Comparing Samples from the $\mathcal{G}^0$ Distribution using a Geodesic Distance
Alejandro C. Frery, Juliana Gambini

TL;DR
This paper introduces a novel method for comparing SAR image samples modeled by the $ ext{G}^0$ distribution using a Geodesic Distance, enabling effective quantification of local texture and scale differences.
Contribution
It proposes a new approach employing Geodesic Distance for sample comparison from the $ ext{G}^0$ distribution, including three tests and permutation-based distribution estimation.
Findings
Effective discrimination between SAR image samples based on local parameters.
Three new tests for sample comparison using GD are proposed.
Permutation methods accurately estimate test probability distributions.
Abstract
The distribution is widely used for monopolarized SAR image modeling because it can characterize regions with different degree of texture accurately. It is indexed by three parameters: the number of looks (which can be estimated for the whole image), a scale parameter and a texture parameter. This paper presents a new proposal for comparing samples from the distribution using a Geodesic Distance (GD) as a measure of dissimilarity between models. The objective is quantifying the difference between pairs of samples from SAR data using both local parameters (scale and texture) of the distribution. We propose three tests based on the GD which combine the tests presented in~\cite{GeodesicDistanceGI0JSTARS}, and we estimate their probability distributions using permutation methods.
Click any figure to enlarge with its caption.
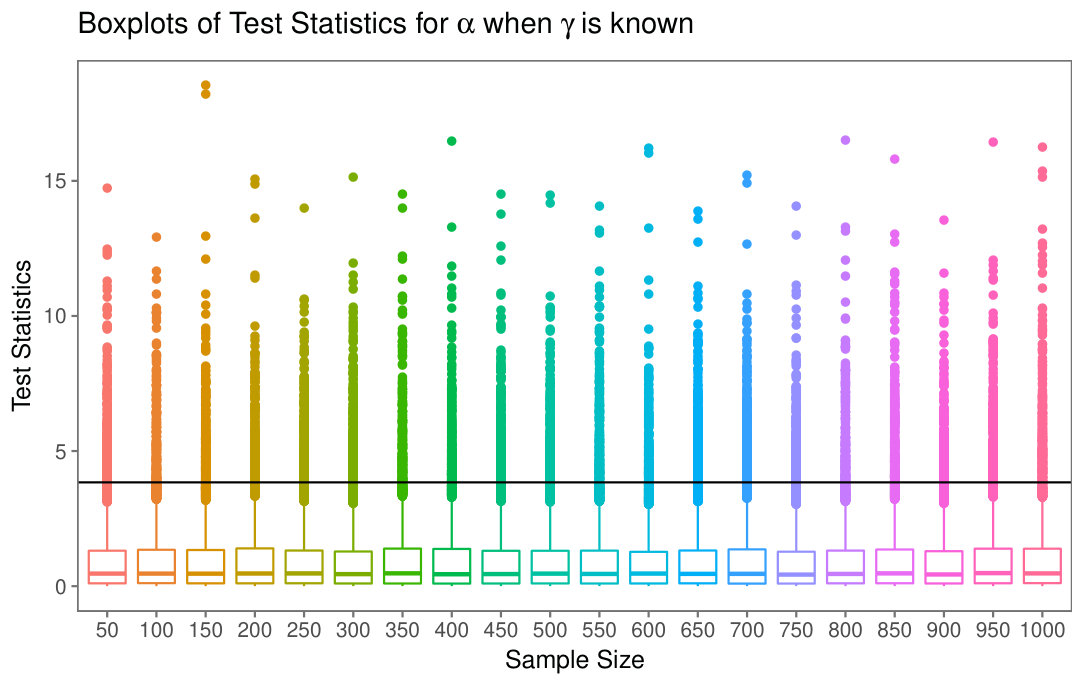 Figure 1
Figure 1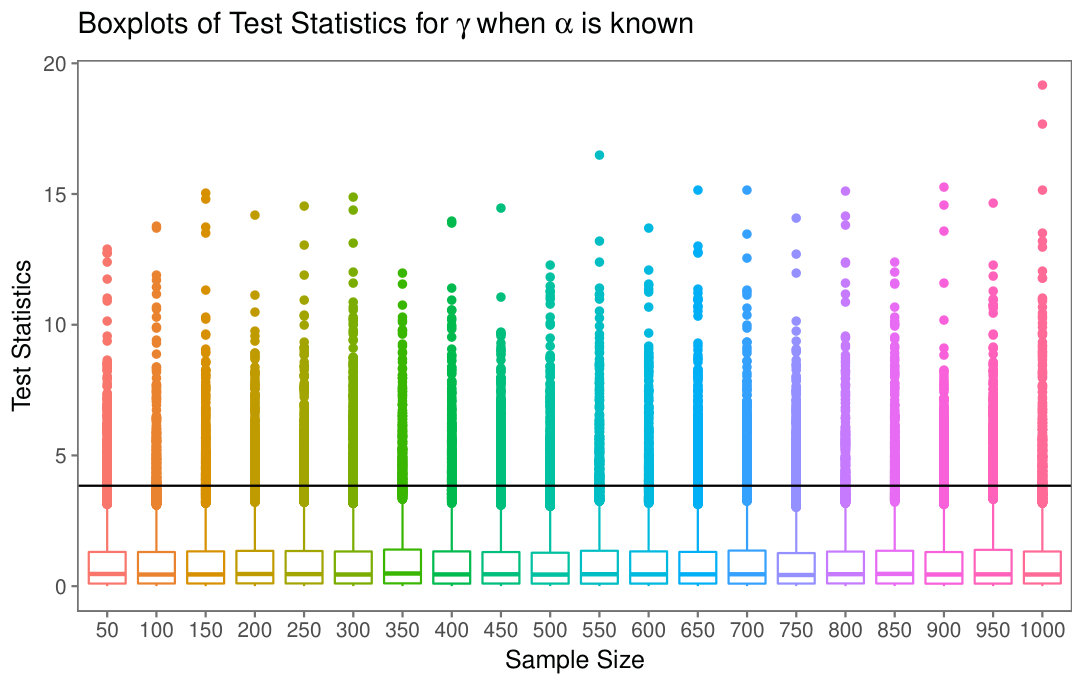 Figure 2
Figure 2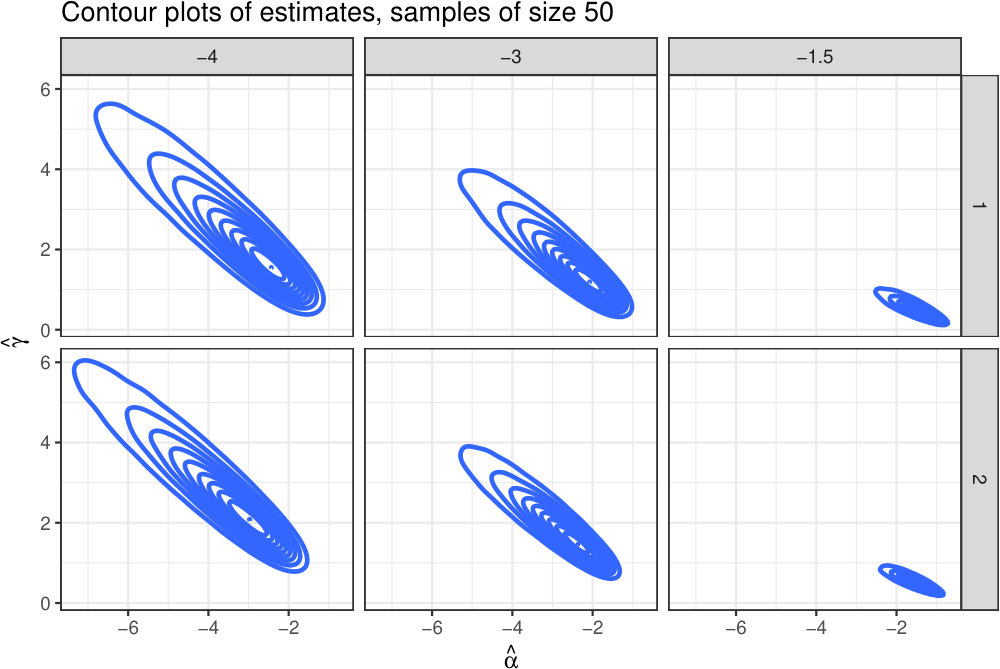 Figure 3
Figure 3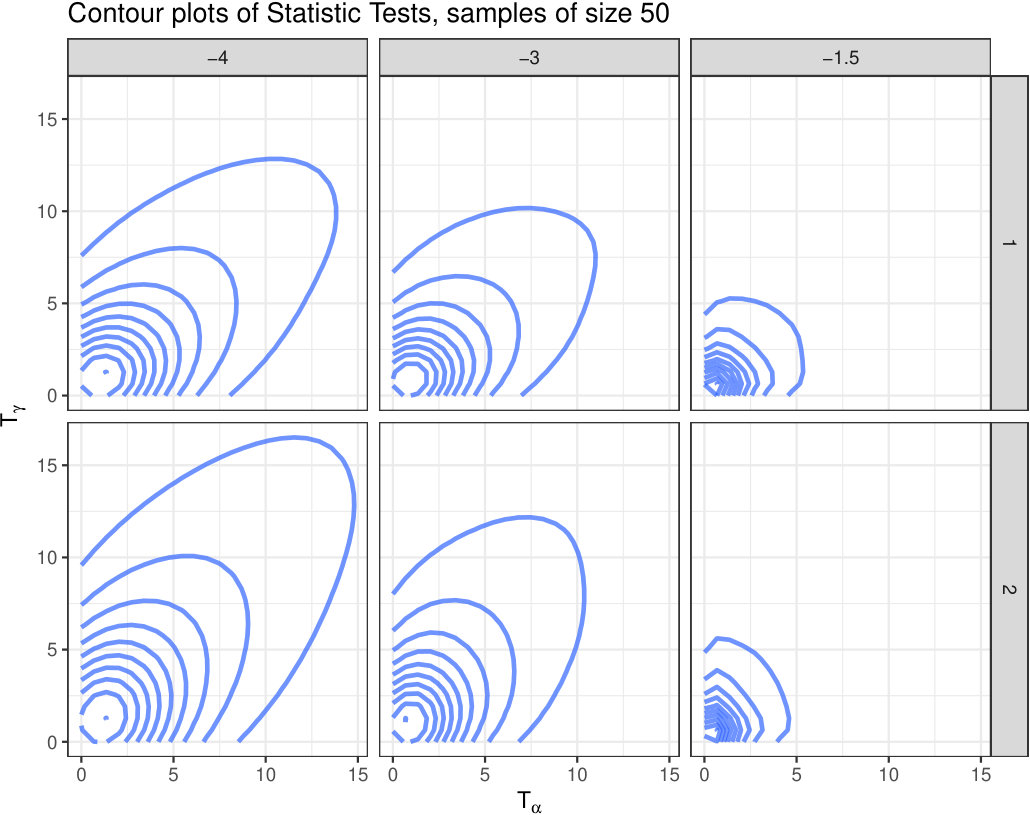 Figure 4
Figure 4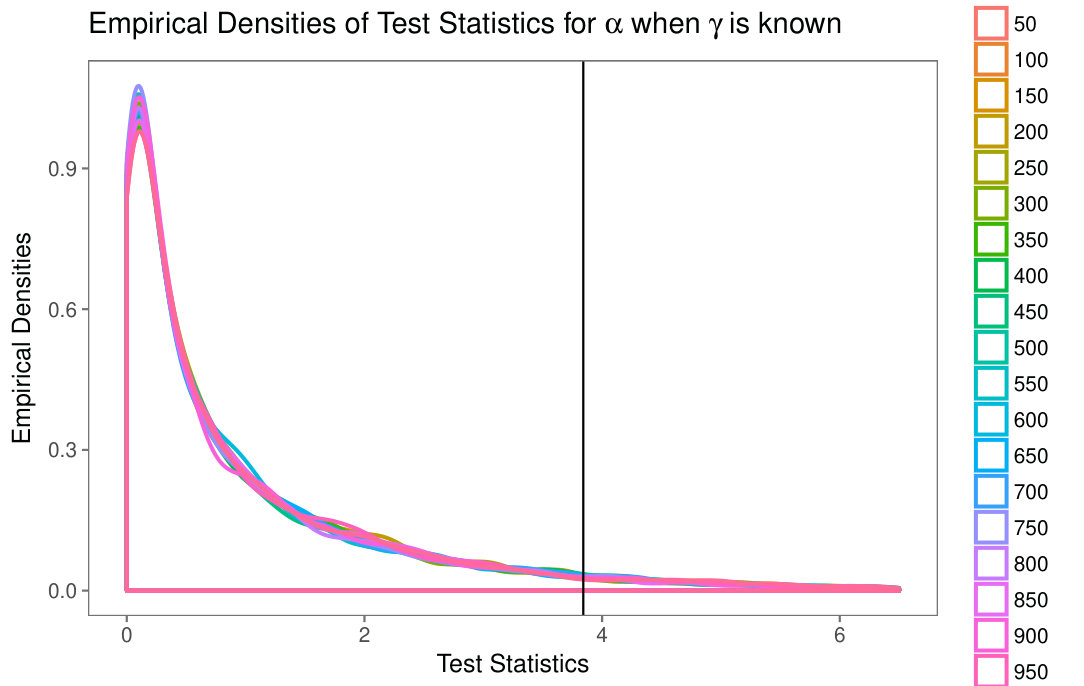 Figure 5
Figure 5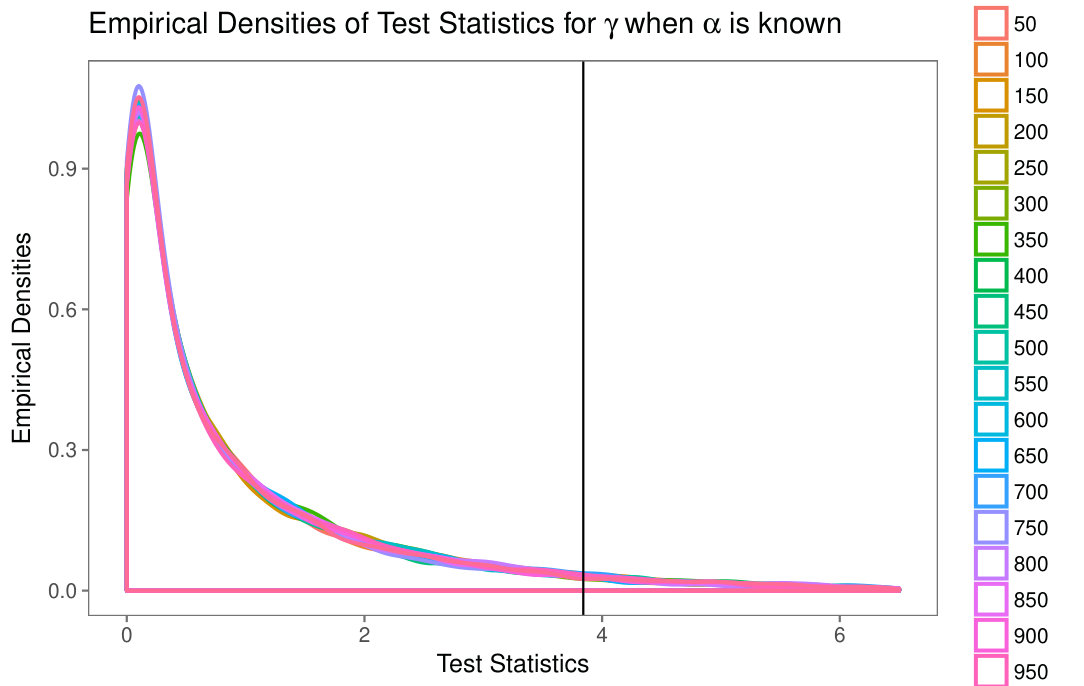 Figure 6
Figure 6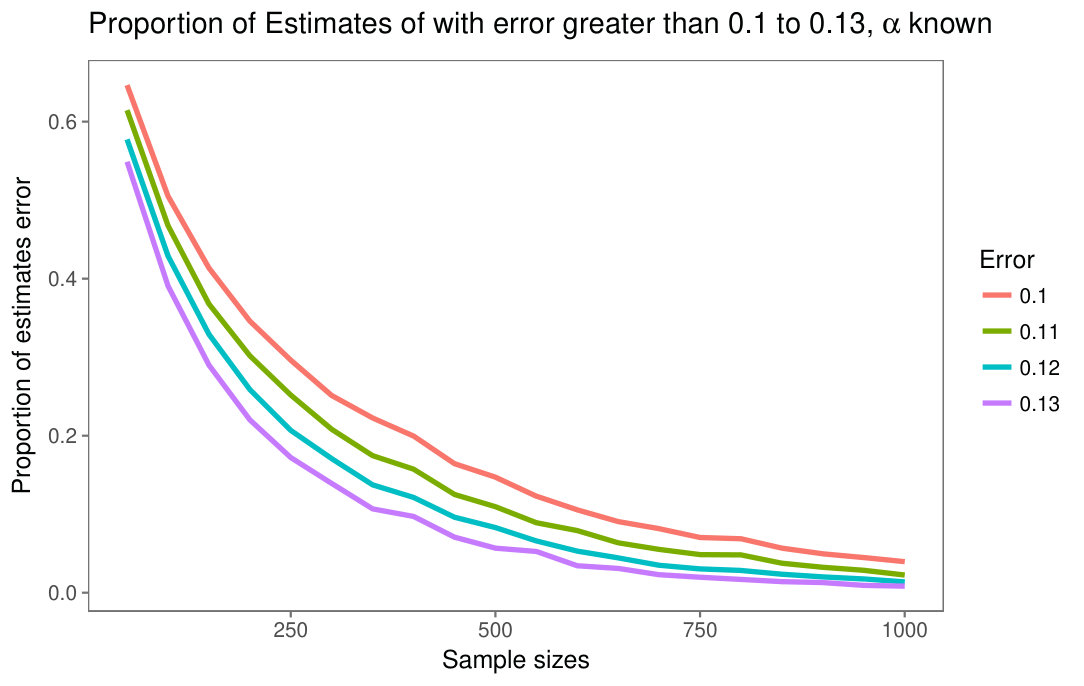 Figure 7
Figure 7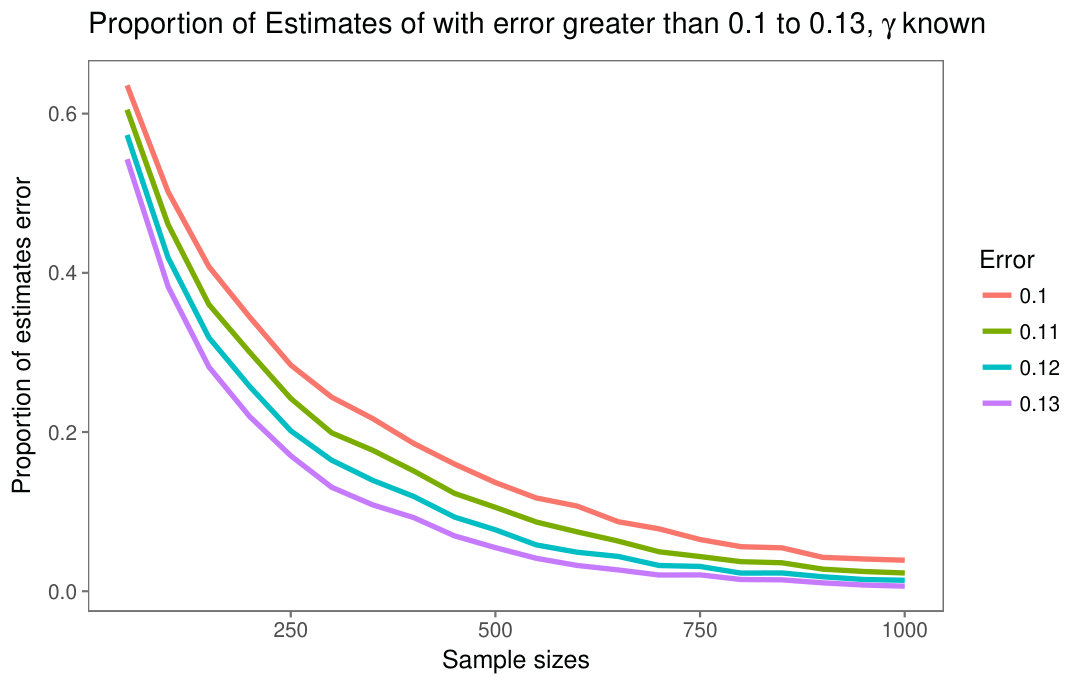 Figure 8
Figure 8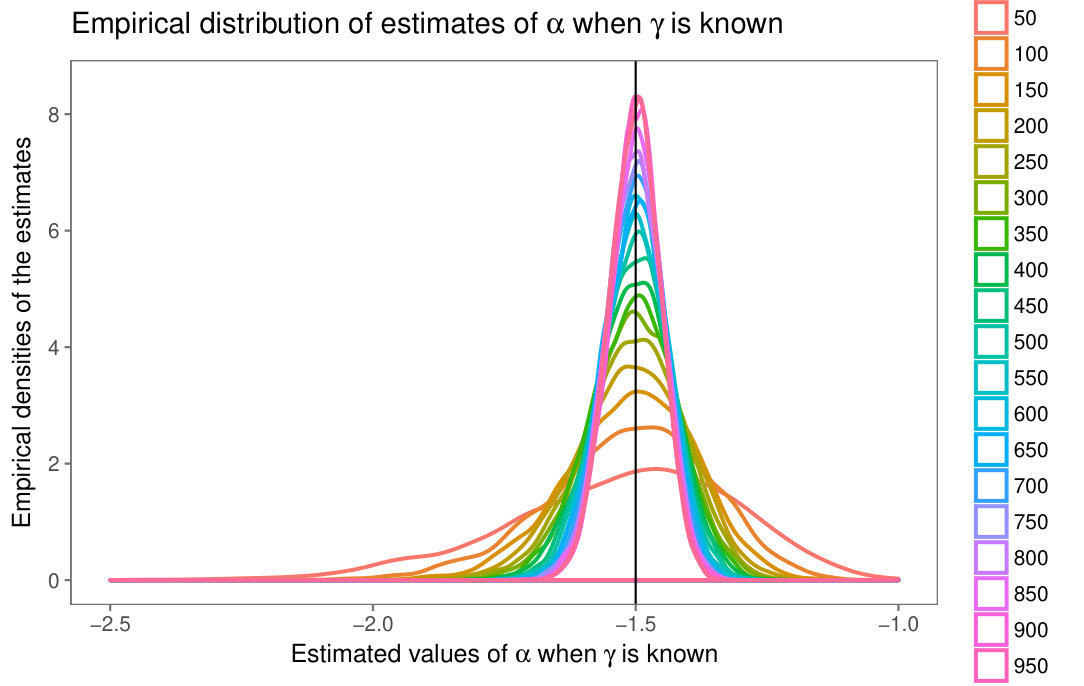 Figure 9
Figure 9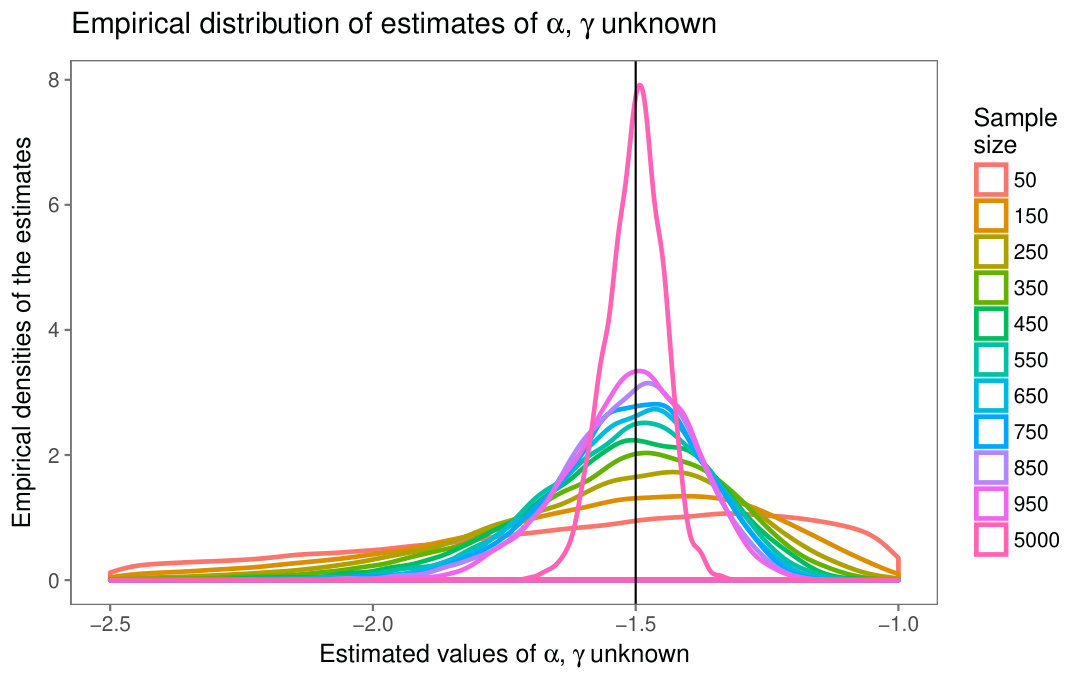 Figure 10
Figure 10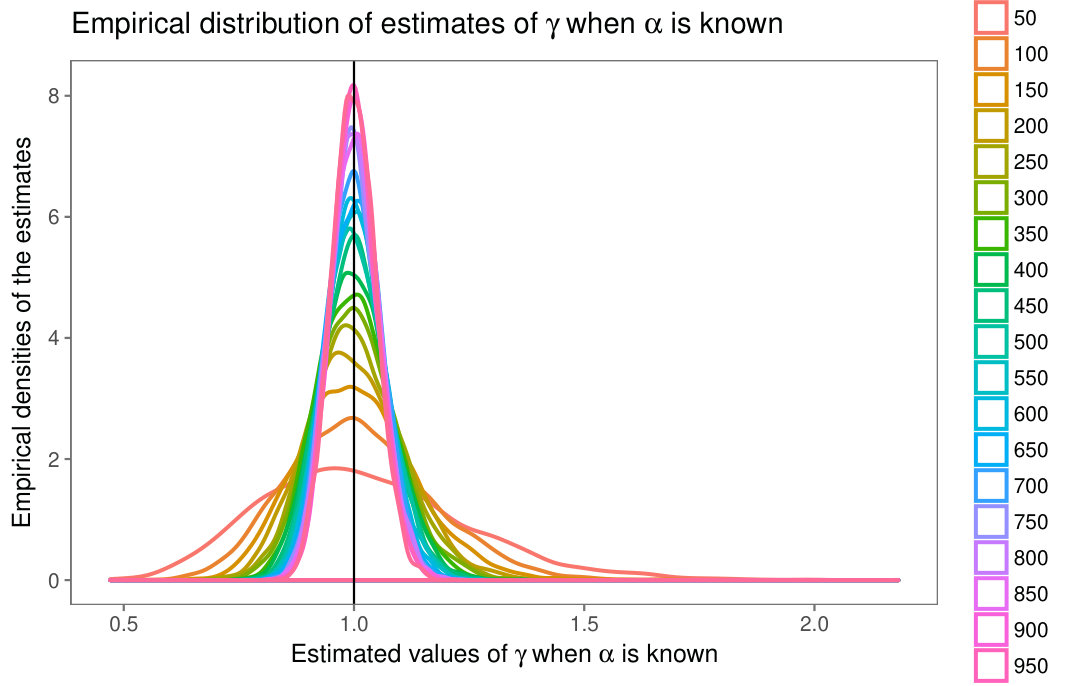 Figure 11
Figure 11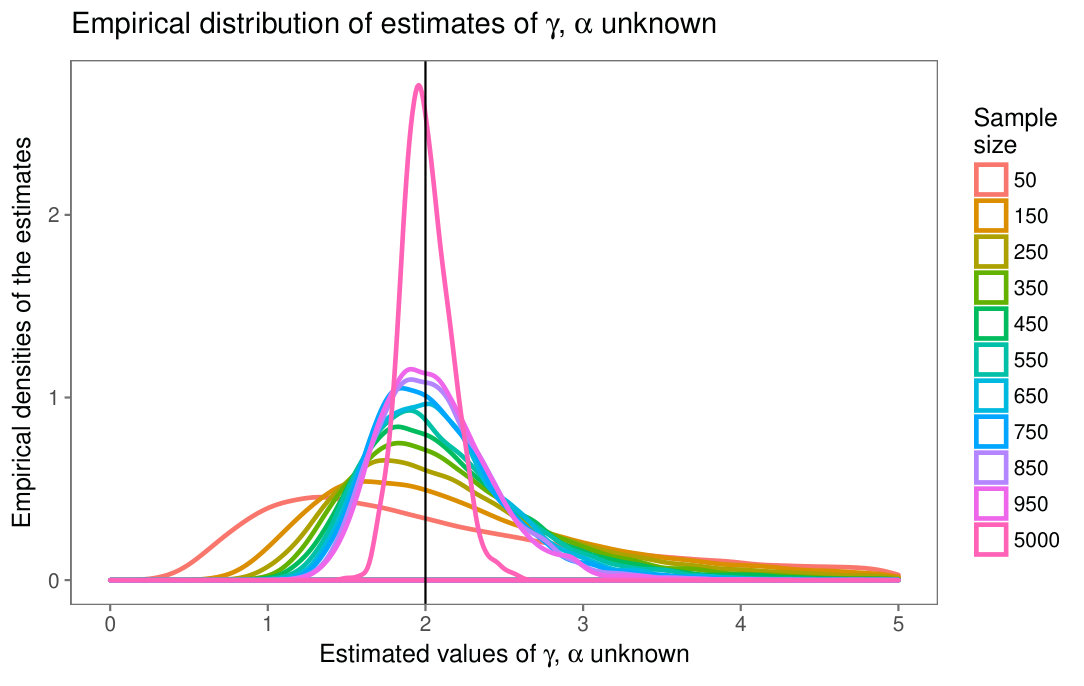 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14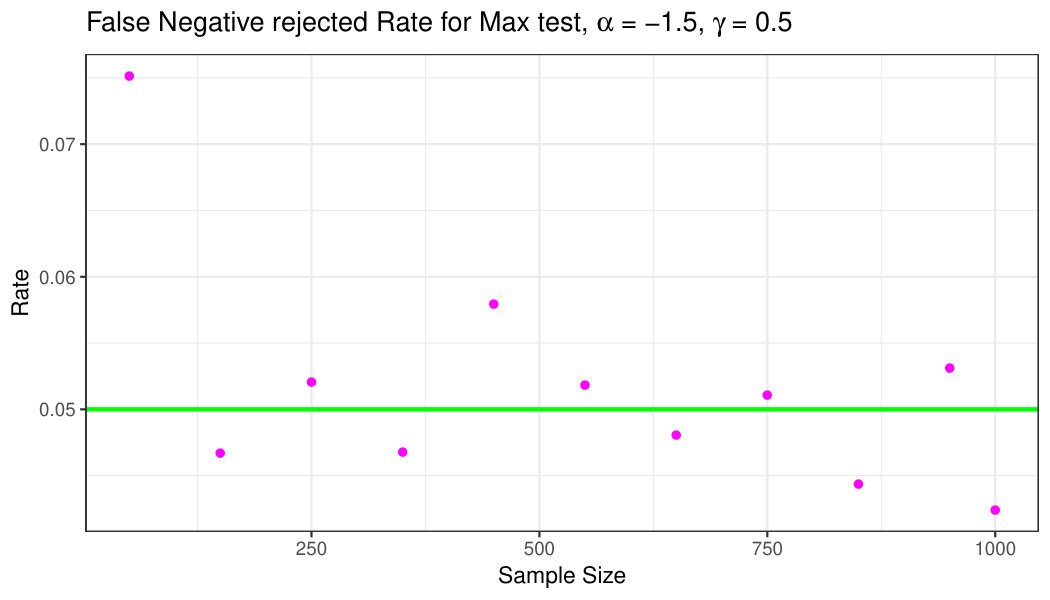 Figure 15
Figure 15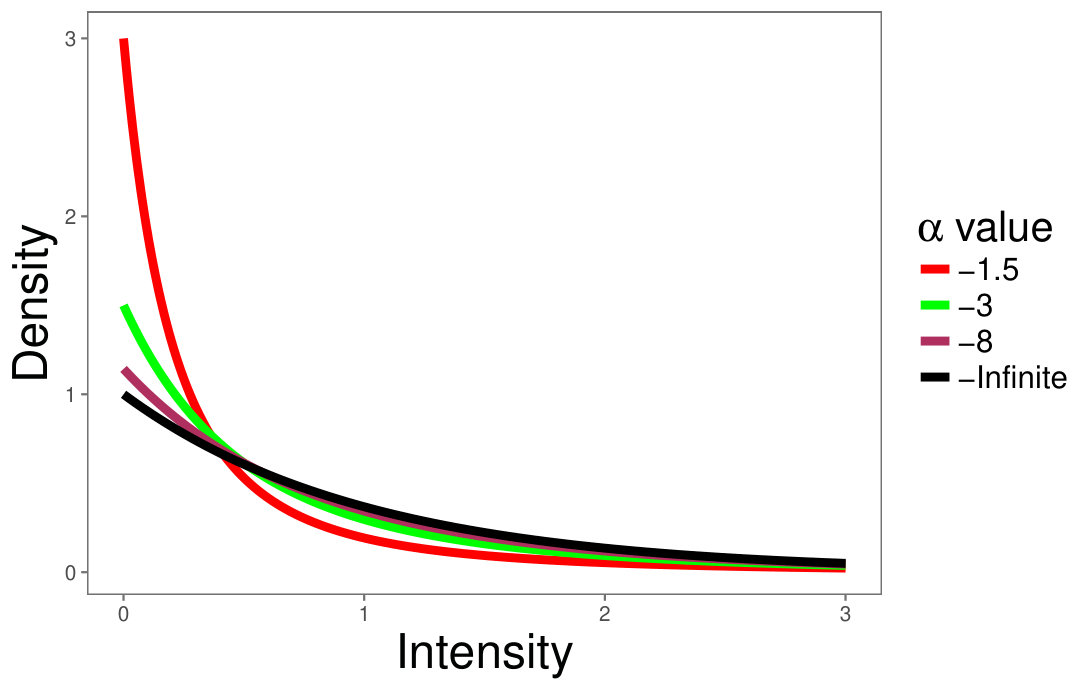 Figure 16
Figure 16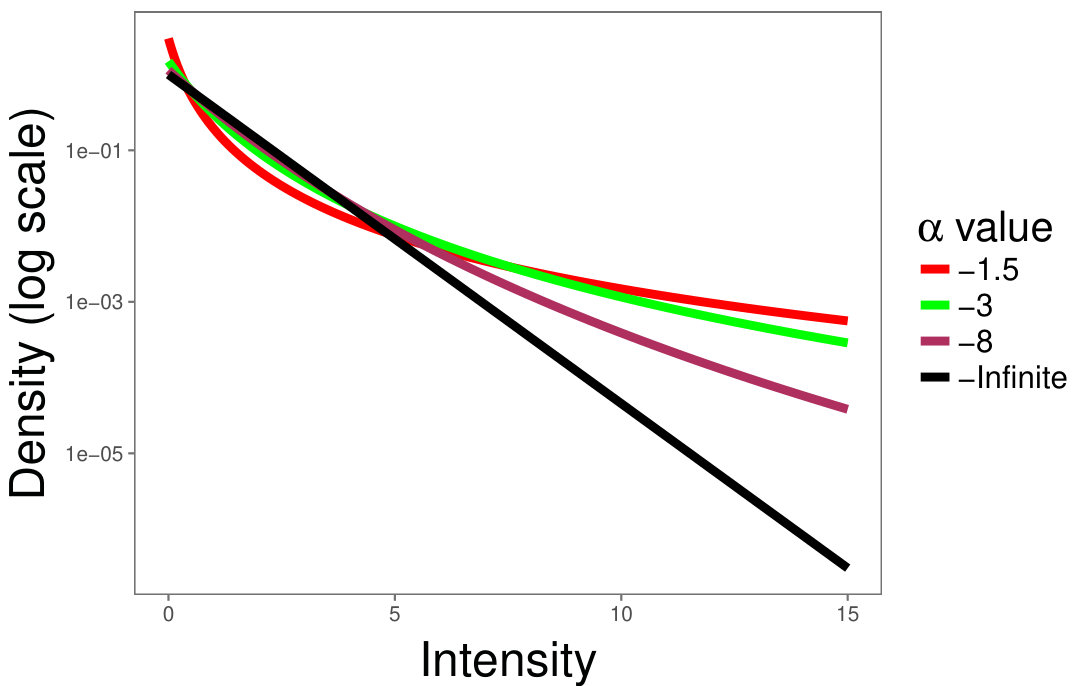 Figure 17
Figure 17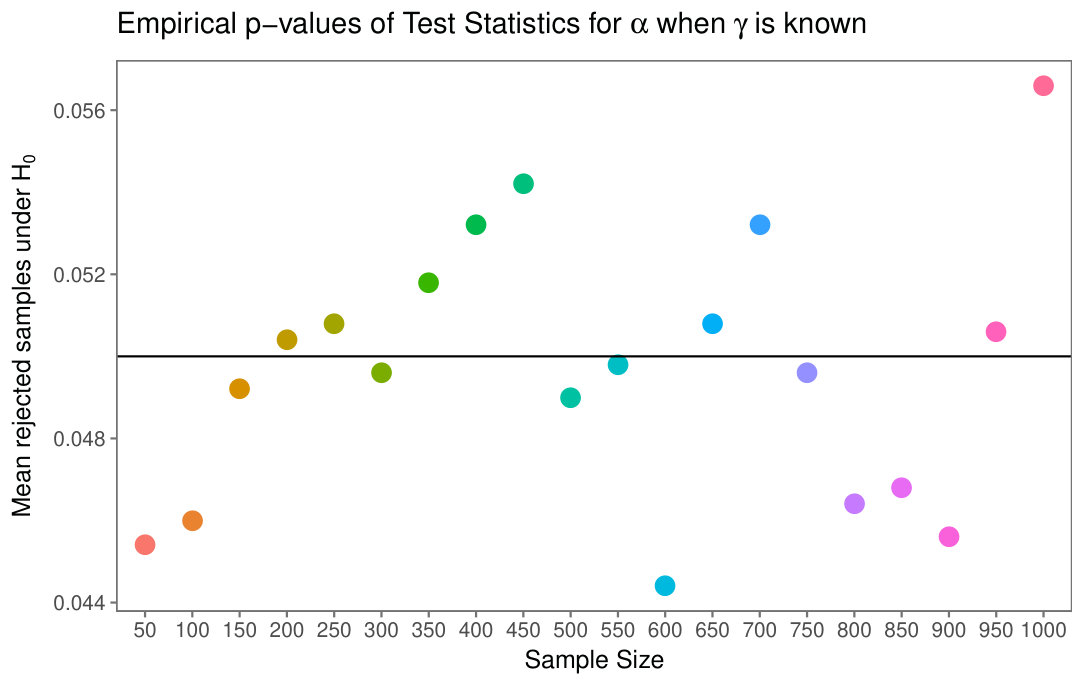 Figure 18
Figure 18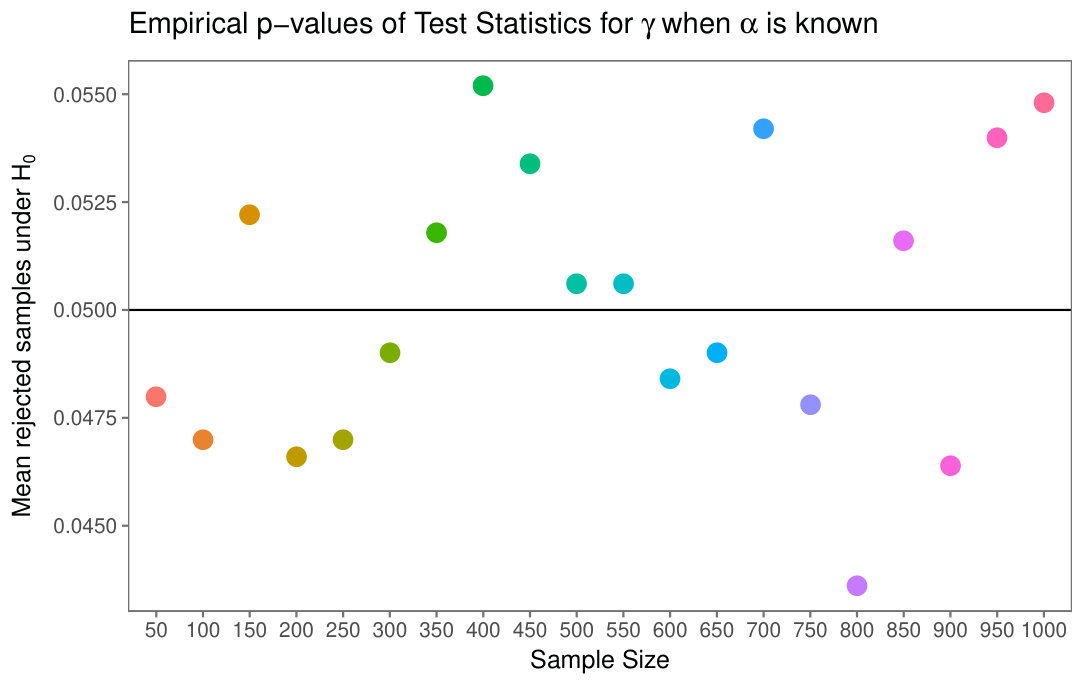 Figure 19
Figure 19| R-rate | R-rate | R-rate | |||
|---|---|---|---|---|---|
| 1 | |||||
| 1 | |||||
| 2 | -1.5 | ||||
| 2 | -4 | ||||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsSynthetic Aperture Radar (SAR) Applications and Techniques · Medical Image Segmentation Techniques · Colorectal Cancer Screening and Detection
Comparing Samples from the Distribution using a Geodesic Distance
Alejandro C. Frery, Juliana Gambini Alejandro C. Frery is with the Laboratório de Computação Científica e Análise Numérica, Universidade Federal de Alagoas, Av. Lourival Melo Mota, s/n, 57072-900, Maceió – AL, Brazil, [email protected] Gambini is with the Depto. de Ingeniería Informática, Instituto Tecnológico de Buenos Aires, Av. Madero 399, C1106ACD Buenos Aires, Argentina and with Depto. de Ingeniería en Computación, Universidad Nacional de Tres de Febrero, Pcia. de Buenos Aires, Argentina, [email protected].
Abstract
The distribution is widely used for monopolarized SAR image modeling because it can characterize regions with different degree of texture accurately. It is indexed by three parameters: the number of looks (which can be estimated for the whole image), a scale parameter and a texture parameter. This paper presents a new proposal for comparing samples from the distribution using a Geodesic Distance (GD) as a measure of dissimilarity between models. The objective is quantifying the difference between pairs of samples from SAR data using both local parameters (scale and texture) of the distribution. We propose three tests based on the GD which combine the tests presented in [20], and we estimate their probability distributions using permutation methods.
Keywords: Geodesic Distance, Dissimilarity Measure, Distribution
I Introduction
Automatic detection of differences between samples from SAR (Synthetic Aperture Radar) images is both challenging and necessary. It has important applications in, among others, urban planning [28], disaster management [7], emergency response [29], environmental monitoring, and ecology [16]. The main idea is developing methods for automatic discrimination of regions with different levels of texture and/or roughness. As in [13, 14], we adopt the distribution as model for the data.
The distribution is widely used for monopolarized SAR image modeling because it can characterize different regions accurately. It is indexed by three parameters: the number of looks (which can be estimated for the whole image), a scale parameter , and a texture parameter . The last two are local parameters and relate directly to the target.
Nacimento et al. [21] obtained test statistics based on Information Theory to assess the null hypothesis that two samples were produced by the same law, provided the same number of looks is known. The approach consisted of first computing - divergences between the models, indexing their symmetrized versions with maximum likelihood estimates and scaling appropriately to obtain test statistics. These tests, under mild regularity conditions, follow asymptotically laws. These divergences and associated test statistics were successfully applied to region discrimination [27], segmentation [18], and parameter estimation [12].
Two issues make their use somewhat difficult, though, namely (i) they require the numerical integration of expressions that, more often than not, involve special functions, and (ii) the choice of the particular test statistic might be considered arbitrary (different choices of the functions and lead, among infinitely many others, to the Kullback-Leibler, Hellinger, Bhattacharya, Triangular, Harmonic, Jensen-Shannon, and Rényi of order divergences). The Geodesic Distance solves the second difficulty, as it is unique, and gives a partial solution to the first one.
The Geodesic Distance can be used to measure the difference between two parametric distributions. It was presented by Rao [24, 25], and since then it has been studied by several authors [31, 19, 1]. In Ref. [30, 17], it is used as measure of contrast between samples by means of statistical tests presented in [26, 19, 21], where the authors demonstrated that its distribution is .
To the best of the authors’ knowledge, there is no closed expression for the geodesic distance between two models with both and unknown, given . In this work, we analyze several statistical hypothesis tests depending on both parameters to discriminate two samples from models with both parameters unknown. We use permutation methods to estimate the distribution of such tests statistics since no explicit results are available.
The paper unfolds as follows. Section II recalls properties of the model, including parameter estimation by maximum likelihood. Section III presents the expressions for the GD with one parameter known. Section IV analyzes the behavior of the test statistics based on a known parameter. In Section V we study the more realistic situation of estimating both scale and texture, while assuming known the number of looks. Finally, in Section VI we present conclusions and outline future work.
II SAR Imagery and the Model
Under the multiplicative model, the return in monopolarized SAR images can be modeled as the product of two independent random variables, one corresponding to the backscatter and other to the speckle noise . In this manner, models the return in each pixel. For monopolarized data, speckle is modeled as a distributed random variable with unitary mean and shape parameter , the number of looks. A good choice for the backscater distribution is the reciprocal of Gamma law that gives rise to the distribution for the return [11]. The mathematical tractability and descriptive power of the distribution make it an attractive choice for SAR data modeling [22]. The probability density function for intensity data under the distribution is:
[TABLE]
where and . If , the distribution becomes an exponential law. The -order moments are given by
[TABLE]
To simplify calculation and with the intention of obtaining comparable results, in most experiments, we deal with a restricted case which assumes .
Using that and that in (2), assuming and imposing we find the following relation between and :
[TABLE]
Then, the random variable with distribution has unitary mean. This allows us to simplify the calculations and to obtain results which do not depend on image brightness.
One of the essential features of the distribution is the ability to interpret its parameters. The parameter is a texture parameter, which is related to the roughness or number of elementary backscatterers of the target. Values close to zero (typically above ) suggest extremely textured targets, as urban zones. As the value decreases, it indicates regions with moderate texture (usually ), as forest zones. Textureless targets, e.g. pasture, usually produce .
The parameter of the distribution is a scale parameter, that is, if , then .
Fig. 1 shows the densities of distributions for (black, maroon, green, red, respectively) in linear (Fig. 1(a)) and semi-logarithmic (Fig. 1(b)) scales.
The difference between these densities becomes more apparent in semi-logarithmic scale, where the limiting distribution (for ) appears as a straight line. The larger is, the more prone the random variable to produce extreme values is.
Given the sample of independent and identically distributed random variables with common distribution with , , a maximum likelihood estimator of satisfies
[TABLE]
where is the likelihood function under the distribution. This leads to and such that
[TABLE]
where is the digamma function. In many cases no explicit solution for this system is available and numerical methods have to be used. In this work, we applied the BFGS [4] optimization algorithm.
III Geodesic Distance between Models
Naranjo-Torres et al. [20] obtained two cases of geodesic distances between distributions with a known number of looks: the cases where either the texture or the scale is known. These are given, respectively by
[TABLE]
The first equation can be solved explicitly for :
[TABLE]
where and are given by
[TABLE]
Notice that depends on the texture , while is independent of the scale . Both (5) and (6) depend on the number of looks .
To the best of the authors’ knowledge, there is no closed expression for the geodesic distance between two models with both and different, given known.
Both distances can be turned into test statistics (see [30, 17]) by indexing with maximum likelihood estimators based on samples of sizes and , and then rescaling:
[TABLE]
We will denote
[TABLE]
Under the null hypothesis of equal parameters, when proportionally, both and follow a distribution, so it is possible to compute the -value of two samples under and either reject or not this hypothesis [19].
Section IV presents an analysis of the behavior of these test statistics and . Section V studies ways of combining them to produce a two-parameter test.
IV Analysis of One-parameter tests
In this Section, we analyze the finite sample size behavior of the test statistics defined in (7) and (8) using Monte Carlo experiments. We obtained the samples following the guidelines presented in Ref. [6].
The parameter space for the first experiment was and the same sample size for and . We obtained five thousand independent replications for each sample size, and maximized the following reduced log-likelihood function:
[TABLE]
We produced two independent samples in each replication in order to compute a distance from the respective estimated models.
Fig 2(a) presents the sample densities of for and . They are all centered around the true value and, as expected, the larger the sample size is, the smaller the variability is. Small values of yield more asymmetric densities than their larger counterpart. The parameter space and number of replications for the second experiment were the same, but the reduced log-likelihood to be maximized was
[TABLE]
Similar conclusions can be drawn from the sample densities of the maximum likelihood estimators of , when and are known; cf. Fig. 2(b).
The behavior shown in Fig. 2 is consistent across other values of and . Both (9) and (10), as well as the two-parameter reduced log-likelihood function presented below were optimized using the maxLik routine [15] available in R [23].
Figures 3(a) and 3(b) show the proportion of estimates whose error is larger than , , , , when the parameter is known and when the parameter is known, respectively. The experiment consists of generating 5000 samples of size , with distribution. In this case , , . It can be observed that the proportion of estimates with error dramatically decreases as the sample size increases. This evidences that bias of the maximum likelihood estimates strongly depends on the sample size. Sample sizes greater than or equal to provide acceptable results but, in practical situations, one is often interested in smaller samples, e.g. for filters which compute estimates over windows of size . The selected values of the parameters are arbitrary, in order to show an example of the maximum likelihood estimator behavior as the sample size increases.
As said, in each replication two independent samples were generated, and an estimate computed with each. Each pair of estimates is then used to compute either or , depending on the experiment. Our main interest lies in the finite sample behavior of these test statistics.
IV-A Finite Sample Size Behavior of
For each sample size, we have five thousand samples of . We will analyze the distribution of these test statistics, and the empirical size of the test when compared with the asymptotic result.
Fig. 4(a) shows the boxplots of the test statistics for different sample sizes, along with the theoretical cut value at (approximately , the of the distribution).
Fig. 5(a) shows the sample densities of the test statistics for different sample sizes, along with the theoretical cut value at the (approximately , the of the distribution).
Neither Fig. 4(a) nor Fig. 5(a) suggest any significant change of distribution of when the sample size varies, an evidence that is a large enough sample size to attain the asymptotic properties.
Fig. 6(a) presents the empirical size of tests for different sample sizes, along with the theoretical cut value. The minimal and maximal deviation between the empirical and theoretical -values are, respectively, and .
IV-B Finite Sample Size Behavior of
For each sample size, we have five thousand samples of . We will analyze the distribution of these test statistics, and the empirical size of the test with respect to the asymptotic value.
Fig. 4(b) shows the boxplots of the test statistics for different sample sizes, along with the theoretical cut value at the (approximately , the of the distribution). Fig. 5(b) shows the sample densities of the test statistic, for different sample sizes, along with the theoretical cut value at the (approximately , the of the distribution).
Neither Fig. 4(b) nor Fig. 5(b) suggest any significant change of distribution of when the sample size varies, evidence that is a large enough sample size to attain the asymptotic properties. This motivates the use of a single model, namely the distribution, for computing quantiles.
Figs. 6(b) presents the empirical size of test for different sample sizes, along with the theoretical cut value. The minimal and maximal deviation between the empirical and theoretical -values are, respectively, and .
V Analysis of Two-parameter tests
In this section, we analyze the more realistic situation of estimating both the scale and texture parameters, while assuming the number of looks known. As mentioned, we opted for computing the maximum likelihood estimator of by maximizing the reduced log-likelihood function which, for known, is
[TABLE]
Again, the routine maxLik was the tool employed for maximizing (11).
Whereas maximizing (9) and (10) poses no numerical problem, (11) has well-reported problems caused by cases where this likelihood becomes flat [10]. In order to avoid such problems without introducing specialized techniques that depart from the concept of maximum likelihood, only solutions satisfying where considered feasible. The number of replications is computed over feasible solutions.
The parameter space of the study is the product of the sets , , and . For each , the scale is , so the expected value is . Following the recommendations discussed in [5], the number of replications changes with the sample size as ; we empirically found produces reliable results with an acceptable computational cost.
The plots in Fig. 7 show the empirical densities of the estimators of texture and scale, Fig. 7(a) for the case , and , Fig. 7(b) for the case , and .
The difference between Figs. 2(a) and 7(a) is noticeable in terms of spread and centrality. The same observation holds when comparing figures 2(b) and 7(b). The effect of missing the information of one parameter is, thus, remarkable.
Fig. 8 shows the contour plots of the estimates for samples of size and all the cases here considered. This figure corroborates that it is not adequate to assume that and can be uncorrelated, let alone independent.
This relationship between estimators is also exhibited by the tests statistics that use them. Fig. 9 shows the contour plots of .
In practice, one needs to discriminate regions with unknown texture and scale, so a test statistic for both parameters, say is required.
The strong relationship between and is evident, so is the same relationship between test statistics, therefore just adding and and assuming that the sum follows a law might not be a good idea. This justifies the following analysis which aims at finding relevant properties of two-to-one transformations of , in search for a test statistic for assessing the null hypothesis of having two samples from the same distribution. We analyze the following test statistics:
[TABLE]
Eqs. (12), (13) and (14) are combinations of statistics for a single free parameter, given in Eqs. (7) and (8), but their distributions are unknown and, thus, we can not apply a hypothesis test to decide if two samples come from the same distribution or not. So, to solve this problem, we estimate these distributions using permutation methods, as explained in Section V-A.
V-A Permutation Methods
Permutation methods are a type of statistical significance test which can be applied to statistics with unknown distribution. They were developed by R. Fisher and E. J. G. Pitman [9]. The authors of Refs. [2, 3] explain the advantages of this type of tests. There are at least two kinds of permutation tests:
Exact:
in which all possible reorganizations of the sample are considered. This kind has high computational cost, depending on the sample size.
Random:
which consider a certain amount of permutations, usually or . They are more appropriate if the sample size is large.
In this work we test if two samples and are from the same distribution, then we pose the null hypothesis and we want to know the probability of rejecting it. With this objective, we estimate the empirical distributions of the tests from equations (12), (13) and (14) by means of the following steps. For more information see [8].
Choose a statistic , from Eqs. (12), (13) or (14). 2. 2.
Generate and random samples of sizes and , respectively, both from the same distribution granting the null hypothesis. Let perm be the number of permutations; in our experiment . 3. 3.
Compute the estimates and with each sample. 4. 4.
Calculate the observed statistic value, , with the data from and . 5. 5.
Repeat for :
- •
Shuffle de joint sample and divide it in two groups of sizes and , say and , respectively.
- •
Compute the estimates and for each sample and .
- •
Calculate the statistic value using the permuted samples, .
- •
Compare the observed statistic value calculated in Step 4 with the statistic computed after permutation . 6. 6.
The proportion of differences equal to or larger than the observed statistic value serve as the for the permutation test, or:
[TABLE] 7. 7.
If , the null hypothesis is rejected at level .
V-B Results of applying Permutation Methods
We use devised Monte Carlo experiments to quantify empirical rejection rate (R-rate) generated by the proposed tests, under the Null Hypothesis. The experiment is repeated times.
Table I shows the results of applying the permutation test to the statistic given in Eqs. (12), (13) and (14), for values of , and , at level . For lack of space, we present only the results for , and , corresponding to small, medium and large samples. We inform the rejection rate under the null hypothesis (false negative rate) which is the estimated test size. Tests and exhibit the closest empirical sizes to the nominal level. It can be observed that if the sample size increases, the false negative rate is not necessarily reduced.
Figure 10 shows the false negative rate for the test in Eqs. 14, under the Null Hypothesis depending on the sample size, for , , . It can be observed that the false negative rate fluctuates around the value of the level , represented with a green straight line and the highest value of the false negative rate is given for the sample size .
V-C Application in Edge Detection
In this section, we present an application of the proposed method to the problem of edge detection in actual SAR images. Gambini et al. [14] proposed a general and flexible algorithm for edge detection which is based on finding, in a narrow strip of data, the point where there is maximum evidence of a change of properties. Naranjo-Torres et al. [20] used a geodesic distance between models as a measure of this change, assuming the distribution with known scale parameter. In this work, we use the same algorithm but considering two parameters unknown: texture , and scale . In order that this work is self-contained, we briefly explain the algorithm. For more information see [20].
Let be an actual SAR image of lines and columns of pixels. In this application, we use only one line of data, i.e., a strip of size . In each step , we divide the line in two disjoint samples, and used to estimate the parameters and , respectively, by maximum likelihood. Then, the -value is computed using the method described in Section V-A.
Finally, we estimate the transition point as the position at which is minimum: . The method is sketched in Algorithm 1, where is the original image, and are the numbers of rows and columns of the input image. Notice that the minimum sample size is set to three observations.
Figure 11 shows the results of applying the edge detector algorithm. Figure 11(a) shows the SAR image, and presents the area where the edge detection was performed. Figure 11(b) shows the result of applying the edge detector to each line in a selected region.
VI Conclusions and Future Work
Unable to calculate the geodesic distance of the distribution depending on two free parameters, we carried out a study dedicated to evaluating the possibility of using a combination of tests based on the geodesic distance with a single unknown parameter, as calculated in Ref. [20].
We compare three statistics whose distributions are unknown. We use permutation methods to estimate their empirical distributions.
The results show that, under the null hypothesis, the false negative rate fluctuates around the rejection level, even with small samples. It can be observed that if the sample size increases, the false negative rate is not necessarily reduced; this encourages us to continue the investigations with small samples. The results are promising and can be readily employed in speckled image processing and analysis.
Simulations were performed using the R language and environment for statistical computing version 3.0.2 [23].
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. Atkinson and A. F. Mitchell. Rao’s distance measure. Sankhyā: The Indian Journal of Statistics, Series A (1961-2002) , 43:345–365, 1981.
- 2[2] K. J. Berry, J. E. Johnston, and P. W. Mielke. Permutation methods. WIR Es Computed Statistic , 3:527–542, 2011.
- 3[3] K. J. Berry, J. E. Johnston, P. W. Mielke, and L. A. Johnston. Permutation methods. part II. Wiley Interdisciplinary Reviews: Computational Statistics , pages e 1429–n/a, 2017. e 1429.
- 4[4] C. G. Broyden. A class of methods for solving nonlinear simultaneous equations. Mathematics of Computation , 19:577–593, 1965.
- 5[5] O. H. Bustos and A. C. Frery. Reporting Monte Carlo results in statistics: suggestions and an example. Revista de la Sociedad Chilena de Estadística , 9(2):46–95, Dec. 1992.
- 6[6] D. Chan, A. Rey, J. Gambini, and A. C. Frery. Sampling from the GI 0 distribution. Monte Carlo Methods and Applications , 24(4):271–287, 2018.
- 7[7] F. Dell’Acqua and P. Gamba. Remote sensing and earthquake damage assessment: Experiences, limits, and perspectives. Proceedings of the IEEE , 100(10):2876–2890, 2012.
- 8[8] A. R. Feinstein. Permutation tests and statistical significance. M. D. Computing: Computers in Medical Practice , 10:28–41, 1993.