Understanding the Signature of Controversial Wikipedia Articles through Motifs in Editor Revision Networks
James R. Ashford, Liam D. Turner, Roger M. Whitaker, Alun Preece,, Diane Felmlee, Don Towsley

TL;DR
This study analyzes editor interaction patterns in Wikipedia articles using motif analysis of revision networks, revealing distinct clustering in controversial articles that could aid in predicting controversy.
Contribution
The paper introduces motif analysis of editor revision networks to distinguish controversial from non-controversial Wikipedia articles, offering a novel approach without semantic analysis.
Findings
Controversial articles show more clustering of editor interactions.
A small set of triads significantly characterizes controversy.
Motif profiles can potentially predict article controversy.
Abstract
Wikipedia serves as a good example of how editors collaborate to form and maintain an article. The relationship between editors, derived from their sequence of editing activity, results in a directed network structure called the revision network, that potentially holds valuable insights into editing activity. In this paper we create revision networks to assess differences between controversial and non-controversial articles, as labelled by Wikipedia. Originating from complex networks, we apply motif analysis, which determines the under or over-representation of induced sub-structures, in this case triads of editors. We analyse 21,631 Wikipedia articles in this way, and use principal component analysis to consider the relationship between their motif subgraph ratio profiles. Results show that a small number of induced triads play an important role in characterising relationships between…
Click any figure to enlarge with its caption.
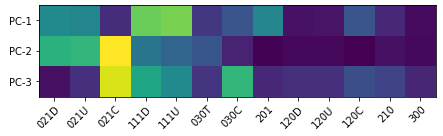 Figure 1
Figure 1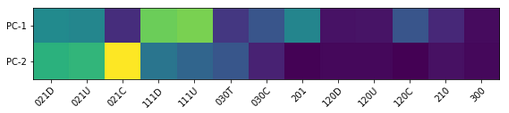 Figure 2
Figure 2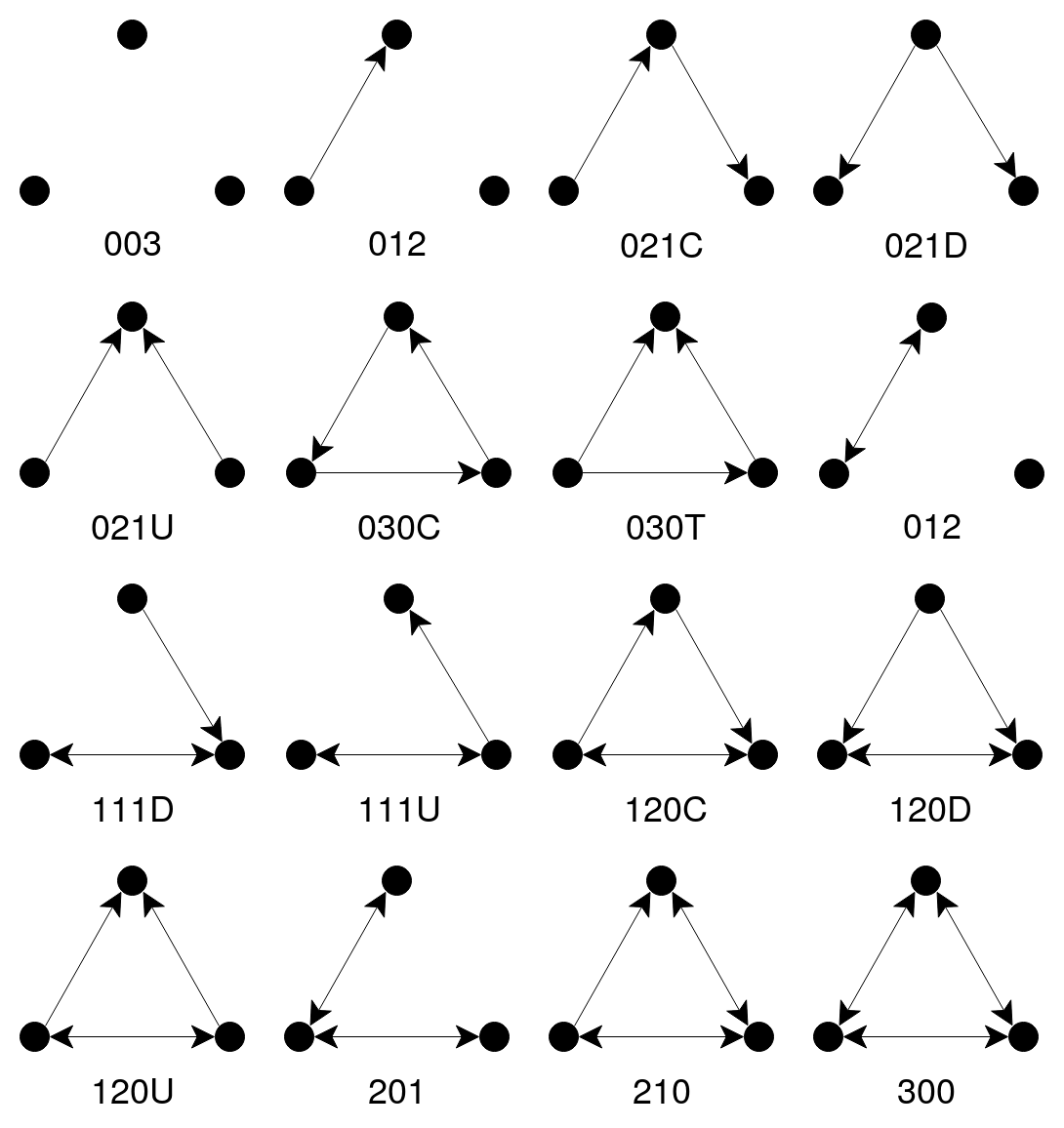 Figure 3
Figure 3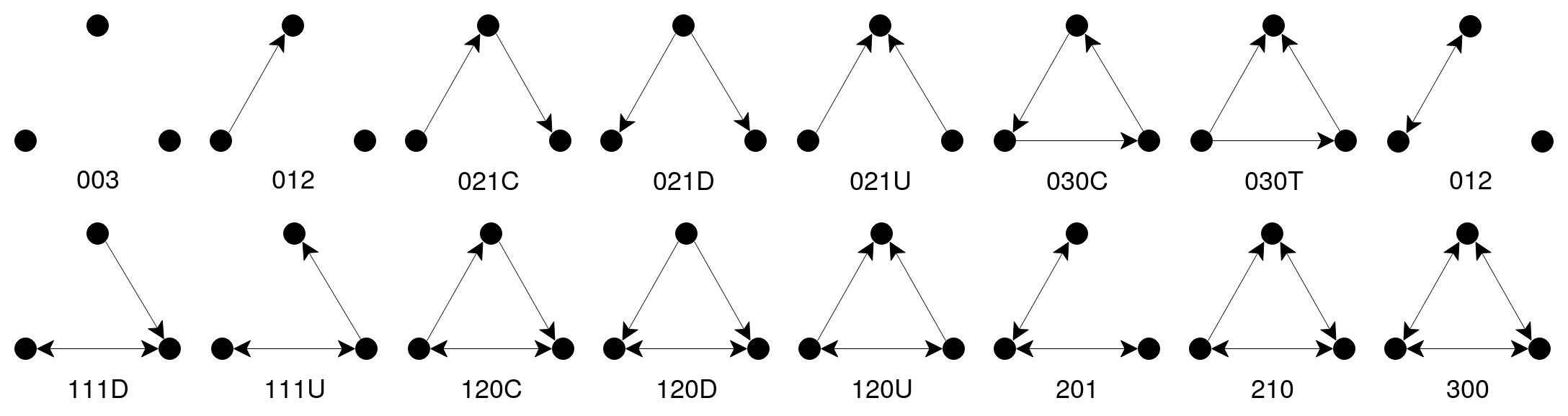 Figure 4
Figure 4 Figure 5
Figure 5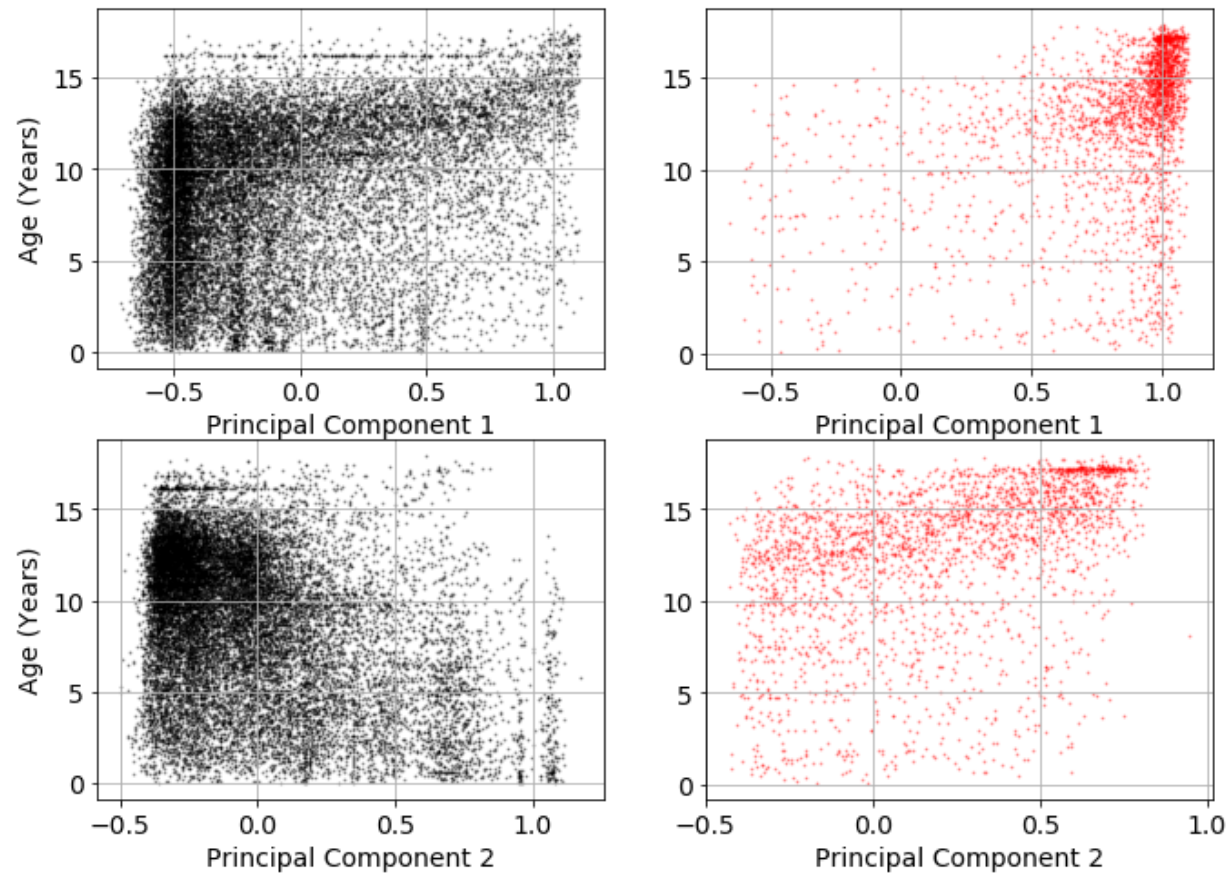 Figure 6
Figure 6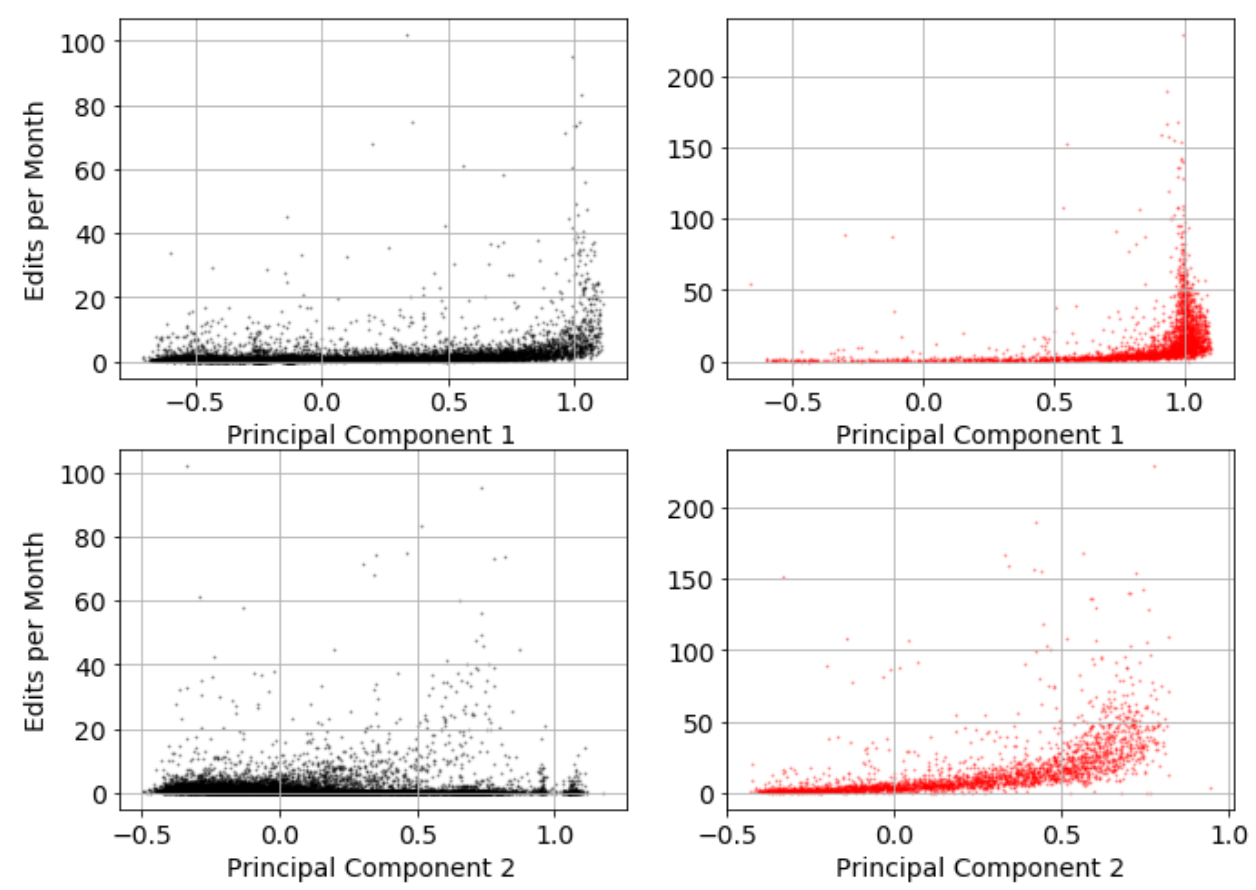 Figure 7
Figure 7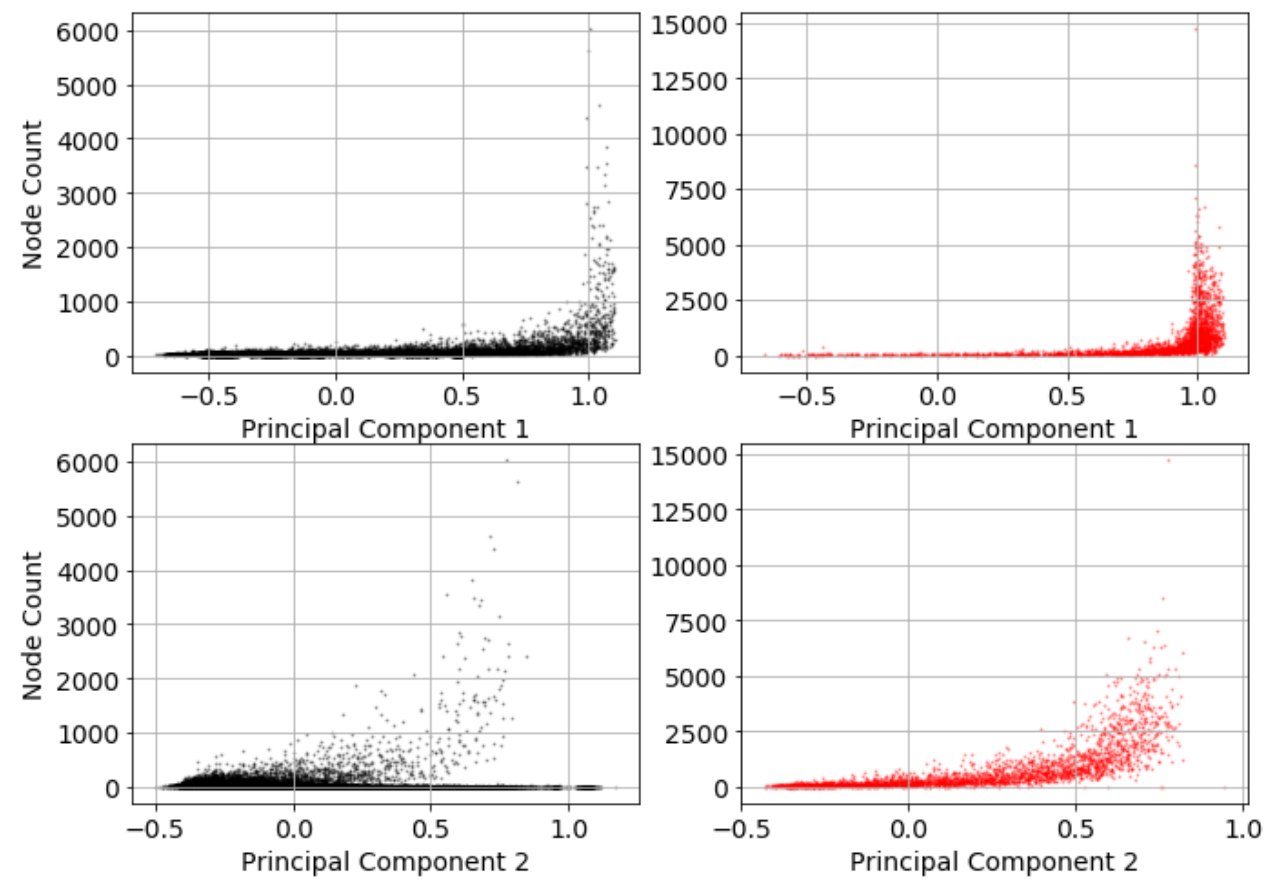 Figure 8
Figure 8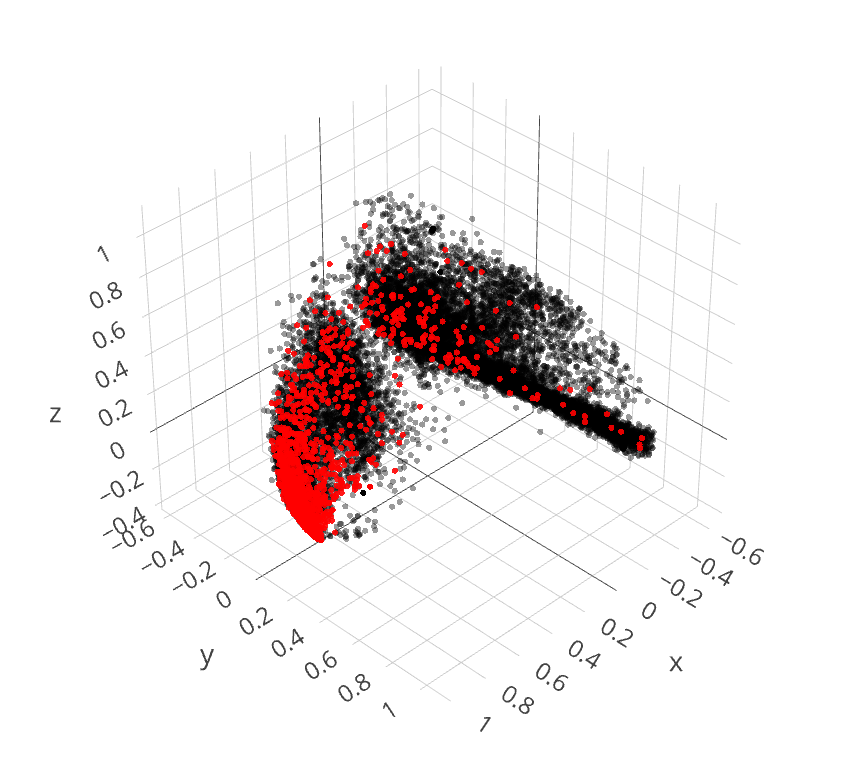 Figure 9
Figure 9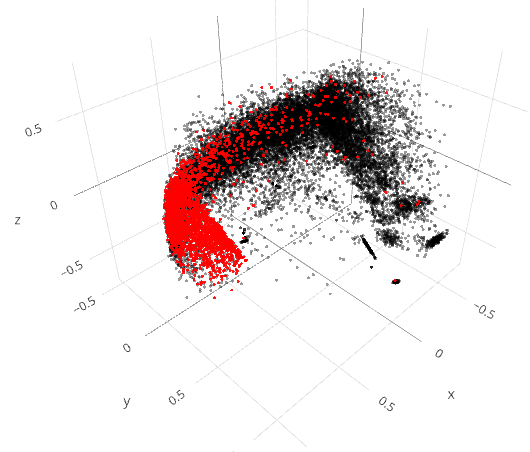 Figure 10
Figure 10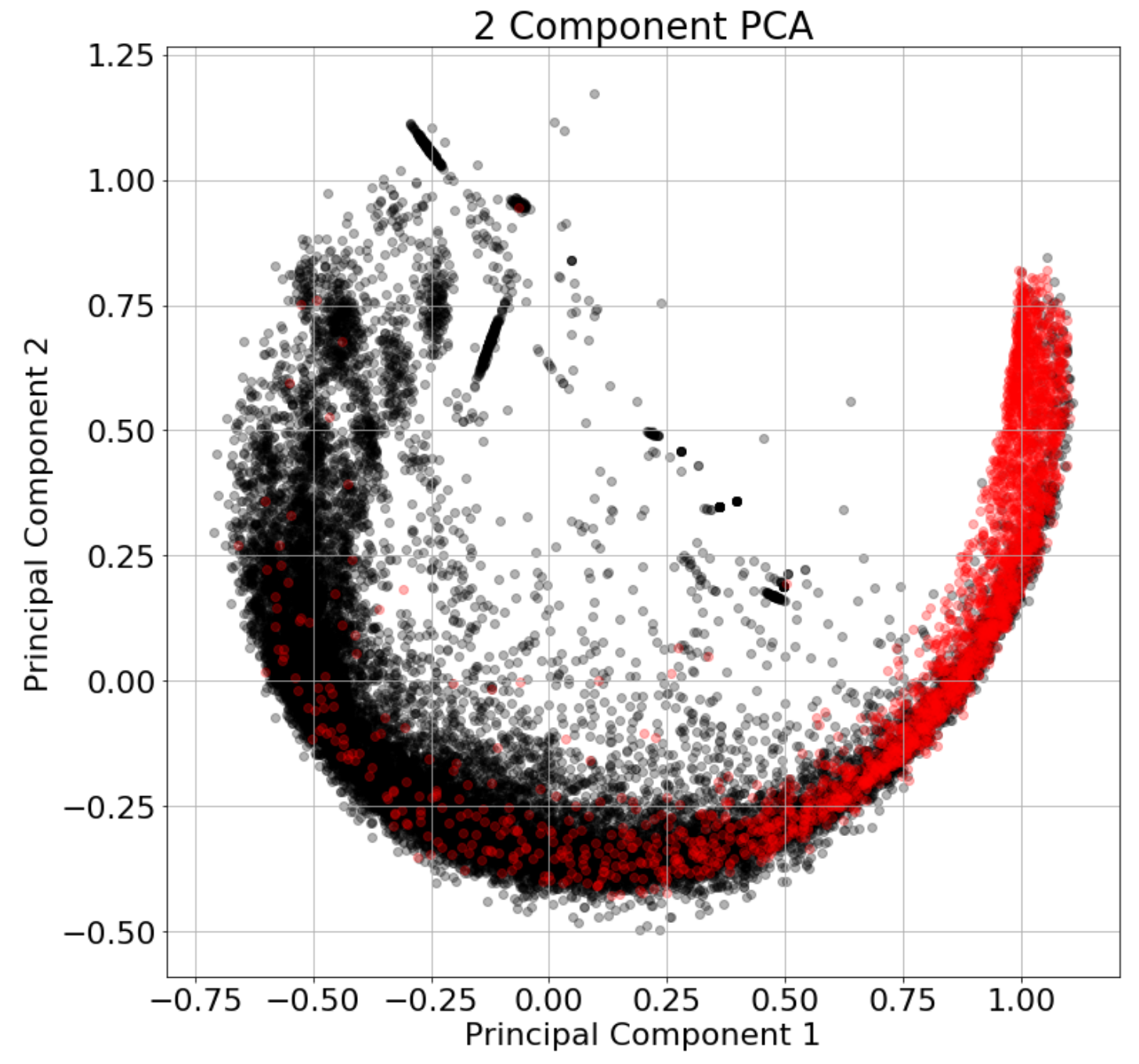 Figure 11
Figure 11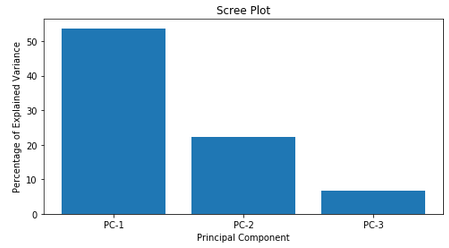 Figure 12
Figure 12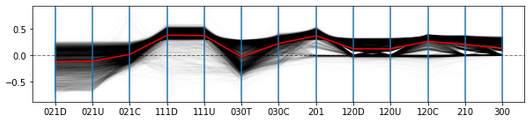 Figure 13
Figure 13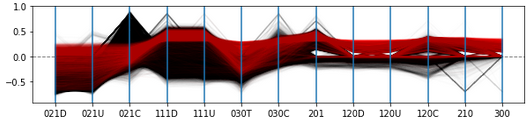 Figure 14
Figure 14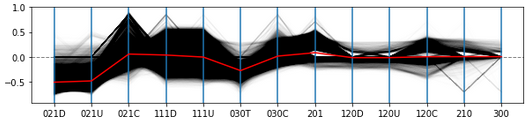 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17| 021D | 021U | 021C | 111D | 111U | 030T | 030C | 201 | 120D | 120U | 120C | 210 | 300 | |
| PC-1 | 0.332 | 0.321 | -0.126 | 0.509 | 0.522 | 0.145 | 0.205 | 0.318 | 0.078 | 0.079 | 0.204 | 0.117 | 0.065 |
| PC-2 | 0.427 | 0.438 | 0.643 | -0.278 | -0.242 | 0.207 | 0.104 | -0.052 | 0.059 | 0.06 | 0.047 | 0.074 | 0.06 |
| PC-3 | 0.074 | 0.127 | -0.609 | -0.398 | -0.332 | 0.136 | 0.441 | 0.115 | 0.131 | 0.130 | 0.19 | 0.167 | 0.112 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsWikis in Education and Collaboration · Open Source Software Innovations · Software Engineering Research
Understanding the Signature of Controversial Wikipedia Articles through Motifs in Editor Revision Networks
James R. Ashford
School of Computer Science and Informatics, Cardiff University,
UK
,
Liam D. Turner
School of Computer Science and Informatics, Cardiff University,
UK
,
Roger M. Whitaker
School of Computer Science and Informatics, Cardiff University,
UK
,
Alun Preece
Crime and Security Research Institute, Cardiff University,
UK
,
Diane Felmlee
Dept. of Sociology & Criminology, Pennsylvania State University,
USA
and
Don Towsley
College of Information and Computer Sciences, University of Massachusetts Amherst, USA
(2019)
Abstract.
Wikipedia serves as a good example of how editors collaborate to form and maintain an article. The relationship between editors, derived from their sequence of editing activity, results in a directed network structure called the revision network, that potentially holds valuable insights into editing activity. In this paper we create revision networks to assess differences between controversial and non-controversial articles, as labelled by Wikipedia. Originating from complex networks, we apply motif analysis, which determines the under or over-representation of induced sub-structures, in this case triads of editors. We analyse 21,631 Wikipedia articles in this way, and use principal component analysis to consider the relationship between their motif subgraph ratio profiles. Results show that a small number of induced triads play an important role in characterising relationships between editors, with controversial articles having a tendency to cluster. This provides useful insight into editing behaviour and interaction capturing counter-narratives, without recourse to semantic analysis. It also provides a potentially useful feature for future prediction of controversial Wikipedia articles.
Network Motifs, Wikipedia, Controversy, Complex Networks
††journalyear: 2019††copyright: iw3c2w3††conference: Companion Proceedings of the 2019 World Wide Web Conference; May 13–17, 2019; San Francisco, CA, USA††booktitle: Companion Proceedings of the 2019 World Wide Web Conference (WWW ’19 Companion), May 13–17, 2019, San Francisco, CA, USA††doi: 10.1145/3308560.3316754††isbn: 978-1-4503-6675-5/19/05
1. Introduction
Wikipedia has become a tremendous platform for crowdsourcing knowledge, representing a cornerstone of the World Wide Web (Doan et al., 2011). It allows the ”wisdom of the crowd” (Surowiecki and James, 2005) to potentially emerge, providing intelligence on a vast range of topics (Brabham, 2008). However, complex dynamics support the emergence of content, since the formation of Wikipedia articles involves both human cooperation and human conflict, based on the extent of convergent and divergent views. Narrative and counter-narrative frequently jostle for presence in a articles, representing a source of friction that is seen through editor interaction (Sepehri-Rad and Barbosa, 2015a) and in the semantics of article content (Rad and Barbosa, 2012a). Wikipedia conveniently provides a list of controversial content that are labelled by the Wikipedia community themselves111https://en.wikipedia.org/wiki/Wikipedia:List_of_controversial_issues.
In an age of misinformation (Acemoglu et al., 2010; Mocanu et al., 2015; Vicario et al., 2016), understanding characteristics of controversial articles has increased in importance. Because of the controversial nature of some topics, the narrative in a Wikipedia article may contain misleading information that stops a neutral consensus emerging. Prior work in this area has established insights such as the predictability of controversy from editor behaviour (Rad and Barbosa, 2012a), such as deletions, reversions, and statistics from the collaboration network, prediction of article quality taking insights from multiple models (Wu et al., 2012), and interactions between users, bots, admin and pages (Jurgens and Lu, 2012). There has also been a number of different types of network developed to assess Wikipedia articles, including collaboration networks (Brandes et al., 2009) that capture the positive or negative relationship between editors, edit networks that capture ”undoing” of edits by a third party (Kittur et al., 2007) and affiliation networks (Kane and Ransbotham, 2016).
Our focus in this paper is to further understand the relationship between small groups of editors, as induced by their editing sequences, by using a revision network. This does not require information on the nature of the editing undertaken - it simply captures the ordering in which editing occurs and is therefore a simple metric to infer. Editors are represented by nodes and a directed edge from node to indicates that ”Editor A edits the article after Editor B” (see Figure 1). From this, we seek to determine the extent to which controversial articles exhibit a distinctive signature relative to those that are deemed non-controversial.
There has already been some consideration of revision networks in the literature (Iba et al., 2010; Keegan et al., 2012), where more recently the emphasis (Wu and Cunningham, 2015) has been to combine them with other network representations. However, given the fundamental nature of revision networks, it is interesting to question the extent to which they hold sufficient information to characterise controversial Wikipedia articles. Currently this is not well-understood, and motivates our work.
1.1. Hypotheses
We hypothesise that interaction differences between small sub-groups of Wikipedia editors is sufficient to distinguish between controversial articles and non-controversial articles. To address this we consider the extent to which revision networks of Wikipedia articles have different local induced substructures based on their having controversial classifications. Our approach is based on techniques from complex networks (Milo et al., 2002, 2004), that have been successful in classifying diverse and complex biological networks based on their latent induced subgraphs.
To achieve this at scale, and in contrast to previous literature (Sepehri-Rad and Barbosa, 2015a; Rad and Barbosa, 2012a; Jurgens and Lu, 2012), we assess a relatively large sample of Wikipedia articles, involving over 21,000 Wikipedia articles, by determining their subgraph ratio profiles. Each such profile represents the under and over representation of induced triads in the revision network of a Wikipedia article using 13 dimensions of connected triads, while also normalising for differences in network size.
Understanding the relationship between Wikipedia articles is important, as it allows us to determine the extent to which they may cluster. The sample we are considering represents 21,631 articles each represented in 13 dimensions. Therefore we perform dimensionality reduction, and project the subgraph ratio profiles into lower dimensional spaces. This allows us to examine the relationship both within and between controversial and non-controversial articles.
The results draw attention to distinctive clustering patterns concerning controversial Wikipedia articles. We further assess the results by examining the correlation with a range of variables, allowing to understand the role of substructures. The findings reaffirm that the sequence of editing provides an important mechanism to understand Wikipedia articles, independent of an article’s topic and without recourse to semantic analysis.
2. Related Work
Understanding the content of crowd-sourced platforms such as Wikipedia and the behaviour of their contributors is of wide research interest (Surowiecki and James, 2005). Wikipedia represents a dynamic network of articles with a structure resembling that of the World Wide Web (Zlatić et al., 2006), whereby dominant articles act as connectivity hubs. Dynamics also exist within the formation and maintenance of individual Wikipedia articles, through open and collaborative editing.
Interactions between editors range from positive to negative, where debates and arguments lead to different patterns of revision (e.g., (Rad and Barbosa, 2012a; Laniado et al., 2011)), capturing behaviours such as vandalism (Potthast et al., 2008) and the propagation of disinformation (Kumar et al., 2016). Characterising articles and contributors through revisions provides a means for Wikipedia to manage and review its content. This is potentially labour intensive and has led to interest in creating and exploiting methods to detect issues (e.g.,(Adler et al., 2011; Sepehri-Rad and Barbosa, 2015b)).
Controversial articles have become an increasing point of focus, and characterised as such by Wikipedia. Automated methods for classifying articles have received much attention (e.g., (Rad and Barbosa, 2012b; Wu et al., 2012; Wu and Cunningham, 2015). The associated revision log for Wikipedia articles has been shown to provide a basis to examine potential controversy through examining the collaborative behaviour of individual editors within an article (Sepehri-Rad and Barbosa, 2015b) or across multiple articles (Wu et al., 2011). An article’s revision log identifies the structure underlying temporal interactions (Wu and Cunningham, 2015), and provides insight into how articles and contributors’ habits may evolve over time (Jurgens and Lu, 2012). Features from the aggregation of this, such as number of edits, revision, and previous version restorations have been shown to correlate (e.g., (Sepehri-Rad and Barbosa, 2015b)).
Treating the revision log as a network between editors (Sepehri-Rad and Barbosa, 2015a) has been shown to provide additional useful features using graph theory and social network analysis techniques (e.g., (Rad and Barbosa, 2012b)). This has ranged from global features such as the degree distribution (e.g., (Sepehri-Rad and Barbosa, 2015b)), through to analysis of local sub-structures concerning the articles with which editors interact (e.g., (Wu et al., 2011)).
However, there has been little investigation of controversial articles based on the under or over representation of local-substructures. Called network motif analysis, this approach originated from biology (Milo et al., 2004; Braines et al., 2018), and has been used to good effect in characterising other complex networks, including technology (e.g., (O’Callaghan et al., 2012)). In terms of Wikipedia, motif analysis has been used to determine how articles point to each other (Zlatić et al., 2006) and in assessing interactions between editors and different Wikipedia articles (Wu et al., 2011). Our contribution is two-fold: firstly to use motif analysis to understand the fundamental revision networks, and secondly to consider the role of motifs in differentiating between controversial and non-controversial articles.
3. Methods
3.1. Dataset
We collected revision history logs and article meta-data of a sample of Wikipedia articles () through Wikipedia’s web API222https://en.wikipedia.org/w/api.php. The revision logs contain time-series events and meta-data attributing the revision to a particular user at a given time. Within this set of articles, a subset () are considered to be ’controversial’ as they are listed in Wikipedia’s ”List of controversial issues”1. The remaining articles () are random articles that are not contained in the controversial issue list to serve as a basis for comparison. These were taken from an original sample of 23,000 articles (20,000 non-controversial and 3,000 controversial), from which articles were removed if they did not contain sufficient information for motif analysis.
3.2. Network Construction
For each article, we construct a revision network (in the same manner as (Keegan et al., 2012; Wu and Cunningham, 2015)) where nodes represent unique editors and directed edges show that an editor added a revision after another editor. We traverse the revision log list to build a network that spans the article’s lifetime, adding nodes and edges as they appear in each event. Specifically let the revision network of a Wikipedia article be defined by , where each editor is represented by a node . An edge indicates that editor edits the article after editor . This excludes self-loops and editor editing after editor multiple times does not result in a multi-edge.
A simple example can be found in Figure 1, which describes how the network is constructed. Two extreme examples from the dataset shown in Figures 3a and 3b. This form of representation is potentially useful as large articles do not typically follow a linear or incremental structure. For example, it is highly likely that users will restore work back to an earlier revision should a revision become vandalised or irrelevant. Editors are likely to refer back to previous editor’s work. These behaviours result in complex sequential patterns that are captured through revision networks.
3.3. Network Motif Analysis
Network motif analysis focuses on determining the under or over representation of induced subgraphs (Milo et al., 2002; Braines et al., 2018), as compared to an alternative sample of graphs (i.e., a null-model that acts a relevant baseline for comparison). Dyads, triads and tetrads are often considered as induced subgraphs such over and under-represented induced subgraphs are called network motifs or anti-motifs. In this analysis, we examine each article’s revision network using triads, representing how all possible triples of editors may sequentially interact. Triads are sufficiently large enough to capture both direct and indirect reciprocity between editors, while not being of a scale that is impeded by combinatorial complexity - there are 13 possible connected triads, shown in Figure 2. The coded names listed in Figure 2 are provided as part of the convention used in the triad census algorithm (Batagelj and Mrvar, 2001).
For each article, we calculate the subgraph ratio profile (SRP) as defined by Milo et al (Milo et al., 2004). This accounts for variations in network size. This is achieved by determining the relative abundance of each type of triad compared to random graphs generated by the null-model. For each type of triad , we firstly calculate :
[TABLE]
where is the number of such triads observed in the graph under observation, and is the average frequency of such triads seen across the sample of networks composed by the null model. In this case the null model uses 100 random graphs with the same number of nodes and edges as the graph under observation. The value of is set to (Milo et al., 2004; Tu et al., 2018) to prevent the result from being misleadingly large when a subgraph rarely appears. This process is repeated for each triad and normalised across triads to form the subgraph ratio profile (SRP) for a given network. The SRP, denoted , denotes the extent of under or over representation of the triad , and is defined by:
[TABLE]
3.4. Article comparison and dimensionality reduction
The SRP composed for each article provides a 13-dimensional vector whose components indicate the extent of triad representation relative to networks in the null model. To assess these collectively, we use principal component analysis (PCA) that allows the SRPs to be considered in a lower dimensional space. We apply three and two dimensional PCA. Finally, we make comparison with a number of external variables (number of editors/nodes, age of article, and revision rate) to understand potential correlations with motifs.
4. Results
4.1. Subgraph Ratio Profiles
We first examine the SRPs that arise from both controversial and non-controversial articles in isolation (Figures 4 and 5 respectively). To find significant triads, we use a cutoff value of +0.3 and -0.3. We determine that controversial articles are strongly represented by triads 111D, 111U and 201, which attain average SRP scores of 0.382, 0.375, 0.372, with relatively low dispersion (SDs of 0.136, 0.149 and 0.124 respectively). Interestingly, together these represent a chain of three nodes, where one edge is reciprocated, with the other edge covering all possible directional types (i.e., reciprocated, directed in, directed out).
In contrast, the results for the non-controversial articles provide a different profile. Here 021D and 021U are significantly under represented (average SRP scores of -0.511, -0.485), albeit with higher standard deviations present (SDs of 0.192, 0.2). Interestingly these anti-motifs (021D and 021U) relate to a lack of subgraphs where directed edges either emanate from or are received by a single node in the triad. Such configurations relate to the role of a mediating editor that may be presented with or respond to the editing of others. In other words, such mediators have a reduced role in non-controversial articles.
The comparison between these subgraph ratio profiles is shown in Figure 6. These profiles are quite distinct. We also calculate the Pearson correlation coefficient for each distinct pair of articles in three groups - controversial articles, non-controversial articles and all articles. Controversial articles provide the greatest correlation to each other (M=, SD=). Non-controversial articles have a lower mean correlation (M=, SD=) which is similar to the result when considering all articles together (M=, SD=).
4.2. Principal Component Analysis
We analyse the 21,631 subgraph ratio profiles to determine the relationship in terms of relative clustering. We apply PCA in order to reduce the 13 dimensions of the SRPs down to a more manageable form. We initially project the SRPs into 3-dimensional space for clarity, as seen in Figure 7. This presents a distinctive region where controversial articles are dominant. This provides evidence for a distinction between the controversial and non-controversial articles, consistent with the variation in motifs identified in the previous section.
The PCA coefficients (Table 1) that define the three dimensions reveals that principal component one ( axis in Figure 7) primarily depends on triads 111D and 111U. Principal component two ( axis in Figure 7) primarily depends on triad 021C. The third principal component primarily depends on triads 021C and 030C. However, we also note that when represented in the three dimensional space, the revision networks have limited dispersion in the third dimension (i.e., vertical dimension as plotted).
Calculating the percentage of explained variance by principal component confirms that the first principal component produces 53.7% of the shared variance, the second produces 22.3% and the third produces the least with 6.7%. This confirms that the third principal component provides a limited contribution to representation of the total variance across the significant ratio profiles. This supports representation through two principal components, as plotted in Figure 8, with the relative composition of each principal component being near identical to PC-1 and PC-2 in Table 1. As anticipated, this is similar dependency on the first and second primary components in the three dimensional representation.
Representation in two dimensions further clarifies the distinction between controversial and non-controversial revision networks. In particular, from Figure 8 we note that both classes of article exhibit a similar maximum and minimum range against principal component two, which is primarily defined by the linear path between three nodes (021C). However, it is the variation in the first principal component, dominated by 111D and 111U, which represent linear paths with reciprocation on one edge, that differentiate the non-controversial from controversial. High values in principal component one correlate with controversial articles - in other words, controversial articles exhibit more reciprocation on top of possible linear paths.
4.3. Additional Metrics
We examine the relationship between revision networks and primary external variables (number of editors/nodes, age of article, and revision rate) using motifs. Specifically, using the dimensions of two-dimensional PCA analysis, we examine the correlation with the external variables, and how this differs between controversial and non-controversial articles. The results are shown in Figures 9, 10 and 11.
The greatest differences between controversial and non-controversial articles occur with respect to article age (Figure 10). Here, controversial articles with high age cluster against high values of principal component one, and to some extent this occurs for principal component two. This contrasts against the clustering seen for non-controversial articles.
Figure 10 also shows that controversial articles have a tendency to be older. The high values in principal component one and two which align with dense clustering of controversial articles show that while such articles accumulate the linear revision path between authors (021C which dominates principal component two), controversial articles also accumulate instances of linear paths where one edge is reciprocated (i.e., 111D and 111U which dominate principal component one).
5. Discussion
Motif analysis of revision networks gives insight into how the temporal editing relationship between small groups of Wikipedia authors create signatures that allow controversial articles to be distinguished. In contrast to previous work, we have investigated this using a relatively large sample of Wikipedia articles, where distinct patterns emerge. This provides strong support for our hypothesis, and reaffirms the importance of the revision network as a simple but fundamental element in editing Wikipedia.
Through motif analysis, we identify that reciprocation on linear paths among triads of editors in the revision network is over represented in controversial Wikipedia articles. These motifs are defined by the triads 111D, 111U and 201. In contrast, the revision networks from non-controversial articles exhibit two anti-motifs, involving the under representation of triads involving two directed edges either arriving at or emanating from a mediating node (triads 021D and 021U). These motifs and the underlying subgraph ratio profiles represent an unusual and distinctive profile that we believe represent distinctive ”super-families” beyond those seen in other technologically related networks, such as the world wide web (Zlatić et al., 2006).
Performing dimensionality reduction upon the subgraph ratio profiles from each revision network allows us to further understand the relationships between Wikipedia articles. Our analysis shows that the structure of the data is amenable to reduction to two dimensions, where the principal components are dominated by triads 111D and 111U in the first component, and mainly 021C in the second component, but with lesser contributions from triads 021D and 021U.
The results from two-dimensional principal analysis are illuminating - the dominant triads in both components, as listed above, correspond to linear paths, i.e., open triads which represent sequences of editing without indirect reciprocity. The extent and format of reciprocated (i.e., bidirectional) edges on these open triads is sufficient to define the two principal components. The dominant triads in the first principal component each involve reciprocation on one edge, where as interestingly, in the second principal component, the dominant triads are open triads with no reciprocated edges. From this we deduce that short paths, rather than short loops of editing that represent indirect reciprocity, are important features in characterising Wikipedia revision networks.
We also observe through two-dimensional principal component analysis that it is the first principal component that strongly distinguishes between the revision networks of controversial and non-controversial articles. The dominant triads defining this capture the extent of direct reciprocation being present. Finally, through consideration of the principal components against additional external variables, we find in particular that article age plays a role in distinguishing the controversial articles. High values in both principal components aligns with strongest clustering of controversial articles, which is not the case for non-controversial articles.
6. Conclusion
The analysis has given insights into the structure underlying revision networks from Wikipedia articles, and has shown that a relatively small number of features, in terms of substructures in revision networks, characterise controversial Wikipedia articles. The results have identified key clusters of editorial interactions to this effect, in support of the hypothesis. These are distinctive and indicate that the revision networks for controversial and non-controversial Wikipedia articles have differentiated subgraph ratio profiles. Our study gives understanding as to how prediction or classification of articles can be enhanced using the latent structures relating to editor behaviour. This also reaffirms the importance of the revision network as a simple but useful representation for assessment of Wikipedia articles.
Acknowledgements
This research was sponsored by the U.S. Army Research Laboratory and the U.K. Ministry of Defence under Agreement Number W911NF-16-3-0001. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the U.S. Army Research Laboratory, the U.S. Government, the U.K. Ministry of Defence or the U.K. Government. The U.S. and U.K. Governments are authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation hereon.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1(1)
- 2Acemoglu et al . (2010) Daron Acemoglu, Asuman Ozdaglar, and Ali Parandeh Gheibi. 2010. Spread of (mis)information in social networks. Games and Economic Behavior 70, 2 (2010), 194–227.
- 3Adler et al . (2011) B Thomas Adler, Luca De Alfaro, Santiago M Mola-Velasco, Paolo Rosso, and Andrew G West. 2011. Wikipedia vandalism detection: Combining natural language, metadata, and reputation features. In International Conference on Intelligent Text Processing and Computational Linguistics . Springer, 277–288.
- 4Batagelj and Mrvar (2001) Vladimir Batagelj and Andrej Mrvar. 2001. A subquadratic triad census algorithm for large sparse networks with small maximum degree. Social Networks 23, 3 (2001), 237 – 243. https://doi.org/10.1016/S 0378-8733(01)00035-1 · doi ↗
- 5Brabham (2008) Daren C Brabham. 2008. Crowdsourcing as a Model for Problem Solving: An Introduction and Cases. Convergence 14, 1 (2008), 75–90.
- 6Braines et al . (2018) Dave Braines, Diane Felmlee, Don Towsley, Kun Tu, Roger M Whitaker, and Liam D Turner. 2018. The role of motifs in understanding behavior in social and engineered networks. In Next-Generation Analyst VI , Vol. 10653. International Society for Optics and Photonics, 106530 W.
- 7Brandes et al . (2009) Ulrik Brandes, Patrick Kenis, Jürgen Lerner, and Denise Van Raaij. 2009. Network analysis of collaboration structure in Wikipedia. In Proceedings of the 18th international conference on World wide web . ACM, 731–740.
- 8Doan et al . (2011) Anhai Doan, Raghu Ramakrishnan, and Alon Y. Halevy. 2011. Crowdsourcing Systems on the World-Wide Web. Commun. ACM 54, 4 (April 2011), 86–96.