Fact Discovery from Knowledge Base via Facet Decomposition
Zihao Fu, Yankai Lin, Zhiyuan Liu, Wai Lam

TL;DR
This paper introduces a new task called fact discovery from knowledge bases, focusing on discovering facts related to a known head entity, and proposes a facet decomposition framework with auto-encoder and feedback components, showing promising results.
Contribution
It presents a novel fact discovery task and a facet decomposition framework with auto-encoder and feedback mechanisms, addressing limitations of existing KB completion methods.
Findings
Framework achieves promising results on benchmark datasets.
Effective in discovering different kinds of facts.
Extensive analysis demonstrates framework's versatility.
Abstract
During the past few decades, knowledge bases (KBs) have experienced rapid growth. Nevertheless, most KBs still suffer from serious incompletion. Researchers proposed many tasks such as knowledge base completion and relation prediction to help build the representation of KBs. However, there are some issues unsettled towards enriching the KBs. Knowledge base completion and relation prediction assume that we know two elements of the fact triples and we are going to predict the missing one. This assumption is too restricted in practice and prevents it from discovering new facts directly. To address this issue, we propose a new task, namely, fact discovery from knowledge base. This task only requires that we know the head entity and the goal is to discover facts associated with the head entity. To tackle this new problem, we propose a novel framework that decomposes the discovery problem…
Click any figure to enlarge with its caption.
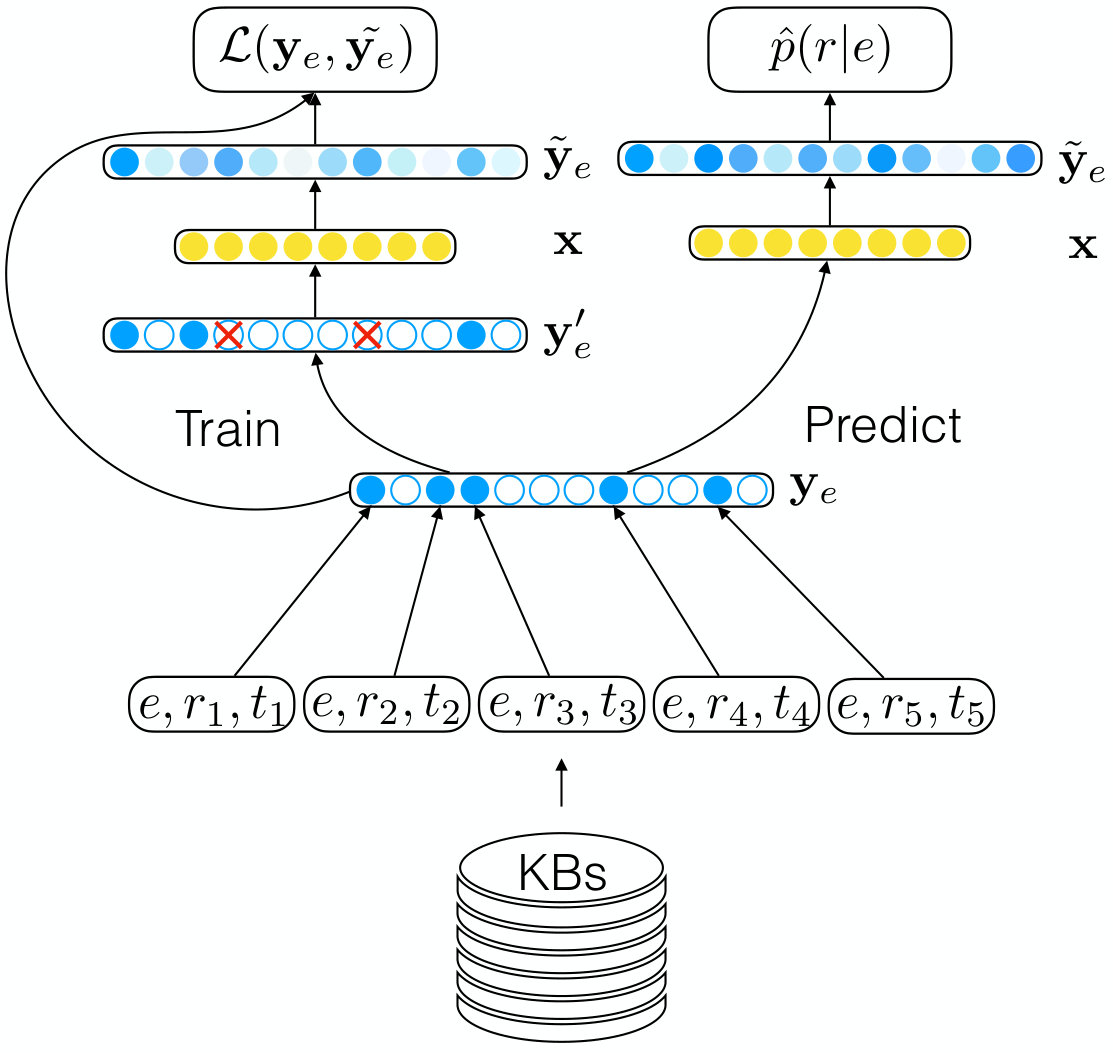 Figure 1
Figure 1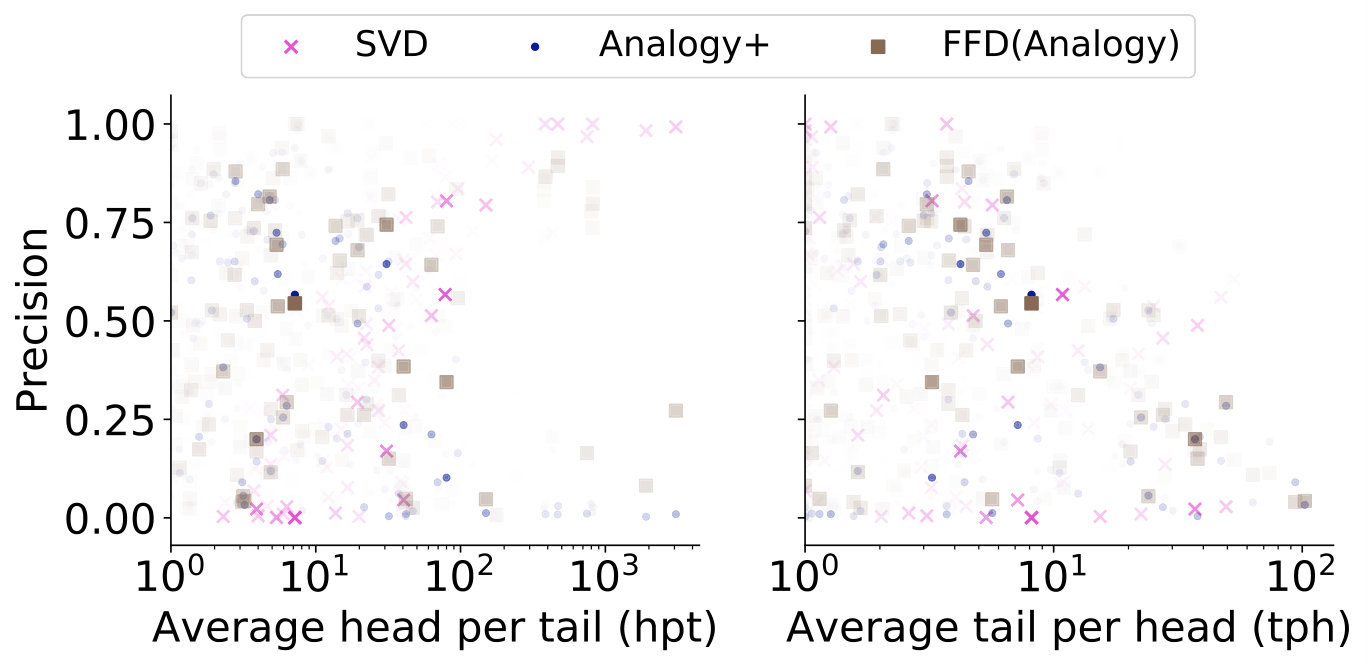 Figure 2
Figure 2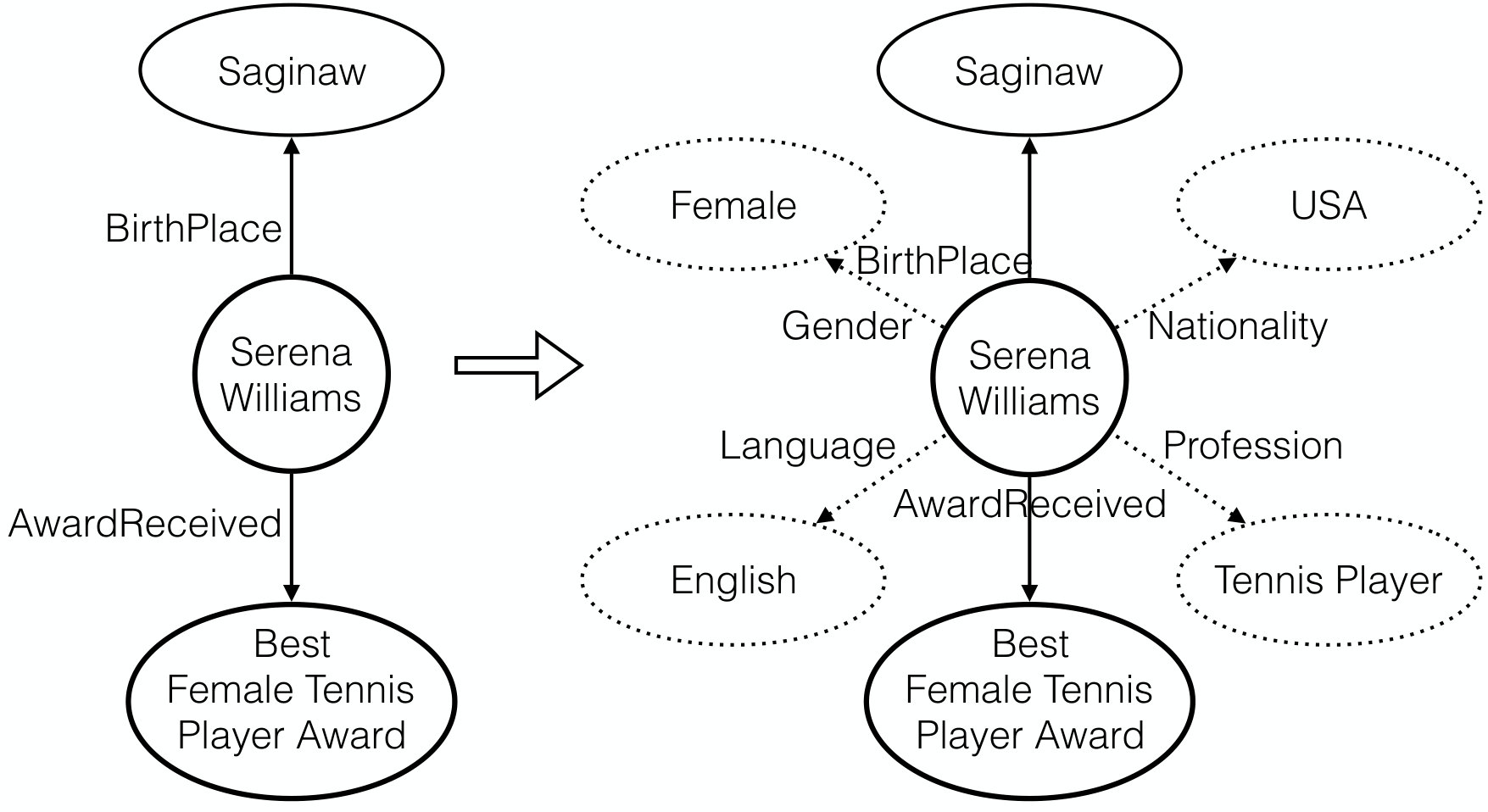 Figure 3
Figure 3| Method | MAP | precision | recall | F1 |
|---|---|---|---|---|
| SVD | 0.0873 | 0.0897 | 0.2143 | 0.1265 |
| NMF | 0.0827 | 0.0857 | 0.2048 | 0.1209 |
| DistMult+ | 0.1086 | 0.1068 | 0.2552 | 0.1506 |
| Complex+ | 0.2384 | 0.1608 | 0.3842 | 0.2267 |
| Analogy+ | 0.2367 | 0.1606 | 0.3837 | 0.2265 |
| FFD (DistMult) | 0.2486 | 0.1939 | 0.4633 | 0.2734 |
| FFD (Complex) | 0.2723 | 0.1991 | 0.4758 | 0.2808 |
| FFD (Analogy) | 0.2769 | 0.2001 | 0.4779 | 0.2821 |
| FFD (Analogy) w/o FL | 0.2308 | 0.1978 | 0.4725 | 0.2788 |
| Relation Ratio | train | test | valid |
|---|---|---|---|
| 10% | 451,214 | 41,861 | 41,013 |
| 20% | 462,395 | ||
| 30% | 475,841 | ||
| 40% | 491,498 | ||
| 50% | 509,339 |
| Relation Ratio | MAP | precision | recall | F1 |
|---|---|---|---|---|
| 50% | 0.2101 | 0.1851 | 0.4421 | 0.2609 |
| 40% | 0.2099 | 0.1768 | 0.4224 | 0.2493 |
| 30% | 0.2167 | 0.1686 | 0.4029 | 0.2378 |
| 20% | 0.2236 | 0.1623 | 0.3878 | 0.2289 |
| 10% | 0.2497 | 0.1534 | 0.3664 | 0.2162 |
| Relation | Tail | In RT pair | SVD | Analog+ | FFD (Analogy) |
|---|---|---|---|---|---|
| Located In | USA | ||||
| Located In | California | ||||
| Located In | Stanford | ||||
| Educational Institution | Stanford Law School | ||||
| Graduates Degree | Law Degree | ||||
| Graduates Degree | Juris Doctor | ||||
| Mail Address State | California | ||||
| Mail Address City | Stanford | ||||
| Parent Institution | Stanford University | ||||
| Tuition Measurement | US Dollar | ||||
| Webpage Category | WebPage |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsTopic Modeling · Advanced Graph Neural Networks · Data Quality and Management
Fact Discovery from Knowledge Base via Facet Decomposition
Zihao Fu1, Yankai Lin2, Zhiyuan Liu2, Wai Lam1
1 Department of Systems Engineering and Engineering Management
The Chinese University of Hong Kong, Hong Kong
2 Department of Computer Science and Technology,
State Key Lab on Intelligent Technology and Systems,
National Lab for Information Science and Technology, Tsinghua University, Beijing, China Corresponding author: Zhiyuan Liu ([email protected]).
Abstract
During the past few decades, knowledge bases (KBs) have experienced rapid growth. Nevertheless, most KBs still suffer from serious incompletion. Researchers proposed many tasks such as knowledge base completion and relation prediction to help build the representation of KBs. However, there are some issues unsettled towards enriching the KBs. Knowledge base completion and relation prediction assume that we know two elements of the fact triples and we are going to predict the missing one. This assumption is too restricted in practice and prevents it from discovering new facts directly. To address this issue, we propose a new task, namely, fact discovery from knowledge base. This task only requires that we know the head entity and the goal is to discover facts associated with the head entity. To tackle this new problem, we propose a novel framework that decomposes the discovery problem into several facet discovery components. We also propose a novel auto-encoder based facet component to estimate some facets of the fact. Besides, we propose a feedback learning component to share the information between each facet. We evaluate our framework using a benchmark dataset and the experimental results show that our framework achieves promising results. We also conduct extensive analysis of our framework in discovering different kinds of facts. The source code of this paper can be obtained from https://github.com/thunlp/FFD.
1 Introduction
Recent years have witnessed the emergence and growth of many large-scale knowledge bases (KBs) such as Freebase Bollacker et al. (2008), DBpedia Lehmann et al. (2015), YAGO Suchanek et al. (2007) and Wikidata Vrandečić and Krötzsch (2014) to store facts of the real world. Most KBs typically organize the complex structured information about facts in the form of triples (head entity, relation, tail entity), e.g., (Bill Gates, CEOof, Microsoft Inc.). These KBs have been widely used in many AI and NLP tasks such as text analysis Berant et al. (2013), question answering Bordes et al. (2014a), and information retrieval Hoffmann et al. (2011).
The construction of these KBs is always an ongoing process due to the endless growth of real-world facts. Hence, many tasks such as knowledge base completion (KBC) and relation prediction (RP) are proposed to enrich KBs.
The KBC task usually assumes that one entity and the relation are given, and another entity is missing and required to be predicted. In general, we wish to predict the missing entity in or , where and denote a head and tail entity respectively. Similarly, the RP task predicts the missing relation given the head and tail entities and their evidence sentences, i.e. filling . Nevertheless, the assumption of knowing two parts of the triple is too strong and is usually restricted in practice.
In many cases, we only know the entity of interest, and are required to predict both its attributive relations and the corresponding entities. As shown in Figure 1, the task is to predict the fact triples when given only the head entity, i.e. filling . Since any entity can serve as the head entity for identifying its possible fact triples, this task should be more practical for real-world settings. This task is non-trivial since less information is provided for prediction. We name the task as Fact Discovery from Knowledge Base (FDKB).
Some existing methods such as knowledge base representation (KBR) can be applied to tackle the FDKB task with simple modifications. KBR models typically embed the semantics of both entities and relations into low-dimensional semantic space, i.e., embeddings. For example, TransE Bordes et al. (2013) learns low-dimensional and real-valued embeddings for both entities and relations by regarding the relation of each triple fact as a translation from its head entity to the tail entity. TransE can thus compute the valid score for each triple by measuring how well the relation can play a translation between the head and tail entities. Many methods have been proposed to extend TransE to deal with various characteristics of KBs Ji et al. (2015, 2016); He et al. (2015); Lin et al. (2015a).
To solve the FDKB task using KBR, one feasible way is to exhaustively calculate the scores of all combinations for the given head entity . Afterwards, the highly-scored facts are returned as results. However, this idea has some drawbacks: (1) It takes all relations to calculate ranking scores for each head entity, ignoring the nature of the head entity. The combination of all possible relations and tail entities will lead to huge amount of computations. (2) A large set of candidate triples immerses the correct triples into a lot of noisy triples. Although the probability of invalid facts getting a high score is small, with the large size of the candidate set, the total number of invalid facts with high score is non-negligible.
To address the above issues, we propose a new framework named as fact facet decomposition (FFD). The framework follows human being’s common practice to identify unknown facts: One typically firstly investigates which relation that a head may have, and then predicts the tail entity based on the predicted relation. This procedure actually utilizes information from several perspectives. Similarly, FFD decomposes fact discovery into several facets, i.e., head-relation facet, tail-relation facet, and tail inference facet, and model each facet respectively. The candidate fact is considered to be correct when all of the facets are trustworthy. We propose a novel auto-encoder based entity-relation component to discover the relatedness between entities and relations. Besides, we also propose a feedback learning component to share the information between each facet.
We have conducted extensive experiments using a benchmark dataset to show that our framework achieves promising results. We also conduct an extensive analysis of the framework in discovering different kinds of facts. The contributions of this paper can be summarized as follows: (1) We introduce a new task of fact discovery from knowledge base, which is more practical. (2) We propose a new framework based on the facet decomposition which achieves promising results.
2 Related Work
In recent years, many tasks Wang et al. (2017) have been proposed to help represent and enrich KBs. Tasks such as knowledge base completion (KBC) Bordes et al. (2013); Wang et al. (2014); Ji et al. (2015, 2016); Wang et al. (2017) and relation prediction (RP) Mintz et al. (2009); Lin et al. (2015a); Xie et al. (2016) are widely studied and many models are proposed to improve the performance on these tasks. However, the intention of these tasks is to test the performance of models in representing KBs and thus they cannot be used directly to discover new facts of KBs. Moreover, our FDKB task is not a simple combination of the KBC and RP task since both of these two tasks require to know two of the triples while we assume we only know the head entity.
A common approach to solving these tasks is to build a knowledge base representation (KBR) model with different kinds of representations. Typically, one element of the triples is unknown. Then, all entities are iterated on the unknown element and the scores of all combinations of the triples are calculated and then sorted. Many works focusing on KBR attempt to encode both entities and relations into a low-dimensional semantic space. KBR models can be divided into two major categories, namely translation-based models and semantic matching models Wang et al. (2017).
Translation-based models such as TransE Bordes et al. (2013) achieves promising performance in KBC with good computational efficiency. TransE regards the relation in a triple as a translation between the embedding of head and tail entities. It means that TransE enforces that the head entity vector plus the relation vector approximates the tail entity vector to obtain entity and relation embeddings. However, TransE suffers from problems when dealing with 1-to-N, N-to-1 and N-to-N relations. To address this issue, TransH Wang et al. (2014) enables an entity to have distinct embeddings when involving in different relations. TransR Lin et al. (2015b) models entities in entity space and uses transform matrices to map entities into different relation spaces when involving different relations. Then it performs translations in relation spaces. In addition, many other KBR models have also been proposed to deal with various characteristics of KBs, such as TransD Ji et al. (2015), KG2E He et al. (2015), PTransE Lin et al. (2015a), TranSparse Ji et al. (2016).
Semantic matching models such as RESCAL Nickel et al. (2011), DistMultYang et al. (2014), Complex Trouillon et al. (2016), HolE Nickel et al. (2016) and ANALOGY Liu et al. (2017) model the score of triples by the semantic similarity. RESCAL simply models the score as a bilinear projection of head and tail entities. The bilinear projection is defined with a matrix for each relation. However, the huge amount of parameters makes the model prone to overfitting. To alleviate the issue of huge parameter space, DistMult is proposed to restrict the relation matrix to be diagonal. However, DistMult cannot handle the asymmetric relations. To tackle this problem, Complex is proposed assuming that the embeddings of entities and relations lie in the space of complex numbers. This model can handle the asymmetric relations. Later, Analogy is proposed by imposing restrictions on the matrix rather than building the matrix with vector. It achieves the state-of-the-art performance. Besides, Bordes et al. (2011); Socher et al. (2013); Chen et al. (2013); Bordes et al. (2014b); Dong et al. (2014); Liu et al. (2016) conduct the semantic matching with neural networks. An energy function is used to jointly embed relations and entities.
3 Problem Formulation
We denote as the set of all entities in KBs, is the set containing all relations. and stand for the size of each set respectively. A fact is a triple in which and . is the set of all true facts.
When a head entity set is given, a new fact set is to be discovered based on these head entities. The discovered fact set is denoted as . Our goal is to find a fact set that maximizes the number of correct discovered facts:
[TABLE]
in which is a user-specified size.
4 Methodology
4.1 Fact Facet Decomposition Framework
Problem (1) is intractable since the set is unknown. We tackle this problem by estimating a fact confidence score function for each fact in and maximizing the total score. The problem is then formulated as:
[TABLE]
To integrate the information from various facets of the fact, our framework, known as Fact Facet Decomposition (FFD) framework, decomposes the fact discovery problem into several facet-oriented detection tasks. A fact is likely to be correct if all facets provide supportive evidence. The facets are as follows:
Head-relation facet: A fact is likely true, if the head entity has a high probability of containing the relation. This is denoted as ; 2. 2.
Tail-relation facet: A fact is likely true, if the tail entity has a high probability of containing the relation. This is denoted as ; 3. 3.
Tail inference facet: A fact is likely true, if the score of the tail entity is high with respect to the given head and relation. This is denoted as .
Therefore, the facet confidence score can be expressed as:
[TABLE]
where are weight parameters. The head-relation facet and the tail-relation facet can be both modeled with an entity-relation facet component. The tail inference facet can be modeled by a KBR component.
4.1.1 Entity-relation Facet Component
The entity-relation component estimates the probability of a relation given an entity. The structure is shown in Figure 2. It is modeled as the logarithm of the estimated conditional probability:
[TABLE]
where or . aims at measuring the probability of a relation that this entity may have. In order to estimate this probability, the existing relations of a head or tail entity is used to infer other related relations. For example, if a head entity has an existing fact in which the relation is “BirthPlace”, we may infer that this head entity may be a person and some relations such as “Gender”, “Language” may have a high probability of association with this head entity. Therefore, the problem is transformed into a problem that estimates the relatedness between relations. To infer the probability of each relation based on existing relations, we employ a denoising auto-encoder Vincent et al. (2008) which can recover almost the same representation for partially destroyed inputs. Firstly, facts related to an entity is extracted from the KBs. Then, this entity is encoded by the existing relations. Let be the 0-1 representation of relations that has. indicates whether the entity has the relation or not. During the training phase, non-zero elements in is randomly set to zero and the auto-encoder is trained to recover the corrupted elements. The corrupted vector is denoted as .
Formally, our structure encoder first maps the corrupted one-hot vector to a hidden representation of the entity through a fully connected layer:
[TABLE]
where is the translation matrix and is the bias vector. is the vector representation of the entities in a hidden semantic space. In this space, similar entities are close to each other while entities of different types are far from each other. If some relations are missing, the fully connected layer will also map the entity into a nearby position.
Afterwards, is used to recover the probability distribution for all relations through a fully connected layer and a sigmoid layer:
[TABLE]
where and is the weight matrix and bias vector of the reverse mapping respectively. is the recovered probability distribution of each relation (therefore, the sum of each element in does not necessarily equal to 1). This layer will map the entity representation in the semantic space into a probability vector over all relations. Since similar entities are located in the adjacent area, they are likely to have a similar relation probability. Therefore, the probability of missing relations will also be high though the relations are unknown.
We use the original one-hot representation of the relations and the recovered relation probability to calculate a loss function:
[TABLE]
The loss function forces the output to be consistent with which makes it capable of discovering all related relations from known relations. It can be optimized with an Adam Kingma and Ba (2015) based optimizer.
When predicting new facts, the one-hot representation is sent into the auto-encoder directly instead of using the corrupted representation. The result is the estimated probability of each relation, i.e.
[TABLE]
This probability will be high if the relation is closely related to the existing relations of the entity .
4.1.2 Tail Inference Facet Component
We use a KBR component to model the tail inference facet . Three KBR models are investigated namely DistMult, Complex, and Analogy.
The DistMult model defines the score function as , in which are vector representation of the head, relation and tail respectively. The learning objective is to maximize the margin between true facts and false facts.
It can decrease the score of the wrong facts and increase the score of the true facts at the same time.
The Complex model employs complex number as the KBR embedding. Therefore, the score function is defined as , in which are complex vectors and stands for the conjugate of .
The Analogy model does not restrict the relation matrix to be diagonal. Therefore, the score function is , in which is the matrix corresponding to the relation . Since many relations satisfy normality and commutativity requirements, the constraints can thus be set as and . Solving such a problem is equivalent to optimizing the same objective function with the matrix constrained to almost-diagonal matricesLiu et al. (2017).
After the score function is calculated, the tail inference facet is modeled by a softmax function:
[TABLE]
It should be noted that the normalization step is only conducted on the tail entities since the head and relation are the input of the model. We only use these three models due to the limited space. Other models can be embedded into our framework easily in the same way.
4.2 Fact Discovery Algorithm
As mentioned above, we need to calculate , and . and are computed by the entity-relation component while is computed by the tail inference component. Recall that a fact is likely to be true when all the facets exhibit strong support. In other words, we can prune away the fact if one of the facets is low and stop calculating other facets. Based on this strategy, we design two additional constraints on Problem (2). Therefore, this method can be viewed as a shrink of the constraint space of the optimization problem. The new problem can be expressed as:
[TABLE]
where is an indicator function. if and otherwise. and are the user-specified parameters indicating top- or top- relations are considered. and are fixed hyperparameters.
Problem (10) is actually a mixed integer linear programming problem. We start to solve this problem from the constraints. Since is independent of the given , it can be preprocessed and can be reused for other queries. When a head entity is given, we firstly calculate and get top- relations ranked by . Then, for each relation, is used to get the top- entities. Afterwards, the tail inference facet will be calculated for all remaining relations and entities and top- triples will be cached. Finally, top- facts ranked by the facet confidence score is returned as the new facts discovered for the entity , where stands for the average fact number for each head entity.
4.3 Feedback Learning
The three facets depict the characteristics of the KBs from different perspectives. For example, the head-relation facet indicates which relation the head entity may have. The tail-relation facet can be interpreted in a similar manner. We propose a feedback learning (FL) component for the facets to share the information in different perspectives with each other. FL feeds the predicted facts back to the training set to enhance the training procedure and iterates the process of predicting and training several times. In each iteration, the information from different perspectives is shared with each facet via the newly added facts.
Specifically, after predicting the top- facts for each head entity, we select top- () most probable facts according to the score of each triple and then feed them into the existing knowledge base for re-training the FFD model. We repeat the above updating operation several rounds.
5 Experiment
5.1 Dataset
We evaluate our framework by re-splitting a widely used dataset FB15k Bordes et al. (2013), which is sampled from Freebase. It contains relations and entities.
In FB15k, some of the testing set’s head entities do not appear in the training set as head entities. To evaluate our framework, we construct the new dataset. We re-split FB15k into training (), validation () and testing () set, and make sure that there is no overlap between the three sets. For all head entities in , a relation ratio is used to assign the facts into training and testing set. relations of a head entity are in the training set while the other are in the testing set. In order to evaluate the task, we require that the head entities in is the same as the testing head entity and is a subset of the training head set, i.e. . We set . After the splitting, the training, testing and validation set size is , and respectively.
5.2 Comparison Models
To demonstrate the effectiveness of our framework, we provide several strong comparison models that can be used for solving this task.
5.2.1 Matrix Factorization Models (SVD and NMF)
MF models firstly count the frequency of all relation-tail pairs. Some low-frequency relation-tail pairs are ignored to save computational time. Afterwards, we build a (head, relation-tail) co-occurrence matrix , in which is the size of the relation-tail pair set. Each element in the matrix represents whether the head entity has the relation-tail pair or not. Then, the matrix will be decomposed by the product of two matrices, i.e.
[TABLE]
in which . is the hidden category number of the head and relation-tail pairs. The decomposition can be achieved in several ways with different assumptions. Two kinds of matrix decomposition models are used namely SVD Halko et al. (2011) and NMF Lee and Seung (1999).
In the prediction stage, a new matrix is constructed by . For each row in , we record top- relation-tail pairs and their scores. The MF models always suffer from the sparsity problem since a lot of relation-tail pairs are ignored.
5.2.2 KBR+ Models (DistMult+, Complex+ and Analogy+)
The most straightforward method of estimating the fact confidence score is to use KBR model directly to evaluate each triples’ score. We exhaustively score all possible combinations of relations and tails and use the highly-scored facts to make up the set . We select some state-of-the-art models including DistMult Yang et al. (2014), Complex Trouillon et al. (2016) and Analogy Liu et al. (2017). We denote them as DistMult+, Complex+ and Analogy+.
After a KBR model learns a score function , the probability of each pair with respect to a given head entity can be estimated by a softmax function:
[TABLE]
Afterwards, the score of each fact is sorted and top- relation-tail pairs for a head entity are regarded as the predicted results.
5.3 Experimental Setup
There are 2,000 head entities in the testing set. Therefore, we predict the corresponding relation and tail entity with respect to these 2,000 head entities. In MF models, only relation-tail pairs that occur more than 3 times in the training set are considered (24,615 pairs in total). For each head entity, we set . In KBR+, we also set . For our framework, we set , , , . The auto-encoder iterates for 1,000 epochs and the learning rate for Adam is 0.005. For the feedback learning component, we set . With this setting, each model returns 100,000 facts.
We use four evaluation metrics, including precision, recall MAP, and F1 in relation prediction. Precision is defined as the ratio of the true positive candidates’ count over the number of all the retrieved candidates’ count. Recall is defined as the ratio of the true positive candidates’ count over all the positive facts’ count in the testing set. MAP Manning et al. (2008) is a common evaluation method in information retrieval tasks. F1 is defined as the harmonic mean of the precision and recall.
5.4 Experimental Results
The experimental result is shown in Table 1. From the experiment result, we observe the followings:
FFD based model outperforms other models in all metrics. It illustrates the advantage of our decomposition design. Moreover, in FFD, using Analogy to predict outperforms Complex. One reason is that the discovery algorithm harnesses the relatively large parameter space of Analogy and avoids some occasionally emerging wrong facts. 2. 2.
The relation of the head entity can be correctly predicted. This is because, in training, we remove some relations and the auto-encoder is trained to learn to recover the missing relations based on the remaining relations. 3. 3.
The MF based models (i.e. SVD and NMF) do not perform as good as KBR+ models and FFD. The reason is partially due to the sparsity problem in MF models. A lot of relation-tail pairs have not been used as the feature and thus cannot be predicted. 4. 4.
Different from the traditional KBC task, Complex performs slightly better than Analogy. One reason is that Analogy’s constraint is looser than Complex. Therefore, it may easily predict wrong facts due to error propagation. 5. 5.
The ablation experiment shows that the feedback learning can improve the performance effectively.
To illustrate the capability of handling different kinds of relations, we plot the accuracy with respect to different kinds of relations. We use heads per tail (hpt) and tails per head (tph) index to represent the difficulty of each relation. If the relation’s index is high, it means that each head of the relation may have more tails or vice versa. These relations are more difficult to predict. This is the similar problem of 1-N, N-1 and N-N relation in KBC task. The plot is shown in Figure 3. From the figure, we can observe the followings:
FFD can be adapted to all kinds of relations with different hpt and tph. 2. 2.
MF, KBR+, FFD models can handle relations with relatively high hpt but fail with high tph. This is because our goal is to predict the relation and the tail based on the head. Therefore, the choice may be harder to make with high tph. 3. 3.
As the hpt grows, the precision of SVD model also grows. The reason is that as hpt grows, the sparsity problem is alleviated. Therefore, the performance of SVD grows.
5.5 Sparsity Investigation
The MF model suffers from the sparsity problem since a lot of relation-tail pairs do not appear in the training set. We examine the training set and observe that 97.46% relation-tail pairs do not appear and 0.34% relation-tail pairs appear for only one time. These pairs can hardly provide any information for the MF models either.
To test whether our framework is capable of dealing with the data sparsity problem. We remove training facts which contains head entities in according to a specific ratio. We decrease the relation ratio ranging from to to explore the effectiveness of our framework in discovering new facts. The dataset statistics is shown in Table 2. We apply FFD (Analogy) on each dataset. As shown in Table 3, precision, F1 and recall decrease since the data becomes more and more sparse. MAP increases slightly since it is averaged on all extracted facts. When the number of extracted facts decreases, some facts ranked at the bottom with low scores are excluded.
5.6 Case Study
We provide a case study to demonstrate the characteristics of different models and show that our FFD can utilize more information. We choose the head entity “Stanford Law School” (Freebase ID: /m/021s9n). The predicted facts of SVD, Analogy+ and FFD (Analogy) are shown in Table 4. From the table, we can observe the followings:
FFD (Analogy) can predict facts such as (“Located In”, “Stanford”) and (“Mail Address City”, “Stanford”) while other methods fail. It implies that this model can predict some relation with multiple possible tails. 2. 2.
Analogy+ outperforms SVD in general while fails to exceed FFD (Analogy). The reason is that it fails to predict some general facts like (“Located In”, “USA”) or (“Tuition Measurement”, “US Dollar”). This may due to the high scores given to some wrong facts. 3. 3.
The SVD model can only predict those facts whose relation and tail belong to the selected relation-tail pairs while Analogy+ and FFD (Analogy) can predict more facts. 4. 4.
SVD model prefers to predict some basic facts such as “Located In” and “Tuition Measurement”. This is because those relations appear a lot of times in the training set and have limited possible tail entities. Therefore, it is easy for SVD model to make such prediction.
6 Conclusions and Future Work
In this paper, we introduce a new task of fact discovery from knowledge base, which is quite important for enriching KBs. It is challenging due to the limited information available about the given entities for prediction. We propose an effective framework for this task. Experimental results on real-world datasets show that our model can effectively predict new relational facts. We also demonstrate that the feedback learning approach is useful for alleviating the issue of data sparsity for the head entities with few facts.
Facts discovery from knowledge base is essential for enriching KBs in the real world. Despite the fact that our work shows some promising results, there still remains some challenges: (1) There exists much more internal information such as relational paths and external information such as text, figures and videos on the web, which can be used to further improve the performance. (2) The feedback learning approach in this paper is to simply utilize those confident predicted relational facts to enhance the model. Reinforcement learning may help us dynamically select those informative and confident relational facts.
Acknowledgments
The work described in this paper is partially supported by grants from the Research Grant Council of the Hong Kong Special Administrative Region, China (Project Codes: 14203414) and the Direct Grant of the Faculty of Engineering, CUHK (Project Code: 4055093). Liu and Lin are supported by the National Key Research and Development Program of China (No. 2018YFB1004503) and the National Natural Science Foundation of China (NSFC No. 61572273, 61661146007).
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Berant et al. (2013) Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. Semantic parsing on freebase from question-answer pairs. In Proceedings of EMNLP , pages 1533–1544.
- 2Bollacker et al. (2008) Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In Proceedings of SIGMOD , pages 1247–1250.
- 3Bordes et al. (2014 a) Antoine Bordes, Sumit Chopra, and Jason Weston. 2014 a. Question answering with subgraph embeddings. In Proceedings of EMNLP , pages 615–620.
- 4Bordes et al. (2014 b) Antoine Bordes, Xavier Glorot, Jason Weston, and Yoshua Bengio. 2014 b. A semantic matching energy function for learning with multi-relational data. Machine Learning , 94(2):233–259.
- 5Bordes et al. (2013) Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In Proceedings of NIPS , pages 2787–2795.
- 6Bordes et al. (2011) Antoine Bordes, Jason Weston, Ronan Collobert, Yoshua Bengio, et al. 2011. Learning structured embeddings of knowledge bases. In Proceedings of AAAI , pages 301–306.
- 7Chen et al. (2013) Danqi Chen, Richard Socher, Christopher D Manning, and Andrew Y Ng. 2013. Learning new facts from knowledge bases with neural tensor networks and semantic word vectors. In Proceedings of ICLR .
- 8Dong et al. (2014) Xin Dong, Evgeniy Gabrilovich, Geremy Heitz, Wilko Horn, Ni Lao, Kevin Murphy, Thomas Strohmann, Shaohua Sun, and Wei Zhang. 2014. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of SIGKDD , pages 601–610.