A Solution for Dynamic Spectrum Management in Mission-Critical UAV Networks
Alireza Shamsoshoara, Mehrdad Khaledi, Fatemeh Afghah, Abolfazl Razi,, Jonathan Ashdown, Kurt Turck

TL;DR
This paper proposes a team reinforcement learning approach for dynamic spectrum management in UAV networks, optimizing sensing, relaying, and relocation to enhance performance during critical missions with spectrum scarcity.
Contribution
It introduces a novel reinforcement learning algorithm for UAVs to dynamically allocate spectrum and tasks, improving network efficiency in mission-critical scenarios.
Findings
The algorithm converges effectively in simulations.
Optimized spectrum leasing improves data throughput.
Relocation strategies enhance UAV network longevity.
Abstract
In this paper, we study the problem of spectrum scarcity in a network of unmanned aerial vehicles (UAVs) during mission-critical applications such as disaster monitoring and public safety missions, where the pre-allocated spectrum is not sufficient to offer a high data transmission rate for real-time video-streaming. In such scenarios, the UAV network can lease part of the spectrum of a terrestrial licensed network in exchange for providing relaying service. In order to optimize the performance of the UAV network and prolong its lifetime, some of the UAVs will function as a relay for the primary network while the rest of the UAVs carry out their sensing tasks. Here, we propose a team reinforcement learning algorithm performed by the UAV's controller unit to determine the optimum allocation of sensing and relaying tasks among the UAVs as well as their relocation strategy at each time. We…
Click any figure to enlarge with its caption.
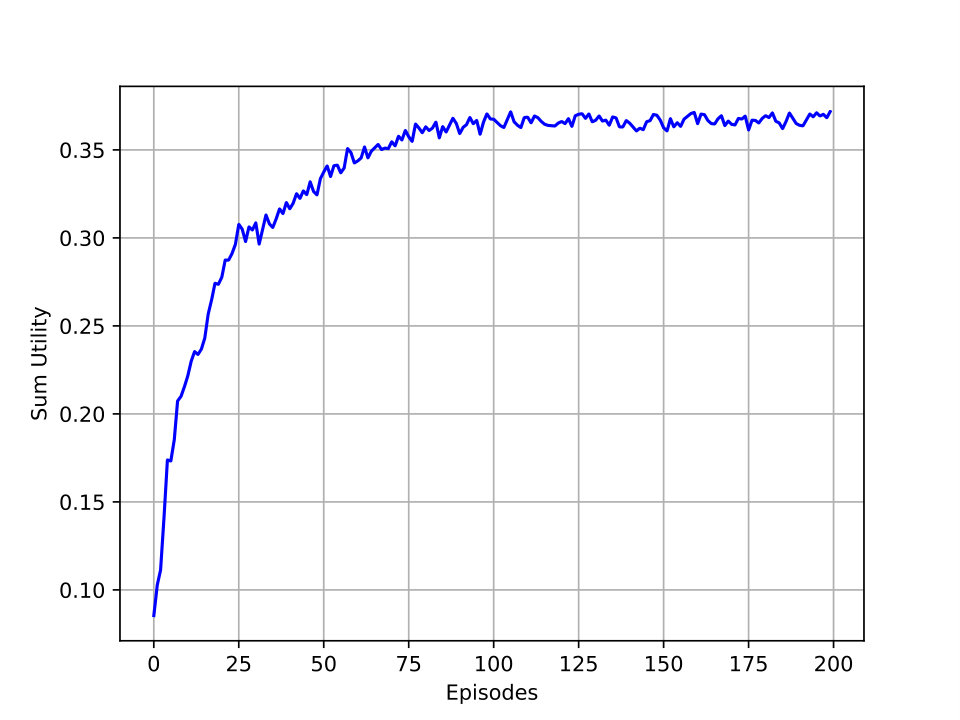 Figure 6
Figure 6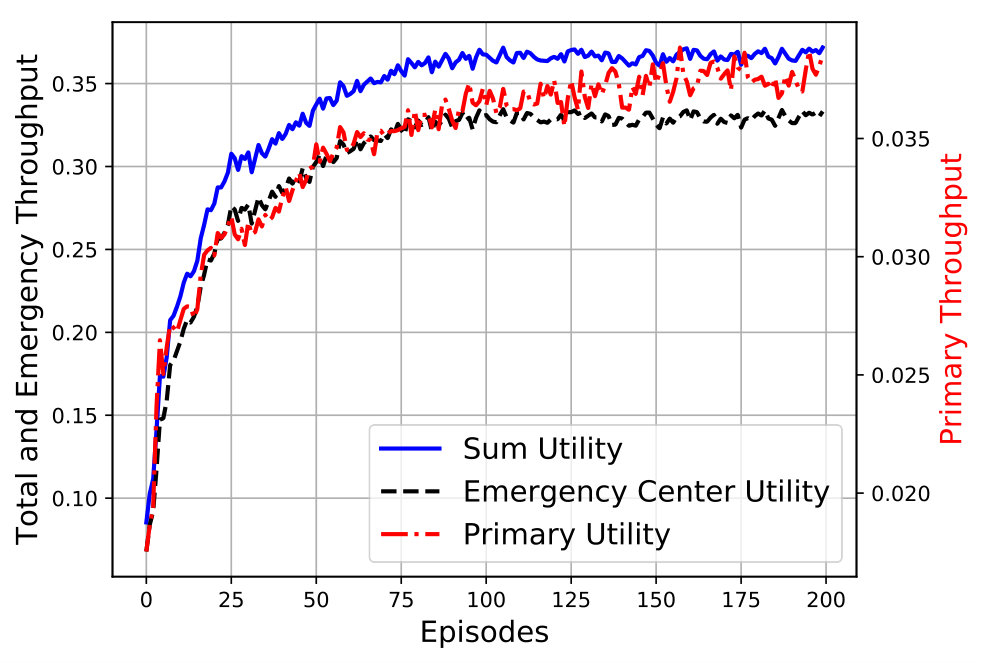 Figure 6
Figure 6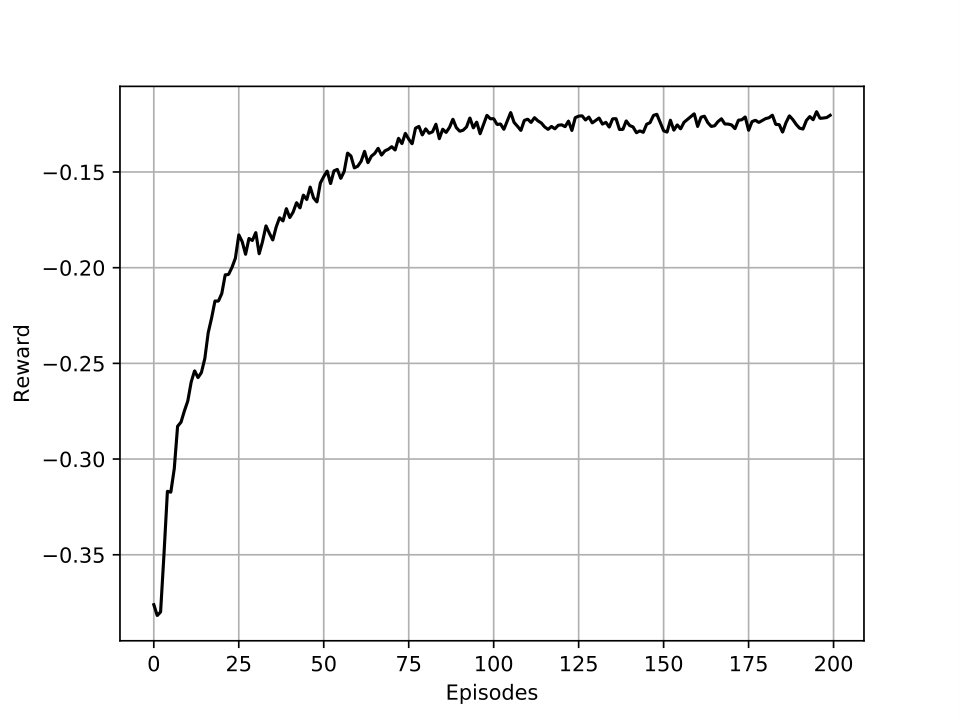 Figure 6
Figure 6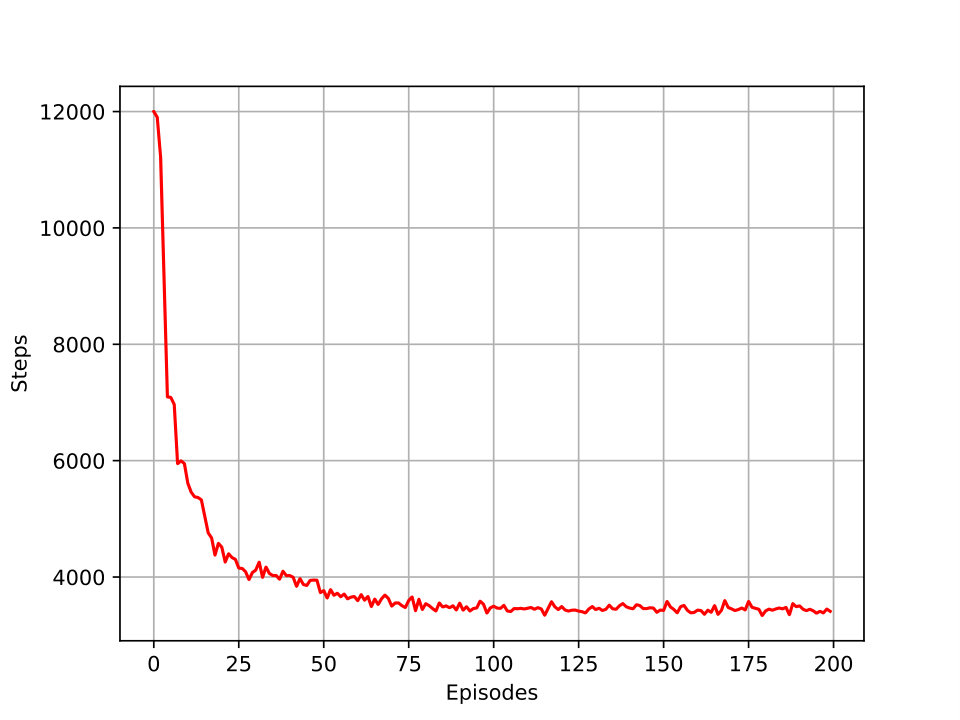 Figure 6
Figure 6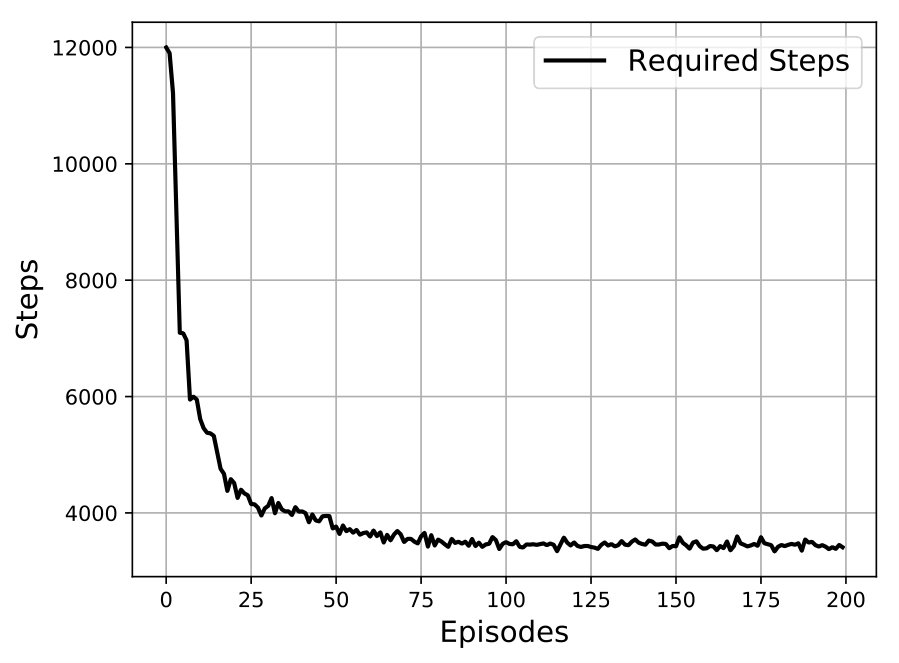 Figure 6
Figure 6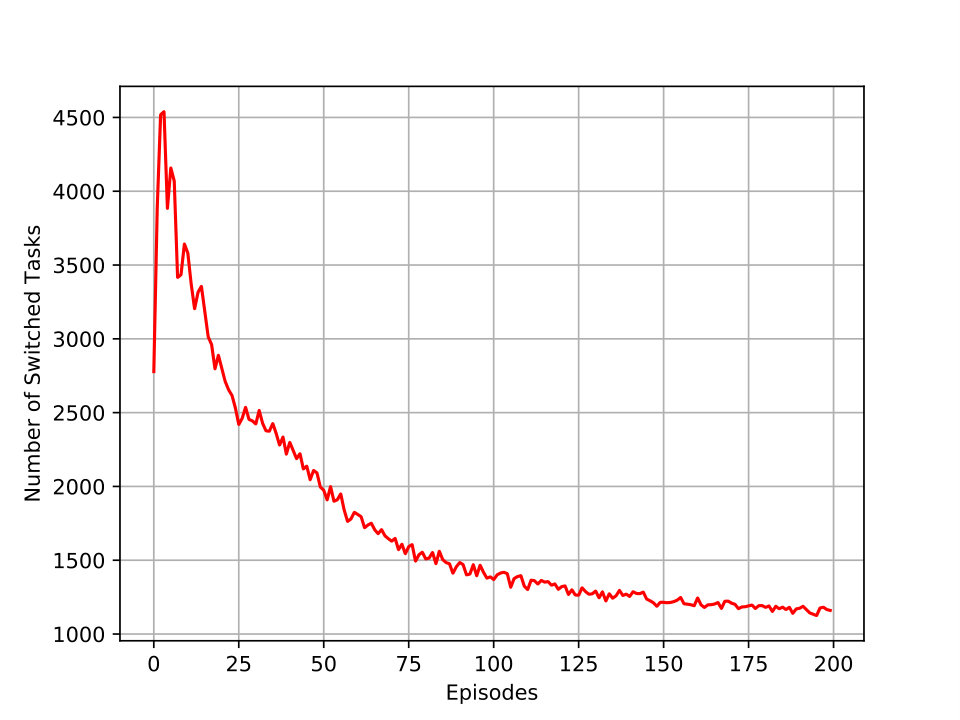 Figure 6
Figure 6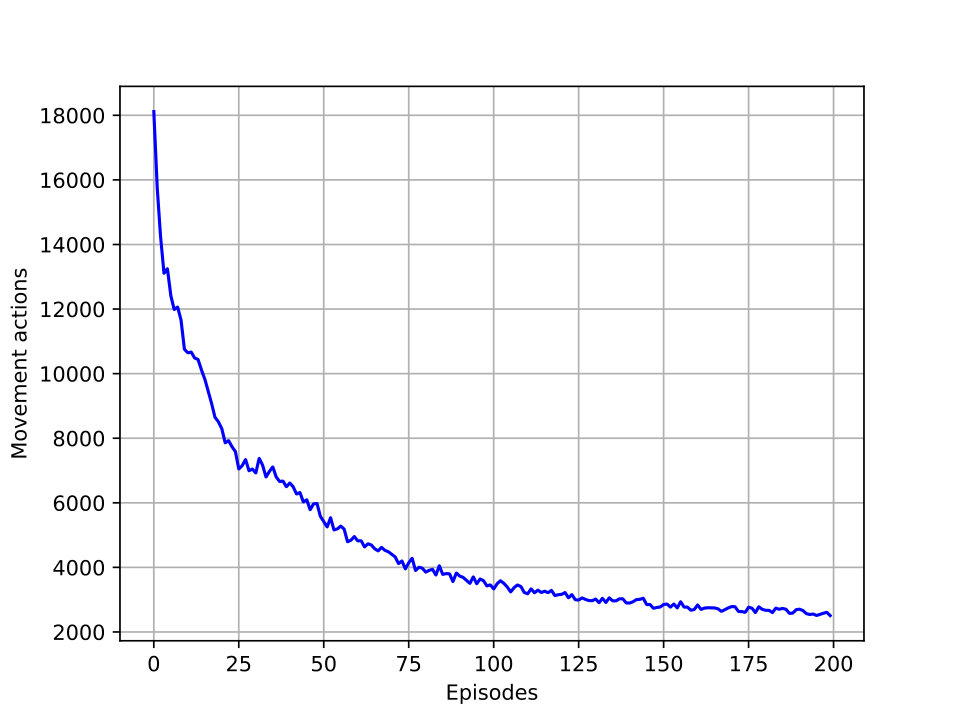 Figure 6
Figure 6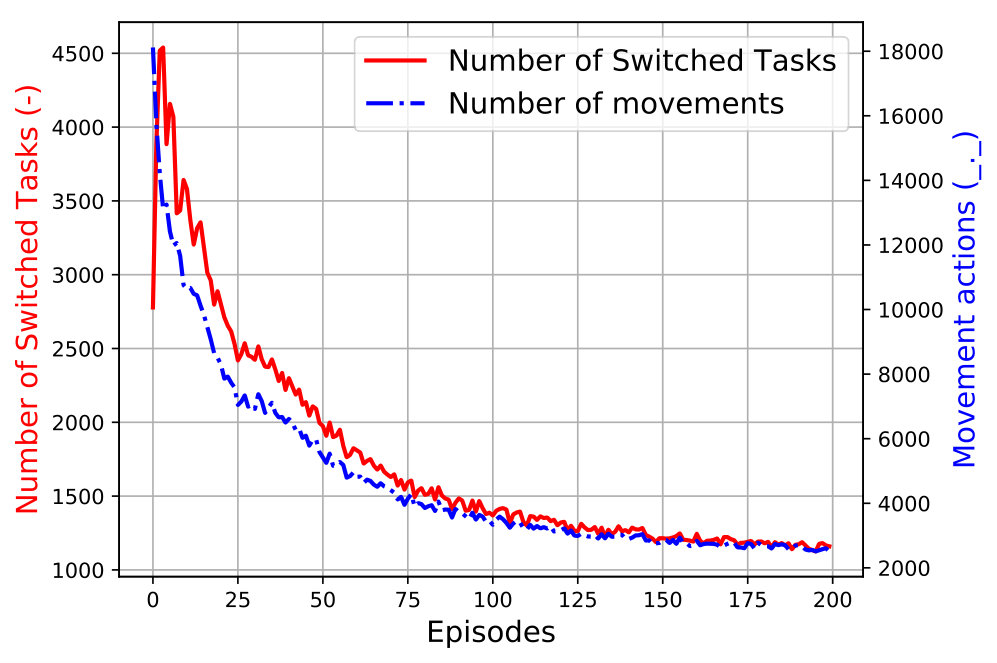 Figure 6
Figure 6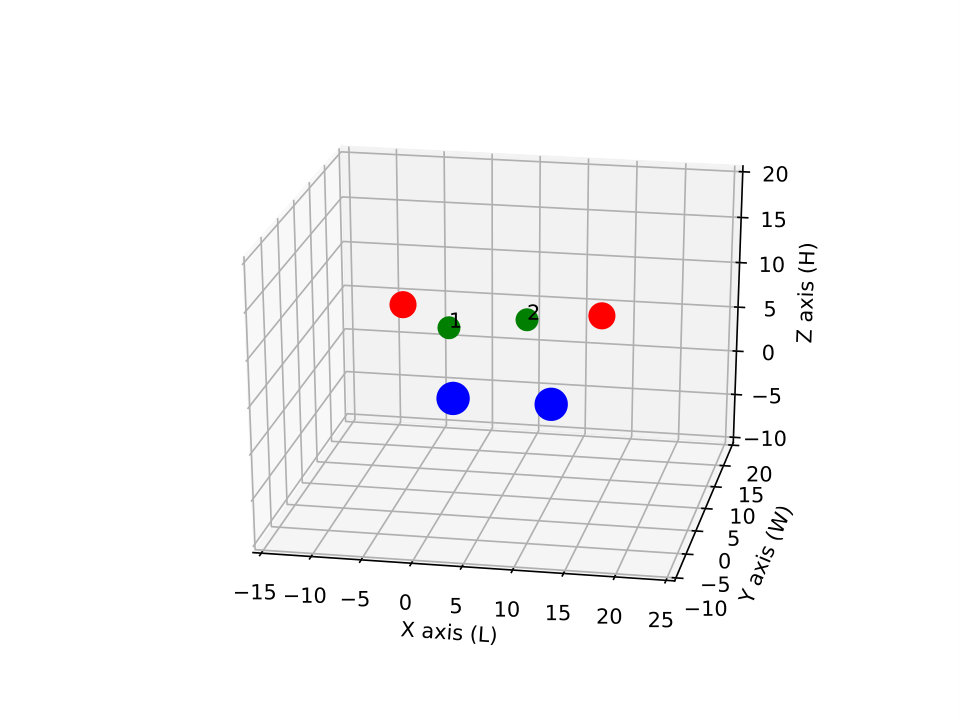 Figure 9
Figure 9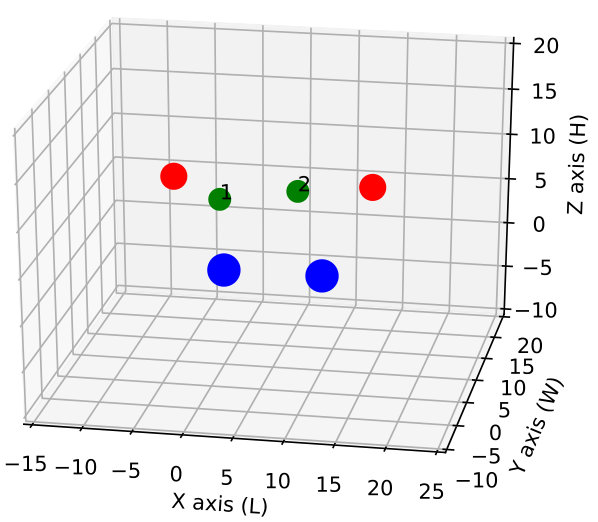 Figure 10
Figure 10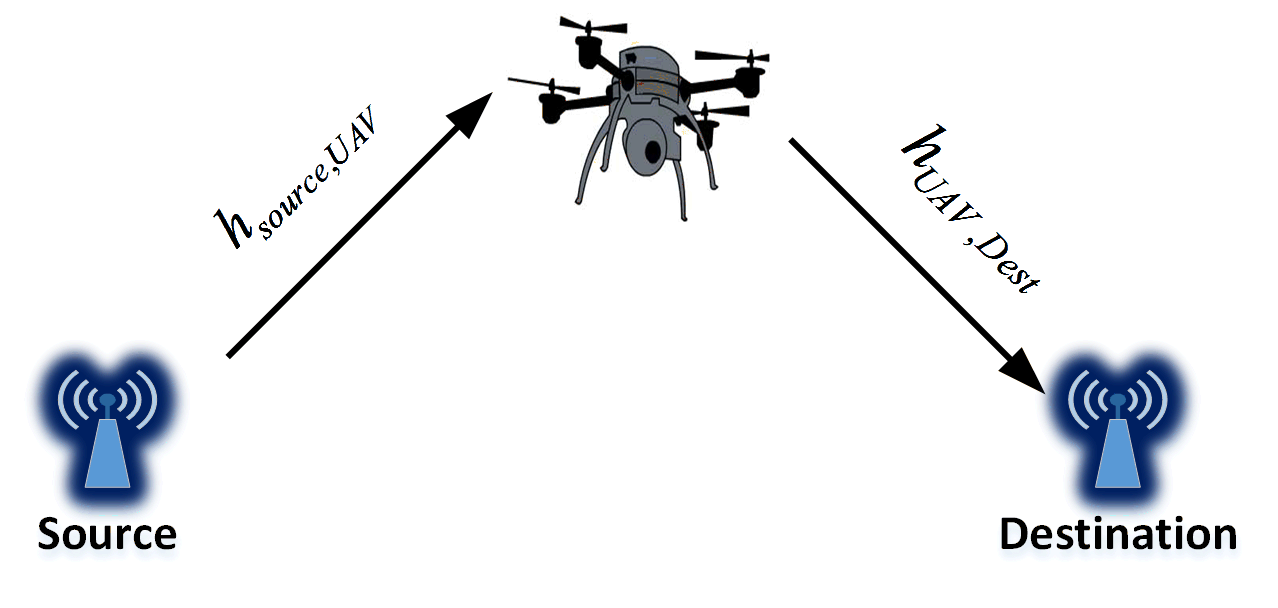 Figure 11
Figure 11 Figure 12
Figure 12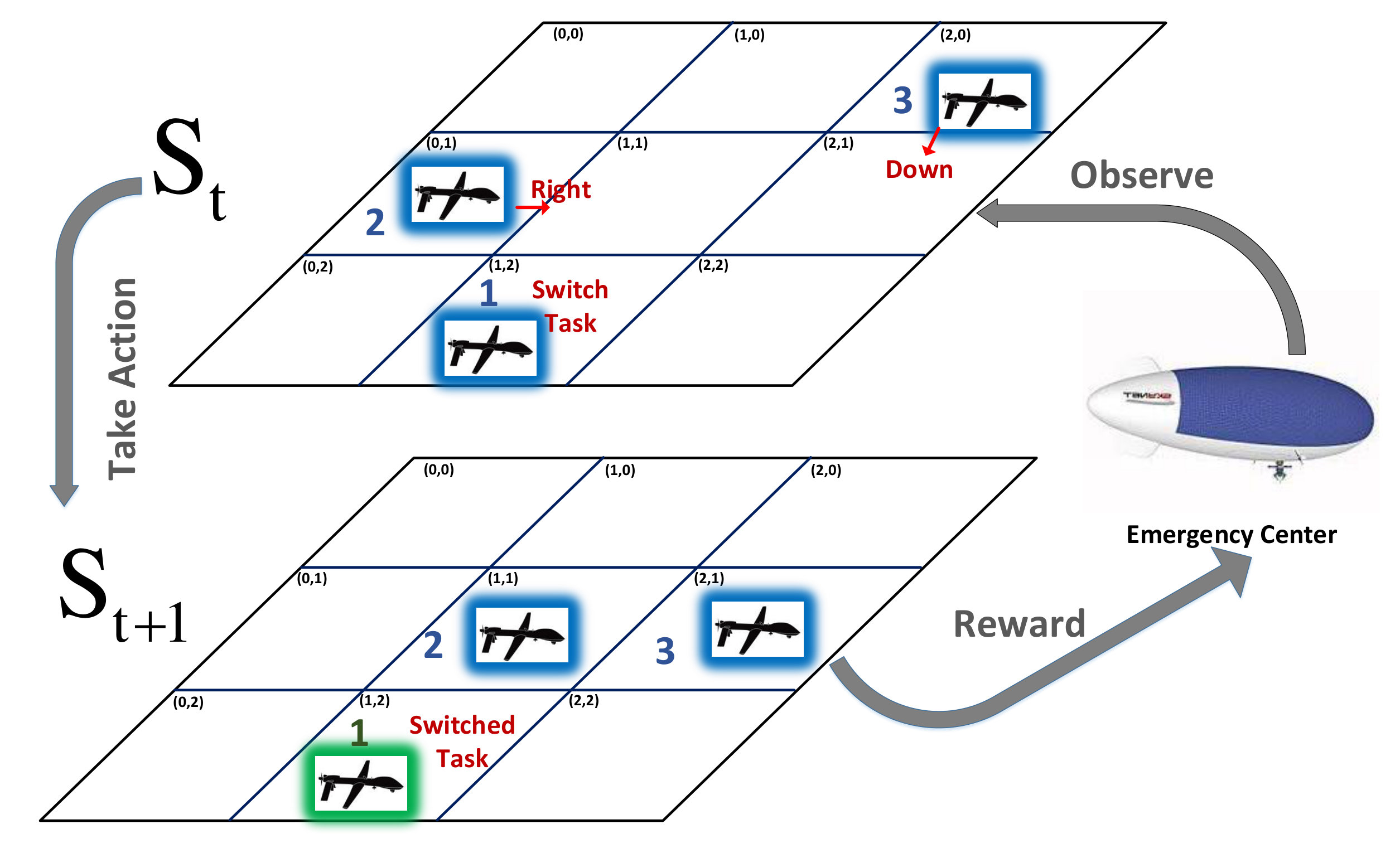 Figure 13
Figure 13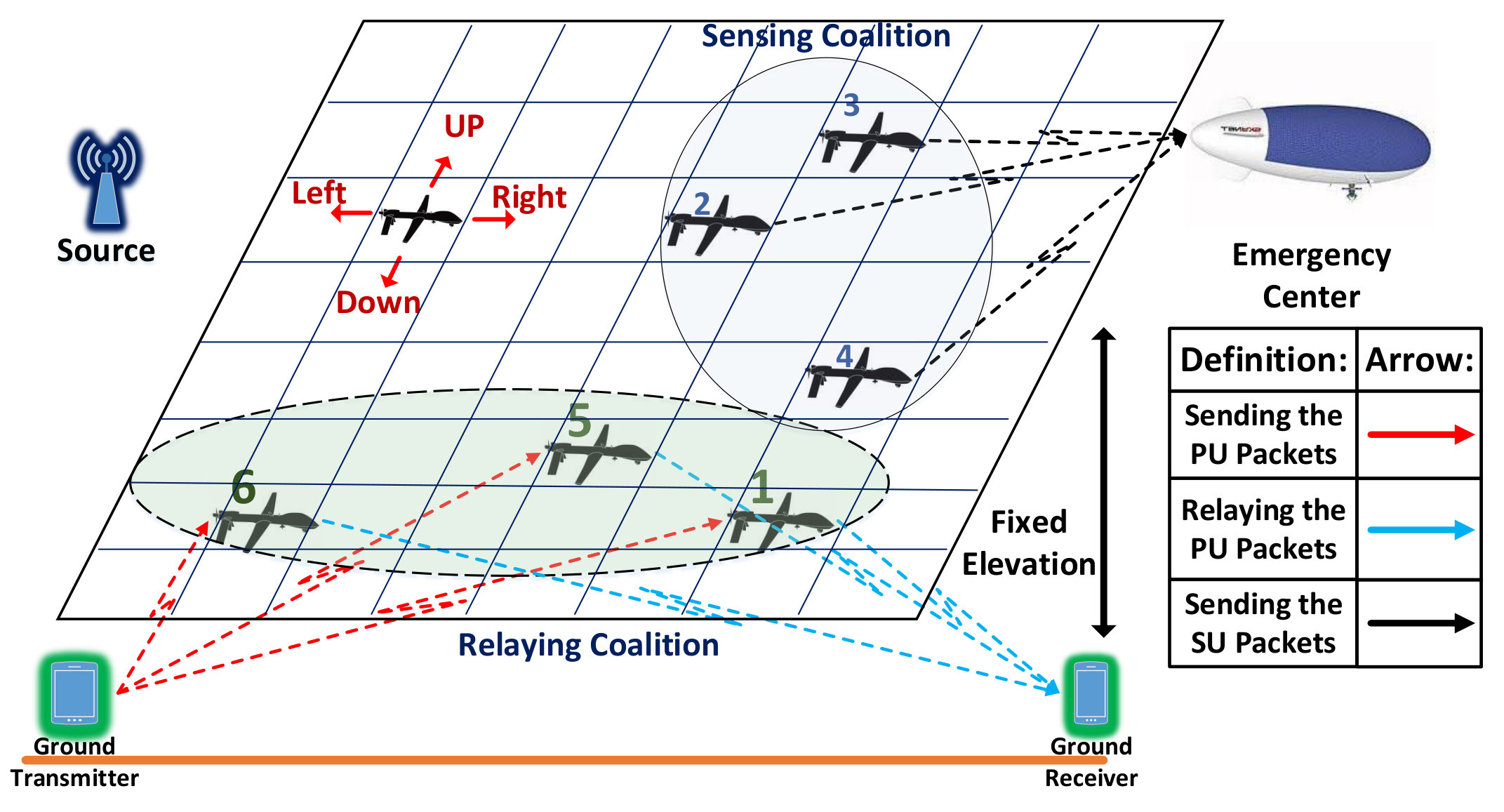 Figure 14
Figure 14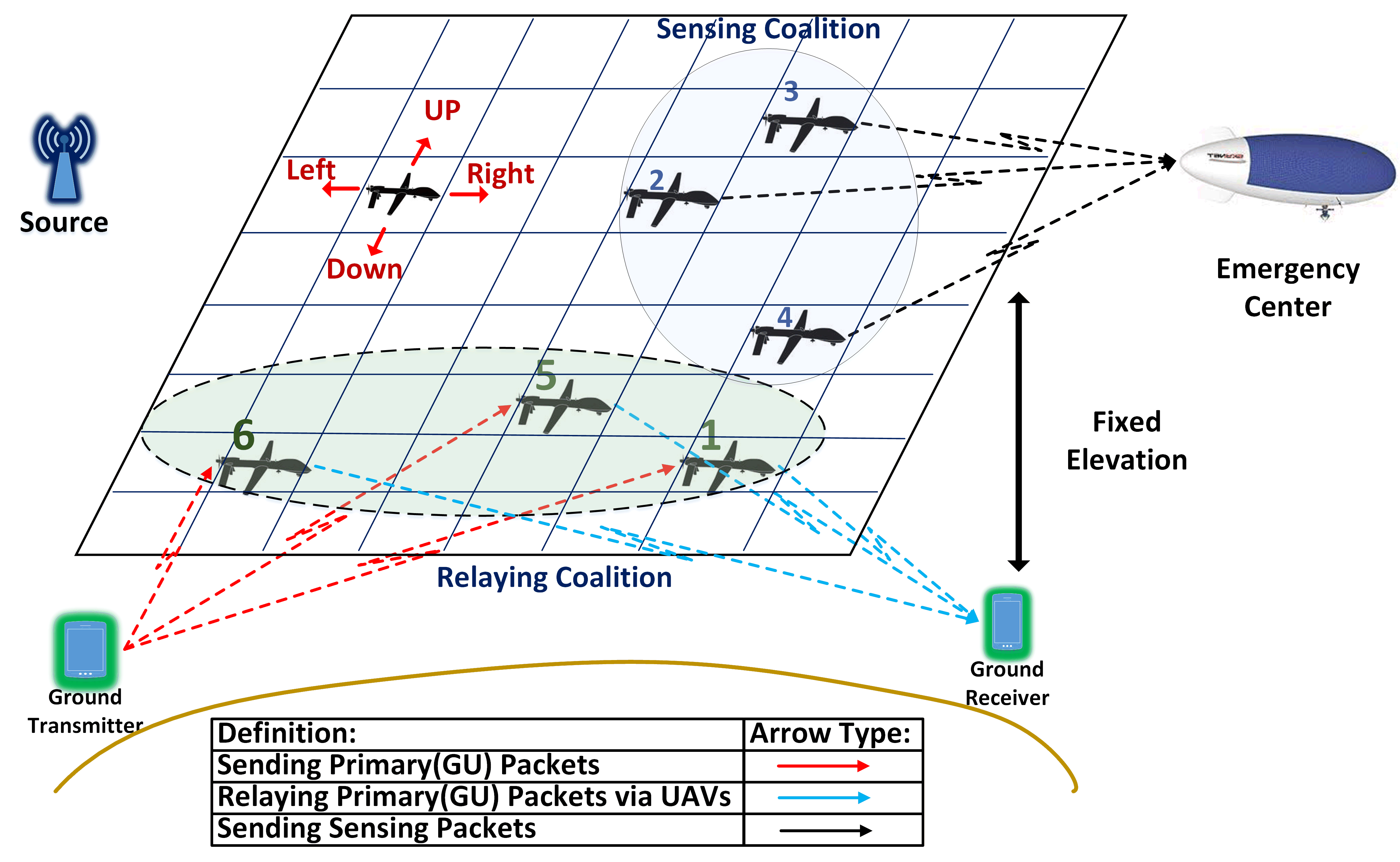 Figure 15
Figure 15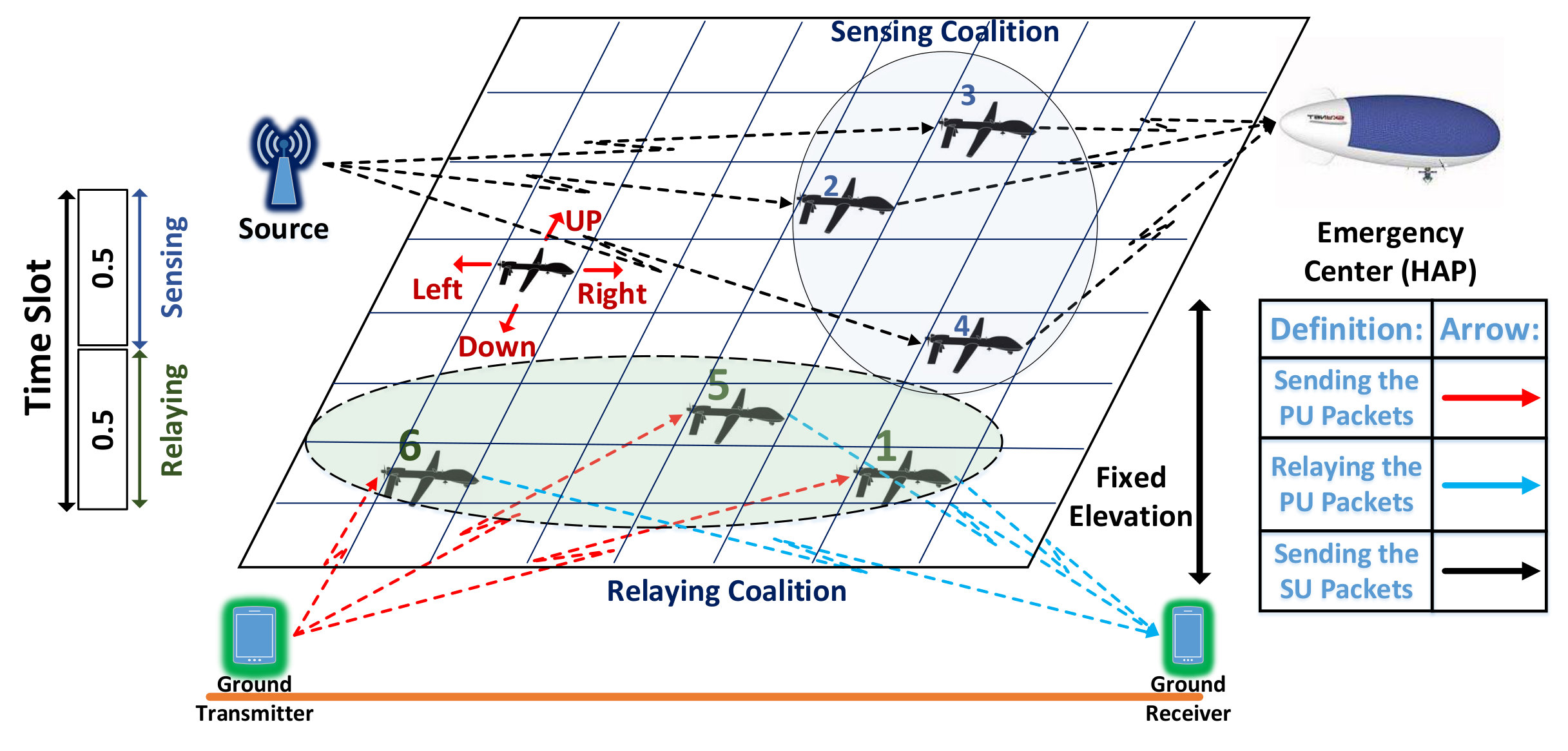 Figure 16
Figure 16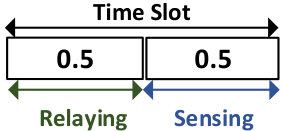 Figure 17
Figure 17| Component | Description | Sample size |
|---|---|---|
| Actions | Making decisions about moving or the task | 6 |
| # of Agents | Number of UAVs | 2 |
| State | Considering a grid for all agents together | |
| Q-Table | State(Location), Action(Movement or Task) values | |
| Reward | Difference of throughput |
| Grid Size: | 22 (4) | 33 (9) | 44(16) | 55 (25) | 66 (36) | 88 (64) | 1010 (100) |
|---|---|---|---|---|---|---|---|
| Number of States: | 44=16 | 99=81 | 1616=256 | 625 | 1,296 | 4,096 | 10,000 |
| Size of the Q-Table: | 576 | 2,916 | 9,216 | 22,500 | 46,656 | 147,456 | 360,000 |
| Number of Iterations: | 10 | 10 | 10 | 10 | 10 | 10 | 10 |
| Number of Episodes in each Iteration: | 200 | 200 | 200 | 200 | 200 | 200 | 200 |
| Number of Steps in each Episode: | 120 | 800 | 2,000 | 5,000 | 12,000 | 20,000 | 30,000 |
| Process Time for each epoch (Sec): | 0.102628 | 0.762713 | 2.425558 | 8.757846 | 49.007077 | 146.936207 | 291.176670 |
| Total required time: | 205.256s | 25.4m | 80.85m | 4.8h | 27.2h | 3 days | 6 days |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Code & Models
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Taxonomy
TopicsUAV Applications and Optimization · Distributed Control Multi-Agent Systems · Cognitive Radio Networks and Spectrum Sensing
A Solution for Dynamic Spectrum Management in Mission-Critical UAV Networks
Alireza Shamsoshoara1, Mehrdad Khaledi 2, Fatemeh Afghah 1, Abolfazl Razi 1,
Jonathan Ashdown3, Kurt Turck 3
1School of Informatics, Computing and Cyber Systems, Northern Arizona University, Flagstaff, AZ, USA
2 Mathematics & Computer Science Department, Suffolk University, Boston, MA, USA
3 Air Force Research Laboratory, Rome, NY, USA
Abstract
In this paper, we study the problem of spectrum scarcity in a network of unmanned aerial vehicles (UAVs) during mission-critical applications such as disaster monitoring and public safety missions, where the pre-allocated spectrum is not sufficient to offer a high data transmission rate for real-time video-streaming. In such scenarios, the UAV network can lease part of the spectrum of a terrestrial licensed network in exchange for providing relaying service. In order to optimize the performance of the UAV network and prolong its lifetime, some of the UAVs will function as a relay for the primary network while the rest of the UAVs carry out their sensing tasks. Here, we propose a team reinforcement learning algorithm performed by the UAV’s controller unit to determine the optimum allocation of sensing and relaying tasks among the UAVs as well as their relocation strategy at each time. We analyze the convergence of our algorithm and present simulation results to evaluate the system throughput in different scenarios.
Index Terms:
multi-agent systems, reinforcement learning, spectrum sharing, task allocation, UAV networks
I Introduction
Unmanned Aerial Vehicles (UAV) have several advantages such as flexibility, agility, wide field of imaging view and low deployment cost over ground-based infrastructures; hence, are widely used in many applications such as surveillance, disaster relief, wildlife monitoring, and military applications [1, 2, 3, 4, 5, 6]. Also, UAVs face many security challenges based on the vast area of applications. Many methods such as key sharing, authentication, authorization, and so on have been proposed for these devices in the past few years [7, 8]. In some of these missions such as disaster monitoring and military applications, the pre-allocated spectrum for UAVs is not sufficient to collect and transmit high-throughput imagery data in certain locations or times, hence an on-demand access to additional spectrum is required. In this paper, we propose a solution for securing extra spectrum for the UAV networks.
In this solution, the UAV network leases a portion of time access to the licensed spectrum of a terrestrial network. In order to compensate the spectrum access grant, some of the UAVs provide relaying service for the terrestrial network, while the rest of UAVs perform their regular sensing and transmission tasks using the leased spectrum. The allocation of relaying and sensing tasks among the UAVs as well as selecting their motion strategy is performed by a high-capability drone which serves as controller unit of the entire network. This optimization is performed considering various factors such as the position of the UAVs and ground0based nodes, the quality of communication channels as well as the expected lifetime of the drones.
Cooperative spectrum leasing as a property-right model spectrum sharing solution has been studied previously in the context of cognitive radio networks [9, 10, 11, 12, 13, 14]. The main objective of these works is maximizing the benefits of the primary network through optimal time allocation between the primary and secondary networks. The ignorance of the performance of the secondary network, can cause significant operation problems in critical missions.
The task allocation problem to select UAVs for relaying or sensing tasks can be modeled as a multi-agent reinforcement learning (MARL) problem [15]. In a cooperative MARL problem, multiple learning agents work together to achieve a system-wide optimal solution. There have been efforts to solve task coordination in a fully distributed manner. However, the proposed solutions impose a heavy computation and decision making loads to the UAVs, and still may not converge to an optimal solution. Hence, distributed task allocation solutions are not practically feasible in highly dynamic systems [16, 17]. In this paper, we consider a remote sensing situation where the UAVs send their individual information to a UAV node designated for data fusion and overall management of the network. We assume that the UAV network does not own spectrum and opportunistically uses an external spectrum to complete the remote sensing mission. We present an algorithm based on team reinforcement learning to maximize the total utility of the system by re-positioning and determining the proper task for each drone, while minimizing the number of steps to achieve the optimal configuration. We provide experimental results to verify the convergence of the proposed algorithm.
II System Model
Let us assume a network of UAVs in a proximity of a licensed transmitter-receiver pair that are willing to share their spectrum with the UAV network in exchange for cooperative relaying service. The primary network is considered as a terrestrial network; while the secondary network consists of the UAVs that hover in a constant altitude. The primary pair may be in need of cooperative relaying services for experiencing a low quality direct transmission due to several reasons such as long distance between the transmitter and receiver, shadowing and fading effects. In this paper, we assume that there is no direct transmission link between the PU’s transmitter and receiver, however, the proposal spectrum sharing method can be used in scenarios where the PU participates in spectrum leasing to take advantage of cooperative diversity gain. We assume that the UAVs are managed by a high altitude platform (HAP) UAV called as emergency center located in a fixed location [3].
The UAV network owns a dedicated frequency bandwidth for control commands and exchanging critical information, however it requires additional spectrum to transmit high resolution video and images during a disaster monitoring mission. In order to provide additional on-demand spectrum, the UAVs can participate in a cooperative spectrum leasing transaction with the primary network. In this case, the PU will lease half of its time access to its spectrum to the sensing UAVs, and the relay UAVs will assist the PU with forwarding their packets during the other half of the time slot. In other words, the UAVs can serve in two sensing and relaying modes. Here, we consider a centralized control scenario in which the emergency center determines the action of each UAV in terms of their motion and their role (relaying or sensing) to maximize the network utility.
Let us consider a case where UAVs perform as relay, and the remaining perform the sensing task. An example of this scenario with and is depicted in Fig. 1. In this model, we consider a 2-D random walk for the UAVs, so that they can change their locations into adjacent cells in the grid using one of the four movement actions . The UAVs are not allowed to take diagonal steps.
The channels between all nodes including the UAVs, the emergency center, and the PU are calculated based on pairwise distances during each time slot. Following similar works including [18], we assume that CSI parameters are known for the HAP UAV. Channel coefficient for each pair of users is defined as follows: i) is the channel parameter between the primary transmitter and UAV, ii) carries the channel information between the UAV and the primary receiver, and iii) and denote the channel parameters between the UAV and the source and the emergency center respectively. Moreover, we assume that the noise terms at the receiver sides are normally distributed symmetric complex values, .
In the literature, many papers including [19, 20] address power optimization; while we assume that the transmission power is arbitrary but constant for all transmitters.
Based on Fig. 2, we divide each time slot into two parts. We assume that, relaying UAVs receive the primary packet and forward them to the primary receiver in the first half. And in the second half, sensing UAVs forward the collected data to the emergency center. In each half slot, UAVs utilize full-duplex for the transmission.
The received signal for the UAV can be written as follow:
[TABLE]
In (1), subscript can be source or PU transmitter, is the signal sent by by the PU transmitter or the source and is the received signal at UAV . On the other side of the transmission, the received signal for the emergency center or the primary receiver is written as follow:
[TABLE]
where subscript can represent the emergency center or the PU-receiver, is the transmitted signal by UAV , and is the received signal at the receiver which can be the emergency center or the PU-receiver. In both (1) and (2), defines the effect of path loss between nodes and .
In this work, we utilized the Amplify and Forward (AF) relaying mode at the relay UAVs. Based on [21, 22], the throughput for the emergency center receiver can be obtained as:
[TABLE]
where and are transmission power for source and UAV respectively. is the background noise power. denotes the index for the relay(UAV). On the other hand, the throughput rate for the primary receiver is shown as:
[TABLE]
where is the primary transmitter power. It is noteworthy that (3) and (4) are true for single relay scenarios. This system involves a multi-agent scenario including relay UAVs and a set of sensing UAVs, hence the transmission rate of the relaying and sensing sub-systems can be defined as follows if denotes the sensing set and is the set of relaying UAVs:
[TABLE]
[TABLE]
where, and are the achievable rates using multi UAVs. Since we assumed the distances between the source and emergency center and also PT and PR are long, we can eliminate both and terms from the rate (). At the end of each time slot, the PU receiver and the emergency center announce their received throughput to the UAVs in order to provide them with a feedback (i.e., reward) based on the previous states and their taken actions.
Based on the definitions in our system model, we can define the reward or gain as a throughput difference for the whole system between to consecutive time slots such as and :
[TABLE]
where, and are two control parameters. Reward in (7) is obtained based on the location of the UAVs, their tasks, and the distance to their destinations or from their sources. The goal of our proposed model is to find the best location for UAVs and the right task that result in an optimal summation throughput rate. In Section III, we use this reward function to develop a reinforcement technique for task allocation and motion planning.
III Multi-Agent Team Reinforcement Learning
Multi-Agent Reinforcement Learning (MARL) algorithms can be categorized into three branches based on the nature of the problem. First, all the agents work cooperatively with each other. In this branch, all the agents have the same goal of maximizing the common discount factor. Also, they all have the same reward function. In the second category, the agents are fully competitive which is known as zero-sum games. In third one, the behavior of agents is a mixture of two previous groups which is neither competitive nor cooperative. Our problem in this paper is the type with fully cooperative agents. Two approaches to solve these kinds of problems are Nash Q-learning and team learning [23, 24]. We aim to use the team Q-learning for our UAVs. In the team learning approach, a single learner such as the emergency center monitors the behavior of all agents. The reason we chose this algorithm is that the single learner can utilize simple machine learning algorithms such as Q-learning in the multi-agent learning environment similar to the scenario in this paper. To model a single UAV agent in the learning environment, the Markov Decision Process (MDP) is investigated. In each step, the UAV interacts with its environment which is the state of the problem. In this specific problem, the state for the UAV is the location on the grid size. Let denote the state for each UAV at step , where is the set for all possible states. Time step is different and it depends on the grid size of the UAVs. The UAV at each state such as can follow an action based on a policy form an action set . The action set is Up(0), Down(1), Left(2), Right(3), Emergency Task(4), Relaying Task(5). The first four actions change the location for the UAV and keep the previous task from the previous location. However, the last two actions, keep the UAV in same location, but decide on its task. Action changes to for the whole system. Based on the new state , the updated reward is awarded to the system based on the (7). In a single-UAV environment, the goal of the UAV is to find the optimal policy which chooses actions that maximize the standing for expected discounted reward over time where is a discount factor. SARSA [25] and Q-learning [26] are two general algorithms for the RL problems. Each MPD consists of a 4-tuple where, is a finite set of states, is a finite set of actions, or is the probability that choosing an action for a single UAV will change its state from to at the time . or is the expected awarded reward when a single UAV changes its state from to due to action . This immediate reward is obtained based on (7) in this special problem. Then, the single agent can update its Q-value based on:
[TABLE]
where is the learning rate. These equations and relations are valid for a single-learner. However, in multi-agent environment, multiple UAVs follow the taken action at the same time without sharing any information with each other. Hence, the action vector such as leads the system from to for all UAVs. Using team Q-learning, (8) can be modified and written as:
[TABLE]
where is the action vector when the UAVs are placed in state and is the action-value for the whole system. There are three kinds of rewards based on the (7). If the throughput summation in a new state is greater than the previous state, then the positive reward is given to the system. If the difference is zero, then there is no reward for that (zero value). If the difference is negative between the new state and the previous state, then a negative reward is obtained by the system. The issue for team Q-learning is the process of exploration. Considering a 1010 grid size for 2 UAVs defines 100 states for each UAVs; then, defining a team of 2 UAVs makes 10,000 states for the system just for locations without considering any tasks. This huge number of states can be time-consuming for the learning process. Action selection method is another important module for the Q-learning which stands for selecting the actions which the UAVs will perform to proceed the learning process. These methods base a fulcrum for exploration and exploitation searches [27]. In this paper, we used -greedy exploration with a constant value for the which means the system chooses random actions with the probability of and selects the best actions based on the maximum value in the Q-table with the probability of . This method is defined in:
[TABLE]
where is the number of UAVs and is the action vector for UAVs which brings the maximum Q value. Table I summarizes the mapping information for the team Q-learning and the definitions in this specific problem.
In the past few years, deep learning has absorbed lots of attention in different areas such as biomedical signal processing [28, 29, 30], pattern recognition, computer vision, autonomous vehicles, and natural language processing. Moreover, in recent studies, it has been shown that deep learning tools can be utilized alongside with reinforcement learning challenges to give a bright consciousness of the environment to the agents [31, 32, 33, 26, 34].
IV Simulation Results
In the following simulations, we consider a ground-based PU transmitter-receiver pair as well as a pair of drone-based source and emergency center with randomly initialized locations. We split the tiled coverage area into tiles, where drones are allowed to move in four directions . Channels between nodes are calculated based on the , where is Euclidean distance between nodes and . We arbitrarily use , (defined in Eq. 7), , , , , , , and =, unless otherwise specified explicitly. In the -greedy exploration, we consider a constant rate for the exploration and exploitation phases. The number of states is for drones. We execute the MARL algorithm for 200 episodes to fill in the Q-tables for all drones based on their actions and locations. We use sequential episodes, where the resulting Q-tables for each episode is used to initialize Q-tables for the next episode. The number of steps per episode to cover the entire state space is calculated based on the experience and the number of states. We then repeat each experiment in 10 external iterations for enhanced accuracy and avoiding bias to initialization. Timing value for each scenario is provided for Python implementation with Intel Xeon(R) CPU @ 3.50GHz and 16.0GB RAM. The simulation parameters are summarized in Table II.
Figure 3 shows the sum utility for primary and emergency network and the summations of those for each episode. The sum utility represents the accumulated utility during all steps of the episode. We observe that due to using sequential learning, the latter episodes yield a higher sum utility suggesting that the algorithm converges to its final value faster. This behavior is valid for both primary and secondary networks.
Figure 4 demonstrates the number of times that UAVs switched their task and also the number of times they changed their locations in each episode. Each value at each point for a specific episode is the summation for both UAVs for all taken steps. It is logical that the HAP starts searching all states by switching tasks in each location to get a new reward. However, as simulation goes on, the HAP starts learning from its past experiences and switches the tasks for the UAV networks fewer compared to the beginning of each iteration. Also, HAP forces the UAVs to explore more locations in smaller episodes. For larger episodes, the number for movements or changing location is less than the beginning of the iteration. These behaviors demonstrate the learning process toward the optimal location and task to gain a higher throughput rate for both networks.
Fig. 5 shows the required steps to get 90% of the throughput summation in each episode. The number of steps is decreasing when the number of episodes is increasing which explains the learning behavior and denotes that in less necessary steps, the emergency center can find the best states (Location) and actions for all UAVs to get the optimal reward.
All figures in this section are sketched for the grid 66 (36). Based on Table II, the process time for each iteration is increasing exponentially for larger grid size. Moreover, this process time is dependent to the number of UAVs. This happens due to the nature of the team reinforcement learning. Since we are using distance-based deterministic channel coefficients, offline learning methods can be used to fill in the Q-tables.
V Conclusion
In this paper, we introduced a solution for dynamic spectrum sharing in which a network of search-and-rescue UAVs needs an additional spectrum to send critical information such as videos to the emergency center. In this method, some of the UAVs provide a relaying service for a primary network in exchange for borrowing an additional required spectrum. We proposed a team-learning MARL algorithm, in which the emergency center of the UAV networks can determine the optimal actions of the UAVs in terms of their motion as well as the optimum task. It is worth mentioning that, in practice, the UAV network is trained by this learning mechanism in an offline manner to identify the best set of actions for different situations and use this knowledge for fast decision making during the missions. Simulation results showed the proposed distributed method converges to the optimal locations and tasks for both the primary and emergency network. The optimal state is the win-win solution for both groups. For the future works, we are working on other learning methods to reduce the effect of states (locations and tasks) and agents (UAVs) on the performance of the algorithm. Due to the exponential behavior of team learning, it takes time for offline learning; however, we aim to increase the number of UAVs and the grid size at the same time.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] “Gartner says almost 3 million personal and commercial drones will be shipped in 2017,” Feb 2017. [Online]. Available: http://www.gartner.com/newsroom/id/3602317
- 2[2] M. Khaledi, A. Rovira-Sugranes, F. Afghah, and A. Razi, “On greedy routing in dynamic uav networks,” in 2018 IEEE International Conference on Sensing, Communication and Networking (SECON Workshops) , June 2018, pp. 1–5.
- 3[3] S. Mousavi, F. Afghah, J. D. Ashdown, and K. Turck, “Leader-follower based coalition formation in large-scale uav networks, a quantum evolutionary approach,” in IEEE INFOCOM 2018-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS) . IEEE, 2018, pp. 882–887.
- 4[4] S. mousavi, F. Afghah, J. D. Ashdown, and K. Turck, “Use of a quantum genetic algorithm for coalition formation in large-scale uav networks,” Ad Hoc Networks , vol. 87, pp. 26–36, 2019.
- 5[5] H. Peng, A. Razi, F. Afghah, and J. Ashdown, “A unified framework for joint mobility prediction and object profiling of drones in uav networks,” Journal of Communications and Networks , vol. 20, no. 5, pp. 434–442, 2018.
- 6[6] A. Rovira-Sugranes, F. Afghah, and A. Razi, “Optimized compression policy for flying ad hoc networks,” in 2019 16th IEEE Annual Consumer Communications & Networking Conference (CCNC) . IEEE, 2019, pp. 1–2.
- 7[7] A. Shamsoshoara, “Overview of blakley’s secret sharing scheme,” ar Xiv preprint ar Xiv:1901.02802 , 2019.
- 8[8] A. shamsoshoara, “Ring oscillator and its application as physical unclonable function (puf) for password management,” ar Xiv preprint ar Xiv:1901.06733 , 2019.