TL;DR
GumDrop employs a model stacking ensemble approach for discourse unit segmentation and connective detection, demonstrating adaptability across diverse datasets in the DISRPT 2019 Shared Task.
Contribution
It introduces a novel ensemble stacking method with three component stacks tailored for sentence splitting, discourse segmentation, and connective detection.
Findings
Effective generalization to datasets of varying sizes.
Improved performance through heterogeneous ensemble models.
Flexible architecture adaptable to different dataset characteristics.
Abstract
In this paper we present GumDrop, Georgetown University's entry at the DISRPT 2019 Shared Task on automatic discourse unit segmentation and connective detection. Our approach relies on model stacking, creating a heterogeneous ensemble of classifiers, which feed into a metalearner for each final task. The system encompasses three trainable component stacks: one for sentence splitting, one for discourse unit segmentation and one for connective detection. The flexibility of each ensemble allows the system to generalize well to datasets of different sizes and with varying levels of homogeneity.
Click any figure to enlarge with its caption.
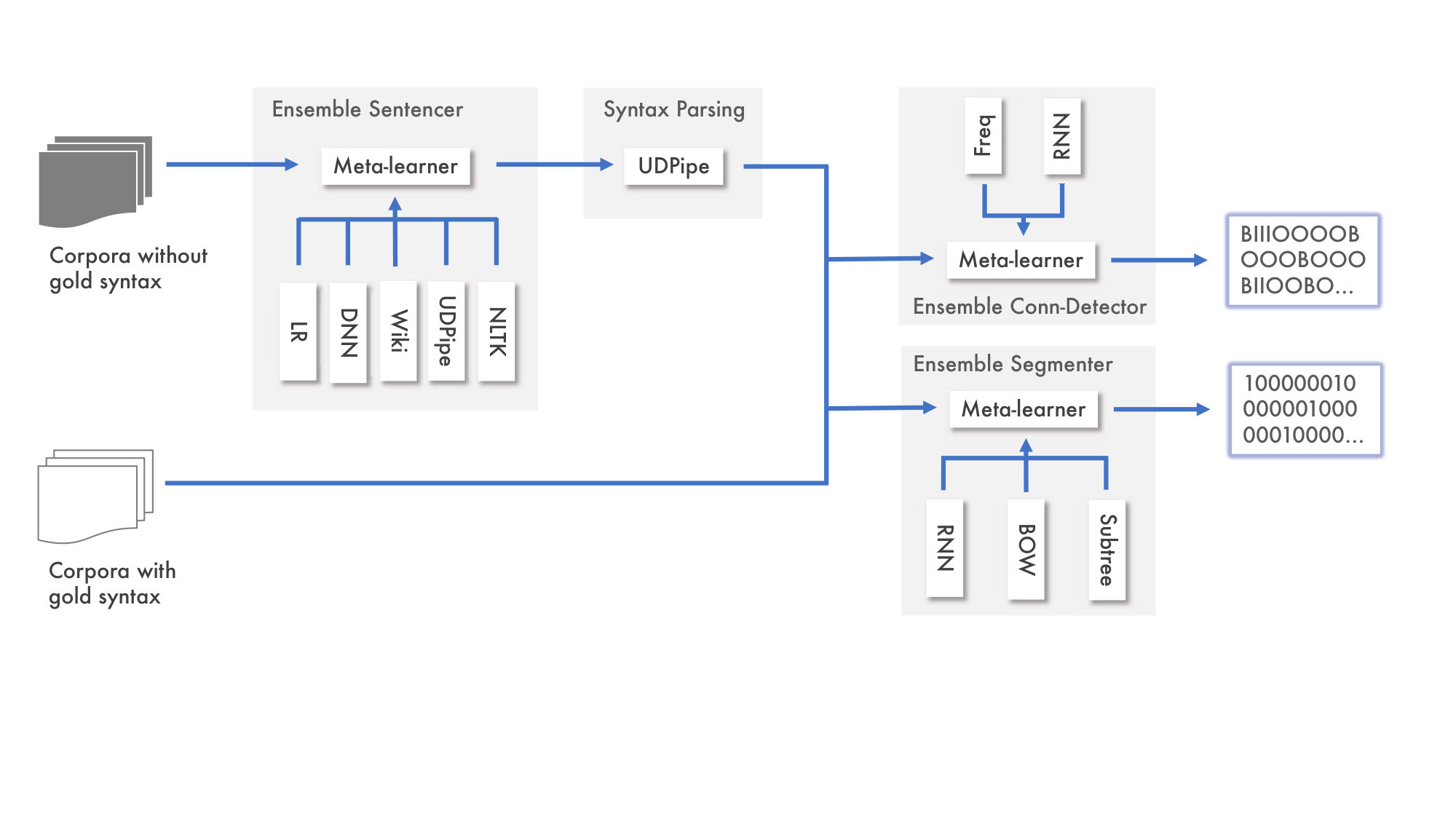 Figure 1
Figure 1| Sentence splitting | EDU/connective segmentation | |||||||||
| Feature | LR | NLTK | UDPipe | WikiSent | DNN | Meta | Subtree | RNN | BOW | Meta |
| word | n | y | y | y | y | top 100 | top 200 | y | top 200 | top 100 |
| chars | f/l | n | y | n | n | n | n | y | n | n |
| upos/xpos | y | n | n | n | n | y | y | y | y | y |
| case | y | n | n | n | n | y | y | n | n | y |
| #char_types | y | n | n | n | n | n | n | n | n | n |
| tok_len | y | n | n | n | n | y | y | n | n | y |
| tok_frq | y | n | n | n | n | n | n | n | n | n |
| genre | n | n | n | n | n | y | y | y | n | y |
| quot/paren | n | n | n | n | n | n | y | n | n | y |
| sent% | n | n | n | n | n | y | y | n | n | y |
| deprel | – | – | – | – | – | – | y | y | n | y |
| headdist | – | – | – | – | – | – | y | bin | n | y |
| depbracket | – | – | – | – | – | – | y | y | n | y |
| children | – | – | – | – | – | – | y | n | n | n |
| Baseline (./!/?) | NLTK | LR | GumDrop | |||||||||
| corpus | P | R | F | P | R | F | P | R | F | P | R | F |
| deu.rst.pcc | 1.00 | .864 | .927 | 1.00 | .864 | .927 | .995 | .953 | .974 | .986 | .986 | .986 |
| eng.pdtb.pdtb | .921 | .916 | .918 | .899 | .863 | .880 | .891 | .970 | .929 | .963 | .948 | .955 |
| eng.rst.gum | .956 | .810 | .877 | .943 | .807 | .870 | .935 | .885 | .909 | .977 | .874 | .923 |
| eng.rst.rstdt | .901 | .926 | .913 | .883 | .900 | .891 | .897 | .991 | .942 | .963 | .946 | .954 |
| eng.sdrt.stac | .961 | .290 | .446 | .990 | .283 | .440 | .805 | .661 | .726 | .850 | .767 | .806 |
| eus.rst.ert | .964 | 1.00 | .982 | .945 | .972 | .958 | 1.00 | 1.00 | 1.00 | 1.00 | .997 | .998 |
| fra.sdrt.annodis | .970 | .910 | .939 | .965 | .910 | .937 | .957 | .943 | .950 | .985 | .905 | .943 |
| nld.rst.nldt | .991 | .919 | .954 | .983 | .919 | .950 | .951 | .931 | .941 | .980 | .964 | .972 |
| por.rst.cstn | .984 | .992 | .988 | .967 | .967 | .967 | .984 | .992 | .988 | .984 | .984 | .988 |
| rus.rst.rrt | .867 | .938 | .901 | .737 | .927 | .821 | .948 | .980 | .964 | .952 | .972 | .962 |
| spa.rst.rststb | .912 | .851 | .881 | .938 | .845 | .889 | .996 | .934 | .964 | .993 | .934 | .963 |
| spa.rst.sctb | .860 | .920 | .889 | .852 | .920 | .885 | .889 | .960 | .923 | .857 | .960 | .906 |
| tur.pdtb.tdb | .962 | .922 | .942 | .799 | .099 | 176 | .979 | .979 | .979 | .983 | .984 | .983 |
| zho.pdtb.cdtb | .959 | .866 | .910 | .– | .– | .– | .954 | .975 | .965 | .980 | .975 | .978 |
| zho.rst.sctb | .879 | .826 | .852 | .– | .– | .– | 1.00 | .811 | .895 | .991 | .795 | .882 |
| mean | .939 | .863 | .888 | .915 | .790 | .815 | .945 | .931 | .937 | .963 | .933 | .947 |
| std | .046 | 167 | 128 | .079 | .273 | .235 | .055 | .089 | .065 | .046 | .070 | .050 |
| Gold syntax | Baseline | Subtree | RNN | GumDrop | ||||||||
| corpus | P | R | F | P | R | F | P | R | F | P | R | F |
| deu.rst.pcc | 1.0 | .724 | .840 | .960 | .891 | .924 | .892 | .871 | .881 | .933 | .905 | .919 |
| eng.rst.gum | 1.0 | .740 | .850 | .974 | .888 | .929 | .950 | .877 | .912 | .965 | .908 | .935 |
| eng.rst.rstdt | 1.0 | .396 | .567 | .951 | .945 | .948 | .932 | .945 | .939 | .949 | .965 | .957 |
| eng.sdrt.stac | .999 | .876 | .933 | .968 | .930 | .949 | .946 | .971 | .958 | .953 | .954 | .953 |
| eus.rst.ert | .981 | .530 | .688 | .890 | .707 | .788 | .889 | .754 | .816 | .909 | .740 | .816 |
| fra.sdrt.annodis | 1.0 | .310 | .474 | .943 | .854 | .897 | .894 | .903 | .898 | .944 | .865 | .903 |
| nld.rst.nldt | 1.0 | .721 | .838 | .979 | .927 | .952 | .933 | .892 | .912 | .964 | .945 | .954 |
| por.rst.cstn | .878 | .435 | .582 | .911 | .827 | .867 | .815 | .903 | .857 | .918 | .899 | .908 |
| rus.rst.rrt | .760 | .490 | .596 | .809 | .745 | .775 | .821 | .710 | .761 | .835 | .755 | .793 |
| spa.rst.rststb | .974 | .647 | .777 | .921 | .792 | .851 | .759 | .855 | .804 | .890 | .818 | .853 |
| spa.rst.sctb | .970 | .577 | .724 | .938 | .631 | .754 | .901 | .649 | .754 | .898 | .679 | .773 |
| zho.rst.sctb | .924 | .726 | .813 | .880 | .744 | .806 | .843 | .768 | .804 | .810 | .810 | .810 |
| mean | .957 | .598 | .724 | .927 | .823 | .870 | .881 | .841 | .858 | .914 | .853 | .881 |
| Pred syntax | Baseline | Subtree | RNN | GumDrop | ||||||||
| corpus | P | R | F | P | R | F | P | R | F | P | R | F |
| deu.rst.pcc | 1.0 | .626 | .770 | .924 | .867 | .895 | .876 | .867 | .872 | .920 | .898 | .909 |
| eng.rst.gum | .956 | .599 | .737 | .948 | .777 | .854 | .910 | .805 | .854 | .940 | .772 | .848 |
| eng.rst.rstdt | .906 | .368 | .524 | .916 | .871 | .893 | .883 | .911 | .897 | .896 | .914 | .905 |
| eng.sdrt.stac | .956 | .253 | .401 | .849 | .767 | .806 | .819 | .814 | .817 | .842 | .775 | .807 |
| eus.rst.ert | .970 | .543 | .696 | .917 | .705 | .797 | .877 | .747 | .807 | .901 | .734 | .809 |
| fra.sdrt.annodis | .980 | .285 | .442 | .938 | .824 | .877 | .892 | .915 | .903 | .945 | .853 | .896 |
| nld.rst.nldt | .991 | .663 | .794 | .951 | .849 | .897 | .938 | .835 | .883 | .947 | .884 | .915 |
| por.rst.cstn | .879 | .440 | .586 | .935 | .867 | .900 | .788 | .883 | .833 | .930 | .851 | .888 |
| rus.rst.rrt | .664 | .463 | .545 | .825 | .717 | .767 | .813 | .731 | .770 | .821 | .748 | .783 |
| spa.rst.rststb | .912 | .566 | .698 | .934 | .772 | .845 | .820 | .871 | .845 | .875 | .798 | .835 |
| spa.rst.sctb | .888 | .565 | .691 | .870 | .637 | .735 | .813 | .595 | .687 | .853 | .655 | .741 |
| zho.rst.sctb | .798 | .589 | .678 | .806 | .643 | .715 | .803 | .607 | .692 | .770 | .696 | .731 |
| mean | .908 | .497 | .630 | .901 | .775 | .832 | .853 | .798 | .822 | .887 | .798 | .839 |
| Gold syntax | Baseline | Freq | RNN | GumDrop | ||||||||
| corpus | P | R | F | P | R | F | P | R | F | P | R | F |
| eng.pdtb.pdtb | .964 | .022 | .044 | .836 | .578 | .683 | .859 | .871 | .865 | .879 | .888 | .884 |
| tur.pdtb.tdb | .333 | .001 | .002 | .786 | .355 | .489 | .759 | .820 | .788 | .766 | .816 | .790 |
| zho.pdtb.cdtb | .851 | .259 | .397 | .715 | .618 | .663 | .726 | .628 | .674 | .813 | .702 | .754 |
| mean | .716 | .094 | .148 | .779 | .517 | .612 | .781 | .773 | .776 | .819 | .802 | .809 |
| Pred syntax | Baseline | Freq | RNN | GumDrop | ||||||||
| corpus | P | R | F | P | R | F | P | R | F | P | R | F |
| eng.pdtb.pdtb | .964 | .022 | .044 | .836 | .578 | .683 | .811 | .798 | .805 | .846 | .828 | .837 |
| tur.pdtb.tdb | .333 | .001 | .002 | .786 | .355 | .489 | .761 | .821 | .790 | .768 | .817 | .792 |
| zho.pdtb.cdtb | .851 | .259 | .397 | .715 | .618 | .663 | .705 | .590 | .642 | .806 | .673 | .734 |
| mean | .716 | .094 | .148 | .779 | .517 | .612 | .759 | .736 | .746 | .806 | .773 | .788 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\noautomath
GumDrop at the DISRPT2019 Shared Task: A Model Stacking Approach to Discourse Unit Segmentation and Connective Detection
Yue Yu
Computer Science
Georgetown University \AndYilun Zhu
Linguistics
Georgetown University \AndYang Liu
Linguistics
Georgetown University \ANDYan Liu
Analytics
Georgetown University \AndSiyao Peng
Linguistics
Georgetown University \AndMackenzie Gong
CCT
Georgetown University \AndAmir Zeldes
Linguistics
Georgetown University \AND {yy476,yz565,yl879,yl1023,sp1184,mg1745,az364}@georgetown.edu
Abstract
In this paper we present GumDrop, Georgetown University’s entry at the DISRPT 2019 Shared Task on automatic discourse unit segmentation and connective detection. Our approach relies on model stacking, creating a heterogeneous ensemble of classifiers, which feed into a metalearner for each final task. The system encompasses three trainable component stacks: one for sentence splitting, one for discourse unit segmentation and one for connective detection. The flexibility of each ensemble allows the system to generalize well to datasets of different sizes and with varying levels of homogeneity.
1 Introduction
Although discourse unit segmentation and connective detection are crucial for higher level shallow and deep discourse parsing tasks, recent years have seen more progress in work on the latter tasks than on predicting underlying segments, such as Elementary Discourse Units (EDUs). As the most recent overview on parsing in the framework of Rhetorical Structure Theory (RST, Mann and Thompson 1988) points out (Morey et al., 2017, 1322) “all the parsers in our sample except [two] predict binary trees over manually segmented EDUs”. Recent discourse parsing papers (e.g. Li et al. 2016, Braud et al. 2017a) have focused on complex discourse unit span accuracy above the level of EDUs, attachment accuracy, and relation classification accuracy. This is due in part to the difficulty in comparing systems when the underlying segmentation is not identical (see Marcu et al. 1999), but also because of a relatively stable SOA accuracy of EDU segmentation as evaluated on the largest RST corpus, the English RST Discourse Treebank (RST-DT, Carlson et al. 2003), which already exceeded 90% accuracy in 2010 Hernault et al. (2010).
However, as recent work Braud et al. (2017b) has shown, performance on smaller or less homogeneous corpora than RST-DT, and especially in the absence of gold syntax trees (which are realistically unavailable at test time for practical applications), hovers around the mid 80s, making it problematic for full discourse parsing in practice. This is more critical for languages and domains in which relatively small datasets are available, making the application of generic neural models less promising.
The DISRPT 2019 Shared Task aims to identify spans associated with discourse relations in data from three formalisms: RST Mann and Thompson (1988), SDRT Asher (1993) and PDTB Prasad et al. (2014). The targeted task varies actoss frameworks: Since RST and SDRT segment texts into spans covering the entire document, the corresponding task is to predict the starting point of new discourse units. In the PDTB framework, the basic locus identifying explicit discourse relations is the spans of discourse connectives which need to be identified among other words. In total, 15 corpora (10 from RST data, 3 from PDTB-style data, and 2 from SDRT) in 10 languages (Basque, Chinese, Dutch, English, French, German, Portuguese, Russian, Spanish, and Turkish) are used as the input data for the task. The heterogeneity of the frameworks, languages and even the size of the training datasets all render the shared task challenging: training datasets range from the smallest Chinese RST corpus of 8,960 tokens to the largest English PDTB dataset of 1,061,222 tokens, and all datasets have some different guidelines. In this paper, we therefore focus on creating an architecture that is not only tailored to resources like RST-DT, and takes into account the crucial importance of high accuracy sentence splitting for real-world data, generalizing well to different guidelines and datasets.
Our system, called GumDrop, relies on model stacking Wolpert (1992), which has been successfully applied to a number of complex NLP problems (e.g. Clark and Manning 2015, Friedrichs et al. 2017). The system uses a range of different rule-based and machine learning approaches whose predictions are all fed to a ‘metalearner’ or blender classifier, thus benefiting from both neural models where appropriate, and strong rule-based baselines coupled with simpler classifiers for smaller datasets. A further motivation for our model stacking approach is curricular: the system was developed as a graduate seminar project in the course LING-765 (Computational Discourse Modeling), and separating work into many sub-modules allowed each contributor to work on a separate sub-project, all of which are combined in the complete system as an ensemble. The system was built by six graduate students and the instructor, with each student focusing on one module (notwithstanding occasional collaborations) in two phases: work on a high-accuracy ensemble sentence splitter for the automatic parsing scenario (see Section 3.2), followed by the development of a discourse unit segmenter or connective detection module (Sections 3.3 and 3.4).
2 Previous Work
Following early work on rule-based segmenters (e.g. Marcu 2000, Thanh et al. 2004), Soricut and Marcu (2003) used a simple probabilistic model conditioning on lexicalized constituent trees, by using the highest node above each word that has a right-hand sibling, as well as its children. Like our approach, this and subsequent work below perform EDU segmentation as a token-wise binary classification task (boundary/no-boundary). In a more complex model, Sporleder and Lapata (2005) used a two-level stacked boosting classifier on syntactic chunks, POS tags, token and sentence lengths, and token positions within clauses, all of which are similar to or subsumed by some of our features below. They additionally used the list of English connectives from Knott (1996) to identify connective tokens.
Hernault et al. (2010) used an SVM model with features corresponding to token and POS trigrams at and preceding a potential segmentation point, as well as features encoding the lexical head of each token’s parent phrase in a phrase structure syntax tree and the same features for the sibling node on the right. More recently, Braud et al. (2017b) used a bi-LSTM-CRF sequence labeling approach on dependency parses, with words, POS tags, dependency relations and the same features for each word’s parent and grand-parent tokens, as well as the direction of attachment (left or right), achieving F-scores of .89 on segmenting RST-DT with parser-predicted syntax, and scores in the 80s, near or above previous SOA results, for a number of other corpora and languages.
By contrast, comparatively little work has approached discourse connective detection as a separate task, as it is usually employed as an intermediate step for predicting discourse relations. Pitler and Nenkova (2009) used a Max Entropy classifier using a set of syntactic features extracted from the gold standard Penn Treebank Marcus et al. (1993) parses of PDTB Prasad et al. (2008) articles, such as the highest node which dominates exactly and only the words in the connective, the category of the immediate parent of that phrase, and the syntactic category of the sibling immediately to the left/right of the same phrase. Patterson and Kehler (2013) presented a logistic regression model trained on eight relation types extracted from PDTB, with features in three categories: Relation-level features such as the connective signaling the relation, attribution status of the relation, and its relevance to financial information; Argument-level features, capturing the size or complexity of each of its two arguments; and Discourse-level features, which incorporate the dependencies between the relation in question and its neighboring relations in the text.
Polepalli Ramesh et al. (2012) used SVM and CRF for identifying discourse connectives in biomedical texts. The Biomedical Discourse Relation Bank Prasad et al. (2011) and PDTB were used for in-domain classifiers and novel domain adaptation respectively. Features included POS tags, the dependency label of tokens’ immediate parents in a parse tree, and the POS of the left neighbor; domain-specific semantic features included several biomedical gene/species taggers, in addition to NER features predicted by ABNER (A Biomedical Named Entity Recognition).
3 GumDrop
Our system is organized around three ensembles which implement model stacking.
A trainable sentencer ensemble which feeds an off-the-shelf dependency parser 2. 2.
A discourse unit segmenter ensemble, operating on either gold or predicted sentences 3. 3.
A connective detector ensemble, also using gold or predicted sentences
Each module consists of several distinct sub-modules, as shown in Figure 1. Predicted labels and probabilities from sub-modules, along with features for every token position are fed to a blender classifier, which outputs the final prediction for each token. By learning which modules perform better on which dataset, in which scenario (gold or predicted syntax) and in what linguistic environments, the ensemble remains robust at both tasks in both settings.
Since the sub-modules and the ensembles are trained on the same training data, a crucial consideration is to avoid over-reliance on modules, which may occur if the metalearner learns about module reliability from data that the sub-modules have already seen. To counter this, we use 5-fold multitraining: each base module is trained five times, each time predicting labels for a disjoint held-out subset of the training data. These predictions are saved and fed to the ensemble as training data, thereby simulating the trained sub-modules’ behavior when exposed to unseen data. At test time, live predictions are gathered from the sub-modules, whose reliability has been assessed via the prior unseen multitraining data.
3.1 Features
Table 1 gives an overview of the features we extract from the shared task data, and the modules using those features for sentence splitting and EDU segmentation/connective detection. Features derived from syntax trees are not available for sentence splitting, though automatic POS tagging using the TreeTagger Schmid (1994) was used as a feature for this task, due to its speed and good accuracy in the absence of sentence splits.
Most modules represent underlying words somehow, usually in a 3 or 5-gram window centered around a possible split point. An exception is the LR module, which uses only the first/last (f/l in Table 1) characters to prevent sparseness, but which also uses #char_types features, which give the count of digits, consonant, vowel and other characters per word. Modules with ‘top 200/100’ use only the n most frequent items in the data, and otherwise treat each word as its POS category. Neural modules (DNN, RNN) use 300 dimensional FastText Bojanowski et al. (2017) word embeddings, and in the case of the RNN, character embeddings are also used. For Chinese in the LR module, we use the first/last byte in each word instead of actual characters.
The feature genre gives the genre, based on a substring extracted from document names, in corpora with multiple genres. The features quot/paren indicate, for each token, whether it is between quotation marks or parentheses, allowing modules to notice direct speech or uncompleted parentheses which often should not be split. The feature sent% gives the quantile position of the current sentence in the document as a number between 0–1. This can be important for datasets in which position in the document interacts with segmentation behavior, such as abstracts in early portions of the academic genres in the Russian corpus, which often leave sentences unsegmented.
The features deprel, headdist and depbracket are not available for sentence splitting, as they require dependency parses: they give the dependency relation, distance to the governing head token (negative/positive for left/right parents), and a BIEO (Begin/Inside/End/Out) encoded representation of the smallest relevant phrase boundaries covering each token for specific phrase types, headed by clausal functions such as ‘advcl’, ‘xcomp’ or ‘acl’ (see Figure 2). For the RNN, headdist is binned into 0, next-left/right, close-left/right (within 3 tokens) and far-left/right. The children feature set is unique to the Subtree module and is discussed below.
3.2 Sentence Splitting
DNN Sentencer A simple Deep Neural Network classifier, using 300 dimensional word embeddings in a Multilayer Perceptron for tokens in a 5–9-gram window. Optimization on dev data determines the optimal window size for each dataset. Flexible window sizes enable the DNN model to remember the surrounding tokens in both small and large datasets. Starting and ending symbols (‘s’ and ‘/s’) for each document guarantee the model can always predict the correct label when a new document starts.
Logistic Regression Sentencer
The Logistic Regression (LR) Sentencer uses sklearn’s Pedregosa et al. (2011) LogisticRegressionCV implementation to predict sentence boundaries given a variety of character-level information. The beginning/ending characters (first/last letter), auto-generated POS tags and character/frequency count representations (number of consonants/vowels/digits/other, token length, token frequency) are applied to a sliding 5-gram window (categorical features are converted into 1-hot features). One advantage of the LR model is its reliability for smaller datasets where character-level features prevent sparseness (including the top 200 feature decreases performance).
Wiki-Based Sentencer
The Wiki-Based Sentencer relies on the frequencies and ratios of paragraph-initial tokens extracted from Wikipedia articles obtained from Wikipedia database dumps for all languages.111 Traditional Chinese characters were converted into simplified Chinese to be consistent with shared task data. The rationale is that even though we have no gold sentence splits for Wikipedia, if a token occurs paragraph-initial, then it must be sentence-initial. For each Wiki paragraph, we extract the first “sentence” based on text up to the first sentence final character (./?/!), and then the first word is obtained based on automatic tokenization. Though this approach is coarse, we are able to get a good approximation of frequently initial words thanks to the large data. The frequencies and ratios of tokens being sentence initial are recorded, and thresholds of frequency10 and ratio 0.5 are set to collect the most relevant tokens. The main purpose of this module is to capture potential sentence split points such as headings, which are not followed by periods (e.g. Introduction in English).
UDPipe + NLTK
Additionally, we used UDPipe and NLTK’s freely available models as predictors for the ensemble. For Simplified Chinese, we retrained UPipe using data from the Chinese Treebank, not overlapping CDTB’s shared task data.
EnsembleSentencer
As a metalearner receiving input from the base-modules, we used tree-based algorithms selected via optimization on dev data, either RandomForest, ExtraTrees, GradientBoosting (using sklearn’s implementation), or XGBoost Chen and Guestrin (2016). In addition to the submodules’ probability estimates, the metalearner was given access to token features in a trigram window, including word identity (for the top 100 items), POS tags, and orthographic case.
3.3 Discourse Unit Segmentation
The feature space for segmentation is much larger than for sentence splitting, due to availability of syntactic features (cf. Table 1). Additionally, as usefulness of features varies across datasets (for example, some lanaguage use only the UPOS column, or UPOS is trivially predictable from XPOS), we performed automatic variable filtering per dataset for both the Subtree and the Ensemble module below. We removed all categorical variables with a Theil’s U value of implication above .98 (meaning some feature A is predictable based on some feature B), and for numerical variables, based on Pearson’s r0.95.
SubtreeSegmenter
This module focuses on dependency subgraphs, looking at a trigram around the potential split point. In addition to word, orthographic case, POS, and deprel features from Table 1, the module uses a children feature set, extracting information for the node token, neighbors, parent and grandparent, including:
- •
their labels and depth (rank) in the tree
- •
labels of closest/farthest L/R children
- •
left/right span length and clause BIOE
- •
whether L/R neighbors share their parent
The features are illustrated in Figure 2. If we consider a split at the node word ‘given’, we collect features for two tokens in each direction, the parent (‘ignore’) and grandparent (‘allowed’). The left span of children of ‘given’ is 1 token long, and the right 2 tokens long. We additionally collect for each of these tokens whether they have the same parent as their neighbor to the right/left (e.g. ‘ants’ has the same parent as ‘as’), as well as the nearest and farthest dependency label on descendents to each side of the node (here, mark for both closest and farthest left child of ‘given’, and det (closest) and obj (farthest) on the right. The BIOE bracket feature is a flattened ‘chunk’ feature indicating clauses opening and closing (B-advcl, etc.) These features give a good approximation of the window’s syntactic context, since even if the split point is nested deeper than a relevant clausal function, discrepancies in neighbors’ dependency features, and distances implied by left/right spans along with dependency functions allow the reconstruction of pertinent subtree environments for EDU segmentation. The feature count varied between 86–119 (for rus.rst.rrt and eng.sdrt.stac respectively), due to automatic feature selection.
BOWCounter
Rather than predicting exact split points, the BOWCounter attempts to predict the number of segments in each sentence, using a Ridge regressor with regularization optimized via cross-validation. The module uses the top 200 most frequent words as well as POS tags in a bag of words model and predicts a float which is fed directly to the ensemble. This allows the module to express confidence, rather than an integer prediction. We note that this module is also capable of correctly predicting 0 segmentation points in a sentence (most frequent in the Russian data).
RNNSegmenter
To benefit from the predictive power of neural sequence models and word embeddings with good coverage for OOV items, we used NCRF++ Yang and Zhang (2018), a bi-LSTM/CNN-CRF sequence labeling framework. Features included Glove word embeddings for English Pennington et al. (2014) and FastText embeddings Bojanowski et al. (2017) for other languages, trainable character embeddings, as well as the features in Table 1, such as POS tags, dependency labels, binned distance to parent, genre, and BIEO dependency brackets, all encoded as dense embeddings. We optimized models for each dataset, including using CNN or LSTM encoding for character and word embeddings.
Ensemble Segmenter
For the metalearner we used XGBoost, which showed high accuracy across dataset sizes. The ensemble was trained on serialized multitraining data, produced by training base-learners on 80% of the data and predicting labels for each 20% of the training data separately. At test time, the metalearner then receives live predictions from the sub-modules, whose reliability has been assessed using the multitraining data. In addition to base module predictions, the metalearner is given access to the most frequent lexemes, POS tags, dependency labels, genre, sentence length, and dependency brackets, in a trigram window.
3.4 Connective Detection
Frequency-based Connective Detector
This module outputs the ratios at which sequences of lexical items have been seen as connectives in training data, establishing an intelligent ‘lookup’ strategy for the connective detection task. Since connectives can be either a single B-Conn or a B-Conn followed by several I-Conns, we recover counts for each attested connective token sequence up to 5 tokens. For test data, the module reports the longest possible connective sequence containing a token and the ratio at which it is known to be a connective, as well as the training frequency of each item. Rather than select a cutoff ratio for positive prediction, we allow the ensemble to use the ratio and frequency dynamically as features.
RNN Connective Detector
This module is architecturally identical to the RNN EDU segmenter, but since connective labels are non-binary and may form spans, it classifies sequences of tokens with predicted connective types (i.e. B-Conn, I-Conn or not a connective). Rather than predicted labels, the system reports probabilities with which each label is suspected to apply to tokens, based on the top 5 optimal paths as ranked by the CRF layer of NCRF’s output.
Ensemble Connective Detector
The connective ensemble is analogous to the segmenter ensemble, and relies on a Random Forest classifier fed the predicted labels and probabilities from base connective detectors, as well as the same features fed to the segmenter ensemble above.
4 Results
Sentence Splitting
Although not part of the shared task, we report results for our EnsembleSentencer and LR module (best sub-module on average) next to a punctuation-based baseline (split on ‘.’, ‘!’, ‘?’ and Chinese equivalents) and NLTK’s Bird et al. (2009) sentence tokenizer (except for Chinese, which is not supported). Since most sentence boundaries are also EDU boundaries, this task is critical, and Table 2 shows the gains brought by using the ensemble. GumDrop’s performance is generally much higher than both baselines, except for the Portuguese corpus, in which both the system and the baseline make exactly 2 precision errors and one recall error, leading to an almost perfect tied score of 0.988. Somewhat surprisingly, NLTK performs worse on average than the conservative strategy of using sentence final punctuation. The LR module is usually slightly worse than the ensemble, but occasionally wins by a small margin.
Discourse Unit Segmentation
Table 3 gives scores for both the predicted and gold syntax scenarios. In order to illustrate the quality of the submodules, we also include scores for Subtree (the best non-neural model) and the RNN (best neural model), next to the ensemble. The baseline is provided by assuming EDUs overlap exactly with sentence boundaries.
Overall the results compare favorably with previous work and exceed the previously reported state of the art for the benchmark RST-DT dataset, in both gold and predicted syntax (to the best of our knowledge, 93.7 and 89.5 respectively). At the same time, the ensemble offers good performance across dataset sizes and genres: scores are high on all English datasets, covering a range of genres, including gold STAC (chat data), as well as on some of the smaller datasets, such as Dutch, French and German (only 17K, 22K and 26K training tokens each). Performance is worse on the SCTB corpora and Russian, which may be due to low-quality parses in the gold scenario, and some inconsistencies, especially in the Russian data, where academic abstracts and bibliographies were sometimes segmented and sometimes not. Comparing the ensemble to the RNN or subtree modules individually shows that although they each offer rather strong performance, the ensemble outperforms them for all datasets, except German, where Subtree outperforms it by a small margin, and STAC, where the RNN is slightly better, both showing just half a point of improvement.
For automatically parsed data, the table clearly shows that eng.rst.stac, eng.rst.gum and zho.rst.sctb are the most problematic, in the first case since chat turns must be segmented automatically into sentences. This indicates that a trustworthy sentencer is crucial for discourse unit segmentation and thus very useful for this shared task. Here the EnsembleSentencer brings results up considerably from the punctuation based baseline. The ensemble achieves top performance for most datasets and on average, but the RNN performs better on French, Subtree on Portuguese, and both are tied for Spanish RSTSTB.
Connective Detection
Results for connective detection are shown in Table 4. As a baseline, we consider assigning each word in the test data a connective label if and only if it is attested exclusively as a connective in the training set (case-sensitive). As the results show, the baseline has low recall but high precision, correlated with the size of the corpus (as exhaustivity of exclusive connective words increases with corpus size).
The frequency-based connective detector gives a reasonable result with a rather simple strategy, using a threshold of 0.5 as the connective detection ratio. More importantly, it is useful as input for the ensemble that outperforms the sequence labeling RNN by itself on every dataset. We suspect at least two factors are responsible for this improvement: firstly, the imbalanced nature of connective annotations (the vast majority of words are not connectives) means that the RNN achieves over 99% classification accuracy, and may have difficulty generalizing to rare but reliable connectives. Secondly, the RNN may overfit spurious features in the training data, to which the frequency detector is not susceptible. Coupled with the resistance of tree ensembles to overfitting and imbalanced problems, the ensemble is able to give a better solution to the task.
5 Error Analysis
5.1 EDU Segmenter
In both gold and predicted syntax scenarios, the RST corpora in Russian, Spanish and Chinese (rst.rus.rrt, spa.rst.sctb and zho.rst.sctb) achieve the lowest F-scores on this task. Leaving the sentencer performance aside, this error analysis for EDU segmentation will mainly focus on the gold syntax scenario of these three corpora.
Coordinating Conjunctions (CCONJ)
Only particular types of coordinated structure consist of two discourse units in different corpora, e.g. VP coordination, or each coordinate predicate having its own subject, etc. For example, in eng.rst.gum, two coordinated verb phrases ([John is athletic but hates hiking] are annotated as one discourse unit whereas [John is athletic] [but he hates hiking] is divided into two units since both coordinates have their own subjects. Additionally, if one coordinate VP has a dependent adverbial clause, multiple units are annotated. However, even with dependency features included in GumDrop, precision and recall errors happen with different coordinating conjunctions. These include and, or in English, y (‘and’), o (‘or’) in Spanish, and i (‘and’), a (‘but’), ili (‘or’) in Russian.
Subordinating Conjunctions (SCONJ)
GumDrop sometimes fails when there is an ambiguity between adpositions and subordinating conjunctions. Words that can function as both cause problems for segmentation since subordinate clauses are discourse units but adpositional phrases are not in most datasets. Ambiguous tokens include to, by, after, before in English, en (‘in’), de (‘of’), con (‘with’), por (‘by’) in Spanish, as well as zai (‘at’) in Chinese.
Classifying the boundary of subordinate clauses is another problem. The depbracket feature can identify the beginning of a subordinate clause when the main clause precedes it. However, when they are in reverse order as in Figure 3, GumDrop fails to identify the beginning of the second discourse unit possibly due to the absence of a second B-feature at jiaoshi.
Enumerations and Listings
In rus.rst.rrt, the special combination of a number, a backslash and a period, e.g. 1. , 2. etc., is used for enumeration. However, their dependency labels vary: root, flat, nmod etc. Due to the instability of the labels, these tokens may result in recall errors, suggesting possibile improvements via parser postprocessing. Similar errors also occur with 1, 2 in Spanish and variants of hyphens/dashes in Russian.
5.2 Connective Detection
Co-occurring Connective Spans
Unlike EDU segmentation, where only splits are marked, connectives are spans that consist of a mandatory B-Conn and possible I-Conn labels. However, in Chinese, it is possible for a a connective to consist of discontinuous spans. In (1), both zai ‘at’ and the localizer zhong, are connectives and are required to co-occur in the context. However, the system fails to capture the relationship between them.
(1) zai cunmin zizhi zhong …
P:at villager autonomy LC:in
B-Conn
B-Conn
‘Under the autonomy of villagers…’
Syntactic Inversions
Syntactic inversion as a connective is also problematic since no content words are involved: For instance, though the system is able to identify B-Conn in both (2) and (3), it is hard to determine whether content words, such as the verbs (fueling and yinrenzhumu), belong to the connective span or not. The model can be potentially improved by handling these using dependency features.
(2) Further fueling the belief that …
B-Conn I-Conn
(3) … geng yinrenzhumude de shi …
more striking DE COP
B-Conn I-Conn
‘the more striking thing is that …’
6 Conclusion and Future Work
A main lesson learned from the present work has been that while RNNs perform well on large and consistent datasets, such as RST-DT, they are not as robust when dealing with smaller datasets. This was especially apparent in the predicted syntax scenario, where decision tree ensembles outperformed the RNN on multiple datasets. At the same time, the model stacking approach offers the advantage of not having to choose between neural and tree-based models, by letting a metalearner learn who to believe and when.
Although we hope these results on the shared task dataset represent progress on discourse unit segmentation and connective detection, we would also like to point out that high accuracy (95% or better) is still out of reach, and especially so for languages with fewer resources and in the realistic ‘no gold syntax’ scenario. Additionally, the architecture used in this paper trades improvements in accuracy for a higher level of complexity, including complex training regimes due to multitraining and a variety of supporting libraries. In future work, we plan to integrate a simplified version of the system into tools that are easier to distribute. In particular, we aim to integrate automatic segmentation facilities into rstWeb Zeldes (2016), an open source RST editor interface, so that end users can more easily benefit from system predictions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Asher (1993) Nicholas Asher. 1993. Reference to Abstract Objects in Discourse . Kluwer, Dordrecht.
- 2Bird et al. (2009) Steven Bird, Edward Loper, and Ewan Klein. 2009. Natural Language Processing with Python . O’Reilly, Sebastopol, CA.
- 3Bojanowski et al. (2017) Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. 2017. Enriching word vectors with subword information. TACL , 5:135–146.
- 4Braud et al. (2017 a) Chloé Braud, Maximin Coavoux, and Anders Søgaard. 2017 a. Cross-lingual RST discourse parsing. In Proceedings of EACL 2017 , pages 292–304, Valencia, Spain.
- 5Braud et al. (2017 b) Chloé Braud, Ophélie Lacroix, and Anders Søgaard. 2017 b. Does syntax help discourse segmentation? not so much. In Proceedings of EMNLP 2017 , pages 2432–2442, Copenhagen.
- 6Carlson et al. (2003) Lynn Carlson, Daniel Marcu, and Mary Ellen Okurowski. 2003. Building a discourse-tagged corpus in the framework of Rhetorical Structure Theory. In Current and New Directions in Discourse and Dialogue , Text, Speech and Language Technology 22, pages 85–112. Kluwer, Dordrecht.
- 7Chen and Guestrin (2016) Tianqi Chen and Carlos Guestrin. 2016. XG Boost: A scalable tree boosting system. In KDD ’16 Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages 785–794, San Francisco, CA.
- 8Clark and Manning (2015) Kevin Clark and Christopher D. Manning. 2015. Entity-centric coreference resolution with model stacking. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2015) , pages 1405–1415, Beijing.
