TL;DR
Mercator is a novel embedding method that accurately maps complex networks into hyperbolic space by combining machine learning and maximum likelihood, revealing underlying geometric and degree distribution properties.
Contribution
Introduces Mercator, a new hyperbolic embedding algorithm that infers node positions, hidden degrees, and model parameters using a hybrid machine learning and likelihood approach.
Findings
Outperforms existing embedding algorithms in accuracy.
Effectively infers hidden degrees and global parameters.
Handles networks with arbitrary degree distributions.
Abstract
We introduce Mercator, a reliable embedding method to map real complex networks into their hyperbolic latent geometry. The method assumes that the structure of networks is well described by the PopularitySimilarity static geometric network model, which can accommodate arbitrary degree distributions and reproduces many pivotal properties of real networks, including self-similarity patterns. The algorithm mixes machine learning and maximum likelihood approaches to infer the coordinates of the nodes in the underlying hyperbolic disk with the best matching between the observed network topology and the geometric model. In its fast mode, Mercator uses a model-adjusted machine learning technique performing dimensional reduction to produce a fast and accurate map, whose quality already outperform other embedding algorithms in the literature. In the refined…
Click any figure to enlarge with its caption.
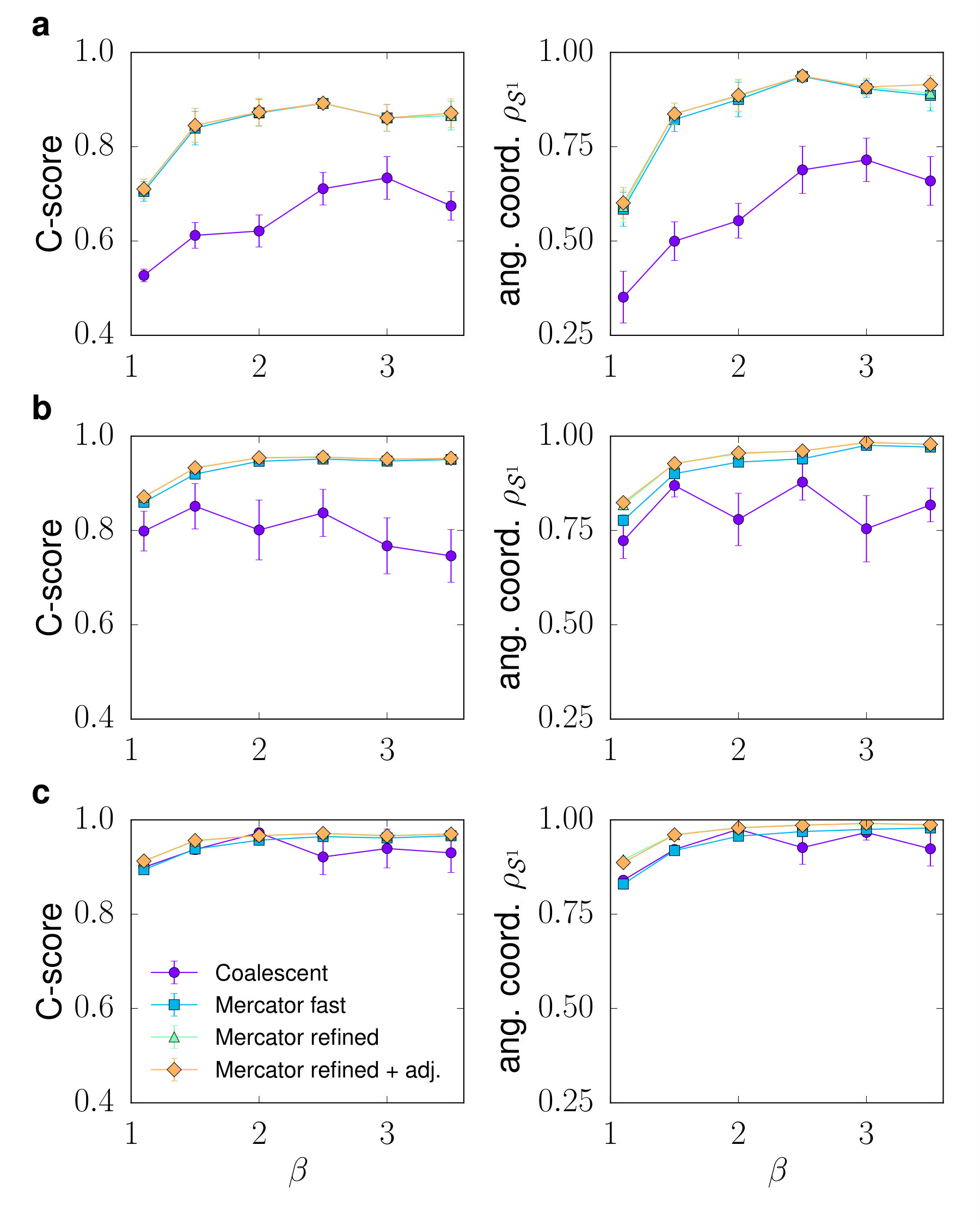 Figure 1
Figure 1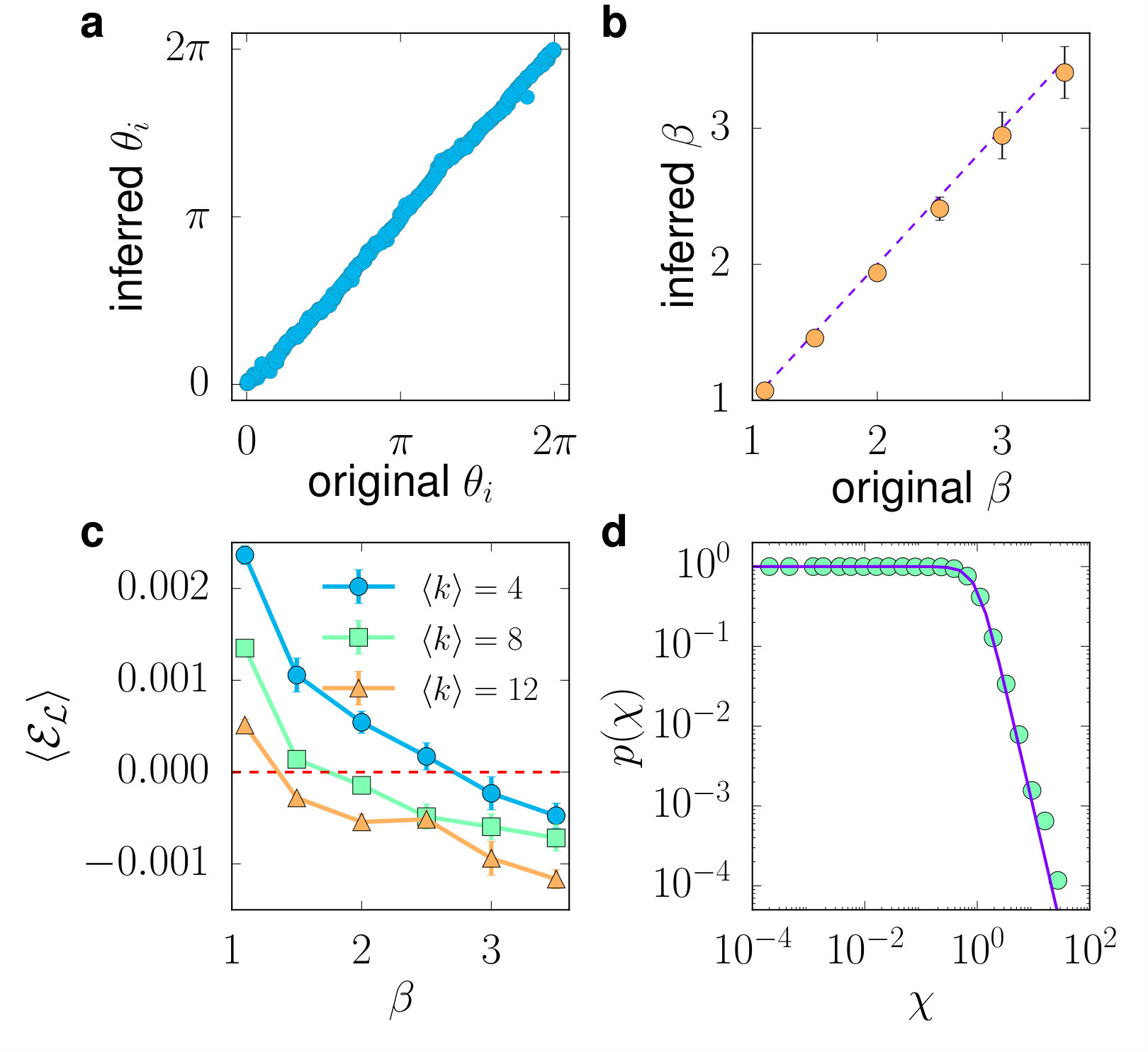 Figure 2
Figure 2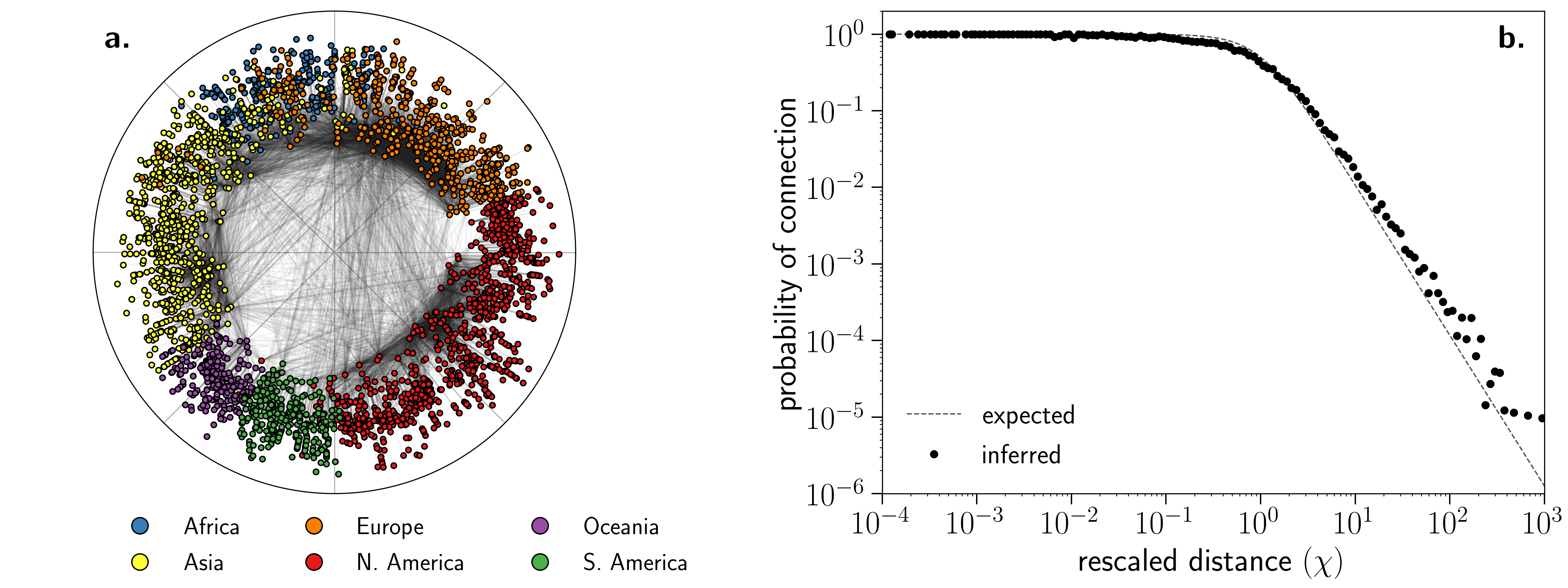 Figure 3
Figure 3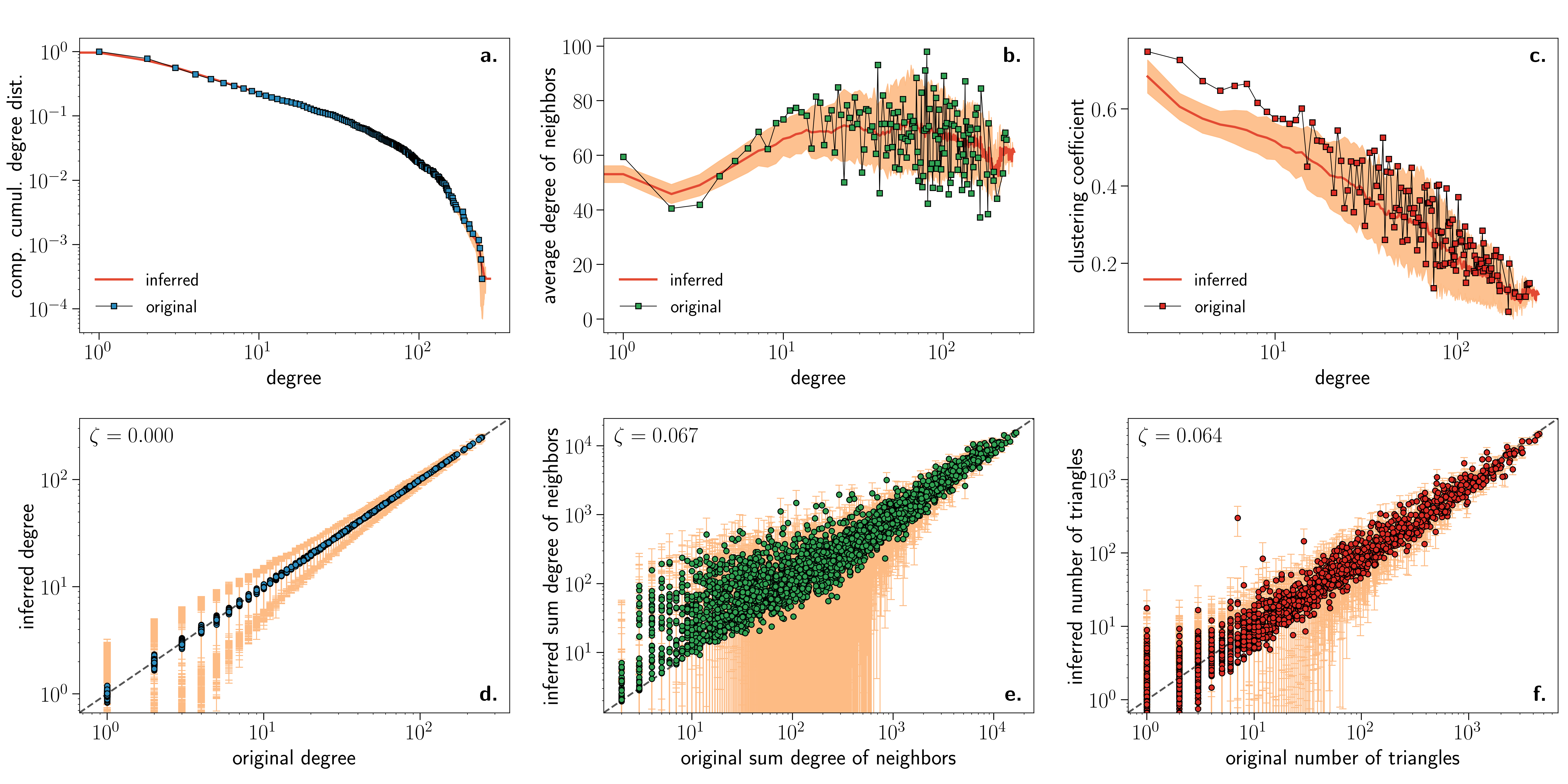 Figure 4
Figure 4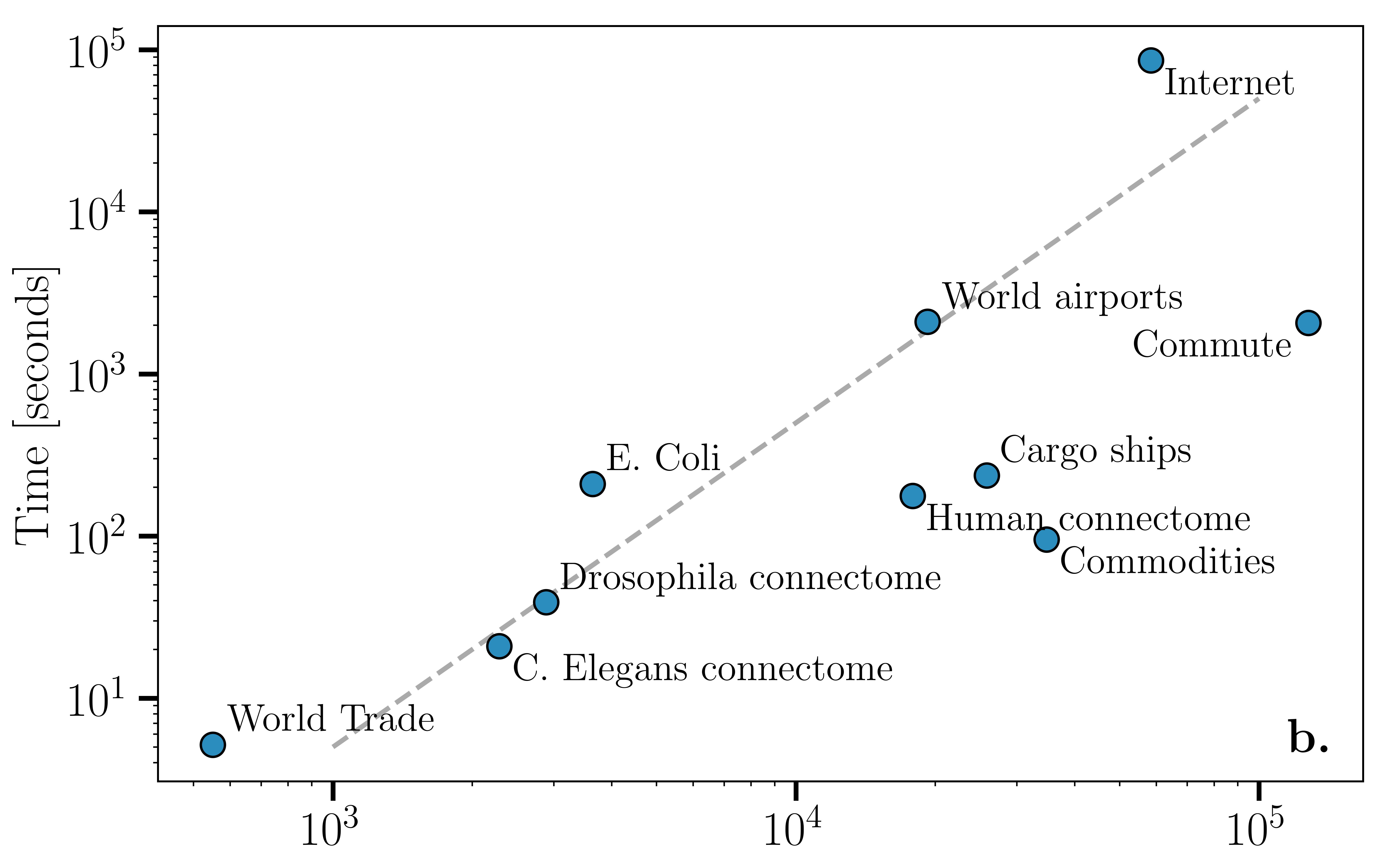 Figure 5
Figure 5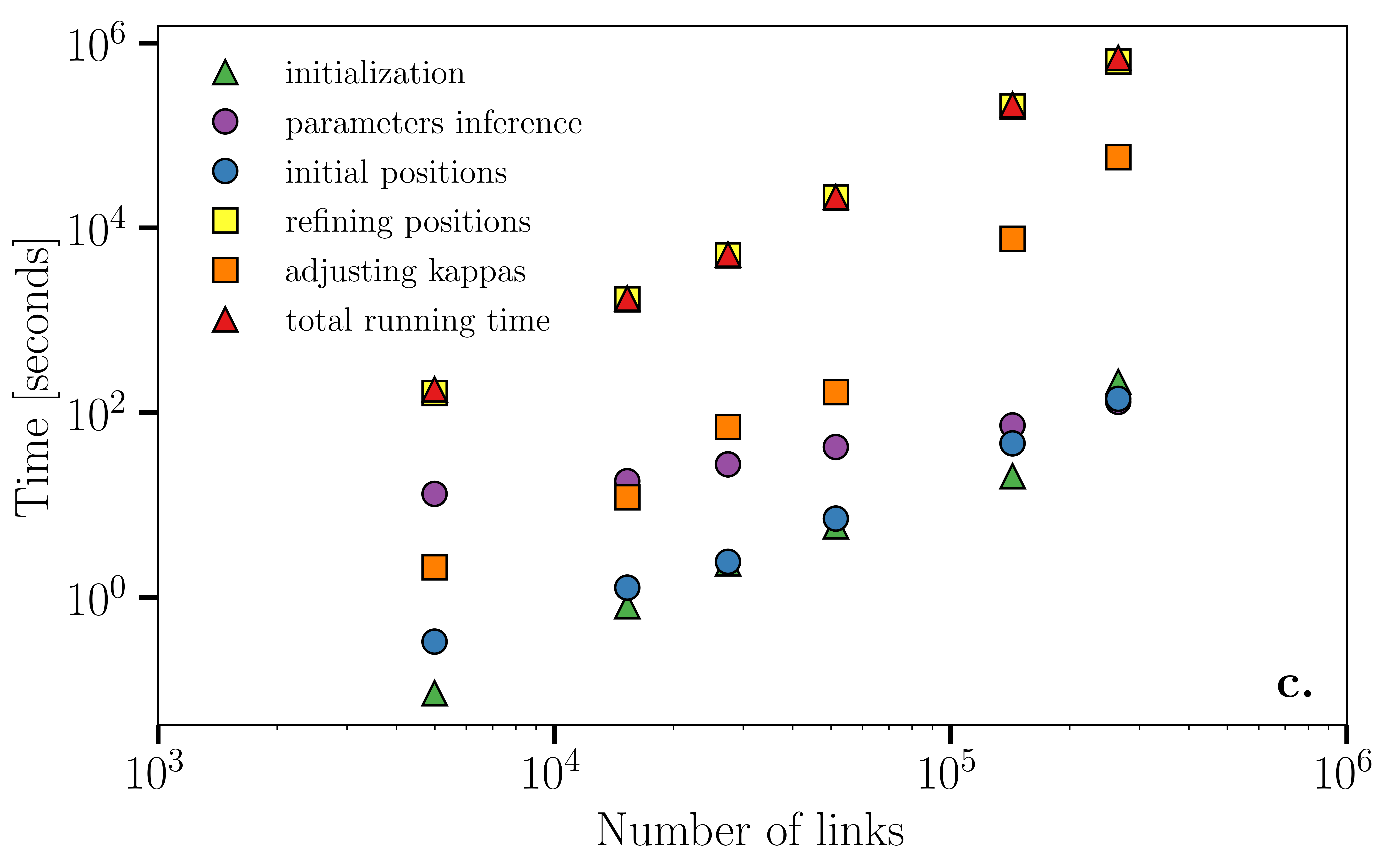 Figure 6
Figure 6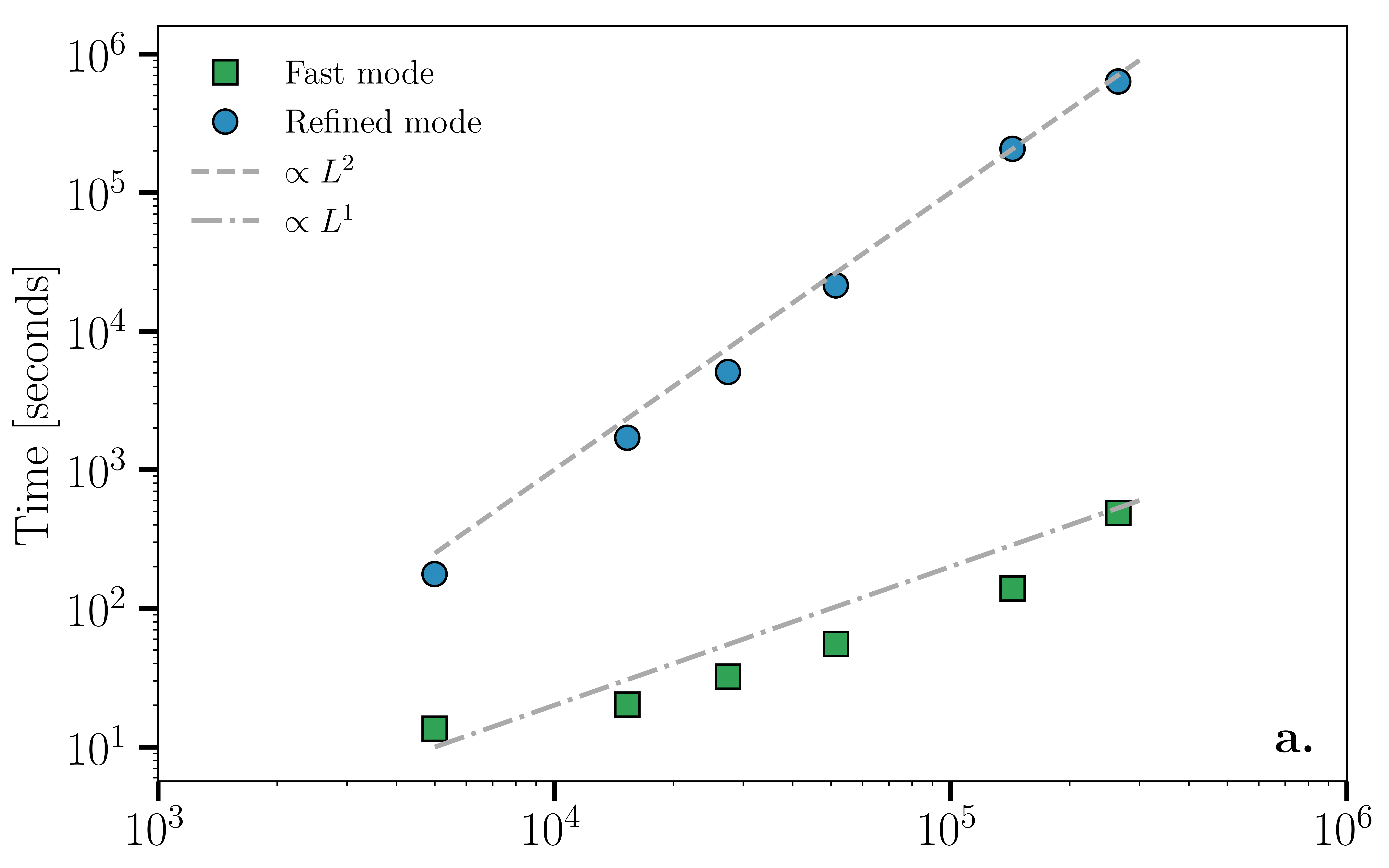 Figure 7
Figure 7Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
††thanks: Both authors contributed equally to this work††thanks: Both authors contributed equally to this work††thanks: Corresponding author: [email protected]
Mercator: uncovering faithful hyperbolic embeddings of complex networks
Guillermo García-Pérez
QTF Centre of Excellence, Turku Centre for Quantum Physics, Department of Physics and Astronomy, University of Turku, FI-20014 Turun Yliopisto, Finland
Complex Systems Research Group, Department of Mathematics and Statistics, University of Turku, FI-20014 Turun Yliopisto, Finland
Antoine Allard
Département de physique, de génie physique et d’optique, Université Laval, Québec (Québec), Canada G1V 0A6
Centre de modélisation mathématique, Université Laval, Québec (Québec), Canada G1V 0A6
M. Ángeles Serrano
Departament de Física de la Matèria Condensada, Universitat de Barcelona, Martí i Franquès 1, E-08028 Barcelona, Spain
Universitat de Barcelona Institute of Complex Systems (UBICS), Universitat de Barcelona, Barcelona, Spain
Institució Catalana de Recerca i Estudis Avançats (ICREA), Passeig Lluís Companys 23, E-08010 Barcelona, Spain
Marián Boguñá
Departament de Física de la Matèria Condensada, Universitat de Barcelona, Martí i Franquès 1, E-08028 Barcelona, Spain
Universitat de Barcelona Institute of Complex Systems (UBICS), Universitat de Barcelona, Barcelona, Spain
Abstract
We introduce Mercator, a reliable embedding method to map real complex networks into their hyperbolic latent geometry. The method assumes that the structure of networks is well described by the PopularitySimilarity static geometric network model, which can accommodate arbitrary degree distributions and reproduces many pivotal properties of real networks, including self-similarity patterns. The algorithm mixes machine learning and maximum likelihood approaches to infer the coordinates of the nodes in the underlying hyperbolic disk with the best matching between the observed network topology and the geometric model. In its fast mode, Mercator uses a model-adjusted machine learning technique performing dimensional reduction to produce a fast and accurate map, whose quality already outperform other embedding algorithms in the literature. In the refined Mercator mode, the fast-mode embedding result is taken as an initial condition in a Maximum Likelihood estimation, which significantly improves the quality of the final embedding. Apart from its accuracy as an embedding tool, Mercator has the clear advantage of systematically inferring not only node orderings, or angular positions, but also the hidden degrees and global model parameters, and has the ability to embed networks with arbitrary degree distributions. Overall, our results suggest that mixing machine learning and maximum likelihood techniques in a model-dependent framework can boost the meaningful mapping of complex networks.
I Introduction
The main hypothesis of network geometry states that the architecture of real complex networks has a geometric origin Serrano et al. (2008); Krioukov et al. (2010); Papadopoulos et al. (2012). The nodes of the complex network can be characterized by their positions in an underlying metric space so that the observable network topology—abstracting their patterns of interactions—is then a reflection of distances in this space. This simple idea led to the development of a very general framework able to explain the most ubiquitous topological properties of real networks Serrano et al. (2008); Krioukov et al. (2010), namely, degree heterogeneity, the small-world property, and high levels of clustering. Network geometry is also able to explain in a very natural way other non-trivial properties, like self-similarity Serrano et al. (2008) and community structure Zuev et al. (2015); García-Pérez et al. (2018); Muscoloni and Cannistraci (2018a), their navigability properties Boguñá et al. (2009); Gulyas et al. (2015); Boguñá et al. (2010), and is the basis for the definition of a renormalization group in complex networks García-Pérez et al. (2018). The geometric approach has also been successfully extended to weighted networks Allard et al. (2017) and multiplexes Kleineberg et al. (2016, 2017).
Beyond being a formal theoretical framework to explain the topology of real networks, network geometry can be used to develop practical applications for real systems, including routing of information in the Internet Boguñá et al. (2010), community detection Boguñá et al. (2010); Serrano et al. (2012); García-Pérez et al. (2016), prediction of missing links Papadopoulos et al. (2012); Wang et al. (2016); Kitsak et al. (2019), a precise definition of hierarchy in networks García-Pérez et al. (2016), and downscaled network replicas García-Pérez et al. (2018), to name a few. However, applications require faithful embeddings of real-world networks into the hidden metric space using only the information contained in their topology. Several algorithms have been proposed to solve this problem, most of which either use maximum likelihood estimation techniques Boguñá et al. (2010); Papadopoulos et al. (2015a, b); Bläsius et al. (2016); Blasius et al. (2018), machine learning Alanis-Lobato et al. (2016a); Muscoloni et al. (2017); Muscoloni and Cannistraci (2018b), or a combination of both Alanis-Lobato et al. (2016b).
Maximum likelihood (ML) techniques assume that the network under study has been produced by a given model —a geometric one— and finds the value of its parameters that maximize the probability for the model to generate the observed topology. This technique requires finding the coordinates of every nodes in the latent geometry that maximize the likelihood function: a task that, in general, is NP-hard and consequently must rely on heuristics to obtain a reasonable approximate solution. Maximum likelihood methods are therefore generally slow, and their accuracy depends strongly on the chosen heuristic as well as on the quality of the underlying theoretical model.
In contrast, machine learning techniques are fast and model independent, so they can be used to find embeddings of large networks. A promising and accurate method is based on Laplacian Eigenmaps (LE) Alanis-Lobato et al. (2016a); Muscoloni et al. (2017), originally designed to find dimensional reductions of sets of points Belkin and Niyogi (2001). The original method requires the definition of Euclidean distances between nodes in , but since no information is available about the “real Euclidean” distances between connected pairs of nodes in networks, the use of heuristic arguments is necessary to estimate these distances Muscoloni et al. (2017). A more fundamental problem with machine learning methods is that the embeddings are performed on Euclidean spaces. However, as shown in Krioukov et al. (2010); Papadopoulos et al. (2012), the geometry of real complex networks is better described by hyperbolic rather than Euclidean geometry, where angular coordinates on a circle are a proxy for the similarity between nodes, and their radial coordinates account for their popularity, which is typically measured by their degrees Serrano et al. (2008). Machine learning methods are only able to infer the angular coordinates corresponding to the similarity sub-space while radial coordinates have to be inferred using some geometric model. Hence, these methods end up being model dependent as well.
Consequently, both types of methods are very sensitive to the model used to describe the network. References Papadopoulos et al. (2015a, b); Alanis-Lobato et al. (2016a); Muscoloni et al. (2017); Muscoloni and Cannistraci (2018b) are based on the PopularitySimilarity Optimization (PSO) model described in Papadopoulos et al. (2012), which uses a simple mechanism to explain the emergence of an effective hyperbolic geometry in growing networks. However, this model can only generate pure power-law degree distributions with , whereas the degree distribution in many real networks shows important deviations from such pure power laws. Moreover, the model does not spontaneously generate the nested hierarchy of self-similar subgraphs with increasing average degree, as observed in real systems Serrano et al. (2008).
In this paper, we introduce Mercator, a ready-to-use C++ code 111The code will be available at https://github.com/networkgeometry/mercator upon publication. that mixes the best of the maximum likelihood and machine learning approaches. The mixing of the two techniques was explored in Ref. Alanis-Lobato et al. (2016b) using the PSO model to maximize the likelihood function. Instead, we use the static version of the same type of PopularitySimilarity geometric models, the model Serrano et al. (2008); Krioukov et al. (2010), that can accommodate arbitrary degree distributions and can reproduce the self-similarity patterns observed in real networks. The first step in Mercator is to apply a LE approach, as in Ref. Muscoloni et al. (2017), but using the model instead of the PSO to infer the weights of the Laplacian matrix. Doing so yields a first (and fast) embedding method that already outperforms the one of Ref. Muscoloni et al. (2017). The resulting embedding uses only information about pairs of connected neighbors, and can be further improved by using it as a starting point in a ML optimization—based again on the model—that uses information from both connected and not-connected pairs of nodes. The final result is the most accurate embedding method currently available in the literature. Yet, the final complexity of the method is for sparse networks with nodes, which makes it competitive for real applications.
II Methodological background
II.1 The model
The model is the simplest among the class of geometric models Serrano et al. (2008). The similarity space is a one dimensional sphere—a circle of radius —where nodes are distributed with a fixed density, set to one without loss of generality, so that 222Notice that in thermodynamic limit the curvature of the circle vanishes and the model is effectively defined on .. Each node is also given a hidden variable proportional to its expected degree. In general, and the angular position can be correlated and distributed according to an arbitrary distribution . In such case, the model is able to generate community structure Zuev et al. (2015); García-Pérez et al. (2018); Muscoloni and Cannistraci (2018a) and can reproduce different degree-degree correlation patterns and clustering spectra.
Once all nodes are assigned a tuple , each pair of nodes is connected with probability
[TABLE]
where is the arc length of the circle between nodes and separated by an angular distance . Parameters and control the average degree and the clustering coefficient, respectively. The model can be defined using any connection probability as long as it is an integrable function with Serrano et al. (2008). The particular functional form that we chose here (the Fermi distribution) is the one that defines maximally random ensembles of geometric graphs that are simultaneously clustered, small-world, and with heterogeneous degree distributions.
If nodes are uniformly distributed over the circle, we have . In this case, the choice guarantees that, in the thermodynamic limit, the expected degree of a node with hidden variable is and the network average degree is . It is therefore possible to associate unambiguously the hidden variable with the node degree. For finite systems, however, the values of the hidden variables must be evaluated numerically. It is also important to notice that the parameter is, in fact, superfluous since it can be absorbed in the definition of ; would then be proportional, but not exactly equal, to the expected degree. As a result, the embedding task only requires the estimation of parameters: the hidden variables , , and the parameter .
II.1.1 Hyperbolic representation. The model
Quite remarkably, the model can be expressed as a purely geometric model in the hyperbolic plane. By mapping the expected degree of each node to a radial coordinate as
[TABLE]
with , the connection probability becomes
[TABLE]
where
[TABLE]
is a good approximation of the hyperbolic distance between two nodes separated by an angular distance and with radial coordinates and 333This approximation is reasonably accurate for pairs of nodes separated by , whose fraction converges to one in the thermodynamic limit.. The connection probability thus becomes a function of the hyperbolic distance alone, which turns the model into a purely geometric one and has important consequences for the global connectivity of the network. For instance, topological shortest paths closely follow geodesic curves in the hyperbolic plane, and can therefore be used to efficiently navigate the network Boguñá et al. (2009, 2010). Furthermore, when the distribution of expected degrees follows a power law of exponent , the radial distribution in the hyperbolic plane is
[TABLE]
with and . Nodes are therefore homogeneously distributed in the hyperbolic plane for and are quasi-homogeneously distributed for other values of . In this paper, we use the model for likelihood maximization, and its equivalent version for visualization purposes.
II.2 Embedding techniques
Mercator exploits two different embedding techniques, based on ML and on LE, which are briefly outlined in this section.
II.2.1 Model-corrected Laplacian Eigenmaps
Laplacian Eigenmaps was originally designed as a method for dimensional reduction. Given a set of points with the Euclidean metric, LE finds a mapping of these points with such that the loss function
[TABLE]
is minimized. Here, is the euclidian distance between points and in and is a decreasing function of the distance between the same pair of points in the original Euclidean space . Intuitively, placing pairs of points far apart in if they were originally close in increases the loss function Eq. (6). Minimizing should therefore yield a faithful dimensional reduction of the data.
In the case of network embedding, our aim is to find coordinates of nodes in of a network whose structure can be modeled by the model. To do so, the weight function is taken to be proportional to the adjacency matrix so that it is only different from zero if nodes and are connected. Yet, the weight associated to connected pairs of nodes is still assumed to be a decreasing function of their original Euclidean distance, which must somehow be estimated from the network structure. To do so, we leverage the model and estimate the expected distance in (the chord length) of a pair of nodes based on their degrees. The set of coordinates that minimize the loss function is the solution of a generalized eigenvalue problem with the Laplacian matrix, for which very fast algorithms exist if the network is sparse Lehoucq and Sorensen (1996).
II.2.2 Maximum likelihood estimation
Given a real network with adjacency matrix , maximum likelihood estimation finds the values of , , that provide a good match between the model and the observed network. The posterior probability, or likelihood, that a network specified by its adjacency matrix is generated by the model is
[TABLE]
where the function is the joint probability that the model generates simultaneously the set of hidden variables and the adjacency matrix . Using Bayes rule, we then compute the likelihood that the hidden variables take particular values conditioned on the observed adjacency matrix
[TABLE]
where
[TABLE]
is the prior probability density function of the hidden variables,
[TABLE]
is the probability that the model generates the adjacency matrix conditioned on the hidden variables , and is the connection probability given by Eq. (1).
If we have information about the prior distribution of hidden variables, , Bayesian estimators can be obtained by maximizing the likelihood in Eq. (8). However, in most cases, prior information is not available. We then use an improper prior distribution , and obtain the maximum likelihood estimator as the set of values that maximize Eq. (10) or, equivalently, its logarithm
[TABLE]
The maximization with respect to the expected degrees can be performed semi-analytically. The derivative of Eq. (11) with respect to the expected degree of node is
[TABLE]
where the second term on the right hand side is the expected degree of node , and the first term is its actual degree . The value that maximizes the likelihood is therefore the solution of
[TABLE]
The term on the right hand side can be evaluated in the model assuming a homogeneous angular distribution of nodes on the circle. We use this method to provide estimates of the expected degrees that are then used to maximize the likelihood function with respect to the angular coordinates, as explained in Sec. A.6.
III Mercator at a glance
We have now all the theoretical background to briefly describe Mercator; the full details are given at Secs. A.1–A.7. Given a network with adjacency matrix , we first measure its average degree , average clustering coefficient , and all individual nodes’ degrees . Second, we estimate hidden degrees and parameters and . Third, we estimate the angular ordering of nodes using the model-corrected LE, and adjust the angles according to the expected angular separation between consecutive nodes given by the model. This yields Mercator’s fast mode version, which produces a first embedding. Fourth, the angular coordinates are refined using ML. Finally, hidden degrees are readjusted given the newly inferred angular positions. All the steps together conform Mercator refined mode. More precisely, Mercator executes the following steps.
III.1 Fast mode
Propose an approximate value for and compute . 2. 2.
Using Eqs. (1) and (13), adjust the hidden variables such that the expected degree of each node in the model matches the observed degree in the original network. This step assumes that nodes are homogeneously distributed and uses the values of and from step 1. The initial guess is (the degree of node in the original network). 3. 3.
Using results from steps 1 and 2, evaluate the theoretical value of the average clustering coefficient of the network in the model. If this value differs from the one measured for the original network, adjust the value of and return to step 1. Otherwise, proceed to step 4. 4. 4.
For every connected pair of nodes with hidden variables and and original degrees , estimate their expected chord length in as , where is the expected angular separation between connected nodes and in the model. 5. 5.
Construct a weighted Laplacian matrix , where is the diagonal matrix with entries and weights are given by with being the variance of . Then solve the generalized eigenvalue problem
[TABLE]
We note and the first two eigenvectors with the smallest nonzero eigenvalues. 6. 6.
Assign an angular position to each node as . 7. 7.
Make a sorted list of the nodes based on their angular position . Nodes of degree 1 that were excluded at step 4 are now reinserted in the sorted list randomly before or after their unique neighbor. Note that the angular coordinates computed at step 6 are only used to determine the order in which nodes are located angularly. Their precise angular coordinates are evaluated at the next step. 8. 8.
For each pair of consecutive nodes in the list, evaluate its expected angular separation using the model conditioned on whether the two nodes are connected or not, their hidden variables and , and the fact that they are consecutive. Finally, all gaps are normalized to sum up to . This produces a set of angular coordinates for each node .
These 8 steps summarize a fast and accurate embedding procedure that, as discussed in Sec. IV, already outperforms current state-of-the-art methods. The next section explains how its accuracy can be further increased.
III.2 Refined mode
The embedding can be significantly improved with ML techniques using the embedding obtained with the fast mode of Mercator as initial conditions. This is due to the fact that ML uses the information contained both in the presence and absence of links in the network, whereas LE only relies on the information conveyed by the presence of links. The major drawback of ML is the complex configuration space that needs to be explored to find the optimal embedding. However, if the starting point of the exploration is good enough, the maximization of the likelihood function is easy and efficient. Thus, starting from the embedding obtained with the fast mode, we proceed as follows.
Extract the onion decomposition of the network Hébert-Dufresne et al. (2016) and sort nodes accordingly, starting with the node in the deepest layer 444The onion decomposition is a generalization of the -core decomposition that provides the internal organization of each -shell. It therefore offers a more precise way to order nodes than based on their position in the -core decomposition alone.. Doing so allows the likelihood optimization phase to begin with the most central nodes (based on mesoscale topological information) thereby greatly facilitating the finding of an acceptable local maximum in the configuration space. 2. 10.
For each node in the sorted list, find the average angular coordinate of its neighbors. 3. 11.
Sample angular positions around this average value using a normal distribution whose standard deviation is set to half of the angular distance between this average value and the farthest neighbor. 4. 12.
Compute the local log-likelihood of the sampled angular positions
[TABLE]
where is computed with Eq. (1), and set the new angular position of the node to the sampled angle with highest log-likelihood. 5. 13.
Once the position of every node has been optimized once, repeat step 2 to find a better estimate of the hidden variables using the newly inferred angular positions. This last step is optional, although it generally leads to substantial improvements of the final embedding.
IV Validation in synthetic networks
We test Mercator using synthetic networks of different average degrees and clustering coefficients generated with the model, and consider several quality measures to check the accuracy of the embeddings. We first focus on its capability to recover the angular coordinates. Figure 1 shows the C-score Muscoloni et al. (2017), defined as the fraction of pairs of nodes that are correctly ordered in the circle, as well as the Pearson correlation coefficient between the real and inferred angular coordinates 555Notice that the model is invariant with respect to global rotations and inversions of the angular coordinates. Therefore, we consider the maximal Pearson correlation coefficient over all such possible transformations. The results of the two versions of Mercator are compared with those obtained using the Coalescent embedding presented in Ref. Muscoloni et al. (2017), which was reported to give the best node orderings with respect to other embedding algorithms in the literature. Notice that Mercator is able to outperform the results even in its fast mode, especially for networks with a low average degree. As an example, Fig. 2a depicts the inferred angular coordinates versus the real ones for one of the networks considered.
Mercator also has the clear advantage of systematically inferring the hidden degrees and global model parameters. In Fig. 2b we show that the inference of is very precise for all the synthetic networks considered in this section. This has important implications for applications that require finding a good congruency between the network and the model. Indeed, Mercator is able to find embeddings with very high likelihoods. To quantify this, we consider the relative likelihood difference , where is the geometric average of the likelihood over all pairs of nodes. Hence, a positive (negative) indicates that the inferred embedding has a higher (lower) likelihood than the real coordinates and model parameters. Strikingly, for low values of , the embeddings found by Mercator have (Fig. 2c). Finally, Fig. 2d presents an example of the empirical connection probability (fraction of connected pairs as a function of the rescaled distance ), which is extremely congruent with Eq. (1). Put together, these results reveal that Mercator is not just the most accurate algorithm in terms of the reconstruction of the angular coordinates of synthetic networks—arguably the most difficult aspect of the embedding problem—, but it also determines correctly all other model parameters, including hidden degrees.
V Embedding of real networks
Another strength of Mercator is its ability to embed networks with arbitrary degree distributions. As an illustration, we embedded several real-world complex networks from different domains whose degree distributions include clean scale-free, heavy-tailed, and arbitrary distributions. More specifically, the networks under study are: the world airport network 666Downloaded from https://openflights.org/data.html., the neural network of the visual cortex of the Drosophila Melanogaster at the neuron level Takemura et al. (2013), the neural network of the C. Elegans worm Varshney et al. (2011), a human connectome Avena-Koenigsberger et al. (2018); Hagmann et al. (2008), the metabolic network of the bacterium E. Coli Orth et al. (2011); Serrano et al. (2012), the world trade web García-Pérez et al. (2016), a US commute network Grady et al. (2012), a cargo ships network Kaluza et al. (2010), a US commodities network Grady et al. (2012), and the Internet at the Autonomous Systems level Boguñá et al. (2010).
One particularly telling example is the airports network whose truncated power-law degree distribution with exponent cannot be easily embedded with methods based on the PSO model. In the case of real networks, we do not have access to the “real” coordinates to compare with those obtained from our embeddings. Yet, in some cases, metadata related to the similarity between nodes is available and can be used to test whether an embedding is meaningful or, instead, is an artifact of the algorithm. In the case of the airports network, geography is such metadata. Figure 3a shows the hyperbolic embedding obtained by Mercator in the slow mode with nodes colored according to the continent they belong to (separating North and South America). Airports belonging to the same continent appear clustered in similar angular positions, thus supporting the relation between the angular space of the embedding and similarity among nodes. Similar analyses were carried out for the Internet at the autonomous systems level Boguñá et al. (2010), metabolic networks Serrano et al. (2012), and the world trade web García-Pérez et al. (2016). A strong correlation between the angular distribution of points and available metadata was found in all cases. In light of these results, we conclude that our geometric embeddings are meaningful and capture attributes that contribute to the similarity among the elements of complex networks.
Beyond this qualitative agreement, we tested the extent to which the embedding inferred by Mercator is accurate enough to reproduce the topology of the airports network. To do so, we first compare the expected connection probability Eq. (1) with the inferred value of against the empirical connection probability, computed using the inferred coordinates of the nodes (). This remarkable agreement confirms that the rescaled distance provides a meaningful measure to characterize the interaction between nodes in the network. Second, we used the set of coordinates as well as the parameters and to generate an ensemble of synthetic networks using Eq. (1). We then compared several topological properties of this ensemble with those measured on the original network. Specifically, the first row of Fig. 4 shows the results for the complementary cumulative degree distribution , the average nearest neighbors’ degree , and the clustering spectrum . The final adjustment of hidden degrees in step #13 of the Mercator algorithm strongly enhances the reproduction of the degree distribution. Notice that the model does not include any mechanism to control degree-degree correlations or the shape of the clustering spectrum (recall that is chosen based on the average clustering coefficient only). Yet, the generated network ensemble reproduces these two quantities with remarkable precision. This is particularly interesting in the case of the average nearest neighbors’ degree, which shows a non-trivial assortative behavior for low degrees both in the real network and the ensemble. This suggests that the non-uniform angular distribution of nodes inferred by Mercator (and so the network geometric properties) is partly responsible for the observed degree-degree correlations in real complex networks.
The ensemble of synthetic networks generated from the estimated geometric parameters of the airports network performs also very well at reproducing topological properties of individual nodes. The second row of Fig. 4 shows scattered plots of the degree of a given node, the sum of degrees of its neighbors, and number of triangles attached to it in the generated network ensemble versus the same quantities measured on the original network. For each node, we also compute the confidence interval, and shows the fraction of nodes whose original property (degree, sum of neighbors’ degree, number of triangles) lies outside this interval. Results show that the fraction of points outside this interval is around , which is consistent with the (or ) confidence interval. These results, supported by those presented in the Supplementary Information, clearly illustrate the accuracy of the embeddings provided by Mercator. To the best of our knowledge, such accuracy cannot be obtained with other existing embedding methods.
VI Computational complexity
We now support our claim that the computational complexity of Mercator scales as for sparse networks composed of nodes (and links). Figure 5a and 5b show the running time in seconds in function of the number of links () for both synthetic and real networks. In both cases, we find that Mercator’s refined mode does indeed roughly scale as although it is clear that other topological properties influence the final total running time. With respect to the fast mode, we find that the computational complexity is roughly linear within the range in the number of links that was considered. Finally, Fig. 5c breaks down the running time into the time spent in each of the Mercator major steps, and doing so shows how most of the running time is spent during the ML step.
VII Conclusions
In this work, we introduce and deliver the full code of Mercator, the most accurate method to embed complex networks into their latent metric spaces. We showed that the quality of the embeddings can be significantly improved by a proper combination of machine learning techniques and powerful statistical methods. Thanks to this combination, Mercator is able to overcome some of the drawbacks of other techniques which, for instance, require perfect power laws in the whole domain of degrees, a condition that is not met by many real networks. Our results also indicate that the obtained embeddings are able to recover ground truth information not contained in the network topology. We expect Mercator to become a standard tool within the toolbox of network scientists and anybody interested in retrieving information from big data systems admitting a network representation.
Acknowledgements.
We acknowledge support from the project Mapping Big Data Systems: embedding large complex networks in low-dimensional hidden metric spaces – Ayudas Fundación BBVA a Equipos de Investigación Científica 2017; James S. McDonnell Foundation Scholar Award in Complex Systems; the ICREA Academia prize, funded by the Generalitat de Catalunya; Ministerio de Economía y Competitividad of Spain, project no. FIS2016-76830-C2-2-P (AEI/FEDER, UE). GGP acknowledges financial support from the Academy of Finland via the Centre of Excellence program (Project no. 312058 as well as Project no. 287750), and from the emmy.network foundation under the aegis of the Fondation de Luxembourg. AA acknowledges financial support from the project Sentinelle Nord of the Canada First Research Excellence Fund, from “la Caixa” Foundation and from the Spanish “Juan de la Cierva-incorporación” program (IJCI-2016-30193).
Appendix A Mercator in details
We now provide the full details of Mercator.
A.1 Sketch of the method
The model has two global parameters that need to be inferred; , controlling the average degree and , which determines the level of clustering in the network. In addition, every node is assigned two hidden variables: a hidden degree and an angular coordinate . The following method finds the values of , and for which the expected degrees in the model , that is, in synthetic networks generated with uniformly distributed angular positions, equal the observed degrees in the real network and, moreover, the expected mean local clustering of the embedding matches the real value. To that end, some values of and are proposed. Next, the corresponding are calculated. Finally, the expected clustering coefficient is computed and is adjusted if the predicted value is not within an acceptable range of the original value.
The method relies on the assumption that all nodes with the same degree have the same hidden degree. Therefore, the first preliminary step is reading the network and counting the number of nodes in every degree class , that we denote by .
A.2 Inferring the hidden degrees
This step assumes some given value of and the corresponding , where is the observed average degree. We then assign to every degree class the hidden degree given by as the initial guess. The aim of the following algorithm is to adjust this relation so that , where can be set, for instance, to . To solve this problem, we need a way to reckon the values of from the relation . To that end, it is useful to consider the probability for two nodes with hidden degrees and to be connected in the ensemble of networks with global parameters , , and uniformly distributed angular coordinates. This probability is given by
[TABLE]
Starting from the initial guess , we perform the following steps to refine the relation :
Initialize expected degrees: For every degree class , set .
- 2.
Compute expected degrees: For every pair of degree classes , compute using Eq. (A.2). Set and . By doing so, we add the expected number of connections of a node in degree class with nodes in degree class and vice-versa. Notice that, when , we set instead.
- 3.
Compute largest deviation: Let be the maximal deviation between degrees and expected degrees. If , the values of need to be corrected. Then, for every degree class , set , where is a random variable drawn from . The rationale behind this transformation is that every degree-class hidden degree is corrected according to its expected-degree excess or deficiency; the random variable prevents the process from getting trapped in a local minimum. Next, go to step 1 to compute the expected degrees corresponding to the new set of . Otherwise, if , hidden degrees have been inferred for the current global parameters.
A.3 Inferring parameter
To infer , we need to compute the expected mean local clustering given the current values of the global parameters as well as of the hidden-degree distribution provided by and found using the algorithm from the last subsection. The method is based on the following idea. Suppose we want to estimate the expected clustering of some node with degree . According to the definition of mean local clustering, this quantity is given by the probability for two randomly chosen neighbors of the node to be connected, which can be computed in two steps: first, we randomly choose two of its neighbors and draw their distances to the node from the distribution of distances between connected nodes in the model. Second, we compute the distance between the two neighbors and, with it, the probability for them to be connected. Two important points require some clarification:
- a.
The model is uncorrelated at the hidden level. Therefore, in the calculation of the clustering, we draw the two neighbors from the uncorrelated distribution .
- b.
The distribution of angular distance between two connected nodes with hidden degrees and , , where stands for the corresponding adjacency-matrix element, is given by
[TABLE]
In the above expression, is the connection probability between the two nodes with hidden degrees and separated by a distance . The distribution of distances in the model is simply , since angular coordinates are uniformly distributed. Finally, is given in Eq. (A.2). Equation (16) therefore reads
[TABLE]
The expected mean local clustering can now be found following three steps:
Initialize mean local clustering: Let represent the expected mean local clustering of degree class . Set for all .
- 2.
Compute expected mean local clustering spectrum: For every degree class , do times:
- i.
Draw two variables from .
- ii.
Draw the corresponding random variables from the distributions given in Eq. (17).
- iii.
Consider the two semicircles spanned by the diameter of the circle passing through the degree- node. It is equally likely for its two neighbours to lay in the same or in different semicircles. Hence, with probability , set or .
- iv.
Set , where is the probability for nodes 1 and 2 to be connected.
- 3.
Compute expected mean local clustering: The expected mean local clustering can be readily computed as .
If the error in the expected mean local clustering , where is the desired precision and is the observed mean local clustering coefficient, we can accept the current value of and proceed to the inference of the angular coordinates. Otherwise, needs to be corrected and the hidden degrees must be recalculated accordingly by repeating the process explained in the previous subsection. Notice that, since the expected mean local clustering coefficient is a monotonic function of , the process can be iterated efficiently using the bisection method. In practice, however, we use a modified version of the bisection method in which the upper bound is let free until we reach a value of for which the expected clustering is higher than the observed one. More precisely, we start with a value for picked uniformly between 2 and 3. Then, while the expected clustering is lower than the observed one, we increase by multiplying it by 1.5. When we reach a value for which the observed clustering is surpassed, we start the regular bisection method. We also note that, for , is enough. Of course, if more precision is required, must be increased to guarantee that the fluctuations in the computed are small enough.
A.4 Angular coordinates
Having inferred the values for the parameters , and , we are in a position to infer the angular coordinates, , of each node. This is performed by following two steps: a machine learning step providing an initial ordering of the nodes as well as realistic positions, and a second step in which nodes are moved in order to maximize the likelihood that the model generated the original edge list.
A.5 Initial ordering and positions
This step is a modified version of the Laplacian Eigenmaps (LE) algorithm introduced in Ref. Belkin and Niyogi (2001) and used in Refs. Alanis-Lobato et al. (2016a); Muscoloni et al. (2017). This machine learning algorithm was originally conceived for dimensionality reduction. The main idea is as follows. Given a set of points in , the algorithm first constructs a RGG by, for instance, connecting points located at a distance below some threshold in -dimensional Euclidean space. Once this graph is known, the points are mapped to with by diagonalizing the corresponding Laplacian and assigning to every point the coordinates , where is the -th component of the -th Laplacian eigenvector with non-null eigenvalue (the eigenvectors are ordered according to their eigenvalues). It can be shown that these coordinates minimize the squared distances between connected pairs in the RGG,
[TABLE]
while preventing all nodes from collapsing into a single point. Furthermore, the relevance of every connection in the RGG in the above expression can be modulated by assigning a weight to it according to
[TABLE]
where is the distance between the points in and is a scaling factor fixed as the mean of the squares of all the distances Muscoloni et al. (2017). The same procedure then leads to the minimization of
[TABLE]
The approach taken by Refs. Alanis-Lobato et al. (2016a); Muscoloni et al. (2017) is to consider the network to be embedded as the RGG generated in a higher-dimensional space. Hence, by proceeding to the dimensionality reduction in (typically ) dimensions, we obtain an embedding in , which can be radially normalized so that all points lay in . The improvement in Ref. Muscoloni et al. (2017) is to assign weights according to some heuristic and, once the coordinates on the plane are known, these are used to infer the ordering of nodes only. The final coordinates are computed by distributing all nodes on the circle with . We now propose an improvement based on assigning the weights in the Laplacian matrix as well as the gaps according to the model.
Laplacian Eigenmaps for node ordering: Since degree-one nodes do not add geometric information, we remove them at this step and work with the subgraph of nodes with . We then apply the Laplacian Eigenmaps method to such graph after weighting every links according to Eq. (19), where we use
[TABLE]
as a proxy for the distance and is the expected angular distance between nodes and in the model conditioned to the fact that they are connected. The above expression simply maps such expected angular distance onto the corresponding cord length, since Laplacian Eigenmaps is designed to work on Euclidean space and, therefore, it seems natural to consider the model as embedded in for the algorithm. The expected distance between the nodes can be readily computed from Eq. (17) as
[TABLE]
Since a similar approach developed in Ref. Muscoloni et al. (2017) has been shown to yield very good results in terms of the angular ordering of the nodes, we use this machine learning step to define a sequence of angular coordinates
[TABLE]
for the nodes in the subgraph, where the angles in are ordered in increasing order. Each is computed as
[TABLE]
where and are the and coordinates of node found by LE. Once we have the ordering of nodes with , we reincorporate the degree-one nodes. This can be easily done by replacing every node with degree-one neighbors by the sequence in , where is the -th degree-one neighbor of node (in any arbitrary order) and is the floor function. Such operation yields a new sequence of nodes including all the nodes in the original graph.
- 2.
Order-preserving adjustment: This last step of the approximate embedding locates the nodes on the circle preserving the ordering of the nodes in . To that end, we set every node’s coordinate such that the gap between two consecutive nodes in is proportional to the expected gap between two consecutive nodes with the same hidden variables and adjacency-matrix element in the model. We do this in two steps:
- i.
Computing the expected gaps: Let nodes and be consecutive in . The distribution for the length of the gap between them can be obtained from Bayes’ rule, as in Eq. (16),
[TABLE]
where now is an exponential distribution with mean ,
[TABLE]
and
[TABLE]
The expected gap can thus be computed as
[TABLE]
Both integrals can be carried out numerically.
- ii.
Normalizing the gaps: By applying the last step to every pair of consecutive nodes (including the pair ), we obtain a sequence of expected gaps which, however, needs not sum up to , so we normalize each as
[TABLE]
Finally, we can assign every node’s coordinate sequentially, starting with , as .
A.6 Likelihood maximization
This stage of the embedding algorithm adjusts the angular coordinates that maximize the likelihood for the observed network to be generated by the model. As opposed to previously proposed likelihood-maximization schemes, we do not need to explore a vast region of configuration space, since the machine learning stage provides a set of coordinates located near an optimal configuration. Hence, we visit every node once and propose several new angular coordinates for it, keeping the one with higher log-likelihood. The steps we follow are:
Define a new ordering of nodes: We visit the nodes in the order defined by the network’s onion decomposition. In the sequence, the ordering among nodes belonging to the same layer in the decomposition is random.
- 2.
Find new optimal coordinates: For every node , we select the optimal coordinate among candidate positions generated in the vicinity of the mean angular coordinate of its neighbors. This is achieved in three steps:
- i.
Compute mean coordinate of node ’s neighbors: Let node have neighbors, which we now label with index . Since nodes lay on a circle, we must compute their mean angular coordinate using the vector sum of their positioning vectors in . The polar angle of the resulting vector sum is given by
[TABLE]
where the hidden degrees in the above expression weight the contribution of every neighbor’s positioning vector, as proposed in Ref. Bläsius et al. (2016).
- 2.
Propose new positions around : We generate candidate angular coordinates from a normal distribution with mean and standard deviation given by
[TABLE]
where is the angular distance between and the most distant neighbor of node , i.e.,
[TABLE]
- 3.
Select the most likely candidate position: Compute the local log-likelihood of every candidate position as well as of node ’s current angular coordinate according to
[TABLE]
Locate node at the angular position maximizing the local log-likelihood.
A.7 Adjusting hidden degrees
The final process adjusts hidden degrees according to the hidden coordinates found so that . The algorithm is similar to the initial inference of hidden degrees:
Compute expected degrees: For every node , set
[TABLE]
- 2.
Correct hidden degrees: Let be the maximal deviation between degrees and expected degrees. If , the set of hidden degrees needs to be corrected. Then, for every node , set , where is a random variable drawn from . As in Sec.A.2, the random variable prevents the process from getting trapped in a local minimum. Next, go to step 1 to compute the expected degrees corresponding to the new set of hidden degrees. Otherwise, if , hidden degrees have been inferred for the current global parameters and angular coordinates.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Serrano et al. (2008) M. A. Serrano, D. Krioukov, and M. Boguñá, Physical Review Letters 100 , 078701 (2008).
- 2Krioukov et al. (2010) D. Krioukov, F. Papadopoulos, M. Kitsak, A. Vahdat, and M. Boguña, Physical Review E 82 , 036106 (2010) . · doi ↗
- 3Papadopoulos et al. (2012) F. Papadopoulos, M. Kitsak, M. A. Serrano, M. Boguñá, and D. Krioukov, Nature 489 , 537 (2012).
- 4Zuev et al. (2015) K. Zuev, M. Boguná, G. Bianconi, and D. Krioukov, Scientific reports 5 , 9421 (2015).
- 5García-Pérez et al. (2018) G. García-Pérez, M. Á. Serrano, and M. Boguñá, Journal of Statistical Physics , https://doi.org/10.1007/s 10955 (2018).
- 6Muscoloni and Cannistraci (2018 a) A. Muscoloni and C. V. Cannistraci, New Journal of Physics 20 , 052002 (2018 a) .
- 7Boguñá et al. (2009) M. Boguñá, D. Krioukov, and K. C. Claffy, Nature Physics 5 , 74 (2009).
- 8Gulyas et al. (2015) A. Gulyas, J. J. Bíró, A. Kőrösi, G. Rétvari, and D. Krioukov, Nature Communications 6 , 7651 (2015).
