Learning relevant features for statistical inference
C\'edric B\'eny

TL;DR
This paper introduces a method to identify features most inferable from another data view using deep canonical correlation analysis, enabling joint distribution estimation and improved supervised learning.
Contribution
The paper demonstrates that features with high correlation in DCCA are optimal for inference and introduces a non-parametric joint distribution representation for various inference tasks.
Findings
Effective inference on occluded MNIST images.
Representation captures multiple modes of data.
Automatic regularization and faster convergence in supervised learning.
Abstract
Given two views of data, we consider the problem of finding the features of one view which can be most faithfully inferred from the other. We find that these are also the most correlated variables in the sense of deep canonical correlation analysis (DCCA). Moreover, we show that these variables can be used to construct a non-parametric representation of the implied joint probability distribution, which can be thought of as a classical version of the Schmidt decomposition of quantum states. This representation can be used to compute the expectations of functions over one view of data conditioned on the other, such as Bayesian estimators and their standard deviations. We test the approach using inference on occluded MNIST images, and show that our representation contains multiple modes. Surprisingly, when applied to supervised learning (one dataset consists of labels), this approach…
Click any figure to enlarge with its caption.
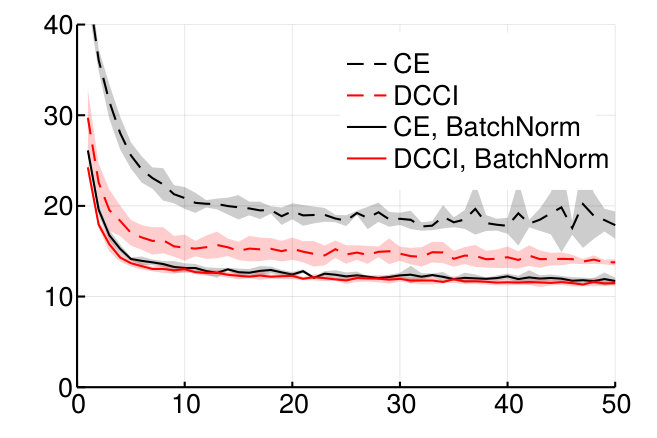 Figure 1
Figure 1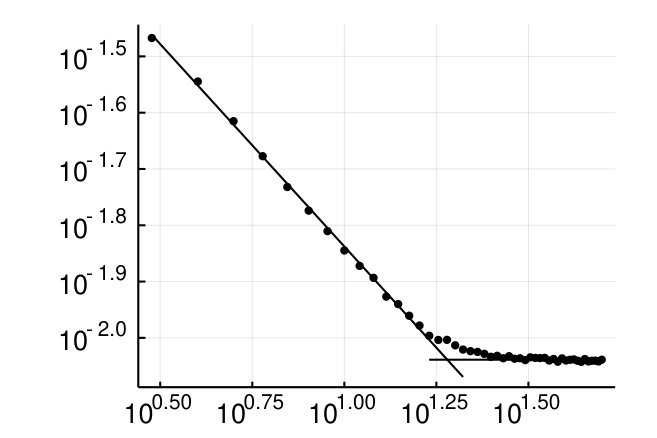 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6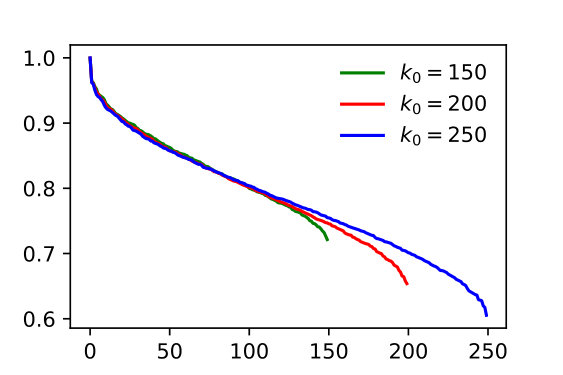 Figure 7
Figure 7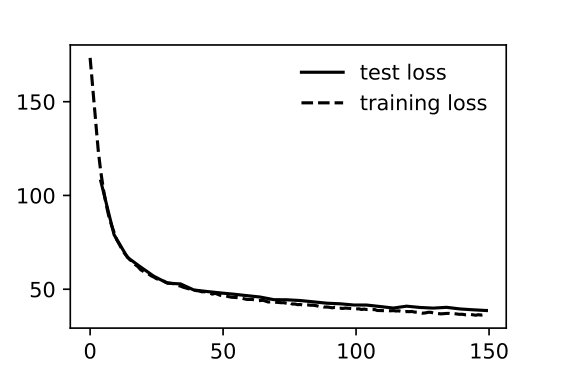 Figure 8
Figure 8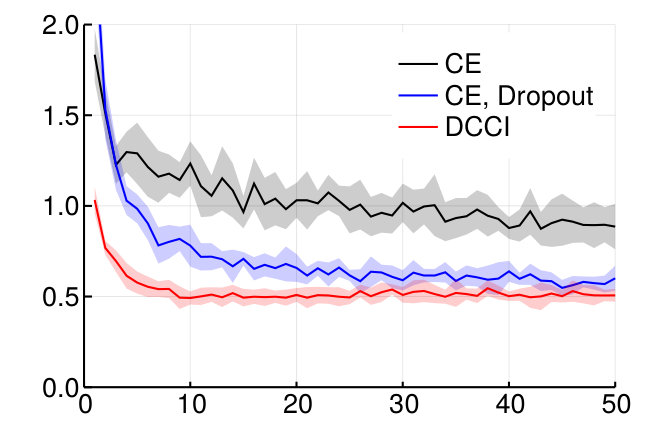 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Mechanics and Entropy · Gaussian Processes and Bayesian Inference · Generative Adversarial Networks and Image Synthesis
Learning relevant features for statistical inference
Cédric Bény
(January 15, 2020)
Abstract
Given two views of data, we consider the problem of finding the features of one view which can be most faithfully inferred from the other. We find that these are also the most correlated variables in the sense of deep canonical correlation analysis (DCCA). Moreover, we show that these variables can be used to construct a non-parametric representation of the implied joint probability distribution, which can be thought of as a classical version of the Schmidt decomposition of quantum states. This representation can be used to compute the expectations of functions over one view of data conditioned on the other, such as Bayesian estimators and their standard deviations. We test the approach using inference on occluded MNIST images, and show that our representation contains multiple modes. Surprisingly, when applied to supervised learning (one dataset consists of labels), this approach automatically provides regularization and faster convergence compared to the cross-entropy objective. We also explore using this approach to discover salient independent variables of a single dataset.
1 Introduction
Given samples from an unknown joint probability distribution , we want to construct a useful representation of the conditional probabilities and , so that we that we can infer one view from the other on new data.
For instance, and could be past and future histories of dynamical data, visual and auditory inputs, actions and their effects, etc.
Following the approach introduced in [1, 2] in the context of quantum information theory, we look at the problem as follows: the conditional distributions can be thought of as representing a noisy communication channel (stochastic map). This channel is a linear map between spaces of typically ludicrously large dimensions (the spaces of all probability distributions over or ). We want a pair of small subspaces on which the channel is minimally noisy. Specifically, we look for those vectors representing probability distributions over which lose least distinguishability under the channel, where the distinguishability is measured by the divergence.
We show in Section 3 that this is equivalent to performing a singular value decomposition of the channel (seen as an operator in Hilbert space) and keep only the components with the largest singular values. Moreover, the full singular value decomposition is equivalent to the decomposition in terms of canonical variables introduced in [3], namely,
[TABLE]
where and are real non-linear functions such that , , and are the singular values.
This can also be interpreted as a classical version of the Schmidt decomposition for pure quantum states, where the Fisher information metric plays the role of the Hilbert space inner product (Section 3).
The practical advantage of this representation for inference (or prediction) is that it reduces the evaluation of conditional expectations to that of empirical averages over the (unconditional) marginal .
As observed in [4], the span of the first canonical variables , is what is learned by the deep canonical correlation analysis (DCCA) [5]. Indeed, these variables are those which maximize the correlations subject to the same constraints as above. (This reduces to CCA [6] when , are linear maps).
In this work, besides establishing this new information-theoretical interpretation of canonical variables and DCCA, we experiment with using this representation for performing inference on new data. Moreover, we propose a strategy for extracting disentangled variables from the canonical variables, inspired by analytical solutions.
2 Related work
This general problem (of building an effective representation of the conditional probability distributions implied by joint samples) covers many existing approaches in different contexts. For instance, if the variables has few possible states, then it reduces to a classification problem, usually solved by minimizing the crossentropy between a predicted distribution and the one-hot encoding of the classes.
When has a large number of states, or is fundamentally continuous, existing approaches usually do not model the whole conditional distribution, but either provide the average (regression), or approximately sample from it.
The main class of methods which allows for sampling from the conditional distributions are variational: a deterministic neural networks produces the parameters of analytical classes of probabilities. This includes variational autoencoders [7] (e.g., [8, 9]), and approaches based on the minimum description length principle such as [10].
Alternatively, it may also be possible to use adversarial training [11], by using a conditional [12] version of an energy-based GAN [13].
By contrast, our approach doesn’t require the training of a generative model. Instead, conditional expectations are constructed as linear combinations of unconditional empirical averages over the training data.
The information-theoretical approach that we propose is very close to that introduced in [14], and further developed in [15] in the context of classical information theory. The authors consider the problem of sending information through a channel with an infinitesimal bound on the mutual information of the encoding operation. This leads to the same singular value problem.
Other approaches to equipping CCA or DCCA with an information-theoretic interpretation have explored different directions. For instance, in [9], the authors generalize a probabilistic interpretation for CCA in terms of gaussian distributions, which leads to a variational approach. In [16], additional constraints on the mutual information between the data and the learned variables are added to the optimizations.
A previous attempt at designing a numerical solution for our singular value problem can be found in [17]. In that work, the relevant variables were represented through a PCA kernel produced by Monte Carlo sampling, but wasn’t practical.
3 Theory
We formalize the problem by assuming that our data was sampled from an unknown joint distribution over two random variables and .
Let and denote the linear spaces spanned by all probability distributions over and respectively. Here we assume that and take finitely many values for simplicity, but this formalism can be straightforwardly extended to infinite-dimensional vector spaces.
We will need inner products on and , to make them into real Hilbert spaces. We use the Fisher information metrics evaluated at the points and respectively (marginals of ), that is,
[TABLE]
for any vectors and .
Below we also call the marginals and respectively when omitting their arguments ( and ).
These inner products allow us to define the divergence:
[TABLE]
which a measures of statistical distinguishability between and . Specifically, it quantifies how easy it is to reject the null hypothesis that the state is when it is actually , based on the empirical distribution obtained from independent samples. It is also the lowest order approximation of the Kullback-Leibler divergence.
The joint distribution yields conditional distributions and . These can be understood as the components (or kernels) of stochastic maps and respectively. Explicitely, if and , then the images and are defined by
[TABLE]
These stochastic maps and perform inference of one variable given some (possibly imperfect) knowledge about the other, with priors given by the marginals or of depending on the direction of the inference. Importantly, is the transpose of in terms of the inner products defined above:
[TABLE]
We now have the tools to address the problem mentioned in the introduction. The distinguishability between and after the action of the channel is since . Hence we want to find the distributions which maximize the relevance [1].
[TABLE]
where . The inner-product formulation makes it clear that this amounts to finding the eigenvector with largest eigenvalue for the symmetric map , which is also the singular vector with largest singular value for . On can then go on to find the eigenvector with next largest eigenvalue and so on, which are automatically orthogonal.
In practice, the inner products are more tractable to compute if we express elements and in terms of variables and as and , or
[TABLE]
for all . Indeed, this yields simply
[TABLE]
We are now in measure to make the connection with DCCA [5]. Indeed, the aims of DCCA is to maximize the correlations over function and such that . But, using and , we have
[TABLE]
which is maximized by the left- and right- singular vectors and of with largest singular value.
Given all the singular vectors and with singular values , we obtain the representation
[TABLE]
which, using a more standard notation and the Kronecker delta , yields Eq. 1:
[TABLE]
where and .
3.1 Non-diagonal form and relevant variables
For the purpose of the optimization and inference, we do not need to full diagonal decomposition, but just functions and , , which have the same span as the canonical variables and respectively for (assuming that are the largest singular vector). Below we refer to and as the most relevant variables.
Because these functions may not be orthogonal, we need the covariance matrices
[TABLE]
If denote the components of in the sense that then, using our inner products to isolate , we obtain . Similarly, the components of are . This implies that the sum of the square of the singular values of restricted to the spans of the vectors and for all , which is what we want to maximize, is just given by
[TABLE]
This is the DCCA objective. Below we use the objective function , for the cosmetic reason that its optimal value is zero.
Moreover, the corresponding truncated representation of the conditional distribution is
[TABLE]
where we used the fact that the components of are .
Of course, This approach can produce a faithful representation of the correlations only if is actually close to being of rank (see Theorem 1 in Appendix B for a more precise statement). If we interpret the relevant subspace as a space of probability over latent variable, this means that our latent variables have at most discrete states.
However, even if the rank corner of is a not a good approximation, this strategy allows us to nevertheless do the correct inference on certain random variables, namely those which are in the span of the canonical variables!
Indeed, the exact conditional expectation of is (assuming is the actual rank of ),
[TABLE]
where the last truncation is exact if due to the assumption that the basis and have the same span as the largest right and left singular vectors of respectively.
For instance, if is Gaussian, the canonical variables can be computed analytically, as in [3] or [18] in the multivariate case. Solutions for other distributions were also computed in [19].
Notably, for any two dimensional Gaussian, the space of most relevant variables is simply spanned by the moments and for . Hence, in this case the first moments can be inferred exactly using only the most relevant variables (See Appendix C).
4 Algorithm
Let us explicit the algorithm resulting from the above analysis.
We assume that we are given independent samples from the otherwise unknown joint distribution .
We first perform DCCA [5]. That is, we need two independent deterministic feed-forward neural networks. The first maps to a set of real-valued variables . The second maps to a different set of variables .
The parameters of the neural networks are to be set to minimize the objective function
[TABLE]
where the matrices can be approximated over a mini-batch , via
[TABLE]
We found that, provided the batch size is sufficiently large compared to (about 10 times in our experience), this can be minimized using ADAM or direct gradient descent. However, to guarantee stability when using large , we needed to explicit the gradient of the objective function in order to force the use of the Moore-Penrose pseudo-inverses for and in both the forward and backward passes, in addition to using 64 bits floats in these computations.
Once the relevant variables have been learned, we still need to use the training data in a second step. Indeed, suppose that we wish to use our model to infer the value of some function , i.e., to compute its approximate expectation value in terms of the conditional distribution . Then we need to store, for each variable , the quantities
[TABLE]
where the average is to be taken on the full training batch (of size ). The same can be done exchanging with and with for the reverse inference.
For instance, if a data point is composed of real components —such as pixel color components for an image—and we are interested in the estimator which minimize the expected distance to the predicted values of these components, then we need the expectation values of the components for all , and possibly higher moments to gain more knowledge about the shape of the posterior distribution, such as the second moments , etc.
Inference can then be performed with new data using
[TABLE]
Moreover, the accuracy of these predictions does not depend on the rank if is taken in the span of the relevant variables, i.e., , for which .
The reverse inference formulas are obtained simply by the exchanges , , and .
5 Experiments
In all our experiments, we used the ADAM optimizer with learning rate . We used the Flux package [20] for Julia, as well as Tensorflow.
As usual the data is divided into a training set and a testing set. No aspect of the testing set is used during training. The loss function refers to Eq. (16). In order to monitor overfitting, we compute a “test loss” and a “training loss”. The test loss is computed from the trained variables using only the test data, and accordingly, the training loss is computed purely using the training data.
Moreover, when performing inference on test data using Eq. (21), we use the covariances and expectations (Equ. (20)) built from the training data only.
5.1 Inference on occluded MNIST
In this experiment, we use the left and right halves of the MNIST digit images as correlated variables and . The goal is to obtain the expected left halves given the right halves, or vice versa.
The training set was augmented by random small rotations and displacements to make the task more ambiguous, as we want to explore the uncertainty in the prediction.
The relevant variables were represented by two convolutional neural networks of identical architecture. They are composed of four convolutional layers and one fully connected layer, an architecture that performs well for supervised learning on this dataset. For ease of implementation, these CNN have the whole image as input, but with either half zeroed (same value as black pixels). Half-width CNNs with proper padding at the cut perform similarly.
After training, we used the training dataset to also compute the expected pixel gray value as well as their covariance for each relevant variable using Eq. (20).
These were used into Eq. (21) to compute the mean pixel gray values and their covariances over the conditional probability of given on test data. This mean is the Bayesian estimator for the distance between half images, i.e., it should minimize the expected distance over the conditional distribution, where where is the value of the ith pixel. (This is equivalent to minimizing the mean square error).
The results on a randomly selected subset of test digits is shown in Fig. 1. For each example, we also computed the images obtained by adding plus or minus one standard deviation along the direction of greatest variance in the space of relevant variables. This reveals the main ambiguities (such as between and or and which share a similar right half).
The graph of the singular values shows that the rank cutoff of is too low to capture all of the relevant variables (the sudden drop at the end is not robust to an increase in the cutoff), but the results are reasonable nevertheless. This shows that our representation of the conditional distributions contains valuable information besides the simple mean.
5.2 Supervised learning
In the context of a supervised classification task, one of the dataset (the labels) is of sufficiently low dimensionality that we can use a complete basis over its probability space as our relevant variables, such as the standard one-hot encoding of labels. This serves as a good first sanity test for our approach. Surprisingly, we find that it converges faster than standard approaches, and without the need for regularization.
Let the variable stands for the labels, with values in . The probability space consists of vectors with real components. The canonical basis corresponds to the one-hot encoding (Kronecker delta). All we need is a neural network to encode variables on . After learning the most relevant variables , we apply the reverse of Eq. (21) for function , and use the maximum component of expected value to infer the labels from the data.
Let us refer to this procedure as DCCI (Deep Canonical Correlations based Inference).
We tested this approach on the MNIST and CIFAR10 datasets, and compared the results to the standard cross-entropy objective (Fig. 2).
We plotted the accuracy as function of the epoch rather than clock time which would depend on many factors. But the time per epoch is roughly the same for each approaches in the above experiments. Indeed, the training time is dominated by the forward and backward evaluations of the neural networks which are identical. (However, the time it takes to evaluate our objective can become significant for much larger number of labels , since it involves the inversion of matrices of dimension . This is in addition to the fact that a greater dimension would require also larger batches.)
We found that, without regularization, simply changing the objective from cross-entropy to DCCI provided a large improvement both of convergence speed and final accuracy for both models.
On MNIST, DCCI alone also outperformed cross-entropy with dropout. (Dropout did not yield any improvement in conjunction with DCCI). However, adding batch-normalization layers on the CIFAR example, erased any distinction between DCCI and cross-entropy.
5.3 Structure of the relevant variables
We mentioned in Section 3 that if is a two-dimensional Gaussian distribution with zero mean, then the most relevant variables of are the first powers of itself, independently of the covariance matrix. This implies that the canonical variables are the Hermite polynomials in (which results from applying the Gram-Schmidt procedure to the basis ).
A similar property holds for multivariate Gaussians, namely, the less relevant singular values are polynomials in the more relevant ones. If this is true more generally, it should be possible to further compress and organize the latent space extracted with DCCA by finding a minimal set of generators, which ought to also be in the span of the most relevant variables.
We applied DCCA to a synthetic dataset to explore this idea, shown in Fig. 3. In this case, we actually performed a final SVD to obtain the unique uncorrelated canonical variables, and ordered them by decreasing relevance (their respective singular values).
Here, consists of two real numbers, distributed uniformly within a ring and a disk. The variable is obtained by adding a random Gaussian shift to with a small standard deviation. The more relevant variables ought to be those which are more robust to such small random displacement. This formalizes the idea that we are interested in extracting “large-scale” variables [17].
We would expect the relevant independent variables to be: the binary variable indicating whether the point is in the disk or the ring and the angle around the ring, followed by the radial component in the ring, and finally the Cartesian coordinates inside the disk. This is precisely what we see in Fig. 3.
Indeed—if we put aside for now the fact that the angle itself is not directly represented—besides the constant function, the two most relevant variables are the sine and cosine of the angle, followed by the binary variable separating the disk from the ring.
But these variables ought to span the space of probabilities over the relevant variables, not just the variables themselves. Hence the next six variables are sines and cosines of smaller wavelength, which can encode probability distributions which are increasingly more precisely localized, down to a precision (wavelength) comparable with the diameter of the inner disk. Accordingly, the next two most relevant variables are the Cartesian coordinates inside the disk. This is followed by additional moments of the angle, down to a wavelength equal to the ring’s thickness, at which point we see the radius in the ring appear.
As mentioned, we see that the angle itself is not represented, likely because it is discontinuous. However, as shown also in Fig. 3, creating a gap in the ring allows for the angle to emerge as most relevant variable. This suggests that this approach may be able to automatically learn intrinsic coordinates of the latent variable manifold.
5.4 Independent variables and generative model
If we postulate that the independent (or disentangled) relevant latent variables can be found in the linear span of the relevant variables, we can attempt to extract them by optimizing a neural network composed of two parts. Firstly, a linear layer maps the relevant variables to a small number of outputs (equal to the latent dimension). The purpose of this linear layer is to find the independent variables. These latent variables are then processed by an arbitrarily complex generative network to produce a possible value of the variable . As objective function, we may us an appropriate measure of similarity between the output and the data element from which the variables were obtained.
We tested this idea as follows. We took to consist of the MNIST digits, and produced by randomly permuting neighboring pixels in the image, until the mean displacement per pixel is of order . In addition, we added independent Gaussian noise to the pixel values. (Hence the noise map simulates the coarse-graining channel introduced in [21]).
As in the previous experiment, we do so to implement our intuition that the more relevant variables ought to be the ones which are of larger scale, or more robust to local perturbations.
The relevant variables of the clean images were produced by the same convolutional neural network as in Section 5.2, while the variables of the coarse-grained images were extracted by a network of the same geometry, but with half the number of filters and neurons.
We extracted the most relevant out of learned variables in this way. (The least relevant variables in this system happen to be highly dependent on the total number of variables and hence cannot be trusted to be correct). As a second step, we trained a linear layer coupled to a network composed of fully-connected layers of hidden neurons each. We refer to the number of output neurons in the first linear layer as the latent dimension.
As input, this network received the variables extracted from MNIST images using the above convolutional neural net (after it was fully trained using DCCA), and was trained to minimize the mean square error between its output and the original MNIST digit.
The resulting best mean square errors are shown in Fig. 4, as function of the latent dimension. Here we see a distinct change of polynomial scaling law at dimension . Increasing the dimension further provides no improvement. This behaviour is compatible with our hypothesis that the extra variables are just functions of those first twenty variables (functions which are effectively re-implemented by the generative network).
Images generated by sampling from a Gaussian approximation of the latent distribution for different latent dimensions are shown in Fig. 4. Below dimension , most generated image can be recognized as a specific digit.
6 Outlook
We studied the classical (non-quantum) form of the theory introduced in [1], and found that the relevant observables of that theory are just the most correlated canonical variables in the sense of DCCA [5], and can be learned effectively using standard machine learning methods.
This point of views on DCCA provided us with several new insights. The first is that the learned relevant variables provide a useful representation of a joint probability distribution. We showed that performing inference using this representation can outperform crossentropy in predicting classes. Our experiments on halves of MNIST also show that the conditional distribution we obtain can effectively represent the uncertainty in the prediction of high-dimensional data.
A second insight relates to the interpretation of the canonical variables as spanning directions in the space of probability distributions. As suggested by the gaussian solutions and our experiment on synthetic data, we postulate that the canonical variables are functions of a small number of independent generators contained in their span. This hypothesis is supported by our experiment on MNIST, but further work is required to find a way to cleanly extract these variables.
We have yet to explore the potential applications of one of the salient aspect of this approach to inference, the fact that the canonical variables learned using DCCA are also those which can be most reliably predicted, irrespective of the value of the cutoff. To see why this is potentially significant, we observe that a central feature of scientific exploration is that we are not so concerned with making predictions about some given variables, as much as we are with discovering variables which can be predicted.
Another important feature of this approach is the fact that the resulting model allows for the direct evaluation of the expectation values in the posterior distribution without sampling. In particular this allows for the evaluation of credible intervals. Hence it should be especially suited to scientific applications where the ability to quantify uncertainty is essential.
Finally, the relationship that we established with theory of quantum origin points towards a potential quantum generalization of DCCA that would apply to quantum data, or classical measurements of quantum systems.
Acknowledgments
We would like to thank Joël Bény and Raban Iten for helpful suggestions. We are also indebted to an anonymous ICLR2020 referee for pointing out the connection between our approach and DCCA. This work was supported by the National Research Foundation of Korea (NRF-2018R1D1A1A02048436).
Appendix A Extra information about the algorithm
A.1 Alternative interpretation of the objective
If we write and for the value of our variables on the dataset, then , and . The DCCA objective can then be written as
[TABLE]
where and are the projectors on the ranges of and respectively. Hence, we are maximizing the overlap between those ranges (which represent possible linear combinations of datapoints, respectively determined from variables of one or the other correlated views.)
A.2 Heuristic
Batch size—In our experiments, we observed that the batch size during training needs to be an order of magnitude larger than the number of variables (rank cutoff). When the batch size was too small, learning seemed to converge normally in terms of training and test loss, but resulted in variables which yield dramatically different losses when evaluated on larger batches, and yield spurious predictions.
Constant variables—The loss function takes value between [math] and because the constant variable always has relevance . The constant variable could be enforced a priori rather than learned, which, due to the objective, automatically forces the learned variables to have zero expectation values (be orthogonal to the constant variable). This might have advantages in certain circumstances, but in our experiments we found that this sometime hindered convergence.
Invertibility issues—The covariance matrices and can be ill-conditioned, potentially causing the gradient to “explode” because of the inverses et involved in the loss function. This can be avoided either by using the Moore-Penrose pseudo-inverse, or by replacing by in the loss for some small positive number , and likewise for .
Symmetries in the loss function—The loss only depends on the span of the variables and , hence it has a very large group of symmetries. In particular, it is invariant under a change of the norm of each variable independently from each other. Because of that, it is preferable not to have a linear last layer. Using a hyperbolic tangent as last nonlinearity worked in our experiments.
Regularization—In all our tests, dropout had no beneficial effect. In fact, our objective seems to already provide a form of regularization, as shown in Section 5.2.
Appendix B Theory in more details
We consider two correlated random variables and with a joint probability distribution . We assume that we are able to numerically evaluate expectations with respect to this distribution, for instance because we can sample from it. We want to use this ability in order to compute expectations with respect to the conditional distributions and , where and are the marginals of . Below we sometime remove the subscripts , or if there is no ambiguity.
For instance, suppose we generated samples of given , through explicit knowledge of . Then the evaluation of expectations with respect to is the subject of Bayesian inference. However, this is generally done in a context where the variable has low dimensionality and parameterizes a hand-crafted model. Our approach, however, is free of such a model and the variable can be of very high dimensionality.
B.1 Inner product on probability vectors
In order to define our strategy, we need to equip the spaces of probability distributions for and with an inner product structure. Let us focus on , and assume that it takes discrete values to avoid unnecessary technicalities. The set of probability vectors is a convex subset of the real linear space . Let us equip this space with the product
[TABLE]
for any . We also write . Importantly, this depends explicitly on the fixed probability vector , which we took to be the marginal of . If has full support, this makes into a real inner product space. The same can be done for the variable , yielding the inner product for .
Had we interpreted and as tangent vectors to , considered as a manifold, this would be the Fisher information (Riemannian) metric, as in [2]. But this quantity is also meaningful for finite vectors: the induced norm distance between and any probability vector is the -divergence:
[TABLE]
The set of conditional probability distributions form a stochastic map, i.e., a linear map , , where
[TABLE]
for any .
It is straightforward to check that the stochastic map defined by
[TABLE]
is the transpose of with respect to the inner products we defined [22], i.e., for all and ,
[TABLE]
Also, we observe that and .
B.2 Eigen-relevance decomposition
We can use the inner products on and to define a singular value decomposition of the stochastic map . That is, there is an orthonormal family of and an orthonormal family of , such that
[TABLE]
for . For each , is a singular value of , whose square we call the relevance of the vector . Moreover since the divergence is contractive under any stochastic map. Given that is the transpose of :
[TABLE]
Equivalently, is an eigenvector of and is an eigenvectors of , both with eigenvalue .
Because maps to , we always have the dual eigenvectors and with eigenvalue .
B.3 Low-rank approximation
Typically, the dimension of the space of probabilities is more than astronomically large. For instance, if the values of consists of small gray level images of pixels, then . However, in many case, only very few of these dimensions may be relevant for the purpose of inferring other variables.
The core of our approach is to approximate and by restricting them to the span of the first eigenvectors and with largest singular values . That is, if we order the singular values , in decreasing order, we propose to use the approximations
[TABLE]
to and respectively, for some typically much smaller than , and any , .
We denote the components of and by and , e.g.,
[TABLE]
Since and are adjoint, we can define . Although the marginals of are the probability distributions and , the numbers are not necessarily positive.
The quality of this approximation for a given does not directly depend on the dimensionality of and , but only on the amount of correlations between the two variables. Our aim is to use a small enough that the components of and can be computed explicitly.
Theorem 1**.**
* is the map of rank which minimizes the average distance*
[TABLE]
Proof.
The low rank approximation minimizes the distance where
[TABLE]
is the Hilbert-Schmidt (or Frobenius) norm [23]. This follows from the fact that this is also the -norm of the vector of singular values of . Let us find the explicit form of the trace. Each possible value of the variable is associated with a probability distribution when and zero otherwise. These distributions form an orthogonal basis of , and have norms . Therefore,
[TABLE]
∎
B.4 Relevant variables
We express the elements and in terms of the marginals and as simple products:
[TABLE]
for all , where and are real functions of and .
The inner products then simply become correlations among variables. Using also and , we obtain
[TABLE]
These are simple expectation values with respect to , which we assumed is the type of quantity we can evaluate for arbitrary functions .
Since is self-adjoint in terms of this inner product, its eigenvectors are orthogonal, and hence the corresponding variables defined by are uncorrelated. Indeed,
[TABLE]
for all . Moreover, accounting for the eigenvector (corresponding to the constant feature for all ),
[TABLE]
for all . Hence we trivially have
[TABLE]
for all .
Likewise for the eigenvectors of . If :
[TABLE]
for all .
Importantly, this does not mean that the variables nor are “disentangled”, i.e., they are not statistically independent. These variables represent components in the space of probability vectors, rather than the “sample” space. They should be understood as spanning a subspace of the space of functions over the relevant independent variables. We discuss this in more detail in Section 5.3.
B.5 Corners of and loss function
The final piece of puzzle we need, is the ability to express the components (corners) of and in the span of possible non-orthogonal families of variables.
Let us therefore consider two arbitrary families and of variables, which respectively represent the vectors and .
Firstly, we need matrices representing the components of the inner products on and . Those are the symmetric matrices
[TABLE]
The components of are defined by
[TABLE]
Taking the inner product with , we obtain
[TABLE]
The left-hand side can be computed using Equ. 25. It is the matrix
[TABLE]
Therefore, in matrix notation, Equ. (47) is , or
[TABLE]
The components of are obtained by just swapping and , yielding
[TABLE]
Hence the singular values of the corner of defined by the variables and are just the square-root of the eigenvalues of the matrix . In order to find the variables and with the same span as the first eigenvectors , , we just need to maximize all the eigenvalues of . A simple way to do this is to use (minus) the trace of as loss function, since it is the sum of the square of the singular values. We call the relevance of the subspaces defines by the variables ad for all . This yields the loss/cost function:
[TABLE]
Once optimal variables have been found, one can obtain the components of the eigenvectors in the span of through standard numerical diagonalization of .
B.6 Inference
The variables minimizing can be used to infer one variable from the other. For instance, given , the inferred probability distribution over is given by where is when and zero otherwise. In order to compute this, we first need the components of the distribution in terms of the family , i.e., the real numbers such that
[TABLE]
where for all . Taking the inner product with , we obtain
[TABLE]
where the left hand side is also just
[TABLE]
Therefore the components of are explicitly
[TABLE]
It follows that
[TABLE]
Then, for instance, the expected inferred value of is
[TABLE]
For the inference of from , we have
[TABLE]
Appendix C Analytical example
When is any multivariate Gaussian distribution, everything can be computed analytically. Let us consider here the one-dimensional case. We use , and the conditional . That is, is equal to but with some added Gaussian noise. This gives
[TABLE]
It was show in [3], that the most relevant subspace of dimension on the variable is simply spanned by the variables
[TABLE]
. Similarly for ;
[TABLE]
This independence of the relevant variables on the detailed parameters of is a general property of Gaussian joint distributions.
This means, for instance, that the most relevant feature () for predicting the value of given is simply itself. The higher order variables have to do with inferring extra aspects of the probability distribution over .
A set of orthogonal variables can be obtain from the Gram-Schmidt procedure, which, if done from small to large much necessarily yield the eigenvectors and . For illustration purpose, let us work with the non-orthogonal vectors and , keeping only the first vectors.
The three matrices (correlators) we need can be easily computed:
[TABLE]
We obtain
[TABLE]
The eigenvalues of can be read on the diagonal, and the corresponding eigenvectors are , and , which means that the eigenfunctions are in order , and
Because we are working with continuous variables, the true rank of is infinite, even for any finite cutoff on the singular values. Nevertheless, it is instructive to see how the approximate inference fares for rank . Given the value for , the inferred distribution over is
[TABLE]
The approximately inferred first and second moments of is given by integrating the above times (resp. ) over . We obtain
[TABLE]
which are actually exact: they are equal to the first two moments of over as given in Eq. (59).
In fact, it is easy to see that this would be true for the first moments had we kept the most relevant variables.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Cédric Bény and Tobias J Osborne. Renormalisation as an inference problem. (ar Xiv:1310.3188) , 2013.
- 2[2] Cédric Bény and Tobias J Osborne. The renormalisation group via statistical inference. New J. Phys. , 17:083005, 2015. (ar Xiv:1402.4949) .
- 3[3] HO Lancaster. The structure of bivariate distributions. The Annals of Mathematical Statistics , 29(3):719–736, 1958.
- 4[4] Tomer Michaeli, Weiran Wang, and Karen Livescu. Nonparametric canonical correlation analysis. In International Conference on Machine Learning , pages 1967–1976, 2016.
- 5[5] Galen Andrew, Raman Arora, Jeff Bilmes, and Karen Livescu. Deep canonical correlation analysis. In International conference on machine learning , pages 1247–1255, 2013.
- 6[6] Harold Hotelling. Relations between two sets of variates. Biometrika , 28(3/4):321–377, 1936.
- 7[7] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. (ar Xiv:1312.6114) , 2013.
- 8[8] Raban Iten, Tony Metger, Henrik Wilming, Lídia Del Rio, and Renato Renner. Discovering physical concepts with neural networks. (ar Xiv:1807.10300) , 2018.