Privacy Preserving Group Membership Verification and Identification
Marzieh Gheisari, Teddy Furon, Laurent Amsaleg

TL;DR
This paper introduces a novel method for privacy-preserving group biometric verification and identification by jointly learning embedding and aggregation functions, improving security and performance in face recognition tasks.
Contribution
It advances prior work by jointly learning embedding and aggregation, replacing fixed rules with a trainable approach for enhanced privacy and accuracy.
Findings
Joint learning improves privacy-security trade-offs.
Method achieves high verification accuracy.
Enhanced face recognition performance.
Abstract
When convoking privacy, group membership verification checks if a biometric trait corresponds to one member of a group without revealing the identity of that member. Similarly, group membership identification states which group the individual belongs to, without knowing his/her identity. A recent contribution provides privacy and security for group membership protocols through the joint use of two mechanisms: quantizing biometric templates into discrete embeddings and aggregating several templates into one group representation. This paper significantly improves that contribution because it jointly learns how to embed and aggregate instead of imposing fixed and hard coded rules. This is demonstrated by exposing the mathematical underpinnings of the learning stage before showing the improvements through an extensive series of experiments targeting face recognition. Overall, experiments…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1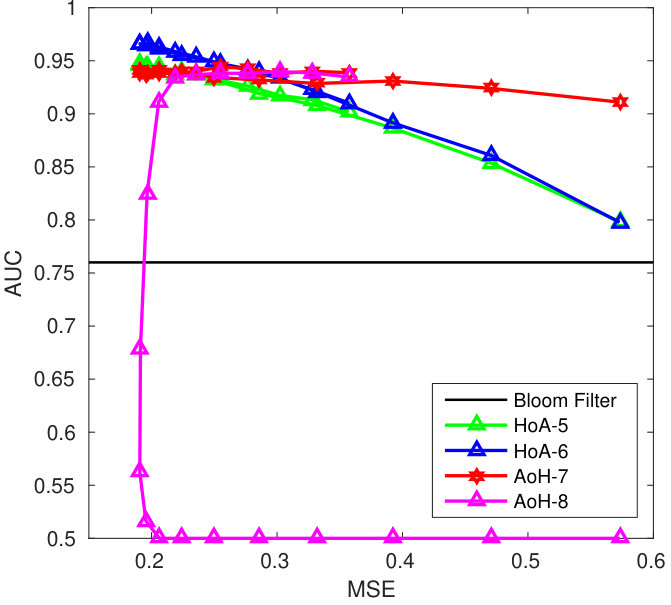 Figure 2
Figure 2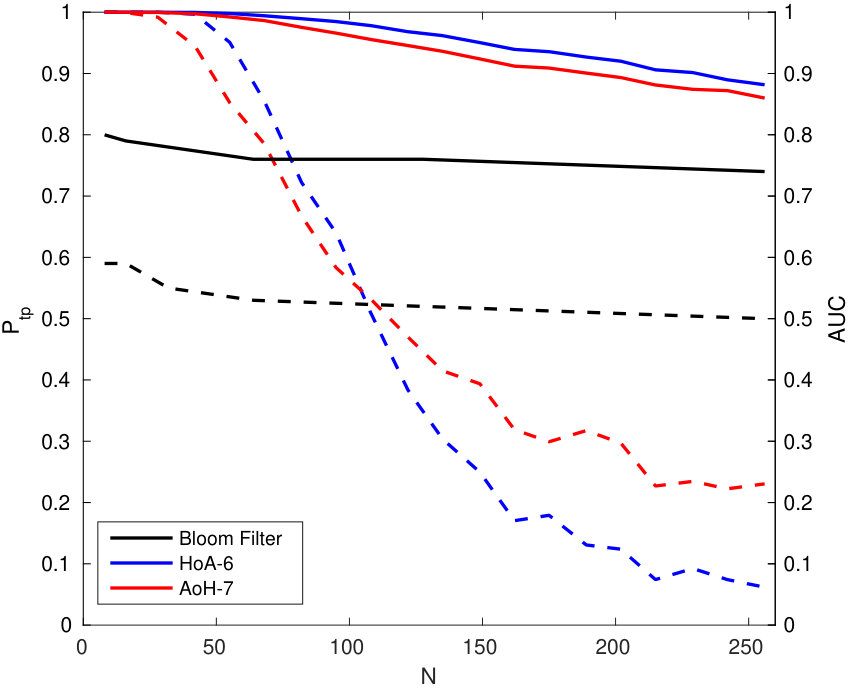 Figure 3
Figure 3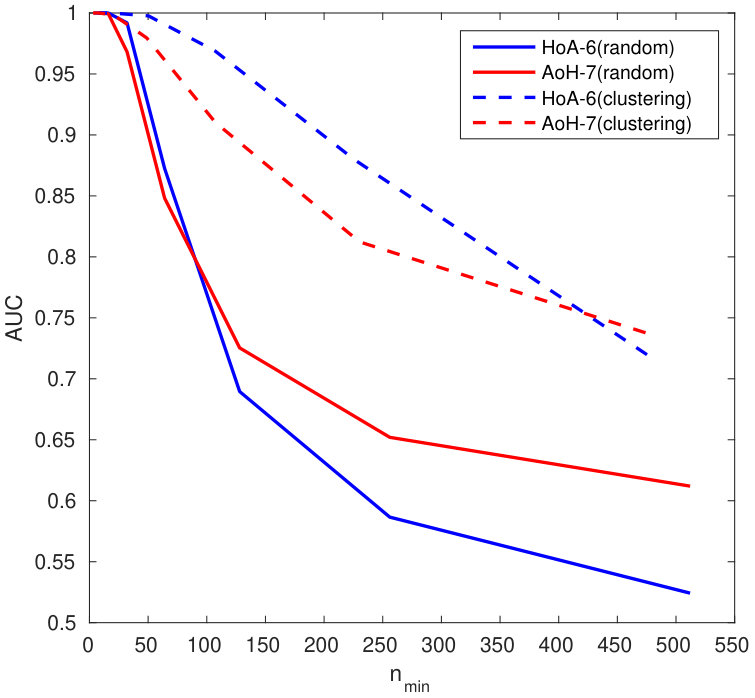 Figure 4
Figure 4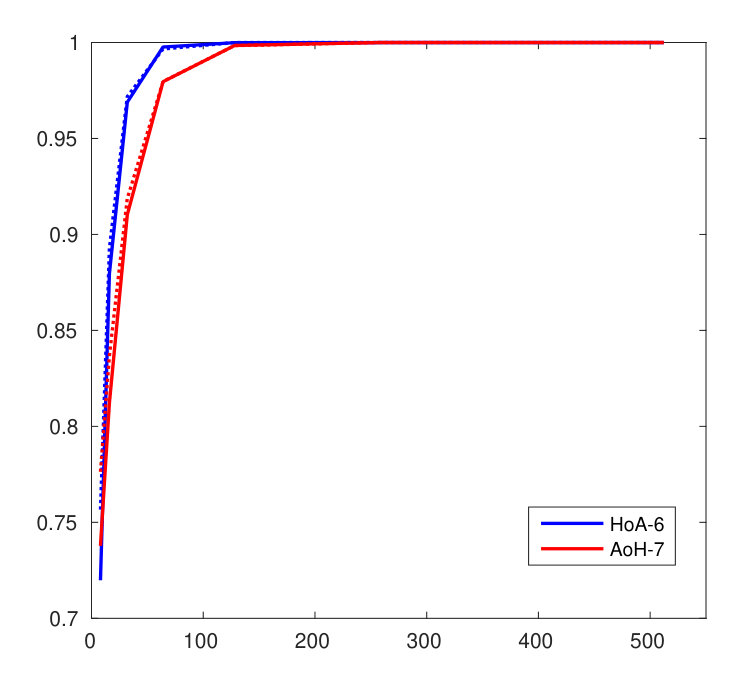 Figure 5
Figure 5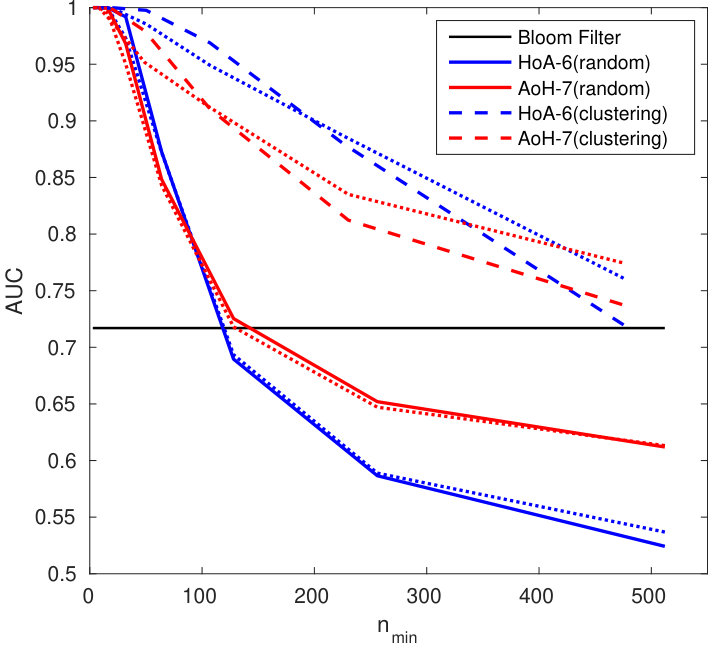 Figure 6
Figure 6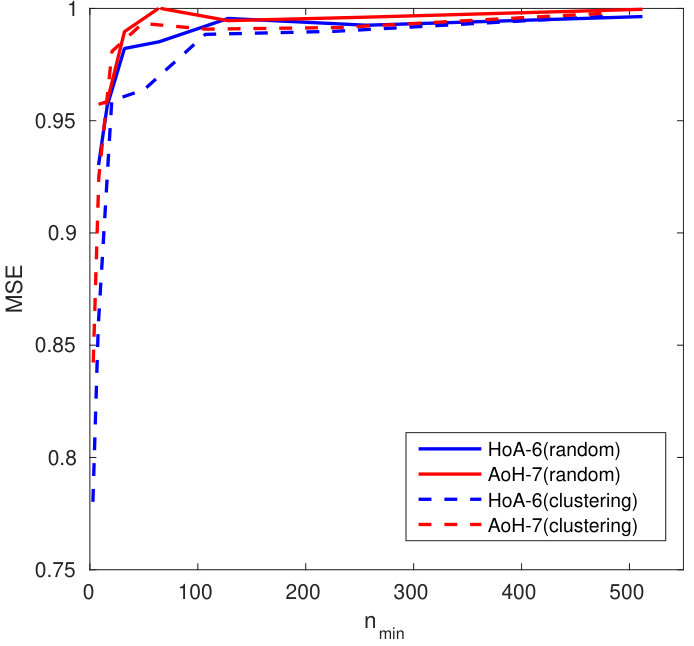 Figure 7
Figure 7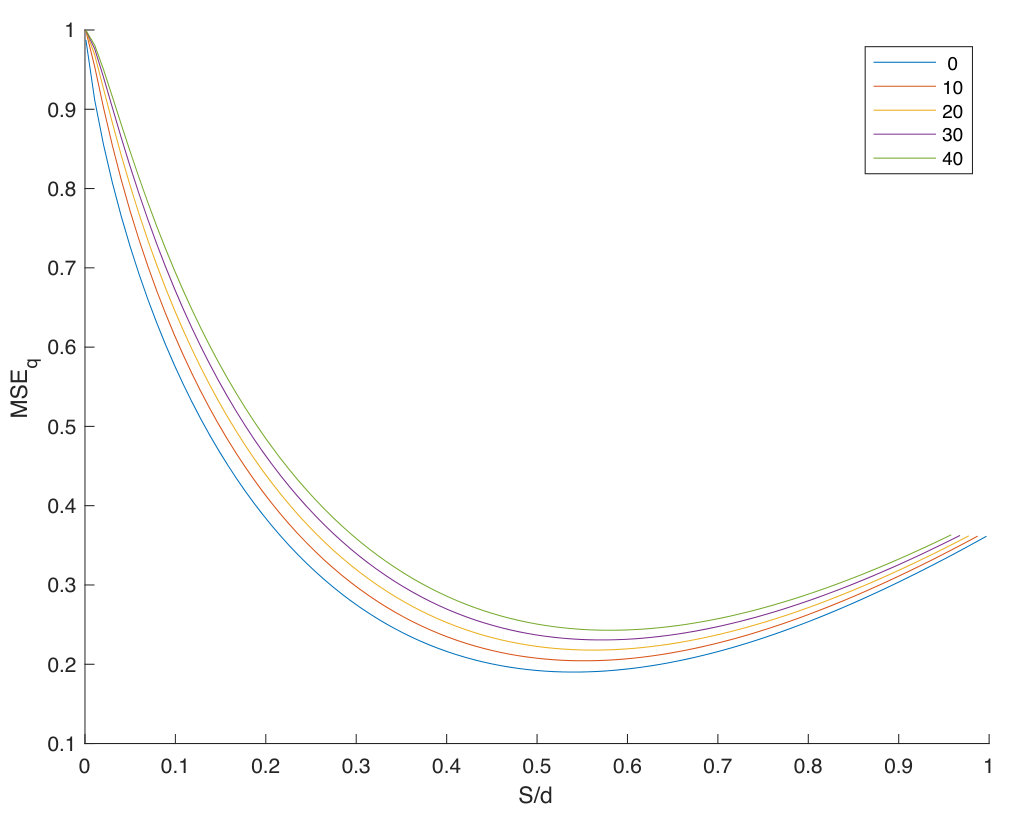 Figure 8
Figure 8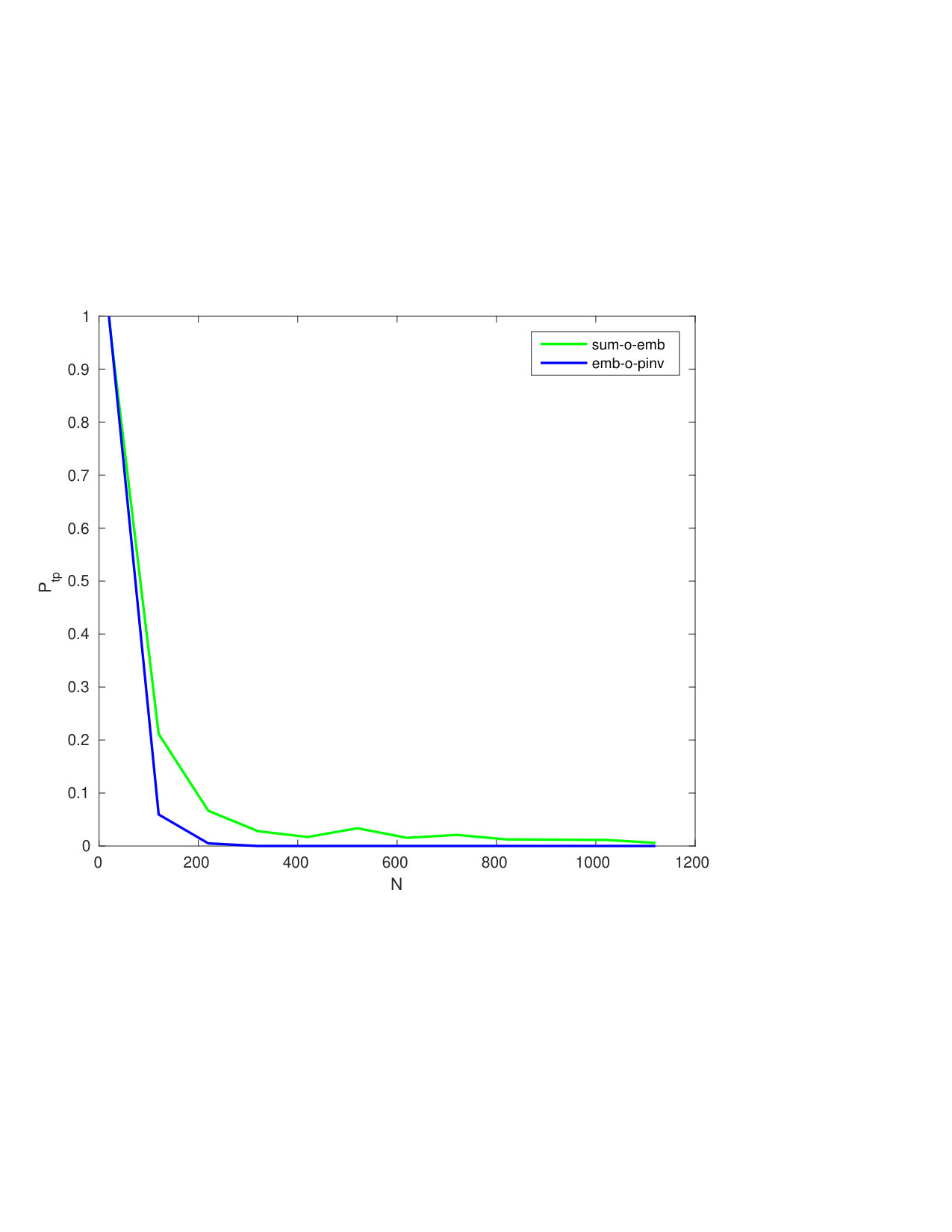 Figure 9
Figure 9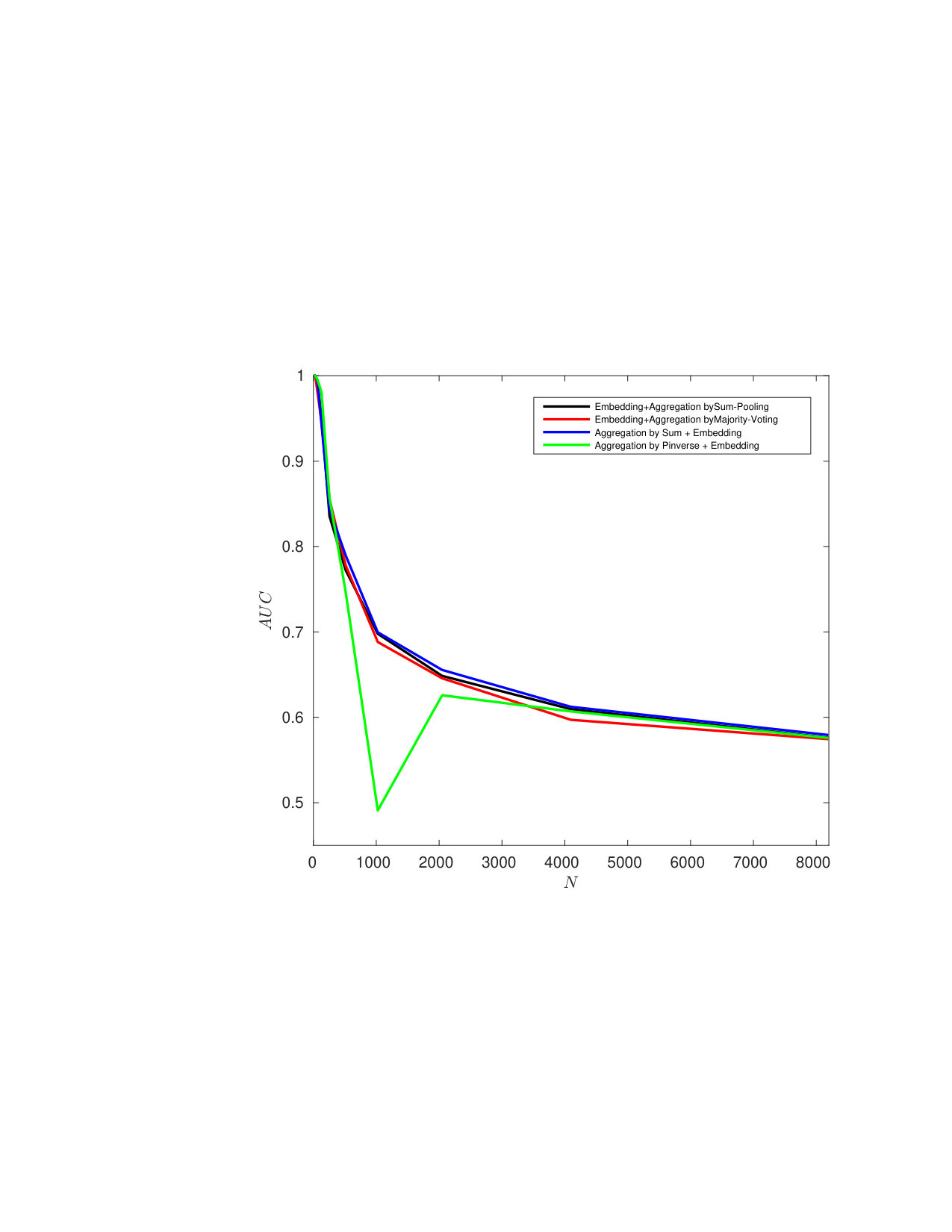 Figure 0
Figure 0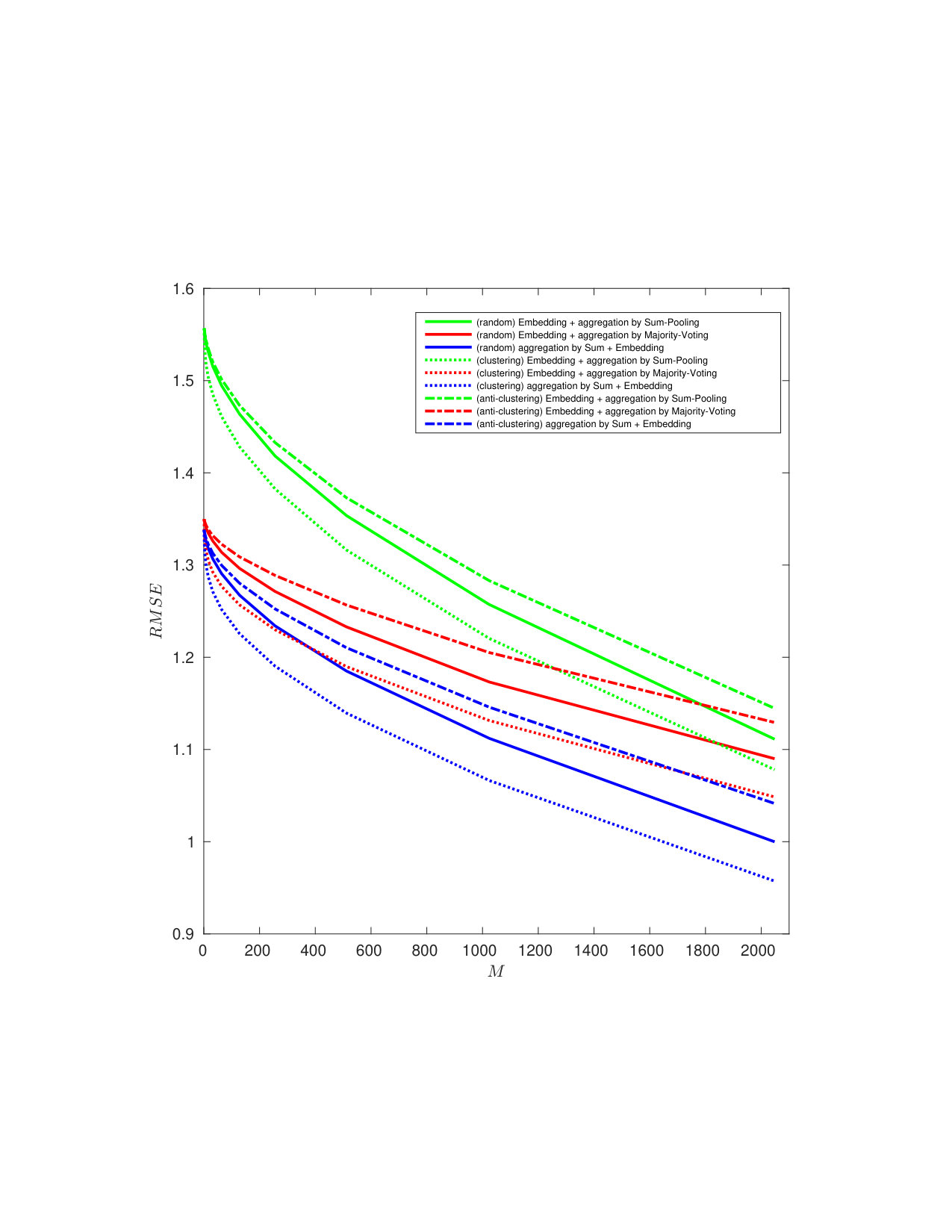 Figure 11
Figure 11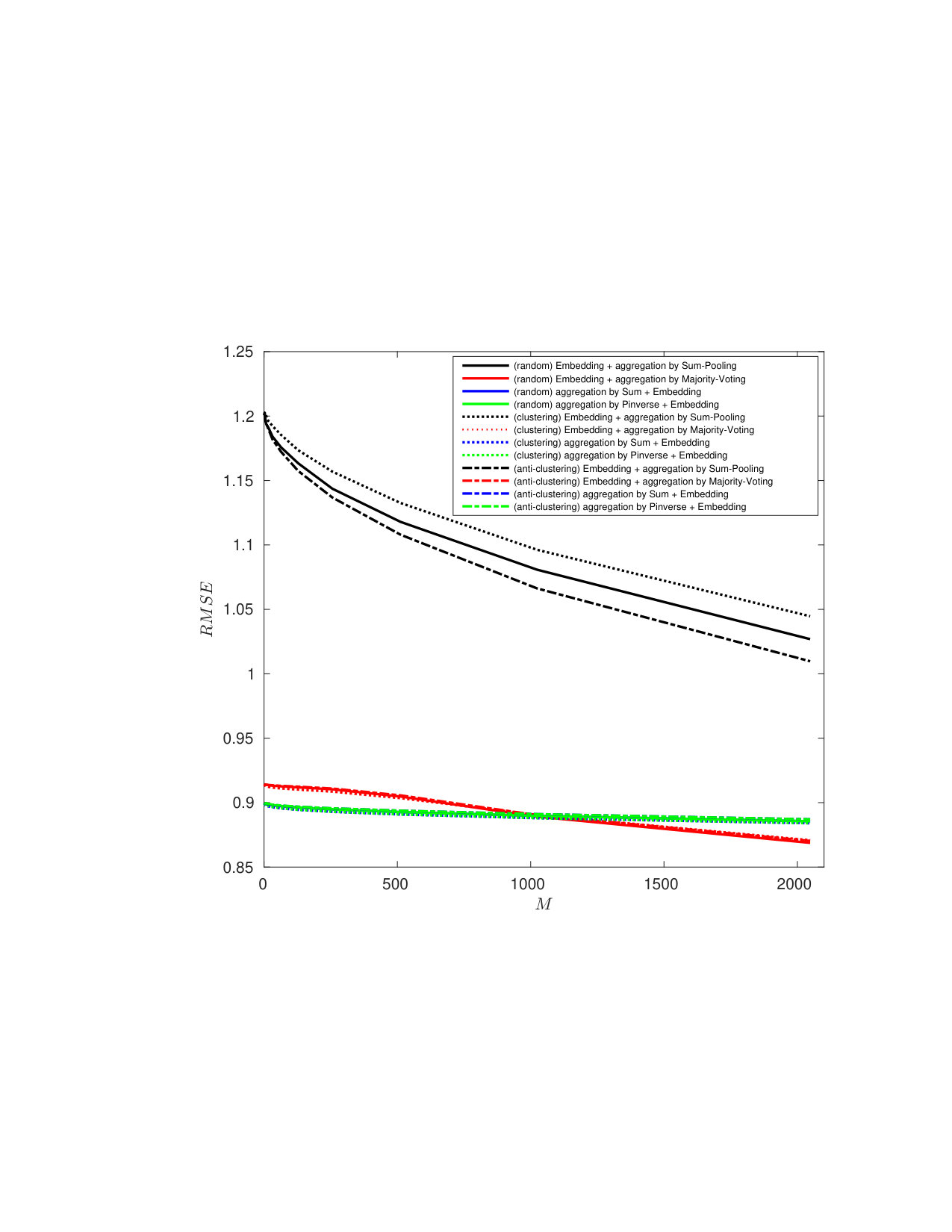 Figure 11
Figure 11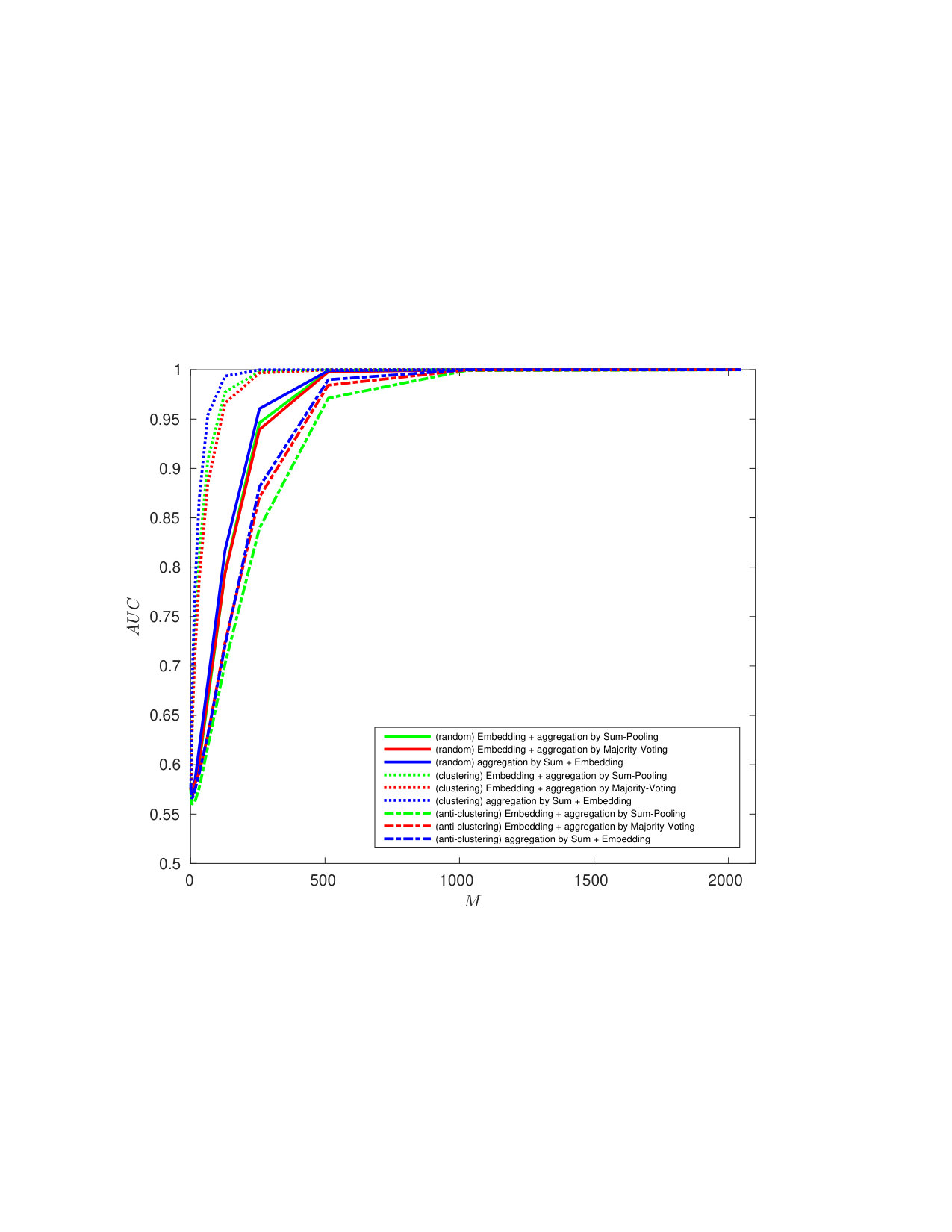 Figure 1
Figure 1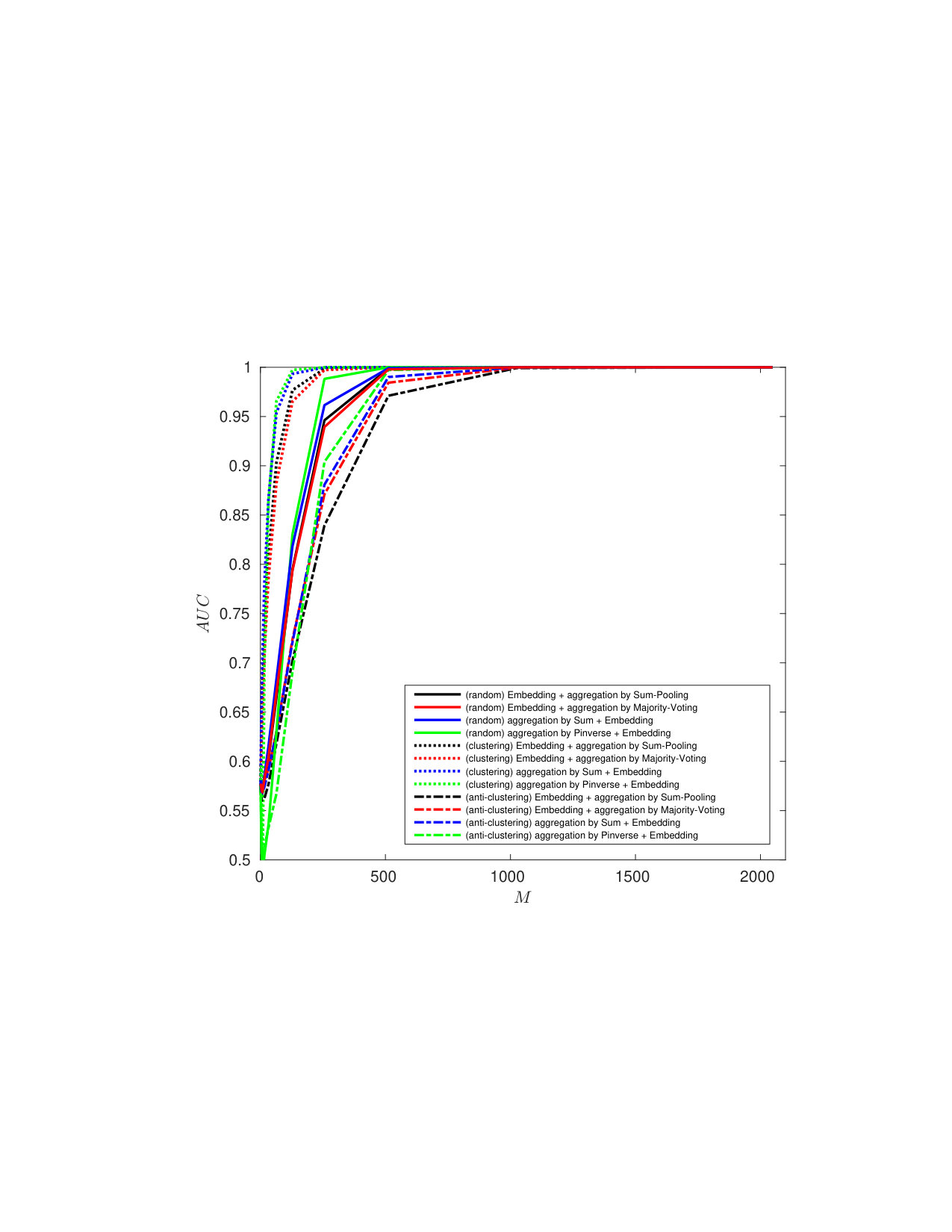 Figure 1
Figure 1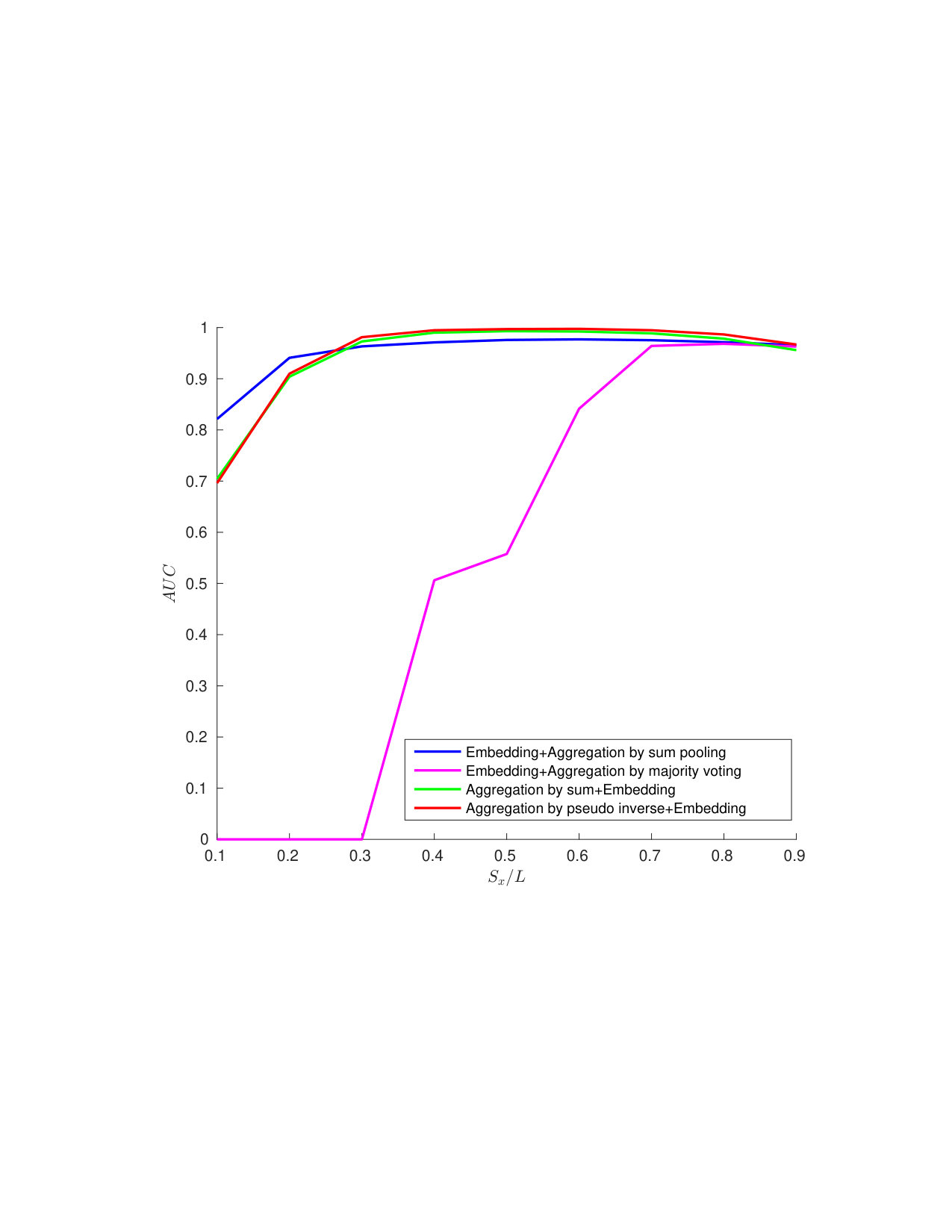 Figure 2
Figure 2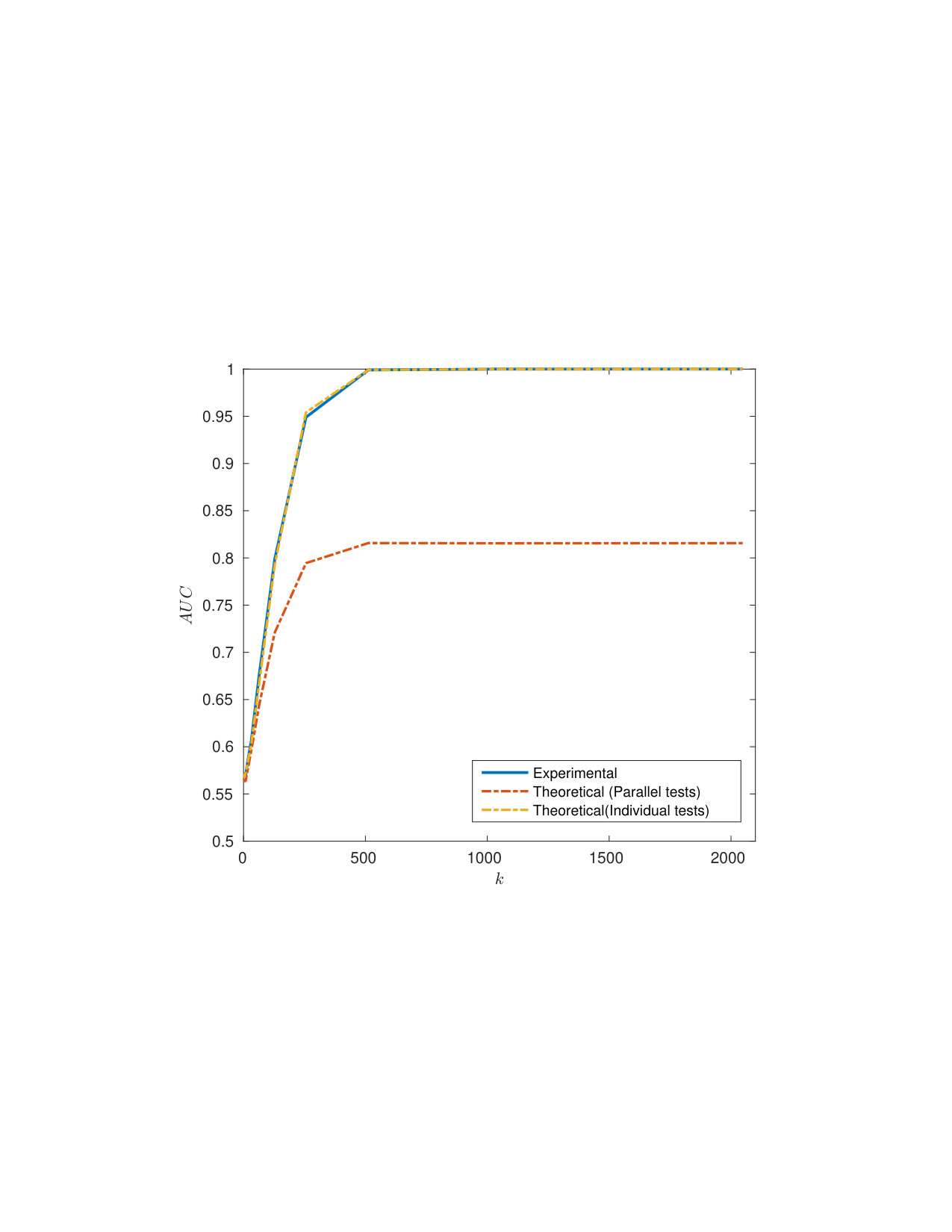 Figure 3
Figure 3 Figure 4
Figure 4 Figure 18
Figure 18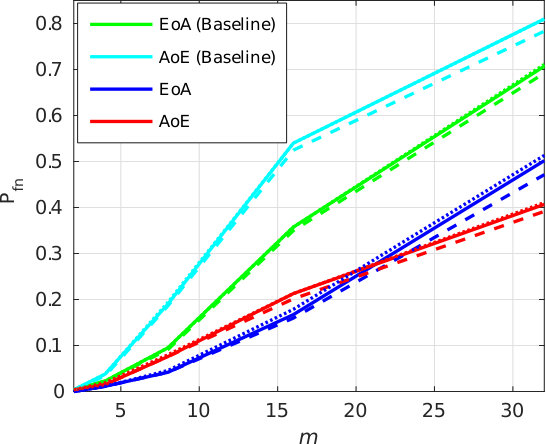 Figure 2
Figure 2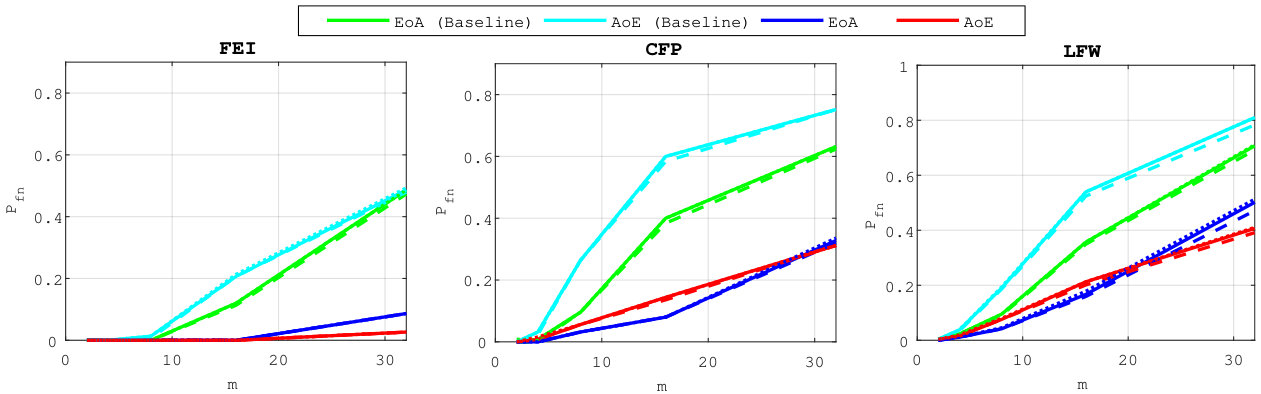 Figure 2
Figure 2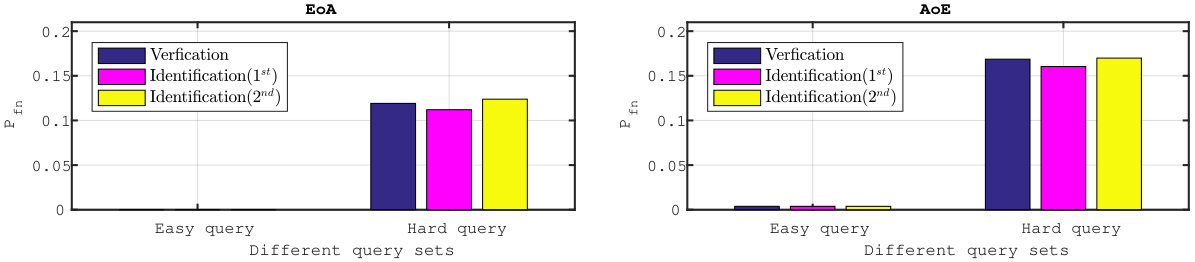 Figure 3
Figure 3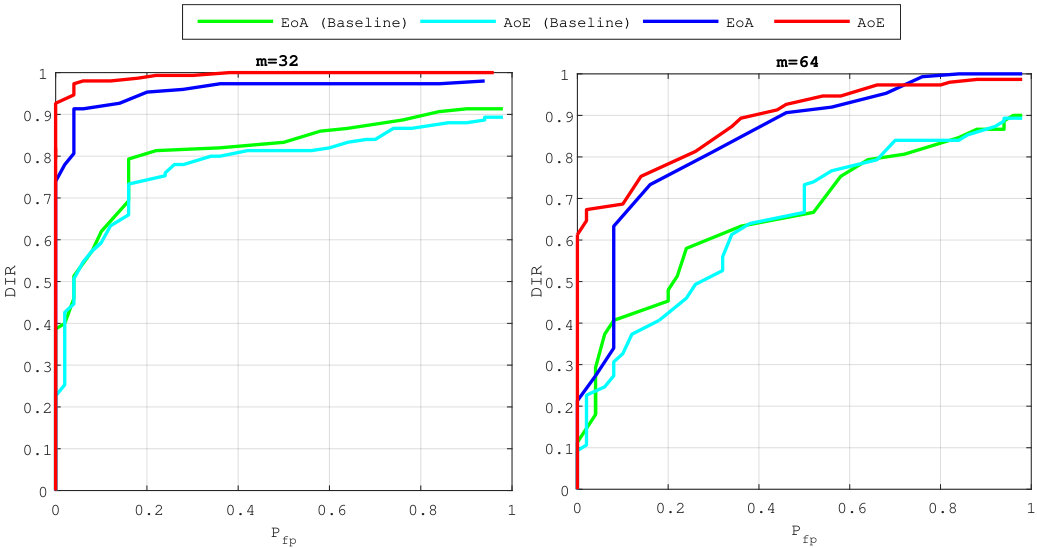 Figure 3
Figure 3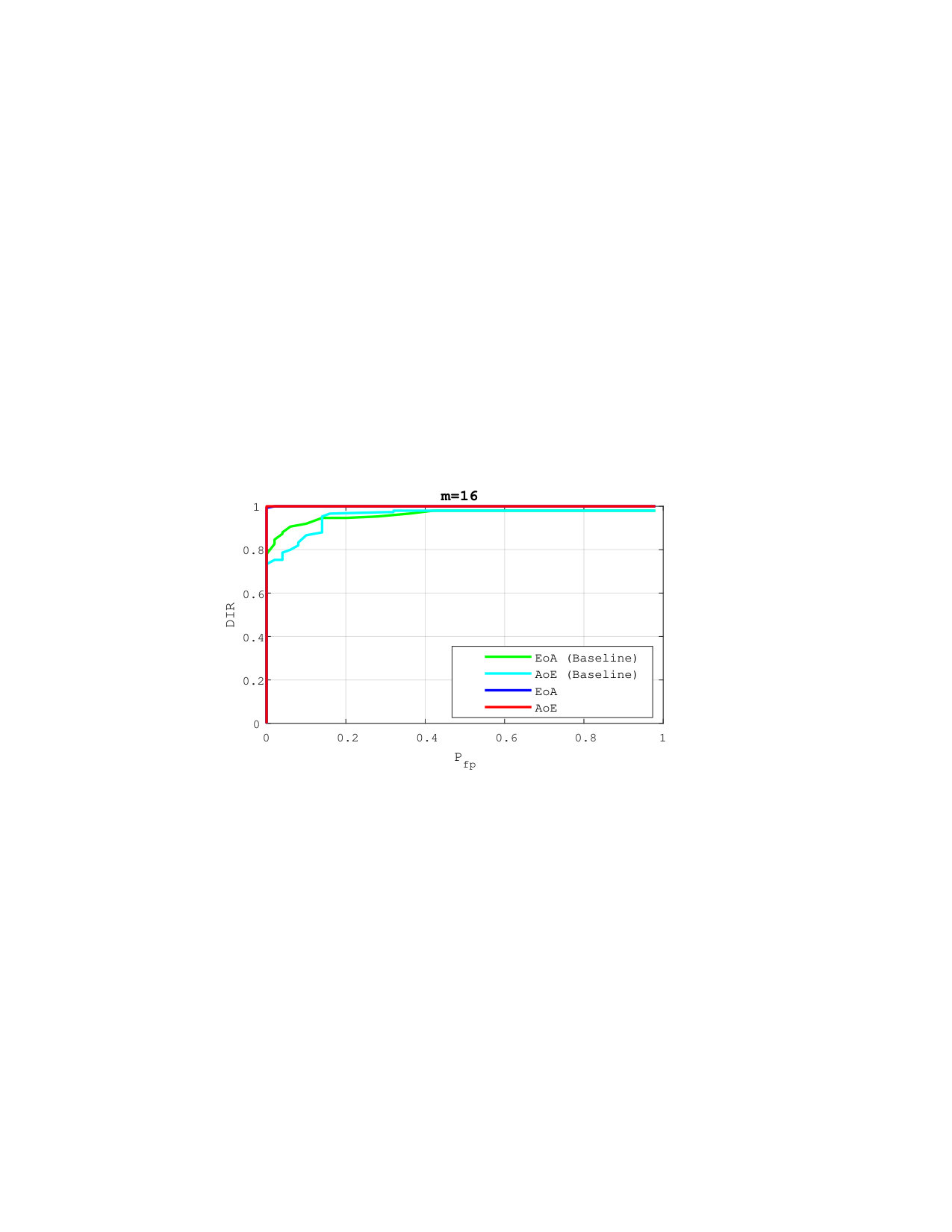 Figure 3
Figure 3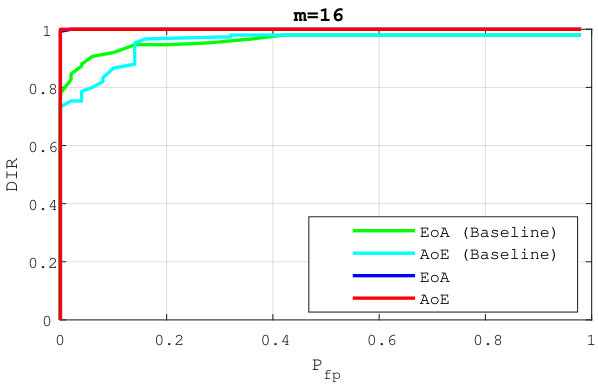 Figure 3
Figure 3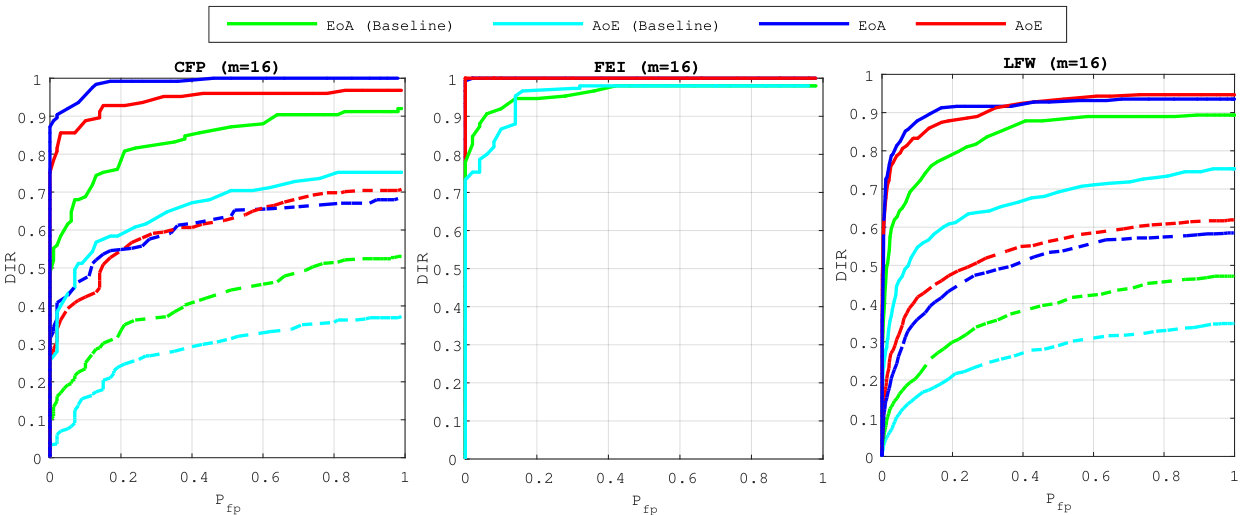 Figure 3
Figure 3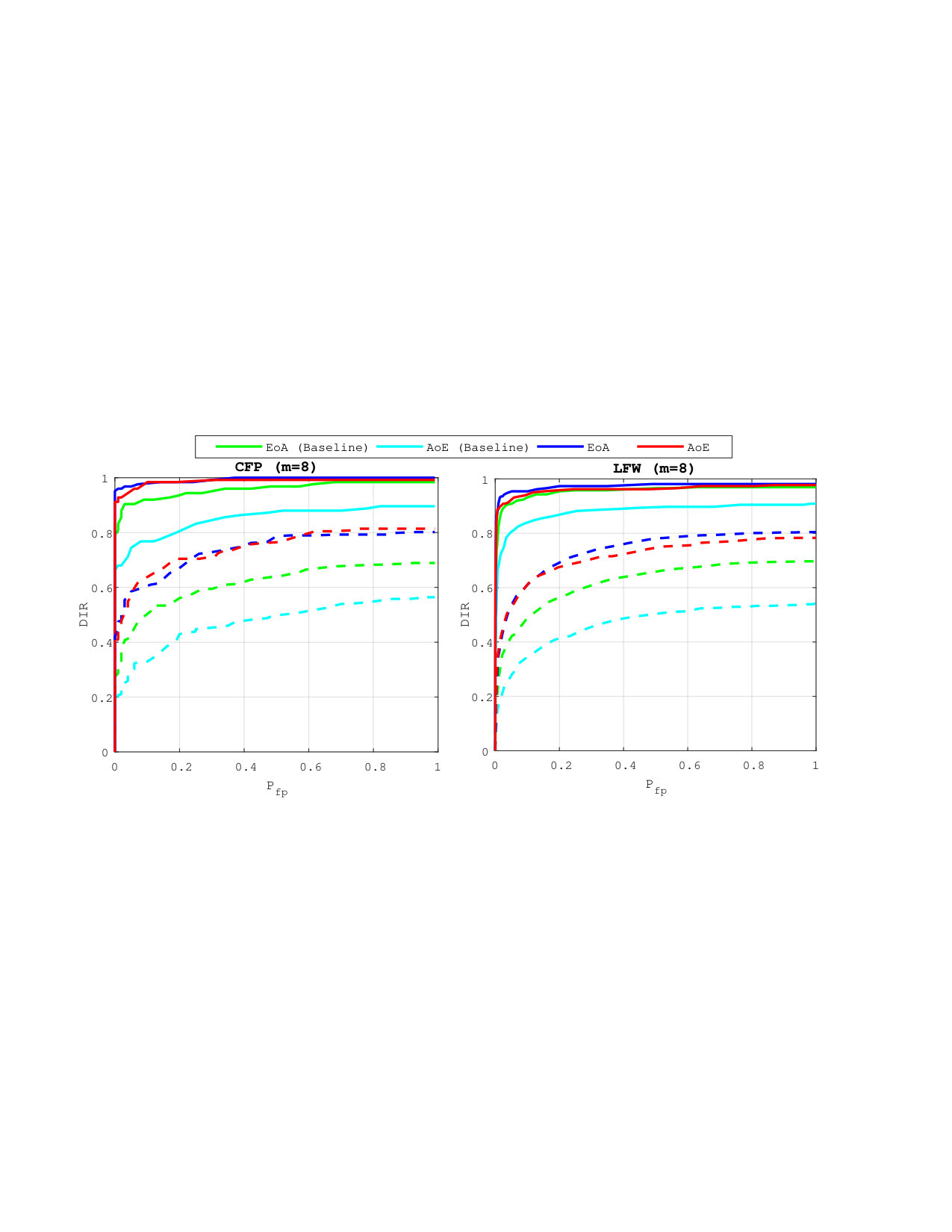 Figure 3
Figure 3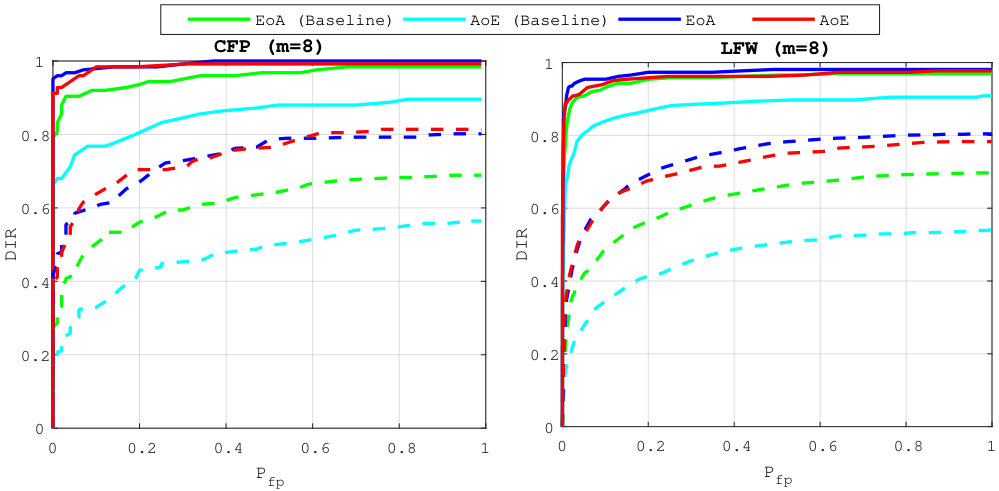 Figure 3
Figure 3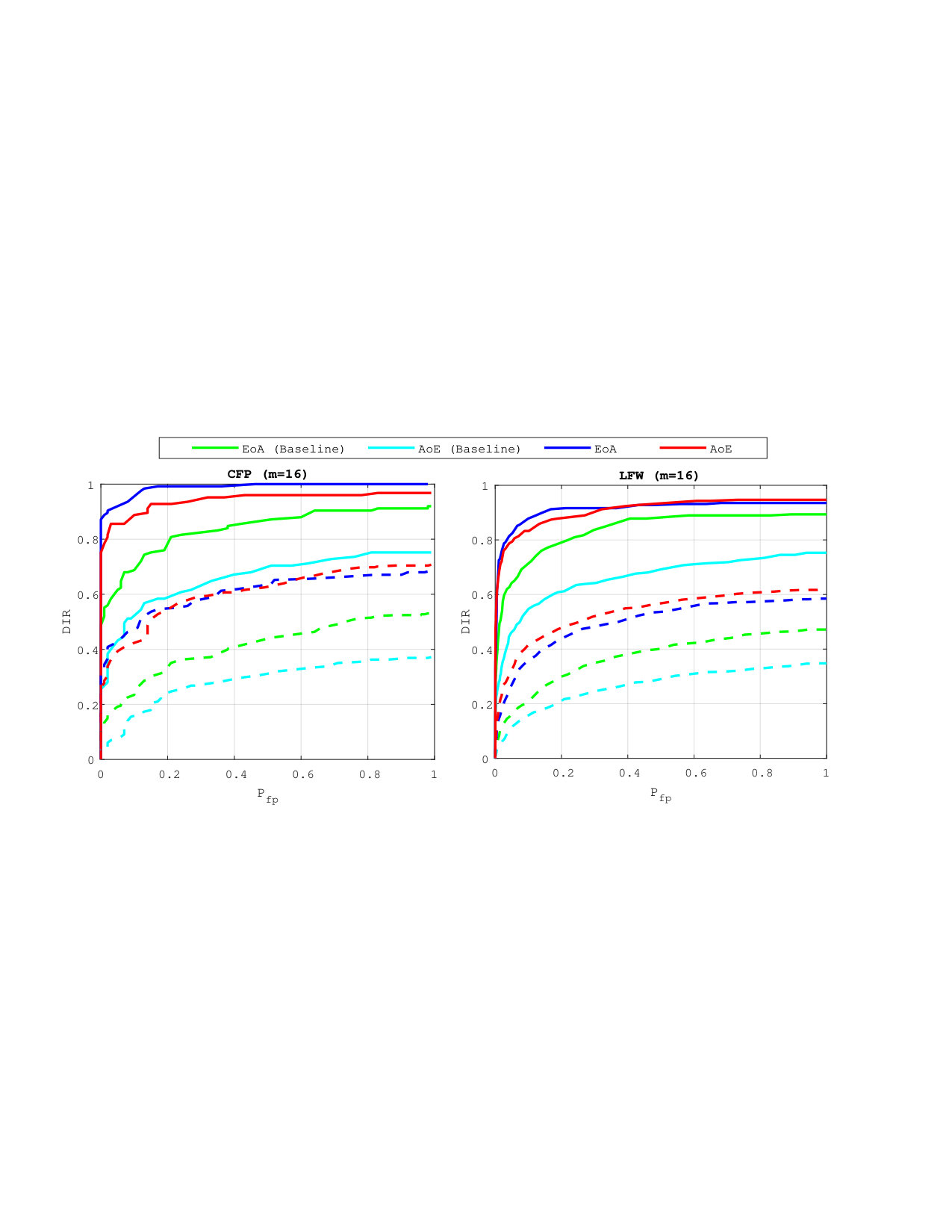 Figure 3
Figure 3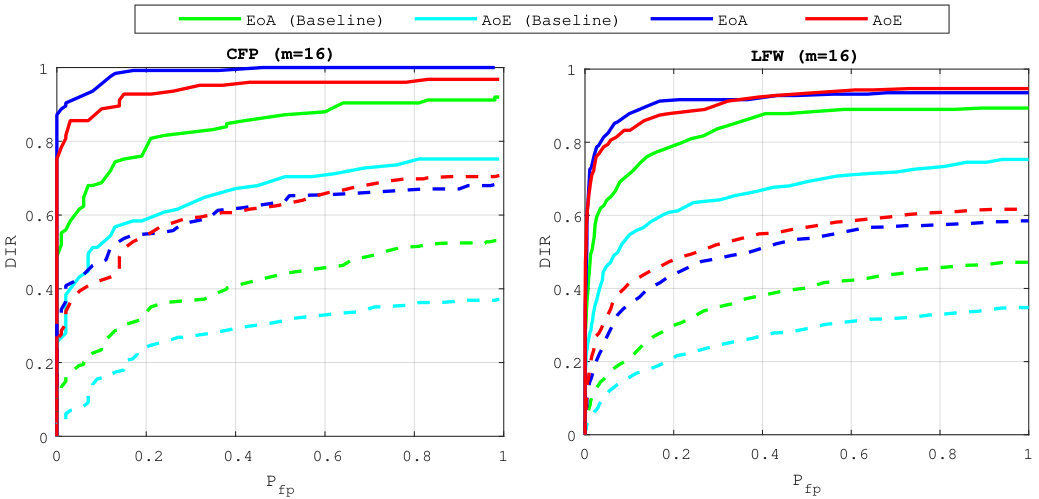 Figure 3
Figure 3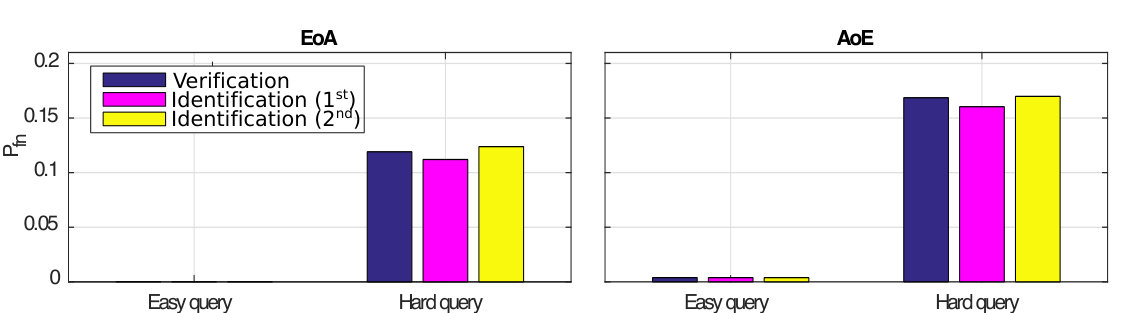 Figure 3
Figure 3 Figure 3
Figure 3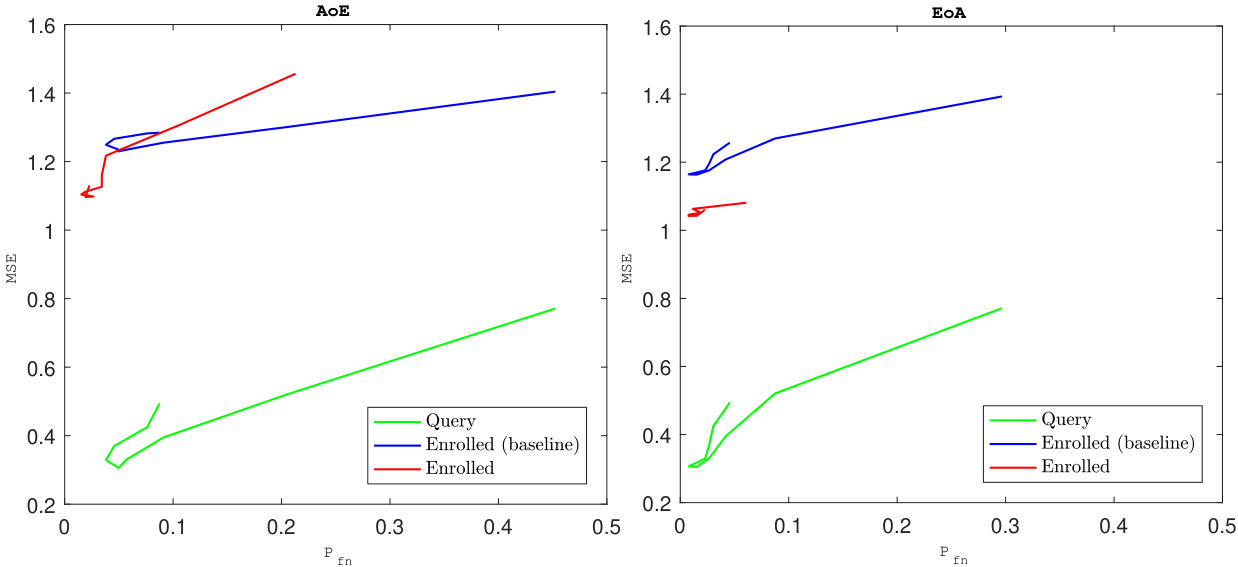 Figure 4
Figure 4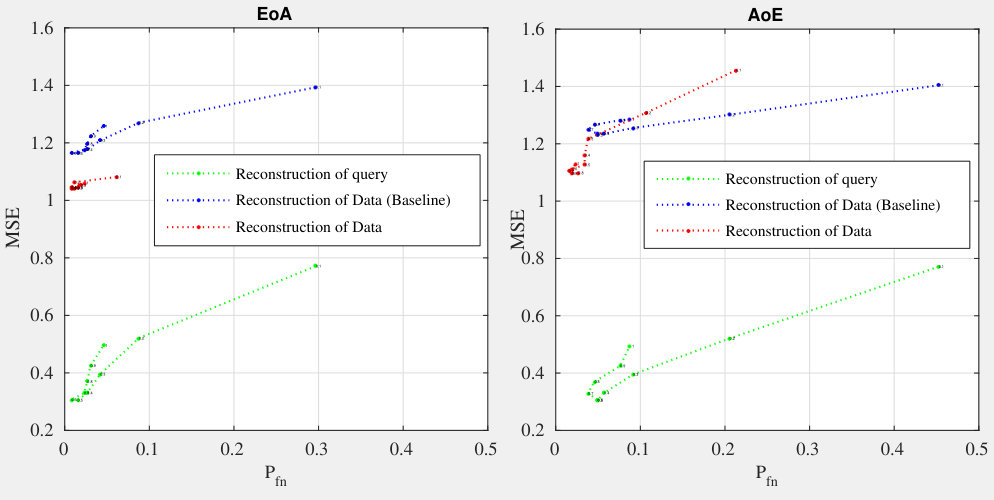 Figure 4
Figure 4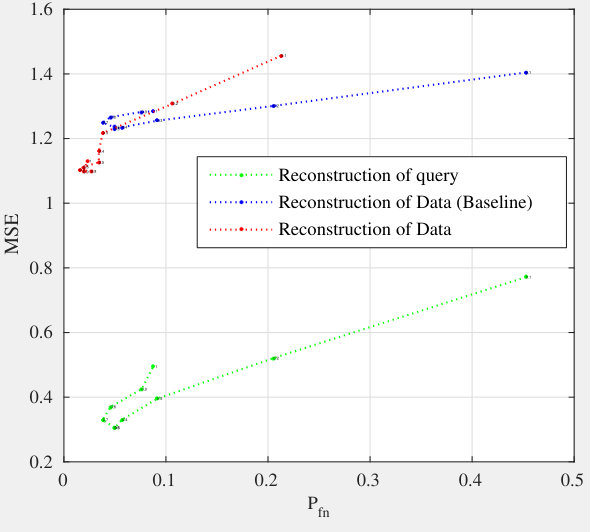 Figure 4
Figure 4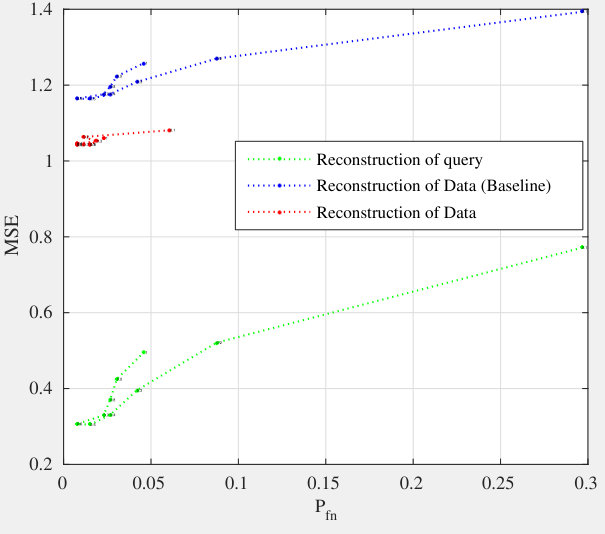 Figure 4
Figure 4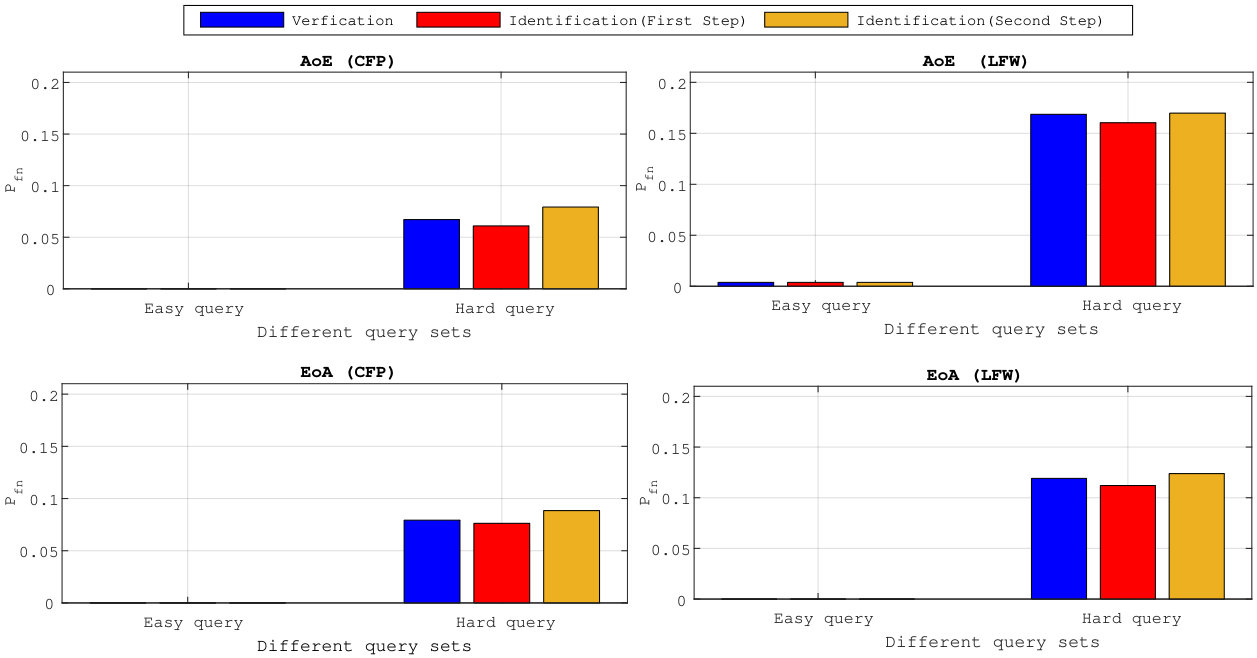 Figure 4
Figure 4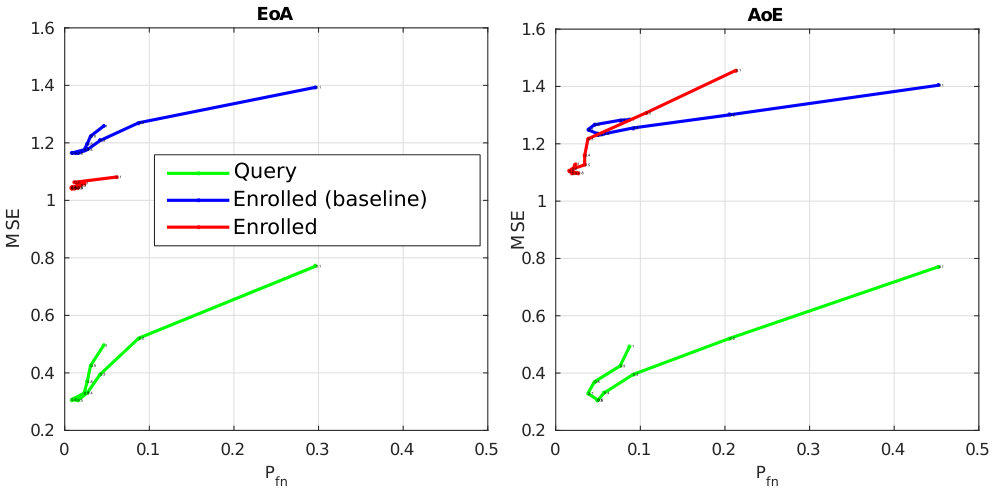 Figure 4
Figure 4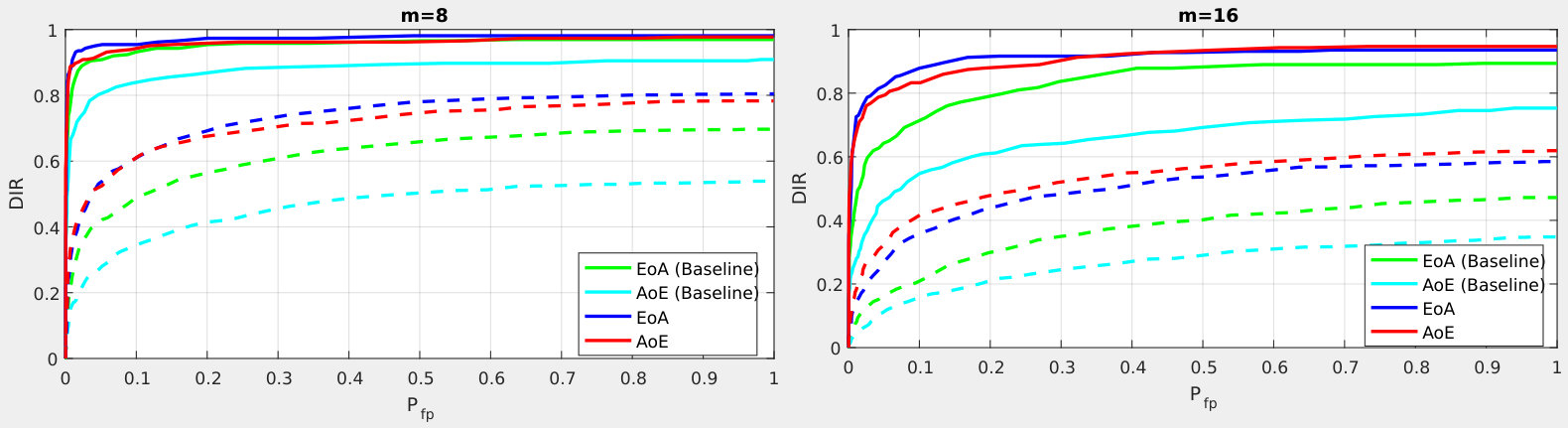 Figure 5
Figure 5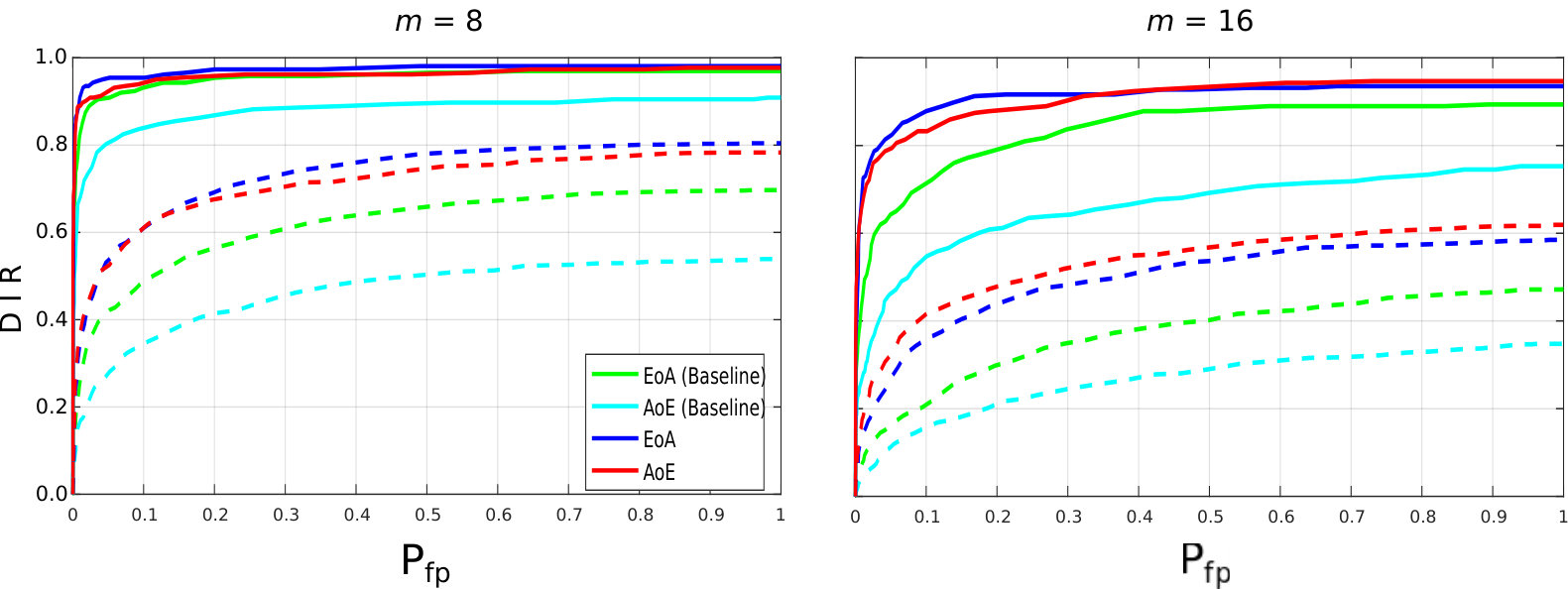 Figure 5
Figure 5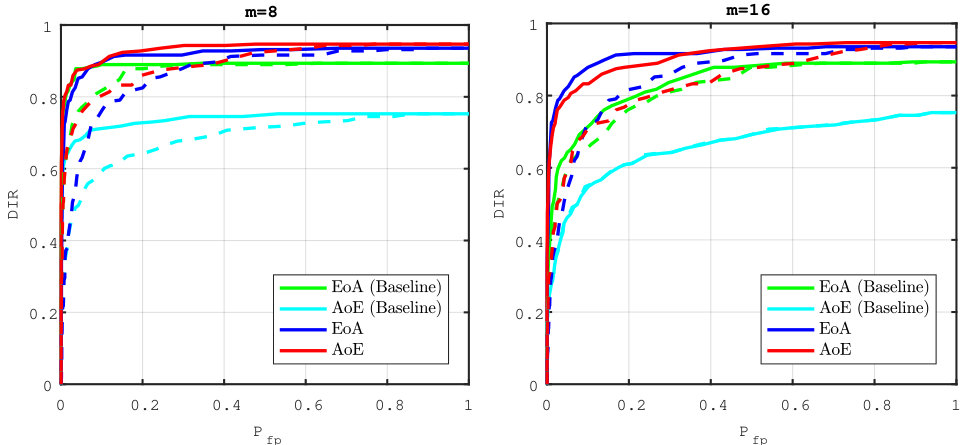 Figure 5
Figure 5Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsBiometric Identification and Security · Privacy-Preserving Technologies in Data · Face recognition and analysis
Privacy Preserving Group Membership Verification and Identification
Marzieh Gheisari, Teddy Furon, Laurent Amsaleg
Univ Rennes, Inria, CNRS, IRISA, France
{marzieh.gheisari-khorasgani, teddy.furon}@inria.fr, [email protected]
Abstract
When convoking privacy, group membership verification checks if a biometric trait corresponds to one member of a group without revealing the identity of that member. Similarly, group membership identification states which group the individual belongs to, without knowing his/her identity. A recent contribution provides privacy and security for group membership protocols through the joint use of two mechanisms: quantizing biometric templates into discrete embeddings, and aggregating several templates into one group representation.
This paper significantly improves that contribution because it jointly learns how to embed and aggregate instead of imposing fixed and hard coded rules. This is demonstrated by exposing the mathematical underpinnings of the learning stage before showing the improvements through an extensive series of experiments targeting face recognition. Overall, experiments show that learning yields an excellent trade-off between security / privacy and the verification / identification performances.
††Research supported by the ERA-Net project ID_IoT 20CH21_167534.
1 Introduction
The verification that an item, a device or an individual is a member of a group is a natural task which forms the basis of many applications granting or refusing access to sensitive resources (buildings, wifi, payment, conveyor units, …). Group membership can be implemented through a two-phase process where an identification is first performed, revealing the identity of the individual under scrutiny, followed by a verification phase where it is checked whether or not the identified individual is indeed a member of the claimed group. That implementation breaks privacy: there is no fundamental reason to identify the individual before running the verification step. It is easier, but not truly needed. It is fundamental to distinguish the members of the group from the non-members, but it does not require to distinguish members from one another.
The same comments hold for group identification. Such a system manages multiple groups, separating e.g. individuals according to the team they work in. The goal is then to identify the precise group a member belongs to, without proceeding first to the identification of the individual.
Privacy preserving protocols exist, for the most part in the area of signal processing in the encrypted domain [19, 4, 13]. These protocols, however, are costly, making them hard to use in practice.
In contrast, some other approaches propose privacy preserving mechanisms that are cheaper to use because they solely rely on pure signal processing techniques, excluding all encryption mechanisms. They tend to be less secure, of course, but they put in the way of malicious users so many obstacles that breaking privacy or counterfeiting identities becomes discouragingly complicated and almost impossible. At their core, these approaches use for example sketching or quantization techniques that prohibit reconstructing identities with sufficient precision [2, 3]. Other techniques embed real vectors into another representational space with the purpose of security and privacy [12, 11].
Recently, Gheisari et al. proposed a privacy preserving group membership verification protocol quantizing identities’ biometric templates into discrete embeddings and aggregating multiple embeddings into a group representation [5]. That scheme has several desirable properties: It is pure signal processing and linear algebra, hence it is cheap to run; quantization and aggregation fully succeed to make reconstruction difficult and impede identification; it is demonstrated to allow trading-off the strength of its security against group verification error rates.
That work, however, is fully deterministic in the sense that it sticks to a set of hard coded rules that drive the way templates are embedded, how they are grouped and then aggregated into group representations. Although well justified and sound, these rules govern the behavior of two independent procedures, one for embedding, the other for aggregating. The main contribution of this paper shows that jointly considering the embedding and aggregation stages results in better performances, i.e. a better membership verification without damaging security.
This paper is therefore revisiting the core mechanisms proposed by Gheisari et al. in [5], by jointly optimizing the embedding and aggregation stages. It is structured as follows. Section 2 defines the context of this work and surveys existing approaches. Then, Section 3 gives a formal problem statement and the details of proposed method are introduced in Section 4. Section 5 presents the experimental protocol and results.
2 Context and Related Work
2.1 Context
Without any loss of generality, group membership verification needs first to acquire templates of items (passive PUF), devices (active PUF), or individuals (biometric trait) and to enroll them into a data structure stored in a server. Then, at verification time, that data structure is queried by a client with a new template and the access is granted or refused. Security assesses that the data structure is adequately protected so that a honest but curious server cannot reconstruct the templates. Privacy requires that verification should proceed without disclosing the identity.
The nature of templates can vary from one application to the other. For example, the templates encode information related to fingerprints, iris, or faces of individuals, or to Physically Unclonable Functions (PUF) like speckle patterns captured from laser-illuminated transparent plastic.
It is worth highlighting two fundamental properties of the templates. The template used at verification time is a noisy version of the one acquired at enrollment time. Lighting conditions, blood pressure, aging, worn-outs, transient physical conditions are possible factors that might cause variations at acquisition time. The verification protocol must be able to absorb such variations and cope with the continuous nature of the templates. However, it is very unlikely that a noisy version of the template corresponding to one group member gets similar enough to the enrolled template of any other group member. The first property is therefore in relation with the continuous and distinguishable nature of the templates. The second property is in relation with the statistical independence of the enrolled templates.
The traditional operational scenario considers a server which runs the group membership verification. The server receives queries from clients. A client acquires a new template and then queries the server. Clients are trusted. The server is honest but curious: It may try to reconstruct the enrolled templates or spy on the queries. The design intends to prevent the server from reconstructing the private template from the system while correctly determining whether or not a user is a member of the claimed group (group verification) or identifying the group of membership (group identification).
2.2 Related Work
2.2.1 Cryptography
There exist cryptographic protocols setting a key management system to provide the members of a group with anonymous authentication [14]. There is no enrollment of biometric or PUF templates since membership is equivalent to holding one of the valid keys. As for biometry or PUF applications, our scenario is different from authentication, identification and secret binding. These applications secure the templates at the server and/or the client sides, but ultimately reveal the identity of the user/object.
Signal processing in the encrypted domain can provide a solution to group membership verification. At enrollment time, each template is quantized and protected with homomorphic encryption. The query is protected in the same manner at the verification stage. This allows to compute distances between the query and the templates in the encrypted domain [19]. There exist protocols for comparing encrypted results to a threshold [4, 13]. These encrypted comparisons are sent back to the clients which decrypt and check whether there is at least one positive. Security and privacy are as high as the security of the cryptographic primitives. Homomorphic encryption, however, is costly, both in terms of memory footprint (space) and CPU consumption (time).
2.2.2 Sketching techniques
Group membership is linked to the well-known Bloom filter that is used to test whether an element is a member of a set. A Bloom filter hashes and blends elements into one array of bits. When used in the context of privacy, it was demonstrated that a server using Bloom filters cannot infer any information on one specific entry [2]. However, a Bloom filter can not be used as is in our application, but it needs two adaptations. First, a Bloom Filter deals with discrete objects whereas we consider continuous high dimensional vectors, the templates. We first need to design a quantizer hashing the continuous templates into discrete objects. That quantizer must absorb the noise, i.e. the difference between the enrolled and the fresh template. Second, at verification time, the hash of the query cannot be sent in the clear for privacy reasons [3]. For instance, Beck and Kerschbaum protect the query with partially homomorphic encryption since there is no need to protect the filter at the server side [1].
2.2.3 Aggregating, Embedding
Aggregating signals into one representation is a very common mechanism in computer vision. Approaches like BoW (Bag of Words) [17], VLAD [8], Fisher vectors [10], aggregate some local descriptors extracted from one image into one global description. However, these approaches are designed to facilitate the identification of similar elements in images and have no security or privacy capabilities.
Another recent aggregation method better fits with the security and privacy requirements that we need. In [7], Iscen et al. use the group testing paradigm to design a strategy for packing a random set of image descriptors into a unique high-dimensional vector. One salient property of that strategy is that the similarity between images can be determined by solely comparing these (few) aggregated vectors to the description of the query, without the need of the original (and numerous) raw image descriptors. This saves space (memory footprint of the database) and time (complexity at query time). These gains are the main motivation of [7].
As for the embedding, our scenario is similar to a privacy-preserving identification mechanism based on sparsifying transform [12, 11]. It obtains a sparse ternary embedding preserving locality information while ensuring privacy of the data users and security of the templates.
Indeed, paper [5] uses the aggregation methods designed in [7] combined with the sparsifying transform [12, 11]. Our design resorts to this latter mechanism for inheriting its privacy-preserving properties as well, yet we replace the former ad-hoc hard coded rules of [7] by a machine learning approach.
2.2.4 Face recognition
Aggregating templates into one group representation also exists in face recognition, but privacy and security are not a requirement in the design of this primitive. They are usually taken into account with an extra layer (see Sect. 2.2.1). In a common approach, multiple face captures of the same person are combined to gain robustness against poses, expression, and quality variations [21]. In our scenario, the group is composed of unique faces of different persons.
Paper [20] computes a single compact descriptor for the faces of celebrities appearing in the same picture. The query is a small set of face descriptors and their system returns photos where these celebrities appear altogether. This paper consists in jointly learning the face description and the aggregation mechanism. The authors report “a minimal loss of discriminability up to two faces per image, and degrades slowly after that”.
Our paper deals with the aggregation for a given on-the-shelf face descriptor. On one hand, our setup is easier because the query is a single face. On the other hand, our group typically comprises more than two faces, and each is possibly captured according to very different conditions.
3 Problem Formulation
This section details the way the group membership problem is formulated and also defines the metrics used to evaluate performances.
3.1 Notations
The set of individuals is denoted as , partitionned into groups: . The size of a group is denoted by . In the experiments of Sect. 5, all the groups share the same size denoted as .
The templates to be enrolled are the vectors , …, . They are stored column wise in matrix according to the partition over the groups: , where stores the templates belonging to , . The output of the enrollment is a matrix composed of the representations of the groups. It is imposed that the group representations are quantized and sparse: with and , . Moreover, the analysis is restricted to the case where .
The template for which the membership has to be verified is a query vector that is cast onto thanks to an embedding before being compared to the group representations.
3.2 Embedding
Function maps a vector to a sequence of discrete symbols. We intentionally choose the sparsifying transform coding described in [12, 11] for its security and privacy good properties. It projects on the column vectors of . The output alphabet is imposed by quantizing the components of . The components having the lowest amplitude are set to 0. The remaining ones are quantized to +1 or -1 according to their sign.
[TABLE]
3.3 Performances Metrics
Paper [5] defines metrics to assess (i) the ability of the protocol to correctly perform the verification task, and (ii) the security and privacy.
3.3.1 Verification Performance
The first metrics is seeded by considering the following two hypotheses:
- •
: The query is related to one of the vectors of group . For instance, it is a noisy version of vector , , with to be a noise vector and .
- •
: The query is not related to any vector in the group.
The group membership test decides which hypothesis is deemed true by comparing to . This is done by first computing a score function and thresholding its result: .
The probabilities of false negative, , and false positive, are summarized by the AUC (Area Under the ROC Curve). Paper [5] also considers for s.t. , a required false positive level, for example.
3.3.2 Security and Privacy Performance
A curious server can reconstruct the query template from its embedding: . This endangers privacy of the querying user. The mean squared error assesses how accurate is this reconstruction:
[TABLE]
assuming that is a white gaussian vector in .
As for the security of the enrolled templates, a curious server can only reconstruct a single vector from the aggregated representation, and this vector serves as an estimation of any template in the group:
[TABLE]
4 Proposed Method
4.1 Variants of the Protocol
Our group membership protocol is based on embedding and aggregation functions. Whereas the embedding function is fixed, we can have two constructions: The aggregation of embeddings or the embedding of the aggregation.
EoA
aggregates raw templates into one vector of , and then embeds this vector. Then, the group representative vector is computed as:
[TABLE]
where is the matrix storing the templates of the -th group.
AoE
first embeds each template according to (1) before aggregating them into :
[TABLE]
This work aims at learning the aggregated vectors and the embeddings jointly. For both construction, this is done by minimizing an objective function summing a cost for embedding and a cost for aggregating .
For AoE (first embed, then aggregate), denote the matrix storing the embeddings of the enrolled templates. Like for , we write with the matrix gathering the embeddings of the templates of group . For EoA (first aggregate, then embed), denote the matrix gathering the aggregations of the templates enrolled in a group.
Matrices and will be defined through optimization problems detailed below. For the embedding, function is still prototyped according to Sect. 3.2. Papers [12, 11] show that privacy and security stem from the sparsifying transform. Only its matrix is learned.
For EoA, Fig. 1 shows that it starts from to create before outputting using matrix . This defines the optimization problem:
[TABLE]
where is the penalty parameter, , , and .
On the other hand, Fig. 1 shows that for AoE, we start from to create using matrix before outputting the group representations . This defines the optimization problem:
[TABLE]
with , , and .
Under both constructions, the optimization is joint because the embedding and the aggregating costs share a common variable ( or ). What follows define the costs and solve the optimization problems.
4.2 AoE: Aggregation of Embeddings
This scheme first embeds and then aggregates by solving (7). The cost for embedding is defined as
[TABLE]
This term represents the fidelity penalty of an embedding w.r.t. a template in the transformed domain.
For each group of embedded templates, the aggregated vector should satisfy some properties as well:
- •
For each group the overall distance between group members and the aggregated vector is minimized.
- •
Aggregated vector should be represented as a sparse ternary code.
The cost of aggregation is then defined as
[TABLE]
We add the following constraints:
[TABLE]
The constraint makes sure that the representative is sparse, ternary, and diverse.
We propose to optimize problem (7) iteratively by alternating updates of one parameter while fixing the remaining ones. Each step minimizes the total cost function lower bounded by 0, insuring a convergence to a local minimum.
-Step.
We fix and and update by solving:
[TABLE]
This problem is a least square Procruste problem with orthogonality constraint. By setting , [15] shows that , where contains the eigenvectors corresponding to the () largest eigenvalues of and contains the eigenvectors of .
-Step.
and being fixed, we can solve the problem for each independently: ,
[TABLE]
According to [12], we first find the solution without considering the constraints and then apply ternarization function (1) to obtain sparse codes. Therefore is found as:
[TABLE]
-Step.
Like for the -step, updating each group representation is done independently, while fixing and :
[TABLE]
Then the representative of -th group is obtained as:
[TABLE]
4.3 EoA: Embedding of Aggregation
We now consider the construction of (6) that first aggregates and then embeds. The cost of the aggregation is defined as:
[TABLE]
Minimizing this cost amounts to equalize the similarity between each members of the group and the aggregated vector . The cost for embedding is defined as previously:
[TABLE]
As for the constraints:
[TABLE]
The optimization problem (6) with these costs and constraints is solved by iterating the following steps.
- Step.
Like for (14), updating while , are fixed is a Procruste problem under orthogonality constraint:
[TABLE]
Similar to (14), we define . The solution is found as , where contains the eigenvectors corresponding to the largest eigenvalues of and the eigenvectors of .
- Step.
When fixing and , the aggregated vector for each group is found independently by minimizing:
[TABLE]
whose solution is
[TABLE]
- Step.
Projection matrix and the group aggregations are fixed. The group representatives are obtained by applying sparse ternarization function on the projected aggregated vectors: .
5 Experiments
We fully implemented the group membership protocol that is described in [5]. Experimenting with this implementation gives the baseline performances. Note that the experimental part of [5] only deals with synthetic data. Our implementation could reproduce these results. However, the sequel presents comparisons on real data.
5.1 Experimental Setup
We evaluate the performances of our scheme with face recognition. Face images are coming from LFW [6], CFP [16] and FEI [18] databases. Face descriptors are obtained from a pre-trained network based on VGG-Face architecture [9]. The output vector of the penultimate layer (i.e. before the final classifier layer) is PCA reduced to a lower dimension ( for LFW and CFP, for FEI database), and then -normalized. The result is the template . The values of , , , and are set empirically as , , , and respectively. Also, not all individuals from these databases are enrolled.
LFW.
Labeled Faces in the Wild contains 13,233 images of faces collected from the web. We used cropped LFW images. The enrollment set consists of individuals with at least two images in the LFW database. One random template of each individual is enrolled in the system, playing the role of . The other templates are used for queries. These are partitioned into two subsets: templates that are correlated with with a similarity bigger than form the “easy queries” set ; the remaining templates with a similarity bigger than form the “hard queries” set. The remaining individuals not enrolled in the system () play the role of impostors (hypothesis ).
CFP.
The Celebrities in Frontal-Profile (CFP) database is composed of subjects with frontal and profile images for each subject in a wild setting. We only use the frontal images. The impostor set is a random selection of individuals. One random template of the remaining individuals is enrolled in the system. Like the setting described for LFW, we have two subsets of queries.
FEI.
We use frontal and pre-aligned images of the Brazilian FEI database. There are subjects with two frontal images (one with a neutral expression and the other with a smiling facial expression). The database is created by random sampling individuals. For each identity, one random image is enrolled while the other is used as query. The remaining individuals are considered as impostors.
At the enrollment phase, all groups have exactly the same number of members: . Individuals are randomly assigned to a group.
The performances of the system are gauged with error probabilities evaluated by Monte Carlo estimator over the testing set. Since is not so large, the confidence interval at is , which prevents us from estimating small probabilities. Therefore, we put our system under stress by selecting a hard setup. First, note that LFW and CFP are difficult datasets due to the ‘in the wild’ variations (poses, illuminations, expressions and occlusions). They do not reflect the application of accessing a building (as mentioned in the Introduction) where the capture environment is more under control and the individuals collaborate. Second, not only the dimension of the templates have been reduced but also the length of the embeddings and the group representation () with a sparsity of (unless stated otherwise). Probabilities of errors are then big but measurable with accuracy. We believe that this protocol makes sense to benchmark approaches.
Two applications scenarios are investigated: group verification and group identification.
Group verification.
A user claims she/he belongs to group . This claim is true under hypothesis and false under hypothesis (i.e. the user is an impostor). Her/his template is embedded, and is sent to the system, which compares to the group representation . The system accepts () or rejects () the claim. This is a two hypothesis test with two probabilities of errors: is the false positive rate and is the false negative rate. The figure of merit is when .
Group identification.
The scenario is an open set identification where the querying user is either enrolled or an impostor. The system has two steps. First, it decides whether or not this user is enrolled. This is verification as above, except that the group is unknow: The system computes , . The system accepts if the minimum of these distances is below a given threshold . The figure of merit is when .
When , the system proceeds to the second step. The estimated group is given by . The figure of merit for this second step is or the Detection and Identification Rate .
5.2 Exp. #1: Comparison to the baseline
Figure 2 shows that our method brings improvement compared to the baseline, since the AoE and the EoA plots are way below the ones corresponding to the baseline. The high probabilities of false negatives for the baseline are caused by the great losses in information: AoE (Baseline) looses information from each template it embeds before the aggregation—the accumulated losses are therefore great; EoA (Baseline) has better performances since plain templates are first aggregated before running the embedding step which causes less information loss.
Our method does not suffer that much from this information loss: EoA and AoE have roughly similar performances, with much more acceptable values.
5.3 Exp. #2: Detection and Identification Rate
Figure 3 compares the performances for group identification with . Our schemes have results close to perfection on the FEI dataset. Easy queries are correctly handled on CFP but not on the LFW dataset at this size of group. Hard queries are more difficult to cope with. This is explained by the poor correlations they have with their corresponding . That poor correlation, already existing on the original templates, before any embedding or aggregation, can only lower the performances of any membership identification scheme.
Figure 4 shows the impact of the size of group on . Packing more templates into one group representation is detrimental even if the queries are well correlated with their corresponding enrolled template. This suggests to split large groups into subgroups of size lower or equal to . This restricts privacy to -anonymity as the server is now able to identify the subgroup a query belongs to.
5.4 Exp. #3: Easy vs. Hard Queries
Figure 5 gives an additional perspective on the phenomenon highlighted above, that is, the genuine similarity between the query and the enrolled template is a key factor. Easy queries are very well handled whereas hard queries are more problematic. Put differently, the proposed method do not severely degrade the recognition power of the descriptors obtained through the VGG16 network. Descriptors poorly correlated already at the image level can only cause poor performance once embedded and aggregated. This is also shown in Fig. 7 which displays some enrolled and querying faces of the ‘in the wild’ datasets LFW and CFP. All the failed identification examples show a change of lighting, pose or expression, and / or occlusion. Yet, such changes do not automatically give a failure.
5.5 Exp. #4: Security and Privacy
As for the security and privacy, the quantities (2) and (3) were measured as empirical average over the dataset.
Knowing that the query has unit norm, the reconstruction mechanism yields a unit vector as follows: . The quality of the reconstruction mainly depends on the sparsity factor . When is small, the template is reconstructed with few columns of . When is big, more columns are used but the amplitude modulating each column is coarsely reconstructed. There might be two values of , one small, one large, providing the same reconstruction MSE. However, these two values do not yield the same performances as shown in Fig. 6.
Reconstructing enrolled templates is even more difficult due to the aggregation (see (3)). Fig. 6 shows that our method has decreased the security a little, but overall the trade-off between security and performances is more interesting especially for AoE.
6 Conclusion
This paper proposes a framework for group membership verification and identification by jointly learning the embedding and the aggregation. Yet, this learning was not completely free. Some guidances were still imposed, especially the prototyping of the embedding based on a sparse ternary quantization. This is mainly for inheriting security and privacy properties of this lossy information processing [12, 11]. It is not clear whether an alternative approach does exist.
Our future work looks at increasing the length of the group representation in order to pack more templates into a group. Yet, this raises scalability issues appealing for faster but approximative learning.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] M. Beck and F. Kerschbaum. Approximate two-party privacy-preserving string matching with linear complexity. In Proceedings of the IEEE International Congress on Big Data , 2013.
- 2[2] G. Bianchi, L. Bracciale, and P. Loreti. ”better than nothing” privacy with bloom filters: To what extent? In Proceedings of the International Conference on Privacy in Statistical Databases , 2012.
- 3[3] D. Boneh, E. Kushilevitz, R. Ostrovsky, and W. E. Skeith. Public key encryption that allows pir queries. In Proceedings of the International Cryptology Conference, Advances in Cryptology , 2007.
- 4[4] Z. Erkin, M. Franz, J. Guajardo, S. Katzenbeisser, I. Lagendijk, and T. Toft. Privacy-preserving face recognition. In Proceedings of the International Symposium on Privacy Enhancing Technologies , 2009.
- 5[5] M. Gheisari, T. Furon, L. Amsaleg, B. Razeghi, and S. Voloshynovskiy. Aggregation and embedding for group membership verification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing , 2019.
- 6[6] G. B. Huang, M. Mattar, T. Berg, and E. Learned-Miller. Labeled faces in the wild: A database forstudying face recognition in unconstrained environments. In Workshop on faces in’Real-Life’Images: detection, alignment, and recognition , 2008.
- 7[7] A. Iscen, T. Furon, V. Gripon, M. Rabbat, and H. Jégou. Memory vectors for similarity search in high-dimensional spaces. IEEE Transactions on Big Data , 2017.
- 8[8] H. Jégou, F. Perronnin, M. Douze, J. Sánchez, P. Pérez, and C. Schmid. Aggregating local image descriptors into compact codes. IEEE Transactions on Pattern Analysis and Machine Intelligence , 34(9):1704–1716, 2012.