HCFContext: Smartphone Context Inference via Sequential History-based Collaborative Filtering
Vidyasagar Sadhu, Saman Zonouz, Vincent Sritapan, Dario Pompili

TL;DR
This paper introduces HCFContext, a novel mobile context inference model that combines Hidden Markov Models with collaborative filtering and privacy-preserving techniques, validated on real-world data.
Contribution
It presents a new collaborative filtering-based HMM model for mobile context inference that incorporates privacy-preserving methods and is validated with real data.
Findings
HCFContext improves context prediction accuracy over baseline models.
The privacy-preserving homomorphic encryption approach is effective.
Models are validated on real-life datasets with positive results.
Abstract
Mobile context determination is an important step for many context aware services such as location-based services, enterprise policy enforcement, building or room occupancy detection for power or HVAC operation, etc. Especially in enterprise scenarios where policies (e.g., attending a confidential meeting only when the user is in "Location X") are defined based on mobile context, it is paramount to verify the accuracy of the mobile context. To this end, two stochastic models based on the theory of Hidden Markov Models (HMMs) to obtain mobile context are proposed-personalized model (HPContext) and collaborative filtering model (HCFContext). The former predicts the current context using sequential history of the user's past context observations, the latter enhances HPContext with collaborative filtering features, which enables it to predict the current context of the primary user based on…
Click any figure to enlarge with its caption.
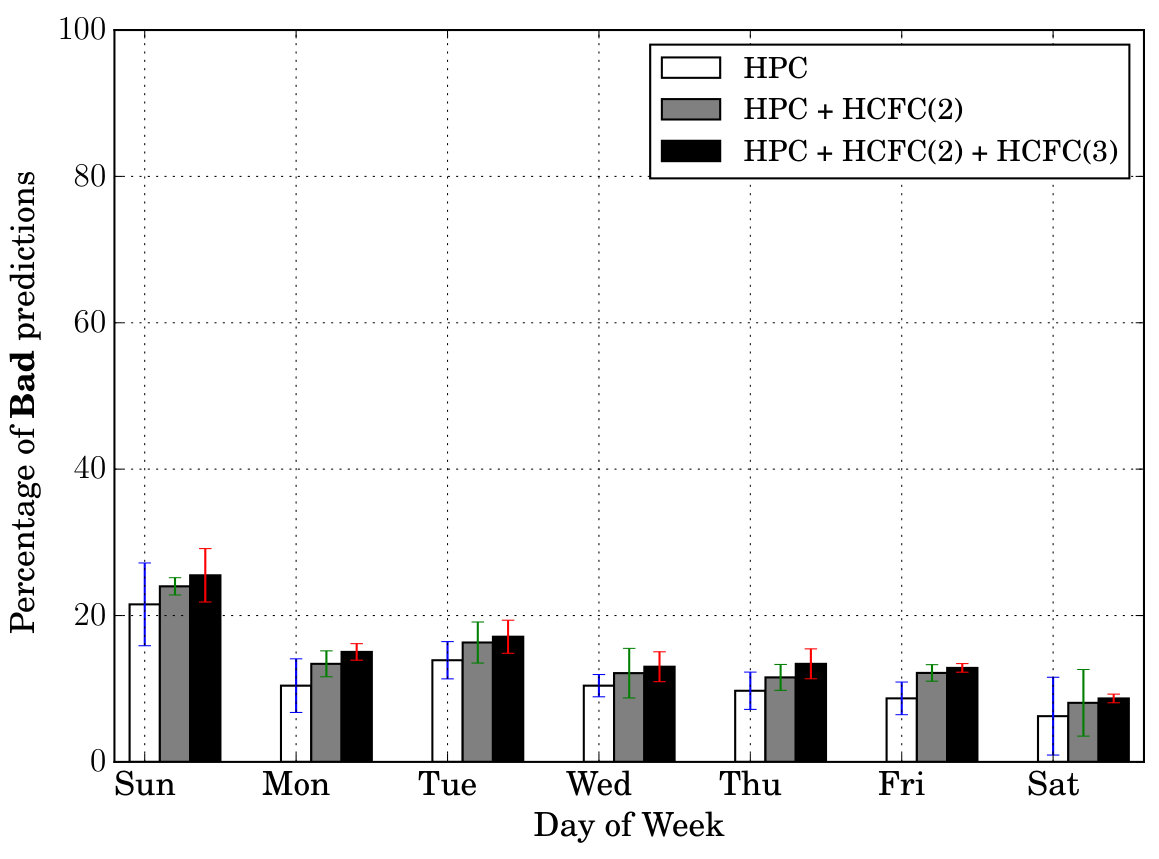 Figure 1
Figure 1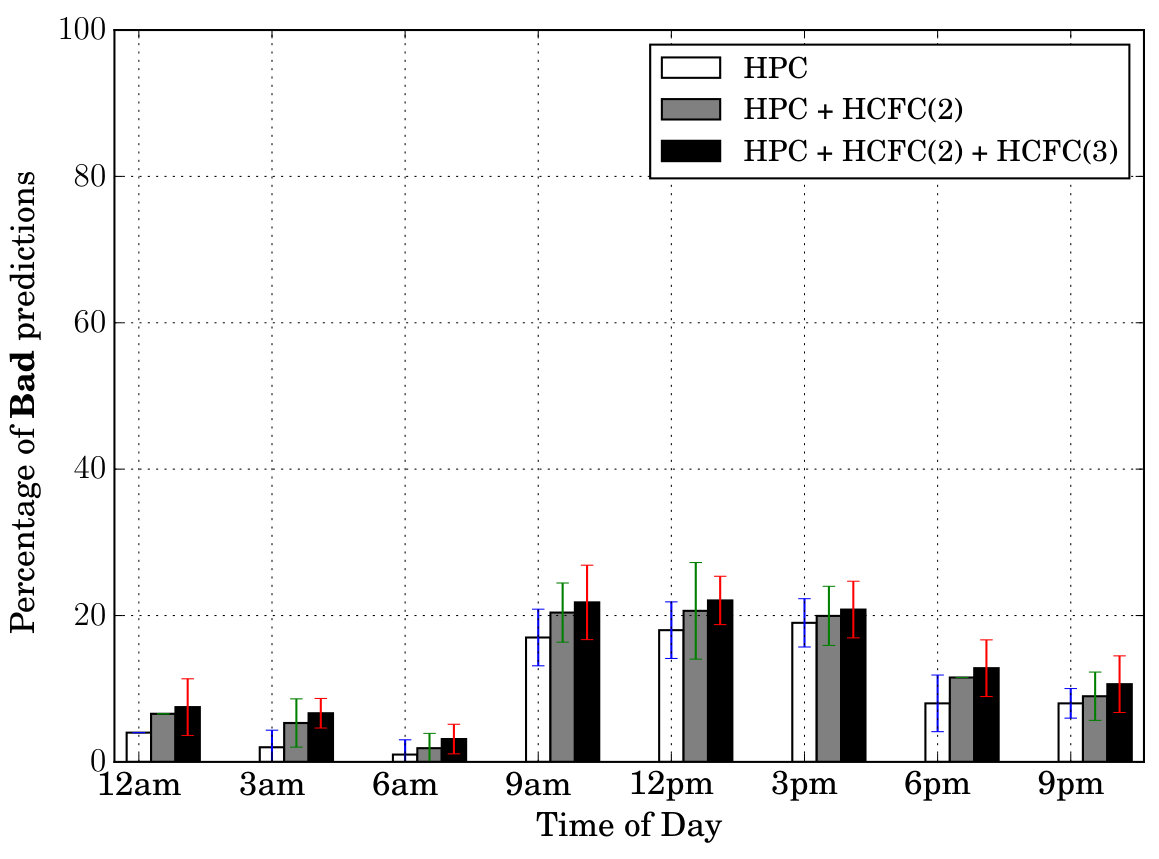 Figure 2
Figure 2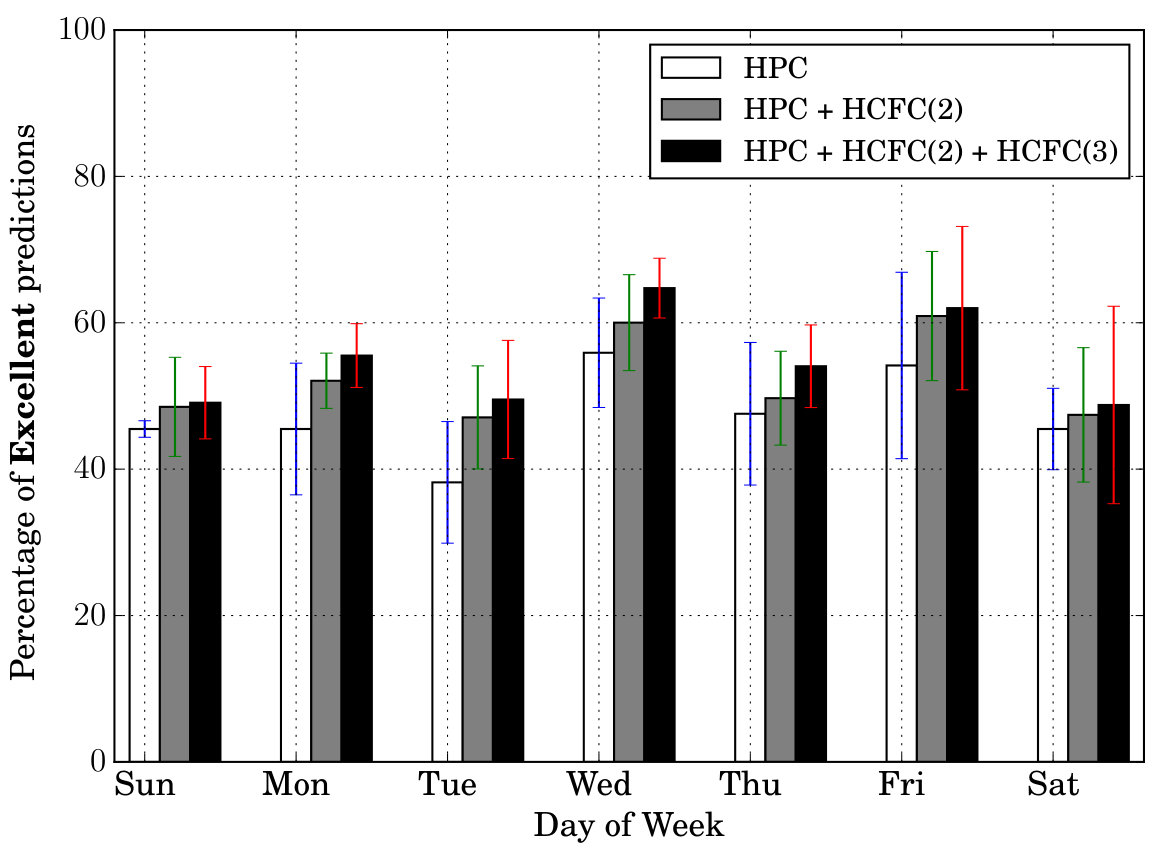 Figure 3
Figure 3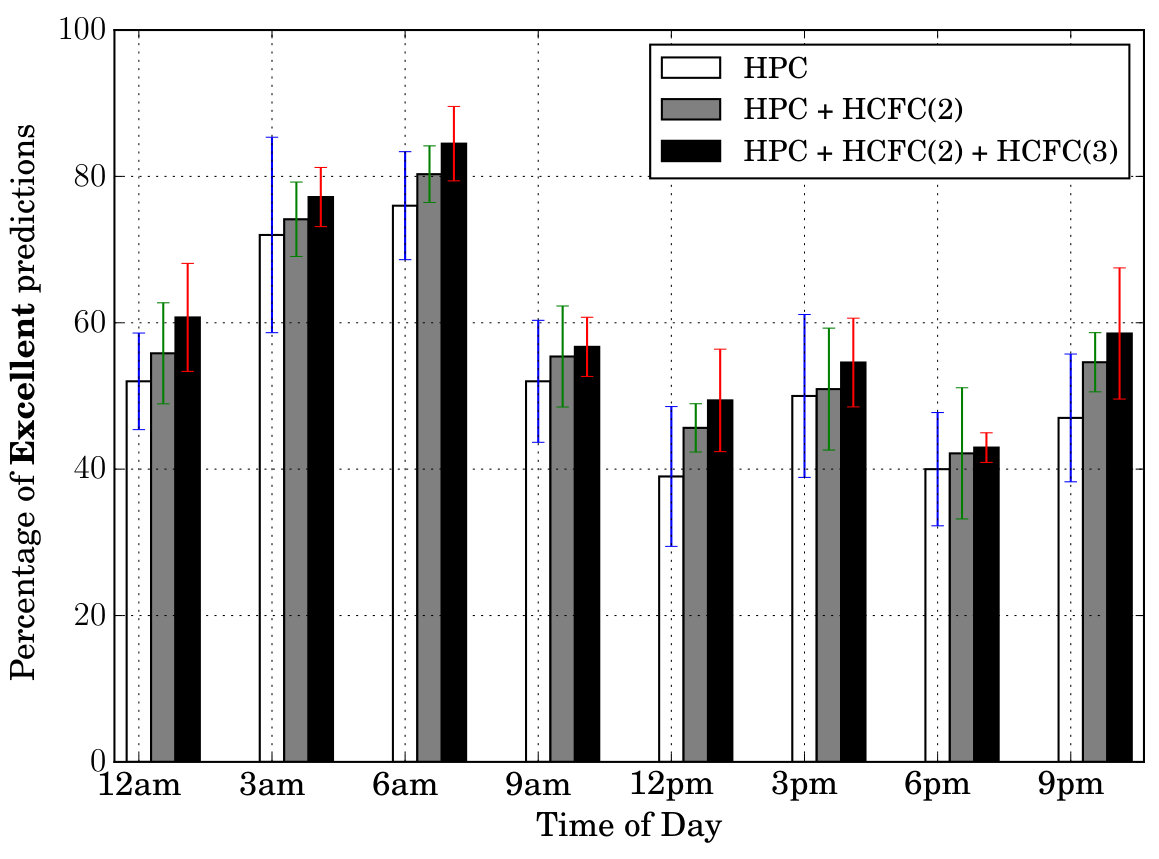 Figure 4
Figure 4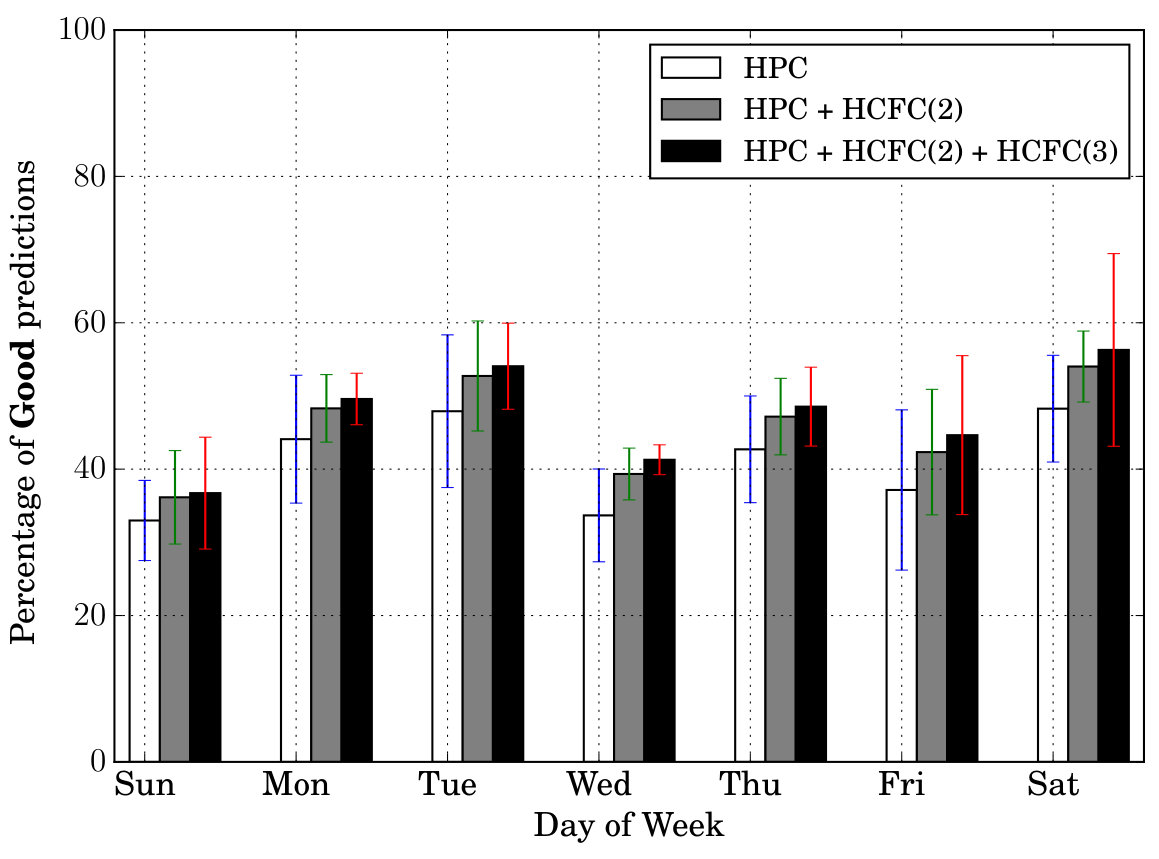 Figure 5
Figure 5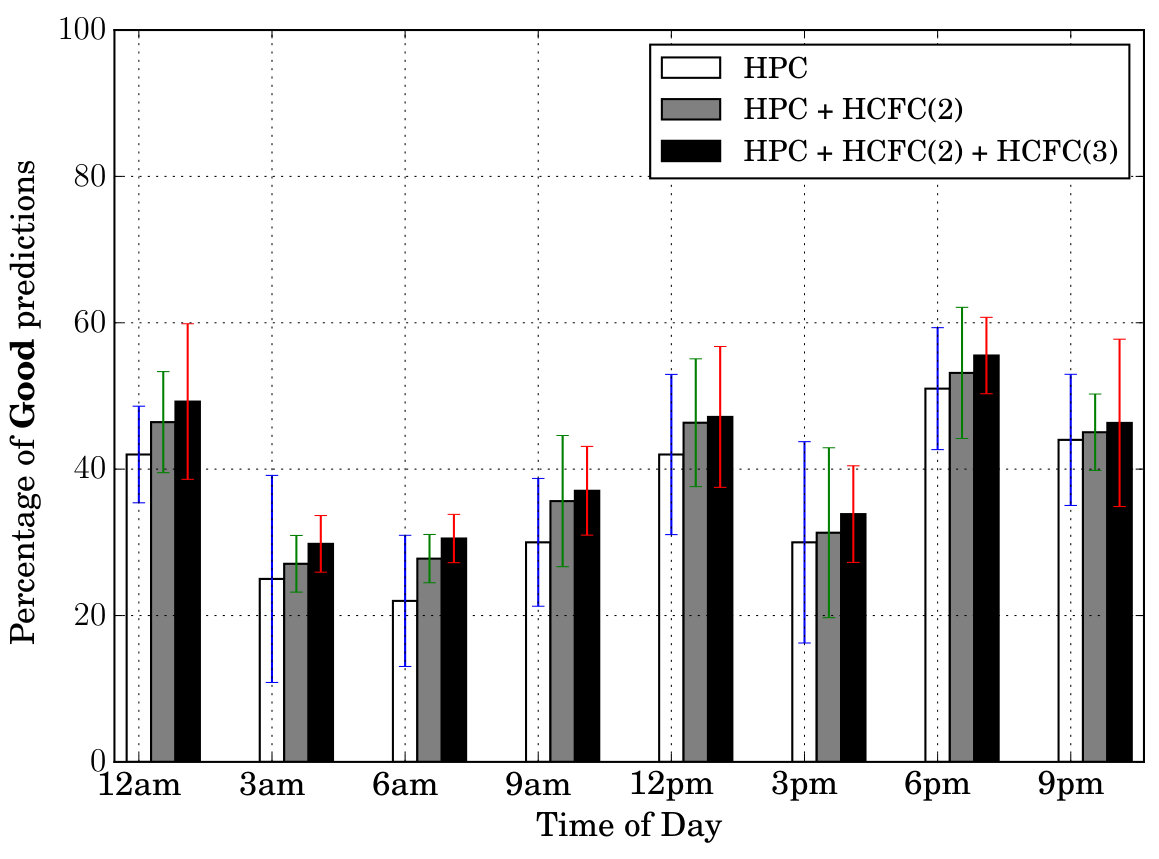 Figure 6
Figure 6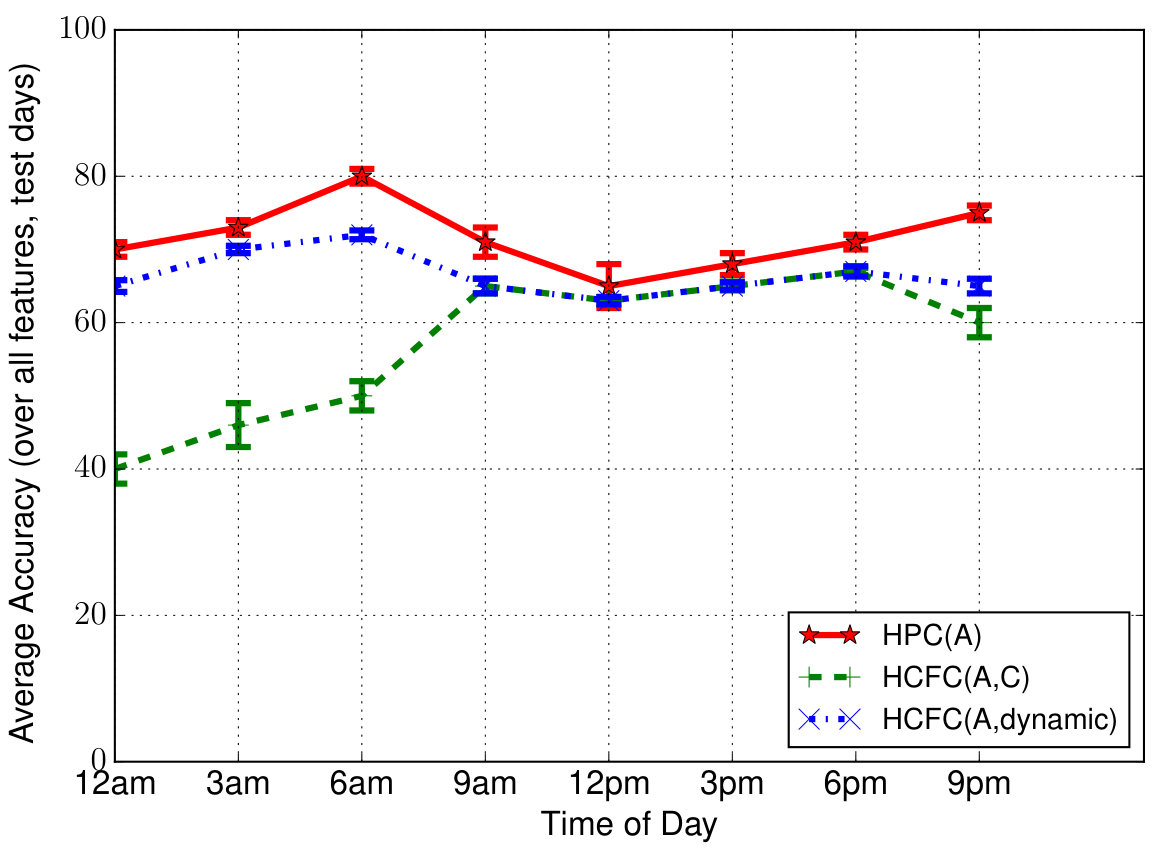 Figure 7
Figure 7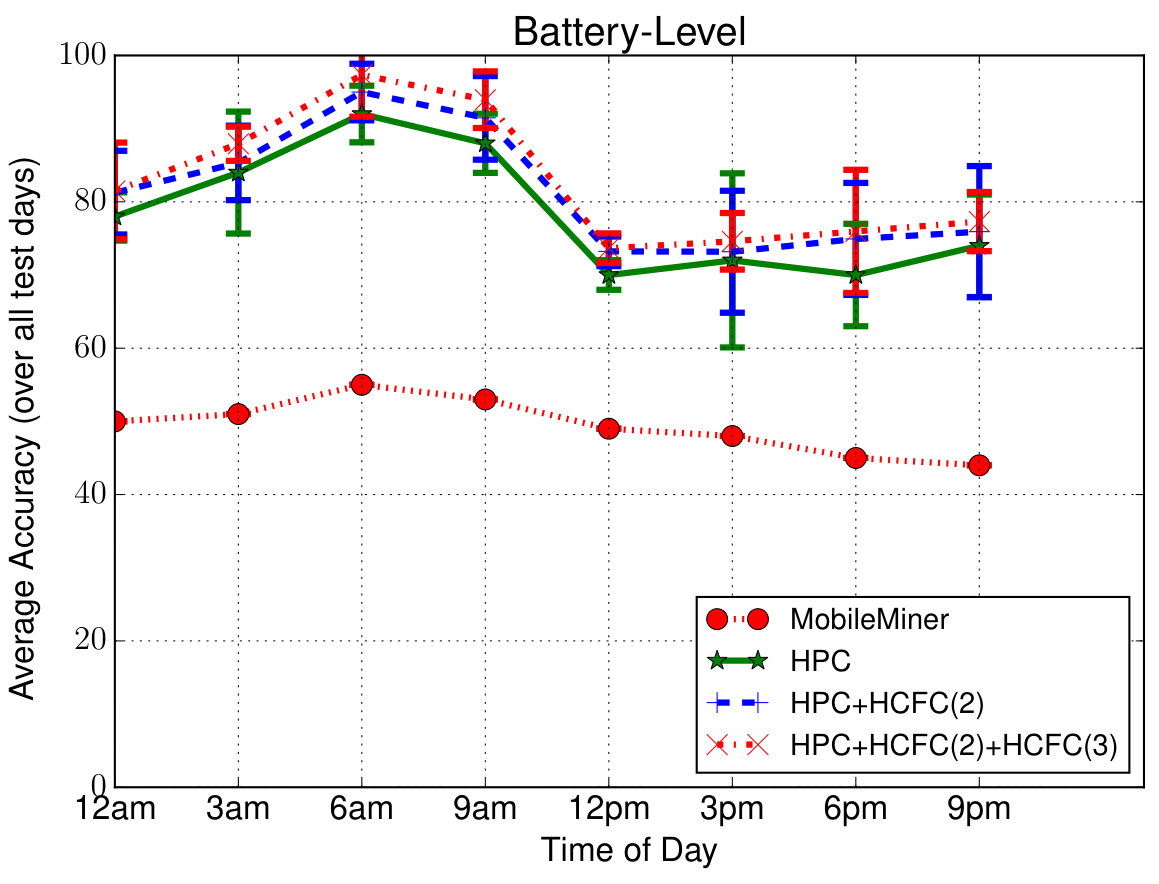 Figure 8
Figure 8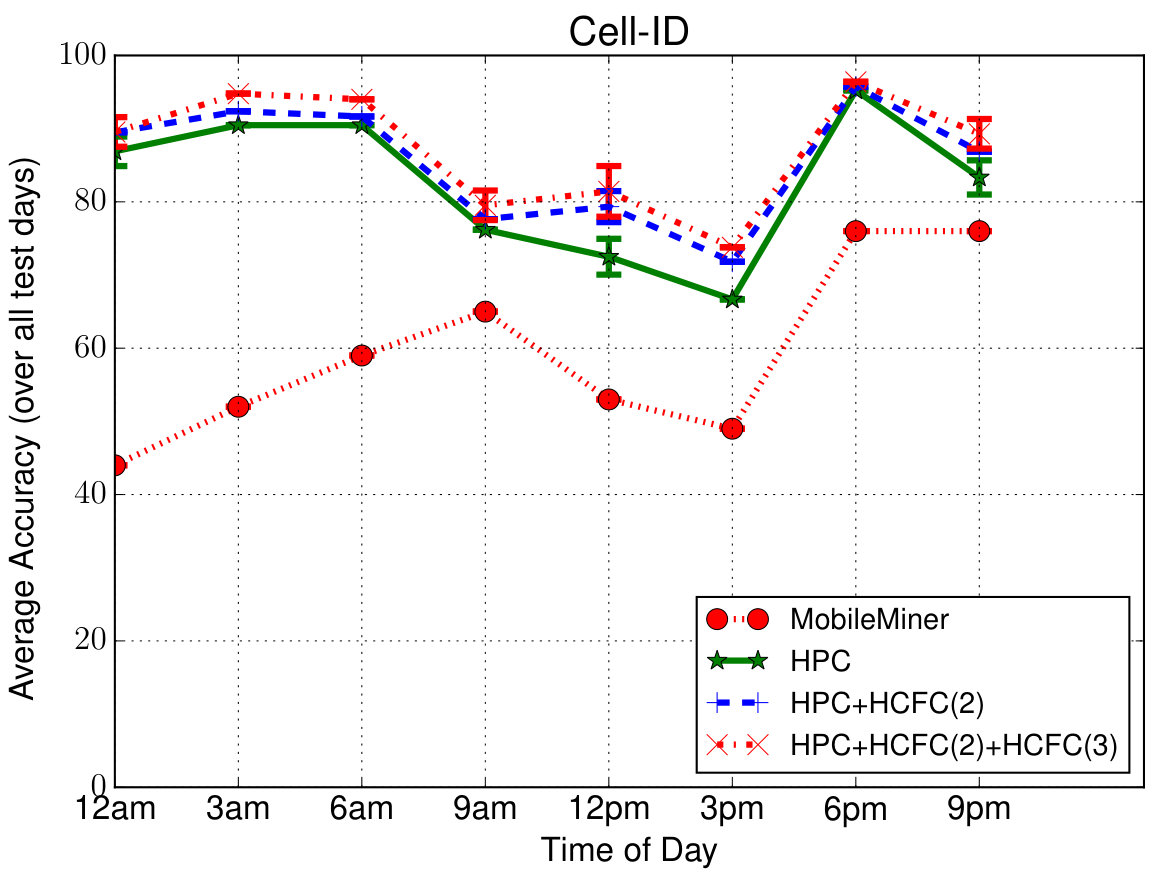 Figure 9
Figure 9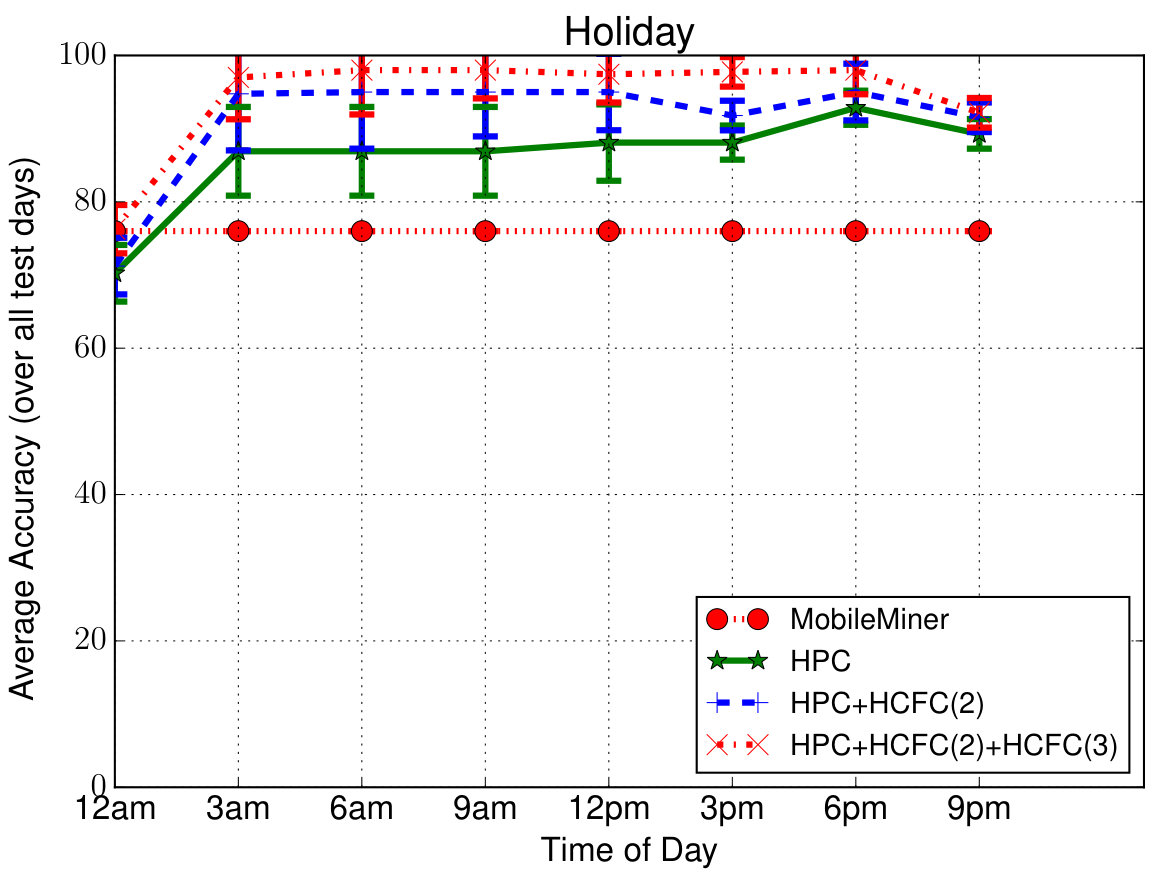 Figure 10
Figure 10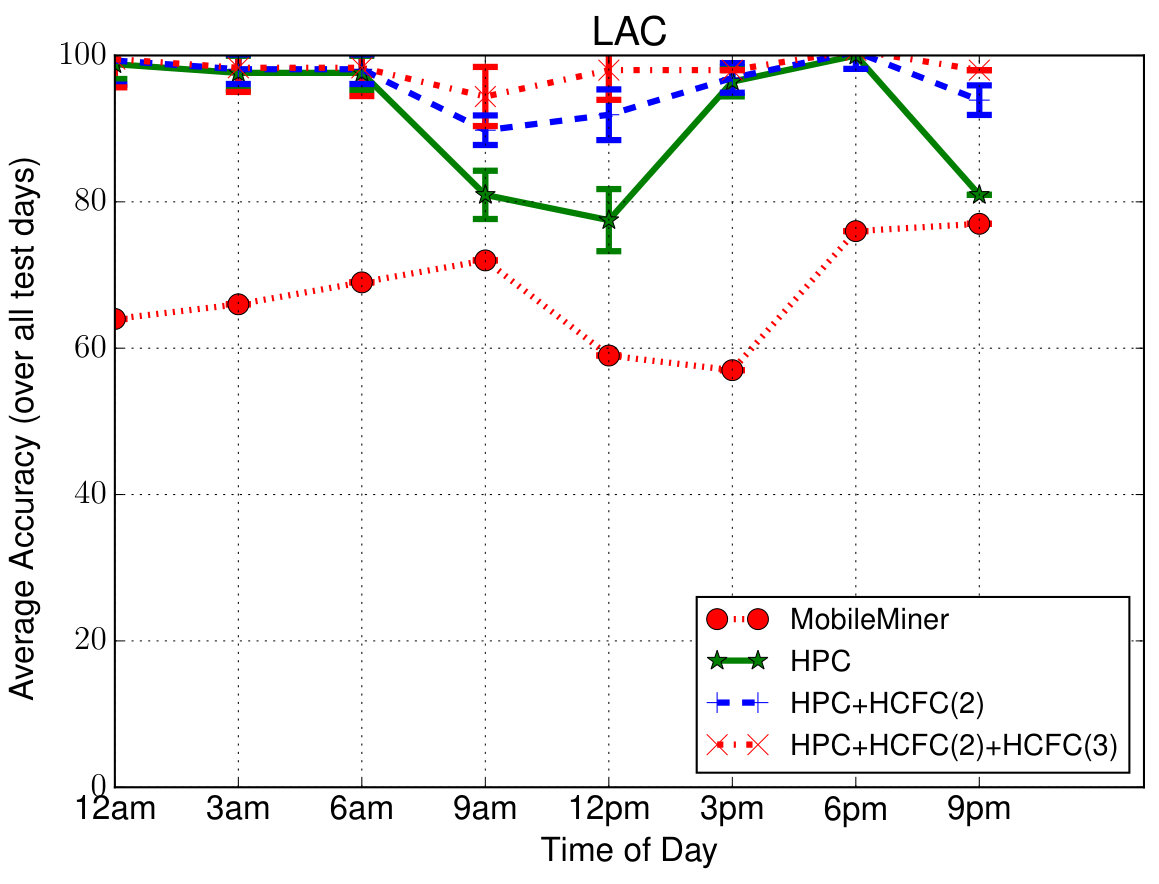 Figure 11
Figure 11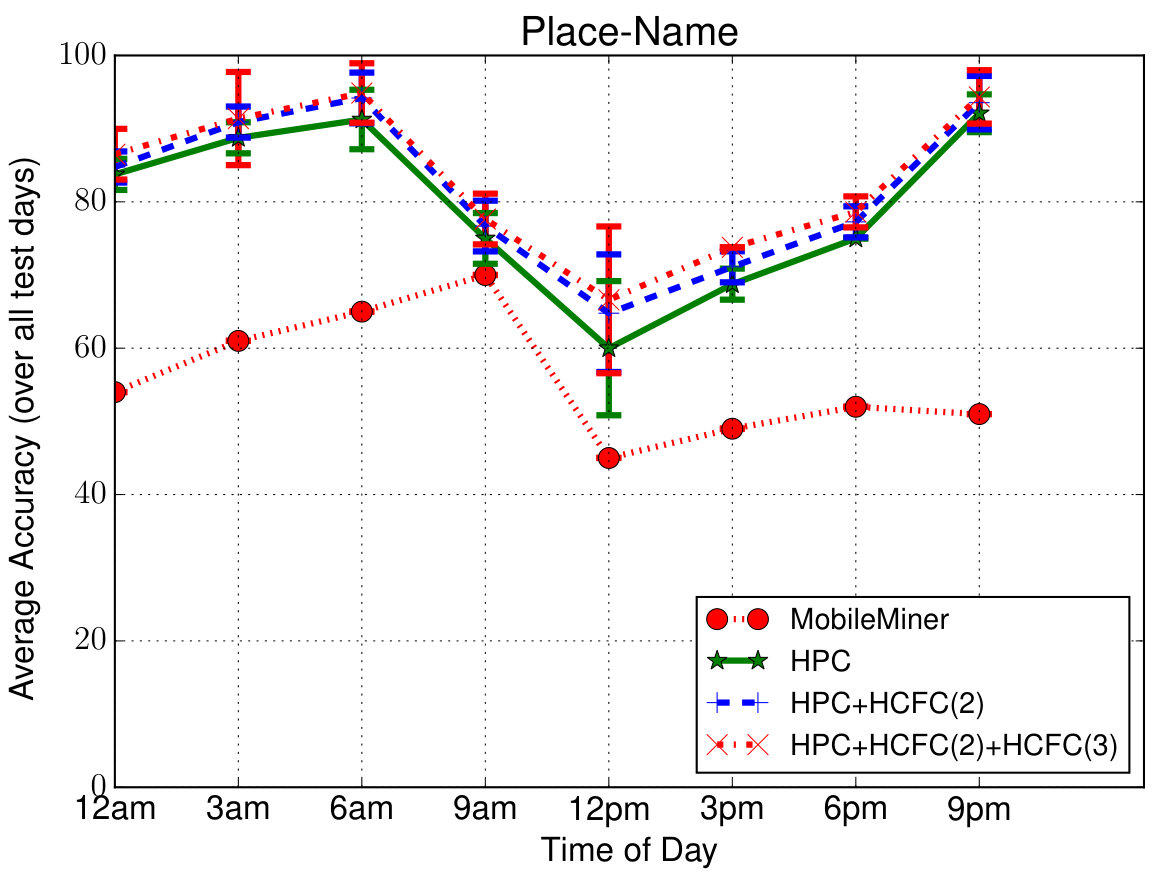 Figure 12
Figure 12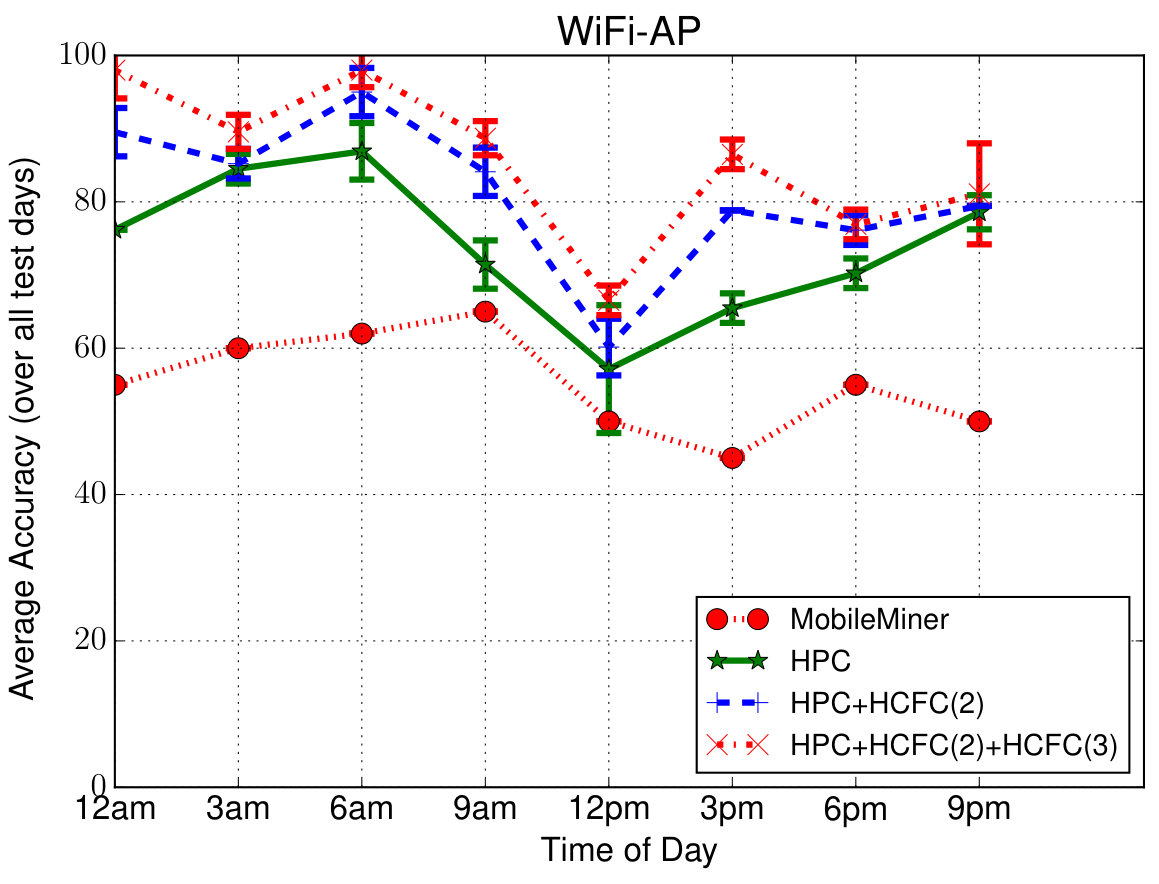 Figure 13
Figure 13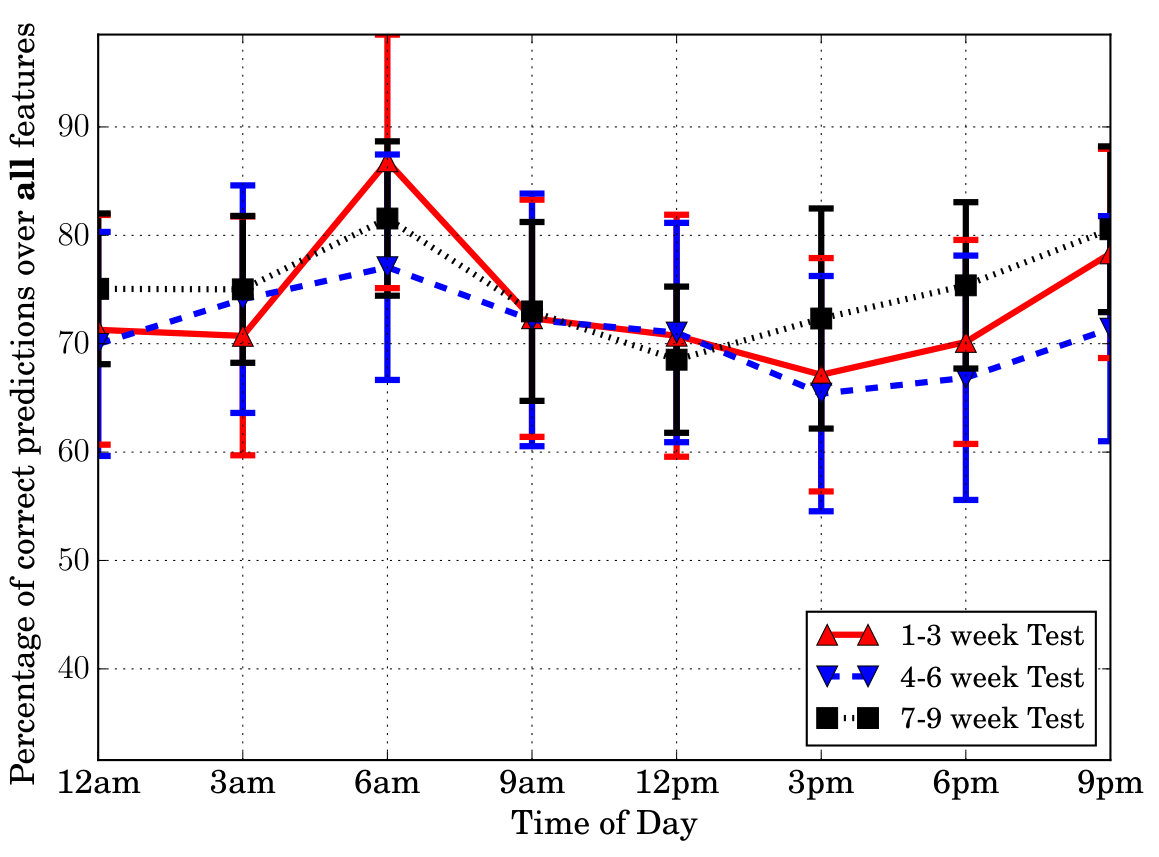 Figure 14
Figure 14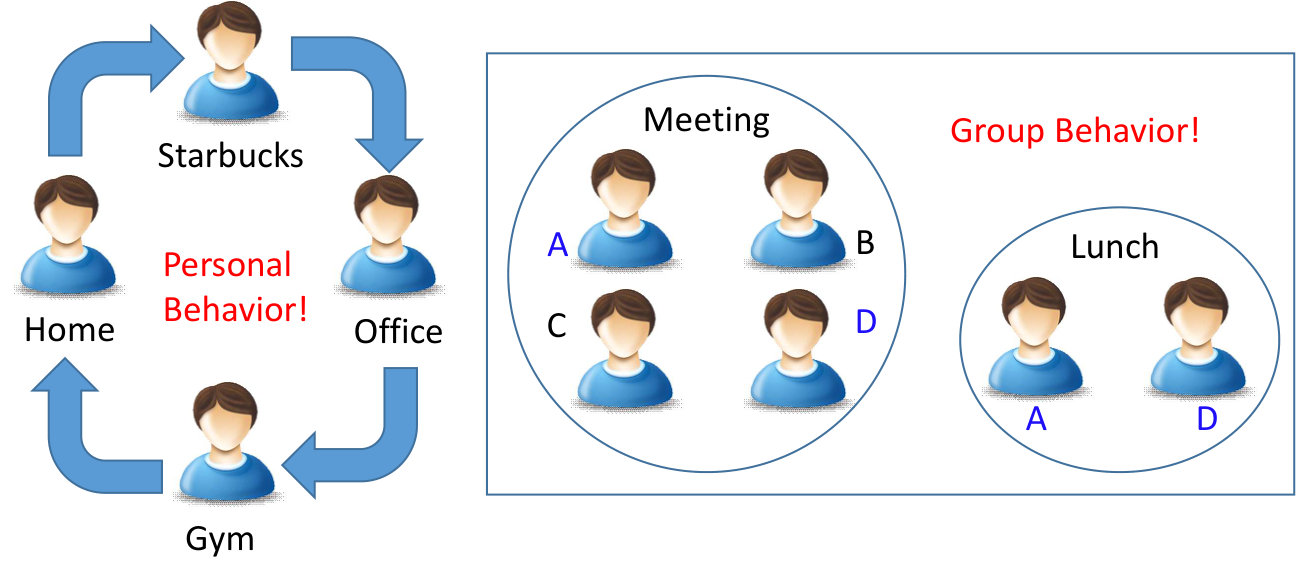 Figure 15
Figure 15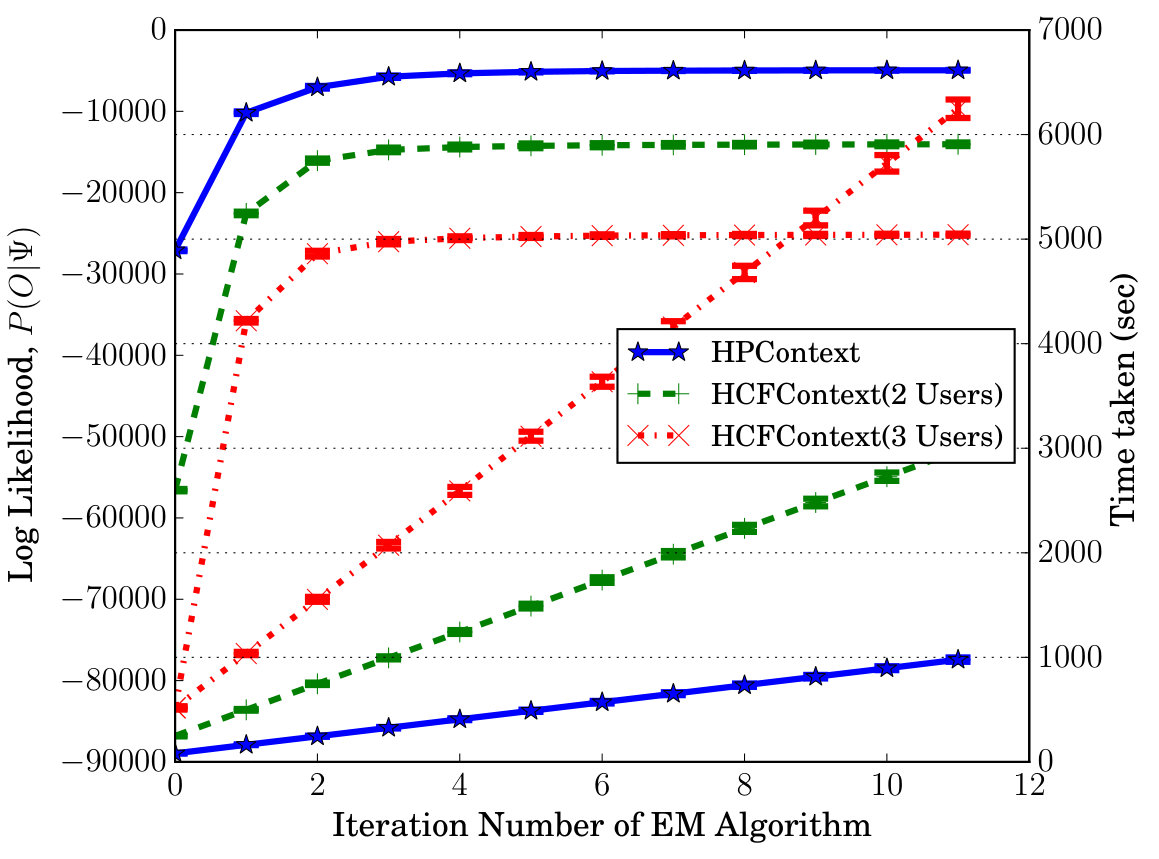 Figure 16
Figure 16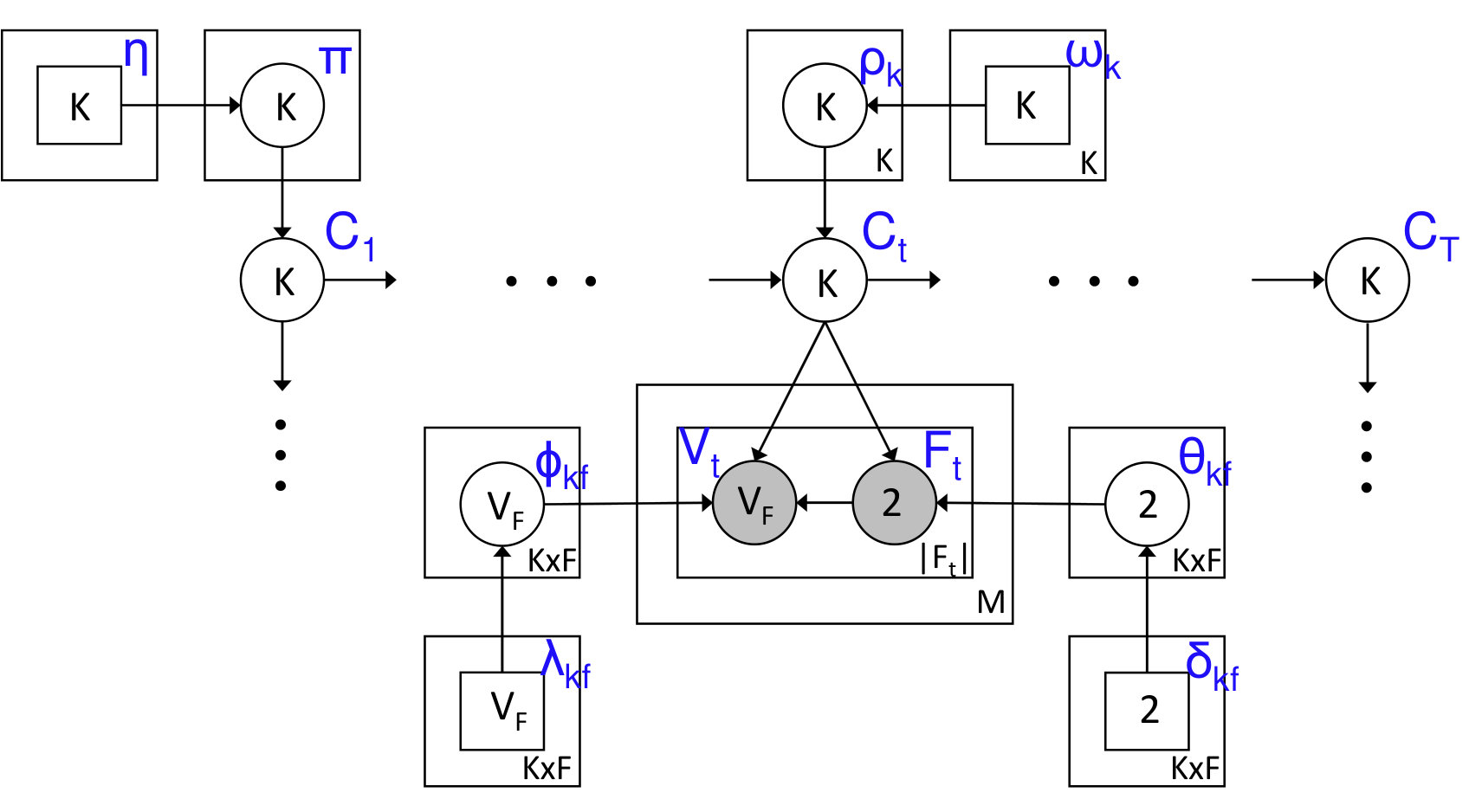 Figure 17
Figure 17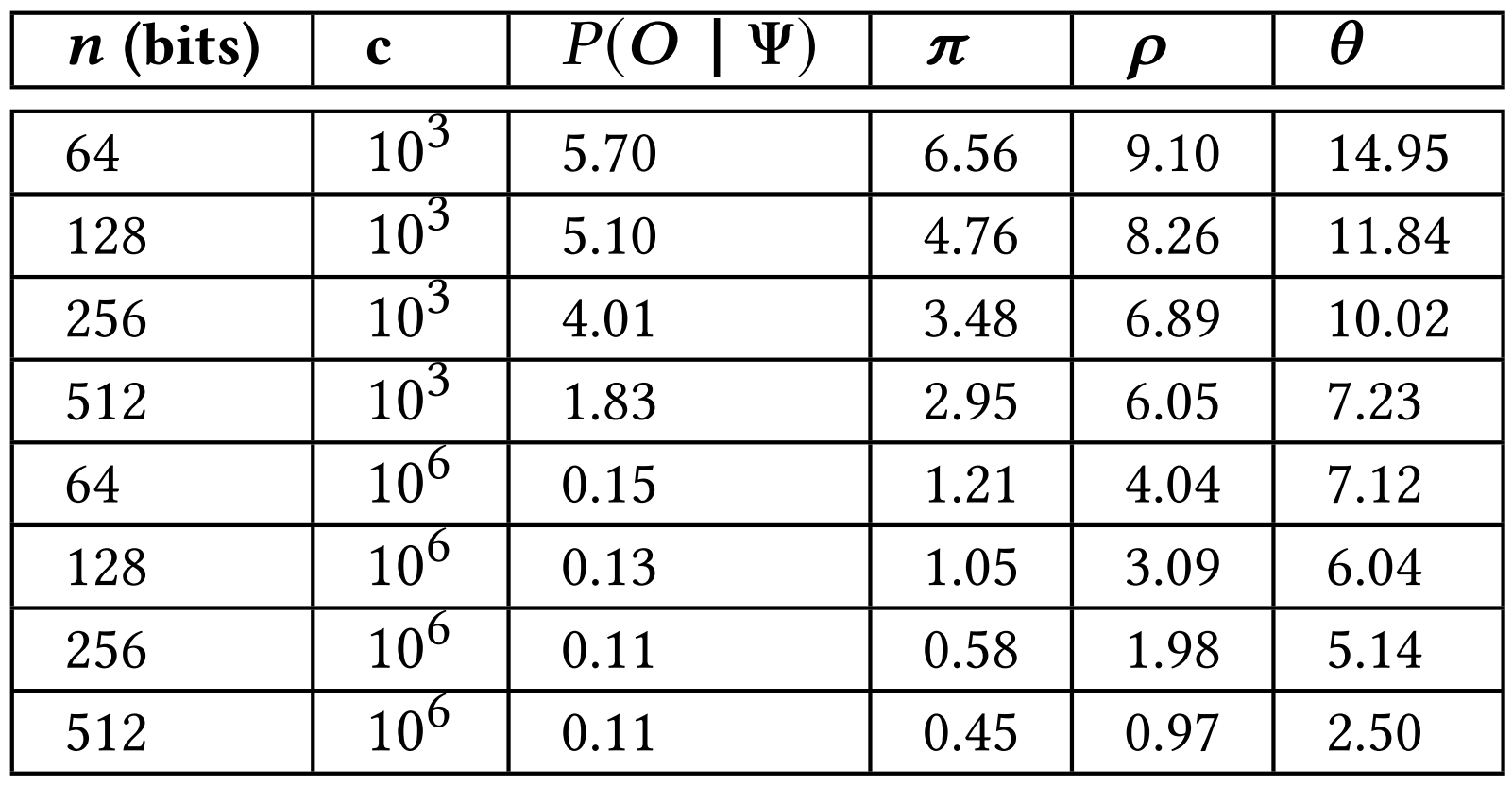 Figure 18
Figure 18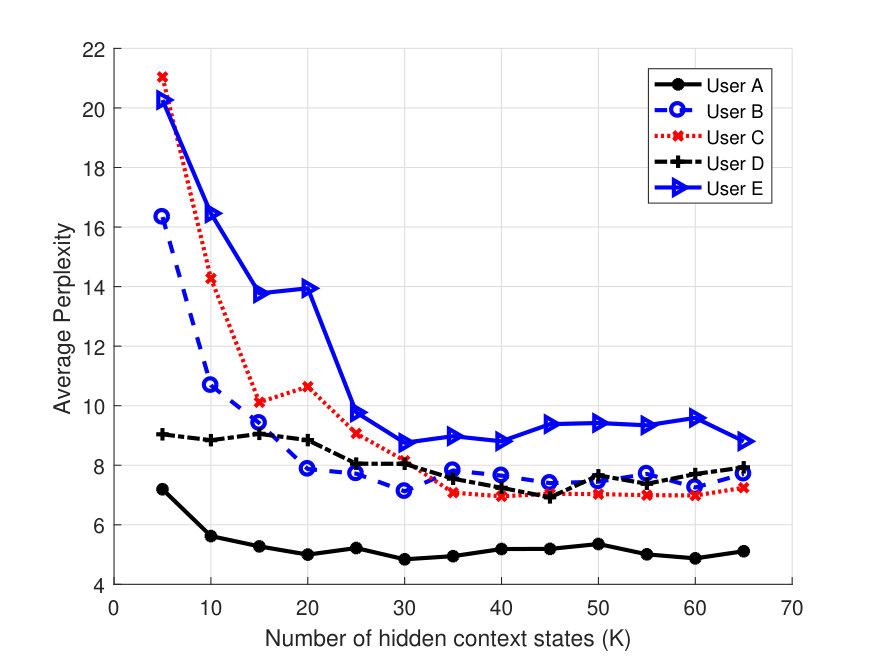 Figure 19
Figure 19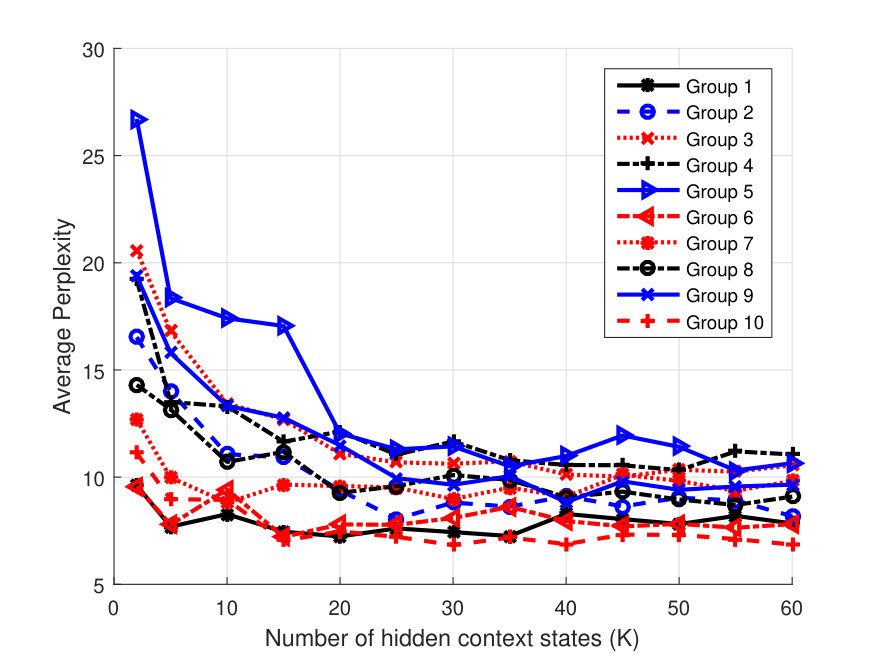 Figure 20
Figure 20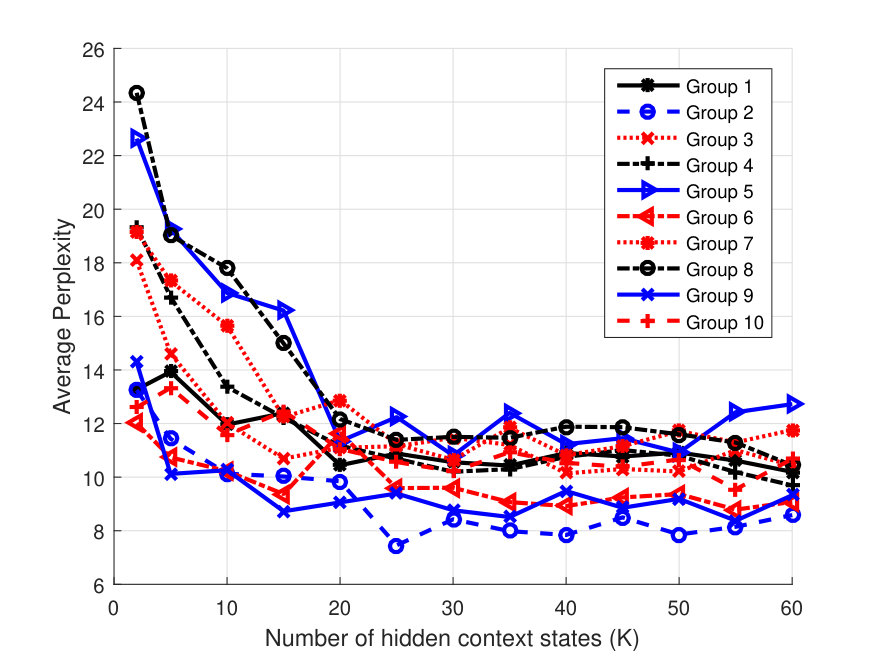 Figure 21
Figure 21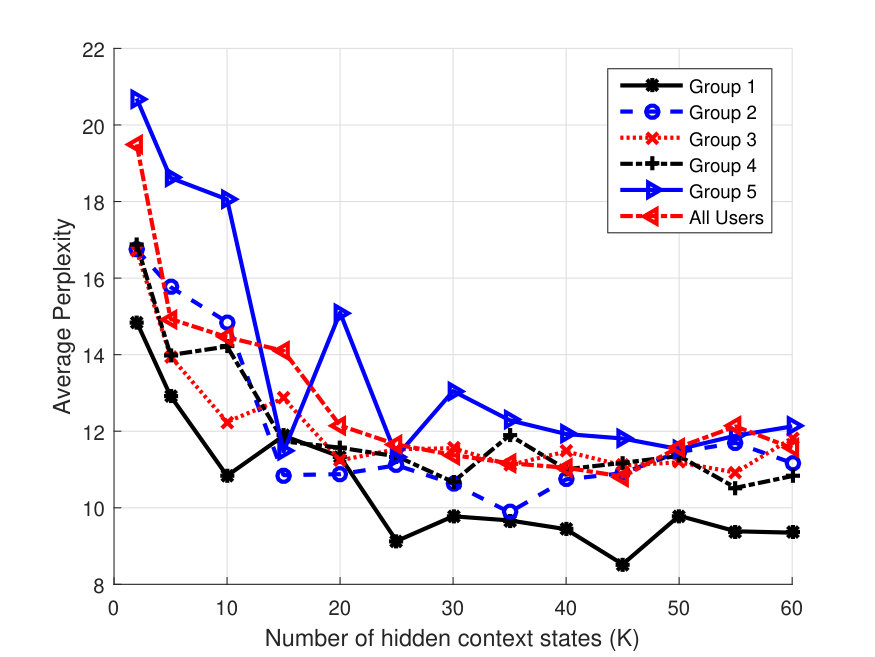 Figure 22
Figure 22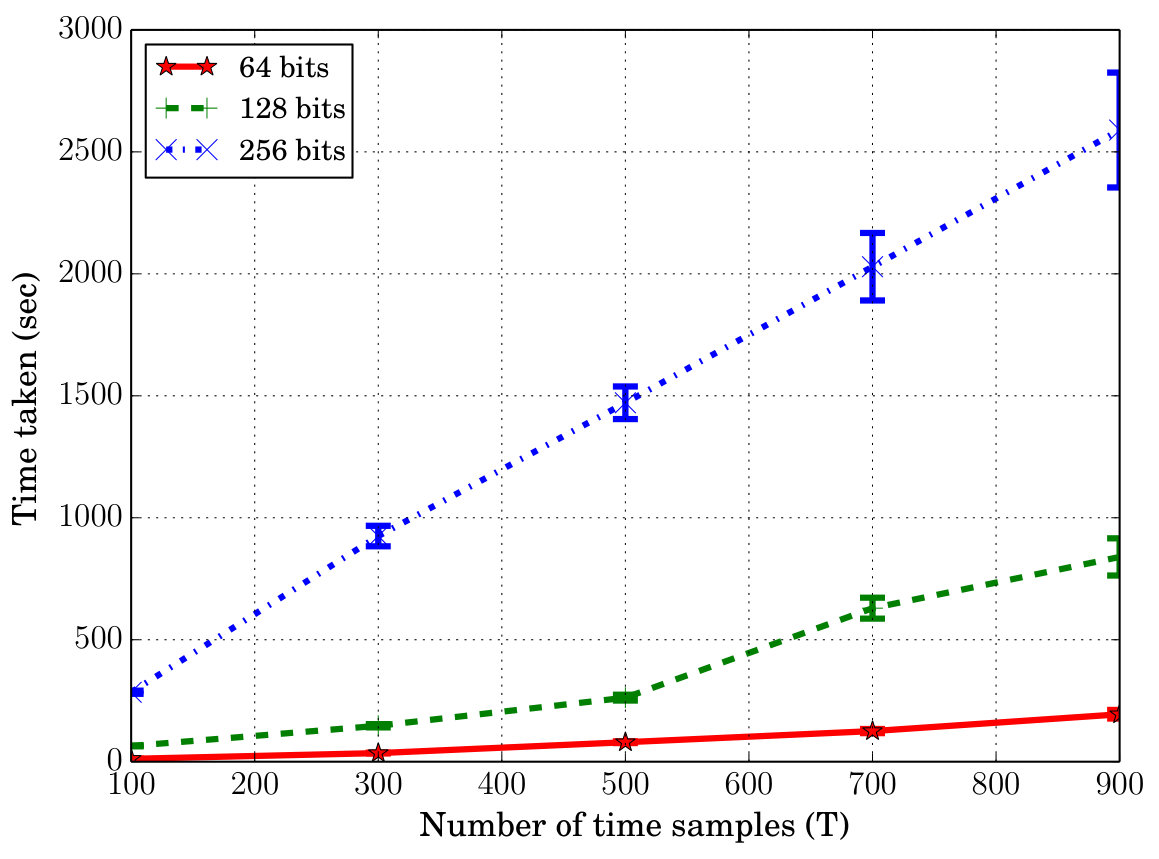 Figure 23
Figure 23| Time () | Context observation of user at time () |
| WiFi: wifi1, CellID: cid1, LAC: lac1, Battery Level: high, Battery Status: discharging, Day Period: morning, Day of week: Monday, Holiday: No | |
| WiFi: wifi2, CellID: cid2, LAC: lac2, Battery Level: medium, Battery Status: discharging, Day Period: noon, Day of week: Monday, Holiday: No | |
| ……….. | |
| WiFi: wifi1, CellID: cid1, LAC: lac1, Battery Level: low, Battery Status: charging, Day Period: night, Day of week: Sunday, Holiday: Yes | |
| Feature | Values | |
|---|---|---|
| WiFi | MAC values of Access Points | 440 |
| Place Name | User defined place name values | 168 |
| Cell ID | Cell ID values | 316 |
| LAC | Location Area Code values | 33 |
| Batt. Level | Low (), Medium (), High (), Full () | 4 |
| Batt. Status | Charging, Discharging, Full | 4 |
| Day Period | Morning: {7 to 11 am}; Noon: {11 am to 2 pm}; Afternoon: {2 to 6 pm}; Evening: {6 to 9 pm}; Night: {9 pm to 7 am} | 5 |
| Day Name | Mon, Tue, Wed, Thu, Fri, Sat, Sun | 7 |
| Holiday | Yes, No | 2 |
| Features | Ground Truth(A) | HPC(A) | HCFC(A,C) | HCFC(A,C,D) | HPC(A) + HCFC(A,C) | HPC(A) + HCFC(A,C) + HCFC(A,C,D) |
|---|---|---|---|---|---|---|
| Wi-Fi AP | 00:bl:f2:9b:05:76 | 00:og:1f:2e:4n:6c(0.32) | 00:bl:f2:9b:05:76(0.43) | 00:bl:f2:9b:05:76(0.41) | 00:bl:f2:9b:05:76(0.27) | 00:bl:f2:9b:05:76(0.32) |
| Place Name | F007 | F007 (0.84) | B003 (0.48) | J023 (0.31) | F007 (0.57) | F007 (0.41) |
| Cell ID | 42534164 | 42534164 (0.62) | 42534164 (0.44) | 48759836 (0.3) | 42534164 (0.53) | 42534164 (0.39) |
| LAC | 8513 | 9353 (0.32) | 8513 (0.47) | 8513 (0.57) | 9353 (0.36) | 8513 (0.41) |
| Battery Level | High | High (0.89) | Medium (0.41) | Medium (0.32) | High (0.57) | High (0.42) |
| Battery Status | Discharging | Discharging (0.95) | Discharging (0.93) | Discharging (0.81) | Discharging (0.94) | Discharging (0.89) |
| Day Period | Afternoon | Afternoon (0.72) | Afternoon (0.82) | Afternoon (0.73) | Afternoon (0.77) | Afternoon (0.75) |
| Day Name | Tuesday | Tuesday (0.59) | Tuesday (0.68) | Tuesday (0.73) | Tuesday (0.63) | Tuesday (0.67) |
| Holiday | No | Yes (0.6) | No (0.7) | No (0.75) | No (0.55) | No (0.62) |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
HCFContext: Smartphone Context Inference via Sequential History-based Collaborative Filtering
Vidyasagar Sadhu1, Saman Zonouz1, Vincent Sritapan2, and Dario Pompili1
1Department of Electrical and Computer Engineering, Rutgers University, New Brunswick, USA
2Cyber Security Division, Department of Homeland Security Science & Technology Directorate, USA
1{vidyasagar.sadhu, saman.zonouz, pompili}@rutgers.edu, [email protected]
Abstract
Mobile context determination is an important step for many context-aware services such as location-based services, enterprise policy enforcement, building/room occupancy detection for power/HVAC operation, etc. Especially in enterprise scenarios where policies (e.g., attending a confidential meeting only when the user is in “Location X”) are defined based on mobile context, it is paramount to verify the accuracy of the mobile context. To this end, two stochastic models based on the theory of Hidden Markov Models (HMMs) to obtain mobile context are proposed—personalized model (HPContext) and collaborative filtering model (HCFContext). The former predicts the current context using sequential history of the user’s past context observations; the latter enhances HPContext with collaborative filtering features, which enables it to predict the current context of the primary user based on the context observations of users related to the primary user, e.g., same team colleagues in company, gym friends, family members, etc. Each of the proposed models can also be used to enhance/complement the context obtained from sensors. Furthermore, since privacy is a concern in collaborative filtering, a privacy-preserving method is proposed to derive HCFContext model parameters based on the concepts of homomorphic encryption. Finally, these models are thoroughly validated on a real-life dataset.
Index Terms:
Mobile context, collaborative filtering, privacy-preserving, personalized model, sensors, location, prediction.
I Introduction
Overview: Mobile device applications provide an increasing number of features customized to match users’ needs. These needs are very often inferred from specific features such as the user location, activity (e.g., running, walking, driving), surrounding people, interacting people, the current app usage on the device, etc. These features collectively define a specific user (mobile) context. Mobile applications are increasingly making use of these contexts such as location-based services (e.g., Foursquare, Google Now, Weather updates, etc.), enhanced reality applications (Pokemon GO [1]), continuous authentication, etc. However, to enable these services, context inference is a much needed and important step (on a relevant note, see our previous work on privacy-preserving, distributed, smartphone localization framework [2]). Most of the existing work focuses on obtaining mobile context instantaneously from sensors which could possibly be hacked, noisy or insufficient and as such cannot be relied in certain security applications. Hence we take a different approach to that problem in this paper by modeling mobile context based on past context data. There are many advantages of modeling the user context by leveraging the sequential nature of context information in a user’s history as it can be used to predict the current or future contexts. The former can be used to validate and/or enhance the possibly hacked/noisy/insufficient sensor context, while the latter can provide some information ahead of time to the benefit of the user [3]. For example, a user’s general routine during weekdays could be to head first to Starbucks near his home, then to his work and then to Gym and back to home as shown in Fig. 1(left). The learned model will capture this behavior and can be used to validate the location of the user obtained via GPS at 5:30 pm to be at Gym (current context prediction) or display coupons related to Starbucks on his phone in advance (future context prediction). The latter can be leveraged by mobile personal assistant technologies such as Apple Siri/Google Now to much benefit of the user.
Motivation: One of the context-aware services is the enterprise data access control as in [4], where policies are defined for enterprise data access based on the phone’s context (e.g., connected Wi-Fi, Cell ID, time, etc.). For example, a policy may be defined to allow the phone to be used to attend a confidential meeting or open a confidential document only when the phone’s context is found to be within a given location and time. In these secure scenarios, it is not suggested to rely solely on the context obtained from the phone’s sensors (e.g., GPS/WiFi and System clock to give location and time) because they could be hacked unknowingly to the user. For example, a virus might change the system clock to show different time or spoof the GPS [5] to show different location. However it is hard to hack a model (more so, a collaborative one) that is learned over a long period of time. Hence our solution can be used to validate the context directly obtained from sensors at that instant. Secondly, it is possible that context from sensors is noisy (due to malfunction) or does not contain enough information. For example, in the case of a tablet or old mobile phone, it may not be able to acquire (accurate) GPS signal. As such it will be helpful if there is another way of obtaining this information such that it complements the context from sensors. Thirdly, as mentioned earlier, future context prediction is useful in certain context-aware services such as mobile personal assistant technologies (Google Now, Apple Siri, etc.), which can help pre-fetch information/pre-plan based on the predicted context.
Our Approach: In order to address the above issues, we first propose a personalized model (HPContext) that predicts the user’s context based on its past sequential history of contexts. Obtaining context through two approaches—sensors and personalized model—adds an extra layer of confidence to the obtained context. However, the following situations are possible: contexts obtained from both approaches are very different, contexts from one of the approaches is not available (e.g., GPS may not be available from phone sensors indoors, etc.) or insufficient leading to uncertainty. In such situations, assuming the user is closely connected to a group of people (e.g., same team colleagues in the company as shown in Fig. 1(right), gym friends, family members, etc.), it is possible that the context of other members in that group of people can provide additional information about his/her context. For example, assume users and often go to lunch together (learned via model). Now somehow if it is known that is going to “Restaurant1” tomorrow for lunch, it is most likely that the context of user tomorrow around 1 pm is “having lunch with at Restaurant1” without having to rely on ’s phone sensors at that instant. Our paper explores this aspect of context to provide a second layer of confidence to the context (over and above the personalized model). For this purpose, we propose to use such context obtained through collaborative filtering of the contexts of users closely related to the primary user (HCFContext). To the authors’ best knowledge, this is the first work to explore collaborative filtering for mobile contexts that can be used to validate and/or enhance the current context obtained from sensors or predict the future context for mobile personal assistant technologies. Additionally we present a privacy-preserving method for parameter estimation (training) of HCFContext, as users may not be willing to share their private data with each other for the same.
Contributions: Our specific contributions are as follows.
- •
We propose a personalized (HPContext) and collaborative filtering (HCFContext) model to predict the users context at any given instant (including future) based on the sequential history of past contexts and based on the theory of Hidden Markov Models (HMMs). We design a novel emission model for these HMMs by considering the unique features and the nitty-gritties of a mobile context (e.g., GPS from sensors may not be always available).
- •
We present a homomorphic encryption based privacy-preserving approach for training the HCFContext.
- •
We validate the efficacy of the proposed models by testing them on a real-life data set belonging to five graduate students collected over two months. We also evaluate our privacy-preserving approach to study its trade-offs.
Paper Outline: In Sect. II, we present the related work and position our paper. In Sect. III, we discuss the proposed models, (HPContext, HCFContext) and the privacy-preserving approach for the parameter estimation of HCFContext. In Sect. IV, we present the results of our proposed approaches. Finally, in Sect. V, we conclude and discuss future directions.
II Related Work
In this section, we position our work with respect to previous works (i) that obtain context with and without users sequential history, (ii) via local collaborative sensing, and (iii) related to privacy-preserving collaborative filtering.
Without Sequential History: There is existing work on modeling mobile contexts without considering the sequential nature of context information. For example, Bao et al. [6] propose an unsupervised approach to model mobile context from raw contextual data using Latent Dirichlet Allocation (LDA). Srinivasan et al. [7] mine the co-occurrences of certain context attributes; frequently and simultaneously occurring context attributes are formulated as association rules to predict what else the user will do (e.g., read comics) given a current context attribute (e.g., listen to jazz). However, unlike ours these approaches do not exploit temporal dependencies among contexts but only consider the behavior at a given instant.
With Sequential History: There is also work that exploits the sequential/temporal dependencies between contexts. For example, Mukherji et al. [8] present Mobile Sequence Miner (MSM) framework that mines frequent sequences occurring in app usage patterns, location visits, and call logs using a frequency-based approach. Farrahi et al. [9] present a probabilistic approach to mine mobile phone data (e.g., location) sequences using Distant N-Gram Topic Model (DNTM) where they model the sequence to be dependent on the starting element of the sequence. There are works that model the user activity using HMM based on sensor measurements [10, 11]. Even though these approaches exploit the sequential nature of contextual information, they neither consider collaborative filtering nor privacy-preserving aspects like we do. We claim that collaborative filtering context has additional context information than context obtained from personal history alone.
Local Collaborative Sensing: There are also works on local collaborative sensing; however, these works do not consider the sequential nature of past information into the collaboration process [12]. For example, Mantyjarvi et al. [13] present a collaborative sensing approach where a device, upon noticing a change in its local context beyond a threshold value, requests contexts from its surrounding devices so as to increase the accuracy of its context vector. Miluzzo et al. [14] use collaboration to increase the confidence of the sensed context through consensus of contexts sensed at surrounding devices. These approaches however do not consider past sequential nature of context information into collaboration.
Privacy-preserving Collaborative Filtering: There is existing literature in the domain of privacy-preserving collaborative filtering and HMM techniques, which can be broadly classified into two categories—data perturbation/randomization to hide the original data albeit with accuracy loss and data encryption with typically no accuracy loss albeit with higher computational complexity. On the former, Polat et al. [15] and Parameswaran et al. [16] present privacy-preserving collaborative filtering techniques based on randomized perturbation and data obfuscation respectively. On the latter, Guo et al. [17] present a privacy-preserving Markov model for sequence classification using homomorphic and ElGamal cryptographic systems. More works in this category can be found in [18, 19, 20]. We present an approach, designed specifically for our scenario, that extends the ideas in this category for privacy preserving multi-party parameter estimation of our HCFContext model.
III Proposed Approach
In this section, we describe HPContext and HCFContext models (Sect. III-A) and a privacy-preserving approach for parameter estimation of HCFContext (Sect. III-B).
III-A Context from Collaborative Filtering (HCFContext)
Problem Formulation: We present here the proposed HCFContext model by designing a novel emission model of a HMM taking into account the multi-user collaborative filtering aspects, as well as the unique features of the mobile context and its nitty-gritties such as feature unavailability. We first start with notation—capital letters denote random variables, whereas their small equivalents are their realizations. A vector variable will be indicated in bold. We model context () as a latent variable in the HMM. For a given user, the observation corresponding to a context state at time will be called context observations (). An example of a user’s context observations from time is shown in Table I. Each observation, , consists of a set of contextual feature-value pairs. These observations are obtained at regular time intervals (e.g., a minute to four hours). It can be seen as an example from the table that the context observation at corresponds to morning when the user is at home (battery is high, probably because the user charges her phone the previous night). The observation at , say after 4 hours, can be interpreted as being at office or workplace (change of WiFi, Cell ID, etc.) with battery level being in medium range. Finally, the observation at (after several days) can be taken to be again at home in the night. We assume that number of latent context states spans across these observations. Considering users , each user has a similar set of observations. Plate notation [21] for our HCFContext model for users is shown in Fig. 2. In plate notation, the number of different categorical values a random variable can take is shown inside the circle or rectangle. A circle is used for a random variable while a rectangle is generally used for hyperparameters. Observable variables are shaded. The number of repetitions of a rectangular block is shown at its bottom right corner. For a given user , the observation at time , is a set of feature-value pairs (as in a row of Table I). We can write , where is the number of available features of user , at time . Generation of each variable in Fig. 2 is described next.
Initial State Model: A prior distribution of contexts, is generated from prior Dirichlet distribution, . is then generated from . We will assume a total of possible context states for HCFContext over all users.
Transition Model: A prior transition distribution of contexts, , is generated from a prior Dirichlet distribution, . is then generated from for a given . Note that and can take a total of categorical values (, current state) for each (, previous state).
Novel Emission Model: For generation under each , since features are not always available (e.g., GPS is not available when indoor or underground, etc.), we will define a separate distribution for features () to account for their availability and then another distribution to obtain the values () for those features at time , as illustrated in Fig. 2. is dependent on , whereas is dependent on both and . An initial feature distribution, , is generated from a prior Dirichlet distribution, . Feature is then generated from , which can take two categorical values—whether the feature is present or not for the given context, . We will assume a total of possible features over all observations of all users. A prior value distribution, , is generated from a prior Dirichlet distribution, . Value is then generated from for a given context and feature . For a given feature , we will assume can take possible values. The priors will be chosen such that the summation and non-negativity constraints on the parameters are satisfied and also to encode prior information. For example, if it is known that a user frequently moves between home to work, the prior parameter for this transition, (), is given a high value.
Parameter Estimation (Training): Given these parameters, , the parameter space of and their hyperparameters, , let us denote the joint probability of all latent contexts and all context observations, , as . Likelihood of the observations is then,
[TABLE]
Training the HMM involves finding the parameters that maximize the likelihood in (1). Given the complex nature of (1) expanded, it is very difficult to derive a closed-form solution of . Hence, we make use of the well-known iterative approach called Expectation Maximization (EM) [22] but modify it to fit our approach. It consists of two important relations viz., forward and backward relations. We can express the full observation probability :
[TABLE]
Forward relation can now be expressed as,
[TABLE]
Similarly, we can express the backward relation as follows,
[TABLE]
Using these relations, we can define two new variables, and , for ease of analysis (denote and similarly for ) as follows,
[TABLE]
We can now compute the model parameters as,
[TABLE]
where is the indicator function with if is true and [math] otherwise. Eqs. (3)-(7) constitute the E-step, while Eqs. (8)-(11) constitute the M-step of the EM algorithm. These steps are iterated until the parameters in M-step converge.
Prediction: We will now use the learned parameters to predict the future observations given past observations. This will be done by first finding the distribution over future states and then by multiplying the distribution over the observations given the future state. In our case, since the observations are feature-value pairs, we will first calculate the distribution over features and then the distribution over values given features. Given that the user has made a sequence of past ‘t’ observations, , the probability that a feature , and then a value for that feature, will be observed at time can be computed, respectively, as follows,
[TABLE]
Note that in (12), (13) is computed as,
[TABLE]
where and can be recursively computed using a procedure similar to (4),
[TABLE]
We compute (12), (13) over all features, , all corresponding values and pick the most probable ones to get the feature-value pairs at .
Determining the Number of Hidden Contexts: So far we have assumed that the number of hidden contexts is given; however, in general this number needs to be determined automatically from the data. We will now detail an original approach to determine the best assuming it lies in the range and that the extremes can be approximately obtained from prior information about the data. To determine the best , we will define a metric called Perplexity that determines how well the chosen fits for prediction tasks over the testing set. Finding perplexity involves calculating the prediction probability over a sequence of observations given a sequence of past observations from the testing set. Perplexity can be defined as follows,
[TABLE]
where is the number of features observed at time for user and can be determined as follows,
[TABLE]
where and . Intuitively, a small perplexity is desired. Although in general the perplexity reduces as increases, a large is not preferred due to the risk of overfitting. Hence, we make use of the rate of decrease in perplexity to determine when to stop increasing , e.g., if it falls below a threshold (say 10%).
HPContext Model: Personalized model is just a special case of the above collaborative filtering model when the number of users is one (i.e., ). The main difference is in the observation probability. Specifically, for user ,
[TABLE]
Remaining equations remain the same with setting .
III-B Privacy-preserving Multi-party Computing
Since the users could possibly be in different contexts while training it is important to preserve their privacy. In this section, we develop algorithms for multi-party parameter estimation of HCFContext (Sect. III-A) while preserving each party’s privacy. Hence model parameters need to be jointly estimated when the individual observations are encrypted. Since the model parameters are known to everyone, the prediction can be carried out by each party on their own. The algorithms we developed for this (extended from [20]) are based on the following well-known primitives—homomorphic encryption [23], secure logsum, and secure negation [24].
The proposed algorithm for secure multi-party computation of data likelihood, is shown in self-explanatory Algorithm 1. It details the steps the parties need to undertake to jointly compute (as per (3), (4)) and the log likelihood of their observation data given the model parameters, . We assume only one party ( in Algo. 1) has both the private and public keys, while the remaining parties () have only the public key. Hence all parties encrypt their private observation data and send it to , where can be any one of , which does the computations on this private encrypted data (as it cannot decrypt it since it has only public key). Whenever it needs to compute secure logsum and secure negation protocols, it consults which has the private key. Algo. 1 can be similarly used to compute as per (5). The proposed algorithm for secure multi-party estimation of model parameters, is shown in Algo. 2. It details the steps taken by the parties to estimate using computed from Algo. 1. In Algo. 2, first computes as per (6) and (7) respectively. It then computes the model parameters, as per eqs. 8, 9, 10 and 11. The computational complexity of Algo. 1 can be seen as due to twice-nested for-loop operating for T timesteps for each party, while it is for Algo. 2 due to triple-nested for-loop.
Threat/Adversary Model: We use a semi-honest setting, where parties keep all their intermediate computations private, and we assume that will not collude with and disclose encrypted values received. The key generation in our security model will be following a standard key exchange mechanism [25] without the need to a third party entity. One may argue that the models themselves may be unreliable as they are based on historical sensor data. Our approach provides protection against this point by comparing sensor context with that obtained from HPContext and HCFContext, and alerting the user in case of significant differences and adaptively learning to ignore false positives.
Floating Point and Negative Numbers: Our algorithms need to encrypt the HMM parameters, which are real numbers. We translate between floating-point numbers and non-negative integers by scaling and rounding off the values. Let be the scaling factor. A real number is translated to integer , where is the largest integer . We incorporate this operation into the encryption and decryption as . For negative numbers, we use modulo arithmetic, i.e., negative numbers are represented by their modular additive inverse. For , . This means our is limited to range .
IV Experimental Evaluation
We describe the experimental setup and results, and evaluate the performance of the privacy-preserving algorithms.
Dataset and Experiment Description: To validate our models, we have used the LifeMap dataset [26], which is freely available online. This dataset consists of fine-grained mobility data such as WiFi fingerprints (MAC address and signal strengths of surrounding Wi-Fi APs), user-defined types of places (workplace, cafeteria, etc.), cell tower ID, etc. These details of 10 users are logged every 2 to 5 minutes for about two months (which is the overlap time among all users) in Seoul, Korea. The users are graduate students of the same lab in the university and as such the data suits our application. We have chosen data corresponding to five users for a period of nine weeks for our experiments. Username, gender and the number of places visited in total for these five users are as follows—GS2 (A), M, 163; GS3 (B), M, 297; GS4 (C), F, 209; GS7 (D), M, 289; GS12 (E), M, 376. The average number of places visited per user is about . However, the number of frequently visited places for each user ranges from 8 to 35 (median 20). We also down sampled the data to 1 hour period to ease the computations i.e., the time instants and are separated by 1 hour. This also means the trained models will be able to capture mostly only those contexts with stay duration of the order of an hour or more. Six weeks of data is used for training and the rest three week data is used for testing. The list of features we have used from this dataset is shown in Table II. Here corresponds to the total number of values taken by that feature. In case of ‘Holiday’, Saturday, Sunday and any public holidays are considered as holidays. In cases where a certain feature’s value is missing, we model it as if the feature is not available at that time using . We have empirically set in our experiments [27] ( is the number of hidden context states). All our results (implemented in Python) are generated on an Intel 4-core i7-2600 CPU @ 3.40GHz, with 8 GB of RAM. *We did not consider a larger dataset as our main idea is to apply collaborative filtering across the user’s closely related users such as labmates, roommates, etc. Also, we could not find larger datasets with similar features. *
Perplexity vs. and Optimal Group Selection: Figure 3(a) shows the averaged perplexity values for different number of hidden states, , for one user case. Since this is a one user case it corresponds to HPContext. The perplexity is calculated by predicting the observations at the next 12 time instants in the test data given the preceding 12 observations on the same day. This has been done over all the days in the three week test data and the results are averaged. From Fig. 3(a), we can observe that perplexity reduces as increases with a pattern of diminishing returns. We can observe that user has the best perplexity and provides a good balance between perplexity and complexity introduced due to higher values. Figure 3(b) shows similar result for 2 users. Since we have 2 users, we have a total of 10-user groups (5C2 combinations). We can observe that Group 10 consisting of users has the best perplexity and provides a good tradeoff. This means that the two users in Group 10 have more similar patterns than the users in other groups. Figure 3(c) shows similar result for 3 users. We can observe that Group 2 (users ) has the best perplexity with providing good tradeoff. Similarly, for 4 user case, we can observe from Fig. 4(a), that (users ) has best perplexity values and provides a good balance. For all user case in the same figure, we can see that provides a good tradeoff. Hence these results can be used to select most related users in a group of 2/3/4, etc. Even though it takes time to find the optimal group via this approach, we feel it is acceptable as it is done only once offline. For the results below, whenever a user or a group of users is mentioned, we considered the above best groups and optimal values. To illustrate the benefits of collaborative filtering contexts, we considered only 2 and 3 user groups as benefits diminish with increase in group size.
Log Likelihood Convergence, Training Times: Figure 4(b) shows the log likelihood (LL) of the training data, , versus the iteration number in the EM algorithm (which is used to estimate parameters of HCFContext) for different models. We have considered six weeks of training data so, . We can see that the LLs have converged and the model significantly improves the initial LL values (upto 30%). We can notice that LLs have approximately converged after iterations. Even then, the converged LLs have lower values due to large number of values for certain features (such as WiFi APs which has about 440 unique values) which makes the value probabilities, , very small. In fact, we encountered underflow problem due to multiplication of several small probabilities and then using such a value in the denominator resulting in values. In order to solve this problem, we have used scaling approach [28] for values. Figure 4(b) also shows the time taken in seconds vs. iterations of EM algorithm. The corresponding time for is about seconds respectively for the three models. These durations are reasonable considering that the training is run offline and very less often. Both these results are averaged over 4 runs and we can notice that the confidence intervals are too minute to be noticed.
Prediction Performance—A Use Case: We relate to the “lunch” use case mentioned in Sect. I. We considered user for this purpose and his most related 2 and 3 user groups as found from above— and —and the corresponding models, HPContext, HCFContext (2), and HCFContext (3), respectively (please note this notation to be used in rest of the paper). We first illustrate the prediction results using a known use case as follows. We manually observed from the data that users usually go to lunch together on weekdays around pm. We wanted to check whether our models are able to capture this group behavior. Hence we predicted the contextual feature-values of user at 1 pm on one randomly selected weekday (Tuesday) in the test period given the observations of previous one-day duration using the above models. Table III shows the results of different models along with ground truth (column 2). All entries correspond to maximum probability values with those probabilities shown in brackets. Incorrect predictions are depicted in bold. We can notice that HPContext (col. 3) does a good job in predicting the personalized features such as Place Name, Battery Level but makes 3 incorrect predictions for more general features such as LAC, Holiday, etc. Note that each feature is predicted independently, e.g., predicting Place Name correctly does not necessarily mean Wi-Fi AP prediction is correct. Interestingly, HCFContext (cols. 4,5) makes correct predictions for those general features but fares badly for personalized features. Hence we combined the two models to obtain better predictions (as can be seen in last two columns) as follows. In case of HPContext + HCFContext (2), we first average the probabilities of values predicted by both models and then take the feature value with the highest average probability; similarly for HPC + HCFC(2) + HCFC(3) (HPC refers to HPContext and HCFC to HCFContext for simplicity).
Prediction Performance—Overall: To evaluate the overall performance, we predicted all the contextual feature value pairs of user at 3 hour increments in the entire 3-week testing period (i.e., in total) given the past observations of one-day duration. In order to compare with other closest approaches, we considered Mobile Miner [7], which is the current state-of-the-art machine learning algorithm to mine contextual co-occurrences. Each feature is considered to be independently co-occurring with the time of day and day of week (as opposed to sequentially occurring in our case), and is modeled using Multinomial Logistic Regression. Figure 5 shows the average prediction accuracy (percentage of correct predictions) for each feature at different times in a day (averaged over all the days). Even though we are able to predict at the hourly level (due to the upsampling mentioned earlier), we show only at 3-hour intervals for clarity. These simulations are also run for 4 runs (to account for randomicities such as random initialization of the model parameters) and the confidence intervals are shown. Due to space limitations, we have shown results only for six features consisting of four location features—Wi-Fi AP, Place Name, Cell ID, Location Area Code (LAC), one device feature—Battery Level and one time feature—Holiday. Others follow similar pattern.
First of all we can notice that the proposed models perform better than Mobile Miner. Second, in case of proposed models, we can notice that the accuracy slightly drops during mid-day compared to other times. The reasons for this drop as follows—(1) the user is more mobile during those times introducing randomness into the data making the model hard to learn; (2) the average number of places visited by each user is (as indicated above) and the value chosen (as a tradeoff between complexity and accuracy) is less than that; (3) the data is down-sampled to one hour interval, meaning, any places with stay duration less than one hour will not be captured well. However it is important to note that the accuracy in such cases is still on an average about 75% which is reasonable to validate/complement the context from sensors. During other times of the day, we can notice that the accuracy is about , which means the models are able to predict the values of those contextual features correctly 90% of the time. Third, we can notice that HPC + HCFC(2) model improves accuracy over HPC to a maximum of especially in more general features such as LAC, Holiday. In case of personalized features such as Place Name, Battery Level, the improvement is minor. We also notice that the additional improvement from HCFC(3) is again minor, about . In total, HCFC contributes upto improvement in accuracy. We have also plotted similar results for each day of the week but could not include them due to space limitations. In addition to above trends in generic/personalized features vs. models, we have noticed a drop in accuracy over weekends (to on average) again owing to increased mobility with less sequential behavior. The average accuracy is about to for the rest of the days (HPC + HCFC(2) + HCFC(3) model).
Prediction Quality: Next, we tested our models’ prediction quality by testing how many of the features (all in Table II) the models are able to predict correctly at a given time of day. For this purpose, we created three categories—Excellent, Good, Bad. If the model is able to predict at least 7 features out of 9 correctly at a given instant, we call it Excellent prediction. Similarly we call 4/5/6 features prediction, a Good prediction and 1/2/3 ([math] is not included) features prediction, a Bad prediction. For example, the prediction corresponding to in Table III is considered a Good prediction, while that belonging to , an Excellent prediction. Figure 6 shows these results (averaged) for different times of day and days of week. In both sets of figures, we can notice that the percentage of Excellent cases is at least . Secondly, the percentage of Excellent cases is more than Good cases which in turn is more than the Bad cases (in particular the Bad cases are very less comparatively).
Test Data Rotation: The performance of the models when the test data chosen is the first (1-3), middle (4-6) and last (7-9) three weeks is shown in Fig. 4(c), which shows the percentage of correct predictions across all features and test days for different choices of test data (results shown only for HPC + HCFC(2) + HCFC(3) for clarity). We can notice that the performance is roughly the same showing robustness of the proposed models to choice of test data and their ability to fully learn users’ sequential patterns using 6 weeks train data.
Contextual Optimal User Group Selection: So far, for a given user, , we have found the optimal user groups considering all times of the day. However, it is more beneficial to find the optimal user group based on the time of the day as is the real scenario. For example, for a given user, the closely related users during the office hours may be different from the closely related users during home hours. Taking this idea into account, we have found the most closely related user for user (i.e., optimal 2-user group) at different times of the day using the perplexity method mentioned earlier. Instead of averaging across all times of the day, we find the user group with minimum average perplexity at each time instant of the day. The results are as follows—, , , , , , , .
Prediction Using Only HCFContext: We now predict the feature-value pairs of user at all time instants in the test period using only the collaborative filtering model, HCFC(2), with dynamic optimal 2-user group obtained from above. Figure 7(a) shows the performance of that model compared against two other models—the personalized model HPC and HCFC(2) with fixed optimal 2-user group . We can notice that dynamic HCFC performs close to HPC and better than fixed HCFC. This indicates that personalized context can be obtained from collaborative filtering of contexts corresponding to user’s closely related users with appropriate dynamic (i.e., time of day/activity the user is performing) selection of closely related users.
Privacy-preserving Algorithms: To evaluate the performance of Algorithms 1, 2, we tested them on a simple HMM with parties, hidden states and observation states per hidden state. We evaluated both the amount of error introduced (due to scaling as mentioned in Sect. III-B)) as well as the time taken to train the HMM and run the predictions. For the former, we calculated the error by comparing with the non-privacy preserving case. We varied the key length (bits) and the scaling factor . The worst-case errors over 10 runs with samples, as percentages, for different parameters is shown in Fig. 7(b). We notice that the error reduces as scaling factor increases (as expected). Similarly, as the key length increases, the error reduces and also security increases. We can notice that for large keys and reasonable scaling factors, the error due to integer approximation and consequent over- or underflow is insignificant (about 2% in the worst case over all parameters). This shows that the effect on the prediction accuracy results above will not be drastic. However, the price is in terms of run-time. Figure. 7(c) shows the average run-times of Algorithm 1 vs. the number of time samples as well as the key length (with ). We can see that the time taken varies linearly with the number of samples used. However, the relation seems to be approximately quadratic with key-length. This result shows the tradeoff between security and run-time. As the key-length is increased, more is the security, less is the amount of error introduced, however the run-times are more. Hence a suitable key length should be chosen that is a compromise between security/error and run-time. The run-times for Algorithm 2 are on average five times more. However these algorithms need to be run only for training the HCFContext which is run very less frequently and offline. Moreover, we will leverage recent advances in encryption and multi-party computation algorithms such as [29] to help further reduce the runtimes of these algorithms, as part of future work.
Real-time Inference and Cold-start: Once the training is complete, model parameters are known to each device. Prediction, then, just involves evaluating (12), (13) by plugging in the learned parameters. These are just a few arithmetic operations and do not involve any compute-intensive encryption/decryption algorithms unlike training which happens offline. Hence, our approach will not have any problems in practical implementations i.e., making predictions in real time. Furthermore, to combat the cold-start problem akin to collaborative filtering based approaches, we suggest to—(i) use sensor context and also obtain user validation for additional security; (ii) use sensor context + HPContext until HCFContext is learnt well.
Energy Considerations: Note that all of the features we worked with are passive, i.e., do not require active probing that consumes energy. One exception is the Wi-Fi, which needs to be turned ON in case it is not ON. In all other cases, we piggyback on the sensor data already available on the phone, reducing energy consumption.
V Conclusion and Future Work
We proposed and evaluated (on a real-life dataset with over accuracy) privacy-preserving, sequential history-based personalized and collaborative-filtering models, for current and future mobile context prediction to validate and/or enhance the sensor context. Their feasibility for practical deployment in security applications and/or mobile personal assistant technologies is shown. As future work, we plan to conduct a pilot study of our models; improve their training times leveraging suboptimal algorithms and enhance their prediction accuracy.
Acknowledgment
We thank the US Department of Homeland Security Science & Technology Directorate (DHS S&T) Cyber Security Division for their support under the contract No. D15PC00159.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Niantic, “Pokemon Go,” http://www.pokemongo.com , 2016.
- 2[2] V. Sadhu, D. Pompili, S. Zonouz, and V. Sritapan, “Collab Loc: Privacy-preserving multi-modal localization via collaborative information fusion,” in Proc. of the International Conference on Computer Communications and Networks (ICCCN) . Vancouver, BC: IEEE, 2017.
- 3[3] V. Pejovic and M. Musolesi, “Anticipatory Mobile Computing: A Survey of the State of the Art and Research Challenges,” ACM Comput. Surv. , vol. 47, no. 3, 4 2015.
- 4[4] G. Salles-Loustau, L. Garcia, K. Joshi, and S. Zonouz, “Don’t just BYOD, Bring-Your-Own-App Too! Protection via Virtual Micro Security Perimeters,” in IEEE/IFIP International Conference on Dependable Systems Networks , 6 2016.
- 5[5] N. O. Tippenhauer, C. Pöpper, K. B. Rasmussen, and S. Capkun, “On the requirements for successful GPS spoofing attacks,” in Proceedings of the 18th ACM conference on Computer and communications security - CCS ’11 . New York, NY, USA: ACM Press, 2011, p. 75.
- 6[6] T. Bao, H. Cao, E. Chen, J. Tian, and H. Xiong, “An Unsupervised Approach to Modeling Personalized Contexts of Mobile Users,” in 2010 IEEE International Conference on Data Mining . IEEE, 12 2010, pp. 38–47.
- 7[7] V. Srinivasan, S. Moghaddam, A. Mukherji, K. K. Rachuri, C. Xu, and E. M. Tapia, “Mobile Miner: mining your frequent patterns on your phone,” in Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing - Ubi Comp ’14 Adjunct . New York, NY, USA: ACM Press, 2014, pp. 389–400.
- 8[8] A. Mukherji, V. Srinivasan, and E. Welbourne, “Adding intelligence to your mobile device via on-device sequential pattern mining,” in Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing Adjunct Publication - Ubi Comp ’14 Adjunct . New York, NY, USA: ACM Press, 2014, pp. 1005–1014.