TL;DR
This paper presents a deep anomaly detection approach for face anti-spoofing that improves generalization and outperforms state-of-the-art methods by using a novel loss function and few-shot probability estimation.
Contribution
It introduces a deep metric learning model with a new metric-softmax loss and a few-shot probability estimation for generalized face anti-spoofing.
Findings
Outperforms all state-of-the-art methods on GRAD-GPAD dataset
Uses a triplet focal loss with a novel metric-softmax loss for discriminative features
Demonstrates effectiveness in few-shot a posteriori probability estimation
Abstract
Face recognition has achieved unprecedented results, surpassing human capabilities in certain scenarios. However, these automatic solutions are not ready for production because they can be easily fooled by simple identity impersonation attacks. And although much effort has been devoted to develop face anti-spoofing models, their generalization capacity still remains a challenge in real scenarios. In this paper, we introduce a novel approach that reformulates the Generalized Presentation Attack Detection (GPAD) problem from an anomaly detection perspective. Technically, a deep metric learning model is proposed, where a triplet focal loss is used as a regularization for a novel loss coined "metric-softmax", which is in charge of guiding the learning process towards more discriminative feature representations in an embedding space. Finally, we demonstrate the benefits of our deep anomaly…
Click any figure to enlarge with its caption.
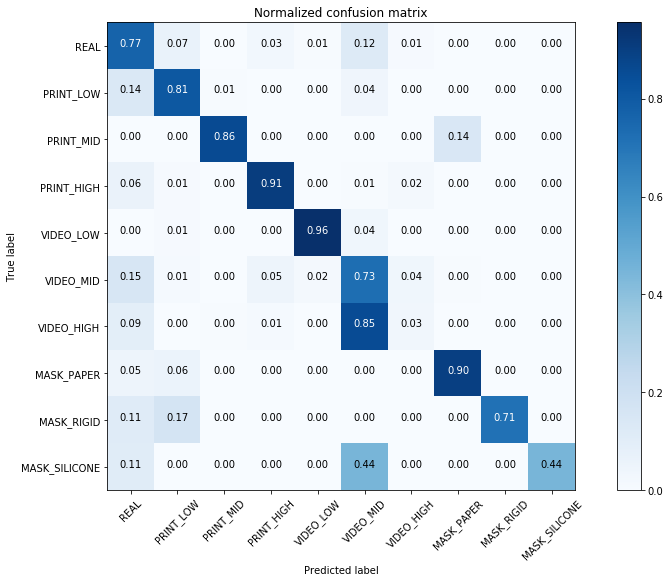 Figure 1
Figure 1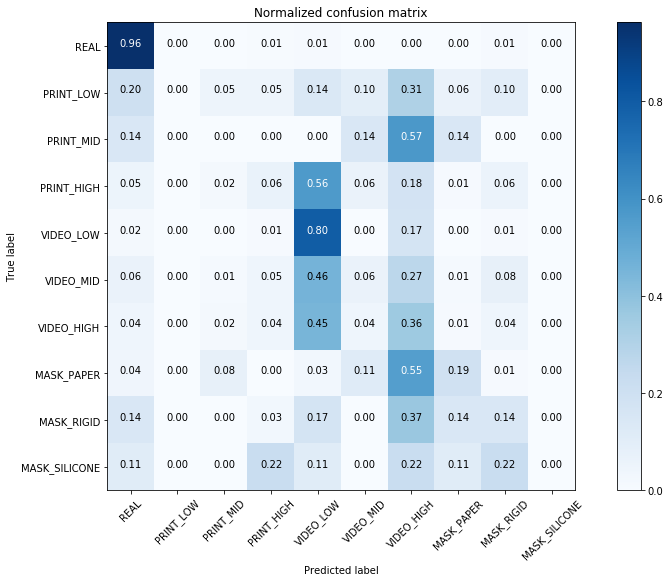 Figure 2
Figure 2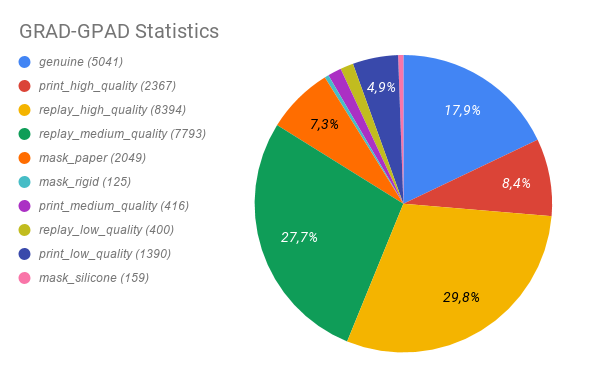 Figure 3
Figure 3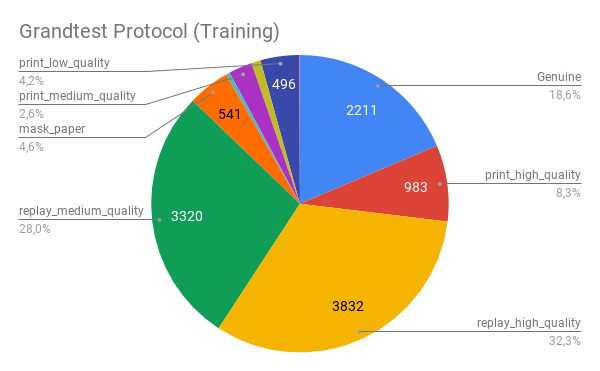 Figure 4
Figure 4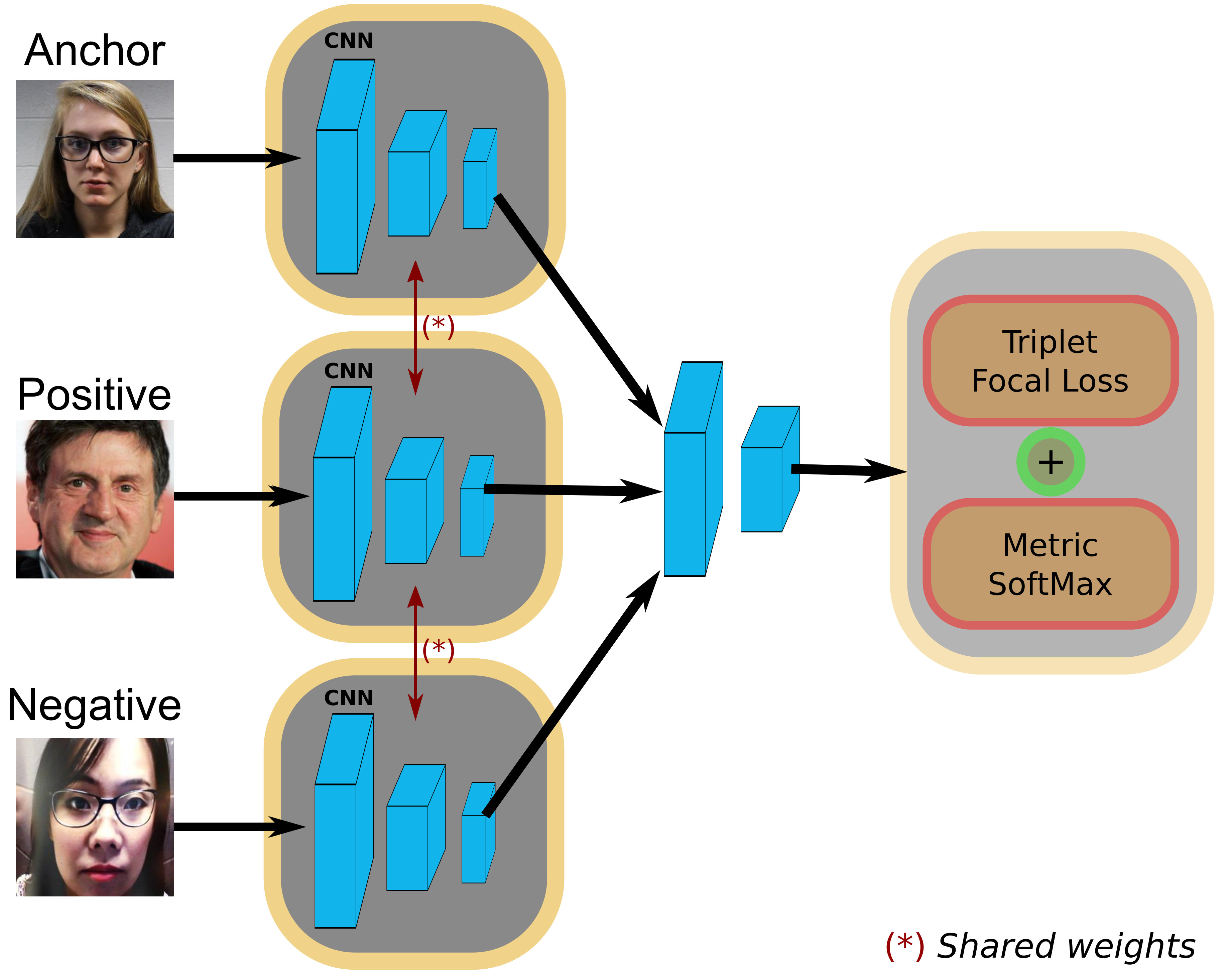 Figure 5
Figure 5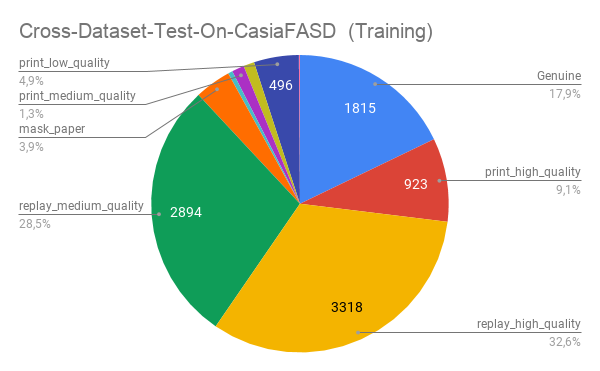 Figure 6
Figure 6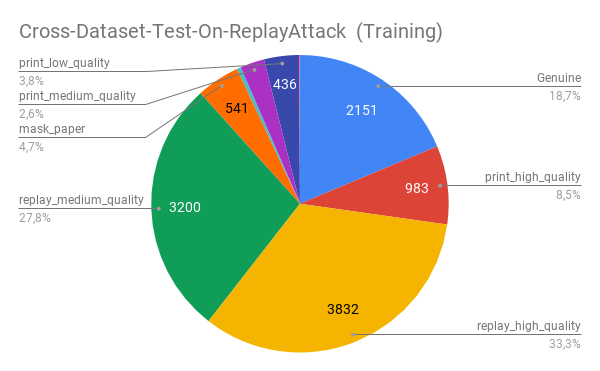 Figure 7
Figure 7| Category | Types | Sub-type | Criteria |
| Presentation Attack Instrument | low | dpi 600pix | |
| medium | 600 dpi 1000pix | ||
| high | dpi 1000pix | ||
| replay | low | res 480pix | |
| medium | 480 res 1080pix | ||
| high | res 1080pix | ||
| mask | paper | paper masks | |
| rigid | non-flexible, plaster | ||
| silicone | silicone masks |
| Algorithm | AER | FAR | FRR | AER |
|---|---|---|---|---|
| Baseline | 17.02 % | 10.72 % | 23.33 % | - |
| Model 1 | 12.46 % | 24.43 % | 0.49 % | 26.8 % |
| Model 2 | 9.80 % | 14.87 % | 4.74 % | 42.42 % |
| Ours | 5.07 % | 6.38 % | 3.77 % | 70.21 % |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
MethodsFocal Loss
Deep Anomaly Detection for Generalized Face Anti-Spoofing
Daniel Pérez-Cabo
Gradiant - UVigo, Spain
David Jiménez-Cabello
Gradiant, Spain
Artur Costa-Pazo
Gradiant, Spain
Roberto J. López-Sastre
University of Alcalá, Spain
Abstract
Face recognition has achieved unprecedented results, surpassing human capabilities in certain scenarios. However, these automatic solutions are not ready for production because they can be easily fooled by simple identity impersonation attacks. And although much effort has been devoted to develop face anti-spoofing models, their generalization capacity still remains a challenge in real scenarios. In this paper, we introduce a novel approach that reformulates the Generalized Presentation Attack Detection (GPAD) problem from an anomaly detection perspective. Technically, a deep metric learning model is proposed, where a triplet focal loss is used as a regularization for a novel loss coined “metric-softmax”, which is in charge of guiding the learning process towards more discriminative feature representations in an embedding space. Finally, we demonstrate the benefits of our deep anomaly detection architecture, by introducing a few-shot a posteriori probability estimation that does not need any classifier to be trained on the learned features. We conduct extensive experiments using the GRAD-GPAD framework that provides the largest aggregated dataset for face GPAD. Results confirm that our approach is able to outperform all the state-of-the-art methods by a considerable margin.
1 Introduction
Whether we like it or not, we are in the era of face recognition automatic systems. These solutions are now beginning to be used intensively in: border controls, on-boarding processes, accesses to events, automatic login, or to unlock our mobile devices. As an example of this last technology, we have the Intelligent Scan111https://www.samsung.com/my/support/mobile-devices/what-is-intelligent-scan-and-how-to-use-it/ that comes with Samsung mobiles, or the FaceID222https://www.apple.com/lae/iphone-xs/face-id/ for iPhones. All these systems are highly valued by consumers because of their usability and its non-intrusive nature. However, there remains one major challenge for all of them, Presentation Attacks (PA).
These commercial systems rely on specialized hardware such as 3D/IR/thermal cameras entailing a far easier option to detect presentation attacks. Besides, this situation restricts the use case to a few specialized devices, incrementing costs dramatically. For the sake of accessibility and costs, we focus on the ubiquitous 2D-camera case, available in almost all mobile devices and easy to acquire and integrate on different checkpoints.
Although face recognition technologies achieve accuracy ratios above human performance in certain scenarios, consumers should be aware that they also introduce two new challenges that compromise their security: the Presentation Attack Detection (PAD) and the generalization capability of these solutions. With respect to the former, for example, a face recognition system with an outstanding 99.9% of accuracy fails simply by presenting a page with your face printed on it. These presentation attacks stand as a major threat for identity impersonation where illegitimate users attempt to gain access to a system using different strategies, e.g. video replay, make-up. Note that it is really easy to obtain audiovisual material from almost every potential user (e.g. Facebook photos, videos on YouTube, etc.), which allows the creation of tools to perform these PAs.
But the generalization problem is also relevant. In a nutshell, the scientific community has failed to provide an efficient method to detect identity impersonation based on face biometrics that is valid for real-world applications. Normally, the state-of-the-art models suffers a severe drop of performance in realistic scenarios, because they exhibit a sort of overfitting behaviour maximizing the results for just the dataset they have been trained on.
In this paper we explicitly address these two challenges. First, we introduce a deep metric learning based approach to deal with the PAD problem. As it is shown in Fig. 1, our solution is trained to learn a feature representation that guarantees a reasonable separability between genuine and impostor samples. Then, the generalization problem is tackled from an anomaly detection approach, where we expect to detect the attacks as if they were out-of-distributions samples that naturally exhibit a higher distance in the embedding space with respect to the real samples in the dataset.
The generalization capability of our solution and its state-of-the-art competitors is thoroughly evaluated using the recent GRAD-GPAD framework [11]. We use the aggregated dataset provided in GRAD-GPAD, which comprises more than 10 different datasets for face anti-spoofing. This aspect results fundamental, because it allows us to deploy extensive inter-dataset experiments, to address the Generalized Presentation Attack Detection problem.
As a summary, in this paper we make the following contributions:
We introduce a novel anomaly detection strategy based on deep metric learning for face anti-spoofing using just still images. 2. 2.
Our model leverages the use a triplet focal loss as a regularizer of a novel “metric softmax” loss, to ensure that the learned features allow for a reasonable separability between real and attacks samples in an embedding space. 3. 3.
A thorough experimental evaluation on GRAD-GPAD shows that our anomaly detection based approach outperforms the state-of-the-art models. 4. 4.
Finally, we propose a novel few-shot a posteriori probability estimation that avoids the necessity of training any classifier for decision making.
The remainder of this paper is organized as follows. Section 2 reviews the main progress and challenges on the problem of generalization for anti-spoofing systems. We introduce our anomaly detection deep model in Section 3. Sections 4 and 5 provide the experimental evaluation and the conclusions, respectively.
2 Related Work
Face-PAD approaches can be categorized regarding the following standpoints: i) from the required user interaction as active [19] or passive [33, 20] methods; ii) from the hardware used for data acquisition as rgb-only [33, 14, 25], rgb-infrared-depth [3, 37] or additional sensors [30] approaches; iii) from the input data type as video-based [1, 28] or single-frame [33, 33] approaches; iv) and, finally, depending on the feature type, from classical hand-crafted features [33, 5] to the newer ones based on automatic learned deep features [20, 18]. These deep models are precisely the responsible for a considerable increase in accuracy for face-PAD, defining the new state of the art.
However, recent studies reveal that the current approaches are not able to correctly generalize [21] using fair comparisons. Actually, the main difficulty for the inclusion of anti-spoofing systems in realistic environments is the Generalized Presentation Attack Detection (GPAD) problem. Some works [12, 25, 11] propose new evaluation protocols, datasets and methods to address the GPAD.
Overall, generalization has been addressed from different perspectives: i) applying domain adaptation techniques [21]; ii) learning generalized deep features [21, 20]; or even iii) using generative models [18]. All these methods are able to slightly mitigate the drop of performance when testing on new unseen scenarios, but they are still far from being suitable for real scenarios.
Traditional methods for face anti-spoofing use a two-class classifier to distinguish between real samples and attacks. Recently, some works suggest that formulating the problem of anti-spoofing as an anomaly detection approach could improve their generalization capacity [2, 25]. In [2], the authors assume that real-accesses share the same nature, in contrast to spoofing attempts that can be very diverse and unpredictable. They present a study to determine the influence of using only genuine data for training and compare it with traditional two-class classifiers. From the experimental results the paper concludes that: i) anomaly detection based systems are comparable to two classes based systems; and ii) neither of the two approaches perform well enough in the evaluated datasets (CASIA-FASD [39], Replay-Attack [8] and MSU-MFSD [33]). On the other hand, the authors of [25] propose a more challenging experiment based on an aggregated dataset that comprises Replay-Attack, Replay-Mobile [10] and MSU-MFSD. They propose a GMM-based anomaly classifier which outperforms the best solutions reported in [2].
In this paper, we reformulate the anomaly detection scheme using a deep metric learning model for face-PAD that highly reduces the problem of generalization. Experiments are performed over the largest aggregated publicly available dataset, the GRAD-GPAD framework [11]. This framework allows us to reinforce the assumption that real access data shares the same nature, provided that the number of identities is large and the capture conditions and devices are diverse enough; that is, the genuine class is well represented by data. Additionally, the highly representative embeddings obtained using the proposed metric learning approach permits outperforming prior works, distinguishing genuine amongst an open-set class of attacks in the most challenging dataset so far.
3 Deep Anomaly Detection for Face GPAD
3.1 Review on Metric Learning
Many works rely on a softmax loss function to separate samples from different classes in deep learning models. However, class compactness is not explicitly considered and samples from different classes might easily overlap in the feature space. Instead, metric learning based losses are designed to address these issues, by promoting inter-class separability and reducing intra-class variance. Note that several metric learning approached have been applied to multiple tasks such as face recognition [26], object retrieval [17] or person re-identification [38], obtaining outstanding generalization performance. In this section we introduce the mathematical notation and our formulation for the problem of deep anomaly detection for face GPAD, from a metric learning perspective.
Let be the feature vector in the embedding space of a data point , where the mapping function is a differentiable deep neural network of parameters , and let be the squared l2-norm between two feature vectors defined by . Usually, is normalized to have unit length for training stability. In a deep metric learning based approach, the objective is to learn a deep model that generates a feature representation to guarantee that samples from the same class are closer in the embedding space, than samples from different categories. For doing so, different loss functions can be found in the literature.
For instance, the center loss proposed in [34] concentrates samples around their class centers in the embedding space (see Eq. 1). It is used in conjunction with the softmax loss to increase intra-class compactness, however the latter does not guarantee a correct inter-class separation.
[TABLE]
where is the number of input tuples in a batch and is the class center corresponding to the ground truth label of sample .
The contrastive loss [9] (see Eq. 2) forces all images belonging to the same class to be close, while samples from different classes should be separated by a margin . It uses tuples of two images as different image pairs {, }: i) positive, if both belong to the same class and ii) negative, otherwise. However, one needs to fix a constant margin for the negative pairs, separating all negative examples by the same margin regardless their visual appearance:
[TABLE]
where for the positive pair and for the negative.
Following the same idea, the authors of the triplet loss [32] extend the contrastive loss to consider positive and negative pairs simultaneously by using a tuple of three images: i) anchor, ii) positive and iii) negative. The goal of the triplet loss in Eq. 3 is to reduce the intra-class variance defined by the anchor-positive pair, while simultaneously increase the inter-class separation by maximizing the euclidean distance between the anchor-negative pair. Despite avoiding a constant margin for the negative pair and obtaining highly discriminative features, it suffers from the complexity of the triplet selection procedure. Nevertheless, it has been successfully addressed in many recent approaches [35, 15, 31].
[TABLE]
where sub-indexes are the anchor, the positive and the negative samples for each triplet within the batch, respectively.
Prior works successfully applied the triplet loss (or any of its variants) using a large number of classes, e.g. face recognition models use thousands of identities, for instance in VGG2 Face data set [7] there are more than 9000 different identities. Such a diversity of classes encourages embeddings to generalize when the number of samples is large enough. In this paper, we show that a triplet loss based model, following an anomaly detection perspective, can actually outperform existing methods for face GPAD.
3.2 Triplet Focal Loss for Anomaly Detection for Face GPAD
We address the face GPAD problem from a metric learning approach with a Triplet focal loss. Technically, we propose to use a modified version of the triplet loss described in [29] that incorporates focal attention, see Eq. 4. The triplet focal loss automatically up-weights hard examples by mapping the euclidean distance to an exponential kernel, penalizing them much more than the easy ones.
[TABLE]
where is the hyper-parameter that controls the strength of the exponential kernel.
The triplets generation scheme is a critical step that highly impacts the final performance. Traditional methods run their sample strategy over the training set in an off-line fashion, and they do not adapt once the learning process starts. Alternatively, we use an approach for triplets selection based on a semi-hard batch negative mining process, where triplets examples are updated during the training process in each mini-batch, avoiding models to collapse.
The goal of the implemented semi-hard batch negative mining (based on [26]) is to choose a negative sample that is fairly hard within a batch but not necessarily the hardest nor the easiest one. For each training step, we select a large set of samples of each class using the current weights of the network. Next, we compute the distances between all positive pairs within this population, i.e. , and, for each positive pair, we compute the distance between the corresponding anchor and all possible negative samples . Finally, we randomly pick a negative sample that satisfies the following margin criteria, , to build the final tuples that are used for training at each step, in the so called mini-batch. This mining strategy has two important benefits: 1) we ensure that all the samples included in a training step are relevant for the learning process; and 2) we improve training convergence thanks to the random selection over the negative samples.
In real face anti-spoofing, attackers are constantly engineering new ways to cheat PAD systems with new attacks, materials, devices, etc. Thus, a classification-like approach is prone to over-fitting to the seen classes and will not generalize well. On the contrary, we follow an anomaly detection based strategy. First, we do not consider the identity of the users as different classes. We define two categories in an anomaly detection setting: 1) the closed-set, referring to the classes that can be correctly modeled during training; and 2) the open-set, referring to all the classes that cannot be fully modeled by the training set. In face GPAD, genuine samples belong to the closed-set category, while impostors belong to the open-set class, motivated by the scarcity or even the lack of training samples to model certain types of attacks. To achieve this, we fix during training the anchor-positive pair to always belong to the genuine class (i.e. the closed-set category) while selecting negative samples from any type of attack (i.e. the open-set category) regardless their identity.
3.3 Triplet Loss Regularization for a Metric-Softmax
Recent work [17] demonstrates that the triplet loss, acting as a regularizer of the softmax function, achieves more discriminative and robust embeddings. In our deep anomaly detection based model, we do not focus on the classification task, but instead we aim at obtaining highly representative embeddings to distinguish genuine samples amongst an open-set class of attacks. We thus propose to add the triplet focal loss as a regularizer of a novel softmax function adapted to metric learning, see Eq. 5. The proposed softmax formulation, coined as metric-softmax ( in Eq. 6), accumulates the probability distribution of each pair within a triplet to be highly separated in an euclidean space. We thus prevent from guiding the learning process towards a binary classification and thus avoiding the well known generalization issues.
[TABLE]
where is the hyper-parameter to control the trade-off between the triplet focal loss and the softmax loss.
The metric learning model proposed obtains a discriminative embedding for every input image. However, we need to provide a posterior probability of whether the image belongs to a genuine sample or to an impersonation attempt. In the experiments, we simply propose to train an SVM classifier with a Radial Basis Function to learn the boundaries between both classes in the feature space.
3.4 Few-shot a Posteriori Probability Estimation
Often, the inherent dynamic nature of spoofing attacks and the difficulty to access data requires to adapt rapidly to new environments where few samples are available. To deal with this problem, we propose a few-shot a posteriori estimation procedure, that does not need any classifier to train on the learned features for decision making in metric learning.
Technically, we proceed to compute the probability of being genuine (see Eq. 7) as the accumulated posterior probability of the input sample () given two reference sets in the target domain, corresponding to the genuine class and the attacks , respectively.
[TABLE]
where is the total number of pairs in both reference sets for every attack and for each dataset involved, sub-index refers to the test image and sub-indexes refer to each of the reference samples in the genuine and attack sets, respectively. In order to satisfy the few-shot constraints we choose to be small in our experiments.
4 Experimental Results
In this section we present the experiments where our novel approach is compared against three state-of-the-art methods from the literature. The approach in [25] computes hand-crafted features based on quality evidences. They obtain a 139-length feature vector from the concatenation of the quality measurements proposed in [14] and [33]. For the second method, we choose [4], which consists in computing a color-based feature vector of high dimensionality (19998-length) by concatenating texture features based on Local Binary Patterns (LBPs) in two different color spaces (i.e. YCbCr and HSV). Finally, the third method is the one proposed in [23], which introduces a two-branch deep neural network that incorporates pixel-wise auxiliary supervision constrained by the depth reconstruction for all genuine samples (attacks are forced to belong to a plane) and the estimation of a remote PhotoPlethysmoGraphy (rPPG) signal to add temporal information. Despite being the state of the art for face anti-spoofing, this model requires to pre-process genuine samples in order to compute the depth estimation and the corresponding rPPG signal, that impacts in the usability and bounds the performance to the methods for depth reconstruction and rPPG estimation. The code for the first two algorithms is based on the reproducible material provided by the authors333https://github.com/zboulkenafet/Face-anti-spoofing-based-on-color-texture-analysis 444https://gitlab.idiap.ch/bob/bob.pad.face/. Results for [23] are obtained using our own re-implementation of their approach.
4.1 GRAD-GPAD Framework
Regardless almost every paper comes with its own reduced dataset [24, 23, 37, 21], there is no agreed upon a PAD benchmark, and as a consequence, the generalization properties of the models are not properly evaluated. During a brief inspection of the capture settings of available face PAD datasets, one can easily observe that there is no unified criteria in the goals of each of them, leading to a manifest built-in bias. This specificity in the domain covered by most of the datasets can be observed in different scenarios: i) some of them focus on a single type of attacks (e.g. masks - 3DMAD [13], HKBU [22], CSMAD [3]); ii) others focus on the study of different image sources (depth/NIR/thermal) such as CASIA-SURF [37] or CSMAD; iii) others attempt to simulate a certain scenario like a mobile device setting, where the user hold the device (e.g. Replay-Mobile [10], OULU-NPU [6]), or a webcam setting, where the user is placed in front of a fixed camera (e.g. Replay-Attack [8], SiW [23]), or even a stand-up scenario where users are recorded further from the camera (e.g. UVAD [27]).
For our experiments, we propose to use the recently published GRAD-GPAD framework [11] that mitigates the aforementioned limitations. GRAD-GPAD is the largest aggregated dataset that unifies more than 10 datasets with a common categorization in two levels, to represent four key aspects in anti-spoofing: attacks, lightning, capture devices and resolution. It allows not only a fair evaluation of the generalization properties, but also a better representativity of the face-PAD problem thanks to the increased volume of data. For the sake of the extension of the paper we focus on the evaluation based on the instruments used to perform attacks (i.e. PAI - Presentation Attack Instruments) using the categorization in Table 1 (i.e. the Grandtest protocol).
We conduct all the experiments using the GRAD-GPAD framework, where we add the UVAD dataset [27] to further increase the total number of samples in more than 10k images. In Fig. 2 we show the population statistics of the whole GRAD-GPAD dataset (left figure) and the training split of the Grandtest protocol (right figure).
4.2 Experimental Setup
Network Architecture
We use as our backbone architecture a modified version of the ResNet-50 [16]. We stack both RGB and HSV color spaces in the input volume, and feature dimension is fixed to 512. We use Stochastic Gradient Descent with Momentum optimizer. We start training with a learning rate of using a maximum of 100 epochs. Batch size is fixed to be 12 triplets, i.e. 36 images per batch. As suggested in the original works, and values in Eq. 4 are set to 0.3 and 0.2, respectively.
Pre-processing
Since our approach follows a frame-based procedure, instead of using the full videos we only pick the central frame of each video. We use as inputs of the network the cropped faces detected using the method proposed in [36].
Metrics
To compare our method with prior works we use the metrics that have been recently standardized in the ISO/IEC 30107-3555https://www.iso.org/standard/67381.html: i.e. False Acceptance Rate (FAR), False Rejection Rate (FRR), Half Total Error Rate (), Attack Presentation Classification Error Rate (APCER), Bonafide Presentation Classification Error Rate (BPCER) and Average Classification Error Rate (ACER). We would like to highlight the importance of the ACER metric because it entails the most challenging scenario, where performance is computed for every attack independently, but it only considers the results for the worst scenario. Thus it penalizes approaches performing well on certain types of attacks. HTER reflects the overall performance of the algorithm in a balanced setting where FAR is equal to FRR, i.e. for Equal Error Rate (EER).
Protocols
We evaluate our method on two settings within the GRAD-GPAD framework: 1) intra-dataset; and 2) inter-dataset. For the intra-dataset setting we use the Grandtest protocol and for the inter-dataset evaluation we use the leave-one-dataset-out protocols, provided by the framework: the Cross-Dataset-Test-On-CASIA-FASD and the Cross-Dataset-Test-On-ReplayAttack. In these protocols, one of the datasets (CASIA-FASD and Replay-Attack, respectively) is excluded during training. Results are provided by evaluating the models in the excluded dataset (Test split).
4.3 Ablation study
The scientific contribution of our work is twofold. First, we introduce a reformulation of the face PAD problem from a deep anomaly detection perspective using metric learning. Second, we propose to use a triplet focal loss as a regularization for a novel softmax loss function adapted to metric learning, coined as “metric-softmax”. To show the influence of each of these contributions, we conduct the following experiments. We start from a classification-like triplet loss based model, i.e. without the anomaly detection approach. This first approach is named as Baseline in Table 2, where tuples for the triplets are selected randomly from the set of classes (genuine + 9 different attacks in GRAD-GPAD). We then incrementally incorporate our contributions. Model 1 includes the anomaly approach using the triplet loss. In Model 2 we included the focal attention into the triplet loss formulation. And finally, Ours represents the whole pipeline of our system, where the proposed metric-softmax term is added. The results reported in Table 2 show the influence of each contribution in the final performance.
Note that for this ablation study, we use the development split of the Grandtest protocol of GRAD-GPAD, and the performance is shown in terms: FAR, FRR and Average Error Rate (AER). Besides, performance is computed using the accumulated metric-softmax distribution described in Eq. 7 with and by randomly choosing samples from the training set.
We show in Table 2 that, when we incorporate the focal attention into the triplet, i.e. Model 2, we achieve a relative improvement of 42.42% in terms of AER. This aspect reveals the importance of a mining strategy in the learning process. Finally, the introduction of the proposed metric-softmax term, achieves a remarkable relative improvement of 70.21% of AER.
Furthermore, we show in Fig. 3 the True Positive Rate (TPR) confusion matrices for the Baseline (left) and our approach (right). We assess that, with the anomaly detection approach, we are able to highly differentiate genuine from impostor samples, regardless the classification of the attack instrument. Note that the baseline obtains poor performance for genuine samples classification, despite classifying correctly the different attacks, which highly penalizes its global performance.
4.4 Intra-Dataset Evaluation
In order to fairly compare our approach with the state-of-the-art methods, we train an SVM-RBF classifier for each of them using their corresponding features. Additionally, for the Auxiliary model [23], we report the results just using the L2-Norm from the depth map (Auxiliary∗), as it is proposed by the authors in their original work. For all the experiments, we use in Eq. 7 for the few-shot a posteriori probability estimation (Ours†) experiment. Note that, both the original method proposed in [23] (Auxiliary∗) and our approach with a posteriori estimation, do not need to use any classifier with the learned features.
Results in Table 3 demonstrate that both our novel approaches outperform the state-of-art methods, even using the most challenging metric (ACER). These results highlight that the learned feature space has a high discrimination capability and that our model performs the best.
4.5 Inter-Dataset Evaluation
In order to assess the generalization capabilities, we perform two cross-dataset evaluations where a whole dataset is excluded from the training step. In the first experiment, we leave out CASIA-FASD [39] for the test set. In the second one, ReplayAttack [8] is excluded during learning. In both experiments, none of the samples from the test dataset are used neither in the training set nor in the development set.
4.5.1 Test on CASIA-FASD
As it is shown in Fig. 4, the training set for this experiment includes all types of attacks, however the domain is different (i.e. different environments, lighting conditions, capture devices, etc.). CASIA-FASD is one of the smallest datasets for face anti-spoofing samples. Therefore, considering only its test set for the evaluation would highly penalize the performance in case of miss-classification. This fact is reflected in Table 4, where performance significantly drops in all methods, except for our approach, where we are able to keep a reasonable good performance: from an ACER of 10.14% (see Table 3) to 16.8%.
In Table 4 we show that HTER and ACER values for our approach are almost the same. We argue that, despite the domain shift introduced by this protocol, the learned embeddings during training are robust enough to generalize in this setting. Instead, the other methods in the experiment are highly penalized, showing that they tend to overfit on the training set to a greater extent.
Besides, we show that our few-shot a posteriori estimation pipeline (Ours*†*) achieves similar performance compared to the SVM version in this Test on CASIA-FASD setup. Thus, we assess that the learnt embedding space generalizes enough so that we can avoid using a classifier with the feature vectors and estimate the a posteriori probability by simply using . This classiffier-free model is also able to outperform all state-of-the-art methods, including Auxiliary∗ that neither requires a classifier.
4.5.2 Test on Replay-Attack
The motivation behind selecting to leave out the Replay-Attack dataset is to show the impact in the performance of face-PAD algorithms of unseen attacks belonging to a new domain: this dataset contains all the samples for replay-low-quality attacks (see Fig. 5). This entails a far more challenging scenario.
The results reported in Table 5 show a severe drop of performance for all the methods, specially for ACER, where all the approaches are highly penalized by the unseen attack and achieves performance close to random choice. This fact is due to the addition of a new attack that has never seen before in combination with a strong domain change, highly impacting on APCER (i.e. the attack classification). Interestingly, our proposal based on few-shot a posteriori estimation keeps exactly the same performance compared with our method with an SVM, again assessing that we can replace the classifier using a few samples. Besides, we obtain the best overall performance HTER and the best BPCER (ACER is close to random choice for all the methods).
5 Conclusions
In this work we introduce a novel approach that addresses the problem of generalization in face-PAD, following an anomaly detection pipeline. We leverage deep metric learning to propose a new “metric-softmax” loss that applied in conjunction with the triplet focal loss drives to more robust and generalized features representations to distinguish between original and attack samples. We also propose a new a posteriori probability estimation that prevents us from the need of training any classifier for decision making. With a thorough experimental evaluation in the challenging GRAD-GPAD framework we show that the proposed solution outperforms prior works by a considerable margin.
Acknowledgements
We thank our colleagues of the Biometrics Team at Gradiant for their valuable contributions. Special mention to Esteban Vazquez-Fernandez, Julián Lamoso-Núñez and Miguel Lorenzo-Montoto.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] A. Anjos and S. Marcel. Counter-measures to photo attacks in face recognition: A public database and a baseline. In International Joint Conference on Biometrics (IJCB) , 2011.
- 2[2] S. R. Arashloo, J. Kittler, and W. Christmas. An anomaly detection approach to face spoofing detection: A new formulation and evaluation protocol. IEEE Access , 2017.
- 3[3] Sushil Bhattacharjee, Amir Mohammadi, and Sébastien Marcel. Spoofing Deep Face Recognition With Custom Silicone Masks. In BTAS , 2018.
- 4[4] Z. Boulkenafet, J. Komulainen, and A. Hadid. Face spoofing detection using colour texture analysis. IEEE Transactions on Information Forensics and Security (TIFS) , 11(8):1818–1830, Aug 2016.
- 5[5] Zinelabidine Boulkenafet, Jukka Komulainen, and Abdenour Hadid. On the generalization of color texture-based face anti-spoofing. Image and Vision Computing , 77:1–9, 2018.
- 6[6] Z. Boulkenafet, J. Komulainen, Lei. Li, X. Feng, and A. Hadid. OULU-NPU: A mobile face presentation attack database with real-world variations. In IEEE International Conference on Automatic Face and Gesture Recognition , May 2017.
- 7[7] Q. Cao, L. Shen, W. Xie, O. M. Parkhi, and A. Zisserman. Vggface 2: A dataset for recognising faces across pose and age. In International Conference on Automatic Face and Gesture Recognition , 2018.
- 8[8] Ivana Chingovska, André Anjos, and Sébastien Marcel. On the effectiveness of local binary patterns in face anti-spoofing. In BIOSIG , September 2012.
