Informative sample generation using class aware generative adversarial networks for classification of chest Xrays
Behzad Bozorgtabar, Dwarikanath Mahapatra, Hendrik von Teng, Alexander, Pollinger, Lukas Ebner, Jean-Phillipe Thiran, Mauricio Reyes

TL;DR
This paper introduces an active learning framework combined with a class-aware GAN to generate realistic chest X-ray images, effectively addressing class imbalance and improving disease classification with less data.
Contribution
It presents a novel combination of active learning and class-aware GANs for data augmentation in medical imaging, enhancing classification performance with fewer labeled samples.
Findings
Achieves state-of-the-art performance using only 35% of the dataset.
Effective data augmentation improves disease detection accuracy.
Reduces data annotation effort significantly.
Abstract
Training robust deep learning (DL) systems for disease detection from medical images is challenging due to limited images covering different disease types and severity. The problem is especially acute, where there is a severe class imbalance. We propose an active learning (AL) framework to select most informative samples for training our model using a Bayesian neural network. Informative samples are then used within a novel class aware generative adversarial network (CAGAN) to generate realistic chest xray images for data augmentation by transferring characteristics from one class label to another. Experiments show our proposed AL framework is able to achieve state-of-the-art performance by using about of the full dataset, thus saving significant time and effort over conventional methods.
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3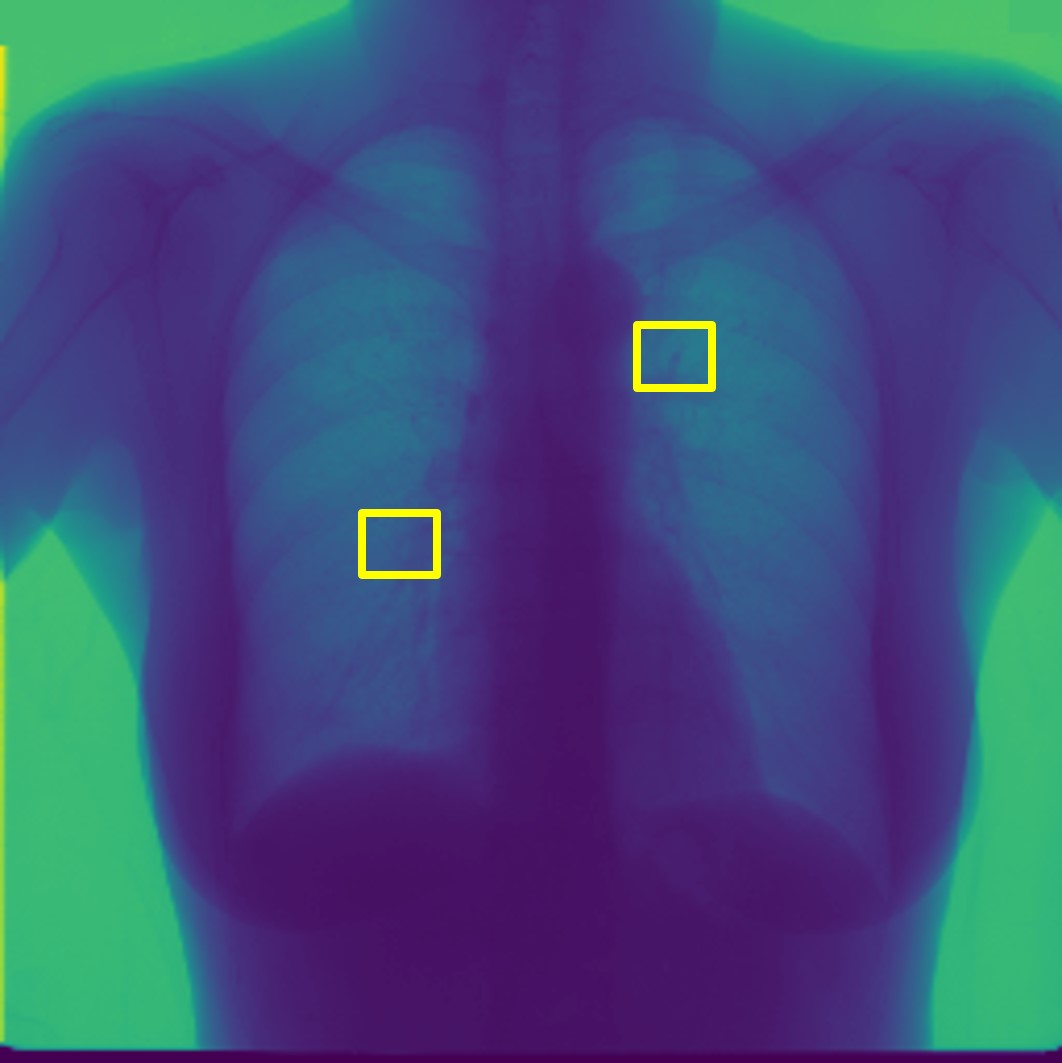 Figure 4
Figure 4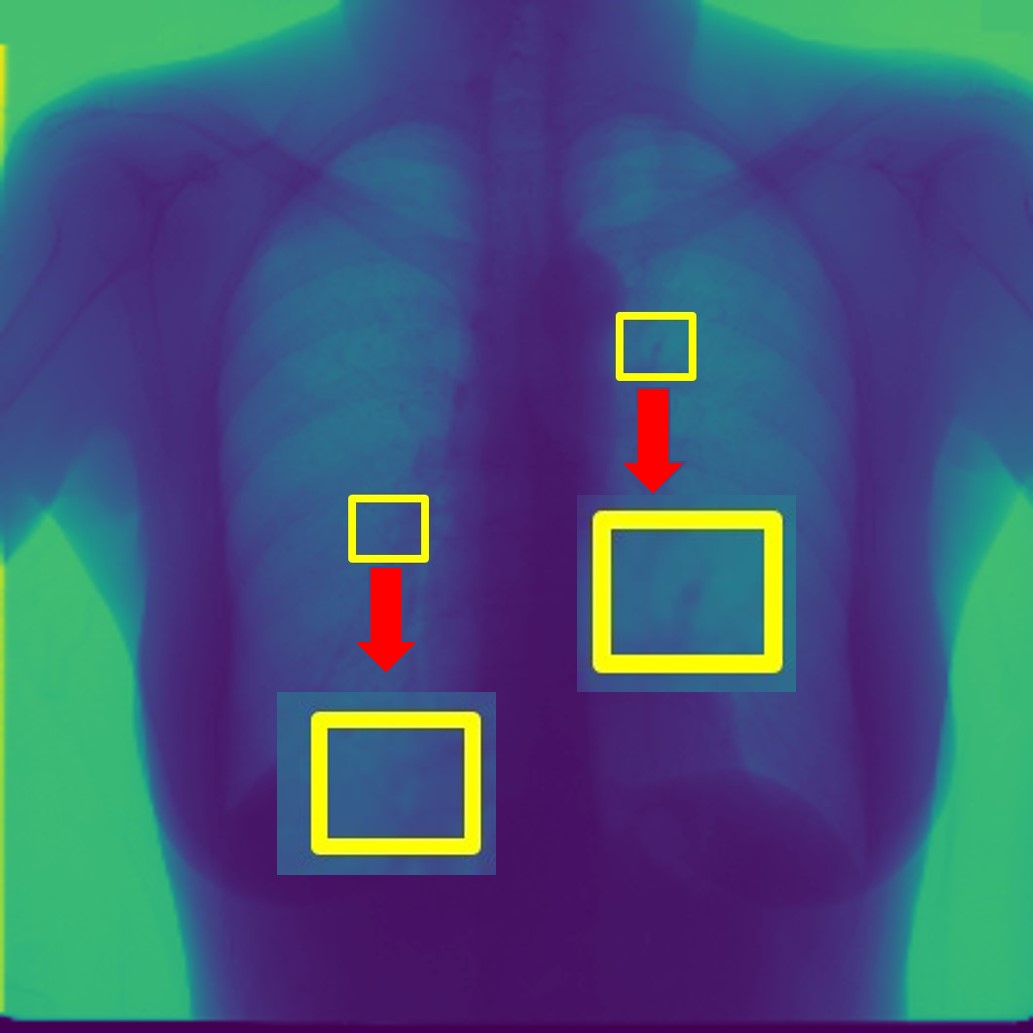 Figure 5
Figure 5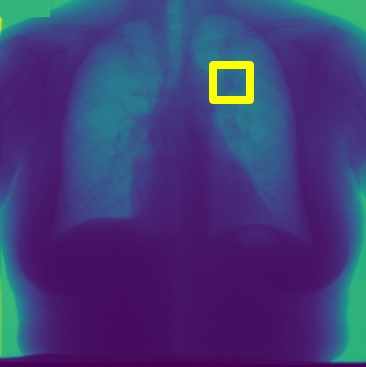 Figure 6
Figure 6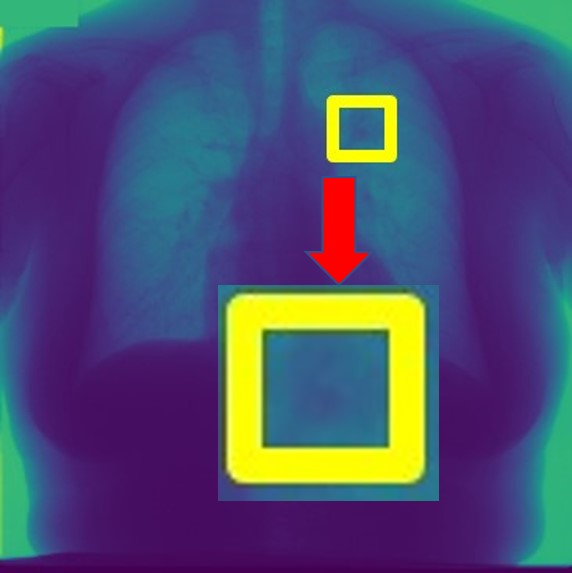 Figure 7
Figure 7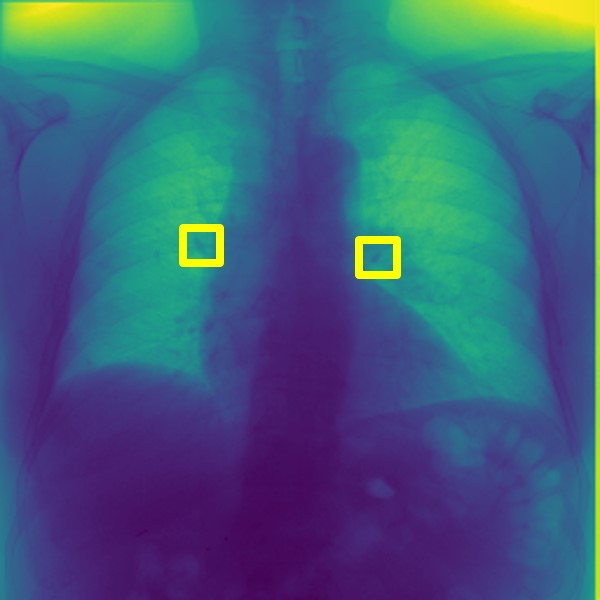 Figure 8
Figure 8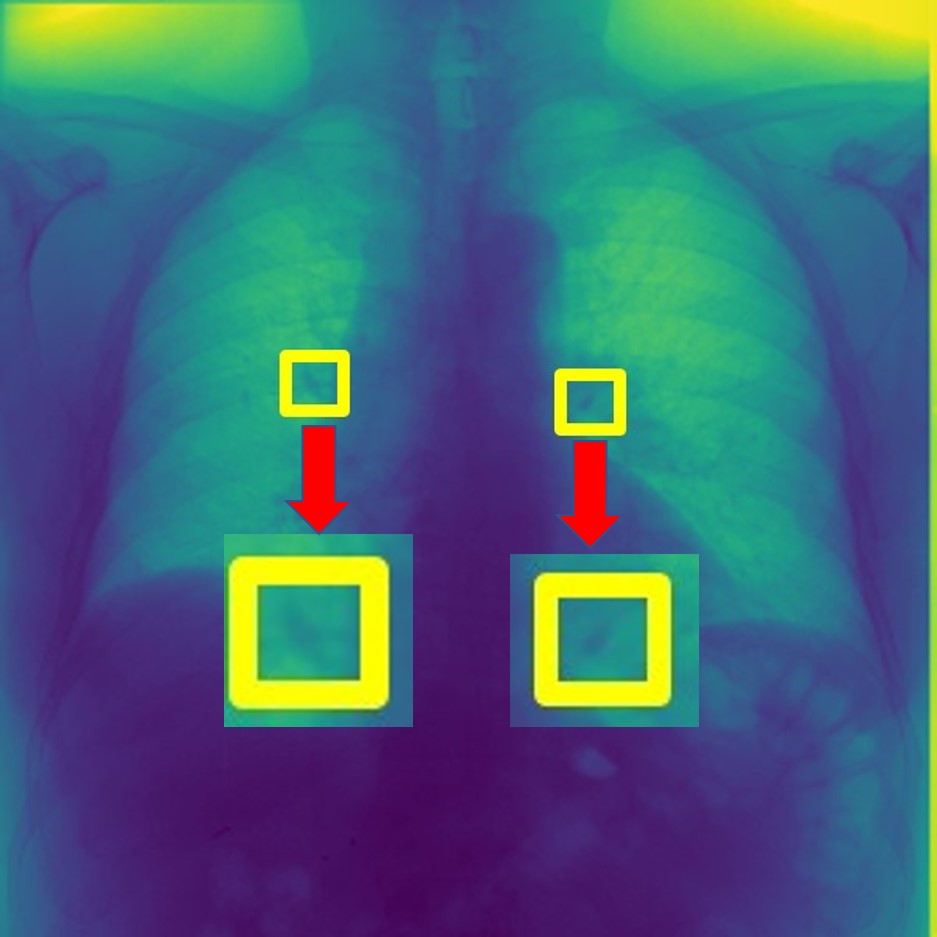 Figure 9
Figure 9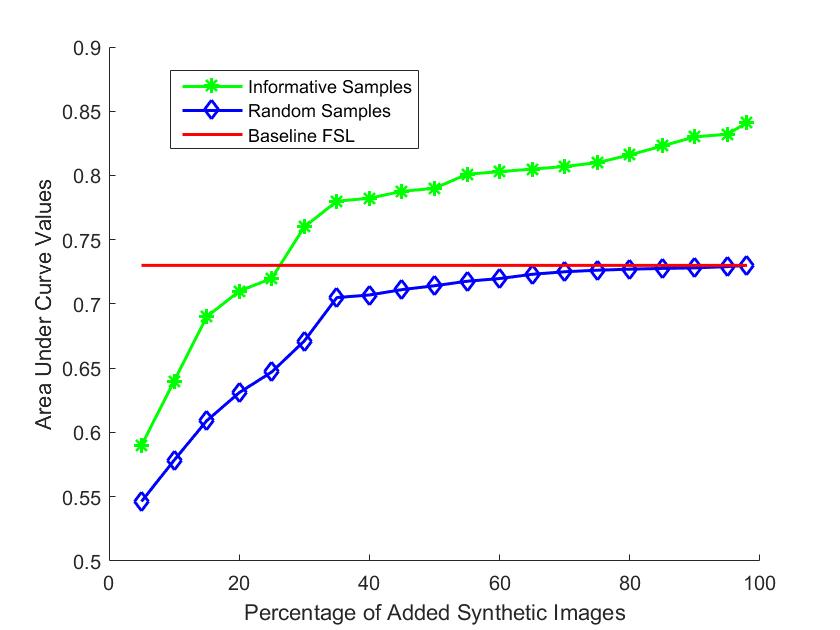 Figure 10
Figure 10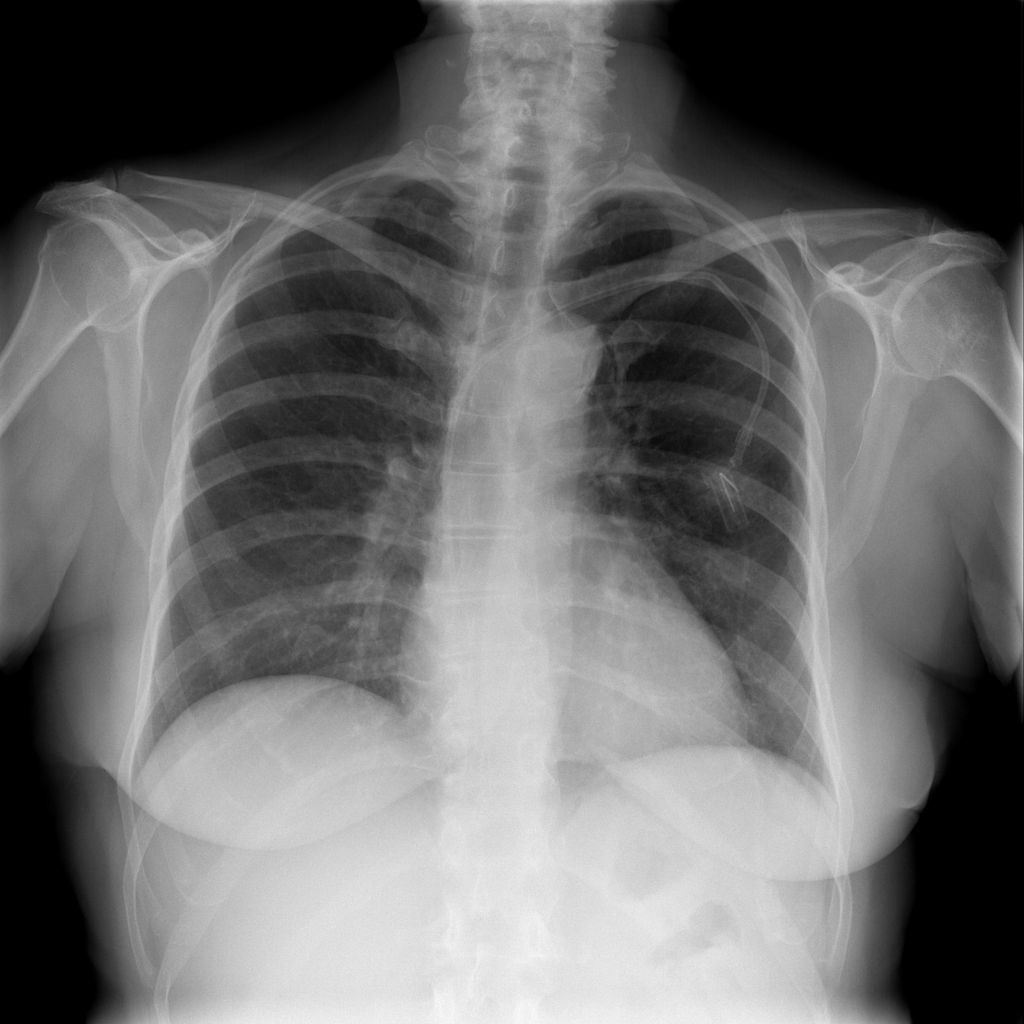 Figure 11
Figure 11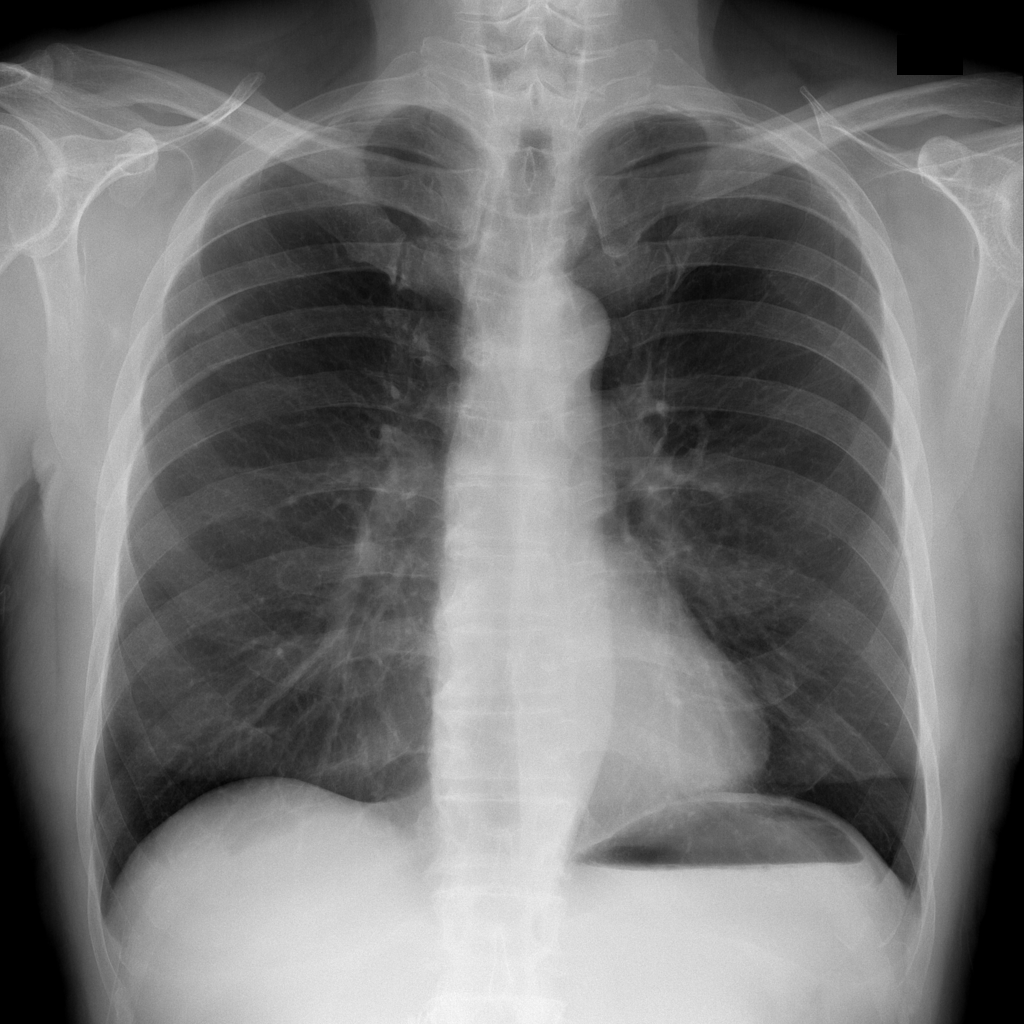 Figure 12
Figure 12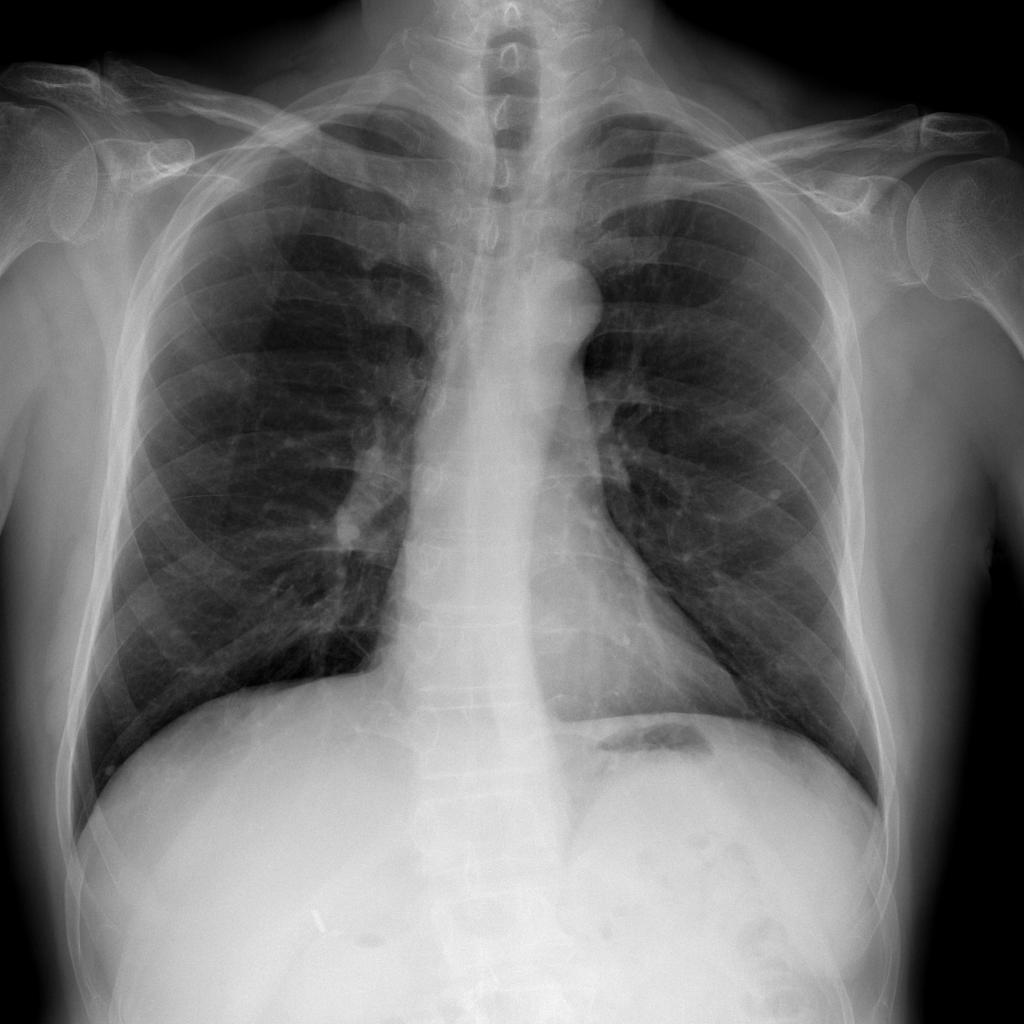 Figure 13
Figure 13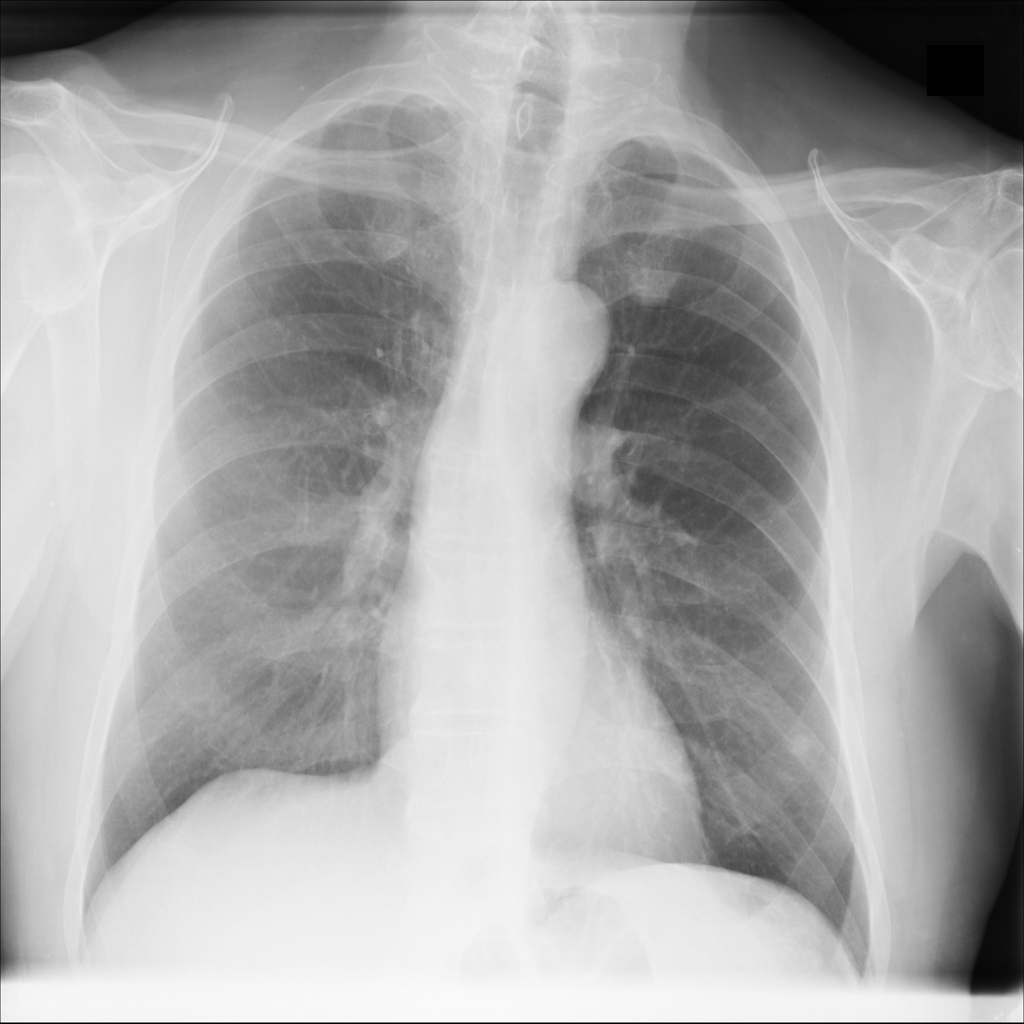 Figure 14
Figure 14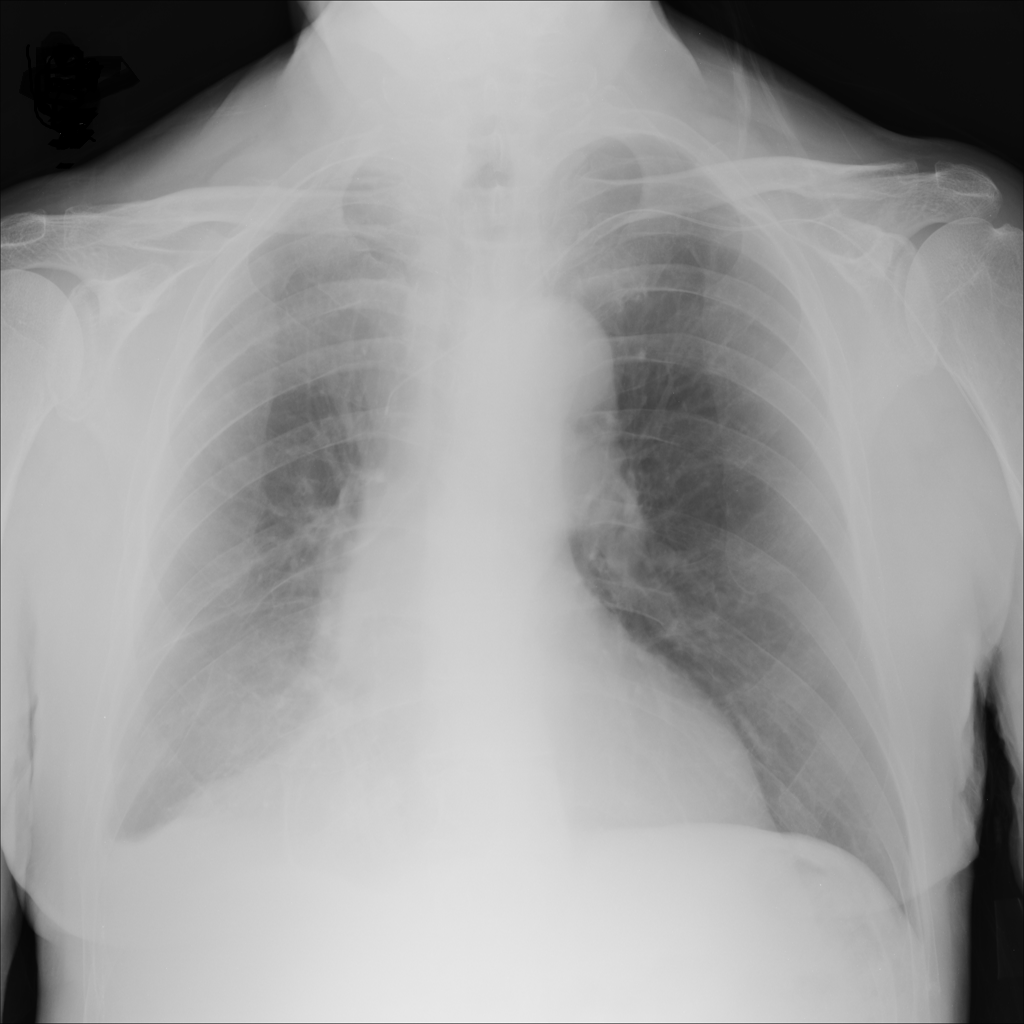 Figure 15
Figure 15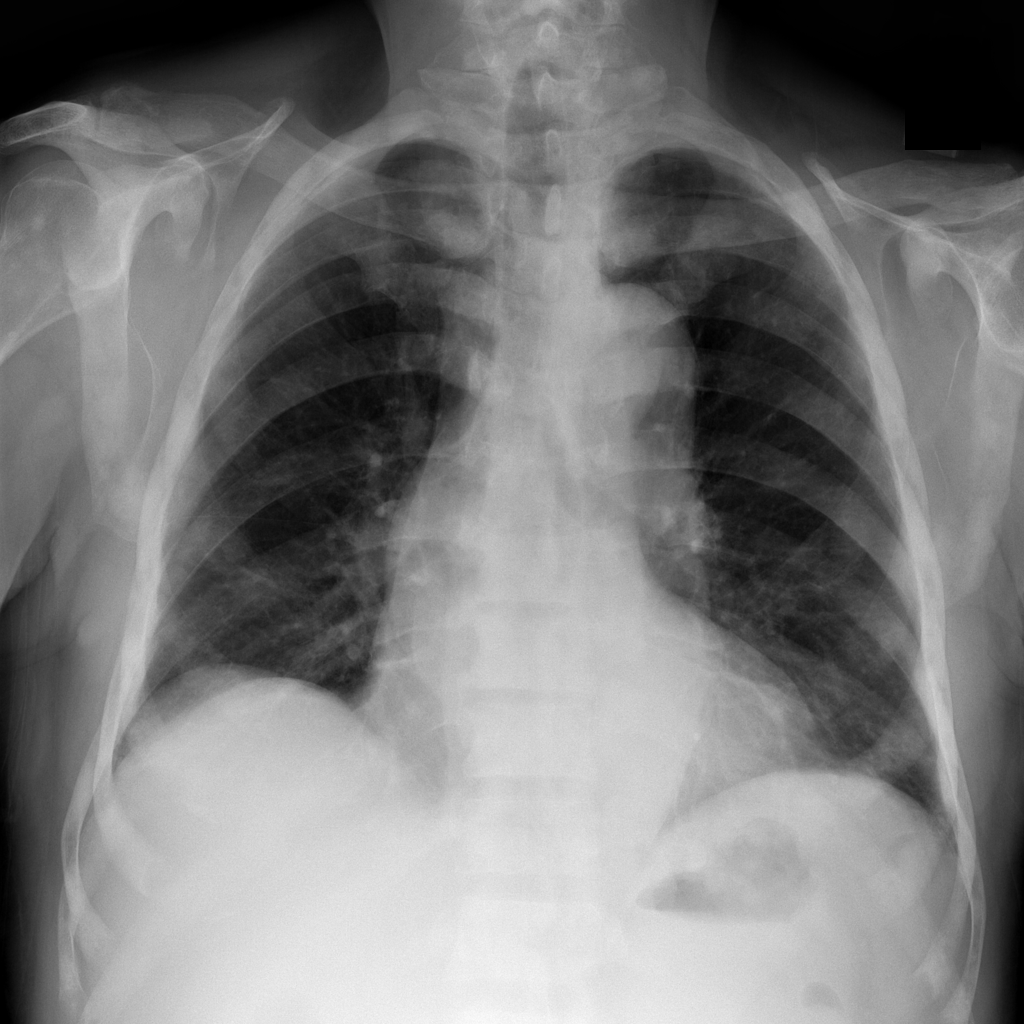 Figure 16
Figure 16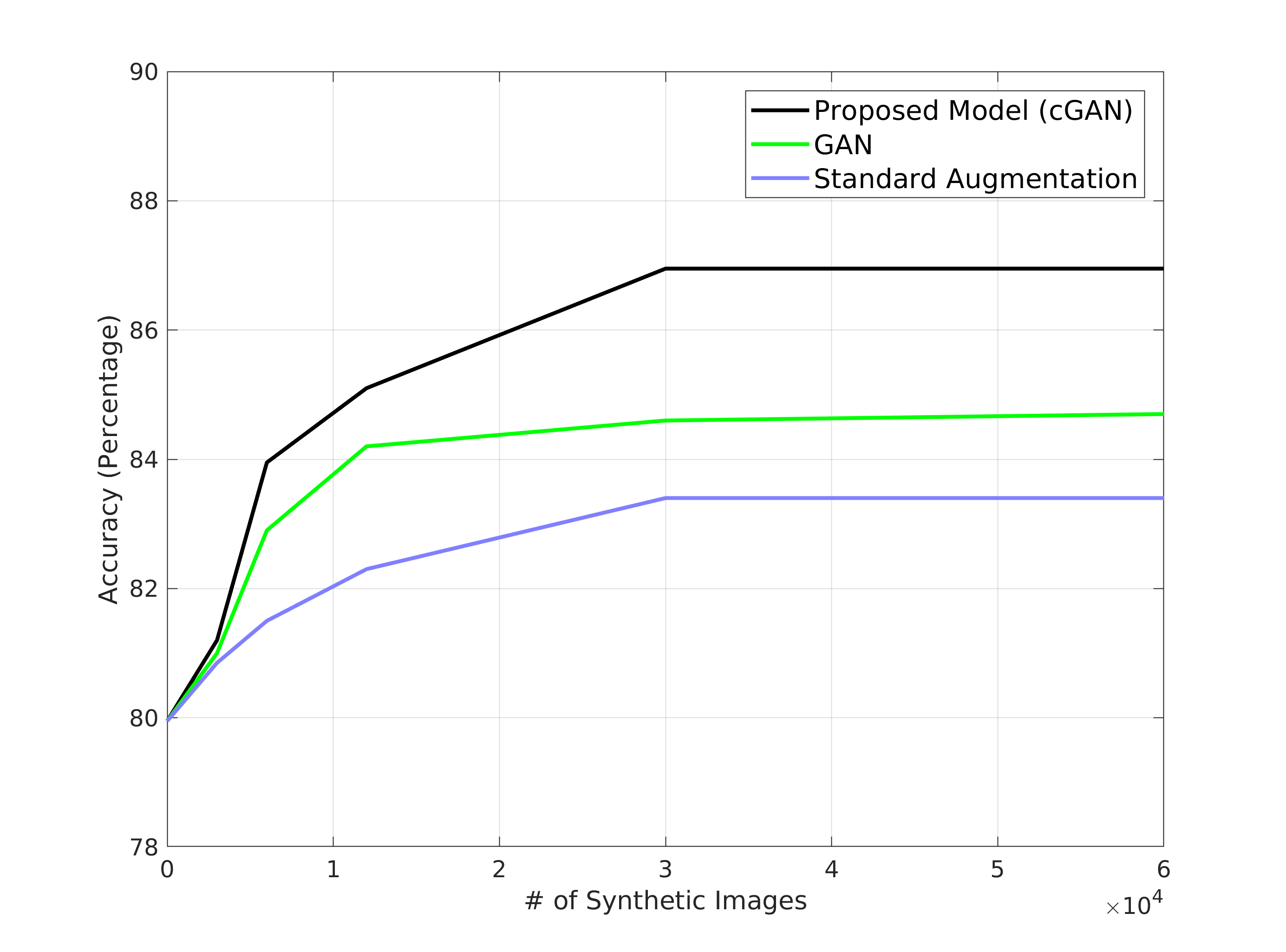 Figure 17
Figure 17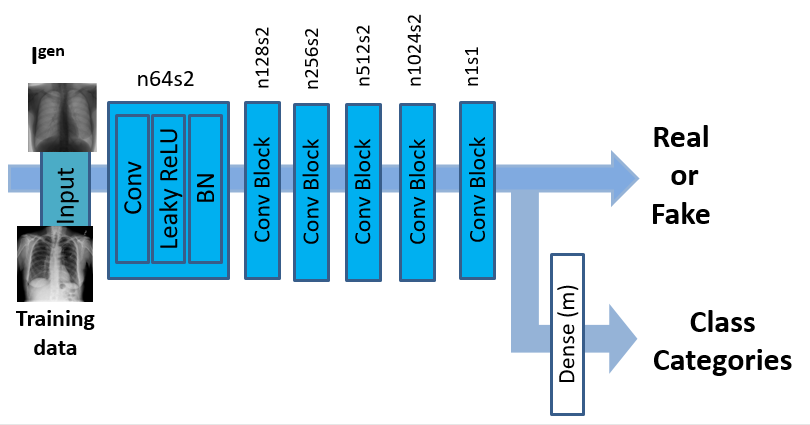 Figure 18
Figure 18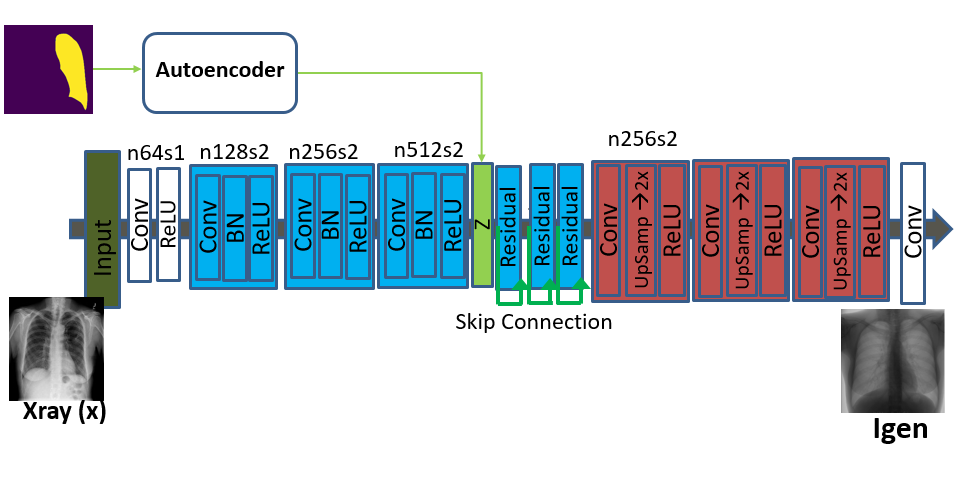 Figure 19
Figure 19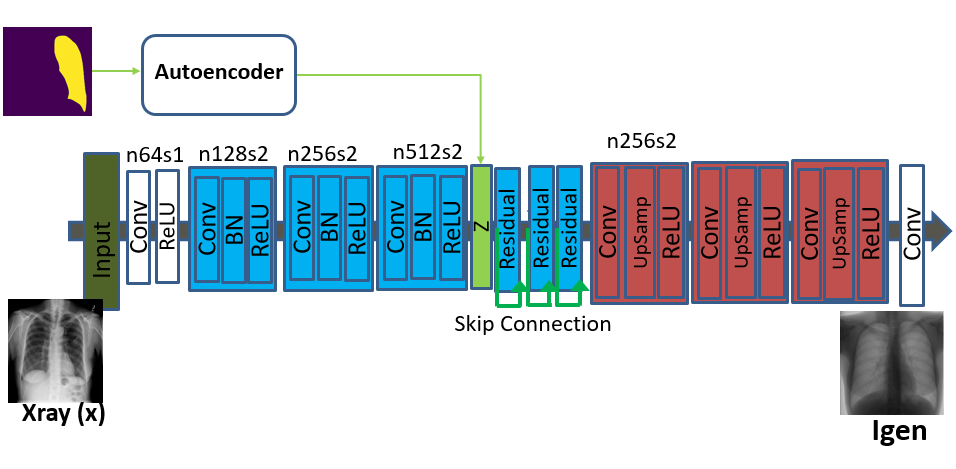 Figure 20
Figure 20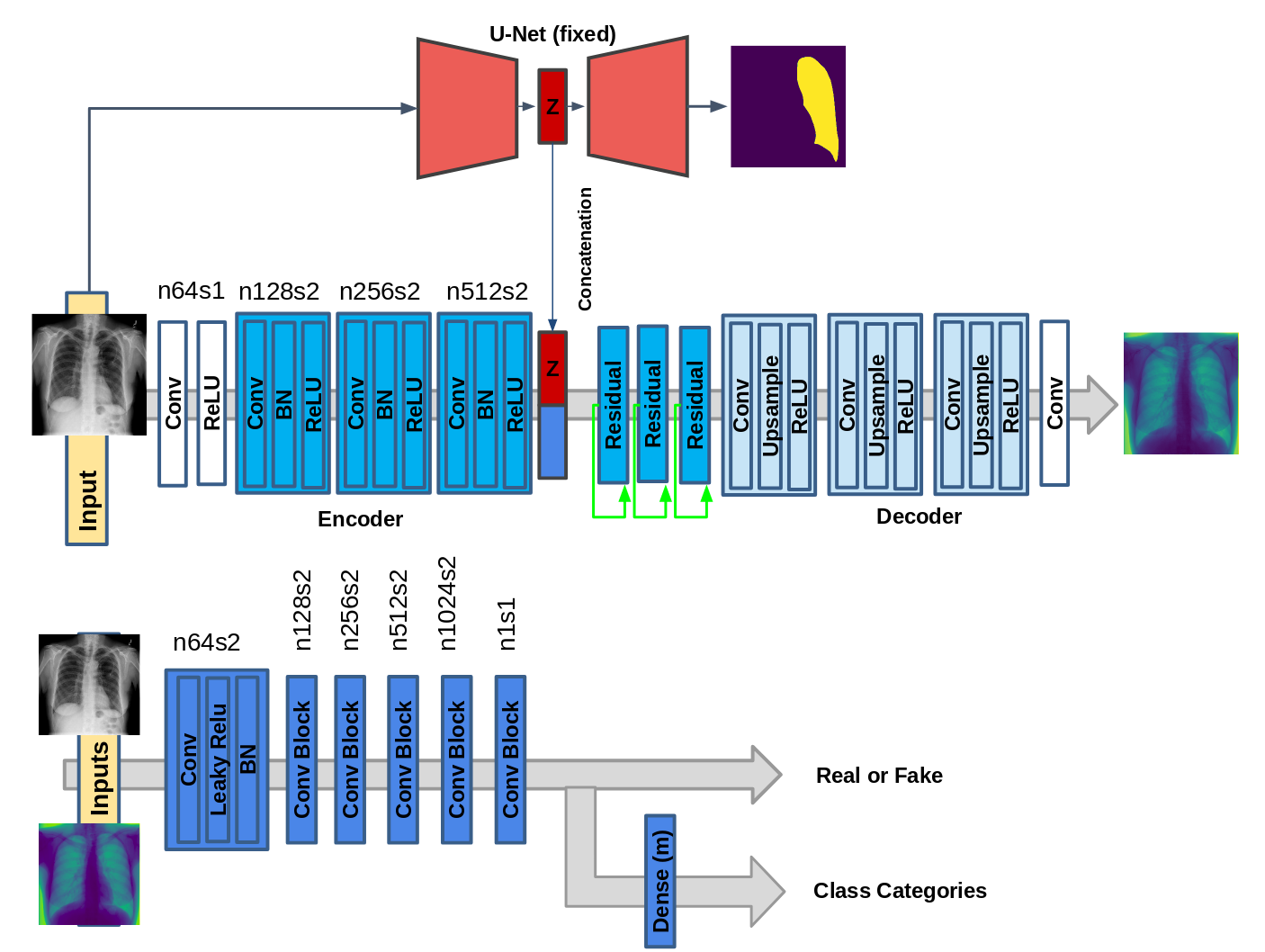 Figure 21
Figure 21| Diseased | Training Samples | |||
|---|---|---|---|---|
| Image | ||||
| Atel. | 14.24 | 0.7456 | 0.7765 | 0.8094 |
| Card. | 3.42 | 0.8653 | 0.8856 | 0.9248 |
| Eff. | 16.43 | 0.8121 | 0.8231 | 0.8638 |
| Infil. | 24.53 | 0.6923 | 0.7011 | 0.7345 |
| Mass | 7.094 | 0.7915 | 0.8188 | 0.8676 |
| Nodule | 7.80 | 0.7384 | 0.7532 | 0.7802 |
| Pneu. | 1.67 | 0.7128 | 0.7321 | 0.7680 |
| Pneumot. | 6.54 | 0.8275 | 0.8412 | 0.8887 |
| Consol. | 5.76 | 0.7245 | 0.7422 | 0.7901 |
| Edema | 2.84 | 0.8126 | 0.8347 | 0.8878 |
| Emphy. | 3.10 | 0.8571 | 0.8876 | 0.9371 |
| Fibr. | 2.08 | 0.7348 | 0.7562 | 0.8047 |
| PT | 4.17 | 0.7487 | 0.7634 | 0.8062 |
| Hernia | 0.28 | 0.8465 | 0.8694 | 0.9164 |
| Active learning ( labeled) | ||||
| 5% | 10% | 15% | 25% | |
| 0.5832 | 0.6013 | 0.6375 | 0.6691 | |
| 0.6129 | 0.6539 | 0.7053 | 0.7321 | |
| 0.4981 | 0.5274 | 0.5672 | 0.5952 | |
| 0.5464 | 0.5784 | 0.6091 | 0.6471 | |
| Active learning ( labeled) | ||||
| 30% | 35% | 50% | ||
| 0.6985 | 0.7236 | 0.7408 | 0.7578 | |
| 0.7662 | 0.7859 | 0.7981 | 0.8065 | |
| 0.6216 | 0.6462 | 0.6782 | 0.6842 | |
| 0.6723 | 0.7047 | 0.7142 | 0.7263 | |
| Training Samples with AL and FSL | |||
| Atel. | 0.7701 | 0.7987 | 0.7351 |
| Cardi.y | 0.8792 | 0.9208 | 0.8711 |
| Eff. | 0.8205 | 0.8588 | 0.8173 |
| Infil. | 0.7459 | 0.7859 | 0.7047 |
| Mass | 0.8114 | 0.8627 | 0.8203 |
| Nodule | 0.7682 | 0.7954 | 0.7376 |
| Pneu. | 0.7579 | 0.7898 | 0.7341 |
| Pneumot. | 0.8389 | 0.8912 | 0.8412 |
| Consol. | 0.7387 | 0.8054 | 0.7517 |
| Edema | 0.8276 | 0.8829 | 0.8597 |
| Emphy. | 0.8831 | 0.9228 | 0.9052 |
| Fibr. | 0.7625 | 0.8174 | 0.7751 |
| PT | 0.7568 | 0.7965 | 0.7817 |
| Hernia | 0.8765 | 0.9187 | 0.8938 |
| Active learning ( labeled) | ||||
| 5% | 10% | 15% | 25% | |
| 0.5592 | 0.5841 | 0.6135 | 0.6416 | |
| 0.6022 | 0.6411 | 0.6755 | 0.7037 | |
| 0.4873 | 0.5147 | 0.5529 | 0.5794 | |
| 0.5380 | 0.5643 | 0.5932 | 0.6345 | |
| Active learning ( labeled) | ||||
| 30% | 35% | 50% | ||
| 0.6724 | 0.7013 | 0.7184 | 0.7287 | |
| 0.7347 | 0.7518 | 0.7754 | 0.7852 | |
| 0.6022 | 0.6221 | 0.6501 | 0.6714 | |
| 0.6531 | 0.6782 | 0.6933 | 0.7044 | |
| Active learning ( labeled) | ||||
| 5% | 10% | 15% | 25% | |
| 0.5131 | 0.6013 | 0.6375 | 0.6691 | |
| 0.5478 | 0.5827 | 0.6237 | 0.6783 | |
| 0.5741 | 0.6175 | 0.6653 | 0.7024 | |
| 0.5867 | 0.6311 | 0.6795 | 0.7191 | |
| Active learning ( labeled) | ||||
| 30% | 35% | 50% | ||
| 0.6985 | 0.7236 | 0.7408 | 0.7578 | |
| 0.7014 | 0.7216 | 0.7398 | 0.7516 | |
| 0.7253 | 0.7561 | 0.7702 | 0.7887 | |
| 0.7408 | 0.7732 | 0.7812 | 0.8016 | |
| Atel. | 0.7294 | 0.7325 | 0.7387 | 0.7314 |
| Cardio. | 0.8679 | 0.8692 | 0.8754 | 0.8702 |
| Eff. | 0.8104 | 0.8134 | 0.8081 | 0.8128 |
| Infil. | 0.7076 | 0.7098 | 0.6976 | 0.7126 |
| Mass | 0.8176 | 0.8193 | 0.8247 | 0.8246 |
| Nodule | 0.7418 | 0.7345 | 0.7405 | 0.7321 |
| Pneu. | 0.7281 | 0.7386 | 0.7305 | 0.7397 |
| Pneumot. | 0.8375 | 0.8463 | 0.8427 | 0.8359 |
| Consol. | 0.7532 | 0.7465 | 0.7572 | 0.7427 |
| Edema | 0.8642 | 0.8621 | 0.8515 | 0.8548 |
| Emphy. | 0.9104 | 0.9074 | 0.9135 | 0.9004 |
| Fibr. | 0.7729 | 0.7825 | 0.7813 | 0.7696 |
| PT | 0.7894 | 0.7827 | 0.7749 | 0.7792 |
| Hernia | 0.8874 | 0.8904 | 0.8986 | 0.9025 |
| Atel. | 0.7263 | 0.7306 | 0.7374 | 0.7321 |
| Cardio. | 0.8687 | 0.8736 | 0.8682 | 0.8741 |
| Eff. | 0.8192 | 0.8064 | 0.8218 | 0.8098 |
| Infil. | 0.6989 | 0.7024 | 0.7114 | 0.6987 |
| Mass | 0.8126 | 0.8252 | 0.8171 | 0.8215 |
| Nodule | 0.7461 | 0.7398 | 0.7297 | 0.7304 |
| Pneu. | 0.7387 | 0.7294 | 0.7254 | 0.7332 |
| Pneumot. | 0.8472 | 0.8433 | 0.8348 | 0.8391 |
| Consol. | 0.7502 | 0.7561 | 0.7481 | 0.7542 |
| Edema | 0.8637 | 0.8529 | 0.8674 | 0.8563 |
| Emphy. | 0.9028 | 0.9086 | 0.9104 | 0.9137 |
| Fibr. | 0.7704 | 0.7781 | 0.7834 | 0.7729 |
| PT | 0.7854 | 0.7803 | 0.7829 | 0.7873 |
| Hernia | 0.8875 | 0.8958 | 0.8982 | 0.8914 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsAI in cancer detection · COVID-19 diagnosis using AI · Generative Adversarial Networks and Image Synthesis
Informative sample generation using class aware generative adversarial networks for classification of chest Xrays
Behzad Bozorgtabar
Dwarikanath Mahapatra
Hendrik von Teng
Alexander Pollinger
Lukas Ebner
Jean-Phillipe Thiran
Mauricio Reyes
Signal Processing Laboratory (LT55), Ecole Polytechnique Féderale de Lausanne (EPFL-STI-IEL-LT55), Station 11, 1015 Lausanne, Switzerland
Center for Biomedical Imaging, Lausanne, Switzerland
IBM Research Australia, Melbourne 3006, Australia
University Institute for Diagnostic, Interventional, and Pediatric Radiology, University Hospital Bern, Switzerland
Department of Radiology, University Hospital Center (CHUV), University of Lausanne (UNIL), Lausanne, Switzerland
University of Bern, Bern 3014, Switzerland
Abstract
Training robust deep learning (DL) systems for disease detection from medical images is challenging due to limited images covering different disease types and severity. The problem is especially acute, where there is a severe class imbalance. We propose an active learning (AL) framework to select most informative samples for training our model using a Bayesian neural network. Informative samples are then used within a novel class aware generative adversarial network (CAGAN) to generate realistic chest xray images for data augmentation by transferring characteristics from one class label to another. Experiments show our proposed AL framework is able to achieve state-of-the-art performance by using about of the full dataset, thus saving significant time and effort over conventional methods.
keywords:
GAN, Active learning , Classification , Chest Xray , Informative Samples
††journal: Computer Vision and Image Understanding
1 Introduction
Medical image classification is an essential component of computer aided diagnosis systems, where deep learning (DL) approaches have led to state-of-the-art performance (Tajbakhsh et al., 2016). Robust DL approaches need large labeled datasets, which is challenging to obtain for medical images because of: 1) limited expert availability; 2) intensive manual effort required to curate (i.e. label) datasets; and 3) paucity of images for specific disease labels leading to class imbalance. In most public medical image databases, there is a severe class imbalance. For example in the NIH chest Xray-14 dataset (Wang et al., 2017b) more than of the patient samples consist of normal cases, and the remaining dataset has samples from different disease types. The diseased samples are not uniformly distributed with the least represented case comprising less than of the diseased samples while the most represented case has more than of the diseased samples.
Consequently, algorithms trained on this dataset will be biased towards the majority class. Although a weighted cross entropy cost function may be used to overcome this imbalance, in practice we find that this is not optimal for datasets with multiple classes (in this case ). To overcome the limitations of unbalanced datasets we propose an active learning (AL) based approach to identify informative samples and also generate more samples for the minority classes. Our approach has the advantage of: 1) training the algorithm on the most informative samples so as to achieve at-par performance with the state-of-the-art methods, albeit with much less labeled data; 2) ensuring equal representation of all classes to improve the robustness of the trained classifier.
Existing active learning approaches overcome data scarcity by incrementally selecting the most informative unlabeled samples, querying their labels and adding them to the labeled training set (Li and Guo, 2013). AL systems are first initialized with a relatively small set of labeled data. In subsequent iterations, the most informative samples (and corresponding labels) are queried and added to the training set to update the model. AL in a DL framework poses the following challenges: 1) labeled samples generated by current AL approaches are too few to train or fine-tune convolutional neural networks (CNNs); 2) Existing AL methods select informative samples using application specific metrics, while feature learning and model training are jointly optimized in CNNs. Thus fine-tuning CNNs in the traditional AL framework may not lead to model convergence (Wang et al., 2017a). We propose a AL based framework using Class Aware Generative Adversarial Networks (CAGANs) for synthetic sample generation and use it for CNN based classification of medical images. We achieve state-of-the-art results using fewer real images while we benefit from synthetic images.
1.1 Related Work
GANs (Goodfellow et al., 2014) have been used in various applications such as image super resolution (Ledig and et. al., 2016; Mahapatra et al., 2017), image synthesis and image translation using conditional GANs (cGANs) (Isola et al., 2017) and cycle GANs (cycleGANs) (Zhu et al., 2017). Frid-Adar et al. (Frid-Adar et al., 2018) propose a data augmentation method using GANs that synthetically enlarges the training dataset for model improvement. In the standard GAN framework (Goodfellow et al., 2014), the generator learn a mapping from random noise vector z to output image y: . Conditional GANs (cGANs) (Isola et al., 2017) learn a mapping from observed image x and random noise vector z, to y: .
Semi-supervised learning (SSL) (Chapelle et al., 2006) and active learning (Settles and Craven, 2008) methods have been used to overcome the limitations of insufficient labeled samples in medical applications such as segmenting anatomical structures (Iglesias et al., 2011; Mahapatra et al., 2013c) and detecting cancerous regions (Doyle et al., 2011). An important component of AL systems is the query strategy to select the most “informative” sample and popular approaches include uncertainty sampling (Lewis and Catlett, 1994), query-by-committee (QBC) (Freund et al., 1997) and density weighting (Settles and Craven, 2008). An excellent review of different query strategies is given in (Settles and Craven, 2008).
In recent work on using AL with deep neural networks (DNNs), Gal et. al. (Gal et al., 2017) use Bayesian deep neural networks to design an active learning framework for high dimensional data. Wang et al. (Wang et al., 2017a) propose a ‘cost-effective AL approach for computer vision applications, which leverages unlabeled data with high classification uncertainty and high confidence to update the classifier. Yang et al. (Yang et al., 2017) use AL with fully convolutional networks (FCN) for segmenting histopathology images.
In our recent work (Mahapatra et al., 2018a), we proposed a conditional GAN (cGAN) based approach for AL based medical image classification and segmentation. As our second contribution, we hypothesized that a time-effective (i.e. reduced expert monitoring/correction) active learning approach can be obtained by joining the process of sample selection, via its informativeness, and data augmentation for model training improvement. In particular, we proposed image synthesis model that learns to generate realistic images from samples chosen by means of model uncertainty using a Bayesian deep neural network. Thus, the system not only generates realistic samples, but utilizes the model uncertainty estimates on input samples to drive its data augmentation process on challenging samples. Promising preliminary results were obtained for image segmentation and classification of lung images.
In this paper we build on these preliminary results of (Mahapatra et al., 2018a) and expand the study to a much larger dataset. In addition, we perform a deeper comparison to standard data augmentation approaches and analyze the benefits of utilizing a proposed GAN based model, by comparing it to a regular GAN for synthetic data generation. Finally, we extend the methodology to a Class-Aware Generative Adversarial Network (CAGAN) to incorporate a class balancing component, which is able to transfer image characteristics across samples of different classes.
We test the proposed approach for the key task of medical image classification for disease detection, demonstrating its ability to yield models with high accuracy while reducing the number of samples required for training. The rest of the paper is arranged as follows: Section 2 describes our method and highlights our active learning framework. Section 3 describes the dataset, the detailed implementation of our method and the results of different experiments. Finally we conclude with Section 4 with a summary of our findings and potential future work.
1.2 Contributions
Our paper makes the following contributions:
We propose a Class-Aware Generative Adversarial Network based AL framework that boosts a classifier using synthetically generated samples and transfers learnt characteristics between different classes; 2. 2.
We show that use of our approach leads to realistic generated images that contribute to improving the performance of a classification system despite having very small number of real training samples. Further, compared to GANs, we show that a better performance can be attained through a proposed CAGAN model to focus the data augmentation process on samples the model has difficulties with. 3. 3.
The synthetically generated images are able to alleviate the common problem of class imbalance in medical image analysis tasks thus resulting in more robust classification systems.
2 Methods
We first describe our approach (CAGAN) in 2.1, then the proposed AL approach will be discussed in 2.4. The former generates realistic samples that introduces meaningful information in the training mode, while the latter identifies informative samples to improve model performance. This is different from conventional AL approaches, which identify informative samples using an uncertainty measure. Since medical datasets acquired in a few locations under similar conditions offer limited diversity, uncertainty may not be very effective due to model bias. Our framework is able to overcome this limitation using three components for: 1) sample generation; 2) classification model; and 3) sample informativeness calculation.
To show the usefulness of the generated images, we employ a data augmentation strategy for our experiments. A few annotated samples are used to finetune a pre-trained VGG16 (Simonyan and Zisserman., 2014) (or any other classification network) using standard data augmentation such as rotation, translation and scaling. The sample generator takes an input image of any class (the base class label) and generates realistic looking images of the specified class label which may be different from the base label. A Bayesian neural network (BNN) (Kendall and Gal, 2017) calculates generated images’ informativeness and highly informative samples are added to the labeled image set. The new training images are used to fine-tune the previously trained classifier. This updated classifier is tested on a separate validation set which is different from the training and test set and whose size does not change. If the classification performance of the updated classifier on the validation set (in terms of AUC values) does not change significantly for such updates then we assume there are no more informative images and we stop the sample selection.
The training steps are summarized in Algorithm 1. Note that we split our entire labeled set into training, test and validation folds. Network tuning is done using the training and validation set while all reported performance metrics are on the test set.
2.1 Class Aware Generative Adversarial Network
We present a variant of the GAN model namely Class Aware Generative Adversarial Network (CAGAN). Here, our objective is to train a generator that translates an input image into an output image conditioned on the latent vector (obtained from a pre-trained autoencoder that takes as input the output of a segmentation network), i.e., . Additionally, we introduce class information to a GAN by adding an explicit class loss term that allows the discriminator to produce probability distributions over both sources and class labels. It should be noted that the proposed approach is different from conditional GAN, where image attributes (e.g. classification categories) are fed into both generator and discriminator, respectively.
The segmentation network mentioned earlier is a UNet Ronneberger et al. (2015) that is trained to segment both lungs from an input xray image. This is done to get an automated segmentation output. During training phase, we use the manual segmentation masks of available images and this network can be used for new images that may be added to the training set. The UNet architecture consists of an encoder part with 4 convolutional layers each with filter size of and filters in each layer. The output of the final convolution layer is connected to a dimensional fully connected layer. This is then connected to the decoder path with convolution layers having filters of size in each layer.
Algorithm 1
- 1:procedure Focused Active learning based classification
2: U-Net *Pre-trained Segmentation Network *
3: CN *Initialize Classification Network *
4: CAGAN *Initialize Class Aware Generator Network *
5: loop:
6: For each input image and known target class
7: Generate latent code from U-Net
8: Use CAGAN to generate synthetic images of specified class , using and input image .
9: Quantify informativeness of generated images using Eq. 8.
10: Sort generated images in descending order of informativeness and select top informative ones
11: Re-train CN with new added informative images
12: Check performance on separate validation set
13: If AUC on validation set improves, continue to loop.
14: close
15: Outputs: Trained CN and CAGAN
end
2.1.1 Adversarial Loss
To synthesize realistic images, we adopt an adversarial loss . This reassures our network to favor solutions that reside on the manifold of natural images, by seeking to fool the discriminator network.
[TABLE]
where generates a fake image conditioned on both an observed image and the latent vector , while seeks to detect which examples are fake. The term denotes a probability distribution over sources given by .
2.1.2 Classification Loss
Now, let assume that we are given the input image and classification label pair as part of the training data. For a given input image and a target label , our goal is to generate output image, which is properly classified to the corresponding class label . To do this, we add an auxiliary classifier on top of and impose the classification loss when optimizing both networks and . We disentangle the classification loss into two terms: a classification loss of real images used to optimize , and a classification loss of fake images used to optimize . The classification loss of real images is defined as:
[TABLE]
where the term represents a probability distribution over classification labels computed by . The class loss term indicates to the model that the information we classify on will generate images, which match the target labels . On the other hand, the loss function for the classification of fake images is defined as:
[TABLE]
In above equation, is optimized to minimize this objective for correct prediction on the classifier, which demonstrates results closer to the original ones.
2.1.3 Content Loss
Using the adversarial and classification losses, the generator is trained to generate realistic images with the corresponding classes. However, it does not guarantee that synthetic images preserve the content of input images. To address this problem , we use content loss ():
[TABLE]
denotes the normalized mutual information (NMI) between and , and is used to determine similarity of image’s intensity distribution. is the intensity mean square error. In addition, we use the VGG loss based on the ReLU activation layers of the pre-trained VGG-16 network described in (Simonyan and Zisserman., 2014). We then define the VGG loss as the distance between the feature representations of a reconstructed image and real image using Relu 4-1 layer. For similar images, gives higher value while and give lower values.
2.1.4 Overall Objective
Finally, the generator and discriminator are trained with a linear combination of the loss terms:
[TABLE]
[TABLE]
where and are hyper-parameter that control the relative importance of classification loss and content loss, compared to the adversarial loss. We set and in all of our experiments.
2.1.5 Importance of latent space information
As explained earlier we use the latent vector encoding of the lung mask in the CAGAN to generate realistic xray images. The primary motivation in doing so is to condition the image generation on the lung shape and add additional information to make the generated images more realistic.
Another factor behind the use of latent shape information is to change the shape of the lung masks and generate a diverse set of images with different image characteristics. Change in lung shape is effected by changing the contour of the lung mask and using b-splines to get a smooth shape.
2.2 CAGAN Implementation
It is non-trivial to train GAN models in a stable manner. To address this problem, we generalize the state-of-the-art Wasserstein GAN to the context of image generation for more stable convergence. In fact, we replace Eq. 1 with a Wasserstein GAN having gradient penalty defined as:
[TABLE]
where is sampled uniformly along a straight line between a pair of a real and a generated images and is set to 10 in all experiments.
2.3 CAGAN Architecture
CAGAN has the generator network composed of three convolution layers with a stride size of two, followed by batch normalization and ReLU activation for downsampling, three residual blocks, and three transposed convolution layers with the stride size of two for upsampling before the last convolutional layer. We utilize PatchGANs (Li and Wand, 2016) for the discriminator network, which classifies whether local image patches are real or fake.
The discriminator has six convolution layers with the kernels increasing by a factor of from to . Leaky ReLU is used and strided convolutions reduce the image dimension when the number of features is doubled. The last convolutional layer is followed by dense layer to output probabilities for different classes. See Figure 1 for schematic diagrams of CAGAN.
2.3.1 Synthetic Image Generation
During the test stage, the generator takes as input the test Xray image and the latent vector encoding of a mask (either original or altered) and outputs a realistic Xray image whose label class is the same as the original image.
For every test image, we obtain up to modified masks (by changing the lung mask) and their generated images. Figure 3 shows examples of real and generated images from the NIH dataset (Wang et al., 2017b). The top row shows the real images while the bottom row shows images obtained using our method. Figure 2 (a) shows an original normal image from the SCR chest Xray dataset (van Ginneken et al., 2006) while Figs. 2 (b,c) show generated ‘normal’ images similar to real dataset. Figure 2 (d) shows an image with nodules from the SCR chest Xray dataset, and Figs. 2 (e,f) show generated ‘nodule’ images. Although the nodules are very difficult to observe with the naked eye, we highlight its position using yellow boxes. It is quite obvious that the generated images are realistic and suitable for training. Other examples of real and generated images from the NIH database are shown in Figure 3.
2.4 Sample Informativeness Using Uncertainty
Each generated image’s uncertainty is calculated using the method described in (Kendall and Gal, 2017). In short, two types of uncertainty measures can be calculated from a Bayesian neural network - epistemic and aleotaric uncertainty. Aleotaric uncertainty models the noise in the observation while epistemic uncertainty models the uncertainty of model parameters, i.e., how uncertain is the model in correctly classifying the image sample. We adopted (Kendall and Gal, 2017) to calculate uncertainty by combining the above two types. We give a brief description below and refer the reader to (Kendall and Gal, 2017) for details. For a BNN model mapping an input image , to a unary output , the predictive uncertainty for pixel is approximated using:
[TABLE]
is the BNN output for the predicted variance for pixel , and being a set of sampled outputs.
3 Experiments
3.1 Dataset Description
We apply our method to the NIH ChestXray14 dataset (Wang et al., 2017b), which has frontal-view X-rays from unique patients with disease labels (multi-labels for each image), which are obtained from associated radiology reports.
The pathologies are ‘Cardiomegaly’, ‘Emphysema’, ‘Effusion’, ‘Hernia’, ‘Nodule’, ‘Pneumothorax’, ‘Atelectasis’, ‘Pleural Thickening’ (PT), ‘Mass’, ‘Edema’, ‘Consolidation’, ‘Infiltration’, ‘Fibrosis’ and ’Pneumonia’. For further details we refer the reader to (Wang et al., 2017b). Table 1 illustrates the percentage distribution of different labels within the diseased images only. Note that almost all images have multiple labels associated with them and hence the percentage values do not necessarily add up to . An interesting observation is that ‘Infiltration’ label is shared by of the diseased images while only images are labelled ‘Hernia’. This is indicative of severe class imbalance and our proposed method aims to overcome this common problem in medical image analysis.
3.2 Implementation Details
Our method was implemented in TensorFlow. We use Adam (Kingma and Ba, 2014) with and batch normalization. Mean square error (MSE) based ResNet was used to initialize . The final GAN was trained with update iterations at learning rate . Training and test was performed on a NVIDIA Tesla K GPU.
Our experiments focus primarily on classification. Recent work (Rajpurkar et al., 2017) on the NIH-14 dataset used a DenseNet architecture (Huang et al., 2016) to achieve state of the art performance in classification. To illustrate the benefits of using our AL approach we explain the working using a network. We also present results for active learning with other classifiers like ResNet (He et al., 2016) and DenseNet (Huang et al., 2016) (which is the basis for CheXNet (Rajpurkar et al., 2017)). The VGG16, ResNet and DenseNet have all been pre-trained on the Imagenet dataset (Deng et al., 2009).
First, we split our entire dataset into training (), validation () and test (), at the patient level such that all images from one patient are in a single fold. We use a network (Simonyan and Zisserman., 2014) pre-trained on the Imagenet dataset (Deng et al., 2009) as our base network. Initially, we choose samples images from each of the classes and augment them using rotation and translation. We refer to this step as standard data augmentation (DA). Using this augmented dataset we fine tune the last layer of . From the remaining images in the training dataset the task is to identify the most informative samples from each class and add them to the training set. Recall that different image classes are not equally represented and hence it is essential to have equal representation of each class in the training batches.
Using the VGG16 network (after finetuning) we identify the most informative images across all classes and rank them according to their informativeness value as calculated using the BNN described in Sec 2.4. Note that the Bayesian network is created by taking the instantaneous (or any other) classifier after finetuning and modifying its weights. This is done to ensure that the informative samples are determined by the classifier at its current state. We take the top informative samples irrespective of the class label and use them along with our pre-trained CAGAN network to generate informative samples of other classes.
Conventional GANs would be able to generate image samples that have the same class label as the input image. However, as described in Sec 2, by using CAGANs we can generate images of different classes despite the input image belonging to a another class. Using the most informative samples (from the initial pool) we generate samples of each of the classes. Subsequently, the most informative samples of each class are chosen and used to finetune the classifier. The samples that were chosen as informative are now removed from the labeled training set. The updated classifier is again used to identify informative samples from the updated training set and the entire sequence of steps is repeated. After every update/finetuning the classifier is used to classify the samples in the validation dataset. The iterative sequence of steps (involving informative sample selection, data augmentation and finetuning) continues till the area under curve (AUC) value from the validation dataset does not change by more than for three consecutive iterations. Once this condition is met we consider the classifier as the final model and we use it to determine performance on the test set.
To compare our AL approach with a fully supervised learning (FSL) based method we use the CheXNet method (Rajpurkar et al., 2017). We also finetune and classifiers (without sample selection) to obtain baseline performance for the fully supervised case. For all the FSL classifiers we use weighted cost functions to account for data imbalance. These set of results serve as the baseline to compare our active learning methods. Table 2 summarizes the results for baseline FSL settings and our proposed method. Note that all performance measures are reported for the test set.
3.3 Classification Results
In this section, we show results for the active learning (AL) scenario and compare it with conventional fully supervised learning (FSL) methods that use the same training set for training the model and report results on the test set. The area under curve (AUC) values are reported in each case. For the FSL case we show results for the following classifiers - , (He et al., 2016) and CheXNet (Rajpurkar et al., 2017). , and denote our AL based network with base classifier of , and , respectively. and denote the FSL setting, where pre-trained and classifiers were fine-tuned using the given data. denotes our implementation of CheXNet (Rajpurkar et al., 2017).
We initiate our AL experiment by taking an initial of the training samples, add new samples, and continue with the training till convergence. We also report results on the FSL methods by randomly selecting data from the training set and using it for training. Table 1 summarizes the performance of the FSL methods for all pathologies when using the entire training set. Since the whole training set is used there is no scope for informative sample selection and hence AL based results are not shown. The numbers in Table 1 are the baseline methods against which the AL based methods are compared. We also provide the percentage of diseased images having the corresponding disease label.
An important observation is for some pathologies the AUC using is higher than obtained using . This is especially true for those pathologies with a higher percentage representation in the dataset. This can be explained as follows. ‘Infiltration’ has more images is higher than others. Although the images are more, the quality of the Xray images makes it difficult to distinguish multiple pathologies. As a result many images are misclassified and the corresponding AUC decreases. However, by using informative sample selection and synthetic image generation we are able to overcome these limitations and train a better classifier that performs better on the test image set. However, we do not see a corresponding AUC increase for all classes, especially those which have a small representation in the test data.
Table 2 summarizes the AUC values for the ‘Infiltration’ pathology class when using different percentage of training data for AL and FSL methods. We do not show numbers for all pathologies but select ‘Infiltration’ since it has the highest representation in the data set. Similar trends are observed for all pathologies.
An important observation from Table 2 is the fact that reaches the peak performance at a fraction () of the entire training set. In this case by using of informative training data, reaches an AUC similar to of at training data. With the addition of more training data the performance of all the AL methods improve. The improvement is higher initially and stabilizes after the threshold because it does not encounter informative samples that are significantly different from those already in the training set. If we set a condition that informative samples be added only if they improve the classifier AUC by atleast then informative samples are not added after samples have been used from the training set. This observation confirms the fact that state of the art performance can be achieved with fewer training samples provided they are informative by providing qualitatively different information. Note that the threshold is for this dataset and will be different for other datasets.
Table 3 shows the performance of AL and FSL methods when using upto of the training data. For FSL methods the numbers are an average of runs that randomly select of the training data to train the classifiers. We show results only for since it is the best performing FSL method. We observe that the different AL based methods generate AUC values close to those of the corresponding FSL method in Table 1 . This clearly indicates that by selecting only the informative samples, and using synthetic samples AL based methods perform as good as state-of-the-art FSL methods. By using informative samples in the training step the classifier learns more discriminative information with fewer samples compared to the FSL scenario where informative and uninformative samples are used for model training. This translates to use of shallow networks and fewer computing resources.
3.3.1 Results on the SCR Dataset
We run a set of classification experiments on the SCR chest XRay database van Ginneken et al. (2006) which has Xray images of patients - normal and nodule images. The images are resized to pixels to ease the network’s computational burden. The dataset is divided into training (), validation () and test () folds.
In Table 4 we present results for different FSL and AL based classification approaches, similar to the results on the NIH dataset in Table 2. The advantages of active learning are also demonstrated on the SCR dataset. This verifies the fact that our active learning approach does a good job in selecting informative samples and augmenting them across two different datasets.
In another set of experiments we used the training and validation folds of the NIH dataset and the test fold of the SCR dataset. However the classification performance decreased (AUC for the best case) since images from the two datasets are very different in appearance. In principle we can use a pre-processing technique that transforms the input image to the same appearance as the training set. However the relevant method is beyond the scope of this paper.
3.4 Influence of Informative Sample Selection and Image Generation
In this section, we analyze the role of informative sample selection and the subsequent generation of synthetic images. We perform classification using the following methods using a DenseNet network:
- uses standard data augmentation (DA) in place of CAGAN based sample generation. After identifying the most informative samples using BNN, we augment it by standard data augmentation through rotation, translation and flipping. This helps to quantify the importance of conditional GAN based synthetic sample generation. 2. 2.
- uses data augmentation using a normal GAN without a conditional input variable. The GAN is trained to generate multiple images from the informative images with the same diseased label as the original. During training the input image is the original image and the outputs are rotated, translated and flipped versions of the original. 3. 3.
- uses data augmentation using a data augmentations GANs (DAGAN) Antoniou et al. (2017). The DAGAN is trained to generate multiple images from the informative images with the same diseased label as the original. 4. 4.
- does classification without using the Bayesian Neural network for calculating informativeness. Instead it uses classification uncertainty of the image as a measure of informativeness. Classification uncertainty is obtained as the entropy of class labels.
The results are summarized in Table 5 for ‘Infiltration’ when using different training data percentages. Compared to our originally proposed method, , comes closest followed by . This indicates that using GAN based synthetic data generation is more informative than standard DA as GAN introduces some new information compared to standard DA. Additionally, using conditional GAN based image generation generates much more informative samples. This can be explained by the fact that using CAGANs translates information from one disease class to another, whereas in standard GAN based augmentation we do not obtain the diversity information from other classes. The results also prove that use of a Bayesian neural network to determine classification uncertainty is more accurate than using classification uncertainty.
3.5 Plausibility of Generated Images
It is essential for generated images to be realistic and represent real medical images with disease symptoms. We test this hypothesis with the following different experiments:
We first separate the real and synthetic images into training, validation and test folds with splitting done at the patient level. This ensures that for any particular patient all the real and synthetic images are in only one of the three folds. 2. 2.
We denote the set of real images as Real and the set of synthetic images as Synthetic. In one experiment we train a FSL based CheXNet classifier on real images (from its corresponding training fold) and test on synthetic images(from the corresponding test fold). This experiment is denoted as in Table 6. In the second experiment we train a CheXNet classifier on synthetic images and test on real images. the results are summarized under . 3. 3.
We create a new dataset by randomly mixing images from the corresponding folds of Real and Synthetic and denote it as Mix. Note that in Mix the same patient level split is maintained. We train a CheXNet on the training set and apply it on the test set. The results are summarized under in Table 7. 4. 4.
We report results for other experiments such as: (train on Mix and test on Real); 2) ; 3) ; 4) ; and 5) . Note that the results for are already reported in Table 1 under . 5. 5.
For all the above experiments we use a FSL based CheXNet classifier.
If the generated images are realistic then they would have similar performance as that of the base images, and mixing of the datasets should not impact performance to a large degree. Tables 6 and 7 summarize the performance of the different experiments for the ‘Infiltration’ disease label. The numbers in both tables clearly indicate that there is no significant difference in the performance of real and synthetic images. We also observe similar performance measures when mixing up the real and synthetic images. This shows that the synthetic images generated by our method are realistic and preserve the label information.
3.5.1 Adding Synthetic Images to Training Set
In another set of experiments we take a fixed number of real images ( images in total with images from each of the classes), use them to fine tune a DenseNet and calculate the AUC values on the test set. The initial images represent approximately of the training fold. Subsequently, we generate synthetic images as described before and add images in each iteration ( most informative images from each class). Here we do not add any of the actual training images but only the generated synthetic images. This set up is used to provide additional validation of the plausibility of generated images.
In Figure 4 the green plot shows the change of AUC values for different number of added informative synthetic images. The axis shows the number of added synthetic images as a percentage of the number of images. We observe that as the number of synthetic images increases the AUC for ‘Infiltration’ increases and finally surpasses the AUC of at the threshold. This is similar to our previous results where the AL based method achieves similar performance as (red plot) with of the training images.
The blue plot in Figure 4 shows the AUC values when we add synthetic images without choosing the most informative ones. In this case the AUC value comes close to that of at around of the training set which is observed for fully supervised learning scenario. These results clearly demonstrate that the synthetic images are as good as the real images. In a situation where we have very few real images, synthetic images generated by our method will do a good job of data augmentation and contribute to achieving state of the art performance despite fewer samples to begin with.
3.6 Validation of Synthetic Images By Clinical Experts
We also validate the authenticity of generated images through visual examination by clinical experts. A minutes session was set with three experienced radiologists with over years of experience in the diagnosis of lung conditions from X-ray/CT images. The experts were tasked to perform a diagnosis on synthetically generated images that are linked (conditional part of the CAN) to a pre-determined disease/condition (e.g. infiltration, cardiomegaly, no-finding, effusion, atelectasis, nodule, emphysema). The set of images were sequentially displayed to each expert, without including any information about the condition/disease label. Each expert assessed each image and a “Yes/No” disagreement was recorded (on a different computer screen). For cases with multiple labels, a partial agreement was recorded along with the agreed condition (e.g. “Yes for effusion”).
Of the reviewed cases full agreement (i.e. exact diagnosis) was reached on average on () cases. Partial agreement was reached on average on () cases, and on three cases the experts were not sure and mentioned that a full CT image, or lateral views would be required. For inter-expert agreement, we note that among experts an average of 71.5% for full agreements (i.e. experts agreed on all disease labels) and of 84% for partial agreement (experts agreed on one or more, but not all disease labels) was found.
According to the experts, most of the disagreement stems from two main reasons. First, the poor resolution and sharpness of the generated images makes if difficult to get an accurate diagnosis from a single view. Poor resolution is a known issue with GANs when generating realistic images. Second, the radiologists commented several times that the generated disease/condition was very subtle and would require a sharper image to agree with the proposed label. Specifically, for nodules, the experts commented on the need of 3D information (CT image) to rule out potentially transversally imaged vessels that resemble nodules. Regardless of the aforementioned issues with resolution and sharpness, the expert reviewers (seeing the system’s synthetically generated images for the first time) commented on the impressive ability of the system to create realistically-looking images while mimicking conditions/diseases.
4 Conclusion
We have proposed an active learning method that selectively uses new training samples featuring high levels of informativeness, as assessed by a Bayesian Neural Network. Beyond the state-of-the-art in AL, the proposed approach proposes a variant of GAN, called here CAGAN, to generate new synthetic samples of realistic-looking images while informing on class label. This feature is further used to alleviate the class imbalance problem and hence improve model’s performance. Results on the publicly available NIH ChestXray dataset, featuring one of the largest medical image datasets, show the benefits of the proposed AL approach to yield improved accuracy and learning rates than standard data augmentation techniques and GAN-based synthetic sample generation. Our experiments demonstrate that, with about labeled samples we can achieve almost equal classification and segmentation performance as obtained when using the full dataset. This is made possible by selecting the most informative samples for training. Thus the model sees all the informative samples first, and achieves optimal performance in fewer iterations.
The performance of the proposed AL based model translates into significant savings in annotation effort and clinicians’ time. These results are of great interest to the medical image computing and radiology-oriented scientific communities in need of machine learning technologies that can cope with the intrinsic difficulties of scaling up the process of curating medical images within the daily routine of medical experts. The proposed AL approach can be inserted into a Human-Machine learning system where radiology experts act as monitors and correctors of computer-generated results, which are selectively chosen for continuous model improvement, hence reducing operator’s time while optimizing model learning rate. In addition, the improved learning rate of the proposed AL approach is expected to bring benefits to clinical scenarios where imaging protocols and/or vendor characteristics (e.g. future transition to 7T MRI scanners) evolve, and existing ML techniques need to feature better levels of adaptability to such changes.
This study has some limitations and related future work that is worth mentioning. First, we note that this study focuses on the quantitative metrics evaluating the accuracy and learning rate of the model rather than assessing the realism of the synthetically generated images. This would necessitate a dedicated medical expert-review panel participating in the study to verify the class-matching of the several thousands of synthetically generated lung lesions. Second, application of the approach to other medical datasets is necessary to confirm generalization of our findings. In this regards, as future work we plan to further investigate the proposed CAGAN framework to handle multi-sequence imaging protocols (e.g. combined T1, T1-c, T2, FLAIR MRI sequences) where model uncertainty stems unequally from different image sequences. This could be used to adapt our CAGAN framework to emphasize sequence-specific patterns that need to be learned by a model, so to make it more robust to confounder effects that tend to appear more in an specific sequence. Another line of future work comprises extending the proposed approach to domain adaptability to design an active learning framework capable of adapting in a fast manner to new imaging sequences, protocols (e.g. MRI strength fields), and different imaging vendors.
References
- Antoniou et al. (2017)
Antoniou, A., Storkey, A., Edwards, H., 2017.
Data augmentation generative adversarial networks, in: arXiv preprint arXiv:1711.04340,.
- Chapelle et al. (2006)
Chapelle, O., Scholkopf, B., Zien, A., 2006.
Semi-Supervised Learning.
MIT Press,Cambridge, MA.
- Choi et al. (2017)
Choi, Y., Choi, M., Kim, M., Ha, J.W., Kim, S., Choo, J., 2017.
StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation, in: arXiv preprint arXiv:1711.09020.
- Deng et al. (2009)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei., L., 2009.
ImageNet: A Large-Scale Hierarchical Image Database, in: CVPR09.
- Doyle et al. (2011)
Doyle, S., Monaco, J., Feldman, M., Tomaszewski, J., Madabhushi., A., 2011.
An active learning based classification strategy for the minority class problem: application to histopathology annotation.
BMC Bioinformatics. 12, 1–14.
- Frangi et al. (1998)
Frangi, A., Niessen, W., Vincken, K., Viergever, M., 1998.
Multiscale vessel enhancement filtering, in: MICCAI, pp. 130–137.
- Freund et al. (1997)
Freund, Y., Seung, H., Shamir, E., Tishby, N., 1997.
Selective sampling using the query by committee algorithm.
Machine Learning 28, 133–168.
- Frid-Adar et al. (2018)
Frid-Adar, M., Klang, E., Amitai, M., Goldberger, J., Greenspan1, H., 2018.
Synthetic data augmentation using gan for improved liver lesion classification, in: In Proc IEEE ISBI, pp. 289–293.
- Gal et al. (2017)
Gal, Y., Islam, R., Ghahramani, Z., 2017.
Deep Bayesian Active Learning with Image Data, in: Proc. International Conference on Machine Learning.
- van Ginneken et al. (2006)
van Ginneken, B., Stegmann, M., Loog., M., 2006.
Segmentation of anatomical structures in chest radiographs using supervised methods: a comparative study on a public database.
Med. Imag. Anal. 10, 19–40.
- Goodfellow et al. (2014)
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y., 2014.
Generative adversarial nets, in: Proc. NIPS, pp. 2672–2680.
- Hajeb et al. (2012)
Hajeb, S., Rabbani, H., Akhlaghi., M., 2012.
Diabetic retinopathy grading by digital curvelet transform.
Comput Math Methods Med. , 7619–01.
- He et al. (2016)
He, K., Zhang, X., Ren, S., Sun, J., 2016.
Deep residual learning for image recognition, in: In Proc. CVPR.
- Huang et al. (2016)
Huang, G., Liu, Z., van der Maaten, L., Weinberger, K., 2016.
Densely connected convolutional networks, in: https://arxiv.org/abs/1608.06993,.
- Iglesias et al. (2011)
Iglesias, J., Konukoglu, E., Montillo, A., Tu, Z., Criminisi, A., 2011.
Combining generative and discriminative models for semantic segmentation of ct scans via active learning, in: IPMI, pp. 25–36.
- Isola et al. (2017)
Isola, P., Zhu, J., Zhou, T., Efros, A., 2017.
Image-to-image translation with conditional adversarial networks, in: CVPR.
- Jaderberg et al. (2015)
Jaderberg, M., Simonyan, K., Zisserman, A., Kavukcuoglu, K., 2015.
Spatial transformer networks, in: NIPS, pp. –.
- Kendall and Gal (2017)
Kendall, A., Gal, Y., 2017.
What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?, in: Advances in Neural Information Processing Systems.
- Kingma and Ba (2014)
Kingma, D., Ba, J., 2014.
Adam: A method for stochastic optimization, in: arXiv preprint arXiv:1412.6980,.
- Klein et al. (2010)
Klein, S., Staring, M., Murphy, K., Viergever, M., Pluim., J., 2010.
Elastix: a toolbox for intensity based medical image registration.
IEEE Trans. Med. Imag. 29, 196–205.
- Kuang et al. (2014)
Kuang, H., Guthier, B., Saini, M., Mahapatra, D., Saddik, A.E., 2014.
A real-time smart assistant for video surveillance through handheld devices., in: In Proc: ACM Intl. Conf. Multimedia, pp. 917–920.
- Ledig and et. al. (2016)
Ledig, C., et. al., 2016.
Photo-realistic single image super-resolution using a generative adversarial network.
CoRR abs/1609.04802.
- Lewis and Catlett (1994)
Lewis, D., Catlett, J., 1994.
Heterogenous uncertainty sampling for supervised learning, in: Proc. ICML, pp. 148–156.
- Li and Wand (2016)
Li, C., Wand, M., 2016.
Precomputed real-time texture synthesis with markovian generative adversarial networks, in: European Conference on Computer Vision, Springer. pp. 702–716.
- Li and Guo (2013)
Li, X., Guo, Y., 2013.
Adaptive active learning for image classification, in: Proc. CVPR.
- Li et al. (2016)
Li, Z., Mahapatra, D., J.Tielbeek, Stoker, J., van Vliet, L., Vos, F., 2016.
Image registration based on autocorrelation of local structure.
IEEE Trans. Med. Imaging 35, 63–75.
- Liao et al. (2017)
Liao, R., Miao, S., de Tournemire, P., Grbic, S., Kamen, A., Mansi, T., Comaniciu, D., 2017.
An artificial agent for robust image registration, in: AAAI, pp. 4168–4175.
- Mahapatra (2011)
Mahapatra, D., 2011.
Neonatal brain mri skull stripping using graph cuts and shape priors, in: In Proc: MICCAI workshop on Image Analysis of Human Brain Development (IAHBD).
- Mahapatra (2012a)
Mahapatra, D., 2012a.
Cardiac lv and rv segmentation using mutual context information, in: Proc. MICCAI-MLMI, pp. 201–209.
- Mahapatra (2012b)
Mahapatra, D., 2012b.
Groupwise registration of dynamic cardiac perfusion images using temporal information and segmentation information, in: In Proc: SPIE Medical Imaging.
- Mahapatra (2012c)
Mahapatra, D., 2012c.
Landmark detection in cardiac mri using learned local image statistics, in: Proc. MICCAI-Statistical Atlases and Computational Models of the Heart. Imaging and Modelling Challenges (STACOM), pp. 115–124.
- Mahapatra (2012d)
Mahapatra, D., 2012d.
Skull stripping of neonatal brain mri: Using prior shape information with graphcuts.
J. Digit. Imaging 25, 802–814.
- Mahapatra (2013a)
Mahapatra, D., 2013a.
Cardiac image segmentation from cine cardiac mri using graph cuts and shape priors.
J. Digit. Imaging 26, 721–730.
- Mahapatra (2013b)
Mahapatra, D., 2013b.
Cardiac mri segmentation using mutual context information from left and right ventricle.
J. Digit. Imaging 26, 898–908.
- Mahapatra (2013c)
Mahapatra, D., 2013c.
Graph cut based automatic prostate segmentation using learned semantic information, in: Proc. IEEE ISBI, pp. 1304–1307.
- Mahapatra (2013d)
Mahapatra, D., 2013d.
Joint segmentation and groupwise registration of cardiac perfusion images using temporal information.
J. Digit. Imaging 26, 173–182.
- Mahapatra (2014)
Mahapatra, D., 2014.
Automatic cardiac segmentation using semantic information from random forests.
J. Digit. Imaging. 27, 794–804.
- Mahapatra (2016)
Mahapatra, D., 2016.
Combining multiple expert annotations using semi-supervised learning and graph cuts for medical image segmentation.
Computer Vision and Image Understanding 151, 114–123.
- Mahapatra (2017)
Mahapatra, D., 2017.
Semi-supervised learning and graph cuts for consensus based medical image segmentation.
Pattern Recognition 63, 700–709.
- Mahapatra et al. (2017)
Mahapatra, D., Bozorgtabar, B., Hewavitharanage, S., Garnavi, R., 2017.
Image super resolution using generative adversarial networks and local saliency maps for retinal image analysis, in: MICCAI, pp. 382–390.
- Mahapatra et al. (2018a)
Mahapatra, D., Bozorgtabar, B., Thiran, J.P., Reyes, M., 2018a.
Efficient active learning for image classification and segmentation using a sample selection and conditional generative adversarial network, in: MICCAI, pp. 580–588.
- Mahapatra et al. (2018b)
Mahapatra, D., Bozorgtabar, S., Thiran, J.P., Reyes, M., 2018b.
Efficient active learning for image classification and segmentation using a sample selection and conditional generative adversarial network, in: In Proc. MICCAI (2), pp. 580–588.
- Mahapatra and Buhmann (2013)
Mahapatra, D., Buhmann, J., 2013.
Automatic cardiac rv segmentation using semantic information with graph cuts, in: Proc. IEEE ISBI, pp. 1094–1097.
- Mahapatra and Buhmann (2014a)
Mahapatra, D., Buhmann, J., 2014a.
Analyzing training information from random forests for improved image segmentation.
IEEE Trans. Imag. Proc. 23, 1504–1512.
- Mahapatra and Buhmann (2014b)
Mahapatra, D., Buhmann, J., 2014b.
Prostate mri segmentation using learned semantic knowledge and graph cuts.
IEEE Trans. Biomed. Engg. 61, 756–764.
- Mahapatra and Buhmann (2015a)
Mahapatra, D., Buhmann, J., 2015a.
A field of experts model for optic cup and disc segmentation from retinal fundus images, in: In Proc. IEEE ISBI, pp. 218–221.
- Mahapatra and Buhmann (2015b)
Mahapatra, D., Buhmann, J., 2015b.
Obtaining consensus annotations for retinal image segmentation using random forest and graph cuts, in: In Proc. OMIA, pp. 41–48.
- Mahapatra and Buhmann (2015c)
Mahapatra, D., Buhmann, J., 2015c.
Visual saliency based active learning for prostate mri segmentation, in: In Proc. MLMI, pp. 9–16.
- Mahapatra and Buhmann (2016)
Mahapatra, D., Buhmann, J., 2016.
Visual saliency based active learning for prostate mri segmentation.
SPIE Journal of Medical Imaging 3.
- Mahapatra and Ge (2019)
Mahapatra, D., Ge, Z., 2019.
Training data independent image registration with gans using transfer learning and segmentation information, in: In Proc. IEEE ISBI, pp. 1–4.
- Mahapatra et al. (2018c)
Mahapatra, D., Ge, Z., Sedai, S., Chakravorty., R., 2018c.
Joint registration and segmentation of xray images using generative adversarial networks, in: In Proc. MICCAI-MLMI, pp. 73–80.
- Mahapatra et al. (2014a)
Mahapatra, D., Gilani, S., Saini., M., 2014a.
Coherency based spatio-temporal saliency detection for video object segmentation.
IEEE Journal of Selected Topics in Signal Processing. 8, 454–462.
- Mahapatra et al. (2013a)
Mahapatra, D., J.Tielbeek, Makanyanga, J., Stoker, J., Taylor, S., Vos, F., Buhmann, J., 2013a.
Automatic detection and segmentation of crohn’s disease tissues from abdominal mri.
IEEE Trans. Med. Imaging 32, 1232–1248.
- Mahapatra et al. (2014b)
Mahapatra, D., J.Tielbeek, Makanyanga, J., Stoker, J., Taylor, S., Vos, F., Buhmann, J., 2014b.
Active learning based segmentation of crohn’s disease using principles of visual saliency, in: Proc. IEEE ISBI, pp. 226–229.
- Mahapatra et al. (2014c)
Mahapatra, D., J.Tielbeek, Makanyanga, J., Stoker, J., Taylor, S., Vos, F., Buhmann, J., 2014c.
Combiningmultiple expert annotations using semi-supervised learning and graph cuts for crohn s disease segmentation, in: In Proc: MICCAI-ABD.
- Mahapatra et al. (2013b)
Mahapatra, D., J.Tielbeek, Vos, F., Buhmann, J., 2013b.
A supervised learning approach for crohn’s disease detection using higher order image statistics and a novel shape asymmetry measure.
J. Digit. Imaging 26, 920–931.
- Mahapatra et al. (2015a)
Mahapatra, D., Li, Z., Vos, F., Buhmann, J., 2015a.
Joint segmentation and groupwise registration of cardiac dce mri using sparse data representations, in: In Proc. IEEE ISBI, pp. 1312–1315.
- Mahapatra et al. (2006)
Mahapatra, D., Routray, A., Mishra, C., 2006.
An active snake model for classification of extreme emotions, in: IEEE International Conference on Industrial Technology (ICIT), pp. 2195–2199.
- Mahapatra et al. (2008a)
Mahapatra, D., Roy, S., Sun, Y., 2008a.
Retrieval of mr kidney images by incorporating spatial information in histogram of low level features, in: In 13th International Conference on Biomedical Engineering.
- Mahapatra et al. (2008b)
Mahapatra, D., Saini, M., Sun, Y., 2008b.
Illumination invariant tracking in office environments using neurobiology-saliency based particle filter, in: IEEE ICME, pp. 953–956.
- Mahapatra et al. (2013c)
Mahapatra, D., Schffler, P., Tielbeek, J., Vos, F., Buhmann, J., 2013c.
Semi-supervised and active learning for automatic segmentation of crohn’s disease, in: Proc. MICCAI, Part 2, pp. 214–221.
- Mahapatra and Sun (2008a)
Mahapatra, D., Sun, Y., 2008a.
Nonrigid registration of dynamic renal MR images using a saliency based MRF model, in: Proc. MICCAI, pp. 771–779.
- Mahapatra and Sun (2008b)
Mahapatra, D., Sun, Y., 2008b.
Registration of dynamic renal mr images using neurobiological model of saliency, in: Proc. ISBI, pp. 1119–1122.
- Mahapatra and Sun (2008c)
Mahapatra, D., Sun, Y., 2008c.
Using saliency features for graphcut segmentation of perfusion kidney images, in: In 13th International Conference on Biomedical Engineering.
- Mahapatra and Sun (2010)
Mahapatra, D., Sun, Y., 2010.
Joint registration and segmentation of dynamic cardiac perfusion images using mrfs., in: Proc. MICCAI, pp. 493–501.
- Mahapatra and Sun. (2010)
Mahapatra, D., Sun., Y., 2010.
An mrf framework for joint registration and segmentation of natural and perfusion images, in: Proc. IEEE ICIP, pp. 1709–1712.
- Mahapatra and Sun (2010a)
Mahapatra, D., Sun, Y., 2010a.
Retrieval of perfusion images using cosegmentation and shape context information, in: Proc. APSIPA Annual Summit and Conference (ASC).
- Mahapatra and Sun (2010b)
Mahapatra, D., Sun, Y., 2010b.
Rigid registration of renal perfusion images using a neurobiology based visual saliency model.
EURASIP Journal on Image and Video Processing. , 1–16.
- Mahapatra and Sun (2010c)
Mahapatra, D., Sun, Y., 2010c.
A saliency based mrf method for the joint registration and segmentation of dynamic renal mr images, in: Proc. ICDIP.
- Mahapatra and Sun (2011a)
Mahapatra, D., Sun, Y., 2011a.
Mrf based intensity invariant elastic registration of cardiac perfusion images using saliency information.
IEEE Trans. Biomed. Engg. 58, 991–1000.
- Mahapatra and Sun (2011b)
Mahapatra, D., Sun, Y., 2011b.
Orientation histograms as shape priors for left ventricle segmentation using graph cuts, in: In Proc: MICCAI, pp. 420–427.
- Mahapatra and Sun (2012)
Mahapatra, D., Sun, Y., 2012.
Integrating segmentation information for improved mrf-based elastic image registration.
IEEE Trans. Imag. Proc. 21, 170–183.
- Mahapatra et al. (2012)
Mahapatra, D., Tielbeek, J., Buhmann, J., Vos, F., 2012.
A supervised learning based approach to detect crohn’s disease in abdominal mr volumes, in: Proc. MICCAI workshop Computational and Clinical Applications in Abdominal Imaging(MICCAI-ABD), pp. 97–106.
- Mahapatra et al. (2013d)
Mahapatra, D., Tielbeek, J., Vos, F., ., J.B., 2013d.
Crohn’s disease tissue segmentation from abdominal mri using semantic information and graph cuts, in: Proc. IEEE ISBI, pp. 358–361.
- Mahapatra et al. (2013e)
Mahapatra, D., Tielbeek, J., Vos, F., Buhmann, J., 2013e.
Localizing and segmenting crohn’s disease affected regions in abdominal mri using novel context features, in: Proc. SPIE Medical Imaging.
- Mahapatra et al. (2013f)
Mahapatra, D., Tielbeek, J., Vos, F., Buhmann, J., 2013f.
Weakly supervised semantic segmentation of crohn’s disease tissues from abdominal mri, in: Proc. IEEE ISBI, pp. 832–835.
- Mahapatra et al. (2015b)
Mahapatra, D., Vos, F., Buhmann, J., 2015b.
Crohn’s disease segmentation from mri using learned image priors, in: In Proc. IEEE ISBI, pp. 625–628.
- Mahapatra et al. (2016)
Mahapatra, D., Vos, F., Buhmann, J., 2016.
Active learning based segmentation of crohns disease from abdominal mri.
Computer Methods and Programs in Biomedicine 128, 75–85.
- Mahapatra et al. (2008c)
Mahapatra, D., Winkler, S., Yen, S., 2008c.
Motion saliency outweighs other low-level features while watching videos, in: SPIE HVEI., pp. 1–10.
- Miao et al. (2016)
Miao, S., Z.J. Wang, Y.Z., Liao, R., 2016.
Real-time 2d/3d registration via cnn regression, in: IEEE ISBI, pp. 1430–1434.
- Osokin et al. (2017)
Osokin, A., Chessel, A., Salas, R., Vaggi, F., 2017.
GANs for biological image synthesis, in: arXiv preprint arXiv:1708.04692.
- Pathak et al. (2016)
Pathak, D., Krähenbühl, P., Donahue, J., Darrell, T., Efros, A., 2016.
Context encoders: Feature learning by inpainting, in: Proc. CVPR, pp. 2536–2544.
- Radau et al. (2009)
Radau, P., Lu, Y., Connelly, K., Paul, G., et. al ., 2009.
valuation framework for algorithms segmenting short axis cardiac MRI, in: The MIDAS Journal-Cardiac MR Left Ventricle Segmentation Challenge.
- Rajpurkar et al. (2017)
Rajpurkar, P., Irvin, J., Zhu, K., Yang, B., Mehta, H., Duan, T., Ding, D., Bagul, A., Langlotz, C., Shpanskaya, K., Lungren, M.P., Ng, A., 2017.
Chexnet: Radiologist-level pneumonia detection on chest x-rays with deep learning, in: arXiv preprint arXiv:1711.05225,.
- Ronneberger et al. (2015)
Ronneberger, O., Fischer, P., Brox, T., 2015.
U-net: Convolutional networks for biomedical image segmentation, in: In Proc. MICCAI, pp. 234–241.
- Rueckert et al. (1999)
Rueckert, D., Sonoda, L., Hayes, C., Hill, D., Leach, M., Hawkes., D., 1999.
Nonrigid registration using free-form deformations: application to breast mr images.
IEEE Trans. Med. Imag.. 18, 712–721.
- Settles and Craven (2008)
Settles, B., Craven, M., 2008.
An analysis of active learning strategies for sequence labeling tasks, in: Empirical methods in natural language processing, pp. 1070–1079.
- Simonyan and Zisserman. (2014)
Simonyan, K., Zisserman., A., 2014.
Very deep convolutional networks for large-scale image recognition.
CoRR abs/1409.1556.
- Sokooti et al. (2017)
Sokooti, H., de Vos, B., Berendsen, F., Lelieveldt, B., Isgum, I., Staring, M., 2017.
Nonrigid image registration using multiscale 3d convolutional neural networks, in: MICCAI, pp. 232–239.
- Tajbakhsh et al. (2016)
Tajbakhsh, N., Shin, J., Gurudu, S., Hurst, R.T., Kendall, C., Gotway, M., Liang., J., 2016.
Convolutional neural networks for medical image analysis: Full training or fine tuning?.
IEEE Trans. Med. Imag. 35, 1299–1312.
- Viergever et al. (2016)
Viergever, M., Maintz, J., Klein, S., Murphy, K., Staring, M., Pluim, J., 2016.
A survey of medical image registration.
Med. Imag. Anal 33, 140–144.
- de Vos et al. (2017)
de Vos, B., Berendsen, F., Viergever, M., Staring, M., Isgum, I., 2017.
End-to-end unsupervised deformable image registration with a convolutional neural network, in: arXiv preprint arXiv:1704.06065.
- Vos et al. (2012)
Vos, F.M., Tielbeek, J., Naziroglu, R., Li, Z., Schffler, P., Mahapatra, D., Wiebel, A., Lavini, C., Buhmann, J., Hege, H., Stoker, J., van Vliet, L., 2012.
Computational modeling for assessment of IBD: to be or not to be?, in: Proc. IEEE EMBC, pp. 3974–3977.
- Wang et al. (2017a)
Wang, K., Zhang, D., Li, Y., Zhang, R., Lin., L., 2017a.
Cost-effective active learning for deep image classification.
IEEE Trans. CSVT. 27, 2591–2600.
- Wang et al. (2017b)
Wang, X., Peng, Y., Lu, L., Lu, Z., Bagheri, M., Summers, R., 2017b.
Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases, in: In Proc. CVPR.
- Wang and et. al. (2004)
Wang, Z., et. al., 2004.
Image quality assessment: from error visibility to structural similarity.
IEEE Trans. Imag. Proc. 13, 600–612.
- Wu et al. (2016)
Wu, G., Kim, M., Wang, Q., Munsell, B.C., , Shen., D., 2016.
Scalable high performance image registration framework by unsupervised deep feature representations learning.
IEEE Trans. Biomed. Engg. 63, 1505–1516.
- Yang et al. (2017)
Yang, L., Zhang, Y., Chen, J., Zhang, S., Chen, D., 2017.
Suggestive Annotation: A Deep Active Learning Framework for Biomedical Image Segmentation, in: Proc. MICCAI, pp. 399–407.
- Zhu et al. (2017)
Zhu, J., T.park, Isola, P., Efros, A., 2017.
Unpaired image-to-image translation using cycle-consistent adversarial networks, in: arXiv preprint arXiv:1703.10593.
- Zilly et al. (2015)
Zilly, J., Buhmann, J., Mahapatra, D., 2015.
Boosting convolutional filters with entropy sampling for optic cup and disc image segmentation from fundus images, in: In Proc. MLMI, pp. 136–143.
- Zilly et al. (2017)
Zilly, J., Buhmann, J., Mahapatra, D., 2017.
Glaucoma detection using entropy sampling and ensemble learning for automatic optic cup and disc segmentation.
In Press Computerized Medical Imaging and Graphics 55, 28–41.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Antoniou et al. (2017) Antoniou, A., Storkey, A., Edwards, H., 2017. Data augmentation generative adversarial networks, in: ar Xiv preprint ar Xiv:1711.04340,.
- 2Chapelle et al. (2006) Chapelle, O., Scholkopf, B., Zien, A., 2006. Semi-Supervised Learning. MIT Press,Cambridge, MA.
- 3Choi et al. (2017) Choi, Y., Choi, M., Kim, M., Ha, J.W., Kim, S., Choo, J., 2017. Star GAN: Unified generative adversarial networks for multi-domain image-to-image translation, in: ar Xiv preprint ar Xiv:1711.09020.
- 4Deng et al. (2009) Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei., L., 2009. Image Net: A Large-Scale Hierarchical Image Database, in: CVPR 09.
- 5Doyle et al. (2011) Doyle, S., Monaco, J., Feldman, M., Tomaszewski, J., Madabhushi., A., 2011. An active learning based classification strategy for the minority class problem: application to histopathology annotation. BMC Bioinformatics. 12, 1–14.
- 6Frangi et al. (1998) Frangi, A., Niessen, W., Vincken, K., Viergever, M., 1998. Multiscale vessel enhancement filtering, in: MICCAI, pp. 130–137.
- 7Freund et al. (1997) Freund, Y., Seung, H., Shamir, E., Tishby, N., 1997. Selective sampling using the query by committee algorithm. Machine Learning 28, 133–168.
- 8Frid-Adar et al. (2018) Frid-Adar, M., Klang, E., Amitai, M., Goldberger, J., Greenspan 1, H., 2018. Synthetic data augmentation using gan for improved liver lesion classification, in: In Proc IEEE ISBI, pp. 289–293.