Heterofusion: Fusing genomics data of different measurement scales
Age K. Smilde, Yipeng Song, Johan A. Westerhuis, Henk A.L. Kiers,, Nanne Aben, Lodewyk F.A. Wessels

TL;DR
This paper addresses the challenge of integrating genomics data measured at different scales, proposing three fusion methods, including two novel approaches, and demonstrating their application with real-world data.
Contribution
The paper introduces two new data fusion methods for heterogeneity of measurement scales in genomics, expanding tools available for systems biology research.
Findings
Two new fusion methods demonstrated on real genomics data
Methods effectively handle binary, ordinal, interval, and ratio data
Enhanced integration of heterogeneous biological measurements
Abstract
In systems biology, it is becoming increasingly common to measure biochemical entities at different levels of the same biological system. Hence, data fusion problems are abundant in the life sciences. With the availability of a multitude of measuring techniques, one of the central problems is the heterogeneity of the data. In this paper, we discuss a specific form of heterogeneity, namely that of measurements obtained at different measurement scales, such as binary, ordinal, interval and ratio-scaled variables. Three generic fusion approaches are presented of which two are new to the systems biology community. The methods are presented, put in context and illustrated with a real-life genomics example.
Click any figure to enlarge with its caption.
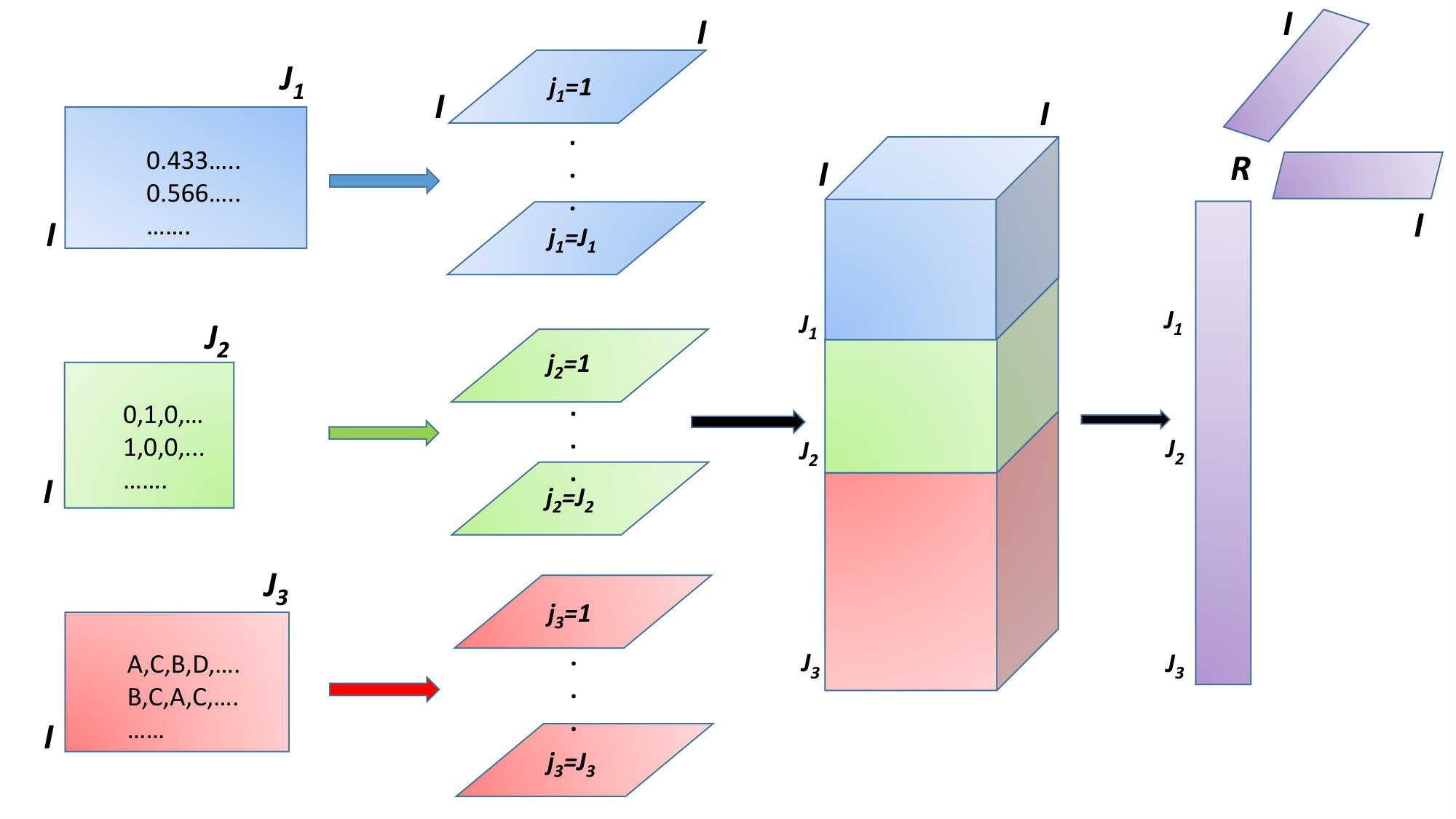 Figure 1
Figure 1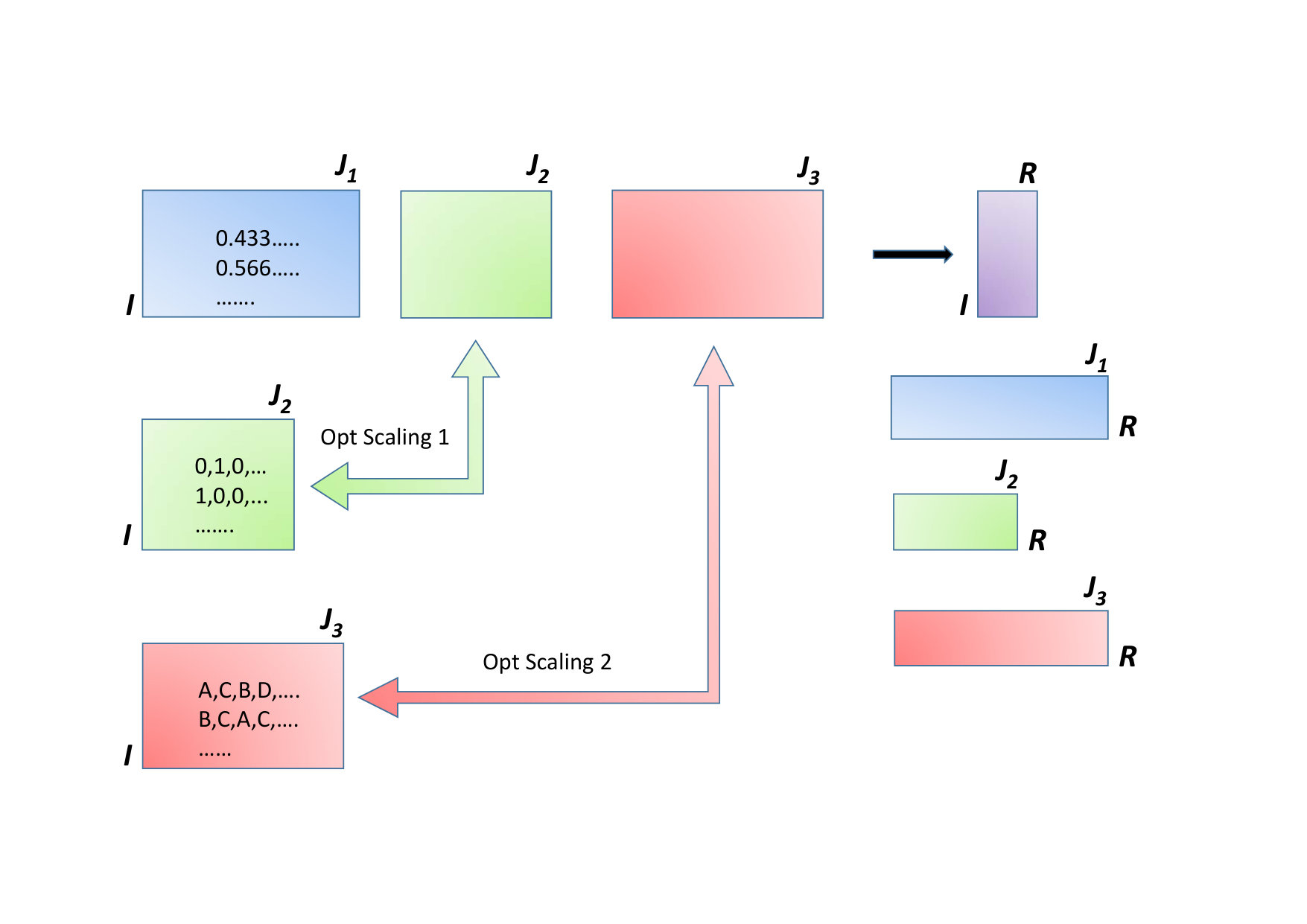 Figure 2
Figure 2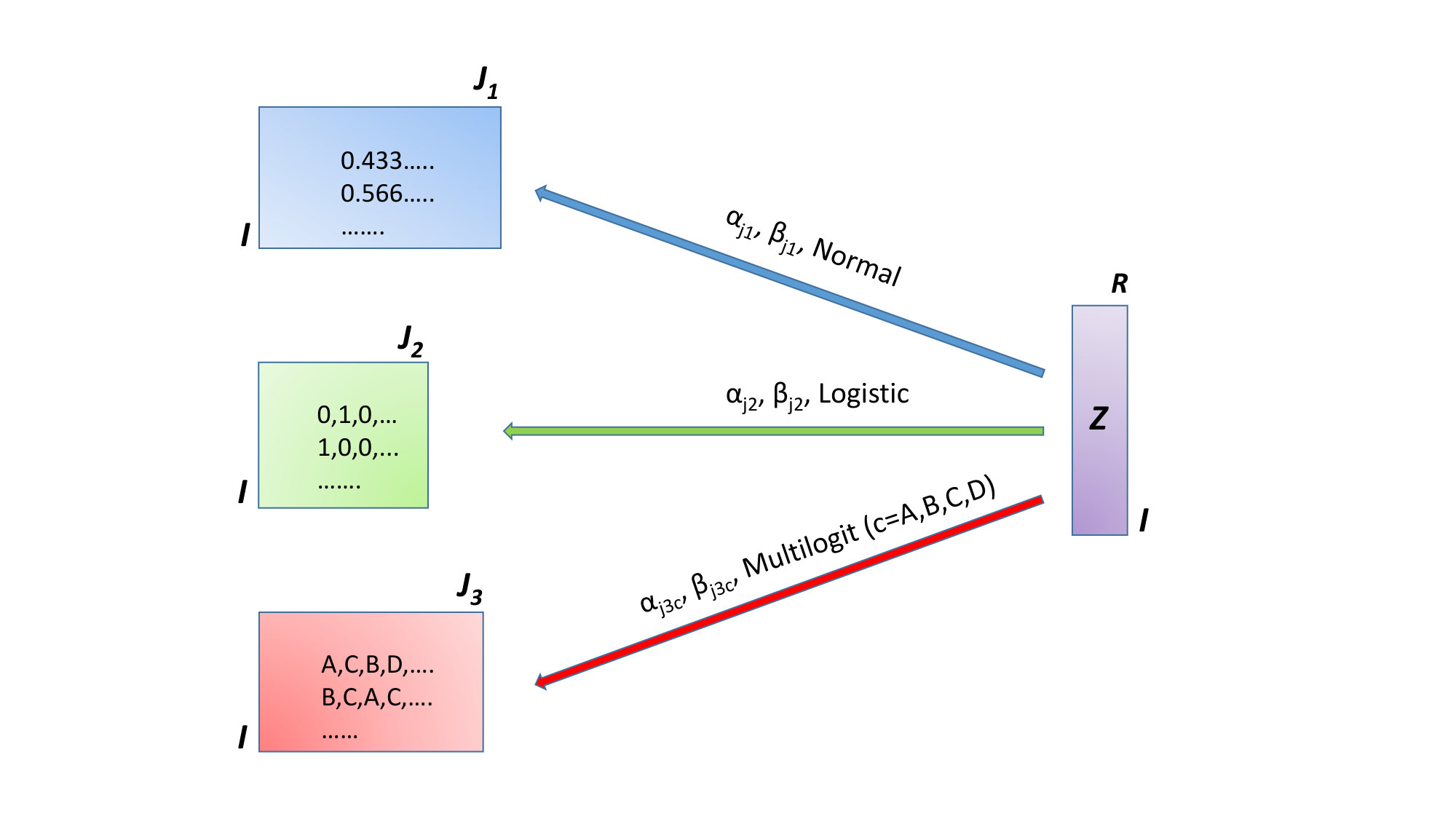 Figure 3
Figure 3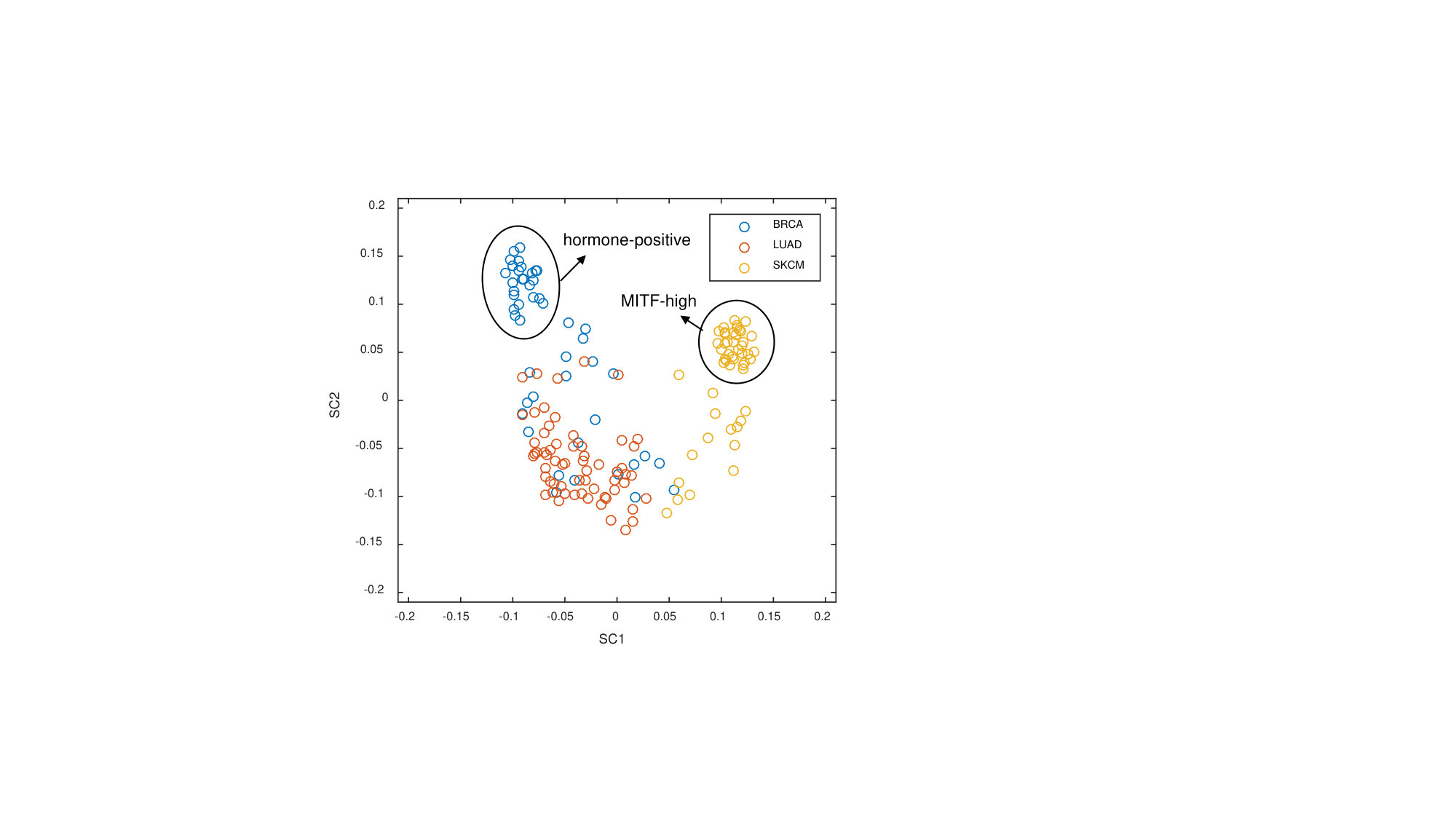 Figure 4
Figure 4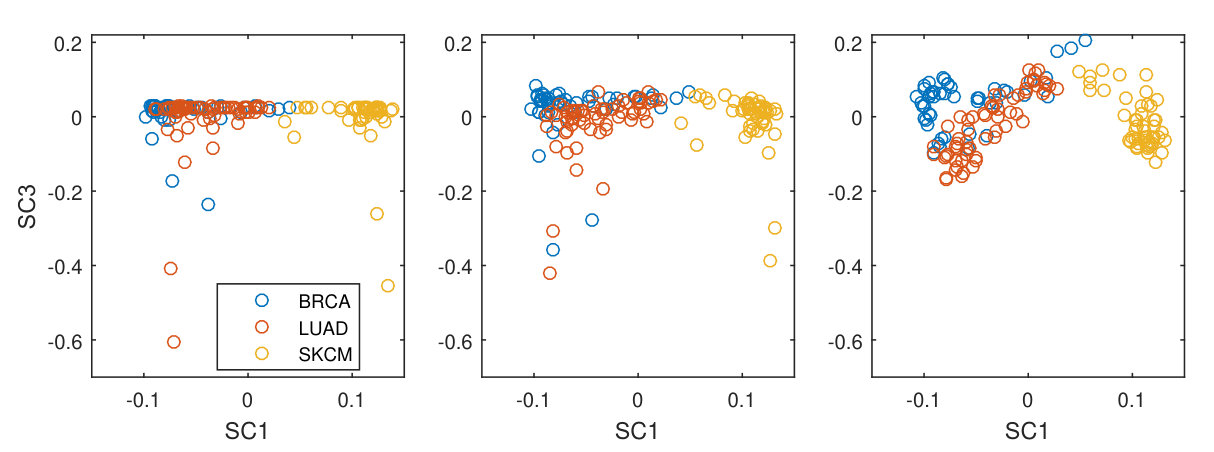 Figure 5
Figure 5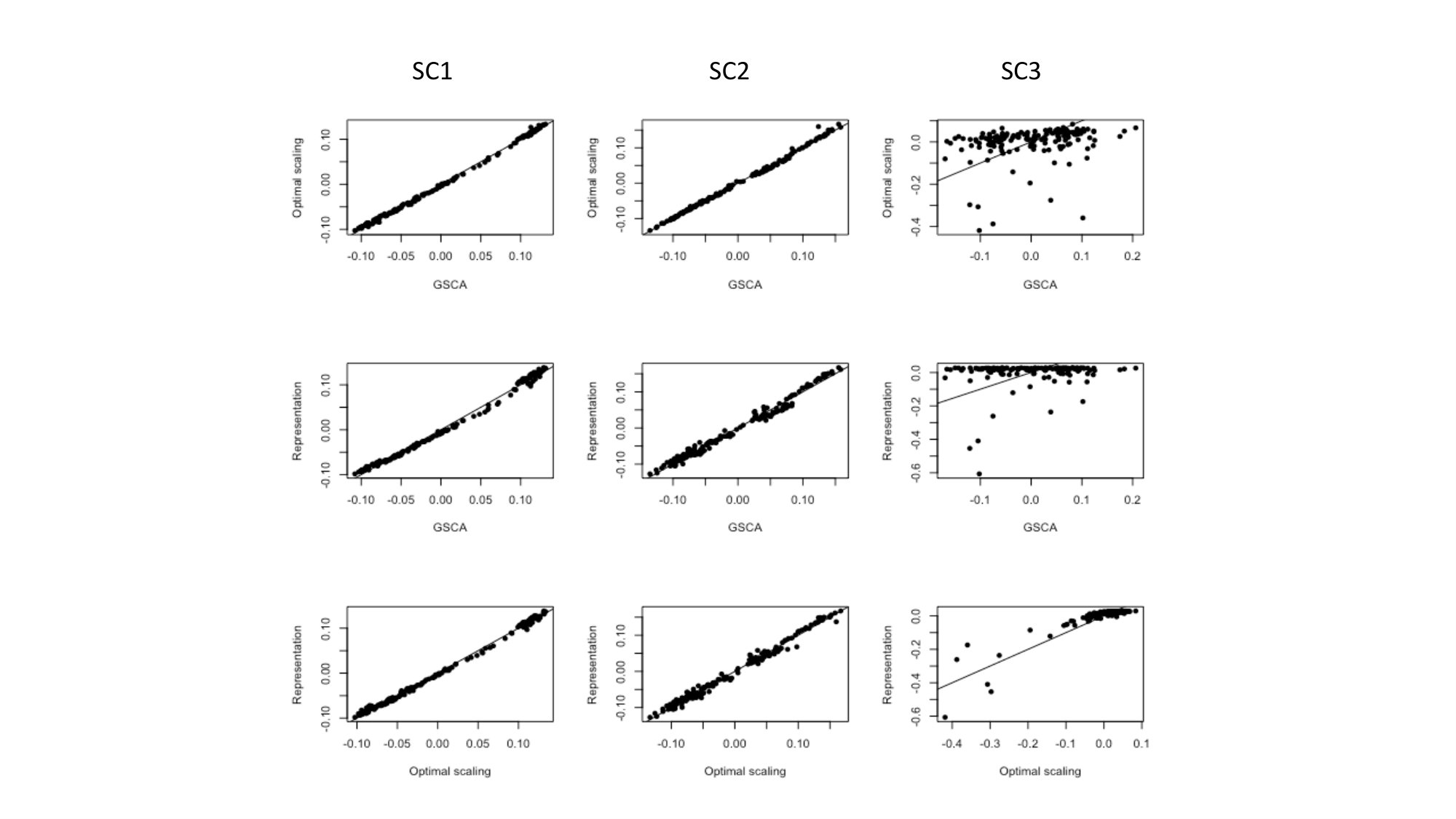 Figure 6
Figure 6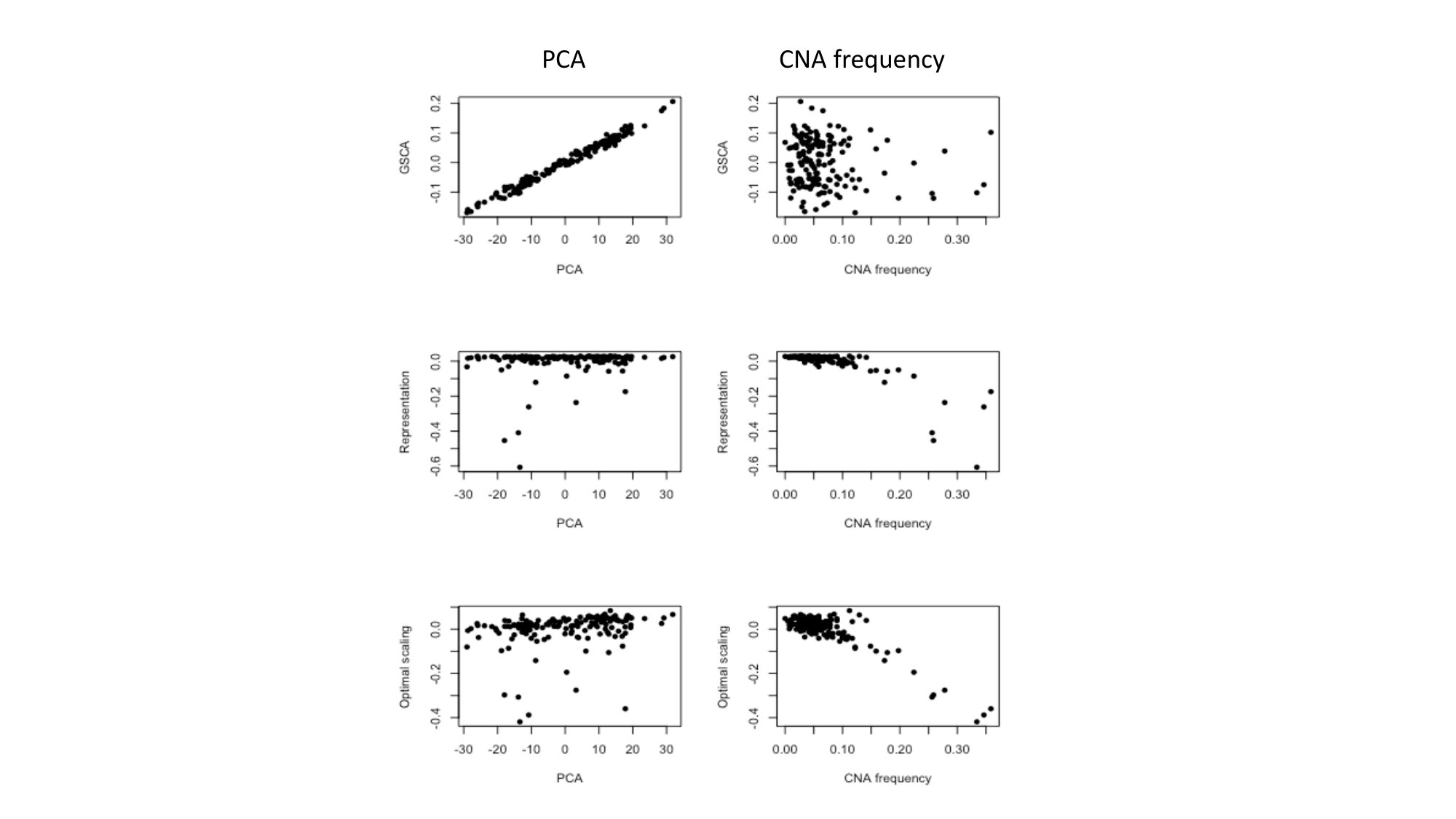 Figure 7
Figure 7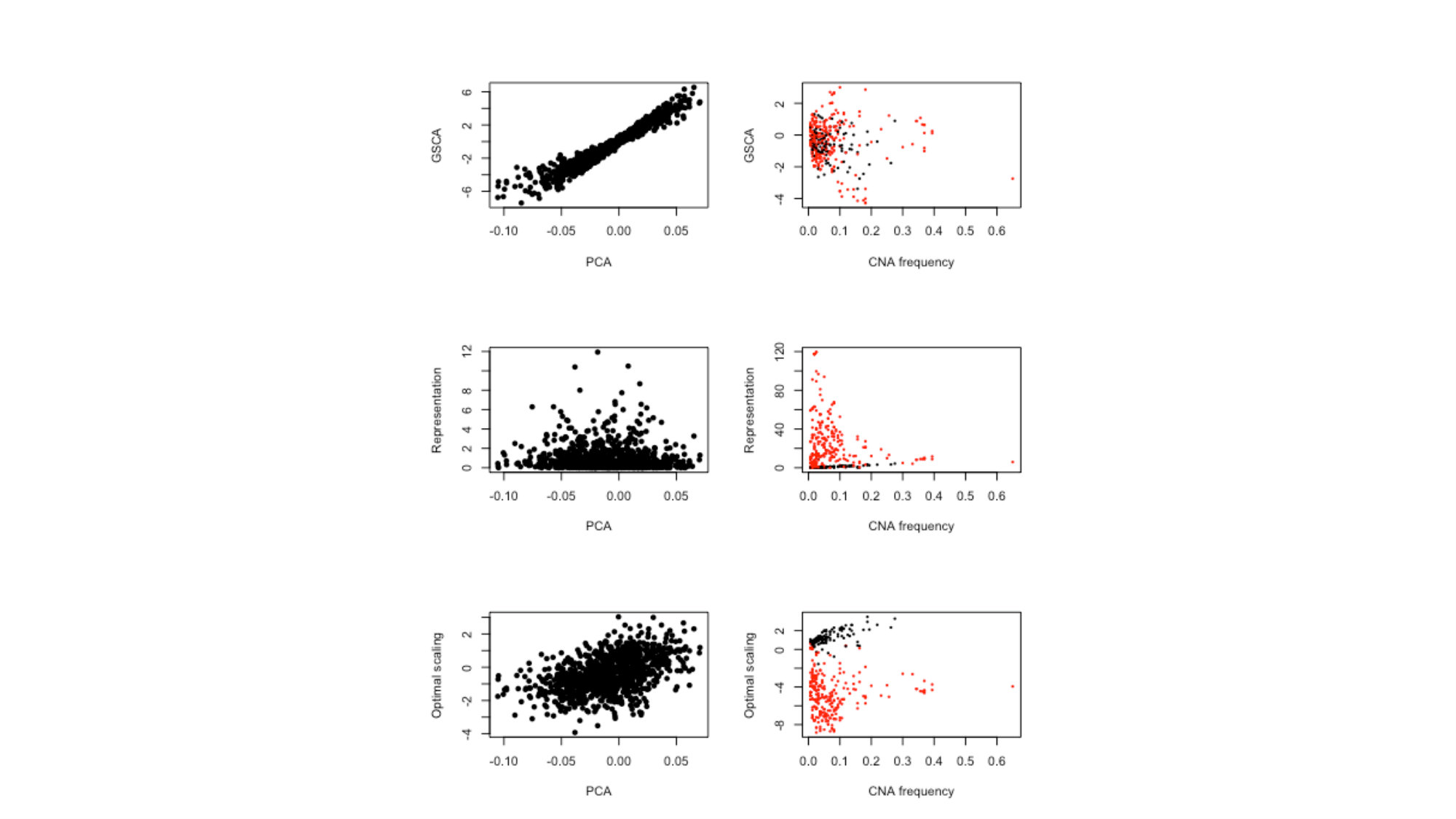 Figure 8
Figure 8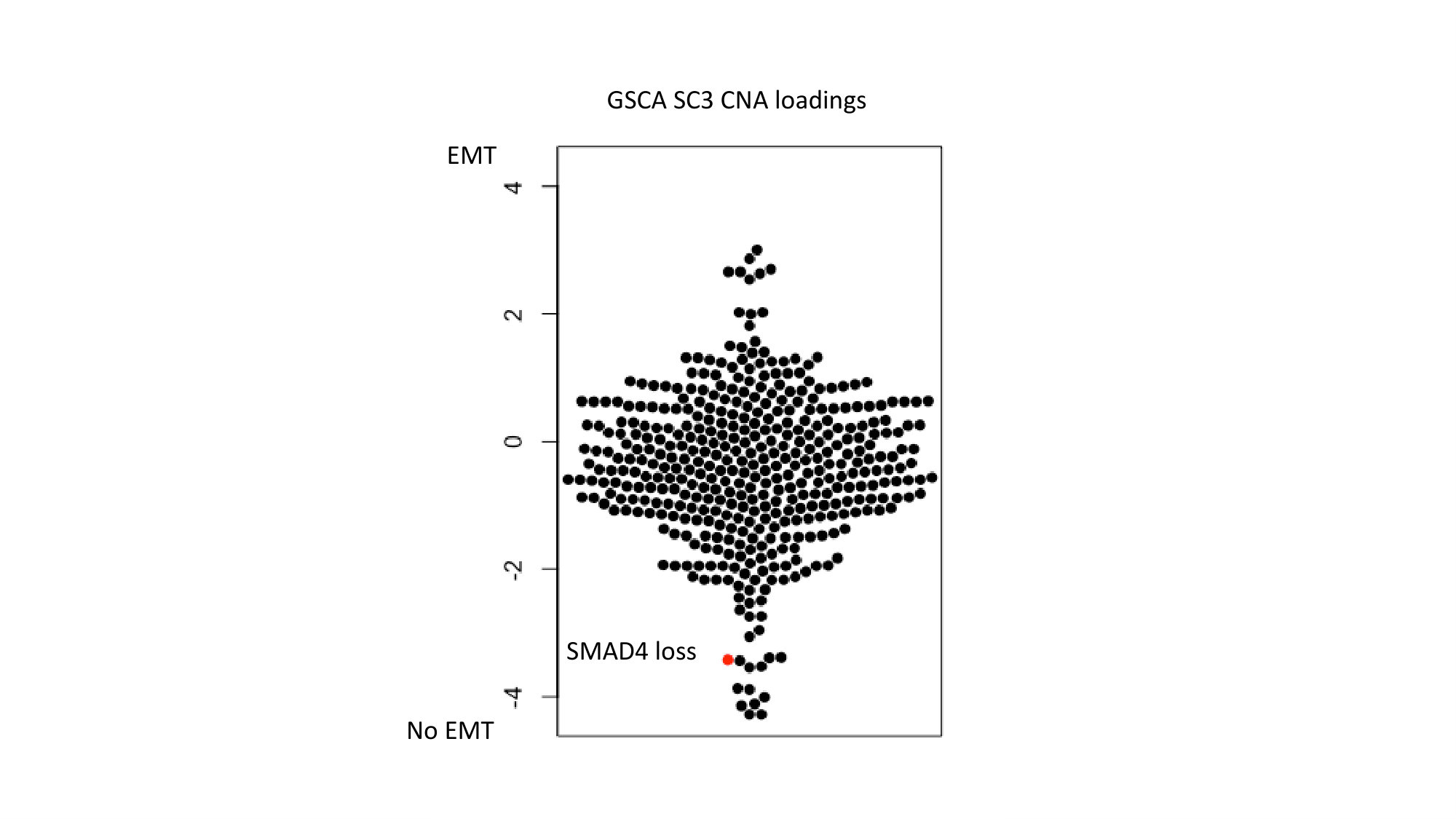 Figure 9
Figure 9| Method | IDIOMIX | OS-SCA | GSCA | PCA | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Data type | Binary | Quant | Total | Binary | Quant | Total | Binary | Quant | Total | Quant |
| SC1 | 0.06 | 9.32 | 6.60 | 13.65 | 22.15 | 16.14 | 63.58 | 22.11 | 23.64 | 22.15 |
| SC2 | 0.03 | 2.38 | 1.69 | 5.66 | 10.17 | 7.48 | 15.72 | 10.19 | 10.39 | 10.17 |
| SC3 | 3.73 | 0.01 | 1.10 | 4.99 | 4.52 | 4.35 | 6.17 | 4.48 | 4.54 | 4.52 |
| Cum | 3.82 | 11.70 | 9.39 | 24.29 | 36.84 | 27.96 | 85.47 | 36.77 | 38.58 | 36.84 |
| total | |||
|---|---|---|---|
| total |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Heterofusion: fusing genomics data of different measurement scales
A.K. Smilde**1*, Y. Song1, J.A. Westerhuis1, H.A.L. Kiers2,
N. Aben3, L.F.A. Wessels3
[TABLE]
1 Abstract
In systems biology, it is becoming increasingly common to measure biochemical entities at different levels of the same biological system. Hence, data fusion problems are abundant in the life sciences. With the availability of a multitude of measuring techniques, one of the central problems is the heterogeneity of the data. In this paper, we discuss a specific form of heterogeneity, namely that of measurements obtained at different measurement scales, such as binary, ordinal, interval and ratio-scaled variables. Three generic fusion approaches are presented of which two are new to the systems biology community. The methods are presented, put in context and illustrated with a real-life genomics example.
Keywords: data fusion, data integration, low-level fusion, measurement scales, heterogeneous data
2 Introduction
2.1 General
With the availability of comprehensive measurements collected in multiple related data sets in the life sciences, the need for a simultaneous analysis of such data to arrive at a global view on the system under study is of increasing importance. There are many ways to perform such a simultaneous analysis and these go also under very different names in different areas of data analysis: data fusion, data integration, global analysis, multi-set or multi-block analysis to name a few. We will use the term data fusion in this paper.
Data fusion plays an especially important role in the life sciences, e.g., in genomics it is not uncommon to measure gene-expression (array data or RNA-sequencing (RNAseq) data), methylation of DNA and copy number variation. Sometimes, also proteomics and metabolomics measurements are available. All these examples serve to show that having methods in place to integrate these data is not a luxury anymore.
2.2 Types of data fusion
Without trying to build a rigorous taxonomy of data fusion it is worthwhile to distinguish several distinctions in data fusion. The first distinction is between model-based and exploratory data fusion. The former uses background knowledge in the form of models to fuse the data; one example being genome-scale models in biotechnology (Zimmermann et al., 2017). The latter does not rely on models, since these are not available or poorly known, and thus uses empirical modeling to explore the data. In this paper, we will focus on exploratory data fusion.
The next distinction is between low-, medium-, and high-level fusion Steinmetz et al. (1999). In low-level fusion, the data sets are combined at the lowest level, that is, at the level of the (preprocessed) measurements. In medium-level fusion, each separate data set is first summarized, e.g., by using a dimension reduction method or through variable selection. The reduced data sets are subsequently subjected to the fusion. In high-level fusion, each data set is used for prediction or classification of an outcome and the prediction or classification results are then combined, e.g, by using majority voting (Doeswijk et al., 2011). In machine learning this is known as early, intermediate and late integration. All these types of fusions have advantage and disadvantages which are beyond the scope of this paper. In this paper, we will focus on low- and medium-level fusion.
The final characteristic of data fusion relevant for this paper is heterogeneity of the data sets to be fused. Different types of heterogeneity can be distinguished. The first one is the type of data, such as metabolomics, proteomics and RNAseq data in genomics. Clearly, these data relate to different parts of the biological system. The second one is the type of measurement-scale in which the data are measured that are hoing to be fused. In genomics, an example is a data set where gene-expressions are available and mutation data in the processed form of Single Nucleotide Variants (SNVs). The latter are binary data and gene-expression is quantitative data. They are clearly measured at a different scale. Ideally, data fusion methods should consider the scale of such measurements and this will be the topic of this paper.
2.3 Types of measurement scales
The history of measurement scales goes back a long time. A seminal paper drawing attention to this issue appeared in the 40-ties (Stevens, 1946). Since then numerous papers, reports and books have appeared (Suppes and Zinnes, 1962; Krantz et al., 1971; Narens, 1981; Narens and Luce, 1986; Luce and Narens, 1987; Hand, 1996). The measuring process assigns numbers to aspects of objects (an empirical system), e.g, weights of persons. Hence, measurements can be regarded as a mapping from the empirical system to numbers, and scales are properties of these mappings.
In measurement theory, there are two fundamental theorems (Krantz et al., 1971): the representation theorem and the uniqueness theorem. The representation theorem asserts the axioms to be imposed on an empirical system to allow for a homomorphism of that system to a set of numerical values. Such a homomorphism into the set of real numbers is called a scale and thus represents the empirical system. A scale possesses uniqueness properties: we can measure the weight of persons in kilograms or in grams, but if one person weighs twice as much as another person, this ratio holds true regardless the measurement unit. Hence, weight is a so-called ratio-scaled variable and this ratio is unique. The transformation of measuring in grams instead of kilograms is called a permissible transformation since it does not change the ratio of two weights. For a ratio-scaled variable, only similarity transformations are permissible; i.e. where is the variable on the original scale and is the variable on the transformed scale. This is because
[TABLE]
Note that this coincides with the intuition that the unit of measurement is immaterial.
The next level of scale is the interval-scaled measurement. The typical example of such a scale is degrees Celsius and the permissible transformation is affine; i.e. . In that case, the ratio of two intervals is unique because
[TABLE]
Stated differently, the zero point and the unit are arbitrary on this scale.
Ordinal-scaled variables represent the next level of measurements. Typical examples are scales of agreement in surveys: strongly disagree, disagree, neutral, agree and strongly agree. There is a rank-order in these answers, but no relationship in terms of ratios or intervals. The permissible transformation of an ordinal-scale is a monotonic increasing transformation since such transformations keep the order of the original scale intact.
Nominal-scaled variables are next on the list. These variables are used to encode categories and are sometimes also called categorical. Typical example are gender, race, brands of cars and the like. The only permissible transformation for a nominal-scaled variable is the one-to-one mapping. A special case of a nominal-scaled variable is the binary (0/1) scale. Binary data can have different meanings; they can be used as categories (e.g. gender) and are then nominal-scale variables. They can also be two points on a higher-level scale, such as absence and presence (e.g. for methylation data).
The above four scales are the most used ones but others exists (Suppes and Zinnes, 1962; Krantz et al., 1971). Counts, e.g., have a fixed unit and are therefore sometimes called absolute-scaled variables (Narens and Luce, 1986). Another scale is the one for which the power transformation is permissible; i.e. which is called a log-interval scale because a logarithmic transformation of such a scale results in an interval-scale. An example is density (Krantz et al., 1971). Sometimes the scales are lumped in quantitative (i.e. ratio and interval) and qualitative (ordinal and nominal) data.
An interesting aspect of measurement scales is to what extent meaningful statistics can be derived from such scales (see Table 1 in (Stevens, 1946)). A prototypical example is using a mean of a sample of nominal-scaled variables which is generally regarded as being meaningless. This has also provoked a lot of discussion (Adams et al., 1965; Hand, 1996) and there are nice counter-examples of apparently meaningless statistics that still convey information about the empirical system (Michell, 1986). As always, the world is not black or white.
2.4 Motivating example
Examples of fusing data of different measurement scales are abundant in modern life science research. We will first give a short description of modern measurements in genomics that will illustrate this. In a sample extracted from biological systems (e.g. cells) it is possible to measure the mRNA molecules. This is done nowadays with RNAseq techniques and in essence the mRNA are counts per volume, hence, a concentration. Epigenetics concerns, amongst other, the methylation of some of the sites of a DNA molecule and is in essence a binary variable (yes/no methylated at a given location of the DNA). Another feature in genetics is whether a location of the DNA is mutated, a phenomenon called SNVs (single nucleotide variants), which is also binary. Lastly, there are Copy Number Variations (CNVs) of genes on the genome which is in essence a (limited) number of counts and sometimes expressed as Copy Number Abberations (CNA) with a binary coding (no: normal number of copies, yes: aberrant number of copies). If we move to the field of metabolomics and proteomics, then most of the measurements are relative intensities and in some cases - when calibration lines have been made - concentrations which are ratio-scaled.
The above exposition clearly shows that if we want to fuse different types of genomics data, or fuse genomics data with metabolomics and/or proteomics then there is a problem of different measurement scales. This problem is aggravated by the fact that some of this data is very high-dimensional. SNP and methylation data can contain 100.000 features or variables, RNAseq data has usually around 20.000 genes. Shotgun proteomics data (based on LC-MS or LC-MS/MS) can also easily contain 100.000 features. Hence, in many cases dimension reduction has to take place, asking for methods to deal properly with the corresponding measurement scale. For some of the methods to be discussed in this paper there are already examples in the literature. There are examples of the use of the parametric approach using latent variables (Shen et al., 2009; Mo et al., 2013) and also of the optimal scaling approach (van Wietmarschen et al., 2011, 2012). For the third approach to be discussed, we have not found examples yet in the life sciences. We will come back to these examples in Section 5.
2.5 Goal of the paper
In this paper, we describe low- and mid-level fusion ideas of data of different measurement scales. We will restrict ourselves to data sharing the object mode. Mid-level fusion first selects variables and then is subjected to the methods described below. These methods can be applied in different fields of science, but we will illustrate them by using a genomics example.
We think this paper is needed since the different methods originate from different fields of data analysis, psychometrics and bioinformatics with limited cross-talk between those fields; we will try to fill this gap. Moreover, there are relationships between the methods and this might help in selecting the proper method for a particular application. Hence, we will also discuss the properties of the different methods.
We will select and discuss methods that provide coordinates of the objects that can be used for plotting and visualizing the relationships between the objects. Moreover, we think it is also worthwhile to consider methods that generate importance values for the variables in the different blocks since this will facilitate interpretation of the results in substantive terms.
3 Theory
3.1 Three basic ideas
We will describe three basic ideas that can be used for fusion of data of different measurement scales on a conceptual level. A more detailed explanation is given in following Sections. One of these methods is parametric and thus depends on distributions (Mo et al., 2013). The other two methods are non-parametric and based on concepts of representation matrices (Zegers, 1986; Kiers, 1989) and optimal scaling (Gifi, 1990).
The first idea is illustrated in Figure 1 (Kiers, 1989). Suppose we have three blocks of data, the first block () contains ratio-scaled data, the second block () binary data and the third block () categorical data with each of the variables having four categories (labeled A, B, C and D). Each variable in each block is represented by an representation matrix (to be explained later). Then these representation matrices can be stacked and the resulting three-way array can be analyzed by a suitable three-way method using components giving coordinates for the objects and weights for the variables.
The second idea is illustrated in Figure 2 (Gifi, 1990; Michailidis and de Leeuw, 1998). The original matrices are subjected to optimal scaling and the fusion problem is solved as one global optimization problem (to be explained later). The idea of optimal scaling goes back already to R. Fisher and nice introductions are available (Young, 1981). For the first block, the variables remain the same but for the second and third block these variables are (optimally) transformed. Using optimal scaling, the three blocks are made comparable and are analyzed simultaneously by a multiblock method (e.g. Simultaneous Component Analysis or Consensus PCA) giving coordinates for the objects (the matrix) and loadings (the (), () and () matrices) for the transformed variables.
The third idea relies on the explicit use of the latent variables collected in (see Figure 3) (Mo et al., 2013). These latent variables are then thought to generate the manifest variables in the different blocks using different distributions. For the ratio-scaled block, a regression model is assumed based on the normal distribution and with parameters and . For the binary block, a logit or probit model is assumed with parameters and . The final - categorical - block is modeled by a multilogit model with parameters and where .
We will use the following conventions for notations. A vector is a bold lowercase and a matrix () a bold uppercase. Running indices will be used for samples (=1,…,) with is the number of samples; we will use likewise the indices =1,…, for the data blocks; variables within a data block are indexed by =1,…, and we will use =1,…, as an index for latent variables or components.
3.2 Representation matrices approaches
3.2.1 Representation matrices
Idea of representation matrices.
Suppose we have a data matrix with columns containing the scores of the objects on variable . Such a score can be a ratio-scaled value, but can also be a binary value, a categorical value or an ordinal-scaled value. A representation operator works on this vector and produces a representation matrix which serves as a building block to calculate associations between variables and to analyze several variables simultaneously (Zegers, 1986; Kiers, 1989). Such a representation matrix can be a vector (), a rectangular matrix () or a square matrix (). Let and be the representation matrices for variables and , respectively, then a general equation of the association between variables and is
[TABLE]
where the symbol ’tr’ is used to indicate the trace of a matrix. In most cases that follow below the representation matrices are standardized (centered and scaled to length one111An alternative is scaling to variance one, but this only differs with the same constant for each variable.) and in these cases Eqn. 3 simplifies to
[TABLE]
since both and are one. As will be shown in the following, Eqn. 4 can generate the familiar associations such as the Pearson correlation or the Spearman correlation. An extensive description of all kinds of representation matrices is beyond the scope of this paper; we will discuss the most relevant ones for the problem of heterofusion. The idea of representation matrices222Their original name was quantification matrices but that name has also been used differently. Hence our choice to rename such matrices. goes back to the work of Janson and Vegelius (1982) and Zegers (1986). Examples of different representation matrices are given in Section 6.
Representation matrices for ratio- and interval-scaled values.
For ratio- and interval-scaled values, two types of representation matrices can be defined: vectors and square matrices. If represents the raw scores of the objects on variable then the vector quantification can be this vector itself (i.e. ) or a standardized version of it. When the latter is used in Eqn. 4, Pearson’s -value is obtained. In standard multivariate analysis this is by far the most used representation matrix.
There is also another possibility for ratio- and interval-scaled values, namely square representation matrices. Two examples are the following. Define
[TABLE]
where 1 is an column of ones. This generates a skew-symmetric matrix enumerating all differences between the object-scores of variable (for an example, see 6.2). Hence, distances between objects are obtained per variable and these distance matrices can be subjected to an INDSCAL model (Kiers, 1989). Upon standardizing by and using this (and a similarly defined ) in Eqn. 4 gives again Pearson’s -value. Another example is using where is the standardized version of . Using this (and a similarly defined ) in Eqn. 4 gives Pearson’s value. Such representation matrices correspond to the blue-squared matrices in Figure 1 and are the basis of Kernel and Multidimensional Scaling methods (check!).
Representation matrices for ordinal-scaled values.
When the data are ordinal-scaled, then the vector of readings can be encoded in terms of rank-orders . For the earlier example of strongly disagree, disagree, neutral, agree, strongly agree such a ranking may be encoded as 1 (strongly disagree) to 5 (strongly agree). Then again - as in the ratio-scaled variables - representation can be done using the vectors or their standardized version. In the latter case, applying Eqn. 4 to this version gives the Spearman’s rank-order correlation coefficient. Another representation is by using (the raw-) in Eqn. 5 instead of and this generates Spearman’s rank-order correlation coefficient after using Eqn. 3.
Representation matrices for nominal-scaled values.
We will discuss the representation matrices for nominal-scaled variables separately for binary data and categorical data. We first discuss representation matrices for categorical data. We have to distinguish two situations: one in which all categorical variables have the same number of categories and the situation that this is not the case. Since the latter is more general and encountered more often, we will restrict ourselves to this case. Then only square representation matrices are available. These are based on indicator matrices (Zegers, 1986; Kiers, 1989; Gifi, 1990). If variable has four categories (A,B,C,D), then this can be encoded in the rectangular matrix where each column in represents a category and each row an object. This matrix has only zeros or ones; where is one, if and only if object belongs to the category represented by . The representation matrix can now be built using the products . There are very many versions of such square representation matrices based on indicator matrices and some of them give rise to a known correlation, e.g.,
[TABLE]
where is the centering operator and is a diagonal matrix containing the marginal frequencies of categories for variable . The corresponding correlation coefficient is the so-called coefficient (Tschuprow, 1939). These representation matrices correspond to the red-square matrices in Figure 1. Examples are given in Section 6.3.
For binary data (if all variables are binary) then rectangular representation matrices are possible. This comes down to the same idea as above, namely, to consider the binary variables as representing two categories. This results then in representation matrices of sizes . When fusing with other types of variables is the goal, then a squared type of representation is needed such as in Eqn. 6 and visualized in Figure 1 (green matrices). Examples are given in Section 6.4.
3.2.2 Data fusion using representation matrices
To illustrate how to use representation matrices we will work with four data matrices, each on a different measurement scale and sharing the same set of samples. The first matrix contains ratio- or interval-scaled data; the second matrix contains ordinal-scaled data; the third contains nominal data and the last matrix contains binary data.
The representation matrices can now be used in a three-way model for symmetric data. The basic model for a single data block is the INDSCAL (INdividual Differences SCALing) model:
[TABLE]
where is the diagonal matrix with the row of the loadings on its diagonal and the matrix contains the object scores. The loadings are nonnegative to ensure the fitted part of the model () to be positive (semi-) definite. If the additional constraint that is used, then the model is called INDORT (INDscal with ORThogonal constraints) (Kiers, 1989).
The INDORT method can now be generalized to analyze simultaneously all blocks by simply stacking all similarity matrices on top of each other (see Figure 1):
[TABLE]
where is the diagonal matrix with the row of the loadings on its diagonal and the matrix contains the object scores. This model is called IDIOMIX for obvious reasons (Kiers, 1989).
3.3 Optimal scaling approaches
There are many ways to explain optimal scaling; we will follow the exposition given by Michailidis and de Leeuw (1998). Suppose that the matrix contains categorical variables not necessarily with the same number of categories. Each variable can now be encoded with indicator matrix where is the number of categories for variable as discussed before. The idea of optimal scaling is to find objects scores and category quantification matrices such that the following problem is solved (Michailidis and de Leeuw, 1998):
[TABLE]
under the constraints that and these scores are centered around zero (to avoid trivial solutions of Eqn. 9). This method - including the alternating optimization method to solve Eqn. 9 - is called homogeneity analysis or HOMALS for short (Gifi, 1990). The rows of give a low dimensional representation of the objects and the matrices give the optimal quantifications of the categorical variables. Note that these matrices are not loadings; they give quantifications for the categorical variables which are different for the components, namely where is the column of .
Upon restricting the rank of to be one, we arrive at non-linear PCA (PRINCALS) (Gifi, 1990; Michailidis and de Leeuw, 1998). Then Eqn. 9 can be rewritten as
[TABLE]
with the same constraints on as before (i.e. ). As an identification constraint for and we impose . Now, the vectors are the loadings and contain the quantifications which are the same for all dimensions of the solution. The relationship between (linear) PCA and non-linear PCA becomes clear when rewriting Eqn. 10 (following (Gifi, 1990), p.167-168) as
[TABLE]
using the constraints on and . The function in Eqn. 11 differs only a constant from the function
[TABLE]
as follows from rewriting using the constraints on and :
[TABLE]
Thus, it has been shown that problem Eqn. 10 subject to the constraints and is equivalent to the problem
[TABLE]
where has rows and is written as where the superscript ’*’ represents the optimal scaled data, and this is seen to be the (non-linear) analog of ordinary PCA (Gifi, 1990).
The nature of the measurement scale can now be incorporated by allowing the quantifications to be free for nominal-scale data and monotonic for ordinal-scaled data. The latter quantification ensures the order in the ordinal-scaled data. Framed in terms of Eqn. 14 this becomes:
[TABLE]
where and are elements of ; and are elements of . Ties in the original data can be treated in different ways depending on whether the underlying measurements can be considered continuous or discrete (De Leeuw et al., 1976; Takane et al., 1977; Young et al., 1978) but this is beyond the scope of this paper.
There are close similarities between optimal scaling and multiple correspondence analysis (Kiers, 1989; Michailidis and de Leeuw, 1998). Binary data represents a special case. When considered as categorical data, non-linear PCA using optimal scaling is the same as performing a (linear) PCA on the standardized binary data, for a proof, see Appendix (De Leeuw, 1973; Kiers, 1989).
3.3.1 Data fusion using optimal scaling matrices
There are different ways to use optimal scaling for fusing data. One method generalizes (generalized) canonical correlation analysis (OVERALS (Van der Burg et al., 1988)) and the other method generalizes simultaneous component analysis (SCA) (MORALS (Young, 1981)). Experiences with generalized canonical correlations show that this method tends to overfit for high-dimensional data. An attempt to overcome this problem is by introducing sparsity constraints (Waaijenborg et al., 2008), but it is not trivial to combine this with optimal scaling. Hence, we chose to use the extension of SCA. Note that SCA was originally developed for analyzing multiple data sets sharing the same set of variables (Ten Berge et al., 1992), but it can likewise be formulated for multiple data sets having the sampling mode in common (van Deun et al., 2009). Using the latter interpretation of SCA leads to the following approach.
We take the same data matrices as in Section 3.2.2 and upon writing the problem becomes
[TABLE]
with an obvious partition of the loading matrix and where the term ’Par’ stands for all parameters. Apart from the scores and loadings these are the following. For the ratio- interval-scaled block there are no extra parameters since the original scale is used (i.e. . The second - ordinal-scaled - block puts restrictions on following the restrictions of Eqn. 15. The third (nominal-) block has underlying indicator matrices and associated quantifications and loadings obey the rules of Eqn. 10. Finally, the binary block is simply the standardized version of and this ensures an optimal scaling as mentioned above. Note that this way of fusing data assumes an identity link function (Van Mechelen and Smilde, 2010) and is thus an extension of methods like Consensus PCA and SCA. We will call this method OS-SCA in the sequel. There is no differentiation between common and distinct components (Smilde et al., 2017)
3.4 Parametric approaches
A different class of methods has its roots in factor analysis and can be summarized as follows (see Figure 3). The basic idea is that a set of (shared) latent variables is responsible for the variation in all the blocks (Shen et al., 2009; Curtis et al., 2012; Mo et al., 2013) and, subsequently, models are built for the individual blocks based on those shared latent variables. We will describe the Generalized Simultaneous Component Analysis (GSCA) method (Song et al., 2018) in more detail since that is the method used in this paper. If is the binary data matrix, then we assume that there is a low-dimensional deterministic structure underlying and the elements of follow a Bernoulli distribution with parameters , thus . The function can be taken as the logit link and , are the elements of and , respectively. The is now assumed to be equal to where represent the off-set term, the common scores and the loadings for the binary data.
The quantitative measurements are assumed to follow the model where the elements of are normally distributed with mean 0 and variance . The matrix contains the loadings of the quantitative data set; are again the common scores and the constraints and are imposed for identifiability. The shared information between and is assumed to be represented fully by the common latent variables . Thus and are stochastically independent given these latent variables and the negative log-likelihoods of both parts can be summed:
[TABLE]
and minimized simultaneously. This requires some extra constraints; details are given elsewhere (Song et al., 2018).
4 Practical issues and examples
4.1 Genomics example
The genomics example is from the field of cancer research and the data are obtained from the Genomics in Drugs Sensitivity in Cancer from the Sanger Institute (http://www.cancerrxgene.org/). Briefly, this repository consists of measurements performed on cell lines pertaining to different types of cancer. We used the copy number aberration (CNA) and gene-expression data of the cell lines related to breast cancer (BRCA), lung cancer (LUAD) and skin cancer (SKCM). After selecting the samples which had values for all these types of cancer we filtered the gene-expression data by selecting the 1000 variables with the highest variance across the samples. The CNA data contains amplifications and losses of DNA-regions as compared to the average copy numbers in the population. Both amplifications and losses are encoded as ones indicating deviances. The zeros in the CNA data indicate a normal diploid copy number. This provides us with samples; binary values for the CNA data and variables for the gene-expression data.
For the representation approach we built a three-way array of size and performed an IDIOMIX analysis. For the binary part, this array contains the slabs according to Eqn. 6 and for the gene-expression part, the slabs are defined by the outer products of the samples in the gene-expression data after auto-scaling the columns of that data. The optimal scaling result are obtained by auto-scaling both raw data sets and subsequently perform an (OS-)SCA on the concatenated data . The final way of fusing the two data sets is by using the GSCA model.
The amounts of explained variations are shown in Table 1 which contains a lot of information and should be interpreted with care.
First, for IDIOMAX, OS-SCA and the quantitative part of the GSCA model the explained variation is calculated using sums-of-squares. This is not the case for the binary part of GSCA (for details, see Song et al. (2018)). Second, IDIOMAX on the one hand and OS-SCA, GSCA on the other hand are very different types of models, i.e., they use the data directly (OS-SCA, GSCA) or indirectly (IDIOMAX) so a simple comparison of explained sums-of-squares between these types of models is difficult. The final column of the table reports the amounts of explained variation of a regular PCA on the (autoscaled) gene-expression data.
The first observation to make regarding the values in Table 1 is that the amounts of explained variations of the PCA model of the gene-expression data is closely followed by the amounts of explained variations in the gene-expression simultaneous components for OS-SCA and GSCA. This means that the data fusion is dominated by the gene-expression block. This is confirmed by plotting the scores of PC1 and PC2 of the PCA on gene-expression against the SC-scores 1 and 2 of OS-SCA and GSCA: these are almost on a straight line (plot not shown). Although the explained variances for IDIOMAX are much lower, the same observation is valid for IDIOMAX: also for this method the first two SC-scores resembles the ones of a PCA on the gene-expression almost perfectly. This dominance of the gene-expression block in the data fusion as reflected in the first two components cannot completely be explained by the differences in block sizes (1000 variables for gene-expression and 410 variables for the CNA block) but is also due to dominant intrinsic systematic patterns in the gene-expression data.
To get a feeling for what is represented in the first two SCs (that are virtually identical across the three methods), we show the scores for the GSCA method on SC1 and SC2 in Figure 4.
The scores show a clear separation in cancer types with specific sub-clusters for hormone-positive breast cancer (within the BRCA-group) and MITF-high melanoma (in the SKCM group) (for a more elaborate interpretation see Song et al. (2018)).
Whereas the three approaches give similar results for the first two simultaneous components, qualitative differences can be seen in SC3. This is especially apparent in Table 1 where the third component for IDIOMIX is now dominated by the CNA data. This is visualized in Figure 5 which shows the score plots of SC1 versus SC3 for all methods which are clearly different.
To further confirm this, the scores of the different methods for the three different components were plotted against each other (see Figure 6) and this confirms that indeed the first two SCs are very similar for all methods, but that SC3 shows differences where GSCA is the most deviating.
To shed some light on this deviating behavior, we plotted the scores of a PCA on the gene-expression data against the SC-scores of the fusion methods for the third component, see Figure 7.
The left panels in this figure show that SC3 from GSCA is very similar to the PC3 of a PCA on the gene-expression data alone (see also again Table 1). The same does not hold true for the other methods. The CNA values are available for each sample and thus the scores on the fusion SC3 can be plotted against the frequency at which such an aberration occurs (number of ones divided by the total). From the right panels of Figure 7, it then becomes clear that SC3 of IDIOMAX and OS-SCA are mostly picking up the differences in frequencies, contrary to the GSCA-SC3 scores.
A similar comparison can be made for the loadings, see Figure 8. The left panels show the PC3 loadings from gene-expression using PCA and the fusion methods. In the right panels the fusion loadings are plotted against CNA frequencies (now across DNA-positions) and those show no correlation. As explained earlier, the aberrations can either be amplifications or losses and those are clearly picked up by the loadings of IDIOMAX and OS-SCA.
To interpret the GSCA-loadings, these loadings were subjected to a Gene Set Enrichment Analysis (GSEA). This resulted in a highly significant enrichment for epithelial-mesenchymal transition (EMT), a process undergone by tumor cells frequently associated with invasion of surrounding tissues and subsequent metastases. The largest positive loading on GSCA-PC3 for the gene-expression is ZEB1, a transcription factor associated with EMT. A plot of the loadings of the CNA data is shown in Figure 9 and one of the loadings identifies SMAD4 loss as an important factor. SMAD4 is required for TGF- driven EMT which confirms the finding that the GSCA gene-expression loadings are strongly enriched for EMT (Tian and Schiemann, 2009).
Summarizing, IDIOMAX and OS-SCA are very similar for the whole analysis. For the first two SCs, also the GSCA resembles the other approaches. The difference of GSCA is in the third SC. It seems that GSCA is focussing more on the gene-expression data; whereas IDIOMAX and OS-SCA pick up specific aspects of the CNA data in this third SC. The results of the GSCA-SC3 are biologically relevant; this is less the case for SC3 of the other approaches. It may be that GSCA is focussing more on the common variation between the two data sets and is less influenced by the distinctive parts (Smilde et al., 2017). This needs further exploration in a follow-up paper.
5 Discussion
In this paper we have described and compared three methods of fusing data of different measurement scales. We used the example of quantitative and binary data, but all methods can also deal with ordinal data. For the example, it appears that IDIOMAX and OS-SCA give very similar results whereas GSCA is different. One of the reasons may be that the methods deal differently with common and distinct parts of the data.
All methods have meta-parameters, that is, prior choices have to be made. For IDIOMAX, this is the type of representation to select; for OS-SCA it is the type of restrictions to apply; for GSCA it is the distribution to assume for the separate data sets. All methods also require selecting the complexity of the models, i.e., the number of components. The selection of all these meta-parameters will, in practice, be made based on a mixture of domain knowledge and validation, such as cross-validation or scree-tests for selecting model complexity.
We hesitate in giving recommendations regarding which method to use for a particular application. First, the example of this paper concerns an exploratory study for which it is always difficult to judge the relative merits of the methods. Secondly, the cultural background of the investigator plays a role. In data analysis and chemometrics, the culture is to avoid distributional assumptions and have a more data analytic approach, thus resulting in a preference for IDIOMAX or OS-SCA. In statistics and, to some extent, in bioinformatics there is more a tendency to go for parametric modes, hence, GSCA in our context. Thirdly, these methods have not yet been used to a large extent by researchers, hence, experience on their behavior upon which a recommendation can be based is lacking.
In terms of ease of use, we have a slight preference for IDIOMAX. Once the representation matrices are built, standard three-way analysis software can be used to fit the models. There is also software available for OS-SCA and GSCA, but this software is more difficult to implement.
There remain open issues to be investigated. Some of the more prominent ones is to understand the behavior of the methods regarding common, distinct and local components in fusing data sets. Little has been done in this field regarding data of different measurement scales.
6 Appendix
6.1 Optimal scaling of binary data equals analyzing standardized data
The fact that optimal scaling of binary data equals the analysis of standardized data can be shown as follows. Suppose that a binary vector has values of zero, values of one and values in total, and is the optimal scaled value for the zeros and for the ones. In optimal scaling, the optimal scaled variables need to get some kind of normalization. A common set of choices (see (Gifi, 1990)) is to make sure that the scaled values have mean zero and variance one. This leads to the following two equations:
[TABLE]
and these equations can be solved for and since and are known. This gives two values for ; one positive and one negative. The values of follow automatically with the opposite sign. Hence, both solutions are practically equal.
6.2 Examples of representation matrices for ratio- and interval-scaled data
We will illustrate some ideas of representation matrices using a small example of an matrix :
[TABLE]
and the standardized version of this is
[TABLE]
where indeed , and the latter being the correlation between and . The square representation using Eqn. 5 on gives
[TABLE]
which is skew-symmetric () and contains all the differences between the elements of . The standardized version of is
[TABLE]
and a similar matrix can be made for . Then using Eqn. 4 on the pairs and gives a value of one; and on the pair gives 0.913, which is the Pearson’s correlation again.
Alternative square representations of and are
[TABLE]
and
[TABLE]
and using Eqn. 4 on and gives 0.833 which is the squared Pearson’s correlation between the original variables.
6.3 Examples of representation matrices for nominal data
We will illustrate some ideas on representing nominal data using two categorical variables and . The first variable contains four categories encoded as A,B,C,D and reads ; the second variable has three categories encoded as I,II,III and reads where the roman capitals are used to show that the two variables encode different types of categories. The indicator matrices are now
[TABLE]
and
[TABLE]
and a special feature of this kind of data becomes present namely that some objects have exactly the same rows in (and similarly in ). Moreover, the matrices show closure (). The marginal frequencies are collected in
[TABLE]
and
[TABLE]
with obvious properties.
Simple representations of these variables are now
[TABLE]
and
[TABLE]
and these representations are encoding which objects have equal categories in the variables. The more complex representations (according to Eqn 6) are now
[TABLE]
and
[TABLE]
which are indeed double centered and standardized. Using Eqn. 4 on the matrices and gives the correlation coefficient .
6.4 Examples of representation matrices for binary data
As an example for binary data we will use a simple data set consisting of two binary variables and which are columns of
[TABLE]
with indicator matrices
[TABLE]
and
[TABLE]
A correlation measure between binary variables is the -coefficient which is defined as
[TABLE]
where the values are shown in Table 2. For the example, this -coefficient equals which is also equivalent to the Pearson correlation between and .
There are two alternative square representations of and . The first uses Eqn. 6 based on the indicator matrices and the results are
[TABLE]
and
[TABLE]
and when these are used in Eqn. 4 the result is which is the square of the -coefficient.
The other representations are based on the standardized -variables and (with ). It now holds that and, hence, both representations coincide.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Adams et al. (1965) Adams, E., Fagot, R., and Robinson, R. (1965). A theory of appropriate statistics. Psychometrika , 30 (2), 99–127.
- 2Curtis et al. (2012) Curtis, C., Shah, S. P., Chin, S. F., Turashvili, G., Rueda, O. M., Dunning, M. J., Speed, D., Lynch, A. G., Samarajiwa, S., Yuan, Y. Y., Graf, S., Ha, G., Haffari, G., Bashashati, A., Russell, R., Mc Kinney, S., Langerod, A., Green, A., Provenzano, E., Wishart, G., Pinder, S., Watson, P., Markowetz, F., Murphy, L., Ellis, I., Purushotham, A., Borresen-Dale, A. L., Brenton, J. D., Tavare, S., Caldas, C., and Aparicio, S. (2012). The genomic and transcriptomic archite
- 3De Leeuw (1973) De Leeuw, J. (1973). Canonical analysis of categorical data . Ph.D. thesis, University of Leiden.
- 4De Leeuw et al. (1976) De Leeuw, J., Young, F., and Takane, Y. (1976). Additive structure in qualitative data: an alternating least squares method with optimal scaling features. Psychometrika , 41 (4), 471–503.
- 5Doeswijk et al. (2011) Doeswijk, T. G., Smilde, A. K., Hageman, J. A., Westerhuis, J. A., and van Eeuwijk, F. A. (2011). On the increase of predictive performance with high-level data fusion. Analytica Chimica Acta , 705 (1-2), 41–47.
- 6Gifi (1990) Gifi, A. (1990). Nonlinear Multivariate Analysis . John Wiley & Sons.
- 7Hand (1996) Hand, D. J. (1996). Statistics and the theory of measurement. Journal of the Royal Statistical Society Series A-statistics in Society , 159 , 445–473.
- 8Janson and Vegelius (1982) Janson, S. and Vegelius, J. (1982). Correlation-coefficients for more than one scale type. Multivariate Behavioral Research , 17 (2), 271–284.