Some Limit Properties of Markov Chains Induced by Stochastic Recursive Algorithms
Abhishek Gupta, Hao Chen, Jianzong Pi, Gaurav Tendolkar

TL;DR
This paper studies the limit properties of Markov chains generated by stochastic recursive algorithms, showing convergence to deterministic contraction trajectories and invariant distributions, with applications to machine learning and dynamic programming.
Contribution
It establishes weak convergence and ergodic properties of Markov chains induced by iterated random operators, extending understanding of stochastic recursive algorithms.
Findings
Random sequences converge weakly to contraction operator trajectories.
Time averages of the sequences converge to invariant distribution means.
Applications include logistic regression and dynamic programming algorithms.
Abstract
Recursive stochastic algorithms have gained significant attention in the recent past due to data driven applications. Examples include stochastic gradient descent for solving large-scale optimization problems and empirical dynamic programming algorithms for solving Markov decision problems. These recursive stochastic algorithms approximate certain contraction operators and can be viewed within the framework of iterated random operators. Accordingly, we consider iterated random operators over a Polish space that simulate iterated contraction operator over that Polish space. Assume that the iterated random operators are indexed by certain batch sizes such that as batch sizes grow to infinity, each realization of the random operator converges (in some sense) to the contraction operator it is simulating. We show that starting from the same initial condition, the distribution of the random…
Click any figure to enlarge with its caption.
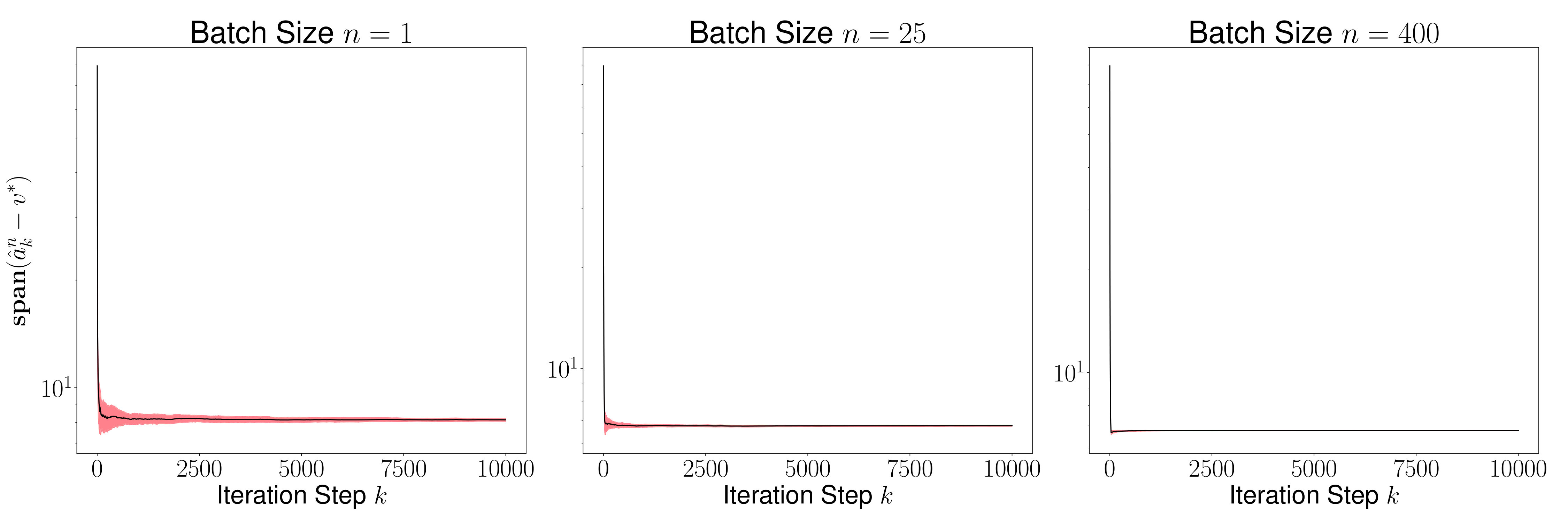 Figure 1
Figure 1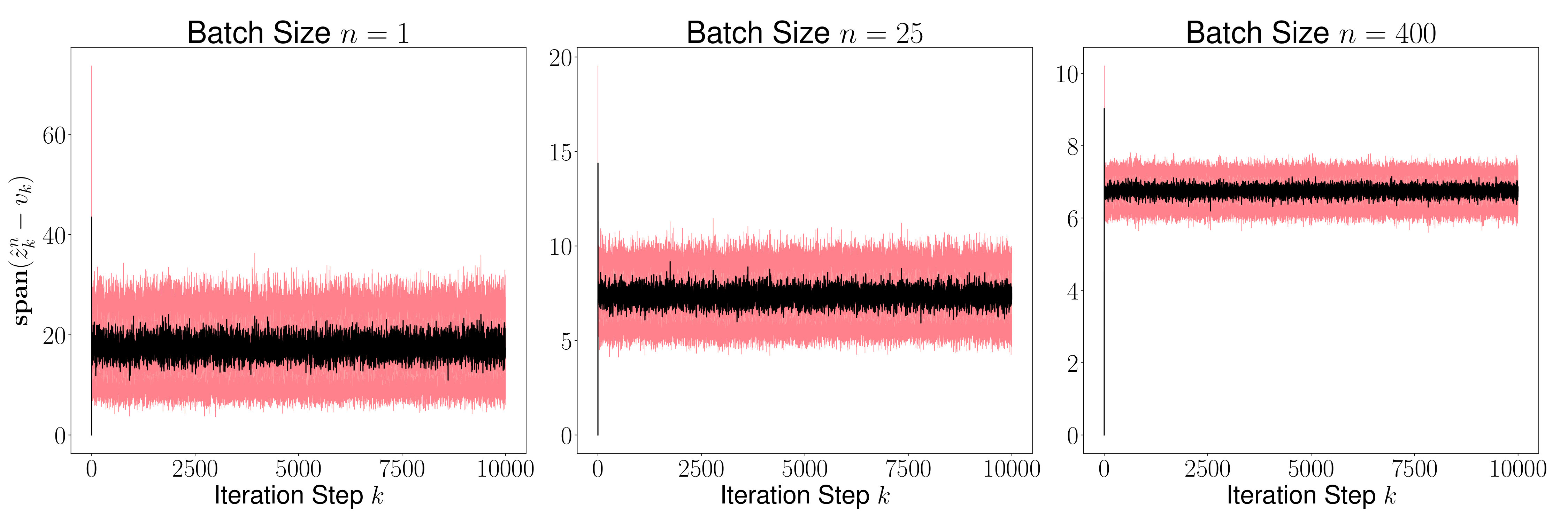 Figure 2
Figure 2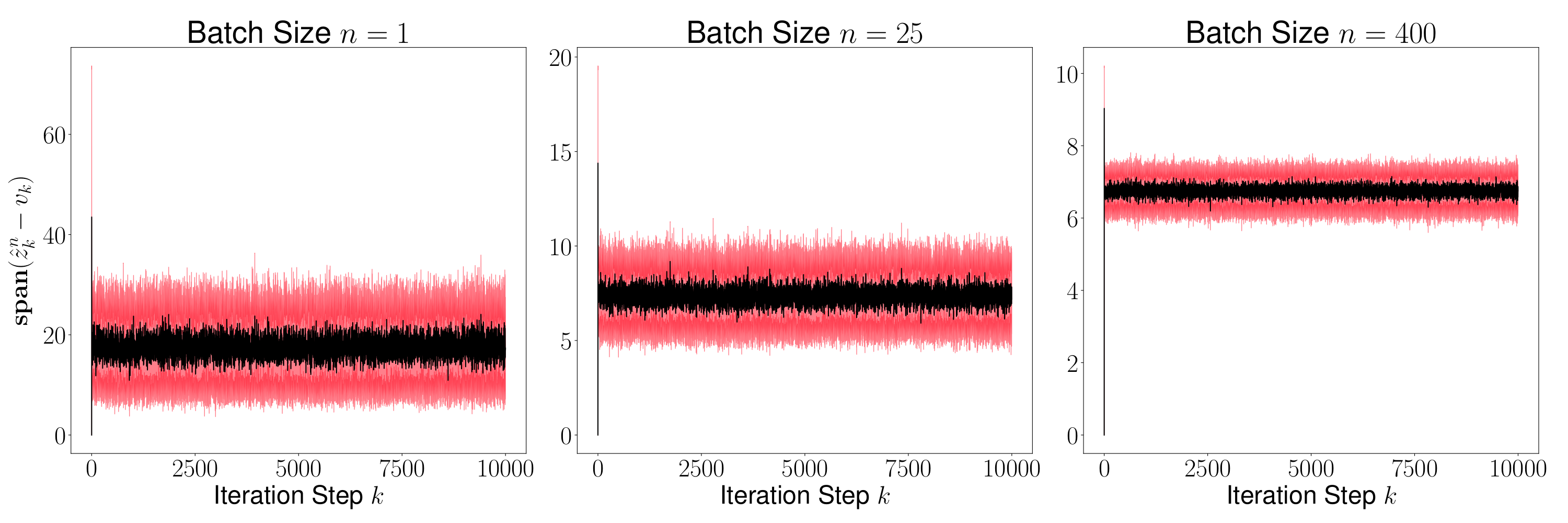 Figure 3
Figure 3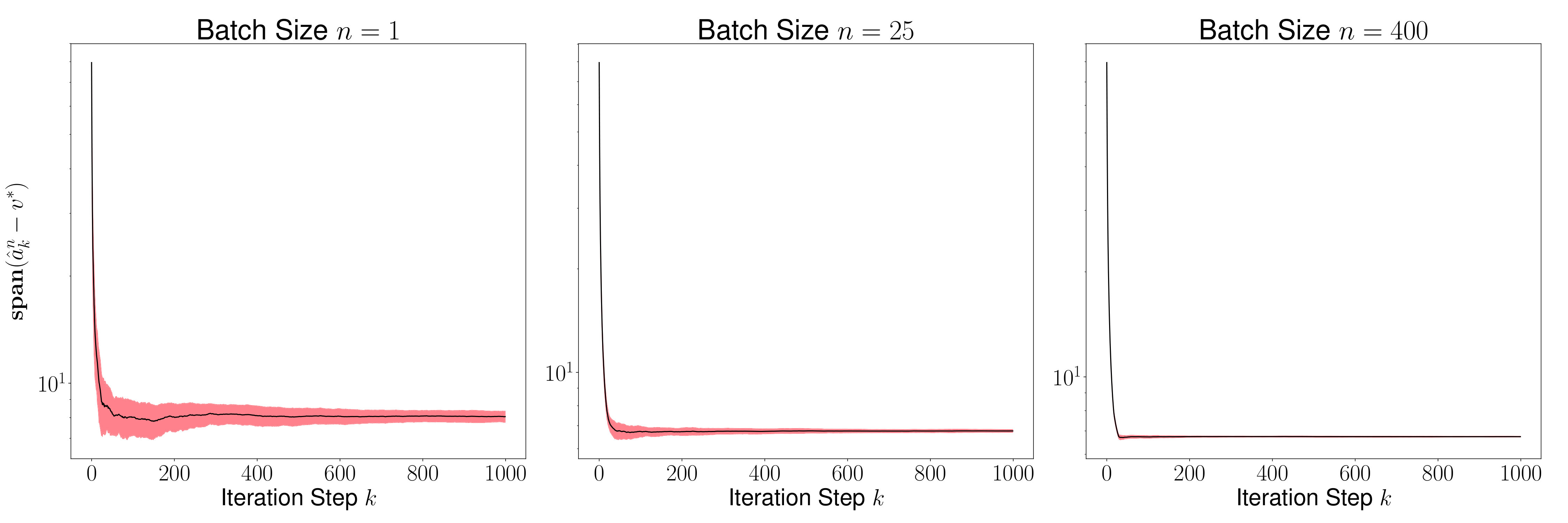 Figure 4
Figure 4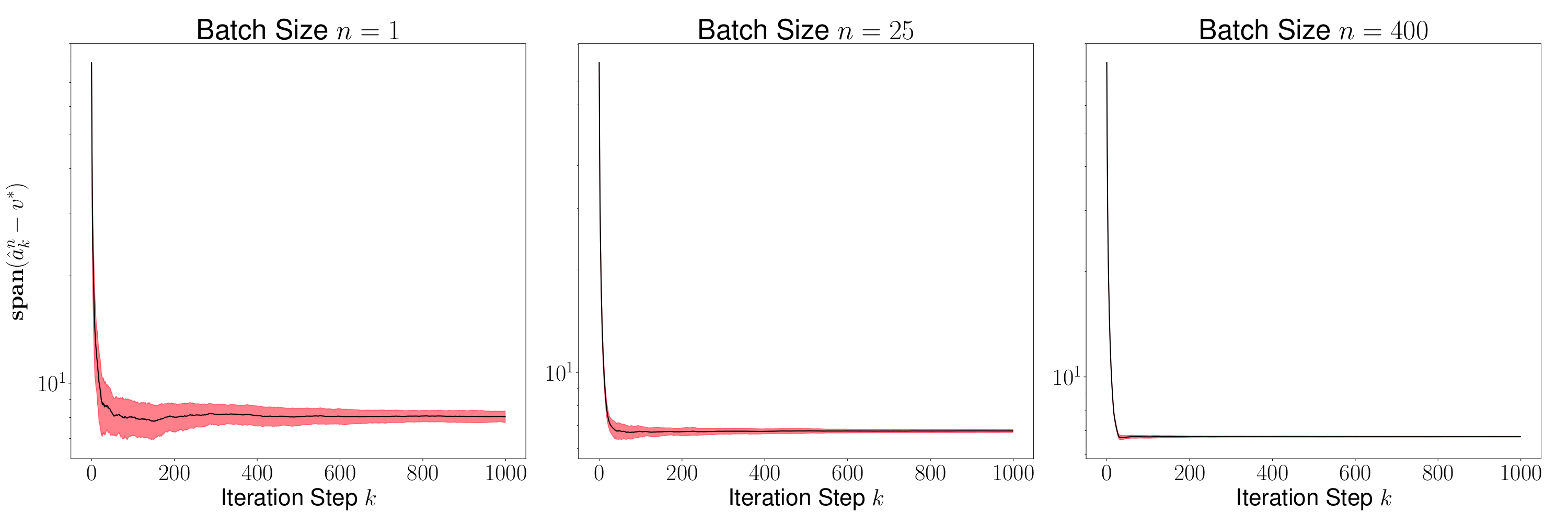 Figure 5
Figure 5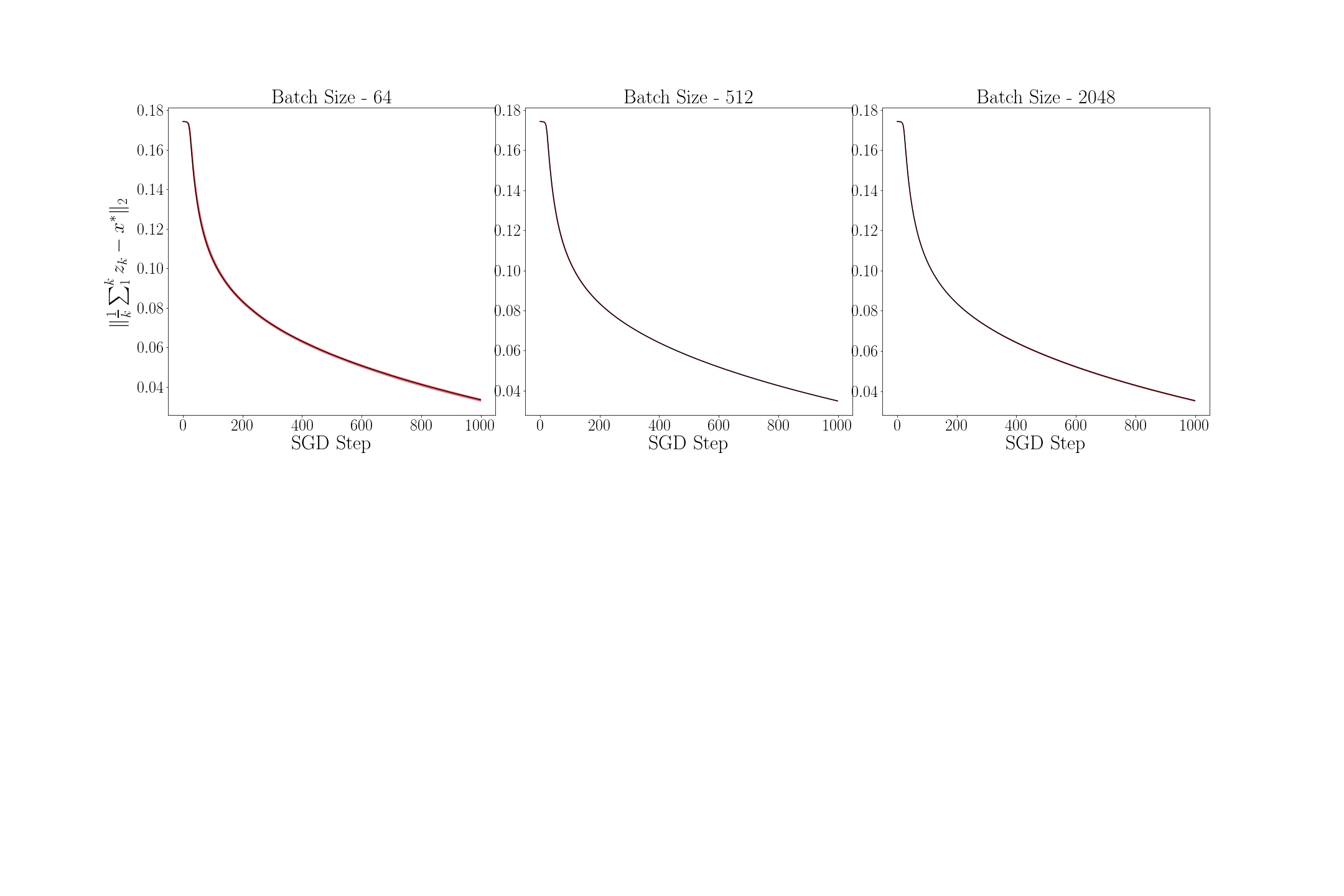 Figure 6
Figure 6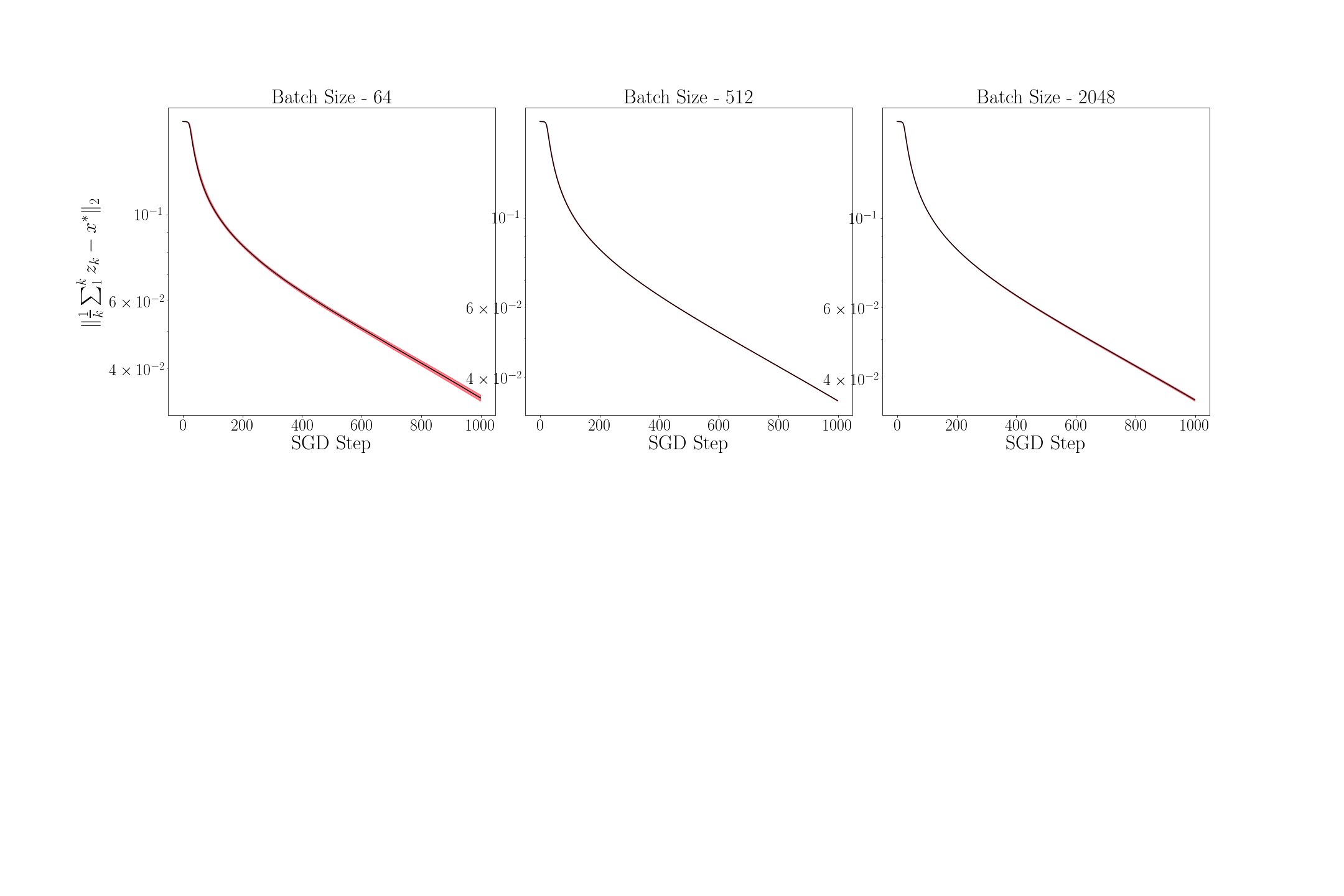 Figure 7
Figure 7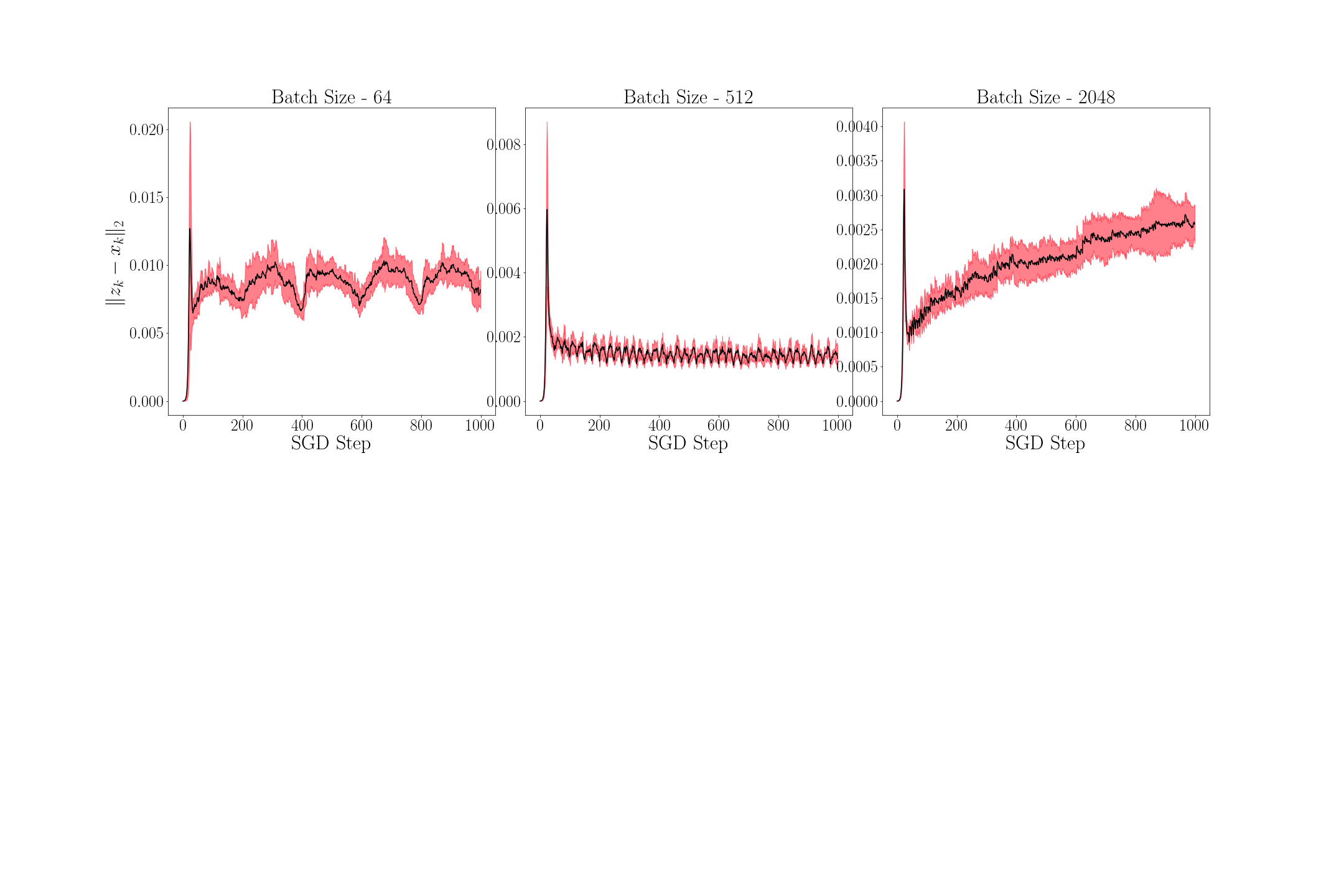 Figure 8
Figure 8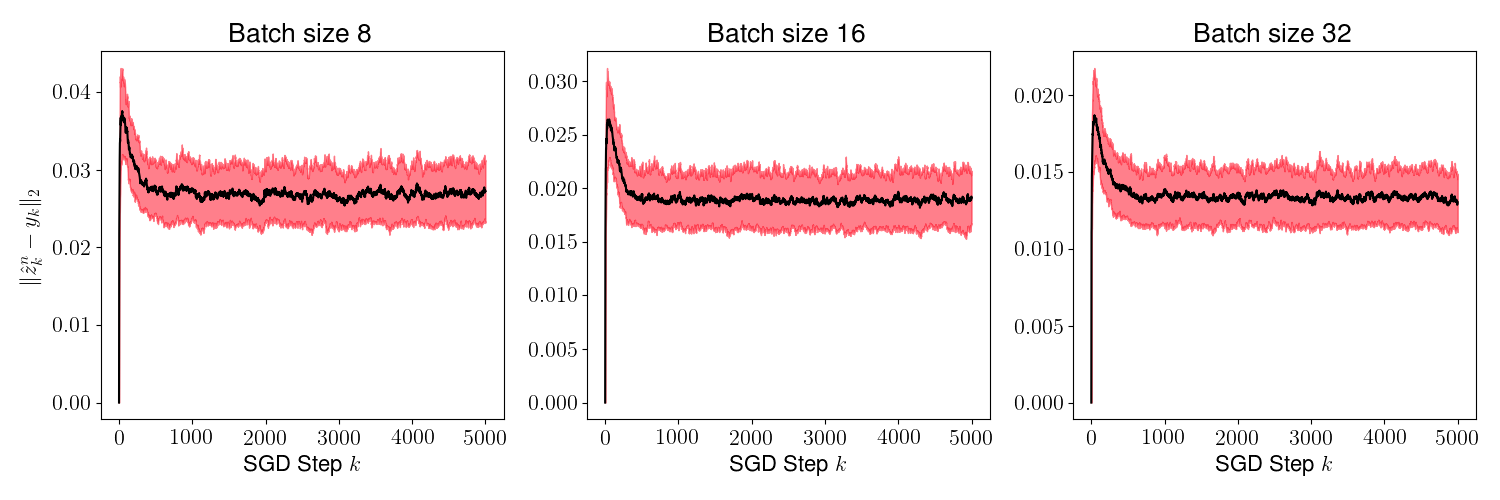 Figure 9
Figure 9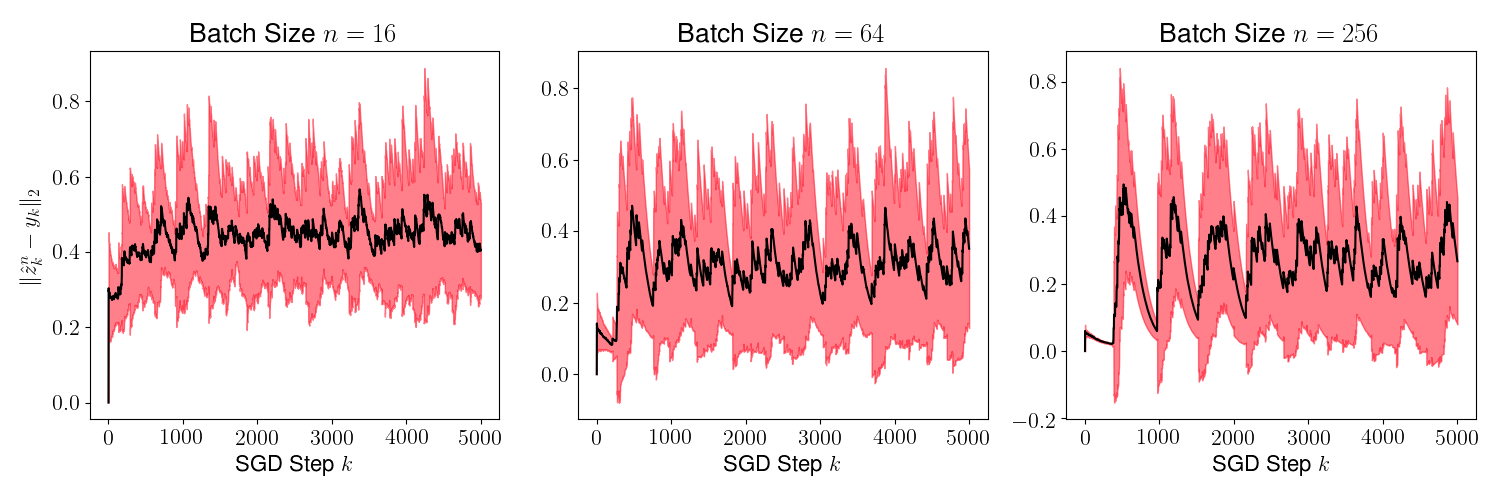 Figure 10
Figure 10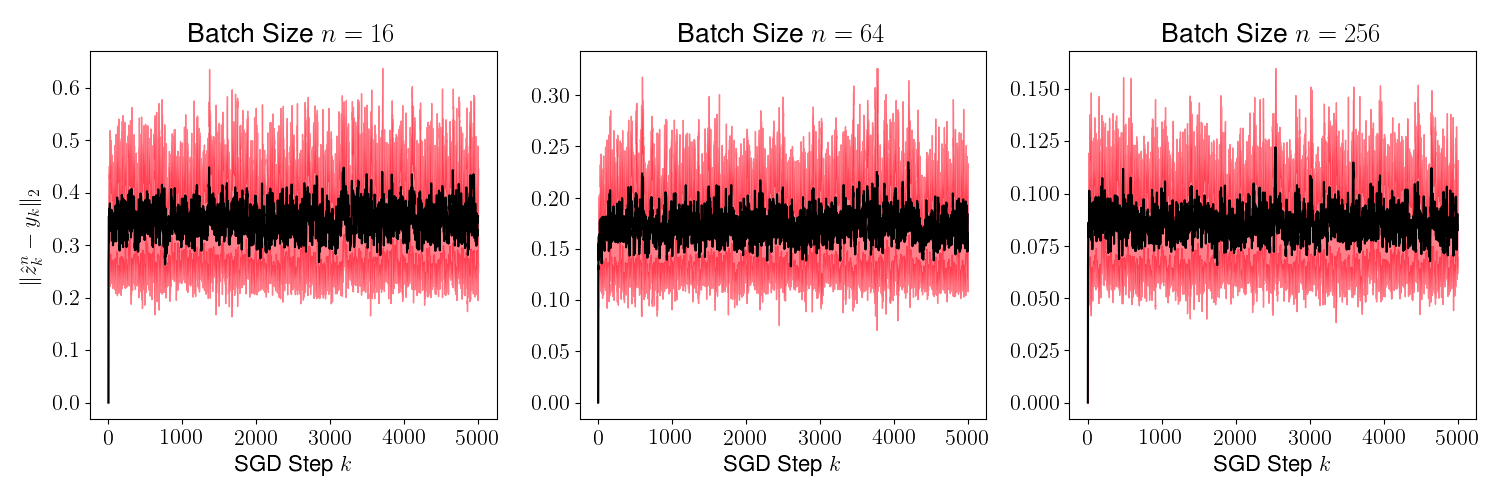 Figure 11
Figure 11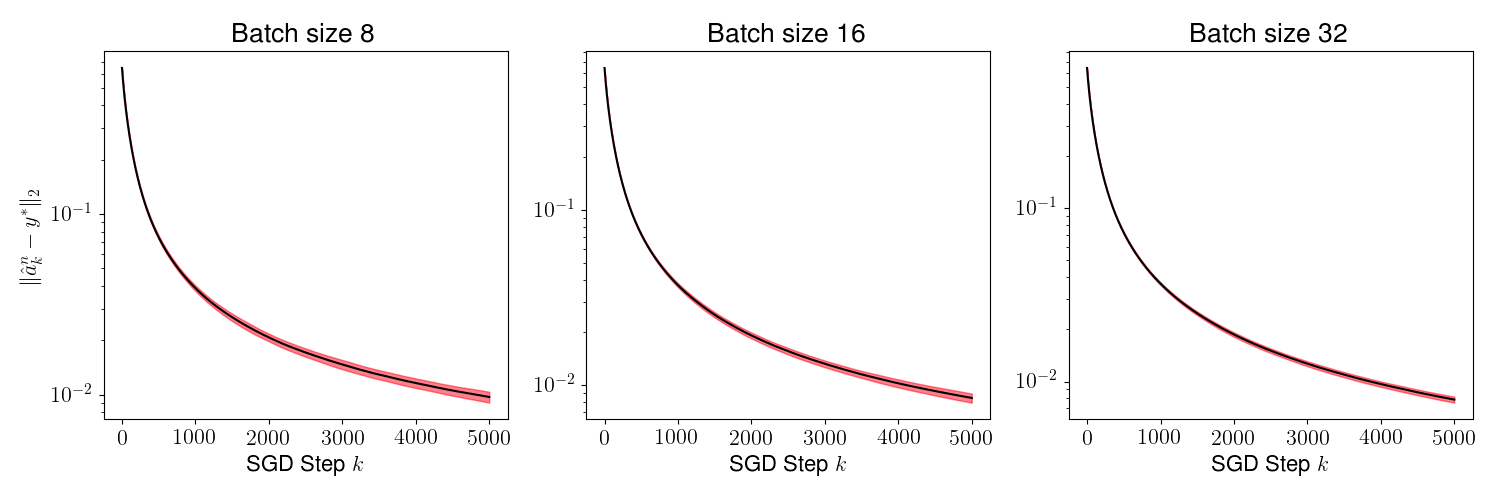 Figure 12
Figure 12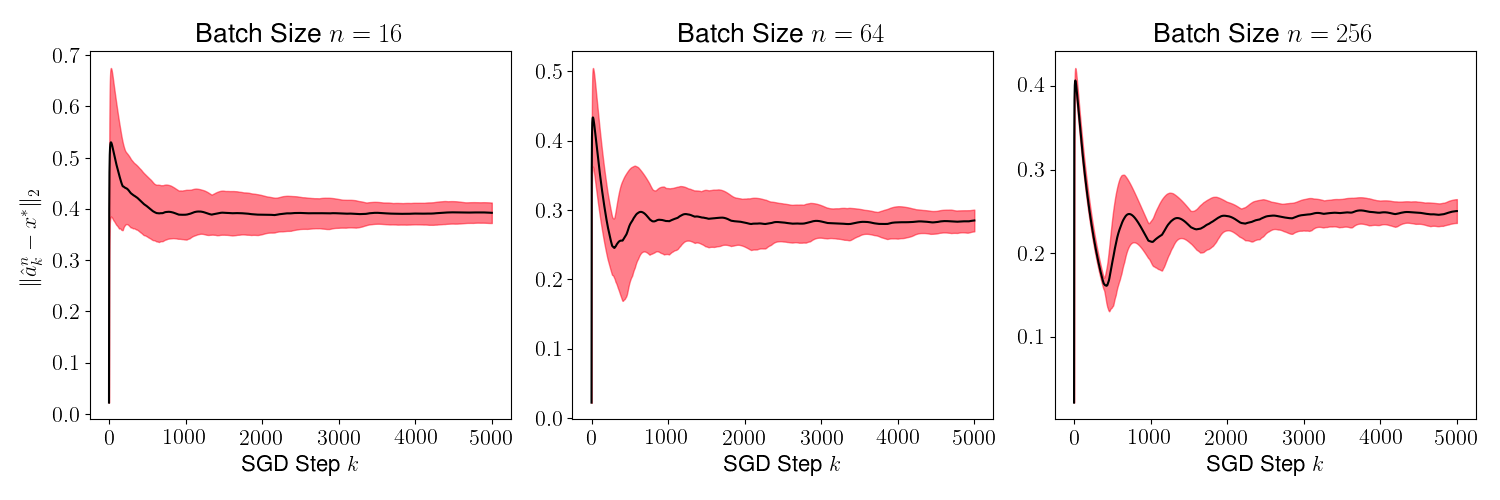 Figure 13
Figure 13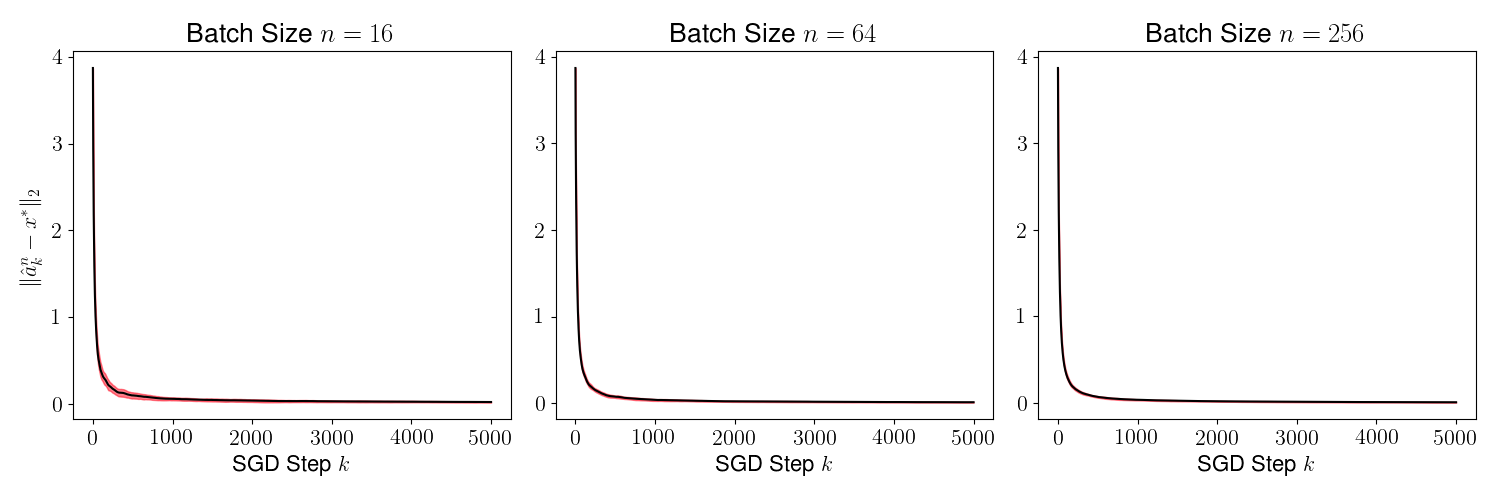 Figure 14
Figure 14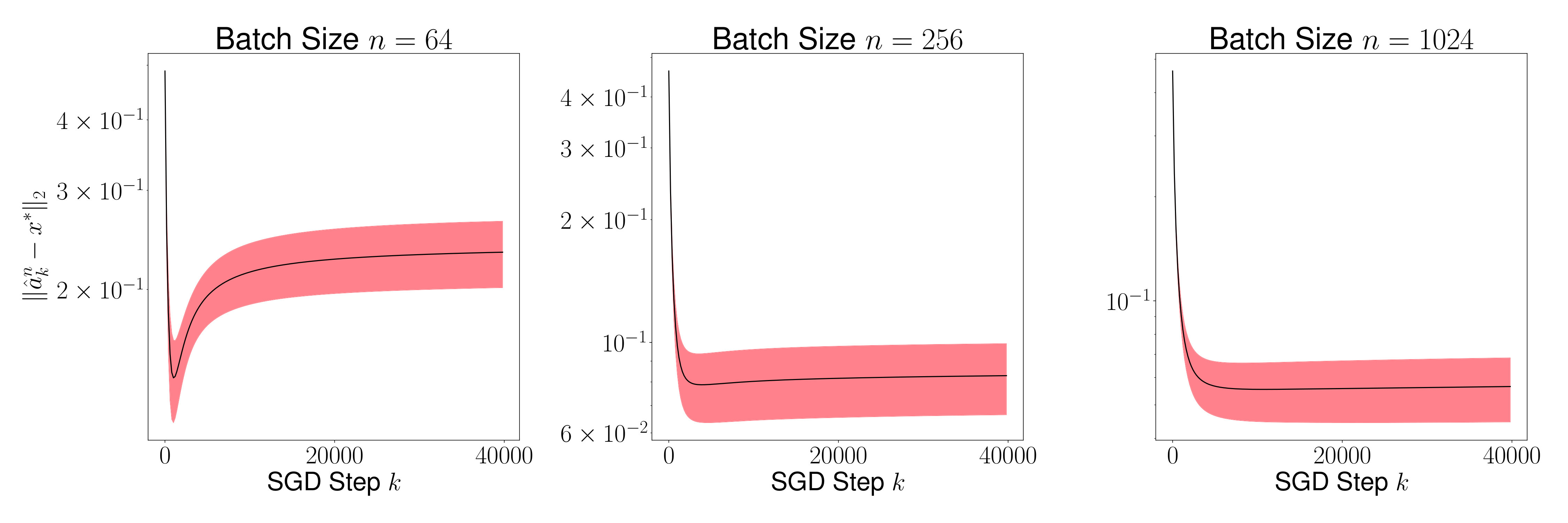 Figure 15
Figure 15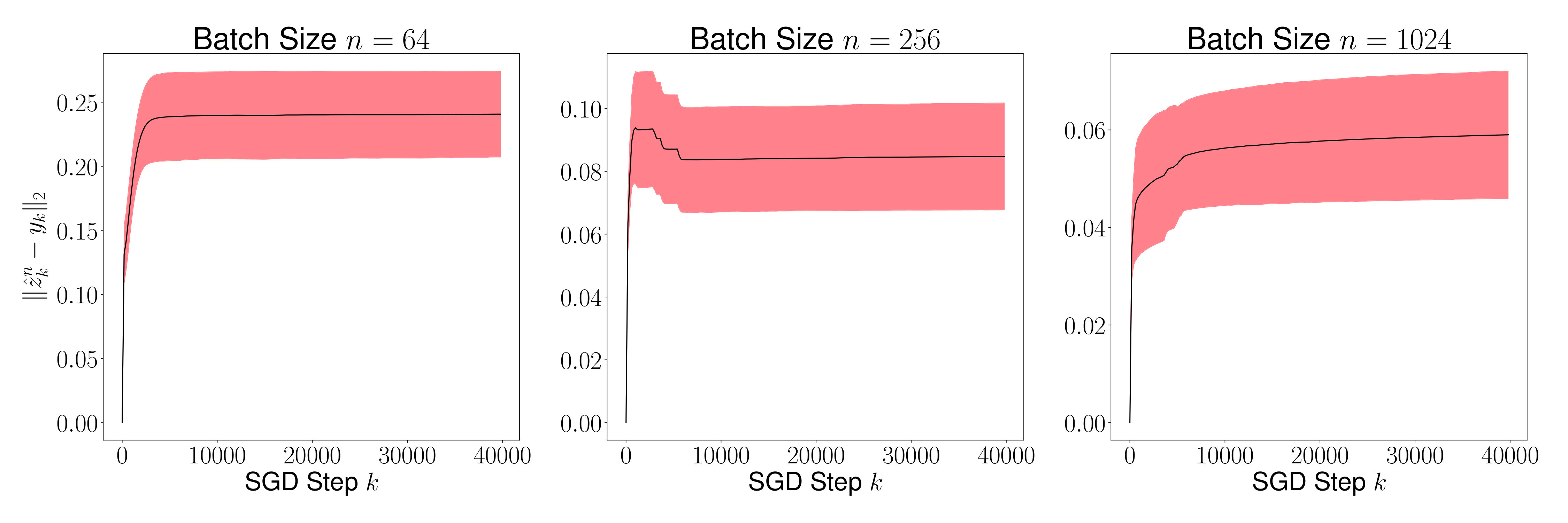 Figure 16
Figure 16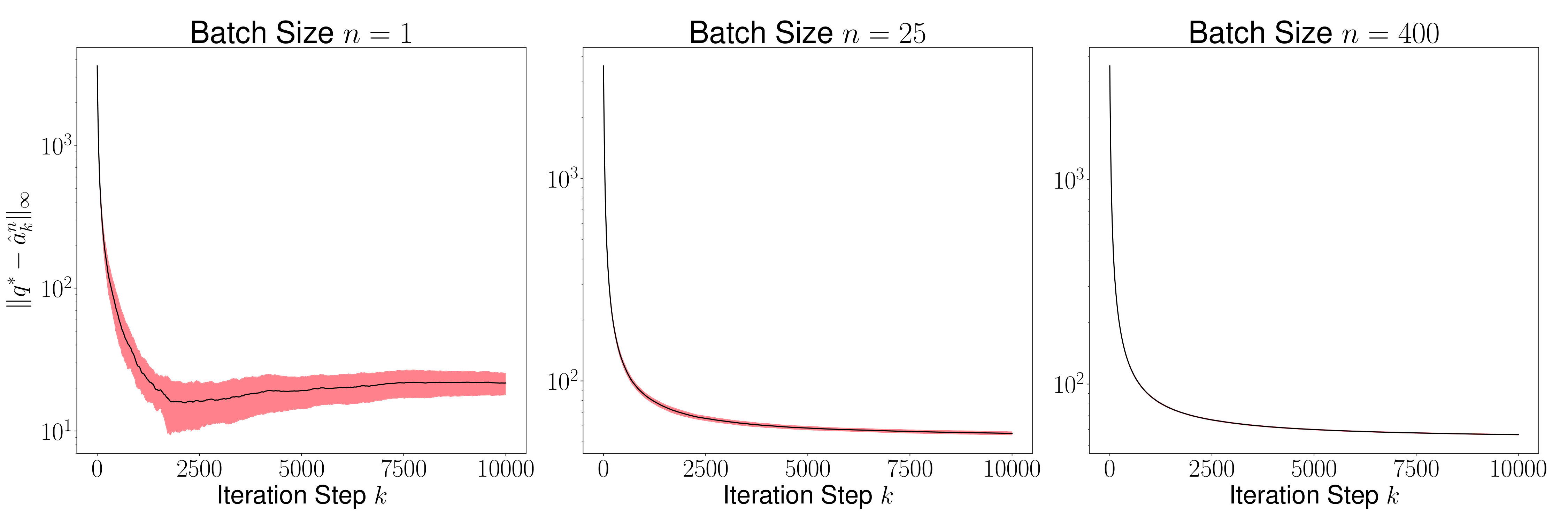 Figure 17
Figure 17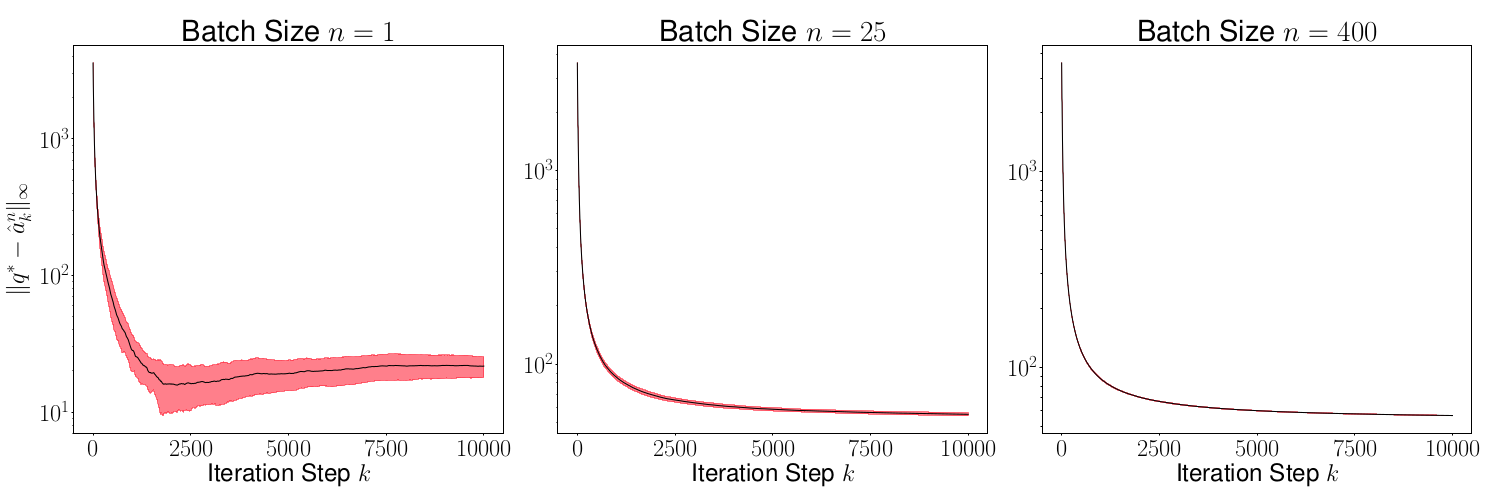 Figure 18
Figure 18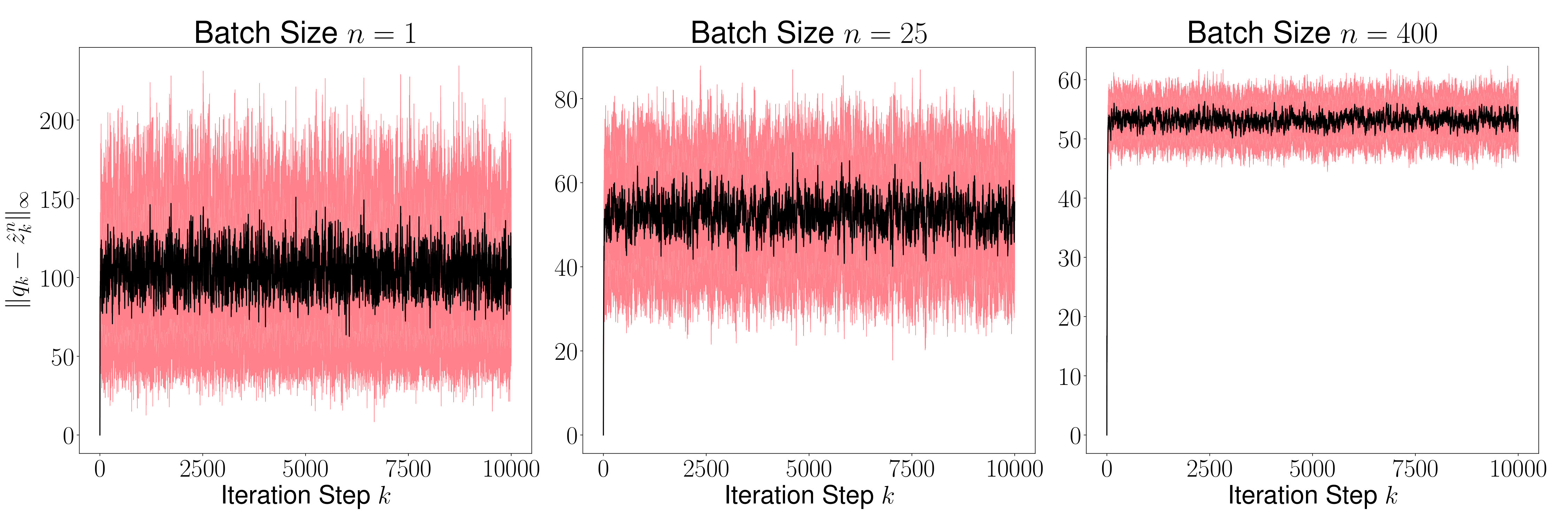 Figure 19
Figure 19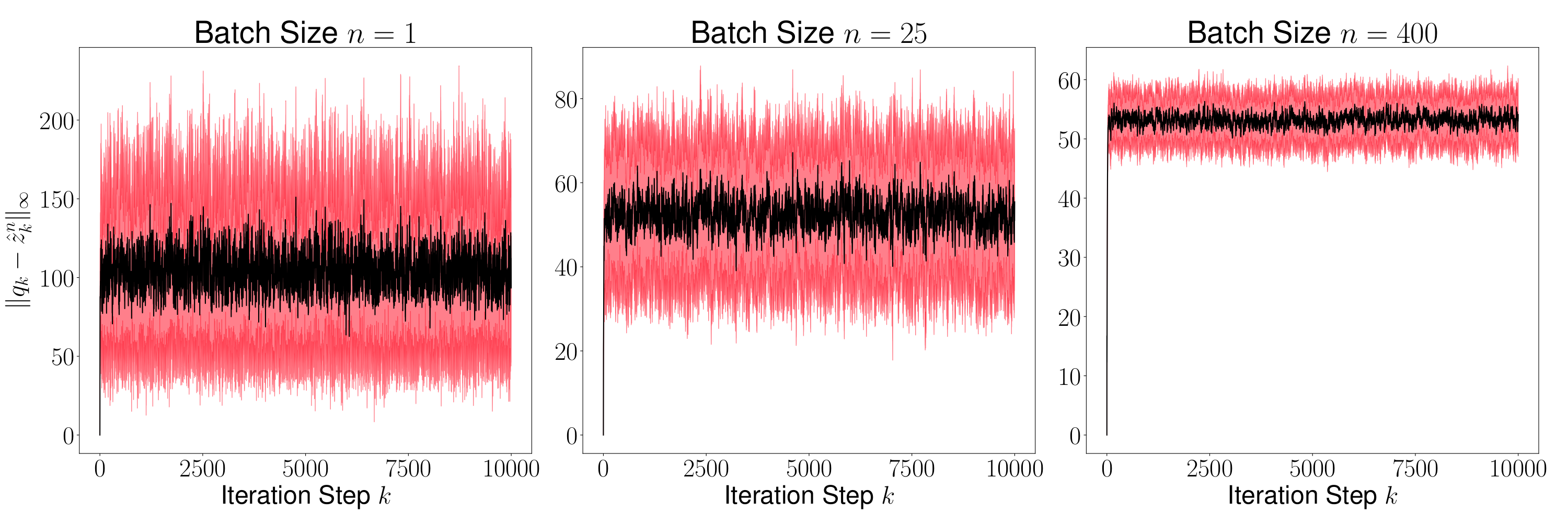 Figure 20
Figure 20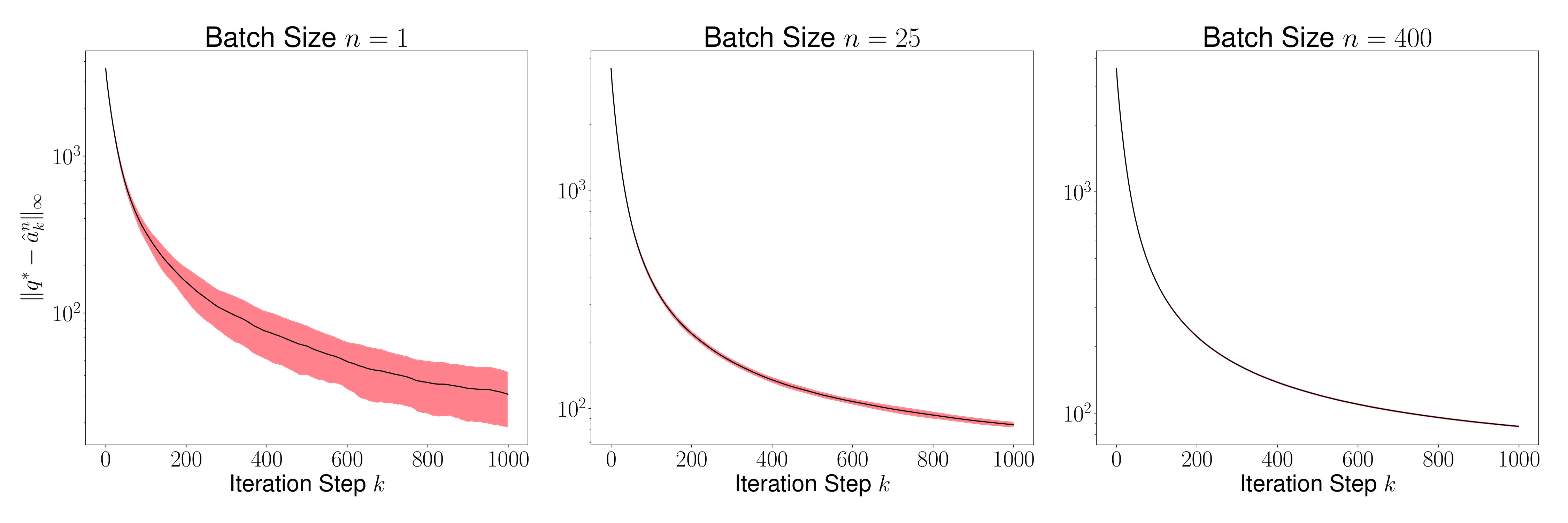 Figure 21
Figure 21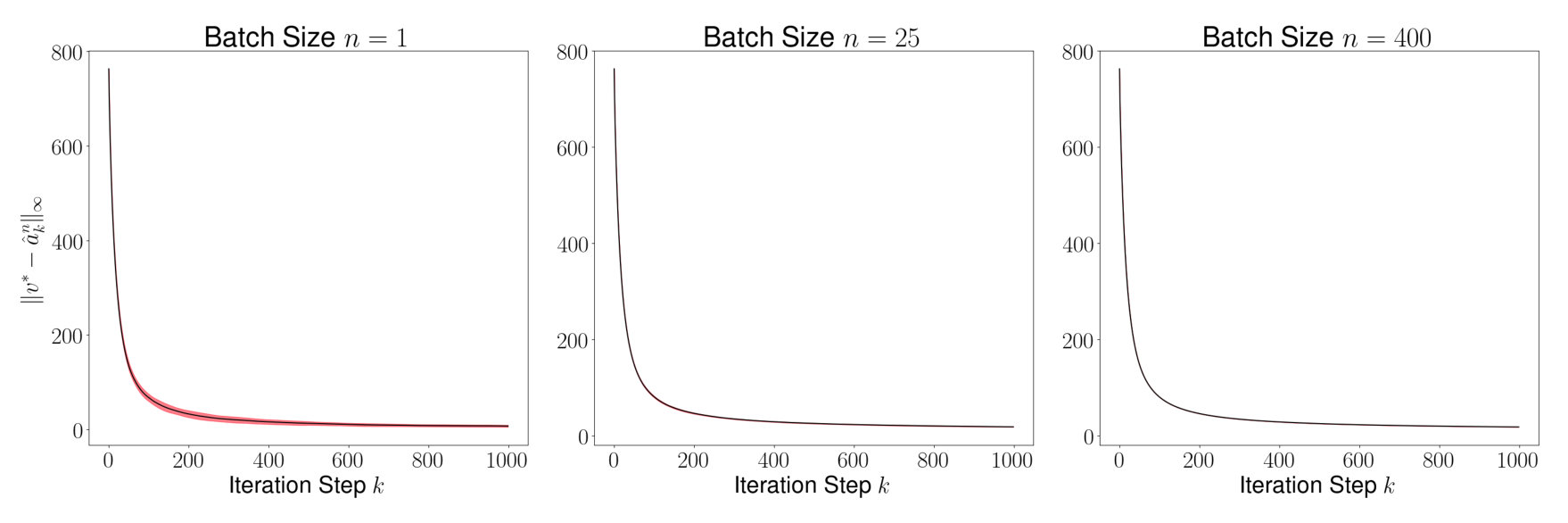 Figure 22
Figure 22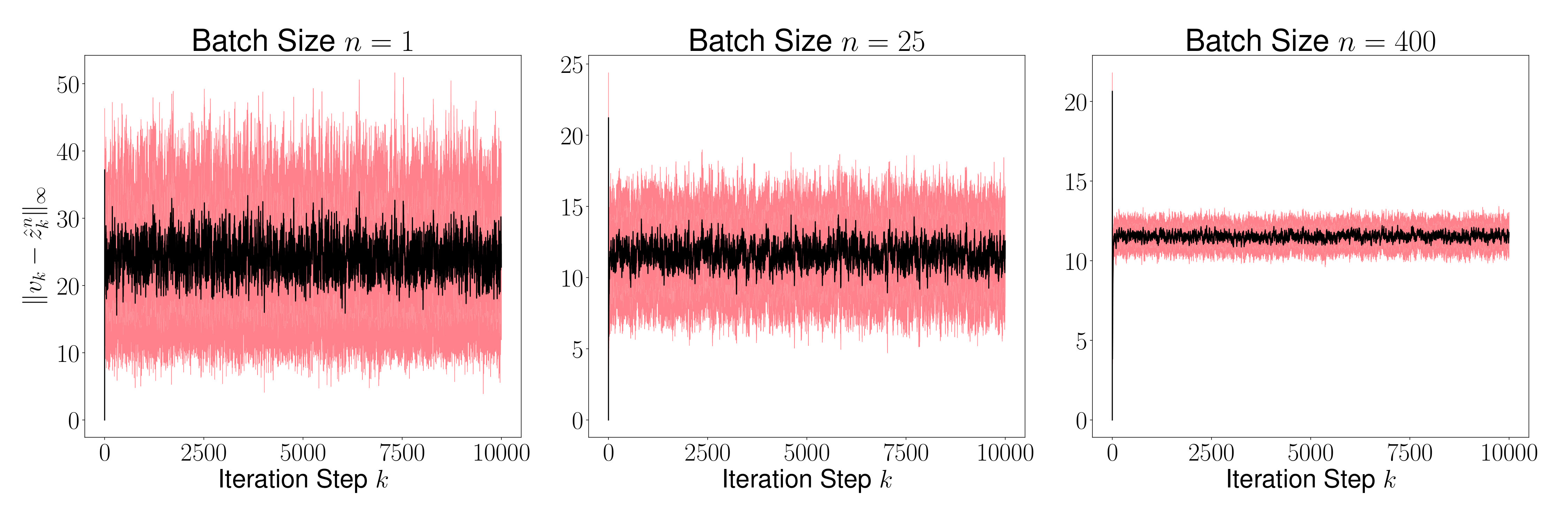 Figure 23
Figure 23 Figure 24
Figure 24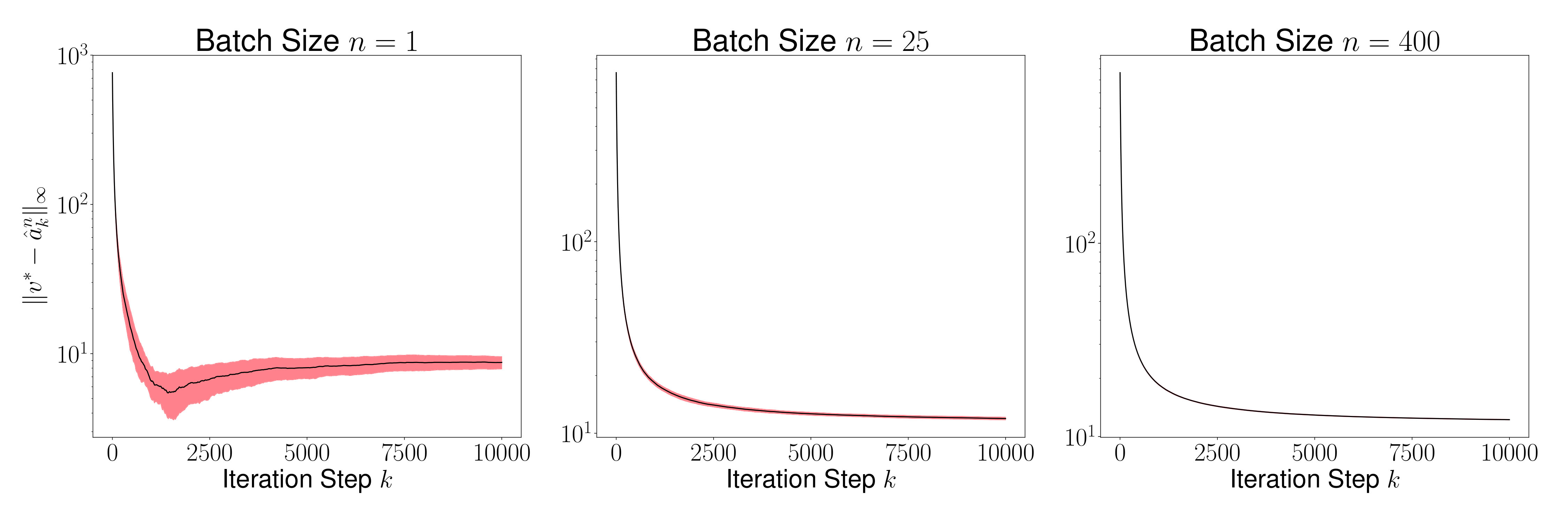 Figure 25
Figure 25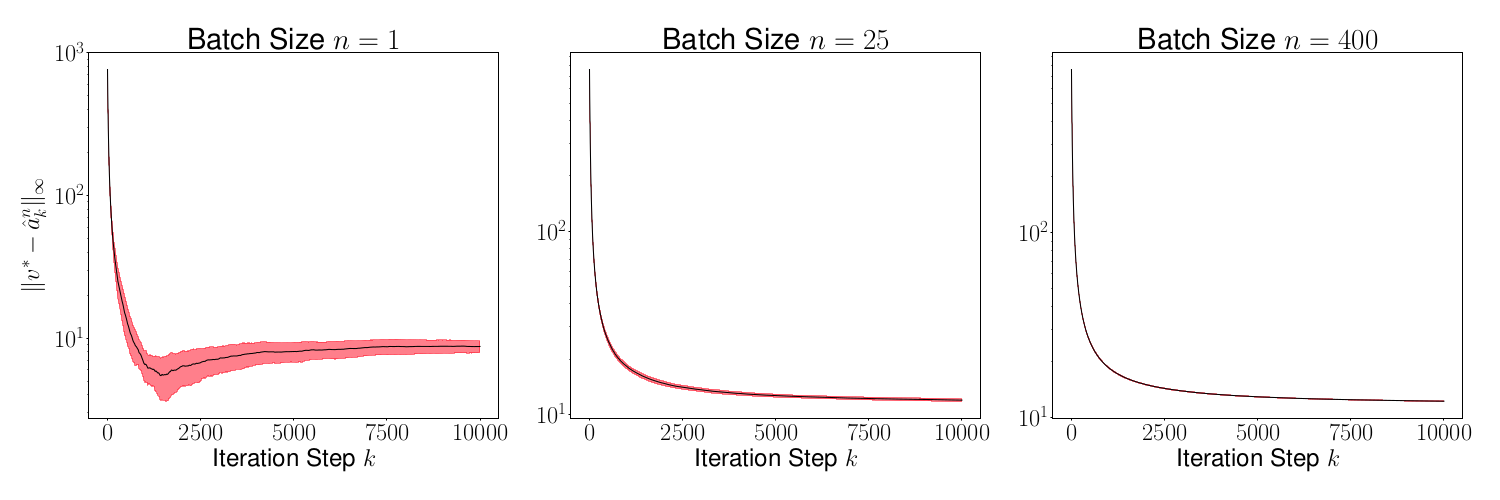 Figure 26
Figure 26Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsMarkov Chains and Monte Carlo Methods · Stochastic Gradient Optimization Techniques · Statistical Methods and Inference
\newsiamremark
remarkRemark \newsiamremarkassumptionAssumption
\newsiamthmclaimClaim \newsiamremarkexampleExample
\headersMarkov Chains Induced by Recursive Stochastic AlgorithmsA. Gupta, G. Tendolkar, H. Chen, J. Pi
Some Limit Properties of Markov Chains Induced by Recursive Stochastic Algorithms††thanks: Submitted to the editors.
\fundingThe authors gratefully acknowledge support from ARPA-E NEXTCAR Program, NSF ECCS Grant 1610615, and NSF CRII Award 1565487.
Abhishek Gupta
Hao Chen
Jianzong Pi
Gaurav Tendolkar Abhishek Gupta, Hao Chen, and Jianzong Pi is with the Electrical and Computer Engineering Department, The Ohio State University, 2015 Neil Avenue, Columbus, OH 43210, USA. (, , ). Gaurav Tendolkar is with Microsoft Corp., 599 N Mathilda Avenue, Sunnyvale, CA 94085, USA. . [email protected]
Abstract
Recursive stochastic algorithms have gained significant attention in the recent past due to data driven applications. Examples include stochastic gradient descent for solving large-scale optimization problems and empirical dynamic programming algorithms for solving Markov decision problems. These recursive stochastic algorithms approximate certain contraction operators and can be viewed within the framework of iterated random operators. Accordingly, we consider iterated random operators over a Polish space that simulate iterated contraction operator over that Polish space. Assume that the iterated random operators are indexed by certain batch sizes such that as batch sizes grow to infinity, each realization of the random operator converges (in some sense) to the contraction operator it is simulating. We show that starting from the same initial condition, the distribution of the random sequence generated by the iterated random operators converges weakly to the trajectory generated by the contraction operator. We further show that under certain conditions, the time average of the random sequence converges to the spatial mean of the invariant distribution. We then apply these results to logistic regression, empirical value iteration, and empirical Q value iteration for finite state finite action MDPs to illustrate the general theory develop here.
keywords:
Stochastic Gradient Descent, Empirical Dynamic Programming, Constant Stepsize Q learning, Iterative Random Maps, Feller Markov Chains
{AMS}
93E35, 60J20, 68Q32
1 Introduction
There has been a surge of interest in using randomization to reduce computational burden in machine learning and reinforcement learning. For instance, in training neural networks with a large amount of data, stochastic gradient descent is frequently employed instead of the usual gradient descent. In data-driven Markov decision problems, empirical dynamic programming and generative models have been employed to determine approximately optimal policies and value functions. In these algorithms, instead of computing the expected value of certain functions at each step of the iteration, one computes the empirical expected value that is rather easy to compute if enough data is available. This simple trick reduces the runtime to determine a reasonably good solution.
It turns out that the outputs of these recursive stochastic algorithms (RSAs) can be viewed as Markov chains. Indeed, if the parameters of the algorithm do not change with iteration, then the RSAs can be thought of as an iterated random operator acting onto certain spaces. Consider, for instance, the case of stochastic gradient descent, where the stepsize remains constant, data samples picked at every iteration are i.i.d., and the number of data samples remain constant. Then, each step of the stochastic gradient descent algorithm can be viewed as a random operator. To see this, let us consider the problem of minimizing a sum of functions, , :
[TABLE]
In usual gradient descent, one fixes a stepsize , and runs the iteration
[TABLE]
where we used to denote the exact gradient descent map. We note here that under reasonable assumptions on and , becomes a contraction operator under some norm on (usually norm is used).
In contrast, in stochastic gradient descent, the operator applied at every step of the algorithm changes. At time step of the stochastic gradient descent algorithm, let be the set of indices that are sampled independently and uniformly from the set of all indices . Then, we have
[TABLE]
Since the set of (random) indices is i.i.d., the operator is independent of the past maps and is “identically distributed”. This implies that the (random) sequence is a Markov chain. It should also be noted that the exact gradient descent operator and stochastic gradient descent operator are related – is a consistent estimate of the for any .
A similar setup is considered in empirical dynamic programming using a generative model for dynamic decision process. Consider a controlled Markov process in which is the state of a system and is the action of the decision maker. Let denote the transition probability of the next state being given the current state and action and be the corresponding cost. We use to denote the discount parameter. In the value iteration algorithm, one needs to compute , where is some real-valued function of the state. This leads to the usual Bellman operator that acts on the space of value functions and is given by
[TABLE]
It is not difficult to see that is a contraction operator with the contraction coefficient , when the space of value functions is endowed with the sup norm. If there is enough data, one can replace with its “empirical” average, given by , where are samples of the next state given that the current state-action pair is . Thus, the random Bellman operator acts on the space of value functions and is given by
[TABLE]
In this case as well, is a consistent estimate of the for any value function . When the state or action space is continuous, then the above operator also features an additional function fitting component. The analysis of such algorithms involves understanding the error introduced due to function fitting, as well as the number of samples used at every iteration.
In fact, in both of the examples above, it is readily observed that the original operator is a contraction map. This is no accident – contraction mapping theorem forms the bedrock of most of the proofs of convergence algorithms used in optimization or MDP problems. Some examples are noted below:
The Bellman operator for a class of stochastic shortest path problems is a contraction operator under an appropriate weighted sup norm [9, 7]. 2. 2.
The Bellman operator for a class of average cost MDPs is a contraction operator under the span seminorm over the quotient space [63, 2]. 3. 3.
Some variational inequality problems involve contraction operators under the usual 2 norm [29, p. 143]. 4. 4.
The Bellman operator for continuous state MDP is a contraction operator over the space of continuous and bounded functions over the state space of the MDP (it requires a variety of assumptions as elucidated in [40, 41, 28]). 5. 5.
The resolvent of a strongly monotone operator is a contraction operator [65]. Many other contraction operators used in the context of optimization algorithms are discussed in Section 5 of [65].
In data driven applications, computing the exact (contraction) operator is either computationally expensive or impossible. Thus, one has to use random mappings, that are drawn independent of the past operators, and that simulate the effect of contraction mapping. The two examples explained above are merely instances of this more general methodology. The primary purpose of the paper is to devise sufficient conditions on the relationship between random maps and the deterministic contraction operator so that (a) the convergence properties of new algorithms can be readily established, and (b) find common threads between the convergence.
1.1 Our Contribution
The primary contribution of this paper is to conceptually unify the convergence analysis of certain RSAs in optimization, machine learning, and reinforcement learning using the tools from the Markov chain theory. This is achieved by leveraging several results available for convergence and stability for Feller Markov chains established in [19], [56, Sec. 18.5], [17, Sec. 8], and [49]. Our key contributions are summarized below.
Consider the deterministic sequence ( compositions of the exact operator ) and the Markov chain with . It is natural to assume that using the deterministic operator yields the best convergence guarantee. We use independent samples of data to approximate by , then it introduces error at every time step. How does this error accumulate? Most authors bound , where is the fixed point of the operator . Instead, we are interested in the error , noting that triangle inequality yields
[TABLE]
We derive a sufficient condition on the random operators and its relationship with the exact operator so that the sequence of distributions over the sequence output by the RSA converges in weak* topology to the unit mass over the trajectory output by the exact algorithm as the parameter . This further implies that is close to with high probability. Using the inequality in (1) above, we conclude that the error term is less than plus a small error with high probability.
We further show that the sufficient condition is satisfied in a sufficiently general class of problems encountered in stochastic gradient descent for strongly convex loss functions and synchronous empirical dynamic programming for MDPs with discounted cost criterion. These examples serve to illustrate how to apply the results to derive this property of an RSA. 2. 2.
Existence of invariant distributions of RSAs is an important property, as it implies some form of stability of the algorithm. A Markov chain does not admit invariant distribution if it features a cyclic behavior or diverges to infinity (there could be other reasons for the non-existence of an invariant distribution, but these two are more common). In an RSA, we do not usually expect a cyclic behavior due to randomization. Thus, if an RSA admits an invariant distribution, then it implies that the iterates will not diverge with high probability. Thus, establishing the existence of an invariant distribution is an important problem, which we address here.
We show that the Markov chains generated by many RSAs satisfy the weak Feller property, that is, if is a continuous and bounded function, then is also a continuous and bounded function. The existence (and in some case, the uniqueness) of an invariant measure of Feller Markov chains has been presented in [17]. We apply these results to conclude that under some reasonable assumptions, the chains generated by stochastic gradient descent and empirical dynamic programming algorithms admit invariant distributions. In certain cases, we can show that this invariant distribution is unique. 3. 3.
There has been a sustained interest in using time-averages in stochastic gradient descent and deep Q learning. Particularly, references [67, 55, 45, 54, 78] propose that fixing the stepsize in stochastic gradient descent algorithms and using the average of the tail of the random sequence leads to a better performance of the trained algorithm. Within the context of reinforcement learning, [3] and [82] propose averaging the deep Q function iterates to arrive at a solution with lower variance.
Indeed, we show here that under some conditions on the random operators, the variance reduction property of time-average (or in these cases, tail average) is largely due to the fact that the Markov chain output by RSA may be admitting a unique invariant distribution. This part leverages the law of large numbers for Markov chains, presented in [19, 56]. 4. 4.
We complement the theoretical contributions with numerical simulations of two RSAs – stochastic gradient descent for logistic regression, empirical value iteration for discounted MDP with a generative model, and synchronous batch Q value iteration for discounted MDP.
While we present complete proofs of two of our main results stated here, we admit that our proofs require minor tweaks of existing results in the literature. The need for presenting the complete proofs are twofold: Our hypotheses differ in some ways from the hypotheses presented in the standard texts, particularly in [49], [56, Section 18.5], and [19]. Moreover, to construct the complete proofs using these texts under our hypotheses require substantial effort on the part of the reader. To ease this burden, we chose to furnish the complete proofs using the notation adopted here.
1.2 Previous Work
Convergence proofs of randomized optimization and learning algorithms are usually obtained from specifically tailored arguments, which are not generalizable to other settings. For instance, the convergence of stochastic gradient descent, stochastic variance reduction gradient descent (SVRG), and stochastic average gradient (SAG) descent follow a completely different, and often involved, sequence of arguments [18, 14, 47, 36, 67, 24]. The argument usually starts with identifying some conditions on the functions, such that for every iteration , one can upper bound (where we used the notation introduced above) by a function that decays as grows. These tailored methods usually also yield the convergence rates specific to those algorithms.
It would be conceptually elegant to determine a set of more general conditions which can be readily applied to these algorithms and many of its variants to establish the asymptotic convergence to the fixed point of the map. The stochastic approximation theory is one such elegant theory [16, 43, 50, 15]. There are two types of stochastic approximation algorithms – one with decreasing (also called tapering or diminishing) stepsize and other one with constant stepsize. In decreasing stepsize algorithms, the stepsize has to converge to 0 as the number of iteration goes to infinity (the stepsize is not summable, but is square summable). This leads to the almost sure convergence guarantee to the fixed point in the limit. For constant stepsize, the theory says that the iterates will eventually enter a neighborhood of the fixed point and do a random walk within that neighborhood.
We now present a sample of decreasing stepsize RSAs whose convergence is ascertained using the stochastic approximation theory. Under reasonable assumptions on the loss function, stochastic gradient descent and distributed asynchronous gradient descent methods converge almost surely to the optimal solution [79, 31, 32]. The convergence of reinforcement learning algorithms usually invoke some version of the stochastic approximation theorem. Reference [44, 80, 1, 10] studies the convergence of various types of Q learning algorithms developed for discounted cost or average cost MDPs with finite state and action spaces. The convergence of on-policy reinforcement learning algorithm SARSA is established in [74]. More recently, the stochastic approximation theory has been used to establish the convergence of policy gradient, temporal difference, and other related methods in [76, 90, 94, 91, 88, 89]. For more information on various reinforcement learning algorithms and their convergence proofs, we refer the reader to books [2, 77, 9] and recent survey papers [92, 93].
Decreasing stepsize RSAs do not yield approximate solutions in a reasonable time frame. As a result, constant stepsize algorithms are gaining traction as a way to speed up the computation at the cost of tolerating a small error in the final result; see, for example, [30, 58, 4, 27, 26], where constant stepsizes are used in the context of the stochastic gradient descent-type algorithms and [6, 75, 59, 68] for their usage in the reinforcement learning algorithms.
Constant stepsize stochastic approximation over finite dimensional state space has been studied in [16, 43], where the authors derive the asymptotic concentration results. It is well-understood that in stochastic gradient descent with constant stepsize, the sequence generated by the algorithm gets closer to the optimal solution, but then does a random walk around the optimal solution [26]. The closeness of the random walk to the optimal solution depends on the number of random samples one uses at each iteration of the algorithm. Similarly, in Q learning algorithm, constant stepsize Q learning has been studied in [6] (both synchronous and asynchronous version are studied). Convergence of constant stepsize temporal difference methods with linear function approximation is studied in [51, 23, 11, 35, 75]. Empirical value iteration and their variants, studied in a number of works under varying assumptions [86, 87, 21, 57, 22, 46, 48, 37, 73], are also examples of constant stepsize stochastic approximation algorithms.
When the stepsize is taken as a constant in a RSA, then the output of the RSA forms a Markov chain. The goal of this paper is to study the limit properties of such a Markov chain. There are two ways the limit can be taken. Either the sample size used at every time step can grow to infinity or the number of iterations can escape to infinity. We study both the limits in this paper. We note here that the generality of the model and minimal assumptions do not allow us to derive a finite time guarantee, which has significant importance in the machine learning and the reinforcement learning communities. Further, our proof approach is not algorithm-dependent. We leave these important problems for a future work.
Our work is largely motivated by the analysis of empirical dynamic programming in [37]. This work viewed empirical dynamic programs within the framework of iterated random operators. It used stochastic dominance based arguments to derive bounds on the asymptotic probability of error (between the random outputs of the algorithm and the optimal solution) being large. Inspired by this work, we extended the arguments to empirical relative value iteration in [34]. We further relaxed some conditions on random operators assumed in [37] in our follow up work [33]. The aim of this paper is to further expand the analysis and present conditions on random operators and its relationship to the exact operator to arrive at insightful conclusions about the random sequences generated by these RSAs.
1.3 Outline of the Paper
The paper is organized as follows. Section 2 presents a common mathematical framework to study the problem of convergence and stability of Markov chains induced by RSAs. We also state the three main questions we address. Section 3 presents some motivating examples where the mathematical framework we develop can be applied. Through these examples, we also illustrate certain desirable properties that the random operators enjoy. In Section 4, we show that the distributions over the trajectories generated by RSA converges to the Dirac mass over the trajectory generated by the exact algorithm. This constitutes the first main result of the paper. In Section 5, we study some sufficient conditions on the operators such that the resulting Markov chain admits an invariant distribution. We also study conditions under which the invariant distribution is unique. Section 6 then introduces the assumptions and establishes the weak law of large numbers for Markov chains. This constitutes the second main result of the paper. The proofs of the two main results are presented in Sections 8 and 9. We finally conclude our discussion in Section 10.
1.4 Notations
Let be a Polish space, which is defined as a complete separable metric space with metric . We use to denote the set of all probability distributions over . We use to denote the Dirac mass over . The notations and denote, respectively, the set of all continuous and bounded functions and uniformly continuous and bounded functions over the set . We use to denote the set of (possibly unbounded) continuous functions over the set . We say that a sequence of measures converges to in weak* sense iff for every , as . This is usually also referred to as weak convergence in probability theory literature.
We use to denote an indicator function, which takes the value of 1 if is true and 0 otherwise. By a slight abuse of notation, we also use to be the indicator function over a measurable set .
2 Problem Formulation
Let be a Polish space with metric . Consider a contraction operator with contraction coefficient and the unique fixed point denoted by . This means
[TABLE]
Starting from any initial point , define the iterates
[TABLE]
By the Banach contraction mapping theorem, this iteration converges to . In fact, we have
[TABLE]
As discussed previously, in many instances, it is beneficial or required in many iterative algorithms to use randomization to evaluate an approximation of using a random operator. We now formulate a framework to analyze the output of this RSA rigorously.
Let be a standard probability space, where is the set of uncertainties, is the Borel -algebra over and be the probability distribution function over . Let be a random operator that is used at the iteration and is indexed by a natural number . The index would capture, for instance, the stepsize, the number of random samples used to approximate the operator , etc. Although is a function of , we will suppress this dependence for ease of exposition. Thus, . We make the following assumption on the independence of the sequence of operators .
{assumption}
For every , and are statistically independent and identically distributed for .
2.1 Key Questions
Consider the stochastic process that starts from and define for all . Due to Assumption 2 and the fact that does not change with time, the stochastic process is a time-homogeneous Markov chain. One can view as an -valued Markov chain with the Markov transition kernel given by
[TABLE]
for any Borel set . Note that does not depend on the time index , since what we have here is a time-homogeneous Markov process.
2.1.1 Convergence of Distribution of Trajectories
We are interested in deriving conditions on the random maps under which the random sequence generated by RSA is close to the deterministic sequence generated by exact algorithm with high probability. Let us formulate the precise mathematical problem. We let denote the joint distribution of the sequence . Endow with the product topology so that it becomes a Polish space. Then, is defined by
[TABLE]
where are Borel sets in .
In the similar vein, one can also view the iterates defined in (2) as a Markov chain on the same probability space , with the distribution over this sequence defined by
[TABLE]
This is a Dirac mass on the sequence . Our first result, stated in Section 4, proves that under a mild assumption on the random operators , the sequence of measures converges in the weak* sense to .
A similar setup was considered by Karr [49]. It studies the convergence properties of a class of Feller Markov chains parametrized by such that the transition probability converges in some sense to a transition probability as . Although our assumptions are slightly different, the proof essentially imitates the one in [49] except for a couple of key steps. We also discuss numerical implication of this result in Section 4.
2.1.2 Existence of Invariant Measures for Fixed
For the Markov chain , one of the key questions is the existence of an invariant distribution. An invariant probability distribution of the Markov chain is a probability measure such that for any Borel set , we have
[TABLE]
A desirable property of a Markov chain is to have an invariant distribution, since it implies that the RSA satisfies a form of stability. More importantly, it implies that the Markov chain will not escape to infinity with probability 1. There is a large body of literature that studies the problem of the existence of invariant measures for Harris recurrent Markov chains that take values in continuous state spaces [17, 56]. However, the Markov chain generated by the RSAs seldom satisfy the strong recurrence structure required for Harris recurrent chains.
Instead, these chains satisfy the weak Feller conditions, for which there are limited results in the literature. Nonetheless, we show that many RSAs satisfy certain desirable properties, which can be leveraged to not only guarantee the existence of an invariant distribution, but also establish the uniqueness of the invariant distribution. These properties of the random operators are discussed in Section 5. This further leads to strong conclusions about the weak law of large numbers, as we discuss next.
2.1.3 Convergence of Time Average of Iterates
The weak law of large numbers for independent and identically distributed (i.i.d.) random variables states that the time average of i.i.d. random variables converges to the mean of the distribution in probability under fairly mild conditions. In fact, such a version of the weak law of large numbers is also available for Feller Markov chains. This is established for Feller chains in [19] for chains residing in a compact Hausdorff space with a unique invariant measure, and in [56, Section 18.5] for the non-compact case under certain technical conditions, which include existence of an invariant measure. It turns out that this result can be proved simply under the uniqueness of the invariant measure if the starting point is chosen according to certain specific distribution (in fact, we do not need other technical conditions of [56, Section 18.5]). We prove this result in Section 6, the proof of which is adapted from the results from [19] and [56].
We illustrate the theoretical results using numerical simulations for batch gradient descent, empirical value iteration, and synchronous batch Q learning in Section 7.
3 Motivating Examples
We present here two examples where we illustrate how the random operator framework can be applied.
3.1 Stochastic Gradient Descent in Logistic Regression
Logistic regression has been widely used in many binary or multi-class classification problems. For simplicity, we consider the logistic regression with binary classification. Let be the set of feature vectors. Let denote the labeled dataset with data points and their labels. Our task is to model conditional probability distribution of label given the feature vector . In logistic regression, we model as where are the parameters of to be learned from the data, where is defined below:
[TABLE]
Our goal is to compute the parameter that maximizes the log likelihood (or equivalently, minimizes the negative log likelihood) given the labeled data. The log likelihood of i.i.d data under conditional distribution is given by
[TABLE]
It can be shown that the derivatives of are given by
[TABLE]
Consequently, each is a convex function, and thus, is a convex function over the space . If the matrix is full rank and , then it immediately follows that is a full rank matrix with positive eigenvalues. Consequently, is strongly convex, and therefore has a unique minimum . This minimum can be computed using the usual gradient descent algorithm. The algorithm starts at , picked arbitrarily, and proceeds in the direction of in small steps of size :
[TABLE]
where is the gradient descent map (dependent on the parameter ). It can be further shown that if is sufficiently small, then the operator is a contraction on , endowed with the Euclidean norm. We note here that the above arguments would be true if is a collection of strongly convex and smooth loss functions.
In practice, the exact gradient computation of loss function is computationally expensive as it requires evaluating gradients at every time step. Therefore, to ease the computational burden, a mini-batch Stochastic Gradient Descent (SGD) is employed. In the mini-batch SGD, at every step , the gradient is approximated by a small, randomly sampled, subset (of size ) of the data set. To introduce this algorithm, let be the randomly sampled subset of size . The state is updated as
[TABLE]
Note that is now a random operator.
Remark 3.1**.**
Any realization of this random operator with small values of need not be a contraction since is a rank 1 positive semidefinite matrix. One could add a regularizer to the loss function to make it strongly convex. In particular, if the loss function is chosen as
[TABLE]
then is a contraction operator for a sufficiently small irrespective of the used.
Some obvious properties of these random operators are:
is continuous in . 2. 2.
For every and , we have
[TABLE] 3. 3.
Suppose that for any compact set , is uniformly bounded, that is, there exists such that . Then, for any ,
[TABLE]
This statement can readily be proved using the Hoeffding inequality and the union bound.
Let us depart from the specific case of logistic regression, and consider the case where can be any strictly concave function for all . Then, satisfies the following property.
If all the eigenvalues of the Hessian of satisfy for all , then every realization of the random operator is a contraction map with contraction coefficient for an appropriately picked .
We now introduce the empirical dynamic programming algorithm in the context of value iteration for MDP with discounted cost criteria.
3.2 Empirical Value Iteration for Discounted Cost MDP
Consider a Markov Decision Problem (MDP) problem described by 4 tuple , where is the finite state space, is the finite action space, and is the cost function. The state transitions according to . Let denote the set consisting of all possible deterministic policies . The infinite horizon discounted cost starting from state and following policy is given by
[TABLE]
where is the discount factor. The goal is to compute the optimal value . Let be the set of all ; this space is isomorphic to the Euclidean space .
It can be shown that the optimal infinite horizon discounted cost is a fixed point of a contraction map , where is the Bellman operator given by
[TABLE]
Due to the Banach contraction mapping theorem, admits a unique fixed point, which is equal to . The iterative process of finding this unique fixed point is called the Value Iteration algorithm:
[TABLE]
In data driven applications, it is often the case that for all possible state-action pairs, multiple realizations of the next states are available. In this situation, we can replace the expectation in (8) to the empirical average. This algorithm is referred to as empirical dynamic programming, and is written as
[TABLE]
where are independent and identically distributed samples of the next state given the current state-action pair , redrawn at every independently from the past realizations. The above intuition can be turned into an algorithm to determine an approximately optimal value function, and is known as the empirical value iteration algorithm:
[TABLE]
Note that is a random operator, and its realization is dependent on the samples generated . The following properties of are obvious:
is a contraction with contraction coefficient . Therefore, is continuous. 2. 2.
For every and , we have
[TABLE] 3. 3.
In fact, we have a stronger property here. For any compact set , we have for every
[TABLE]
where . This immediately yields
[TABLE] 4. 4.
Let be endowed with the partial order such that implies for all . If , then satisfies
- (a)
If , then . 2. (b)
If , then . 3. (c)
If , then as .
3.3 Observations
Through the two examples above, we observed that the approximate operator corresponding to the contraction operator is context dependent. In the case of stochastic gradient descent, it is constructed by picking certain loss functions randomly and then averaging their gradients. In the case of empirical dynamic programming, the approximate operator involves computing the empirical average of the future expected value. Nonetheless, there are some fundamental properties that the empirical operator satisfies in both situations. For instance, the property stated in (7) in the context of logistic regression is (mathematically) the same as the property stated in (12) in the context of empirical value iteration. Similarly, every realization of the random operator is a contraction map under certain reasonable assumptions. We will consider more examples in Section 7, where we show that these properties (or some minor variant of these properties) are enjoyed by other empirical dynamic programming algorithms as well.
The other important observation is that every realization of random operator may also satisfy some other desirable properties. For instance, in the empirical value iteration example, if we endow with a partial order and the cost is nonnegative, then every realization of satisfies certain monotonicity properties. This is very useful in establishing the existence of unique invariant measure, as we show in Section 5. This property is, unfortunately, not satisfied by the logistic regression problem. This property is also not satisfied by the empirical relative value iteration for the average cost MDP. However, we will show that the realizations of the random operators in these cases have some other desirable properties that lead to the existence and uniqueness of the invariant measure.
We now turn our attention to introducing our first main result in the next section.
4 Weak* Convergence of the Distribution of Trajectories
We now study the convergence property of the sequence of distributions , which is defined in (3). Before we study that, we need to ensure that the random operator is “close to” the operator in some sense. Accordingly, we make the following assumption.
{assumption}
For every compact set , , and , there exists such that
[TABLE]
We recall here that this assumption is satisfied by the logistic regression and empirical value iteration for discounted cost MDP (see (7) and (12) within the discussion at the end of Subsections 3.1 and 3.2). We are now in a position to introduce our first main result.
Theorem 4.1**.**
If Assumptions 2 and 4 hold, then converges in weak topology to as , where is defined in (4). *
Proof 4.2**.**
*The proof is based on the proof by [49], except that our hypotheses are slightly different from those in [49]. For completeness, we present a proof in Section 8. *
Levy-Prohorov’s metric over the space of probability measures over Polish spaces metrizes the weak* topology [60]. Generally speaking, if distributions of two random variables are close to each other in Levy-Prohorov’s metric, then it does not imply that the random variables will be close to each other. As an instance, the Levy-Prohorov’s metric between the measures of two independent and identically distributed random variables is zero, but the difference between the random variables themselves is not zero. If one of the random variables is deterministic (that is, its distribution is a Dirac mass), then the random variable must be close to the deterministic variable with high probability. This is established in the lemma below.
Let be a Polish space with metric . Let be the Levy-Prohorov’s metric on the space of probability measures over . This metric is defined as follows. For a Borel set , let be defined as
[TABLE]
Let . Then, is defined by
[TABLE]
We are now in a position to introduce our next result. We believe that this result may not be new, but we could not locate a reference where this result is proved.
Lemma 4.3**.**
Let and be a unit mass at point . If , then for any random variable distributed according to the law , we have
[TABLE]
Proof 4.4**.**
Let be an open ball around . Let be defined as
[TABLE]
Note that , which implies . Let be a random variable distributed according to the law . Then, from the definition of Levy-Prohorov’s metric, we know that
[TABLE]
The proof then follows from noting that
[TABLE]
*The proof is established. *
As a consequence of the lemma above, we conclude that since the distribution converges to the Dirac delta function , it implies that for sufficiently large, the random sequence generated by RSA lies within a small tube around the trajectory induced by the deterministic contraction operator with high probability. This is illustrated in the Figure 1.
To see this, let and . Endow the space with the following metric:
[TABLE]
It can be readily established that defined above is a metric on . Then, due to Lemma 4.3, we conclude that
[TABLE]
Next, note that if satisfies , then is within neighborhood of for most of the .
5 Existence of Invariant Measures for Fixed
In this section, we identify conditions on the operators so that the Markov chain admits a unique invariant distribution, denoted by , as . The existence of an invariant measure yields insight about “stability” of an RSA. In particular, if there is no invariant distribution, then it is likely the case that the sequence generated by RSA can blow up with positive probability. Thus, by tweaking the RSA (for instance, by changing the stepsize or increasing the number of samples), one can ensure that the sufficient conditions noted below are satisfied, thereby establishing that the RSA is stable and yields finite values with probability 1.
In the case where there exists unique invariant measure under certain assumptions on the initial condition, then it means that any element in the tail of the random sequence generated by the RSA will have its law as the invariant distribution. This is a crucial step in proving that the time average of for any converges in probability to the spatial average of the function with respect to the invariant measure . This important result is established in the next section.
To state the assumptions, we drop the subscript wherever possible since the statistical properties of and are independent and identical to each-other as long as . Below, we list three assumptions under which we can show that admits an invariant distribution.
To introduce our first assumption, we need to assume a partial order exists on the normed space (we will drop the completeness requirement on the space for this assumption). For instance, could be the Euclidean space with the natural partial order, wherein , implies for all . The limit of an increasing sequence satisfying under this partial order may escape to infinity. Thus, it is required to bound the space to ensure that the sequences do not diverge along any of the coordinates. Another example of a normed space with partial order is the space of measurable functions from a Euclidean space to , denoted by (where is a fixed positive real number). This space features a natural partial order, wherein iff for every .
{assumption}
The following conditions are satisfied:
is a bounded normed space (not necessarily Polish) with partial order . This ordering satisfies the following property: For any sequence satisfying , there exists a minimal element such that for all . This is denoted as . 2. 2.
The operator satisfy
- (a)
Monotonicity 1: exists such that almost surely. 2. (b)
Monotonicity 2: If , then almost surely. 3. (c)
Continuity: If , then as almost surely.
Assumption 5 is satisfied in Markov decision processes with non-negative cost functions. This has been noted in Subsection 3.2 in the context of empirical value iteration for discounted cost criterion. However, this is also satisfied in MDP for total cost criterion with an absorbing state and having a proper policy (that is, there is a stationary policy under which the MDP terminates in an absorbing state with probability 1). The proof of the last claim follows from arguments similar to the one made in Subsection 3.2; see, for example, Chapter 1 of [9], and standard texts on MDPs with total cost criterion [40, 41, 8].
For RSAs involving MDPs, the point can be chosen easily. Assuming that the costs are non-negative, one could take the zero function as the initial value function or Q function – and the Monotonicity 1 condition is satisfied almost surely.
{assumption}
For and , let denote the Lipschitz coefficient of . The following conditions are satisfied:
is a compact Polish space. 2. 2.
For , there exists , such that for any , there exists a such that
[TABLE]
The notable point in Assumption 5 is that the assumption requires to be compact. It is satisfied in empirical value iteration for MDP with average cost criterion, as long as we project the value functions outside a sufficiently large compact set back to that compact set. We adopted this approach earlier in [34] to ensure that the value functions obtained through repeated use of empirical operators do not blow up. During simulations, however, we never needed to use projection, as the value functions were bounded.
{assumption}
The following conditions are satisfied:
is a Polish space. 2. 2.
There exists such that the operator satisfy
[TABLE]
where is the fixed point of . 3. 3.
Let denote the Lipschitz coefficient of . Then,
[TABLE]
Assumption 5 is satisfied in stochastic gradient descent of strongly convex and smooth functions as noted in Subsection 3.1. This is also trivially satisfied in the empirical value iteration for an MDP with a discounted reward criterion, as we have noted in Subsection 3.2.
Remark 5.1**.**
*Assumption 5(ii) is typically proved using concentration of measures results, like Hoeffding inequality [42, 52, 64] or the theory of empirical processes [61, 81]. Some references where such inequalities have been used in empirical dynamic programming for continuous state MDPs are [57, 38, 33]. *
Our next theorem summarizes the main result of this section. Let denote the distribution of .
Theorem 5.2**.**
Suppose that Assumption 2 holds. Additionally, if either one of three assumptions, Assumptions 5, 5, 5, holds, then there exists an invariant measure such that converges to in weak topology. Further, the invariant measure is unique under either of the following circumstances:*
Assumption 5 holds, and the RSA is always initialized with , where is defined in Assumption 5. 2. 2.
Assumption 5 holds. 3. 3.
Assumption 5 holds.
Proof 5.3**.**
*Under Assumption 5, the existence of invariant measures is proved in [17, Theorem 8.1, p. 79-81]. Under Assumption 5, the existence of invariant measures is proved in [12] and [17, Theorem 8.2, p. 82-83]. Under Assumption 5, the existence and uniqueness result is established in [25, Theorem 1.1, p. 87]. *
Remark 5.4**.**
We can replace the assumption of being a compact Polish space in Assumption 5 by making the following assumption. There exists such that if , then for any , there exists such that for any , we have
[TABLE]
*If the above condition and Assumption 5 (2) holds, then one can show that for any initial condition , a unique invariant distribution exists. For a proof, we refer the reader to [17, p. 179]. However, proving (13) is satisfied in usual RSAs appears to be difficult in our experience. *
We now turn our attention to establishing the law of large numbers for time averages of the outputs from a RSA.
6 Averaging of Iterates and The Weak Law of Large Numbers
RSAs with constant stepsize and averaging of iterates have received significant attention recently. Nemirovski et. al. in [58] develops an algorithm for stochastic gradient descent with averaging of the last few iterates and shows that the algorithm is robust to stepsize selection and yields better results when properties of the loss functions (such as strong convexity parameter, Lipschitz coefficient of the derivative, etc.) are unknown. Along similar lines, [5, 4, 27] study stochastic gradient descent based algorithms with constant stepsize and averaging and derive the finite time guarantees on the loss achieved with averaged output. We note here that the constant stepsize algorithms with averaging are fundamentally different from Polyak-Ruppert averaging used in stochastic approximation [62, 50], where the stepsizes decreases at a rate slower than .
Motivated by the above references, in this section, we consider the problem of convergence of the sequence of averages of the random sequence (or of for some ). As stated in Subsection 1.1, averaging of the last few outputs of an RSA is used to reduce the variance in the final output of the algorithm. Specifically, if we terminate the iteration of RSA at , and output , there is a small chance that this output is far from . It is generally believed that if we average the last few outputs (assuming none of them are ), then it reduces the variance in the output. We establish this result rigorously here, under the assumption that the Markov chain has a unique invariant distribution.
We will assume throughout that the Markov chain admits an invariant distribution (the precise assumption is stated in the sequel). The time-average of the Markov chain is precisely the law of large numbers for Markov chains. It has been studied within the context of Markov chains over compact spaces in [19] and over general locally compact spaces in [56, Sec 18.5]. Let us formulate the problem precisely.
Consider a continuous function . Let denote the invariant measure of the Markov chain . We have already studied the conditions under which such an invariant measure would exist in Theorem 5.2. In what follows, we show that under relatively mild assumptions, we have
[TABLE]
Note that in the expression above, the term is the spatial average of the function at the invariant distribution. Thus, what we show is that the time average converges in probability to the spatial average – which implies that is a discrete time ergodic process.
Let us define the operator and its adjoint , where is endowed with the weak* topology, as follows:
[TABLE]
{assumption}
The distribution of the initial condition is picked from a set . Either of the following two conditions holds:
There exists a unique invariant measure such that for any , converges in weak* topology to . 2. 2.
There exists a unique invariant measure such that for any , the averaged operator satisfies
[TABLE]
where denotes compositions of applied on and the convergence is in weak* sense.
From the Stolz-Cesaro theorem [20, Theorem 2.7.1, p.59], it is easy to show that if Assumption 6(1) holds, then Assumption 6(2) holds as well. However, the converse may not be true. To prove our next result, we only need Assumption 6(2) to hold. It should be noted that Assumption 6(1) may be rather easy to prove using Theorem 5.2.
Theorem 6.1**.**
*If Assumptions 2 and 6 hold, then (14) holds. *
Proof 6.2**.**
*The proof essentially follows the steps in [19] and [56, Theorem 18.5.1, p. 478], except that we relax the assumption on compactness of the state space as assumed in [19] and replace the hypotheses in [56] with Assumption 6. For completeness, a detailed proof is presented in Section 9. *
One way the presentation of Assumption 6 departs from the traditional Markov chain literature is as follows. It is generally assumed that , that is, for every , converges in weak* topology to . This is a very strong assumption from the applicability viewpoint in RSAs. In particular, it is possible to pick the most suitable initialization for the RSAs, which implies that can be picked appropriately. For example, in empirical dynamic programming for MDPs, one can initialize the value function to be 0. Then, we can utilize Assumption 5 (with ) to establish the existence of a unique invariant distribution using Theorem 5.2. Incidentally, for the law of large numbers to hold, we do not need the stronger condition of .
We now have a corollary of the result above, which we capture as a theorem below due to its importance and applicability to RSAs.
Theorem 6.3**.**
Suppose that is a compact set. Suppose further that either of the following conditions hold:
Assumption 5 holds, and the RSA is always initialized with , where is defined in Assumption 5. 2. 2.
Assumption 5 holds. 3. 3.
Assumption 5 holds.
Consider the average of the Markov chain
[TABLE]
*If Assumptions 2 holds, then for any initialization , a unique invariant distribution exists and converges almost surely to the mean of the distribution . *
Proof 6.4**.**
*The existence of a unique invariant measure is due to Theorem 5.2. Since is a compact set, we can take to conclude that converges almost surely to by [19]. *
The result in (14) requires to be a bounded function over . We now consider the case where is a potentially unbounded continuous function. To establish essentially the same result, we need to make the following additional assumption. {assumption} There exists a random variable such that
[TABLE]
and for -almost all .
Theorem 6.5**.**
*Suppose that is a continuous function (potentially unbounded). If Assumptions 2, 6, and 6 hold, then (14) holds. *
Proof 6.6**.**
*The proof is presented in Subsection 9.1. *
It is easy to see in practice if Assumption 6 holds or not, particularly when . If the random iterates are uniformly bounded during a single run of the RSA, then Assumption 6 holds along that trajectory. If almost all independent runs of the RSA is not expected to “blow up”, then the time average of the iterates is likely going to have the variance reduction property–the time average converges in probability to the spatial average.
We now turn our attention to illustrating the application of Theorems 4.1, 6.1, and 6.5 in various optimization and empirical dynamic programming algorithms.
7 Numerical Simulations
In this section, we complement the theoretical results proved above with extensive numerical simulations. We conduct simulations of minibatch stochastic gradient descent for logistic regression on MNIST dataset, empirical value iteration for discounted and average cost MDPs, and empirical Q-value iteration.
7.1 Stochastic Gradient Descent
Consider the task of classifying a subset of MNIST handwritten digits, where we consider only the images corresponding to the numbers 0 and 1. Each data point is a pixel image with the corresponding label (either [math] or ). We use logistic regression and Poisson regression with an regularizer for the classification task. We refer the reader to Subsection 3.1 for details of this problem for the logistic regression. The loss function for the logistic regression with the regularizer is
[TABLE]
The loss function for Poisson regression with regularizer is
[TABLE]
The first and the second derivatives of this loss function is
[TABLE]
We use here the notations introduced in Subsection 3.1. We transform each image into a vector and append at the beginning of the vector. Thus, the space . Thus, the space . As mentioned previously, the variable represents the batch size picked at every SGD iteration step. We pick arbitrarily in and set . Then, we run the exact gradient descent and the minibatch SGD as follows:
[TABLE]
As discussed in Subsection 3.1, it is clear that the exact gradient descent is a contraction map for stepsize small enough. Therefore, converges to the optimal solution . We can make the following claim about the operator :
Theorem 7.1**.**
The random operator satisfies Assumptions 2, 4. If is sufficiently small, then also satisfies Assumption 5. Let denote the distribution of and be the Dirac mass on . We have converges to in weak topology as and there exists a unique invariant distribution of the Markov chain for any . *
Proof 7.2**.**
*The first conclusion follows from the discussion leading to (7) in Subsection 3.1. For sufficiently small, every realization of is a contraction as discussed in Remark 3.1. We only need to show that Part 2 of Assumption 5 is satisfied. Since is finite, can take only finitely many values, and therefore Part 2 of Assumption 5 is trivially satisfied. The existence of invariant distribution then follows from Theorem 5.2. *
As a result of the theorem above, we conclude that is generally small for most , and its variance converges to 0 as increases. This is evident in Figures 2 and 4, where we plot the distance for various values of (batch sizes) and ranging from 0 to 5000. The black curve is the mean and the red region shows one standard deviation of the distance over 1000 sample paths of the minibatch SGD iterations. We picked the same initial condition for all the sample paths to generate the figure.
Figures 3 and 5 plots , and we observe that the variance of time averages reduces as grows large for any batch size . This variance reduction of time averages can be attributed to the contraction property of the random maps , which in turn is due to the addition of a strongly convex regularizer to the empirical loss function.
7.2 Empirical Value Iteration for Discounted Cost MDP
We consider here the empirical value iteration for discounted Markov decision processes (MDP) as described in Subsection 3.2. Consider the value iteration algorithm applied to an MDP in which there are 20 states and 5 actions. We generate the state transition probability matrix for this MDP randomly at the beginning of the simulation.
We use here the notation introduced in Subsection 3.2. We initialize arbitrarily and set , and define the iterates of exact value iteration and empirical value iteration as
[TABLE]
We can prove the following result.
Theorem 7.3**.**
The random operator satisfies Assumptions 2, 4, and 5. As a result, we conclude:
Let denote the distribution of and be the Dirac mass on . We have converges to in weak topology as .* 2. 2.
There exists a unique invariant distribution of the Markov chain . Further, the sequence of distribution of converges to this invariant distribution . 3. 3.
The time average converges in probability to the mean of as .
Proof 7.4**.**
The proof follows from the discussions in Subsection 3.2, where we show that satisfies Assumptions 4 and 5.
*Moreover, since every realization of is a contraction operator with coefficient , if , then . Thus, there is no loss of generality in restricting to be in the compact set . The fact that the time averages converge in probability to the mean of the invariant distribution is a direct application of Theorem 6.3. *
Figure 6 shows the mean (black line) and the variance (red region) of for every time step for . To compute the mean and the variance, 1000 sample paths were taken. As proved in Theorem 7.3 above, the mean of becomes smaller as grows. Figure 7 shows the mean and the variance of for for . For every , since the sequence of distribution of converges to a unique invariant distribution, converges in probability to the mean of the invariant distribution. We observe in the figure that the variance of reduces as grows implying that the average is close but not equal to . We further observe that the variance of is vanishingly small for large values of – a result that we have not formally proved here, and can be addressed in a future work.
7.3 Synchronous Batch Q-Value Iteration for Discounted Cost MDP
Q-value iteration is another algorithm that, like value iteration, computes the optimal value function in MDPs. Let denote the set of all Q-value functions . Similar to Bellman operator of value iteration, we define an operator as
[TABLE]
Similar to Bellman operator, is a contraction on . Further, it can be shown that the fixed point of is , which is defined as , where . The Q-value iteration starts with an arbitrary and generates the sequence according to , which converges to as .
The exact operator, as in other cases considered in the paper, can be approximated by the empirical operator :
[TABLE]
where are i.i.d. samples of the next state given the current state-action pair .
Let us define , where . Let be the time averaged version of . The properties of the random operator for empirical Q-value iteration has the same properties as listed in Theorem 7.3 for the case of empirical value iteration. Thus, we omit repetition of essentially the same result here. The simulation results are plotted in Figure 8 and 9.
Figure 8 shows the mean (black line) and the variance (red region around the mean) of for various values of for ranging from to . This mean and variance is computed using 1000 sample paths of the algorithm starting from the same initial for all sample paths. As is evident, the mean reduces as we increase the sample size .
Figure 9 plots the mean and the variance of . Once again, we observe that the variance reduces as increases since the Markov chain admits a unique invariant measure.
8 Proof of Theorem 4.1
To prove Theorem 4.1, we need to introduce some further notation. Define and we use to denote the convergence in weak topology. Let denote the projection operator that projects a sequence to its first components, that is,
[TABLE]
For a measure , let denote the pullback of the measure to the first components. We note the following fact from probability theory.
Theorem 8.1** ([13], Theorem 2.8).**
*Let be a sequence of measures. Then, if and only if for every . *
Recall that is a measure defined on a stochastic sequence and we would like to show that . Due to the theorem above, all we need to establish is that for every . We will establish this result via an induction argument following [49].
Fix . For , let for all measurable . Thus, the statement is true for . In the induction step, we prove that if and for every closed set and , we have
[TABLE]
By the Portmanteau theorem [13, Theorem 2.1], we then conclude that for every . We divide the proof into three steps.
Step 1: We show that for any uniformly continuous function , the map is also uniformly continuous since is Lipschitz operator.
Lemma 8.2**.**
*If , then . *
Proof 8.3**.**
Fix . Since , we can pick a such that for any with , . Now, for any with , we know that
[TABLE]
Taking and , we conclude that
[TABLE]
*This implies that . *
Step 2: Next, we establish a consequence of Assumption 4 and Lemma 8.2. Let . We assume that for all , which serves as the induction hypothesis.
Lemma 8.4**.**
Suppose that Assumption 4 holds. Then, for every , there exists an such that
[TABLE]
and
[TABLE]
Proof 8.5**.**
*Lemma 8.2 implies that is uniformly continuous. The first result is a direct consequence of the induction hypothesis. The proof of the second result is presented in Appendix A. *
Step 3: We now complete the proof by establishing the induction step using the result from Lemma 8.4. We again follow [49]. Let be any closed set. Then, using Lemma 8.4, for any , there exists such that
[TABLE]
Now, for any closed, we can construct a sequence of such that for all and . This leads us to the following inequality for every :
[TABLE]
Taking the limsup on both sides and using (15), we arrive at the following inequality
[TABLE]
Now, since the right side holds for every , we take the limit and use the bounded convergence theorem to conclude
[TABLE]
Collecting the two inequalities in (16) and (17), we conclude that
[TABLE]
The proof of the lemma is complete.
9 Proof of Theorem 6.1
We first introduce some notations. For , we define , as
[TABLE]
The following equation follows immediately from the above definitions:
[TABLE]
Define . Define the constant function as
[TABLE]
The average of the functions , denoted by , is
[TABLE]
For a function and a set , we use to denote the restriction of the function on the set . We now prove three lemmas that lead to the result. For the next result, let us define the occupation measure over the set as
[TABLE]
We claim the following.
Lemma 9.1**.**
If Assumptions 2 and 6 holds, then for every , there exists a compact set such that
[TABLE]
Proof 9.2**.**
Note that since for any by Assumption 6, we conclude from Prohorov’s theorem that the sequence is tight. Thus, for , let be the compact set such that
[TABLE]
Further, we note that for any set , we have
[TABLE]
Using the above identity and using Markov’s inequality, we conclude that
[TABLE]
*The proof of the theorem is complete. *
Lemma 9.3**.**
*Let be a compact set. Then, the sequence of functions is uniformly bounded and equicontinuous and converges uniformly to . *
Proof 9.4**.**
First, we note that for all , which implies that is uniformly bounded.
The proof of equicontinuity follows directly from Assumption 6(2) and Ascoli theorem. Note that as , we get
[TABLE]
*Thus, by Ascoli’s theorem, is an equicontinuous sequence of functions. The result then follows using Assumption 6(2). *
Next, we establish the following result.
Lemma 9.5**.**
For every , we have
[TABLE]
Proof 9.6**.**
*See Appendix B. *
The proof can now be completed easily. Fix and recall the definition of the set from Lemma 9.1. We now note that for every and , we have
[TABLE]
Since uniformly on the compact set due to Lemma 9.3, we can pick sufficiently large such that for all and , we get
[TABLE]
For such , as , the first summand goes to 0 by Lemma 9.5. In the third summand, we know that is less than with probability at least due to Lemma 9.1 for sufficiently large . Collecting all these results, we conclude that
[TABLE]
This completes the proof of the theorem.
9.1 Proof of Theorem 6.5
In order to prove the result, let us first consider the function , which always takes non-negative values. Let be the clipped function, in which case, . Define , and note that by assumption, . It is obvious that for any , if we pick , then .
Note that for this case, for any , the following inequality holds:
[TABLE]
In the next lemma, we show that each of the summand on the right is small with high probability.
Lemma 9.7**.**
*Let . If Assumptions 2, 6, and 6 hold, then (14) holds. *
Proof 9.8**.**
For any , there exists (a random natural number) such that
[TABLE]
Indeed, one can take , in which case,
[TABLE]
Further, due to the monotone convergence theorem, there exists such that
[TABLE]
Now, pick . Let us define as the set such that
[TABLE]
For every , pick such that ; such a always exists due to Theorem 6.1. Define . This immediately implies that
[TABLE]
For every , pick sufficiently large such that , , and pick any . We use (20) to conclude that
[TABLE]
*Since , the proof of the lemma is complete. *
We can now complete the proof of Theorem 6.5 using the result above. Pick and define such that and . This immediately yields . Further, we have
[TABLE]
Now, it is easy to conclude from Lemma 9.7 that the convergence in probability result in (14) holds for both and , due to which the convergence in probability result holds for the function itself.
10 Conclusion
In this paper, we studied the convergence of random sequences generated from certain RSAs used in machine and reinforcement learning problems. If the randomization device used within the algorithm is independent at every iteration, and the maps do not change (for instance, the stepsize is taken as constant), then the random sequence generated can be viewed using the lens of Markov chains. We leveraged the theory of Feller Markov chains to deduce many interesting characteristics of the random sequence and their distributions. Specifically, under reasonable conditions, we showed that the entire random sequence is close to the sequence generated by the exact algorithm with high probability for sufficiently large. We further showed that the average of the random sequence converges to the mean of the invariant distribution if the sequence if there exists a unique invariant measure of the Markov chain.
We expect that the results presented here can be applied to MDPs over continuous state and action spaces (referred to as continuous MDPs). Indeed, finite time guarantees of empirical value iteration for continuous MDPs with function approximator have been presented in [57, 72, 71, 38, 70, 39, 33] under a variety of assumptions on the MDPs and performance criteria. Convergence of asynchronous algorithm for continuous MDPs with non-parametric function approximation is presented in [69]. It will be interesting to investigate if the output of these algorithms satisfy the sufficient conditions for Theorem 4.1 and 6.1. It will also be interesting to apply the results presented here to variance reduced algorithms [73, 83, 66, 85, 84] that have been developed recently.
Another problem left for future research is to determine bounds on for any for every and . Such bounds would unify our understanding of finite time guarantees for RSAs and allow us to improve the existing algorithms. We hope that the unified framework developed in this paper will be useful for analyzing many other learning algorithms in the future, particularly for analyzing MDPs over compact uncountable state and action spaces.
Appendix A Proof of Lemma 8.4
Since in weak topology as , we conclude that \Big{(}\mu_{n}\circ\Pi_{l}^{-1}\Big{)}_{n\in\mathbb{N}} is tight. For a fixed , let be the compact set such that
[TABLE]
We now need the following result.
Lemma A.1**.**
If Assumption 4 holds, then for any , compact set and , there exists such that
[TABLE]
Proof A.2**.**
Since is uniformly continuous, for every , there exists a such that for any with , we have . Since Assumption 4 holds, there exists such that
[TABLE]
This implies
[TABLE]
*The proof of the lemma is complete. *
We are now in a position to prove the result. Consider the following expressions
[TABLE]
The proof of the lemma is complete.
Appendix B Proof of Lemma 9.5
Define for all and . Let us define random variables for as
[TABLE]
Thus, . By definition of , we have for any
[TABLE]
We use the above expression to establish the following identity.
Lemma B.1**.**
For , we have
[TABLE]
Proof B.2**.**
For any , we have
[TABLE]
This yields
[TABLE]
For any , (22) yields
[TABLE]
Consider the second summand in (24). For any , we have
[TABLE]
These expressions immediately establish the equality in (23).
Lemma B.3**.**
For a fixed , we have
[TABLE]
Proof B.4**.**
For any and , let denote the -algebra generated by . We show that forms a martingale with respect to the -algebra . By the definition of , we immediately have for any ,
[TABLE]
This implies
[TABLE]
*The proof then is an immediate consequence of the strong law of large numbers for martingales in [53, p. 66]. *
Now note that for any , as , the right side of (23) converges to 0 almost surely by Lemma B.3. This yields the result.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] J. Abounadi, D. P. Bertsekas, and V. Borkar , Stochastic approximation for nonexpansive maps: Application to Q-learning algorithms , SIAM Journal on Control and Optimization, 41 (2002), pp. 1–22.
- 2[2] A. L. Almudevar , Approximate iterative algorithms , CRC Press, 2014.
- 3[3] O. Anschel, N. Baram, and N. Shimkin , Averaged-DQN: Variance reduction and stabilization for deep reinforcement learning , in Proceedings of the 34th International Conference on Machine Learning-Volume 70, JMLR. org, 2017, pp. 176–185.
- 4[4] F. Bach , Adaptivity of averaged stochastic gradient descent to local strong convexity for logistic regression , The Journal of Machine Learning Research, 15 (2014), pp. 595–627.
- 5[5] F. Bach and E. Moulines , Non-strongly-convex smooth stochastic approximation with convergence rate o (1/n) , in Advances in neural information processing systems, 2013, pp. 773–781.
- 6[6] C. L. Beck and R. Srikant , Error bounds for constant step-size Q-learning , Systems & Control Letters, 61 (2012), pp. 1203–1208.
- 7[7] D. P. Bertsekas , Dynamic Programming and Optimal Control , vol. I & II, Athena Scientific Belmont, MA, 2011.
- 8[8] D. P. Bertsekas , Abstract dynamic programming , Athena Scientific Belmont, MA, 2013.