TL;DR
The paper introduces BIT, a biologically inspired visual tracker based on the human visual system, which combines shallow neural features with advanced learning mechanisms and acceleration techniques to achieve real-time, accurate, and robust tracking.
Contribution
It presents a novel biologically inspired model for visual tracking that integrates neural-inspired features with efficient learning and detection methods for improved performance.
Findings
Achieves approximately 45 frames per second in tracking.
Performs favorably against state-of-the-art methods in accuracy and robustness.
Demonstrates effectiveness on large-scale benchmark datasets.
Abstract
Visual tracking is challenging due to image variations caused by various factors, such as object deformation, scale change, illumination change and occlusion. Given the superior tracking performance of human visual system (HVS), an ideal design of biologically inspired model is expected to improve computer visual tracking. This is however a difficult task due to the incomplete understanding of neurons' working mechanism in HVS. This paper aims to address this challenge based on the analysis of visual cognitive mechanism of the ventral stream in the visual cortex, which simulates shallow neurons (S1 units and C1 units) to extract low-level biologically inspired features for the target appearance and imitates an advanced learning mechanism (S2 units and C2 units) to combine generative and discriminative models for target location. In addition, fast Gabor approximation (FGA) and fast…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22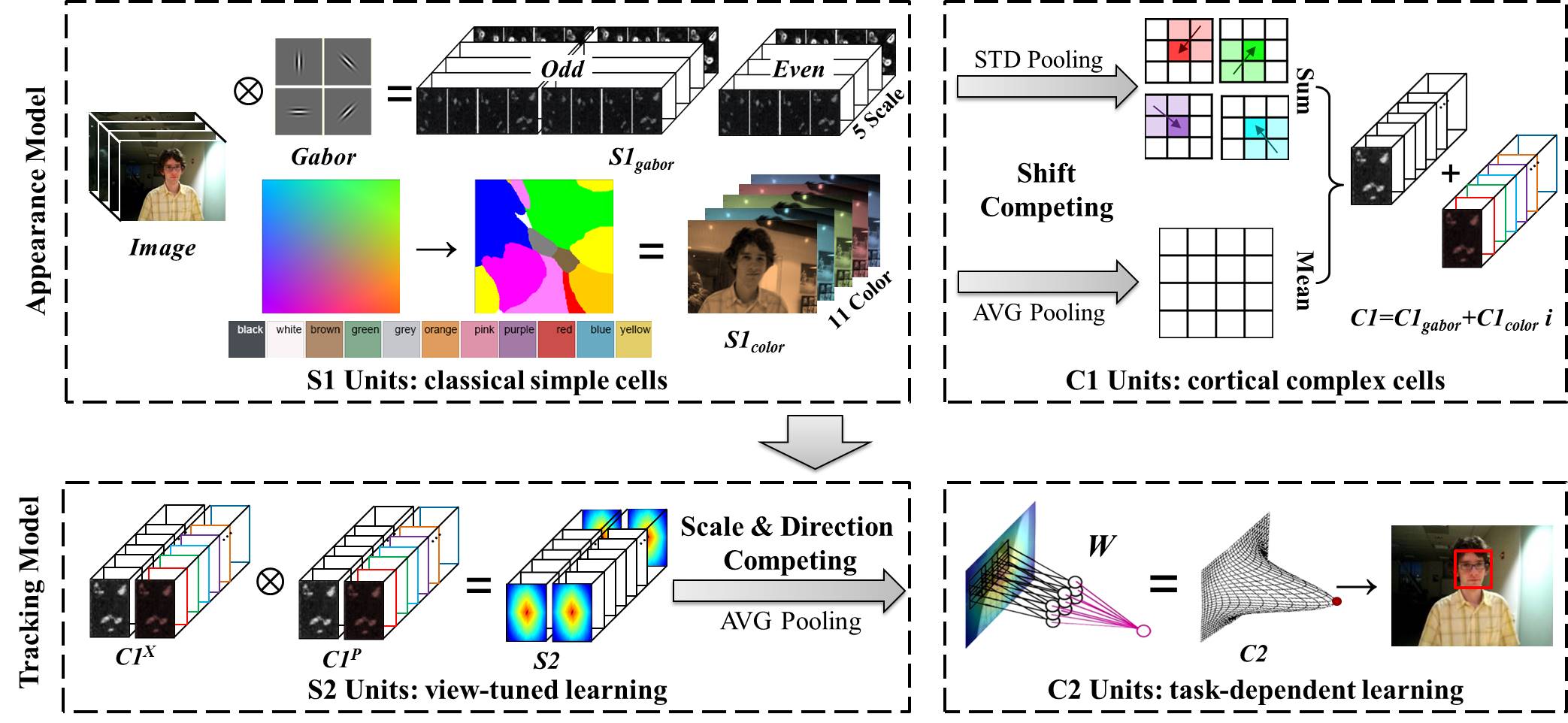 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| Scale | Receipt-field | ||
|---|---|---|---|
| 1 | 2.8 | 3.5 | |
| 2 | 3.6 | 4.6 | |
| 3 | 4.5 | 5.6 | |
| 4 | 5.4 | 6.8 | |
| 5 | 6.3 | 7.9 |
| BIT | RPT[58] | TGPR[59] | ICF[60] | KCF[3] | Struck[23] | SCM[12] | TLD[55] | VTS[61] | MIL[25] | IVT[9] | |
| Basketball | 1.000 | 0.924 | 0.994 | 1.000 | 0.923 | 0.120 | 0.661 | 0.028 | 1.000 | 0.284 | 0.497 |
| Bolt | 1.000 | 0.017 | 0.017 | 1.000 | 0.989 | 0.020 | 0.031 | 0.306 | 0.089 | 0.014 | 0.014 |
| Boy | 1.000 | 1.000 | 0.987 | 1.000 | 1.000 | 1.000 | 0.440 | 1.000 | 0.980 | 0.846 | 0.332 |
| Car4 | 0.973 | 0.980 | 1.000 | 1.000 | 0.950 | 0.992 | 0.974 | 0.874 | 0.363 | 0.354 | 1.000 |
| CarDark | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.639 | 1.000 | 0.379 | 0.807 |
| CarScale | 0.718 | 0.806 | 0.790 | 0.806 | 0.806 | 0.647 | 0.647 | 0.853 | 0.544 | 0.627 | 0.782 |
| Coke | 0.931 | 0.962 | 0.945 | 0.887 | 0.838 | 0.948 | 0.430 | 0.684 | 0.189 | 0.151 | 0.131 |
| Couple | 0.607 | 0.679 | 0.600 | 0.107 | 0.257 | 0.736 | 0.114 | 1.000 | 0.100 | 0.679 | 0.086 |
| Crossing | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.617 | 0.417 | 1.000 | 1.000 |
| David | 1.000 | 1.000 | 0.977 | 1.000 | 1.000 | 0.329 | 1.000 | 1.000 | 0.962 | 0.699 | 1.000 |
| David2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.978 | 1.000 |
| David3 | 1.000 | 1.000 | 0.996 | 1.000 | 1.000 | 0.337 | 0.496 | 0.111 | 0.742 | 0.738 | 0.754 |
| Deer | 0.831 | 1.000 | 0.859 | 0.817 | 0.817 | 1.000 | 0.028 | 0.732 | 0.042 | 0.127 | 0.028 |
| Dog1 | 1.000 | 1.000 | 1.000 | 0.994 | 1.000 | 0.996 | 0.976 | 1.000 | 0.811 | 0.919 | 0.980 |
| Doll | 0.986 | 0.987 | 0.943 | 0.947 | 0.967 | 0.919 | 0.978 | 0.983 | 0.946 | 0.732 | 0.757 |
| Dudek | 0.862 | 0.849 | 0.751 | 0.899 | 0.859 | 0.897 | 0.883 | 0.597 | 0.871 | 0.688 | 0.886 |
| FaceOcc1 | 0.877 | 0.663 | 0.664 | 0.855 | 0.878 | 0.575 | 0.933 | 0.203 | 0.485 | 0.221 | 0.645 |
| FaceOcc2 | 0.933 | 0.990 | 0.468 | 0.968 | 0.972 | 1.000 | 0.860 | 0.856 | 0.936 | 0.740 | 0.993 |
| Fish | 1.000 | 1.000 | 0.975 | 1.000 | 1.000 | 1.000 | 0.863 | 1.000 | 0.992 | 0.387 | 1.000 |
| FleetFace | 0.581 | 0.562 | 0.453 | 0.627 | 0.556 | 0.639 | 0.529 | 0.506 | 0.642 | 0.358 | 0.264 |
| Football | 0.798 | 0.801 | 0.997 | 0.801 | 0.796 | 0.751 | 0.765 | 0.804 | 0.796 | 0.790 | 0.793 |
| Football1 | 0.973 | 0.932 | 0.986 | 0.986 | 0.959 | 1.000 | 0.568 | 0.554 | 0.892 | 1.000 | 0.811 |
| Freeman1 | 1.000 | 0.972 | 0.933 | 0.393 | 0.393 | 0.801 | 0.982 | 0.540 | 0.969 | 0.939 | 0.807 |
| Freeman3 | 0.817 | 0.996 | 0.774 | 0.896 | 0.911 | 0.789 | 1.000 | 0.767 | 0.702 | 0.048 | 0.761 |
| Freeman4 | 0.993 | 0.880 | 0.580 | 0.951 | 0.530 | 0.375 | 0.509 | 0.410 | 0.219 | 0.201 | 0.346 |
| Girl | 1.000 | 0.924 | 0.918 | 0.916 | 0.864 | 1.000 | 1.000 | 0.918 | 0.874 | 0.714 | 0.444 |
| Ironman | 0.157 | 0.181 | 0.217 | 0.199 | 0.217 | 0.114 | 0.157 | 0.120 | 0.247 | 0.108 | 0.054 |
| Jogging.1 | 0.977 | 0.228 | 0.993 | 0.977 | 0.235 | 0.241 | 0.228 | 0.974 | 0.225 | 0.231 | 0.225 |
| Jogging.2 | 1.000 | 0.179 | 0.997 | 0.186 | 0.163 | 0.254 | 1.000 | 0.857 | 0.186 | 0.186 | 0.199 |
| Jumping | 0.093 | 1.000 | 0.946 | 0.383 | 0.339 | 1.000 | 0.153 | 1.000 | 0.236 | 0.997 | 0.208 |
| Lemming | 0.491 | 0.537 | 0.349 | 0.509 | 0.495 | 0.628 | 0.166 | 0.859 | 0.554 | 0.823 | 0.167 |
| Liquor | 0.986 | 0.937 | 0.271 | 0.431 | 0.423 | 0.390 | 0.276 | 0.588 | 0.364 | 0.199 | 0.207 |
| Matrix | 0.360 | 0.440 | 0.390 | 0.350 | 0.170 | 0.120 | 0.350 | 0.160 | 0.200 | 0.180 | 0.020 |
| Mhyang | 1.000 | 1.000 | 0.947 | 1.000 | 1.000 | 1.000 | 1.000 | 0.978 | 1.000 | 0.460 | 1.000 |
| MotorRolling | 0.049 | 0.049 | 0.091 | 0.049 | 0.043 | 0.085 | 0.037 | 0.116 | 0.049 | 0.043 | 0.030 |
| MountainBike | 0.987 | 1.000 | 1.000 | 1.000 | 1.000 | 0.921 | 0.969 | 0.259 | 0.996 | 0.667 | 0.996 |
| Shaking | 0.970 | 0.995 | 0.970 | 0.025 | 0.025 | 0.192 | 0.814 | 0.405 | 0.921 | 0.282 | 0.011 |
| Singer1 | 1.000 | 0.986 | 0.684 | 0.689 | 0.980 | 0.641 | 1.000 | 1.000 | 1.000 | 0.501 | 0.963 |
| Singer2 | 0.036 | 0.913 | 0.970 | 0.038 | 0.945 | 0.036 | 0.112 | 0.071 | 0.358 | 0.404 | 0.036 |
| Skating1 | 1.000 | 1.000 | 0.805 | 1.000 | 1.000 | 0.465 | 0.768 | 0.318 | 0.890 | 0.130 | 0.108 |
| Skiing | 0.136 | 0.136 | 0.123 | 0.111 | 0.074 | 0.037 | 0.136 | 0.123 | 0.062 | 0.074 | 0.111 |
| Soccer | 0.949 | 0.944 | 0.158 | 0.967 | 0.793 | 0.253 | 0.268 | 0.115 | 0.505 | 0.191 | 0.173 |
| Subway | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.983 | 1.000 | 0.251 | 0.240 | 0.994 | 0.223 |
| Suv | 0.979 | 0.529 | 0.658 | 0.979 | 0.979 | 0.572 | 0.978 | 0.909 | 0.535 | 0.123 | 0.447 |
| Sylvester | 0.839 | 0.979 | 0.955 | 0.851 | 0.843 | 0.995 | 0.946 | 0.949 | 0.820 | 0.651 | 0.680 |
| Tiger1 | 0.927 | 0.977 | 0.284 | 0.958 | 0.975 | 0.175 | 0.126 | 0.456 | 0.117 | 0.095 | 0.080 |
| Tiger2 | 0.449 | 0.814 | 0.723 | 0.485 | 0.356 | 0.630 | 0.112 | 0.386 | 0.162 | 0.414 | 0.082 |
| Trellis | 1.000 | 1.000 | 0.979 | 1.000 | 1.000 | 0.877 | 0.873 | 0.529 | 0.503 | 0.230 | 0.332 |
| Walking | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0.964 | 1.000 | 1.000 | 1.000 |
| Walking2 | 0.440 | 0.684 | 0.988 | 1.000 | 0.440 | 0.982 | 1.000 | 0.426 | 0.408 | 0.406 | 1.000 |
| Woman | 0.940 | 0.938 | 0.968 | 0.938 | 0.938 | 1.000 | 0.940 | 0.191 | 0.198 | 0.206 | 0.201 |
| ALL | 0.817 | 0.811 | 0.766 | 0.764 | 0.739 | 0.656 | 0.649 | 0.608 | 0.575 | 0.475 | 0.499 |
| No. Best | 23 | 23 | 11 | 20 | 15 | 14 | 14 | 11 | 8 | 3 | 8 |
| No. Worst | 8 | 10 | 14 | 12 | 15 | 26 | 23 | 28 | 29 | 41 | 33 |
| BIT | RPT[58] | TGPR[59] | ICF[60] | KCF[3] | Struck[23] | SCM[12] | TLD[55] | VTS[61] | MIL[25] | IVT[9] | |
| IV | 0.764 | 0.827 | 0.687 | 0.696 | 0.717 | 0.558 | 0.594 | 0.537 | 0.573 | 0.349 | 0.418 |
| SV | 0.786 | 0.802 | 0.703 | 0.707 | 0.667 | 0.639 | 0.672 | 0.606 | 0.582 | 0.471 | 0.494 |
| OCC | 0.854 | 0.765 | 0.708 | 0.817 | 0.744 | 0.564 | 0.640 | 0.563 | 0.534 | 0.427 | 0.455 |
| DEF | 0.817 | 0.748 | 0.768 | 0.754 | 0.751 | 0.521 | 0.586 | 0.512 | 0.487 | 0.455 | 0.409 |
| MB | 0.663 | 0.783 | 0.578 | 0.654 | 0.621 | 0.551 | 0.339 | 0.518 | 0.375 | 0.357 | 0.222 |
| FM | 0.643 | 0.745 | 0.575 | 0.612 | 0.581 | 0.604 | 0.333 | 0.551 | 0.353 | 0.396 | 0.220 |
| IPR | 0.783 | 0.795 | 0.706 | 0.739 | 0.731 | 0.617 | 0.597 | 0.584 | 0.579 | 0.453 | 0.457 |
| OPR | 0.831 | 0.807 | 0.741 | 0.741 | 0.724 | 0.597 | 0.618 | 0.596 | 0.604 | 0.466 | 0.464 |
| OV | 0.654 | 0.641 | 0.495 | 0.584 | 0.555 | 0.539 | 0.429 | 0.576 | 0.455 | 0.393 | 0.307 |
| BC | 0.789 | 0.840 | 0.761 | 0.698 | 0.725 | 0.585 | 0.578 | 0.428 | 0.578 | 0.456 | 0.421 |
| LR | 0.369 | 0.478 | 0.539 | 0.516 | 0.379 | 0.545 | 0.305 | 0.349 | 0.187 | 0.171 | 0.278 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsSPEED: Separable Pyramidal Pooling EncodEr-Decoder for Real-Time Monocular Depth Estimation on Low-Resource Settings
BIT: Biologically Inspired Tracker
Bolun Cai, Xiangmin Xu, Xiaofen Xing, Kui Jia, Jie Miao, and Dacheng Tao B. Cai, X. Xu (✉), X. Xing and J. Miao are with the School of Electronic and Information Engineering, South China University of Technology, Guangzhou, Guangdong, China (e-mail: [email protected]; [email protected]; [email protected]; [email protected]).K. Jia is with the department of Computer and Information Science, Faculty of Science and Technology, University of Macau, E11 Avenida da Universidade, Taipa, Macau SAR, China. (e-mail: [email protected]).D. Tao is with the Centre for Quantum Computation & Intelligent Systems and the Faculty of Engineering and Information Technology, University of Technology Sydney, 81 Broadway Street, Ultimo, NSW 2007, Australia (e-mail: [email protected]).ⓒ 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
Abstract
Visual tracking is challenging due to image variations caused by various factors, such as object deformation, scale change, illumination change and occlusion. Given the superior tracking performance of human visual system (HVS), an ideal design of biologically inspired model is expected to improve computer visual tracking. This is however a difficult task due to the incomplete understanding of neurons’ working mechanism in HVS. This paper aims to address this challenge based on the analysis of visual cognitive mechanism of the ventral stream in the visual cortex, which simulates shallow neurons (S1 units and C1 units) to extract low-level biologically inspired features for the target appearance and imitates an advanced learning mechanism (S2 units and C2 units) to combine generative and discriminative models for target location. In addition, fast Gabor approximation (FGA) and fast Fourier transform (FFT) are adopted for real-time learning and detection in this framework. Extensive experiments on large-scale benchmark datasets show that the proposed biologically inspired tracker performs favorably against state-of-the-art methods in terms of efficiency, accuracy, and robustness. The acceleration technique in particular ensures that BIT maintains a speed of approximately 45 frames per second.
Index Terms:
Biologically inspired model, visual tracking, fast Gabor approximation, fast Fourier transform.
I Introduction
Visual object tracking is a fundamental problem in computer vision. It has a wide variety of applications [1] including motion analysis, video surveillance, human computer interaction and robot perception. Although visual tracking has been intensively investigated in the past decade, it is still challenging caused by various factors such as appearance variations, pose change, occlusion. To improve visual tracking, one may need to address all of these challenges by developing better feature representations of visual targets and more effective tracking models.
Target objects in visual tracking are commonly represented as handcrafted features or automated features. Histogram based handcrafed features have been introduced to tracking, such as a color histogram [2] embedded in the mean-shift algorithm to search the target, a histogram of oriented gradients (HOG) [3] to exploit local directional edge information, and a distribution field histogram [4] to balance descriptor specificity and the landscape smoothness criterion. In addition, local binary patterns (LBP) [5], scale-invariant feature transform (SIFT) [6] and Haar-like features [7] have also been explored to model object appearance. Handcrafted features only achieve partial success in coping with the challenges of appearance variations, scale change, and pose changes, yet requiring domain expertise for appropriate designs. On the other hand, automated feature extraction is able to learn self-taught features [8] from input images, which can be either unsupervised such as principal component analysis (PCA) [9], or supervised such as linear discriminant analysis (LDA) [10]. For example, many recent tracking methods including local linear coding (LLC) [11], sparsity-based collaborative model (SCM) [12], multi-task tracker (MTT) [13] and multi-view tracker (MVT) [14] use learned sparse representations to improve the robustness against various target variations. However, due to the heavy computations involved in learning and optimization, most of these automated features trade real-time efficiency for the robustness. In summary, both handcrafted and automated features have their limitations, and it remains an important task to develop better feature representations of objects in visual tracking.
A tracking model is used to verify the prediction of any state, which can be generative or discriminative. In generative models [15, 16], tracking is formulated as a search for the region within a neighborhood that is most similar to the target object. A variety of search methods based on generative models have been developed to estimate object states; for instance, a generalized Hough transform [17] for tracking-by-detection, a sparsity-based local appearance generative model [18], and an object similarity metric with a gradient-based formulation [19] to locate objects. However, generative models ignore negative samples in the background, resulting in vulnerability caused by background confusion. Recently, discriminative models [20, 21] have been developed which consider the information of the object and the background simultaneously, and learn binary classifiers in an online manner to separate the foreground from the background. Numerous classifiers have been adopted for object tracking, such as multi-view SVM (MVS) [22], structured SVM (Struck) [23], online AdaBoost (OAB) [24], and online multi-instance learning (MIL) [25], as well as several semi-supervised models [26]. However, discriminative models pay insufficient attention to the eigen basis of the tracking target and are unable to evaluate the credibility of the tracking results precisely. Therefore, a successful model should exploit the advantages of both generative and discriminative methods [12, 27] to account for appearance variations and to effectively separate the foreground target from the background.
Primates are acknowledged to be capable in high performance visual pattern recognition, as they can achieve invariance and discrimination uniformly. Recent research findings in brain cognition and computer vision demonstrate that the bio-inspired models are valuable in enhancing the performance of object recognition [28], face identification [29], and scene classification [30]. We expect applying visual cortex research to object tracking would also be feasible and meaningful. Robust tracking target representation based on expert biological knowledge is able to avoid the parameter adjustment of handcrafted features and the parameter learning of automated features. In addition, the biological visual cognitive mechanism provides the inspiration for combining the generative model and discriminative model to handle appearance variations and to separate the target from the background effectively. This paper develops biologically inspired tracker (BIT) based on the ventral stream in the visual cortex. In line with expert biological knowledge and heuristics, a new bio-inspired appearance model is proposed which simulates multi-cue selective (classical simple cells, S1 units) and multi-variant competitive (cortical complex cells, C1 units) mechanism in shallow neurons to target representation, and achieves an appropriate trade-off between discrimination and invariance. A two-layer bio-inspired tracking model proposed for advanced learning combines the generative and discriminative model: the response of view-tuned learning (S2 units) is a generative model via convolution and a fully connected classifier simulates neuronal network for task-turned learning (C2 units) as a discriminative model. BIT exploits fast Gabor approximation (FGA) to speed up low-level bio-inspired feature extraction (S1 units and C1 units) and fast Fourier transform (FFT) to speed up high-level bio-inspired learning and dense sampling (S2 units and C2 units).
To evaluate the proposed BIT in terms of tracking accuracy, robustness, and efficiency, we conduct extensive experiments on the CVPR2013 tracking benchmark (TB2013) [31] and the Amsterdam Library of Ordinary Videos (ALOV300++) database [32]. Experimental results show that BIT outperforms existing top-performing algorithms in terms of accuracy and robustness. Moreover, BIT enhances speed via fast Gabor approximation and fast Fourier transform. It processes approximately 45 frames per second for object tracking on a computer equipped with Intel i7 3770 CPU (3.4GHz) and is therefore suitable for most real-time applications.
The remainder of this paper is organized as follows. In Section II, we review the research works related to bio-inspired models and the tracking methods based on bio-inspired models. In Section III, we introduce the proposed biologically inspired tracker (BIT) and discuss both the appearance model and the tracking model in detail. Section IV gives the experimental results on both the qualitative and quantitative analysis, including the comparison with other methods and an analysis of each part of our method. We conclude our paper in Section V.
II Related Work
Humans and primates outperform the best machine vision systems on all vision tasks with regard to most measures, and thus it is critical yet attractive to emulate object tracking in the visual cortex. Understanding how the visual cortex recognizes objects is a critical question for neuroscience. A recent theory [33] on the feed-forward path of visual processing in the cortex is based on the ventral stream processing from the primary visual cortex (V1) to the prefrontal cortex (PFC), which is modeled as a hierarchy of increasingly sophisticated representations. In the ventral stream, a bio-inspired model called HMAX [34] has been successfully applied to machine vision and consists of alternating computational units called simple (S) and complex (C) cell units. In the primary visual cortex, the simple units combine intensity inputs with a bell-shaped tuning function to increase scale and direction selectivity. The complex units pool their inputs through a pooling operation (e.g. MAX, AVG or STD), thereby introducing gradual invariance to scale and translation. In the inferotemporal (IT) cortex (the so-called view-tuned units), samples of features were suggested that were highly selective for particular objects while being invariant to ranges of scales and positions. Note that a network comprised of units from the IT cortex to PFC is among the most powerful in terms of learning to generalize, which is equivalent to regularizing a classifier on its outputs tuning function.
Deep neural networks as a bio-inspired model can self-learn features from raw data without resorting to manual tweaking, and have achieved state-of-the-art results in several complicated tasks, such as image classification [35], object recognition and segmentation [36]. However, considerably less attention has been given to applying deep networks for visual tracking, because only the target state in the first frame is available to train deep networks. Fan et al. [37] proposed a human tracking algorithm that learns a specific feature extractor with convolutional neural networks from an offline training set of 20000 samples. In [38], Wang and Yeung proposed a deep learning tracking method that uses a stacked de-noising auto-encoder to learn the generic features from 1 million images sampled from the Tiny Images dataset [39]. Both methods pay particular attention to the offline learning of an effective feature extractor with a large amount of auxiliary data, yet they do not fully take into account the similarities in local structural and inner geometric layout information between the targets over subsequent frames, which is useful and effective for distinguishing the target from the background for visual tracking. In addition, the above tracking methods based on deep networks cannot guarantee real-time performance because multilayer operations take intensive computation.
In the ventral stream, an HMAX model [34] proposed for object recognition and scene classification has proven to be effective. However, the original bio-inspired model is designed for classification problems and is therefore difficult to apply straightforwardly to object tracking. In [40], A bio-inspired tracker called discriminant saliency tracker (DST) uses a feature-based attention mechanism and a target-tuned top-down discriminant saliency detector for tracking, which does not explicitly retain appearance models in the previous frames resulting in invalidation in the challenges of occlusion or background cluster. Zheng et al. [41] presented an object tracking algorithm by using a bio-inspired population-based search algorithm, called particle swarm optimization (PSO). PSO introduces the cognitive mechanism of birds and fishes to accelerate the convergence in the potential solution space, so that the optimal solution can be found in a short time. However, PSO only focuses on the tracking model and loses sight of the importance of features. Li et al. [42] proposed a simplified biologically inspired feature (SBIF) for object representation and combined SBIF with a Bayesian state inference tracking framework which utilized the particle filter to propagate sample distributions over time. The SBIF tracker extracts a robust representation feature, but ignores the advanced learning mechanism in the ventral stream and applies the time-consuming particle filter as the tracking model. In [43], a simple convolutional network encodes the local structural information of the tracking object using a set of normalized patches as filters, which are randomly extracted from the target region in the first frame. All the convolution maps are extracted from raw intensity images, therefore no importance is attached to the low-level bio-inspired feature. In this paper, a novel visual tracker based on a bio-inspired model is developed to improve the aforementioned shortcomings.
III Biologically Inspired Tracker
BIT is an HMAX model [34] that partially mimics the ventral stream. It is particularly designed for visual tracking, and can be divided into two main components: a bio-inspired appearance model and a bio-inspired tracking model (as shown in Fig. 1). The bio-inspired appearance model is subdivided into classical simple cells (S1 units) and cortical complex cells (C1 units); the bio-inspired tracking model is divided into view-tuned learning (S2 units) and task-dependent learning (C2 units). In addition, FGA and FFT are exploited to significantly save computations.
III-A Bio-inspired Appearance Model
Appearance representation plays an important role in a vision system, and we present a bio-inspired appearance model. In line with bioresearch on the striate cortex and extrastriate cortex, classical simple cells (S1 units) show that a variety of selective and cortical complex cells (C1 units) maintain feature invariance. The proposed bio-inspired appearance model achieves the unification of invariance and discrimination between different tracking targets by a hierarchical model.
III-A1 S1 units – classical simple cells
In the primary visual cortex (V1) [44], a simple cell receptive field has the basic characteristics of multi-orientation, multi-scale and multi-frequency selection. S1 units can be described by a series of Gabor filters [45], which have been shown to provide an appropriate model of cortical simple cell receptive fields. In contrast to the traditional bio-inspired feature of the HMAX model, which uses single even Gabor filters (contrast insensitive), we consider that odd Gabor filters (contrast sensitive) are also important for target representation, because they can extract not only the texture intensity but also the texture gradient direction. The odd and even Gabor functions have been shown to provide a good model of cortical simple cell receptive fields and are defined by
[TABLE]
where , , the filter patch coordinate , the orientation , scales with 2 parameters (the effective width and the wavelength ). Following [45], we arranged a series of Gabor filters to form a pyramid of scales, spanning a range of sizes from to pixels in steps of two pixels to model the receipt-field of the simple cells (parameter values of Gabor filters shown in Table I are the standard setting in bio-inspired model). The filters come in 4 orientations () on even Gabor filters and 8 orientations () on odd Gabor filters, thus leading to 60 different S1 receptive field types in total. The corresponding result of classical simple cells is given by
[TABLE]
where is the original gray-scale image of tracking sequences.
In scene classification [46] and saliency detection [47], the joint color and texture information is shown to be important. To effectively represent a color target, we unify S1 units with both the color and texture information. The color units are inspired by the color double-opponent system in the cortex [48]. Neurons are fired by a color (e.g., blue) and inhibited by another color (e.g., yellow) in the center of the receptive field, as are neurons in the surrounding area. Color names (CN) [49] are employed to describe objects, and these are linguistic color labels assigned by humans to represent colors in the real world. There are 11 basic colors: black, brown, green, pink, red, yellow, blue, grey, orange, purple and white. However, the use of RGB color in computer vision can usually be mapped to a probabilistic 11 dimensional color attributes by the mapping matrix, which is automatically learned from images retrieved by Google Images search. Color name probabilities are defined by
[TABLE]
where , , correspond to the RGB color values of images, is the index of color names, and indicates a mapping matrix from RGB to 11 dimensional color probabilities. In order to keep the same feature dimension as in one scale, is set to 0 and is set to 0 for gray image.
In this paper, a color target is represented by 60 feature maps of complex number, of which 60 texture feature maps are obtained from multi-scale Gabor filters convoluted with the input image as the real part, and 12 color feature maps are copied five times corresponding to 5 scales as the imaginary part. Combining the texture feature with the color feature through the real and imaginary parts, complex feature maps maintain the balance between different types of features and take full advantage of the complex frequency signal information of FFT to reduce the computation operations by almost half.
III-A2 C1 units – cortical complex cells
The cortical complex cells (V2) receive the response from simple cells and have the function of primary linear feature integration. C1 units [50] correspond to complex cells, which show the invariance to have larger receptive fields (shift invariance). Ilan et al. [51] suggested that the spatial integration properties of complex cells can be described by a series of pooling operations. Riesenhuber and Poggio [33] argued for and demonstrated the advantages of using the nonlinear MAX operator over the linear summation operation SUM, and Guo et al. [52] proposed another nonlinear operation called standard deviation STD for human age estimation. In this paper, a different pooling method is used for shift competing on each different feature map.
In order to keep C1 unit features what are changes in bias, invariance to gain can be achieved via local normalization. In [52], the STD operation has been shown to outperform pure MAX pooling for revealing the local variations that might be significant for characterizing subtlety. Dalal and Triggs [53] used four different normalization factors for the histograms of oriented gradients. Based on [53, 52], an enhanced STD operation in a cell grid of size is shown as (4), where is a normalization factor and is the shift bias.
[TABLE]
[TABLE]
In addition, the mapping of the S1 color units from the RGB image by point-to-point is sensitive to noise, therefore an AVG pooling operation is used for color features. The C1 color unit responses are computed by subsampling these maps using a cell grid of size as C1 texture units. From each grid cell, a single measurement is obtained by taking the mean of all 16 elements. In summary, response is
[TABLE]
III-B Bio-inspired Tracking Model
The tracking model is developed to verify any object state prediction, which can be either generative or discriminative. Based on the learning mechanism of advanced neurons, the IT cortex and PFC are explored to design bio-inspired tracking model. In this paper, a tracking method based on an advanced learning mechanism is presented to combine generative and discriminative models, corresponding to the view-tuned learning (S2 units) and the task-dependent learning (C2 units).
III-B1 S2 units – view-tuned learning
The tuning properties of neurons in the ventral stream of the visual cortex, from V2 to the IT cortex, play a key role in visual perception in primates, and in particular for object recognition abilities [54]. This training process can be regarded as a generative model, in which S2 units pool over afferent C1 units within its receptive field. Each S2 unit response depends on a radial basis function (RBF) [45] on the Euclidean distance between a new input and a stored prototype . For an image patch from the previous C1 layer, the response of the corresponding to S2 units is given by:
[TABLE]
where defines the sharpness of the tuning coefficient. At runtime, S2 response maps are computed across all positions by (7) for each band of C2 units.
According to (7), we know the S2 units response corresponds to a kernel method based on RBF, which can be rewritten similarly to the linear function as follows (8), when the RBF is a standard normal function ().
[TABLE]
Here and as self-correlation coefficient almost keep changeless nearly constant with marginal effects on S2 units, and roughly locates in the linear region of exponential function. Moreover, linear kernel is usually preferred in time-critical problems such as tracking, because the weight vector can be computed explicitly. Therefore, the S2 units dense response map was calculated using a linear function instead of RBF. The C1 units response of new input is expressed as and the response of stored prototype is , where is the index of 60 feature maps corresponding to 12 orientations and 5 scales. To achieve scale and orientation invariance, an AVG pooling operation is used for the fusion of multi-feature maps:
[TABLE]
III-B2 C2 units – task-dependent learning
The task-specific circuits from the IT cortex to the PFC learn the discrimination between target objects and background clusters. According to bioresearch [54], the routine running in PFC as a classifier is trained on a particular task in a supervised way and receives the activity of a few hundred neurons in the IT cortex. The classifier can indeed read-out the object identity and object information (such as position and size of the object) from the activity of about 100 neurons in the IT cortex with high accuracy and in an extremely short time. Supervised learning at this stage involves adjusting the synaptic weights to minimize error in the training set. In this paper, a convolutional neural network (CNN) is used as (10), which corresponds to the task-specific circuits found in C2 units with neurons from the IT cortex to the PFC.
[TABLE]
where is the synaptic weights of the neural network. In addition, a fast estimate method of will be introduced in the next subsection III-C.
III-C Real-time bio-inspired tracker
Due to the time-sensitive nature of tracking, modern trackers walk a fine line between incorporating as many samples as possible and keeping computational demand low. A practical visual tracker should reach a speed of at least 24 frames per second (the standard frame rate of films). Past visual trackers based on bio-inspired models are unable to maintain real-time because of complex neuron simulation, such as SBIF tracker [42] and discriminant saliency tracker [40]. In this paper, an FGA and an FFT are applied to speed up the hierarchical bio-inspired model.
III-C1 Fast Gabor Approximation (FGA)
To retain the invariance of bio-inspired feature, a series of multi-scale and multi-orientation Gabor filters is used for convolution with gray images. Therefore, a 60 times convolution operation seriously affects the instantaneity of the BIT framework. In this paper, we propose FGA to reduce the computational cost, which is inspired by histograms of oriented gradients (HOG)[53]. HOG uses horizontal and vertical gradients to approximate the gradient intensity in each orientation. Using several pairs of 1-D Gabor filters ( and ), which are at 5 different scales and orthogonal to each other as in Section III-A1, 10 multi-scale orthogonal Gabor response maps at a pixel are computed as
[TABLE]
Let and be the orientation and magnitude of the Gabor gradient at a pixel in an image showing as (12), by which the response of the multi-orientation S1 units is approximated.
[TABLE]
We define a pixel-level feature map that specifies a sparse response of Gabor magnitudes at each pixel to approximate multi-orientation in the S1 units. When belongs to the range of corresponding orientations, the magnitude is set as the approximate response of S1 units as
[TABLE]
[TABLE]
III-C2 Fast Fourier Transform (FFT)
Many tracking approaches [55, 12, 18] have featured tracking-by-detection, which stems directly from the development of discriminative methods in machine learning. Almost all of the proposed tracking-by-detection methods are based on a sparse sampling strategy. In each frame, a small number of samples are collected in the target neighborhood by particle filter, because the cost of not doing so would be prohibitive. Therefore, speeding up the dense sampling of the S2 and C2 response calculation is a key feature of BIT. In this subsection, a real-time BIT based on dense sampling via FFT [56] will be introduced. At time , a S2 units dense response map was calculated by a linear function instead of RBF as
[TABLE]
According to dot-product in frequency-domain equivalent to convolution in time-domain [57], we note that (15) can be transformed to the frequency domain, in which FFT can be used for fast convolution. That is,
[TABLE]
where denotes the FFT function and is the elementwise dot-product.
As with S2 units, the FFT algorithm can also be used for fast convolution and deconvolution in C2 units. Note that the convolutional neural network is comprised of units with Gaussian-like tuning function together on their outputs. In order to estimate the neuronal connection weights W, the C2 units response map of an object location is modeled as
[TABLE]
where is a scale parameter and is the center of the tracking target. The neuron connection weights is therefore shown as
[TABLE]
The object location in the ()-th frame is determined by maximizing the new C2 response map.
[TABLE]
where and denotes the inverse FFT function.
Depending on the spatial and frequency domains, a classical method of tracking model update is used in this paper. At the -th frame, the BIT is updated by
[TABLE]
where is a learning parameter, is the C1 units spatial model and is the frequency model of neural weights computed by (18).
Based on FGA and FFT, the proposed real-time bio-inspired tracker is summarized in Algorithm 1.
IV Experiments
We evaluate our method on two popularly used visual tracking benchmarks, namely the CVPR2013 Visual Tracker Benchmark (TB2013) [31] and the Amsterdam Library of Ordinary Videos Benchmark (ALOV300++) [32]. These two benchmarks contain more than 350 sequences and cover almost all challenging scenarios such as scale change, illumination change, occlusion, cluttered background, and/or motion blur. Furthermore, these two benchmarks evaluate tracking algorithms with different measures and criteria, which can be used to analyze the tracker from different views.
We use the same parameter values of BIT on the two benchmarks. Parameters of the bio-inspired appearance model are given in Table I. Tracking model parameters mentioned in Sec. III-B are specified as follows: the learning rate is set to 0.02, and the scale parameter of is set to 0.1 or 0.08 according to the C2 response in the first five frames. (When the average trend is ascending, is set to 0.1 or is set to 0.08 otherwise). The proposed tracker is implemented in MATLAB 2014A on a PC with Intel i7 3770 CPU (3.4GHz), and runs more than 45 frames per second (fps) on this platform.
IV-A Comparison of results on the CVPR2013 benchmark
The CVPR2013 Visual Tracker Benchmark (TB2013) [31] contains 50 fully annotated sequences, as shown in Fig. 2. These sequences include many popular sequences used in the online tracking literature over the past several years. For better evaluation and analysis of the strength and weakness of tracking approaches, these sequences are annotated with 11 attributes: illumination variation (IV), scale variation (SV), occlusion (OCC), deformation (DEF), motion blur (MB), fast motion (FM), in-plane rotation (IPR), out-of-plane rotation (OPR), out-of-view (OV), background clutter (BC), and low resolution (LR). In this paper, we compare our method with 11 representative tracking methods. Among the competitors, RPT [58], TGPR [59], ICF [60] and KCF [3] are the most recent state-of-the-art visual trackers; Struck [23], SCM [12], TLD [55], VTS [61] are the top four methods as reported in the benchmark; IVT [9] and MIL [25] are classical tracking methods which are used as comparison baselines.
The best way to evaluate trackers is still a debatable subject. Averaged measures like mean center location error or average bounding box overlap penalize an accurate tracker that briefly fails more than they penalize an inaccurate tracker. According to [31], the evaluation for the robustness of trackers is based on two different metrics: the precision plot and success plot. The precision plot shows the percentage of frames on which the Center Location Error (CLE) of a tracker is within a given threshold , where CLE is defined as the center distance between the tracker output and the ground truth. The success plot also counts the percentage of successfully tracked frames by measuring the Intersection Over Union (IOU) metrics on each frame, and the ranking of trackers is based on the Area Under Curve (AUC) score. Following the setting in [31], we conduct the experiment using the one-pass evaluation (OPE) strategy for a better comparison with the latest methods.
Fig. 3 shows the qualitative comparison with selected trackers over all 50 sequences on the TB2013. BIT mainly focuses on the position of the bounding box and ensures the scale robustness by multi-scale filters in S1 units, resulting in the lack of size adjustment of the bounding box. The AUC score is sensitive to bounding box size. In the success plot, a scale estimation method [62] is only used to estimate bounding box size, not to aid target location and model updating. However, many trackers (eg. TGPR [59], KCF [3], Struck [23]) are the lack of size adjustment of the bounding box, so the precision plot is emphatically analyzed. According to the precision plot ranked by a representative precision score (), our method achieves better average performance than other trackers. The performance gap between our method and the reported best result in the literature is 0.6% for the tracking precision measure; our method achieves 81.7% accuracy while the best state-of-the-art is 81.1% (RPT [58]). Moreover the BIT significantly outperforms the best tracker in the benchmark [31] by 15.4% (Struck [23]) in mean CLE at the threshold of 20 pixels. The results for all the trackers and all the video sequences are given in Table II. Our biologically inspired tracker ranks as the best method 23 times. The equivalent number of best place rankings for RPT, TGPR, ICF and KCF are 23, 11, 20 and 15 respectively. Another observation from Table II is that the BIT rarely performs inaccurately; there are only eight occasions when the proposed tracker performs significantly worse than the best method (no less than 80% of the highest score for one sequence).
Table III and Fig. 4 show the performance plots for 11 kinds of challenge in visual tracking, i.e., fast-motion, background-clutter, motion-blur, deformation, illumination-variation, in-plane-rotation, low-resolution, occlusion, out-of-plane-rotation, out-of-view and scale-variation. Clearly, the BIT almost achieved excellent performances in 11 typical challenge subsets, especially on IV, SV, OCC, DEF, IPR, OPR, and OV. Multi-direction Gabor filters used in S1 units contribute to the robustness of illumination (IV) and rotation (IPR and OPR). Pooling operations in C1 and S2 units provide the shift and scale competitive mechanism to deal with deformation (DEF) and scale variation (SV). Moreover, the generative model in S2 units and the discriminative model in C2 units rise to the challenges of OCC and OV respectively. However, the STD pooling operation in C1 units achieves the shift invariance and at the same time weakens the appearance ability to low resolution (LR) targets.
IV-B Comparison of results on ALOV300++
To further validate the robustness of the BIT, we conduct the second evaluation on a larger dataset [32], namely the Amsterdam Library of Ordinary Videos (ALOV300++), which was recently developed by Smeulders et al.. It consists of 14 challenge subsets, with 315 sequences in total, and focuses on systematically and experimentally evaluating the robustness of trackers in a large variety of situations including light changes, low contrast, occlusion, etc. In [32], survival curves based on F-score were proposed to evaluate each tracker’s robustness and demonstrate its effectiveness. To obtain the survival curve of a tracker, a F-score for each video is computed , where , , and , , respectively denote the number of true positives, false positives and false negatives in a video. A reasonable choice for the overlap of target and object is the PASCAL criterion [63]: , where denotes the tracked bounding box in frame , and denotes the ground truth bounding box in frame . A survival curve shows the performance of a tracker on all videos in the dataset. The videos are sorted according to the F-score, and the graph gives a bird’s eye view of the cumulative rendition of the quality of the tracker on the whole dataset.
To evaluate the BIT on the ALOV300++ dataset [32], we ran the BIT on all 315 sequences using the ground truth of the first frame as the initialization and the same parameters as the previous evaluation. Because the F-score is also sensitive to bounding box size, DSST [62] is only used to estimate bounding box size same as the success plot in Section IV-A. We compare our tracker with the top four popular trackers (Struck [23], VTS [61], FBT [64], TLD [55]) which were evaluated in [32]. In addition, we also run ICF [60], DSST[62], KCF [3] and TGPR [59] on ALOV300++, which are recognized as the state-of-art trackers in the previous evaluation, and two classical trackers (IVT [9] and MIL [25]) are used as comparison baselines. The survival curves of the ten trackers and the average F-scores over all sequences are shown in Figure 5, which demonstrates that the BIT achieves the best overall performance compared to the 10 trackers in this comparison. From the figure, we can see that the proposed tracker outperforms ICF [60] by 0.008 in mean F-score and the survival rate () of the BIT is 59.36% compared to the second best tracker 55.87% - a difference of 3.49%.
IV-C Tracking model analysis
According to the introduction, tracking model can be generative or discriminative. For generative models, tracker searches for the most similar region to the target object within a neighborhood. For discriminative models, tracker is a classifier to distinguish the target object from the background. However, generative models ignore negative samples in the background and discriminative models pay insufficient attention to the eigen basis of the tracking target. In this paper, BIT proposed for advanced learning combines the generative and discriminative model: the response of view-tuned learning (S2 units) is a generative model and a fully-connected network classifier simulates for task-turned learning (C2 units) as a discriminative model. In order to prove the effect of hybrid-model, we compare the tracking scores between BIT without C2 units, BIT without S2 units and intact BIT on the TB2013 showed in Fig. 6. For the generative model only (without C2 units), the object location is determined by maximizing the S2 response map as . For the discriminative model only (without S2 units), the convolutional neural network in C2 units receives the activity from C1 units directly as . Clearly, the hybrid-model (81.7%) achieved excellent performances in comparison to single-model (74.9% and 51.7%). In addition, the performance gap between the discriminative model and the generative model in the literature is 23.2% for the tracking precision measure. Because background information is critical for effective tracking, which can be exploited by using advanced learning techniques to encode the background information in the discriminative model implicitly or serving as the tracking context explicitly.
IV-D Tracking speed analysis
The experiments were run on a PC with Intel i7 3770 CPU (3.4GHz), and we report the average speed (in fps) of the proposed BIT method in Table IV and compare it with the state-of-the-art visual trackers referred to in Sec. IV-A. In this paper, the average speed score is defined as the average fps over all the sequences, which objectively evaluates sequences where the initialization process usually dominates the computational burden. According to the standard frame rate of films, we consider that a processing speed of more than 24 fps is equivalent to real-time processing.
Table IV and Fig.7 show the tracking speed and the tracking scores on the TB2013 [31]. According to the table, our method tracks the object at an average speed of 45fps, which is significantly faster than the second best tracker RPT (4.1 fps). Furthermore, the speed of our proposed BIT is close to twice that of the real-time criterion, which leaves a substantial amount of time in which to increase modified strategies to further improve tracking performance.
V Conclusion
In this paper, we successfully applied a bio-inspired model to real-time visual tracking. To the best of our knowledge, this is the first time this has been achieved. Inspired by bioresearch, the proposed novel bio-inspired tracker models the ventral stream of the primate visual cortex, extracting low-level bio-inspired features in S1 and C1 units, and simulating high-level learning mechanisms in S2 and C2 units. Furthermore, the complicated bio-inspired tracker operates in real-time since fast Gabor approximation (FGA) and fast Fourier transform (FFT) are used for online learning and detection. Numerous experiments with state-of-the-art algorithms on challenging sequences demonstrate that the BIT achieves favorable results in terms of robustness and speed.
The human visual system is a complex neural network which is multi-layered and multi-synaptic, and the BIT pays little attention to a number of visual cognitive mechanisms. A well-known multi-store memory model (which includes sensory memory, short-term memory, and long-term memory) is proposed by Atkinson and Shiffrin [65], which provides some ideas for tracking-by-detection to improve out-of-view and long-term challenges. Moreover, a multi-stored prototype [34] is used for object recognition in S2 units, which has proved to be effective for local occlusion and partial deformation. In addition, C2 units using a single layer convolutional network cannot perfectly simulate neuron connections in PFC, which provides a good starting platform for further research into multi-layer neural networks.
Acknowledgment
This work is supported by the National Natural Science Foundation of China (#61171142, #61401163), the Science and technology Planning Project of Guangdong Province of China (#2011A010801005, #2012B061700102, #2014B010111003, #2014B010111006) and Australian Research Council Projects (FT-130101457 and DP-140102164).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K. Cannons, “A review of visual tracking,” Dept. Comput. Sci. Eng., York Univ., Toronto, Canada, Tech. Rep. CSE-2008-07 , 2008.
- 2[2] D. Comaniciu, V. Ramesh, and P. Meer, “Kernel-based object tracking,” Pattern Analysis and Machine Intelligence , vol. 25, no. 5, pp. 564–577, 2003.
- 3[3] J. F. Henriques, R. Caseiro, P. Martins, and J. Batista, “High-speed tracking with kernelized correlation filters,” Pattern Analysis and Machine Intelligence , vol. 37, no. 3, pp. 583–596, 2015.
- 4[4] L. Sevilla-Lara and E. Learned-Miller, “Distribution fields for tracking,” in Computer Vision and Pattern Recognition . IEEE, 2012, pp. 1910–1917.
- 5[5] T. B. Dinh, N. Vo, and G. Medioni, “Context tracker: Exploring supporters and distracters in unconstrained environments,” in Computer Vision and Pattern Recognition . IEEE, 2011, pp. 1177–1184.
- 6[6] H. Zhou, Y. Yuan, and C. Shi, “Object tracking using sift features and mean shift,” Computer vision and image understanding , vol. 113, no. 3, pp. 345–352, 2009.
- 7[7] K. Zhang, L. Zhang, and M.-H. Yang, “Real-time compressive tracking,” in Computer Vision–ECCV . Springer, 2012, pp. 864–877.
- 8[8] R. Raina, A. Battle, H. Lee, B. Packer, and A. Y. Ng, “Self-taught learning: transfer learning from unlabeled data,” in Proceedings of the 24th international conference on Machine learning . ACM, 2007, pp. 759–766.
