3G structure for image caption generation
Aihong Yuan, Xuelong Li, Xiaoqiang Lu

TL;DR
This paper introduces a 3-gated model that effectively fuses global and local image features for improved image caption generation, outperforming existing methods.
Contribution
It proposes a novel 3-gated architecture that adaptively combines global and local image features for more accurate image captioning.
Findings
Outperforms state-of-the-art methods in image captioning
Effectively combines global and local image features
Enhances the relationship modeling between images and text
Abstract
It is a big challenge of computer vision to make machine automatically describe the content of an image with a natural language sentence. Previous works have made great progress on this task, but they only use the global or local image feature, which may lose some important subtle or global information of an image. In this paper, we propose a model with 3-gated model which fuses the global and local image features together for the task of image caption generation. The model mainly has three gated structures. 1) Gate for the global image feature, which can adaptively decide when and how much the global image feature should be imported into the sentence generator. 2) The gated recurrent neural network (RNN) is used as the sentence generator. 3) The gated feedback method for stacking RNN is employed to increase the capability of nonlinearity fitting. More specially, the global and local…
Click any figure to enlarge with its caption.
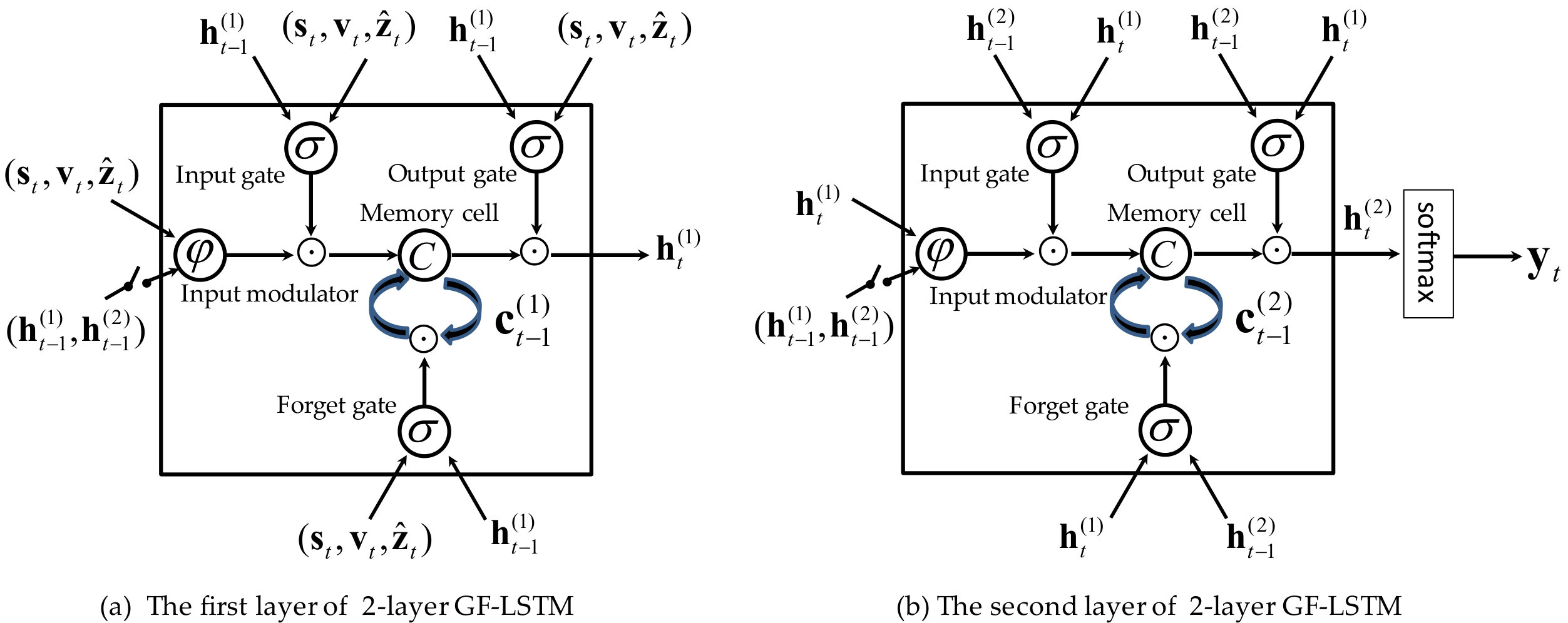 Figure 1
Figure 1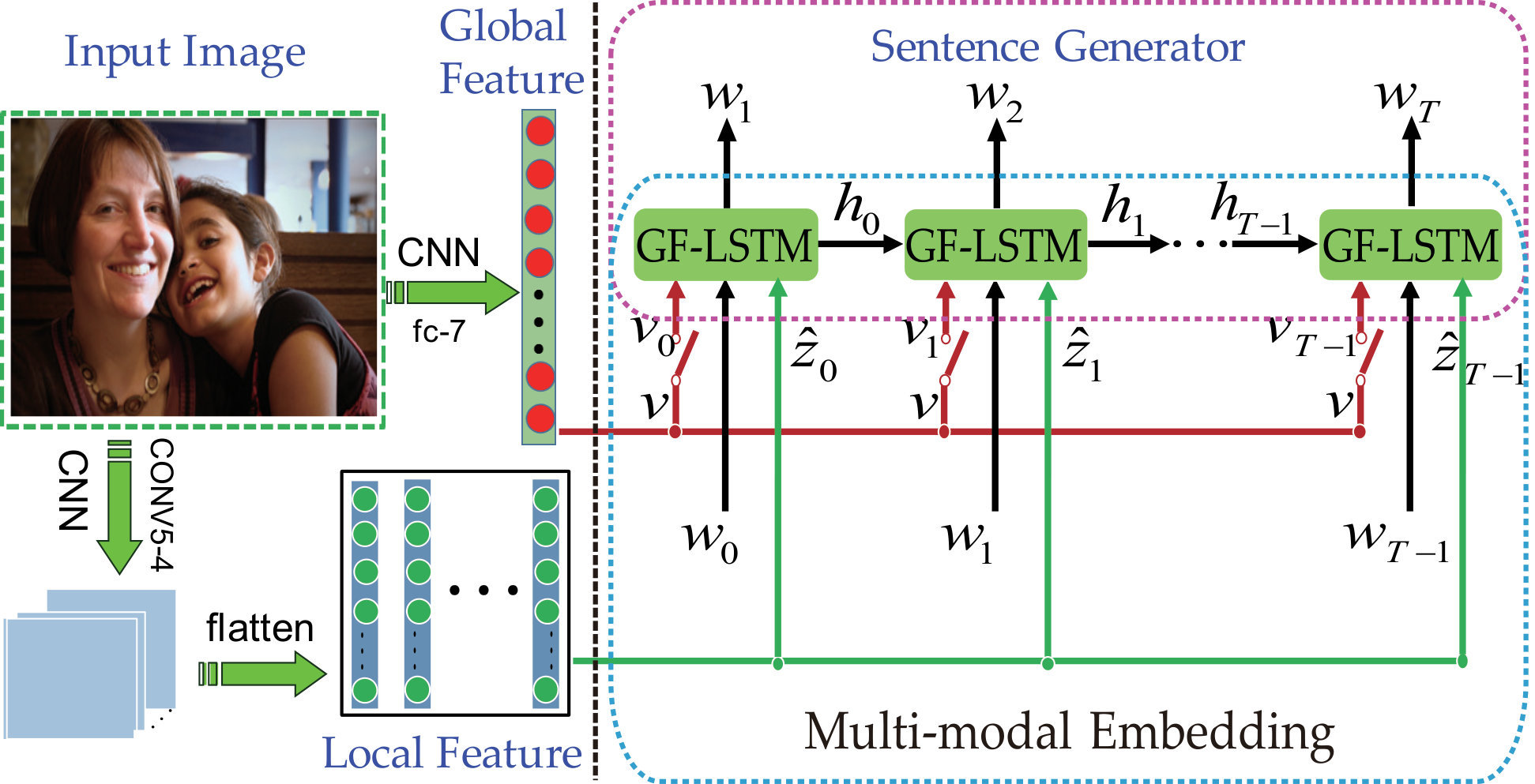 Figure 2
Figure 2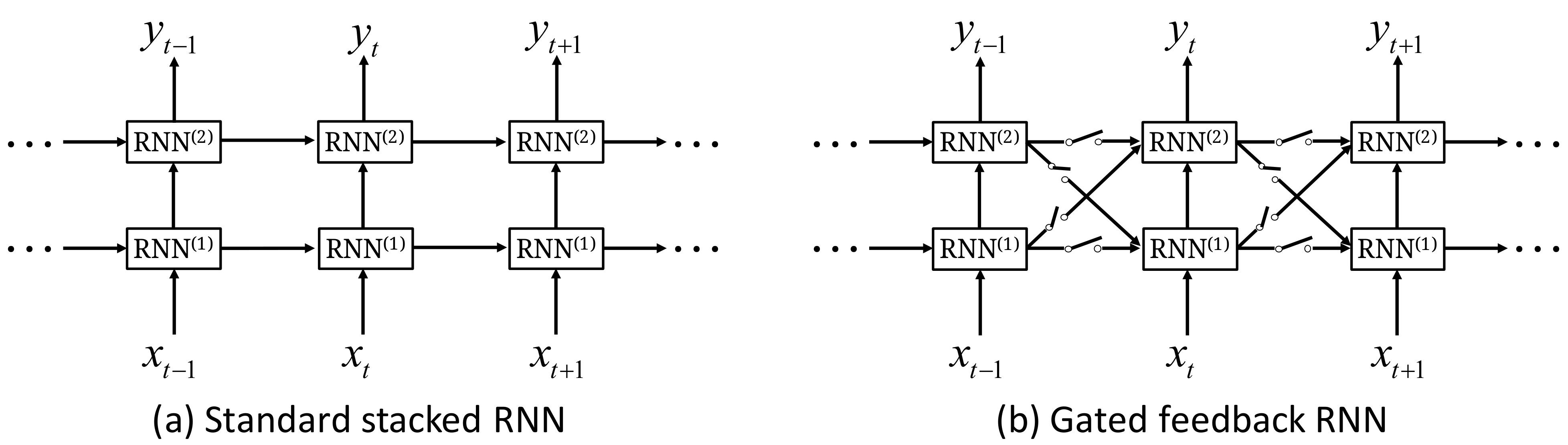 Figure 3
Figure 3 Figure 4
Figure 4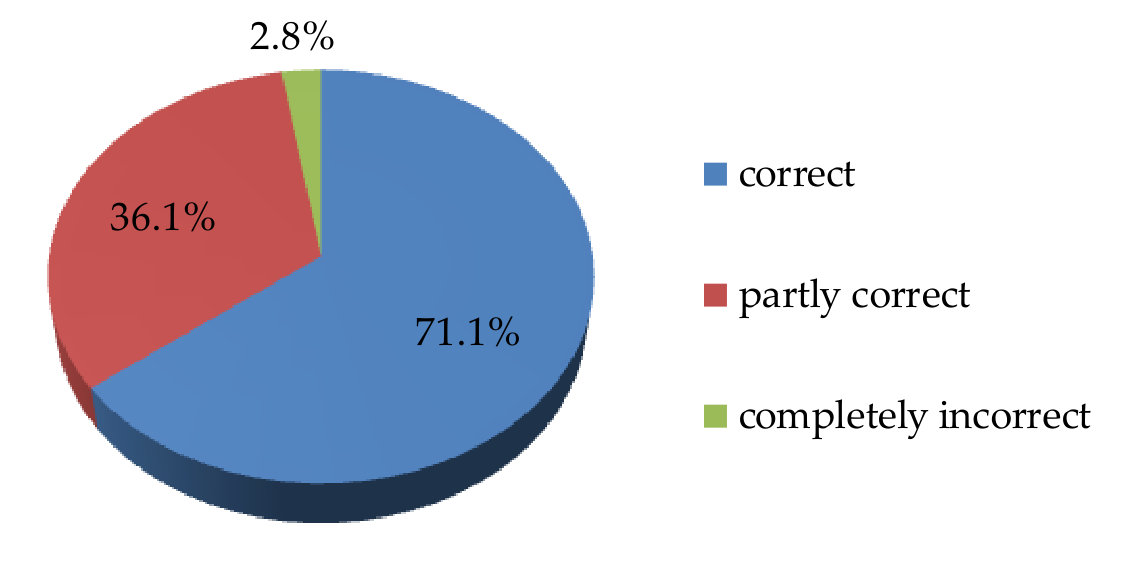 Figure 5
Figure 5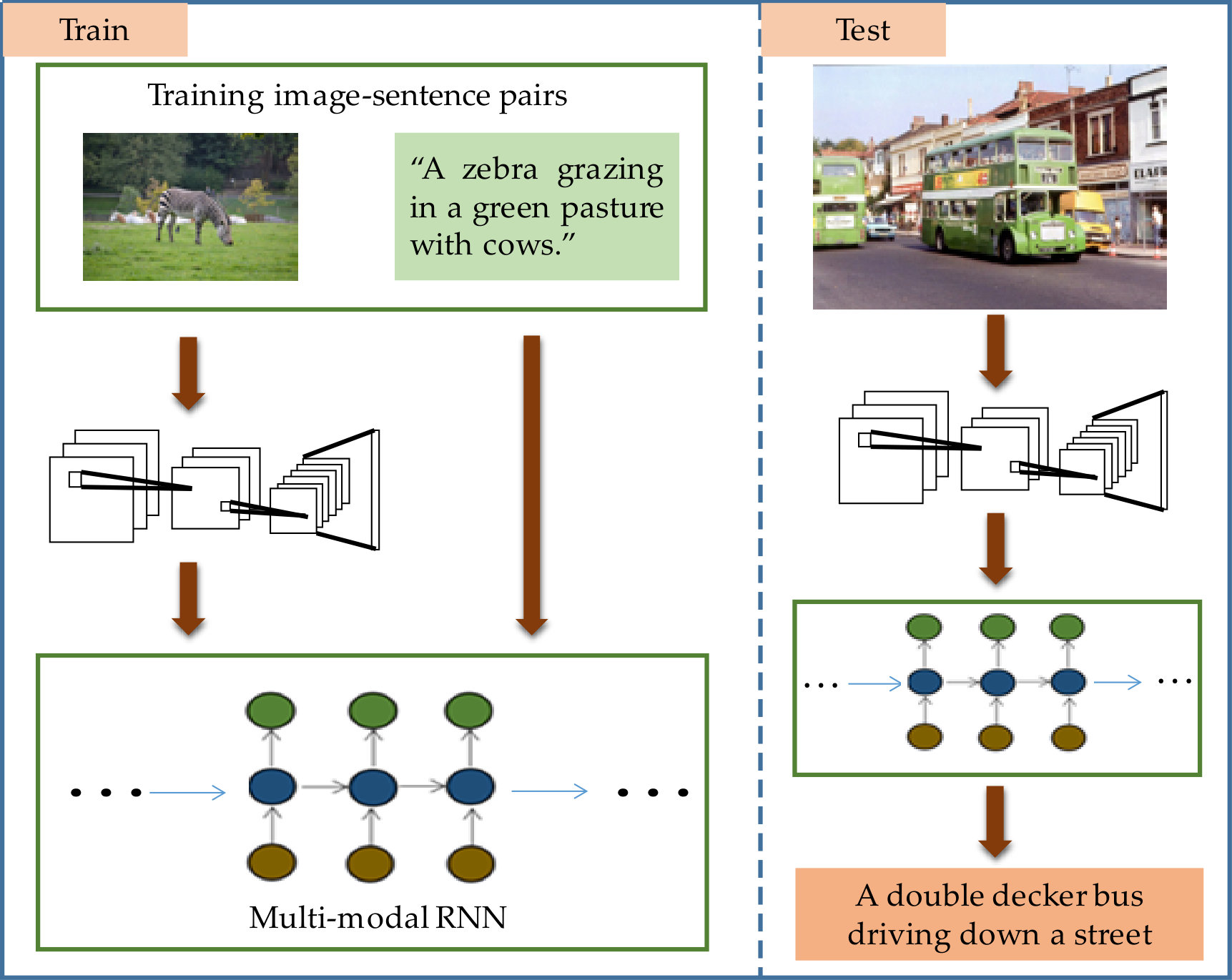 Figure 6
Figure 6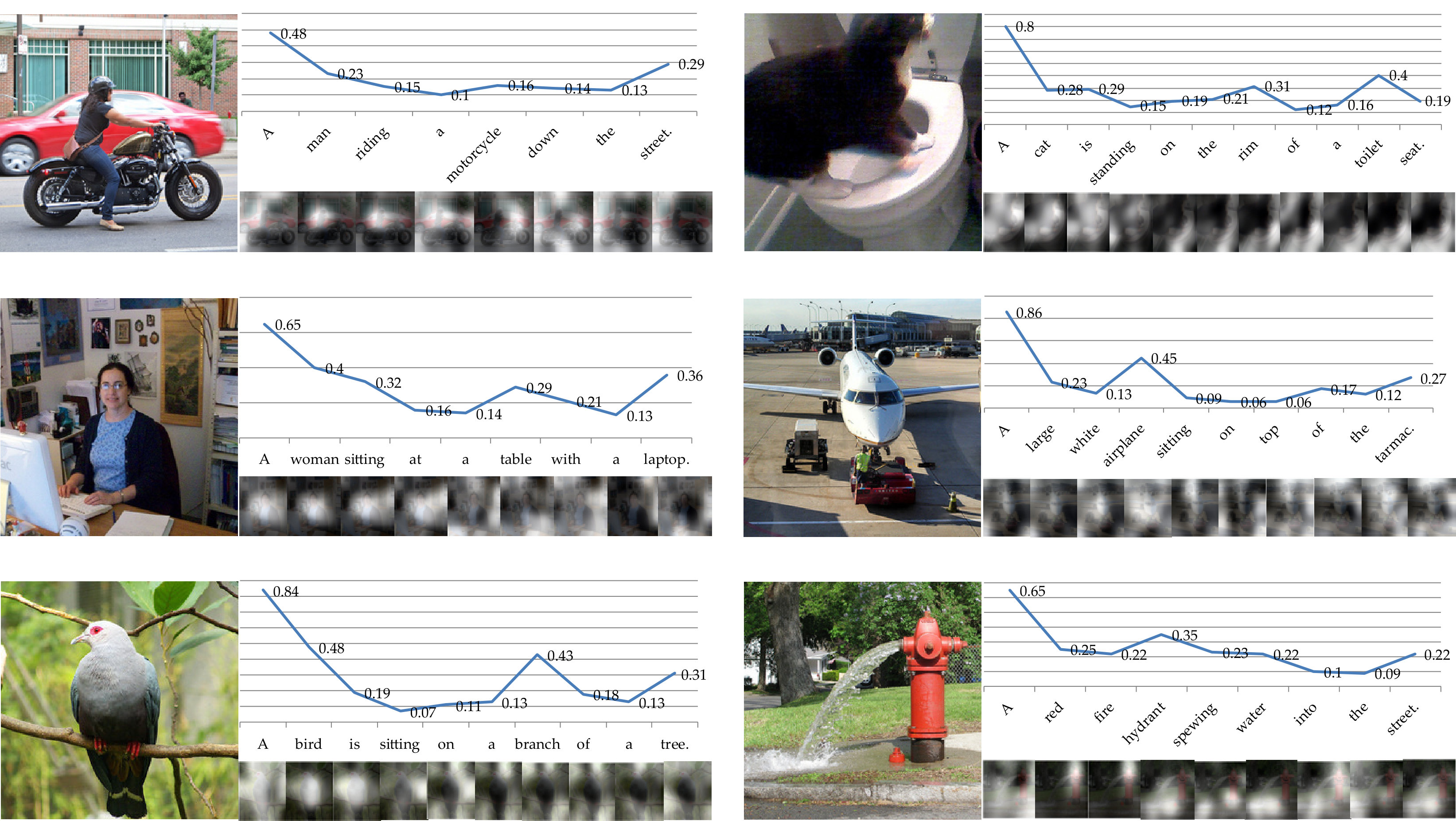 Figure 7
Figure 7| Flickr8K | Flickr30K | MS COCO | ||||||||||||||||||||||||||||
| Model |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
| global image feature based | ||||||||||||||||||||||||||||||
| m-RNN [11] | 56.5 | 38.6 | 25.6 | 17 | - | 60 | 41 | 28 | 19 | - | 66.8 | 48.8 | 34.2 | 23.9 | 22.1 | |||||||||||||||
| DeVS [8] | 57.9 | 38.3 | 14.5 | 16 | 16.7 | 57.3 | 36.9 | 24 | 15.7 | 15.3 | 62.5 | 45 | 32.1 | 23 | 19.5 | |||||||||||||||
| LRVR [43] | - | - | - | 14.1 | 18 | - | - | - | 12.6 | 16.4 | - | - | - | 19 | 20.4 | |||||||||||||||
| Google-NIC [7] | 63 | 41 | 27 | - | - | 66.3 | 42.3 | 27.7 | 18.3 | - | 66.6 | 46.1 | 32.9 | 24.6 | 23.7 | |||||||||||||||
| LRCN [10] | - | - | - | - | - | 58.8 | 39.1 | 25.1 | 16.5 | - | 62.8 | 44.2 | 30.4 | 21 | - | |||||||||||||||
| attention-based | ||||||||||||||||||||||||||||||
| NIC-VA [29] | 67 | 44.8 | 29.9 | 19.5 | 18.9 | 66.7 | 43.4 | 28.8 | 19.1 | 18.4 | 68.9 | 49.2 | 34.4 | 24.3 | 23.9 | |||||||||||||||
| ATT-FCN [30] | - | - | - | - | - | 64.7 | 46.0 | 32.4 | 23.0 | 18.9 | 70.9 | 53.7 | 40.2 | 30.4 | 24.3 | |||||||||||||||
| (RA+SS)-ENSEMBLE [9] | - | - | - | - | - | 64.9 | 46.2 | 32.4 | 22.4 | 19.4 | 72.4 | 55.5 | 41.8 | 31.3 | 24.8 | |||||||||||||||
| 3G | 69.9 | 48.5 | 34.4 | 23.5 | 22.3 | 69.4 | 45.7 | 33.2 | 22.6 | 23.0 | 71.9 | 52.9 | 38.7 | 28.4 | 24.3 | |||||||||||||||
| 5-Refs | 40-Refs | |||||||||||||||||||
| Model |
|
|
|
|
|
|
|
|
|
|
||||||||||
| Human | 66.3 | 46.9 | 32.1 | 21.7 | 25.2 | 88.0 | 74.4 | 60.3 | 47.1 | 33.5 | ||||||||||
| DeVS [8] | 65.0 | 46.4 | 32.1 | 22.4 | 21.0 | 82.8 | 70.1 | 56.6 | 44.6 | 28.0 | ||||||||||
| MSR [44] | 69.5 | 52.6 | 39.1 | 29.1 | 24.7 | 88.0 | 78.9 | 67.8 | 56.7 | 33.1 | ||||||||||
| NN [45] | 70 | 52 | 38 | 28 | 24 | 87 | 77 | 66 | 54 | 32 | ||||||||||
| MLBL [46] | 67 | 50 | 36 | 26 | 22 | 85 | 75 | 63 | 52 | 33.1 | ||||||||||
| NIC-VA [29] | 70.5 | 52.8 | 38.3 | 27.7 | 24.1 | 88.1 | 77.9 | 65.8 | 53.7 | 32.2 | ||||||||||
| RA [9] | 72.2 | 55.6 | 41.8 | 31.4 | 24.8 | 90.2 | 81.7 | 71.1 | 60.1 | 33.6 | ||||||||||
| ATT [30] | 73.1 | 56.5 | 42.4 | 31.6 | 25.0 | 90 | 81.5 | 70.9 | 59.9 | 33.5 | ||||||||||
| Att [47] | 73 | 56 | 41 | 31 | 25 | 89 | 80 | 69 | 58 | 33 | ||||||||||
| 3G | 70.1 | 53.2 | 39.3 | 29.1 | 23.4 | 88.2 | 79.0 | 68 | 56.9 | 31.7 | ||||||||||
| Model | B-1 | B-2 | B-3 | B-4 | METEOR |
|---|---|---|---|---|---|
| 3G (AlexNet) | 63.2 | 48.1 | 33.2 | 22.5 | 18.3 |
| 3G (GoogleNet) | 70.8 | 52.3 | 39.1 | 28.2 | 22.9 |
| 3G (VGG) | 71.6 | 52.2 | 39.0 | 28.9 | 23.8 |
| Model | B-1 | B-2 | B-3 | B-4 | METEOR |
|---|---|---|---|---|---|
| Google-NIC | 66.6 | 46.1 | 32.9 | 24.6 | 23.7 |
| LRCN | 62.8 | 44.2 | 30.4 | 21 | - |
| NIC-VA | 68.9 | 49.2 | 34.4 | 24.3 | 23.9 |
| GL-NIC | 70.9 | 50.9 | 36.7 | 26.0 | 25.3 |
| Model | B-1 | B-2 | B-3 | B-4 | METEOR |
|---|---|---|---|---|---|
| NIC-VA (2-layer LSTM) | 70.1 | 50.3 | 35.7 | 25.5 | 24.6 |
| NIC-VA (GF-LSTM) | 71.6 | 51.5 | 37.2 | 26.5 | 25.5 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
3G Structure for Image Caption Generation
Aihong Yuan
Xuelong Li
Xiaoqiang Lu
Center for OPTical IMagery Analysis and Learning (OPTIMAL),
Xi’an Institute of Optics and Precision Mechanics, Chinese Academy of Sciences,
Xi’an 710119, Shaanxi, P. R. China.
University of Chinese Academy of Sciences, Beijing 100049, P. R. China.
Abstract
1112019 Elsevier. Personal use of this material is permitted. Permission from Elsevier must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.
It is a big challenge of computer vision to make machine automatically describe the content of an image with a natural language sentence. Previous works have made great progress on this task, but they only use the global or local image feature, which may lose some important subtle or global information of an image. In this paper, we propose a model with 3-gated model which fuses the global and local image features together for the task of image caption generation. The model mainly has three gated structures. 1) Gate for the global image feature, which can adaptively decide when and how much the global image feature should be imported into the sentence generator. 2) The gated recurrent neural network (RNN) is used as the sentence generator. 3) The gated feedback method for stacking RNN is employed to increase the capability of nonlinearity fitting. More specially, the global and local image features are combined together in this paper, which makes full use of the image information. The global image feature is controlled by the first gate and the local image feature is selected by the attention mechanism. With the latter two gates, the relationship between image and text can be well explored, which improves the performance of the language part as well as the multi-modal embedding part. Experimental results show that our proposed method outperforms the state-of-the-art for image caption generation.
keywords:
Image caption generation, deep learning, convolutional neural network, recurrent neural network, multi-modal learning.
††journal: Journal of Neurocomputing
1 Introduction
Image caption generation aims to automatically generate a natural language sentence to describe the content of a given image. It is a vital task of scene understanding which is one of the fundamental goals of computer vision and artificial intelligence [1, 2]. However, image caption generation is a challenging task. It not only needs to recognize objects in an image, but also needs to capture and express their relationships and attributes with natural language [3].
To address the aforementioned challenge, many methods have been developed and a lot of gratifying results have been achieved in recent years. These methods are roughly divided into two categories: 1) retrieval-based methods [4, 5, 6] and 2) multi-modal neural network (MMNN) based methods [7, 8, 9, 10]. Although these methods, especially the MMNN-based methods, have attained promising results, further improvements should be got over some limitations.
1.1 Motivation and Overview
To generate length-variable and form-variable sentences, we follow the MMNN-based methods. However, in most existing methods, only global image feature or local image feature is used to generate sentences, which may lose some important image information. It is easy to understand that global image feature can catch the overall information of an image and local image information can dig out the fine-grained relationships between image regions and language elements. Therefore, we use a global-local image feature fusing strategy, which can fully mine the image information.
Moreover, the sentence generator in image captioning model should learn both hierarchical and temporal representation very well. While, most of the previous methods use the single-layer “vanilla” RNN [11, 12, 8] or single-layer LSTM, which cannot learn the hierarchical representation well [13, 14]. Meanwhile, the issue of learning multiple adaptive timescales (i.e. the quickly and slowly changing components) [13, 14] should also be considered in caption generation, because the sentence is a sequence signal which consists of both fast-moving and slow-moving components [13]. In the natural language processing field, gated feedback RNN (GF-RNN) has attracted the attention of many researchers, because GF-RNN can not only solve the long-term dependency problem in “vanilla” RNN, but also learn multiple adaptive timescales.
Motivated by the aforementioned reasons, we propose a novel 3G model in this paper. More specially, 1) both the global and local image features are input into the multi-modal embedding part for making full use of image information; 2) the gated RNN and gated feedback connecting strategy are used to improve the performance of the language model. This model mainly contains 3 gated modules: gate for global image feature, gated RNN and gated feedback connecting for stacked RNN. So we name it 3G for short. When we fuse the global and local image feature, the first gate is used to control when and how much the global image information should be input into the multi-modal embedding part. The gate is motivated by the gate structure of long-short term memory (LSTM) unit. Recently, RNN is used as the most popular language model. However, “vanilla” RNN is hard to capture the long term dependencies. So we choose LSTM, one kind of gated RNN, as the language model. It is the second gate. Moreover, in order to explore the nonlinear relationship between the image and text, the most effective strategy for stacked RNN—gated feedback RNN (GF-RNN) [13] is used as the multi-modal part as well as the sentence generator. It is the third gate. With the 3-gated structure, the image information is fully utilized and the performance of the language model is strengthened.
1.2 Contributions
Our main contributions are listed as follows:
An end-to-end 3G model is proposed to accomplish the image caption generation task. The proposed model contains 3-gated structure, and it can be fully trained with the stochastic gradient descent (SGD) method. 2. 2.
The global and local image features are used in this paper, which makes full use of image information to improve the caption quality. 3. 3.
The gated feedback connecting strategy is used for stacking the LSTM, which solves the issues of long-term dependency and learning multiple adaptive timescales. In other words, the gated RNN and gated feedback connecting strategy make the multi-modal embedding and language parts much stronger than the previous methods.
A shorter version of this paper appears in [15]. The main extensions in the current work are:
In terms of innovation, we have added a new technological novelty in the caption generating part: gated feedback LSTM is first used to generate the description for image and the gated feedback connecting strategy can well explore the nonlinear relationship between text and image. 2. 2.
Since the language part in this paper is GF-LSTM, the formulas of the GF-LSTM is introduced in detail in Section 3 and the language generating process modeled by the GF-LSTM is detail stated in Section 4. 3. 3.
More experiments and more experimental details has been added in Section 5.
1.3 Organization
The rest of this paper is organized as follows. In Section 2, some previous works are briefly introduced. Then the gated feedback LSTM (GF-LSTM) model is introduced in Section 3. Section 4 presents our model for image caption generation. To validate the proposed method, the experimental results are shown in Section 5. At last, Section 6 makes a brief conclusion for this paper.
2 Related Work
The problem of describing images with natural language sentences has recently attracted increasing interests and many methods have been proposed. These methods can be roughly divided into two categories: Retrieval-based Methods [4, 5, 6] and MMNN-based methods [7, 8].
Retrieval-based methods retrieve similar captioned images and generate new descriptions by retrieving a similar sentence from the training dataset [4]. However, the style of the describing sentences generated by these kind methods is lack of variety.
With the wide use of convolutional neural networks (CNNs) and recurrent neural networks (RNNs) in computer vision and natural language processing [16, 17, 18, 19, 20, 21, 22, 23, 24, 25], MMNN-based Methods have become the most popular mechanism for image caption generation [11, 26, 3, 27]. As illustrated in Fig. 1, the most common model contains three important parts: a vision part, a language module part and a multi-modal part.
MMNN-based methods can generate length-variable sentences and solve the drawbacks of retrieval-based methods. For instance, Mao et al. [11] proposed a model called m-RNN to predict the next word conditioned on both previous words and the global image feature generated by CNN at each time-step. Kiros et al. [28] proposed a similar joint multi-modal embedding model by using a powerful CNN and a LSTM that encodes text. Vinyals et al. [3, 7] combined CNN with LSTM to create an end-to-end network that can generate natural language sentences for images. Similarly, Karpathy et al. [12, 8] also proposed a multi-modal RNN model, and unlike [11], they use the global image feature generated by CNN only at the first time-step. Therefore, one problem is coming: when and how much the global image information should be input into the RNN. These models do not reach a consensus and cannot solve this problem. To address this problem, gating mechanism is used to control the global image feature when and how much be input into the RNN in this paper. The aforementioned models only use the global image feature output by CNN as the whole image information. However, they cannot provide fine-grained modeling of the inter-dependencies between different visual elements and the relationship between the image and text [9]. That is the second problem
To address the second problem, attention-based methods has been proposed [9, 29, 30, 31]. Xu et al. [29] exploited attention mechanism for image caption generation. It used the feature map output from the convolutional layer of the CNN as image information. By flattening the feature map into a fixed number vectors, every image was broken into tiles with fixed size. Each vector denotes one tile feature. When predicting the next word, the previous generated word will select the tiles. [30] generates natural language sentence with attention transitioning on the lexical representation. Moreover, attention mechanism is widely used in other computer vision and natural language processing tasks [32, 33, 34, 35].
In this paper, we retain the attention part as the local image feature. To improve the performance of the language part, gated feedback connecting strategy is used for stacking the LSTM.
3 Gated Feedback LSTM
In this paper, 2-layer GF-LSTM unit is used as sentence generator, so we introduce the GF-LSTM at first.
In previous works, sentence generation models based on RNNs have shown powerful capabilities to generate target sentences. In order to further enhance representing capabilities of RNN, a conventional way is stacking multiple recurrent layers [13]. However, as shown in Fig. 2.(a), signals in standard stacked RNN only flow from lower layers to upper recurrent layers. Fig. 2.(b) shows gated feedback stacking for RNN. Signals not only can flow from previous lower layers to current upper layers, but also can flow from previous upper layers to current lower layers. [13] has confirmed that GF-RNN shows the best performance on natural language processing among the standard stacking RNN with the same layers and single layer gated RNN (e.g. LSTM or GRU).
We take Fig. 2.(b) as an example and choose LSTM as RNN model, according to [13], the global gates which control previous hidden states to current hidden states are defined as follows:
[TABLE]
where superscript denotes the level of layers, superscript denotes state transiting from layer to layer . stands for weight vector for the current input and represents weight vector for the previous hidden states. {\bf{h}}_{t-1}^{(1,2)}={\left[{\begin{array}[]{*{20}{c}}{{{\left({{\bf{h}}_{t-1}^{(1)}}\right)}^{T}}}&{{{\left({{\bf{h}}_{t-1}^{(2)}}\right)}^{T}}}\end{array}}\right]^{T}}\in\mathbb{R}^{2h} denotes the previous states. Through Eq. (1) we know that gate is a single scalar and its value depends on the current lower hidden state and the previous hidden states.
After computing the gates, we describe how to use these gates in LSTM. When computing the current input gate, output gate, forget gate, memory and the current hidden state, is not used, so these formulas are the same as raw LSTM formulas. We rewrite the three gate formula of LSTM unit as follows:
[TABLE]
[TABLE]
[TABLE]
where superscript , and denote weights matrixes and stands for the biases. , , , and represent the current and the -th layer’s input gate, forget gate, output gate, the -th hidden state and the previous -th hidden state, respectively. When the superscript , . denotes the sigmoid activation function.
The current memory and the hidden state are computed as follows:
[TABLE]
[TABLE]
where indicates the current memory, denotes the updating memory content. “” denotes element multiplication.
The computing formula of updating memory content is different from standard stacked LSTM. The updating memory content of the gated feedback LSTM at the -th layer is computed as follows:
[TABLE]
where and stand for weights matrixes. Gate is defined in Eq. (1). Through this equation, we can know that controls how much the previous hidden state is used to compute the current updating memory content.
4 Proposed Approach
Overview. Fig. 3 shows the architecture of our 3G model. To make full use of the image information, the global and local image features are input into the multi-modal embedding module. The first gate controls when and how much the global feature is input into the multi-modal embedding module. While the local feature is selected by the attention mechanism. Another two gates are used in the language and the multi-modal embedding module parts. The gated structure is used to improve the performance of the language model. In this section, we interpret our 3G model in detail.
In the image caption generation task, when given an image, the most wanted sentence should be generated with a maximal probability. In many previous works, probability models are widely used. Similarly, our approach also uses probability generation models for this task. In other words, the LSTM module outputs a probability at each time-step. And we maximize the joint probability conditioned on the given image. So the objective function is written as follows:
[TABLE]
and we rewrite it as log likelihood function:
[TABLE]
We compute with chain rule:
[TABLE]
where in these three equations denotes all of the parameters needed to train. denotes the -th image-sentence pairs and is the sentence length. In our model, GF-LSTM is used to model the condition probability (see Section 4.3).
4.1 Image Representation
Almost all of the state-of-the-art methods used deep CNN to encode the image, because deep CNN can learn discriminative and representative features from the data such as the given images. Similar to the previous methods, we use the VGG-19 as the image features extractor. More specially, outputs of FC7 and CONV5-4 layers are used as global and local features of the images, respectively.
4.1.1 Image Global Feature Representation
The VGG-19 is pre-trained on ImageNet and used as the image encoder in our model. The global representation of image I is as follows:
[TABLE]
where denotes the image I, is the output of the FC7 layer. The matrix is an embedding matrix which projects -dimension image feature vectors into the embedding space with -dimension and denotes the bias. is the so-called image global feature representation.
4.1.2 Image Local Feature Representation
When a raw image I is input to VGG-19, the CONV5-4 layer outputs feature map . Then, we flatten this feature map into , where . This processing program can be written as follows:
[TABLE]
where denotes the feature of -th location of image I. In other words, each image I is divided into regions and every represents one region. In the training stage, the proposed method explores the relationship between words and image locations. In other words, when a word is imported, the word will guide which locations should be selected.
4.2 Sentence Representation
In our model, we encode words into one-hot vectors. We denote any sentence as , where denotes the -th word in the sentence. We embed these words into embedding space. The concrete formula is as follows:
[TABLE]
where is the embedding matrix of sentences which projects the word vector into the embedding space. So the projection matrix is a matrix where is the size of the dictionary and is the dimension of the embedding space.
4.3 Gated Feedback LSTM for Sentence Generation
Two-layer gated feedback LSTM is used as the sentence generator in our method. In other words, RNN model in Fig. 3 is two-layer gated feedback LSTM. Differing from Fig. 2.(b), every LSTM unit has three inputs: , and .
4.3.1 LSTM Model
Because the input of model is more complex than the GF-LSTM introduced in Section 3 and GF-LSTM model is core in our model, in this subsection, we introduce our formulas in detail. Fig. 4 shows the diagram of 2-layer GF-LSTM in our 3G model. The function denotes the hyperbolic tangent function (i.e. ). First, according to the structure shown in Fig. 4, three gates are rewritten as follows:
[TABLE]
[TABLE]
[TABLE]
where , , and denote weights matrixes and stands for biases. and are the global and local image features, respectively. Their calculating formulas are introduced in the next two subsections.
Formulas of the current memory and hidden state are the same as Eqs. (2)—(3). The updating memory contents are computed as follows:
[TABLE]
where gate is computed in Eq. (1). , , and are weights matrixes. are biases.
The LSTM module outputs a probability at each time-step. We write it as the following formulas:
[TABLE]
[TABLE]
where and denote passing forward parameters. is an output of LSTM at the -th time-step. is a probability vector, of which each element represents the predicting probability of the corresponding word.
Having built the GF-LSTM model, initializing the system is another important thing to do. The memory and the hidden state are initialized by the following formulas:
[TABLE]
[TABLE]
where and are initial weights. and are initial biases.
4.3.2 Gate for Global Image Feature
occurs several times in Section 4.3. And it is an output of global image feature controlled by gate. In previous works [11, 28, 3, 7, 12, 8], the vast majority of them import the global feature defined in Eq. (6) at the first time-step or at each time-step into the RNN decoder, but Vinyals et al. [3, 7] find that global feature imported at the first time-step is better than that at every time-step. They explain that global feature imported at each time-step may bring more noise to the system. But images in the benchmark image-caption datasets are high quality with little noise. Therefore, this reason may be a little far-fetched. In this paper, we want to design a robust algorithm that can autonomously decide when and how much the global feature should be imported into the decoder. Inspired by the gating mechanism exploited in LSTM, we design a gate before the global feature is imported into the multi-modal embedding part. The gate is defined as follows:
[TABLE]
where is the weight vector, is the bias. So the -th gate is a scaler and its value correlates with the previous time-step 2-layer hidden state .
After calculating the gate, the global image feature at time-step is computed as follows:
[TABLE]
Through Eq. (18), if we set at , is imported into the decoder at each time-step. If we set at and at , is only imported into the decoder at the first time-step. Theoretically speaking, the 3G model proposed in this paper is more general and more robust.
4.3.3 Attention Mechanism for Local Image Feature
The local image feature denotes the local information of image. Here we use the attention mechanism as introduced in [29] for local feature. At each time-step, the attention mechanism uses the previous hidden state to decide the local feature. The attention model is defined as follows:
[TABLE]
[TABLE]
where and are weights. is defined in Eq. (7). is the bias. The annotation vector {{\bf{\alpha}}_{t}}\buildrel\Delta\over{=}{\left[{\begin{array}[]{*{20}{c}}{{\alpha_{t1}}}&\cdots&{{\alpha_{tC}}}\end{array}}\right]^{T}}\in{\mathbb{R}^{C}} is a probability vector whose each dimension value denotes the probability of the corresponding local image feature. In our algorithm, we use the soft attention model. Therefore, is calculated as follows:
[TABLE]
Through Eq. (21), the regions are selected at time-step by the annotation vector .
After designing the model and combining the objective function in Eq. (4), the loss function of our model can be written as follows:
[TABLE]
where is the parameter set which includes parameters of the GF-LSTM, embedding matrixes in Section 4.1 and Section 4.2 and all gate models.
The proposed model is trained with back-propagation through time (BPTT) algorithm [36, 37] to minimize the cost function .
5 Experiments
In this section, we begin by describing the publicly available datasets used for training and testing the model and the evaluating metrics for image caption generation. Then some typical state-of-the-art models are simply introduced. Finally, we show the quantitative results compared with the recent state-of-the-art methods and analyze the experimental results.
5.1 Datasets
In this subsection, three benchmark datasets are introduced. They are Flickr8K [38], Flickr30K [39] and MS COCO [40]. Among them, Flickr8K and Flickr30K have 8,092 and 31,783 images respectively, and each image has 5 reference sentences. The images in these two datasets focus on people and animals performing some actions. The most challenging MS COCO datast has 82,783 images and most of the images have 5 reference sentences, but there are also some images have references in excess of 5.
5.2 Evaluation Metrics
In order to evaluate the proposed method, two objective metrics are used in this paper. They are BLEU [41] and METEOR [42]. These two metrics are originally designed for evaluating the quality of the automatically machine translation. BLEU score represents the precision ratio of the generated sentence compared with the reference sentences. METEOR score reflects the precision and recall ratio of the generated sentence. It is based on the harmonic mean of uniform precision and recall. For BLEU, we use the scores from BLEU-1 to BLEU-4, which denote the precision of N-gram (N equals to 1, 2, 3 and 4). For both two metrics, the higher score they are, the higher quality of the generated sentences they have.
5.3 Comparison Models
In this subsection, some typical state-of-the-art models are briefly introduced. These models are both using CNN + RNN diagram which is the most effective diagram for image caption generation, but they have some differences in detail.
m-RNN [11]. Multi-modal recurrent neural network (m-RNN) contains three parts: a vision part, a language module part and a multi-modal part. The vision part is a pre-trained deep CNN to extract the feature of the images. The language model encodes each word in the dictionary and stores the semantic temporal context. The multi-modal part connects the image representation and word embedding together by a one-layer representation. This model imports the image representation into the multi-modal module at each time-step. The structure of LRCN [26] is similar to this model except the language model: LRCN uses LSTM as the language model while m-RNN uses the “vanilla” RNN.
- 2.
Google-NIC [3, 7]. Unlike m-RNN, Google-NIC just projects the image feature into the embedding space and imports it into the RNN at the first time-step. Therefore, the RNN here is not only the language model, but also the multi-modal model. DeVS [12, 8] is very similar to this model, but they also have a little difference, where LSTM is used as sentence generator in Google-NIC but “vanilla” RNN is used in DeVS.
- 3.
NIC-VA [29]. This model has several variations in different tasks such as image caption generation, machine translation, video clip description and speech recognition and has achieved great success in these tasks. In image caption generation task, the attention model uses the output of the CNN convolutional layer as the image representation. Through flatten operation, every vector stands for one local image feature. These features would be selected by the attention mechanism and input into RNN at each time-step. This model properly draws on the human attention mechanism, so it gets a great success.
5.4 Experiment Setup
5.4.1 Dataset Processing
Before the experiment, we have preprocessed the datasets as [12] did. At first, we convert all letters of sentences to lowercase and remove non-alphanumeric characters. Then we get rid of words that occur less than five times on the training set. Because some images in MS COCO have more than 5 corresponding sentences, we discard these data to grantee every image has the same number of describing sentences. Since the ground-truth captions of the MS COCO test set are blind to the public, we use the publicly released splits222https://cs.standford.edu/people/karpathy/deepimagesent which is used in DeVS within 5,000 testing images.
5.4.2 Image Feature
In the proposed model, deep features generated from the CONV5-4 and FC7 layers of VGG-19 are used to represent the images. In our experiments, the global image feature is generated from the FC7 layer. Therefore, the global feature is a 4096-dimension vector (i.e. in Section 4.1.1 equals to 4096). The local image feature output from the CONV5-4 layer. Through flattening, the local feature set of one image has 196 vectors with a dimension of 512 (i.e. , in Section 4.1.2).
5.4.3 Word Encoding
In our model, we encode words into one-hot vectors. For example, the benchmark dataset has different words, every word is encoded into a -dimension vector, in which only one value equals to 1 and others equal to 0. So the location of 1 in the vector denotes the corresponding word in the dictionary. It implies that in Section 4.2 equals to .
5.4.4 Training Option
The proposed model is trained with stochastic gradient descent (SGD) using adaptive learning rate algorithms. Similar to [29], the RMSProp algorithm is used for the Flickr8K dataset and for Flickr30K/MS COCO.
5.5 Results Evaluation and Analysis
Table 1 gives a summary performance of different models on the three benchmark datasets. Capital letters M in Table 1 stands for the METEOR score. Setting on MS COCO has some minor differences among the compared models, because the test set of MS COCO has no given reference sentences. There is no standard split. For example, DeVS [12, 8], LRCN [26] and NIC-VA [29] isolate 5,000 images from the validation set as testing set, m-RNN chooses 4,000 validation images and 1,000 testing data from the validation set, Google-NIC [3, 7] selects 4,000 images from the validation sets as testing set while LRVR [43] tests its model on the validation set with 1,000 images. In fact, the more testing data, the more challenging for the proposed models are. 5000 testing images are used in our experiment. The experimental results demonstrate that our 3G model is better than other state-of-the-art models. The results of the other compared models excepting NIC-VA are transcribed from their corresponding articles and we reproduce the results of the NIC-VA with the released code333https://github.com/kelvinxu/arctic-captions.
Through the experimental results in Table 1, it can be observed that our 3G model almost gets the highest score on Flickr8K and Flickr30K. On the MS COCO dataset, the (RA+SS)-ENSEMBLE [9] gets a higher score on BLEU-2 to BLEU-4 than ours. But our 3G model shows a better performance on BLEU-1 and METEOR. Moreover, (RA+SS)-ENSEMBLE [9] needs to obtain a scene vector for each image. More specially, it needs to use Latent Dirichlet Allocation (LDA) to obtain a “scene vector” for each image. The model also need to train a multilayer perceptron to predict the scene vector. Therefore, (RA+SS)-ENSEMBLE is more complex than the proposed model in this paper. Table 1 shows that the attention-based methods are more effective than the global image feature based methods. This means the attention mechanism is more effective than other models only using the global image feature. However, the 3G model proposed in this paper shows a better or at least comparable performance, which confirms the effectiveness of the proposed model. The quantitative results in Table 1 proves that the global image feature using gating mechanism and the gated feedback LSTM for multi-modal embedding plays an important role on the image caption generation task. Three main points make our 3G model better than the other state-of-the-art models. First, the proposed 3G model in this paper exploits the visual attention mechanism. Second, the introduction of the global image feature with gating control is a good supplement because the visual attention part mainly focuses on the local of the given image. Third, the 2-layer GF-LSTM makes our language model stronger than other language models in the contrast models.
MS COCO team hosts a test server allowing people to evaluate their models online 444https://competitions.codalab.org/competitions/3221. The evaluation is on the test set, of which the reference sentences are blind to the public. Each image in the test set is labelled with 40 sentences. We evaluate the proposed model on the test server and Table 2 shows the performance of the published state-of-the-art image captioning models on the online COCO test server. The test results are split into two categories: 5-Refs and 40-Refs, which respectively denote the results for 5 reference sentences and 40 reference sentences. In Table 2, the compared methods can be divided into two categories. 1) “CNN-RNN” diagram and 2) Detector+“CNN-RNN” diagram. In the first category, only image feature is used to generate the sentence. However, the second category methods need extra image information attained by the extra detector. Therefore, DevS [8], MSR [44], MLBL [46], NIC-VA [29] and our 3G belong to the first category; while RA [9], ATT [30] and Att [47] belong to the second category. Through analyzing the results in Table 2, we can draw two conclusions. First, the proposed method in this paper shows the best performance among the first kind of methods. In other words, our method shows the best performance when only the image feature is used. Specially, compared with the spatial attention method, NIC-VA, almost all the scores are improved by our method (except the B-1 for 5-Refs and METEOR). Second, the methods under the Detector+“CNN-RNN” diagram are obviously better than the first kind of methods. Because they utilize more image information to generate the describing sentence. For instance, object detector is used before the image feature representation in RA model. The detector needs be pre-trained on the extra object detecting dataset. For ATT and Att, extra image attribute information needs to be input into the sentence generator and the attribute detector is trained on the pre-labeled dataset. Therefore, RA, ATT and Att reasonably outperform the proposed method. Meanwhile, it also implies that our method still has potential for improvement if more image information is used.
In the experiments, we choose the VGG-Net as the image feature extractor. The main reasons are as follows: 1) almost all the state-of-the-art contrast methods compared in the experiments use the VGG-Net as image feature extractor [12, 11, 48, 29]; 2) VGG-Net is considered as one of the most effective feature extractor which can extract the discriminative and expressive feature for image. However, we also add an extra experiment to verify the effectiveness of the different image features and the results are shown in Table 3. Among the models in Table 3, the image features are extracted by the corresponding network in the parentheses. For AlexNet and VGG-Net, the feature maps output by the last convolutional layer are used as the local image features and the feature vector output by the FC-7 layer is used as the global image feature. For GoogleNet, we use the output from the Inception (4c) as the local feature and the AVG-POOL layer’s output as the global image feature. As can be seen in Table 3, the model with AlexNet is less powerful than the model with GoogLeNet or VGG-Net. This is mainly because GoogLeNet and VGG-Net can learn the discriminative and representative features in a hierarchical manner. Model with VGG-Net gets higher scores on B-1, B-4 and METEOR metrics than the model with GoogLeNet.
Fig. 5 shows the generated captions with the spatial attention maps and the value of the global image feature gates. We can see that the first word and the object words have relatively larger values and the non-visual words have relatively smaller values. It confirms that the non-visual words (except the first word) such as “a” and “on” need less visual information (with smaller values of global image feature gates). Conversely, when generating a visual word such as “airplane”, it needs more visual information (with a larger value of global image feature gate).
We also add a crowdsourcing experiment on the MS COCO test set. To complete the human-based evaluation, we randomly sample 1000 images from the MS COCO test set. The corresponding sentences are generated by our trained model. After that, the image-caption pairs are evaluated by 5 persons. The quality of the sentences is divided into three categories: the sentence describes the image 1) correctly, 2) partly correct, or 3) completely incorrect. When the sentence can describe all the content of the corresponding image, and it is also with spelling and grammatical correctness, this sentence should be judged to be correct. When the sentence can partly describe the content of the image, or it has small defects in spelling or grammar, this sentence should be judged partly correct. When the sentence cannot describe the content of the image, or it is unreadable, we consider this sentence is completely incorrect. Every image-caption pair is marked with one of the categories by each person. At last, we compute the percentage of each category. The result is shown in Fig. 6. The figure shows that descriptions completely reflect the contents of the corresponding images. Only sentences are completely irrelevant to the images. Therefore, the human-based evaluation further validates the effectiveness of the proposed 3G model.
Furthermore, we want to know how much the global image feature using gating mechanism and the gated feedback LSTM for multi-modal embedding affect the model. Someone may also think the increase of the performance may be caused by the gated feedback LSTM but not the global image feature with gating control, because the gated feedback RNN is proved effective in language tasks [13]. To evaluate the effectiveness of both the gate for global image feature and the gated feedback LSTM, two groups of experiments have been done on MS COCO.
5.5.1 The effectiveness of image feature fusion with gated mechanism
In order to verify the effect of the introduction of the image global feature with gating control, we use the 1 layer LSTM as the decoder, which we name it GL-NIC in Table 4. Experimental results in Table 4 prove that the fusion of the global image feature and the local image feature is useful for image caption generation. In fact, the contrast models can be regarded as the special situations of GL-NIC : 1) when setting , at every time-step, GL-NIC degenerates as LRCN; 2) when setting for all , GL-NIC degenerates as NIC-VA; 3) when setting for all , at and for other , GL-NIC degenerates as Google-NIC. Therefore, fusing the global and local image features with gated mechanism can be more comprehensive and robust to describe the content of the image.
5.5.2 The effectiveness of the gated feedback LSTM
To test and verify the effect of the gated feedback LSTM on MS COCO, the branch of the global image feature is discarded from the proposed 3G model. Then the 3G model is degenerated as NIC-VA with GF-LSTM sentence generator. So the model is named as NIC-VA (GF-LSTM) in Table 5. We compared NIC-VA (GF-LSTM) model with NIC-VA model. However, the decoder in NIC-VA is 1-layer LSTM, for the sake of fairness, we changed the decoder in NIC-VA into 2-layer stacked LSTM. We mark this model as NIC-VA-2-LSTM. Table 5 shows that the performance of NIC-VA (GF-LSTM) is better than NIC-VA (2-layer LSTM). This is because the GF-LSTM can deal with the issue of learning multiple adaptive timescales. The gated feedback collecting method which is a strategy to increase the depth of the LSTM not only uses the previous equal level hidden state, but also uses the previous higher level hidden state. In fact, J. Chung et al. [13] has proven that the GF-RNN outperforms the traditional stacked RNN, especially as the number of nesting levels grows or the length of target sequences increases.
Fig. 7 shows some examples of image caption generation on the validation set of the MS COCO. The red font sentences are generated by our 3G model, while the black font sentences are given references which are annotated by human beings. According to Fig. 7 (a), our 3G model can accomplish the image caption generation task very well. Specially, our 3G model can not only generate the proper sentences to describe the main contents of the given images, but also give more elaborate descriptions for the given images. For example, the first image of the second column, the reference describes the relationship of the motorcycles and building (“motorcycles parked in front of a building”), while the sentence generated by our 3G model not only describe the relationship between them, but also describe the relationships between the motorcycles (“next to each other”). Another interesting but not intentional discovery is that our 3G model can generate grammatical correcting sentences, which may be ignored by humans. For instance, the third image of the second column, the first letter “p” should be capitalized but the reference gives the lower case. Some little errors like this will not be occur in our 3G model.
Some negative examples are also shown in Fig. 7 (b). Such as the third image in column 4, the generated sentence is “A zebra standing on snow covered ground next to a forest”, but in fact only a few trees which cannot determine whether it is a forest. Despite that our model makes a small mistake on the scene background, our model always tries to describe all the content of one image. In fact, the sentence generated by 3G model describes the main contents of the image (“A zebra standing on snow covered ground”), but the background gets a little mistake (the zebra may not stand “next to a forest”). The descriptions generated for the first and the second images in column 4 also have some mistakes. We think this may be caused by the repeated scene and reference sentences. That is to say, when a plane in an image, the plane often accompanied by a runway. So the model has learned much knowledge like this, when importing an image similar but having some differences with this scene, the model may generate the wrong description. This problem can be well solved by increasing the number and variety of the dataset.
Generally speaking, two main reasons make the proposed model in this paper able to complete the image caption generation task very well. Firstly, the most advanced language model—GF-LSTM—is used in the proposed 3G model. Secondly, gated global image feature and attention-based local image feature are fused for image representation, which is beneficial to seize the accurate, comprehensive and meticulous information of images.
6 Conclusion
In this paper, a 3G model for image caption generation is proposed. The proposed model shows the better performance than other state-of-art model on three benchmark datasets. 3G model mainly has three gating structures: 1) gate for the global image feature, 2) gate for recurrent neural network and 3) gated feedback for multi-layer recurrent neural networks. Through the gated structure, the global image feature can be robustly selected to input into the multi-modal embedding model. We choose the gated recurrent neural network as language model because it solves the long term dependency problem in “vanilla” RNN. Gated feedback collection for multi-layer recurrent neural networks can deal with the problem of learning multiple adaptive timescales, and this makes GF-RNN more proper for language model than the standard stacked RNN. So, for both the image feature information and the language model, the proposed 3G model in this paper reinforces the recent state-of-the-art models for image caption generation.
Acknowledgement
This work was supported in part by the National Natural Science Foundation of China under Grant nos. 61761130079, 61472413, and 61772510, in part by the Key Research Program of Frontier Sci- ences, CAS, under Grant no. QYZDY-SSW-JSC044, in part by the Young Top-Notch Talent Program of Chinese Academy of Sciences under Grant no. QYZDB-SSWJSC015 and in part by the National Key R&D Program of China no. 2017YFB0502900.
References
- [1]
S. Ahmad, L. Cheong, Facilitating and exploring planar homogeneous texture for indoor scene understanding, in: Proceedings of the European Conference on Computer Vision, 2016, pp. 35–51.
- [2]
V. Dhiman, Q. Tran, J. J. Corso, M. Chandraker, A continuous occlusion model for road scene understanding, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4331–4339.
- [3]
O. Vinyals, A. Toshev, S. Bengio, D. Erhan, Show and tell: A neural image caption generator, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 3156–3164.
- [4]
M. Hodosh, P. Young, J. Hockenmaier, Framing image description as a ranking task: Data, models and evaluation metrics, Journal of Artificial Intelligence Research 47 (2013) 853–899.
- [5]
G. Kulkarni, V. Premraj, V. Ordonez, S. Dhar, S. Li, Y. Choi, A. C. Berg, T. L. Berg, Babytalk: Understanding and generating simple image descriptions, IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (12) (2013) 2891–2903.
- [6]
R. Socher, A. Karpathy, Q. V. Le, C. D. Manning, A. Y. Ng, Grounded compositional semantics for finding and describing images with sentences, Transactions of the Association for Computational Linguistics 2 (2014) 207–218.
- [7]
O. Vinyals, A. Toshev, S. Bengio, D. Erhan, Show and tell: Lessons learned from the 2015 MSCOCO image captioning challenge, IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (4) (2017) 652–663.
- [8]
A. Karpathy, L. Fei-Fei, Deep visual-semantic alignments for generating image descriptions, IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (4) (2017) 664–676.
- [9]
K. Fu, J. Jin, R. Cui, F. Sha, C. Zhang, Aligning where to see and what to tell: Image captioning with region-based attention and scene-specific contexts, IEEE Trans. Pattern Anal. Mach. Intell. 39 (12) (2017) 2321–2334.
- [10]
J. Donahue, L. A. Hendricks, M. Rohrbach, S. Venugopalan, S. Guadarrama, K. Saenko, T. Darrell, Long-term recurrent convolutional networks for visual recognition and description, IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (4) (2017) 677–691.
- [11]
J. Mao, W. Xu, Y. Yang, J. Wang, Z. Huang, A. Yuille, Deep captioning with multimodal recurrent neural networks (m-rnn), in: Proceedings of the International Conference on Learning Representations, 2015.
- [12]
A. Karpathy, F. Li, Deep visual-semantic alignments for generating image descriptions, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 3128–3137.
- [13]
J. Chung, Ç. Gülçehre, K. Cho, Y. Bengio, Gated feedback recurrent neural networks, in: Proceedings of the International Conference on Machine Learning, 2015, pp. 2067–2075.
- [14]
J. Chung, S. Ahn, Y. Bengio, Hierarchical multiscale recurrent neural networks, CoRR abs/1609.01704.
- [15]
A. Yuan, X. Li, X. Lu, FFGS: feature fusion with gating structure for image caption generation, in: Proceeding of the Chinese Conference on Computer Vision, 2017, pp. 638–649.
- [16]
J. T. Chien, Y. C. Ku, Bayesian recurrent neural network for language modeling, IEEE Transactions on Neural Networks and Learning Systems 27 (2) (2016) 361–374.
- [17]
C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, A. Rabinovich, Going deeper with convolutions, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 1–9.
- [18]
K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, in: Proceedings of the International Conference on Learning Representations, 2015.
- [19]
A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, in: Proceedings of the Advances in Neural Information Processing Systems, 2012, pp. 1097–1105.
- [20]
K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [21]
C. Dong, C. C. Loy, K. He, X. Tang, Image super-resolution using deep convolutional networks, IEEE Transactions on Pattern Analysis and Machine Intelligence 38 (2) (2016) 295–307.
- [22]
F. Liu, C. Shen, G. Lin, I. D. Reid, Learning depth from single monocular images using deep convolutional neural fields, IEEE Transactions on Pattern Analysis and Machine Intelligence 38 (10) (2016) 2024–2039.
- [23]
Z. C. Lipton, A critical review of recurrent neural networks for sequence learning, CoRR abs/1506.00019.
- [24]
J. Chung, C. Gulcehre, K. Cho, Y. Bengio, Empirical evaluation of gated recurrent neural networks on sequence modeling, arXiv preprint arXiv:1412.3555.
- [25]
K. Cho, B. Van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, Y. Bengio, Learning phrase representations using rnn encoder-decoder for statistical machine translation, arXiv preprint arXiv:1406.1078.
- [26]
J. Donahue, L. Anne Hendricks, S. Guadarrama, M. Rohrbach, S. Venugopalan, K. Saenko, T. Darrell, Long-term recurrent convolutional networks for visual recognition and description, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 2625–2634.
- [27]
B. Qu, X. Li, D. Tao, X. Lu, Deep semantic understanding of high resolution remote sensing image, in: Proceedings of the International Conference on Computer, Information and Telecommunication Systems, 2016, pp. 1–5.
- [28]
R. Kiros, R. Salakhutdinov, R. S. Zemel, Unifying visual-semantic embeddings with multimodal neural language models, CoRR abs/1411.2539.
- [29]
K. Xu, J. Ba, R. Kiros, K. Cho, A. C. Courville, R. Salakhutdinov, R. S. Zemel, Y. Bengio, Show, attend and tell: Neural image caption generation with visual attention, in: Proceedings of the International Conference on Machine Learning, 2015, pp. 2048–2057.
- [30]
Q. You, H. Jin, Z. Wang, C. Fang, J. Luo, Image captioning with semantic attention, in: Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4651–4659.
- [31]
Z. Yang, Y. Yuan, Y. Wu, W. W. Cohen, R. Salakhutdinov, Review networks for caption generation, in: Proceeding of the Advances in Neural Information Processing Systems (NIPS), 2016, pp. 2361–2369.
- [32]
V. Mnih, N. Heess, A. Graves, K. Kavukcuoglu, Recurrent models of visual attention, in: Proceedings of the Advances in Neural Information Processing Systems, 2014, pp. 2204–2212.
- [33]
J. Ba, V. Mnih, K. Kavukcuoglu, Multiple object recognition with visual attention, CoRR abs/1412.7755.
- [34]
L. Bazzani, H. Larochelle, L. Torresani, Recurrent mixture density network for spatiotemporal visual attention, CoRR abs/1603.08199.
- [35]
D. Bahdanau, K. Cho, Y. Bengio, Neural machine translation by jointly learning to align and translate, CoRR abs/1409.0473.
- [36]
M. Fairbank, E. Alonso, D. Prokhorov, An equivalence between adaptive dynamic programming with a critic and backpropagation through time, IEEE Transactions on Neural Networks and Learning Systems 24 (12) (2013) 2088–2100.
- [37]
P. J. Werbos, Backpropagation through time: what it does and how to do it, Proceedings of the IEEE 78 (10) (1990) 1550–1560.
- [38]
C. Rashtchian, P. Young, M. Hodosh, J. Hockenmaier, Collecting image annotations using amazon’s mechanical turk, in: Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, 2010, pp. 139–147.
- [39]
P. Young, A. Lai, M. Hodosh, J. Hockenmaier, From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions, Transactions of the Association for Computational Linguistics 2 (2014) 67–78.
- [40]
T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, C. L. Zitnick, Microsoft coco: Common objects in context, in: Proceedings of the European Conference on Computer Vision, 2014, pp. 740–755.
- [41]
K. Papineni, S. Roukos, T. Ward, W.-J. Zhu, Bleu: a method for automatic evaluation of machine translation, in: Proceedings of the annual meeting on Association for Computational Linguistics, Association for Computational Linguistics, 2002, pp. 311–318.
- [42]
S. Banerjee, A. Lavie, Meteor: An automatic metric for mt evaluation with improved correlation with human judgments, in: Proceedings of the acl workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Vol. 29, 2005, pp. 65–72.
- [43]
X. Chen, C. Lawrence Zitnick, Mind’s eye: A recurrent visual representation for image caption generation, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 2422–2431.
- [44]
H. Fang, S. Gupta, F. N. Iandola, R. K. Srivastava, L. Deng, P. Dollár, J. Gao, X. He, M. Mitchell, J. C. Platt, C. L. Zitnick, G. Zweig, From captions to visual concepts and back, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 1473–1482.
- [45]
J. Devlin, S. Gupta, R. B. Girshick, M. Mitchell, C. L. Zitnick, Exploring nearest neighbor approaches for image captioning, CoRR abs/1505.04467.
- [46]
R. Kiros, R. Salakhutdinov, R. S. Zemel, Multimodal neural language models, in: Proceedings of the International Conference on Machine Learning, 2014, pp. 595–603.
- [47]
Q. Wu, C. Shen, P. Wang, A. Dick, A. ven den Hengel, Image captioning and visual question answering based on attributes and external knowledge, IEEE Transactions on Pattern Analysis and Machine Intelligence 40 (6) (2018) 1367–1381.
- [48]
R. Kiros, R. Salakhutdinov, R. S. Zemel, Unifying visual-semantic embeddings with multimodal neural language models, Transactions of the Association for Computational Linguistics (2015) 1–13.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] S. Ahmad, L. Cheong, Facilitating and exploring planar homogeneous texture for indoor scene understanding, in: Proceedings of the European Conference on Computer Vision, 2016, pp. 35–51.
- 2[2] V. Dhiman, Q. Tran, J. J. Corso, M. Chandraker, A continuous occlusion model for road scene understanding, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 4331–4339.
- 3[3] O. Vinyals, A. Toshev, S. Bengio, D. Erhan, Show and tell: A neural image caption generator, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 3156–3164.
- 4[4] M. Hodosh, P. Young, J. Hockenmaier, Framing image description as a ranking task: Data, models and evaluation metrics, Journal of Artificial Intelligence Research 47 (2013) 853–899.
- 5[5] G. Kulkarni, V. Premraj, V. Ordonez, S. Dhar, S. Li, Y. Choi, A. C. Berg, T. L. Berg, Babytalk: Understanding and generating simple image descriptions, IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (12) (2013) 2891–2903.
- 6[6] R. Socher, A. Karpathy, Q. V. Le, C. D. Manning, A. Y. Ng, Grounded compositional semantics for finding and describing images with sentences, Transactions of the Association for Computational Linguistics 2 (2014) 207–218.
- 7[7] O. Vinyals, A. Toshev, S. Bengio, D. Erhan, Show and tell: Lessons learned from the 2015 MSCOCO image captioning challenge, IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (4) (2017) 652–663.
- 8[8] A. Karpathy, L. Fei-Fei, Deep visual-semantic alignments for generating image descriptions, IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (4) (2017) 664–676.