Neural Network Aided Computation of Mutual Information for Adaptation of Spatial Modulation
Anxo Tato, Carlos Mosquera, Pol Henarejos, Ana P\'erez-Neira

TL;DR
This paper demonstrates that neural networks can accurately and efficiently estimate the achievable rate in index modulation communication links, significantly outperforming traditional analytical methods in accuracy and computational complexity.
Contribution
The work introduces a neural network-based approach for real-time capacity estimation in index modulation systems, reducing complexity and improving accuracy over existing methods.
Findings
Neural network reduces MSE in capacity estimation by 100 times.
Neural network decreases computational complexity by 50 times.
Method extends effectively to multiple antennas and polarizations.
Abstract
Index Modulations, in the form of Spatial Modulation or Polarized Modulation, are gaining traction for both satellite and terrestrial next generation communication systems. Adaptive Index Modulation based links are needed to fully exploit the transmission capacity of time-variant channels. The adaptation of code and/or modulation requires a real-time evaluation of the channel achievable rates. Some existing results in the literature present a computational complexity which scales quadratically with the number of transmit antennas and the constellation order. Moreover, the accuracy of these approximations is low and it can lead to wrong Modulation and Coding Scheme selection. In this work we apply a Multilayer Feedforward Neural Network to compute the achievable rate of a generic Index Modulation link. The case of two antennas/polarizations is analyzed throughly showing the neural…
Click any figure to enlarge with its caption.
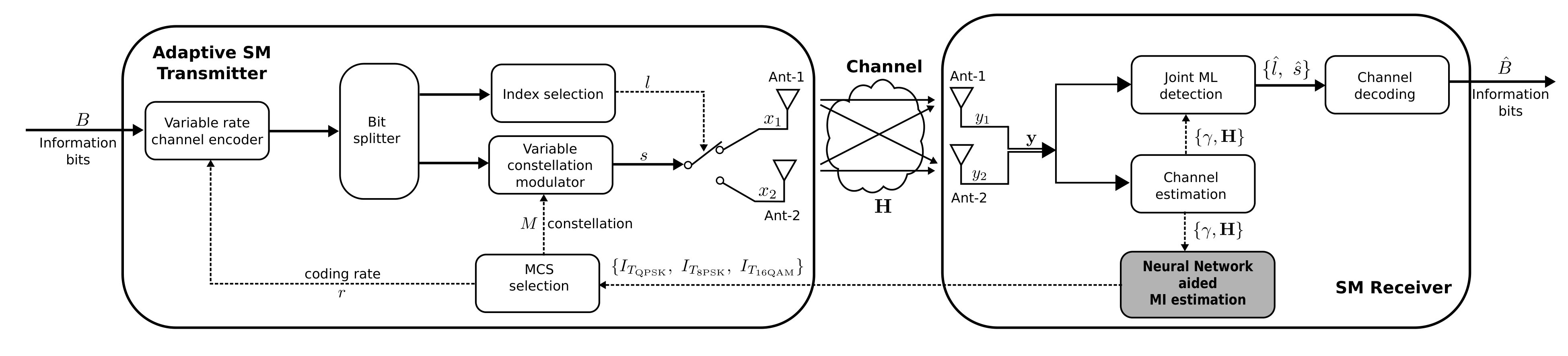 Figure 1
Figure 1 Figure 2
Figure 2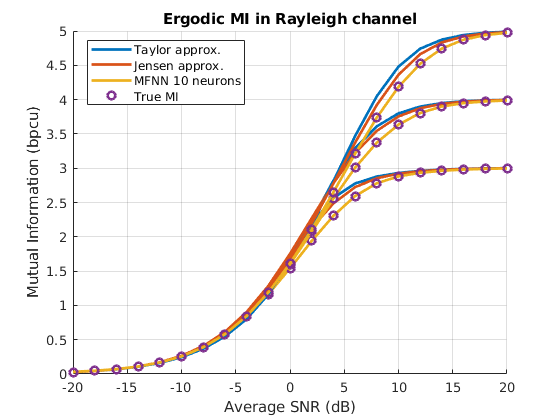 Figure 3
Figure 3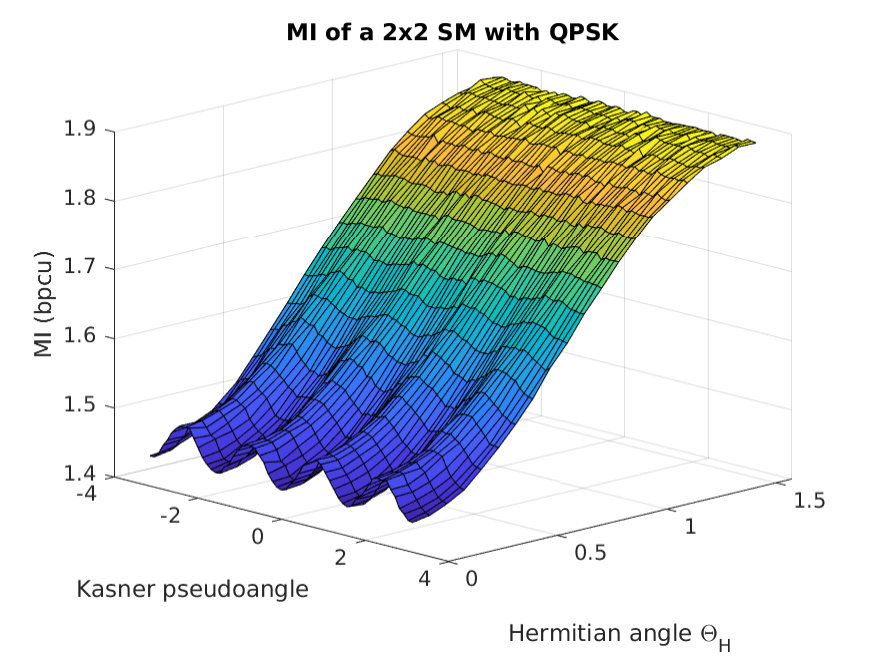 Figure 4
Figure 4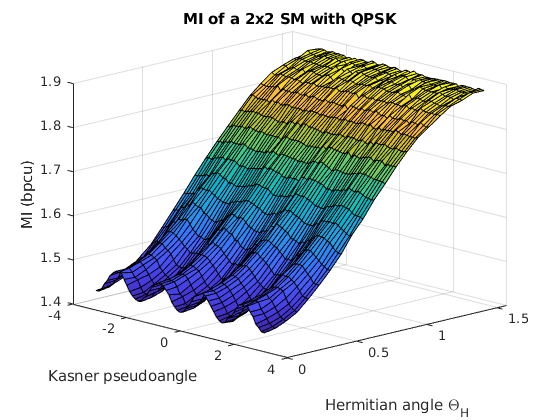 Figure 5
Figure 5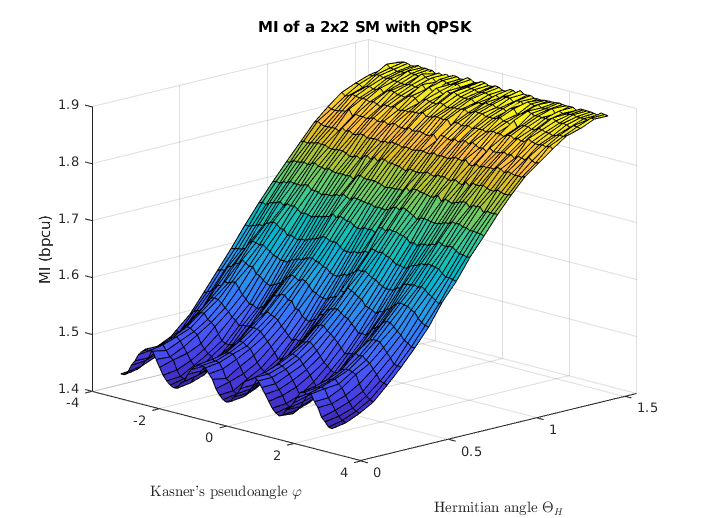 Figure 6
Figure 6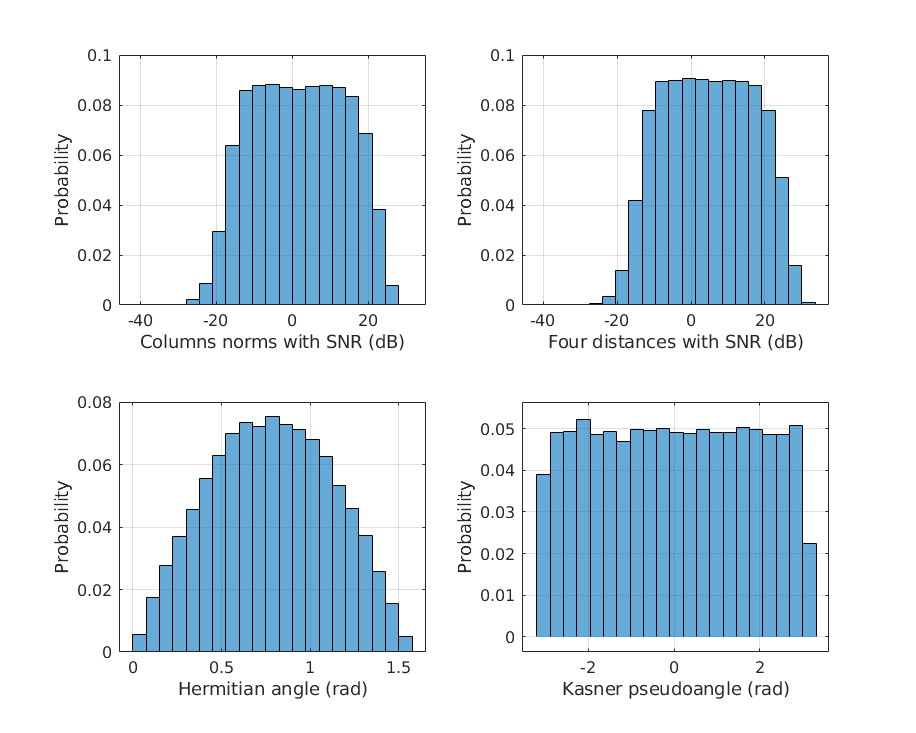 Figure 7
Figure 7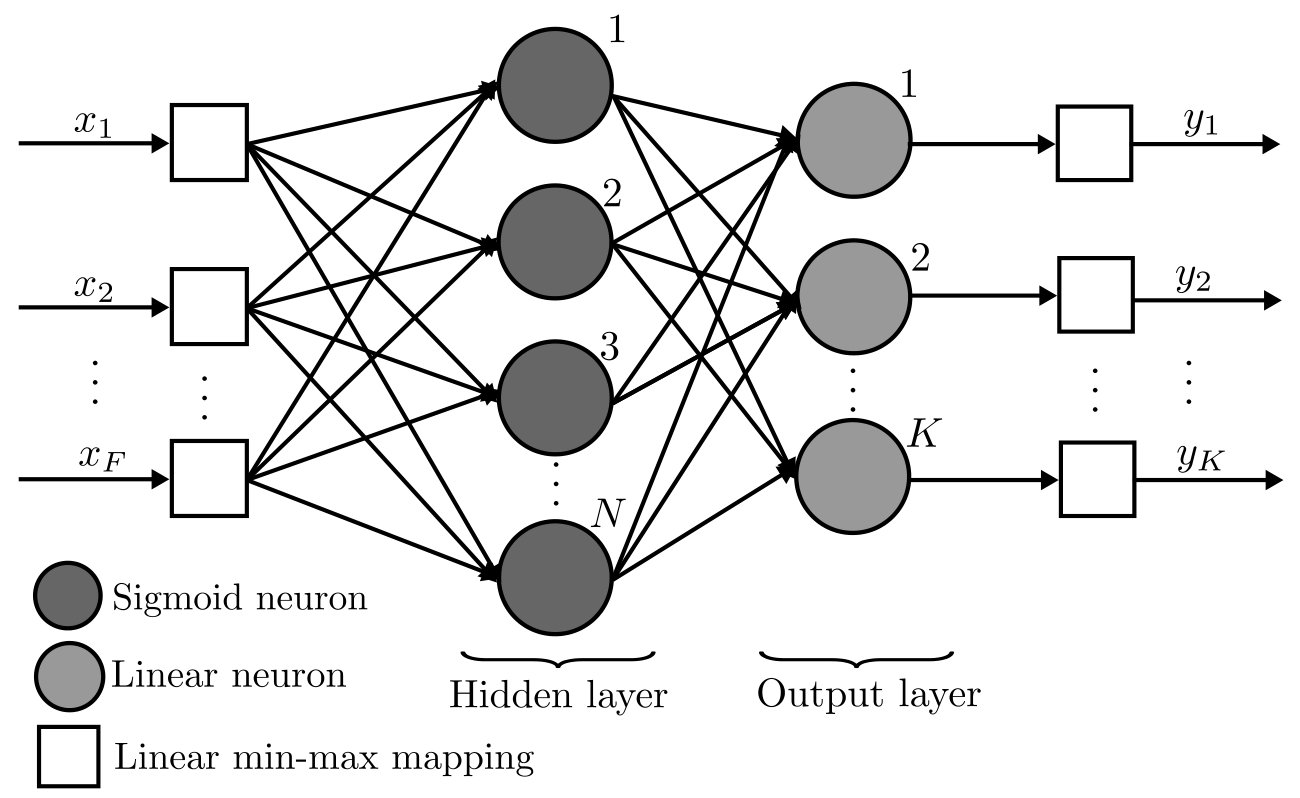 Figure 8
Figure 8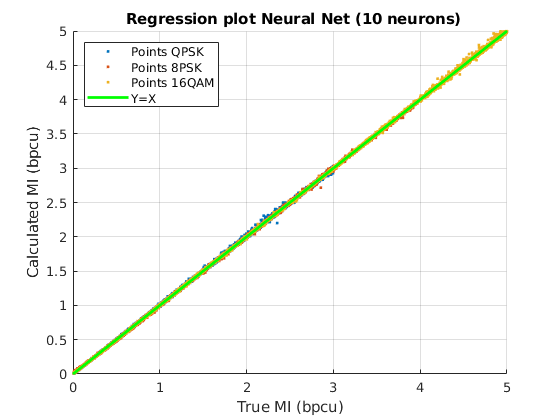 Figure 9
Figure 9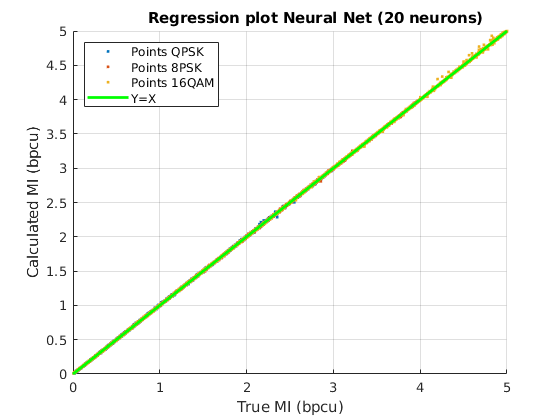 Figure 10
Figure 10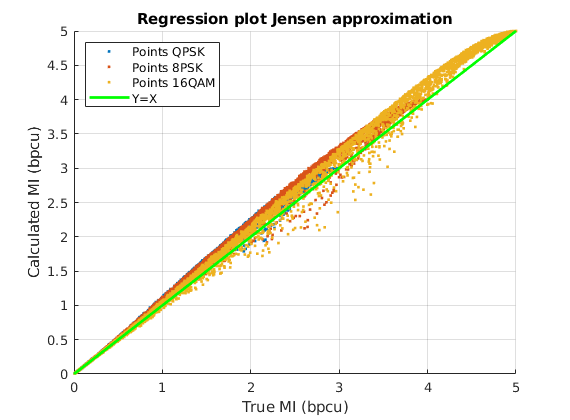 Figure 11
Figure 11 Figure 12
Figure 12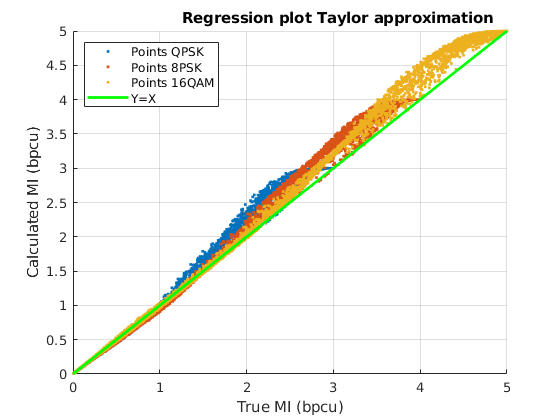 Figure 13
Figure 13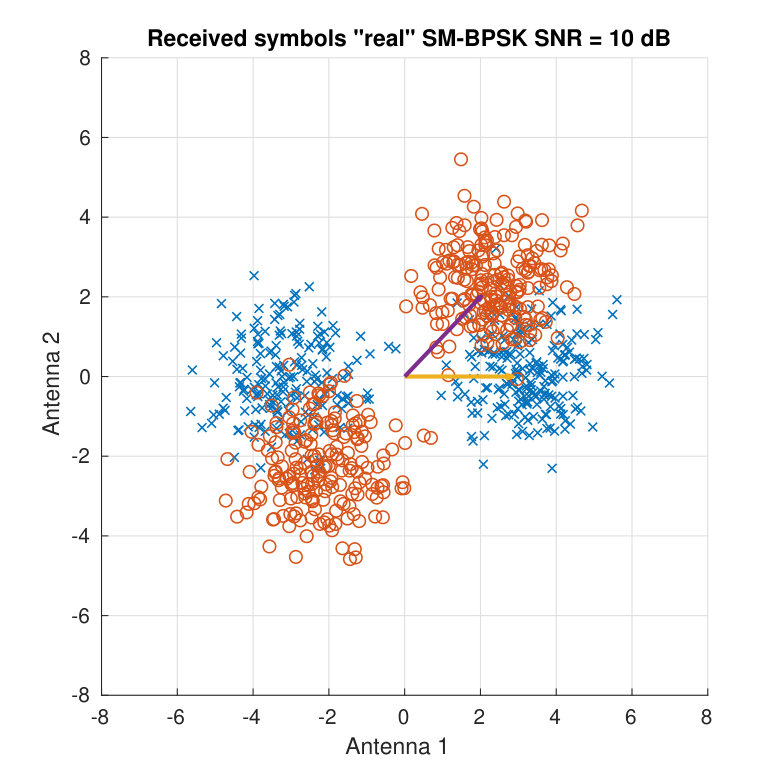 Figure 14
Figure 14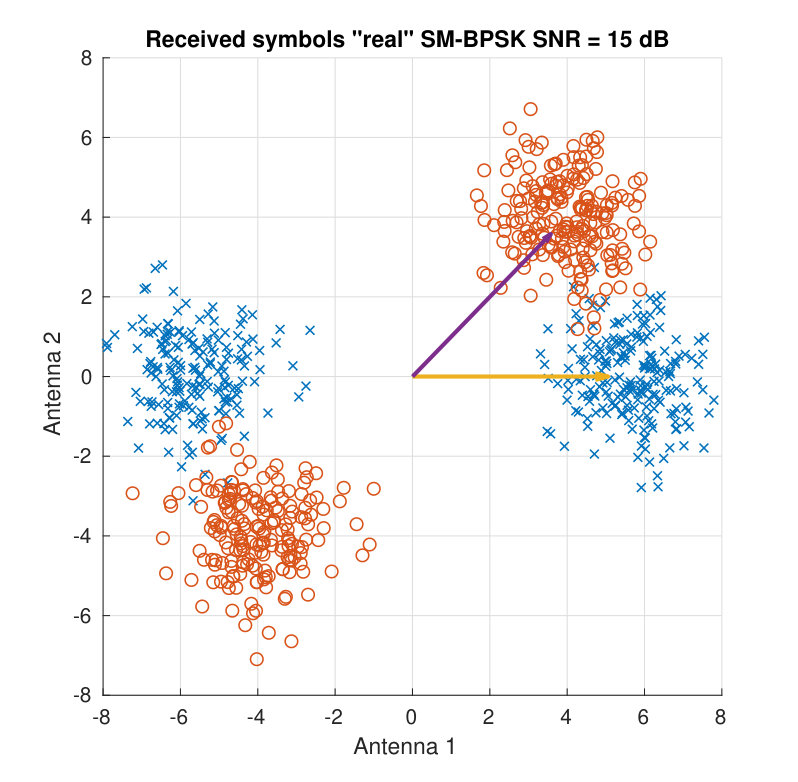 Figure 15
Figure 15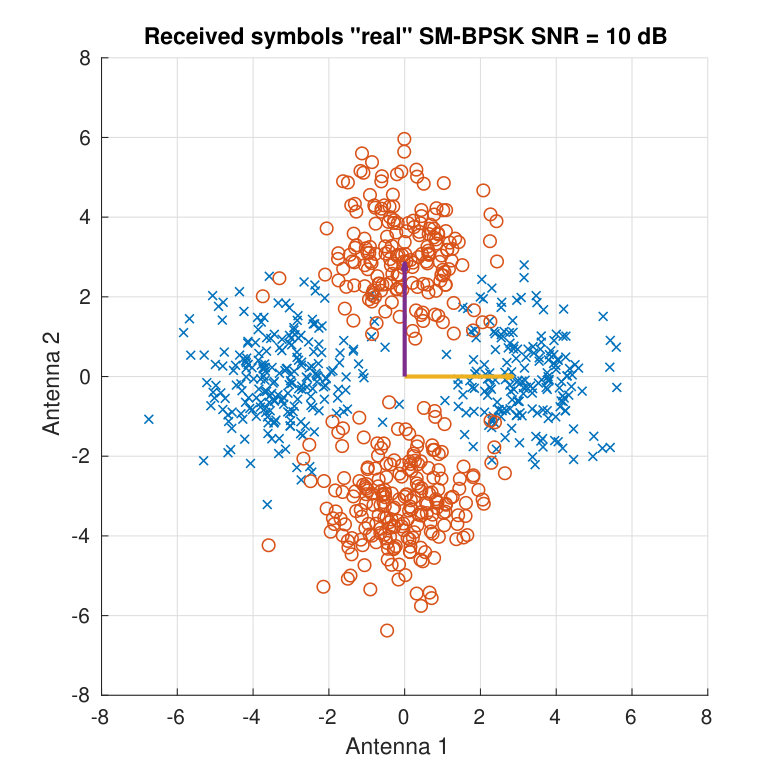 Figure 16
Figure 16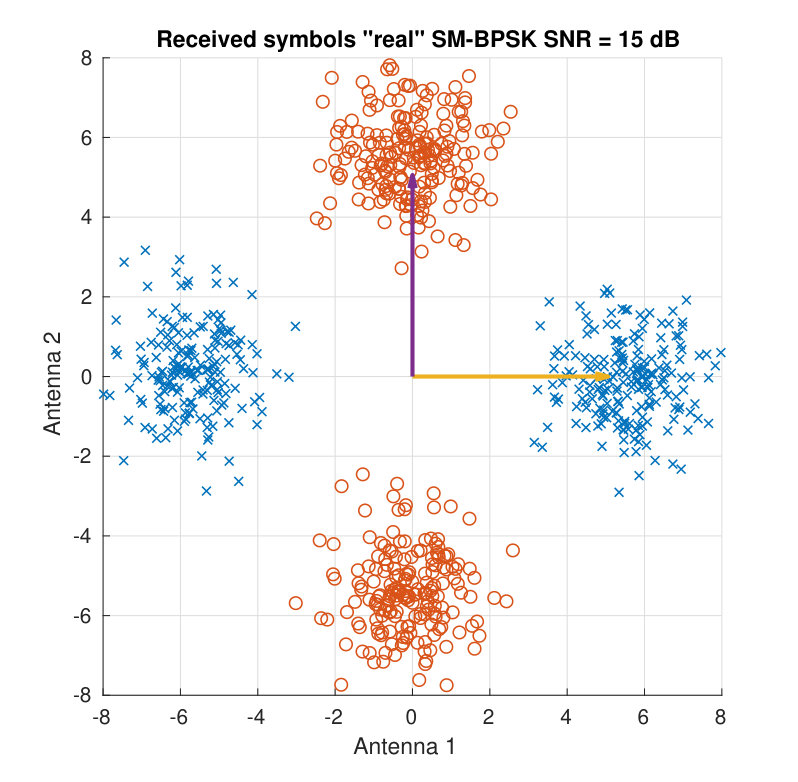 Figure 17
Figure 17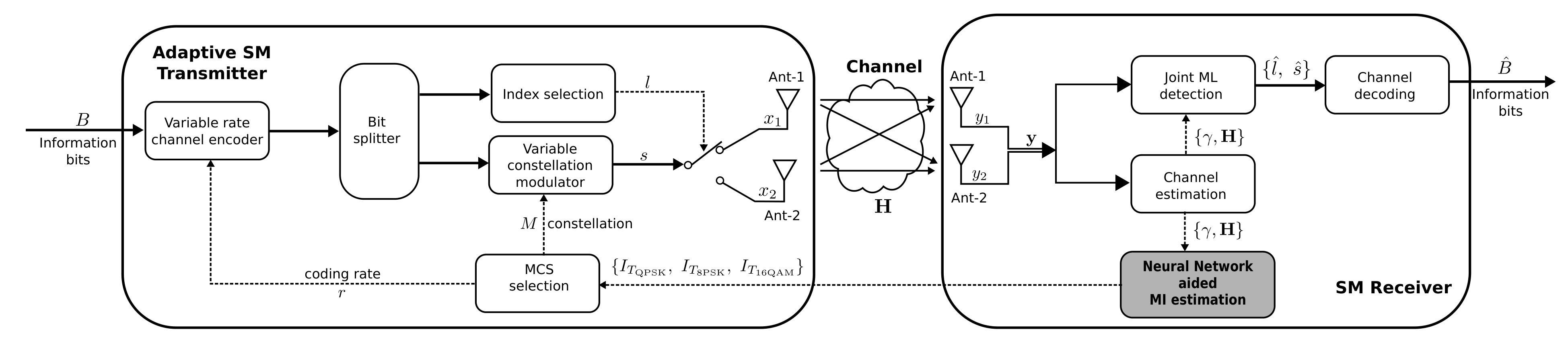 Figure 18
Figure 18 Figure 19
Figure 19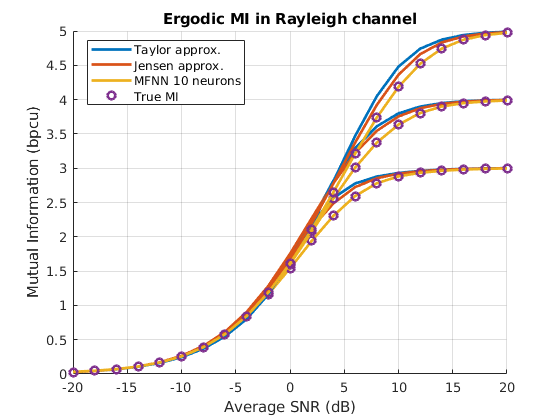 Figure 20
Figure 20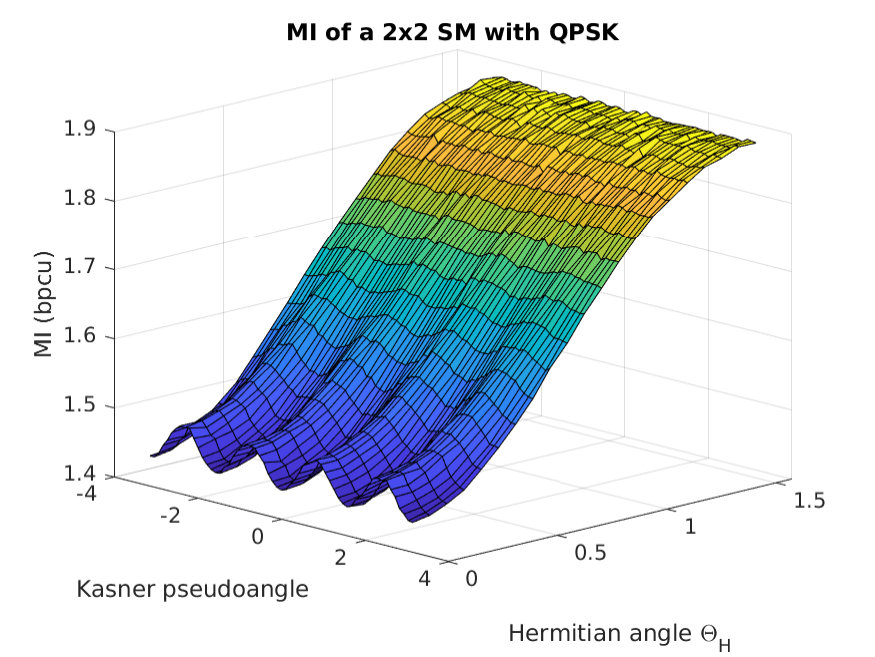 Figure 21
Figure 21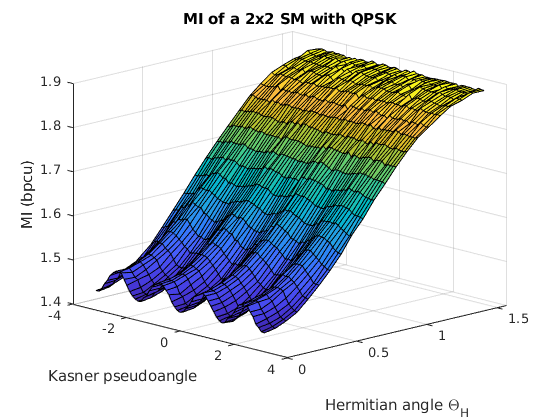 Figure 22
Figure 22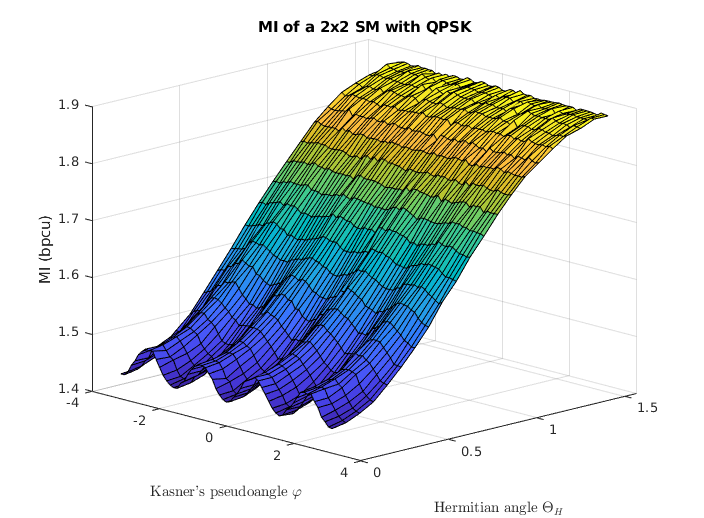 Figure 23
Figure 23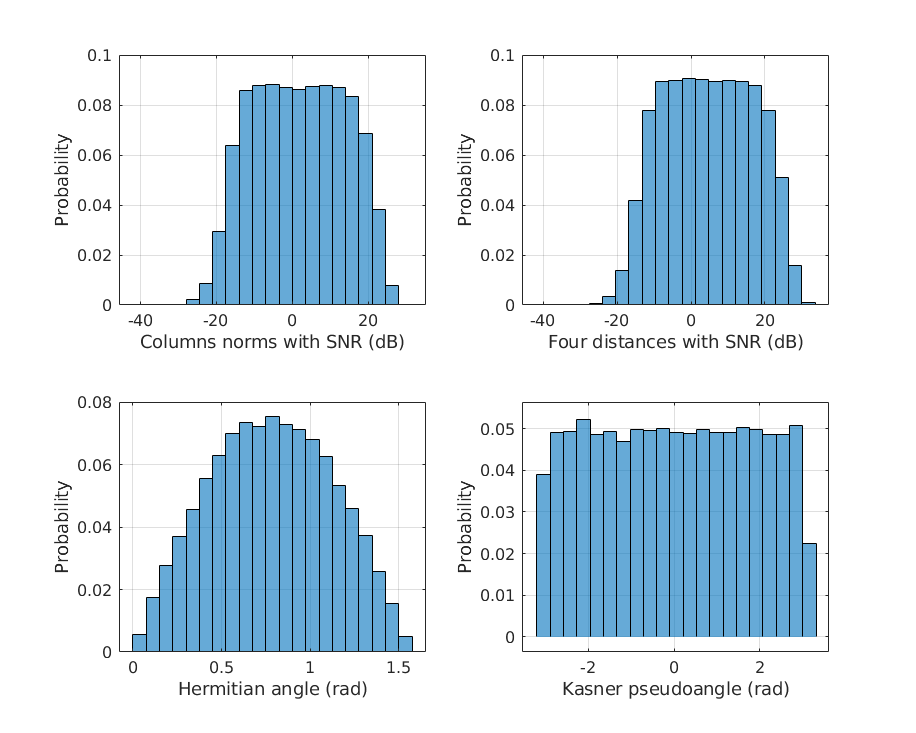 Figure 24
Figure 24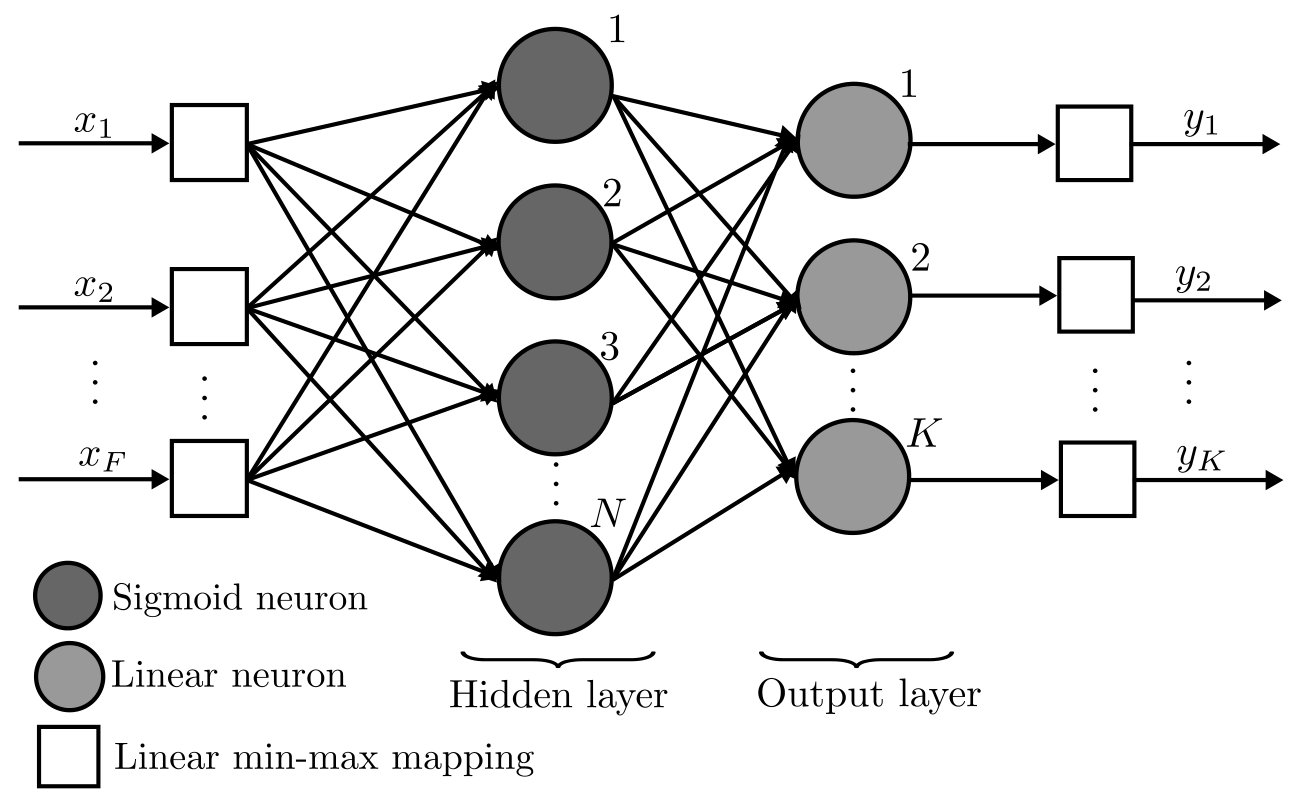 Figure 25
Figure 25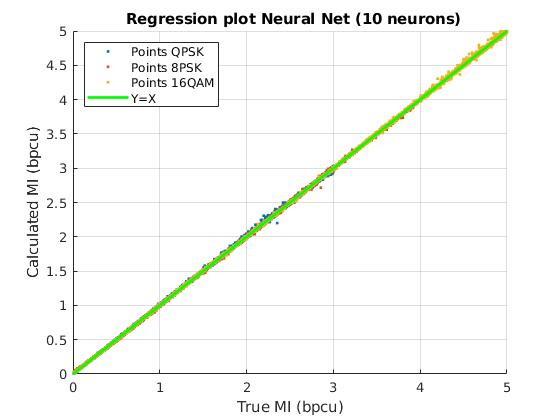 Figure 26
Figure 26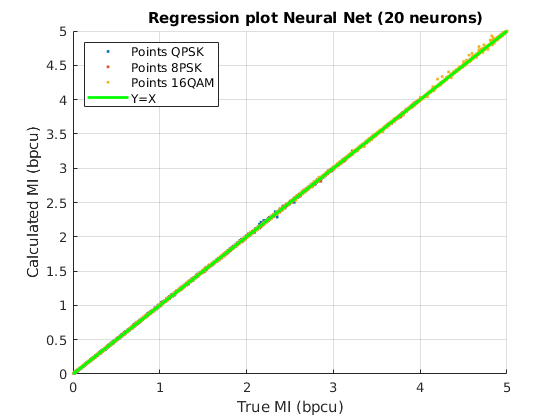 Figure 27
Figure 27 Figure 28
Figure 28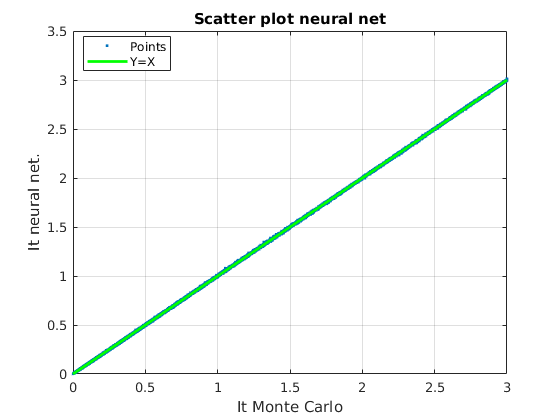 Figure 29
Figure 29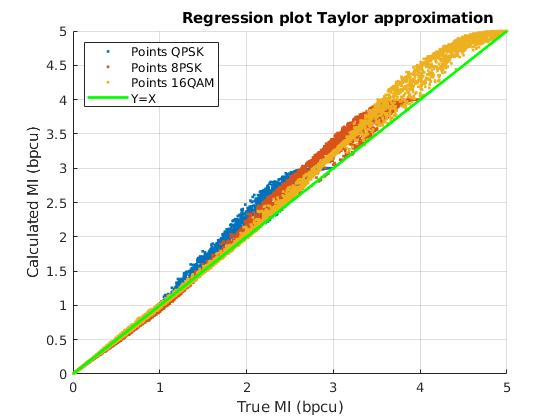 Figure 30
Figure 30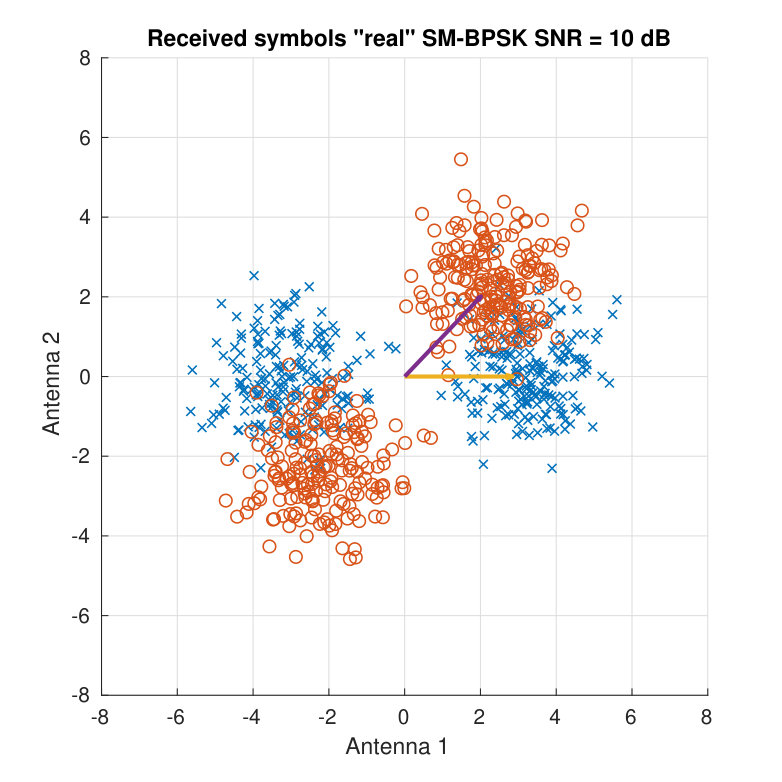 Figure 31
Figure 31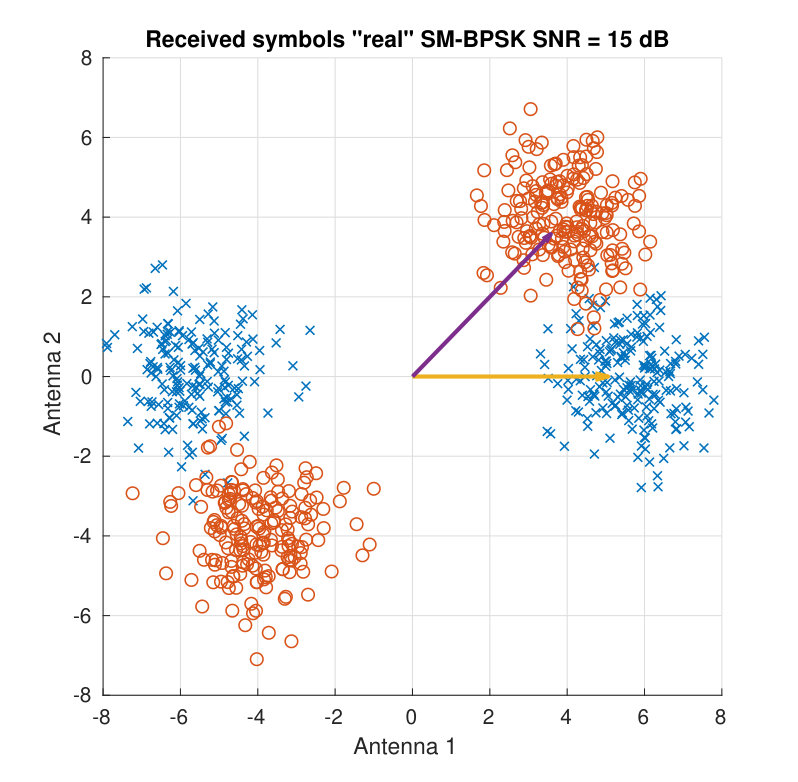 Figure 32
Figure 32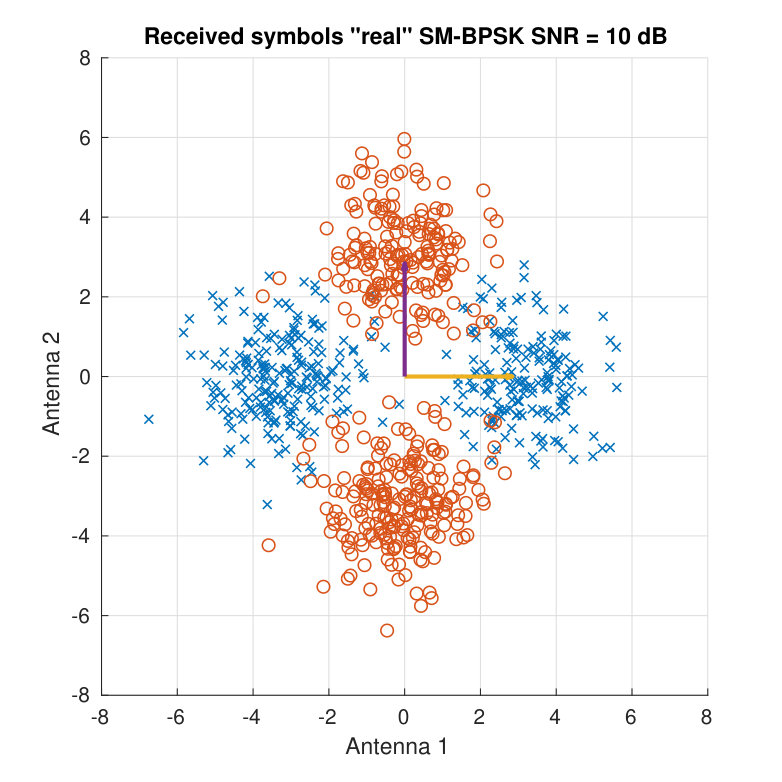 Figure 33
Figure 33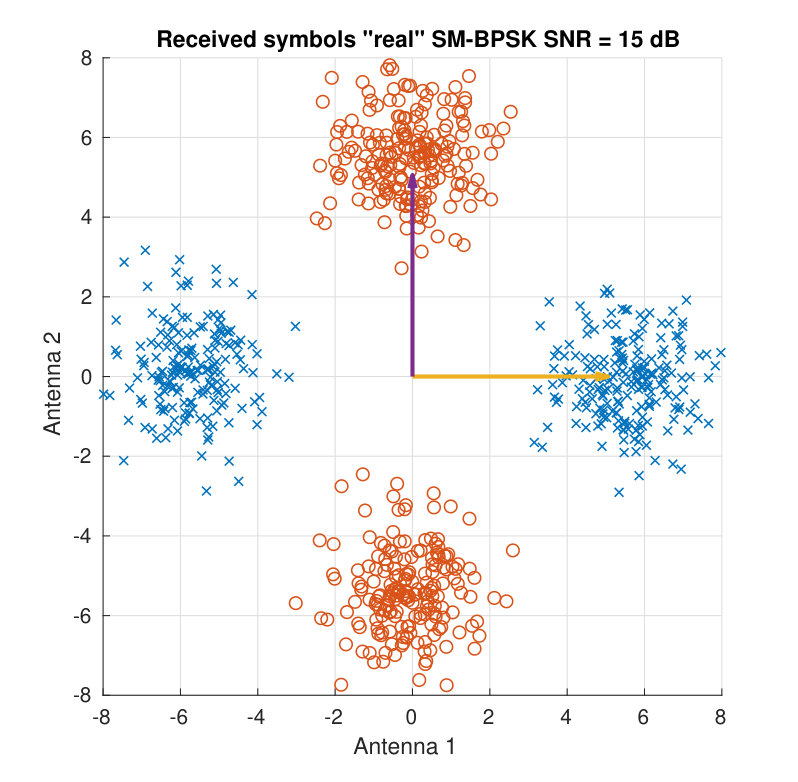 Figure 34
Figure 34| Option | Input features | Description of the features |
|---|---|---|
| i | ||
| ii | ||
| iii | ||
| iv | ||
| v |
| Input features option | Number of features | Global MSE (10 neurons) | Global MSE (20 neurons) |
|---|---|---|---|
| i) Columns norm and projection | |||
| ii) Columns norm and angles | |||
| iii) Columns norm and distances | |||
| iv) Columns norm, distances and projection | |||
| v) Columns norm, distances and angles |
| Taylor approximation | Jensen based approximation | MFNN option (v) 20 neurons | |
| Real products | |||
| 3 | - | ||
| Other non-linear operations | - | ||
| Time for calculations | s | s | s |
| NN input features | Global MSE | QPSK | 8PSK | 16QAM | ||||
| Max. error | Max. error | Max. error | ||||||
| SM (20 neurons), option (ii) | ||||||||
| SM (20 neurons) | ||||||||
| SM (, 20 neurons) | ||||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Neural Network Aided Computation of Mutual Information for Adaptation of Spatial Modulation
Anxo Tato1, Carlos Mosquera1, Pol Henarejos2, Ana Pérez-Neira23
1 atlanTTic Research Center, Universidade de Vigo, Galicia, Spain
2 Centre Tecnològic de Telecomunicacions de Catalunya (CTTC), Castelldefels, Spain
3 Dept. of Signal Theory and Communications, Universitat Politècnica de Catalunya (TSC-UPC)
Email: {anxotato, mosquera}@gts.uvigo.es, {pol.henarejos, ana.perez}@cttc.cat
Abstract
Index Modulations, in the form of Spatial Modulation or Polarized Modulation, are gaining traction for both satellite and terrestrial next generation communication systems. Adaptive Spatial Modulation based links are needed to fully exploit the transmission capacity of time-variant channels. The adaptation of code and/or modulation requires a real-time evaluation of the channel achievable rates. Some existing results in the literature present a computational complexity which scales quadratically with the number of transmit antennas and the constellation order. Moreover, the accuracy of these approximations is low and it can lead to wrong Modulation and Coding Scheme selection. In this work we apply a Multilayer Feedforward Neural Network to compute the achievable rate of a generic Index Modulation link. The case of two antennas/polarizations is analyzed throughly showing the neural network not only a one-hundred fold decrement of the Mean Square Error in the estimation of the capacity compared with existing analytical approximations, but it also reduces fifty times the computational complexity. Moreover, the extension to an arbitrary number of antennas is explained and supported with simulations. More generally, neural networks can be considered as promising candidates for the practical estimation of complex metrics in communication related settings.
Index Terms:
Mutual Information, Capacity, Index Modulation, Spatial Modulation, Polarized Modulation, Neural Networks, MFNN, Machine Learning, Adaptive Communications, ACM, Link Adaptation.
I Introduction
The evaluation of the achievable physical layer rate of a given modulation scheme is an important theoretical problem with very relevant use in practice. Most modern communication standards, e.g., [1], [2] or [3], incorporate some sort of Adaptive Coding and Modulation (ACM) mechanism, generically known as link adaptation. This consists typically on varying the modulation order and/or the coding rate of the channel encoder to track the varying channel conditions. The ultimate goal is to adjust the transmitted bit rate to the information that the channel can support for a given bit error probability.
Link adaptation makes it necessary for the transmitter to estimate somehow the mutual information (MI) between the transmit and received waveforms on a per-frame basis, so that the most efficient Modulation and Coding Scheme (MCS) can be chosen. In most cases, the receiver computes some metric related to the MI and sends it back to the transmitter end. This metric can be in the form of the average or effective Signal to Interference and Noise Ratio (SINR), or some Channel Quality Indicator (CQI) specifically suited to the set of MCS available to the transmitter [4]. In essence, the receiver must estimate the maximum amount of information that can be transmitted reliably through the channel; for all this, the estimation of the MI plays an instrumental role.
A particular family of modulation schemes, known as Index Modulations (IM) [5], have attracted a great deal of interest in the last few years. Among others, we can cite Spatial Modulation (SM) [6]-[7] or Polarized Modulation (PMod) [8]. SM and its more sophisticated variants are proposed for next generation of wireless networks due to several advantages. In comparison to single-antenna techniques, the spectral efficiency increases, with a simpler and more energy efficiency hardware than in other multi-antenna techniques [5]. Another interesting version is that studied in [8], where the authors propose the use of PMod to increase the spectral efficiency of next generation mobile satellite communications; if Multiple-Input-Multiple-Output (MIMO) signal processing techniques are applied to Dual Polarization (DP) satellite systems, the performance of single-antenna (or single polarization) links can be notably enhanced. DP schemes were also highlighted in [9] as a means to improve the satellite coverage in remote areas to serve the increasing number of Internet of Things (IoT) devices.
In this paper we present a novel method to compute the mutual information without Channel State Information at the Transmitter (CSIT) of a 22 SM system, and show how to generalize it to an arbitrary number of antennas. The results are also valid to other types of IM, like PMod. This calculation is needed, for example, in an adaptive SM system where the transmitter uses this mutual information, obtained and fed back by the receiver, to select the proper MCS. Results requiring numerical integration, for example by means of Monte Carlo simulations, can be found in the literature [10] and [11]. One value of this work is that it explores a radically new approach to solve an essential problem in the practical application of Information Theory: the mutual information of non-conventional modulations is computed by means of Machine Learning (ML) tools.
The use of ML at the physical layer of communication systems is gaining momentum, see the recent surveys [12] and [13]. In particular, Neural Networks (NN) have been successfully used for channel estimation and equalization [14], signal recognition and modulation classification [15], [16], detection in MIMO Generalized SM [17], and learning of physical layer parameters in Cognitive Radio [18], among others. In [19] and [20] NNs are applied to perform link adaptation in multicarrier systems. In [21], a Multilayer Feedforward Neural Network (MFNN) is used to predict the performance of a WiFi cell. A deep NN is proposed in [22] to decide the optimal power allocation in a wireless resource management problem. In this latter reference the NN is used to obtain the optimal power allocation values, much more efficiently (by speeding up the computational time in several orders of magnitude) than the baseline iterative algorithm which solves the corresponding non-convex optimization problem. Besides NNs, Support Vector Machines (SVM) have been also studied for the selection of physical layer parameters in communication settings with a large number of degrees of freedom [23].
The current work applies a one-hidden layer MFNN as a facilitator scheme to compute the MI in an adaptive SM link, based on some specifically selected input features which can be easily obtained from the MIMO channel matrix, together with the Signal to Noise Ratio (SNR). To the best of our knowledge, it is the first time that a NN is proposed to estimate the MI of a channel. In the particular scenario of SM, the evaluation of the capacity, needed for adaptation purposes, is numerically demanding when needed on-the-fly.
The shallow NN proposed to calculate the MI of a generic SM system, valid also for PMod, outperforms recent approximations found in the literature such as [11] and [24], both in terms of estimation accuracy and computational complexity. In order to avoid the numerical evaluation of the involved integrals, these references provide two different approximations of the MI for a specific symbol constellation, with a complexity scaling with the square of the constellation size and the number of antennas. As opposed, the proposed solution has a much lower complexity, which is independent of the size of the constellation.
The main contribution of this work is the accurate evaluation of the MI of spatial modulations, which have resisted so far those attempts to obtain simple expressions. Moderate size standard neural networks will be seen to be up to the task provided that a careful extraction of channel parameters and training are performed. The proposed solution to calculate the MI enables also to perform a different type of adaptation in SM systems. Due to the lack of accurate MI evaluation methods, works like [7] and [25] only consider the selection of the modulation order in an adaptive system. However, with the accurate MI obtained with the NN, the transmitter could not only adapt the modulation scheme, but also the coding rate of the channel encoder, allowing a fine granularity in the available transmit MCS. Moreover, due to the lower complexity of the proposed method, the receiver can compute the MI more often and then follow faster channel variations, so that the adaptation speed is not necessarily limited by the complexity of the computation of the channel capacity.
The rest of the paper is structured as follows. Section II explains our system model and introduces the reader into Spatial Modulation. Then, Section III presents the expressions to compute the mutual information of SM. It also replicates the analytical expressions existing in the literature to approximate the MI, and to be used for benchmarking purposes. Afterwards, in Section IV a brief introduction to Multilayer Feedforward Neural Networks is included before dealing with their specific application to the evaluation of the MI of a SM for different constellations. Afterwards, Section V presents the simulation results in detail for the case of two dimensions. Then, Section VI explains how to generalize the method to obtain the MI of systems with a higher number of antennas. Lastly, the main conclusions are drawn in Section VII.
Notation: Upper (lower) boldface letters denote matrices (vectors). , , and , denote Hermitian transpose, transpose, identity matrix and vector of ones, respectively. applied to vectors denotes the Euclidean norm. is the expected value operator. and denote the Hadamard (pointwise) matrix product and division. , , and denote the real part, imaginary part, conjugate and absolute value of a complex number, respectively.
II System model
Traditional digital modulation schemes transmit information modulating only the amplitude, phase and/or frequency of a sinusoidal carrier. However, Index Modulations (IM) benefit from the fact that the transmitter has several building blocks, being these antennas, polarizations or subcarriers, for example, to map additional bits of information to the block selected to transmit the conventional modulated signal [26]. As illustration, consider SM with transmit antennas: in addition to the bits to index each symbol in a constellation of elements, bits can be used to select which of the antennas is active at a given instant to transmit the symbol. Similarly, PMod, by means of the transmit polarization carries information. In this paper we will focous our attention in the case with , so that one input bit is used to select the active transmit dimension, although a latter section will explain how to extend the results for . Hereafter, SM is used instead of IM but keep in mind that results apply to a generic IM, never mind how are interpreted the dimensions (antennas, polarizations, frequencies…).
The system model of a SM for a given discrete time instant is
[TABLE]
where is the received vector, the average Signal to Noise Ratio (SNR), the channel matrix, the transmitted signal and the Additive White Gaussian (AWGN) noise vector. Since has only one component different from zero (component ) and its value is , (1) can be also expressed as
[TABLE]
where denotes the column of , . We assume a unit power constraint, i.e., .
Fig. 1 shows a block diagram of an adaptive SM system. The transmitter modifies the coding rate of the channel encoder and the constellation order of the modulator according to the different mutual information (MI) values calculated and reported by the receiver. In this way, the transmitter adjusts the transmission rate dynamically to the maximum MI that the channel conditions allow at each time instant. Thus, a fine selection of the coding rate is possible due to the accurate calculation of the MI. This approach differs from previous works, [7] and [25], where the modulation was the only degree of freedom.
The mapping from the achievable rate (MI) reported by the receiver to the MCSs to be used by the transmitter depends on the strength of the channel codes and the receiver implementation. In a practical system a backoff margin should be enforced based on the distance to capacity of the different MCS. An alternative adaptation method is presented in [27]. Instead of using the neural network to calculate the MI, the MCS is selected directly. This requires the training of the network with data from the MCSs performance obtained from extensive Monte Carlo simulations for a vast number of different channel matrices and SNRs.
We should remark again that the model (1) and the block diagram of Fig. 1 apply to a generic IM, with the matrix characterizing the channel effects of the specific domain considered, being this polarization, frequency or space. The adaptive SM transmitter requires the knowledge of the MI at each channel realization to perform the link adaptation. In this work we do not deal with the MCS selection at the transmitter, since we focus our attention only on the NN aided MI estimation, denoted by the gray block at the receive side. In order to minimize the overhead of the return link, the receiver estimates the SNR and the channel matrix , computes the MI and sends it back to the transmitter. Next section provides the expressions to compute the MI of a SM system for an arbitrary constellation. A more practical scheme for calculating these MIs, making use of a NN, will be presented later in Section IV.
III Capacity and Mutual Information
The expression of the Spatial Modulation (SM) capacity conditioned to a given realization of the channel matrix is given by
[TABLE]
where is the Mutual Information (MI) between the two random variables and conditioned to , and the maximization is performed for all possible distributions of the transmitted signal [28]. In (3), , and denote the probability density functions (PDF) of the random variables of the complex transmit signal , the complex transmit symbol , and the hopping index which selects the antenna/polarization used to transmit the symbols. The units of the capacity in (3) are bits per channel use, bpcu. The transmitter is expected to operate with only partial CSIT (it only knows the MI, neither nor ), so it will select either index with the same probability. The capacity is achieved in (3) when the transmit symbols belong to a Gaussian codebook [10], i.e., when .
The MI in (3) can be expressed as a function of the entropies of the involved random variables:
[TABLE]
where is used for the differential entropy, and is simply written as
[TABLE]
As in [10], the received vector follows a Gaussian distribution of the form
[TABLE]
where and . With this, the entropy of in (4) reads as
[TABLE]
It is then clear than the computation of the MI requires the numerical evaluation of the above integral, which can be too demanding for a receiver updating the estimate of the link capacity for adaptation purposes. In this paper we will compute the MI by means of Monte Carlo integration as a reference for comparing the approximation performed by the neural network.
Practical communication links use symbols from a constellation with a finite alphabet. Hereafter, we will refer to the corresponding mutual information, or constrained capacity, simply as total mutual information, , since this includes the information carried by both hopping index and symbol :
[TABLE]
The particularization of (4) for a constellation with symbols has been made in [11], and it is replicated in (9) for the sake of completeness. Monte Carlo integration will be also used to compute (9), by generating random values of the noise .
In an effort to find more convenient expressions to handle in practice, some results have been presented in the literature as approximations to the mutual information (9). On the one side, Guo et al [24] used the Jensen’s inequality and corrected the ensuing bias to get
[TABLE]
Here is a set with vectors in of the form
[TABLE]
for and , where are the columns of the channel matrix, and the symbols of the constellation.
A different approach resorting to the Taylor Series Expansion was followed in [11], yielding expression (12) as an approximation of . The interested reader is referred to [11] for the definitions of each element of the equation. One drawback of both (10) and (12) is that the computational complexity of the MI calculation increases with the square of the constellation order and the number of antennas .
This paper develops a more efficient and accurate scheme to compute the MI of a SM system, which avoids the quadratic complexity increment with the constellation cardinality. This is especially relevant for practical use, given the need to estimate on the fly the channel capacity for link adaptation purposes. In an adaptive coding and modulation (ACM) system, the receiver must feed back to the transmitter a metric related to the achievable rate, so that the transmitter can select the appropriate MCS111The receiver itself can also make this choice and report back the corresponding index to the transmitter.. This estimation process needs to be both simple and accurate, since errors will lead to wrong choices of MCSs, and lower rates than supported or decoding mistakes will occur. The proposed scheme to estimate the achievable rate is based on a simple NN with only one hidden layer, and which provides different outputs, one per constellation in case several are available. The computational burden is much lower than that of any other previously known alternatives, so the MI can be updated more often and faster variations of the channel conditions can be tracked as a benefit.
IV Neural Network-based Mutual Information Estimation
The evaluation of the Mutual Information (MI) (9) can be interpreted as a non-linear mapping from the channel matrix and the SNR to the MI. Multilayer Feedforward Neural Networks (MFNNs), well-known for their fitting capabilities of non-linear functions [29]-[30], will be used to estimate in (9). In particular, the MFNN to be employed, a one hidden layer network, is detailed in Fig. 2. The input features, , need to be extracted by means of a function from the channel matrix and the SNR , as . The input variable selection is highly relevant for the performance of the learning process of the network. Later we will detail how the feature extraction is applied based on our domain knowledge, that is, our knowledge of the particular problem we are addressing. Alternatively, a more complex deep neural network with several hidden layers could be used, so that the relevant features for this problem are learned by the intermediate layers, and all the channel matrix coefficients are used directly as inputs without any processing. However, as detailed later, we found this solution underperforming the one hidden layer with carefully selected input features.
In the following, the variables in blue will denote the internal parameters of the neural network, and will be the intermediate internal variables at the -th layer. Each of the neural network inputs goes through a linear preprocessing block to adjust the neurons input to the range . This initial scaling is expressed as
[TABLE]
with the gain and the offset .
The hidden layer is made of neurons, also named processing units, each applying a weighted linear combination of its inputs, a bias and a non-linear function, also known as activation function:
[TABLE]
The matrix and the vector collect the weights and the offsets. As activation function we will use the hyperbolic tangent:
[TABLE]
The output layer of neurons applies a linear processing of the form
[TABLE]
for matrix and vector . Finally, there is a last stage to accommodate the range of the network outcome:
[TABLE]
with the gain and the offset .
The output vector is expressed as .
The different parameters of the network –weights and biases in (13)-(16)– will be obtained under supervised learning. The Levenberg-Marquardt (LM) backprogation algorithm [31] will be used to minimize the Mean Squared Error (MSE) on the test set:
[TABLE]
with and the network output and the true MI values, respectively, for the training tuples , . The true MI values are obtained by numerical evaluation of (9) for different symbol constellations. The training of the network is performed off-line, so that receiver terminals only need to evaluate (13)-(16) for adaptation purposes. The computational complexity of the NN will be evaluated later in comparison to that of previous methods presented in the literature [11]-[24].
Hereafter, we focus on the MI calculation of a SM system and next section will provide simulation results for this particular case. However, the underlying philosophy applies to SM with a higher number of antennas, not only . Section VI will show how to extend the results to obtain the MI of SM systems with a larger number of antennas. Remarkably, the neural network entails always a degree of complexity about two orders of magnitude lower compared to that of the analytical approximations, even for SM systems with high number of antennas/dimensions.
IV-A Input Variable Selection
The output of the network in Fig. 2 is the MI estimation for different constellations, as an approximation of the true MI function (9). This depends on the channel matrix and the SNR ; in the following we will see how to pre-process these values for a better network performance.
For a Maximum Likelihood receiver, the pairwise error probability (PEP) between and is given by [25],[32]
[TABLE]
for the AWGN case. This PEP depends on the distance among supersymbols . The set of different supersymbols for a given channel matrix and the transmitted constellation is
[TABLE]
The MI will be also affected by all the involved distances, as inferred from (9). For convenience, we put together the squared distances among all the pairs of supersymbols under the matrix of size , with the respective entries given by
[TABLE]
where and . Matrix can be also expressed as
[TABLE]
The matrix on the diagonal is a function of the symbols in the constellation :
[TABLE]
whereas the matrix contains all the distances between supersymbols of different antennas/polarizations:
[TABLE]
Note that the matrix can be expressed as the sum of four rank- matrices:
[TABLE]
With this, we have that . Even further, if the constellation of symbols is known, then only four real values are required to describe the dependence of and with the channel matrix , namely, and the real and imaginary parts of the scalar product . Alternatively, the scalar product can be expressed as [33]
[TABLE]
where and denote, respectively, the Hermitian angle and the Kasner’s pseudo-angle between two complex vectors. Thus, the four values serve to characterize the matrix .
For illustration purposes, Fig. 3 shows the received symbols for a real BPSK case. Two different SNR values and two different channel matrices are employed to display the clouds of received symbols. Both the SNR and the angle between the column vectors of determine the distance among the different color clouds.
The impact of the two angles and in the final MI can be grasped with the aid of Fig. 4, which shows a 3D representation of the MI as function of both angles. Monte Carlo simulations were run for a QPSK constellation, with both columns having the same norm, = 1, and . With this, the structure of the channel matrix is the following:
[TABLE]
It can be seen that the MI has a strong dependance with the Hermitian angle. If the two columns are orthogonal and the MI is maximum, whereas for the columns are considered parallel, and the MI is reduced. Moreover, the Kasner’s pseudoangle only affects the MI significantly when is close to zero, creating a small ripple, due to the radial symmetry of the constellation. However, for , the MI is barely affected by the Kasner’s pseudoangle. Instead, if the phase determines to which extent the receiver can tell which antenna transmitted the observed symbol.
After extensive training cases, we have observed that performance can be enhanced if, as part of the input parameters, the distances among the supersymbols are also included. Four distances, , are used; this is the number of different entries of matrix in (23) when a QPSK constellation is employed. It turns out that these four quantities suffice for the neural network to compute a good estimate of the MI for other constellations too, such as 8PSK and 16QAM, even though the number of different entries of the matrix is higher.
IV-B Neural Network Operation
We will use a unique MFNN to estimate the mutual information for different symbol constellations. outputs will provide the estimate of the mutual information for QPSK, 8PSK and 16QAM constellations. Following the above considerations, the input features will correspond to different options to characterize the distance matrix . Table I depicts the different feature sets that will be used for testing the performance of the network. Essentially, four inputs is the lowest number of inputs to test following the previous discussion222Note that the number of real values to characterize and is nine.. Values are sorted in ascending order given the invariance of the capacity to the labeling of the dimensions and symbols. As to the number of neurons, and will be used in the simulations.
Training of the network will be based on extensive amount of data, by generating a large number or random channels for different values of SNR. The reference true capacity values for the different constellations will be obtained after computing (9) by the Monte Carlo method.
V Simulation results
For performance evaluation, a dataset of realizations of the channel matrix is used, randomly generated following a unit-variance Rayleigh distribution, i.e., . Each channel matrix is associated with a different SNR whose value in decibels is drawn from a uniform random variable between and dB. The true MI with QPSK, 8PSK and 16QAM constellations of each realization of () is calculated with a Monte Carlo simulation using (9) with realizations of the complex Gaussian noise . We limit ourselves to these low order constellations, which are more likely to be used with SM. However, other constellations, like 64QAM, could be easily added to the system at the expense of increasing the time required for obtaining the dataset with Monte Carlo simulations -note the two summations over all the constellation symbols in (9).
The dataset is divided into two independent parts. samples () are reserved for the final test of the performance of the MFNN and the analytical approximations (equations (10 and (12)). The remaining samples () and samples () are employed for training and validation of the neural network, respectively.
Firstly, the impact of the selection of the input features in the performance of the MFNN is evaluated. For this, several NNs are trained using in each case one of the sets of inputs detailed in Table I. Fig. 5 shows some histograms with the statistical distribution of the features obtained from the dataset. The distances and the norms include the SNR term and are shown in dB, whilst the unit of the angles is the radian.
Then, the global MSE obtained with the trained NNs when calculating the three MI values is obtained by using the entries of the dataset reserved for testing. Table II collects the values of MSE for five different selections of the input features and for both numbers of neurons ( and ). It shows the best MSE in the testing dataset after trainings with different NN parameters initialization. If the NNs are fed directly with the real and imaginary parts of the channel matrix coefficients, the MSE is very high, in the order of . Nevertheless, at least two orders of magnitude improvement is achieved when the NNs are fed with the input features detailed in Table I.
In Table II, it can be observed how the Hermitian angle and the Kasner’s pseudoangle , options (ii) and (v), improve the NN estimation with respect to the use of the real and imaginary parts of the projection, options (i) and (iv). Furthermore, the addition of the four distances to the set of inputs, cases (iii), (iv) and (v), serves to reduce the MSE as compared to cases (i) and (ii). Finally, the MSE reaches a minimum value of about when the four distances and the two column norms are combined with the two angles for the neurons MFNN.
Secondly, the two NNs with and neurons and the input features selection (v), are compared with the analytical approximations from the literature, (10) and (12), in Table III. Both Taylor and Jensen based approximations have a similar MSE, around , which is outperformed by all the NN reported in Table II. Moreover, when we compare the analytical approximations with the best NNs of the table, the improvement in the MSE is about and times with a NN of and neurons, respectively.
As noted previously, the calculation of the MI could be addressed with a deep neural network, a MFNN with several hidden layers, using as inputs the channel matrix coefficients (scaled by the SNR) directly. With this approach, the network extracts the relevant features at the intermediate layers, so that the last layer computes the MI. We have tested this approximation for a number of layers ranging from one to ten, and a number of neurons per layer between and . It was found that a deep network with at least three layers of neurons can perform better than the Taylor and Jenson approximations, yielding an MSE in the order of . However, the deep networks do not overcome the peformance of the one-hidden layer MFNN which the input features of row (v) of Table I. In addition, the training of these deep networks is much more time consuming, and the learning algorithm has more difficulties to converge to those parameter values providing a good performance.
As shown in Table III, the analytical approximation suffers a maximum error of , in the 16-QAM constellation, which is reduced to in the case of the MFNN with neurons. The improvement is even more noticeable with the value: a little bit more than for the analytical approximations, and times smaller with the neural network.
Fig. 6 shows a graphical view of the estimated MI values: the scatter plot of the values of the true MI (X axis) are shown together with the values of the MI computed with each method (Y axis) for the three constellations, QPSK, 8PSK and 16QAM. The green line Y=X sets the perfect match of the MI. It can be seen that the analytical approximations provide better results for lower values of MI, while for MIs close to their maximum (, or , depending on the constellation), they have a noticeable positive bias. Remarkably, both NNs with and neurons in the hidden layer, match the true value of the MI almost perfectly, clearly outperforming the analytical approximations.
The accuracy achieved by the MFNN has a direct impact on the implementation of adaptive IM links. The quality of the tracking of the MI allows to use smaller back-off margins for the selection of the MCS; large errors make it necessary to use highly conservative margins in the selection of the MCS to guarantee a prescribed error decoding metric, thus reducing the transmission rate.
Finally, the ergodic MI of an Index Modulation system with QPSK, 8PSK and 16QAM constellations under Rayleigh fading is shown in Fig. 7. For each value of SNR, realizations of the channel matrix are generated, similarly to the NN dataset, and the true MI in each case is calculated with a Monte Carlo simulation with realizations of the noise. Afterwards, the ergodic MI for each SNR point is calculated by averaging the instantaneous values of the MI. The true ergodic MI, shown with circles, is compared with that obtained by averaging the instantaneous MI calculated with each method, the two analytical approximations and the neurons neural network. As it can be seen, the neural network matches perfectly the true ergodic MI, which is overestimated by the other methods for moderate values of the SNR.
In addition to the estimation accuracy, the computational complexity is key for practical implementation: the MI computation must be done at the receive side, which has knowledge of the SNR and the channel matrix . This evaluation must be such that an on-line tracking of the channel is made to report the estimated MI back to the receiver.
In this regard, Table IV shows the computational complexity of each method after counting the number of mathematical operations required to compute the MIs for the three constellations. In the case of the analytical approximations, the table shows a lower bound of the number of operations since it only counts the most demanding instructions, which are repeated times. In the case of the NN, all the required operations are counted, including the preprocessing of and to calculate the inputs of the NN.
The numbers in Table IV reveal that the MFNN is not only more accurate, but also less computationally demanding. The MFNN requires about times fewer multiplications and non linear operations than the analytical approximations. This is in line with the required time to compute with Matlab® the three MIs for all the testing dataset, in a computer equipped with an i7-4510U 2 GHz processor. From another point of view, the laptop only allows to make an estimation of the MIs every ms with the Taylor approximations, which gets reduced to ms with the NN. With respect to the off-line training duration, each training of the NN took typically less than minutes.
VI Extension to a higher number of antennas
This paper is focused mainly on a SM system with two dimensions in order to study thoroughly the impact of the different input features selection. However, this approach can be easily extended to compute the MI in scenarios with a higher number of antennas. This section aims to explain how to apply the same philosophy to obtain the MI of a and SM systems, providing also some cles to keep the complexity bounded for higher numbers of antennas.
Let us recall Table I, which portraits several selections of the NN input features for the case of antennas. As can be seen, the performance improves from the top to the botton; in order to avoid too a large number of input features in systems with a higher number of antennas, we propose to apply option (ii) as a trade-off between performance and complexity. This option makes use of the channel column norms (scaled by the SNR) and the angles. Whilst the number of norms increases only linearly with the transmit antennas, the number of angles raises rapidly with since there are angles, a tuple () for each possible combination of two transmit antennas. For example, in a system with antennas there are pairs of angles. However, we have found out that it is not necessary to give the values of all the angles explicitly to the neural network. A few values characterizing the statistical distribution of the angles suffice for the NN to estimate the MI with an MSE similar to those values reported in Table II.
The MI evaluation in a SM system with antennas can be easily done with an MFNN trained with the proper dataset, obtained now with Rayleigh matrices, and using as input features the four values of and the six pairs of angles . In the case of an IM system we propose to reduce the pairs of angles to just values per type of angle (Hermitian and Kasner). These values are the quantiles of the angles distribution for probabilities taken from [math] to at equal steps. For example, for the distribution of the angles is characterized by the minimum, the th percentile, the th percentile (the median), the th percentile and the maximum. Therefore, the MFNN for obtaining the set of MI of an IM system has as input features the columns norms , and the quantiles of the Hermitian angle and the Kasner’s pseudoangle , respectively.
For testing purposes, we have generated two additional datasets, one with Rayleigh matrices and another with Rayleigh matrices. Again, each channel matrix has associated a random SNR value between and dB, and we have calculated the MI of each pair () for several constellations (QPSK, 8PSK and 16QAM) using Monte Carlo simulations. Following the same procedure of training and testing described in Section V, we have obtained two trained MFNNs for calculating the three MI values of and SM systems, respectively.
Table V sums up the results obtained with these two neural networks. Note that for the system we have used only quantiles. If we compare the results of and antennas provided in Table V with those obtained with the best network for the antennas scenario from Table III, using neurons and input features option (v), the NN performs a little worse in the setup with more antennas, although the errors are of the same magnitude. However, a fair comparison with the NN for SM which uses the same type of input features, i.e., option (ii) from Table II, reveals that the MSE is slightly better when the number of dimensions grows.
VII Conclusions
The implementation of next generation adaptive Spatial Modulation links requires practical mechanisms to estimate the mutual information for a given signalling strategy. An accurate and timely computation of this constrained capacity serves to adapt the constellation order, and apply a fine tuning of the coding rate of the channel encoder, providing a better fit to the maximum achievable rate. The method proposed in this paper to calculate the constrained capacity is a very simple Multilayer Feedforward Neural Network, which can obtain the Mutual Information for different symbol constellations simultaneously. The neural network is more accurate and less computationally demanding than the analytical approximations existing in the literature.
VIII Acknowledgments
This work was funded by the Xunta de Galicia (Secretaria Xeral de Universidades) under a predoctoral scholarship (cofunded by the European Social Fund) and it was partially funded by the Agencia Estatal de Investigación (Spain) and the European Regional Development Fund (ERDF) under project MYRADA (TEC2016-75103-C2-2-R). It was also funded by the Xunta de Galicia and the ERDF (Agrupación Estratéxica Consolidada de Galicia accreditation 2016-2019). Furthermore, this work has received funding from the Spanish Agencia Estatal de Investigación under project TERESATEC2017-90093-C3-1-R (AEI/FEDER,UE); and from the Catalan Government (2017 SGR 891 and 2017 SGR 1479).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] LTE; evolved universal terrestrial radio access (E-UTRA); physical layer procedures. ETSI TS 136 213 V 14.2.0 (2017-04) .
- 2[2] IEEE Standard for Information technology– Telecommunications and information exchange between systems. Local and metropolitan area networks– Specific requirements–Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications–Amendment 4: Enhancements for Very High Throughput for Operation in Bands below 6 G Hz. IEEE Std 802.11ac-2013 , pages 1–425, Dec 2013.
- 3[3] Satellite component of UMTS (S-UMTS); family SL satellite radio interface. ETSI TS 102 744 , Oct. 2015.
- 4[4] Krishna Sayana and Jeff Zhuang. Link performance abstraction based on mean mutual information per bit (MMIB) of the LLR channel, 2007.
- 5[5] E. Basar. Index modulation techniques for 5G wireless networks. IEEE Communications Magazine , 54(7):168–175, July 2016.
- 6[6] R. Mesleh, H. Haas, C. W. Ahn, and S. Yun. Spatial modulation - a new low complexity spectral efficiency enhancing technique. In 2006 First International Conference on Communications and Networking in China , pages 1–5, Oct 2006.
- 7[7] P. Yang, M. Di Renzo, Y. Xiao, S. Li, and L. Hanzo. Design Guidelines for Spatial Modulation. IEEE Communications Surveys Tutorials , 17(1):6–26, Firstquarter 2015.
- 8[8] P. Henarejos and A. I. Perez-Neira. Dual Polarized Modulation and Reception for Next Generation Mobile Satellite Communications. IEEE Transactions on Communications , 63(10):3803–3812, Oct 2015.