On Modification of an Adaptive Stochastic Mirror Descent Algorithm for Convex Optimization Problems with Functional Constraints
Mohammad S. Alkousa

TL;DR
This paper introduces a modified adaptive stochastic mirror descent algorithm for constrained convex optimization, improving efficiency by selectively considering constraints and providing convergence analysis and numerical validation.
Contribution
It proposes a new modification to existing algorithms that reduces computational time by not evaluating all constraints at every step, while maintaining optimal convergence rates.
Findings
The modified algorithm achieves the same optimal complexity of O(ε^{-2})
Numerical experiments demonstrate improved efficiency over standard methods
The approach effectively handles multiple convex functional constraints in stochastic settings
Abstract
This paper is devoted to a new modification of a recently proposed adaptive stochastic mirror descent algorithm for constrained convex optimization problems in the case of several convex functional constraints. Algorithms, standard and its proposed modification, are considered for the type of problems with non-smooth Lipschitz-continuous convex objective function and convex functional constraints. Both algorithms, with an accuracy of the approximate solution to the problem, are optimal in the terms of lower bounds of estimates and have the complexity . In both algorithms, the precise first-order information, which connected with (sub)gradient of the objective function and functional constraints, is replaced with its unbiased stochastic estimates. This means that in each iteration, we can still use the value of the objective function and…
Click any figure to enlarge with its caption.
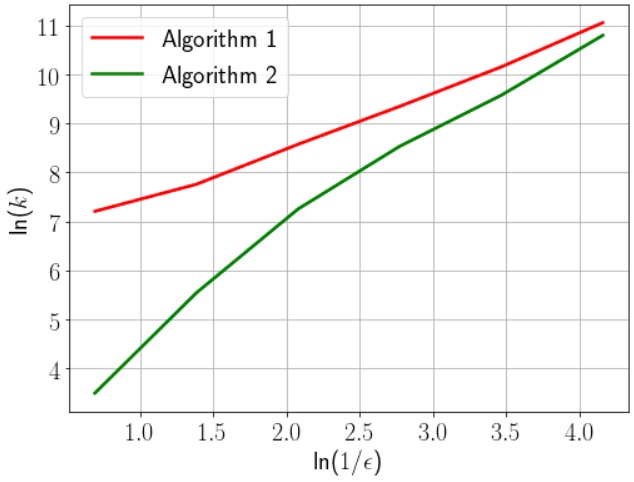 Figure 1
Figure 1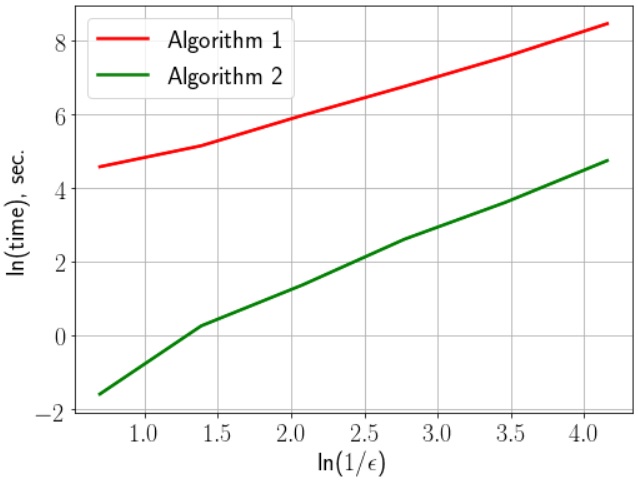 Figure 2
Figure 2| Example 1 | ||||
| Algorithm 1 | Algorithm 2 | |||
| Iterations | Time (sec) | Iterations | Time (sec) | |
| 30 157 | 618.79 | 27 007 | 22.47 | |
| 12 827 | 254.34 | 11 071 | 10.04 | |
| 7 452 | 139.99 | 5 713 | 4.62 | |
| Example 2 | ||||
| Algorithm 1 | Algorithm 2 | |||
| Iterations | Time (sec) | Iterations | Time (sec) | |
| 104 513 | 2008.12 | 90 154 | 82.38 | |
| 18 814 | 358.02 | 17 584 | 15.3 | |
| 5 451 | 115.47 | 4 834 | 5.45 | |
| Example 1 | ||||
| Algorithm 1 | Algorithm 2 | |||
| Iterations | Time (sec) | Iterations | Time (sec) | |
| 6 717 | 9.770 | 5 366 | 0.476 | |
| 5 726 | 7.975 | 5 334 | 0.452 | |
| 8 017 | 11.076 | 5 574 | 0.500 | |
| 6 427 | 8.890 | 5 243 | 0.445 | |
| 6 775 | 9.530 | 5 348 | 0.474 | |
| 7 339 | 10.232 | 6 187 | 0.582 | |
| 6 599 | 9.160 | 5 287 | 0.452 | |
| 6 235 | 8.665 | 5 400 | 0.456 | |
| 6 709 | 9.175 | 6 095 | 0.512 | |
| 6 928 | 9.671 | 5 360 | 0.471 | |
| Example 2 | ||||
| Algorithm 1 | Algorithm 2 | |||
| Iterations | Time (sec) | Iterations | Time (sec) | |
| 6 519 | 10.496 | 5 178 | 0.656 | |
| 6 238 | 9.750 | 4 634 | 0.523 | |
| 5 364 | 8.287 | 4 615 | 0.679 | |
| 5 862 | 9.255 | 5 029 | 0.677 | |
| 6 025 | 9.331 | 4 506 | 0.569 | |
| 5 341 | 10.687 | 4 688 | 0.672 | |
| 6 227 | 12.981 | 4 995 | 0.576 | |
| 5 847 | 9.509 | 4 616 | 0.603 | |
| 5 486 | 8.515 | 4 760 | 0.620 | |
| 6 294 | 10.140 | 4 551 | 0.585 | |
| 6 055 | 11.598 | 4 534 | 0.596 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsOptimization and Variational Analysis
11institutetext: Moscow Institute of Physics and Technology, Moscow, Russia
11email: [email protected]
On Modification of an Adaptive Stochastic Mirror Descent Algorithm for Convex Optimization Problems with Functional Constraints††thanks: This paper accepted to the print as a chapter in the forthcoming book: Communications in Mathematical Computations and Applications, IACMC2019, Springer.
Mohammad S. Alkousa
Abstract
This paper is devoted to a new modification of a recently proposed adaptive stochastic mirror descent algorithm for constrained convex optimization problems in the case of several convex functional constraints. Algorithms, standard and its proposed modification, are considered for the type of problems with non-smooth Lipschitz-continuous convex objective function and convex functional constraints. Both algorithms, with an accuracy of the approximate solution to the problem, are optimal in the terms of lower bounds of estimates and have the complexity . In both algorithms, the precise first-order information, which connected with (sub)gradient of the objective function and functional constraints, is replaced with its unbiased stochastic estimates. This means that in each iteration, we can still use the value of the objective function and functional constraints at the research point, but instead of their (sub)gradient, we calculate their stochastic (sub)gradient. Due to the consideration of not all functional constraints on non-productive steps, the proposed modification allows saving the running time of the algorithm. Estimates for the rate of convergence of the proposed modified algorithm is obtained. The results of numerical experiments demonstrating the advantages and the efficient of the proposed modification for some examples are also given.
Keywords:
Lipschitz-continuous function, non-smooth constrained optimization, adaptive stochastic mirror descent, stochastic (sub)gradient.
1 Introduction
Large scale non-smooth convex optimization is a common problem for a range of computational areas including statistics, computer vision, general inverse problems, machine learning, data science and in many applications arising in applied sciences and engineering. Since what matters most in practice is the overall computational time to solve the problem, first-order methods with computationally low-cost iterations become a viable choice for large scale optimization problems.
Generally, first-order methods have simple structures with a low memory requirement. Thanks to these features, they have received much attention during the last decade. There are a lot of first-order methods for solving the optimization problems in the case of non-smooth objective function. Some examples of these methods, to name but a few, are: subgradient methods [23, 26, 30], subgradient projection methods [23, 26, 30], OSGA [22], bundle-level method [23], Lagrange multipliers method [9] and many others.
There is a long history of studies on continuous optimization with functional constraints. The recent works on first-order methods for convex optimization with convex functional constraints include [5, 14, 16, 32, 33, 34] for deterministic constraints and [1, 2, 15, 35] for stochastic constraints. However, the parallel development for problems with non-convex objective functions and also with non-convex constraints, especially for theoretically provable algorithms, remains limited, see [17] and references therein.
The mirror descent algorithm which originated in [20, 21] and was later analyzed in [7], is considered as the non-Euclidean extension of subgradient methods. The standard subgradient methods employ the Euclidean distance function with a suitable step-size in the projection step. Mirror descent extends the standard projected subgradient methods by employing a nonlinear distance function with an optimal step-size in the nonlinear projection step [18]. Mirror descent method not only generalizes the standard gradient descent method, but also achieves a better convergence rate [12]. In addition, Mirror descent method is applicable to optimization problems in Banach spaces where gradient descent is not [12]. An extension of the mirror descent method for constrained problems was proposed in [6, 20].
Usually, the step-size and stopping rule for mirror descent algorithms require to know the Lipschitz constant of the objective function and constraint, if any. Adaptive step-sizes, which do not require this information, are considered for unconstrained problems in [8], and for constrained problems in [6]. Some optimal mirror descent algorithms, for convex optimization problems with non-smooth convex functional constraint and both adaptive step-sizes and stopping rules, are proposed in [5]. Also, there were considered some modifications of these algorithms for the case of problems with many functional constraints in [31].
If we focus on the problems of minimization of an objective function consisting of a large number of component functionals, such as where are convex, then in each iteration of any iterative minimization procedure computing a single (sub)gradient becomes very expensive. Therefore there is an incentive to calculate the stochastic (sub)gradient where is a random variable taking its values in . This mean that , were is chosen randomly in each iteration from the set , or instead, one can employ randomly chosen a mini-bach approach in which a small subset is chosen randomly, then . This randomly calculating of the (sub)gradient is known as stochastic (sub)gradient.
In the stochastic version of an optimization method, the exact first-order information is replaced with its unbiased stochastic estimates, where the exact first-order information is unavailable. This permits accelerating the solution process, with the earning from randomization growing progressively with problem’s sizes. A different approach to solving stochastic optimization problems is called stochastic approximation (SA), which was initially proposed in a seminal paper by Robbins and Monro in 1951 [28]. An important improvement of this algorithm was developed by Polyak and Juditsky [24, 25]. More recently, Nemirovski et al. [19] presented a modified stochastic approximation method and demonstrated its superior numerical performance for solving a general class of non-smooth convex problems.
This paper is devoted to a new modification of an adaptive stochastic mirror descent algorithm (see Algorithm 4 in [5]. This algorithms is listed as Algorithm 1, below), which is proposed to solve the stochastic setup (randomized version) of the convex minimization problems in the case of several convex functional constraints. This means that we can still use the value of the objective function and functional constraints at the research point, but instead of their (sub)gradient, we use their stochastic (sub)gradient. Namely, that we consider the first-order unbiased oracle that produces stochastic (sub)gradients of the objective function and functional constraints, see for example [13, 29]. We consider the arbitrary proximal structure and the type of problems with non-smooth Lipschitz-continuous objective function. Furthermore, it has been proved a theorem to estimate the rate of convergence of the proposed modification, from this theorem we can see that the modified algorithm achieves the optimal complexity of the order for the class of problems under consideration (see [20]).
The rest of the paper is organized as follows. In Section 2 we give some basic notation, summarize the problem statement and standard mirror descent basics. In Section 3 we display the adaptive stochastic mirror descent algorithm (Algorithm 4 in [5]). Section 4 is devoted to the proposed modified algorithm and proving a theorem about the rate of convergence of this algorithm and its optimal complexity estimate. In the last section, we consider some numerical experiments that allow us to compare the work of standard algorithm and its proposed modification for certain examples.
2 Problem Statement and Standard Mirror Descent Basics
Let be a finite-dimensional vector space, endowed with the norm , and is the conjugate space of with the following norm
[TABLE]
where is the value of the continuous linear functional at .
Let be a closed convex set, and convex subdifferentiable functionals. We assume that and are Lipschitz-continuous, i.e. there exist and , such that
[TABLE]
[TABLE]
It is clear that instead of a set of functionals we can see one functional , such that
[TABLE]
It means that at every point there is a subgradient , and . Recall that for a differentiable functional , the subgradient coincides with the usual gradient.
In this paper, we consider the stochastic setup of the following convex constrained optimization problem
[TABLE]
For the stochastic setup of the problem (3), we introduce the following assumptions (see [4, 5]). Given a point , we can calculate the stochastic (sub)gradients and , where and are random vectors. These stochastic (sub)gradients satisfy
[TABLE]
where denote to the expectation, and
[TABLE]
To motivate these assumptions, let be a standard unit simplex in , we consider the following optimization problem
[TABLE]
where is a given matrix and are given vectors in (See [5])
The exact computation of the gradient takes arithmetic operations, which is expensive, when is very large, for the huge-scale optimization problems. In this setting, it is natural to use the randomization to construct a stochastic approximation for . Let be a random variable its values with probabilities respectively. Let denote the -th column of the matrix . Since ,
[TABLE]
where denote to the probability of an event.
Thus, we can use as a stochastic gradient of (i.e. ), which can be calculated in arithmetic operations.
Let be a distance generating function, which is continuously differentiable and -strongly convex with respect to the norm , i.e.
[TABLE]
and assume that Suppose, we have a constant such that where is a solution to the problem (3).
Note that if there is a set of optimal points for (3) , we may assume that
[TABLE]
For all , we consider the corresponding Bregman divergence, which was initially studied by Bregman [10] and later by many others (see [3]),
[TABLE]
In particular, in the standard proximal setup (i.e. Euclidean setup) we can choose , then . Another setups, for example entropy, , simplex, spectahedron and many others, can be found in [8].
We also assume that the constant is known, such that
[TABLE]
For all and , the proximal mapping operator (mirror descent step) is defined as
[TABLE]
We make the simplicity assumption, which means that is easily computable.
Let be a solution to (3) and is given, we say that a (random) point is an expected -solution to (3) if
[TABLE]
The following well-known lemma describes the main property of the proximal mapping operator (see [5, 8]).
Lemma 1
Let be a convex subdifferentiable function over the convex set and for some , and random vector. Then for each we have
[TABLE]
3 Adaptive Stochastic Mirror Descent Algorithm
In [5] it was considered an adaptive method, for the convex optimization problem (3) in the stochastic setup described above (see Algorithm 1). In this setting, the output of the algorithm is random, in the sense of (7). The adaptivity of this method is in terms of step-size and stopping role, which is mean that we do not need to know the constants and in advance. We assume that, on each iteration of the algorithm, independent realizations of the random variables and are generated. In this section, we show this algorithm and the fundamental result of the estimate about the convergence rate of this algorithm.
As can be seen from the items of the Algorithm 1, the needed point (Ensure) is selected among the points for which . Therefore, we will call step productive if . If the reverse inequality holds then step will be called non-productive.
Let denote the set of indexes of productive and non-productive steps produced by Algorithm 1, respectively. denote the number of productive and non-productive steps, respectively.
For the complexity estimate of Algorithm 1, the next result was obtained in [4, 5].
Theorem 3.1
*Let equalities (4) and inequalities (5) hold. Assume that a known constant is such that inequality (6) holds. Then Algorithm 1 stops after no more than
[TABLE]
iterations and is an expected -solution to problem (3) in the sense of (7).
4 The Modification of an Adaptive Stochastic Mirror Descent Algorithm
In this section, we consider a modification of an Algorithm 1. The idea of this modification was considered in [31] for some adaptive mirror descent algorithms to solve the deterministic setup of the convex optimization problems with Lipschitz-continuous functional constraints. This idea is summarized as: when we have a non-productive step , i.e. , then instead of calculating the subgradient of the functional constraint with max-type , we calculate (sub)gradient of one functional , for which we have . The proposed modification allows saving the running time of algorithm due to consideration of not all functional constraints on non-productive steps.
Denote
[TABLE]
By Lemma 1, with and , we have for all
[TABLE]
the same for all , we have (remember that, with we mean any constraint, such that ),
[TABLE]
Taking summation, in each side of (9) and (10), over productive and non-productive steps, we get
[TABLE]
Using (6), we have
[TABLE]
Whence, by the definition of step-sizes
[TABLE]
where we used the inequality
[TABLE]
which can be proved by induction. Since, for , , we get
[TABLE]
Thus from (12) and the stopping criterion of Algorithm 2, we have
[TABLE]
We can rewrite (13) as follows
[TABLE]
By the convexity of , we get
[TABLE]
where . By the definition of (see the Ensure of Algorithm 2), we get the following inequality
[TABLE]
As long as the inequality (16) is strict, the case of is impossible (i.e. ). Now by taking the expectation in (16) we obtain
[TABLE]
but , (see [4]). Thus
[TABLE]
At the same time, for it holds that . Then, by the definition of and the convexity of we get
[TABLE]
Thus we have come the following result
Theorem 4.1
*Let equalities (4) and inequalities (5) hold. Assume that a known constant is such that inequality (6) holds. Then Algorithm 2 stops after no more than
[TABLE]
iterations and is an expected -solution to problem (3) in the sense of (7).
Remark 1
From the estimate (18) we can see that Algorithm 2 achieves the complexity of the order , which is an optimal, for the studied class of non-smooth functions, from the point of view of the theory of lower bounds of estimates, according to Nemirovski and Yudin (see [20]).
5 Numerical Experiments
In order to compare Algorithms 1 and 2, and to show the advantages of the proposed modified algorithm some numerical tests were carried out. We consider some different examples of the following non-smooth finite-sum problem
[TABLE]
where each summand is a Lipschitz-continuous function. This problem is ubiquitous in many areas and applications, in particular in machine learning applications, is the total loss function whereas each represents the loss due to the -th training sample [11, 27].
In our experiments, we consider the following two examples of the problem (19)
Example 1
[TABLE]
where the coefficients and for each .
Example 2
[TABLE]
where , for each , are positive definite matrices, i.e. .
For the coefficients and constants , in example 1, with different values of . Let be a matrix with entries drawn from different random distributions. Then are rows in the matrix , which is obtained from , by eliminating the last column, and are the entries of the last column in the matrix . The positive definite matrices , in example 2, with different values of , are drawn from different random distributions. In more details, the entries of and , with different values of , are drawn
When , from the Gumbel distribution with the location of the mode equaling and the scale parameter equaling . 2. 2.
When , from the standard exponential distribution with a scale parameter of . 3. 3.
When , from the uniform distribution over .
For the functional constraint , we take and linear functionals, where the coefficients and for are taken as follows: Let be a Toeplitz matrix with the first row and the first column . Then are rows in the matrix , which is obtained from , by eliminating the last column, and are the entries of the last column in the matrix , i.e. the eliminated column.
For more clarification, when and , then the Toeplitz matrix with the first row and the first column has the form
[TABLE]
The proximal structure is given by Euclidean norm and squared Euclidean norm as a prox-function. We choose starting point , , and
For any and in , the following inequality holds
[TABLE]
Therefore, we can choose
Our experiments are motivated by the need to solve the problem (3) when either the dimension is large or when the objective function is of a finite sum structure, as in examples 1 and 2, with , the number of components, being large.
We run Algorithms 1 and 2, in order to both Examples 1 and 2, with . The results of the work of Algorithms 1 and 2 are represented in Table 1, below. These results demonstrate the comparison between the number of iterations and the running time (in seconds) for each algorithm.
All experiments were implemented in Python 3.4, on a computer fitted with Intel(R) Core(TM) i7-8550U CPU @ 1.80GHz, 1992 Mhz, 4 Core(s), 8 Logical Processor(s). RAM of the computer is 8GB.
From Table 1, in order to both examples 1 and 2, we can see that the modified Algorithm 2 always works better than Algorithm 1. It is clearly shown in all experiments according to the number of iterations and especially according to the running time of the algorithms. The running time of Algorithm 2 is very small compared to the running time of Algorithm 1 (on average, it is smaller 25 times). This feature of the Algorithm 2 is very important in all applications of mathematical optimization.
Remark 2
Now, as in the previous, to compare Algorithms 1 and 2, with and different values of , some additional numerical tests were carried out. The coefficients and , for each , are the entries of the Toeplitz matrix, which is described above. The entries of the matrices are drawn from the uniform distribution over . We run Algorithms 1 and 2 with the same previous parameters and the set . The results of Algorithms 1 and 2, in order to the examples 1 and 2 are represented in Table 2, below. These results demonstrate the comparison between the number of iterations and the running time (in seconds) for each algorithm, with different values of .
From Table 2, we can see that Algorithm 2 works better than Algorithm 1 according to the number of iterations and especially according to the running time of algorithms.
5.1 Additional Experiments: Fermat-Torricelli-Steiner problem
In this subsection some additional numerical experiments connected with the analogue of the well-known Fermat-Torricelli-Steiner problem with some non-smooth functional constraints, were carried out.
For a given set of points, in -dimensional Euclidean space , we need to solve the problem (3), where the objective function is given by
[TABLE]
The functional constraint is given by , where the coefficients and are taken as in the previous experiments (the entries of the Toeplitz matrix ).
We take the points in the unit ball . The coordinates of these points are drawn from the uniform distribution over .
We choose the standard Euclidean proximal setup, starting point and . We run Algorithms 1 and 2 with and different values of accuracy .
The results of the work of Algorithms 1 and 2, are presented in Fig. 1(a) (the number of iterations produced by the studied algorithms to reach an -solution of the proposed problem as a function of accuracy) and Fig. 1(b) (the required running time of the studied algorithms, in seconds, as a function of accuracy).
From Fig. 1(a) and Fig. 1(b), we see that both Algorithms 1 and 2 are optimal, where they achieve the complexity of the order , which is optimal estimate for the studied class of non-smooth functions. But Algorithm 2 is more efficiently and works better than Algorithm 1, according to the number of iterations and the running time. We note that the running time of Algorithm 1 is very long compared with the running time of Algorithm 2, where by Algorithm 2 one needs a few seconds, when needs more and more minutes by Algorithm 1, to achieve a solution and to reach its stopping criterion. Therefore the efficiency of Algorithm 2 is represented by its very high execution speed compared with Algorithm 1.
6 Conclusions
In this work, a new modification of an adaptive stochastic mirror descent algorithm was proposed to solve the stochastic setting of the convex minimization problem in the case of Lipschitz-continuous objective function and several convex functional constraints. In each iteration of the proposed modified algorithm, we calculate the stochastic (sub)gradient of the objective function or the functional of constraint, which is prevalent and effective in Machine Learning scenarios, large-scale optimization problems, and their applications. The proposed modification allows saving the running time of algorithm due to the consideration of not all functional constraints on non-productive steps. Furthermore, it has been proved a theorem to estimate the rate of convergence of the proposed modified algorithm. Numerical experiments for a geometrical problem, Fermat-Torricelli-Steiner problem, with convex constraints are presented. The results of carried out numerical experiments illustrate the advantages of the modified Algorithm 2 and illustrate that the running time of this Algorithm is very small compared to the running time of the standard Algorithm 1.
Acknowledgments: The author is very grateful to Alexander V. Gasnikov, Fedor S. Stonyakin and Alexander G. Biryukov for fruitful discussions.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Alkousa M. S.: On Some Stochastic Mirror Descent Methods for Constrained Online Optimization Problems. Computer Research and Modeling, 11 (2), 205–217 (2019).
- 2[2] Basu K., Nandy P.: Optimal Convergence for Stochastic Optimization with Multiple Expectation Constraints. (2019). https://arxiv.org/pdf/1906.03401.pdf
- 3[3] Bauschke H. H., Borwein J. M., Combettes P. L.: Bregman monotone optimization algorithms. SIAM Journal on Controal and Optimization 42 (2), 596–636 (2003).
- 4[4] Bayandina A.: Adaptive Stochastic Mirror Descent for Constrained Optimization. (2017). https://arxiv.org/pdf/1705.02031.pdf
- 5[5] Bayandina A., Dvurechensky P., Gasnikov A., Stonyakin F., Titov A.: Mirror descent and convex optimization problems with non-smooth inequality constraints. In: Large-Scale and Distributed Optimization, 181–213. Springer, Cham (2018).
- 6[6] Beck A., Ben-Tal A., Guttmann-Beck N., Tetruashvili L.: The comirror algorithm for solving nonsmooth constrained convex problems. Operations Research Letters 38 (6), 493–498 (2010).
- 7[7] Beck A., Teboulle M.: Mirror descent and nonlinear projected subgradient methods for convex optimization. Oper. Res. Lett. 31 (3), 167–175 (2003).
- 8[8] Ben-Tal A., Nemirovski A.: Lectures on Modern Convex Optimization. Society for Industrial and Applied Mathematics, Philadelphia (2001).