Optimal Recovery of Precision Matrix for Mahalanobis Distance from High Dimensional Noisy Observations in Manifold Learning
Matan Gavish, Ronen Talmon, Pei-Chun Su, Hau-Tieng Wu

TL;DR
This paper investigates the estimation of Mahalanobis distance and its precision matrix from noisy high-dimensional data, providing theoretical insights, optimal shrinkage methods, and applications to manifold learning and dynamical systems.
Contribution
It introduces an asymptotically optimal shrinker for precision matrix estimation, extending results to manifold settings and analyzing the impact of noise on Mahalanobis distance.
Findings
Identifies the noise threshold where Mahalanobis distance fails
Proposes an optimal shrinker for precision matrix estimation
Demonstrates improved performance over classical methods
Abstract
Motivated by establishing theoretical foundations for various manifold learning algorithms, we study the problem of Mahalanobis distance (MD), and the associated precision matrix, estimation from high-dimensional noisy data. By relying on recent transformative results in covariance matrix estimation, we demonstrate the sensitivity of \MD~and the associated precision matrix to measurement noise, determining the exact asymptotic signal-to-noise ratio at which MD fails, and quantifying its performance otherwise. In addition, for an appropriate loss function, we propose an asymptotically optimal shrinker, which is shown to be beneficial over the classical implementation of the MD, both analytically and in simulations. The result is extended to the manifold setup, where the nonlinear interaction between curvature and high-dimensional noise is taken care of. The developed solution is applied…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2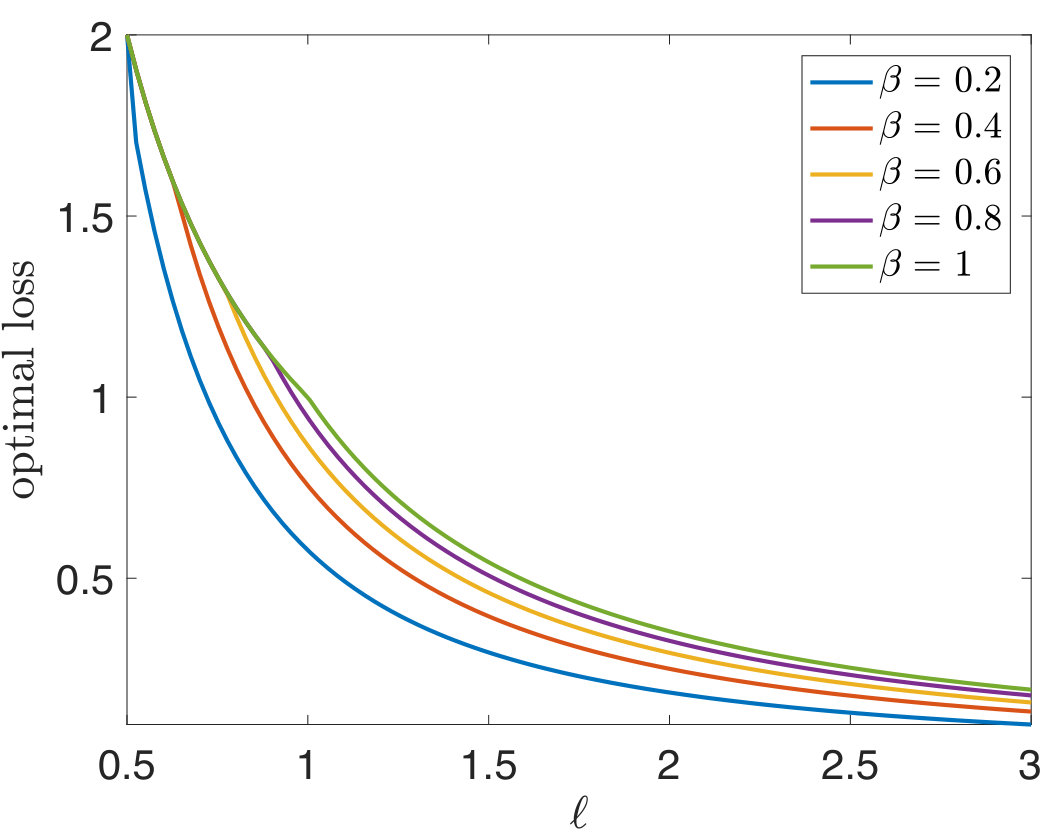 Figure 3
Figure 3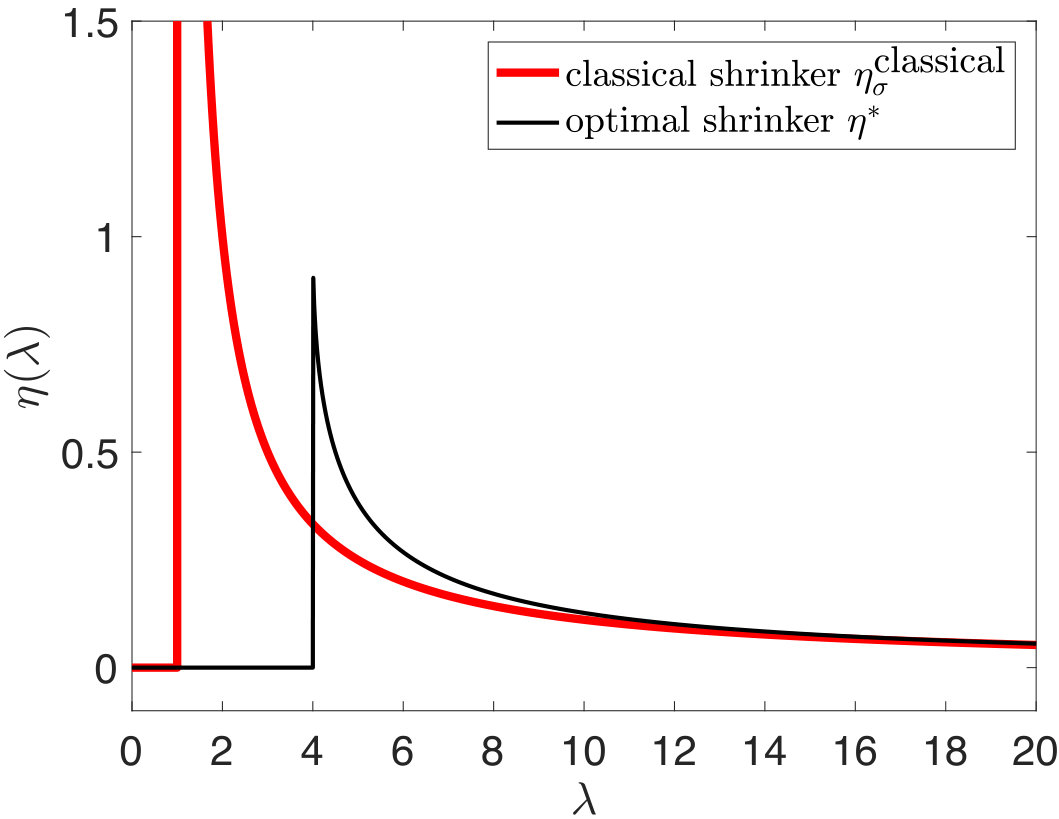 Figure 4
Figure 4| 18.78 1.16 | 0.78 0.54 | 55.98 2.09 | 1.32 0.93 | ||
|---|---|---|---|---|---|
| 23.72 1.19 | 1.41 0.87 | 59.42 2.10 | 2.59 1.74 | ||
| 33.54 1.53 | 2.18 1.31 | 64.04 1.69 | 5.19 2.99 | ||
| 26.86 2.70 | 2.41 1.55 | 60.88 4.22 | 4.06 2.54 | ||
| 42.66 3.43 | 4.78 2.65 | 69.06 3.43 | 10.65 5.38 | ||
| 58.59 3.24 | 9.84 4.63 | 77.24 2.81 | 31.52 17.56 | ||
| 34.70 4.89 | 4.05 2.35 | 64.11 5.57 | 8.39 3.91 | ||
| 54.72 4.46 | 10.62 4.69 | 75.54 3.63 | 23.97 12.49 | ||
| 69.65 3.97 | 21.35 7.94 | 83.30 2.78 | 62.99 19.34 | ||
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsStatistical Mechanics and Entropy · Sparse and Compressive Sensing Techniques · Blind Source Separation Techniques
Optimal Recovery of Precision Matrix for Mahalanobis Distance from High Dimensional Noisy Observations in Manifold Learning
Matan Gavish
The School of Computer Science and Engineering, Hebrew University of Jerusalem
,
Ronen Talmon
The Department of Electrical Engineering, Technion – Israel Institute of Technology
,
Pei-Chun Su
The Department of Mathematics, Duke University
and
Hau-Tieng Wu
The Department of Mathematics and Department of Statistical Science, Duke University
Abstract.
Motivated by establishing theoretical foundations for various manifold learning algorithms, we study the problem of Mahalanobis distance (MD), and the associated precision matrix, estimation from high-dimensional noisy data. By relying on recent transformative results in covariance matrix estimation, we demonstrate the sensitivity of MD and the associated precision matrix to measurement noise, determining the exact asymptotic signal-to-noise ratio at which MD fails, and quantifying its performance otherwise. In addition, for an appropriate loss function, we propose an asymptotically optimal shrinker, which is shown to be beneficial over the classical implementation of the MD, both analytically and in simulations. The result is extended to the manifold setup, where the nonlinear interaction between curvature and high-dimensional noise is taken care of. The developed solution is applied to study a multiscale reduction problem in the dynamical system analysis. Mahalanobis distance, large large , optimal shrinkage, precision matrix
2000 Math Subject Classification: 34K30, 35K57, 35Q80, 92D25
1. INTRODUCTION
High-dimensional datasets encountered in modern science often exhibit nonlinear low-dimensional structures. One prominent approach to deal with such point clouds is to model their nonlinear structures by manifolds. In the last two decades, this direction has led to the emergence of a multitude of manifold learning methods, including the classical ISOMAP [42], locally linear embedding (LLE) [29], Hessian LLE [8], eigenmap [4], and diffusion maps [5], as well as the more recent vector diffusion maps [33], multiview diffusion maps [21], and alternating diffusion maps [18, 41], to name but a few. Typically in manifold learning, point clouds in are assumed to be sampled from a -dimensional smooth manifold embedded in , usually with some additional contaminating noise. In this setting, the manifold represents the “essence” or the “signal” of the data. Consequently, the goal in manifold learning is to recover the geometric or topological structure of the manifold from the data points, and in turn, to use the recovered structure to embed the high-dimensional data in a low-dimension space, facilitating a compact and informative representation of the data. This approach has been successfully applied to applications from a broad range of fields, e.g. dynamical systems modeling [38, 48], sleep stage assessment [45, 22], cryo electro microscope [34], image denoising [31], single channel blind source separation like fetal electrocardiogram analysis [36] and stimulation artifact removal for the intracranial electroencephalogram [1], and long term physiological signal visualization and analysis [20, 43].
Classical manifold learning methods heavily rely on meaningful measures of pairwise discrepancy between data points. In this so-called metric design problem, the data analyst aims to find a useful metric representing the relationship between data points embedded in a high-dimensional space. In this paper, we study the Mahalanobis Distance (MD) – a popular, and arguably the first method for metric design [23, 26]. MD was originally proposed in 1936 with the classical low-dimensional setting in mind, namely, for the case where the ambient dimension is much larger than the dataset size . Interestingly, due to its useful statistical and invariance properties, MD became the basis of several geometric data analysis techniques [49, 44, 47], aimed specifically at the high-dimensional regime .
In a recent line of work [30, 37], a variant of MD was proposed and used to reveal hidden intrinsic manifolds underlying high-dimensional, possibly multimodal, observations. The main purpose of MD in this hidden manifold setup is handling possible deformations caused by the observation or sampling process. Broadly, this is carried out by estimating a quadratic form of the Jacobian of the (unknown) observation function, which is equivalent to estimating the precision matrix locally on the manifold. It was recently shown that MD is also implicitly used in the seminal LLE algorithm [29], when the barycenter step is properly expressed [24].
As the number of dimensions in typical data analysis applications continues to grow, it becomes increasingly crucial to understand the behaviour of MD, as well as other metric design algorithms, in the high-dimensional regime . At first glance, it might seem that this regime poses little more than a computational inconvenience for metric design using MD. Indeed, it is easy to show that in the absence of measurement noise, MD cares little about the increase in the ambient dimension . This paper however calls attention to the following key observation. In the high-dimensional regime , in the presence of ambient measurement noise, a new phenomenon emerges, which introduces various nontrivial effects on the performance of MD. Depending on the noise level, in the high-dimensional regime, MD may be adversarially affected or even fail completely. Clearly, the assumption of measurement noise cannot be realistically excluded, and yet, to the best of our knowledge, this phenomenon has not been previously fully studied. A first step in this direction was taken in [6], with the calculation of the distribution of MD under specific assumptions.
Let us describe this key phenomenon informally at first. The computation of MD involves estimation of the inverse covariance matrix, or precision matrix, corresponding to the data at hand. Classically, the estimation relies on the sample covariance, which is inverted using the Moore-Penrose pseudo-inverse. It is well-known that, in the high dimensional setup, or in the regime , the sample covariance matrix is a poor estimator of the underlying covariance matrix. Indeed, advances in random matrix theory from the last decade imply that the eigenvalues and eigenvectors of the sample covariance matrix are both biased, namely, do not converge to the corresponding eigenvalues and eigenvectors of the underlying population covariance matrix [28, 14]. Such biases in small eigenvalues, which lead to inaccurate covariance matrix estimation, become immense when applying the Moore-Penrose pseudo-inverse.
This challenge in the high dimensional setup is amplified when we have a nonlinear manifold structure. Inverting small (inconsistent) eigenvalues is challenging when evaluating the precision matrix, and this issue becomes more challenging in the context of manifold learning, where the estimation of MD is performed locally [30, 37]. Ideally, under the manifold assumption, in infinitely small neighborhoods and for a sufficiently large number of samples without noise, the rank of the local sample covariance equals the dimension of the manifold, which is typically smaller than the dimension of the ambient space, making the sample covariance low-rank with distinct strictly zero eigenvalues. However, in practice, due to the finite sample set, the considered neighborhoods cannot be sufficiently small. In such cases, depending on the manifold curvature, samples from the manifold depart from the tangent space to the manifold, and the rank of their sample covariance matrix undesirably grow, where the eigenvalues related to curvature are much smaller compared with those related to the tangent space. When noise exists, the situation is further complicated by the interaction between those curvature related small eigenvalues and the relatively few points compared with the ambient space dimension.
In this paper, we study this problem and propose a remedy. By relying on formal existing results in covariance matrix estimation, we measure the sensitivity of MD to measurement noise. Under the assumption that locally the data on the manifold lie on a low-dimensional linear subspace embedded in the ambient space and that the measurement noise is Gaussian white, we are able to determine the exact asymptotic signal-to-noise ratio at which MD fails, and quantify its performance otherwise. Then, we propose a better MD estimator based on the idea of shrinkage of the associated precision matrix. It has been known since the 1970’s [35] that by shrinking the sample covariance eigenvalues one can significantly mitigate the noise effects and improve the covariance estimation in high-dimensions. We formulate the classical MD as a particular choice of shrinkage estimator for the eigenvalues of the sample covariance. Building on recent results in high-dimensional covariance estimation, including the general theory in [7] and a special case with application in random tomography [32, Section 4.4], we find an asymptotically optimal shrinker for the precision matrix estimation, which is better than the classical implementation of the MD, whenever MD is computed from noisy high-dimensional data. We show that under a suitable choice of a loss function for the estimation of MD, our shrinker is the unique asymptotically optimal shrinker; the improvement in asymptotic loss it offers over the classical MD is calculated exactly. We then extend the above established results to handle the challenge of designing a better metric when applying diffusion map. This extension is nontrivial due to the nontrivial interaction of curvature and noise, and the finite sampling size. Finally, we apply diffusion maps with the proposed estimate of MDto separate slow and fast dynamics when the observation is contaminated by high dimensional noise.
While the present paper focuses on MD, we posit that the same phenomenon holds much more broadly and in fact affects several widely-used manifold learning, particular in metric learning algorithms. In this regard, the present paper seeks to highlight the fact that manifold learning and metric learning algorithms will not perform as predicted by the noiseless theory in high dimensions, and may fail completely beyond a certain noise level.
2. PROBLEM SETUP
2.1. Manifold model
When a point cloud has a nontrivial nonlinear structure, or even nontrivial topological structure, a common approach is to model this structure by a manifold. This is known as the so-called manifold assumption. Such manifold assumption holds for various practical data. Examples include cryo-electro microscopy [34], phase spaces of dynamical systems [38, 48], and various biomedical signals [36, 1, 20, 43]. The main feature of this manifold assumption is that the points are distributed on a nonlinear set so that they are nonlinearly related, which generalizes the commonly used linear model.
To model by the manifold model, consider a -dimensional random vector , which is a measurable function with respect to the probability space , where is the probability measure defined on the sigma algebra in the event space . We assume that the range of is supported on a -dimensional compact, smooth Riemannian manifold isometrically embedded in via . In this work, we assume that is boundary-free to simplify the exposition. We shall mention that the commonly considered linear model is a special manifold model, where the manifold is an affine linear subspace space of .
On the manifold, the associated statistical setup is as follows. Let be the Borel sigma algebra of , and let denote the probability measure induced from . Clearly, is defined on . Denote to be the Riemannian volume density of associated with the metric . For simplicity, we assume that is absolutely continuous with respect to the induced Riemannian measure on , denoted by . By the Radon-Nikodym theorem, for any , there exists a non-negative measurable function defined on such that . The probability density function (pdf) of on is defined to be . We further assume that is bounded away from [math] and smooth. When is constant, we call a uniform random sampling scheme; otherwise it is nonuniform. Now we introduce the key quantity of interest in this paper, the local covariance matrix.
Definition 1**.**
Fix . For an open simply connected neighborhood of , , define
[TABLE]
as the local covariance matrix associated with centered at , where
[TABLE]
is the volume of , and is the indicator function of the set .
One main goal of considering this local covariance is capturing those directions with maximal variation of the dataset. From the knowledge of principal component analysis, those directions are the eigenvectors of the local covariance matrix with the largest eigenvalues. We have some remarks. First, by Nash’s isometric embedding theorem, is of rank , where for any . Second, in existing literature, there is another different definition of the local covariance matrix, in which the mean is replaced with . In general, the two definitions are different, even when the set is perfectly symmetric, e.g. is a ball, and is uniform. Indeed, since the range of is supported on , when is not flat, might deviate from the center of due to the curvature of the manifold; that is, . While this seems to be a problem, it was shown in [24] that the difference between the center of and is negligible (expressed as a higher order term in the error) when the diameter of is sufficiently small. Broadly, since locally the manifold can be well approximated by an affine subspace, when the diameter of is sufficiently small, the data located in can be well approximated by the tangent space to the manifold at , i.e., . This point will be further addressed in Section 2.2.
The above derivation leads to the following local statistical model, which enables to further study the local structure of a manifold. For and an open, simply connected neighborhood of , , we define a new random vector
[TABLE]
with mean and covariance matrix . By definition, is a bounded random vector, and hence, all its moments are finite. Also, as has been widely discussed in the literature (see [24] and reference therein), the first dominant eigenvectors of form an accurate estimate of the tangent space to the manifold at . Specifically, if , for , where , then the span of approximates .
Often in applications, the manifold is not directly accessible due to additional noise, and we can only sample
[TABLE]
where . As a consequence, for , in the presence of noise, the corresponding local random vector can be recast as
[TABLE]
with mean and covariance matrix . Although is not a bounded random vector, all its moments are finite.
We remark that the local set can be defined in several plausible ways, depending on the problem at hand. A common choice is the ball with the center at and the radius . In other applications, might be an ellipsoid [30, 37, 24] or a more general setup, depending on the metric of interest. We will revisit to this issue in the sequel.
2.2. Linear spiked model
In manifold learning, local kernels are commonly used, e.g., kernels based on radial basis functions. The use of kernels implies that only points around the center of the kernel contribute to the algorithm outcome. Therefore, considering those points located inside the neighborhood of , , is sufficient for analyzing a manifold learning algorithm with a local kernel. Since the bandwidth of the kernel is typically small, the diameter of the local set is small as well. Consequently, by the definition of a manifold, data in can be well approximated by the tangent space to the manifold at , which is a low dimensional affine subspace. Note that in the special case that the manifold is a linear affine subspace, all points are located by a low dimensional space.
Since locally the manifold can be viewed merely as a linear subspace, the local statistical model described in Section 2.1 can be well approximated by the classical linear spiked model (or spiked covariance model [14]), which is detailed next with slight modifications in the notation. We note that in this section, deviations of the samples from a linear space due to the manifold curvature will not be treated, and their affect will be considered together with the affect of the ambient noise. However, we will extend and test the ability of the proposed estimator to handle such phenomena in the simulation study in Section 6.
We now consider the spike model. In plain English, a spike model is a manifold model when the manifold is an affine subspace, where the dimension of the affine subspace is fixed. Consider a point cloud in supported on a -dimensional linear subspace, where . For simplicity, we assume that the point cloud is sampled independently and identically (i.i.d.) from
[TABLE]
where denotes the mean and denotes the population covariance matrix, whose rank is equal to . Note that we could consider a random vector with mean [math] and a finite fourth moment [7]; since this could only increase the notational burden without providing additional insights, we focus on this simplified model.
It is often convenient to note that a point cloud sampled from can be understood as sampling i.i.d. from a -dim random vector
[TABLE]
where , , , and for . Thus, the -dimensional linear affine subspace is the space spanned by , which could be understood as spikes and hence the nomination of the model, and shifted by . We note that this global linear model is related to the local structure of a manifold in (2) in the following way: here is the center point on the manifold in (2), and the -dimensional linear affine subspace spanned by is the tangent space at , while we need extra components to capture the curvature of the manifold.
Similarly to the manifold model, suppose that the samples of , which we refer to as the signal, are not directly observable. Instead, the observed data consist of samples from the random variable
[TABLE]
where and is a Gaussian measurement noise independent of , which we assume for simplicity to be white.
3. PRECISION MATRIX AND MAHALANOBIS DISTANCE ESTIMATION
The focal point of this paper is the estimation of the MD under the manifold model from a statistical standpoint, which, as described in Section 2, leads to the classical linear spiked model. The estimation of the MD involves the estimation of the local precision matrix. Therefore, we start this section with details on the estimation of the precision matrix in Section 3.1, followed by a detailed description of the estimation of the MD in Section 3.2.
3.1. Precision matrix estimation and its challenge
In Section 2.1 and Section 2.2, we showed that the local and global statistical models are seemingly very similar. Indeed, at first glance, both models consist of a hidden “signal” component ((2) and (5)) and noisy accessible observations ((4) and (7)). Furthermore, under both models, the local and global population covariance matrices of the “signal” component ( and ) are approximately low rank and precisely low rank, respectively.
However, one of the main claims of this work is that although the two models seem equivalent, subtle differences between them, particularly in the context of precision matrix estimation, become fundamental.
Let us consider first the estimation of the precision matrix in the simpler, classical linear spiked model described in (5) and (7). Without noise, the computation of the precision matrix of could be simply implemented using the Moore-Penrose pseudo-inverse. Suppose the eigendecomposition of is given by where and . Then, the pseudo-inverse is given by , namely, inverting the non-zero eigenvalues. The introduction of additive noise poses a significant challenge for such an estimation, since the small eigenvalues could be mixed with the noise. While the contribution of such small eigenvalues is limited in the composition of the covariance matrix, in the composition of the precision matrix their affect becomes significant.
In addition to this classical challenge, the estimation of the precision matrix under the manifold model poses another layer of complexity. To simplify the discussion, we assume that is a simply connected ball, that is , where is a Euclidean ball in of radius centered at with a sufficiently small . In this case, the geometric picture of the local covariance matrix is well captured by [46, Proposition 3.1], which is summarized as follows. Fix . Assume that the manifold is translated and rotated properly, so that and the tangent space in , , is spanned by , where is a unit -dim vector with in the -th entry. We have the following asymptotical expansion of (2) when is sufficiently small:
[TABLE]
where is a -sphere, is the volume of , and the implied constant in depends on the second fundamental form at . From a statistical perspective, this expansion well captures the intuition that the variability of the data located in is restricted to only few directions aligned with . Indeed, by applying the perturbation theory to (8), the eigenvectors of corresponding to the largest eigenvalues provide an approximate basis for the embedded tangent plane . The expression of the covariance matrix in (8) implies that there is a significant spectral gap between the top eigenvalues and the remaining ones, which depend on the curvature of the manifold. Furthermore, these remaining eigenvalues could be very small with order higher than . In other words, under the manifold setting, in contrast to the linear spiked model, even in the noiseless case, the covariance is not strictly low rank with only nonzero eigenvalues. Such small eigenvalues due to the curvature of the manifold, if not properly taken care before taking inverse to estimate the precision matrix, the obtained precision matrix might be deformed. Such small eigenvalues can be added to the noise components and together they obscure the spectral gap. Thus, it is necessary for determining the “effective rank” of the matrix, which is essential for the calculation of the precision matrix. For more details, we refer the readers to the detailed discussion in [46, 24].
In addition to the above challenge due to the curvature, the presence of noise particularly in the manifold setting imposes another challenge – that is, how to find the true neighbors? Specifically, note that the neighboring points of denoted by need to be identified from the noisy samples. When , i.e. in the noiseless case, a neighbor can be easily identified if the diameter of is sufficiently small. However, when , i.e., in the presence of noise, it is not clear if a neighbor determined from the noisy point cloud is truly a neighbor. Concretely, let denote a set of identical and independent (i.i.d.) random samples from , and , where is sampled from . Then, in general does not imply . Thus, a naive approach to determine neighbors might fail. To the best of our knowledge, there are only few existing algorithms for determining neighbors when the point cloud is noisy. For example, determining a neighbor by the diffusion distance [5], which has a solid theoretical support when noise exists [12, 13]. Since finding neighbors is still a challenging problem on its own, in this paper, we focus only on estimating the precision matrix, and subsequently, the MD, assuming that the true neighbors are known.
3.2. Mahalanobis distance
We are now ready to define the MD: we start with the definition of the MD under the manifold model, and then for reference, we present the typical definition under the global linear spiked model.
Under the manifold model, since the covariance matrix may have no strictly zero eigenvalues even in the noiseless case due to the curvature, we consider the following definition of the MD.
Definition 2** (Mahalanobis distance under the manifold model).**
Suppose . The MD between and is defined by
[TABLE]
where is the truncated pseudo-inverse of degree defined by
[TABLE]
is the eigendecomposition of , and .
Note that the knowledge of the manifold dimension is required for this definition; yet, it is in general not available and needs to be estimated.
For comparison, consider also the classical definition of the MD under the global linear spiked model.
Definition 3** (Mahalanobis distance under the linear spiked model).**
The MD between an arbitrary point and the underlying signal distribution (5) is defined by
[TABLE]
where denotes the Moore-Penrose pseudo-inverse.
Let us take a closer look at the latter definition. Since is semi-positive definite, by the Cholesky decomposition, we have , where . Hence
[TABLE]
which indicates that geometrically, MD evaluates the relationship between and (the mean of) by a proper linear transform. In Section 3.3, we relate to the inverse of the Jacobian of arbitrary unknown observation functions and show that it gives rise to an important invariance property of the MD in the context of manifold learning. Here, we only demonstrate a primary merit of MD, which stems from its invariance to rotation and rescaling. Importantly, this invariance property holds for both definitions: under the linear spiked model as well as under the manifold model. Consider the linear spiked model and a random variable , where models rescaling and models rotation. Here denotes the group of -by- orthogonal matrices. The population covariance matrix of is
[TABLE]
and its population mean is rotated and rescaled to . To demonstrating the invariance, suppose and observe the MD between and :
[TABLE]
The same argument holds for the MD under the manifold model; for brevity, we omit the details.
Now, recall that the goal in this work is to estimate the MD between a point and , when we only have access to noisy data sampled from in (7). Concretely, assume that is a sample of data points. Since is unknown, the quantity , or in (10), must be estimated from the (noisy) data. For simplicity, we assume below that and are known; these assumptions can easily be removed in applications to real data. As discussed in Section 3.1, the notable challenge in estimating the MD from local samples of is the estimation of the precision matrix via the pseudo-inverse, stemming from the interaction of the small eigenvalues of and the noise. In addition, as discussed in Section 3.1, the main difference between (5) and (2) is that in (5), the covariance matrix is global and strictly of low rank, whereas in (2), the covariance matrix depends on , and its rank is in general higher than when the manifold is of dimension , yet only its first eigenvalues are dominant. In the context of MD, this rank difference might lead to unwanted consequences if we consider Definition 3. Below we demonstrate it with an example.
Assume for simplicity that the pdf is uniform, and is sufficiently small. From (8), we observe a clear spectral gap between the first eigenvalues and the remaining ones. Therefore, we would expect that the behavior of in (2) is similar to that of in (5). However, we need to be careful with the associated precision matrices, and hence, with the two definitions of MD. Suppose that the main interest in estimating the MD is recovering the geodesic distance when the manifold cannot be directly accessed. It has been shown in [24, Theorem 8 (3)] that even if the manifold can be directly accessed, defining the MD between a point and by as in (10) might lead to a biased estimate of the geodesic distance. To be more precise, when the rank of is greater than and is sufficiently small, asymptotically we have
[TABLE]
which means that the MD cannot even recover the basic geodesic distance since the order of the error is of the same order as the geodesic distance. Broadly, this bias is the result of the interaction of the small eigenvalues related to the curvature, particularly the second fundamental form, and the fact that the vector is not intrinsic to the manifold and might contain component that is normal to the tangent space at .
3.3. Motivating example
A motivating example for the centrality of the MD under the manifold model in data analysis was presented in [30], and later elaborated in the empirical intrinsic geometry (EIG) framework presented in [37, 39] with various applications, e.g., [40, 11, 45, 10, 9, 22, 17].
Suppose the manifold is merely an image of a different, intrinsic, and inaccessible manifold of interest , that is , where is a diffeomorphic map. We may call the latent space. In applications, could represent the distortion of the data introduced by some measurement equipment. This “distortion model” is often of key important since it critically affects the intrinsic information we have interest in, even if noise does not exist. Under this model, it is shown in [30, Section 3] that when and are both Euclidean spaces, for , the following holds:
[TABLE]
where and . A similar statement for the case when and are both manifolds and is a diffeomorphism is given in [24]. It was further shown in [30] and [24] that if we have i.i.d. sampled from adhering to the statistical manifold models discussed above, then
[TABLE]
for a sufficiently small neighborhood . Remarkably, by combining (13) and (14), a small variant of the MD can recover the distance between and from the hidden intrinsic manifold based on samples from without explicit information on the map , thereby solving a completely blind inverse problem.
The above distortion model was studied in [37] in the context of a nonlinear dynamical system. Denote the dataset or the point cloud as , where is sampled at the -th time stamp. The key assumption is that comes from observing an inaccessible intrinsic dynamics that satisfies the stochastic differential equation
[TABLE]
where is an unknown drift function and is the standard -dimensional Brownian motion. We call the subset of that hosts the phase space; for example, an open subset of , or a smooth manifold embedded in .
The observation is modeled by a diffeomorphic function so that , where is sampled from the intrinsic dynamics at the -th time stamp. We call the observation transform. Based on (15), and the fact that
[TABLE]
by the Ito’s formula, we obtain that
[TABLE]
since is the drift. By combining the above facts, it is shown in [30, Section 3] that when and are sufficiently close and the phase space is flat, we could recover the intrinsic distance between and by
[TABLE]
where is the covariance matrix associated with the observation process (i.e., the deformed Brownian motion). Furthermore, it is shown in [30, 37] that can be estimated by the covariance matrix of , where is chosen by the user. The key relevant fact here is that since the covariance matrix of is , the related open set is an ellipsoid with principle semi-axes described by the non-degenerate eigenvalues and eigenvectors of .
To conclude, the intrinsic signal model in (15) and the observation model (16) are generic and can describe a broad range of applications. Therefore, the ability to recover the distances between samples of the intrinsic process from observations in a nonparametric and unsupervised manner using an estimate of the Mahalanobis distance is very powerful. Indeed, this model was used for system identification [40], molecular dynamics [11], sleep analysis [45, 22], model reduction [10], speech processing [9], and gene expression data [17].
3.4. Shrinkage Estimators
For any -by- matrix estimated from , consider the estimator for MD
[TABLE]
using Definition 3. The extension to Definition 2 is straight-forward. In order to quantitatively measure the performance of any MD estimator , it is useful to introduce a loss function. For any estimator of the form (19), the absolute value of the estimation error with respect to the true value (10) is
[TABLE]
As the test vector is arbitrary, it is natural to consider the worst case, and define the loss of at the (unknown) underlying low-dimensional covariance :
Definition 4**.**
The worst case loss function of an estimator of the form (19) for (10) is defined as
[TABLE]
where is the matrix operator norm.
It is also reasonable to consider the root mean squared estimation error of all possible test vectors. The discussion below follows the same line. To keep the notation light, the dependence of on and as well as the dependence of on the sample are implicit.
Consider matrices of the form , where and is the sample covariance. We call the shrinkage estimator of with . A typical example is the classical MD estimator, which is a shrinkage estimator with , where
[TABLE]
From [23], in the traditional setup when the dimension is fixed and , the classical MD estimator obtains zero loss asymptotically.
Theorem 1**.**
Let be fixed independently of . Then
[TABLE]
Proof.
Since it is well known that as , substituting with in (20) and taking limit with complete the proof. ∎
When grows with , such that with , the situation is quite different. It is known that in this situation the sample covariance matrix is an inconsistent estimate of the population covariance matrix [15], and Theorem 1 might not hold; that is, the classical MD estimator might not be optimal. The following questions naturally arise when :
- (1)
Is there an optimal shrinkage (OS) estimator with respect to the loss ? 2. (2)
How does the loss of the optimal shrinkage estimator compare with the loss ?
In the sequel, we attempt to answer these questions.
4. OPTIMAL RECOVERY OF PRECISION MATRIX FOR MAHALANOBIS DISTANCE UNDER THE SPIKED MODEL
We start the derivation of the OS for MD under the linear spiked model, which involves the OS for the precision matrix. Its extension to the manifold model requires only an additional mild condition, which will be discussed in Section 5. Without loss of generality, we set the noise level and will discuss the general case subsequently.
Assumption 1** (Asymptotic()).**
The number of variables grows with the number of observations , such that as , for .
Assumption 2** (Spiked model).**
Suppose with the eigendecompostion:
[TABLE]
where , is a matrix whose diagonal consists of spikes , which are fixed and independent of and , and the off-diagonal elements are set to zero. For completeness, denote . Note that we assume that all spikes are simple. When , it is the null case.
Denote the eigendecompostion of as
[TABLE]
where are the empirical eigenvalues and is the matrix, whose columns are the empirical eigenvectors , . Under Assumption 1 and Assumption 2, results collected from [25, 2, 3, 28] imply three important facts about the sample covariance matrix .
- (1)
Eigenvalue spread. Suppose Assumption 1 holds and consider the null case where . As , the spread of the empirical eigenvalues converges to a continuous distribution called the “Marcenko-Pastur” law [25],
[TABLE]
where and are the limiting bulk edges. 2. (2)
Top eigenvalue bias. Suppose Assumption 1 and Assumption 2 hold. For , the empirical eigenvalues
[TABLE]
as , where
[TABLE]
is defined on and . For , since the empirical eigenvalues follow the Marcenko-Pastur law (24). 3. (3)
Top eigenvector inconsistency. Suppose Assumption 1 and Assumption 2 hold. Let and be the cosine and sine values of the angle between the -th population eigenvector and the -th empirical eigenvector after properly adjusting the sign of each empirical eigenvector. Note that there exists a sequence of so that converges almost surely (a.s.) to . In the following we assume that the empirical eigenvectors have been properly rotated. It is known that when , and , where
[TABLE]
and
[TABLE]
are defined on .
The above three properties imply that the classical estimator may not be the best estimator in general, and for the purpose of estimating MD in particular. Inspired by [7], we may “correct” the bias of the eigenvalues to improve the estimation.
Definition 5**.**
The asymptotic loss function is defined as
[TABLE]
assuming the limit exists.
To find a shrinkage estimator that minimizes , it is natural to construct the estimator by recovering the spikes using the biased eigenvalues . From the inversion of (25), recalling that , we can define
[TABLE]
when , and consider the shrinkage function
[TABLE]
Note that since taking inverse of a matrix is nonlinear, it is not clear if the above naive idea will lead to the OS estimator of the precision matrix for the MD estimate. Nevertheless, it is reasonable to expect the existence of an optimal shrinkage function satisfying
[TABLE]
for any spikes . Below we show that this naive idea, , is in fact the OS estimator for our purpose.
4.1. Derivation of the Optimal Shrinker when
Definition 6**.**
A function is called a shrinker if it is continuous when , and when .
Note that this shrinker is a bulk shrinker considered in [7, Definition 3]. Based on the assumption of a shrinker , the associated shrinkage estimator converges almost surely, that is
[TABLE]
where the right hand side is the eigendecomposition of . Thus, the sequence of loss functions also almost surely converges as
[TABLE]
As a result, the limit in (28) exists when is a shrinker, and we have the following theorem which in turn gives rise to the optimal shrinker. Note that while the biased eigenvalues could be recovered by the quadratic relationship between the biased eigenvalues and the population eigenvalues (25), true (population) eigenvectors and empirical eigenvectors are not collinear [7] and so far we do not have a way to recover the biased eigenvectors. The main idea beyond the proof is respecting this fact, and when we find the optimal way to correct the eigenvalues, the biased eigenvectors should be taken into account. With the control of this eigenvector bias, the OS will be derived.
Theorem 2** (Characterization of the asymptotic loss).**
Suppose . Consider the spiked covariance model satisfying Assumption 1 and Assumption 2 and a shrinkage function . We have a.s.
[TABLE]
where is given by
[TABLE]
where
[TABLE]
[TABLE]
Proof.
Based on the property of “simultaneous block-diagonalization” for and in [7, Section 2], the properties of “orthogonal invariance” and “max-decomposability” for the operator norm in [7, Section 3], and the convergence of and in (26) and (32), we have
[TABLE]
where
[TABLE]
when and otherwise, and
[TABLE]
When , the loss converges a.s. to , where
[TABLE]
Now we evaluate for different .
When , denote the eigenvalues of as and . If we have , and hence ; otherwise, we have , and hence . For , since , we have
[TABLE]
which equals since by the definition of shrinkage function. Thus, . Finally, for , is a zero matrix, and thus . This concludes the proof. ∎
Figure 1 illustrates the obtained asymptotic loss for several values as a function of the spike strength in a single spike model. It is clear that for each , there is a transition at . An immediate consequence of Theorem 2 is that is an optimal shrinker.
Corollary 1**.**
Suppose and Assumption 1 and Assumption 2 hold. Define the asymptotically optimal shrinkage function as
[TABLE]
where argmin is evaluated on the set of all possible shrinkage functions. Then, is unique and equals given in (30). Moreover, its associated loss is
[TABLE]
where
[TABLE]
Note that this result coincides with the findings reported in [7]. Precisely, it is shown in [7, (1.12)] that for the operator norm, (29) is the optimal shrinkage for the covariance matrix and precision matrix. In this corollary, we show that for the Mahalanobis distance, which is related to the precision matrix, the optimal estimator is also achieved by the optimal shrinkage, taking into account.
Proof.
Based on Theorem 2, the optimal shrinker leads to . Note that for , the optimal shrinker achieves . Thus, by the same argument in [7], if we could solve for any , we find the optimal shrinker. To simplify the notation, we abbreviate by .
For and , we have . By a direct calculation, we get
[TABLE]
For and , we have , and similarly by taking the derivative of (35) we have
[TABLE]
As a result, the partial derivative of the loss function is decreasing when and increasing when with a discontinuity at while the loss function is continuous. Thus, the loss function reaches the minimum when . These facts imply that when . Furthermore, by substituting with in (35) or (36), we get . By definition, when . Thus, for , , and for , . Finally, it is clear that is continuous when , and when . We thus conclude that is the optimal shrinker. ∎
We compare our result with another naive approach; that is, obtaining the covariance by the optimal shrinkage with respect to the operator norm, and then taking the Moore-Penrose pseudo-inverse. Let denote the optimal shrinker for the covariance matrix recovery obtained from [7] with respect to the operator norm loss function. With the same notation, that is, and as in (2), the optimal shrinker satisfies
[TABLE]
where is defined in (29). Note that in [7], the authors aimed to recover , while we recover . In other words, the authors in [7, (1.12)] showed that when the operator norm is considered, the OS estimator is the same as correcting the eigenvalues according to the relationship (25). Thus, our result coincides with the inverse of when .
We note the following interesting phenomenon stemming from Theorem 2 and Corollary 1. If there exists a nontrivial spike that is weak enough so that is sufficiently small compared with , then is dominated by . Consequently, in this large large regime, we cannot “rescue” this spike, and the associated signal is lost in the noise, as can be seen in Corollary 1.
Figure 2 illustrates the obtained optimal shrinker with the classical shrinker overlay, for and . Clearly, compared with the classical shrinker, the obtained optimal shrinker truncates the eigenvalues more aggressively.
4.2. Derivation of the Optimal Shrinker when
To handle the general case when , we first rescale the data and model by setting and , and consider the following shrinker defined on :
[TABLE]
Note that since plays the role of estimating the precision matrix, we re-normalize it by dividing by . The shrinkage estimator for becomes , the general optimal shrinker becomes
[TABLE]
and the associated loss is
[TABLE]
5. EXTENSION TO THE MANIFOLD MODEL
We now come back to the manifold learning problem with the manifold setup described in Section 2.1. We argue that despite the challenge mentioned in Section 3.1, the developed theorem in Section 4.1 can be extended to study the manifold model in the large large setup with proper modifications. Note that For each , there exists an orthonormal basis of so that the -dimensional compact smooth manifold is isometrically embedded in the subspace spanned by for a fixed . In other words, while the rank of associated with depends on , it is bounded uniformly from above by . Note that in general can be much larger than , yet it is fixed due to the well known Nash’s isometric embedding theory [27], which guarantees the existence of that is independent of and . We put the following assumption.
Assumption 3**.**
Assume , where is a Euclidean ball centered at [math] with the radius , and is diffeomorphic on . We call an ellipsoid.
Note that since is diffeomorphic, in general is not really an ellipsoid unless is linear. But to simplify the terminology, we abuse the notation and still call it an ellipsoid. Also note that the elliptic radii of is of order with the implied constant depending on the Jacobian of when is sufficiently small.
Based on the developed theorem in Sections 4.1 and 4.2, we state the following theorem that secures the recovery of MD under the manifold model in Definition 2. The basic idea beyond this theorem is twofold. First, it relies on the result from [24, Lemma 3 and Lemma 6] stating that when is sufficiently small, there is a sufficiently large gap between the first eigenvalues of and the remaining small eigenvalues. Second, as discussed in Section 4.1, any nontrivial eigenvalue that satisfies is ignored by the optimal shrinkage.
Theorem 3**.**
Assume Assumptions 1-3 hold. Fix . Suppose so that and when . Assume the maximal elliptic radius of is , where , and the ratio of the maximal and minimal elliptic radii is fixed for all . When is sufficiently small, all nontrivial eigenvalues of except the top eigenvalues are set to zero by the optimal shrinkage .
Proof.
By [24, Lemma 6], the local covariance matrix has the following asymptotical expansion when is sufficiently small:
[TABLE]
where is the volume of . A derivation, similar to the derivation in [24, Lemma 3], yields that when is sufficiently small, the top eigenvalues of are of order , and the remaining eigenvalues are of order equal to or higher than . In other words, the “signal strength” is of order while the noise strength is . Note that there are at most non-zero eigenvalues.
By (42), all eigenvalues smaller than are eliminated by the optimal shrinkage. Combining the above, since , and are all fixed, when is sufficiently small so that is sufficiently small and is sufficiently large, all nontrivial eigenvalues of except the top eigenvalues are set to zero by the optimal shrinkage . Indeed, by the assumption that and , we know that and when is sufficiently small for some universal constants and . Therefore, for and for , and hence we conclude the proof. ∎
We conclude this section with several remarks on this theorem. First, the condition seems to be limited since the noise level goes to zero when goes to zero. This condition is needed if we want to properly estimate the precision matrix locally within an ellipsoid over a manifold with elliptic radii of order . In practice, plays the role of “bandwidth” which reflects the “resolution” of how accurate we could estimate the quantity we have interest. For example, in the motivating EIG example discussed in Section 3.3, we need an accurate precision matrix estimation so that the geodesic distance in the latent space can be accurately estimated. Such precision matrix via (17) is less affected by the curvature if is small. However, if the noise level is fixed, then is bounded from below, so that we have a limited accuracy when we recover the geodesic distance on the latent space, and hence the latent space itself by DM.
Second, this theorem also suggests that we always need the noise to attain a reasonable estimate of MD; that is . This statement is certainly counterintuitive, since in the linear spiked model, noise absence is desired and beneficial. To clarify this point, note that in general the dimension of the manifold is unknown, but it is needed so that we can define a sensible MD on the manifold in Definition 2. See the discussion in Section 3.2. Thus, a dimension estimation is needed. This theorem mainly says that when is sufficiently large so that the condition in Theorem 3 holds, we could get the MD in Definition 2 even if we do not know the dimension. If the noise is not sufficiently big and we do not know the dimension, then we cannot obtain the desired MD. If the dimension is known, or can be robustly estimated when noise exists, then this lower bound condition can be removed. The above facts stem from the complicated nonlinear interaction of nonlinear manifold structure and high dimensional noise. Finally, we mention that this result extends the EIG study in [24] under the manifold model when noise exists.
6. SIMULATION STUDY
To numerically compare the optimal shrinker and the classical shrinker, we set and consider the number of samples so that . For simplicity, we set for . We consider . Suppose , are sampled i.i.d. from the random vector , where is the unit vector with -th entry , for , and is independent of when . The noisy data is simulated by , where is the noise matrix, is independent of and is randomly sampled from . In the simulation, we take . For each , we repeat the experiment times and report the mean and variance of the loss .
Figure 3 shows the loss of the optimal and classical shrinkers when and in a logarithmic scale. We observe that the loss using the classical shrinker is significantly larger. This stems from the fact that in the large and large regime, there are eigenvalues greater than that are not associated with the signal. When applying the classical shrinker (21) (the Moore-Penrose pseudo-inverse), these irrelevant eigenvalues contribute significantly, leading to high loss. Conversely, the optimal shrinker is much more ‘selective’ (as illustrated in Figure 2), associating larger eigenvalues with the noise, thereby increasing the robustness of the estimator.
Recall that our main motivation for considering MD in the high-dimensional regime comes from manifold learning. Next, we test the performance of the proposed OS algorithm on high-dimensional data lying on a lower-dimensional manifold. Consider the following model
[TABLE]
where is sampled from a curved manifold with one chart embedded in that is parametrized by
[TABLE]
, , and is the noise level. Note that since the precision matrix estimation and MD estimation are both local, we consider this one-chart manifold without loss of generality. Suppose the ambient dimension is fixed at . For various values of , we sample pairs uniformly from and generate nonuniform points on by (45). Then, these points are corrupted by additive noise with various levels according to (44). The normalized loss of MD is computed by
[TABLE]
where is an arbitrary point on the manifold and is the estimated covariance matrix. We examine two reference points: and . For each case, the simulation was repeated for times, and the mean and standard deviation of errors are reported. In Table 1, we compare the performance of the OS estimator, , where is the sample covariance, to the performance of the classical estimator . We observe that the OS outperforms the classical estimator in this well-controlled manifold setup, and we could see that the larger the noise, the worse the performance is. Moreover, the higher the dimension is, that is, the larger the is, the worse the performance is.
7. APPLICATION TO DYNAMICAL SYSTEM ANALYSIS
Next, we apply our OS estimator on the multiscale reduction problem studied in [10]. We consider the following two-dimensional stochastic differential equation (SDE)
[TABLE]
where and are independent standard Bronwian motion and is a small constant quantifying the scale of . This SDE defines a dynamical system with two time scales, where is a slow variable and is a fast variable. Suppose the state of the system is hidden and we have access to it through an embedding in a high dimension space via the map
[TABLE]
In addition, suppose the high-dimensional observation is contaminated by noise:
[TABLE]
[TABLE]
where
[TABLE]
are independent standard Brownian motion, and is the noise level.
In [10], diffusion maps [5] with a Gaussian kernel based on the MD [30] was applied to effectively reduce the dimensionality of the system by attenuating the fast variable and recovering the slow variable. Specifically, the following kernel matrix was used:
[TABLE]
where is defined by
[TABLE]
where is the local population covariance of the observed stochastic process at the point , and is the selected kernel scale.
We generate samples of the noisy observation , where and . At each sampling point , we generate a trajectory consisting of samples of noisy observations with sampling time interval starting at , such that we have samples: drawn approximately from the local distribution at . Here, we set , where is from (46). Let denote the local sample mean of . The local sample covariance is given by
[TABLE]
For the estimation of the local precision at , that is, from the noisy samples , we test two methods. The first method is based simply on the pseudo-inverse of . The second method is based on the OS estimator that is applied to (52) to estimate the local precision estimation. Once the local precision matrices are estimated, we construct the following distance matrix , whose elements are given by
[TABLE]
We examine three cases of observation functions and :
Case I.
Let
[TABLE]
and set , , , , , , , and to the percent quantile of the distance matrix acquired from (53). These parameters are taken from [10].
Case II.
Let
[TABLE]
and set the parameters as in Case I.
Case III.
Let
[TABLE]
We set the parameters as in Case I and II, except for , which is set to a finer value , and , which is set to percent quantile of the distance matrix . These observations functions create a “half-moon” shape, and where considered in [10].
In Fig. 4, we compare the results obtained for Case I by diffusion maps based on three distance matrices. The first distance matrix is a variant of (53), where the noisy signal is replaced by the clean signal . These results are plotted in the leftmost column. The second distance matrix is (53), where the estimates of the precision matrix are based on the pseudo-inverse. These results are plotted in the middle column. The third distance matrix is (53), where the estimates of the precision matrix are based on the proposed OS. These results are plotted in the rightmost column. In the first row, we show a scatter plot of the slow variable against its most correlated eigenvector of the transition matrix associated with the diffusion map. In the second row, we show the scatter plot of the fast variable against its most correlated eigenvector of the transition matrix associated with the diffusion map. The correlation between the respective variables and eigenvectors is shown in red above each subplot. In the third row, we present the eigenvalues of the transition matrix associated with the diffusion map, where is the -th largest eigenvalue. The eigenvalues corresponding to the eigenvectors presented in the first and second rows (corresponding to the slow and fast variables) are marked by red and blue circles, respectively. Fig. 5 and Fig. 6 are the same as Fig. 4, but for Case II and Case III.
We observe that all three figures present consistent results and trends. Focusing first on the leftmost column, we see that the use of MD in diffusion maps based on the clean signal recovers accurately the slow variable and attenuates the fast variable , conforming to the results presented in [10] for only a 2-dimensional observations. In the middle column, we see that the addition of noise hinders both the recovery of the slow variable as well as the attenuation of the fast variable, when the pseudo-inverse is used for the estimation of the MD. In contrast, in the rightmost column, we see that when the proposed OS is used, the obtained results based on the noisy signal are comparable to the results obtained based on the clean signal in the leftmost column.
These results demonstrate, in the context of manifold learning, that the estimation of the MD based on the pseudo-inverse fails in the high-dimensional regime with the presence of noise. In addition, they show that using the proposed optimal shrinker indeed offers a remedy and gives rise to accurate manifold learning.
8. CONCLUSIONS
We proposed a new estimator for MD based on precision matrix shrinkage. For an appropriate loss function, we show that the proposed estimator is asymptotically optimal and outperforms the classical implementation of MD using the Moore-Penrose pseudo-inverse of the sample covariance. Importantly, the proposed estimator is particularly beneficial when the data is noisy and in high-dimension, a case in which the classical MD estimator might completely fail. Consequently, we believe that the new estimator may be useful in modern data analysis applications, involving for example, local principal component analysis, metric design, and manifold learning.
In this work, we focused on the case in which the intrinsic dimensionality of the data (the rank of the covariance matrix) is unknown, and therefore, it was not explicitly used in the estimation. Yet, in many scenarios, this dimension is known. In this case, it could be beneficial to consider a direct truncation and use only the top eigen-pairs for the estimation of the precision matrix. While the benefit from such a truncation has been shown empirically in several applications [38, 45, 48, 22], it still requires a systematic investigation. For example, identifying the rank of the signal, or estimating the dimension of a manifold, are by themselves highly challenging tasks [16, 19]. Note that in the particular manifold setup, knowing the manifold dimension is essentially different from the rank-aware shrinker discussed in [7]; as we showed here, under the manifold setup, the rank of the covariance matrix associated with points residing inside a small neighborhood of any point on the manifold could be much larger than . Since the focus of this paper is MD recovery, the associated loss function for the OS of the precision matrix is the operator norm. As is discussed in [7], there are other loss functions that we can choose, like the Frobenius norm, the nuclear norm, etc. It would be interesting to explore if the OS for the precision matrix under those norms when they are needed. We shall also mention that the manifold model discussed in this paper is a simplified model for more complicated datasets with more nonlinear structure. While it is possible to apply the principle component analysis approach to denoise the data when the smooth compact manifold assumption holds thanks to the fixed mentioned in Section 5, in general this approach might not be optimal, particularly when the geometric structure is more complicated. The current work explores this situation with a simplified manifold model and paves a way toward more complicated setups, and these cases will be explored in our future work.
Acknowledgements
MG has been supported by H-CSRC Security Research Center and Israeli Science Foundation grant no. 1523/16. MG and RT were supported by a grant from the Tel-Aviv University ICRC Research Center. We thank the anonymous reviewers for their constructive comments and critiques that highly improve the original manuscript.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Sankaraleengam Alagapan, Hae Won Shin, Flavio Fröhlich, and Hau-Tieng Wu. Diffusion geometry approach to efficiently remove electrical stimulation artifacts in intracranial electroencephalography. Journal of neural engineering , 2018.
- 2[2] J. Baik, G. Ben Arous, and S. Peche. Phase transition of the largest eigenvalue for non-null complex sample covariance matrices. Ann. Probab. , 33(5):1643–1697, 2005.
- 3[3] J. Baik and J. W. Silverstein. Eigenvalues of large sample covariance matrices of spiked population models. Journal of Multivariate Analysis , 97(6):1382 – 1408, 2006.
- 4[4] M. Belkin and P. Niyogi. Laplacian eigenmaps for dimensionality reduction and data representation. Neural computation , 15(6):1373–1396, 2003.
- 5[5] R. R. Coifman and S. Lafon. Diffusion maps. Applied and computational harmonic analysis , 21(1):5–30, 2006.
- 6[6] D. Dai and T. Holgersson. High-dimensional CL Ts for individual mahalanobis distances. In Müjgan Tez and Dietrich von Rosen, editors, Trends and Perspectives in Linear Statistical Inference , pages 57–68, 2018.
- 7[7] D. L. Donoho, M. Gavish, and I. M. Johnstone. Optimal Shrinkage of Eigenvalues in the Spiked Covariance Model. The Annals of Statistics , 46(4):1742–1778, November 2018.
- 8[8] D. L. Donoho and C. Grimes. Hessian eigenmaps: Locally linear embedding techniques for high-dimensional data. P. Natl. Acad. Sci. USA , 100(10):5591–5596, 2003.