SocialIQA: Commonsense Reasoning about Social Interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, Yejin Choi

TL;DR
Social IQa is a large-scale benchmark designed to evaluate and improve commonsense reasoning about social interactions, highlighting the gap between current models and human understanding.
Contribution
It introduces the first extensive social interaction reasoning benchmark and demonstrates its utility for transfer learning to other commonsense tasks.
Findings
Benchmark is challenging for existing models.
Models lag behind humans by over 20%.
Achieves state-of-the-art on other reasoning tasks.
Abstract
We introduce Social IQa, the first largescale benchmark for commonsense reasoning about social situations. Social IQa contains 38,000 multiple choice questions for probing emotional and social intelligence in a variety of everyday situations (e.g., Q: "Jordan wanted to tell Tracy a secret, so Jordan leaned towards Tracy. Why did Jordan do this?" A: "Make sure no one else could hear"). Through crowdsourcing, we collect commonsense questions along with correct and incorrect answers about social interactions, using a new framework that mitigates stylistic artifacts in incorrect answers by asking workers to provide the right answer to a different but related question. Empirical results show that our benchmark is challenging for existing question-answering models based on pretrained language models, compared to human performance (>20% gap). Notably, we further establish Social IQa as a…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1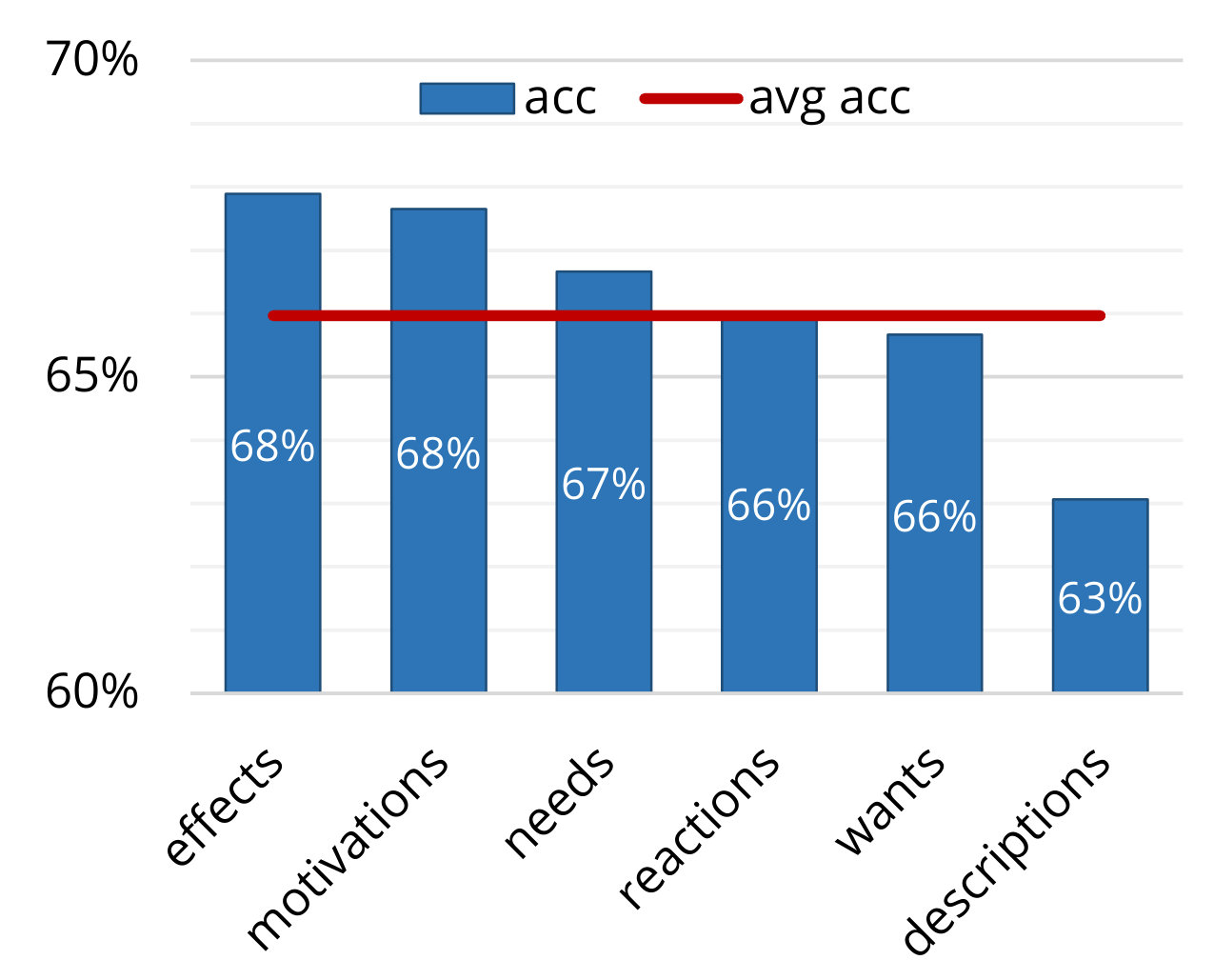 Figure 2
Figure 2 Figure 3
Figure 3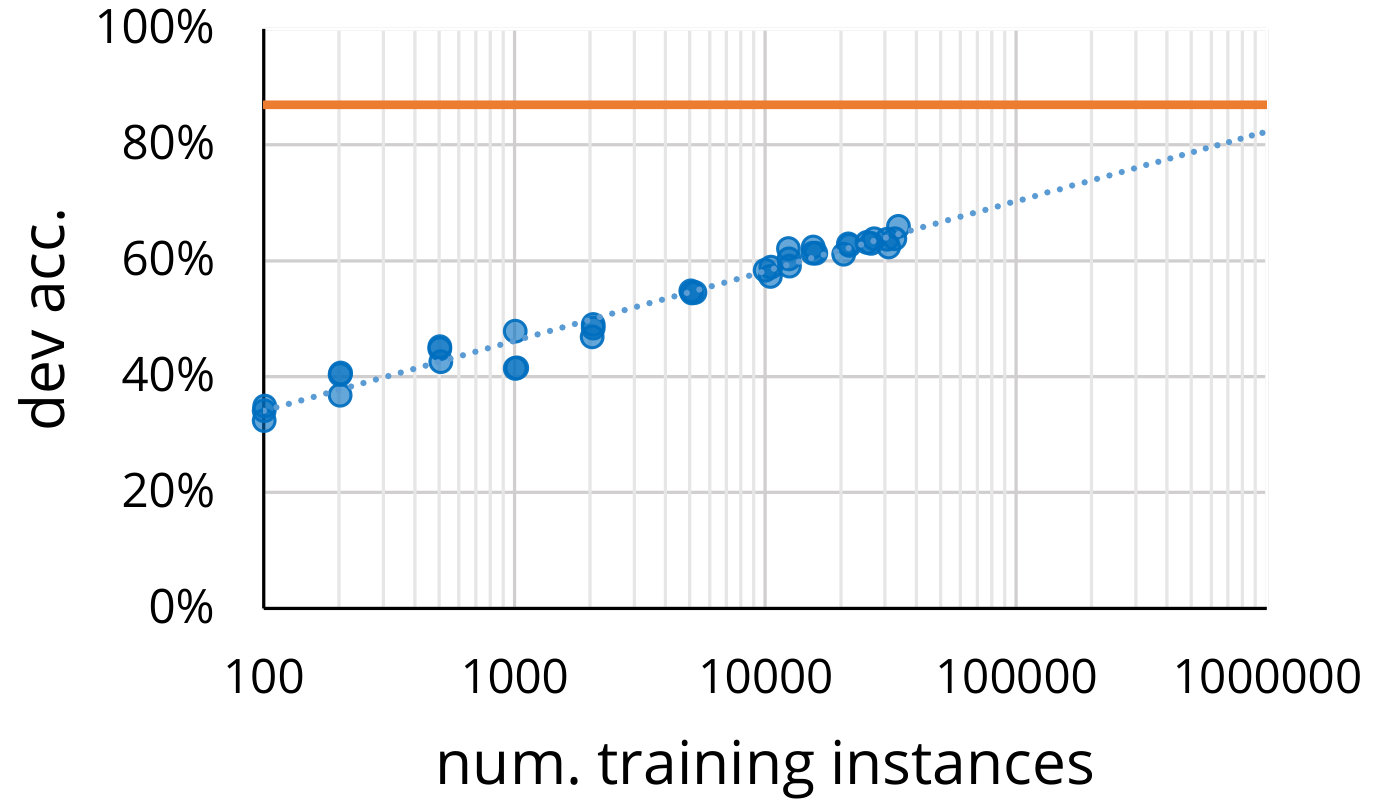 Figure 4
Figure 4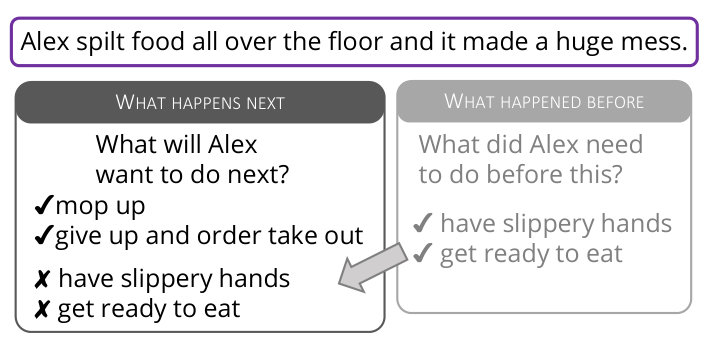 Figure 5
Figure 5 Figure 6
Figure 6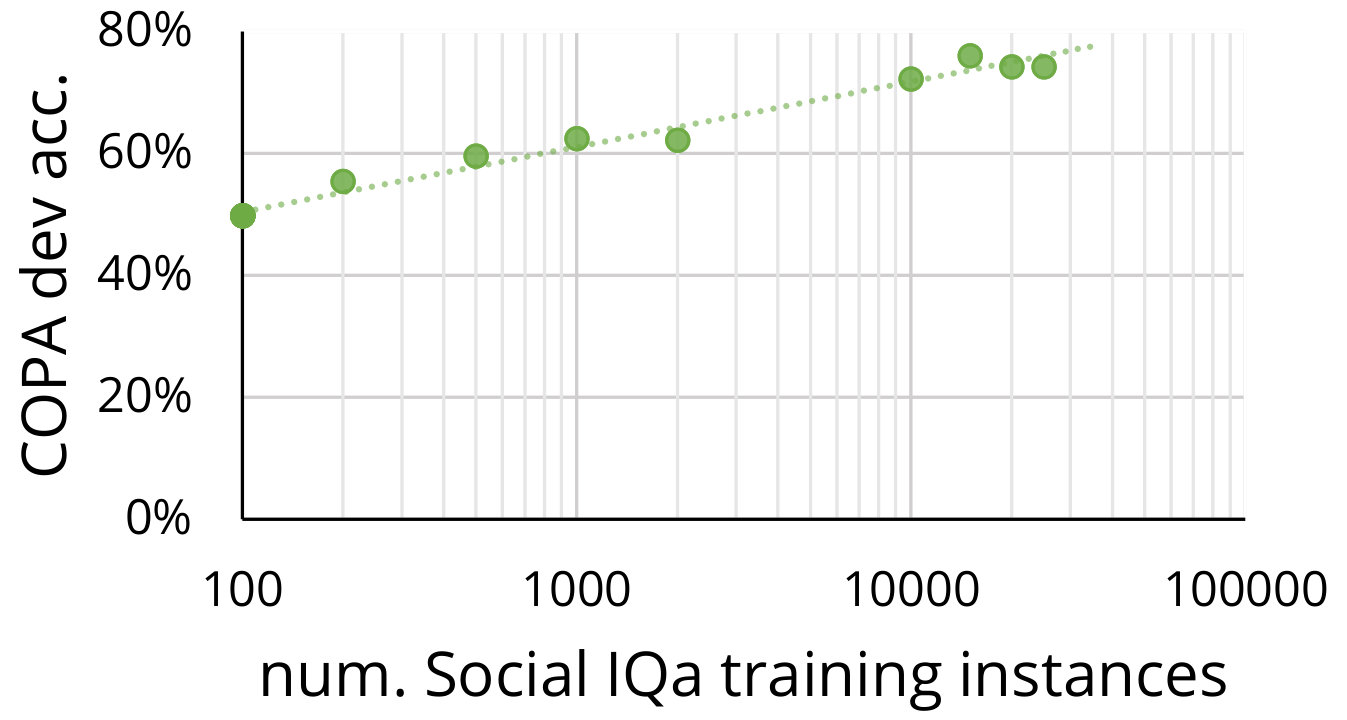 Figure 7
Figure 7| Social IQa | ||
| # QA tuples | train | 33,410 |
| dev | 1,954 | |
| test | 2,224 | |
| total | 37,588 | |
| Train statistics | ||
| Average # tokens | context | 14.04 |
| question | 6.12 | |
| answers (all) | 3.60 | |
| answers (correct) | 3.65 | |
| answers (incorrect) | 3.58 | |
| Unique # tokens | context | 15,764 |
| question | 1,165 | |
| answers (all) | 12,285 | |
| answers (correct) | 7,386 | |
| answers (incorrect) | 10,514 | |
| Average freq. of answers | answers (correct) | 1.37 |
| answers (incorrect) | 1.47 | |
| Model | Accuracy (%) | |
| Dev | Test | |
| Random baseline | 33.3 | 33.3 |
| GPT | 63.3 | 63.0 |
| BERT-base | 63.3 | 63.1 |
| BERT-large | 66.0 | 64.5 |
| w/o context | 52.7 | – |
| w/o question | 52.1 | – |
| w/o context, question | 45.5 | – |
| Human | 86.9* | 84.4* |
| Context | Question | Answer | |||
|---|---|---|---|---|---|
| (1) | Jesse was pet sitting for Addison, so Jesse came to Addison’s house and walked their dog. | What does Jesse need to do before this? | (a) feed the dog | ||
| ✓ | (b) get a key from Addison | ||||
| (c) walk the dog | |||||
| (2) | Kai handed back the computer to Will after using it to buy a product off Amazon. | What will Kai want to do next? | (a) wanted to save money on shipping | ||
| ✓ | (b) Wait for the package | ||||
| (c) Wait for the computer | |||||
| (3) | Remy gave Skylar, the concierge, her account so that she could check into the hotel. | What will Remy want to do next? | (a) lose her credit card | ||
| (b) arrive at a hotel | |||||
| ✓ | (c) get the key from Skylar | ||||
| (4) | Sydney woke up and was ready to start the day. They put on their clothes. | What will Sydney want to do next? | (a) go to bed | ||
| (b) go to the pool | |||||
| ✓ | (c) go to work | ||||
| (5) | Kai grabbed Carson’s tools for him because Carson could not get them. | How would Carson feel as a result? | (a) inconvenienced | ||
| (b) grateful | |||||
| (c) angry | |||||
| (6) | Although Aubrey was older and stronger, they lost to Alex in arm wrestling. | How would Alex feel as a result? | (a) they need to practice more | ||
| (b) ashamed | |||||
| (c) boastful |
| Task | Model | Acc. (%) | ||
|---|---|---|---|---|
| best | mean | std | ||
| COPA | Sasaki et al. (2017) | 71.2 | – | – |
| BERT-large | 80.8 | 75.0 | 3.0 | |
| BERT-Social IQa | 83.4 | 80.1 | 2.0 | |
| WSC | Kocijan et al. (2019) | 72.5 | – | – |
| BERT-large | 67.0 | 65.5 | 1.0 | |
| BERT-Social IQa | 72.5 | 69.6 | 1.7 | |
| DPR | Peng et al. (2015) | 76.4 | – | – |
| BERT-large | 79.4 | 71.2 | 3.8 | |
| BERT-Social IQa | 84.0 | 81.7 | 1.2 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
- 🤗google/gemma-3-4b-itmodel· 1.5M dl· ♡ 12721.5M dl♡ 1272
- 🤗google/gemma-3-27b-itmodel· 1.0M dl· ♡ 19401.0M dl♡ 1940
- 🤗unsloth/gemma-3-12b-it-GGUFmodel· 101k dl· ♡ 178101k dl♡ 178
- 🤗google/gemma-3-1b-itmodel· 1.4M dl· ♡ 8991.4M dl♡ 899
- 🤗google/gemma-3-12b-it-qat-q4_0-ggufmodel· 7.1k dl· ♡ 2627.1k dl♡ 262
- 🤗google/gemma-3-270mmodel· 83k dl· ♡ 100383k dl♡ 1003
- 🤗google/gemma-7bmodel· 30k dl· ♡ 329330k dl♡ 3293
- 🤗google/gemma-2-2b-itmodel· 368k dl· ♡ 1314368k dl♡ 1314
- 🤗google/gemma-3-12b-itmodel· 2.6M dl· ♡ 6982.6M dl♡ 698
- 🤗google/gemma-3-12b-it-qat-q4_0-unquantizedmodel· 28k dl· ♡ 8128k dl♡ 81
Videos
Llama 2: Full Breakdown· youtube
Social IQa:
Commonsense Reasoning about Social Interactions
Maarten Sap⋆ ♢♡ Hannah Rashkin⋆ ♢♡ Derek Chen♡ Ronan Le Bras♢ Yejin Choi♢♡
♢Allen Institute for Artificial Intelligence, Seattle, WA, USA
♡Paul G. Allen School of Computer Science & Engineering, Seattle, WA, USA
{msap,hrashkin,dchen14,yejin}@cs.washington.edu
{ronanlb}@allenai.org
Abstract
We introduce Social IQa, the first large-scale benchmark for commonsense reasoning about social situations. Social IQa contains 38,000 multiple choice questions for probing emotional and social intelligence in a variety of everyday situations (e.g., Q: “Jordan wanted to tell Tracy a secret, so Jordan leaned towards Tracy. Why did Jordan do this?” A: “Make sure no one else could hear”). Through crowdsourcing, we collect commonsense questions along with correct and incorrect answers about social interactions, using a new framework that mitigates stylistic artifacts in incorrect answers by asking workers to provide the right answer to a different but related question. Empirical results show that our benchmark is challenging for existing question-answering models based on pretrained language models, compared to human performance (20% gap). Notably, we further establish Social IQa as a resource for transfer learning of commonsense knowledge, achieving state-of-the-art performance on multiple commonsense reasoning tasks (Winograd Schemas, COPA).
††footnotetext: ⋆ Both authors contributed equally.
1 Introduction
Social and emotional intelligence enables humans to reason about the mental states of others and their likely actions Ganaie and Mudasir (2015). For example, when someone spills food all over the floor, we can infer that they will likely want to clean up the mess, rather than taste the food off the floor or run around in the mess (Figure 1, middle). This example illustrates how Theory of Mind, i.e., the ability to reason about the implied emotions and behavior of others, enables humans to navigate social situations ranging from simple conversations with friends to complex negotiations in courtrooms Apperly (2010).
While humans trivially acquire and develop such social reasoning skills Moore (2013), this is still a challenge for machine learning models, in part due to the lack of large-scale resources to train and evaluate modern AI systems’ social and emotional intelligence. Although recent advances in pretraining large language models have yielded promising improvements on several commonsense inference tasks, these models still struggle to reason about social situations, as shown in this and previous work Davis and Marcus (2015); Nematzadeh et al. (2018); Talmor et al. (2019). This is partly due to language models being trained on written text corpora, where reporting bias of knowledge limits the scope of commonsense knowledge that can be learned Gordon and Van Durme (2013); Lucy and Gauthier (2017).
In this work, we introduce Social Intelligence QA (Social IQa), the first large-scale resource to learn and measure social and emotional intelligence in computational models.111Available at https://tinyurl.com/socialiqa Social IQa contains 38k multiple choice questions regarding the pragmatic implications of everyday, social events (see Figure 1). To collect this data, we design a crowdsourcing framework to gather contexts and questions that explicitly address social commonsense reasoning. Additionally, by combining handwritten negative answers with adversarial question-switched answers (Section 3.3), we minimize annotation artifacts that can arise from crowdsourcing incorrect answers Schwartz et al. (2017); Gururangan et al. (2018).
This dataset remains challenging for AI systems, with our best performing baseline reaching 64.5% (BERT-large), significantly lower than human performance. We further establish Social IQa as a resource that enables transfer learning for other commonsense challenges, through sequential finetuning of a pretrained language model on Social IQa before other tasks. Specifically, we use Social IQa to set a new state-of-the-art on three commonsense challenge datasets: COPA Roemmele et al. (2011) (83.4%), the original Winograd (Levesque, 2011) (72.5%), and the extended Winograd dataset from Rahman and Ng (2012) (84.0%).
Our contributions are as follows: (1) We create Social IQa, the first large-scale QA dataset aimed at testing social and emotional intelligence, containing over 38k QA pairs. (2) We introduce question-switching, a technique to collect incorrect answers that minimizes stylistic artifacts due to annotator cognitive biases. (3) We establish baseline performance on our dataset, with BERT-large performing at 64.5%, well below human performance. (4) We achieve new state-of-the-art accuracies on COPA and Winograd through sequential finetuning on Social IQa, which implicitly endows models with social commonsense knowledge.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Apperly (2010) Ian Apperly. 2010. Mindreaders: the cognitive basis of” theory of mind” . Psychology Press.
- 2Baron-Cohen et al. (1985) Simon Baron-Cohen, Alan M Leslie, and Uta Frith. 1985. Does the Autistic Child have a “Theory of Mind”? Cognition , 21(1):37–46.
- 3Davis and Marcus (2015) Ernest Davis and Gary Marcus. 2015. Commonsense reasoning and commonsense knowledge in artificial intelligence. Commun. ACM , 58:92–103.
- 4Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL .
- 5Espinosa and Lieberman (2005) José H. Espinosa and Henry Lieberman. 2005. Eventnet: Inferring temporal relations between commonsense events. In MICAI .
- 6Ganaie and Mudasir (2015) MY Ganaie and Hafiz Mudasir. 2015. A Study of Social Intelligence & Academic Achievement of College Students of District Srinagar, J&K, India. Journal of American Science , 11(3):23–27.
- 7Goodwin et al. (2012) Travis Goodwin, Bryan Rink, Kirk Roberts, and Sanda M Harabagiu. 2012. UTDHLT: Copacetic system for choosing plausible alternatives. In NAACL workshop on Sem Eval , pages 461–466. Association for Computational Linguistics.
- 8Gordon and Hobbs (2017) Andrew S Gordon and Jerry R Hobbs. 2017. A Formal Theory of Commonsense Psychology: How People Think People Think . Cambridge University Press.