TL;DR
VITAMIN-E introduces a dense feature point-based monocular SLAM algorithm that achieves high accuracy and robustness by tracking numerous local extrema, utilizing a novel optimization for efficiency, and generating detailed 3D maps in real time.
Contribution
The paper presents a new SLAM method that processes extremely dense feature points with a novel optimization, outperforming existing methods in accuracy and robustness.
Findings
Outperforms state-of-the-art SLAM methods like DSO, ORB-SLAM, LSD-SLAM.
Achieves real-time dense 3D mapping using only a CPU.
Demonstrates high accuracy and robustness on EuRoC dataset.
Abstract
In this paper, we propose a novel indirect monocular SLAM algorithm called "VITAMIN-E," which is highly accurate and robust as a result of tracking extremely dense feature points. Typical indirect methods have difficulty in reconstructing dense geometry because of their careful feature point selection for accurate matching. Unlike conventional methods, the proposed method processes an enormous number of feature points by tracking the local extrema of curvature informed by dominant flow estimation. Because this may lead to high computational cost during bundle adjustment, we propose a novel optimization technique, the "subspace Gauss--Newton method", that significantly improves the computational efficiency of bundle adjustment by partially updating the variables. We concurrently generate meshes from the reconstructed points and merge them for an entire 3D model. The experimental results…
Click any figure to enlarge with its caption.
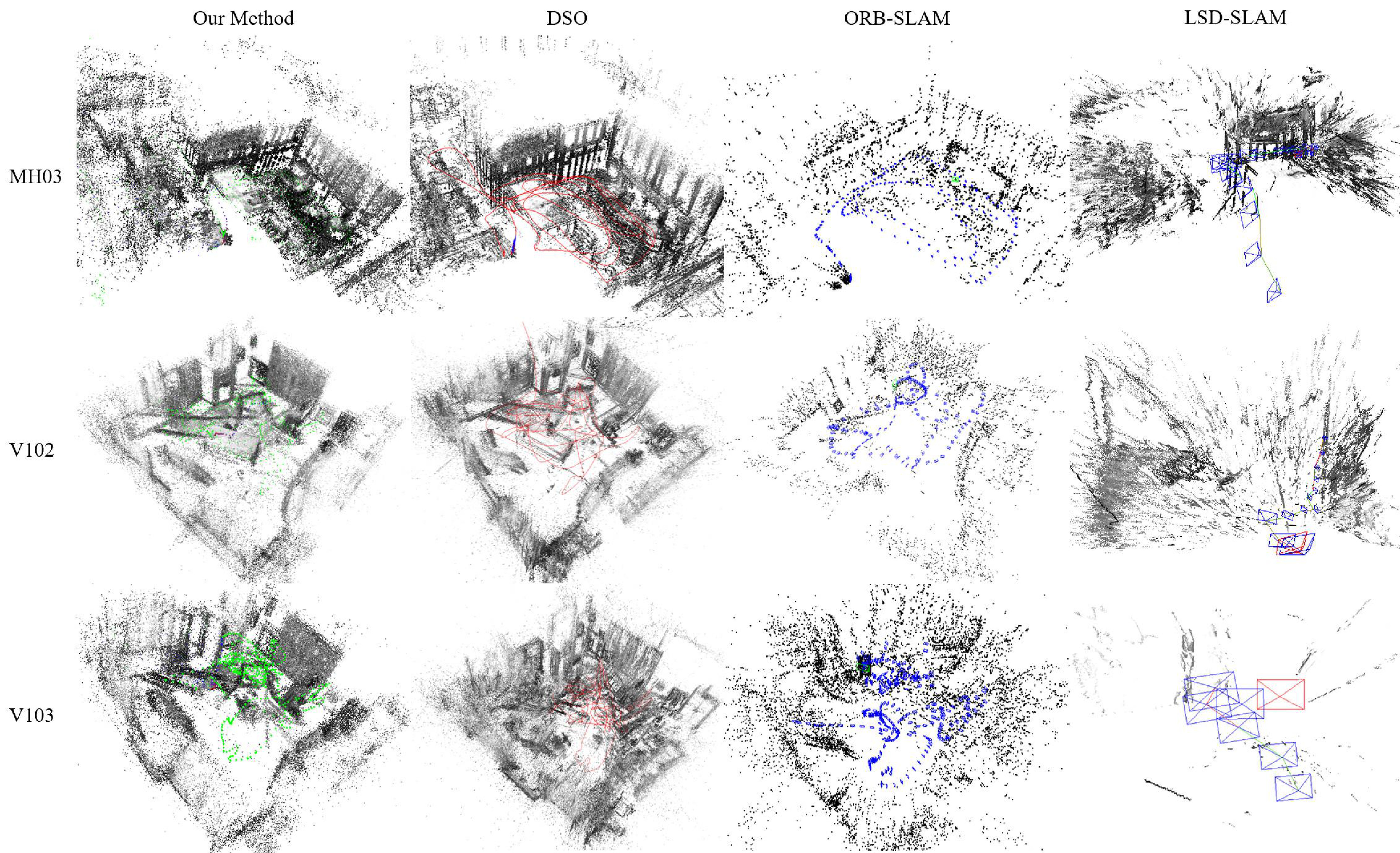 Figure 1
Figure 1 Figure 2
Figure 2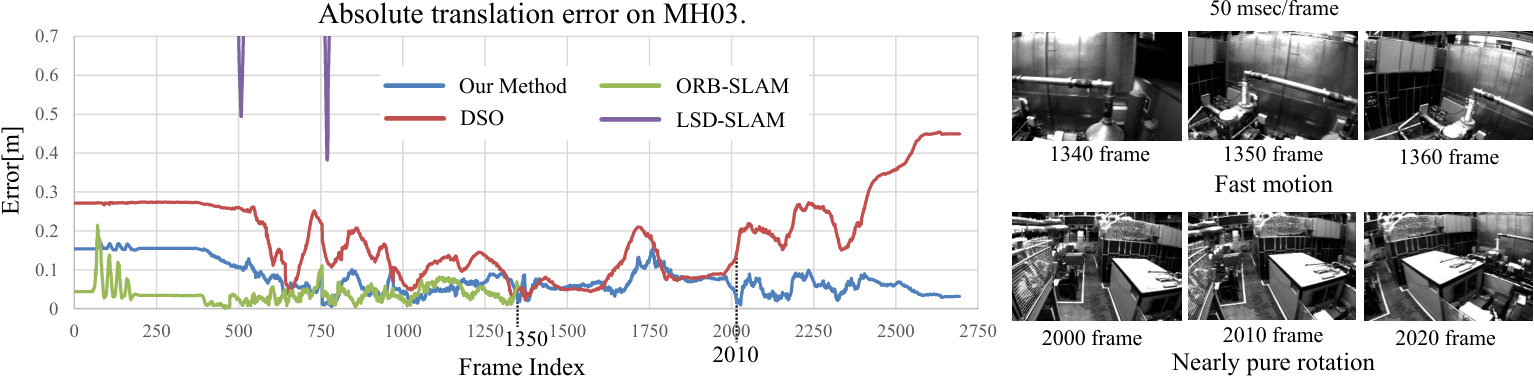 Figure 3
Figure 3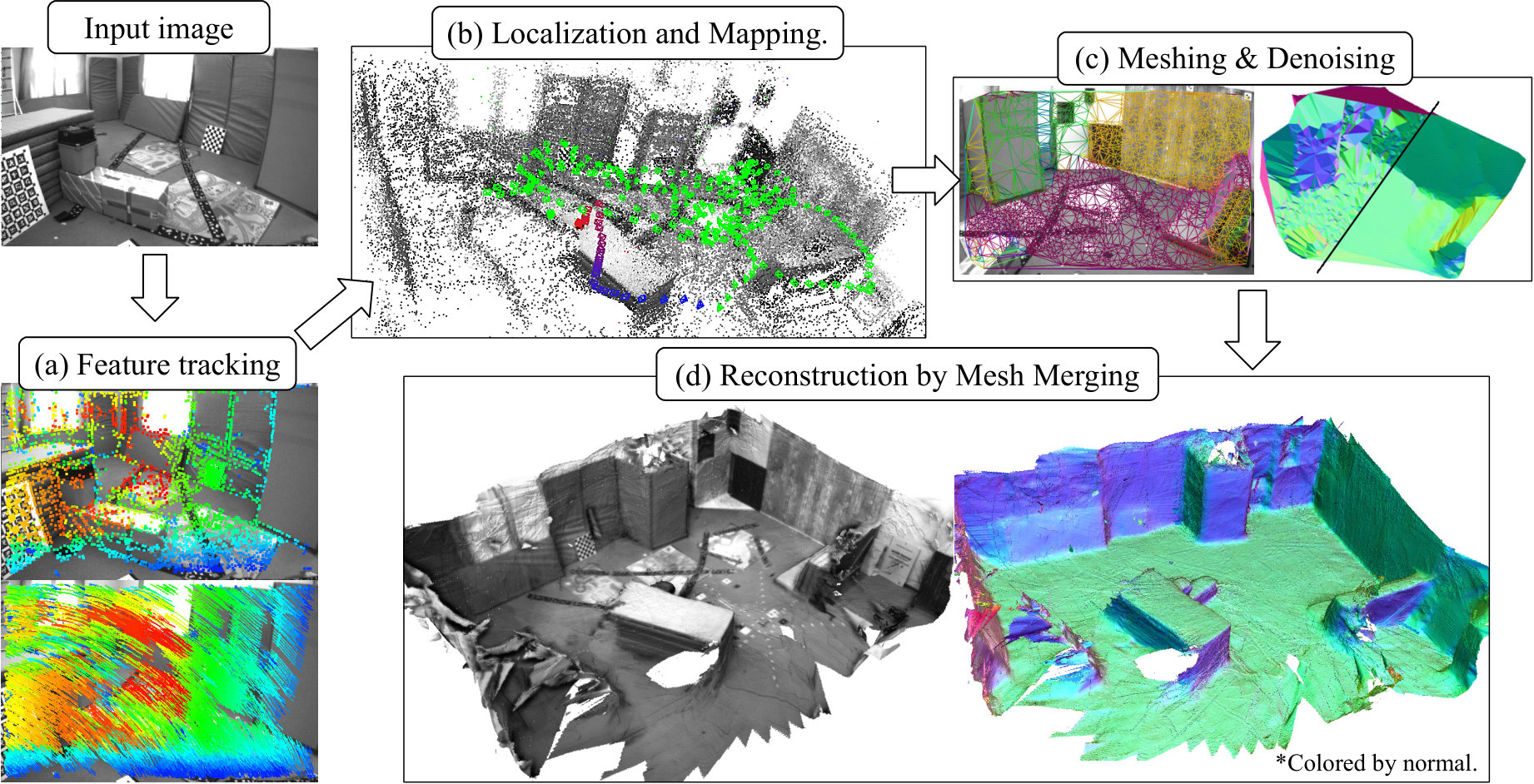 Figure 4
Figure 4 Figure 5
Figure 5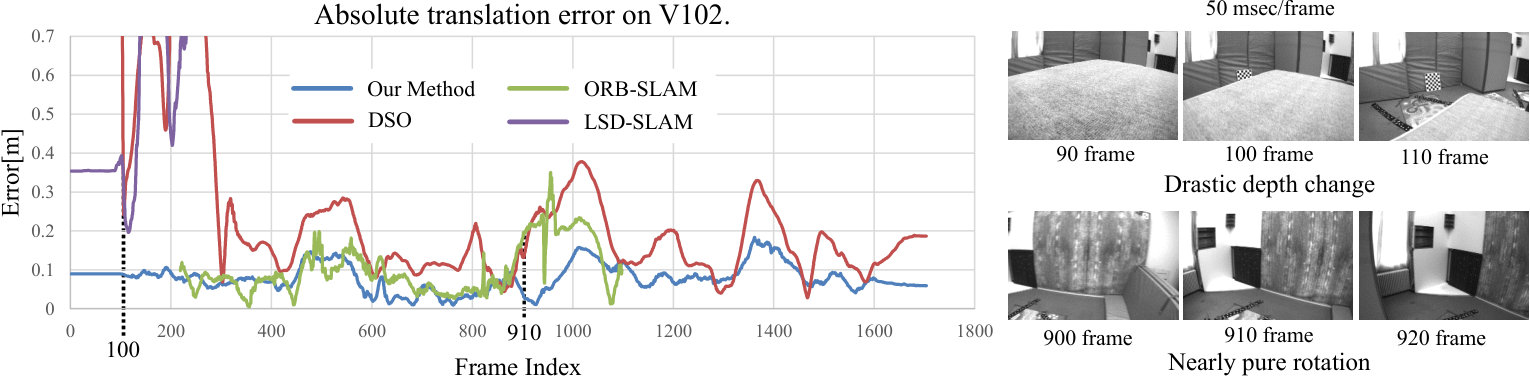 Figure 6
Figure 6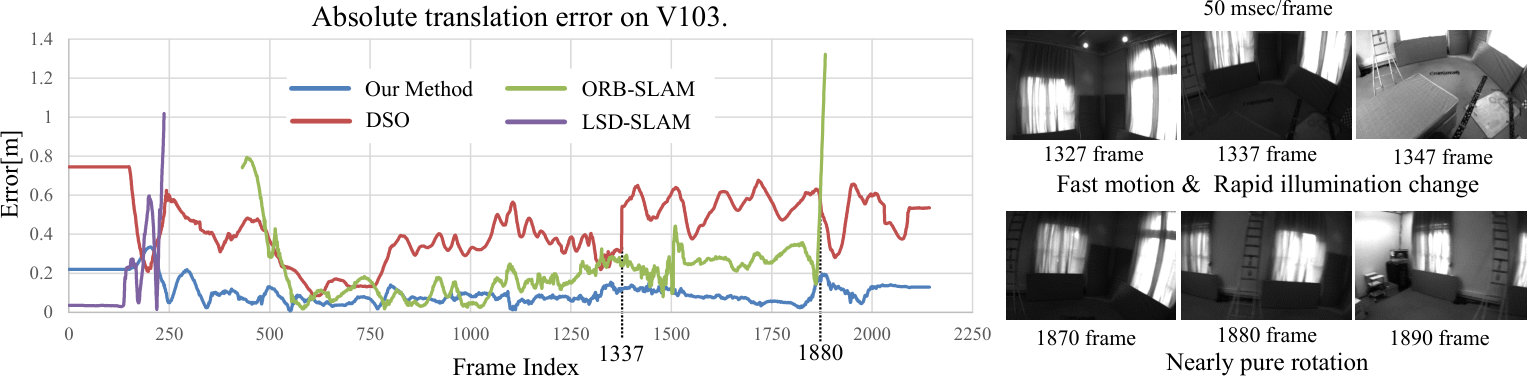 Figure 7
Figure 7| Sequence name | Our method | DSO[6] | ORB-SLAM[21] | LSD-SLAM[5] | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| (no. of images) | w/o loop closure | w/o loop closure | ||||||||||
| MH01 easy | 12.9 0.5 | cm | 6.0 0.8 | cm | 5.2 1.1 | cm | (44.9 7.2) | cm | ||||
| (3682) | 100.0 0.0 | % | 100.0 0.0 | % | 97.7 1.6 | % | 28.9 23.6 | % | ||||
| 0 0 | 0 0 | 19 11 | ||||||||||
| MH02 easy | 8.8 0.5 | cm | 4.2 0.2 | cm | 4.1 0.4 | cm | (58.3 6.9) | cm | ||||
| (3040) | 100.0 0.0 | % | 100.0 0.0 | % | 92.4 1.1 | % | 73.0 1.5 | % | ||||
| 0 0 | 0 0 | 56 6 | ||||||||||
| MH03 medium | 10.6 1.3 | cm | 21.1 0.9 | cm | (4.5 0.4) | cm | (266.2 61.3) | cm | ||||
| (2700) | 100.0 0.0 | % | 100.0 0.0 | % | 48.9 0.8 | % | 28.4 20.7 | % | ||||
| 0 0 | 0 0 | 0 0 | ||||||||||
| MH04 difficult | 19.3 1.6 | cm | 20.3 1.0 | cm | 33.6 9.4 | cm | (136.4 114.3) | cm | ||||
| (2033) | 100.0 0.0 | % | 95.7 0.0 | % | 95.2 0.8 | % | 27.2 7.0 | % | ||||
| 0 0 | 5 0 | 6 1 | ||||||||||
| MH05 difficult | 14.7 1.1 | cm | 10.2 0.6 | cm | 14.9 4.6 | cm | (27.4 16.4) | cm | ||||
| (2273) | 100.0 0.0 | % | 95.5 0.0 | % | 90.0 4.0 | % | 22.7 0.5 | % | ||||
| 0 0 | 2 0 | 18 5 | ||||||||||
| V101 easy | 9.7 0.2 | cm | 13.4 5.8 | cm | 8.8 0.1 | cm | (20.0 22.8) | cm | ||||
| (2911) | 100.0 0.0 | % | 100.0 0.0 | % | 96.6 0.0 | % | 11.6 11.2 | % | ||||
| 0 0 | 0 0 | 1 0 | ||||||||||
| V102 medium | 9.3 0.6 | cm | 53.0 5.5 | cm | (14.5 11.7) | cm | (67.0 14.0) | cm | ||||
| (1710) | 100.0 0.0 | % | 100.0 0.0 | % | 52.0 3.3 | % | 15.2 0.1 | % | ||||
| 0 0 | 0 0 | 17 4 | ||||||||||
| V103 difficult | 11.3 0.5 | cm | 85.0 36.4 | cm | (37.2 20.7) | cm | (29.3 2.0) | cm | ||||
| (2149) | 100.0 0.0 | % | 100.0 0.0 | % | 65.5 8.8 | % | 11.0 0.1 | % | ||||
| 0 0 | 0 0 | 56 26 | ||||||||||
| V201 easy | 7.5 0.4 | cm | 7.6 0.5 | cm | 6.0 0.1 | cm | (131.3 20.4) | cm | ||||
| (2280) | 100.0 0.0 | % | 100.0 0.0 | % | 95.2 0.0 | % | 74.1 8.9 | % | ||||
| 0 0 | 0 0 | 0 0 | ||||||||||
| V202 medium | 8.6 0.7 | cm | 11.8 1.4 | cm | 12.3 2.7 | cm | (42.1 9.2) | cm | ||||
| (2348) | 100.0 0.0 | % | 100.0 0.0 | % | 99.5 1.2 | % | 11.3 0.2 | % | ||||
| 0 0 | 0 0 | 0 0 | ||||||||||
| V203 difficult | 140.0 5.2 | cm | 147.5 6.6 | cm | (104.3 64.0) | cm | (17.7 1.6) | cm | ||||
| (1922) | 100.0 0.0 | % | 100.0 0.0 | % | 16.8 15.9 | % | 11.9 0.2 | % | ||||
| 0 0 | 0 0 | 233 123 | ||||||||||
| Our method | DSO | ORB-SLAM | LSD-SLAM |
| 36 msec/frame | 53 msec/frame | 25 msec/frame | 30 msec/frame |
| Front-end | Back-end | |||
|---|---|---|---|---|
| Feature tracking | Localization & mapping | Meshing & denoising | TSDF updating & marching cubes | TSDF updating & marching cubes |
| (low-resolution; voxel size 15 cm) | (high-resolution; voxel size 2.5 cm) | |||
| 36 msec/frame | 25 msec/frame | 45 msec/frame | 175 msec/time | 4000 msec/time |
|
Our method |
DSO |
SVO |
ORB-SLAM (with loop closure) |
ORB-SLAM (w/o loop closure) |
LSD-SLAM (with loop closure) |
LSD-SLAM (w/o loop closure) |
||
|---|---|---|---|---|---|---|---|---|
| TUM | fr2_desk | 1.7 cm | - | 6.7 cm | 0.9 cm | - | 4.5 cm | - |
| RGB-D | fr2_xyz | 0.4 cm | - | 0.8 cm | 0.3 cm | - | 1.5 cm | - |
| Living Room 0 | 0.9 cm | 1.0 cm | 2.0 cm | - | 1.0 cm | - | 12.0 cm | |
| ICL- | Living Room 1 | 11.0 cm | 2.0 cm | 7.0 cm | - | 2.0 cm | - | 5.0 cm |
| NUIM | Living Room 2 | 3.1 cm | 6.0 cm | 10.0 cm | - | 7.0 cm | - | 3.0 cm |
| Living Room 3 | 2.4 cm | 3.0 cm | 7.0 cm | - | 3.0 cm | - | 12.0 cm | |
| Office Room 0 | 31.6 cm | 21.0 cm | 34.0 cm | - | 20.0 cm | - | 26.0 cm | |
| ICL- | Office Room 1 | 40.1 cm | 83.0 cm | 28.0 cm | - | 89.0 cm | - | 8.0 cm |
| NUIM | Office Room 2 | 3.8 cm | 36.0 cm | 14.0 cm | - | 30.0 cm | - | 31.0 cm |
| Office Room 3 | 5.5 cm | 64.0 cm | 8.0 cm | - | 64.0 cm | - | 56.0 cm |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
VITAMIN-E: VIsual Tracking And MappINg
with Extremely Dense Feature Points
Masashi Yokozuka, Shuji Oishi, Thompson Simon, Atsuhiko Banno
Robot Innovation Research Center,
National Institute of Advanced Industrial Science and Technology (AIST), Japan
{yokotsuka-masashi, shuji.oishi, simon.thompson, atsuhiko.banno}@aist.go.jp
Abstract
In this paper, we propose a novel indirect monocular SLAM algorithm called “VITAMIN-E,” which is highly accurate and robust as a result of tracking extremely dense feature points. Typical indirect methods have difficulty in reconstructing dense geometry because of their careful feature point selection for accurate matching. Unlike conventional methods, the proposed method processes an enormous number of feature points by tracking the local extrema of curvature informed by dominant flow estimation. Because this may lead to high computational cost during bundle adjustment, we propose a novel optimization technique, the ”subspace Gauss–Newton method”, that significantly improves the computational efficiency of bundle adjustment by partially updating the variables. We concurrently generate meshes from the reconstructed points and merge them for an entire 3D model. The experimental results on the SLAM benchmark dataset EuRoC demonstrated that the proposed method outperformed state-of-the-art SLAM methods, such as DSO, ORB-SLAM, and LSD-SLAM, both in terms of accuracy and robustness in trajectory estimation. The proposed method simultaneously generated significantly detailed 3D geometry from the dense feature points in real time using only a CPU.
1 Introduction
Simultaneous localization and mapping (SLAM) is a key technology for applications such as autonomous systems and augmented reality. Whereas LiDAR-based SLAM[34, 11, 25] is well established and widely used in autonomous vehicles, visual SLAM with a monocular camera does not provide sufficient accuracy and robustness, particularly regarding dense map reconstruction, to replace LiDAR-based SLAM. Although some visual SLAM algorithms that use stereo cameras[7, 32], RGB-D cameras[12, 14, 33], and inertial sensors[20, 18, 2, 28, 19] have achieved high performance, these methods are based on pure monocular SLAM; hence, improving monocular SLAM is important.
Monocular SLAM methods can be classified into two types: direct methods and indirect methods.
Direct methods: Direct methods estimate camera poses and reconstruct the scene by minimizing the photometric error defined as a sum of the intensity difference between each pixel in the latest image and the reprojection of the color / monochrome 3D map. Direct methods, such as LSD-SLAM[5], SVO[9], and DSO[6], process almost all pixels in incoming images. They do not require exact pixel correspondences among multiple views unlike indirect methods, which leads to denser map reconstruction. However, direct methods are susceptible to image noise, luminance fluctuation, and lens aberration because they directly use pixel intensities. To overcome this drawback, Bergmann et al.[1] proposed a normalization method against luminance fluctuation and a calibration method for lens aberration. As another approach, Zhang et al.[35] proposed an auto-exposure method that is suitable for direct methods.
Indirect methods: Indirect methods minimize the geometric error between observed 2D feature points and reprojections of the corresponding 3D points. As a result of the use of feature descriptors, indirect methods such as PTAM[15] and ORB-SLAM[21] are robust against brightness changes and image noise. Additionally, indirect methods explicitly establish feature point correspondences; hence, outliers are easily removed using RANSAC[8] or M-estimation[27]. This characteristic, however, can be a drawback: Indirect methods carefully select stable feature points, thus the reconstructed 3D map tends to be sparse and does not provide detailed geometry. Densification methods, such as PMVS[10] and the extension L-PMVS[26], might be useful for obtaining dense geometry; however, they are offline methods and not applicable in real time.
In this paper, we propose the novel VIsual Tracking And MappINg with Extremely dense feature points, “VITAMIN-E,” which is highly precise, robust, and dense because of the tracking of a large number of feature points. Indirect methods are inherently robust against noise, illumination change, and outliers as a result of the use of feature descriptors. Retaining this advantage, we reconstruct detailed 3D maps by establishing dense point correspondence. The contributions of this study are as follows: We first introduce a new dense feature point tracking algorithm based on dominant flow estimation and curvature extrema tracing. This allows VITAMIN-E to process an enormous number of feature points; however, the need to maintain them simultaneously might lead to a high computational cost. Therefore, we also introduce a novel optimization technique, called subspace Gauss–Newton method, for bundle adjustment. The optimization technique significantly improves the efficiency of bundle adjustment by partially updating the variables. Moreover, VITAMIN-E generates meshes from the reconstructed feature points and integrates them using a truncated signed distance function (TSDF)[22, 30, 24]. Compared with not only conventional indirect methods but also state-of-the-art direct methods, VITAMIN-E provides highly detailed 3D geometry as shown in Figure 1 in real time using only a CPU
2 Dense Feature Point Tracking
2.1 Feature Point Tracking
Indirect methods that use image descriptors can be unstable because of incorrect feature point correspondences. They build feature point correspondences between multiple views by matching the descriptors. Extracting consistent descriptors over multiple frames, however, becomes difficult because descriptors vary as the monocular camera changes its pose. Methods such as the KLT tracker[29] that continuously track feature points while updating the feature descriptors might be useful for overcoming the problem. However, because the tracked positions drift as a result of a minute change of feature descriptors, the correspondences over multiple views tend to be incorrect. These problems originate with the use of feature descriptors.
Rather than associating feature points based on descriptors, VITAMIN-E tracks the local extrema of curvature in incoming images. In the proposed method, feature points denote the extrema of curvature on image intensities. Let be an image, then curvature of image is as follows:
[TABLE]
where represents the partial derivative of with respect to , which can be obtained using a Sobel operator or similar technique. VITAMIN-E builds point correspondences over multiple images by tracking the local maximum point of curvature , which is the extension of to time domain . Figure 2(a) shows an example scene from which a large number of extrema of curvature are extracted. Whereas conventional indirect methods rely only on feature points with a large curvature to obtain stable correspondences, the proposed method tracks all detected extrema to reconstruct detailed geometry.
2.2 Dominant Flow Estimation
After detecting the extrema of curvature, the proposed method estimates a dominant flow that represents the average of optical flow over the images, which provides a good initial value to extrema tracking and makes it significantly stable, as explained later. Specifically, we determine the corresponding feature pairs between current and previous images using the BRIEF[4] feature. Because we only have to identify coarse feature pairs over consecutive frames at this moment, feature matching is performed on low-resolution images, subsampled to 1/6 of the former size.
Then, we fit the affine transformation model to the feature pairs. and denote the position of a feature point in the previous and current frame, respectively, and and represent a matrix of and a 2D translation, respectively. and are obtained by minimizing cost function using the Gauss–Newton method:
[TABLE]
where and denote the total number of corresponding points and a kernel function for M-estimation, respectively. The following Geman–McClure kernel with scale parameter is used in VITAMIN-E :
[TABLE]
As a result of M-estimation, the dominant flow represented by and can be estimated stably, even for low-resolution images, and it allows us to roughly predict the position of feature points in the next frame. Note that VITAMIN-E does not rely on conventional feature matching in its core but only for prior information for dense extrema tracking, as described in the next section. Whereas conventional feature matching has difficulty in making all feature points couple correctly between consecutive frames, affine transformation is easily obtained when at least three correspondences are given.
2.3 Curvature Extrema Tracking
VITAMIN-E tracks feature points by tracing the extrema of image curvature by making use of the dominant flow. Because it depends only on extrema instead of feature descriptors used in conventional indirect methods, VITAMIN-E is free from the variation of feature descriptors caused by image noise or illumination changes, which makes VITAMIN-E highly robust.
According to the dominant flow represented by and , we first predict a current position of tracking point :
[TABLE]
Next, prediction is corrected to by maximizing evaluation function :
[TABLE]
where stores the curvature in each pixel, and and denote an evaluation function and weight for the prediction, respectively. The maximization is performed using the hill climbing method, with as the initial position. Specifically, maximum point is obtained by iterating the hill climbing method in eight neighboring pixels at each step until it reaches the local maximum value of . Function prevents the maximization process from falling into wrong extrema, thereby playing a regularization role.
Note that extrema tracking can easily fall into local solutions because there are many extrema in image curvature and it is almost impossible to distinguish them without any descriptors. However, the prediction according to the dominant flow boosts the accuracy of extrema tracking and enables it to approach the optimal solution.
3 Bundle Adjustment for Dense Tracking
3.1 Bundle Adjustment
Bundle adjustment iteratively adjusts the reconstructed map by minimizing reprojection errors. Given the -th 3D point , the -th camera’s rotation and translation , and the 2D position of observed in the -th camera frame, the objective function is formulated as follows:
[TABLE]
where and are the numbers of feature points and camera poses respectively, denotes the 3D-2D projection function, and is a kernel function for M-estimation. Specifically, optimal camera variables = (, ) and are obtained by applying the Gauss–Newton method to Equation 6, which results in iteratively solving the following equations:
[TABLE]
where , and and represent the Hessian matrix and gradient around of , respectively. and can be represented by the camera variable block and the feature point variable block as follows:
[TABLE]
Hessian matrix in bundle adjustment has a unique structure: and are sparse matrices with only diagonal elements in block units, whereas is a dense matrix. Efficient solutions that focus on this unique structure are the keys to developing highly precise and robust visual SLAM.
State-of-the-art monocular SLAM methods, such as ORB-SLAM[21] and DSO[6], solve Equation 7 by decomposing it using the Schur complement matrix instead of directly solving it:
[TABLE]
where and . The decomposition allows us to solve bundle adjustment faster. The number of camera variables is remarkably smaller than that of feature point variables, and the inverse matrix of can be easily calculated because it has only diagonal components; thus, the Schur complement matrix whose size is is significantly tiny compared with the original , and the inverse matrix is rapidly computable.
Equation 9 is also called marginalization. When regarding as a new and as a new , the decomposition is equivalent to eliminating all feature point variables from cost function . State-of-the-art SLAMs make themselves efficient using the marginalization technique to prevent the increase in computational cost caused by a large number of variables.
However, in the case of maintaining thousands of feature points in every frame, as in the dense extrema tracking in VITAMIN-E, the size of matrix fundamentally cannot be made sufficiently small because variable elimination is applicable only to old variables unrelated to the current frame for stability. Moreover, the size of the Schur complement matrix is proportional to the number of feature points; thus, the calculation cost of bundle adjustment over tens of thousands points, where the size of is 100,000 100,000 or more, becomes too high to run bundle adjustment in real time.
3.2 Subspace Gauss–Newton Method
To deal with the explosion in the size of , we propose a novel optimization technique called the “subspace Gauss–Newton method.” It partially updates variables rather than updating all of them at once, as in Equations 9 and 10, by decomposing these equations further as follows:
[TABLE]
[TABLE]
Equation 11 updates of a camera variable, and Equation 12 of a feature point variable. , , and are matrices of , , and , respectively. The subspace Gauss–Newton method iteratively solves Equations 11 and 12 until and converge, respectively.
These formulae are extensions of the Gauss–Seidel method, which is an iterative method to solve a linear system of equations, and equivalent to solving the Gauss–Newton method by fixing all variables except the variables to be optimized. The advantage of the proposed subspace Gauss–Newton method is that it does not require a large inverse matrix, unlike Equation 9, but instead, only an inverse matrix of at most. Additionally, as in ORB-SLAM[21] and DSO[6], further speedup is possible by appropriately performing variable elimination that sets most elements of and to zero. Because the proposed optimization method limits the search space in the Gauss–Newton method to its subspace, we call it the “subspace Gauss–Newton method.” 111 Alternating optimization, such as our method, has been used in some contexts[36][31]. See the supplementary information for details of the novel aspect of our method.
4 Dense Reconstruction
A large number of accurate 3D points are generated in real time with VITAMIN-E as a result of the dense extrema tracking and subspace Gauss–Newton method described in previous sections. This leads not only to point cloud generation but also allows further dense geometry reconstruction that cannot be achieved by conventional indirect methods.
Meshing and Noise Removal: We first project the 3D points onto an image and apply Delaunay triangulation to generate triangular meshes. Then, We use NLTGV minimization proposed by Greene et al[23] to remove noise on the meshes. NLTGV minimization allows us to smooth the meshes, thereby retaining local surface structures, unlike typical mesh denoising methods such as Laplacian smoothing. Figure 2(c) shows example results of Delaunay triangulation and smoothing with NLTGV minimization.
Mesh Integration in TSDF: Finally, we integrate the meshes in a TSDF to reconstruct the entire geometry of the scene. The TSDF represents an object shape by discretizing the space into grids that store the distance from the object surface, and can merge multiple triangular meshes by storing the average value of distances from the meshes to each grid.
5 Experimental Results
5.1 Setup
We evaluated the performance of the proposed VITAMIN-E on the visual SLAM benchmark EuRoC[3]. 222 See the supplementary information for experimental results on other datasets.
The dataset was created using flying drones equipped with a stereo camera and an IMU in an indoor environment, and provided ground truth of trajectories obtained by a Leica MS 50 laser tracker and Vicon motion capture. EuRoC is also well-known for data variations, with different difficulties ranked by the movement speed and lighting conditions. In this experiment, we compared results obtained using VITAMIN-E and other monocular SLAM methods, DSO[6], ORB-SLAM[21], and LSD-SLAM[5], using only the left images of the stereo camera in the EuRoC dataset. Note that because VITAMIN-E and DSO[6] do not include loop closing and relocalization, these functions in ORB-SLAM[21] and LSD-SLAM[5] were disabled to evaluate performance fairly. Similar evaluations can be found in the papers on DSO[6] and SVO[9].
VITAMIN-E ran on a Core i7-7820 HQ without any GPUs, threading each process for real time processing. Initialization was performed using essential matrix decomposition. Bundle adjustment is significantly sensitive to the initial value of the variable. In VITAMIN-E, we initialized the camera variables using P3P[17, 13] with RANSAC[8] and feature point variables using triangulation. Note that the proposed bundle adjustment ran so fast that we applied it to every frame rather than each key frame as in ORB-SLAM and DSO. To manage the TSDF, OpenChisel[16] was used in our implementation because of its ability to handle a TSDF on a CPU.
5.2 Evaluation Criteria
The evaluation on EuRoC was performed according to the following criteria:
Localization success rate: We defined the localization success rate as , where and denote the number of images that were successfully tracked and the images in the entire sequence, respectively. If the success rate was less than 90%, we regarded the trial as a failure. When localization failed even once, the methods could not estimate the camera position later because loop closing and relocalization were disabled in this experiment. Therefore, robustness greatly contributed to the success rate.
Localization accuracy: The localization accuracy was computed by scaling the estimated trajectories so that the RMSE from ground truth trajectories was minimized because scale is not available in monocular SLAM. Note that we did not evaluate the accuracy when the success rate was less than 90% because the RMSE of very short trajectories tends to have an unfairly high accuracy.
Number of initialization retries: Initialization plays an important role in monocular visual SLAM and significantly affects the success rate. Because different methods have different initialization processes, the number of initialization retries in each method is not directly comparable, but can be a reference regarding whether the method has a weakness in initialization in certain cases.
5.3 Results and Discussion
Table 1 shows the experimental results. The results were obtained by applying each method to the image sequences in EuRoC five times, and Table 1 shows the average values and the standard deviations of the aforementioned criteria. Bold font is used to emphasize the highest accuracy in each sequence. Regarding LSD-SLAM, the results of initialization retries are not included in the table because LSD-SLAM did not have a re-initialization function and failed to initialize in any sequences. We thus manually identified the frame for which the initialization worked well in each trial, so the number of retries of LSD-SLAM was excluded from the evaluation.
The EuRoC image sequences MH01, MH02, MH04, MH05, V101, V201, and V202 are relatively easy cases for visual SLAM because the camera motion is relatively slow and the illumination does not change frequently. By contrast, the camera moves fast in MH03, V102, V103, and V203, and additionally the lighting conditions dynamically change in V102, V103, and V203. Furthermore, in V203, the exposure time is so long that we can see severe motion blur in the image sequence, particularly in an extremely dark environment.
Even for the challenging environments, VITAMIN-E never lost localization and outperformed other SLAM methods, DSO, ORB-SLAM, and LSD-SLAM, both in terms of accuracy and robustness, as shown in Table 1. Particularly, in the sequences that contain fast camera motion, such as V102 and V103, the proposed method was superior to the existing methods. The reconstruction results are shown in Figures 3 and 4. Despite the proposed VITAMIN-E successfully generating dense and accurate geometry compared with its competitors, it performed equally fast on a CPU, as shown in Tables 2 and 3. Note that the smaller the size of the voxel in a TSDF for a detailed 3D model, the higher the computational cost.
The high accuracy and robustness of VITAMIN-E derives from tracking a large number of feature points and performing bundle adjustment for every frame. Sharing reprojection errors among variables is important for accurate monocular SLAM, and the proposed method efficiently diffuses errors to an enormous number of variables via fast bundle adjustment. Simultaneously, it prevents localization failure caused by losing sight of some feature points by handling a large number of feature points.
6 Conclusion
In this paper, we proposed a novel visual SLAM method that reconstructs dense geometry with a monocular camera. To process a large number of feature points, we proposed curvature extrema tracking using the dominant flow between consecutive frames. The subspace Gauss–Newton method was also introduced to maintain an enormous number of variables by partially updating them to avoid a large inverse matrix calculation in bundle adjustment. Moreover, supported by the accurate and dense point clouds, we achieved highly dense geometry reconstruction with NLTGV minimization and TSDF integration.
VITAMIN-E is executable on a CPU in real time, and it outperformed state-of-the-art SLAM methods, DSO, ORB-SLAM, and LSD-SLAM, both in terms of accuracy and robustness on the EuRoC benchmark dataset. Performance should be improved when loop closing is introduced in VITAMIN-E, and fusing IMU data would also be effective to stably estimate the camera pose for challenging environments such as EuRoC V203.
**Acknowledgements: This work was supported in part by JSPS KAKENHI, Japan Grant Numbers 16K16084 and 18K18072, and a project commissioned by the New Energy and Industrial Technology Development Organization (NEDO). **
Supplementary Material
This supplementary material provides additional experimental results and the detail of our optimization method.
1.Additional Experiments
We conducted additional experiments on the TUM RGB-D benchmark[5] dataset and ICL-NUIM[4] noisy synthetic dataset. The results are shown in Table 1, which cites scores of competitors from [1] under the same conditions. The parameters of VITAMIN-E were fixed in all experiments.
Our method worked well and achieved a relatively high trajectory accuracy in a variety of scenes. The worst case was Office Room , in which the average trajectory error of VITAMIN-E was cm: the camera explored a textureless environment, where only edges of the floor and walls could be seen at 18 sec, which led to difficulty in extracting curvature extrema and thus unstable tracking. Edge-based SLAMs, such as LSD-SLAM, achieved better localization performance in such scenes, whereas for point-based SLAMs’ (including our method), performance tended to degrade.
2.Optimization
Alternating optimization (AO) is used in some contexts such as color map optimization [2]. In structure from motion (SfM), AO is called “resection intersection (RI),” which optimizes camera poses and feature positions alternately. [3] concluded that although RI has numerical stability in optimization, it is not suitable for SfM because of its slow convergence compared with the standard Gauss–Newton method which optimizes all variables simultaneously.
However, we found that this is not the case in visual odometry (VO). VO sequentially optimizes variables frame by frame; thus, most old variables are already optimized and we only need to optimize the latest camera pose and feature points. Whereas the Gauss–Newton method optimizes all variables, the proposed subspace Gauss–Newton method inspired by RI efficiently updates partial variables. Specifically, our method enables RI to eliminate some variables by leveraging the Schur complement. Variable elimination plays an important role in VO because the number of variables increases with each frame. Previous RI only solves nonlinear optimization by partially updating variables fixing the other, which results in high computational costs. By constrast, the proposed subspace Gauss–Newton method applies RI to nonlinear optimization problems after quadratic approximation, that is, , using the Schur-complement, thus enabling the real-time RI optimization required in Visual SLAM.
References
- [1] Christian Forster, Zichao Zhang, Michael Gassner, Manuel Werlberger and Davide Scaramuzza. SVO: Semidirect visual odometry for monocular and multicamera systems. IEEE Transactions on Robotics, 33(2):249–265, 2017.
- [2] Qian-Yi Zhou and Vladlen Koltun. Color Map Optimization for 3D Reconstruction with Consumer Depth Cameras. ACM Trans. Graph., 33(4):155:1–155:10, 2014.
- [3] Bill Triggs, Philip Mclauchlan, Richard Hartley and Andrew Fitzgibbon. Bundle Adjustment - A Modern Synthesis. Proc. of the Int. WS on Vision Algorithms: Theory and Practice, 2000.
- [4] Ankur Handa, Thomas Whelan, John McDonald and Andrew J. Davison. A Benchmark for RGB-D Visual Odometry, 3D Reconstruction and SLAM. IEEE Intl. Conf. on Robotics and Automation, ICRA, 2014.
- [5] Jürgen Sturm, Nikolas Engelhard, Felix Endres, Wolfram Burgard and Daniel Cremers. A Benchmark for the Evaluation of RGB-D SLAM Systems. Proc. of the International Conference on Intelligent Robot Systems (IROS), 2012.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Paul Bergmann, Rui Wang, and Daniel Cremers. Online photometric calibration of auto exposure video for realtime visual odometry and SLAM. IEEE Robotics and Automation Letters , 3, 2018.
- 2[2] Michael Blosch, Sammy Omari, Marco Hutter, and Roland Siegwart. Robust visual inertial odometry using a direct ekf-based approach. In Proc. of International Conference on Intelligent Robots (IROS) , 2015.
- 3[3] Michael Burri, Janosch Nikolic, Pascal Gohl, Thomas Schneider, Joern Rehder, Sammy Omari, Markus W Achtelik, and Roland Siegwart. The Eu Ro C micro aerial vehicle datasets. International Journal of Robotics Research , 35(10):1157–1163, 2016.
- 4[4] Michael Calonder, Vincent Lepetit, Christoph Strecha, and Pascal Fua. BRIEF: Binary robust independent elementary features. In Proc. of European Conference on Computer Vision (ECCV) , 2010.
- 5[5] Jakob Engel and Daniel Cremers. LSD-SLAM: Large-scale direct monocular SLAM. In Proc. of European Conference on Computer Vision (ECCV) , 2014.
- 6[6] Jakob Engel, Vladlen Koltun, and Daniel Cremers. Direct sparse odometry. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2018.
- 7[7] Jakob Engel, Jörg Stückler, and Daniel Cremers. Large-scale direct slam with stereo cameras. In Proc. of International Conference on Intelligent Robots (IROS) , 2015.
- 8[8] Martin A. Fischler and Robert C. Bolles. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM , 24(6):381–395, 1981.
