guide the next position of a specific walker is based on the fact that the complementary ensemble carries valuable information about the target density, which gives a way of adapting the trial move always aiming the target distribution (this is encoded in the affine invariant proposal), rendering the method very powerful. A more detailed description of affine invariant ensemble samplers can be found in [118].
3.4 Burn-in and convergence
It is expected that chains generated from MCMC methods fairly sample the target distribution once convergence to a stationary distribution has been achieved, that is, no matter where the parameters were initially sampled: the ensemble of walkers are led to the peak of the target distribution and their values oscillate close to the mean value for each parameter. Thus, the first steps in the chain should not be accounted for sampling in order to remove the dependence on the starting point [113]. This period in which walkers still have a “memory” from where they started is called burn-in period.
How long should we run different MCMC chains in order to get good estimates of the parameters? To answer this question, we will adopt a well-known convergence test called Gelman-Rubin convergence criterion [119], which basically compares variance between different chains in order to assess convergence. Suppose we are working with chains in our MCMC and that iterations were performed for each chain. Suppose also that burn-in period has already finished. Let represent a point in parameter space in position and chain . We define the mean of each chain and the mean of all the chains, respectively, as
[TABLE]
where index represents points in a chain and runs over the chains. The chain-to-chain variance and mean within-chain variance are defined, respectively, as
[TABLE]
The total or true variance for the estimator is defined as the weighted average . One can also define the pooled variance
[TABLE]
which takes into account sampling variability of the estimator [114]. In the initial sampling, when the distribution is over-dispersed, is large because chains are also dispersed and variance between them is high. At the same time, overestimates because of the term in (3.32). Also, is smaller than because exploration of parameter space is still insufficient (that is, is still high). However, as , chain-to-chain variance goes to zero and approaches true variance , which renders close to 1. Thus, the ratio , named potential scale reduction factor, is the quantity of interest chosen to monitor convergence, in which a value close to one means that convergence has been achieved. The value of used to stop sampling is chosen according to the level of precision desired, the number of parameters in the theory and the computational cost for every MCMC point, where usual choices are 1.1, 1.03 and 1.01 [120].
3.5 Principal components analysis
Before describing the next tool, it is useful to motivate its application. In order to constrain the dark energy equation of state, we are going to use an interpolation that makes to be a smooth and continuous function because is integrated over redshifts whenever shows up. To this purpose, dark energy equation of state is sampled in six redshift bins, , with corresponding values for the equation of state . Including more than six bins does not effectively improve the constraints [121]. The last redshift () is chosen according to the fact that this is the epoch in which dark energy started to dominate the expansion of the Universe [96]. We construct as
[TABLE]
where “spline” means we are using cubic spline interpolation between ’s. The parameters are MCMC parameters and must be constrained by data on the same way that other cosmological parameters do (e.g. , , …).
Once chains containing ’s are obtained, after marginalizing over all the remaining parameters, we must face the fact that estimates for ’s are correlated because their covariance matrix is not diagonal. Therefore, one needs to perform a rotation in parameter space, which rewrites ’s in a different basis, in order to obtain new estimates that have a diagonal covariance matrix. The procedure adopted to this purpose is called principal components analysis (PCA) [35, 36, 37] and it is described as follows.
Let us define as the Fisher information matrix [27, 113] of a set of estimators (’s in our problem) of parameters measured from observations, assuming that can be approximated by the inverse covariance matrix [36] of the estimators as
[TABLE]
The decorrelation matrix is the matrix that diagonalizes the Fisher matrix (or ) and thus satisfies the relation
[TABLE]
in which is the diagonal matrix containing the eigenvalues of and the rows of are the eigenvectors of .
The quatity of interest is because this new set of ’s is uncorrelated due to the fact that its covariance matrix is, using (3.34) and (3.35),
[TABLE]
which is diagonal and represents the variances of the ’s (elements of are necessarily positive). The set is called principal components and the rows of are weights (or window functions) that relate the principal components to the initial set . It is interesting to notice that one might scale the decorrelated quantities to unity variance by multiplying them by the square root of the diagonal elements of . Thus, relation (3.35) yields
[TABLE]
As pointed out in [36], there are infinite choices of decorrelation matrices satisfying (3.37). For example, choosing an orthogonal matrix and performing a rotation in leads to another decorrelation matrix: . There is an interesting choice for which renders its weights (rows) positive almost everywhere, with very small negative contributions [36]. This choice is the square root of the Fisher matrix , defined as
[TABLE]
where we normalize such that its rows sum to unity. With this choice, the covariance matrix of the new parameters is diagonal [35]. We adopt this choice in our work.
Chapter 4 Results
This chapter displays analyses performed via MCMC sampling using emcee for different combinations of datasets. The first analysis accounts for BAO, cosmic clocks (CC) and supernovae (SN) datasets combined because these ones have lower constraining power than CMB data. The second analysis accounts only CMB data for constraining parameters and the third analysis considers all datasets combined in order to improve constraints. In the last section, a comparison with previous results is performed .
We developed a code in Python for sampling six cosmological parameters, six dark energy equation of state parameters, fifteen “nuisance” parameters from Planck 2015 data and four “nuisance” parameters from JLA dataset. In addition, as we are working with a time-dependent dark energy equation of state , when using CMB data we employ a modified version of CAMB which uses a Parameterized Post-Friedmann (PPF) [122, 123, 124] prescription for dark energy in order to cross the phantom divide [27], i.e. , multiple times. Parameter details are described in Table 4.1.
In results presented in the next sections, we have already removed burn-in and the Gelman-Rubin criterion adopted is for the set BAO+CC+SN, for CMB data and for the set BAO+CC+CMB+SN. These values were chosen according to the size of parameter space and computational cost of each set (which is extremely large for the last two sets). The number of points generated in each MCMC chain is of order for BAO+CC+SN and BAO+CC+CMB+SN sets, while for CMB set is . Also, we generate estimates of the posterior mean of each parameter of interest together with confidence intervals ( and ) and best fit values using GetDist Python package [125].
4.1 BAO+Clocks+Supernovae
The first investigation refers to BAO, cosmic clocks and supernovae datasets combined. The sampling results are displayed in Fig. 4.1, Fig 4.2. and Table 4.2, which show that even by combining these datasets they do not have enough power to constrain parameters completely. This is due to the fact that datasets used in this sampling are very scarce for high redshifts (only cosmic clocks has information close to , while the highest redshit for BAO is and for supernovae is ). In particular, we tested the last three ’s even by adopting a larger prior than [-10,8] (we even used [-50,48]), but they are also not fully constrained in these conditions, which is why we have not applied PCA to dark energy equation of state using this set. On the other hand, convergence has been achieved in a high level and our cosmological parameter estimates for , and are in good agreement (at ) with latest observations from Planck [49].
4.2 CMB
We shall now analyze the impact of CMB data in the parameters. Results are showed in Fig. 4.3, Fig. 4.4, Fig. 4.5 and Table 4.3. Although this sampling has not fully converged, our cosmological parameter estimates are consistent with Planck data [49] at (Fig. 4.3), displaying no deviations when compared to a CDM model (although CMB measurements are in strong tension with Hubble Space Telescope local measurement for the Hubble rate today, [126], a still unsolved problem in cosmology). When we look at the ’s (Fig. 4.4), we see that Planck data alone seems to be able to constrain all dark energy equation of state parameters, differently from the previous dataset analyzed (BAO+CC+SN). Also, when we look at dark energy equation of state evolution (Fig. 4.5), we see that Planck data alone leads to an agreement with CDM model at . It is interesting to notice that, as opposed to the previous section where the first ’s are well constrained, in this case parameter has an error bar larger than other ’s (except for ), which is expected since most of CMB information comes from a high redshift (). If sampling was larger and convergence was achieved, then would probably have the largest error bar.
4.3 BAO+Clocks+CMB+Supernovae
In the main analysis, we combine all datasets: BAO, cosmic clocks, CMB and supernovae. Our parameter estimates are displayed in Fig. 4.6, Fig. 4.7, Fig. 4.8 and Table 4.4. This sampling has converged more than the one from the previous section, although it still has not fully converged yet. As one can see, all cosmological parameters are constrained and consistent with results from Planck [49] at (Fig. 4.6 and Table 4.4). Dark energy equation of state parameters are better constrained than in the previous section because we are now using data (BAO, Clocks, Supernovae) that are also able to constrain parameters at lower redshifts, which can be seen in Fig. 4.7 and Fig. 4.8. On the other hand, this time not all ’s agree with CDM model at : there is a small deviation in and , which agree with CDM model only at . We believe that this deviation happens because sampling has not fully converged and therefore using a longer chain would solve the problem. As expected, is the dark energy equation of state parameter with the smallest error bar, which is explained due to the fact that the greatest amount of information is around the corresponding redshit (). Another interesting fact is that even Planck data has not enough power to constrain the last dark energy equation of state parameter, , inside our prior (in the last section, apparently all ’s were constrained, but now we know that this was just because of the lack of convergence). This can be seen in Fig. 4.7 as a “cut” in the 2D plot of , which prevents it of forming a “smooth edge”.
4.4 Comparison of datasets, results and models
As pointed out in the last chapter, the importance of using different datasets is that only the combination of independent data breaks degeneracies and allows us to better constrain parameters. This is very clear when we look at Fig. 4.9, which shows that the combination of all datasets improves the precision of parameter estimation (for example, in the 2D plot the area estimated using BAO+CC+CMB+SN is smaller than the area estimated using just CMB data alone). We would expect to see the same area in the 2D plot for both BAO+CC+CMB+SN and CMB data alone because at higher redshits, as we have seen, BAO+CC+SN does not have enough power to constrain ’s. Unfortunately, as both chains are not fully converged, we do not see this happening. The important thing is that BAO+CC+SN combination constrains ’s better at lower redshifts, while CMB data constrains ’s better at higher redshifts.
To picture the implications of our results, in Fig. 4.10 we display our estimations of ’s constraints at along with results from Said et al. [121], also at , and a few alternative models to CDM. Said et al. paper uses the following datasets combination: WMAP(Wilkinson Microwave Anisotropy Probe [127])+SNLS(Supernova Legacy Survey [128])+BAO(6 degree Field Galaxy Redshift Survey at [129] and WiggleZ at [130])+(dataset from Moresco et al. [131]). The constraints from Said et al. seem better than our results, despite the fact that the datasets used in our work are more recent (and more precise) and should, at first sight, better constrain the parameters. The only explanation we could think of is that the parametrization for dark energy equation of state may be somehow affecting the results, because while we use a cubic spline interpolation for connecting the ’s Said et al. uses hyperbolic tangent functions for this purpose. Although we have this difficulty, the results from both estimations can be used to rule out or indicate that theoretical models for present in the literature might be wrong, as stated in Fig. 4.10.
Conclusions
The main objective of this work was to analyze how current observations coming from baryon acoustic oscillations, cosmic chronometers, cosmic microwave background anisotropies and type Ia supernovae could better constrain dark energy equation of state and maybe indicate deviations from CDM model, since although this one seems the best theory to explain different observations, it suffers from intrinsic problems that lack of a consistent explanation.
In the fist chapter, we made a review of the background cosmology necessary to understand the basis of the theory. In the second chapter, we described in details the datasets used in our work and the theory behind them in order to picture how data are obtained and what kind of information can be extracted from them. In the third chapter, we concerned about statistical tools to perform the analyses and in the final chapter we explored the results obtained and its consequences to cosmology.
The analysis of the datasets could show us the effect of certain kinds of experiments in parameter estimation. BAO, cosmic chronometers and supernovae data have the power to constrain parameters of low to intermediate redshift, while CMB data constrain parameters better at higher redshifts. However, we did not have very good results for high redshifts even using Planck data, probably from the fact that dark energy does not have much influence in the early Universe in which CMB photons dominate. Maybe combination with other datasets that possess more information at high redshifts (e.g. quasars, redshift space distortion data, CMB lensing) could improve the constrains.
The results obtained in our parameter estimations using MCMC sampling were strongly influenced by the level of convergence achieved in each combination of datasets. The most reliable analysis is the one performed using BAO+CC+SN, because the Gelman-Rubin criterion adopted is very good () and the corner plot is visually acceptable. However, the other two analyses might be biased in a negative way because Gelman-Rubin criterion adopted is not good and corner plot is obviously not very pleasant, for both CMB data alone and BAO+CC+CMB+SN. Despite this problem, it is customary to say that new physics might be presented when we have at least three or four sigmas of discrepancy, and therefore even if our results are biased we do not see possibility for new physics, which tells us that concordance with CDM still remains.
Our work showed the inherent difficulties related to studying dark energy equation of state. Besides the fact that the datasets used do not have enough power to constrain completely, we also need to face the problem of the computational cost of using MCMC methods for sampling, which are generally very expensive in cosmology (in our case because CMB theory generated by CAMB code is extremely complex) and generally demand the use of parallel programming with the help of large computer clusters. As an example, in the sampling with BAO+CC+CMB+SN each MCMC point took 3.5 seconds on average to be generated in the fastest computer we used in this work (CPU: Intel Core i7, cores: 8, memory: SSD 16GB), while we would probably need at least points to finally achieve convergence. The effect of these problems are seen as huge error bars in the dark energy equation of state parameters (the last ’s), turning the evolution of the equation of state very hard to predict.
Using emcee instead of standard parameter estimations codes for cosmology, such as CosmoMC and Monte Python, was made with the intuit of confirming that we could recover old results even with a different sampler. This was successfully achieved, since we tested simple models such as CDM and our cosmological parameter estimation really matched results found in literature. This is important to give us much more confidence in theses codes, which are generally used as a “black box” in most applications to cosmology.
Due to the computational cost problem, it is worth mentioning some alternative tools to MCMC sampling as possible extensions to this work. One of them is Gaussian Processes [135], which provides a surprisingly computationally effective method to reconstruct functions (this has already been applied to [136, 137]) from data at low computational cost. The other one is Variational Inference [138], a tool which has been tested in astrophysics problems [139] and converts the inference problem into an optimization problem, performing parameter estimation much faster than standard MCMC methods.
As a way of helping cosmology students interested in MCMC methods, all the codes developed in this dissertation can be found at Github in reference [140].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Riess et al. [1998] A. G. Riess et al. (Supernova Search Team), Astron. J. 116 , 1009 (1998) , ar Xiv:astro-ph/9805201 [astro-ph] . · doi ↗
- 2Perlmutter et al. [1999] S. Perlmutter et al. (Supernova Cosmology Project), The Astrophysical Journal 517 , 565 (1999) .
- 3Barrow and Cotsakis [1988] J. D. Barrow and S. Cotsakis, Physics Letters B 214 , 515 (1988) . · doi ↗
- 4Dvali et al. [2000] G. Dvali, G. Gabadadze, and M. Porrati, Physics Letters B 485 , 208 (2000) . · doi ↗
- 5Landim and Abdalla [2017] R. G. Landim and E. Abdalla, Physics Letters B 764 , 271 (2017) . · doi ↗
- 6Alcaniz and Lima [2005] J. S. Alcaniz and J. A. S. Lima, Phys. Rev. D 72 , 063516 (2005) . · doi ↗
- 7Ferreira et al. [2017] E. G. M. Ferreira, J. Quintin, A. A. Costa, E. Abdalla, and B. Wang, Phys. Rev. D 95 , 043520 (2017) . · doi ↗
- 8Wang et al. [2016] B. Wang, E. Abdalla, F. Atrio-Barandela, and D. Pavón, Reports on Progress in Physics 79 , 096901 (2016) .