All Optical Neural Network with Nonlinear Activation Functions
Ying Zuo, Bohan Li, Yujun Zhao, Yue Jiang, You-Chiuan Chen, Peng Chen,, Gyu-Boong Jo, Junwei Liu, Shengwang Du

TL;DR
This paper introduces a fully optical neural network that uses spatial light modulators, Fourier lenses, and atomic nonlinearities to perform machine learning tasks at the speed of light with scalable error properties.
Contribution
It presents the first demonstration of an all-optical neural network with nonlinear activation functions using electromagnetically induced transparency in laser-cooled atoms.
Findings
Successfully classified phases of a statistical Ising model.
Demonstrated scalability with maintained error levels.
Achieved intrinsic parallel computation at the speed of light.
Abstract
Artificial neural networks (ANNs) have now been widely used for industry applications and also played more important roles in fundamental researches. Although most ANN hardware systems are electronically based, optical implementation is particularly attractive because of its intrinsic parallelism and low energy consumption. Here, we propose and demonstrate fully-functioned all optical neural networks (AONNs), in which linear operations are programmed by spatial light modulators and Fourier lenses, and optical nonlinear activation functions are realized with electromagnetically induced transparency in laser-cooled atoms. Moreover, all the errors from different optical neurons here are independent, thus the AONN could scale up to a larger system size with final error still maintaining in a similar level of a single neuron. We confirm its capability and feasibility in machine learning by…
Click any figure to enlarge with its caption.
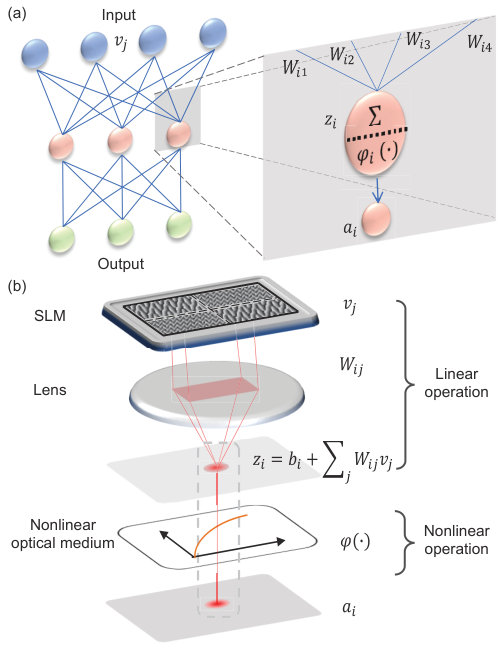 Figure 1
Figure 1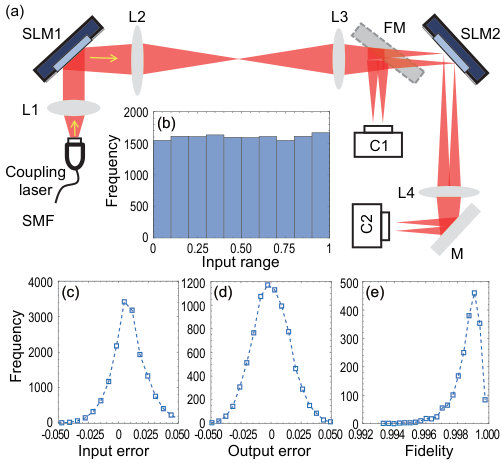 Figure 2
Figure 2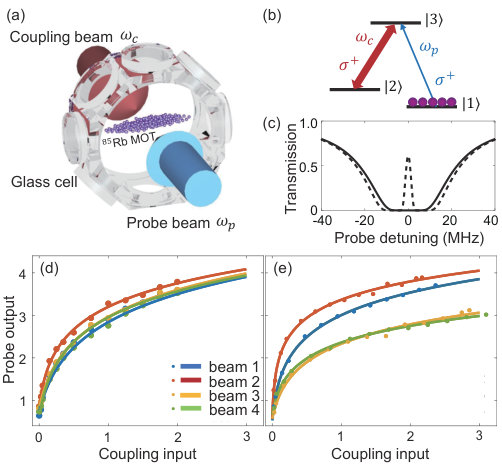 Figure 3
Figure 3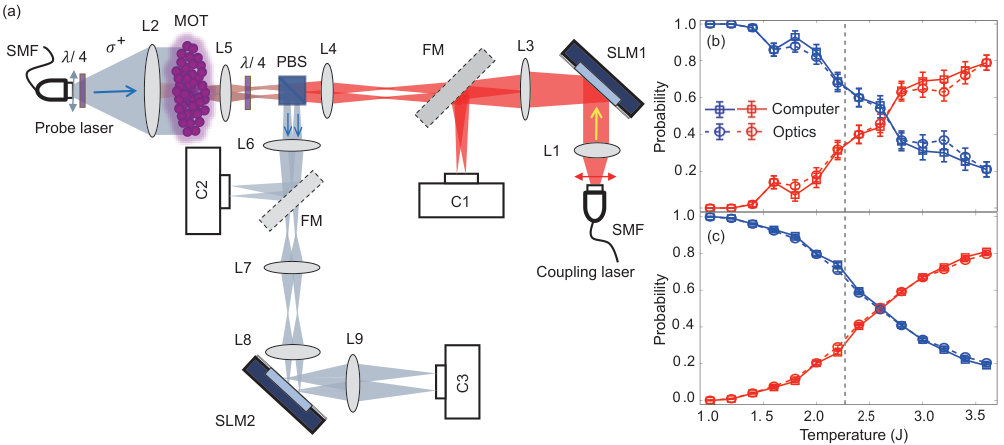 Figure 4
Figure 4Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
††thanks: These authors contributed equally to this work.††thanks: These authors contributed equally to this work.††thanks: These authors contributed equally to this work.
All Optical Neural Network with Nonlinear Activation Functions
Ying Zuo
Department of Physics, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong, China
Bohan Li
Department of Physics, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong, China
Yujun Zhao
Department of Physics, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong, China
Yue Jiang
Department of Physics, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong, China
You-Chiuan Chen
Department of Physics, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong, China
Peng Chen
Department of Physics, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong, China
Gyu-Boong Jo
Department of Physics, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong, China
Junwei Liu
Department of Physics, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong, China
Shengwang Du
Department of Physics, The Hong Kong University of Science and Technology, Clear Water Bay, Kowloon, Hong Kong, China
Abstract
Abstract: Artificial neural networks (ANNs) have now been widely used for industry applications and also played more important roles in fundamental researches. Although most ANN hardware systems are electronically based, optical implementation is particularly attractive because of its intrinsic parallelism and low energy consumption. Here, we propose and demonstrate fully-functioned all optical neural networks (AONNs), in which linear operations are programmed by spatial light modulators and Fourier lenses, and optical nonlinear activation functions are realized with electromagnetically induced transparency in laser-cooled atoms. Moreover, all the errors from different optical neurons here are independent, thus the AONN could scale up to a larger system size with final error still maintaining in a similar level of a single neuron. We confirm its capability and feasibility in machine learning by successfully classifying the order and disorder phases of a typical statistic Ising model. The demonstrated AONN scheme can be used to construct various ANNs of different architectures with the intrinsic parallel computation at the speed of light.
Machine learning techniques, especially artificial neural networks (ANNs), have seen significant growth in the past decades and been demonstrated to be powerful or even surpass the human intelligence in various fields like image recognition, medical diagnosis and machine translation Maren et al. (2014); Jordan and Mitchell (2015). ANNs also show great potential in scientific researches Biamonte et al. (2017); Butler et al. (2018); Carleo et al. (2019); Sarma et al. (2019), especially in discovering new materials Raccuglia et al. (2016), classifying phases of matter Carrasquilla and Melko (2017); Van Nieuwenburg et al. (2017), representing variational wave functions Carleo and Troyer (2017), accelerating Monte Carlo simulations Liu et al. (2017a); Huang and Wang (2017), etc. They may be used to solve some problems which are intractable in conventional appraches Deng et al. (2017a); Liu et al. (2017b); Zhang and Kim (2017); Wang and Zhai (2017); Deng et al. (2017b); Peurifoy et al. (2018); Torlai et al. (2018); You et al. (2018). The magic power of an ANN comes from the extensive interconnections among a large amount of neurons as those in a human brain, while such a large amount of neurons and interconnections require huge computational resources (time and energy) when they are implemented with digital computers Maren et al. (2014).
Unlike electrons in a digit computer, photons as non-interacting bosons could be naturally used to realize multiple interconnections and simultaneous parallel calculations at the speed of light Abu-mostafa and Psaltis (1987); Psaltis et al. (1988); Caulfield et al. (1989); Lu et al. (1990); Appeltant et al. (2011); Larger et al. (2012); Duport et al. (2012). The key ingredients of an ANN are the artificial neurons, which perform both linear and nonlinear transformations for the input signals. In most hybrid optical neural networks (ONNs), optics is mainly used for linear operations and the nonlinear functions are usually implemented electronically Jutamulia and Yu (1996); Paquot et al. (2012); Woods and Naughton (2012); Hughes et al. (2018). Recently ONNs basing on nanophotonic circuits Shen et al. (2017) and light-wave linear diffraction and interference Lin et al. (2018) have been demonstrated for efficient machine learning, but the nonlinear optical activation functions are still in absence for deep networks Bueno et al. (2018); Hughes et al. (2018). Although there have been proposals for implementing nonlinear optical activation functions George et al. (2018); Miscuglio et al. (2018), their experimental realization has become the bottleneck for further extension of ONNs in practical applications.
In this work, we demonstrate all optical neural networks (AONNs) with both tunable linear operations and non-linear activation functions in optics. We use spatial light modulators (SLMs) and Fourier lenses to implement the linear operations. The all optical non-linear activation functions are realized based on electromagnetically induced transparency (EIT) Harris (1997); Fleischhauer et al. (2005) - a light-induced quantum interference effect among atomic transitions. To verify the capability and feasibility of the AONN scheme, we implement several two-layer fully-connected AONNs and use them to successfully classify different phases in a prototypical Ising model.
In a typical ANN as illustrated in Fig. 1(a), neurons are usually arranged in layered structures without connections between different neurons in the same layer, and the output from the neurons in one layer serves as the input for the neurons in next layer. The working principle of an artificial neuron can be abstracted into two steps: 1) receiving multiple weighted input signals from neurons in the preceding layer through a linear operation and adding some linear bias , i.e., , and 2) generating new output signal processing all the input signals through nonlinear activation functions . In our optical configuration, the linear operation is implemented by a SLM and an adjacent Fourier lens, and the nonlinear activitation function is realized with EIT as shown in Fig. 1 (b). Different from the diffractive ONNs where the electric-field neurons are compelx Lin et al. (2018), in our AONN the signals are encoded in light power, thus , and the real matrix elements satisfy .
In the linear operation process, the incident light powers at different areas in the SLM represent the input layer nodes . By imposing multiple phase gratings, the incident light beam can be split into different directions with weight . The SLM is placed at the back focal plane of the lens, which performs Fourier transform and sum all the diffracted beams in the same direction onto a spot at its front focal plane as the linear summation , as shown in Fig. 1(b). The linear bias could be realized similarly. We obtain given matrix elements following the Gerchberg-Saxton iterative feedback algorithm Gerchberg and Saxton (1972); zhen Yang et al. (1994), in which high accuracy () could be achieved in less than 10 iterations(See Fig. S1 in Supplementary Materials (SM) for details). Moreover, it is worth to emphasize that one great advantage of this method is that the error for a given spot does not depend on the total number of spots as long as the resolution of SLM is high enough, which is qualitatively different from the previous implementations Shen et al. (2017); Lin et al. (2018).
Figure 2(a) shows the optical layout for performing the linear operation. Without losing generality, we take an 8-to-4 linear operation as an example. The coupling laser beam output from a single-mode fiber (SMF) is collimated and incident to the first SLM (SLM1), which selectively reflect 8 separate beam spots. These 8 spots are then imaged onto the second SLM (SLM2) as the input through a 4-f optical lens system (L2 and L3). The flip mirror (FM) and the first camera (C1) are used to monitor and measure . The stray coupling light is blocked at the Fourier plane of lens L2. After SLM2, each laser beam is diffracted into 4 beams. The Fourier lens L4 performs a summation operation and the 4 output spots are recorded by the second camera (C2). To characterize the accuracy of the input vectors , we measure error distribution of 2000 random 8-dimension input vectors with elements equally sampled from 0 to 1 [Fig. 2(b)]. As depicted in Fig. 2(c), we obtain very accurate input vectors with a standard deviation of only 0.017. The mean of the error is slightly off zero, due to a possible laser power drift during the measurement.
We next confirm that an arbitrary positively-valued matrix () can be realized by programming SLM2. We take two types of linear operations as examples. The first is the Hankel matrix , a typical symmetric matrix in mathematics whose elements satisfy (See Eqn. S1 in SM). Because we cannot directly measure the matrix elements, we take the error distribution of output vectors using the 2000 random input vectors described previously. As shown in Fig. 2(d), the errors () are very small with a standard deviation of 0.014, where and are the exact and measured vectors respectively. Impressively, they are almost the same as the errors of input vectors even though much more operations are involved here. This result further indicates that the error could maintain in a small level even for multiple linear operations, which is crucial for large scale AONNs. For matrix production, the directions of output vectors are more useful than the exact value of different elements, the accuracy of which could be captured by the fidelity . As shown in Fig. 2(e), the fidelity distribution is narrower than the error, and the mean value of fidelity is around 99.8% for Hankel matrix. The high fidelity suggests that although there are some uncertainties for single elements, the output vectors are actually insensitive to these fluctuations. We also perform the same measurements for a random matrix and obtain similar results (see Eqn. S2 and Fig. S3 in SM for more details).
We now turn to the EIT nonlinear activation function. We work with laser-cooled 85Rb atoms in a dark-line two-dimensional magneto-optical trap (MOT) Zhang et al. (2012) with a longitudinal length of 1.5 cm and an aspect ratio of 25:1, as shown in Fig. 3(a). The atoms are prepared in the ground state , as shown in the atomic energy level digram in Fig. 3(b). The circularly polarized () coupling laser () beams, which are from the outputs of the linear operation, are on resonance to the atomic transmission and incident to the atomic cloud along its transverse direction. A counter-propagating probe laser beam () is on resonance to . In absence of the coupling beam, the atomic medium is opaque to the resonant probe beam which is maximumly absorbed by the atoms, as shown as the solid curve in the transmission spectrum of Fig. 3(c). While in presence of the coupling beam, the quantum interference between the transition paths leads to an EIT Harris (1997); Fleischhauer et al. (2005) transparency spectral window as shown as the dashed curve in Fig. 3(c), where the on-resonance peak transmission and the bandwidth are controlled by the coupling laser intensity. The on-resonance probe laser beam output can be expressed as
[TABLE]
where and are the input and output probe beam intensity, is the atomic optical depth on the transition, and is the dephasing rate between the states and . For 85Rb atoms, MHz, and the non-zero ground-state dephasing rate can be tuned by the stray background magnetic field. is the coupling field Rabi frequency and its square is proportional to the coupling laser intensity (). As shown in Eq. (1), the probe beam intensity is nonlinearly controlled by the coupling beam intensity. The nonlinear activation function is achieved by taking the coupling intensity as the input and the transmitted probe intensity as the output. In experiment, the input probe beam is collimated and its beam size is large enough to cover the entire coupling beam profile. Moreover, Equation (1) also indicates that the the nonlinear activation function is determined by and whose values are different at different positions of the MOT. Therefore, by placing the counter-propagating coupling-probe beams at different positions of the MOT, we can achieve different nonlinear activation functions for different neurons. Figure 3(d) shows nearly identical nonlinear activation functions are obtained by carefully positioning the four input coupling beams. We can also assign these 4 neurons with different nonlinear activation functions, as shown in Fig. 3(e). Clearly, the errors from different nonlinear active functions are also independent. Together with the same advantages of linear operations realized by SLMs and lenses, the AONN scheme could be expected to scale up to large size with error maintained in a small level.
After the demonstration of linear and nonlinear operations, we are ready to assemble a fully functioned AONN using SLMs, lenses, MOT, the coupling and probe laser beams. Next we will show that we can actually apply such an AONN to classify different phases in condensed matter physics. It has been demonstrated recently that neural networks have great potentials to identify different phases including both symmetry-breaking phases Carrasquilla and Melko (2017); Van Nieuwenburg et al. (2017) and topological phases Carrasquilla and Melko (2017); Zhang and Kim (2017). Here we take the prototypical two-dimension Ising model on square lattice as an example for the demonstration. The Ising model could be written as , where represents localized spin on site , and takes the summation over all the nearest neighbors. It is well known that there will be a continuous phase transition with the critical temperature as . In the following simulations and experiments, the interaction strength is set to be , and we take lattice size with periodic boundary conditions as examples. We found a 2-layer fully-connected neural network (FCNN) could work well by using the experimentally measured nonlinear activation functions in Fig. 3(e). Same as that in a conventional electronic computer, our 2-layer AONN consists of one input layer, one hidden layer and one output layer. Optical signal propagates from one layer to the next layer through optical operation units. At the hidden layer, optical information is processed by optical nonlinear active functions before propagating to the output layer.
The detailed optical implementation of the 2-layer AONN is illustrated in Fig. 4(a). The input layer contains neurons with as the linear system size. For the hidden and output layers, there are 4 and 2 neurons, respectively. In this particular configuration, because the input values are binary (0 or 1), the coupling beam input vector and the first linear operation can be realized by a single SLM, as shown as SLM1 in Fig. 4(a) (See Eqn. S5 in SM for details). The horizontally polarized output coupling beam passes through a polarizing beam splitter (PBS) and is incident to the cold atoms in MOT. The 4 transmitted counter-propagating and vertically polarized probe beams are reflected by the PBS and enters SLM2 for a second linear operation which reduce the 4 inputs to 2 outputs recorded by camera C3. The FMs and cameras C1 and C2 are used for configuring the network parameters.
The 2-layer FCNN is initially trained in computer and later finely tuned in the AONN through supervised learning from the labelled raw configurations generated by Monte Carlo (MC) simulations. By using the configurations generated at lower and high temperatures, the AONN learns to label them as the ordered or disordered. The fraction of ordered or disordered configurations among all the samples can be regarded as the probability being in order or disorder states. Then the crossing temperature with both probabilities at could be taken as the phase transition point. Thus, after machine learning, the 2-layer AONN is applied to identify different phases from configurations sampled by MC simulation at intermediate temperature and find the critical phase transition temperature (See Supplementary training of two-layer AONNs for details).
Figures 4(b) and (c) plot the mean probability of configuration sets generated at different temperatures for inputs. In general, the experimental results can well reproduce the whole phase diagram even though we only train the AONN at the temperatures far away from the critical temperature. The experimental phase transition temperature is close to the analytical thermodynamical limit represented by the vertical dash line as the number of sites goes to infinite. It suggests that the AONN successfully capture the essential features, which distinguish the order and disorder phases. To clearly show the performance of our AONN, we first intentionally did the experiments by using only 100 configurations and the results are shown in Fig. 4(b). In the sense of phase classification, the results are not very good. It is reasonable since we only use very few configurations in a very large configure space (100 out of ). However, the results from our AONN and the computer FCNN for the same configurations are nearly identical for all the temperatures, which clearly shows that our AONN has the same accuracy as the well trained computer-based NN. To further demonstrate the capability of our AONN, we then did the experiments with 4000 configurations. As expected, the phase transition curves become smoother because the random errors from statistical fluctuations are strongly reduced, and the optical results are almostly the same as the computer data as shown in Fig. 4(c). All these results confirm that our implementation of AONN is successful and indeed capable to classify different phases for the Ising model.
In summary, we demonstrate an AONN scheme with both tunable linear operations and nonlinear activation functions. The linear interconnections are realized using SLMs and optical lenses. The EIT optical nonlinear activation functions are based on quantum interference. For demonstration, we constructed a 2-layer FCNN for classifying the phases of a prototypical Ising model. While in this work, we focus mainly on the feasibility of the linear operations and nonlinear activation functions, which are the key ingredients of an ANN, the AONN is scalable to a larger system size with more SLMs and EIT nonlinear media, with a cost of longer learning time in finely tuning the network parameters. The reasons are two-fold: (1) As the magic power of ANNs comes from the extensive interconnections between a large mount of neurons, ANNs are error-tolerant and robust against small local random errors, which means even the local parameters are not precise we can still get very good results as long as the number of neurons is large enough just as human brains. For most of problems, more neurons in ANNs usually give better performance; (2) As clearly demonstrated in our experiments, the final error of our AONN is insensitive to the total number of neurons and the error could maintain in a similar level as a single neuron even for large scale AONNs. Such a big advantage inherits from the fact that all the linear and nonlinear active functions in our AONNs are independent and the errors from different optical neurons will not accumulate but may cancel with each other. Implementing a large scale AONN requires more engineering resources and we leave it for future work.
This work was supported by the Hong Kong Research Grants Council (Projects Nos. C6005-17G and ECS26302118). B.L. and Y.C.C. acknowledge the support from the Undergraduate Research Opportunities Program at the Hong Kong University of Science and Technology.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Maren et al. (2014) A. J. Maren, C. T. Harston, and R. M. Pap, Handbook of neural computing applications (Academic Press, 2014).
- 2Jordan and Mitchell (2015) M. I. Jordan and T. M. Mitchell, Science 349 , 255 (2015).
- 3Biamonte et al. (2017) J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, Nature 549 , 195 (2017).
- 4Butler et al. (2018) K. T. Butler, D. W. Davies, H. Cartwright, O. Isayev, and A. Walsh, Nature 559 , 547 (2018).
- 5Carleo et al. (2019) G. Carleo, C. Ignacio, C. Kyle, D. Laurent, S. Maria, T. Naftali, V.-M. Leslie, and Z. Lenka, ar Xiv:1903.10563 (2019).
- 6Sarma et al. (2019) S. D. Sarma, D.-L. Deng, and L.-M. Duan, Physics Today 72 , 48 (2019).
- 7Raccuglia et al. (2016) P. Raccuglia, K. C. Elbert, P. D. Adler, C. Falk, M. B. Wenny, A. Mollo, M. Zeller, S. A. Friedler, J. Schrier, and A. J. Norquist, Nature 533 , 73 (2016).
- 8Carrasquilla and Melko (2017) J. Carrasquilla and R. G. Melko, Nature Physics 13 , 431 (2017).