TL;DR
This paper introduces a robust, scalable 3D shape reconstruction method from multi-modal data that effectively handles calibration uncertainties using parametric level set techniques with ellipsoidal radial basis functions.
Contribution
It presents a novel parametric level set approach that explicitly models calibration uncertainty, enabling accurate 3D reconstruction across diverse data modalities.
Findings
Method accurately represents complex objects.
Reconstruction is robust to measurement sparsity and noise.
Effective across multiple data types like slices and silhouettes.
Abstract
We consider the problem of 3D shape reconstruction from multi-modal data, given uncertain calibration parameters. Typically, 3D data modalities can be in diverse forms such as sparse point sets, volumetric slices, 2D photos and so on. To jointly process these data modalities, we exploit a parametric level set method that utilizes ellipsoidal radial basis functions. This method not only allows us to analytically and compactly represent the object, it also confers on us the ability to overcome calibration related noise that originates from inaccurate acquisition parameters. This essentially implicit regularization leads to a highly robust and scalable reconstruction, surpassing other traditional methods. In our results we first demonstrate the ability of the method to compactly represent complex objects. We then show that our reconstruction method is robust both to a small number of…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1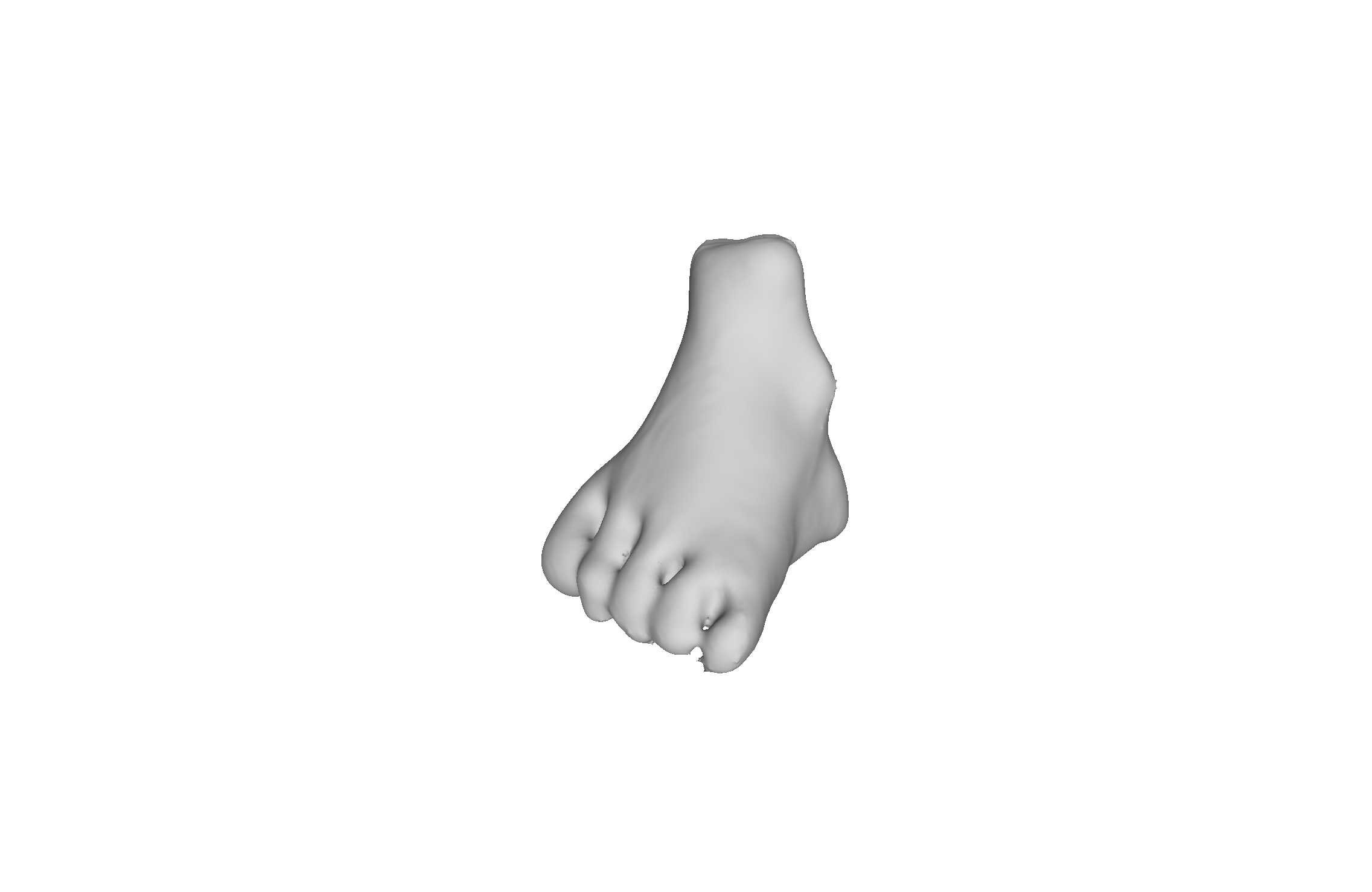 Figure 2
Figure 2 Figure 3
Figure 3 Figure 4
Figure 4 Figure 5
Figure 5 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11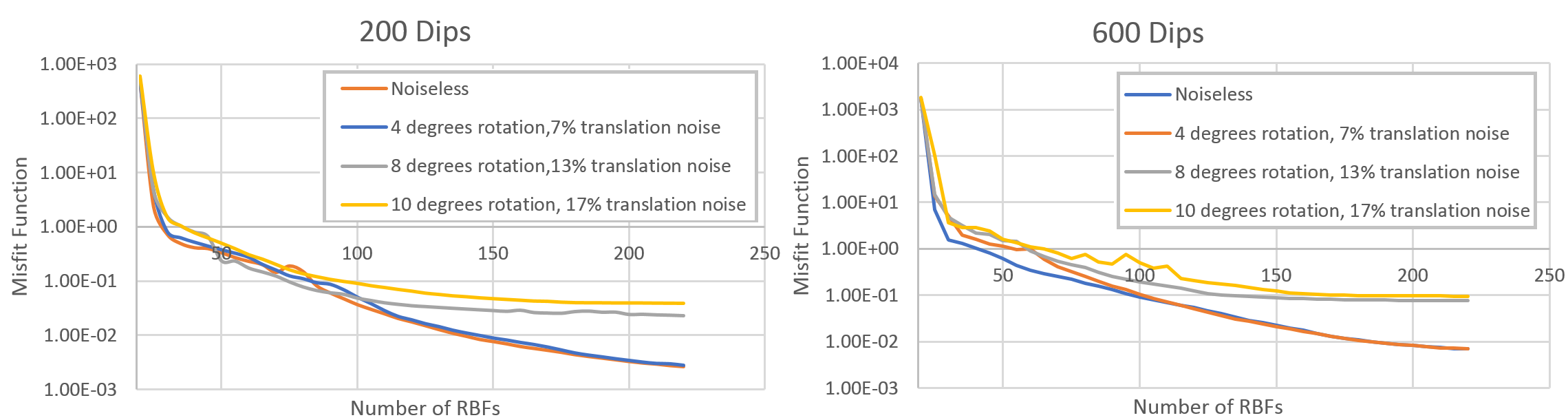 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16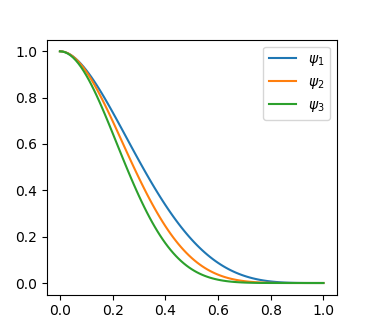 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24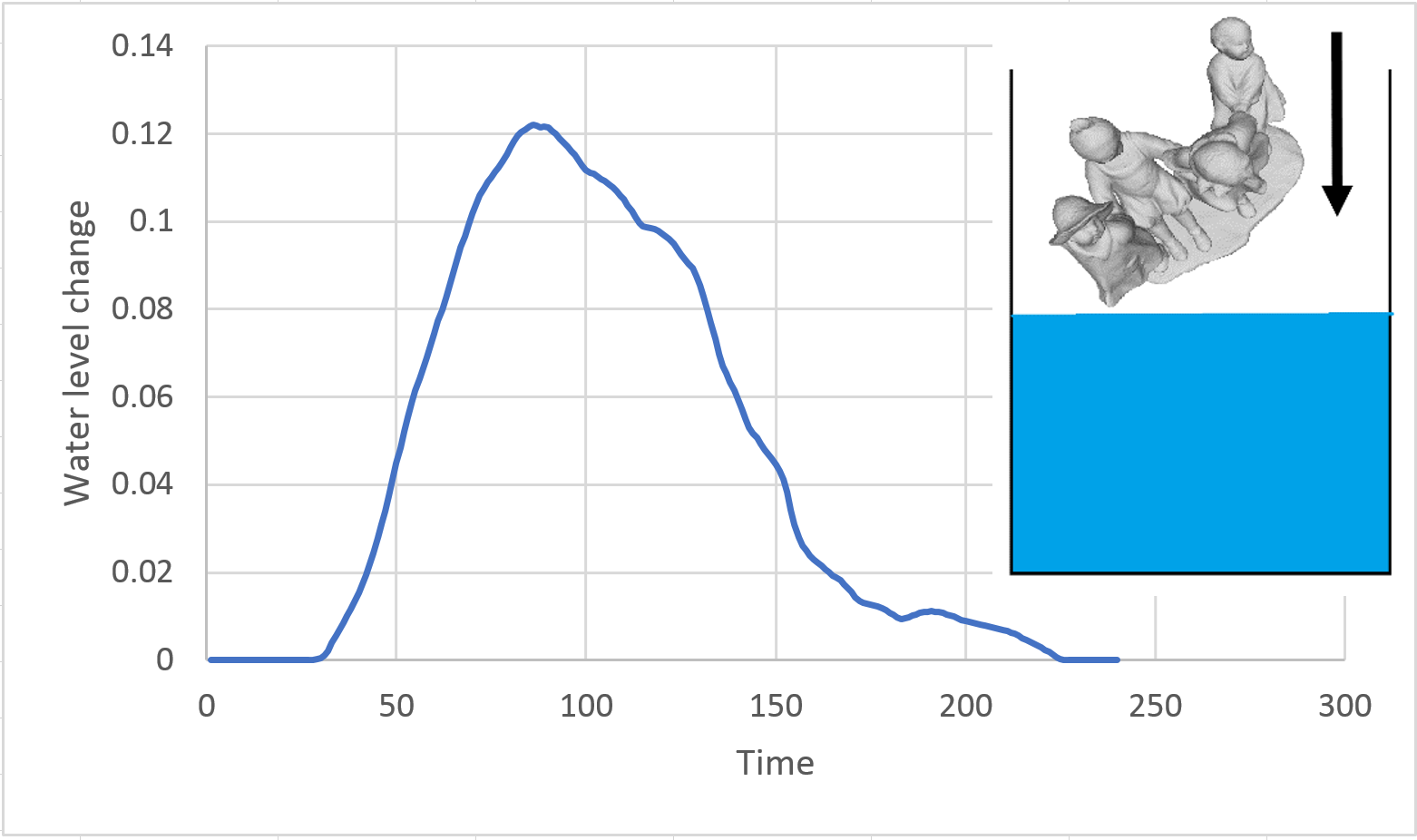 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39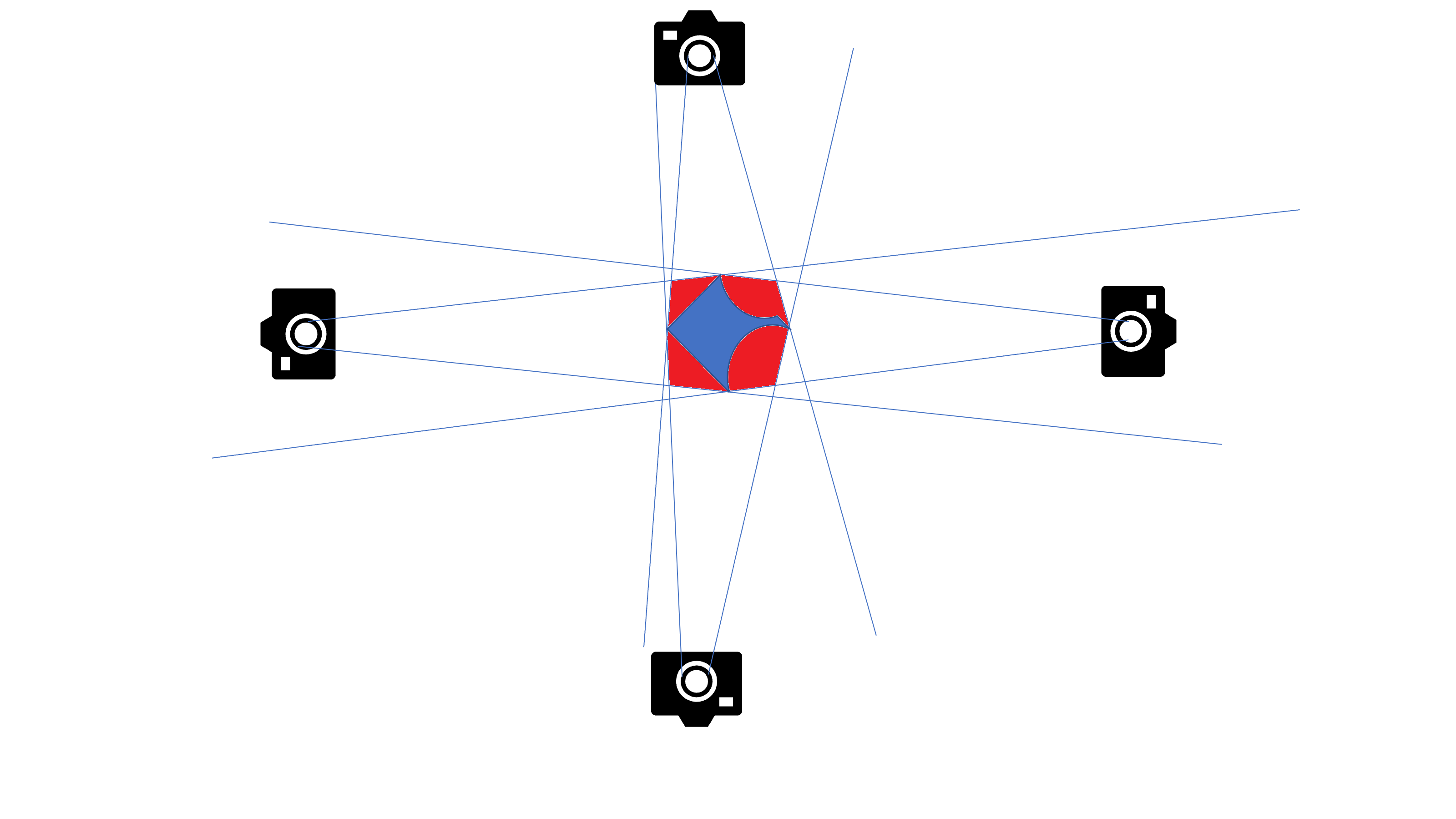 Figure 40
Figure 40Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\headers
Shape Reconstruction Under Calibration UncertaintyEliasof M., Sharf A., and Treister E.
Multi-modal 3D Shape Reconstruction Under Calibration Uncertainty using Parametric Level Set Methods
Moshe Eliasof Computer Science Department, Ben-Gurion University of the Negev, Beer Sheva, Israel. () [email protected], [email protected], erant@cs,bgu.ac.il
Andrei Sharf11footnotemark: 1
Eran Treister11footnotemark: 1
Abstract
We consider the problem of 3D shape reconstruction from multi-modal data, given uncertain calibration parameters. Typically, 3D data modalities can come in diverse forms such as sparse point sets, volumetric slices, 2D photos and so on. To jointly process these data modalities, we exploit a parametric level set method that utilizes ellipsoidal radial basis functions. This method not only allows us to analytically and compactly represent the object, it also confers on us the ability to overcome calibration-related noise that originates from inaccurate acquisition parameters. This essentially implicit regularization leads to a highly robust and scalable reconstruction, surpassing other traditional methods. In our results we first demonstrate the ability of the method to compactly represent complex objects. We then show that our reconstruction method is robust both to a small number of measurements and to noise in the acquisition parameters. Finally, we demonstrate our reconstruction abilities from diverse modalities such as volume slices obtained from liquid displacement (similar to CT scans and XRays), and visual measurements obtained from shape silhouettes as well as point-clouds.
keywords:
3D Shape Reconstruction, Parametric Level Sets, Dip Transform, Joint Reconstruction, Shape from Silhouettes, Point Clouds, Compactly Supported Radial Basis Functions.
{AMS}
65D18, 65J20, 65J22, 68U05.
1 Introduction
The reconstruction of 3D objects is an important task in many disciplines like computer graphics [1, 4, 6, 52, 54], computer vision [27, 16, 26], geophysics [32], computational biology [41], civil engineering, medical applications, architecture, and archaeology, among others. Typically, we have incomplete data measurements of a physical object, and wish to reconstruct the full and continuous object that corresponds to these measurements. In addition to being incomplete, the measurements are usually noisy, and therefore, the aim of the reconstruction process is to find a model that optimally fits the data. This can be done by solving a computational optimization problem, the aim of which is to fit simulated data to existing measurements. These problems are usually ill-posed and non-convex, and solving them with existing methods is often challenging. In many cases—especially when the available data set is small—we need to include some prior information in the reconstruction problem to guide the optimization toward a more plausible solution.
In this work, we focus on problems of 3D shape reconstruction from multi-modal data. That is, measurements of objects that originate from several domains, such as volumetric slices [1, 8, 24, 13, 25, 30, 55], multiview images and object silhouettes [27, 16, 26], and point-clouds [7, 35]. Our aim is to define a robust unifying framework that can jointly process such data to obtain a best fitting shape model. In the shape reconstruction problem, we are essentially searching for a piecewise constant binary function in some domain, which indicates whether there is an object or background at each location. A common approach to such piecewise constant reconstructions exploits level set methods [39, 40], which have been used for shape reconstruction [50] and image segmentation [47]. A particular version of these methods is the parametric level set (PaLS) method [2, 3], an approach that has been used for inverse problems, particularly for medical [28, 18] and geophysical [23, 31] applications. The PaLS method suggests that the level set function is approached analytically rather than by using a computational grid. That is, the shape is analytically parameterized by a linear combination of radial basis functions (RBFs) with limited support, e.g., Gaussian functions. The benefit of using RBFs stems from their ability to compactly yet accurately represent the shape and to adapt it as part of the optimization process. Furthermore, we use compactly supported RBFs. This has a tremendous computational benefit when computing a shape from its parameters, leading to sparse Jacobian matrices, and an efficient optimization process for reconstructing high-resolution objects. This method acts as an implicit regularization towards a reconstruction of an dense object.
In the context of graphical applications, RBFs were previously used for surface reconstruction. The work of [14] suggests using RBFs for surface reconstruction from a point cloud, where the centers and radii of the basis functions are assumed to be known, and the optimization is performed only for the linear coefficients of the RBFs. A later work [33] proposed a multi-scale reconstruction that is obtained with RBFs to capture both the global and local structures of the object, after which the reconstructed shape is obtained by interpolating between the scales. However, such approaches require a large number of basis functions for the reconstruction, in the tens of thousands, conferring a high computational cost on the method. A recent work addressed this issue by devising an efficient GPU implementation of RBF interpolation [17]. As we will show later, our method requires many fewer RBFs (only a few hundred parameters) to represent whole objects, and not just the surface. A recent work [15] proposed employing a deep RBF neural network to encode the spatial distribution of point-clouds for classification. This approach yields competitive classification accuracy (i.e., similar to standard networks [35]), while reducing both the number of learned parameters and the computational costs.
In this work we leverage the PaLS method for shape reconstruction, in which the object is analytically represented as a composition of RBFs, and is made piece-wise constant by applying a smoothed step-like function. The parameters of this representation, which is a collection of spheres, include the centers, radii, and linear coefficients of the RBFs. To the best of our knowledge, we are the first group to use PaLS for graphical applications. To that end, our first contribution to this subject features an enriched PaLS representation that comprises a collection of ellipsoids instead of spheres. This is needed since the conventional PaLS method in 3D often results in blob-like artifacts caused by the spherical basis functions. This can be seen in the work of [28], which performed 3D medical reconstructions using PaLS. While it is arguable whether such artifacts are acceptable in a medical scenario, they are definitely unacceptable in problems where the reconstructed object should be as close as possible to the original (e.g., reconstruction of a piece of art). To avoid undesired artifacts, therefore, we extend the PaLS representation to be ellipsoidal, so that the PaLS method can compactly represent flat and long objects. As we demonstrate later, our framework is capable of accurately representing complexly shaped objects with sharp elements by using several hundred parameters only. Our approach thus reduces complex reconstruction problems of potentially several million parameters using standard volumetric grid values, to problems of a few thousands parameters at most using PaLS to represent the object. The markedly smaller number of parameters using PaLS makes the optimization process efficient and better-posed. As a result, the parametric representation implicitly regularizes the reconstruction and enables us to reconstruct shapes from small data sets. Another, albeit smaller benefit of the compact PaLS representation is the savings in storage—we only need to store the PaLS parameters rather than the volumetric grid values of the object.
An additional significant contribution made by our work relates to handling uncertainty in the calibration (or alignment) parameters. For each measurement, data acquisition methods include certain parameters, e.g., the angle and location relative to the camera at which an image was photographed. The accuracy with which these parameters are known (if they are known at all) varies, generating uncertainty that essentially creates non-trivial noise in the simulated data. Inevitable in real life scenarios, such noise is difficult to model statistically and may hamper the reconstruction if not addressed properly. This is especially evident in cases where the measured data is small. This calibration problem is evident in many reconstruction problems of interest. One may approximate the calibration parameters in addition to the reconstruction, but the process is not straightforward for some problems. For example, in tomography problems there are cases where it is theoretically possible to estimate the calibration (or alignment) parameters and the shape together [5]. Indeed, [21] and [34] apply a procedure that alternates between updating the alignment parameters and the tomographic reconstruction. The work of [51] optimizes for both the shape and the alignment parameters using a Quasi-Newton method, and the derivatives with respect to the alignment parameters are numerically approximated by finite differences. Similarly, the work of [11] tackles the problem with the Levenberg-Marquardt algorithm using a spline representation of the shape to treat the derivatives of the alignment parameters. Similarly, [46] uses a bi-cubic interpolation of the shape and a variety of first order methods for the joint reconstruction of the shape and alignment parameters. A similar situation is also evident in shape reconstruction from point clouds, which also requires a registration in cases where multiple point clouds are given as data. There, the alignment parameters are usually estimated by the Iterative Closest Point (ICP) methods separately from the reconstruction—see [9, 37, 43, 7, 45, 42] and references therein. While the current methods are considered to be quite accurate, there may often be small alignment errors, especially if the overlap between the point clouds is small, or if multiple misaligned clouds are considered. In such cases, having additional data sources of the same object can help correcting the alignment. Our solution to this issue is rooted in the PaLS method whose compact analytic representation allows us to apply transformations or deformations to the object. Thus, we can also include the acquisition parameters in the optimization process as part of the multi-modal reconstruction problem, allowing the reconstruction to adapt to the real acquisition parameters, and handle this uncertainty.
We demonstrate both the issue of the accurate object representation, and the handling of uncertainty in the acquisition parameters by performing rigorous experiments using our method for reconstruction from visual and non visual measurements. For the non visual data, we use the acquisition method of “dip transform”, where the data are obtained by repeatedly dipping the object in liquid, such that each time the object is dipped, it is oriented at a different angle relative to the dipping axis [1]. Using dip transform, though the data acquisition is a simple task, it is tedious to execute, as the data generated from each dip are typically small. To complement this small data, we also experiment with joint shape reconstruction from both the dipping data and visual data, the latter of which comprised silhouette images which are relatively easy to obtain. The visual part of the reconstruction is applied via a modified version of shape from silhouettes (SfS) proposed in [16, 26]. In addition, we perform experiments of shape reconstruction from point clouds.
Our paper is organized as follows: In Section 2, we provide the mathematical formulations of the problems that we investigate. Then, in Section 3, we present the PaLS method, after which we address calibration uncertainty in Section 4. Next in Section 5, we discuss the use of two modalities to perform shape reconstruction using the PaLS method. Finally, in Section 6 we present our empirical results.
2 Problem Formulation
The typical shape reconstruction problem that we consider here is formulated as a binary piecewise constant optimization problem of the form
[TABLE]
where denotes the number of experiments (e.g., photos), is the data measurement that corresponds to experiment , is the binary vector representing the object, and is the simulation of the data measurement according to a given object . We assume that , that is, the simulated data for the true object is approximately equal to the observed data . In the first term of we wish to measure and minimize the simulation error in a least squares sense, which also means that we assume that the simulation error is independent and identically Gaussian distributed soutand ı.i.d.. Since the reconstruction problem is often ill-posed, we usually incorporate in it prior information in the form of the regularization term and its associated parameter , the latter of which balances between the data fidelity term and the regularization [48].
The type of regularization used can be a simple Tikhonov regularization (as in [1]), or it can be a total variation regularization [36], the latter of which promotes smoothness in the reconstructed image but is also able to tolerate edges. To solve the problem (1), a variety of optimization algorithms can be used, most of which are gradient-based iterative methods such as gradient descent or Gauss-Newton. Such algorithms are suitable only in cases where is continuous and real-valued. When using these algorithms, therefore, the problem (1) is solved under the assumption that , and is artificially promoted to be binary by using penalty terms, smoothing regularization and other iterative procedures. This is the case, for example, in [26, 27], which deal with reconstructions of shapes from silhouettes and multi-view data. Generally, assigning to be binary can be a challenge, and may require some heuristics. We demonstrate our framework on the problems below.
2.1 Shape Reconstruction from Tomographic Measurements
A promising recent tomographic acquisition and shape reconstruction technique is the “dip transform” [1]. Designed to reconstruct a shape from liquid displacement measurements that correspond to volumetric slices of the shape, dip transform is similar to other tomographic modalities like X-ray scans, for example, and, in particular, it is not based on visual or surface measurements. Also closely related is the work of [13], involving reconstruction from 2D slices. The dip transform exploits Archimedes law to reconstruct the volume of the object by repeatedly dipping it in a container full of liquid, such that each time the object is dipped, it is oriented at a different angle relative to a given axis. Each dip along an axis creates a trace of liquid volume displacement that represents the volumes of thin slices of the shape along the dipping axis (see Fig. 1). In essence, this technique performs tomographic measurements of the object’s slices. Such measurements enable us to reconstruct hidden elements or transparent shapes, which cannot be measured by rays of light.
Using our notation, the dip transform reconstruction problem is defined as:
[TABLE]
where is a rotation matrix, rotating the object at horizontal and vertical angles and , respectively, and essentially is a permutation matrix. is the “summation over slices” matrix, which generates the water displacement measurements given the rotated , and is the regularization term. Given the angles and ignoring the binary reconstruction requirement, this is a linear inverse problem.
A significant drawback to this approach is that it necessitates a large number of measurements, as each dip only generates a one-dimensional trace, though we need to reconstruct a three dimensional object. In addition, the mechanical and manual acquisition method begets high uncertainty in the acquisition parameters. In actuality, the angles and centering of the object during dipping are only roughly known. In the next sections, we will show how our method resolves both of these problems.
2.2 Shape Reconstruction from Surface Measurements
Another channel of data input used in this paper comprises visual (or surface) measurements. We consider two data modalities. One is the SfS model [29, 27, 16, 26], whose input includes photographs of the object taken from several different angles. These photographs are then binarized to be shadow-like, and subsequently used to estimate the volumetric shape of the object. Another data modality is point clouds, which are commonly used for object scanning and reconstruction [7] using of-the-shelf sensors. Point clouds consist of sets of points which lie on the (visible) surface of the object. The reconstruction from both modalities may be defined similarly to (1) as
[TABLE]
where loss combines model principles (either SfS or point cloud) for the -th experiment, and is again a regularization term. Both modalities are not perfect and have limitations. For example, in SfS we cannot satisfactorily reconstruct concavities in the shape, and indeed, in most cases the hidden areas of the shape, like holes or hollows, are artificially filled during the reconstruction process. In point clouds, certain areas of the surface are often scanned in poor resolution, leaving inaccuracies or holes in the reconstructed surface [1]. Nevertheless, both surface models have the advantages of simplicity and ease of the acquisition.
2.3 Joint Reconstruction
Each of the data modalities mentioned above has its drawbacks. Therefore, in this work we use multiple modalities to improve the quality of the reconstruction given the available data. For example, we use the SfS to complement the data we acquire via the dip transform, and demonstrate the joint reconstruction of the shape within our framework. To obtain this, we define the joint problem:
[TABLE]
where corresponds to the objective in Eq. (2), and balances the impact of the two loss functions. is usually chosen such that the two losses are comparable. This combination of SfS with dip transform enables us to achieve a high quality reconstruction using significantly fewer dipping measurements compared to using the dip transform exclusively. In this case, however, we have to neglect the assumption of a full model that is typical for SfS, since the dip measurements are able to capture an object’s holes and concavities, which are missed by SfS. Therefore, we propose an adapted SfS model that lacks such assumptions (more details in Section 5). In addition, in Section 6 we demonstrate the joint surface reconstruction from SfS and point clouds, to overcome registration problems in point clouds.
3 Parametric Level Sets using Radial Basis Functions
The PaLS approach [2] was originally proposed to solve inverse problems involving a reconstruction of a constant valued body and its background. In our case, in (1) we have a background of zero, and we focus on retrieving the constant-valued object. The choice of the basis functions has a significant impact on the dimensionality and expressiveness of the PaLS representation. Herein, we choose radial basis functions [2], which have been shown to represent 3D models well [14]. To this end, the PaLS representation is defined by:
[TABLE]
where is a Heaviside function used to binarize . There are a few functions that can be used for this purpose, like the function used in [2]. We leverage a piecewise polynomial Heaviside function as shown in Fig. 3(a) to improve the condition number of the Hessian and increase the sparsity of the Jacobian [22]. The function is one of the Wendland RBF functions that appear in Fig. 3(b). For precise definitions of and , refer to the Appendix in Section 8.1. The pseudo-norm is used to prevent division by zero when computing the derivatives for our model.
The RBF together with the distance as an operand leads to a sphere in space. Thus, the representation (5) is a linear combination of spheres, each one with a radius of approximately , centered around . Each basis function has five unknown parameters. We denote:
[TABLE]
to be the vector of the unknown RBF parameters in the optimization process, and to be the discrete version of which is equivalent to (5).
Next, the problem in Eq. (1) is replaced with its PaLS version:
[TABLE]
To solve such a reconstruction problem using a gradient-based method, we need to compute the discrete and its derivatives with respect to the parameters. That is, we need the Jacobian , which we define in Appendix 8.2 in detail. Since our RBFs are compactly supported, the contribution of each basis function is limited by its support, leading to a sparse Jacobian. In addition, each of the derivatives in the Jacobian has a term involving , which is mostly zero except for the object boundaries, hence the Jacobian matrix is very sparse, enabling high resolution reconstructions. While any gradient-based method is suitable to solve a problem like (7), in this work we use the Gauss-Newton (GN) method, which gives the following iteration step:
[TABLE]
where is obtained by a standard Armijo line-search procedure. For , in this case, we use a simple iterated Tikhonov regularization . This regularization is less sensitive to the choice of than standard Tikhonov regularization, which does not depend on the iteration [20]. Since —the number of basis functions—is typically small (several hundreds), it is computationally feasible to solve it by using an exact GN, i.e., invert the Hessian at each iteration. Here, has to be chosen substantial enough so that the Hessian matrix is numerically inevitable and the optimization is stable. Other suitable options to solve this problem include the non-linear conjugate gradients or LBFGS methods. However, these methods will not be able to fully exploit the low dimension and sparsity of the Hessian, and hence are typically slower in this case.
We start the solution process with a small number of RBFs located at random locations around the center of the grid. Then, at each iteration we add a fixed number of new RBFs to the solution and compute the compact representation of the object on-the-fly. The newly added RBFs are located using the gradient of the misfit function w.r.t and multiplied by . A non-zero indicates the areas on the surface of the object where the sensitivities of the PaLS representation are visible (these are the values where ). We also restrict the choice of the new RBF centers to voxels that are distant by at least two grid cells from each other in order not to add basis functions that are too close to each other. We use this heuristic insofar as it is designed to use the least number of parameters possible to reconstruct the object, it guides us to locations in the reconstructed object where its volume is either missing or in excess. The new RBFs are added with the coefficient , and thus, initially they do not influence the objective of the modeling, resulting in a monotone optimization process. At last, we threshold the solution to make it strictly binary. Algorithm 1 summarizes the process.
3.1 Ellipsoidal Radial Basis Functions
Using the standard RBF representation in (5) restricts us to a spherical basis that results in limited expressiveness and spherical effects in the reconstructed objects, as can be observed in [28]. Clearly, this outcome is undesirable in computer graphics applications, especially when objects with flat or sharp elements such as arms, legs or horns, are involved. To render the basis functions more expressive, we suggest that they be enriched to enable them to represent ellipsoids in space rather than spheres. Such enrichment is done by replacing the parameters in (5) with symmetric and positive definite (SPD) matrices . Our ellipsoidal PaLS representation reads:
[TABLE]
where the weighted pseudo norm is given by , and similar to (6), the ellipsoidal parameter vector is
[TABLE]
Our enriched representation denotes a collection of ellipsoids, each with 10 unknowns. For a description of how the derivatives are computed, see the Appendix in Section 8.2. In this case, we also require a regularization to ensure that the matrices remain SPD. To this end, in addition to the Tikhonov regularization on , we use a standard log barrier function () to keep the determinants of away from zero. This regularization is effective, as we do not expect to be too close to singular. In other cases where are expected to be close to singular, the more sophisticated alternative approach of optimization over manifolds [12] may be more suitable. To demonstrate the advantages of the ellipsoidal over the spherical RBFs, we reconstruct a model of a foot that has both detailed and smooth elements (Fig. 4). The figure clearly shows that the proposed ellipsoidal PaLS captures greater detail than the PaLS with basic RBFs, even though the two reconstruction algorithms used the the same number of parameters.
4 Robustness to Calibration Uncertainty and Scalability
Object reconstruction algorithms typically consume data of the object captured in several orientations, e.g., pictures of the object taken at different angles [16]. A major drawback of many algorithms is the assumption that the orientations at which the data were acquired are accurately known and that the noise in the measurements corresponds to a simple probability distribution, e.g., Gaussian. This assumption may be practical in some cases—especially when the data set is large—but it may not be ideal in real-world scenarios with small data. The absence of accurately known acquisition parameters creates noise in the measurements that is difficult to model or predict. Such noise can also be introduced due to a human factor in the data acquisition process, e.g., hands shaking while capturing the object, or due to mechanical inaccuracies in the machine that rotate the object for data collection as in [1]. This often leads to poor reconstruction, especially in cases where the data set is small. To solve these problems, we use the analytic PaLS representation of the object, which allows us to analytically manipulate the object’s position parameters, and we estimate the acquisition parameters as part of the optimization process for the data fit. This is possible because we can differentiate the PaLS representation of with respect to the parameters of the data acquisition.
Consider, for example, the dip transform problem in (2). The PaLS formulation of this problem (analogous to that of the general problem in (7)), is
[TABLE]
Here is a permutation matrix designed to capture the object from different angles and locations that correspond to the -th measurements of the shape, and is a projection operator that simulates the data after the object has been situated according to the acquisition parameters. The operator in (2) is linear. The matrices , however, may require large amounts of storage or be expensive to apply. More importantly, such fixed operators introduce non trivial noise if the acquisition parameters are not accurately known. Therefore, in addition to , we also search for the acquisition parameters encapsulated in and define the rotation and translation operator analytically.
To define the rotation and translation in analytically, we first define the linear transformation of our coordinates
[TABLE]
Here is a orthogonal rotation matrix in azimuth angle and polar angle . is a translation vector, and is the center of the domain that is used as the center of the rotation. This is the transformation that guides the definition of in (2). Next, we define the analytically translated and rotated shape via backward warping according to the transformation (12): . The backward warping is used to avoid discretization problems in the rotation. Note, that the rotated is the analytical definition of the discrete operator , which, up to discretization errors on the mesh, satisfy
[TABLE]
Obviously, the rotated shape can also be represented by PaLS by using what we refer to as “rotated parameters”
[TABLE]
where is the function for rotating the parameters in the angles and translation vector , which together correspond to the -th measurements of the shape. We define below for both versions of the PaLS. To define an inverse problem with analytically rotated parameters (instead of using ), we can simply replace the term in (11) with . As in (11), this will lead to a reconstruction with fixed acquisition parameters, which we incorporate into the inversion, described in the following section. Next, we explicitly define for each of the considered formulations, and the definition of their associated Jacobians appears in the Appendix in Section 8.3.
Rotation for Spherical RBFs
In the simpler version of the PaLS, we plug (13) into (5) and obtain
[TABLE]
The last equality holds because is an orthogonal matrix that does not change the norm of a vector. Hence, only rotates the center of each basis function and is defined by
[TABLE]
Rotation for the Ellipsoidal RBFs
The rotation with respect to the ellipsoidal RBFs is slightly more complicated than in the spherical case, and is given by
[TABLE]
Here, for the -th basis function defined by , we denote its rotation and translation according to the -th acquisition parameters as
[TABLE]
where the last equality holds since is orthogonal.
4.1 Handling Calibration Uncertainty in the Data Acquisition
So far the acquisition parameters were kept fixed, and we did not address the non-trivial noise that originates from inaccuracies in those parameters. Adequately handling such noise is important to produce an accurate reconstruction. Therefore, as part of the reconstruction we also manipulate the PaLS representation parameters of with respect to the parameters of the data acquisition .
To include the data acquisition parameters in the reconstruction, we first extend our (ellipsoidal) inversion parameters:
[TABLE]
The treatment with respect to the spherical RBFs is similar. To have the parameters of the -th basis function rotated by the predicted -th data acquisition parameters, we use the function in (20), but now let the acquisition parameters change throughout the optimization process. By combining Eqs. (11)-(14) together, we obtain our final inverse problem
[TABLE]
This is a version of (11), which applies the rotation of the object by rotating its RBF parameters instead of using the matrices , and includes the data acquisition parameters as unknowns for the optimization. Similar to the previous cases, we use a Tikhonov regularization for the parameters in .
To solve problem (22), we calculate the sensitivities of the rotated with respect to up-to-date predictions of and . To that end, we define the Jacobian of (20) with respect to all of its parameters:
[TABLE]
This Jacobian is defined for all pairs of basis functions and acquisition parameters, and using the chain rule it is multiplies with the PaLS Jacobian to capture the sensitivity of with respect to all the parameters. All the definitions of are found in Appendix 8.4.
5 Joint Reconstruction using PaLS under Calibration Uncertainty
In sections 2.1-2.2, we present two models that are used to reconstruct a three-dimensional object. One of the models, the dip transform, includes information on the volume of the object, but it is also characterized by a complex data acquisition mechanism. The second model, SfS, can only provide information about the object’s surface (as it is visual), but the data are cheap and easy to acquire. Here we demonstrate how, in our framework, these two models can complement one another. Specifically, using the SfS model together with the dip transform can significantly reduce the number of dips required to achieve good volume reconstruction, thus promoting the dip transform to be a more practical technique. The main problem with current SfS models, however, is that they artificially assume that a shape is full underneath its visible surface [29, 27]. Since SfS cannot “see” areas on the shape that are hidden from direct view, this assumption can potentially prevent us from obtaining an accurate assessment of an object’s volume, while such hidden parts may be recovered well by the dip transform. Thus, to complement the dip transform we modify the SfS model to generate its data based only on the object’s surface. To this end, we suggest to use a Softmax function with SfS model, which ensures that the SfS tracks the rays and generates the silhouettes based on a projection of the object’s surface only. This procedure is summarized is Section 5.1.
For the joint reconstruction, we combine the data misfit functions of the two modalities. Refering again to the example of Eq. (4), we obtain:
[TABLE]
where is the joint vector of parameters for the two problems, and therefore, it contains the set of PaLS parameters and separate sets of dip and SfS data acquisition parameters:
[TABLE]
The matrices and extract the relevant parameters from for each of their corresponding modalities, and is used to balance the impact of the different objectives. Note that by using this approach we could, theoretically, combine more than two input channels in our problem. This joint reconstruction is easily set up by using the jInv inversion package [38], which we use for our computations. Joint multi modal inversions using this package were also recently applied in a geophysical context [44, 19].
5.1 No-fill Shape from Silhouettes
The second input source is a modified version of the SfS algorithm that was suggested in [27]. Each pixel in a picture taken by the camera is computed by a ray extending from the camera to that pixel, possibly hitting the object. We denote the constructing ray of the -th pixel by , and its value by ( is the set of indices that constitute the ray). Ideally, we would have a binary 3D object and a 2D silhouette, and if the ray hits the object’s edge or surface, the model should output 1. That is, if we observe two adjacent voxels in the direction of the ray, wherein the value of the first is 0 and that of the other is 1, it indicates that we hit the surface of the object and should output 1. For a real-life silhouette simulation, the part of the object that lies beyond the surface does not influence the result produced by the model.
In practice, we need to work with a smooth transition from 0 to 1, and hence, any voxel that is near the boundary of the object registers a gradual change as it moves from the background to the object itself. Similarly to the ideal case, we wish to recognize this boundary layer and to output the maximum value in that layer for the silhouette. Additionally, we would like the silhouette value to depend on all the voxels in the boundary layer, an element that is of critical importance to the optimization process in the PaLS framework. To achieve such dependence, we define a voting process according to the ray’s first increasing sequence of values , which indicates the rays encountered the object’s boundary.
Our voting process for computing entails performing a softmax of the values of over the first boundary layer in the ray (increasing values of ). That is:
[TABLE]
where is the subset of indices that correspond to increasing values in in the ray . The behavior of the softmax function is controlled by setting ( in our tests). We note that insofar, since the process in (26) is designed to be realistic and is defined only by the shape’s boundaries, the model cannot determine the invisible inner parts of the shape. These parts are left to regularization only. Alternatively, as in our case, one can complement this model with a tomographic model like the dip transform to fill the missing inner information.
5.2 Mesh-free implementation for reconstruction from point clouds
Suppose we are given a set of points that lie on the surface of the object. Because our PaLS framework provides a smooth transition from 0 to 1 using the Heaviside function in Fig. 3(a), our objective is to find the PaLS parameters , s.t.
[TABLE]
where is our binarization threshold parameter in Alg. 1. In order to consistently define the inner and outer sides of the shape for all the points, we use the common technique of [14], as follows. Using the points in we estimate surface normals , and define two additional sets: , and . Then, in our loss function we try to fit (in a least squares sense) for , and for , in addition to (27).
Using the approach above, our loss depends only on the points defined in the three given sets, and there is no need to define a volumetric grid as in the other problems. Hence, we use our PaLS model with a collection of points, in a mesh-free manner. That is, the parameters are estimated using a mesh free minimization of the loss over the points in the clouds, and the shape can be constructed later on an arbitrarily fine mesh. The value of is chosen according to the width of the transition from 0 to 1 in the Heaviside function. In addition, to have a fast implementation, the procedure that computes has to efficiently determine which points in the clouds are relevant for each basis function. We obtain this using a nearest neighbor data structure implemented in the Julia package NearestNeighbors.jl, which is available on GitHub.
6 Results
To validate our proposed framework for 3D shape reconstruction, we conducted several experiments. The first experiment aims to demonstrate that even though the PaLS framework contains a representation using smooth RBFs, it can also be used to represent sharp objects, which are typically difficult to define using basis functions. In the subsequent experiments, we exploit the dip transform model for tomographic data acquisition and compare the reconstructions obtained with our framework to those obtained with the original reconstruction method in [1]. In our third batch of experiments, we demonstrate the robustness of the reconstruction algorithm to uncertainty in the acquisition parameters. Following that, we show that multi-modal shape reconstruction is possible with our framework via the combination of the modified SfS model described in Section 5.1 with the dip transform model. This experiment not only shows that we are able to perform a joint shape reconstruction, it also demonstrates how the large number of experiments required for the dip transform can be substantially reduced. Finally, we show the reconstruction of an object from two given misaligned and non-overlapping point-clouds, and show that their combination with SFS can lead to a correct reconstruction.
All the shape reconstructions are obtained using Gauss-Newton in Algorithm 1 with iterated Tikhonov and log-determinant barrier regularization. Our framework is implemented in the Julia language [10], and we use the inversion package jInv [38] to perform the computations, which are parallelelized over the experiments. We use MeshLab as a final step to post-process the volumetric meshes we obtained. The post-processing steps include Laplacian-smoothing and voxel sub-sampling to avoid artifacts, which can be caused by over-sampling the continuous representation obtained using our framework. Our code for reproducing the results in this work is available online at:
https://github.com/BGUCompSci/ShapeReconstructionPaLS.jl
6.1 Shape Representation using PaLS
The outcome of this experiment serves as a proof of concept for the modeling capabilities of the ellipsoidal PaLS. Given an object defined on a mesh (of size ), we search for and assess the quality with which the PaLS representation models the object (based on a moderate number of RBFs). Since our goal is to enable objects to be modeled with the lowest possible number of parameters, we initialize the reconstruction with 5 RBFs and add only one RBF at each iteration. The results of this experiment can be seen in Fig. 5. We intentionally chose an input object with both flat areas and sharp angles to demonstrate the expressiveness of our model. The results show that our model can faithfully reconstruct both the sharp and the flat elements, tasks that are considered particularly challenging in shape reconstruction. Furthermore, despite the relative complexity of the shape, its reconstruction is done using a small number of parameters. As expected and can be seen in Fig. 5, increasing the number of basis functions (while maintaining a relatively low number of parameters) improves the reconstruction.
Shape Reconstruction Setting and Default Parameters
In Sections 6.2-6.4 we present a few shape reconstruction experiments. To make the experiments realistic, all the data measurements are generated from a binary object using a grid. The data are then down-sampled, and we perform the reconstruction on a grid. We also include uncertainty in the acquisition parameters (detailed later) and Gaussian white noise of variance , where is the volume of a voxel. For the reconstruction, we use algorithm 1 and its default parameters. That is, in all the experiments, we start with 20 randomly located RBFs (), and at each iteration, we add 5 basis functions to improve the reconstruction (). We perform 40 iterations that result in 220 radial basis functions, and a typical reduction of 3 order of magnitude in the data term. The value of the regularization is initially chosen to be and we reduce it by a factor of after each iteration. Note that in every GN iteration, the regularization is zeroed according to the iterated Tikhonov approach described in Section 3. We set the grid domain to be the cube. Each of the initial RBFs is initialized as sphere with a radius of 1 (i.e., ), located randomly around the center of the grid. Its coefficient is initialized with a small random number. When adding RBFs during the optimization process, we set them with a smaller radius of , and zero their coefficient , such that we obtain monotonically non-increasing optimization routine. The location of the added RBFs is determined via the gradient of the objective function w.r.t , such that new basis functions are added at grid points where the magnitude of the gradient is largest to improve the representation of the object where it lacks the most.
6.2 Volumetric vs. PaLS Reconstruction
In this batch of experiments, we demonstrate that our framework can significantly enhance object reconstruction when there is not enough data. We compare the original work [1] using TV regularization and our RBF-based dip transforms for different numbers of dips (small vs. large data) and different degrees of noise in the acquisition parameters. The results are summarized in Fig. 6. First, to accurately reconstruct the object, the number of dips required in our framework (400) is significantly lower compared to the original method, which requires at least 1000 data measurements to produce a good reconstruction (this is aligned with the results in [1]). Secondly, and perhaps more importantly, our method is able to overcome uncertainty in the acquisition parameters, which, in the case of small data, completely ruins the TV reconstruction. In contrast to the tremendous impact that the calibration uncertainty has on reconstruction when using the conventional method, when using our method, its effect is small to insignificant.
6.3 Robustness to Calibration Uncertainty
In this section, we demonstrate the robustness of our reconstruction method to calibration uncertainty as discussed in Section 4.1. We start with an experiment of a reconstruction assuming all the acquisition parameters are known. Then, we gradually increase the calibration uncertainty level until it degrades the results to the extent that the reconstruction no longer resembles the object. Fig. 7 shows that our framework is capable of handling a significant amount of calibration noise—more than 10 degrees of noise in the object’s rotation and 17 percent in its translation. To assess the effect of the data size on the final reconstruction and robustness to noise, we conduct the experiment for low (200) and high (600) numbers of measurements. As expected, as the number of measurements increases, the reconstructions become more robust to calibration noise.
Here we also show the decay of the loss function as we increase the number of RBFs to reconstruct the object (Fig. 8). Note that the loss values do not include the regularization term, and hence they are not necessarily monotonically non-increasing. Our optimization method guarantees a monotonically non-increasing solution for the objective in Eq. (22).
6.4 Multi-modal Joint Reconstruction
Using the formulation in Eq. (24), we are able to use data from two different models to perform joint shape reconstruction. The first model that we use is the dip transform as in the previous experiments. The second input source is a modified version of the SfS algorithm that was suggested in Section 5.1. Figure 10 shows that the use of the dip transform technique alone necessitates a large number of measurements (800) to obtain a good reconstruction, and achieves poor quality when fewer measurements (200) are used. The addition of the visual source significantly improves the reconstruction while reducing the number of the required dips. Thus, we conclude that the joint inversion algorithm is superior in terms of reconstruction accuracy. In addition, perhaps more importantly its use enables a considerable reduction in the number of data measurements needed, a favorable outcome that could promote such experiments which are typically expensive, difficult and/or dangerous to conduct (e.g., CT scans) when using conventional techniques.
6.5 Shape reconstruction from Point Cloud
In this experiment we demonstrate our method for shape reconstruction from point clouds, as well as registration of point clouds. Often, two or more point clouds are given, possibly with some overlapping regions, and the goal is to align them such that they can be viewed as one point cloud for performing tasks like shape reconstruction. To demonstrate the registration and reconstruction from point clouds we generate two non-overlapping point clouds from the shape in Fig. 5(a)—see Fig. 11(a). Then we significantly move one of the point clouds as shown in Fig. 11(b), and try to reconstruct the shape. Since there is no overlap in the point distribution, methods like ICP often struggle to find the correct alignment. Fig. 11(c) shows the a reconstruction using our mesh-free implementation. From an optimization perspective, this reconstruction is good even though it is misaligned—the data term in this experiment was reduced by two orders of magnitude in the optimization process. The drop-like artifacts that appear in the reconstruction are not visible in the misfit term involving the point cloud. We note that our method is able to recover the right alignment for some cases of initialization and choice of parameters, but that is not guaranteed by a low data term, and is not robust. To guarantee the correct reconstruction following a successful optimization, we add another data modality, SfS, which includes silhouettes of the complete shape. Fig 11(d) shows a joint reconstruction from both the point clouds and 8 figures of silhouettes. This time, the point clouds are aligned by the optimization since it has the SfS to guide it towards the right shape, and recover the alignment parameters.
7 Conclusions and Future Work
In this paper, we proposed a general framework for robust and efficient 3D shape reconstruction using parametric level set methods with ellipsoidal radial basis functions. Using a compact PaLS representation, our reconstruction process estimates a relatively low number of parameters, and therefore, it requires a correspondingly small number of data measurements. Our framework has the ability to accurately estimate acquisition parameters as part of the reconstruction, and it is robust to noise that originates from inaccuracies in these parameters. Our framework also supports multi-modal reconstruction, and thus, it can be adapted to incorporate several models in a single shape estimation. The proposed method is capable of reducing the number of required measurements, which can generally be beneficial for models where experiments are expensive, difficult or dangerous to conduct (e.g., MRI scans).
The compact analytical PaLS representation can be used to enhance various applications. For example, it is a natural approach to apply reconstruction from tomographic measurements under deformation [53], where the deformations can be treated analytically using the PaLS representations, and the number of measurements can be reduced. The PaLS can also be considered as a regularization inside a deep neural network architecture, where the insights from this work can be incorporated to reduce the computational cost for 3D shape analysis and image segmentation.
8 Appendix
8.1 The Wendland’s and Heaviside Functions
The Wendland’s compactly supported radial basis functions [49] constitute a family of polynomial RBFs whose range is and zero outside (for , ). A common choice to be used in and is one of the following:
[TABLE]
where denotes the function. In this work, we use because it is the simplest differentiable function and we did not see any change in our experiments when using functions of higher order.
The Heaviside function smoothly transitions between 0 and 1. As shown in Fig. 3(a) and mentioned in [22], we wish to make the derivative of this function (the delta function) as flat as possible to render our Gauss-Newton Hessian better conditioned. We define our Heaviside function to be a smoothed linear transition from 0 to 1 using a piecewise polynomial function. More precisely, it is defined by a transition width and a smoothness width as follows:
[TABLE]
This function and its first derivative are continuous, and it is very similar to the function proposed in [22], using a function to define the transition smoothness. We prefer a polynomial approximation because of computation considerations. As default parameters throughout all the experiments in this paper, we choose , and use the letter to denote the function.
8.2 Derivatives of the Ellipsoidal PaLS Function
Here we show the derivatives of the ellipsoidal PaLS function, and the derivatives of the standard PaLS in (5) are defined in [2]. The -th basis function in the sum of (9) is defined by . For each RBF (containing 10 parameters), we define its radius by:
[TABLE]
Dropping the index , the matrix is defined by 6 parameters due to symmetry:
[TABLE]
We define the operator
[TABLE]
to be the operator that takes the vector and by multiplication transfers it into a vector of size 9 that corresponds to the symmetric matrix in (37). With this notation, the derivatives of are computed by:
[TABLE]
where , and the operator is the column-stack operator transferring a matrix into a vector of size 9. Now we can easily define the derivatives of , as the additional terms are just scalars:
[TABLE]
8.3 The derivatives of the rotated PaLS
As noted before, the radial basis functions can be rotated analytically. Thus, instead of rotating we can simply rotate each of the basis functions according to its rotation parameters. For the spherical RBFs, we have the rotation function in (17) for rotating the -th basis function at angles and translation vector , which corresponds to the j-th measurements of the shape. The Jacobian of (17) with respect to is equal to
[TABLE]
For the ellipsoidal RBFs, the rotation function is defined in (20) and its Jacobian is defined by
[TABLE]
where is the matrix defined in (47) and is an operator that chooses the 6 out of 9 rows of corresponding to the indices of the lower-triangular elements of a matrix. With this operator, the term .
8.4 Derivatives with respect to acquisition parameters
To incorporate the rotation parameters in the optimization process, we need to compute the derivatives of according to them. This way, we are able to overcome uncertainty of the calibration in the data-acquisition process. For spherical RBFs, we have to take the derivatives of (17) with respect to the additional 5 parameters in . We obtain:
[TABLE]
where
[TABLE]
Placing all the partial derivatives together in the Jacobian we obtain:
[TABLE]
For ellipsoidal RBFs, the derivatives of (20) include:
[TABLE]
where
[TABLE]
and the derivative with respect to is similar to (60). Altogether, we obtain the Jacobian:
[TABLE]
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] K. Aberman, O. Katzir, Q. Zhou, Z. Luo, A. Sharf, C. Greif, B. Chen, and D. Cohen-Or , Dip transform for 3d shape reconstruction , ACM Transactions on Graphics (TOG), 36 (2017), p. 79.
- 2[2] A. Aghasi, M. Kilmer, and E. L. Miller , Parametric level set methods for inverse problems , SIAM Journal on Imaging Sciences, 4 (2011), pp. 618–650.
- 3[3] A. Aghasi and J. Romberg , Sparse shape reconstruction , SIAM Journal on Imaging Sciences, 6 (2013), pp. 2075–2108.
- 4[4] H. Avron, A. Sharf, C. Greif, and D. Cohen-Or , ℓ 1 subscript ℓ 1 \ell_{1} -sparse reconstruction of sharp point set surfaces , ACM Transactions on Graphics (TOG), 29 (2010), p. 135.
- 5[5] S. Basu and Y. Bresler , Uniqueness of tomography with unknown view angles , IEEE Transactions on Image Processing, 9 (2000), pp. 1094–1106.
- 6[6] M. Berger, A. Tagliasacchi, L. Seversky, P. Alliez, J. Levine, A. Sharf, and C. Silva , State of the art in surface reconstruction from point clouds , EUROGRAPHICS star reports, 1 (2014), pp. 161–185.
- 7[7] M. Berger, A. Tagliasacchi, L. M. Seversky, P. Alliez, G. Guennebaud, J. A. Levine, A. Sharf, and C. T. Silva , A survey of surface reconstruction from point clouds , in Computer Graphics Forum, vol. 36, Wiley Online Library, 2017, pp. 301–329.
- 8[8] A. Bermano, A. Vaxman, and C. Gotsman , Online reconstruction of 3d objects from arbitrary cross-sections , ACM Transactions on Graphics (TOG), 30 (2011), p. 113.
