FishNet: A Camera Localizer using Deep Recurrent Networks
Hsin-I Chen, Sebastian Agethen, Chiamin Wu, Winston Hsu, Bing-Yu Chen

TL;DR
FishNet introduces a deep recurrent network architecture that leverages fisheye camera data and temporal information to improve 6-DOF camera localization accuracy in outdoor environments.
Contribution
The paper presents a novel RNN-based network architecture with pose regularization for enhanced scene representation and smoother pose estimation in camera localization.
Findings
Effective in outdoor scenery with large overlaps
Achieves smoother pose estimates
Outperforms existing methods on benchmark datasets
Abstract
This paper proposes a robust localization system that employs deep learning for better scene representation, and enhances the accuracy of 6-DOF camera pose estimation. Inspired by the fact that global scene structure can be revealed by wide field-of-view, we leverage the large overlap of a fisheye camera between adjacent frames, and the powerful high-level feature representations of deep learning. Our main contribution is the novel network architecture that extracts both temporal and spatial information using a Recurrent Neural Network. Specifically, we propose a novel pose regularization term combined with LSTM. This leads to smoother pose estimation, especially for large outdoor scenery. Promising experimental results on three benchmark datasets manifest the effectiveness of the proposed approach.
Click any figure to enlarge with its caption.
_img_Fisheye130_0001.png) Figure 1
Figure 1_img_Fisheye180_0001.png) Figure 2
Figure 2_img_Indoor_Fisheye130_0001.png) Figure 3
Figure 3_img_Indoor_Fisheye180_0001.png) Figure 4
Figure 4_img_Indoor_GT.jpg) Figure 5
Figure 5_img_Indoor_Perspective_0001.png) Figure 6
Figure 6_img_Outdoor_GT.jpg) Figure 7
Figure 7_img_Perspective_0001.png) Figure 8
Figure 8_img_Synthetic_City_GT.png) Figure 9
Figure 9_img_Synthetic_Indoor_GT.png) Figure 10
Figure 10_img_T10_seq2.png) Figure 11
Figure 11_img_T2_seq2.png) Figure 12
Figure 12_img_T3_seq2.png) Figure 13
Figure 13_img_T4_seq2.png) Figure 14
Figure 14_img_T5_seq2.png) Figure 15
Figure 15_img_alex_33.png) Figure 16
Figure 16_img_alex_34.png) Figure 17
Figure 17_img_frame00033.png) Figure 18
Figure 18_img_framework.jpg) Figure 19
Figure 19_img_google_33.png) Figure 20
Figure 20_img_google_34.png) Figure 21
Figure 21_img_input_gate.png) Figure 22
Figure 22_img_qualitative_analysis_seq2.png) Figure 23
Figure 23_img_shopfacade_seq3_frame00039.png) Figure 24
Figure 24_img_system.png) Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27 Figure 28
Figure 28 Figure 29
Figure 29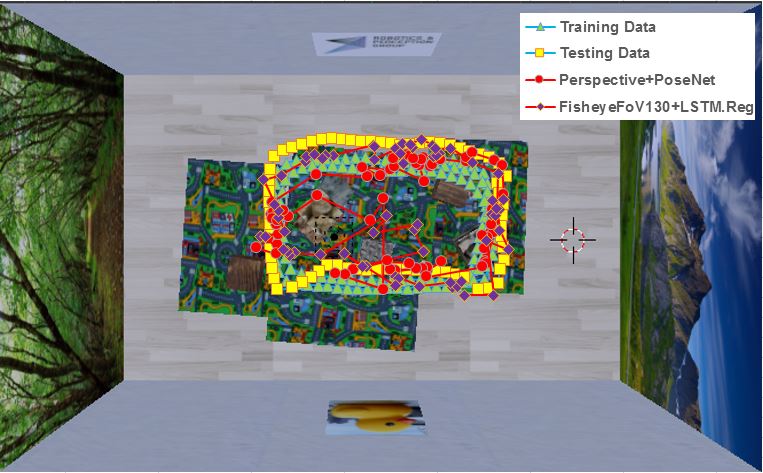 Figure 30
Figure 30 Figure 31
Figure 31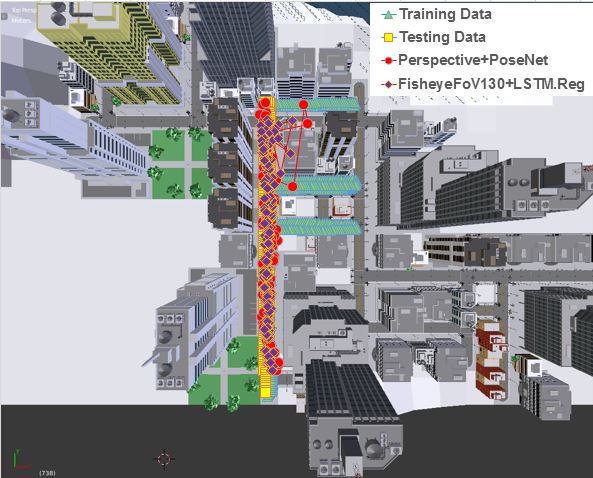 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35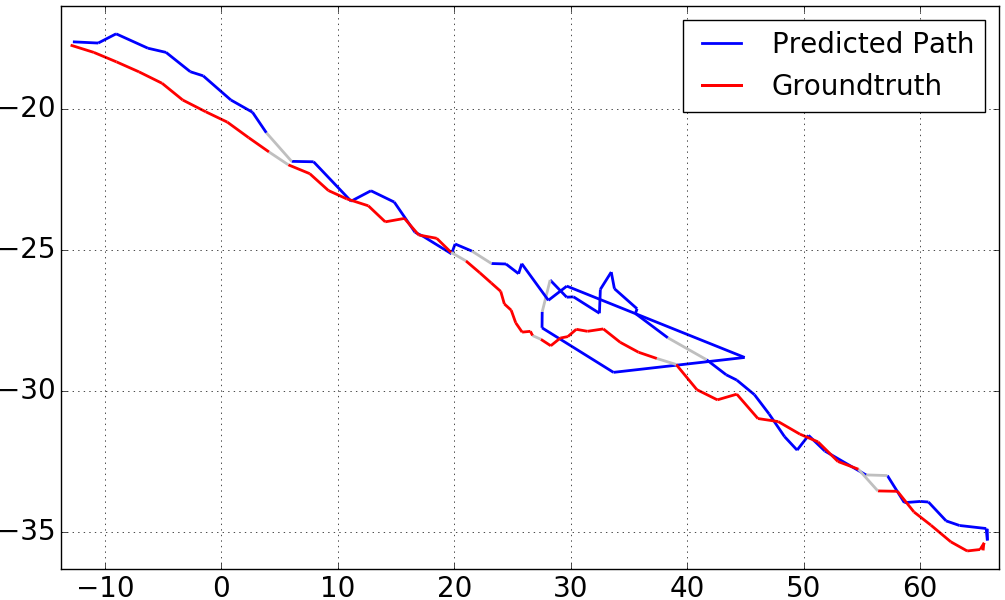 Figure 36
Figure 36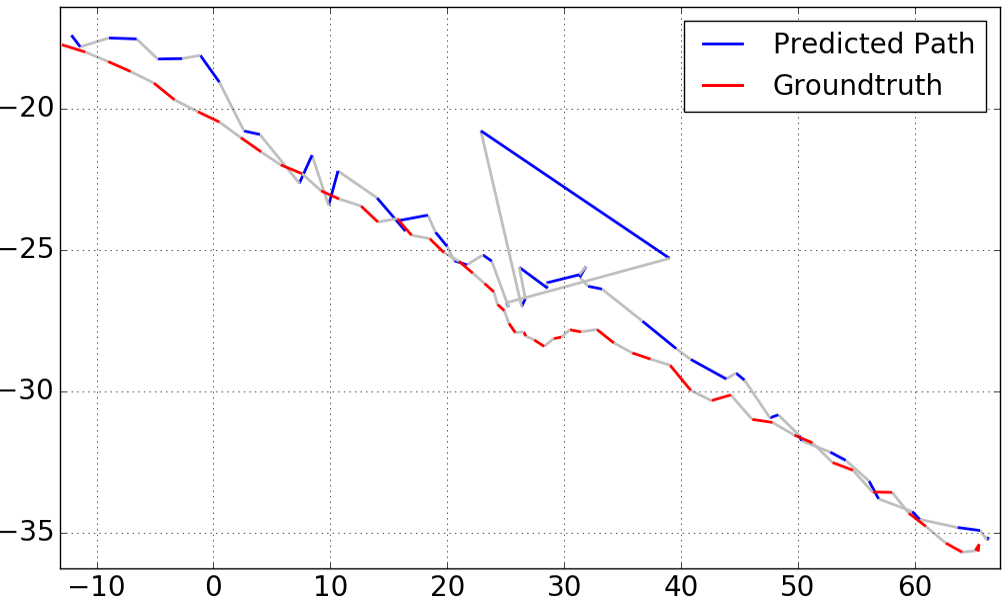 Figure 37
Figure 37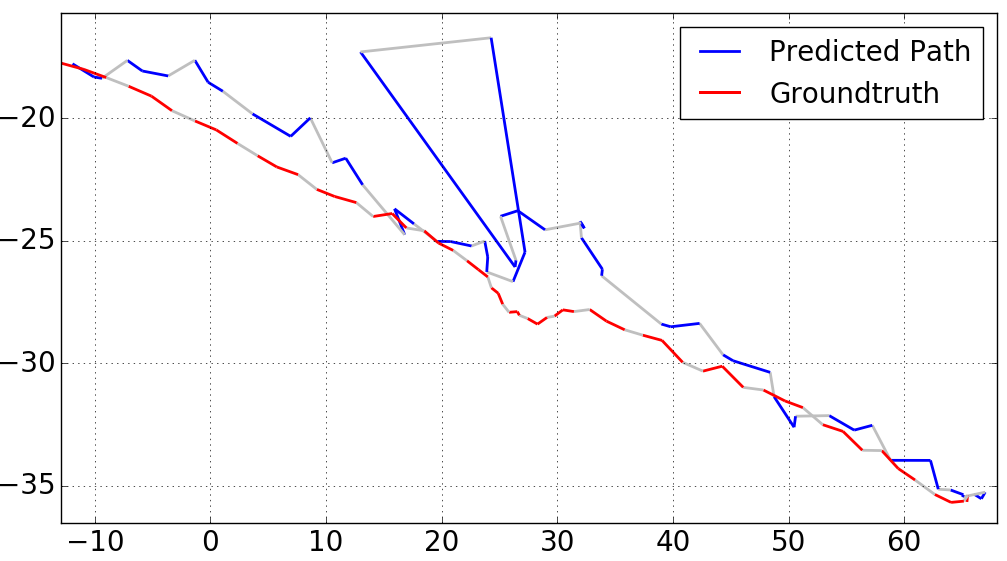 Figure 38
Figure 38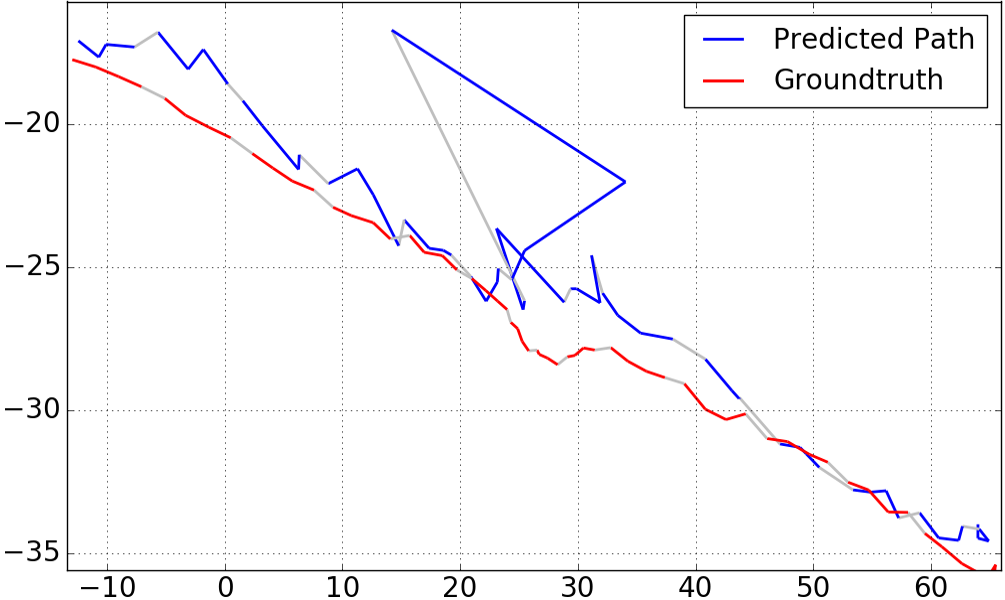 Figure 39
Figure 39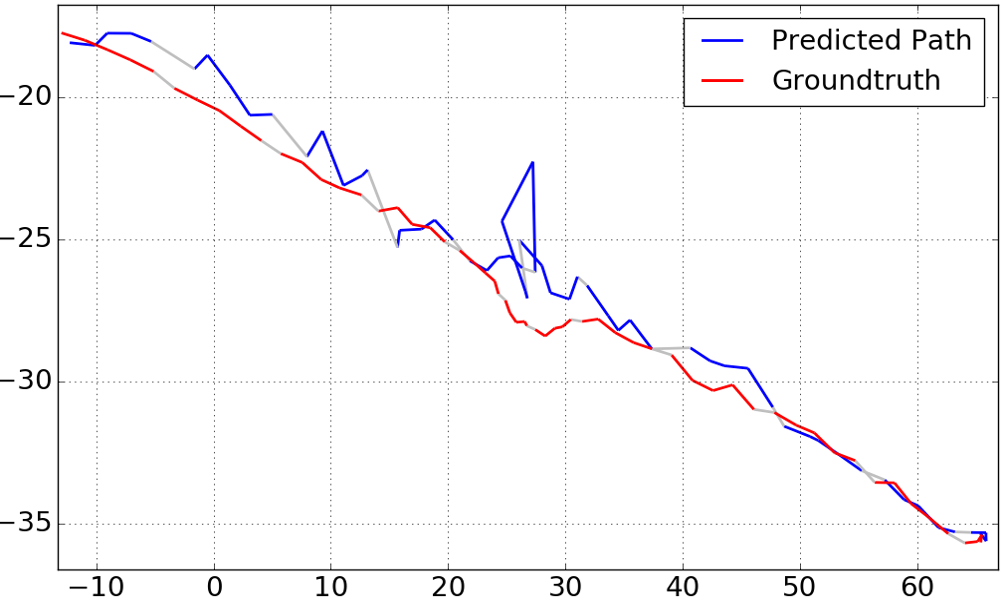 Figure 40
Figure 40| Scene | PoseNet [14] | LSTM | LSTM (Reg.) |
|---|---|---|---|
| Perspective | |||
| Fisheye-130 | |||
| Fisheye-180 | |||
| Average |
| Scene | PoseNet [14] | LSTM | LSTM(Reg.) |
|---|---|---|---|
| Perspective | |||
| Fisheye-130 | |||
| Fisheye-180 | |||
| Average |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsRobotics and Sensor-Based Localization · Advanced Image and Video Retrieval Techniques · Advanced Vision and Imaging
MethodsSigmoid Activation · Tanh Activation · Long Short-Term Memory
11institutetext: National Taiwan University
FishNet: A Camera Localizer using Deep Recurrent Networks
Hsin-I Chen
Sebastian Agethen
Chiamin Wu
Winston Hsu
Bing-Yu Chen
Abstract
This paper proposes a robust localization system that employs deep learning for better scene representation, and enhances the accuracy of 6-DOF camera pose estimation. Inspired by the fact that global scene structure can be revealed by wide field-of-view, we leverage the large overlap of a fisheye camera between adjacent frames, and the powerful high-level feature representations of deep learning. Our main contribution is the novel network architecture that extracts both temporal and spatial information using a Recurrent Neural Network. Specifically, we propose a novel pose regularization term combined with LSTM. This leads to smoother pose estimation, especially for large outdoor scenery. Promising experimental results on three benchmark datasets manifest the effectiveness of the proposed approach.
1 Introduction
Image-based localization, defined as the problem of estimating the position and orientation of a camera, has received substantial attention in the robotics and computer vision community. It is essential for tasks such as landmark recognition [18], autonomous navigation [21], augmented reality [1] and visual odometry [23]. Fig. 1 introduces some of the challenges of this problem – small and barely visible features, occlusions and the need to be robust to perspective and illumination changes.
The main stream of work in this field has been motivated by the above challenges, the need to establish a large enough feature correspondences between a query image and the 3D scene. Structure-based approaches [12, 28, 26, 18] associate image descriptors, e.g., SIFT, with 3D scene points during Structure-from-Motion (SfM) reconstruction. This representative set of 3D points that cover a 3D scene from arbitrary viewpoints allows better registration of query images taken from novel viewpoints. The above effectiveness, however, is achieved at the cost of limited expressiveness – the use of handcrafted local features, and the lack of scalability due to the increasing complexity of 3D scenes and the large memory footprint required for local descriptors.
Given the recent progress in deep learning, several methods proposed the use of Convolutional Neural Networks (CNNs) to learn feature representations for image localization. The central idea is to leverage transfer learning from recognition to re-localization, followed by formulating the pose estimation as a regression [14] or as a classification [38] problem. CNNs have the advantage of the availability of high-level features, while simultaneously reducing the memory consumption. Despite that, the current approaches suffer from at least two shortcomings. First, commonly used transfer learning models are pretrained on unrelated datasets, e.g., classification on ImageNet [25], which may be suboptimal for localization. Besides, without explicitly reconstructing the 3D scene, the lack of global structure information inhibits the network from learning better spatial representations. Second, valuable temporal information is not exploited, causing such approaches prone to failure in the presence of short-term noise.
We aim to address the two aforementioned problems simultaneously. Our approach relies on the insight that tracking visual landmarks over longer periods of time allows to discover more scene structure information. Based upon this, the accuracy of deep pose estimation increases with the availability of sequences of measurements. Complementing that, a wider field-of-view allows larger visual overlap between subsequent images. This implies that deep learning can simultaneously increase robustness as the visual overlap between subsequent images is larger. We leverage this property and increase the field-of-view from both spatial and temporal dimension for 6-DOF camera localization. Specifically, we capture the wider spatial information encoded in multiple adjacent frames using recurrent networks, inspired by [38] and increase the robustness using fisheye camera.
The proposed approach is built upon a Deep Convolutional Network (DCN). By employing Long Short Term Memory (LSTM), a type of recurrent network, we can then leverage the information present in consecutive frames of a sequence. During learning and inference, high-level, pretrained GoogLeNet DCN features are used as input to the LSTM. Temporal coherency of the output pose sequence is enforced by adding a new regularization term to the commonly used regression loss. Between frames, the observer typically moves a small distance only, and further regularization can help to avoid sudden jumps due to noise, such as short-term occlusion.
The resulting model is a scene-specific recurrent network that performs pose regression on image sequences captured by a monocular camera. There are two advantages of this formulation. First, the CNN with recurrent network is capable of exploiting temporal dependencies, therefore uncertainty is reduced. We suggest that – due to the tendency of the fisheye model to project the scene to a wide range of spatial context – such a regularized system with fisheye cameras works particularly well for outdoor scenes. Second, the approach is substantially simpler to formulate than methods based on 2D-to-3D models.
In this work, we apply the presented model to the task of image-based localization. Finally, our approach is comprehensively evaluated on two real-world scenarios, one large outdoor and one indoor scene dataset, as well as one synthetic that includes various camera optics. We also provide comparison with a structure-based approach. Experiments shows that our method is robust and able to localize the images.
Contribution
We investigate the problem of camera localization using a deep learning approach. In summary, our work makes the following contribution:
- •
We are the first to use fisheye imagery in deep learning to increase the field-of-view for image localization.
- •
We propose a new LSTM architecture with a novel regularization term, of which fisheye lens cameras in outdoor scenes profit particularly.
- •
We provide a quantitative comparison of structure-based and learning-based localization approaches and show significant improvements over PoseNet [14]. Experiments show that increasing the camera field-of-view together with our architecture has a significant impact for image localization.
2 Related Work
Localization from Structure
Detail information obtained from a 3D reconstruction of the scene is essential to achieving high localization accuracy [12, 19, 41, 29]. The common pipeline is to use the features descriptors for the 3D points computed during structure from motion [30], formulating the correspondences search as a descriptor matching problem [27]. The -DOF camera pose of a query image can be estimated from the correspondences between 2D local features in the query image and 3D points in the model using camera resectioning. Some notable works have brought about significant progress. Sattler et al. [28] developed prioritized search strategies for efficient 2D-to-3D correspondences search. To further accelerate descriptor matching, a model compression scheme by means of quantizing the point descriptors is introduced in [26]. Although explicitly constructing a 3D model of the structure aids determining the camera’s poses, the cost of memory storage and computations gets more expensive as the size of the 3D model grows. Our solution can leverage the strength of the 3D structure but does not need to store it explicitly.
Localization from Learning
Recent advances in camera localization use predictions from a regression forest to guide the camera pose optimization procedure. Shotton et al. [32] employ a regression forest to infer the pose of a RGB-D camera. Valentin et al. [7] train a regression forest to predict mixtures of anisotropic 3D Gaussians. To show that 6D pose estimation can be acomplished using a single RGB image, Brachmann et al. [2] further marginalize the object coordinate distributions over depth. However, these approaches require depth information during training. Thus, they are better suited for indoor applications.
Deep Convolutional Network
Deep learning is being used for a wide array of computer vision tasks, such as image classification [16, 36, 33], object localization [31] and detection [24], as well as segmentation [8, 6]. Deep Convolutional Networks (DCN), as first being used in [17], have demonstrated impressive abilities at extracting high-level features and form one of the pillars of deep learning. At the same time, we are now able to train networks deeper than ever before with the help of GPU-based training.
Time-variant data is a particular challenge due to its increased size. Nonetheless, it also gives us the opportunity to extract additional useful information. Recent years have seen the use of Recurrent Neural Networks (RNN) to process such data, of which Long Short Term Memory (LSTM) is particularly popular. Previous applications for such sequence learning include video classification [22], natural language generation and processing for image and video captioning [4, 37], and future prediction [35].
In this work, we employ both techniques for the task of camera localization. We use the fact that sequences of video frames can be used by employing RNNs in order to improve localization and reduce impact of intermittent, short-term noise.
Fisheye Camera
has received increasing attention with its broad applications in 3D reconstruction and visual odometry (VO). Unlike a classical pinhole camera that shows only the front view of a scene, a fisheye camera can capture omni-directional lights from the surrounding environment. Caruso et al. [3] proposed a direct monocular SLAM method for wide field-of-view cameras. Im et al. [11] introduced a 3D reconstruction method for stereo-scopic panorama using spherical camera. Zhang et al. [42] studied the impact of different FoV on standard VO module, and show that it can benefit from large field-of-view. Inspired by their work, we also utilized fisheye-lens, characterized by large field-of-view, in order to allow our system to learn more global structure, resulting in more accurate registration that adheres closely to the underlying scene geometry.
3 Model Architecture
We begin with a brief introduction of Long Short Term Memory (LSTM) [10], and then give a formal description of our architecture in Section 3.2. An overview of the proposed scheme for pose regression is shown in Figure 2.
3.1 Long Short Term Memory
Consider an input sequence , of length , where represents the -th element. Such a sequence may for example be the RGB frames of a video clip, or features extracted from a deep convolutional stack.
Given this input, a LSTM produces a time-dependent output by repeatedly updating its cell state . The cell state is manipulated with the help of two control gates, the input gate , and the forget gate , while an output gate controls the output hidden state . The LSTM equations are:
[TABLE]
where is the logistic sigmoid function, and are the parameters of the LSTM model. We term the operations the input-to-hidden transition, and the operations the hidden-to-hidden transition. We also remark here that some literature and implementations may ignore the hadamard terms .
3.2 Camera Pose Regression with LSTM
Given an input sequence , for each frame , our network outputs a pose vector , which can be seperated into a camera position and an orientation represented by a quaternion :
[TABLE]
We adopt GoogLeNet [36] to process the input images, and extract -dimensional features at pool5. These extracted feature map serve as input to a LSTM unit. At each timestep , we first apply the dropout [34] technique on the hidden state of LSTM layer. It then serves as input to a -dimensional pose regressor, which is implemented as a fully-connected layer. The pose regressor then outputs the desired pose .
3.3 Network Loss Function
Given the training images and their ground truths, the euclidean loss is described as followed [14]:
[TABLE]
where and represent the ground truth label for each image, and is a scale factor that balances the loss between the location error and orientation error . In addition, an L2-regularized weight decay – scaled by – is added, as it helped the network generalize better. Following the notation of [14], we omit the normalization term in the following.
Sequence Learning: Regularization
In our work, we consider sequences of length as input. A sequence is a collection of consecutive frames, and as such, it should be expected that the difference between frame and is small. To enforce this, we can add an additional temporal regulization term, weighted by , to our loss function. The total loss function for image is:
[TABLE]
where are the network’s parameter. We define the temporal regulization term to be zero for .
The total loss for a sequence is then the summation over time:
[TABLE]
For a fisheye lens, which is characterized by a large field-of-view, compared to the classical perspective camera, the image projections are smaller under the same image resolution. Thus it is much more suitable for our regualization term since smaller distance and frame rate is required.
4 Experimental Results
In this section, we illustrate our experiments on the aforementioned architecture. We begin with implementation details, compare our system with the established baseline in [14] and structure-based approach in [27], and conclude with an evaluation of Fisheye and Perspective cameras on a synthetic dataset.
Datasets
The performance of the proposed method and various related techniques are evaluated on three publicly available datasets, including the Cambridge Landmark dataset [14], the 7-Scenes dataset [32], and the Multi-FoV synthetic dataset [42]. These sequences exhibit depth variations, contain dynamic moving objects and different spatial content, and thus are very challenging for image-based localization.
The Cambridge Landmark dataset contains outdoor sequences. The appearance of large spatial content, partial occlusions, and urban clutter make localization over this dataset quite challenging. However, it provides a good test-bed to manifest the importance of temporal information (recurrent network), as localization approaches that rely on a single images are not reliable enough. To test indoor scenes, we use the publically available 7-Scenes dataset, which contains large variation in camera height.
Implementation details
Our proposed architecture can be seperated into a CNN feature extractor based on the Inception architecture (GoogLeNet) [36], and the recurrent network with regressor. The GoogLeNet model is initialized with weights pretrained on the ImageNet 1K image classification dataset. The remainder of the network is intialized with random values, where we use Xavier initialization for the recurrent net, and a Gaussian initialization for the regressor. In case of Cambridge, the outdoor dataset, we choose to initialize the position regressor, as it needs to regress large coordinates. For 7-Scenes, we choose , and the orientation regressor is always initialized with . During training, we minimize the Euclidean loss of Eq. 8 using the Adam [15] optimizer. A pixelwise mean is subtracted for each image. All networks take image crops of size as input. During training, the crops are chosen at random positions in the image, while at test time a crop around the center point is being used. We set the hyperparameters as follows: batch size , i.e., processing images in parallel, dropout probablity of , weight decay coefficient , and temporal regularization coefficient . To find the trade-off constant , which regulates position vs. orientation learning, we follow [14] and set it such that the magnitude of both loss terms is about equal. If not otherwise mentioned, we use sequences of frames. All experiments are performed on an NVIDIA Tesla K80 GPU.
4.1 Comparison with deep learning approach
We first run our proposed LSTM architecture and compare it with PoseNet, which does not employ sequence learning. Our results can be found in Table 1 and 2.
We are able to improve localization accuracy and pose estimation for all datasets except Street, on which the network was not able to generalize, i.e., Street test set results remained near those of random initialization. It shows an improvement over PoseNet of up to in Cambridge and in 7-Scene. Results on the Cambridge dataset, which is an outdoor dataset, tend to show greater improvement than for the 7-Scene dataset, which is indoors.
Adding temporal regulization showed some promising results, in particular on KingsCollege, where location accuracy was improved by an additional 0.16m (14% relative to LSTM) . We were not able to improve results using this technique on all datasets however. One issue is the hyperparameter , which requires adjustment according to the distance in position of two consecutive frames: A sequence with large differences in position between frames requires a very small values of , while sequences with minimal frame-by-frame differences may allow larger values.
Memory Footprint & Performance
Using batches of 60 sequences, the average processing time per frame was 16.99 ms during training, and 9.5 ms during inference. The total number of parameters is approximately 13.8 million, of which 5.79 million are GoogleNet convolutional parameters.
4.2 Comparison with 2D-to-3D descriptor matching
In this section, we compare our apporoach with the structure-based approach [27] for image localization. In [27], a 2D-to-3D descriptor matching is used to estimate the camera poses w.r.t a SfM model, where each 3D point is represented by a SIFT descriptor of training images obtained from the reconstruction. As the Cambridge Landmark and 7-Scenes datasets do not contain both feature descriptors and reconstructed 3D model, we extract SIFT descriptors [20] and reconstruct the 3D scene and camera path using Visual-SFM [39, 40]. We then register the generated camera poses to the ground truth poses in case of the Cambridge Landmark dataset [14].
We train a visual vocabulary containing K words on the Cambridge Landmark dataset and a vocabulary of K words on the 7-Scenes dataset. We follow [27] and accept a query image as registered if the best poses estimated by RANSAC [5] from the established 2D-to-3D correspondences have at least inliers. The camera pose is estimated using the standard -point DLT algorithm [9]. For the implementation, we use the released code from the author’s of [27] website111https://www.graphics.rwth-aachen.de/software/image-localization.
Our results are reported in Table 1 as well as Table 2. We found that 2D-to-3D matching consistently produces smaller error on the outdoor dataset. The comparison results validate that the reconstructed 3D point clouds provide global scene structure information required for camera registration. Note that we do not report the localization result on OldHospital because of a corrupted 3D model.
4.3 Comparison of Fisheye and Perspective camera
In the following, we evaluate our method and contrast its behavior for a perspective and a fisheye camera.
4.3.1 Multi-FoV Dataset
To allow a fair comparison, we make use of two synthetic sequences, Urban Canyon and Indoor [42]. The use of synthetic sequences enables us to simulate different camera optics without having any variations in path or pose. That is, for both evaluated cameras, the image data only differs from use of a different camera model. We create three instances of each sequence with varying degree of field of view: Perspective , and Fisheye ().
On the urban canyon dataset, we fix the camera height at to simulate a pedestrian filming and walking throuh streets. For the Indoor dataset, we fix the camera height at to simulate a drone flying around. The image dimensions are kept at the VGA size () which is a typical size of the recordings of dashcams, robotic sensors and drone cameras. The fisheye images suffer from severe distortion in the four corners of the image due to the nature of the projection, and we fill these regions such that – after subtraction of mean – the values equal [math]. An example of our perpspective and fisheye images are shown in Figure 4.
4.3.2 Fisheye analysis
We present our results for the two sequences in Table 3 and Table 4. The addition of LSTM, that is, the use of sequence learning, improves both location and orientation accuracy considerably. A improvement up to on FoV-130 Urban Canyon and on FoV-130 Indoor. However, in this section we explicitly focus on the difference in learning on Perspective camera images and Fisheye camera images. Here, we can see a trend that learning on the Fisheye camera images profited from our regularization scheme, especially on the outdoor Urban Canyon dataset. We hypothesize that the additional overlap between consecutive images due to the larger field of view allows the regularized LSTM to access its full potential. Considering that the performance of pure LSTM slightly degraded, while the regularized system improved, it can be said that the influence by the distortion can be controlled by the regularization term. In addition, we note that, although the underlying GoogLeNet model has only been trained on perspective imagery, it was possible to adapt to the different optics during the learning process.
A visualization of predicted paths for the two sequences is shown in Figure 5. We can observe from the figure that Fisheye with with our LSTM + Reg. gives significant improvement over the original PoseNet using perspective camera.
5 Qualitative Analysis
Figure 6 visualizes our results on sequence 2 of the KingsCollege dataset. The red segmented line represents the groundtruth, whereas the blue segments represent the result of our approach for . A large prediction error is immediately visible in the center region, caused by frames 33 and 34 of the 60 frames sequence. Visual inspection of these frames (see Figure 8) reveals that the scenery is occluded by a passing car. As can be seen in Figure 7, the input gate of the LSTM produces an unusual high median activation at this point, and is therefore “admitting” more data than usual. The center crop for frame 34 exclusively shows the white car, therefore the optimal reaction of the LSTM should have been to not admit any new data.
To investigate why, we visualized the GoogLeNet pool5 feature activation as an overlay on the RGB frames, see Figure 8. We used the mean activations of the 1024-channel GoogLeNet output, and then repeated the same experiment with a network trained from scratch. The overlay clearly shows strong (red) activations in the top left corner.
Given the difference between a pretrained and a from-scratch network, our hypothesis is that the GoogLeNet model has been conditioned on a certain concept (for example, car-related) during pretraining on the ImageNet dataset, which now causes “confusion” to the LSTM unit, while the from-scratch network did not learn the concept, given that cars are an infrequent occurence.
Several mechanisms may solve this issue: Under ideal circumstances, an attention map could be used to filter out irrelevant regions, for example using the mean activations of the from-scratch network. Notice however that the features of the from-scratch networks are of lower quality. An alternative specifically for short-term noise such as passing cars could be a temporal pooling approach.
We also plot the result of sequence 2 (as seen in Figure 6) for other selected values of . These results can be found in Figure 3. One may expect that larger will improve the catastrophic outlier on the path, which is true as can be seen for . We note however, that for larger values of , the overall performance of the system degraded. For , we measured a distance error of and orientation error of , well above the our results for .
6 Conclusion
In this paper, we presented a novel network architecture that performs camera pose regression by aggregating structure correlation from monocular image sequences. The proposed method leverages temporal information from adjacent frames as well as the large field-of-view revealed by fisheye. Our recurrent networks is able to deliever full -DOF camera poses with high accuracy. We apply our model to the outdoor Cambridge dataset, the indoor 7-Scenes dataset as well as a synthesic dataset, on which we evaluate fisheye versus perspective images. Experiments show that the proposed recurrent network architecture is able to effectively localize images compared to the previous approach. In our future work, we plan to investigate spatial attention masks and other mechanisms to supress short term noise.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] C. Arth, C. Pirchheim, J. Ventura, D. Schmalstieg, and V. Lepetit. Instant outdoor localization and SLAM initialization from 2.5d maps. IEEE Trans. Vis. Comput. Graph. , 21(11):1309–1318, 2015.
- 2[2] E. Brachmann, F. Michel, A. Krull, M. Y. Yang, S. Gumhold, and C. Rother. Uncertainty-driven 6d pose estimation of objects and scenes from a single RGB image. In IEEE Computer Vision and Pattern Recognition (CVPR) , pages 3364–3372, 2016.
- 3[3] D. Caruso, J. Engel, and D. Cremers. Large-scale direct slam for omnidirectional cameras. In IROS , 2015.
- 4[4] J. Donahue, L. A. Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, and T. Darrell. Long-term recurrent convolutional networks for visual recognition and description. Co RR , abs/1411.4389, 2014.
- 5[5] M. A. Fischler and R. C. Bolles. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Communications of the ACM , 24(6):381–395, 1981.
- 6[6] R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In IEEE Computer Vision and Pattern Recognition (CVPR) , pages 580–587, 2014.
- 7[7] A. Guzmán-Rivera, P. Kohli, B. Glocker, J. Shotton, T. Sharp, A. W. Fitzgibbon, and S. Izadi. Multi-output learning for camera relocalization. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 1114–1121, 2014.
- 8[8] B. Hariharan, P. A. Arbeláez, R. B. Girshick, and J. Malik. Simultaneous detection and segmentation. In European Conference on Computer Vision (ECCV) , pages 297–312, 2014.