Explicit Spatial Encoding for Deep Local Descriptors
Arun Mukundan, Giorgos Tolias, Ondrej Chum

TL;DR
This paper introduces a kernelized deep local descriptor that explicitly encodes spatial information using Cartesian and polar parametrizations, improving robustness and outperforming existing methods on benchmarks.
Contribution
It presents a novel explicit spatial encoding method for deep local descriptors, enhancing robustness to patch misalignment and outperforming prior approaches.
Findings
Outperforms all other methods on standard benchmarks
Model parameters are independent of patch resolution
Both Cartesian and polar encodings improve robustness
Abstract
We propose a kernelized deep local-patch descriptor based on efficient match kernels of neural network activations. Response of each receptive field is encoded together with its spatial location using explicit feature maps. Two location parametrizations, Cartesian and polar, are used to provide robustness to a different types of canonical patch misalignment. Additionally, we analyze how the conventional architecture, i.e. a fully connected layer attached after the convolutional part, encodes responses in a spatially variant way. In contrary, explicit spatial encoding is used in our descriptor, whose potential applications are not limited to local-patches. We evaluate the descriptor on standard benchmarks. Both versions, encoding 32x32 or 64x64 patches, consistently outperform all other methods on all benchmarks. The number of parameters of the model is independent of the input patch…
Click any figure to enlarge with its caption.
 Figure 1
Figure 1 Figure 2
Figure 2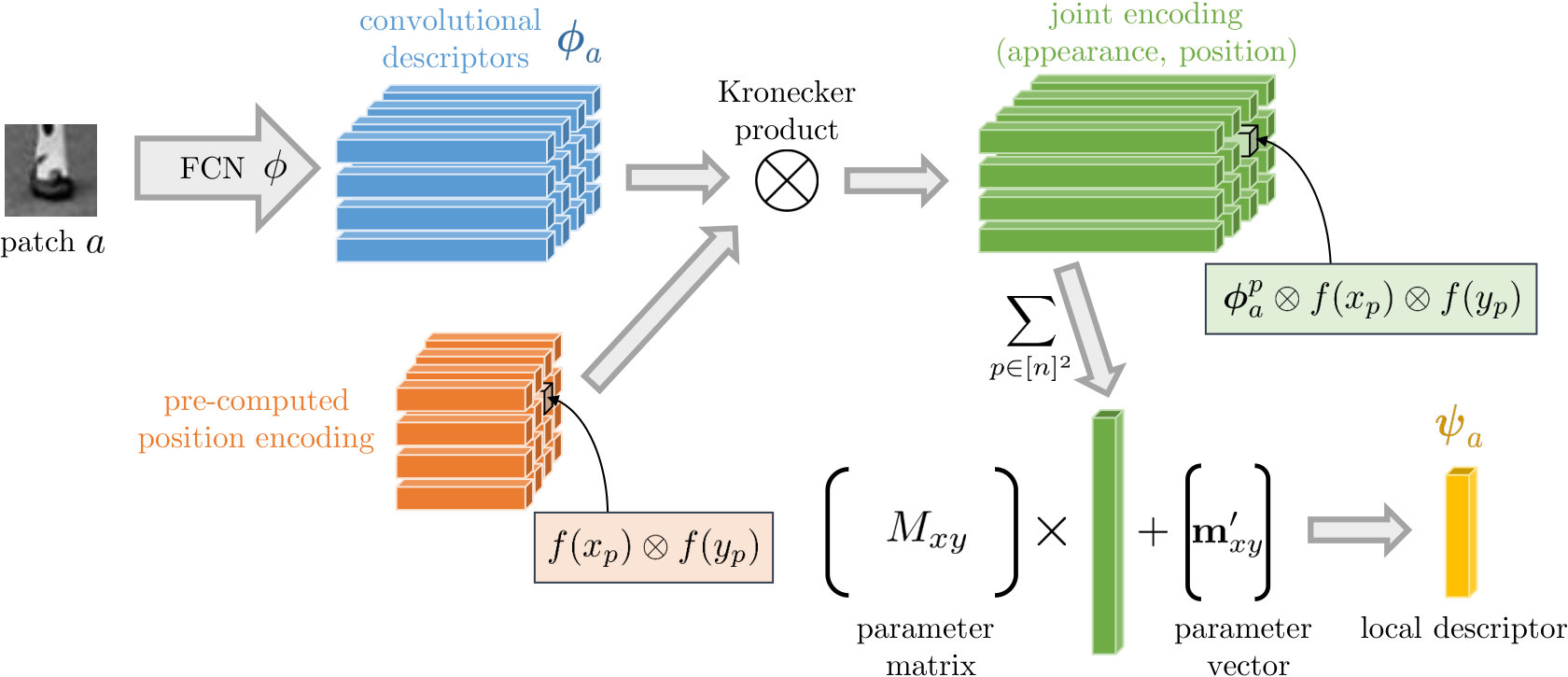 Figure 3
Figure 3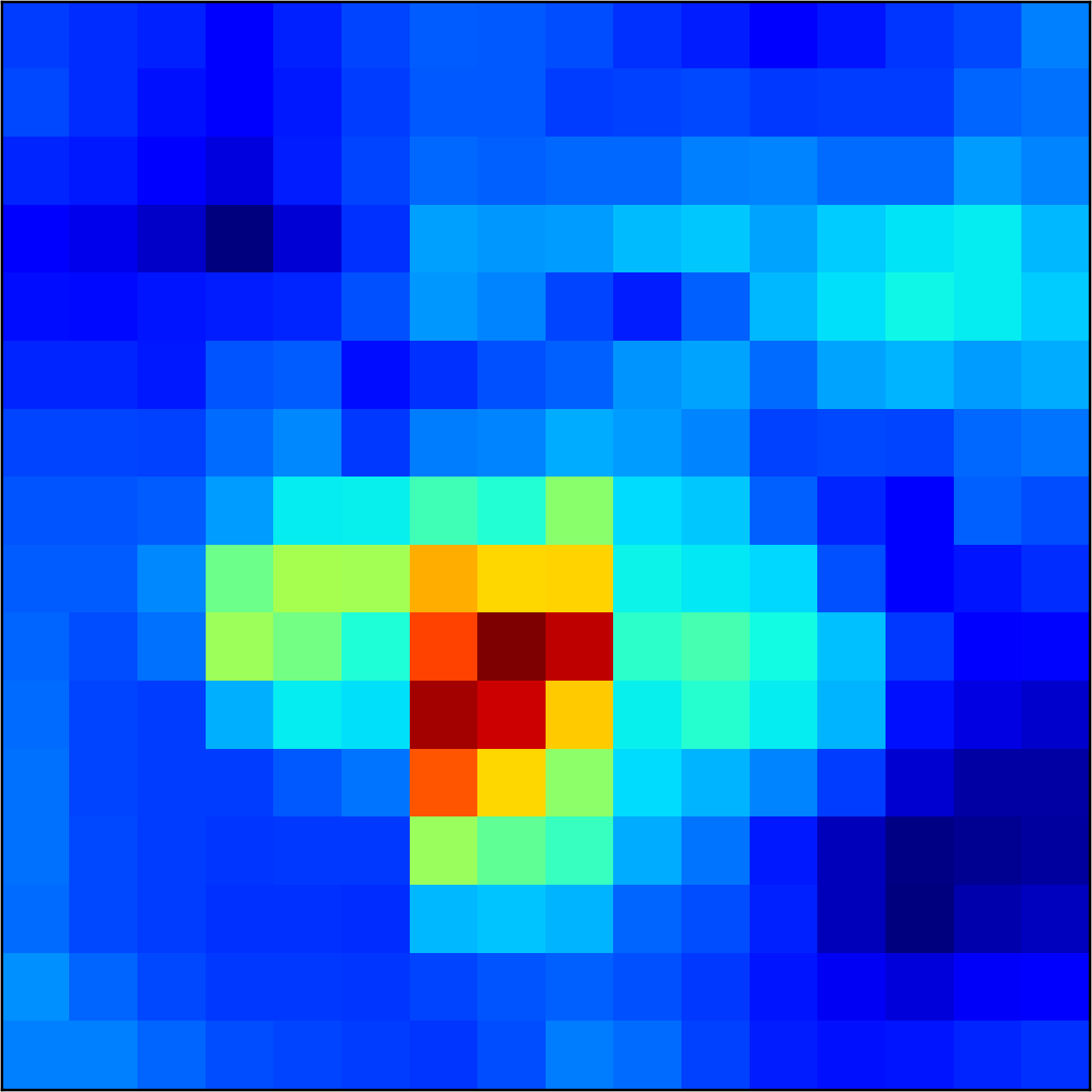 Figure 4
Figure 4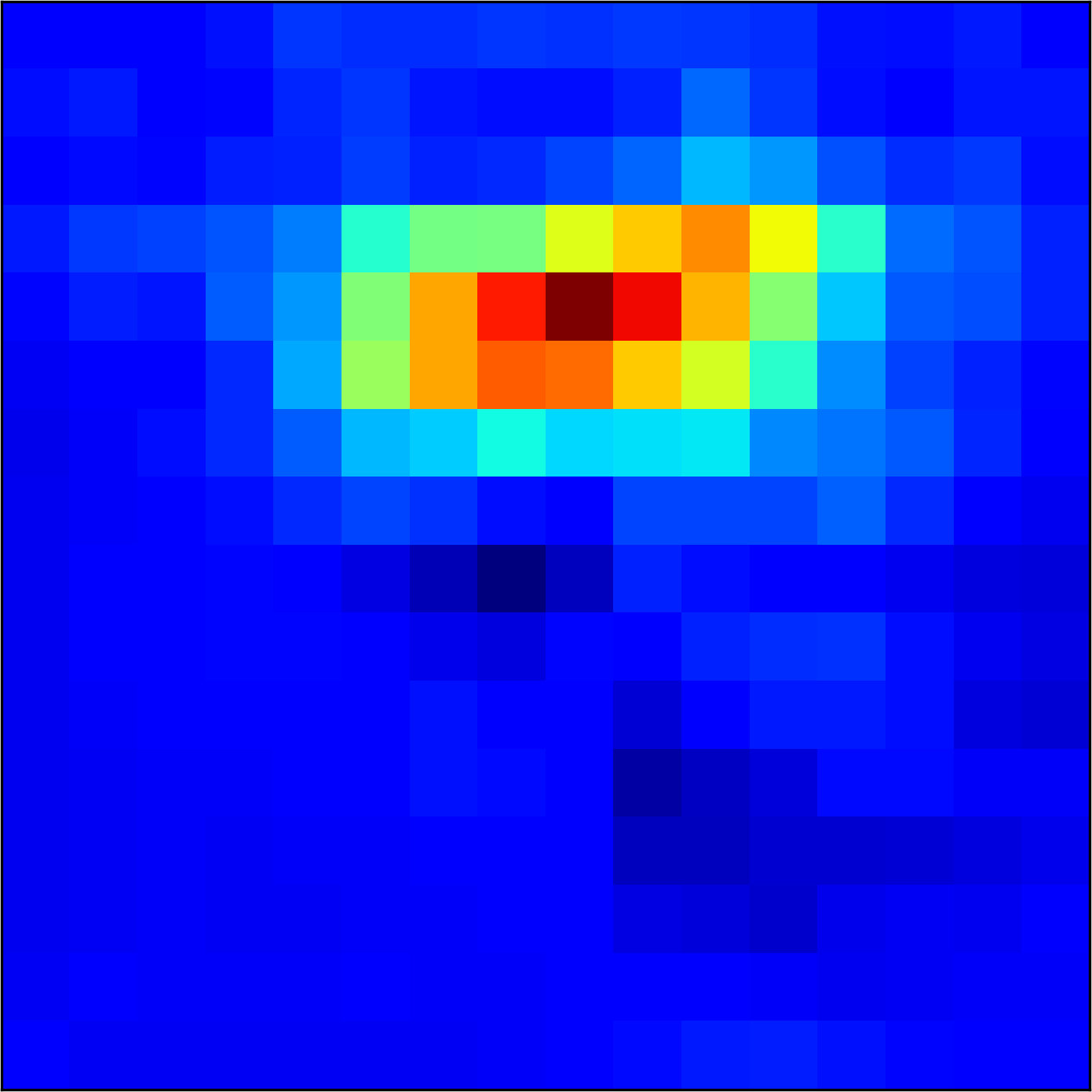 Figure 5
Figure 5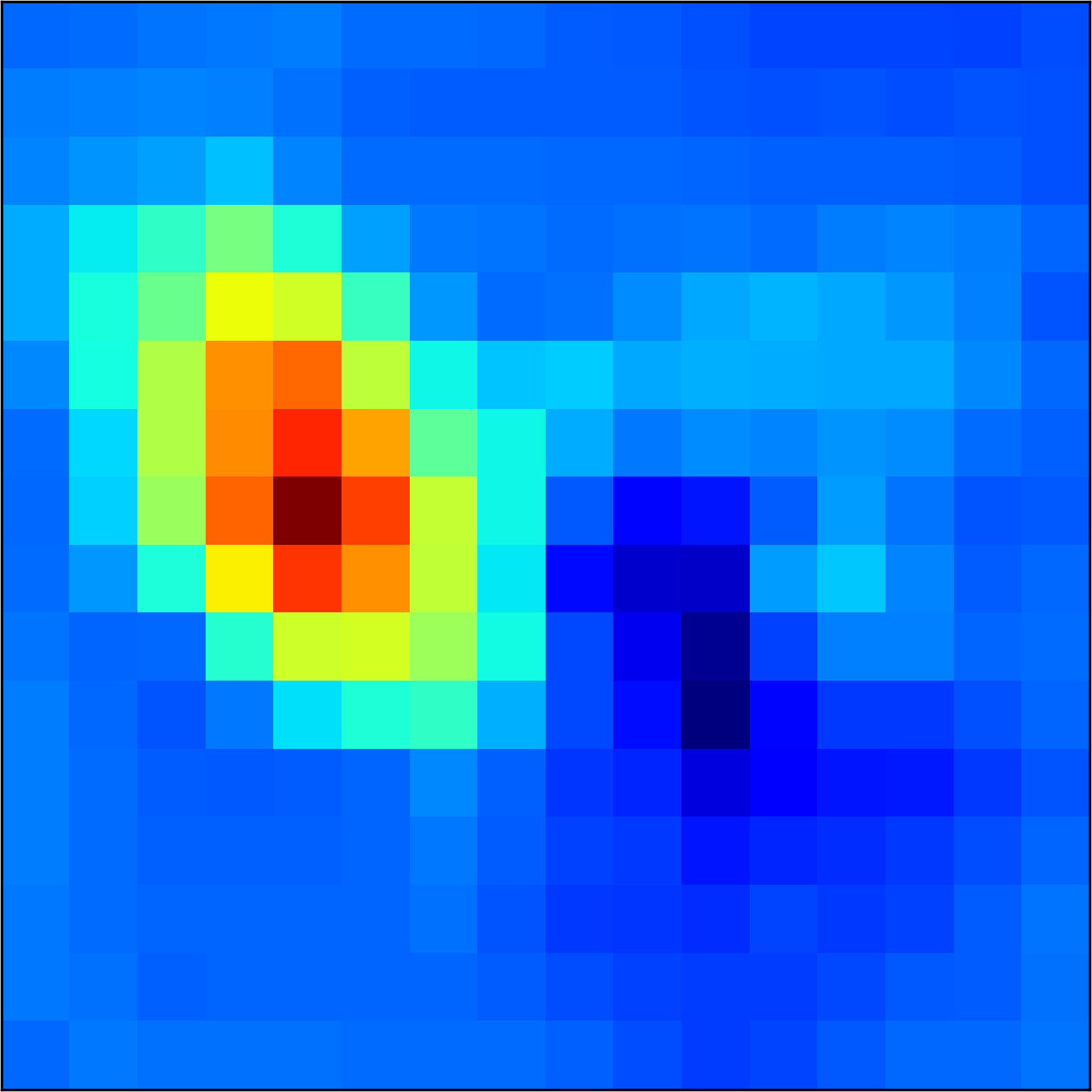 Figure 6
Figure 6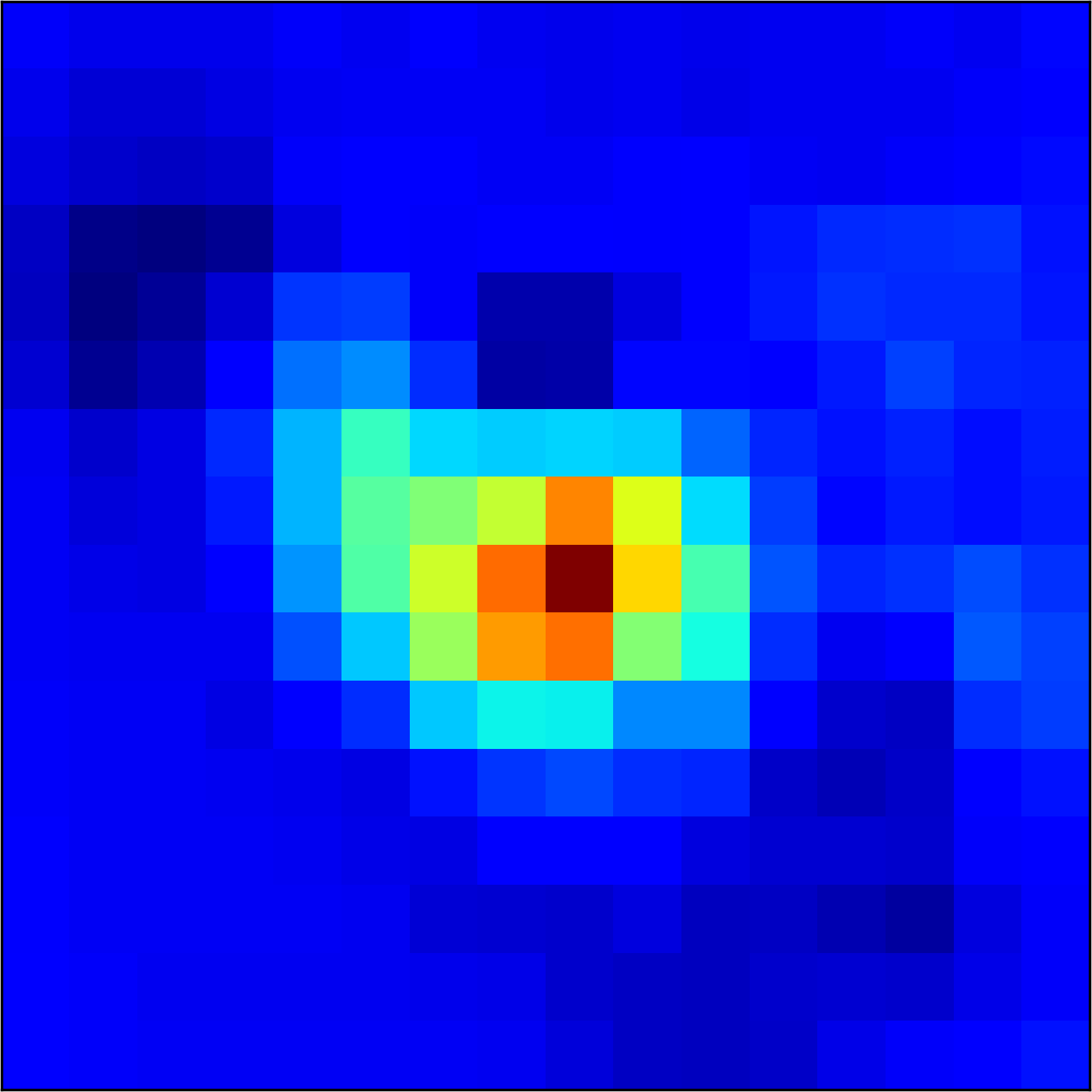 Figure 7
Figure 7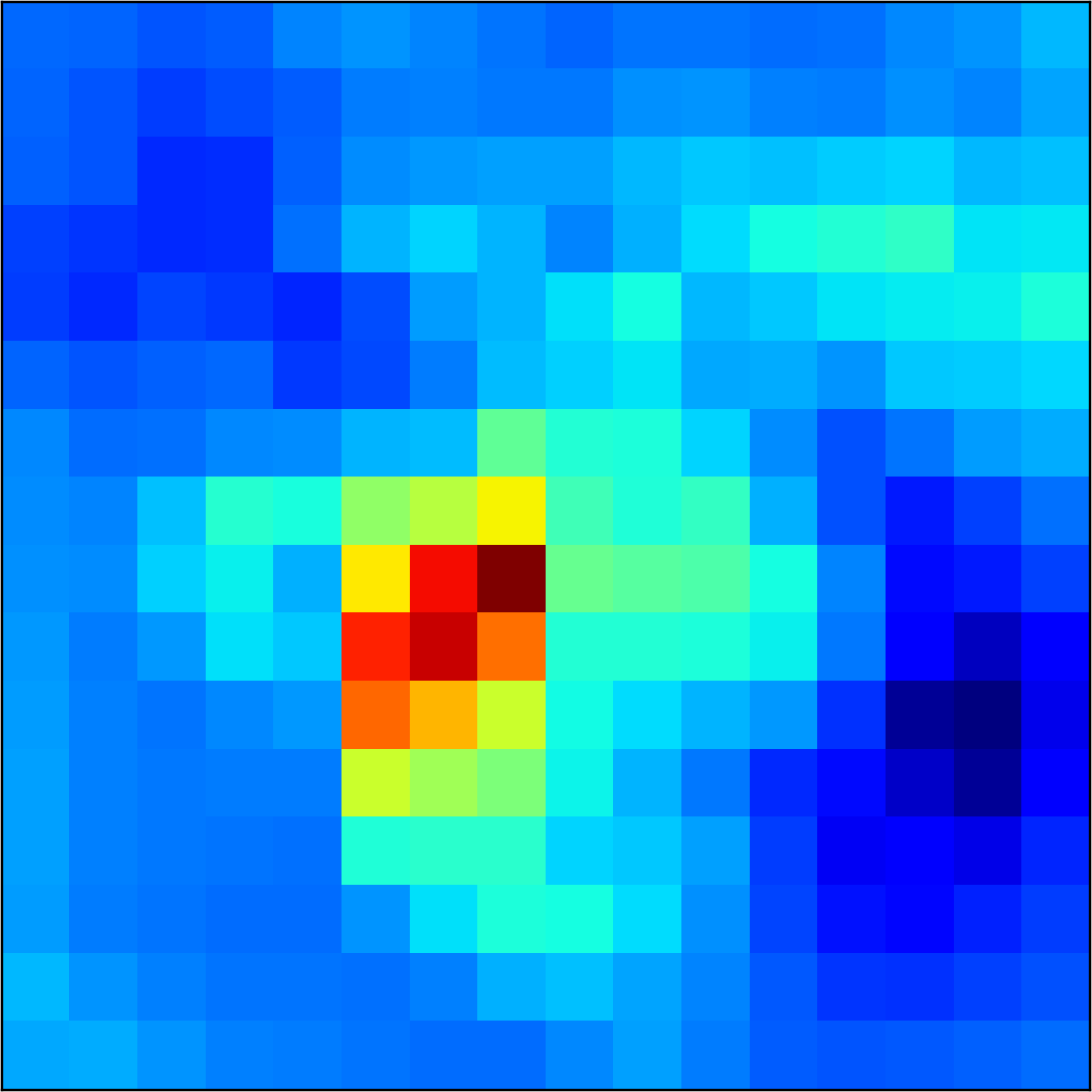 Figure 8
Figure 8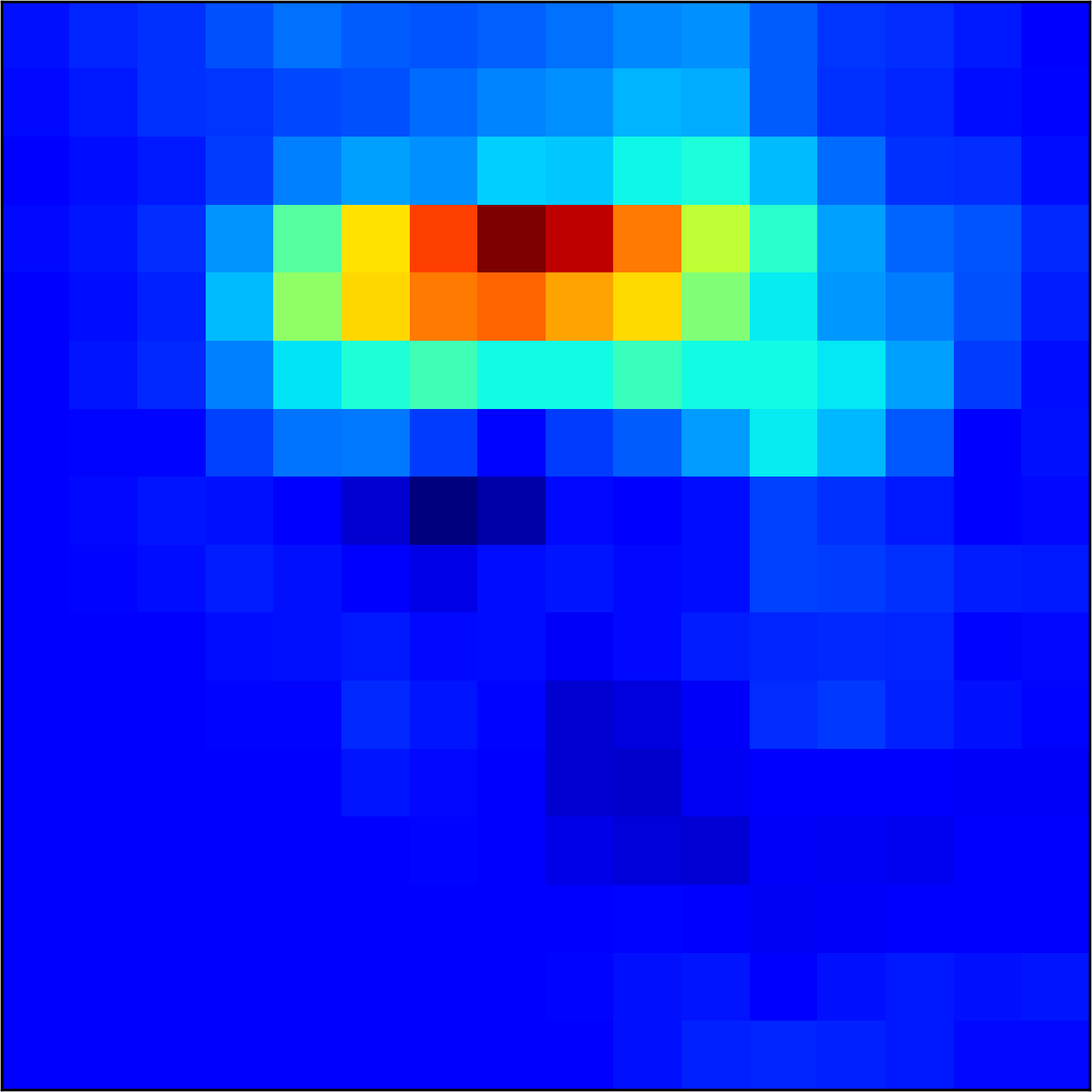 Figure 9
Figure 9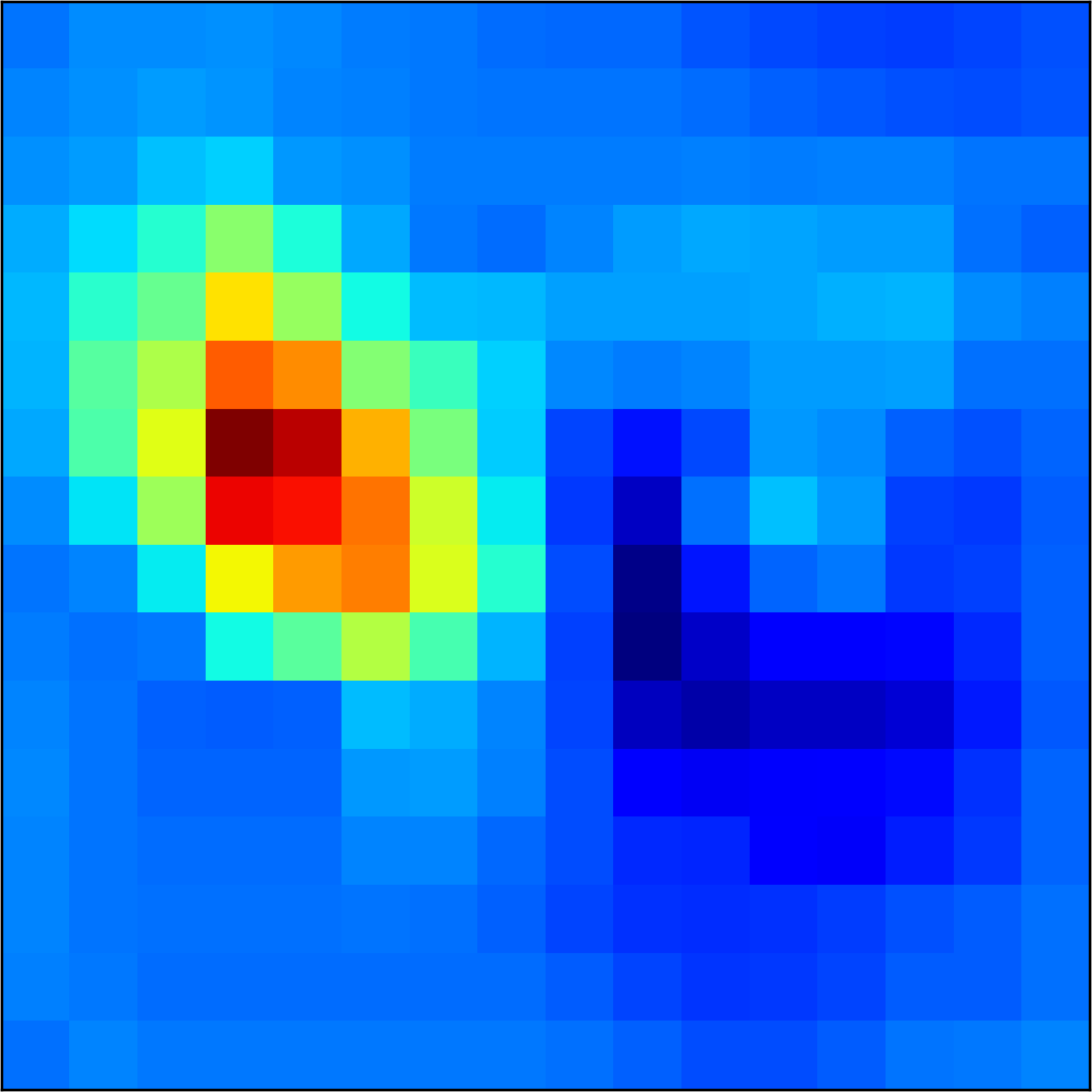 Figure 10
Figure 10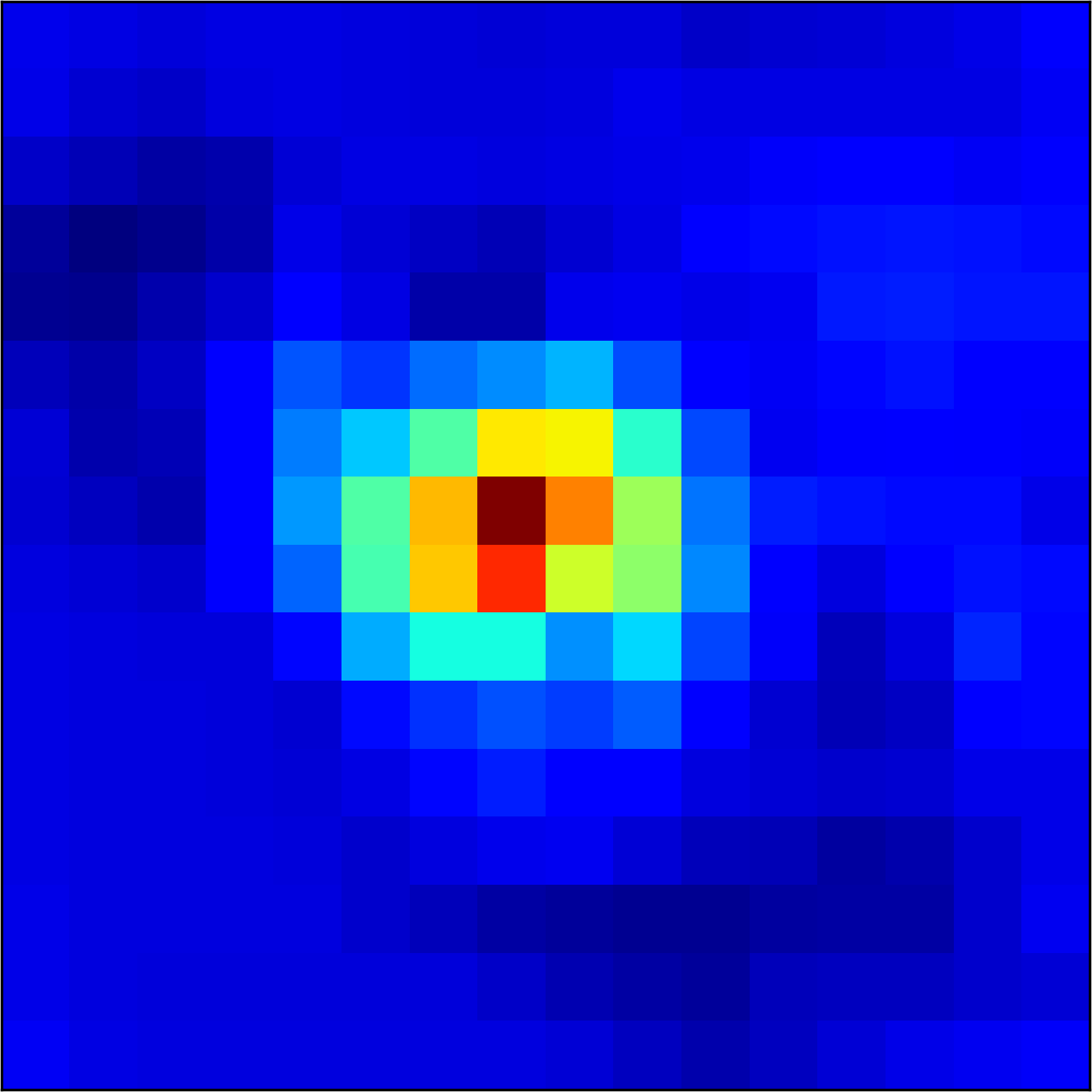 Figure 11
Figure 11 Figure 12
Figure 12 Figure 13
Figure 13 Figure 14
Figure 14 Figure 15
Figure 15 Figure 16
Figure 16 Figure 17
Figure 17 Figure 18
Figure 18 Figure 19
Figure 19 Figure 20
Figure 20 Figure 21
Figure 21 Figure 22
Figure 22 Figure 23
Figure 23 Figure 24
Figure 24 Figure 25
Figure 25 Figure 26
Figure 26 Figure 27
Figure 27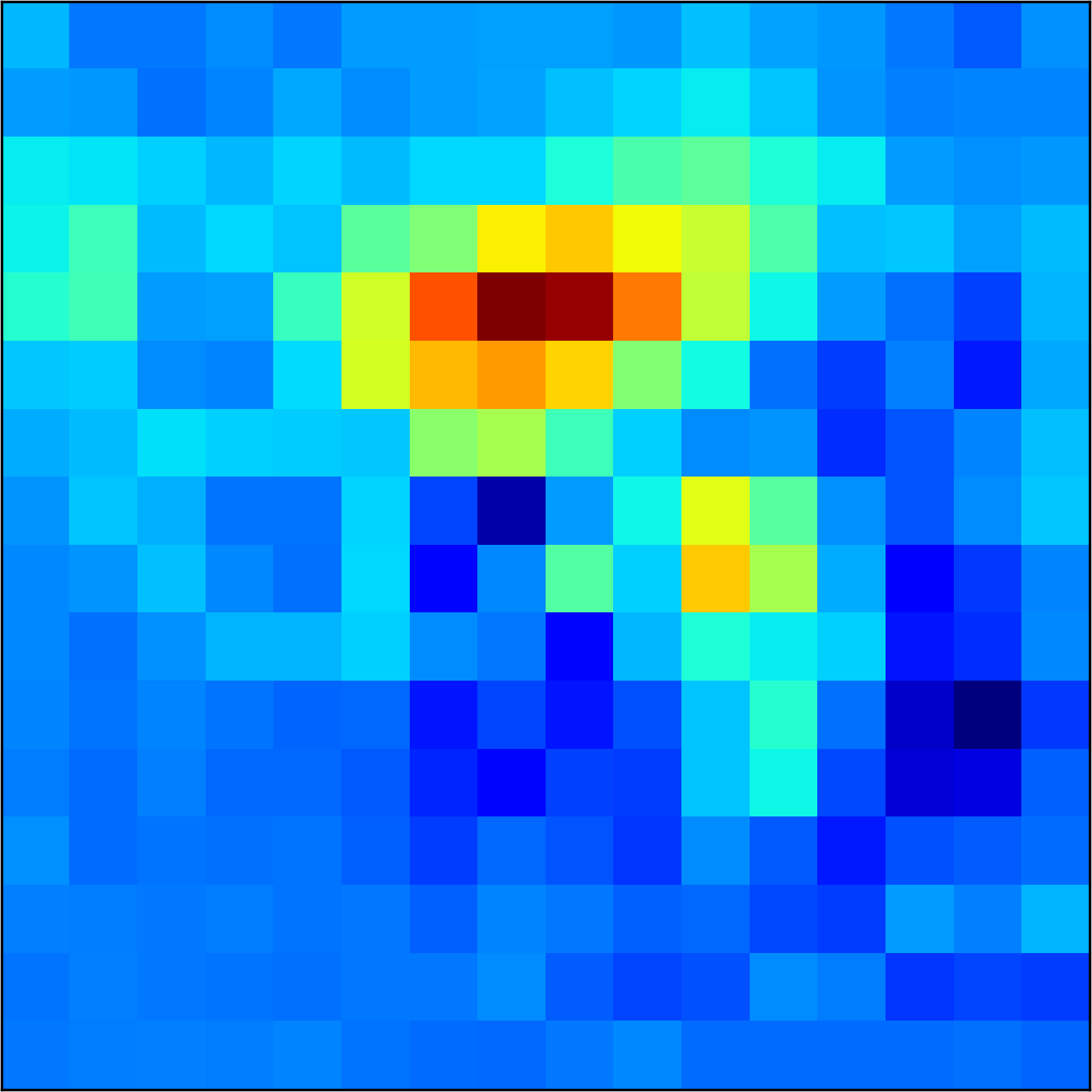 Figure 28
Figure 28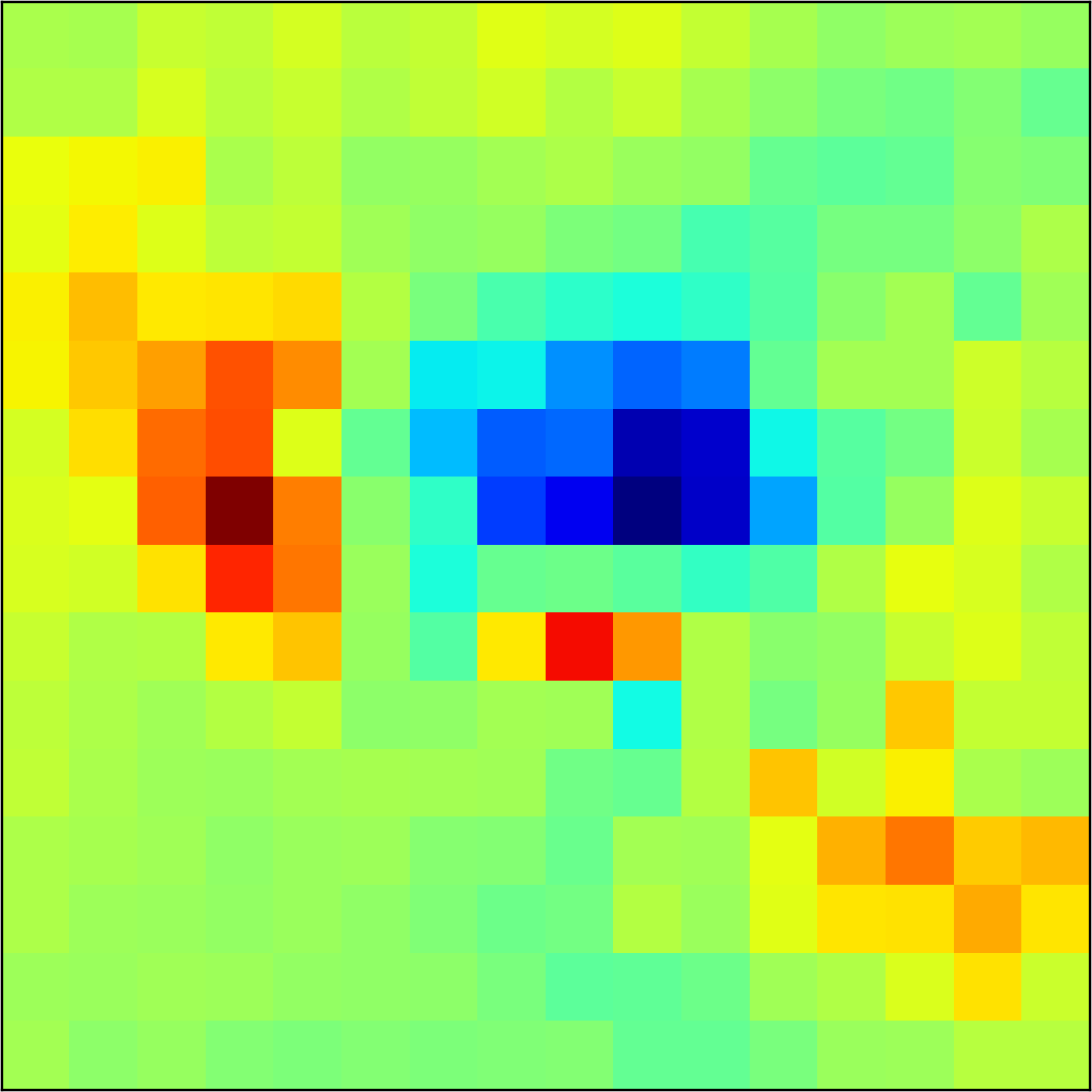 Figure 29
Figure 29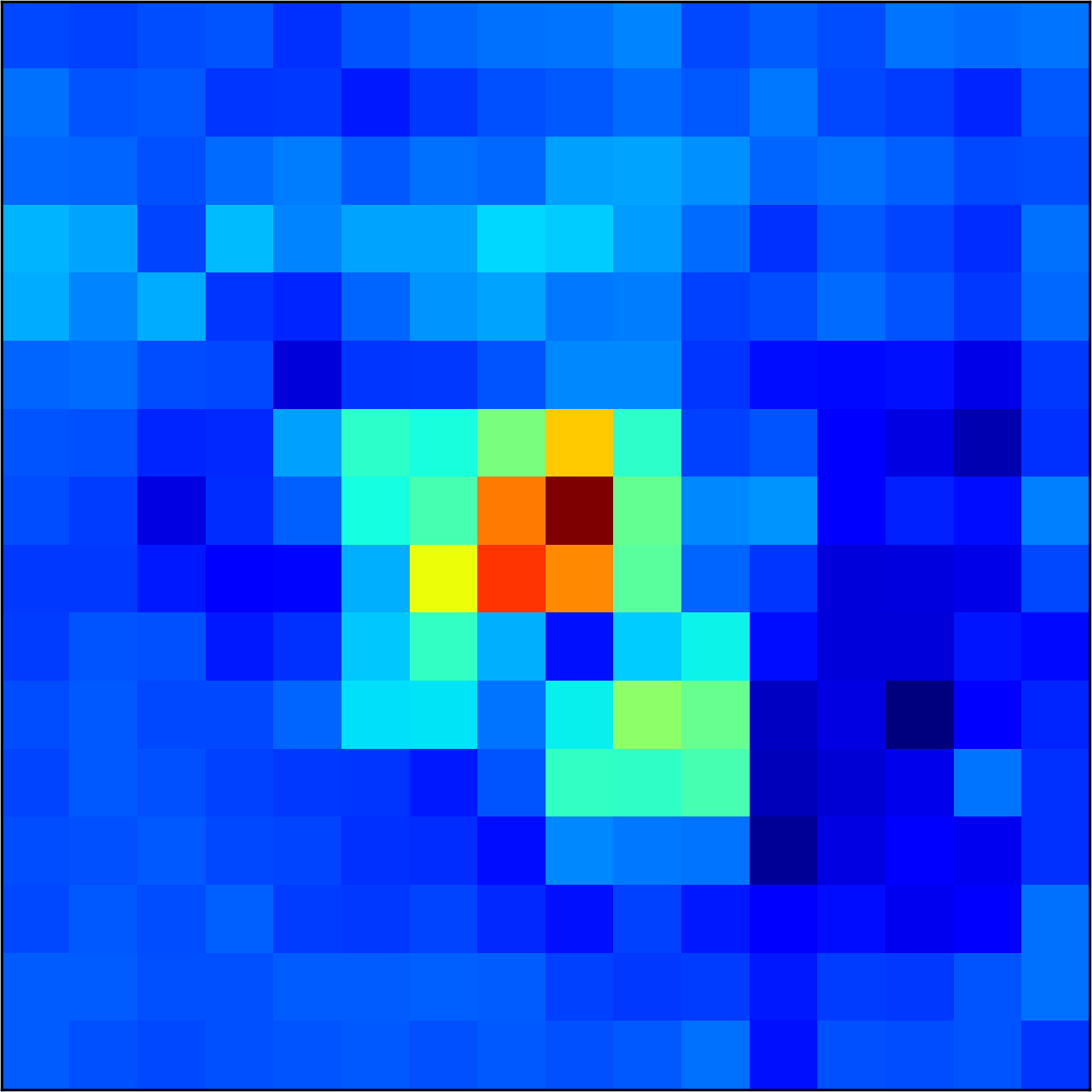 Figure 30
Figure 30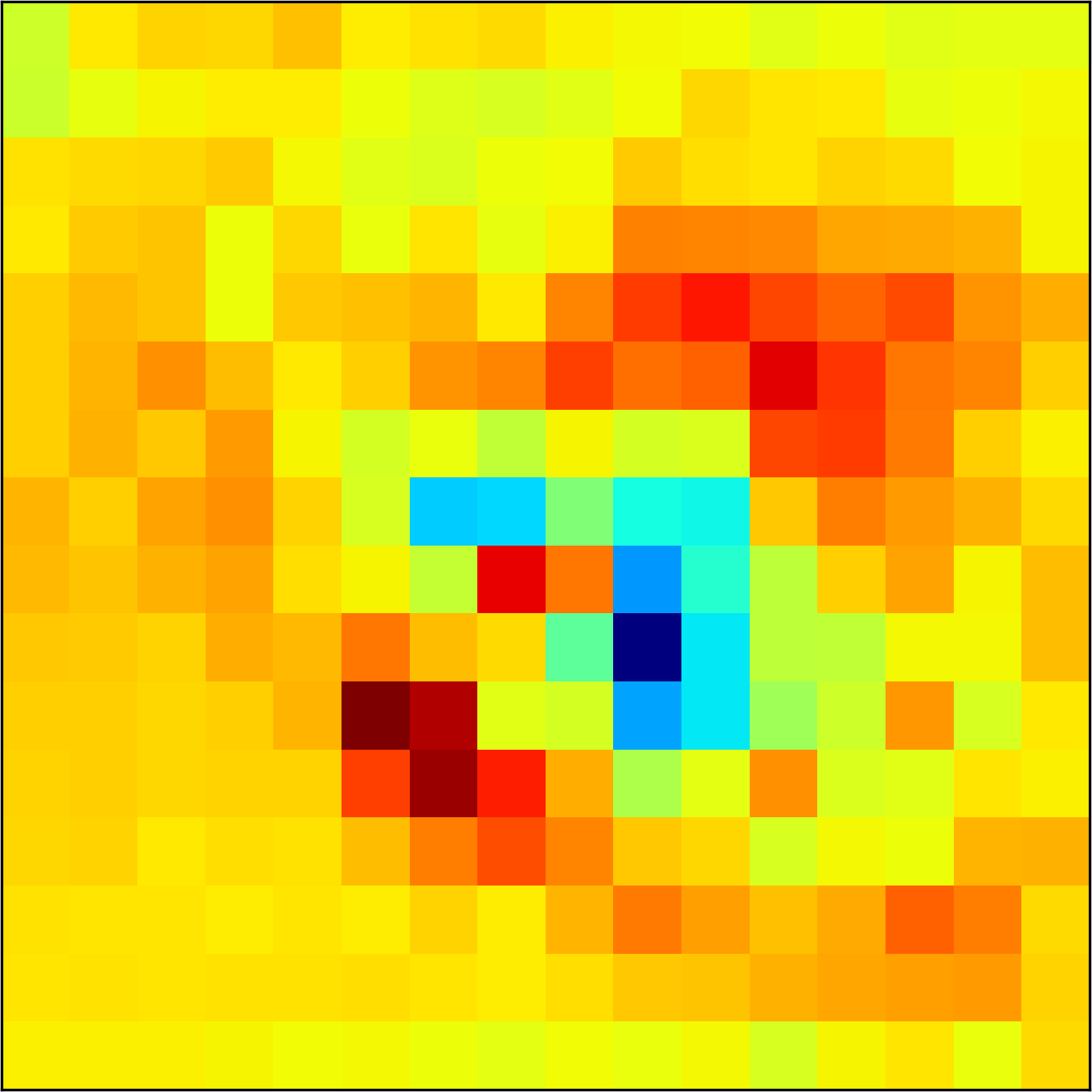 Figure 31
Figure 31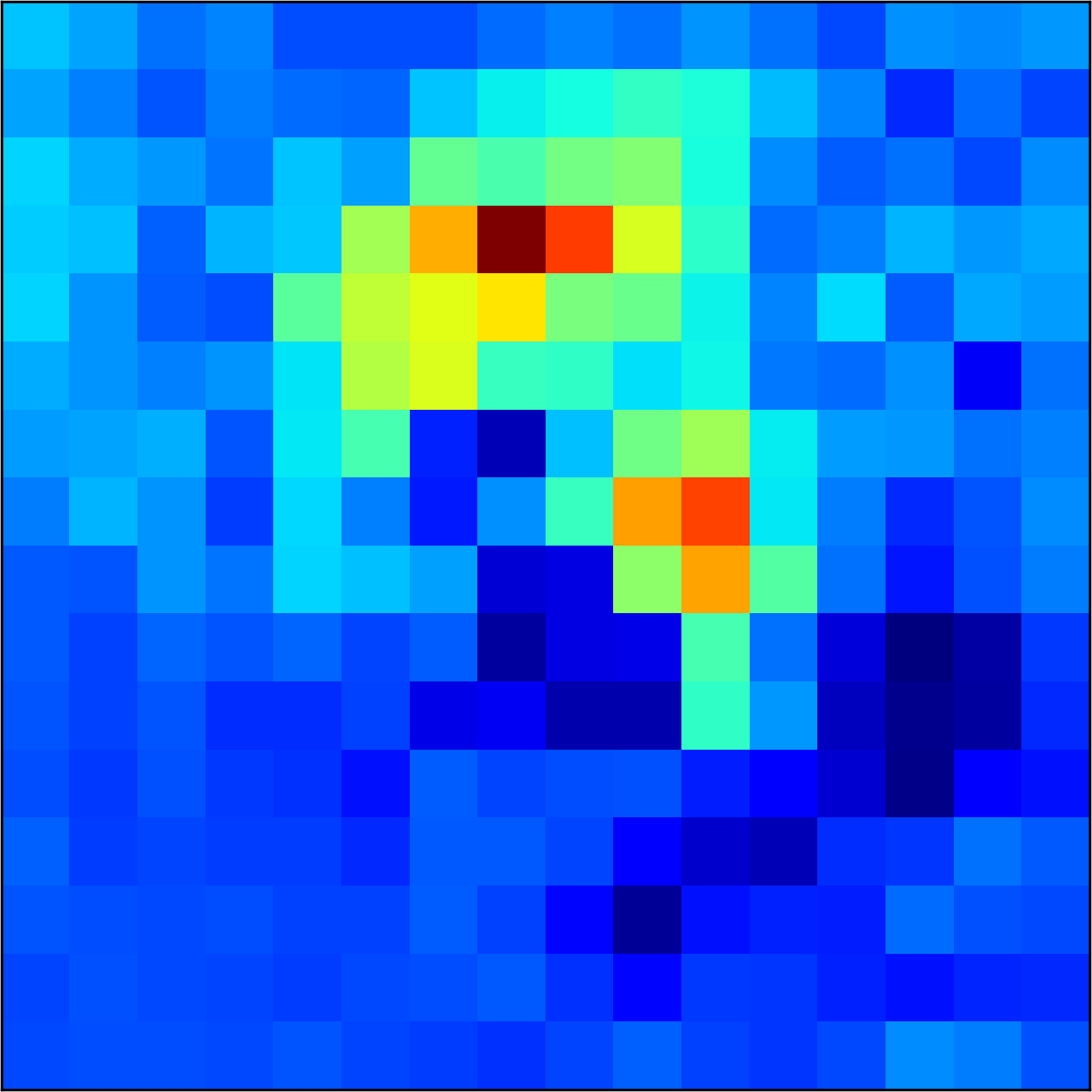 Figure 32
Figure 32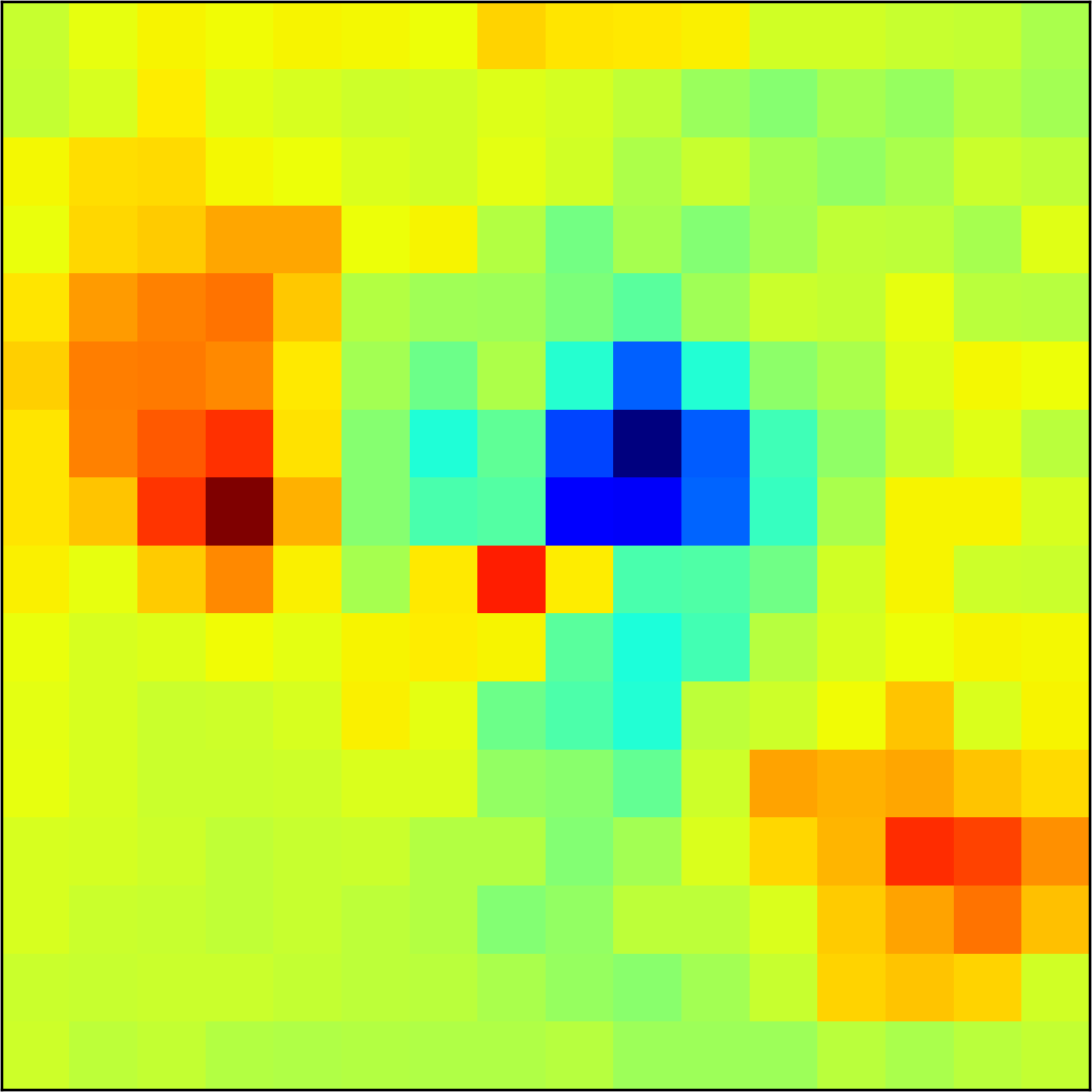 Figure 33
Figure 33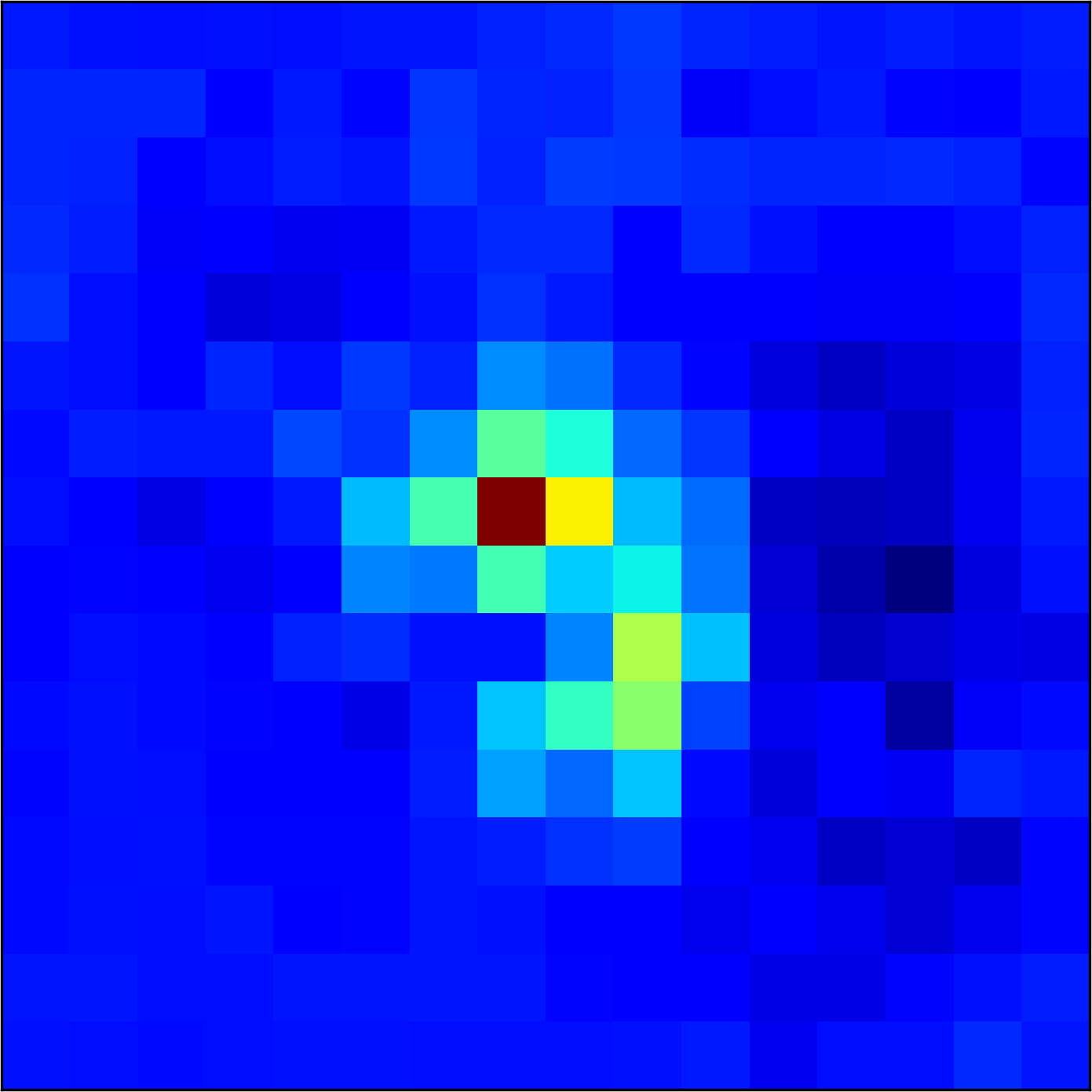 Figure 34
Figure 34 Figure 35
Figure 35 Figure 36
Figure 36 Figure 37
Figure 37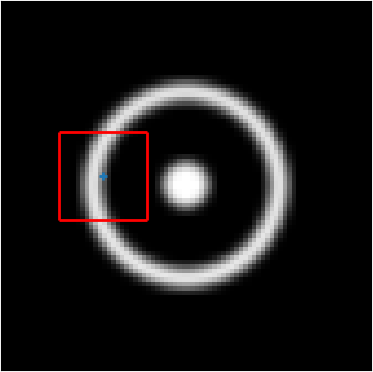 Figure 38
Figure 38 Figure 39
Figure 39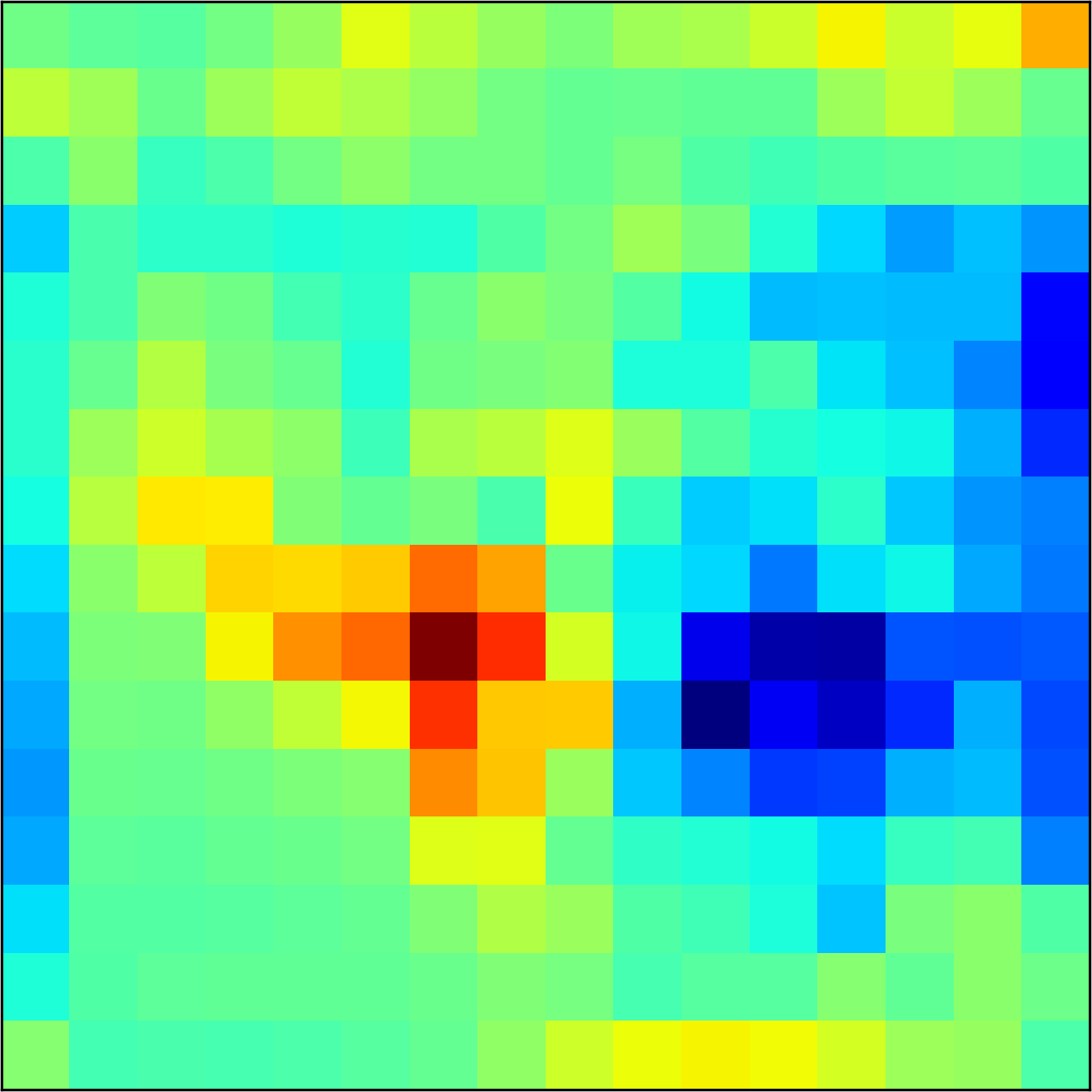 Figure 40
Figure 40| Convolutional part Conv. layer Param. matrix shape # Parameters 1 [ 1, 32, 3, 3 ] 288 2 [ 32, 32, 3, 3 ] 9,216 3 [ 32, 64, 3, 3 ] 18,432 4 [ 64, 64, 3, 3 ] 36,864 5 [ 64, 128, 3, 3 ] 73,728 6 [ 128, 128, 3, 3 ] 147,456 Total 285,984 |
|
|
||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|||||||||||||||||||||||||||||||||
| Test | Liberty | Notredame | Yosemite | |||||
|---|---|---|---|---|---|---|---|---|
| Train | # Parameters | Mean | No | Yo | Li | Yo | Li | No |
| HardNet+ | 1,334,560 | 1.51 0.00 | 1.49 0.00 | 2.51 0.00 | 0.53 0.00 | 0.78 0.00 | 1.96 0.00 | 1.84 0.00 |
| HardNet+ | 1,334,560 | 1.43 0.02 | 1.25 0.03 | 2.35 0.03 | 0.48 0.01 | 0.74 0.02 | 2.15 0.01 | 1.61 0.10 |
| 867,008 | 1.53 0.03 | 1.27 0.03 | 2.31 0.08 | 0.48 0.02 | 0.82 0.05 | 2.58 0.08 | 1.72 0.09 | |
| 1,391,296 | 1.36 0.01 | 1.14 0.03 | 2.16 0.10 | 0.42 0.01 | 0.73 0.02 | 2.18 0.07 | 1.51 0.12 | |
Peer Reviews
No public reviews on file for this paper yet. If you reviewed it on a platform where reviews are public (OpenReview, ICLR, NeurIPS, ICML), you can paste yours below so the community can read it here.
Videos
No videos yet. Explain this paper in a talk, walkthrough, or lecture? Add one.
\IfBeginWith
*paperfig/extern/
Explicit Spatial Encoding for Deep Local Descriptors
Arun Mukundan Giorgos Tolias Ondřej Chum
Visual Recognition Group, FEE, CTU in Prague
Abstract
We propose a kernelized deep local-patch descriptor based on efficient match kernels of neural network activations. Response of each receptive field is encoded together with its spatial location using explicit feature maps. Two location parametrizations, Cartesian and polar, are used to provide robustness to a different types of canonical patch misalignment. Additionally, we analyze how the conventional architecture, i.e. a fully connected layer attached after the convolutional part, encodes responses in a spatially variant way. In contrary, explicit spatial encoding is used in our descriptor, whose potential applications are not limited to local-patches. We evaluate the descriptor on standard benchmarks. Both versions, encoding or patches, consistently outperform all other methods on all benchmarks. The number of parameters of the model is independent of the input patch resolution.
1 Introduction
Local feature extraction and representation is still an essential part of a number computer vision applications across many different problems. A common and well performing procedure is a sequence of three steps: local feature detection [16, 27, 29, 6, 25], local patch rectification into a canonical form, and finally a descriptor construction from the canonical patch [28, 6, 25, 14]. The desired property of the local patch descriptors is that Euclidean distance or a dot product between two descriptors indicates whether they are matching, i.e. the local features are coming approximately from the same surface of a 3D scene. The descriptor methods have shifted from hand-crafted to currently the most successful convolutional neural network (CNN) based approaches [58, 46, 5, 30, 49, 33].
Fully convolutional neural networks takes an image or a patch as input and produces a tensor, where a vector at each spatial location can be seen as a detector response over its receptive field. In the case of variable-sized, or non-aligned input, such as images, the response tensor is transformed into a descriptor typically by some form of global pooling [40, 19, 39], which discards geometric information. The global pooling is analogous to bags-of-features [13, 48] or descriptor aggregation [37, 18]. In the case of aligned input of fixed size, such as rectified image patches, the tensor is vectorized and further processed. Vectorization has similar interpretation to vectorizing spatial bins in SIFT [25]. Commonly, the vectorized tensor is processed by a single fully-connected (FC) layer [30, 49], that can be either interpreted as learned affine (linear and bias) transformation of the space, e.g. whitening and dimensionality reduction, or as spatially dependent embedding with efficient match kernels (EMK) [9, 11] (see Section 3.2). The key contribution of this work is a CNN module that explicitly models the spatial information of a rectified patch. Its applicability is not limited to local descriptors.
Two rectified patches coming from matching local features are far from being identical in general. The difference has two sources, namely appearance change in imaging process and geometric misalignment. The former comes from different light conditions, non-planarity of the surface, imaging artifacts, etc. The latter is caused by the detected feature covering slightly different area of the 3D surface, or incorrect rectification of the patch. These are consequences of either the appearance changes or of insufficient geometric invariance of the detector, i.e. affine invariant detector acting on projectively transformed surface.
Prior work on hand-crafted feature descriptors has shown that it is beneficial to explicitly address the geometric misalignment. Some of the approaches handling this are soft assignment of gradients to bins in SIFT and continuous spatial encoding by kernel methods in different [11] or multiple [32] coordinate systems.
CNNs are powerful in modeling the appearance variance, while weak in modeling the geometric displacement (at least with a single FC layer). Recent methods propose different ways of incorporating spatial information in a CNN [34, 24], but their application field is different than local descriptors. In this work, we propose to model the geometric misalignment by efficient match kernels that explicitly encode the spatial positions of the responses. To encode the spatial information, kernel-based explicit feature maps are used in a similar fashion to hand-crafted features [11, 32]. This can be seen as a transition from soft binning, i.e. overlapping receptive fields, to continuous efficient match kernels. In contrast to models with an FC layer, with efficient match kernels the number of model parameters does not grow with increased resolution of the input patch, i.e. the models for patch input has the same number of parameters as the model for . The applications of the proposed descriptor go beyond that of local-patches, e.g. tasks where encoding spatial position is essential [24, 34].
The rest of the paper is organized as follows. The related work is discussed in Section 2. Conventional deep local descriptors and the proposed ones is discussed in Section 3. Implementation details are detailed in Section 4. Finally, we present and discuss our experiments on standard benchmarks in Section 5.
2 Related work
In this section, we review prior work related to hand-crafted and learned descriptors of local features.
2.1 Hand-crafted descriptors
There are numerous approaches to hand-craft local descriptors. The variants are based on different types of processing of the input patch, such as filter-bank responses [6, 10, 22, 36, 43], pixel gradients [25, 28, 50, 1], pixel intensities [45, 12, 23, 41] and ordering or ranking of pixel intensities [35, 17]. The most prominent direction has been that of gradient histograms, an approach followed also by the most popular hand-crafted local descriptor, namely SIFT [25]. Several improvements and extensions exist in the literature [20, 57, 21, 44, 2, 14]. The RootSIFT [2] variant efficiently estimates Hellinger distance and became a standard choice in approaches and tasks.
Kernel descriptors are derived from the concept of efficient match kernels [9] and form a flexible way to design descriptors with the desired invariant properties. Kernel descriptors have been proposed not only for local patches [11] but also as a global image descriptor [8, 7]. The kernel descriptor of Bursuc et al. [11] was shown to outperform learned descriptors at that time.
2.2 Learning descriptors
Structure-from-Motion and datasets such as PhotoTourism [55] gave rise to learned local descriptors. The learned part varies from their pooling regions [55, 47] and filter banks [55] to transformations for dimensionality reduction [47] and embeddings [38].
Learning is also applied to kernelized descriptors as in the supervised framework by Wang et al. [54]. The local descriptors in their case are not used separately but directly aggregated into a global image representation, while supervision comes at image level. Kernel local descriptors are combined with supervised learning in the form of discriminative projections in the work of Mukundan et al. [32]. Our work is inspired by theirs; we use the same kernel-based position encoding, but on top of convoltutional activations instead of pixel attributes.
2.3 Deep learning of descriptors
The interest in local descriptor learning is lately dominated by deep learning [46, 58, 15, 56, 5, 3]. All examples in the literature use architectures that consist of a sequence of common CNN layers, similar to the ones of generic computer vision tasks, such as object recognition, but less deep and with fewer parameters in total. They typically require a large amount of training data in the form of local patch pairs or triplets. Some of the contributions are about mining hard training samples [46, 30, 26], different loss functions [5], different architectures [49] or training jointly with the local feature detector [56].
Two of the most recent and successful deep local descriptors are L2-Net [49] and HardNet [30]. L2-Net applies the loss function to intermediate feature maps too and the loss function integrates multiple attributes. HardNet extends L2-Net by sampling the hardest within batch samples and currently constitutes the state-of-the-art descriptor. Their common characteristic, which is shared among all ancestors, is that they are using common CNN layers in their architecture. As a consequence, spatial information of convolutional feature maps is not explicitly encoded, but only processed with a standard FC layer.
3 Method
We initially present the current typical architecture for deep local descriptors in the literature. Then, we provide a different perspective that formulates such descriptors as match kernels. It allows us to point out how the encoding of convolutional feature maps is performed in a translation variant way, but without explicitly encoding the spatial information. Finally, we present our novel deep local descriptor which is derived through the same match kernel framework and improves exactly this drawback. We get inspired by hand-crafted kernel descriptors to incorporate explicit position encoding into deep networks for local descriptors. An overview of the proposed descriptor is shown in Figure 1,
3.1 Deep local descriptors
Conventional architectures for deep local descriptors consist of a sequence of convolutional layers, producing translation invariant feature maps, and a final FC layer. We denote the descriptor extraction process by function , where is the size of the input patch and the dimensionality of the final descriptor. Descriptor for patch is given by or equivalently to simplify the notation.
We denote the convolutional part of the network, i.e. a Fully Convolutional Network (FCN), by function . Size of the resulting feature map is related to input size and the architecture of the network. Feature map , equivalently denoted by , is a 3D tensor of activations, which we also view as a 2D grid of -dimensional vectors. We call these vectors convolutional descriptors and use to denote the vector with coordinates on the grid, i.e. 111 and . Each convolutional descriptor corresponds to a region of the input patch that is equal to the receptive field size of the feature map.
The standard practice is to vectorize 3D tensor and feed it to an FC layer with parameters that consist of matrix and bias . The final descriptor is constructed as
[TABLE]
where denotes tensor vectorization. A local descriptor is typically -normalized, which is equivalently achieved by introducing a normalization factor producing descriptor .
Similarity (or distance) between patches and is estimated with inner product (or Euclidean distance) . The -normalized descriptor is always used to compare patches, but we often use (and not ) simply to specify which descriptor variant is used. Several deep local descriptors in the recent literature, namely L2Net [49], HardNet [30], and GeoDesc [26] follow such an architecture and can be formulated in the same way.
3.2 A match-kernel perspective
We provide an alternative, but equivalent, construction of deep local descriptors. We consider matrix as a concatenation of matrices, i.e.
[TABLE]
where . Descriptor in (1) can be now written as
[TABLE]
where . Moreover, patch similarity becomes
[TABLE]
where is a function that encodes a convolutional descriptor in a translation variant way, depending on its position in the grid. The match kernel formulation in (4) interprets deep local descriptor similarity as similarity accumulation for all pairs of positions on the grid. It reveals that matching between convolutional descriptors in and is performed in a translation variant way. The encoding function in the case of conventional deep local descriptors is
[TABLE]
where matrix and come from the parameters of the FC layer. In this work, we propose a new encoding function , not restricted to standard CNN architecture (layers), that explicitly encodes position on the 2D grid.
3.3 Position encoding
Explicit feature maps [53] are used to encode the position. Let be a feature map, where is a design choice defining the dimensionality of the embedding. Such a feature map defines a shift invariant kernel with kernel signature , so that
[TABLE]
The kernel (or the feature map ) is constructed to approximate the Von Mises kernel [51].
We propose encoding function given by
[TABLE]
where is the Kronecker product and and provide the coordinates of position in a Cartesian coordinate system 222For , and .. It is a joint encoding of the convolutional descriptor and the explicit representation of its position. It is inspired by the work of Mukundan et al. [32] who propose a hand-crafted local descriptor that encodes pixel gradients with their positions in the patch. Similarity of two such encodings is given by
[TABLE]
It is equivalent to the product of descriptor similarity and similarity of positions on the Cartesian grid.
Following the paradigm of descriptor whitening of hand-crafted descriptors [32, 4], we propose the final local descriptor
[TABLE]
where and are parameters to be learned during training, while is a weight giving importance according to the distance from the center of the patch. Note that in contrast to (3) the same matrix, i.e. , is used for all convolutional descriptors. As a result the number of required parameters is reduced and multiplication by can be efficiently performed after the summation (10). In analogy to the encoding of position in a Cartesian coordinate system, we additionally propose the encoding w.r.t. a polar coordinate system333For , and , where . by
[TABLE]
and the corresponding descriptor
[TABLE]
Different parameterizations, i.e. using different coordinate system, provide tolerance to different kinds of misalignment between patches. Cartesian offers tolerance to translation misalignment, while polar offers tolerance to rotation and scale misalignment. To benefit from both types of tolerance, we further use the combined encoding that uses the two coordinate systems and is produced by concatenation of the previous encoding. It is defined as function given by
[TABLE]
where is used to show that the two encodings do not need to rely on the same FCN . Subscript refers to the combined coordinate system, but we skip to simplify the notation. The final descriptor proposed in this work is
[TABLE]
where , and left superscript is used to denote that a separate FCN is used for each encoding, correspondingly coordinate system.
4 Implementation details
In this section, we provide implementation details that concern the efficiency of the aggregation, describe the different architectures and their required number of parameters, and finally discuss the training procedure.
4.1 Efficient aggregation
We describe the implementation details for variant , but these hold for other variants too in the same way. Vectors that encode positions are fixed for the 2D grid of size . Thus, we pre-compute and store them in matrix . We reshape 3D tensor into matrix . Given these two matrices and due to the linearity of matrix to vector multiplication we can re-write the descriptor as
[TABLE]
Multiplication makes the computation memory efficient because it avoids explicit storing of the Kronecker product for each . To evaluate (15), the memory requirements are numbers, while to evaluate (16), only numbers are allocated. Using setup and in our experiments, the memory requirements are reduced by a factor of .
4.2 Architecture
We use the HardNet+ [30] architecture for the convolution part, since HardNet+ achieves state-of-the-art performance on all benchmarks. We also use it a baseline to compare with.
The statistics of the convolutional part are described in Table 1 (left). Each convolutional layer is followed by batch normalization and ReLU, while no bias is used. Table 1 (right) provides the total number of parameters for HardNet+ and our networks, namely, plain polar or Cartesian encoding with different dimensionality of the explicit feature maps ( and frequencies used), and the joint encoding with a common () or separate ( and ) convolutional part. Note that for the joint encoding with separate convolutional parts and frequencies, the proposed network needs roughly the same number of parameters as HardNet+ with input patch of size pixels (). In all other settings of the proposed architecture, the number of parameters is significantly reduced. Importantly, the number of parameters for larger patch sizes (such as ), that provide better performance, the number of parameters stays fixed for the proposed architecture. For Hardnet+, the number of parameters of the FC layer increases by a factor of 4 for input patches.
4.3 Training
We would like to highlight the contribution of the explicit spatial encoding and to provide direct comparison to the current state-of-the-art descriptor construction. To avoid changing many things at the same time, we follow exactly the same training procedure as HardNet+, which we briefly review below.
The network is trained with the triplet loss defined as
[TABLE]
acting on a triplet formed by an anchor, a positive (matching to the anchor), and a negative (non-matching to the anchor) descriptor. A batch of size 1024 patches is constructed from 512 pairs of anchor-positive descriptors. Regarding a particular pair in the batch, the positive descriptors of all other pairs are considered as candidate negatives. Finally, the one with the smallest Euclidean distance to the anchor within the batch is chosen as a hard negative to form a triplet.
We use Stochastic Gradient Descent (SGD) to perform the training. The total training set consists of 2 million anchor-positive pairs and the training lasts 10 epochs. Data augmentation is employed by random patch rotation, scaling and flipping. The learning rate is set to 10, and linearly decays to zero withing 10 epochs. Momentum is equal to 0.9 and weight decay to . Random orthogonal initialization is used for the weights of the network [42]. The method is implemented in the PyTorch framework.
5 Experiments
We first describe the datasets and the evaluation protocols used in our experiments, and then present qualitative results showing the impact of the training on patch similarity. Finally we present the results achieved by different variants of our descriptor and show a comparison with the state of the art.
5.1 Datasets and protocols.
We use two publicly available patch datasets, namely PhotoTourism (PT) [55] and HPatches (HP) [4]. We use the former for both training and evaluation, while the latter only for evaluation when training on PT to show the generalization ability of the descriptor.
The PT dataset consists of following 3 separate sets, Liberty, Notredame and Yosemite. Each consists of local features detected with the Difference-of-Gaussians (DoG) detector and verified through an SfM pipeline. Each set comprises about half a million patches, associated with a discrete label which is the outcome of SfM verification. The test set consists of 100k pairs of patches corresponding to the same (positive) 3D point, and an equal number corresponding to different (negative) 3D points. The metric used to measure performance is the false positive rate at 95% of recall (FPR@95). Models are trained on one set and tested on the other two, and the mean of 6 scores is reported.
The HP dataset contains patches of higher diversity and is more realistic. Evaluation is performed on three different tasks, namely verification, retrieval, and matching. Despite the fact that we do not train on HP, we evaluate on all 3 train/test splits and report the average performance to allow future comparisons. We follow the common practice and train our descriptor on Liberty of PT to evaluate on HP.
We repeat each experiment three times, with different random seeds to initialize the parameters, and report mean and standard deviation of the 3 runs. We followed this policy for all variants and datasets.
Recently, larger and more diverse datasets [31, 26] have been introduced to improve local descriptor training. These are shown to improve the performance of state-of-the-art descriptors even by simply replacing the training dataset. We have not included them in our experiments but expect the impact to be similar on our descriptor too.
5.2 Visualizing patch similarity.
We construct encodings , before aggregation, for our descriptors and for the conventional case and construct a similarity map to analyze the impact of the position encoding. We present such visualization in Figure 2. We pick position and compute similarity , for the conventional case, and for ours in the case of the combined descriptor. We observe how all architectures, including the conventional one, result in large similarity values near .
5.3 Results and comparisons.
We train and evaluate different variants of the proposed descriptor. If not otherwise stated, we use input patches of size equal to , which is the standard practice for deep local descriptors. We further examine the case of input patches. We always set and . The dimensionality of the feature maps is controlled by which we set equal to or in our experiments.
Reproducing HardNet+. Our implementation, training procedure, and training hyper-parameters are based on HardNet+ 444https://github.com/DagnyT/hardnet. We reproduce its training and report our own results, proving that our benefit is not an outcome of implementation details. We report both the achieved performed in the original publication and our reproduced ones in all the comparisons.
Baselines for ablation study. We train and test the following two baselines to see the impact of the position encoding. First, we train a descriptor that encodes convolutional descriptors in in a translation invariant way, i.e. no position encoding at all. It is implemented by spatial sum pooling on and given by
[TABLE]
The dimensionality of is equal to and not in this case. However, , making this descriptor directly comparable to all others.
Second, we train a descriptor that encodes the spatial information simply by concatenation, i.e. vectorization of , which does not provide any tolerance to position misalignments. It is given by
[TABLE]
Impact of position encoding. We compare our descriptor with HardNet+ on PT and show results in Table 2. Conceptually it is a comparison between the conventional architecture that uses an FC layer to “feed” the convolutional descriptors to, and our kernel-based approach to explicitly encode the spatial information. Our descriptors (with ) slightly outperforms HardNet+ while it has roughly the same number of parameters. Even the variant with fewer parameters () performs similarly.
A more thorough comparison, examining the impact of the explicit spatial encoding, is performed on HP and presented in Figure 4. Firstly, we evaluate as part of an ablation study. It is translation invariant that totally discards the spatial information. It does not require additional parameters other than the ones for FCN . It has significantly lower performance compared to all the other descriptors. We additionally tried including multiplication by matrix in (18) and did not notice performance improvements. Descriptor is another case not requiring additional parameters. It is translation variant in a “rigid” way, whose tolerance to translation misalignment is restricted to the amount that the large receptive field offers. Despite the very large dimensionality, it is not a top performer. Even our light-weight variant with as few as 127k additional parameters (excluding ) recovers most of the performance loss due to lack of spatial information, i.e. w.r.t. . This result suggests that the common choice of an FC layer for deep local descriptors might be over-parametrized. It is not the best performing either. Our variant is consistently the top performing one on all tasks.
Comparison with the state of the art. We finally present a comparison to the state of the art on HP in Figure 4. The comparison includes a set of hand-crafted and learned local descriptors, namely RSIFT [2], SIFT [25], BRIEF [12], BBoost [52], ORB [41], MKD [32], DeepCompare [58], DDesc [46], TFeat [5], L2Net [49] and HardNet [30]. The proposed descriptor achieves the best performance with a 128D descriptor on all 3 tasks consistently.
6 Conclusions
We interpret conventional convolutional local descriptors as efficient match kernels and show that they learn spatially variant encoding through that last FC layer. We design a novel local descriptor that explicitly encodes the spatial information. We use a combined position parametrization handling different sources of geometric misalignment. It achieves the same performance as state-of-the-art descriptors with fewer parameters and consistently outperforms them on all standard patch benchmarks with the same number of parameters.
Acknowledgments This work was supported by the GAČR grant 19-23165S, the OP VVV funded project CZ.02.1.01/0.0/0.0/16_019/0000765 “Research Center for Informatics” and the CTU student grant SGS17/185/OHK3/3T/13.
The reference list from the paper itself. Each links out to its DOI / PubMed record.
- 1[1] Mitsuru Ambai and Yuichi Yoshida. Card: Compact and real-time descriptors. In ICCV , 2011.
- 2[2] Relja Arandjelovic and Andrew Zisserman. Three things everyone should know to improve object retrieval. In CVPR , 2012.
- 3[3] Vassileios Balntas, Edward Johns, Lilian Tang, and Krystian Mikolajczyk. Pn-net: conjoined triple deep network for learning local image descriptors. In ar Xiv , 2016.
- 4[4] Vassileios Balntas, Karel Lenc, Andrea Vedaldi, and Krystian Mikolajczyk. Hpatches: A benchmark and evaluation of handcrafted and learned local descriptors. In CVPR , 2017.
- 5[5] Vassileios Balntas, Edgar Riba, Daniel Ponsa, and Krystian Mikolajczyk. Learning local feature descriptors with triplets and shallow convolutional neural networks. In BMVC , 2016.
- 6[6] Herbert Bay, Andreas Ess, Tinne Tuytelaars, and Luc Van Gool. Speeded-up robust features (SURF). CVIU , 110(3):346–359, 2008.
- 7[7] Liefeng Bo, Kevin Lai, Xiaofeng Ren, and Dieter Fox. Object recognition with hierarchical kernel descriptors. In CVPR , 2011.
- 8[8] Liefeng Bo, Xiaofeng Ren, and Dieter Fox. Kernel descriptors for visual recognition. In NIPS , December 2010.