Estimation of Linear Motion in Dense Crowd Videos using Langevin Model
Shreetam Behera, Debi Prosad Dogra, Malay Kumar Bandyopadhyay and, Partha Pratim Roy

TL;DR
This paper introduces a Langevin model-based approach to estimate and segment linear crowd flows in dense videos, improving accuracy and speed over existing methods by modeling crowd motion with external, confinement, and disturbance forces.
Contribution
The paper presents a novel Langevin equation-based model for analyzing linear crowd flows, offering faster computation and better accuracy than current crowd segmentation techniques.
Findings
Outperforms state-of-the-art crowd segmentation methods.
Reduces computational overhead significantly.
Accurately estimates linear crowd flows in dense scenarios.
Abstract
Crowd gatherings at social and cultural events are increasing in leaps and bounds with the increase in population. Surveillance through computer vision and expert decision making systems can help to understand the crowd phenomena at large gatherings. Understanding crowd phenomena can be helpful in early identification of unwanted incidents and their prevention. Motion flow is one of the important crowd phenomena that can be instrumental in describing the crowd behavior. Flows can be useful in understanding instabilities in the crowd. However, extracting motion flows is a challenging task due to randomness in crowd movement and limitations of the sensing device. Moreover, low-level features such as optical flow can be misleading if the randomness is high. In this paper, we propose a new model based on Langevin equation to analyze the linear dominant flows in videos of densely crowded…
Click any figure to enlarge with its caption.
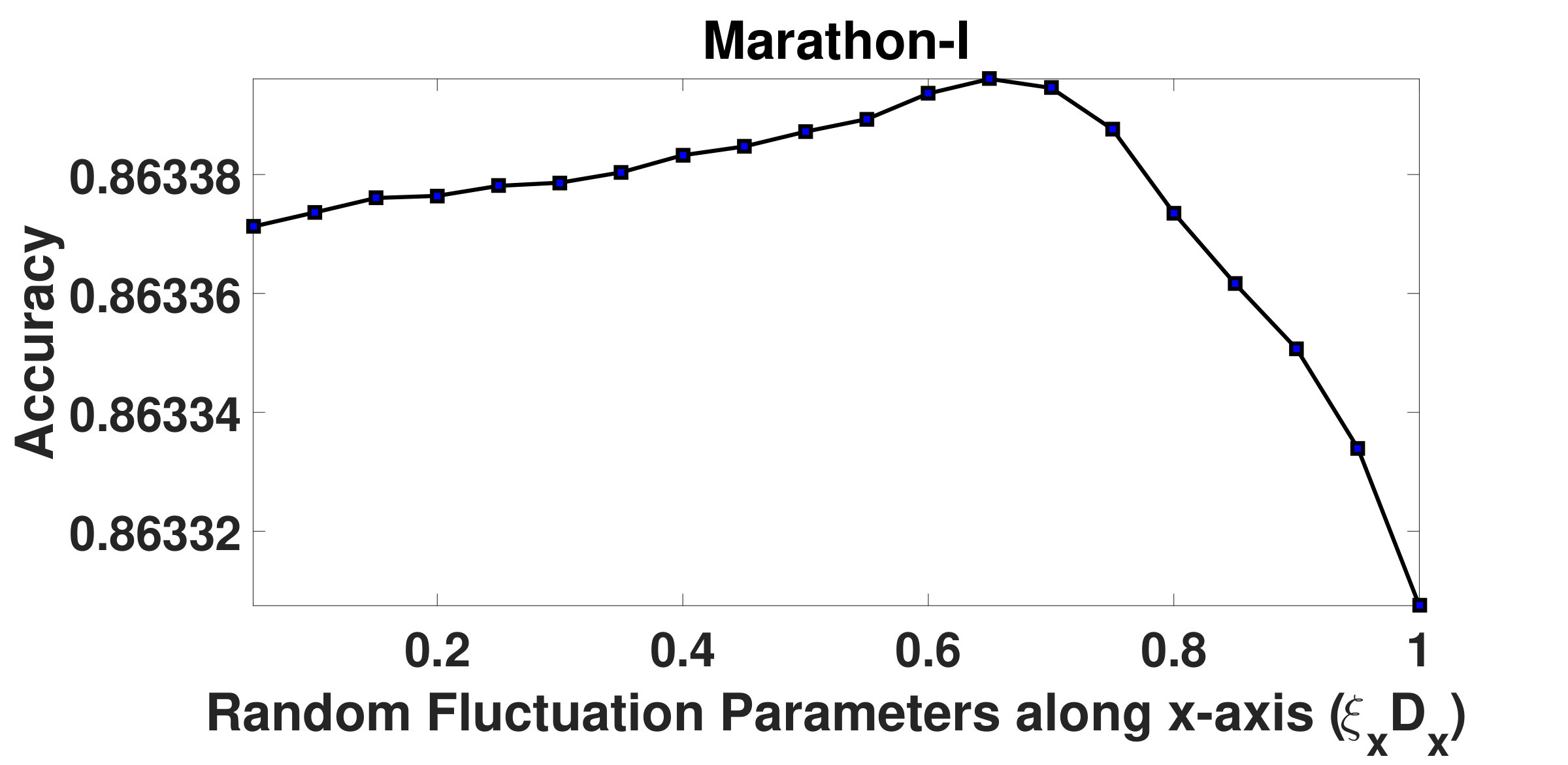 Figure 1
Figure 1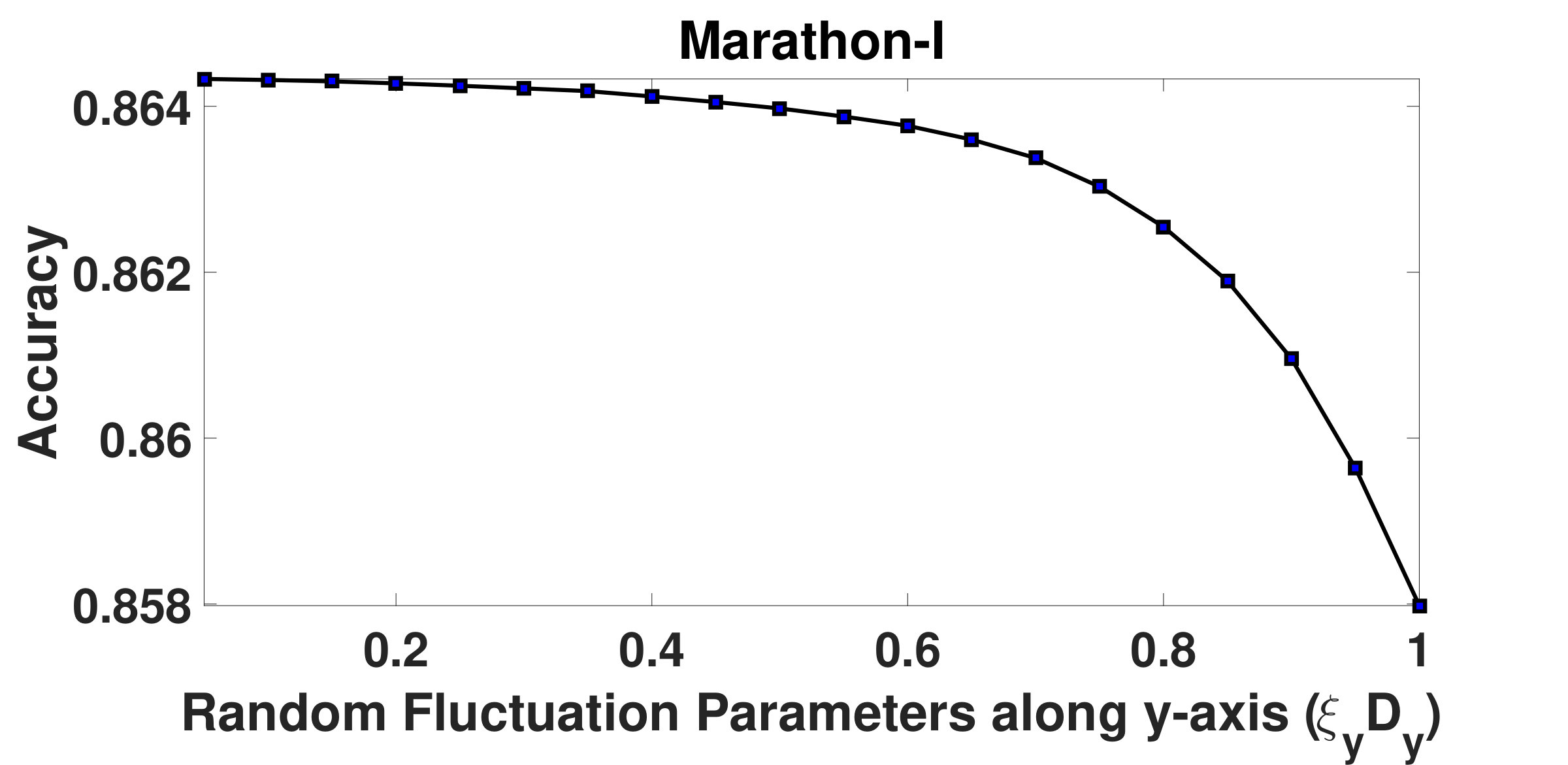 Figure 2
Figure 2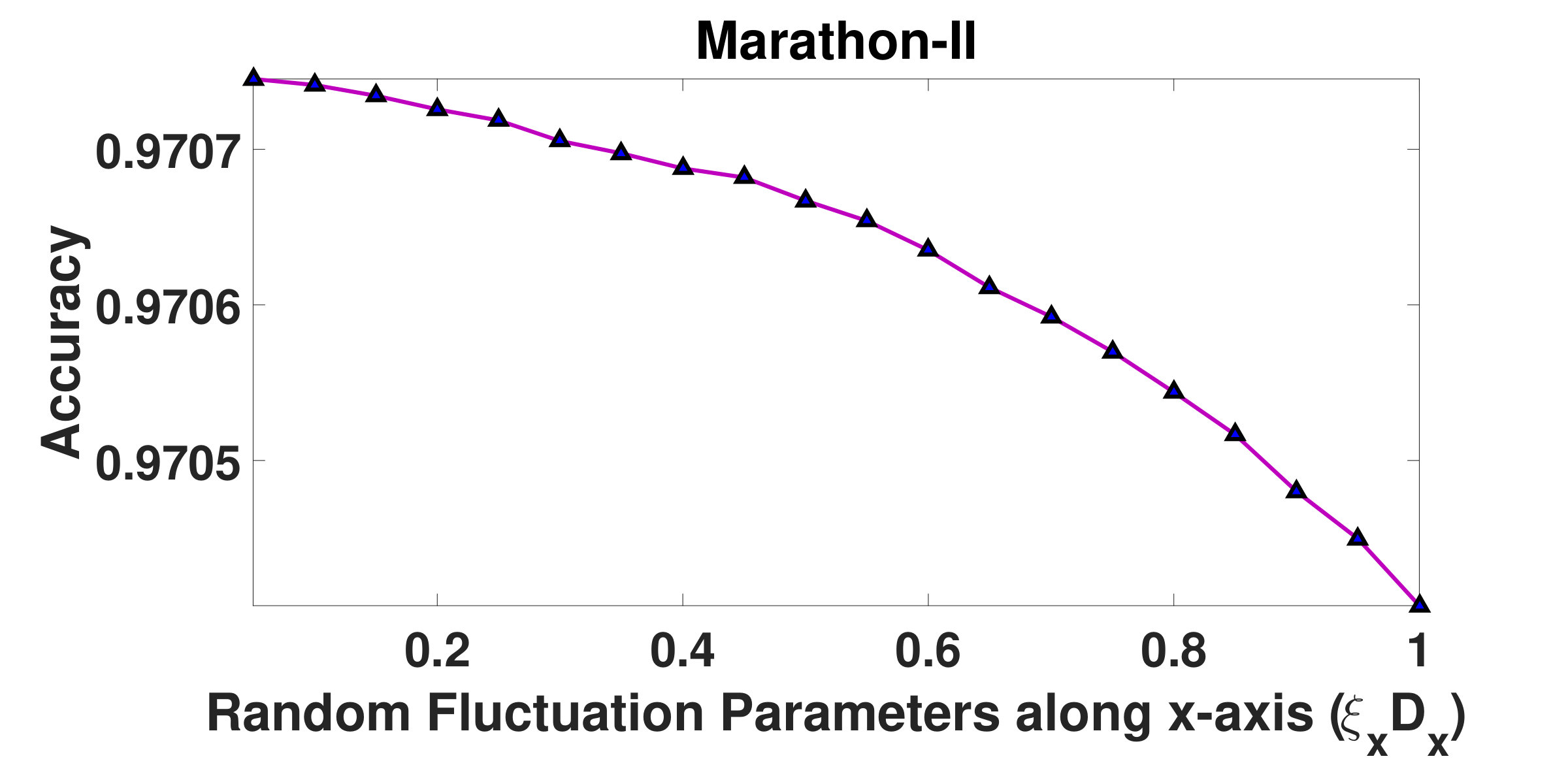 Figure 3
Figure 3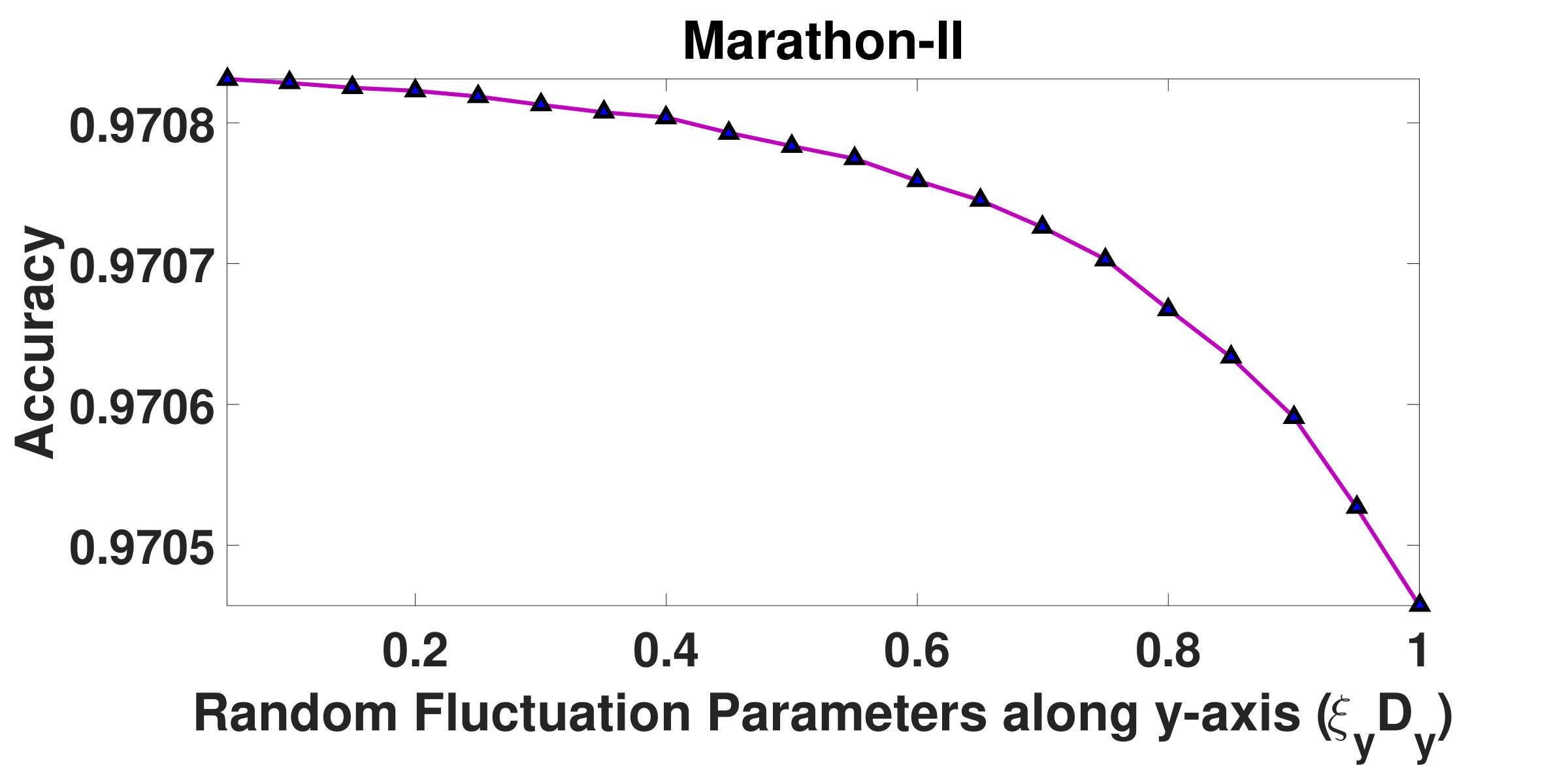 Figure 4
Figure 4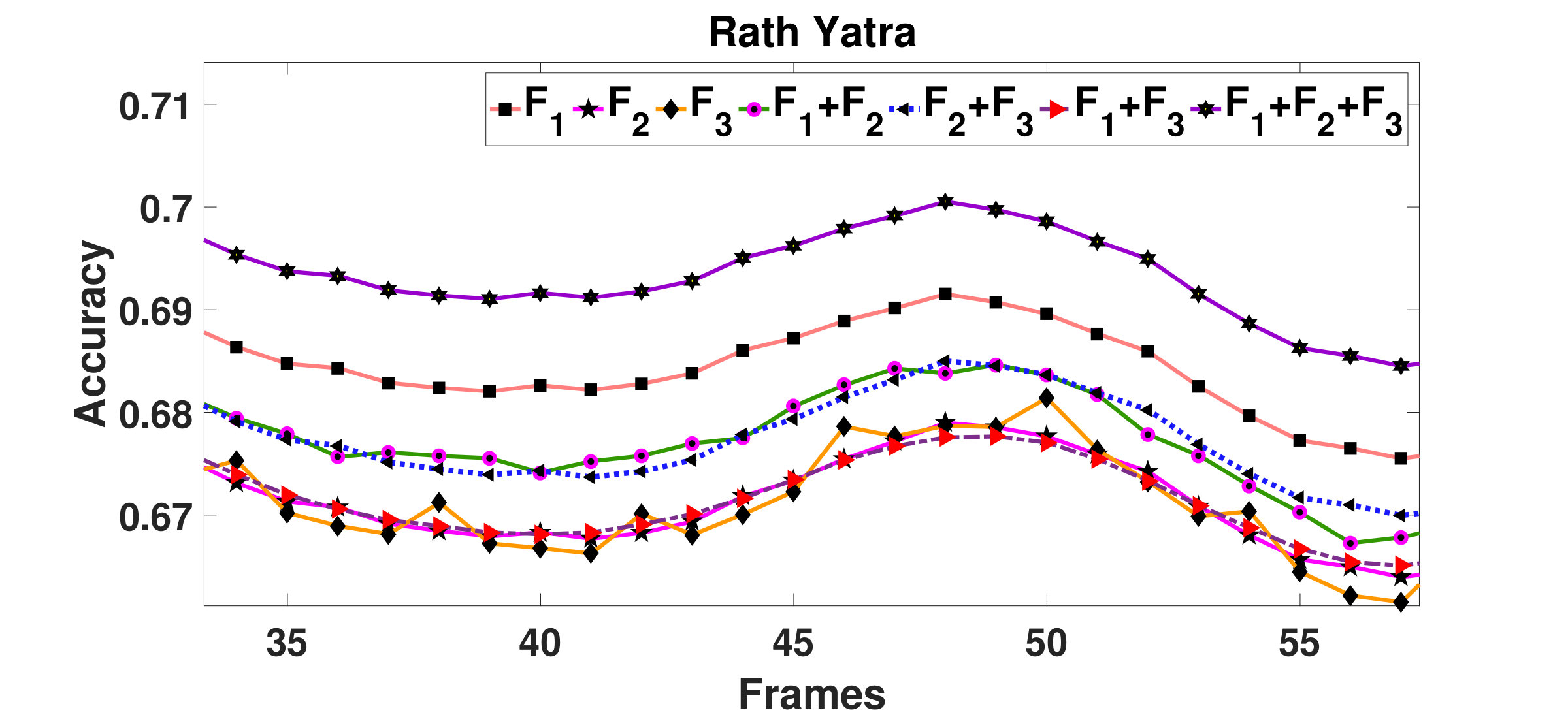 Figure 5
Figure 5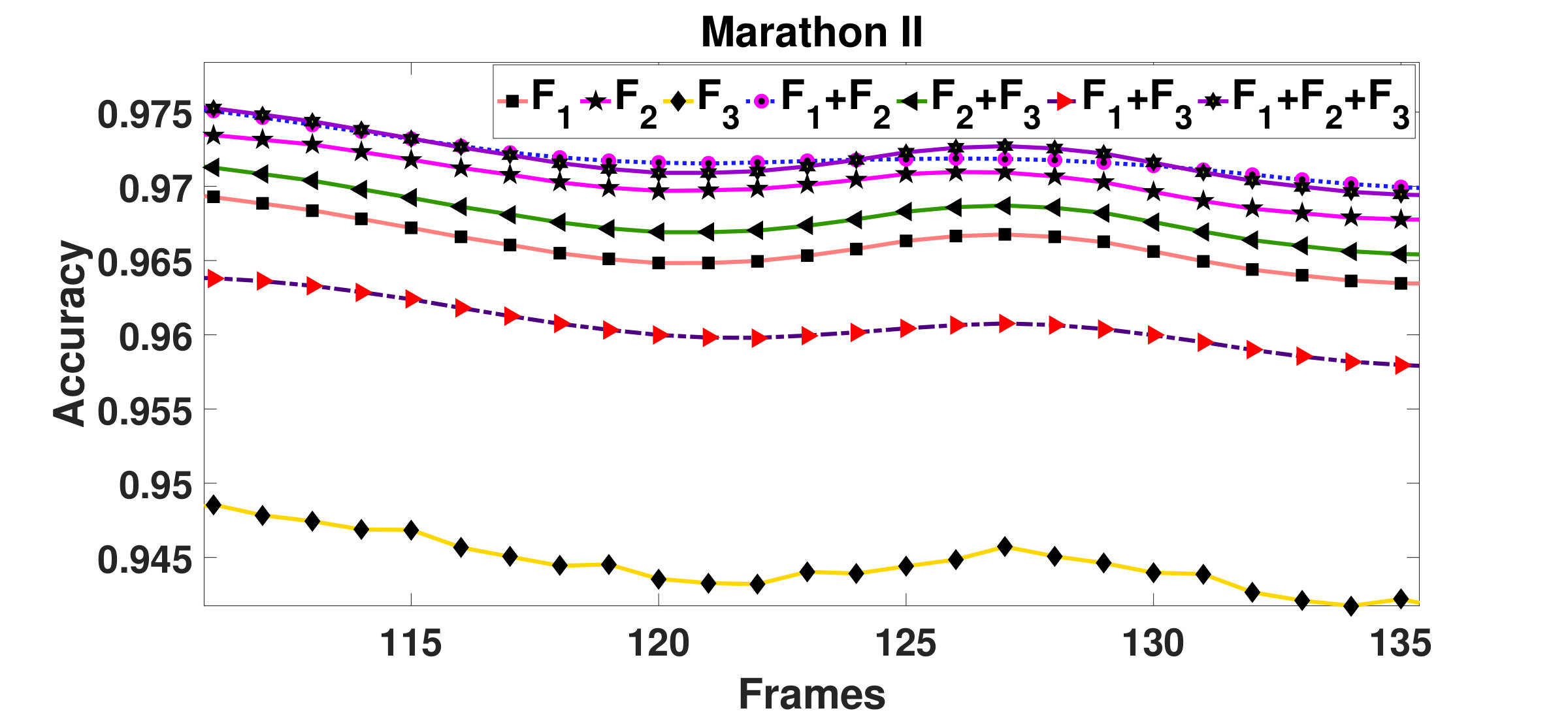 Figure 6
Figure 6 Figure 7
Figure 7 Figure 8
Figure 8 Figure 9
Figure 9 Figure 10
Figure 10 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26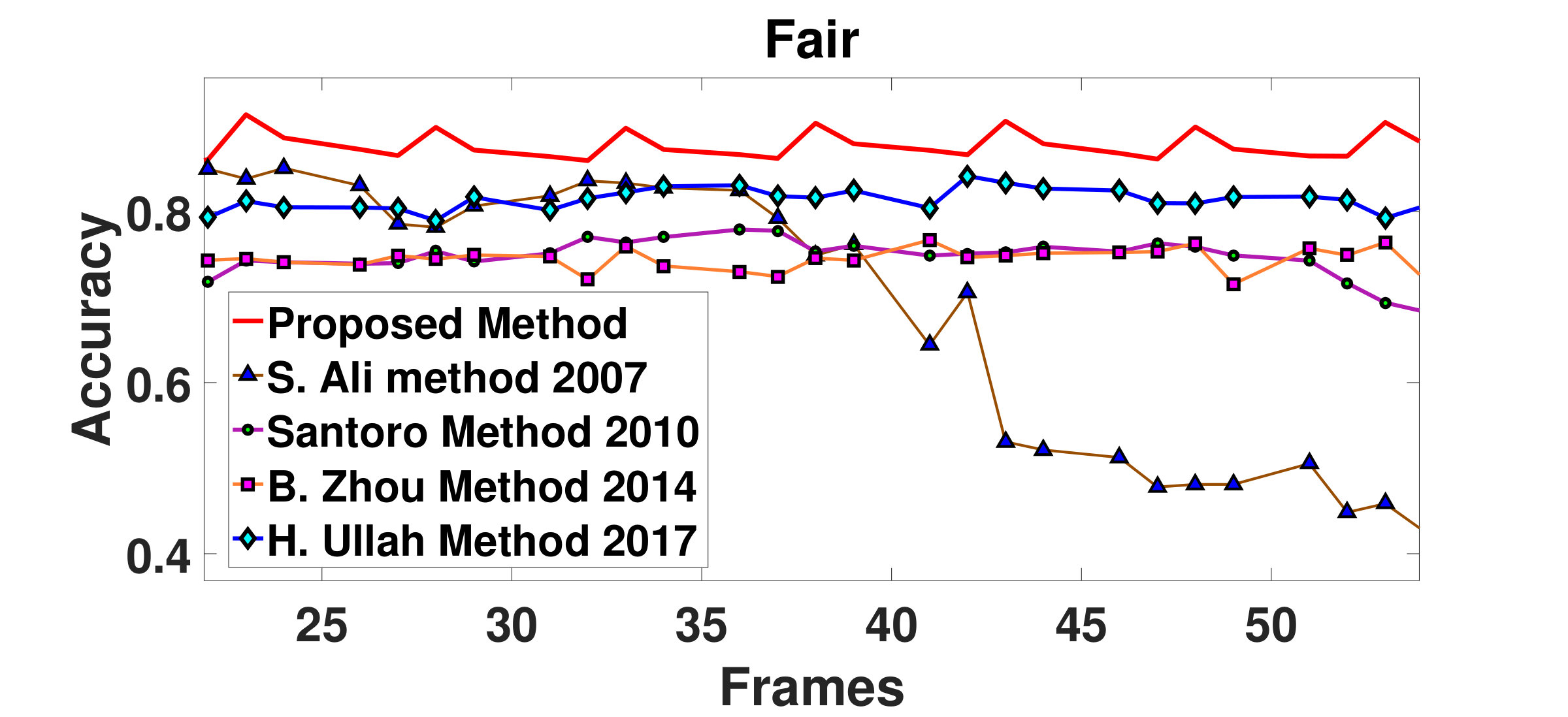 Figure 27
Figure 27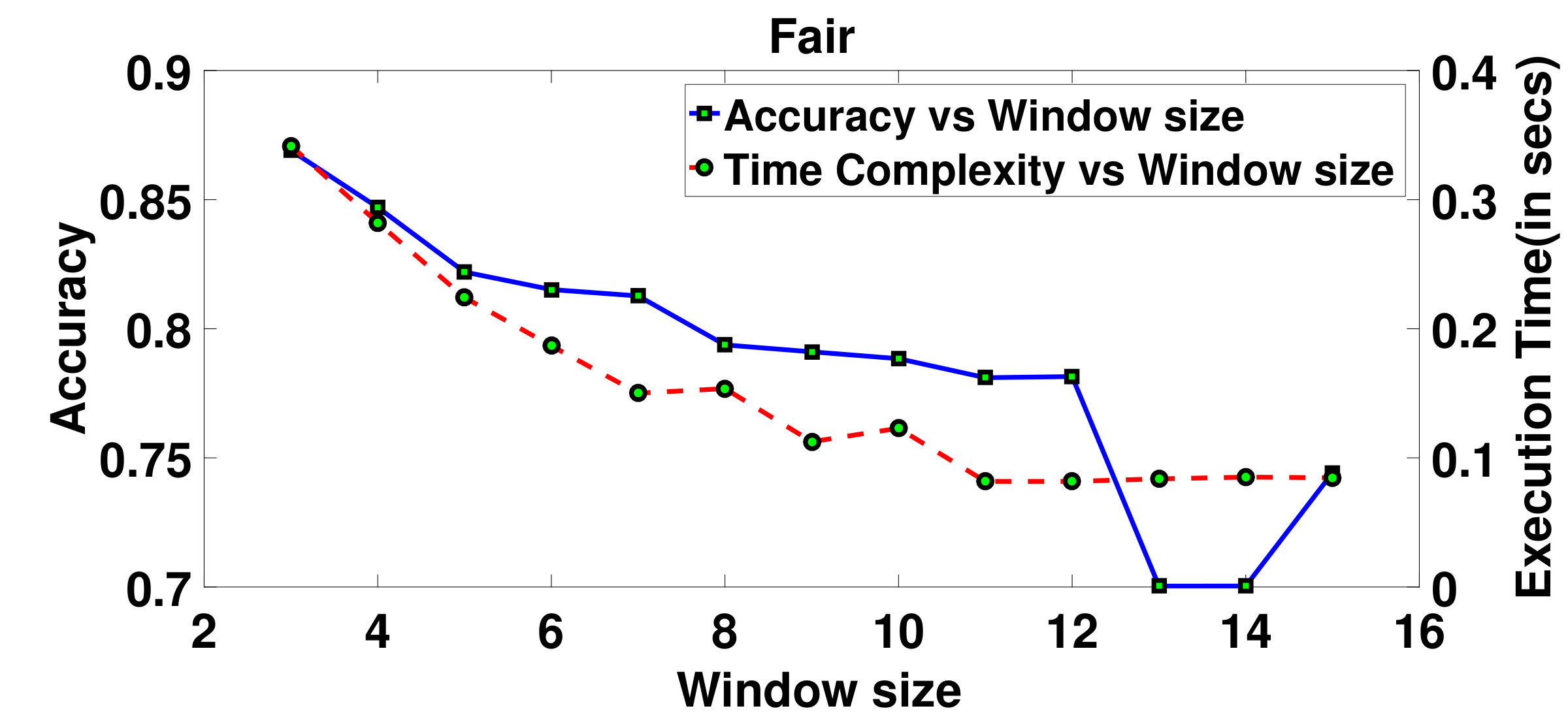 Figure 28
Figure 28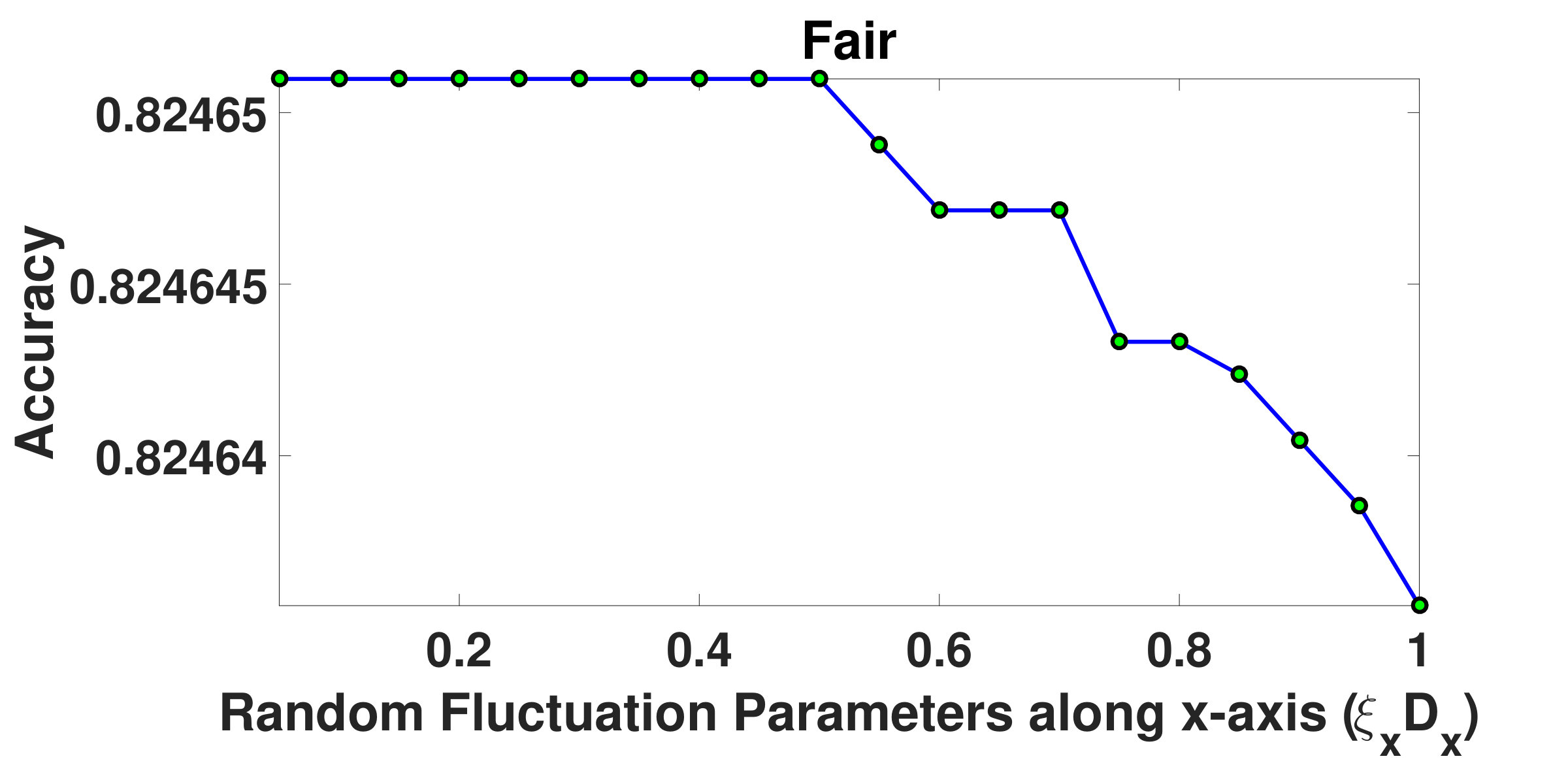 Figure 29
Figure 29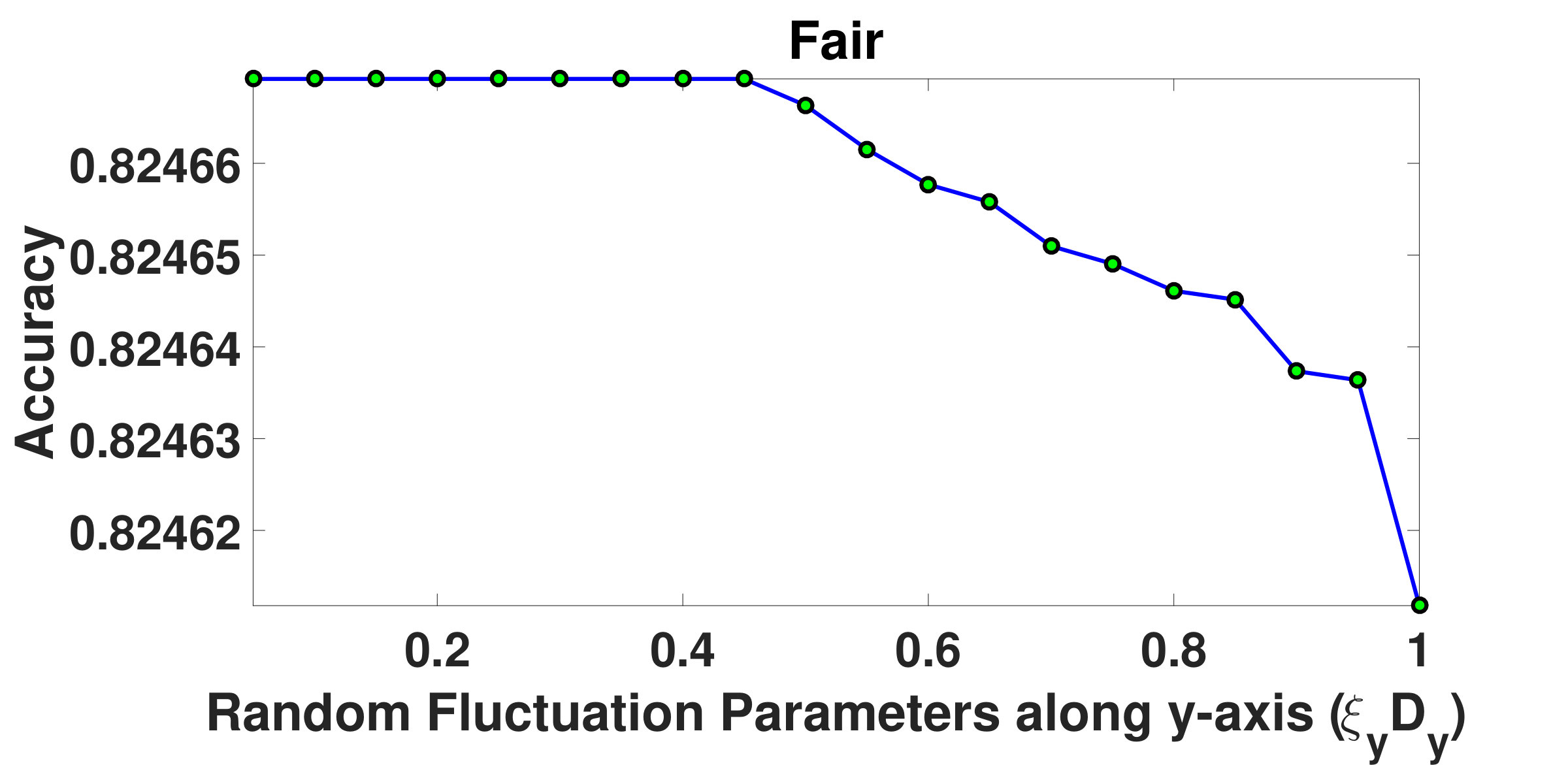 Figure 30
Figure 30 Figure 31
Figure 31 Figure 32
Figure 32 Figure 33
Figure 33 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37 Figure 38
Figure 38 Figure 39
Figure 39 Figure 40
Figure 40| #Dataset | Crowd Density | Types of Motion |
|
||||
|---|---|---|---|---|---|---|---|
| Marathon-I | Sparse |
|
|
||||
| Marathon-II | Dense |
|
|
||||
| Fair | Semi-Dense |
|
|
||||
| Rath Yatra | Semi-Dense |
|
|
| #Dataset | Time taken per frame (in seconds) | ||||
|---|---|---|---|---|---|
| Proposed Method | (Ali and Shah, 2007) | (Santoro et al., 2010) | (Zhou et al., 2014) | (Ullah et al., 2017) | |
| Marathon-I | 0.103 | 8.657 | 1.259 | 0.562 | 0.548 |
| Marathon-II | 0.093 | 9.742 | 2.240 | 0.695 | 0.594 |
| Fair | 0.159 | 12.229 | 1.811 | 0.756 | 0.862 |
| Rath Yatra | 0.139 | 10.682 | 1.834 | 0.702 | 0.744 |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
Estimation of Linear Motion in Dense Crowd Videos using Langevin Model
∗Shreetam Beheraa, Debi Prosad Dograa, Malay Kumar Bandyopadhyayb and Partha Pratim Royc
School of Electrical Science,a
Indian Institute of Technology Bhubaneswar, Bhubaneswar-752050, Indiaa
School of Basic Sciences,b
Indian Institute of Technology Bhubaneswar, Bhubaneswar-752050, Indiab
Department of Computer Science and Engineeringc,
Indian Institute of Technology Roorkee, Roorkee-247667, Indiac
Email: [email protected]a, [email protected]a, [email protected]b, [email protected]c
Abstract
Crowd gatherings at social and cultural events are increasing in leaps and bounds with the increase in population. Surveillance through computer vision and expert decision making systems can help to understand the crowd phenomena at large gatherings. Understanding crowd phenomena can be helpful in early identification of unwanted incidents and their prevention. Motion flow is one of the important crowd phenomena that can be instrumental in describing the crowd behavior. Flows can be useful in understanding instabilities in the crowd. However, extracting motion flows is a challenging task due to randomness in crowd movement and limitations of the sensing device. Moreover, low-level features such as optical flow can be misleading if the randomness is high. In this paper, we propose a new model based on Langevin equation to analyze the linear dominant flows in videos of densely crowded scenarios. We assume a force model with three components, namely external force, confinement/drift force, and disturbance force. These forces are found to be sufficient to describe the linear or near-linear motion in dense crowd videos. The method is significantly faster as compared to existing popular crowd segmentation methods. The evaluation of the proposed model has been carried out on publicly available datasets as well as using our dataset. It has been observed that the proposed method is able to estimate and segment the linear flows in the dense crowd with better accuracy as compared to state-of-the-art techniques with substantial decrease in the computational overhead.
keywords:
Crowd Flow Segmentation, Crowd Dynamics, Visual Surveillance, Langevin Equation
1 Introduction
Recent advancement in computer vision-based crowd surveillance has drawn interests of the researchers and law enforcing agencies across the world. Automatic visual surveillance through expert decision making systems often results in efficient crowd monitoring and management with higher accuracy and better information fusion. Moreover, such intelligent systems can reduce human efforts leading to less errors in estimation. Expert systems guided automatic visual surveillance frameworks can promptly indicate unusual behavior or activity in crowd. Therefore, precautionary measures can be taken in order to avoid undesirable incidents. Such systems can also be used to understand human behavior of the people in crowded situations. However, majority of existing systems find it hard to handle dense crowds such as religious festivals, social and political gatherings because of the complexity of the problem in terms of functionality and time (Junior, Musse, and Jung, 2010). Computer vision research community tend to adopt machine vision-based algorithms in the above situations (Junior, Musse, and Jung, 2010; Yogameena and Nagananthini, 2017).
1.1 Related Work
Flow detection and segmentation are key to develop automatic crowd monitoring systems. Existing research work on crowd flow segmentation are either physics and particle dynamics-based or standard computer vision guided techniques as mentioned in (Zhang, Yu, and Yu, 2018).
1.1.1 Physics or Particle Dynamics-based Methods
In case of physics-based or particle dynamics-based methods, typical fluid-flow model or freely moving particles on air may not be directly applied on crowd. For example, Langevin theory of Brownian motion may not be directly applied on crowd dynamics. However, such physics-based models can be adopted with context imposed restrictions. For example, correlating the actual forces in dense crowded situations with particle dynamics can be interesting. Such models have started to emerge off late (Zhang, Yu, and Yu, 2018). Ali et al. (Ali and Shah, 2007) have used Lagrange particle dynamics to segment high density crowd flows. The same framework has also been used for detecting instabilities in crowd flows. Zhang et al. in (Zhong, Ding, Wu, and Xu, 2008) have used Markov Random Field to define crowd energy upon which wavelet analysis has been performed to detect abnormal behaviors. However, the method is not independent of background and it is sensitive to video shaking. The authors in (Ali and Shah, 2008) have used a scene-structure-based force model to detect individuals in high-density crowd by analyzing its static, dynamic, and boundary floor fields. The algorithm is highly computation intensive. Mehran et al. (Mehran, Moore, and Shah, 2010) have used streaklines for crowd flow analysis. They have used social force graph technique and streaklines to analyze the flow. The authors of (Ji, Chi, and Lu, 2017) have proposed a method based on social force model to detect crowd anomaly at pixel and block levels. In (Wu, Su, Yang, Zheng, Fan, and Zhou, 2017), the authors perform analysis of the crowd based on a bilinear interaction of curl and divergence of the flows. In (Ullah, Uzair, Ullah, Khan, Ahmad, and Khan, 2017), a density independent hydrodynamics model (DIHM) for coherency detection in crowded scenes, has been proposed. The method has the capability to handle changing density over time. The method doesn’t perform finer-level crowd flow segmentation. A spatio-temporal driving force model has been proposed in (Li and Chellappa, 2010) to perform group segmentation in crowded scenarios. However, the model is not view variant and it needs to learn for different views with different parameter settings. In (Chen, Wang, and Yung, 2011), the authors have presented an adaptive human motion analysis and prediction method for understanding the motion patterns in crowds. Solmaz et al. in (Solmaz, Moore, and Shah, 2012) have proposed a method to identify multiple crowd behaviors through stability analysis for dynamical systems avoiding object detection, tracking, or training. Their method cannot capture the randomness in a crowd. In (Lin, Mi, Wang, Wu, Wang, and Mei, 2016), coherent regions in a crowded scene is detected based on thermal diffusion process and time-series clustering. The coherency is lost as the method merges both the motion and non-motion regions together over time. The agent-based method proposed in (Kountouriotis, Thomopoulos, and Papelis, 2014) can model crowd behavior based on group dynamics and agent-based personality traits. Though their method performs reasonably well in real-time scenario, but its performance ceases with increase in the number of agents. In (Zhou, Tang, and Wang, 2015), Zhou et al. have proposed a new mixture model of dynamic pedestrian-Agents (MDA) to learn the collective behavioral patterns of pedestrians in crowded scenes. However, it is unclear that how their method can handle varying density. In (Su, Yang, Zheng, Fan, and Wei, 2013), the authors have proposed a spatio-temporal viscous fluid field to recognize the large-scale crowd behavior from appearance and driven factor perspectives. An application of real-time monitoring of crowd density at Puri Rath Yatra, combined with modeling evacuation scenarios using agent-based simulation has been proposed in (Basak and Gupta, 2017). The technique is useful in predicting scenarios in emergency situations even though the technique is computationally expensive.
1.1.2 Computer Vision-based Methods
Conventional computer vision-based methods like optical flow-based methods have been instrumental in flow segmentation. The method proposed in
(Cheriyadat and Radke, 2008) finds dominant motions of crowd by clustering low-level feature point tracks in videos. Wu et al. (Wu, Yu, and Wong, 2009a) have presented a region growing segmentation scheme based on the translational domain for segmenting crowd flows. The method fails if the translational flow is not local. Santoro et al. (Santoro, Pedro, Tan, and Moeslund, 2010) have used Lucas-Kanade Tracker along with the density-based clustering for analysis of crowd motion. In the last step, a crowd tracker has been applied in each frame of the video. The authors claims their method can detect and track crowd with various shapes. However, the calculations are based on 2D coordinates of the motion point. Thus, the distance calculation between the motion points is not accurate. Moreover, the time complexity increases with the increase in motion points. In (Wu, Yu, and Wong, 2009b), the authors have proposed a new framework for crowd movement analysis. The crowd flow segmentation is performed using optical flow field. An interpolation method based on Delaunay Triangulation has been used to estimate the smooth optical flow field in a robust way. Motion regions are then clustered and a shape derivative technique is combined with a region growing scheme in order to segment a crowd. However, the method cannot detect all motion regions in a typical crowd. The authors in (Lu, Wei, Xing, and Liu, 2017) have proposed a trajectory clustering-based method to understand crowd motion patterns. The method in (Nasir, Lim, Nahavandi, and Creighton, 2014) aims to generate accurate sequence waypoints for the pedestrian walking path by analyzing videos in closed environments only. The authors in (Anwar, Petrounias, Morris, and Kodogiannis, 2012) have developed an anomaly detection method to analyze anomalous events. However, the proposed method works at microscopic level. An Interval-Based Spatio-Temporal Model (IBSTM) have been proposed in (Kardas and Cicekli, 2017) in order to detect untoward events in a video. However, the proposed method is a microscopic event model that cannot deal with macroscopic events such as crowd flow. The method proposed in (Walia, Raza, Gupta, Asthana, and Singh, 2017) uses a multi-stage tracker for precise localization of targets. However, this model is a microscopic model aimed at individual humans only. The authors in (Fernández-Caballero, Castillo, and Rodríguez-Sánchez, 2012) have proposed a finite state machines-based technique for human activity monitoring in a closed scene. The method needs to have prior information about source and destination points. The method described in (Zhou, Tang, Zhang, and Wang, 2014) segments the motion flow in sparse crowds in terms of collectiveness. Fradi et al. (Fradi, Luvison, and Pham, 2017) have proposed local descriptors which provide semantic information and interactive sparse crowd behaviors. However, it is not clear how the method handles dense crowd.
Traditional computer vision algorithms amalgamated with machine learning techniques have also been used for performing crowd flow segmentation in videos. Cao et al. (Cao, Zhang, Ren, and Huang, 2015) have performed large scale crowd analysis using Convolutional Neural Networks (CNN). The authors have combined CNN guided classification with regression to get accurate results. However, a large database with proper labeling must be available for such a method to be successful. The authors in (Zhou, Shen, Zeng, Fang, Wei, and Zhang, 2016) have proposed a spatio-temporal CNN for crowd anomaly detection. In (Kruthiventi and Babu, 2015), crowd flow analysis is performed using Conditional Random Field. However, the method is incapable to handle intersecting flows. Deep learning-based optical flow schemes are also proposed in (Dosovitskiy, Fischer, Ilg, Hausser, Hazirbas, Golkov, Van Der Smagt, Cremers, and Brox, 2015) and (Ilg, Mayer, Saikia, Keuper, Dosovitskiy, and Brox, 2017) to predict optical flow of consecutive frames based on Convolution Neural Networks. But, they do not address the dynamics of typical crowded scenarios. The methods proposed in (Shao, Kang, Loy, and Wang, 2015) and (Long, Shelhamer, and Darrell, 2015) are based on deep learning techniques for scene understanding and semantic segmentation. However, these methods are unable to describe the dynamics of the crowd. The authors of (Chaker, Al Aghbari, and Junejo, 2017) have proposed an unsupervised approach for crowd scene anomaly detection based on the social network model. In the paper (Wu, Ye, Zhao, and Shi, 2018), collective density clustering is performed for detection of coherent crowd regions. However, the method is dependent on stability and accuracy of the tracking algorithm. In (Direkoglu, Sah, and O’Connor, 2017), the angle difference between optical flow vectors, has been used as a feature, fed to Support Vector Machine (SVM) for detecting abnormality in crowd. The authors in (Yuan, Wan, and Wang, 2016) have proposed a sparse representation method for crowd anomaly detection. The work presented in (Chan and Vasconcelos, 2008) and (Ma, Cisar, and Kembhavi, 2009) are based on dynamic mixture model of textures and expected-maximization (EM) algorithm. Such methods can segment motion in traffic and crowd videos. However, the authors have not provided any evidence on how it addresses crowd in terms of varying density.
From the aforementioned work, we have made the following observations:
The methods similar to (Santoro, Pedro, Tan, and Moeslund, 2010) are restricted to be applicable for low and medium density crowd. These methods lack robustness in handling densely crowded scenarios.
- 2.
Though the physics-based (Chaker, Al Aghbari, and Junejo, 2017) and particle-dynamics-based (Ali and Shah, 2007) models partially address the issues in densely crowded scenarios, they are complex in functionality and often leads to increased execution time. Moreover, such methods lack simplicity from the point of implementation.
- 3.
It has also been understood that, none of the existing methods such as (Ali and Shah, 2007) or (Ullah, Uzair, Ullah, Khan, Ahmad, and Khan, 2017) address the movement as random particles in the fluid. This has been one of the key motivations behind the idea presented in this paper.
1.2 Contributions
Following research contributions have been made to mitigate the aforementioned limitations:
We propose a fast computational model to understand the dense crowd flow in videos using Langevin theory of Brownian particles in fluid.
- 2.
Using the aforementioned model, we propose an algorithm that can segment linear and near-linear flows of dense crowd movements in videos with the help of a context adaptive force model.
The rest of the paper is organized as follows. The foundation of Langevin equation is explained in Section 2. In Section 3, we explain how Langevin equation can be adopted for designing expert decision making system to understand crowd flow through segmentation. The results are presented in Section 4 using public datasets as well as using our video dataset. In Section 5, we have concluded the paper with possible future directions.
2 Background and Foundation
Langevin equation is perhaps the simplest way to describe the dynamics of non-equilibrium systems. It is a stochastic differential equation introduced first to describe the motion of a particle in fluid as mentioned in (Langevin, 1908; Coffey and Kalmykov, 2004). Since the motion of a particle is random, it cannot be described only using Newton’s force. In order to estimate the random and fluctuating motions of the particle, the basic Newtonian force is added with two additional force components: frictional force and random force.
Consider the 1D motion of a particle of mass as shown in Fig.1. According to Newton’s second law of motion, the motion of the particle is described using (1),
[TABLE]
where is the mass of the particle, is the velocity of the particle at time and is the instantaneous force exerted on the particle at time .
The instantaneous force as represented in (2), acting on a particle, is originated from the impact received from the surrounding fluid molecules. Langevin suggested that the force can be written as a sum of two components. The first part is an component which basically represents the viscous drag, , where is the frictional coefficient. In general, this frictional force is assumed to be proportional to the velocity of the particle. The second component of this instantaneous force is a rapidly fluctuating part which arises due to random density fluctuations in the fluid.
[TABLE]
The random force averages out to be zero over long intervals as mentioned in (3). The second moment is actually relating the fluctuating force with the viscous drag or dissipative force , which is related to as mentioned in (4),
[TABLE]
where represents an average value considered with respect to the distribution of the realizations of the variable ,
[TABLE]
and is the measure of strength of the fluctuation force, is Boltzmann’s constant, is the temperature, and is the delta function.
3 Proposed Crowd Flow Segmentation Method
The proposed crowd segmentation method using Langevin equation is discussed here. For a given video sequence, over a window of size , the keypoints are extracted and propagated to the proposed model as illustrated in Fig.3. Inside a typical window, this partial flow information is passed on to the proposed model where flow segmentation is carried out over the remaining frames of the window. Windowing ensures re-initialization of the process at regular intervals, which tracks the flow changes in the frames in temporal domain.
3.1 Keypoint Extraction
Dense optical flow using Farneback’s method as described in (Farnebäck, 2003) has been estimated on first two down-scaled frames of . The flow vectors obtained are used to compute magnitude and orientation maps using equations (5) and (6), respectively. The orientation map is quantized into eight bins using a magnitude threshold within . The envelope joining all the bin peaks forms a quantization curve.
[TABLE]
[TABLE]
Using a standard peak detection algorithm upon this quantization curve, the peaks are detected. Keypoints corresponding to these peaks are retained and others are discarded. In the next step, grouping of retained keypoints is performed. Mainly, two factors are considered for grouping: orientation and spatial connectivity. The keypoints surrounding the considered keypoint are in a group if their quantized orientations are equal and they lie within a x neighborhood of the considered keypoint. The last condition accounts for the spatial connectivity of the considered keypoint with its neighboring keypoints. These grouped keypoints are assumed as initial segregated structured flows and are fed to Langevin-based model for the temporal flow segmentation for the remaining frames within the window. The entire process is illustrated in Fig.4.
3.2 Langevin Equation-guided Flow Segmentation
3.2.1 Formulation of Langevin Equation-based Force Model
The dense crowd can be considered analogous to particles moving in the fluid. After careful visual observation of several real-live crowd movement videos, we have realized that, structured crowd usually move together in groups of similar orientations as shown in Fig.2. In such cases, it is possible to approximate the motion with the help of Langevin theory. We have assumed that the force is acting on these groups instead of individual particle. Thus, the resultant force can be reconstructed as combination of various forces acting upon and within the group as represented in (7).
[TABLE]
The resultant force as mentioned in (7) is constituted with external forces arising due to the motion of the group in the surrounding (), the drift forces that may cause the particle to drift along with the group in a particular direction or the confinement forces that confines the particles to stay within the group i.e. (), and disturbances due to the noise in the group ().
For example, if we assume the movement of particles of the group along -axis as depicted in Fig. 2, inertial force on a particle along -axis can be represented as (8),
[TABLE]
where is the mass of the particle, represents the resistive force due to particles and surrounding groups, is the constant drift force, is the strength of the noise, and represents the random force due to random density fluctuations in the considered group. Simplifying (8), we obtain
[TABLE]
The first term in the right hand side of (9) is the resistive or opposing force experienced by the group because of the surrounding particles, while the second term is the drifting force responsible for causing the motion of the particle in the group along -axis. The third term is the force resulted due to the noise and internal disturbances within the group. Similarly, for the force acting on the particles in the group along -axis is represented as in (10),
[TABLE]
where is the mass of the particle, represents the resistive force due to motion of the surrounding group, is the confinement force, is the rate of change of confinement force along -axis along unit length, is the strength of the noise, and represents the represents the random force due to random density fluctuations within the considered group.
3.2.2 Implementation of Langevin-based Force Model for Flow Segmentation
The numerical solutions of (9) and (10) give the predicted velocities of the particles in motion along -axis and -axis as shown in (11) and (12), respectively. Further integrating (11) and (12), we get the new or predicted positions of the particles.
[TABLE]
[TABLE]
Equations (13) and (14) represent the predicted position of the particle with respect to its intial position ,
[TABLE]
[TABLE]
where t is the increment in time. In the above equations, the mass of each particle is set to for consistency.
The segmentation map in the previous section, consists of groups with similar orientations. For each particle i.e. keypoint in the group, equations (9 and 10) and equations (13 and 14) are used to predict the velocity and position of the particle, repsectively. For these groups, drift is the force that controls the overall group movement along -axis. It is basically a group force which is computed as the cumulative sum of acceleration of the particles along -axis as mentioned in (15).
[TABLE]
Similarly, the confinement force confines the group in the - axis which can be estimated as cumulative sum of acceleration of the particles along -axis as in (16),
[TABLE]
where and represent the velocities for the keypoint in the group along x-axis and y-axis, respectively. As mentioned earlier, mass is set to for consistency.
The predicted velocities, , are further used to compute magnitude and orientation maps, which are used to estimate the flow in the remaining frames of the current window avoiding optical flow computation in every consecutive frames. Finally, temporal segmentation maps are obtained representing the dominant flows in the window. The process of flow segmentation is presented in Algorithm 1.
4 Results and Discussions
In this section, we first discuss about the datasets that have been used for evaluation of the proposed method, followed by experiments based on forces and force-parameters of the Langevin-guided segmentation force model. The segmentation results and computational results are presented in Sections 4.5 and 4.4, respectively.
4.1 Datasets
Two video datasets have been used for testing the proposed flow segmentation method. One of them is publicly available dataset containing three different videos. The other one (our dataset) contains ten hours of video recording of Cart Festival (Sri Jagannath Ratha Yatra) at Puri (Odisha, India). The details are presented in Table 1.
4.2 Estimation of the Parameters
The proposed Langevin theory-based model aims to describe the random movement of structured groups in dense crowds. The parameters of force equations are mentioned in (9) and (10).
and are resistive force parameters, which are integral components of resistive forces acting upon the structured groups. Fig.5 and Fig.6 depict how the overall segmentation accuracy varies with and . It has been observed from the graphs that the segmentation is not stable as the accuracy varies for initial values of and . However, beyond certain values of and , the accuracy does not change noticeably indicating a saturation in the segmentation process. It has been found that for Marathon-I and Marathon-II videos, when is chosen to be , the accuracy stabilizes. However, for Fair and Rath Yatra videos, accuracy stabilizes when the value of is set to and , respectively. Similarly, it has been observed that when is outside the range , accuracy is consistent across all videos. We therefore argue, more dense the crowd, more is the value of the resistive force. On the basis of above experiments, both and have been fixed to .
The random fluctuating force consists of the parameters and . These parameters are responsible for creating the disturbances within the group.
In the graphs shown in Fig.7 and Fig.8, it can be observed that when remains within , segmentation output stabilizes. However, when its value is above , segmentation accuracy drops. Similarly, when remains within range, accuracy does not change much. Beyond this, accuracy reduces sharply. Therefore, and have been fixed to and , respectively.
4.3 Ablation Experiment on the Proposed Force Model
This sub-section discusses the results obtained from the ablation experiments performed on the proposed force model presented in (7). For these experiments, seven combinations of forces: , , , + , + + , + and + have been formed in order to understand the importance of each force in the proposed force model. In order to understand the effect of the resistive forces and drift force, Marathon-II video has been chosen for experimentation. The experimental results shown in Fig.9 reveal that the combination of all forces i.e. ++ has the highest accuracy among all other combinations and it is closer to ground truth. Furthermore, it can also be seen that the accuracy related to is less which indicates that the video has less random behavior. Similarly, in order to demonstrate the effect of random force, Rath Yatra video is chosen. It can be seen in the Fig.10 that the combination of all forces has the highest accuracy but most importantly, accuracy due to is overshadowing other forces at certain instances which clearly indicates the randomness in the video.
4.4 Flow Segmentation Results and Comparisons
For comparisons, ground truths have been obtained by marking the dominant flows in the videos. The accuracy is calculated using (17),
[TABLE]
where is the segmented image and is the ground truth image.
Proposed method generates segmented maps within a window. The first segmented map is the output obtained after grouping of optical flow keypoints based on spatial connectivity over a magnitude threshold of . The other segmented maps are obtained using Langevin theory-based model. The method has been compared with methods proposed in (Ali and Shah, 2007), (Santoro et al., 2010), (Zhou et al., 2014),and (Ullah et al., 2017), respectively. The outputs of (Ali and Shah, 2007) and (Ullah et al., 2017) is a segmentation mask which can be used directly in equation (17). However, the method in (Santoro et al., 2010) and (Zhou et al., 2014) produces outputs as clustered, tracked keypoints which are edge-grown, followed by morphological opening to get the segmentation mask. This mask is used for comparison with ground truth image.
Marathon-I video has a unidirectional linear motion flow. Even though the crowd is sparse, the proposed method is able to segment the unidirectional flow. The segmented flow using the proposed method is depicted in Fig.11. The accuracy plot is shown in Fig.15(a). The plot consists of peaks at regular intervals which indicate the initialization of the window where accuracy is maximum. The average accuracy for Marathon-I has been found to be , which is better than the methods proposed in (Ali and Shah, 2007), (Santoro et al., 2010), (Zhou et al., 2014), and (Ullah et al., 2017). Marathon-II is a dense crowd video where people are running in one direction. This video can be considered as a perfect test video where the flow can be observed from the beginning. The images in Fig.12 show how the proposed method is able to segment this increasing flow with an average accuracy of .
Fair video is a semi-dense sequence where people are moving in opposite directions. Our proposed method is able to handle this challenging situation and has segmented the bi-directional structured flows with an average accuracy of , which is better than (Ali and Shah, 2007), (Santoro et al., 2010), (Zhou et al., 2014) and (Ullah et al., 2017), respectively. The segmentation outputs and accuracy plots for this video are shown in Fig.13 and Fig.15(c), respectively.
Rath Yatra video is a sequence where people can be seen pulling the Cart (Rath) in one direction. The sequence consists of both structured as well as unstructured flows. Pulling of the Rath is a structured flow, while the people moving around this structured flow in different directions can be considered as random. The proposed method is able to segment this structured flow with an average accuracy of . Though the average accuracy is marginally lower than (Ali and Shah, 2007), however, the difference is not significant as can be seen in the Table 2. This effect is because of more randomness in the crowd. The segmented maps and the accuracy plots are shown in Fig.14 and Fig.15(d), respectively.
4.5 Computational Performance
We now present the computational overhead of the proposed method. The experiments have been conducted on a desktop computer powered by quad-core processor with GB of memory.
The execution time of the proposed method has been compared with the execution time of popular existing state-of-the-art methods. It can be observed from Table 3 that the proposed method is much faster than other methods. This is because the proposed method calculates optical flow at the start of the window and estimates the flow in the remaining frames of the window. As a result, a good amount of computation time is saved. In another experiment related to execution time, it has been shown how the accuracy and execution time vary over varying window size. It has been shown in Fig.16 that as the window size increases, the accuracy also reduces. Therefore, selection of a reasonable window size is important. From all the graphs in Fig.16, it may be observed that the accuracy is higher and the execution time is considerably lower when the window size is in between to .
5 Conclusion
In this paper, crowd flow segmentation using Langevin equation has been proposed. The method is able to segment the linear flows successfully without the need of estimating the optical flow in every frame. The solutions to the Langevin equations described are able to predict the velocity and position of the key points with noticeable accuracy. Computation time for dominant flow estimation can be substantially reduced using the proposed method. The proposed model can be extended to segment non-linear motion flows. The information obtained from the dominant flows can be used to train machine learning models. These trained models can be used for flow classification and prediction which are important part of intelligent crowd surveillance systems.
Acknowledgement
This research work is funded by Science and Engineering Research Board (SERB), Department of Science and Technology, Government of India through the grant YSS/2014/000046.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1Ali and Shah (2007) Saad Ali and Mubarak Shah. A lagrangian particle dynamics approach for crowd flow segmentation and stability analysis. In IEEE Conference on Computer Vision and Pattern Recognition , pages 1–6, 2007.
- 2Ali and Shah (2008) Saad Ali and Mubarak Shah. Floor fields for tracking in high density crowd scenes. In European Conference on Computer Vision , pages 1–14. Springer, 2008.
- 3Anwar et al. (2012) Fahad Anwar, Ilias Petrounias, Tim Morris, and Vassilis Kodogiannis. Mining anomalous events against frequent sequences in surveillance videos from commercial environments. Expert Systems with Applications , 39(4):4511–4531, 2012.
- 4Basak and Gupta (2017) Biswanath Basak and Sumana Gupta. Developing an agent-based model for pilgrim evacuation using visual intelligence: A case study of ratha yatra at puri. Computers, Environment and Urban Systems , 64:118–131, 2017.
- 5Cao et al. (2015) Lijun Cao, Xu Zhang, Weiqiang Ren, and Kaiqi Huang. Large scale crowd analysis based on convolutional neural network. Pattern Recognition , 48(10):3016–3024, 2015.
- 6Chaker et al. (2017) Rima Chaker, Zaher Al Aghbari, and Imran N Junejo. Social network model for crowd anomaly detection and localization. Pattern Recognition , 61:266–281, 2017.
- 7Chan and Vasconcelos (2008) Antoni B Chan and Nuno Vasconcelos. Modeling, clustering, and segmenting video with mixtures of dynamic textures. IEEE transactions on pattern analysis and machine intelligence , 30(5):909–926, 2008.
- 8Chen et al. (2011) Zhuo Chen, Lu Wang, and Nelson HC Yung. Adaptive human motion analysis and prediction. Pattern Recognition , 44(12):2902–2914, 2011.