Simultaneous regression and feature learning for facial landmarking
Janez Kri\v{z}aj, Peter Peer, Vitomir \v{S}truc, Simon, Dobri\v{s}ek

TL;DR
This paper introduces a novel facial landmarking method that effectively handles pose variations by combining multiple regression models with gating mechanisms, achieving state-of-the-art accuracy and robustness in 3D face data.
Contribution
It proposes a new gating-based framework for facial landmark localization that integrates multiple pose-specific models into a single robust system.
Findings
Achieves state-of-the-art performance across diverse poses
Demonstrates robustness to pose variations in 3D face datasets
Offers rapid processing with the SMUF approach
Abstract
Face alignment (or facial landmarking) is an important task in many face-related applications, ranging from registration, tracking and animation to higher-level classification problems such as face, expression or attribute recognition. While several solutions have been presented in the literature for this task so far, reliably locating salient facial features across a wide range of posses still remains challenging. To address this issue, we propose in this paper a novel method for automatic facial landmark localization in 3D face data designed specifically to address appearance variability caused by significant pose variations. Our method builds on recent cascaded-regression-based methods to facial landmarking and uses a gating mechanism to incorporate multiple linear cascaded regression models each trained for a limited range of poses into a single powerful landmarking model capable of…
Click any figure to enlarge with its caption.
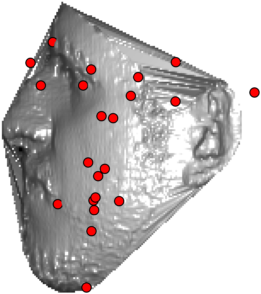 Figure 1
Figure 1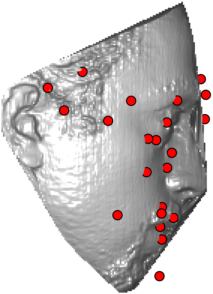 Figure 2
Figure 2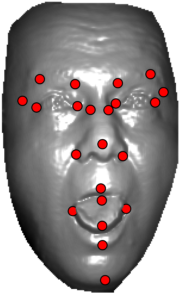 Figure 3
Figure 3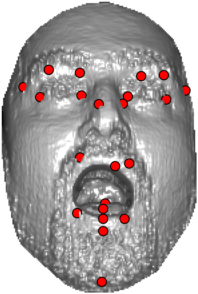 Figure 4
Figure 4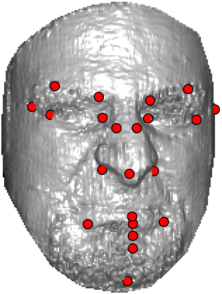 Figure 5
Figure 5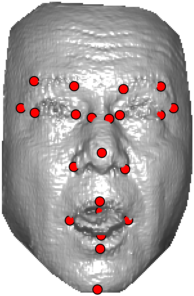 Figure 6
Figure 6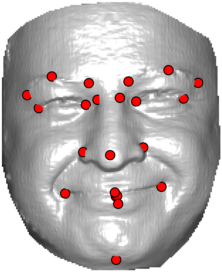 Figure 7
Figure 7 Figure 8
Figure 8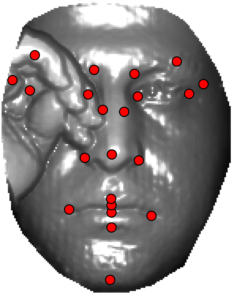 Figure 9
Figure 9 Figure 10
Figure 10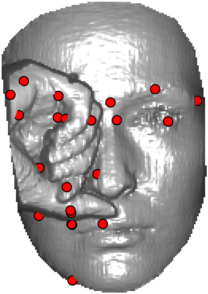 Figure 11
Figure 11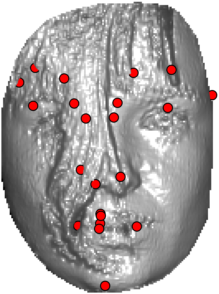 Figure 12
Figure 12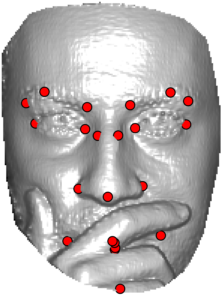 Figure 13
Figure 13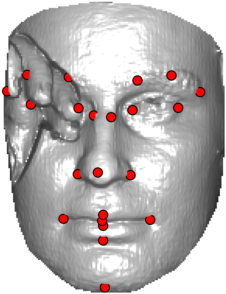 Figure 14
Figure 14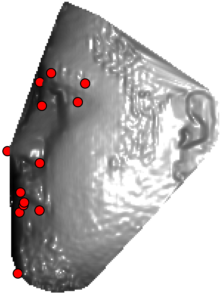 Figure 15
Figure 15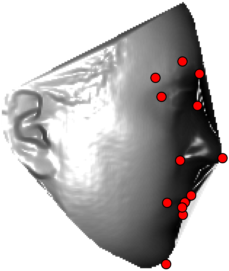 Figure 16
Figure 16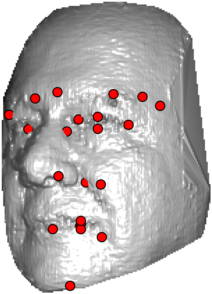 Figure 17
Figure 17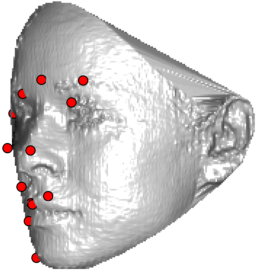 Figure 18
Figure 18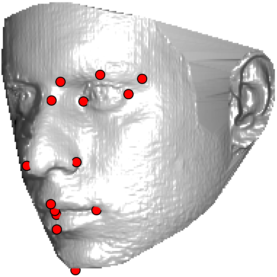 Figure 19
Figure 19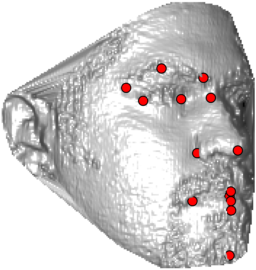 Figure 20
Figure 20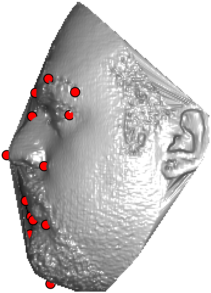 Figure 21
Figure 21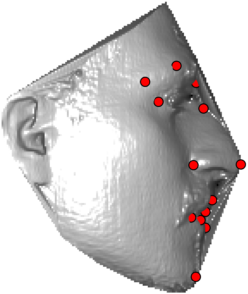 Figure 22
Figure 22 Figure 23
Figure 23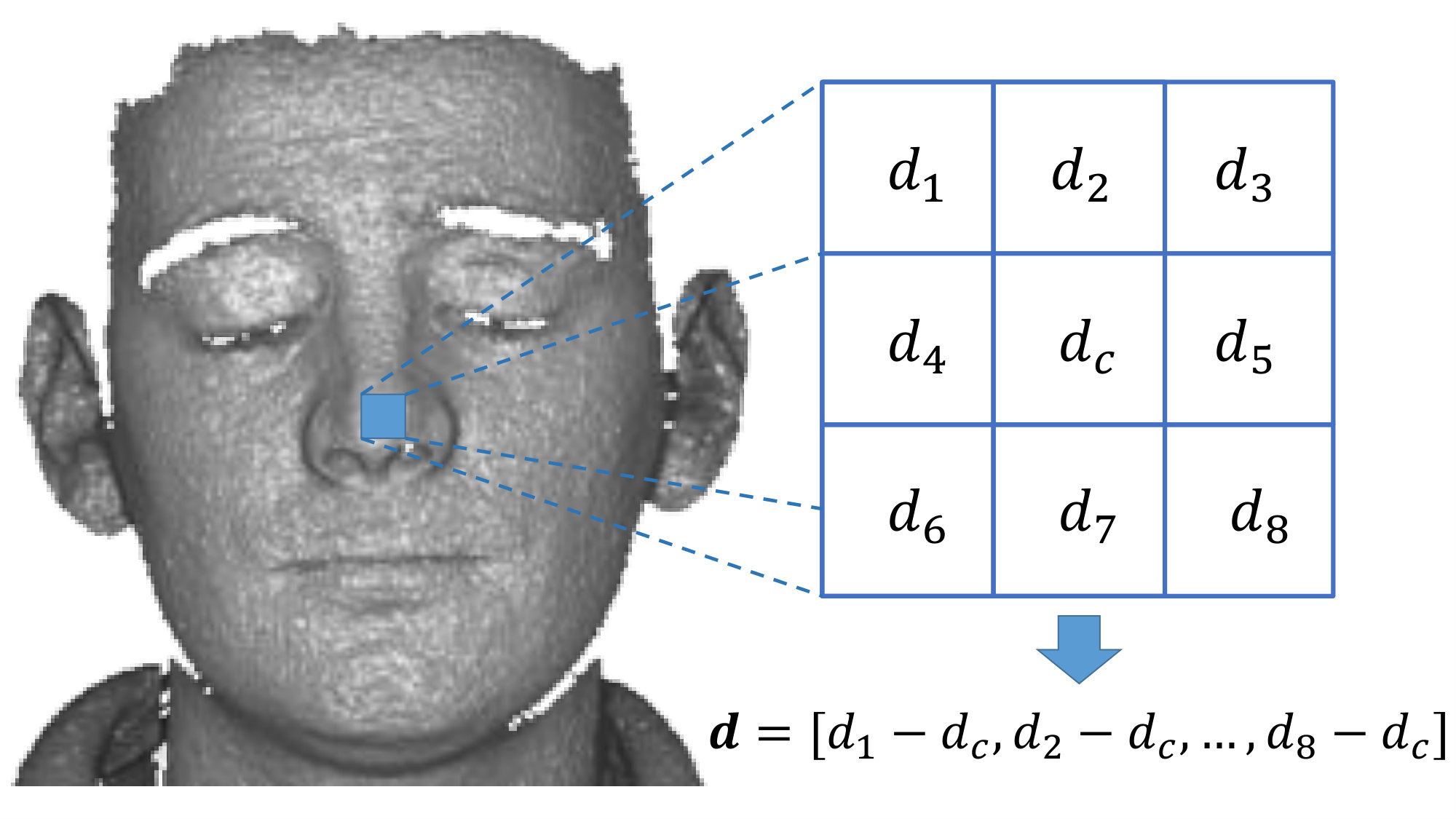 Figure 24
Figure 24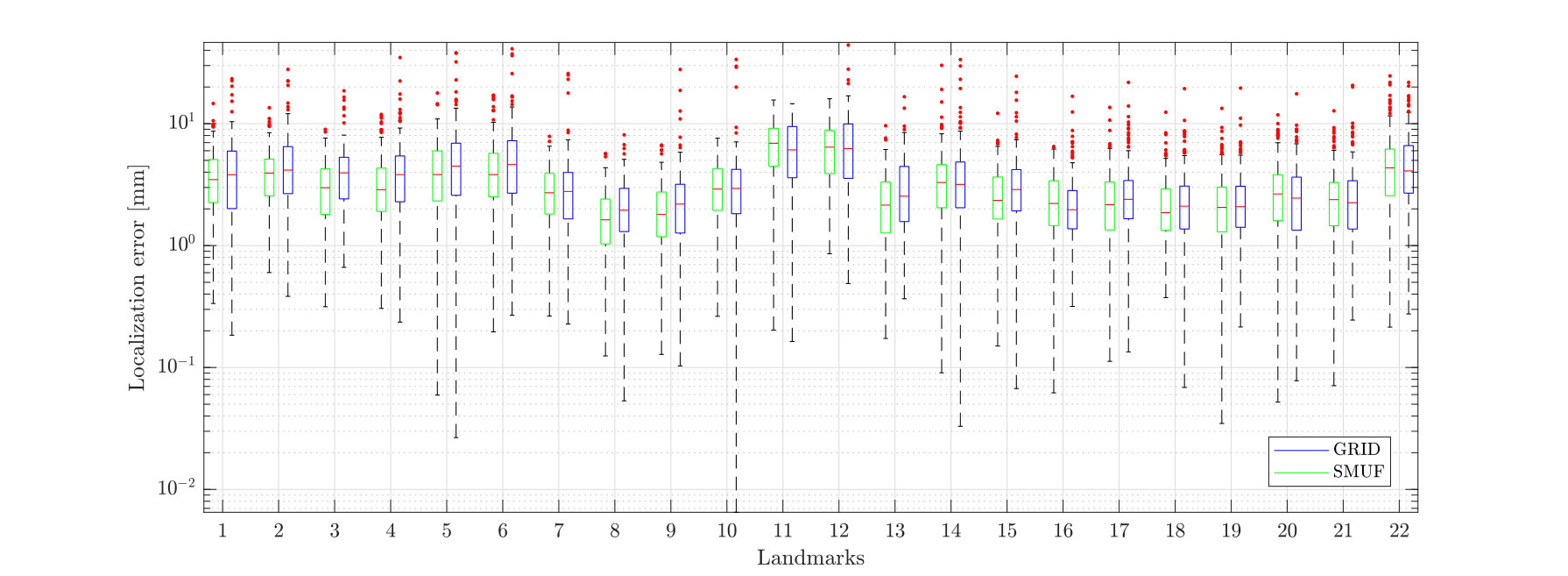 Figure 25
Figure 25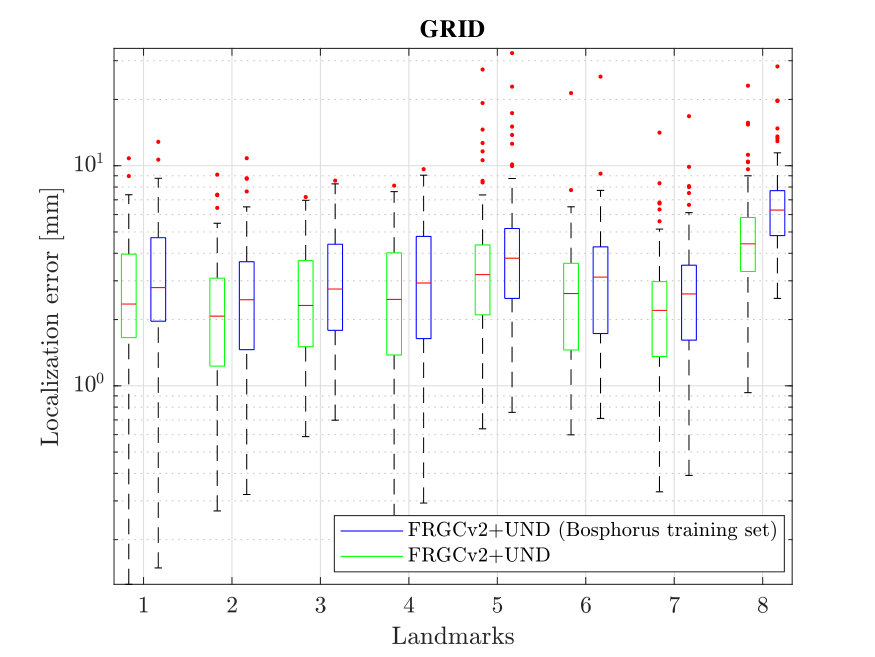 Figure 26
Figure 26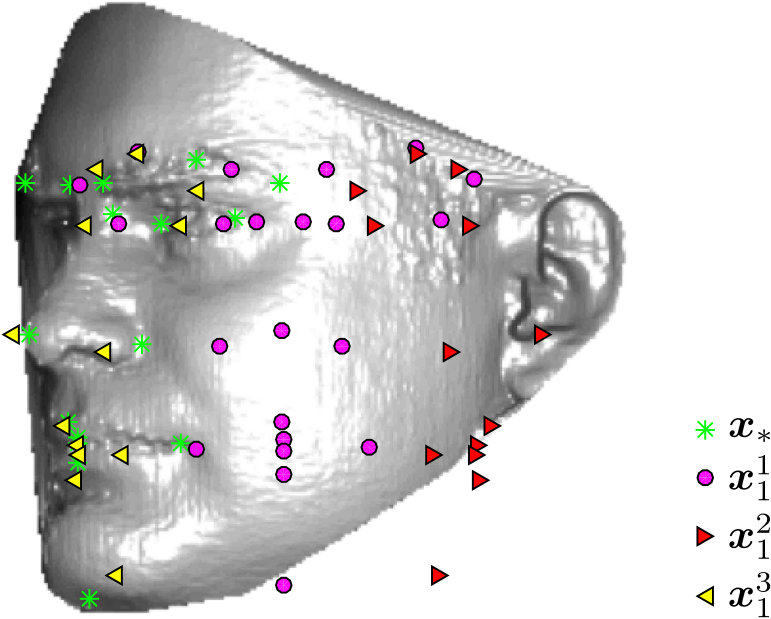 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29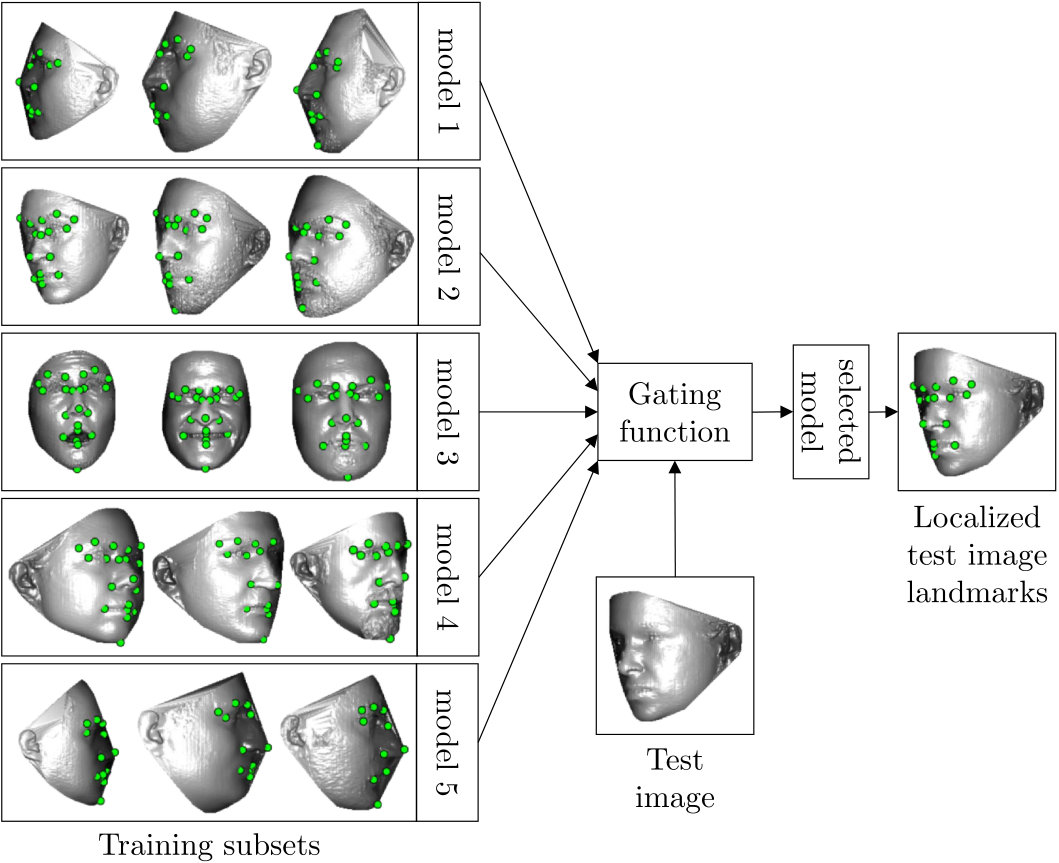 Figure 30
Figure 30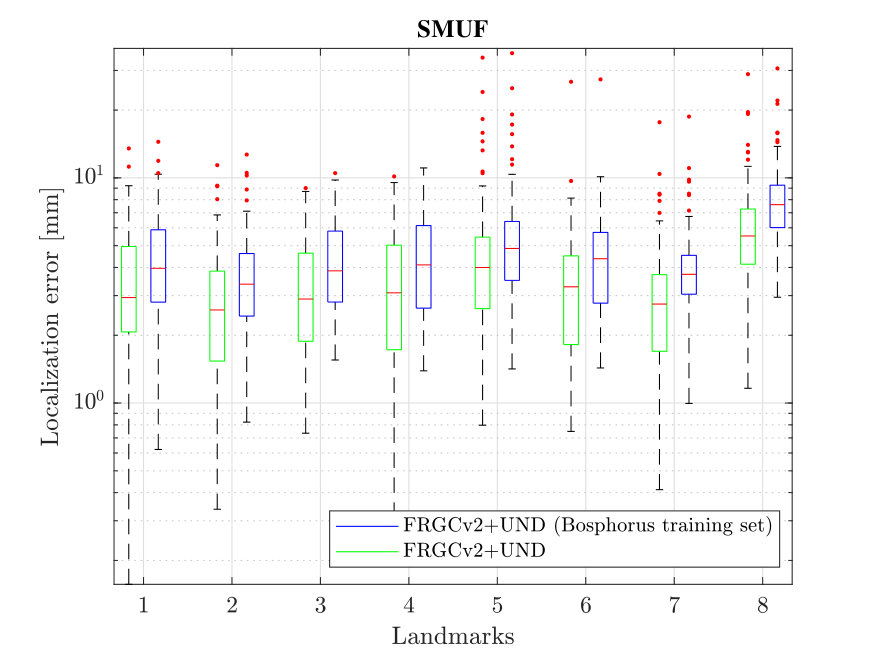 Figure 31
Figure 31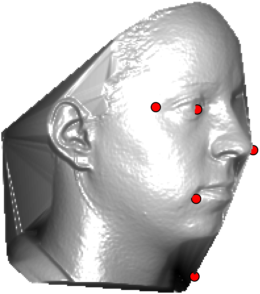 Figure 32
Figure 32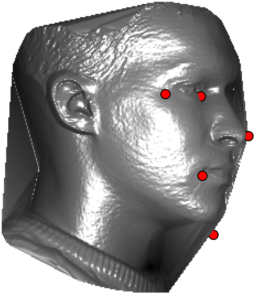 Figure 33
Figure 33 Figure 34
Figure 34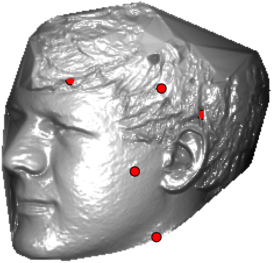 Figure 35
Figure 35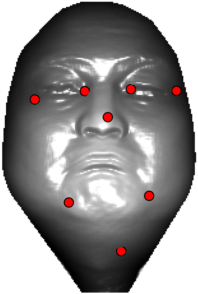 Figure 36
Figure 36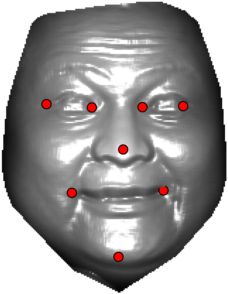 Figure 37
Figure 37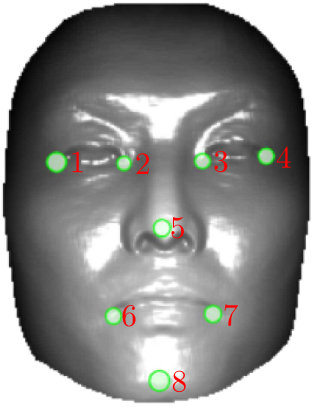 Figure 38
Figure 38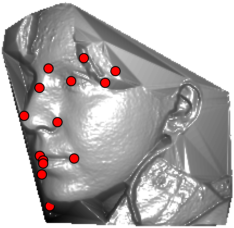 Figure 39
Figure 39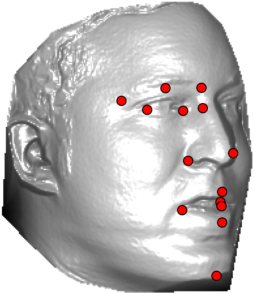 Figure 40
Figure 40| Author | Type | Procedure | Learning algorithm | Features |
|---|---|---|---|---|
| Mian et al. (2007, Mian07 ) | GA | Nose tip detection through the analysis of horizontal slices | Training-free | Depth data |
| Faltemier et al.(2008, Faltemier08 ) | GA | Rotated profile signatures | Training-free | Rightmost 3D profile lines |
| Gupta et al. (2010, Gupta10 ) | GA | ICP coarse alignment, heuristic rules | Training-free | Surface curvatures |
| Segundo et al. (2010, Segundo10 ) | GA | Clustering-based face detection, heuristic rules | Training-free | Depth relief curves, Surface curvatures |
| Alyüz et al. (2010, Alyuz10 ) | GA | Facial symmetry axis, heuristic rules | Training- free | Shape index, Gaussian curvature |
| Passalis et al. (2011, Passalis11 ) | SA-DM | Candidate landmarks fitting to facial landmark model | PCA | Shape index, spin images |
| Zhao et al. (2011, Zhao11 ) | SA-DM | 3D statistical facial feature model | PCA-based learning | Range map, intensity map |
| Fanelli et al. (2012, Fanelli12 ) | SA-DM | Random forest based voting approach | Random forests | Binary tests |
| Fanelli et al. (2013, Fanelli13 ) | SA-GM | Random forests-based regression, AAM | Random forests | Binary tests with trees in forest |
| Perakis et al. (2013, Perakis13 ) | SA-DM | Candidate landmark fitting to facial landmark model | PCA | Shape index, spin images |
| Smolyanskiy et al. (2014, Smolyanskiy14 ) | SA-GM | 2D AMM and 3D morphable face model | PCA | RGBD values |
| Liu et al. (2014, Liu14 ) | SA-GM | Normalized cross correlation and depth-based AAM | PCA | Shape and depth values |
| Song et al. (2014, Song14 ) | SA-GM | Local coordinate coding | Coupled dict. learning | Spin images, synthesized features |
| Cao et al. (2015, Cao15 ) | SA-DM | Cascaded regression | Linear regression | Shape indexed and depth features |
| Sukno et al. (2015, Sukno15 ) | SA-DM | Combinatorial search constrained by a flexible shape model | PCA | APSC descriptors |
| Camgöz et al. (2015, Camgoz15 ) | SA-DM | Cascaded ridge regression | Ridge regression | Multi-scale HOG |
| Feng et al. (2015, Feng15 ) | SA-DM | Cascaded collaborative regression | Weighted ridge regression | Dynamic multi-scale HOG |
| Rai et al. (2016, Rai16 ) | SA-GM | 3D Constrained Local Models | ICA, Point Dist. model | LBP descriptors |
| Wang et al. (2017, Wang17 ) | SA-DM | Joint head pose and facial landmark regression | Classif. guided casc. regression | Random forest feature selection |
| Liu et al. (2017 Liu17 ) | SA-DM | Hidden Markov Models (HMMs) | HMM learning | Spin image |
| Wang et al. (2018 Wang18 ) | SA-DM | CNN based feature extraction and landmark regression | Pre-trained CNN fine-tuning | CNN-based global and local features |
| Database | #images | #subjects | Variability |
|---|---|---|---|
| FRGCv2 | 4007 | 975 | Expression |
| Bosphorus | 4666 | 105 | Expression, occlusion, orientation |
| UND | 1680 | 537 | Orientation |
| Number of descent maps | ||||||
|---|---|---|---|---|---|---|
| 1 DM | 3 DMs | 5 DMs | ||||
| Variation | GRID | SMUF | GRID | SMUF | GRID | SMUF |
| Frontal | ||||||
| Yaw | ||||||
| Yaw | ||||||
| Yaw | ||||||
| Yaw | ||||||
| Yaw | ||||||
| Expressions | ||||||
| Occlusions | ||||||
| Detect. rate [%] | Select. rate [%] | Localization error | ||
|---|---|---|---|---|
| Data set | SMDFL | Perakis Perakis13 | ||
| DB00F | ||||
| DB00F-neut. | ||||
| DB00F-mild | ||||
| DB00F-extr. | ||||
| DB00F45RL | ||||
| DB45R | ||||
| DB45L | ||||
| DB60R | ||||
| DB60L | ||||
| Det. rate | Sel. rate | Localization error | |||
|---|---|---|---|---|---|
| Data set | GRID | SMUF | PerakisPerakis13 | ||
| DB00F | |||||
| DB00F-neut. | |||||
| DB00F-mild | |||||
| DB00F-extr. | |||||
| DB00F45RL | |||||
| DB45R | |||||
| DB45L | |||||
| DB60R | |||||
| DB60L | |||||
| Method & database | |||||||||
| Sukno et al.Sukno15 | Creusot et al.Creusot13 | Passalis et al.Passalis11 | Perakis et al.Perakis13 | LBP | GRID | SMUF | |||
| Landmarks | Bosphorus | Bosphorus | FRGC +UND | FRGC +UND | Bosphorus | FRGC +UND | Bosphorus | FRGC +UND | Bosphorus |
| Inner eye c. | |||||||||
| Outer eye c. | |||||||||
| Nose tip | |||||||||
| Nose c. | n/a | n/a | n/a | n/a | |||||
| Mouth c. | |||||||||
| Chin tip | |||||||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsFace recognition and analysis · Biometric Identification and Security · Face and Expression Recognition
∎
11institutetext: J. Križaj, V. Štruc, and S. Dobrišek22institutetext: University of Ljubljana, Faculty of Electrical Engineering
Tržaška cesta 25, 1000 Ljubljana
Tel.: +386-1-4768-839
Fax: +386-1-4768-316
22email: [email protected] 33institutetext: P. Peer 44institutetext: University of Ljubljana, Faculty of Computer and Information Science
Večna pot 113, 1000 Ljubljana
Simultaneous multi-descent regression and feature learning for facial landmarking in depth images
Janez Križaj
Peter Peer
Vitomir Štruc
Simon Dobrišek
(Received: date / Accepted: date)
Abstract
Face alignment (or facial landmarking) is an important task in many face-related applications, ranging from registration, tracking and animation to higher-level classification problems such as face, expression or attribute recognition. While several solutions have been presented in the literature for this task so far, reliably locating salient facial features across a wide range of posses still remains challenging. To address this issue, we propose in this paper a novel method for automatic facial landmark localization in 3D face data designed specifically to address appearance variability caused by significant pose variations. Our method builds on recent cascaded-regression-based methods to facial landmarking and uses a gating mechanism to incorporate multiple linear cascaded regression models each trained for a limited range of poses into a single powerful landmarking model capable of processing arbitrary posed input data. We develop two distinct approaches around the proposed gating mechanism: i) the first uses a gated multiple ridge descent (GRID) mechanism in conjunction with established (hand-crafted) HOG features for face alignment and achieves state-of-the-art landmarking performance across a wide range of facial poses, ii) the second simultaneously learns multiple-descent directions as well as binary features (SMUF) that are optimal for the alignment tasks and in addition to competitive landmarking results also ensures extremely rapid processing. We evaluate both approaches in rigorous experiments on several popular datasets of 3D face images, i.e., the FRGCv2 and Bosphorus 3D Face datasets and image collections F and G from the University of Notre Dame. The results of our evaluation show that both approaches are competitive in comparison to the state-of-the-art, while exhibiting considerable robustness to pose variations.
Keywords:
Facial landmarking feature learning hand-crafted features pose variations
1 Introduction
Face alignment or facial landmarking refers to the task of locating salient facial features in facial images, which is of paramount importance in various applications including face registration and recognition Masi18 ; Wu19 , expression recognition Zhao16 , face tracking Sanchez18 , normalization of facial pose, size and expressions Liu18 , face synthesis from morphable models and facial animation Park18 to name a few. In real-world scenarios where face images are often acquired in uncontrolled conditions, one has to deal with various unfavorable factors that adversely affect landmarking performance including pose, expression, and illumination variations as well as partial occlusions of the facial areas. These factors influence the appearance of the facial features in traditional 2D images, e.g., Johnston18 but also in 3D (or better said 2.5D) face data used in this work111To be strict, we consider 2.5D images in this work, but will use the terms 3D images and depth images interchangeably to refer to this type of data throughout the paper.. Although some of the existing landmark localization procedures promise to be (at least partially) robust to some of the factors mentioned above (e.g. Perakis13 ; Sukno15 ; Feng15 ), reliable localization of facial landmarks in the presence of highly variable nuisance factors still remains a considerable challenge.
With the advancement of 3D acquisition technology, landmark localization on 3D facial data has recently been researched extensively Kendrick18 ; Sukno15 . Many of the 3D landmarking techniques proposed in the literature in the last few years rely on the so-called cascaded-regression framework, where facial landmarks are estimated by regressing from facial features to landmark locations in a cascaded (iterative) manner Camgoz15 . Techniques following this framework made considerable advancements towards robust facial landmarking, although they generally still use hand-crafted features, such as SIFTs or HOGs Cao15 ; Camgoz15 ; Wang17 . Additionally, these methods typically rely on a single regression model in each stage of the cascade to estimate the facial landmarks regardless of the facial characteristics. However, as facial appearance is a complex function of various factors, such as facial shape, pose, incident illumination, expression, and occlusion, a single model is often not sufficient to capture the broad range of variability commonly encountered with facial-image data and to robustly estimate the location of the most salient facial features.
To address this problem, we propose in this paper a novel gating mechanism that incorporates multiple cascaded regression based models each trained for narrow range of facial posses into a single (coherent) landmarking model that is able to reliably estimate the location of salient facial features from arbitrary posed input face data. The combination of simpler view-specific landmarking approaches provides the combined gating-based model the necessary expressive power to describe the considerable appearance variability typically seen with 3D face data captured under different facial poses and consequently allows it to reliably estimate the landmark locations regardless of the facial pose of the input image. The model is partially motivated by the success of earlier methods designed for 2D images that combine multiple landmarking models trained for face alignment of different views, e.g., ramanan2012face ; yu2013pose ; cootes2000view ; li2002multi ; zhou2005bayesian , but unlike these early methods does not rely on parametric appearance or shape models.
We develop two distinct facial landmarking approaches around the proposed gating mechanism. The first relies on a combination of the Gated multiple RIdge Descent (GRID) mechanism and established HOG features and as illustrated in Fig. 1 achieves remarkable landmarking performance across a broad range of pose variation. Even for poses with yaw rotations of up to , the model is still able to reliably estimate the location of salient facial features. The second approach again relies on the introduced gating mechanism, but in addition to the cascaded regression models needed for face alignment of each group of poses, also learns a feature representation that is used with the regression models for landmark estimation. Specifically, the model Simultaneously learns MUltiple-descent directions as well as binary Feature (SMUF) that are optimal for the alignment task and due to their binary nature also ensure extremely fast execution times. This second approach follows recent trends in computer vision and aims to learn the feature representation that is optimal for a given tasks, but different from deep learning models that are typically used for feature learning Wang18 ; Xia19 , uses a computationally much simpler scheme, where binary features are learned based on a learning objective that can be solved using standard optimization procedures.
To evaluate the proposed landmarking approaches, we conduct experiments on multiple datasets of 3D face images, i.e., the Face Recognition Grand Challenge v2 (FRGCv2), the Bosphorus 3D Face datasets and image collections F and G of the University of Notre Dame. We present extensive experiments and comparisons with state-of-the-art methods from the literature. The results of our evaluation show that the GRID ensures state-of-the-art performance for facial landmark localization in 3D face data across pose, while SMUF yields not only competitive landmarking accuracy, but is also extremely fast.
Our main contributions in this paper are:
- •
We propose a gating mechanism for face alignment in 3D face data that allows us to combine multiple alignment models and foster the combined power of the combined models for face alignment across pose. The use of multiple models adds to the overall localization performance, since each model needs to account only for a limited set of plausible facial variations. With this approach reliable landmarking is possible even under large head rotations such as profile facial images, with yaw rotations up to (see Fig. 1), where many competing methods fail.
- •
We develop two distinct landmarking approaches based on the introduced gating mechanism, where one is optimized for performance and the second one is optimized for both performance and speed. We evaluate both approaches in rigorous experiments on multiple face datasets and report competitive performance in comparison to competing methods from the literature.
- •
We study different configurations of the proposed approaches and investigate their behavior when localizing specific facial landmarks.
The rest of the paper is organized as follows: In Section 2 we describe prior work in the field of facial landmarking with the goal of providing the necessary context for our contributions. In Section 3 we present our gating mechanism and the GRID and SMUF alignment techniques. We describe experiments conducted to evaluate the performance of the proposed methods in discuss results in Section 4. We conclude the paper with some final remarks and future research challenges in Section 5.
2 Related Work
Numerous methods have been proposed in the literature for the task of automatic facial landmark localization over recent years. In this section we present a brief overview of these methods with a focus on alignment techniques that work on 3D images. These techniques can be categorized in various ways, but here we chose to perform a categorization as shown in Fig. 2. We classify existing techniques into two groups: i) techniques that are entirely dependent on geometric information and derive prior knowledge about the facial structure and location of facial landmarks by defining a number of heuristic rules and ii) techniques that rely on trained statistical models. The latter group of techniques is further divided according to the type of the model utilized into generative and discriminative methods. A high-level comparison of the related works discussed in this section is given in Table 1.
2.1 Geometric Approaches
Geometric approaches to facial landmarking are generally training-free and depend solely on the geometric information such as surface curvature or shape index values. A number of rules and heuristics encode the prior knowledge about the relationships between adjacent landmarks (e.g. the nose tip lies on the face symmetry axis, eyes are located above the nose tip, etc.). In most cases, the rules used to define the location of facial landmarks require the face to be in upright and near-frontal position. Moreover, a common downside of these methods is that the landmarks are detected in sequence (commonly starting by detecting a nose tip) and the success rate of finding the next landmark in the sequence is dependent on successfully locating the preceding landmark in the sequence. With these methods an incorrect detection of one landmark affects the detection of all subsequent landmarks.
Exemplar geometric methods Gupta10 ; Segundo10 ; Alyuz10 ; Mian07 ; Faltemier08 start by detecting the nose tip and use its location to constrain the search space of the remaining landmarks. Landmark detection can be grounded on the analysis of Gaussian curvatures Gupta10 , profile curvatures Faltemier08 , and coordinate projections of the depth data Segundo10 , shape index values and facial symmetry lines Alyuz10 or horizontal slices of range images Mian07 to name a few.
2.2 Statistical Approaches
Statistical landmarking approaches also exploit local shape information around candidate landmark locations. Additionally, these methods derive some prior knowledge from the training data about the location constraints and encode the acquired knowledge into a statistical model. Thus, these methods require a training set of facial images with annotated landmarks. Unlike training-free geometric approaches, statistics are utilized uniformly for all landmarks, as there is no need for specific rules for each individual landmark. Since all landmarks are handled simultaneously approaches from this group are typically more robust to local distortions, missing data and occlusions of individual landmarks. However, the fact that statistical methods generally address a complete set of landmarks defined by the model could prove to be a problem when a large number of landmarks is (self-)occluded or data is missing from the input images due to acquisition errors. Recently, efforts have been made to handle such problems, e.g. Sukno15 use a flexible shape model that works even with an incomplete set of landmarks.
In terms of the type statistical model used, approaches from this group can be divided into techniques that rely either on generative or on discriminative models. We discuss both types of techniques in the following two subsections.
2.2.1 Generative Approaches
Landmark locations can be modeled by generative models, such as Active Appearance Models, Active Shape Models Fanelli13 ; Smolyanskiy14 ; Liu14 or morphable models Feng15 . Techniques from this group often learn face appearances (and/or shape) by conducting Principal Component Analysis (PCA) Turk91 on manually annotated and aligned training data. Given a test image, alignment/fitting is achieved by minimizing the difference between the current estimate of the appearance (and/or shape) and the test face. Generally, generative approaches are often computationally expensive and may perform poorly in the presence of occlusions, pose expression and illumination variations due to the involved fitting procedure.
2.2.2 Discriminative Approaches
More recent methods to face alignment focus mostly on discriminative approaches that learn a mapping function that predicts the shape, i.e. landmark locations, directly from corresponding image features. Methods from this category typically offer better landmark localization performance when compared to generative models, especially for faces with greater variability in appearance Feng15 ; Sukno15 ; Camgoz15 ; Cao15 . These methods commonly incorporate shape constraints into the models and use local descriptors that are more robust to appearance variations than conventional depth/intensity pixel values used with generative approaches. Discriminative approaches include random forests Fanelli12 , graph matching Romero09 , cascaded regression Camgoz15 ; Cao15 ; Feng15 ; Wang17 , specifically tailored shape models Passalis11 ; Zhao11 ; Perakis13 ; Sukno15 , hidden Markov models Liu17 and convolutional neural networks Wang18 .
The landmarking techniques proposed in this work fall into the group of discriminative approaches. They build on recent face alignment techniques that rely on cascaded regression models that have proven highly successful for landmark localization from 2D face images, e.g. Xiong14 ; Xiong15 . However, compared to these models our solutions exhibit unique features, such as the novel gating mechanism for exploiting multiple pose-specific landmarking models and the ability to incorporate task-specific binary features into the landmarking procedure.
3 Methodology
In this section we describe GRID and SMUF, two novel facial landmarking approaches build around the gating mechanism illustrated in Fig. 3. As can be seen, the gating mechanism partitions the search space for the landmark localization procedure into a number of sub-domains, where each sub-domain encompasses a range of similar facial poses. A separate landmarking model is then trained for each of the sub-domains and the gating mechanism is used to select the most suitable landmarking model for the given tests image. Based on this overall framework, we develop two distinct landmarking techniques, which are described next.
3.1 GRID Description
We design GRID (Gated Multiple Ridge Descent) in line with the powerful cascaded regression framework to face alignment, where landmark locations (or in other words, the facial shape) are estimated by regressing from facial features to landmark locations in a cascaded manner. In the first step of this framework, features are extracted from some initial landmark configuration (estimated from the training data) and a regression model is applied on the extracted features to predict landmark updates to better align the landmarks with the actual test image. The update results in a new landmark configuration that forms the basis for the next step in the cascade. The entire procedure is then repeated multiple times and, thus, sequentially refines the predicted locations of the facial landmarks in the test image.
With GRID, we train multiple cascaded regression models and integrate them into a gated approach that is robust to pose variations. While different regression models and feature representation have been proposed in the literature for facial landmarking, we built GRID around the Supervised Descent Method (SDM) from Xiong14 that has not proven successful only for facial landmark localization in 2D images Xiong13 , but also for alignment of 3D face images, as we have shown in Camgoz15 ; krivzaj2018localization .
3.1.1 Background
To train the regression models needed for landmarking, SDM requires a number of facial images , where each image has landmarks annotated in the form of a shape vector . The landmark localization task is then posed as a minimization problem over :
[TABLE]
where is a feature extraction function, are features extracted around the ground truth landmarks , is an initial landmark configuration and is a landmark update (known for the training data).
Eq. (1) represents a non-linear least squares problem and in general has no closed-form solution. However, it was shown in Xiong13 that the problem can be solved through a cascade of least squares regression problems. Thus, for each step in the cascade, the solution of the least squares problem results in a regression matrix (also referred to as a descent map, DM) that can be used to predict the update of the landmark locations from the current image features. The learning algorithm is formulated as a minimization of the loss between the true shape updates and the expected updates over all training images, i.e.:
[TABLE]
where is a training-image index and is an average feature vector computed from the ground truth locations over all training images. Eq. (2) now represents a sequence of ordinary least squares regression problems that can be solved in closed form.
During test time, the algorithm starts with some initial landmark locations , for which the face shape (landmark configuration) is defined by the average landmark locations of training images and the position of the face shape is determined by the face detection procedure222The average shape is always placed consistently with respect to the detected facial region., and sequentially updates the initial estimate to obtain the final landmark locations, i.e.:
[TABLE]
so that the final shape converges to for all training images. The number of steps in the cascade, where commonly varies depending on the implementation, but usually values of are between and
3.1.2 Ridge Regression
The original SDM Xiong13 formulation uses a least squares solution of Eq. (2) to learn the DMs, i.e.:
[TABLE]
where is a shape matrix with -th column and is a feature matrix with -th column . To solve Eq. (4) one needs to compute the inverse of , which, however, may be singular when the size of the feature vectors is too large or when the features are correlated. To overcome this issue, the original SDM applies PCA Turk91 to the image features before inverting the matrix.
However, we have shown in Camgoz15 that better landmarking performance is achieved if ridge regression is used in the original feature space instead of least squares regression in the PCA subspace. The optimization function in (2) in this case can be written as
[TABLE]
where denotes a regularization factor and the solution of Eq. (5) is computed as:
[TABLE]
where is an identity matrix. The regularization factor controls the general instability of the least squares estimate. Selecting a suitable value for , avoids over-fitting and helps to produce estimates of that generalize better to unseen data.
3.1.3 Gated Multiple Ridge Descent
Experimental results in Camgoz15 ; Xiong15 ; Xiong13 have shown that the original SDM achieves remarkable landmarking performance on various 2D and 3D datasets. However, it still tends to perform poorly when, for example, large head rotations are present in the facial data Xiong15 . Such rotations cause complex facial appearance variations that are difficult to model and hard to account for when using only a single DM in each step of the landmarking cascade.
To increase the robustness of the model to pose variations, we propose to exploit multiple DMs such that each of the DMs accounts for a specific range of head rotations, as illustrated in Fig. 3. Towards this end, we partition the available training images into pose-specific subsets and train separate regression cascades for each subset in line with Eq. (6).
Once all cascades (series of DMs) are trained, a gating function is used to select the most suitable DM (from the DMs available in the first cascade stage) for a given test image. The selection procedure begins by computing features from the initial landmark locations in the test image. Here, the initial landmark locations (see Fig. 4) are computed by averaging the ground truth shapes over all training images from the -th training subset:
[TABLE]
The most fitting DM for the given test image is then selected based on the output of the gating function :
[TABLE]
where is the feature vector length (in the case of SIFT ), and are the average and the covariance matrix of the ground truth features over the subset , respectively. We select the subset , for which the gating function outputs the lowest value:
[TABLE]
By doing so, we reliably choose the DM that has been trained on images with similar face orientations to the orientation of the test face. For all the subsequent steps we use the DMs that correspond to the -th subset selected in the first step and for efficiency reasons due not change the regression cascade in subsequent steps. Location updates on a given test image are thus computed as
[TABLE]
The described procedure results in significantly improved performance in the case of large head rotations as shown later in Section 4.
It needs to be noted that we rely on HOG features to implement the feature extraction function in GRID. We select HOG features because of their proven performance in prior landmarking models, e.g., Camgoz15 ; krivzaj2018localization .
3.2 SMUF Description
The GRID landmarking approach presented in the previous section relies on HOG features to encode the appearance of the facial landmarks during face alignment. With SMUF (Simultaneous MUlti-descent regression and binary Feature learning) we take a step further and try to learn facial features that are optimal for face alignment. We choose to learn binary features, due to their simplicity and most of all computational simplicity. In the following subsection, we first review the idea of binary feature learning and then develop of SMUF approach that jointly learns a landmarking model as well as corresponding binary features that are optimal for this task.
3.2.1 Binary Feature Learning
Hand-crafted binary features, such as Local Binary Patterns (LBPs) pietikainen2011computer represent powerful image descriptors that have proven highly effective in various computer vision tasks. These features typically rely on pixel comparisons within a local neighborhood and heuristic rules to encode the pixel comparisons into binary codes. As such, they may be suboptimal and better features could potentially be constructed by learning binary features based on some dedicated learning objective.
Gong et al. gong2013iterative , for example, propose a learning objective where binary features are learned from an initial image representation , such that the quantization error is minimized. Since binary features (containing only [math]s and s) can be computed from as
[TABLE]
where is a matrix of hash functions and stands for the signum function, the learning objective that needs to be minimized over on some training data can be written as:
[TABLE]
It was shown by Lu et al. lu2015simultaneous ; lu2018simultaneous that descriptive binary image features can be computed based on the above quantization scheme if pixel (or depth in our case) difference values are used as input for binarization. For SMUF we follow this approach and compute one depth difference vector for each considered landmark, as illustrated in Fig. 5.
3.2.2 Simultaneous DM and Feature Learning
The learning objective presented in the previous section is focused on representational power, as the binary features are computed in a manner that minimizes a quantization loss. To make the features useful for landmarking, we now formulate a joint optimization function that allows us to simultaneously learn a regression cascade and corresponding binary features that are optimal for the landmarking task.
Let be a set of depth-difference vectors extracted from patches centered at the facial landmarks and stands for the cascade stage, . The depth-difference-vector matrix is mapped to a binary feature matrix as follows:
[TABLE]
where is a feature projection matrix and is again the signum function. To learn , we formulate the following optimization problem by re-writing (5) into matrix form and extending it with the additional constraint :
[TABLE]
where
[TABLE]
and , are the depth-difference values of the ground truth landmark locations. As already emphasized above, the objective of is to minimize the quantization loss between the original depth-difference values and the binarized features, so that most of the depth-difference energy can be preserved in the learned binary features.
We find optimal values for and by an iterative optimization procedure, where is initialized to a random orthogonal matrix. If we assume a fixed and compute a partial derivative of in (14) with respect to and set the derivative to zero, we obtain the following solution for :
[TABLE]
In the next step we aim to learn with a fixed and, hence, rewrite (14) as follows:
[TABLE]
If we differentiate (17) with respect to and set the derivative to zero, we obtain the following update rule for :
[TABLE]
The two optimization steps from (16) and (18) are then repeated until both and converge.
Once stable version of and are obtained, we compute the shape update in accordance with
[TABLE]
and repeat the entire procedure for the next stage in the cascade. Note that because is binary, location updates can be computed extremely quickly by simply summing up (specific) rows from .
Finally, we compute separate regression cascades and projection matrices for each of the training subsets, that is, for each considered group of poses and integrate the computed cascades into the overall SMUF approach using the same gating mechanism as described above for the GRID approach.
3.3 Training and testing of GRID and SMUF
The overall processing pipeline for the SMUF landmarking approach is shown in Fig. 6. The procedure for GRID is identical, except for the fact that no features are learned during training.
The training stage for both methods begins by preprocessing all training images were a depth component of the surface normal is computed in each pixel instead of using original depth values. In each image the face is detected using a simple clustering procedure Segundo07 and initial landmark locations are set based on the detected facial area. To capture the variance of the face detection procedure and to enlarge the amount of training data, we define additional initial landmark locations for each training image by randomly sampling scale and displacement parameters for the detected area from a normal distribution. Starting from the initial locations matrix along with the ground truth locations , a number of DMs (and for SMUF also projection matrices ) are learned. The updates (16) and (18) are iteratively re-computed till convergence (we empirically estimated that 4 steps are sufficient) for each shape update step and each of the training subsets.
When a test image is presented to the landmarking procedure, it goes through the same face detection, preprocessing, landmark initialization and feature extraction steps as the training images. DMs and feature projections are then selected as described in Section 3.1.3 and the final landmark locations are computed based on (10).
4 Experiments
In this section we evaluate the proposed GRID and SMUF landmarking approaches and compare them to the state-of-the-art. We report landmarking performance in accordance with standard methodology used in this area Segundo07 for all experiments. Specifically, we use the localization error, i.e. the Euclidean distance in between the location of the detected landmark and the manually annotated ground truth landmark, for performance reporting. Additionally, we also compute the mean localization error over all landmarks of each test face for some of the experiments.
4.1 Experimental Datasets
We conduct experiments with three popular datasets of 3D face images: the Face Recognition Grand Challenge version 2 (FRGCv2) dataset Phillips05 , the Bosphorus 3D Face dataset Savran08 and the University of Notre Dame dataset (collections F and G, hereinafter referred to as UND dataset) Yan05 . We chose these datasets because they are among the most frequently used 3D face datasets and because they contain challenging 3D images with a high degree of variability in face orientations and are, therefore, well suited for assessing the robustness to such variations. The main characteristics of the datasets are summarized in Table 2.
The FRGCv2 dataset contains 3D face images of individuals. Images of the dataset were acquired with a laser-based Konica Minolta Vivid 910 scanner. Subjects exhibit minor pose variations and various facial expressions. We utilize the ground truth landmarks ( landmarks per face) from Perakis13 , which were manually annotated on a subset of images from subjects.
The Bosphorus dataset consists of face samples from subjects. Each sample includes a 2D color image, a 3D point cloud and manually annotated landmarks (in our experiments we exclude ear dimple landmarks and use the remaining landmarks). Next to expression and occlusion variations, images in the dataset also exhibit large variations in pose. Images from the dataset were captured using a structured-light based Inspeck Mega Capturor II Digitizer.
The UND dataset contains semi-profile and profile 3D face images of subjects. For our experiments, we use a subset of images with yaw rotations of \pm$$$ and 174\pm$$$ along with the manual annotations ( landmarks for frontal faces and for non-frontal faces) also provided by Perakis13 . Images from this dataset were captured by the same acquisition device as used with FRGCv2.
4.2 Performance Evaluation on the Bosphorus Dataset
In the first series of experiments we evaluate the performance of GRID and SMUF on the Bosphorus dataset which is particularly suitable to assess the robustness to large pose variations. We perform experiments using a two-fold cross validation setup using half of the images for training and the other half for testing. To increase the size of training data we extend the training set by horizontally flipping each of the aviable training images. We form test sets with respect to the yaw rotation angle or the presence of expressions/occlusions. We implement both methods with cascade stages and use this setup also for all following assessments.
The results of this series of experiments are summarized in Table 3. For both GRID and SMUF, we train three landmarking variants, each with a different number of DMs. The first column in Table 3 marked 1 DM corresponds to the variant that use only one DM that was trained on images with annotated landmarks (these are generally images of near frontal faces, since large rotations lead to self-occlusions and fewer annotations). The second column represents the GRID and SMUF variants with DMs: one DM is computed in the same way as in the variants in column 1, while the second and the third DM is computed using images with the head rotations up to [math] to the left and right, respectively. The varaints in the third column correspond to the setup in Fig. 3 and contain an additional two DMs corresponding to head rotations in the ranges of [$$,$$] and [-$$,-$$]. The DM of the near-frontal images are trained using landmarks per face image, while the DMs of rotated images are trained using landmarks per face as some of the landmarks in these images are typically self-occluded.
As expected, we can observe that the robustness to face rotations is significantly increased when more DMs are utilized. With the GRID and SMUF variants with 5 DMs we achieve reliable landmark localization even on profile face images with yaw rotations up to $\pm$$$. It can also be seen from the last two rows in Table 3 that the same localization errors are obtained for all three variants when evaluated on the frontal face images with expression and occlusion variations. This indicates that the expressions and occlusions do not affect the DM selection process since in all cases the frontal DM is correctly chosen by the gating function.
When comparing the performance of SMUF and GRID, we can see that in general GRID ensures slightly better localization results than SMUF for all implemented variants. However, while there is an evident trend towards lower average localization errors for GRID, it is clear from Table 3 that the performance differences are statistically not significant. Thus, we can conclude that for the Bosphorus dataset both techniques perform more or less equal.
4.3 Evaluation on the FRGCv2 and UND Datasets
In the second series of experiments, we evaluate GRID and SMUF on the joint FRGCv2 and UND datasets. Contrary to the Bosphorus dataset, where images contain solely the head regions and, therefore, using a face detector is not required, images from the FRGCv2 and UND datasets may also contain parts of the upper body and thus face detection is needed to initialize the landmark locations. In this series of experiments we, hence, employ a simple face detector that relies on -means clustering similar to the one presented in Segundo07 . Setting the number of clusters to and including several heuristic conditions, this detector divides a 3D image into three regions that most likely correspond to the background, body and head/face regions. The face region is then selected as the cluster with the lowest mean depth value (see Fig. 7).
The face detector introduces additional variability into the facial regions, since the detected face may still include smaller parts of the upper body, neck and hair. For that reason we also report face mis-detection rates and selection rates for this experiment. Face mis-detection rate is defined as the percentage of images with the discrepancy between the location of face detection box and the locations of ground truth landmarks. The selection rate is defined as the percentage of images where the correct DM has been selected by the gating function, where we define a DM as incorrect if the DM has been trained on right profile face images while the corresponding test image is facing left, or vice versa. The localization errors are then computed exclusively on the images with correct face detections and DM selections. This type of reporting is adapted from Perakis13 , which we use for baseline comparison in this experiment.
The results of the experiments are presented in Table 5. For details on the dataset abbreviations in the first column please refer to Perakis13 , since the experimental setup and the landmark annotations are adopted from there. In short, however, DB00F denotes an image subset with varying facial expressions, which is further partitioned into neutral (neut.), mild and extreme (extr.) facial expressions. The remaining image subsets contain faces with or yaw rotations either to the right (R), the left (L) or both (RL). As the GRID and SMUF methods require non-frontal images to train some of the DMs, our experimental setup differs from Perakis13 only in the construction of training set where we also employ images from the Bosphorus dataset.
Detection and selection rates are consistently above for all subsets as it can be observed from the first two columns in Table 5. Localization errors of our two landmarking approaches are compared to Perakis et al. Perakis13 (last column) which, to the best of our knowledge, achieves the highest performance in the literature on these datasets. The results show the robustness of our methods to both expression variations and to rotations. The mean localization error is under on all tested subsets for both GRID and SMUF. Since the training data is taken from the Bosphorus dataset (acquired with a different 3D camera), the results also imply good generalization to data from different sensors. All experiments from this section were performed using 5 DMs, as we observed earlier in Section 4.2 that this setting is the most robust to rotation variations.
{comment}
4.4 Comparison to the State-of-the-art
In the next series of experiments, we compare the performance of GRID and SMUF to the performance of state-of-the-art landmarking methods from the literature. Specifically, we select the method of Sukno et al.Sukno15 , the technique of Creusot et al. Creusot13 , and the landmarking approaches of Passalis et al.Passalis11 and Perakis et al. Perakis13 for our comparison. To the best of our knowledge these landmarking methods are the only ones that were evaluated on both frontal as well as rotated 3D facial images. Following the experimental protocols of other authors, we used the DB00F45RL subset when performing experiments on the FRGCv2+UND database and used the entire database for experimentation on the Bosphorus dataset. Additionally, we also implement our gated landmarking approach with hand-crafted binary features, that is, with LBPs (uniform, neighborhood size of 8 and radius of 1) to capitalize on the usefulness of learning binary features instead of using off-the-shelf binary feature extractors.
The results of the comparison are shown in Table 6. We observe that on the Bosphorus dataset both GRID and SMUF significantly outperform the competing methods from the literature and achieve not only lower average localization errors, but also significantly smaller standard deviations on these errors. The only exception here are the nose tip and corners, where the method of Sukno performs similarly or slightly better. We also see similar results for the FRGC-UND dataset, where both GRID and SMUF achieve a considerable reduction in the localization errors for all considered landmarks compared to the state-of-the-art.
When comparing the learned binary features used in SMUF to the hand-crafted LBP features, we also see an obvious performance improvement with the learned features, re-enforcing our assumption that learning binary features is beneficial for face alignment. The comparison between GRID and SMUF shows a similar picture as in the previous series of experiments, where GRID was found to perform slightly better than SMUF, but not significantly so.
4.5 Landmark Analysis
In this section we evaluate how the overall localization performance varies across the individual landmarks for both GRID and SMUF. Fig. 8 illustrates the mean localization errors achieved for the individual landmarks - the size of the circles is proportional to the errors. It can be observed that the landmarks corresponding to the nose tip and eye and mouth corners exhibit low localization errors. This is expected as these landmarks correspond to well pronounced facial parts with distinctive “corner-like” shapes. Contrary, landmarks relating to nose saddle points, the chin tip and eyebrow points correspond to indistinctive “edge-like” local shapes and, therefore, result in high localization errors. This observation is also supported by the box plots in Figs. 9 and 10 that show localizations errors of individual landmarks on the Bosphorus and the FRGCv2+UND databases.The presented behaviour is consistent for both evaluated methods.
To further analyze the landmarking performance of GRID and SMUF and their generalization ability, we also performed a cross-database experiment, where we built the test set with images from the FRGCv2+UND dataset, while the training set was generated using images from the Bosphorus dataset. Results relating to the cross-database experiment are illustrated by the green box plots in Fig. 10. When compared to the experiment where both training and test sets are from the FRGCv2+UND dataset, we observe a slight increase in localization errors for most of the landmarks, except the chin tip where the difference between mean errors is larger. We presume that the high mean error for the chin tip comes from the increased appearance variability caused by the face detection procedure needed for the FRGCv2+UND data. (see Fig. 12g). Since such variability is not present in the training set from the Bosphorous dataset, the landmarking procedures cannot learn to accommodate for the inaccuracies of the face detector. In terms of comparison of GRID and SMUF, we see no significant difference in their performance in these experiments.
4.6 Qualitative Evaluation
In this section we qualitativelly assess the landmarking performance of the proposed landmarking methods. Figs. 11 and 12 show exemplar face images from the Bosphorus and UND datasets with localized landmarks marked by red dots. The top rows of both figures contain samples with typical localization performance, where we can see that the method possess stable performance in the presence of different types of variability, such as expressions, partial occlusions and head rotations. However, there are some cases where landmarks are poorly localized. Such samples with large localization errors are exposed in the second rows of Figs. 11 and 12. E.g., large occlusions of face areas (Figs. 11k and 11l) can cause increased localization errors of visible landmarks. Some of the localization errors originate from poor face detection and cropping, where an image can contain also non-head regions (Figs. 12e and 12g) or parts of the face area are cropped out (Fig. 12f). Mis-selected descent maps can also be the cause of landmark localization errors (Figs. 11o, 11p and 12h).
4.7 Computational Cost
In the last series of the experiments we evaluate the time needed by the GRID and SMUF methods to localize landmarks on a single test image on average. We compute the average processing time over randomly selected test images from the Bosphorous dataset. The size of the input images is and we compute the locations of all landmarks during the benchmark. A PC with the following specifications is used for the assessment: Intel Xeon CPU with RAM. Both landmarking techniques theare implemented using Matlab and could be further sped up if implemented with a compiled language such as C/C++. We start from detected and localized face regions and measure the time for feature extraction, DM selection and location updates, which take less than for SMUF (see Fig. 13) and little less than for GRID. When compared to handcrafted features, the learned binary features can be extracted almost 3 times faster than HOG features and 15 times faster than LBP features.
5 Conclusion and Future Work
We have presented two approaches to facial landmark localization from 3D face images, GRID and SMUF, that are robust to rotations, facial expressions and partially also to occlusions. We proposed a gating mechanism that allowed us to incorporate multiple pose-specific landmarking models (based on HOG features) into the alignment procedure and also developed a simultaneous descent map and binary feature learning algorithm around the proposed gating mechanism. To assess performance we evaluated the developed landmarking techniques on three challenging datasets, containing 3D face images with large head rotations. Our results showed that the proposed solutions exhibit high robustness to different types of appearance variations and display competitive performance when compared to the state-of-the-art.
As part of our future work we plan to combine the proposed landmarking methods with face frontalization (or pose correction) procedures and incorporate all developed methods into pose-invariant 3D face recognition systems.
Acknowledgements.
This research was supported in parts by the ARRS (Slovenian Research Agency) Research Program P2-0250 (B) Metrology and Biometric Systems, the ARRS Research Program P2-0214 (A) Computer Vision, and the RS-MIZŠ and EU-ESRR funded GOSTOP.
Compliance with ethical standards
Conflict of interest The authors declare that they have no conflict of interest.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1) Alyüz, N., Gökberk, B., Akarun, L.: Regional Registration for Expression Resistant 3-D Face Recognition. IEEE Transactions on Information Forensics and Security 5 (3), 425–440 (2010)
- 2(2) Camgöz, N.C., Štruc, V., Gökberk, B., Akarun, L., Kindiroğlu, A.A.: Facial Landmark Localization in Depth Images Using Supervised Ridge Descent. In: Computer Vision Workshop (ICCVW), 2015 IEEE International Conference on, pp. 378–383 (2015)
- 3(3) Cao, Y., Lu, B.L.: Neural Information Processing: 22nd International Conference, ICONIP 2015, November 9-12, 2015, Proceedings, Part IV, chap. Intensity-Depth Face Alignment Using Cascade Shape Regression, pp. 224–231. Springer International Publishing, Cham (2015)
- 4(4) Cootes, T.F., Walker, K., Taylor, C.J.: View-based active appearance models. In: Proceedings Fourth IEEE International Conference on Automatic Face and Gesture Recognition (Cat. No. PR 00580), pp. 227–232. IEEE (2000)
- 5(5) Creusot, C., Pears, N., Austin, J.: A Machine-Learning Approach to Keypoint Detection and Landmarking on 3D Meshes. International Journal of Computer Vision 102 (1), 146–179 (2013)
- 6(6) Faltemier, T.C., Bowyer, K.W., Flynn, P.J.: Rotated Profile Signatures for robust 3D feature detection. In: Automatic Face Gesture Recognition, 2008. FG ’08. 8th IEEE International Conference on, pp. 1–7 (2008)
- 7(7) Fanelli, G., Dantone, M., Gall, J., Fossati, A., Gool, L.: Random Forests for Real Time 3D Face Analysis. International Journal of Computer Vision 101 (3), 437–458 (2012)
- 8(8) Fanelli, G., Dantone, M., Gool, L.V.: Real time 3D face alignment with Random Forests-based Active Appearance Models. In: Automatic Face and Gesture Recognition (FG), 2013 10th IEEE International Conference and Workshops on, pp. 1–8 (2013)